
14. Database Security
Porter: Thirtieth floor, sir. You’re expected.
Sam: Um . . . don’t you want to search me?
Porter: No, sir.
Sam: Do you want to see my ID?
Porter: No need, sir.
Sam: But I could be anybody.
Porter: No you couldn’t, sir. This is Information Retrieval.
—TERRY GILLIAM
BRAZIL
The term database security is almost an oxymoron. Practical security is something that most databases largely ignore. For example, most databases don’t provide any sort of encryption mechanism whatsoever. The security mechanisms that are present are rarely standard between databases. This makes database security a difficult topic to which to do justice. We recommend that you supplement this chapter with a thorough read of the documentation that comes with your database, so you can learn about the security functionality available to you and how to use that functionality.
Also note that database security is an entire security subfield of its own. Indeed, there are entire books dedicated to database security, including Database Security [Castano, 1994], Security of Data and Transaction Processing [Atluri, 2000], and Oracle Security [Theriault, 1998]. Our goal here is to provide an introduction to the topic that should be sufficient for the average programmer who needs to use a database. However, if your job involves extensive use of databases, make sure you supplement the information we include in this short chapter with information from one of these sources.
The Basics
One of the biggest concerns with databases is whether the connection between the caller and the database is encrypted. Usually it is not. Few databases support strong encryption for connections. Oracle does, but only if you purchase an add-on (the Advanced Networking Option). MySQL supports SSL connections to the database. There may be others, but connection cryptography isn’t a common feature. If you must use a particular database that doesn’t support encryption, such as Microsoft SQL Server, you may want to consider setting up a virtual private network between the database and any database clients. If you push a lot of data, require efficiency, and get to choose the algorithm, you will probably want to go for a fast stream cipher with a 128-bit key (or AES, otherwise).
One risk to keep in mind when using a database is what sort of damage malicious data from untrusted users can do. This is a large and important problem. We discuss this problem in depth, including several database-related issues in Chapter 12.
All real databases provide password authentication as well as access control to tables in the database based on those accounts. However, the authentication and table-based access control provided usually only affords your application protection against other users of the database. These features are not designed to support an application with its own concept of users. We discuss the basic SQL access control model in the next section.
In practice, your application must enforce its own notion of access control on a database. This job is quite difficult. The easiest part is protecting data. For example, let’s consider a database of documents, in which each document has a security clearance attached to it. We may number the clearances on the documents to reflect security levels: No clearance required, 0; confidential, 1; secret, 2; and top secret, 3. If the current user has confidential clearance to the database contents, we could easily restrict that user’s access to unauthorized data in SQL. For example,
SELECT documents
FROM docdb
WHERE clearance <= 1;
However, there are many kinds of indirect information that can be useful to attackers. An attacker may be able to make inferences based on the information that you provide that reveals things you didn’t want to reveal about your database. This kind of an attack is called a statistical attack, and defending against such attacks is very difficult. We discuss such attacks later in the chapter.
Access Control
Access control in databases is designed to protect users with accounts on a database from each other. Each user can have his or her own tables, and can moderate access to those tables. Usually, applications use a single login to a database. Certainly, you can add a new account to the database for every user of the database. Unfortunately, this solution tends not to scale for large numbers of users. However, it is often a viable option for a database with a small number of important users.
As we’ve mentioned, SQL-driven databases have a notion of users that must authenticate. The other important components for access control are objects, actions, and privileges. Objects are tables, views of tables, and columns in those tables or views. In the SQL 92 standard [SQL 92], you can assign rights to any object. However, in many databases you can only assign rights on a per-table basis.
By default, only the entity who originally creates an object (the owner) has any access at all to that object. This user is able to grant privileges for each type of object to other users. Actions available in SQL include SELECT, for reading data; INSERT, for adding new data to a table; DELETE, for removing data from a table; and UPDATE, for changing data in a table. The SQL 92 standard provides a few more actions, but don’t expect them to be widely implemented.
We can grant one or a set of actions to a particular user for a particular object. Privileges are composed of obvious information: the entity granting the privilege, the entity to which the privilege should be granted, the object for which the permission is granted, and the action granted. Additionally, the SQL 92 standard states that the privilege may specify whether the privilege can be granted to others. However, not every database supports this.
Privileges are extended with the GRANT command, which takes the general form
GRANT action(s) ON object TO user(s).
For example, one of us has his mp3 collection indexed in a database. There is a table named “mp3s,” one named “artists,” one named “cds,” and one named “history.” The “history” table stores what the author has listened to and when. Say that we’d like to allow the user “jt” to be able to browse the music, but not the history. We could issue the following series of commands:

If we’d like to allow that user to add music to our collection and to update the database accordingly, there are two approaches. We could say
GRANT SELECT, INSERT, DELETE, UPDATE
ON mp3s
TO jt;
and repeat for each table. Or, we can usually use the shorthand ALL:
GRANT ALL
ON mp3s
TO jt;
We still need to issue this command once for each table. If we’d like to give everyone access to the mp3s table, we can use the PUBLIC keyword:
GRANT ALL
ON mp3s
TO PUBLIC;
If our implementation allows us to pass on the ability to grant a particular privilege on an object, we do so by appending WITH GRANT OPTION to the command. For example, if we trust the user “jt” to use discretion in showing our music-listening history to people,
GRANT SELECT
ON history
TO jt
WITH GRANT OPTION;
With this command, the user “jt” could allow other people to read from the history table. We could also grant that user write privileges to the table, without extending the GRANT option.
To take away privileges, we use the REVOKE command, which has very similar semantics. For example, to take back all the privileges we’ve granted on the mp3s table, we can say
REVOKE ALL
ON mp3s
FROM PUBLIC;
If we wish to revoke the grant privilege, we use the following syntax:
REVOKE GRANT OPTION
FOR SELECT
ON history
FROM jt;
Revoking the grant privilege also revokes any select privileges on the history table that the user “jt” granted.
Note that many databases have a concept of groups of users similar to the UNIX model. In such databases, you can grant privileges to (and revoke them from) groups as well as individual users.
Using Views for Access Control
A view is a feature provided by most databases that allow for “virtual tables” in a database. Virtual tables are created from one or more real tables in the database. These virtual tables only exist to filter real tables. Once views are created, they can be accessed like any other table.
Views are a nice convenience for enforcing access policies. You can set up a view for each type of user on your system, then only access the set of virtual tables that is assigned to that type of user. For example, say we were to keep an employee information database that is accessed through a middle tier of software running on a trusted server. Say that all information about an employee is kept in a table named employee_info. We may use the full table when a member of the human resources staff is logged in, but we use a separate view for general employees. This move restricts access to potentially sensitive information about other employees, such as social security number and salary.
We can create views using the CREATE VIEW command:
![]()
This declaration would limit the data in the gen_employee_info view to contain only information that should be available to all company employees.
We can include arbitrary SQL code after the SELECT for defining a view. This means that we can restrict the rows visible in a table, not just the columns. For example, let’s consider a student grade database. Students should be able to view their own records, but not anyone else’s record. We can also accomplish this with a view. Let’s say we have another three-tier architecture, and a student with student ID 156 logs in. We can create a view just for that student’s records:
CREATE VIEW student_156_view AS
SELECT *
WHERE sid = 156;
If we want to remove the view at the end of the session, we can run the command
DROP VIEW student_156_view;
Some databases allow for views that are read-write, and not just read-only. When this is the case, WHERE clauses generally aren’t enforced in a view when inserting new data into a table. For instance, if the view from our previous example were writable, student 156 would be able to modify the information of other people, even if the student could only see his own information. Such databases should also implement the SQL 92 standard way of forcing those WHERE clauses to get executed when writing to the database, the CHECK option:

One thing to be wary of when using views is that they are often implemented by copying data into temporary tables. With very large tables, views can be painfully slow. Usually, there are cases when you can provide a very specific WHERE clause, yet the implementation still needs to copy every single row before applying the WHERE clause.
Another caution is that you shouldn’t use views as an excuse to allow clients to connect directly to your database. Remember from Chapter 12: A malicious client will likely just run the command SHOW TABLES; and then access forbidden data directly.
Field Protection
We shouldn’t always assume that other people with database access are actually trustworthy. Therefore, there is a need to protect fields in a database from the prying eyes of the person who has valid access to administer the database. For example, we may wish to store passwords for an end application as cryptographic hashes instead of plain-text strings. We may also wish to keep credit card numbers and the like encrypted.
There are a number of nonstandard ways in which databases may offer this kind of functionality. For example, you might see a PASSWORD data type or a function that takes a string and mangles it. Such functionality is rare. Moreover, it’s best to be conservative, and never to use such functionality. Usually, the cryptographic strength of these features is poor to nonexistent. Many common password storage mechanisms in databases store passwords in a format that is not only reversible, but easily reversible. For instance, there’s a long history of password-decoding utilities for Oracle databases that have circulated in the hacker underground.
Instead of relying on built-in functionality, you should perform your own encryption and your own hashing at the application level using algorithms you trust. That is, encrypt the data before storing it, and decrypt it on retrieval. You will likely need to take the binary output of the cipher and encode it to fit it into the database, because SQL commands do not accept arbitrary binary strings. We recommend encoding data using the base64 encoding algorithm, which does a good job of minimizing the size of the resulting data.
One problem with self-encrypted data in a database is that the database itself provides no way of searching such data efficiently. The only way to solve this problem is to retrieve all of the relevant data, and search through it after decryption. Some interesting new research on searching encrypted data may lead to a practical solution in a real product eventually, but don’t expect useful results for quite some time. Also, expect such a solution to have plenty of its own drawbacks.
An obvious problem, which keeps many from using field encryption, is the performance hit.
A bigger problem with encrypting fields is that you generally end up expanding the data (because the fields generally must be stored as text and not the binary that results from an encryption operation). This may not be possible in some environments without expanding your tables. This is often prohibitive, especially if you’ve got a table design that has been highly tuned to match the underlying hardware or is something that can’t be changed because it’ll break many existing applications that expect a particular table layout.
In a post to the newsgroup sci.crypt in January 1997, Peter Gutmann revealed a technique for encrypting data in a range, in which the ciphertext remains the same size as the plaintext, and also remains within the desired range.
The following is code to encrypt ASCII or ISO 8859-x text in such a way that the resulting text remains in the same character set, and does not grow. Characters outside the range are kept intact and are left unencrypted. The algorithm is described in detail in the comments.




The previous code depends on a function ksg(), which is a key stream generator. In other words, ksg() is a generic placeholder for a traditional stream cipher (PRNG). Of course, you can use any block cipher you wish by running it in OFB mode, CFB mode, or counter mode. The Yarrow PRNG, discussed in Chapter 10, is a good example of a block cipher run in counter mode that could be used for this purpose.
Security against Statistical Attacks
Selling or otherwise giving access to customer databases is a fairly common practice, because there are many organizations that are interested in deriving statistical information from such databases. For example, companies that may consider advertising with your service may like to spend a few days performing statistical queries against your database to determine whether your customer base has suitable representation from their target demographics.
Customer privacy must be taken into account whenever we give others access to customer databases. Although we want companies to advertise with us, we don’t want those companies to figure out who our actual customers are, what they’ve bought from us, and so on. This sort of data should be off-limits.
One obvious strategy is to remove data that’s sensitive, such as people’s name, credit card information, and street address (we probably want to leave in the city and zipcode for the sake of demographics). However, this approach often isn’t sufficient. Ultimately, we’d like to remove any information that may help identify who is associated with a particular row. Any unique data are potentially something we want to remove from the database. We’d really like to avoid all queries that return a single entry. For example, if we happen to know of a customer who lives in Reno, Nevada, and is 72 years old, and there is only one such person in the database, it doesn’t matter that the name and address have been removed. We can now learn things about that one customer that are sensitive (perhaps we could get a list of previous purchases that we would use to direct target the person with advertising, or perhaps we could blackmail that customer).
In some situations, one thing we can do (assuming we control access to the database) is filter out any query that is not an aggregate query (in other words, one that operates on a set of rows, and returns only a single result for that entire set). The aggregate functions in standard SQL are
• AVG(col). Returns the average of the values in a column.
• COUNT(col). Returns the number of values in a column.
• MAX(col). Returns the maximum value in a column.
• MIN(col). Returns the minimum value in a column.
• SUM(col). Returns the sum of the data in the column.
In a SQL statement, an aggregate query looks much like a standard query, but returns a single number:
SELECT AVG(income)
FROM customers
WHERE city = "reno";
Aggregate functions necessarily operate on the individual data records that we’d like to protect. Unfortunately, because the information we’re trying to protect contributes to the information we’re giving out, there are always ways to infer the data we’d like to protect. Enough aggregate queries on a column can almost always render the same information an attacker could get with a direct query of that column. Such attacks require some basic skills with mathematics, though, raising the bar a bit.
As an example, we could be looking to find the annual income of the aforementioned person in Reno, who we are pretty sure is a customer. We would first run the following statistical query:
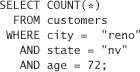
If this query returns 1, then we would run the following query:
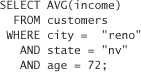
which would give us the actual income of the person in question.
Our next thought may be to restrict any result that applies to fewer than a particular number of tuples. For example, we could refuse to give any aggregate results for which the query applies to fewer than ten people. We would also need to make sure that the complement of the query can’t be used to get the same kind of information. For example, if we make such a restriction, we need to make sure that the following query also fails:
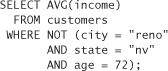
The problem with this strategy is that a clever attacker can always circumvent the restriction through indirection, as long as the attacker knows how to identify a single entry in the database uniquely. In the previous example, the unique way we identify the row is by the city, state, and age combined. It doesn’t matter that we can’t query the database directly for an individual’s income.
The general attack strategy is to identify a query on incomes that can be answered. An attacker can then run that query, logically OR-ed with the information the attacker is interested in obtaining. Then, the attacker runs the same query without the tuple of interest.
Consider the example of finding the income of the unsuspecting attack target in Reno from the point of view of an attacker. For our bogus queries, let’s ask for all people in the state of Virginia. Let’s say that there is a 100-person threshold on any operation that singles out tuples. The first thing we need to know is how many customers are in Virginia:
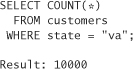
We now ask for the average salary of everyone in the state of Virginia, plus our target:

Let’s say the result is $60,001. Now, we ask for the average salary of everyone in the the state of Virginia, without our target:
SELECT AVG(income)
FROM customers
WHERE state = "va";
Let’s say the result is $60,000:
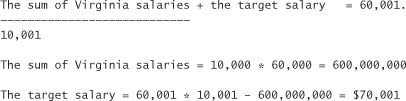
Statistical attacks can be much more clever in their attempt to circumvent potential countermeasures. For example, an attacker may break up queries into pieces to determine that the OR clause affects only one row, and thus may disallow the query. This mechanism would be quite a bit of effort to implement. Plus, there are almost always statistical techniques that can circumvent even this strategy. This puts us in an arms race with clever attackers.
Unfortunately, no one has ever developed a good, general-purpose strategy for defeating a statistical attack. Certainly, taking measures to make such an attack harder is a great idea. Just don’t believe for a minute that any such defense is foolproof. Setting a minimum on the number of rows returned in a query is useful to slow some attackers down, but it won’t stop the smart ones.
One defensive countermeasure that works well is logging queries and performing a manual audit periodically to see if any queries seem suspicious. Of course, this technique is time-consuming and laborious. You would have to be very lucky to catch anyone.
Another good technique is to modify the database in ways that shouldn’t significantly affect the statistical properties, but do affect the ability of an attacker to track individuals. For example, we could use metrics to swap user salaries in ways that keep salary statistics nearly the same on a per-state basis, but cause subtle changes on a per-city basis. Of course, this technique necessarily reduces the accuracy of the database, but it does protect the privacy of its users. A similar technique is to add a bit of noise to statistical results. You have to be careful, and do this in a systematic way. If you add random noise to each query, an attacker can eliminate the noise by repeating the same query over an extended period of time and taking the average value. Instead, you may want to have rules for adding a few “fake” tuples into every result set. The tuples would be real, but would not belong in the result set. The rules for adding them should be fairly arbitrary, but reproducible.
In the final analysis, we have never seen anyone implement a solid, “good enough” solution to the query attack problem. There probably isn’t one. This means that if you are tasked with combating this problem, you probably need to construct your own ad hoc solutions and keep your fingers crossed.
Conclusion
Owing to the extensive work done by SQL standardization bodies, most databases provide plenty of overlap in basic functionality. However, they also tend to provide a startling number of features that are unique to a particular database, and are thus highly unportable. This holds true in the area of security, especially among the well-established commercial databases. You should definitely check the documentation of your database package, because there may be additional mechanisms for access control, auditing, setting quotas, and other things that are worth using.
For example, one of the more interesting features you may have in your tool kit, at least from a security perspective, is the trigger. A trigger is a stored program that is attached to a table, and is called whenever a particular condition is met. In contrast to stored procedures, which can be called at the whim of the person writing SQL, there is no way to call a trigger directly from SQL other than by meeting the condition. You should consider using triggers to implement logging of updates to security-critical or otherwise sensitive data.
Regardless of security features, databases are usually to be viewed as suspect and risky when it comes to security. Developers and administrators are often expected to do most of the legwork. When functionality is provided, such as with password encryption, it is usually better to implement your own solution anyway.
Part of the problem is that databases are steeped in a tradition that dates back long enough that rudimentary access control was more than sufficient for all uses. Another significant factor is that it is essentially impossible to provide a general-purpose solution for many of the most important information security problems inherent in databases. In particular, neither the problem of statistical attacks against databases nor the problem of keeping and searching encrypted data in a database has any good general-purpose solutions.