
10. Randomness and Determinism
“Alea iacta est.” [The die is cast]
—JULIUS CAESAR
on crossing the Rubicon
One software security issue that turns out to be a much bigger problem than many people realize involves misuse of random number generation facilities. Random numbers are important in security for generating cryptographic keys, shuffling cards, and many other things. Many developers assume that random() and similar functions produce unpredictable results. Unfortunately, this is a flawed assumption. A call to random() is really a call to a traditional “pseudo-random” number generator (PRNG) that happens to be quite predictable. Even some developers who are aware of the potential problems convince themselves that an attack is too difficult to be practical. Attacks on random number generators may seem hard, but are usually a lot easier to carry out than people believe.
Randomness is not as cut and dry as one may think: Some streams of numbers are more random than others. Computers, being completely deterministic machines, are particularly bad at behaving randomly (bad software aside). In fact, the only true sources for high-quality “random” numbers involve measuring physical phenomena, such as the timing of radioactive decay, which can be distilled into good random sequences.
Without access to physical devices to provide randomness, computer programs that need random numbers are forced to generate the numbers themselves. However, the determinism of computers makes this algorithmically difficult. As a result, most programmers turn to traditional pseudo-random numbers. In this chapter we discuss how to use pseudo-random numbers effectively, discuss when it is and isn’t appropriate to use them, and talk about what to do when they’re not the right tool for the job. We’ll also discuss entropy, which is close to the idea of “true” randomness, and is important for securing pseudo-random data streams. We explain how to derive it, give advice on how to figure out how much you’ve collected, and show how to use it.
We also give you several real-world examples of random number systems that were exploitable in the real world.
Pseudo-random Number Generators
Computers are completely deterministic machines. Therefore, computers can’t be good at creating data that are truly random. How would a computer create a random number without somehow computing it? The answer is, of course, that it can’t. If an attacker can record everything a machine does, then there can be no secrets. If the attacker knows the algorithm, and can reproduce the execution of the algorithm along with its inputs, then there can be no secrets. Because computers intrinsically cannot produce what people would call “real” random numbers, they must compute them with an algorithm. Such algorithms are called pseudo-random number generators, or PRNGs.
Necessarily, PRNGs accept inputs used to compute random numbers. If these inputs can be known or guessed by an attacker, then the attacker can simulate the stream of random numbers. Therefore, it is important that the input or inputs to our PRNGs are themselves unable to be guessed. In reality, we only require that these inputs (often called a seed) be computationally infeasible to calculate or guess. Seeds are important because they afford predictability when necessary. It can be extraordinarily difficult to debug a program using a hardware random number generator emitting outputs that are not reproducible.
Obviously, we would prefer that our seed data not be created by a call to a PRNG. Instead, we wish to somehow collect “real” randomness. As a result, cryptographers talk about “collecting entropy.” Entropy is a measure of how much “real” randomness is in a piece of data. For example, let’s say we flip a coin, and use the result as 1 bit of entropy. If the coin toss were perfectly fair, then our bit should have an equal chance of being a 0 or a 1. In such a case, we have 1 bit of entropy. If the coin flip is slightly biased toward either heads or tails, then we have something less than a bit of entropy. Ultimately, entropy is what we really want when we talk about generating numbers that can’t be guessed. However, entropy is really difficult to gather on a deterministic computer. It turns out we can gather some, but it is often difficult to figure out how much we have. It’s also usually difficult to generate a lot of it. We discuss methods for gathering entropy later in the chapter.
In practice, what we do is take any entropy we can gather and use it to seed a PRNG. Note that the security of our seed is measured in the exact same way we measure the security of a block cipher. If we honestly believe that our seed data has n bits of entropy, then the best attack for compromising the seed will be a brute-force attack, taking up to 2n operations. Of course, a poor PRNG allows for attacks that take fewer operations.
Therefore, if we have a 32-bit seed, then we end up with quite weak security, even if the seed is generated by some external source that really did produce 32 bits of entropy. If we have a well-chosen 256-bit seed (in other words, we expect it to have close to 256 bits of entropy), then the stream of numbers pouring from a PRNG cannot be guessed, as long as the algorithm turning that seed into a stream of numbers is invulnerable to attack.
So far, we have assumed that the attacker knows the inner workings of our PRNG, and also knows the inner workings of the software using the PRNG. Granted, this is not always the case. Throughout this book we talk about why these kinds of assumptions turn out to be a bad idea. There are plenty of ways in which such assumptions can be violated, many of which are not anticipated by software practitioners. To compensate, we practice the principle of defense in depth, and assume the worst.
The previous assumptions are similar to those that cryptographers make when analyzing cryptographic algorithms. In fact, a good PRNG is considered a cryptographic algorithm, and is said to provide a cryptographically secure stream of random numbers. Therefore, a good cryptographic PRNG is designed in such a way that, given enough entropy, it keeps producing numbers that are hard to guess, even if an attacker knows the full details of the algorithm.
Note that cryptographic PRNGs are essentially synonymous with stream ciphers (a form of symmetric cipher). Stream ciphers produce a series of pseudo-random data, given some starting state (the key), which is XOR-ed with the plaintext to yield the ciphertext.
In contrast to cryptographic PRNGs, there are traditional statistical PRNGs. Statistical PRNGs are not meant for use in security-critical applications. The primary goal of a statistical PRNG is to produce a sequence of data that appears random to any statistical test. Also, statistical random number generators should be able to generate a number within a given range, in which each number is chosen with equal probability (in other words, the outputs need to be uniformly distributed). This doesn’t mean that the results are unpredictable, however. A generator that produces numbers in sequence from one up to the range does a good job at producing numbers that are uniformly distributed, even though it fails the requirement that data look random from a statistical point of view.
Reproducibility is another goal of traditional statistical PRNGs, so you can expect that the seeding of these generators only happens once, at the beginning. In contrast, a good cryptographic PRNG accepts new seed information at any time, something that can be used to help improve the security of the system. In general, because traditional statistical PRNGs were not designed to meet cryptographic goals, they fall prey to cryptographic attacks, not adequately protecting the seed data. Therefore, even if you seed such PRNGs with 256 bits of entropy, you should not expect that much security to pour out the other end.
We should note that cryptographic PRNGs need to meet all the same goals that traditional statistical PRNGs meet. They have an additional requirement that they must provide cryptographic security, given enough entropy as seed data. Therefore, they can also be considered “statistical” PRNGs, which is why we make the distinction of “traditional” generators, which have been around much longer. As a result, when we say that a generator is believed to be “cryptographically secure,” then its output should pass all statistical tests for randomness.
Unfortunately, most of the PRNGs that developers use are of the traditional variety, not the cryptographic variety. Even worse, the random number generators readily available to most programmers are not cryptographic, including rand(), random(), and the like.
Examples of PRNGs
The most common type of PRNG is called a linear congruential generator. This type of generator takes the form
Xn + 1 = (aXn + b) mod c
In other words, the n + 1th number in a stream of pseudo-random numbers is equal to the nth number of times some constant value a, plus some constant value b. If the result is greater than or equal to some constant c, then its value is forced to be in range, by taking the remainder when dividing the result by c. The variables a, b, and c are usually prime numbers. Donald Knuth, in The Art of Computer Programming [Knuth, 1997], goes into detail about how to pick values for these constants that provide good results for statistical applications. This type of generator is easy to attack cryptographically, and should never be used when security is necessary.
As a more concrete example, the code for the Random() call distributed with most versions of Borland compilers is displayed here. Note that the initial seed varies in different versions (thus the ####), and is often set to the current time by convention. The “current time” technique would not be very effective even if used with a better PRNG, because the current time doesn’t contain much entropy. We revisit this problem with examples from real attacks, later in this chapter.
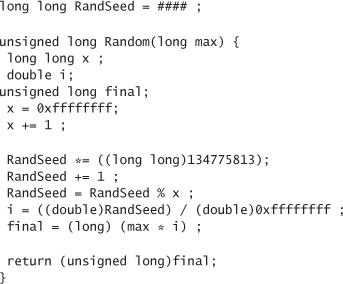
In this generator, if we know that the current value of RandSeed is 12345, then the next integer produced will be 1655067934. The same thing happens every time you set the seed to 12345 (which should not be surprising to anyone because computers are completely deterministic).
Commonly, linear congruential PRNGs produce either an output between zero and one (never being exactly one), or output any integer with equal probability. It is then up to the programmer to scale the number into the desired range. For example, if a programmer wants an integer between zero and nine, he or she would likely take the output of the previous generator, multiply by ten, and then take the floor of the result. Some libraries provide higher level functionality for getting numbers in a particular range, or for getting numbers in a distribution other than uniform.
Most instances of linear congruential PRNGs are highly susceptible to attack because they only operate on 32-bit values. Therefore, the internal state that needs to be guessed is small. Generally, a few outputs are all that are necessary to figure out the entire internal state. There are only four billion possible places on a standard random number “wheel.” (With many random number generation algorithms, including linear congruential generators, all the numbers between 0 and 4,294,967,295 are generated exactly once, then the sequence repeats.) If we observe enough numbers, even if the numbers are adjusted to be somewhere between 0 and 50, we can eventually figure out how the generator was seeded. We can do this by trying all four billion possible seeds in order and looking for a subsequence in the PRNG stream that matches the one your program is exhibiting. Four billion is not a big number these days. Given a handful of good-quality PCs, the supposedly-big-enough space can be “brute forced” in almost real time.
Nonetheless, improving the algorithm to work on 64-bit numbers or 128-bit numbers does not help. This is because these generators are susceptible to other forms of attack, because they essentially give away state with each output.
You should assume that any PRNG not advertised to be “cryptographic” is unsuitable for use in secure programming. For example, geometric PRNGs turn out to be susceptible to cryptographic attacks, and should therefore be avoided.
The Blum-Blum-Shub PRNG
The Blum-Blum-Shub generator is a cryptographic PRNG. Much like the RSA public key cipher, the Blum-Blum-Shub algorithm gains its security through the difficulty of factoring large numbers. Therefore, you need to pick prime numbers of similar sizes to your RSA keys if you desire the same degree of security. This means that you’ll almost certainly be doing modular arithmetic with a software library, because your internal state will be too big to be a primitive type. This makes the Blum-Blum-Shub algorithm impractical for many uses, as it is excruciatingly slow in practice. Nonetheless, this algorithm is important, because, unlike most cryptographic PRNGs, its security is based on a simple mathematical principle (factoring). In contrast, other cryptographic PRNGs tend to base their security on block ciphers or hash functions. Although such primitives may provide excellent security in practice, and may be much faster, it is much harder to analyze their security accurately.1
1. Of course, the computational difficulty of factoring is not proved.
Anyway, here is how the algorithm works. First, pick two large prime numbers, p and q, such that p mod 4 yields 3, and q mod 4 yields 3. These primes must remain secret. Calculate the Blum number N, by multiplying the two together. Pick a random seed s, which is a random number between 1 and N (but cannot be either p or q). Remember, s should be well chosen, and should not be able to be guessed.
Calculate the start state of the generator as follows:
x0 = s2 mod N
This generator yields as little as 1 bit of data at a time. The ith random bit (bi) is computed as follows:
xi = xi − 12 mod n
bi = xi mod 2
Basically, we’re looking at the least significant bit of xi, and using that as a random bit.
It turns out that you can use more than just the single least significant bit at each step. For a Blum number N, you can safely use log2N bits at each step.
The Tiny PRNG
Tiny is a PRNG that is a simple evolution of the Yarrow PRNG [Kelsey 1999] and also facilities for dealing with entropy. We discuss Tiny’s treatment of entropy later in this chapter. Here we only discuss the cryptographic PRNG.
At a high level (the details are slightly more complex), the Tiny PRNG works by encrypting a counter using AES to produce successive blocks of output. The key and the initial state of the counter are derived from the seed data. The end user can request data of nearly arbitrary size, which is generated through successively incrementing the counter and encrypting. Occasionally, Tiny generates a few more blocks of output, and uses this to reseed itself. Additionally, the definition of Tiny specifies how new seed material may be added, even after numbers have been output.
This generator is believed to be secure against all known cryptographic attacks. It is similar in style to a number of other PRNGs. For example, a simple cryptographic PRNG would be to keep a secret key and a counter, and to encrypt the counter to get output. Tiny is slightly more complex, because it seeks to prevent against all possible attacks.
Another common variation is to use a secret counter as an input to a cryptographic hash function such as SHA-1 or MD5. Such a generator depends on the noninvertibility of the hash function for its security. Still other generators rely on compression functions. However, cryptographic hash algorithms always make strong use of compression functions internally.
Attacks against PRNGs
At a high level, there are two kinds of attacks against which a good PRNG must protect, assuming a high-quality seed. We discuss protecting seeds later when we talk about gathering entropy.
First, the PRNG must protect against cryptanalytic attacks. A successful cryptographic attack is any attack that can distinguish generator output from truly random data. Note that it is possible for cryptanalytic attacks on a generator to exist that are impractical in terms of crafting a real-world exploit.
The other kind of attack is an attack against the internal state of the PRNG. The PRNG must defend against any knowledge of the internal state as best it can. Complete compromise should, at the very least, allow the attacker to calculate all future outputs, at least until additional entropy is added to the internal state. Partial compromises may allow for the attacker to guess outputs with a reasonable probability of being correct. A partial compromise may lead to a full compromise if new outputs from the generator give out even more of the internal state, or if the internal state can be guessed.
Linear congruential generators are susceptible to state attacks, because they essentially give away their entire internal state with every output. The only thing that keeps such a generator from being broken after a single input is that developers tend to take the number output from the PRNG and narrow it to a fairly small number of possible values.
How to Cheat in On-line Gambling
Here’s a good example of how poor PRNGs can be broken in practice. In 1999, the Software Security Group at Cigital discovered a serious flaw in the implementation of Texas Hold ‘em Poker, which is distributed by ASF Software, Inc. The exploit allows a cheating player to calculate the exact deck being used for each hand in real time. This means that a player using the exploit knows the cards in every opponent’s hand as well as the cards that make up the flop (cards placed face up on the table after rounds of betting). A cheater can “know when to hold ‘em and know when to fold ‘em” every time. A malicious attacker could use the exploit to bilk innocent players of actual money without ever being caught.
The flaw exists in the card shuffling algorithm used to generate each deck. Ironically, the shuffling code was publicly displayed in an on-line FAQ with the idea of showing how fair the game is to interested players (the page has since been taken down), so it did not need to be reverse engineered or guessed.
In the code, a call to randomize() is included to reseed the random number generator with the current time before each deck is generated. The implementation, built with Delphi 4 (a Pascal development environment), seeds the random number generator with the number of milliseconds since midnight according to the system clock. This means that the output of the random number generator is easily predicted. As we’ve discussed, a predictable “random number generator” is a very serious security problem.
The shuffling algorithm used in the ASF software always starts with an ordered deck of cards, and then generates a sequence of random numbers used to reorder the deck. In a real deck of cards, there are 52! (approximately 2226) possible unique shuffles. Recall that the seed for a 32-bit random number generator must be a 32-bit number, meaning that there are just more than four billion possible seeds. Because the deck is reinitialized and the generator is reseeded before each shuffle, only four billion possible shuffles can result from this algorithm, even if the seed had more entropy than the clock. Four billion possible shuffles is alarmingly less than 52!.
The flawed algorithm chooses the seed for the random number generator using the Pascal function Randomize(). This particular Randomize() function chooses a seed based on the number of milliseconds since midnight. There are a mere 86,400,000 milliseconds in a day. Because this number was being used as the seed for the random number generator, the number of possible decks now reduces to 86,400,000. Eighty-six million is alarmingly less than four billion.
In short, there were three major problems, any one of which would have been enough to break their system:
1. The PRNG algorithm used a small seed (32 bits).
2. The PRNG used was noncryptographic.
3. The code seeded with a poor source of randomness (and, in fact, reseeded often).
The system clock seed gave the Cigital group an idea that reduced the number of possible shuffles even further. By synchronizing their program with the system clock on the server generating the pseudo-random number, they were able to reduce the number of possible combinations down to a number on the order of 200,000 possibilities. After that move, the system is broken, because searching through this tiny set of shuffles is trivial and can be done on a PC in real time.
The Cigital-developed tool to exploit this vulnerability requires five cards from the deck to be known. Based on the five known cards, the program searches through the few hundred thousand possible shuffles and deduces which one is a perfect match. In the case of Texas Hold ‘em Poker, this means the program takes as input the two cards that the cheating player is dealt, plus the first three community cards that are dealt face up (the flop). These five cards are known after the first of four rounds of betting and are enough to determine (in real time, during play) the exact shuffle.
Figure 10-1 shows the GUI for the exploit. The Site Parameters box in the upper left is used to synchronize the clocks. The Game Parameters box in the upper right is used to enter the five cards and to initiate the search. Figure 10-1 is a screen shot taken after all cards have been determined by the program. The cheating attacker knows who holds what cards, what the rest of the flop looks like, and who is going to win in advance.
Figure 10-1 The GUI for Cigital’s Internet poker exploit.
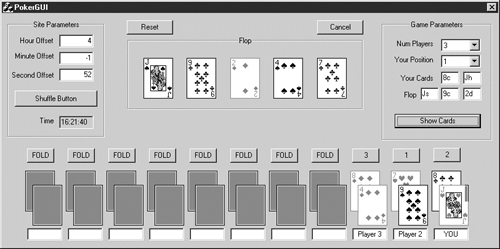
Once the program knows the five cards, it generates shuffles until it discovers the shuffle that contains the five known cards in the proper order. Because the Randomize() function is based on the server’s system time, it is not very difficult to guess a starting seed with a reasonable degree of accuracy. (The closer you get, the fewer possible shuffles through which you have to look.) After finding a correct seed once, it is possible to synchronize the exploit program with the server to within a few seconds. This post facto synchronization allows the program to determine the seed being used by the random number generator, and to identify the shuffle being used during all future games in less than 1 second.
ASF Software was particularly easy to attack. However, most uses of linear congruential PRNGs are susceptible to this kind of attack. These kinds of attack always boil down to how many outputs an attacker must observe before enough information is revealed for a complete compromise. Even if you are only selecting random numbers in a fairly small range, and thus throwing away a large portion of the output of each call to rand(), it usually doesn’t take very many outputs to give away the entire internal state.
Statistical Tests on PRNGs
We mentioned earlier that one of the properties that is important to a high-quality PRNG is that the output be indistinguishable from truly random data. We can use statistical tests to ensure that our PRNG is producing outputs that appear random. Most notably, the FIPS140-1 standard, “Security Requirements for Cryptographic Modules,” [FIPS-RIO-1] discusses a set of statistical tests for such things.
However, any PRNG based on a well-respected cryptographic primitive passes all such tests with ease. Remember, passing such tests is no guarantee that your system cannot be broken. A poorly designed cryptographic PRNG still passes all tests, yet is easy to attack. Also, any time that the seed to a generator is compromised, the generator’s output should still be compromised, even though testing will again pass.
Statistical tests are slightly more interesting for testing the quality of data collected in the entropy-gathering process. We discuss such tests in this context later in this chapter.
Entropy Gathering and Estimation
We don’t want to mislead you into thinking that using a good PRNG gives you any security in and of itself. Remember that even PRNGs such as Tiny and Blum-Blum-Shub are completely predictable if you know the seed. Therefore, once we have selected a good PRNG, we must worry about seeding it with data that possess sufficient entropy for our needs. You can’t hard code a value from the top of your head into your program. Attackers are likely to notice when your code generates the same sequence of numbers every time you run it. Likewise, you can’t ask someone to type in a number manually, because people are not a good source of randomness.
Commonly, people use data that do not contain much entropy to seed PRNGs, including network addresses, host names, people’s names, and the programmer’s mother’s maiden name. These kinds of data are also used frequently when picking cryptographic keys. Note that these values don’t change very often, if at all. If an attacker can figure out how you’re picking your data (usually a safe bet), it becomes a matter of hunting down the requisite information.
A more common thing to do is to seed the PRNG with the current value of the clock. Remember that the clock is only a 32-bit value on most systems, so it can never provide more than 32 bits worth of entropy, which is not enough. When estimating how much entropy we have, we would conservatively estimate no more than 4 bits of entropy. If you then sample the clock on a regular basis, you get very little entropy. Although you may get some, our conservative nature leads us to assume that you do not.
Obviously, we need better ways of generating seed data with sufficient entropy for most applications. This section deals with collecting such data, as well as estimating how much entropy is in those data. Unfortunately, picking and implementing a PRNG is the easy part. Gathering entropy is often quite difficult. More difficult still is determining how much entropy has really been gathered. It usually comes down to an educated guess. Therefore, we recommend that your guesses be very conservative.
Hardware Solutions
Using dedicated hardware for producing entropic data tends to produce entropy at much higher rates than software solutions. Also, assumptions about how much entropy has actually been gathered are more likely to be correct. Of course, there are a number of broken hardware random number generators too.
Suffice it to say that we do realize that hardware-based solutions aren’t always feasible. For example, you may wish to distribute an application to hundreds of thousands of users around the globe, and still need good random numbers on each and every desktop. Until every computer in the world is fitted with a good random number generator in hardware, there will always be a real need for software that comes as close as possible to true randomness.
The way that hardware sources generate their random numbers is to derive them from some natural stochastic process. A good source for random data is measuring the thermal noise off a semiconductor diode, although if improperly shielded, nearby hardware can bias the output. Most commercially available hardware random number generators seem to be of this variety.
One of our favorite hardware solutions involves the use of an electronic Geiger counter that generates a pulse every time it detects a radioactive decay. The time between decays has a strong, pure random component. In particular, nobody can predict whether the time until the next decay will be greater than or less than the time since the previous decay. This yields 1 bit of random information. We could potentially get more. Let’s say, for the sake of example, we’re observing some material that we expect to decay every second, but the decay could happen up to a tenth of a second off in either direction. Instead of comparing the times between two decays, we could time the decay, and use the individual digits as individual base ten random numbers. Maybe the hundredths of a second would be one digit, and the thousandths of a second another. We could siphon off digits in proportion to the accuracy of our timer.
This technique may or may not be good enough. It’s hard to tell without trying it and doing some statistical analysis of the data. What if the hundredths of a second digit is almost always 0, but infrequently is 1? This isn’t very random. What if our clock isn’t all that functional, and the thousandths digit is always even, or at least far more likely to be even? These kinds of problems are fairly commonly encountered. There are all sorts of things that can go wrong, that thus bias the data. In such a case, there is less than 1 bit of entropy per bit of output. Of course, we do not want to produce random numbers that are in any way biased. We discuss how to deal with this problem later in the section Handling Entropy. For now, just know that there are good techniques for taking the data from a hardware source and removing any sort of bias or correlation between bits. Note that our recommendation here is that you always postprocess everything you get from a hardware source, and do not use it directly.
Probably the most widely used commercial device for random numbers is the ComScire QNG, which is an external device that connects to a PC using the parallel port. The device is believed to be well designed, and has done extremely well in statistical analyses of its output. It is capable of generating 20,000 bits (2,500 bytes) per second, which is more than sufficient for most security-critical applications. Even when it is not sufficient, data from the generator can be stored in advance, or multiple generators can be used. Another benefit of this package is that the device driver does statistical tests on numbers as you generate them, and returns an error if data that are statistically nonrandom start being generated. We still recommend postprocessing the data. However, these tests can help you determine when the hardware has failed, and should no longer be trusted as a source of entropy. As of this writing, the device is $295 and is available from https://www.comscire.com/.
A similar device is the RBG 1210 from Tundra (http://www.tundra.com/). Their device has sometimes exhibited a small bias, but otherwise has passed bevies of statistical tests.
The RBG 1210 is an internal card for a PC, and has a variable sampling rate. If you sample too much, successive bits have a high correlation because the internal hardware doesn’t change output fast enough to meet the sampling rate. However, this device should produce as much as 160,000 bits (20,000 bytes) per second.
Another one that has great fun-and-games appeal is lavarand (http://lavarand.sgi.com/). This approach relies on the chaos inherent in a set of operating Lava Lite lamps. A digital camera is set up in front of six lava lamps and is used to take a picture every once in a while. The resulting “noisy” digital image is then cryptographically hashed into a 10-bit seed. This seed is then fed through the Blumb-Blumb-Shub PRNG to produce a small sequence of numbers on their Web site. Don’t use the lavarand in your security-critical code, however! Remember, everybody, including attackers, can see the lavarand sequence on the Web. SGI doesn’t sell lavarand installations either. It wouldn’t be all that hard to build lavarand yourself if you follow the fine, detailed advice on the lavarand Web page.
Nonetheless, lavarand is not intended to compete with the other devices we have discussed. Most of the installations are costly (what with the high price of lava lamps these days), and the generator only outputs approximately 550 bits (a bit less than 70 bytes) per second. It’s also space intensive for such a device, requiring a lamp and a camera. Finally, it’s prone to failures such as broken hardware. To solve the latter problem, SGI uses six lamps on automatic timers, of which three are always on. Everything in their system seems to work extraordinarily well, just with a fairly low bandwidth. Part of the problem is that a photograph needs to be taken and scanned. But the bulk of the problem is that the data have a high potential for statistical bias, and thus are heavily postprocessed before being posted to the Web.
Much of the security community became excited in 1999 when Intel announced that they would start adding thermal-based hardware random number generators to their chipsets, at essentially no additional cost to the consumer. People became even more excited when prominent cryptographers declared the generator an excellent source of random numbers. All Pentium IIIs with an 8xx chipset, 810 or higher, should have this functionality. However, we’ve heard rumors that Intel did not follow through with their plans, and the generator does not appear in future chipsets. As of this writing, we have been unable to confirm or deny these rumors. We do think it would be of great benefit for such generators to be widely available on desktop computers.
There are, of course, other lesser known products for generating random numbers in hardware. There are even a few resources on the Web (see linked to through this book’s companion Web site) that can show those of you who are adept at building hardware how to build your own hardware random number generator on the cheap.
How much entropy do hardware sources actually give? This can certainly vary widely. However, if you’re using a high-quality source, there may be nearly as much entropy as output. We believe that a good, conservative approach is to test output continually with statistical tests (discussed later), and then, if the tests succeed, to assume one quarter the amount of entropy as the number of bits of output. More liberal approaches are probably fine, in practice. However, hardware devices tend to give a high bandwidth of output, so you can probably afford to be conservative. Moreover, we’ve learned many times over that it pays to be conservative when it comes to security.
Software Solutions
We’ve noted that, because computers are completely deterministic, pure software solutions for gathering entropy can always be compromised by an attacker, given the right resources. Really, this is more a theoretical problem than a practical reality. Yes, people could use special devices to figure out exactly what your machine is doing at all times. Yes, an attacker could break into the location where your machine is stored, and change the kernel.
In reality, most applications use software sources of randomness anyway, because external sources for random numbers can be quite inconvenient. After all, hardware sources don’t currently come preinstalled on every desktop. Even when random numbers are only needed on a small number of machines, dedicated hardware remains an additional cost that many people are unwilling to pay.
If we make the assumption that a machine is not completely compromised, then we can get entropy from software. Ultimately, all such entropy is derived from external inputs that affect the state of a deterministic computer. We bank on the idea of measuring inputs that should be unpredictable, such as keyboard presses.
Also, note that even the few inputs a computer does get can cause it to behave in ways that are difficult to simulate. Software is complex, and its behavior can be hard to simulate in real time, especially when an attacker doesn’t know the exact time and value of all inputs. Even when we are not able to measure inputs directly, we can still get entropy from past inputs by sampling frequently changing parts of the system state at some coarse interval.
In fact, there is a common misconception that you shouldn’t trust the state of even one of the best software-based PRNG algorithms at system boot time. The theory is that software is at its most predictable right after boot. Peter Gutmann has found that instincts are wrong in this case [Gutmann, 2001]. A system may produce entropy faster at start-up than at any other time:
This is because the plethora of drivers, devices, support modules, and other paraphernalia which the system loads and runs at boot time (all of which vary in their behaviour and performance and in some cases are loaded and run in nondeterministic order) perturb the characteristics sufficiently to provide a relatively high degree of entropy after a reboot. This means that the system state after a reboot is relatively unpredictable, so that although multiple samples taken during one session provide relatively little variation in data, samples taken between reboots do provide a fair degree of variation.
Currently, we won’t worry about how to take data we gather that may have entropy in it and convert it into a statistically random number. We need to do this, but we discuss it in the section entitled Handling Entropy. For now, when we take a measurement and try to get entropy from it, we take as much related data as possible that may provide any entropy. In particular, we not only use the value of the measurement, we also use the time at which we took the measurement.
Things are best if our entropy is “pushed” to us. For example, when a key press occurs, we then wring more entropy from recording a time stamp than if we poll for the most recent keystroke every tenth of a second. This is because there are far fewer possible values of the time stamp when you poll. However, polling does potentially add a little bit of entropy. When you perform any sort of wait for a particular interval, there is no guarantee that your wait will end exactly on that interval. Usually, your wait ends a little bit late. How much, can vary. Nonetheless, when performing any polling solution, we suggest that you don’t rely on that behavior when estimating entropy.
One common source of entropy involves sampling keyboard or mouse events from the user. If the entropy gathering can be done at the operating system level, you may be able to do this for all such inputs to the machine. In other applications, it is common to ask people to wiggle the mouse or to type text into the keyboard until the program believes it has gathered enough entropy. A problem with this solution is that the data sampled for randomness need to be unavailable to anyone who is a potential attacker. If you plan to read mouse events under X Windows, note that most mouse events are potentially visible as they travel over the network to other applications. On Windows, any application should be able to listen for mouse events, so you should be certain that nothing malicious is running on a machine before using event data as a high-entropy source.
Another problem with mouse events is what to do when the mouse doesn’t change between events or, in the keyboard situation, what to do if someone holds down a key so that it is repeated. There’s usually no real entropy to be gained in such situations. You must avoid estimating any gain in entropy in such cases.
The time stamp that goes with each such event may provide a few bits of entropy. The data are much harder to judge. At the extreme, some people even throw key press data away. We add it to the mix, but estimate no additional entropy from it. Being conservative, we would estimate no more than 2 bits for each mouse and keyboard event measured, and then only if we are sure we have avoided the two problems we have discussed.
Hopefully, even machines that receive moderate use are pretty entropic just from the few inputs they receive, given the complex nature of the software being run. We can try to distill such entropy by timing how long it takes to perform a particular task. We want to avoid oversampling, so we should generally perform that task a large number of times. For example, we may time how quickly we can yield the processor a particular number of times:

The challenge here is to figure out how much entropy this actually provides us in practice. Unfortunately, this is an incredibly complex task, requiring not only a good handle on all possible attacks against a system, but an excellent command of information theory. Entropy estimation is the area in which software random number generation systems are weakest. By that, we don’t necessarily mean that the entropy estimation code leads to attacks. We mean that it tends to be particularly ad hoc, and not necessarily supported by hard fact. We’re not going to use highly accurate techniques for entropy estimation here. The reality is that the computer science research community still needs to address the problem. As a result, we can’t realistically recommend easy solutions. Instead, we’ll use some okay ad hoc techniques to guess how much entropy is present, and then make a conservative guess based on the result.
Right now, most libraries that deal with software-based entropy collection don’t try very hard to estimate how much entropy they have. Instead, they tend to take the “Hail Mary” approach, collecting entropy for a while, and hoping that they collect enough. We would rather have an ad hoc estimate that we believe to be conservative than to have no estimate at all.
An off-the-cuff approach is to look at the time something takes in milliseconds, and then compare the differences between many subsequent timings in a highly controlled environment, trying to see which bits of the difference seem to have some entropy. We look only at the two least significant bytes of the deltas, which should be changing fastest. For each delta, we look at each bit in that byte, and count how many times it was 0 and how many times it was 1:
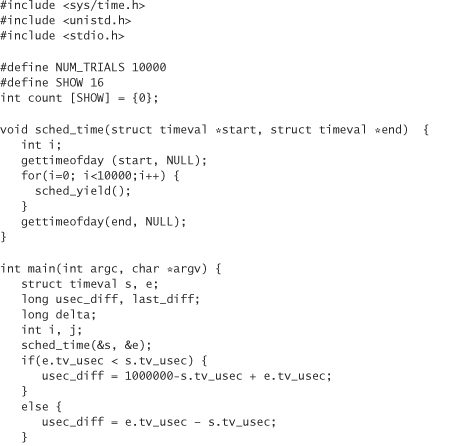
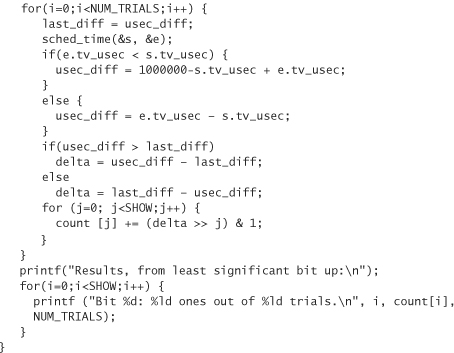
What we do is look to see which bits seem just as likely to be 0 as 1, on an otherwise idle machine (the best condition under which to test such a thing). On a test machine, we get the following results:
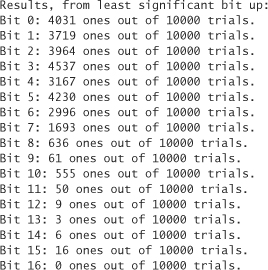
Unfortunately, there seems to be a lot of bias in our output. Even the least significant bits aren’t quite close to half the time (this could be the result of accuracy issues with the clock). This makes it hard to tell how much entropy we’re really getting without applying statistics. However, we can see that we seem to be getting at least half a bit of entropy out of the first 6 bits, because they are either 0 or 1 at least one quarter of the time.
This technique doesn’t test for correlation between individual bits in a timer. Hopefully, there won’t be any, but we’d have to perform better statistical tests to find out for sure. This is a lot of work, so let’s just make due with an estimate that should be conservative no matter what. We also need to be conservative and take into account differences between machines and operating systems, if our code is to be ported. Actually, we should even run a million trials or more before settling on a number. When we run one million trials, we get the following results:
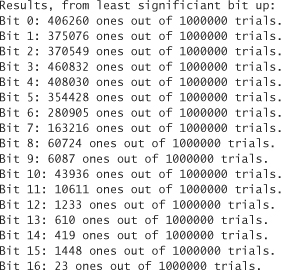
Results seem to confirm that we should be getting at least 3 bits of entropy each time we use this source. Instead of saying we are getting 3 bits or more, we conservatively say that we get only 1 bit (our off-the-cuff strategy here is to take one third of the guess, rounding down).2
2. This metric is pretty arbitrary. Because researchers have not yet given us sound metrics for estimating entropy, we use something that seems to be far more conservative than the expected worse case, given our understanding of the source.
It is important to place entropy estimates in the context of how they will be used. The estimate for our scheduling technique assumes an attack model in which the attacker cannot generate correlated data or otherwise do a better job at guessing the time stamps than one would naively expect.
Nonetheless, this scheme of scheduler yields is something that an attacker on the same machine may be able to duplicate by doing the exact same thing at the exact same time. The attacker should end up getting correlated data (such an attack would be difficult but not impossible to launch). Be sure when estimating entropy to consider every possible attack against which you wish to defend.
Just because there’s a local attack against this collection technique doesn’t mean this technique isn’t useful. It just means that you shouldn’t exclusively rely on it. An attack is somewhat difficult and may never be launched. And when the attack isn’t running, the entropy we gather can be useful. To make the attack much harder, we can time how often we can perform some complex operation. For example, instead of just yielding the scheduler, we may test to see how long it takes us to launch a thread that does nothing, some number of times. Here’s some pthread code that does it (compile with –lpthread):

Our tests indicate this technique is much better at providing entropic data. The low-order 3 bits each give us nearly a full bit of entropy. Overall, this technique would probably give at least 6 bits of entropy per call in real applications, perhaps 7 bits. We conservatively estimate it at 2 bits.
Even if we’re afraid of an attack, we should still use a source, especially if it’s cheaply available. To protect ourselves, we should use defense in depth, using multiple sources, and make assumptions that sources will be compromised. The Tiny Entropy Gateway does exactly that. (We discuss Tiny’s entropy collection in a bit more detail later in the chapter.)
If we seem to be getting less than a few bits per sample for any collection technique, then we should just increase the number of runs we perform when doing timing. However, we must watch out. Too many runs at once can have an impact on performance. You usually want to avoid having a thread that gathers entropy constantly, unless you need to gather a particular amount of entropy before work can continue. Instead, occasionally go out gathering. Treat entropy gathering like garbage collection.
One thing to note is that both the previous techniques (thread timing and timing scheduler yields) are, at some level, correlated, because they both measure process timing as affected ultimately by all inputs to the machine. Therefore, at least from a theoretical point of view, you should probably avoid using more than one of these techniques at once. In practice, it is probably okay to consider both techniques separate entropy sources. However, if you do so, we recommend that you reduce your entropy estimates by at least half.
Another technique for gathering entropy is called TrueRand, written by Don Mitchell and Matt Blaze. The code is pretty UNIX-specific, but it could be adapted to Windows with a bit of effort.
The idea behind TrueRand is that there is some underlying randomness that can be observed even on idle CPUs. The approach involves measuring drift between the system clock, and the generation of interrupts on the processor. Empirical evidence suggests that this drift is present on all machines that use a different clock source for the CPU and interrupt timing, and is a good source of entropy (it hasn’t been broken yet, at least not publicly). However, there are experts who argue otherwise. This entropy should be distinct from that obtained through thread timing and similar techniques. We link to an implementation of TrueRand on this book’s companion Web site.
According to comments in the reference implementation, Matt Blaze believes that TrueRand produces 16 bits of entropy for every 32 bits output by the TrueRand algorithm. There have been a few debates over whether TrueRand really produces that much entropy, or any entropy at all. But because we’ve never seen a method for breaking TrueRand, we’d probably estimate the entropy conservatively at 2 bits per 32 bits output.
Other techniques that are frequently used include recording network traffic as it comes into your machine, timing how long it takes to seek the disk,3 and capturing kernel state information that changes often. For kernel state information, the common technique is to run common commands that tend to change fairly frequently, including ps, w, and df. These commands do not produce a high bandwidth of output. Run tests on the outputs to be sure. Off the cuff, if we were to sample these every second for a minute, we’d probably estimate no more than 2 bits of entropy, especially on a machine that is mostly idle. On a machine with a lot of processes, we may be willing to support more favorable estimates. However, on the whole, we prefer the thread-timing technique; it ultimately measures a lot of the same things, and seems to us to be far less prone to attack. Sometimes the operating system reveals more of its internal state, such as with the /proc file system. This tends to be a better place to collect entropy.
3. This technique is hard to get right, and thus is not recommended because file caching in the operating system can greatly reduce the amount of entropy collected.
One good idea is to tune your entropy estimates on a per-machine basis. Compile statistical tests similar to the ad hoc tests we have provided here, and then generate entropy estimates per source based on that information. If this is too much work, then just make sure your estimates stay conservative.
Poor Entropy Collection: How to Read “Secret” Netscape Messages
Work by Ian Goldberg and David Wagner from January 1996 [Goldberg, 1996a] demonstrates the need to use good entropy sources. Their exploit shows how serious flaws in one of Netscape’s early implementations of SSL made it possible to decrypt encoded communications. This flaw is ancient history of course, but the lessons are important enough to bear repeating.
SSL encrypts most messages with a secret session key. Session keys are one-time keys that are generated for the lifetime of a session and are then thrown away. As in the poker-shuffling case, if the key is predictable, then the whole system is open to attack. Simply put, it is essential that the secret keys come from an unpredictable source.
Netscape’s problem was choosing a bad way to seed their PRNG. Their seed could be completely determined from knowledge of the time of day, the process ID, and the parent process ID.
An attacker using the same box as the attacked browser (say, on a multiuser machine) could easily find out process IDs (in UNIX) using the ps command. Goldberg and Wagner [Goldberg, 1996a] also detail an attack that doesn’t require knowledge of the process IDs (based on the fact that there are usually only 15 bits in each). All that remains is guessing the time of day. Sniffers can be used to snag the precise time a packet goes by, which gives a great starting point for guessing the time of day on the system running Netscape. Getting within a second is pretty easy, and the milliseconds field is crackable in real time (as the poker exploit demonstrated).
Goldberg and Wagner used their attack successfully against Netscape version 1.1. Both the 40-bit international version and the 128-bit domestic version were vulnerable; real keys could be broken in less than 30 seconds. The take home lesson is simple: If you need to generate random numbers to use in cryptography, make sure you gather sufficient entropy.
Handling Entropy
Now that we’ve learned to gather entropy, and figured out how to estimate that entropy, we need to determine what to do with the data coming from our sources.
An entropy handler is an entity responsible for taking an arbitrary amount of data from entropy sources, along with an estimate of how much entropy is in that data. It should process the data and then output random numbers. The difference between an entropy handler and a PRNG is that an entropy handler outputs bits that are hopefully close to purely entropic, meaning that the entropy handler probably can’t output random numbers very quickly at all. Therefore, the outputs of the entropy handler should primarily be used to seed a PRNG. Note that there are some applications when we need to guarantee that our random numbers really do have as much entropy as the number of bits. In particular, the one-time pad (Chapter 11) has this requirement. In such cases, you should also use the entropy handler outputs directly. Similarly, for generating a set of long-term keys, you may wish at least to instantiate a new PRNG just for use in generating that key, and destroy it when you’re done. This way, no other random data are correlated to your key. If you want each key to be cryptographically independent, use raw output from the entropy handler.
The entropy handler obviously doesn’t repeat its inputs as its outputs. It may get a large amount of data with only a single bit of entropy in it (such as the output of the ps command). It will probably distill entropy into fixed-size buffers until it is time to output, to avoid storing lots of unnecessary information.
A problem is how we add entropy to a buffer. We can XOR new data into a buffer, but this technique has some disadvantages. The most important thing to note is that entropy isn’t additive. If you have a bit with an entropy of 1, and you XOR it with another bit with an entropy of 1, the entropy stays at 1, it does not grow to 2. If we have 2 bits with a half bit of entropy, and we XOR them together, we do not get a full bit of entropy, although it is only slightly less (approximately 0.9 bits of entropy). To avoid accidentally combining highly entropic data, we should use a good way of distributing bits through the buffer (often called a pool in this context) that is likely to distribute the bits evenly.
One good solution is to use a cryptographic hash function. A good hash function distributes bits evenly and removes any remaining statistical bias at the same time. Unfortunately, hash functions usually have tiny output sizes, such as 160 bits. If our pool is only a single-hash context, then we can never store more than 160 bits of entropy at a time, no matter how many bits we add. We could use a large number of pools at once to hold onto more bits of entropy, and feed new data into pools until they fill up. This solution is good, except that cryptographic hashes tend to be expensive. If the operating system is sending frequent events to an entropy handler, then this solution is a poor one.
A commonly used technique to circumvent this problem is to use a cryptographic primitive called a linear feedback shift register (LFSR). An LFSR is a type of PRNG. However, it does not provide cryptographic security. What it can provide us is a reasonable solution for distributing entropy evenly throughout a buffer over time.
Traditionally, LFSRs operate on an array of bits, and 1 bit is output at a time. Typically, a new bit is computed by XOR-ing together various bits in the LFSR. Then, the rightmost bit is output, and the pool is rotated 1 bit. The computed bit then becomes the leftmost bit. For our uses, let’s ignore the output step, but XOR in a bit of our input when computing the new bit. The exact bits to XOR are important, and must be carefully considered. We do not treat this matter here, but refer the reader to Bruce Schneier’s Applied Cryptography for more information [Schneier, 1996].
An XOR on a bit is no less expensive than an XOR on a byte. We can keep 8 LFSRs going in parallel, and deal with data 1 byte at a time, instead of 1 bit at a time. This is a good approach. We can also easily operate on 32 LFSRs at once (64 LFSRs on many architectures).
Rotating a buffer of bytes isn’t a good idea from an efficiency point of view. Instead, we use a counter to indicate where the virtual front of the LFSR lives. See the source of EGADS at http://www.securesw.com/egads/.
Now that we can do a reasonable job of storing entropy in a buffer, we need to worry about estimating the amount of entropy in that buffer. We’ve said that entropy isn’t additive. However, it will be close enough to additive that we should not be worried about it, up until the point that we have nearly filled our buffer. This is especially true when we have already been conservative with our estimates. Therefore, simple addition will suffice, as long as we make sure never to extend our estimate past the size of a buffer. To ensure that our entropy estimate remains sound, we should make sure that we never output as many bits as we have in the buffer.
When our entropy handler receives a request for output, it should first ensure that it has the desired amount of entropy available in a buffer. If so, then it needs to convert the buffer into output, making sure that there is not likely to be any discernible pattern in the output. The easiest way to do this is to hash the buffer with a cryptographic hashing algorithm, and output the result. Obviously, the buffer should be at least as big as the hash size, and should generally be a few bytes bigger to make sure our entropy estimates stay sound.
Once we output the hash results, we should clear the contents of the buffer, just to make sure that no traces of old outputs are visible in new outputs, should the cryptographic hashing algorithm ever be completely broken.
Having a single entropy estimate per buffer does not take into account the possibility that attackers could be controlling or monitoring one or more of the input sources. To do this, we should keep separate estimates of how much entropy we have collected from each source. Then, we should create a conservative metric for how much data we are willing to output, taking into account possible source compromise.
Note that we recommend this kind of strategy in all cases, even if you are using a hardware random number generator. It’s better to be conservative, just in case the hardware happens to be untrustworthy or broken.
There are plenty of statistical tests that can be applied to random number generators. They take various forms, but the common thread is that they all examine streams of data from a generator or entropy handler statistically, to see if any patterns can be found in the data that would not be present if the data were truly random. The ComScire hardware random number generator device performs these tests as you use it, and fails at runtime if the tests don’t succeed. This is a nice safety measure, but, in practice, people often make due with only checking the stream up front before first use, and perhaps on rare occasions to ensure that the generator is running at full steam.
As we previously mentioned, the FIPS-140 standard [FIPS 190-1] includes specifications for testing output of random number devices. One of the more widely recognized test suites for ensuring the randomness of a data stream is the DIEHARD package by George Marsaglia. It performs numerous tests on a data stream. Another reasonable package for such tests is pLab. References for both are available on this book’s companion Web site. What these tests do or don’t do doesn’t really matter. We just have to trust that they’re testing the quality of our generator, and listen well if the generator we are using fails them.
We’ve said that all statistical tests should fail to find any trends, given the use of a good cryptographic primitive in the middle. The hash function inside our entropy handler is no exception. Therefore, we should expect always to pass such tests when run against such mechanisms. So are statistical tests useful?
We believe that it is worth applying tests to data that are given as input to an entropy handler. Such tests can dynamically build assurance that we’re really getting the amount of entropy we should be getting. Unfortunately, most data reach our entropy handler in a form that is probably highly biased or correlated, with only a bit of entropy in it. Therefore, these statistical tests do no good in such cases. Such tests are most useful for testing hardware devices that should be returning data that have no bias. However, even if the data do have some bias or correlation, this doesn’t make them unusable. It just means we may need to update our entropy estimates. For example, if a generator produces fully unbiased and uncorrelated bits, we could potentially estimate 1 bit of entropy per 1 bit of output. If, all of a sudden, the generator starts outputting ones three quarters of the time, but seems uncorrelated, we could still assign a half bit of entropy to each bit of output (even though we should probably get suspicious by the sudden change).
We can try to apply statistical tests on our LFSRs. However, we may not get good results because we haven’t been too careful about removing bias and correlation before putting data into those buffers. We don’t have to be, because we expect the hash algorithm to do the job for us.
We can apply different kinds of tests to our data, to approximate whether we are receiving the amount of entropy that is advertised. However, such tests would generally be source dependent. One test that often works well is to run data through a standard compression algorithm. If the data compresses well, then it probably has a low amount of entropy. If it compresses poorly, then it may have a high amount. Good tests of this nature are sorely needed for common entropy collection techniques. Hopefully, the research community will develop them in the near future.
Practical Sources of Randomness
We now turn our attention to the practical side of randomness. How do you get good random data when you only have software at your disposal? Just a few years ago, you would have had to “roll your own” solution, and hope that it was sufficient. Now, there are several good sources for us to recommend. Cryptographically strong random number facilities are even showing up in operating systems and programming languages.
Tiny
Earlier in this chapter, we briefly discussed Tiny, which is a PRNG and an entropy collection algorithm. Tiny is a good example of a conservative system for generating entropy, as well as cryptographic randomness. The PRNG is a simple primitive that relies on the security of AES in counter mode for the security of its output, as well as periodic inputs from the entropy infrastructure to protect against any possible state compromise.
The entropy infrastructure is necessarily more complex, because we would like greater assurance about the quality of the entropy that is output. To protect against sources that are potentially compromised in full or in part, Tiny may throw away a lot of entropy by requiring that multiple sources contribute some minimum to the entropy count. The parameters for that heuristic may be adjusted to be even more conservative. Input from sources is processed with UMAC [Black, 1999].
Additionally, the entropy gateway further protects against tainted input sources with a “slow pool.” The theory behind the slow pool is that we should have data that are reseeded infrequently, using a lot of different entropy, with the hope that if the regular outputs are compromised, we will eventually still be able to produce outputs of adequate security. The slow pool influences the output by providing a seed to a PRNG that is mixed with the “raw” entropy distilled from the accumulators.
Of course, there can be no guarantee that the entropy gateway produces output that really does approach a bit of entropy per bit of output. Attacks may be possible. However, Tiny does its best to protect against all known attacks, falling back on excellent cryptographic security if there does happen to be some sort of compromise for which the system does not already allow, and thus does not detect.
Tiny is far more conservative than the popular alternatives discussed later, especially in its entropy gathering. Even so, a good array of entropy sources can still result in a rate of output for raw entropy that is more than sufficient for typical uses.
The Entropy-Gathering and Distribution System (EGADS) is an infrastructure for random number generation and entropy output based on Tiny. In addition to a raw Tiny implementation, it consists of user space entropy-gathering code that is portable across UNIX variants. There are user space libraries for instantiating PRNGs, and raw entropy can be had by reading from a file. Additionally, there is a version of EGADS for Windows NT platforms, specifically tailored to the operating system.
Random Numbers for Windows
The Windows cryptographic API provides a cryptographic PRNG—the CryptGenRandom call. This function is available on most Windows machines of recent vintage (you may not find it on some Windows 95 machines, however). We’ve made several attempts to find out what this function actually does. Although we believe its pseudo-random number generation is really based on a cryptographic primitive, we can find no other public information about it. We do not know what sorts of entropy sources are used, nor do we know how entropy is used in the system.
If this function ever receives scrutiny from the security community, it may end up being something that is worth using. Until then, we recommend using an alternative mechanism, if at all possible.
Note that people defending this call will say, “It must be good. It’s FIPS compliant.” NIST specifies some tests for random number generators as a small part of the very large FIPS standard. Unfortunately, a FIPS-compliant PRNG is not necessarily high quality. The tests suffer from the same problems as other statistical tests for randomness.
For example, you could FIPS certify a PRNG that seeds with the number 0 and generates output by continually hashing the previous output with SHA-1. You could say, “It must be good. It’s FIPS compliant.” But this is not true. This algorithm is trivial to break.
Random Numbers for Linux
If you’re using a reasonably recent version of Linux (1995 or later), you can get processed entropy and cryptographic pseudo-random numbers directly from the operating system, without having to install any additional software. Linux has a device from which a programmer can read called /dev/random, which yields numbers that amount to processed entropy. If output is requested but not available, the device blocks until the output is ready. The device /dev/urandom outputs pseudo-random numbers. It outputs data as quickly as it can. Modern BSD-based operating systems for the x86 have begun to provide similar services.
These devices are not quite as conservative as alternatives such as Tiny and Yarrow. For example, this package does not worry about potentially tainted data sources. Nonetheless, /dev/random is likely to be more than good enough in practice, as is /dev/urandom.
If you prefer to use the Linux devices, the following C code provides a fairly simple interface to them. You should consider using these interfaces instead of the generator directly, especially considering that the year 2000 saw a spectacular failure in PGP (Pretty Good Privacy), which involved reading from /dev/random improperly, resulting in predictable data.
Our code returns 32-bit random numbers. Of course, this code only works if the devices /dev/random and /dev/urandom are present on the system. This simple wrapper automates the task of getting information from the device and returning it as a number:
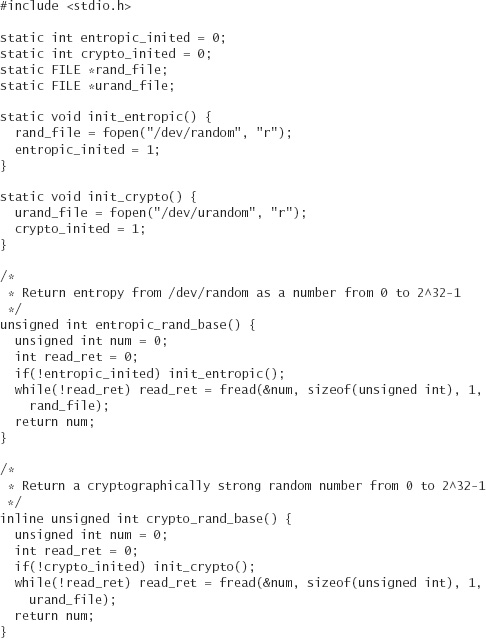


Here’s a header file for the more interesting functions:

Because /dev/random and /dev/urandom appear to be files, as far as the file system goes, they can be used from any programming language.
Random Numbers in Java
If you’re willing to use Java, you can use the class java.security.SecureRandom, which returns a cryptographically strong random number. A benefit of this approach is portability. You can use the exact same code to get secure random numbers on a UNIX box, a Windows machine, or even a Macintosh, without having to install additional software.
Note that in Java you shouldn’t use the SecureRandom class to seed java.util.Random, because java.util.Random is not good enough. java.util.Rand implements a traditional PRNG. As we discussed earlier, these kinds of generators can be attacked fairly easily.
Here’s what the SecureRandom class does (in the Sun JDK). When you create the class, either you pass it a seed or it uses a self-generated seed. The seed is cryptographically hashed with the SHA-1 algorithm. Both the result and the internal state of the algorithm are added to the SHA-1 hash to generate the next number. If you don’t pass in a seed, the seed is generated by the “seeder,” which is itself an instance of SecureRandom. The seeder itself is seeded using internal thread-timing information that should be fairly hard to predict. The requisite timing information can take several seconds to gather, so the first time you create an instance of SecureRandom, you should expect it to hang for a few seconds (as long as 20 seconds, but usually no less than 3 seconds). Unfortunately, this is very slow entropy gathering, even by software standards.
To get around this problem, you may want to use an alternative seeding mechanism, such as the many we discussed earlier. If you are willing to capture keyboard events, source code to do this is available in Jonathan Knudsen’s book, Java Cryptography [Knudsen, 1998].
A brief cryptographic note is in order. The fact that the SHA-1 hash never gets updated with random information after the initial seeding is a bit worrisome to us, especially considering the weaknesses of the SHA-1 compression function. If you can use a more trustworthy package (such as EGADS, mentioned earlier), then we definitely recommend you do so.
If you are looking for raw entropy, such as for a one-time pad, you may want to avoid Java. From what we can tell, it uses the “Hail Mary” approach to entropy estimation, hoping that it has gathered enough. If you do trust that it has gathered a lot (which is probably a reasonable thing to do), you could seed a generator, read one output, and throw it away. Unfortunately, this is bound to be seriously time intensive.
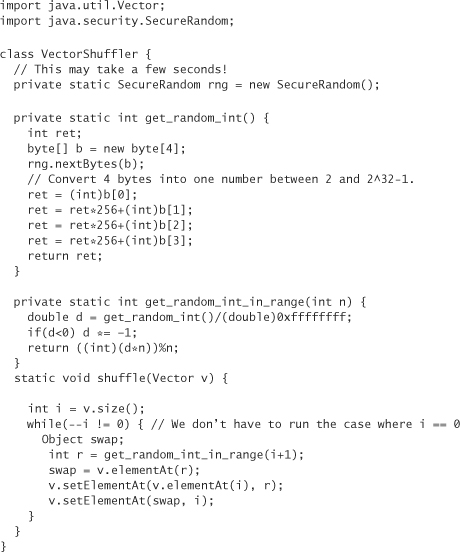
Here’s some simple Java code that shuffles Vector using the SecureRandom class, which we provide as an example of how to use SecureRandom:
Conclusion
In general, we recommend you use the best entropy sources available that can be reasonably integrated with your application. If hardware sources are feasible, use those. We do not recommend using such sources directly, because any source can fail. Instead, use as many sources as possible, including software sources, and feed them to an entropy infrastructure. For most applications, you can get a sufficient bandwidth of random numbers by using only a small amount of entropy and stretching it with a good PRNG, such as Tiny.
We highly recommend that your entropy infrastructure track how much entropy it believes is available. We are very uncomfortable with “Hail Mary” techniques such as the Java SecureRandom implementation in the Sun JDK. Additionally, a good entropy infrastructure should protect against tainted data sources to the best of its ability. Again, we recommend Tiny.
Keep your eye out for new randomness functionality built into the next generation of Intel chips. This is a heartening development. Hopefully the engineers at Intel spent some time learning how to generate random numbers properly, and avoided the pitfalls we discussed earlier.