
In this last chapter of the development part, we will discuss language selection for firmware development. Since there are lots of textbooks introducing the languages themselves, we will not discuss the details of the languages. Instead, we will focus on the security aspects of different languages which may be used in the firmware development.
The main categories of languages are machine language, assembly language, and high-level language. Today probably no one uses the first-generation machine language which has the binary format 0 and 1 to present the machine code. Let’s start from the assembly language.
Assembly Language
- 1)
Non-volatile register access: The non-volatile registers should be preserved in the function call. For example, the RBX is a non-volatile register according to the calling convention. It should be saved in the entry of the function and used and restored upon exit from the function, or it should never be used in the function. If the RBX is used in the function without being saved and restored, the contract between caller and callee is broken.
- 2)
Wrong stack offset: The function uses the stack for the local variable storage and the function parameter. Usually, these data can be accessed with an offset to the stack, such as [RBP – 0x20] or [RSP + 0x38]. RBP is the stack base register. RSP is the stack pointer register. Usually, RBP should be used because it will not be changed once it is set in the entry of the function. It is dangerous to use RSP and offset because RSP is impacted by the stack PUSH and POP instruction. The data may be accessed correctly with [RSP + 0x38]. But after PUSH, the same data should be accessed with [RSP + 0x40].
- 3)
Register misuse: The instruction set only provides a limited number of registers. With assembly language, the programmer must be very clear on which register is used for what purpose. Sometimes an instruction shall use the register RDX, but the code uses another register RAX. It is typical copy-paste error. The programmer copies a chunk of code from somewhere else but forgets to update all places.
- 4)
Loop counter off by one: An instruction set includes a loop counter register, such as RCX in the IA instruction set. The LOOP instruction will cause RCX decrement. Similar to for loop in the C language, the wrong counter may cause off-by-one error (OBOE) and result in the buffer overflow.
- 5)
Confusing syntax: The assembly language does not have standard. Different assembly syntax may have different ways to translate to the machine code. Take IA instruction as an example. The GNU assembly (GSA) uses the AT&T syntax. The Microsoft assembly (MASM) uses the Intel syntax. The biggest problem is that the source and destination order is different between those two syntaxes. If you want to put the value in RCX register to RAX register, you can write “MOV RAX, RCX” in Intel syntax or “MOVQ %RCX, %RAX” in AT&T syntax. We have seen many cases that a developer uses the wrong order because they are only familiar with one of the syntaxes and copy some code and then translate to another syntax.
- 1)
Startup code: This is the first instruction when the CPU powers on. The startup code should set up the environment for the high-level language as soon as possible, such as a stack for the C language.
- 2)
Mode switch: An instruction set may define different CPU execution modes, such as 16-bit real mode, 32-bit protected mode, and 64-bit long mode. Switching between different modes needs some special handling, such as setting up a control register or mode-specific register and switching to a different segment. The high-level language usually does not provide such support.
- 3)
Exception handler: If the system runs into a soft exception or hardware interrupt, the CPU switches to the exception handler. The entry of the exception handler is usually written with assembly language because a high-level language does not handle the CPU context save and restore.
- 4)
Set jump and long jump: Those are two standard C functions. setjump() remembers the current position and longjump() jumps to this position later. Because the current position includes the CPU context, those two functions are implemented in assembly languages.
- 5)
Special instructions: Taking the IA instruction set as an example, it includes special register access such as control register (CR), model-specific register (MSR), streaming SIMD extension (SSE), advanced vector extension (AVX), and so on and a special instruction such as serialize load operations (LFENCE), flash cache line (CFLUSH), performance-improved spin-wait loops (PAUSE), and non-temporal store of data into memory (MOVNTI).
It is recommended to provide a library in the high-level language for the abstraction of those actions. As such, the other code should also call the library to do the work. The assembly language is still useful in these limited areas, but the usage should only be limited in those areas. The rest should belong to the high-level language.
C Language
The C language is probably the most popular and successful language since it was born with the Unix operating system. It is a high-level language, but it can also do the low-level work such as modifying memory content or memory mapped I/O registers in a special address. It is the most suitable language in the firmware area because the firmware needs to access the hardware-related content such as memory or memory mapped I/O register directly, and the C language is good and powerful in this area. With the C language, the developer can fully control the machine’s hardware. We believe it is because of the nature of the C language – C was born to write the Unix operating system.
Now let’s take a look at the C language from the security perspective. According to the Microsoft research, memory safety contributes 70% of the security vulnerabilities in C and C++. We also observed similar data in that the buffer overflow and integer overflow caused 50% of security issues in the firmware area. The reason is that the firmware is also one type of software. Firmware also has the similar memory safety issue including the memory access error such as buffer overflow, use-after-free, and uninitialized data error such as wild pointer, null pointer reference, and so on.
In Chapter 14, we discussed the best practices and guidelines for C programming. In Chapter 15, we discussed the C compiler defensive technology. In Chapter 16, we discussed the firmware kernel enhancements. On the one hand, all of the industry has provided the guidance and tools to address those flaws. On the other hand, people are also looking for a better type-safe language that can help to prevent the developer from introducing the flaws in the first place.
Rust
- 1)
Performance: Rust is blazingly fast and memory efficient. It does not have a runtime or garbage collector. It can power performance-critical services and run on embedded devices. Runtime performance and runtime memory consumption are extremely important to the firmware because a typical firmware runs in a resource-constrained environment. Even for the Intel Architecture (IA) system firmware, it needs to run code in the system management mode (SMM) which only has limited system management RAM (SMRAM), such as 1 MB or 8 MB. Similar constraints are observed by embedded devices. Rust embedded offers flexible memory management, where the dynamic memory allocation is optional. You may choose to use a global allocator and dynamic data structures or statically allocate everything. This is required because the firmware code may run on the flash device without DRAM.
- 2)
Reliability: Rust introduces a rich type system and an ownership model that guarantees memory safety and thread safety, which enables you to eliminate many classes of bugs at compile time. This is probably the most attractive feature. Rust is not the first language to introduce the type safety concept. One big concern of the type-safe language is the performance degradation because of the runtime type check. The performance impact is hard to accept for embedded system or firmware. The advantage of Rust is that many checks have been done at compile time. As such, the final generated binary does not include such checks. With strict rules of syntax, Rust can trace the lifecycle of a data object. As such, no runtime garbage collection is required. This design not only reduces the binary size but also improves the runtime performance.
- 3)
Productivity: Rust has a friendly compiler with useful error messages. The compiler not only shows what is wrong but also gives suggestions on how to fix the error. It teaches you how to write the Rust language. Rust has provided a unit test framework. You can write a set of unit tests just after the function implementation. Rust also considers the interoperability with other languages with the foreign function interface (FFI). Rust can generate a C language–compatible application binary interface (ABI). You can let Rust call the C language or call Rust from the C language.
Rust Security Solution
Rust Security Solution
Type | Subtype | Rust Solution |
|---|---|---|
Access error (spatial) | Buffer overflow (Write) | Use Offset/Index for Slice Runtime Boundary Check – [panic_handler]. |
Buffer over-read | Use Offset/Index for Slice Runtime Boundary Check – [panic_handler]. | |
Access error (temporal) | Use-after-free(dangling pointer) | Ownership – compile-time check. |
Double free | Ownership – compile-time check. | |
Uninitialized data | Uninitialized variable | Initialization – compile-time check. |
Wild pointer | Initialization – compile-time check. | |
NULL pointer deference | Use Option<T> enum Allocation Check – [alloc_error_handler]. | |
Arithmetic issue | Integer overflow | DEBUG: Runtime check – [panic_handler]. RELEASE: Discard overflow data. Compiler flag: -C overflow-checks=on/off. Function: checked|overflowing|saturating|wrapping_ add|sub|mul|div|rem|shl|shr|pow(). |
Type cast | Must be explicit – compile-time check. (Dest Size == Source Size) => no-op (Dest Size < Source Size) => truncate (Dest Size > Source Size) => { (source is unsigned) => zero-extend (source is signed) => sign-extend } |
Ownership
The gist of Rust memory safety is to isolate the aliasing and mutation. Aliasing means there can be multiple ways to access the same data. The data is sharable. Mutation means the owner has the right to update the data. The data can be changed. The danger arises from aliasing + mutation.
Listing 20-1.
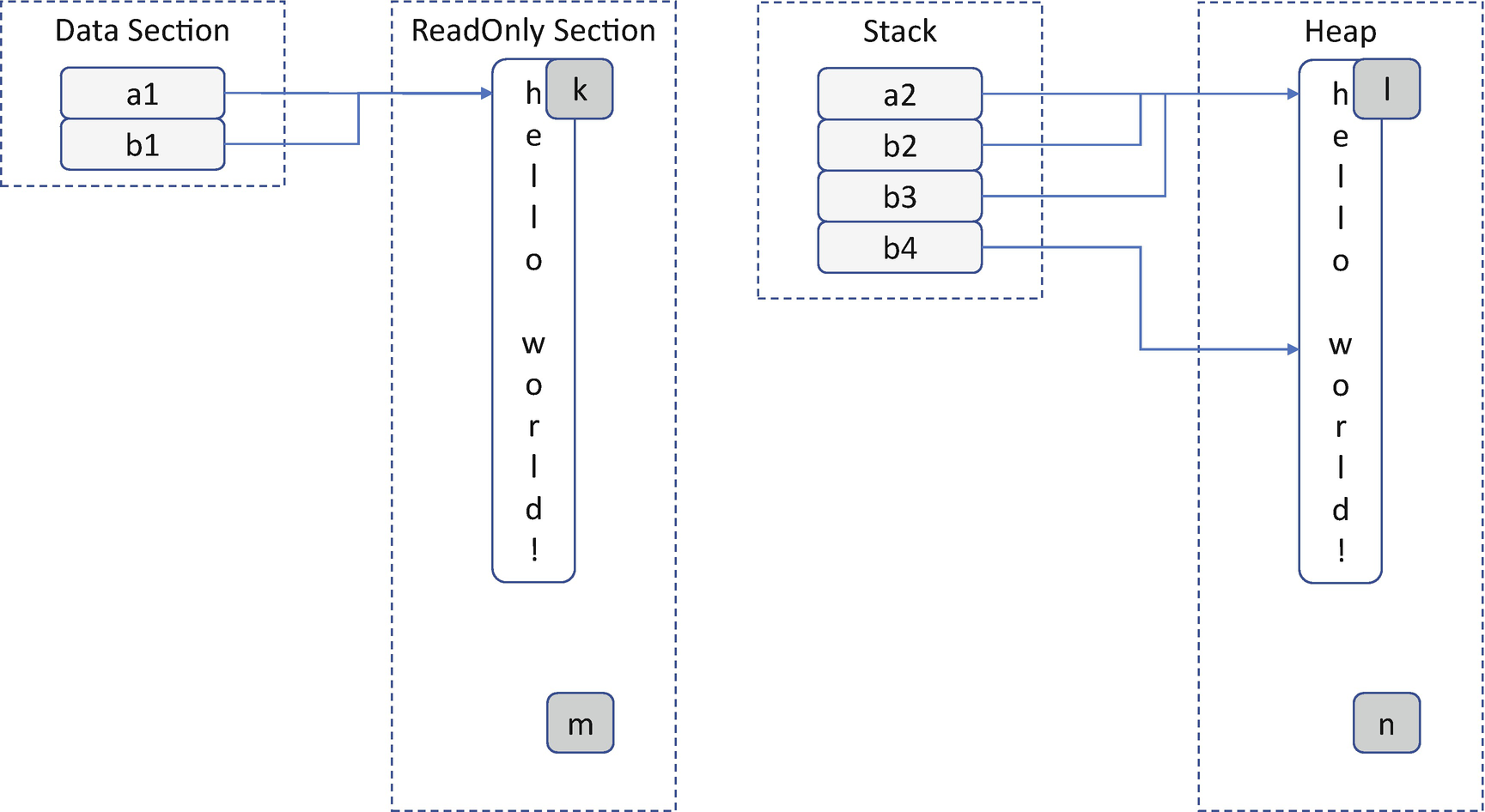
Memory Layout of Listing 20-1
Listing 20-2.
Listing 20-1 can be compiled successfully because the C compiler does not perform any such check. It relies on the developer to do the right thing. With Rust, you cannot write code in such a way. If the data is mutable, it cannot be shared. On the other hand, if the data is shared, it must be mutable. Rust has three basic patterns for programming: ownership, shared borrow, and mutable borrow. Let’s look at them one by one.
Listing 20-3.

Ownership in Rust
Listing 20-4.
Listing 20-5.
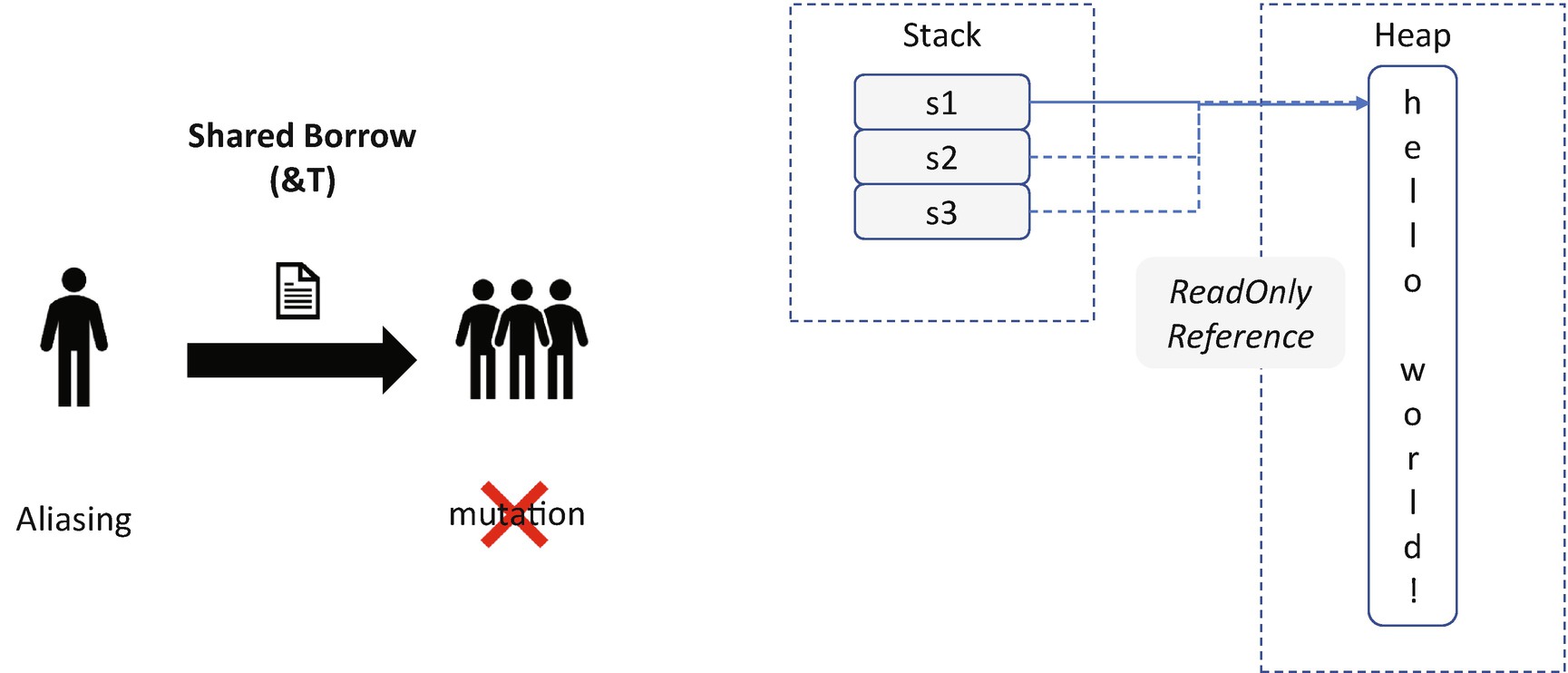
Shared Borrow in Rust
Listing 20-6.
Listing 20-7.
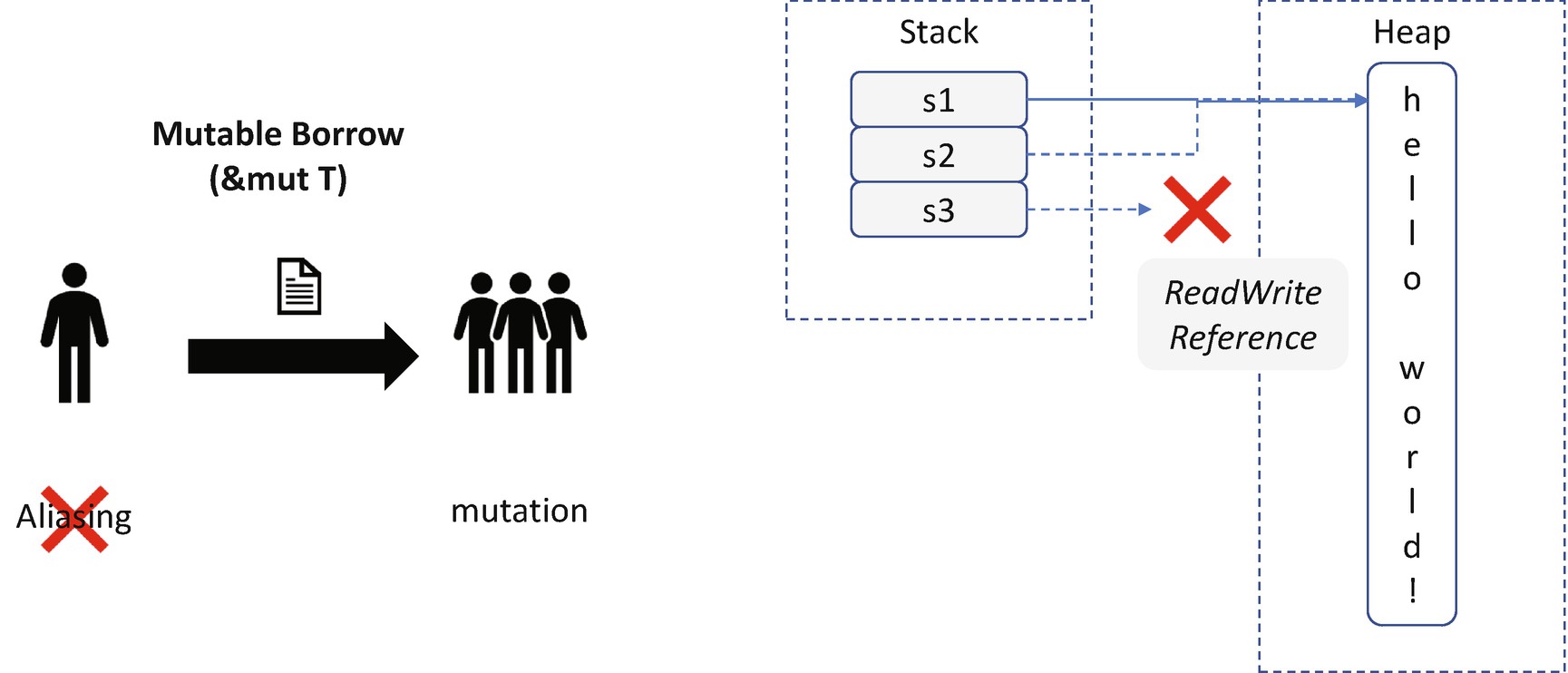
Mutable Borrow in Rust
Listing 20-8.
Listing 20-9.
Listing 20-10.
Listing 20-11.
Option<T> Type
In Listing 20-10, there is a data type – Option<&str>. What is that for?
The C language has NULL pointer concept. Dereference of a NULL pointer causes an exception at runtime. Tony Hoare treated the NULL pointer as a “billion-dollar mistake.” It was invented in 1965 just because it was easy to implement. Eventually it has led to innumerable errors, vulnerabilities, and system crashes.
Listing 20-12.
Listing 20-13.
Listing 20-14.
Boundary Check
Listing 20-15.
Listing 20-16.
Listing 20-17.
Uninitialized Data Check
Rust eliminates the uninitialized data at build time. The compiler does the static analysis to ensure the data used must be initialized in any path, including conditional assignment such as if/else statement. Similar to the C language, there might be false positive, but it is better to eliminate any risk at build time.
Arithmetic Check
Listing 20-18.
- 1)
checked_mul(): The result is Option<T>. If no overflow happens, the result is Some<T>. Otherwise, the result is None.
- 2)
overflowing_mul(): The result is a tuple (T, bool). The first element is a wrapped result. The second element is a bool to show if overflow happens or not.
- 3)
saturating_mul(): The result is T type. It is a saturated value.
- 4)
wrapping_mul(): The result is T type. It is a wrapped value.
Rust Math Operation – a: u32 * b: u32
Method | Overflow Result |
|---|---|
c : Option<u32> = a.checked_mul(b) | c is None. |
(c, o) : (u32, bool) = a.overflowing_mul(b) | c holds the wrapped value. o indicates if overflow happens. |
c : u32 = a.saturating_mul(b) | c holds the maximum u32. |
c : u32 = a.wrapping_mul(b) | c holds the wrapped value. |
c = a * b | c holds the wrapped value in release build. Runtime overflow check fails in debug build. |
Listing 20-19.
Listing 20-20.
A firmware implementation may have external input, such as a Bitmap (BMP) file, a capsule file, a portable and executable (PE) image, a file system, and so on. If the parser needs to perform some math operation, using checked version methods might be a better idea than direct multiplication. It can guarantee the overflow case is well handled.
Besides math operations, type cast might also lead to the data truncation problem. Rust does the build-time check and requests a data type cast explicitly.
All in all, Rust defines a set of very strict rules on using an object and its reference to eliminate memory safety issues. That is one reason that many developers find it is hard to pass compilation, especially for those who are familiar with the C language and satisfied with the freedom brought from the C language. With the C language, the developer can control everything. That also means the developer needs to ensure the code has no memory safety issue. Rust takes another approach. It makes it very hard to write the code to pass the compilation on the first time. The compiler keeps telling you what is forbidden and that there might be a potential problem. But once the code passes the compilation, the Rust language guarantees there is no memory safety issue.
Unsafe Code
So far, we have discussed lots of security solutions brought from Rust, and these solutions can help reduce the amount of security risks in the firmware development. However, this solution brings some limitations. For example, accessing NULL address actually is legal because the tradition Basic Input/Output System (BIOS) sets up the Interrupt Vector Table there. Sometimes, the firmware code needs to access a fixed region memory mapped I/O, such as Trusted Platform Module (TPM) at physical address 0xFED40000. In order to handle such cases, Rust introduces a keyword – unsafe. If the code is inside of an unsafe block, then the compiler does not perform any security check. This is a contract between the developer and the compiler. Unsafe means that the developer tells the Rust compiler “Please trust me.”
Dereference a raw pointer
Call an unsafe function or method.
Access or modify a mutable global static variable.
Implement an unsafe trait.
Access fields of union.
Listing 20-21.
Listing 20-22.
Listing 20-23.
Listing 20-24.
Current Project
Rust is still a young language. It was designed by Mozilla Graydon Hoare, and the first release is at 2014. Because of its security properties, more and more projects are adopting Rust. For example, c2rust can help you convert the C language to the unsafe Rust language. Then people can do refactoring for the unsafe version and turn it into a safe version. Mozilla uses rust for Firefox. Amazon Firecracker is a Rust-based hypervisor. Baidu released Rust-SGX-SDK for the secure enclave and Rust OP-TEE TrustZone SDK as part of MesaTEE. Facebook uses Rust to develop Libra – a decentralized financial infrastructure. Google Fuchsia uses Rust in some components. The OpenTitan hardware root-of-trust uses the Tock OS, which is written in Rust. OpenSK – a Fast Identity Online 2 (FIDO2) authenticator is written in Rust as a Tock OS application. In 2019, Microsoft announced that they would adopt Rust as a systems programming language. In 2020, Microsoft has introduced open source project Verona, a new research language for safe infrastructure programming, which is inspired by Rust.
Firmware projects are including Rust. A rust hypervisor firmware can boot the cloud hypervisor. oreboot is the downstream fork of coreboot – a coreboot without C. EDK II is also adding support to build Rust module in the full UEFI firmware.
Cryptographic algorithms are also being developed in Rust, such as RustCrypto, MesaLink, rusttls, ring, webpki, and so on. The rusttls project includes a security review and audit report by Cure53, which shows the high quality of the code. Hope they can be the replacement for openSSL or mbed TLS in the future. Currently, the ring/webpki depend upon the OS provided random number generation. In order to use the ring/webpki in the firmware, we need a firmware based random number library. For example, the efi-random crate uses the RDRAND and RDSEED instruction in the UEFI/EDK II environment.
Limitation
- 1)
Silicon register lock: We need to use a vulnerability scan tool, such as CHIPSEC.
- 2)
Security policy: We need to perform a policy check to ensure the firmware is configured correctly.
- 3)
Time-of-check/time-of-use (TOC/TOU) issue: We need to carefully perform an architecture review and design review.
- 4)
X86 system management mode (SMM) callout: We need hardware restrictions, such as the SMM_CODE_CHECK feature.
Unsafe components should be appropriately isolated and modularized, and the size should be small (or minimized).
Unsafe components should not weaken the safety, especially of public APIs and data structures.
Unsafe components should be clearly identified and easily upgraded
Writing unsafe code in Rust is same as writing C code. There is no safety guarantee from Rust. Please isolate them, minimize them, and review them carefully.
Others
Other languages are also used in firmware projects. For example, Forth is a language defined in IEEE 1275-1994. It is used for open firmware projects. Some embedded devices use Java Embedded, MicroPython, or the .NET Compact Framework. Those languages require a runtime interpreter. They might be a good candidate as an application language, but they are hard to use as a system language for the firmware development. We also observe that other type safety languages such as Ada or OCaml are used for embedded system, such as the Mirage OS, but they are not widely used.
Summary
In this chapter, we introduced the languages used in firmware development. Because we already introduced a lot on C language in previous chapters, the focus in this chapter is to introduce a new promising language – Rust – including the benefit brought from Rust and its limitation in the firmware security area. This is the last chapter of Part III. In Part IV, we will introduce security testing.
References
Book
[B-1] Peter van der Linden, Expert C Programming: Deep C Secrets, Prentice Hall, 1994
[B-2] Jim Blandy, Jason Orendorff, Programming Rust: Fast, Safe Systems Development, O'Reilly Media, 2017
[B-3] Brian L. Troutwine, Hands-On Concurrency with Rust: Confidently build memory-safe, parallel, and efficient software in Rust, Packt Publishing, 2018
[B-4] Steve Klabnik, Carol Nichols, The Rust Programming Language (Covers Rust 2018), No Starch Press, 2019, https://doc.rust-lang.org/book/
Conference, Journal, and Paper
[P-1] Nicholas Matsakis, “Rust,” Mozilla Research, http://design.inf.unisi.ch/sites/default/files/seminar-niko-matsiakis-rustoverview.pdf
[P-2] Tony Hoare, “Null References: The Billion Dollar Mistake,” in QCon 2009, available at www.infoq.com/presentations/Null-References-The-Billion-Dollar-Mistake-Tony-Hoare
[P-3] Yu Ding, Ran Duan, Long Li, Yueqiang Cheng, Yulong Zhang, Tanghui Chen, Tao Wei, Huibo Wang, “POSTER: Rust SGX SDK: Towards Memory Safety in Intel SGX Enclave,” Computer and Communications Security 2017, https://github.com/apache/incubator-teaclave-sgx-sdk/blob/master/documents/ccsp17.pdf
[P-4] Florian Gilcher, Robin Randhawa, “The Rust Programming Language: Origin, History and Why it's so important for Arm today,” in Linaro Connect 2020, www.youtube.com/watch?v=yE55ZpQmw9Q
[P-5] Bryan Cantrill, “The Soul of a New Machine: Rethinking the Computer,” Stanford Seminar 2020, www.youtube.com/watch?v=vvZA9n3e5pc&list=PLoROMvodv4rMWw6rRoeSpkiseTHzWj6vu&index=4&t=0s
[P-6] Ryan O’Leary, “oreboot,” in Open Source Firmware Conference 2019, available at https://www.youtube.com/watch?v=xJ6zI8MmcUQ
[P-7] Jiewen Yao, Vincent Zimmer, “Enabling Rust for UEFI Firmware,” in UEFI webinar 2020, https://www.brighttalk.com/webcast/18206/428896, https://uefi.org/sites/default/files/resources/Enabling%20RUST%20for%20UEFI%20Firmware_8.19.2020.pdf
Specification and Guideline
[S-1] IEEE, “IEEE Standard for Boot (Initialization Configuration) Firmware: Core Requirements and Practices,” IEEE 1275-1994, available at www.openbios.org/data/docs/of1275.pdf
Web
[W-1] Rust, www.rust-lang.org/
[W-2] Rust Unsafe code guideline, https://github.com/rust-lang/unsafe-code-guidelines
[W-3] c2rust, https://c2rust.com/
[W-4x] Amazon Firecracker, https://github.com/firecracker-microvm/firecracker
[W-5] Rust SGX SDK, https://github.com/apache/incubator-teaclave-sgx-sdk
[W-6] Rust OP-TEE TrustZone SDK, https://github.com/mesalock-linux/rust-optee-trustzone-sdk
[W-7] Facebook Libra, https://github.com/libra/libra
[W-8] Google fuchsia, https://fuchsia.googlesource.com/fuchsia/
[W-9] Tock OS, https://github.com/tock/tock
[W-10] OpenTitan, https://github.com/lowRISC/opentitan
[W-11] OpenSK, https://github.com/google/OpenSK
[W-12] oreboot, https://github.com/oreboot/oreboot
[W-13] EDKII rust support, https://github.com/tianocore/edk2-staging/tree/edkii-rust, https://github.com/jyao1/edk2/tree/edkii-rust/RustPkg, https://github.com/jyao1/ring/tree/uefi_support, https://github.com/jyao1/webpki/tree/uefi_support, https://github.com/jyao1/edk2/tree/edkii-rust/RustPkg/External/efi-random
[W-14] Rust hypervisor firmware, https://github.com/cloud-hypervisor/rust-hypervisor-firmware
[W-15] r-efi, UEFI Reference Specification, https://github.com/r-util/r-efi
[W-16] Rust wrapper for UEFI, https://github.com/rust-osdev/uefi-rs
[W-17] Rust Crypto, https://github.com/RustCrypto
[W-18] MesaLink, https://github.com/mesalock-linux/mesalink
[W-19] RustTls, https://github.com/ctz/rustls/
[W-20] ring – cryptographic operations, https://github.com/briansmith/ring
[W-21] webpki, https://github.com/briansmith/webpki
[W-22] Microsoft – A proactive approach to more secure code, https://msrc-blog.microsoft.com/2019/07/16/a-proactive-approach-to-more-secure-code/
[W-22] Microsoft – why rust for safe systems programming, https://msrc-blog.microsoft.com/2019/07/22/why-rust-for-safe-systems-programming/
[W-23] Open Firmware, www.openfirmware.info/Welcome_to_OpenBIOS
[W-24] mirage OS, https://mirage.io/
[W-25] Cure53, “Security Review and Audit Report RUST TLS,” https://github.com/ctz/rustls/blob/master/audit/TLS-01-report.pdf
[W-26] Project Verona, www.microsoft.com/en-us/research/project/project-verona/, https://github.com/microsoft/verona