
Chapter 3. Mathematical Considerations
Most of this book will be focused on implementation, and practical considerations necessary to get recommendation systems working. In this chapter, you’ll find the most abstract and theoretical concepts of the book. The purpose of this chapter is to cover a few of the essential ideas that undergird the field. It’s important to understand these ideas as they lead to pathological behavior in recommendation systems, and motivate many architectual decisions.
We’ll start by discussing the shape of data you often see in recommendation systems, and why that shape can require some careful thought. Next we’ll talk about the underlying mathematical idea, similarity, that drives most modern recsys. We’ll cover in brief a different way of thinking about what a recommender does, for those with a more statistical inclination. Finally, we’ll use analogies to NLP to formulate the popular approach.
Zipf’s laws in RecSys and the Matthew Effect
In a great many applications of machine learning a caveat is given early: that the distribution of observations of unique items from a large corpus is modeled by Zipf’s law, i.e. the frequency of occurrence drops of exponentially. In recommendation systems, the Matthew Effect appears in the popular item’s click rates, or the popular user’s feedback rates. For example, popular items have dramatically larger click counts than average, and higher engaged users give far more ratings than average.
Take for example the (MovieLens dataset, an extremely popular dataset for benchmarking recommendation systems, in (Jenny Sheng 2020 they observe the behavior shown in Figure 3-1 for number of movie ratings:
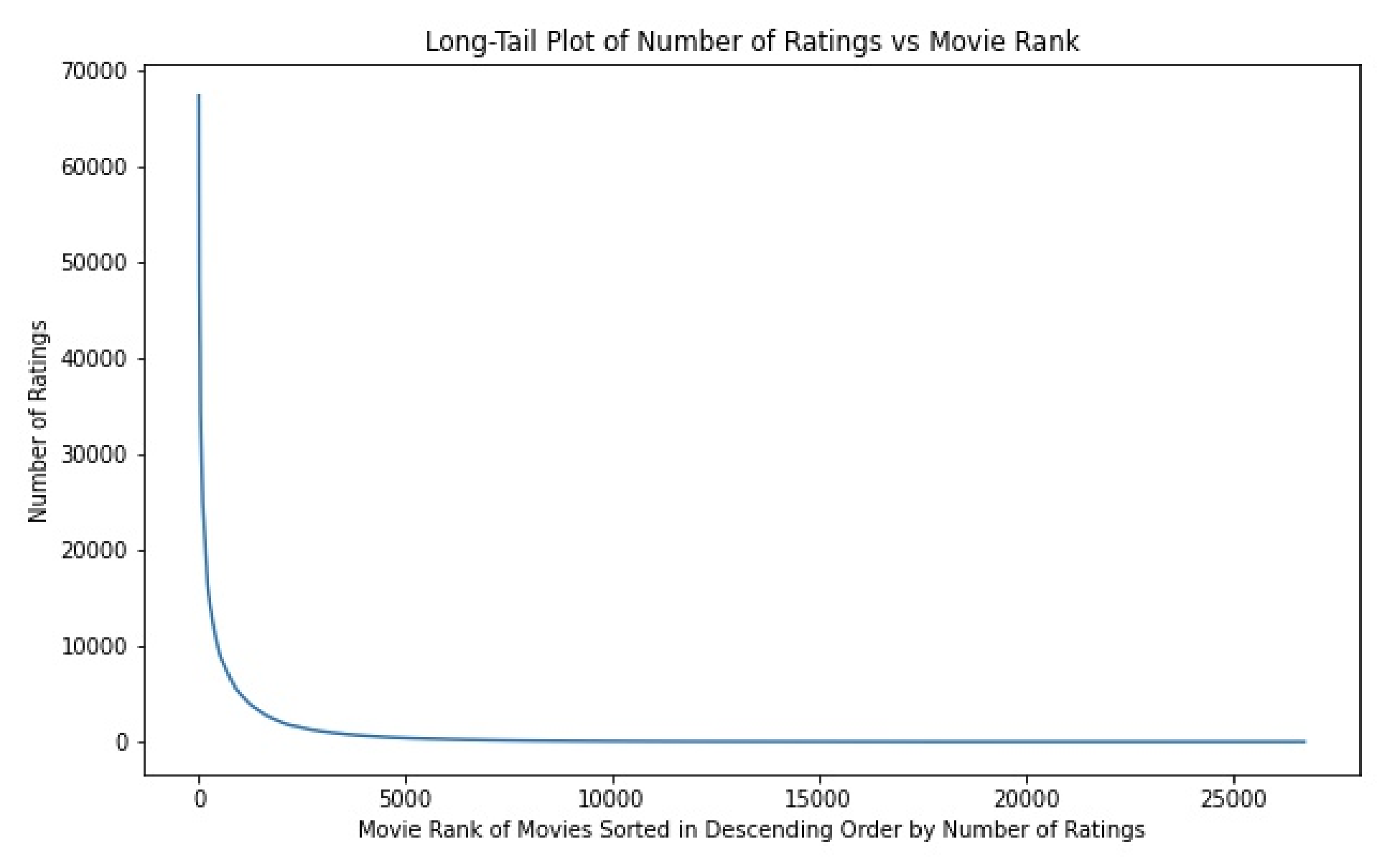
Figure 3-1. Zipfian Distribution of Movierank ratings
At first glance this behavior is obvious and stark, but is it a problem? Let’s assume our recommender will be built as a user-based CF model–as alluded to in Chapter 2–then how might these distributions effect the recommender?
We will consider the distributional ramifications of the above phenomenon. Let the probability mass function be described by the simple Zipf’s law:
for
Let’s consider users
and thus the joint probability of an item appearing in two user’s ratings is:
In words, the probability of two users sharing an item in their rating sets drops off with the square of its popularity rank.
This becomes important when one also considers that our, yet unstated, definition of user-based collaborative filtering is based on similarity in user’s ratings sets. This similarity is the number of jointly rated items by two users, divided by the total number of items rated by either.
Taking this definition we can, for example, compute the similarity score for one shared item amongst
and the average similarity score of two users is generalized to:
via repeated application of the above observation.
These combinatorial formulas indicate not only the relevance of the Zipfian in our algorithms, but we see an almost direct effect on the output of scores. Consider the experiment from (Wang, Wang, and Zhang 2019) on the LastFM dataset. LastFM is a music listening tracker for users to keep track of all the songs they listen to; for LastFM users, the authors demonstrate average similarity scores for pairs of users, and they find this Matthew Effect persists into the similarity matrix:
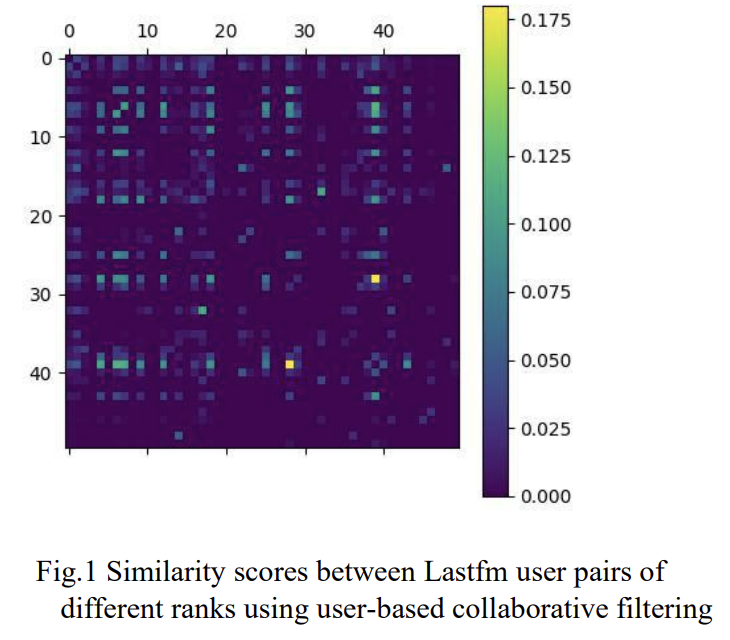
Figure 3-2. Matthew Effect as seen on the LastFM dataset
TODO: Remake this histogram
Observe the radical difference between “hot” cells and all of the others. While these results might seem scary, we’ll consider later some diversity-aware loss functions that we can mitigate some of this. A simpler way is to use downstream sampling methods; which we will discuss as part of our explore-exploit algorithms. Finally, the Matthew Effect is only the first of two major impacts of this Zipfian–let’s turn our attention to the second.
Sparsity
We must now reckon with sparsity. As the ratings skew more and more towards the most popular items, the least popular items are starved for data and recommendations, which is called Data Sparsity. This connects to the linear algebraic definition of sparsity: mostly zeros or not populated elements in a vector. When you consider again our user-item matrix less popular items constitute columns with very few entries–these are sparse vectors. Similarly, at scale we see that the Matthew effect pushes more and more of the total ratings into certain columns, and the matrix becomes sparse in the traditional mathematical sense. For this reason, sparsity is an extremely well known challenge for recommendation systems.
Like above, let’s consider the implication on our collaborative filtering algorithms from these sparse ratings. Again observe that the probability of
then
is the expected number of other users which click the
Again, as we pull back to the overall trends, we observe this sparsity sneaking into the actual computations for our collaborative filtering algorithms, consider the trend of users of different ranks, and how much their rankings are used to collaborate in other user’s rankings:

Figure 3-3. User similarity counts for LastFM dataset
We see that this is an important result to always beware–sparsity pushes emphasis onto the most popular users, and has the risk of making your recommender myopic.
User Similarity for Collaborative filtering
In mathematics, it’s very common to hear discussion of distances–even back to the Pythagorean theorem, we are taught to think of relationships between points as distances or dissimilarity. Indeed, this fundamental idea is canonized in mathematics as part of the definition of a metric:
In machine learning; we often instead concern ourselves with the notion of similarity–an extremely related topic. In many cases, one can directly pass back and forth between similarity and dissimilarity; when
This may seem like a needlessly precise statement, but in fact we’ll see that there are a (variety of options for how to frame similarity. Furthermore, sometimes we even formulate similarity measures where the associated distance measure does not establish a metric on the set of objects. These so-called pseudo-spaces can still be incredibly important, and we’ll see where they come up in the later section on latent spaces.
In the literature, you’ll find a very common practice of papers starting by introducing a new similarity measure, and then training a model you’ve seen before on the new similarity measure. As we’ll see, choices in how you choose to relate objects(users, items, features, etc.) can have a large effect on what your algorithms learn.
For now, let’s laser in on some specific similarity measures. Consider a classic ML problem of clustering; we have a space (usually
So how may we define similarity for our users in collaborative filtering? They’re not obviously in the same space, so our usual tools seem to be lacking.
Pearson correlation
Our original formulation of Collaborative Filtering was to say that users with similar taste collaborate to recommend items for each other. Let two users
is the sum of deviation from
It’s extremely important to keep in mind a few details here:
-
This is the similarity of the jointly distributed variables describing the users’ ratings
-
We compute this via all co-rated items, so user similarity, is defined via item-ratings
-
This is a pairwise similarity measure taking values in
Tip
In Part III we will learn about additional definitions of correlation and similarity which are more well suited for handling ranking data, and in particular that accomodate implicit rankings.
Ratings via similarity
Now that we’ve introduced user-similarity, let’s use it!
For a user
This is the prediction for user
But wait! What’s
Explore–exploit as a RecSys
So far we saw two ideas, slightly in tension with one another:
-
The MPIR, a simple easy to understand recommender
-
The Matthew effect in recommendation systems, and it’s runaway behavior in distributions of ratings
By now, it’s likely that you realize that the MPIR will amplify the Matthew effect, and that the Matthew effect will drive the MPIR to the Trivial recommender in the limit. This is the classic difficulty of maximizing a loss function with no randomization–it very quickly settles into a modal state.
This problem–and many others like it–encourage some modification to the algorithm to prevent this failure mode, and continue to expose the algorithm and users to other options. The basic strategy for explore-exploit schemes, or multi-armed bandits as they’re called, is to take not only the outcome-maximizing recommendation, but also a collection of alternative variants, and randomly determine which to use as response.
Taking a step back: given a collection of variant recommendations, or arms,
Even when not explicitly using a multi-armed bandit, this insight is a powerful and useful framework for understanding the goal of a Recsys. Utilizing the ideas of prior estimates for good recommendations, and exploring other options to gain signal is a core idea we’ll see recurring. Let’s see one practicality of this approach.
So how often should you explore vs. use your reward-optimizing arm? The first best algorithm is
Let’s take the MPIR and slightly modify it to include some exploration.
fromjaximportrandomkey=random.PRNGKey(0)defget_item_popularities()->Optional[Dict[str,int]]:...# Dict of pairs: (item-identifier, count item chosen)returnitem_choice_countsreturnNonedefget_most_popular_recs_ep_greedy(max_num_recs:int,epsilon:float)->Optional[List[str]]:assertepsilon<1.0assertepsilon>0items_popularity_dict=get_item_popularities()# type: Optional[Dict[str, int]]ifitems_popularity_dict:sorted_items=sorted(items_popularity_dict.items(),key=lambdaitem:item[1]),reverse=True,)top_items=[i[0]foriinsorted_items]recommendations=[]foriinrange(max_num_recs):# we wish to return max_num_recsifrandom.uniform(key)>epsilon:# if greater than epsilon, exploitrecommendations.append(top_items.pop(0))else:# otherwise, exploreexplore_choice=random.randint(1,len(top_items))recommendations.append(top_items.pop(explore_choice))returnrecommendationsreturnNone
The only modification to our MPIR is that now we have two cases for each potential recommendation from our max_num_recs; if a random probability is less than our
Note
Note that we’re interpreting maximization of reward as selecting most-popular items. This is an important assumption, and as we move into more complicated recommenders, this will be the crucial assumption that we modify to get different algorithms and schemes.
Collector
The collector here need not change, we still want to get the item popularities first.
Ranker
The ranker also does not change! We begin by ranking the possible recommendations by popularity.
Server
If collector and ranker remain the same, then clearly the server is what must be adapted for this new recommender. This is the case, instead of taking the top items to fill max_num_recs we now utilize our
What should
In the above,
There are other–often better–sampling techniques for optimization. Importance sampling can utilize the ranking functions we build later to integrate the explore-exploit with what our data has to teach.
The NLP-RecSys relationship
Let’s utilize some intuition from a different area of Machine Learning, Natural Language Processing. One of the fundamental models in NLP is word2vec; a sequence–based model for language understanding that utilizes the words which co-occur in sentences together.
For skipgram-word2vec, the model takes sentences of words, and attempts to learn the implicit meaning of words via their co-occurrence relationships with other words in those sentences. Each pair of co-occurring words, constitutes a sample that is 1-hot encoded and sent into a vocabulary-sized layer of neurons, with a bottleneck layer, and a vocabulary-sized output layer for probabilities that words will occur.
Via this network, we reduce the size of our representation to the bottleneck dimension, and thus find a smaller dimensional representation of all our words than the original corpus-sized 1-hot embedding. The thinking is that similarity of words can now be computed via vector similarity in this new representation space.
Why is this related to recommendation systems? Well, because if we take the ordered sequence of user-item interactions, e.g. the sequence of movies a user has rated, you can utilize the same idea from word2vec to find item similarity instead of word similarity. In this analogy, the user history is the sentence.
Previously, using our collaborative filtering similarity, we decided that similar users, can help inform what a good recommendation for a user should be. In this model we instead are finding item-item similarity, so instead we assume that items similar to those a user previously liked, they will also like.
Note
You may have noticed that natural language treats these as sequences, and in fact our user history is too! For now, hold onto this knowledge. Later, this will guide us to sequence-based methods for RecSys.
Vector search
We have build a collection of vector representations of our items, and we claim that similarity in this space (often called a latent-space, representation space, or ambient-space) means similarity in likeability to users.
To convert this to a recommendation, consider a user
Warning
These latent spaces tend to be of high dimension, which Euclidean distance famously performs poorly in. As regions become sparse, the distance function performance decreases–local distances are meaningful but global distances are not to be trusted. Instead, cosine distance shows better performance, but this is a topic of deep exploration. Additionally, instead of minimizing the distance, in practice it’s better to maximize the similarity.
One simple way is to take the closest item to the average of those that
where
This essentially treats all of
which potentially can improve the representativeness of the user feedback in the recommendations. Alternatively, you might find that a user rates movies across a variety of genre and themes. Averaging here will definitely lead to worse results, so maybe you which to simply find recommendations similar to 1 movie the user liked weighted by that rating:
Finally, you may even want to do this process several times for different items a user liked to get
Now we have
Latent-spaces and the geometric power that comes with them for recommendations will be a through-line for the rest of the book. We will often formulate our loss functions via these geometries, and exploit the geometric intuition to brainstorm where to expand our technique next.
Nearest-neighbors search
A reasonable question to ask is “how do I get these vectors that minimize this distance”? In all of the above schemes, we are computing many distances and then finding minimums. In general, the problem of nearest-neighbors is an extremely important and well studied question. While finding the exact nearest-neighbors can sometimes be very slow, a lot of great progress has been made on Approximate Nearest Neighbors search. These algorithms not only return very close to the actual nearest-neighbors, but they perform orders of complexity faster. In general, when you see us (or other publications) computing an