
In this book, we’ve looked at different ways to tackle a variety of categories of queries. However, even if a query retrieves some valid-looking rows, all may not be well. In the previous chapter, we looked at the importance of checking the output to confirm that (at least some of) the expected rows are retrieved, as well as checking to make sure that (at least some) incorrect (or irrelevant) rows are not being returned.
The problems that can befall queries are not just a matter of having the wrong syntax in SQL statements, although that can certainly happen. Problems with the design of the tables or with data values can also affect the accuracy of queries. In this chapter, we will look at some common design and data problems, and also at some of the most common syntactic mistakes.
Poor Database Design
Good database design is absolutely essential to being able to extract accurate information. Unfortunately, you will sometimes be faced with databases that are poorly designed and maintained. Often there is not a great deal you can do. Sometimes you can extract something that looks like the required information, but it should be presented with a caution that the underlying data was probably inconsistent. In this section we look at some common problems and how they might be mitigated.
Data That Is Not Normalized
One of the most common data design mistakes is to have tables that are not normalized. We looked at an example of this in Chapter 1. Rather than having two tables, one for members and one for membership information such as fees, all this data was stored in a single table. As can be seen in Figure 12-1, this has the effect of storing the fee information several times.
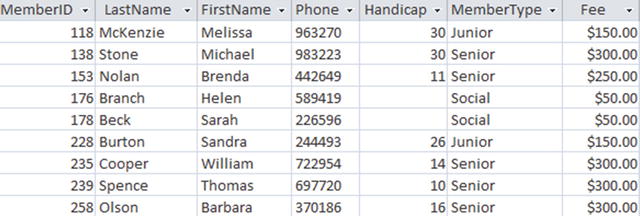
Figure 12-1. A non-normalized Member table containing fee information
What happens now if we are asked to find the fee for senior members? The query here will result in two values: 300 and 250.
SELECT DISTINCT FeeFROM MemberWHERE MemberType = 'Senior'
Although the two values retrieved by the query may be surprising, nothing is wrong with the query or the result. The value for Brenda Nolan, which is inconsistent with the other senior members, gives us the additional fee result. That value may be a typographical error, or it may indicate some sort of discount for Brenda, or it may be an instance of last year’s fee that has not been updated. In either case, there is a problem with the design. The design should allow for regular fees for each grade to be recorded consistently and, if necessary, allow for storage of additional discounting regimes. At this point, other than redesigning the tables, there is nothing we can do but return the list of fees that have been recorded against the senior members. It is just worth understanding the underlying issues.
Another problem you may encounter is a single table that stores multivalued data. The versions of the club tables that we have been using allow a member to belong to just one team. The club may evolve to have several different types of teams (interclub teams, social teams, pairs, foursomes, and so on) that members can belong to at the same time. When the requirement for a second team to be recorded against a member arises, a common short-term fix is to add another Team column to the existing table. Figure 12-2 shows how the Member table might have evolved to allow members to be associated with up to three teams.
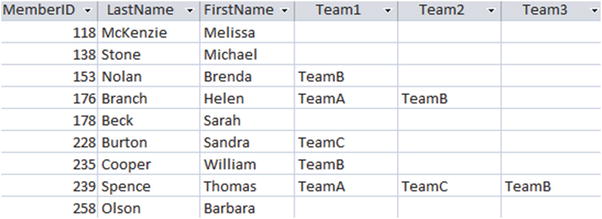
Figure 12-2. Poor table design to store more than one team for a member
Now, suppose we are asked to find those members in TeamB. Brenda has TeamB in the Team1 column, Helen has TeamB in the Team2 column, and Thomas has TeamB in the Team3 column. We need to check every team column for the existence of TeamA. This isn’t difficult, as the query here shows:
SELECT * FROM MemberWHERE Team1 = 'TeamB' OR Team2 = 'TeamB' OR Team3 = 'TeamB';
While we can extract the information we require from the table in Figure 12-2, the design is going to cause problems. We will have trouble if we have queries like “Find members who are in both TeamA and TeamB” or “Find members who are in more than two teams.” You could probably devise queries that would answer these questions, but they would be ungainly. I would ask for the database to be redesigned properly before trying to fulfill such requests. If you meet resistance you can ask them what they will do if a member belongs to four teams or maybe twenty teams.
If members can belong to several teams we have a Many–Many relationship, which should be represented in a relational database with an intermediate Membership table1 — something like the one in Figure 12-3.
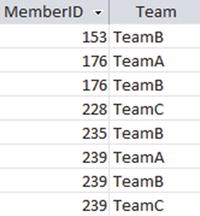
Figure 12-3. A Membership table that records the relationship between members and teams
The Membership table in Figure 12-3 records relationships between members and teams and is very similar to the Entry table, which records relationships between members and tournaments. The Membership table will need to be joined with the Member table to find the associated names, but if that is done we will have the same information as the one in Figure 12-2. With the new Membership table, we can now use all the relational operations, as described in previous chapters, to easily answer questions like “Who is in TeamA and TeamB?” and “Who is in three or more teams?”
We can create a Membership table with the following SQL code. The table includes only two foreign keys, to the existing Member and Team tables, and those fields also form a concatenated primary key.
CREATE TABLE Membership(MemberID INT FOREIGN KEY REFERENCES Member,Team CHAR(20) FOREIGN KEY REFERENCES Team,PRIMARY KEY (MemberID, Team) );
If you don’t mind a bit of manual fiddling about, you can populate the new Membership table with repeated update queries like the one here:
INSERT INTO Membership (MemberID, Team)SELECT MemberID, 'TeamA'FROM MemberWHERE Team1 = 'TeamA' OR Team2 = 'TeamA' OR Team3 = 'TeamA'
The query finds each member who is in TeamA and creates an appropriate row in the Membership table. If there are not too many teams, you can manually alter the second and last lines of the query for each team (TeamA, TeamB, and so on) and populate the new Membership table quite quickly. You then need to delete the Team columns from the Member table in Figure 12-2, and the database will be greatly improved.
Tables with No Primary Key
The previous section gave an example of the problems you can run into if the underlying database has inappropriate tables. You will sometimes find that the database has the correct tables, but they do not have suitable primary or foreign key constraints. In these cases, the underlying data values are likely to be inconsistent. While your queries may be correctly formed, the results will be unreliable. In this section, you will see how you can use queries to find some inconsistencies that may be present in your data.
Suppose that the Membership table in Figure 12-3 had been created without a primary key. This would allow the table to have duplicate rows. For example, we might have two identical rows for member 153 being on TeamB.2 A query to count the number of members on TeamB will produce an incorrect result.
If you try to add a primary key when duplicates already exist, you will get an error. This is one way to find where problems are! Before you can add a primary key you will need to find the duplicated rows and investigate how to resolve the issue. One convenient way to find duplicated values is to do a GROUP BY query (see Chapter 7) on the fields that should be unique and use a HAVING clause to find those with two or more entries. The following query will return duplicated values for our potential primary key fields MemberID and Team:
SELECT MemberID, Team, Count(*)FROM MembershipGROUP BY MemberID, TeamHAVING Count(*) > 1;
If the table has fields other than the primary key fields, you need to manually inspect the values in those columns to decide which row should be deleted. The Membership table, which has only primary key fields, causes a different problem. How do we delete just one copy of the row for member 153 in TeamB? Because the entire rows are the same, we can’t differentiate them, and so any query that deletes one row will delete both. You software might have a tabular-like interface that will allow you to delete just one of the rows, but if not you may have to delete both rows and manually add one back. If there are a lot of duplicate values, then another way to resolve the situation is to create a new table and then insert just the distinct values from the original table. The following query shows how to populate the new table NewMembership:
INSERT INTO NewMembershipSELECT DISTINCT MemberID, TeamFROM Membership;
You will then need to remove all the foreign key constraints referencing the old table, delete that table, rename the new table, and recreate the foreign keys. It’s easier to make sure every table has a primary key from the start!
Tables with Missing Foreign Keys
Another problem is having a Membership table (as in Figure 12-3) with no foreign key constraints . We can then find ourselves with the problem of having a row for member 1118 being in TeamA when no member 1118 is listed in the Member table. We will not be able to add a foreign key constraint if the data has this sort of problem.
There are several ways to find such values of MemberID in the Membership table that do not have a matching entry in the Member table. One way is to use a nested query (discussed in Chapter 4), as shown here:
SELECT ms.MemberID FROM Membership msWHERE ms.MemberID NOT IN(SELECT m.MemberID FROM Member m);
Having found the unmatched values for MemberID, we will then have to decide if it is a typographical error or if we are missing a member from the Member table.
When the data is in a consistent state it will be possible to add a foreign key constraint to the Membership table to make sure it stays that way. The following query will add the constraint to the MemberID field:
ALTER TABLE MembershipADD FOREIGN KEY (MemberID)REFERENCES Member;
Similar Data in Two Tables
Sometimes a database might have extra tables that are not required and will cause problems. An example for our club database might be having a separate table for coaches or managers, as shown in Figure 12-4. The rationale might have been that the extra table would make it easier to create lists of coaches and their phone numbers (which would otherwise require a self join or nested query).
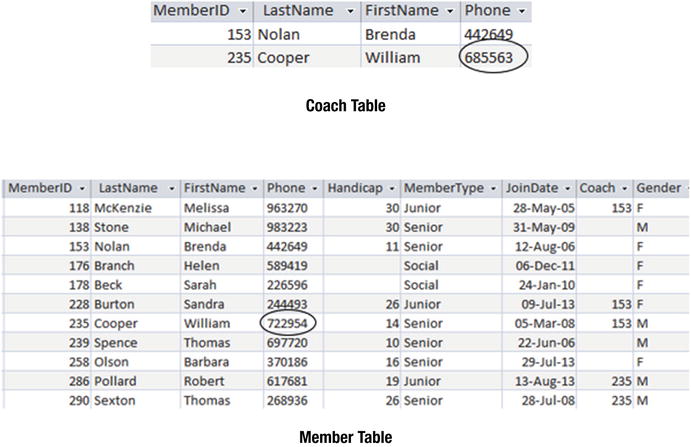
Figure 12-4. An additional table for coaches can lead to inconsistent data
The additional table will inevitably cause problems. In Figure 12-4, we already see inconsistent data for William Cooper’s phone number. The only real cure is to get rid of the extra table.
If the purpose of an additional table like the one in Figure 12-4 is unclear, we can use set operations to investigate which members appear in each of the tables. The intersection operator will find rows for people who are in both tables, and the difference operator will find those people who are in one and not the other. This may help with understanding what the tables represent.
Once the design is correct, creating a view that shows the coach information would be helpful for users who don’t want to be creating self joins every time they want information just about coaches. The following query does the trick:
CREATE VIEW CoachInfo ASSELECT * FROM MemberWHERE MemberID IN(SELECT Coach FROM Member);
Inappropriate Types
Having the fields in a table created with inappropriate types is another problem that can make queries look as though they are not behaving. I’ve seen whole databases where every field is a default text field.
Having the wrong field type means the data misses a great deal of validity checking. For example, if our Member table had all text fields, we could end up with values like “16a” or “1o” in the Handicap column, which should only have integer numbers, or text like “Brenda” in the Coach column, which should only contain IDs of members.
Incorrectly entered values aside, inappropriate types give rise to other problems. Each type has its own rules for ordering values. Text types order alphabetically, numbers order numerically, and dates order chronologically. Different orderings clearly will be an issue if we add an ORDER BY clause to a query. A text field containing numbers will order alphabetically, giving an order like “1,” “15,” “109,” “20,” “245,” and “33,” as described in Chapter 2.
Incorrect types also cause problems when making comparisons. If we ask for values to be compared, the comparison used will depend on how the particular field type involved is ordered. For numbers entered in a text field, we will get comparisons such as “109” < “15” or “33” > “245” as per the ordering described in the previous paragraph. This will cause some odd output if we ask for people with handicaps less than 5, for example. It can be difficult to sort out what is going wrong, because the query syntax is fine and the data appears to be OK. Going behind the scenes to check out the data type might not be something that is immediately obvious.
It is possible to change the type of a column in an existing table, but I find it a bit scary. For example, if you change from text to numeric values, “10” will probably be fine but “1o” will cause an error. I prefer a more conservative approach: I make a new table with the appropriate types, and then insert the old values with the aid of a conversion function. The query that follows shows how we could populate a new table NewMember with IDs and names and with the old text values for the Handicap column converted to numeric values:
INSERT INTO NewMember (MemberID, LastName, FirstName, Handicap)SELECT MemberID, LastName, FirstName, CONVERT(INT Handicap)FROM Member;
This way, we still have the original data if the conversions result in something unexpected.
Problems with Data Values
Even with a well-designed database, we still have the issue of the accuracy of the data that has been entered. As the query designer, you can’t be held responsible for some accuracy problems. If a person’s address has been entered incorrectly, there is not much anyone can do to find or fix the problem (apart from waiting for the mail to be returned to sender). However, you can be aware of a number of things, and even if you can’t fix the problems, you can at least raise some alarms. In addition, it is sometimes possible to fix some problem data with careful use of update queries.
Unexpected Nulls
Nulls can cause all sorts of grief in databases. The real problem (as discussed in Chapter 2) is that a null can mean either that the value is unknown or that the value doesn’t apply for a particular record. If a member in our club has a null value for his Team field, it could mean he isn’t on a team or it could mean that he is on a team but we haven’t recorded which one. As with other data problems, there is not much we can do about this. However, with something like the Gender field, we know that for the golf club, all members need to identify as either male or female. The nulls mean that for some members the gender has not been recorded. The same applies to fields like date of birth.
If, for example, you are asked for a list of the men in the club, it is often a good idea to also run another query for those rows where Gender IS Null. You can then say to your client, “Here are the men, and here are the members I’m not sure about.” Such an approach can help avoid letters from aggrieved gentlemen who don’t appear on the list.
Be aware of the differences between queries with the following two counts: COUNT(*)and COUNT(Gender). The first will count all the rows in the database; the second will count all the rows with a non-null value for gender. In the ideal golf club, these would be the same. In practice, they may not be.
Incorrect or Inconsistent Spelling
Any database will have spelling mistakes in the data at some point. Mr. Philips may appear as Phillips, Philipps, or Philps for various reasons, ranging from illegible handwriting on the application form to a simple data-entry mistake. If you are trying to find information about Mr. Philips and you suspect there might be a problem, you can use functions or wildcards to find similar data. Different products have different ways of doing this.
We can use the keyword LIKE to find similar spellings. The wildcard symbol % (* in Access) stands for any group of characters. Our several versions of spelling for Philips would all be retrieved by the following query:
SELECT * FROM MemberWHERE LastName LIKE 'Phil%';
Another problem involving incorrect or inconsistent spelling arises when you might be expecting a particular set of values or categories in a field. For example, in our Member table, we might be expecting values M or F in the Gender column, but there may be the odd male or m value. In the MemberType column, we expect Junior, Senior, or Associate, but in practice may find jnior or senor. If the tables have been designed with appropriate check constraints or foreign keys, this won’t be a problem. However, often these constraints are not present, so it is useful to check for problematic entries with a query such as the one here:
SELECT * FROM MemberWHERE MemberType NOT IN ('Senior', 'Junior', 'Associate');
Having found the rows that do not conform to expectations it may be possible to amend the data and then apply a check constraint so that it remains consistent. For example, the following query will apply a constraint on the MemberType field so that only the valid values can be entered:
ALTER TABLE MemberADD CONSTRAINT Chk_type CHECK(MemberType IN('Senior', 'Junior', 'Associate'));
Extraneous Characters in Text Fields
A common problem when trying to retrieve data that matches a text value is leading or trailing spaces and other nonprintable characters that have found their way into the data.
If we have a field like FirstName in our database, for example, we may find that there are some spaces before or after the name. Sometimes, if a character field is specified as being a particular length, trailing spaces may be added. If a row has a name has been stored as ' Dan ' then a WHERE clause with the condition FirstName = 'Dan' may not retrieve that row. Most database software will have several functions for dealing with text. There are likely to be forms of trim functions, which remove spaces from the start and end of text values. Check out your documentation to see what your implementation has.
The RTRIM() function in the SQL statement that follows will strip any spaces from the right end of the FirstName value before making the comparison:
SELECT * FROM MemberWHERE RTRIM(FirstName) = 'Dan';
The preceding query does not strip the spaces from the field permanently. The RTRIM() function just returns a value without the spaces in order to make the comparison. However, you can use update queries to permanently remedy some of these data inconsistencies. The query that follows shows how to ensure no values in the FirstName column of the Member table have any leading (LTRIM()) or trailing (RTRIM()) spaces. It essentially replaces all the values with trimmed values:
UPDATE MemberSET FirstName = RTRIM(LTRIM(FirstName));
A more disturbing problem is characters that look like spaces but are actually some other white space characters. This sometimes occurs when data is cut and pasted or otherwise moved between various products and different implementations. This can take some tracking down.
Two other data-entry gotchas are the numbers 0 (zero) and 1 (one) being entered instead of the letters o (oh) and l (el). You can spend hours trying to debug a query that is looking for “John” or “Bill,” but if the underlying data has been mistakenly entered as “J0hn” or “Bi11” you will search in vain.
The moral is that weird things can happen with data values, so when the troubleshooting of your query syntax fails, check the underlying data.
Inconsistent Case in Text Fields
If your SQL implementation is case sensitive, you need to be aware that some data values may not have the expected case. Dan may have had his first name incorrectly entered into the Member table as “dan.” In case-sensitive implementations, a query with the clause WHERE FirstName = 'Dan' will not retrieve his information. As mentioned in Chapter 2, using a function that converts strings of characters to uppercase will help find the right rows. In the query that follows we convert FirstName (temporarily) to uppercase, and then compare that with the uppercase rendition of what we are seeking:
SELECT * FROM MemberWHERE UPPER(FirstName) = 'DAN';
It is quite difficult to find problems with case in names because not all names conform to being lowercase with an uppercase first letter; for example, de Vere and McLennan. But, for fields like Gender (M or F) or MemberType (Junior, Senior, or Associate), we know what we expect the values to be. The best way to ensure that they are consistent is to put a check constraint on the field as discussed earlier in this chapter.
Diagnosing Problems
In the previous sections, we saw problems that can arise with poor database design and inconsistent or incorrect data. Much of the time, however, if the result of your query is not looking quite right, it is probably because you have the wrong SQL statement. The statement may be retrieving rows that are different from what was expected. In Chapter 10 there is a section on some ways that you can check to see if the result of a query is what is expected.
In the previous chapter, I suggested a way to approach queries that lets you build the query up slowly so you can check that each step is returning appropriate rows. However, if you are presented with a full-blown, complex query that is not delivering as expected, you need to pare it down until you find where the problem lies. If you have noticed a problem, then you have a good place to start. You have either noticed an expected row is missing or that a row not satisfying the requirements has been retrieved. Concentrate on finding where in the query that problem is. The following sections offer some suggestions.
Check Parts of Nested Queries Independently
Where you have one query nested inside another, the first thing to check is that the nested part is behaving itself. Take a look at this query:
SELECT *FROM Member mWHERE m.MemberType = 'Junior' AND Handicap <(SELECT AVG(Handicap)FROM Member);
If you are having trouble with a query like this, cut and paste the inner query and run it independently. Check to see if it is returning the correct result. If this is OK, you can try doing the outer query on its own. To do this, just put some value in place of the inner query (such as Handicap < 10) and see if that returns the correct results. If you can narrow down the problem to one part of the query, you have made a good start.
This approach doesn’t work if the inner and outer parts of the query are related (see Chapter 4), but some of the following techniques might help with that situation.
Understand How the Tables Are Being Combined
Many queries involve combining tables with relational operations (join, union, and so on). Make sure you understand how the tables are being combined and whether that is appropriate. Consider a query such as the following:
SELECT m.LastName, m.FirstNameFROM Member m, Entry e, Tournament tWHERE m.MemberID = e.MemberIDAND e.TourID = t.TourID AND t.TourType = 'Open' AND e.Year = 2014;
Three tables are involved in this query. It might take a moment to figure out that they are being joined. Make sure that is appropriate for the question being asked. Chapter 10 has examples of keywords in questions and the appropriate ways to combine tables.
Remove Extra WHERE Clauses
After combining tables, usually only some of the resulting rows are required. In the query in the previous section, only part of the WHERE clause is needed for the join operations. After the join, only the rows satisfying t.TourType = 'Open' AND e.Year = 2014 are retained. If you have rows missing from your result, it is often useful to remove the parts of the WHERE clause that are selecting a final subset of the rows after the join. If the rows are still missing, then you know that (for this example) the problem is occurring in the join.
Retain All the Columns
I’m a big fan of always saying SELECT * in the early stages of developing queries that involve joins. If we suspect a problem with the joins, then by leaving all the columns visible, we can see if the join conditions are behaving as expected. Once we are happy with the rows being retrieved, we can retain just the columns required.
However, if we are combining tables with set operations, this approach will be counterproductive, as projecting the right columns is critical (see the “Do You Have Correct Columns in Set Operations” section later in this chapter).
Check Underlying Queries in Aggregates
If you have a problem with a query involving an aggregate (for example, SELECT AVG(Handicap) FROM ... WHERE ...) check that you have retrieved the correct rows before the aggregate function is applied. Change the query to SELECT * FROM ... WHERE ..., and confirm that this returns the rows for which you want to find the average. In fact, I recommend always doing this with an aggregate, because it is difficult to otherwise check if the numbers being returned are correct.
Common Symptoms
Having tried some of the steps in the previous chapter, you will have simplified your query to isolate where the problem is. In this section, we will look at some specific symptoms and some likely causes.
No Rows Are Returned
It is usually easy to spot a problem with your query when no rows are returned and you know that some should be. Questions that involve “and” or “both” can often have this problem. For example, consider a question such as “Which members have entered tournaments 24 and 36?” A common first attempt (and I still catch myself doing this sometimes) is a query statement such as:
SELECT * FROM EntryWHERE TourID = 24 AND TourID = 36;
The preceding query asks for a row from the Entry table where TourID simultaneously has two different values. This never happens, and so no rows are retrieved. The cure is to use a self join (covered in Chapter 5) or an intersection operation (covered in Chapter 7).
Getting no rows returned from a query may also be an extreme example of one of the problems in the next section.
Rows Are Missing
It can be difficult to spot if some rows are being missed by your query, especially when the set of retrieved rows is large. If you get 1,000 rows returned, you might not notice that one is missing. Careful testing is required, and some ideas for how to do this were discussed in Chapter 10. It is often worthwhile to run through the following list of common errors to see if any might apply.
Should You Have an Outer Join?
Using an inner join when an outer join is required is a very common problem. Suppose that we are trying to get a list of member information that includes names and fees. For this, we need the Member table (for the names) and the Type table (for the fees). A first attempt at a query might be as follows:
SELECT m.LastName, m.FirstName, t.FeeFROM Member m, Type tWHERE m.MemberType = t.Type;
We know there are, say, 135 members, but we are getting only 133 rows from the query. The issue here is that we are performing an inner join (see Chapter 3), so any members with a null value for member type will not appear in the result. Of course, this may be the result you want (those members who have a type and fee), but it is not the correct output if you want a list of all members and the fees for those who have them.
An outer join (also discussed in Chapter 3) that includes all the rows of the Member table will solve this problem. Whenever you have a join, it is worth thinking about the join fields and considering what you want to happen where a row has a null value in that field.
Have Selection Conditions Dealt with Nulls Appropriately?
Nulls can cause quite a few headaches if you forget to consider their effect on your queries. The previous section looked at nulls in a joining field. You also need to remember to check for comparisons involving fields that may contain nulls. We looked at this in Chapter 2 and also earlier in this chapter.
Consider two queries on the Member table with selection conditions Gender = 'M' and Gender <> 'M'. It is reasonable to think that all rows in the Member table should be returned by one of these queries. However, rows with a null in the Gender field will return false for both these conditions (any comparison with a null returns false), and the row will not appear in either result.
Say we want to get a list of members of our club who are not particularly good players (to offer them coaching, perhaps). Someone may suggest a query like the following to find members who do not have a low handicap:
SELECT *FROM Member mWHERE m.Handicap > 10;
The problem is that the preceding query will miss all the members with no handicap. Altering the WHERE condition to m.Handicap > 10 OR m.Handicap IS Null will help in this situation.
Are You Looking for a Match with a Text Value?
It is very disturbing to be trying to find rows for Jim, to be able to see Jim in the table, and to have your query return nothing. This may be caused by one of the problems we looked at in the “Problems with Data Values” section earlier in this chapter.
One quick way to eliminate the possibility of dodgy text values is to use LIKE for comparisons. For example, where you have = 'Jim', replace it with LIKE '%Jim%'. If the query then finds the row you were expecting (possibly along with some others), you know the problem is with the data. As noted earlier, putting the wildcard % (or * in Access) at the beginning and end of the string will find leading or trailing spaces and other nonprintable characters.
Have You Used AND Instead of OR?
We discussed the problem of queries involving the words and or or in the previous chapter (in the “Spotting Key Words in Questions” section). I’ll recap briefly. The word and can be used in natural English to describe both a union and an intersection. When we say “women and children,” we usually mean the union of the set of females and the set of young people. When we say “cars that are small and red,” we mean the intersection of the set of small cars and the set of red cars.
If we are looking for “women and children” and use the selection condition Gender = 'F' AND age < 12, we are actually retrieving the intersection of women and children (or girls). We need the condition to be Gender = 'F' OR age < 12.
It is very easy to unwittingly translate the and in the English question to an AND in the query inappropriately, which can result in missing rows. If in doubt, try drawing the Venn diagrams described in the previous chapter.
Do You Have Correct Columns in Set Operations?
If your query involves intersection or difference operations, the result may have fewer rows than expected because you have projected the wrong columns initially. We looked at this in Chapter 7. Here is a brief example for intersection; the same issue applies to difference operations as well.
We want to find out who has entered both tournaments 25 and 36. We realize that we need an intersection and try the following query:
SELECT * FROM EntryWHERE TourID = 25INTERSECTSELECT * FROM EntryWHERE TourID = 36;
No rows will be returned from this query, regardless of the underlying data. The intersection finds rows that are exactly the same in each set. However, all the rows in the first set will have 25 as the value for TourID 25, and all the rows in the second set will have the value 36. There can never be a row that is in both sets. What we are looking for is the member IDs that are in both sets, so the SELECT clauses in each part of the query should be SELECT MemberID FROM Entry.
The preceding query is an extreme example of retaining the wrong columns, resulting in no rows being returned. The discussion around Figure 7-14 in Chapter 7 shows how retaining different columns in intersection and difference queries can result in very different results. You need to ensure that you are retaining the columns that are appropriate for the question being asked.
More Rows Than There Should Be
It is often easier to spot extra rows than it is to notice that rows are missing from your query result. You only need to see one record that you weren’t expecting, and you can concentrate on the different parts of your query to see where it failed to be excluded. Here are a couple of causes of extra rows.
Did You Use NOT Instead of Difference?
With questions containing the words not or never, a sure way to get extra rows is to use a condition in a WHERE clause when you really need a difference operator. We looked at this issue in Chapter 4. To recap, consider a question like “Which members have never entered tournament 25?” A common first attempt using a select condition is:
SELECT * FROM EntryWHERE TourID <> 25;
The condition in the WHERE clause checks rows one at a time to see if they should be included in the result. If there is a row for member 415 entering tournament 36, then that row will be retrieved, regardless of the possibility that another row shows member 415 entered tournament 25. For example, if member 415 has entered tournament 25 and four other tournaments, we will retrieve four rows when we were expecting none.
The correct procedure for this type of question is to use a nested query (see Chapter 4) or the EXCEPT difference operator (see Chapter 7). We need to find the set of all members (from the Member table) and remove the set of members who have entered tournament 25 (from the Entry table).
If we employ the process approach we might come up with the following query, which looks for the difference between the two sets:
SELECT MemberID FROM MemberEXCEPTSELECT MemberID FROM EntryWHERE TourID = 25;
If we started with an outcome approach we might have arrived at a nested query, as here:
SELECT MemberID FROM MemberWHERE MemberID NOT IN(SELECT MemberID FROM EntryWHERE TourID = 25);
Have You Dealt with Duplicates Appropriately?
It sometimes takes a little thought to decide what needs to be done with duplicate records retrieved from a query. By default, SQL will retain all duplicates. The following two requests sound similar:
Give me a list of the names of my customers.
Give me a list of the cities my customers live in.
In the first, we probably expect as many rows as we have customers; if we have several Johns, we expect them all to be retained. In the second, we expect one row per city. If we have 500 customers living in Christchurch, we don’t expect all 500 rows to be returned.
In the query to find the cities, we want only the distinct values, so we should use the DISTINCT keyword:
SELECT DISTINCT (City) FROM Customer;Incorrect Statistics or Aggregates
If we are using aggregates such as counting, grouping, or averaging and the underlying query misses rows or returns extra rows, then clearly the statistics will be affected. A couple of other things to consider are how nulls and duplicates are being handled.
SQL will not include any null fields in its statistics . For example, COUNT(Handicap) or AVG(Handicap) will ignore any rows with nulls in the Handicap field. It is also important to consider what you want done with duplicates, especially for counting functions. COUNT(Handicap) will return the number of members who have a value in the Handicap column. COUNT(DISTINCT Handicap) will return the number of different values in the Handicap column; if all the members have a handicap of 20, it will return a count of 1.
The Order Is Wrong
If you have used an ORDER BY clause in your query and you are having problems with the order in which the rows are being presented, there is often a problem with the underlying data. Review the “Problems with Data Values” section earlier in this chapter. Check that the field types are appropriate (for example, numeric values aren’t being stored in text fields) and that text values have consistent case and no extraneous characters.
Common Typos and Syntax Problems
Sometimes a query doesn’t run because of some simple problem with the syntax — that is, the way the query is worded. Syntax problems involve things like missing parentheses or incorrect spellings of fields or keywords. Hopefully the database software will alert you if there is a problem with the syntax, but, as some editors are quite basic, that may or may not be helpful in finding and correcting the problem. Here are a few things to check:
Quotation marks: Most versions of SQL require single quotation marks around text values, such as 'Smith' or 'Junior', although some use double quotation marks in some circumstances. If you are cutting and pasting queries, be sure the correct quotation marks have been transferred. When I cut and paste the queries in this book from Word to Access, the quotation marks look OK, but I need to re-enter them. Also check that all the quotation marks are paired correctly. Don’t use quotes around numeric values. Something like Handicap < '12' will cause problems if Handicap is a numeric field.
Parentheses: These are required in nested queries and also can be used to help readability in many queries (such as those with several joins). Check that all the brackets are paired correctly.
Names of tables and fields: It seems obvious that you need to get the names of tables and fields correct. However, sometimes a simple misspelling of a table name or field can cause an unintelligible error message. Check carefully.
Use of aliases: If you use an alias for table names (for example, Member m), check that you have associated the correct alias with each field name.
Spelling of keywords: Some software for constructing SQL queries will highlight keywords, so it is very apparent if you have spelled them incorrectly. If your version doesn’t show this, then check keyword spelling, too. I often type FORM instead of FROM or AVERAGE() instead of AVG().
IS Null versus = Null: Some versions of SQL treat these quite differently. IS Null always works if you are trying to find fields with a null value.
Summary
Before you can correct a query, you need to notice that it is wrong in the first place. It is preferable that we find potential problems before our users find them for us. Always check the rows returned from a query, as described in the previous chapter. When you do discover errors, the following are some ideas for tracking down the cause of the problem:
Check that the underlying tables are combined appropriately (join, intersection, and so on).
Simplify the query by removing selection conditions and aggregates to ensure the underlying rows are correct.
Retain all the columns in a query with joins until you are sure that the tables have been combined appropriately.
Check each part of nested queries or queries involving set operations independently.
Check queries for questions with the words and or not to ensure you have not used selection conditions when you need a set operation or nested query.
Check that the columns retained in queries with set operations are appropriate.
Check that nulls and duplicates have been dealt with properly.
Check that underlying data types are correct and that data values are consistent.