
11. Applying Cryptography
In theory there is no difference between theory
and practice. In practice there is.
—YOGI BERRA
Cryptography is something most developers know a little about, usually just enough to be dangerous. The most commonly encountered mistakes include failing to apply cryptography when it’s really called for, and incorrect application of cryptography even when the need has been properly identified. The usual result of misuse or nonuse of cryptography is that software applications end up vulnerable to a smorgasbord of different attacks.
There are several good books on the foundations of cryptography. The most well-known is Applied Cryptography by Bruce Schneier [Schneier, 1996]. We think Bruce’s book may be a bit misnamed though. It’s more an introduction to all the important theoretical concepts and algorithms that make up cryptography. In many places, it avoids the practical aspects of adding cryptography to an application.
This chapter doesn’t provide a Schneier-esque introduction to cryptography. We recommend Bruce’s book if you are interested in the area. If you are looking for an overview, and are not interested in many details, then we provide an overview of cryptography in Appendix A. Additionally, if you want general advice on selecting cryptographic algorithms for your application, we discuss many common solutions in Appendix A.
This chapter focuses on the more practical side of cryptography. We discuss the most common flaws encountered in applying cryptography. We take a comparative look at different cryptographic libraries that you may use in your own applications, and use one of them to write code (OpenSSL). We also take a high-level look at the functionality provided by SSL, and look at issues with using this protocol. Finally, we study the notorious one-time pad, which can provide perfect security if used properly, but generally should be left out of your applications.
General Recommendations
In this section we make some general experience-based recommendations on how to deploy cryptography in your applications. All of our recommendations come with the caveat that applied cryptography is tricky and context sensitive. If you have lots to lose, make sure someone with real cryptography experience gives you some advice!
Developers Are Not Cryptographers
There is one sweeping recommendation that applies to every use of cryptography. Unfortunately, it’s one that is very often ignored by software developers. It is
Never “roll your own” cryptography!
There are two aspects to this recommendation. First, you should not invent your own cryptographic algorithms. Some people place lots of faith in security by obscurity. They assume that keeping an algorithm secret is as good as relying on mathematically sound cryptographic strength. We argued against this at great length in Chapter 5. It is especially true in cryptography. Writing a cryptographic algorithm is exceptionally difficult and requires an in-depth study of the field. Even then, people tend not to feel confident about algorithms until they have seen years of peer review. There is no advantage against a determined and experienced cryptanalyst in hiding a bad algorithm.
If you don’t know much of the theory behind cryptography, would you expect to do any better at designing an algorithm than the best cryptographic minds of World War II? You shouldn’t. Nonetheless, cryptography as a field has advanced enough since then that all the algorithms used in the war (except for the one-time pad, which has proven security properties; discussed later) are considered poor by today’s standards. Every single one can be easily broken using new cryptanalytic techniques. In fact, most homegrown algorithms we have seen involve XOR-ing the data with some constant, and then performing some other slight transformations to the text. This sort of encryption is almost no better than no encryption at all, and is easy for a cryptographer to break with a small amount of data. Yet, in every case, the people who designed the algorithms were sure they did the right thing, up until the point that the algorithm was broken. In Chapter 5, we talked about several such breaks.
The best bet is to use a published, well-used algorithm that’s been well scrutinized by respected cryptographers over a period of at least a few years.
Additionally, you should refrain from designing your own protocols. Cryptographic protocols tend to be even harder to get right than algorithms, and tend to be easier to attack. The research literature is full of cryptographic protocols, most of which have been broken. Note that even most of the “major” protocols have been broken at least once. For example, SSL version 2 has serious flaws that make it a bad idea to use. Version 1 of the Secure Shell Protocol (SSH) has been broken several times, and should be avoided. Microsoft’s Virtual Private Network (VPN) technology, Point-to-Point Tunneling Protocol has been broken [Schneier, 1998] (of course most of the concerns have since been addressed).
Designing a robust cryptographic protocol requires even more specialized knowledge than designing a robust cryptographic algorithm, because one needs to understand the cryptographic elements and how they can be misused. Essentially, you need to have many of the same skills necessary for designing a secure algorithm, and then some. For example, public key algorithms are very hard to use safely in a cryptographic protocol, because their mathematical properties can leave them vulnerable. In the case of RSA, one does modular exponentiation with the message as the base and the key as the exponent. If the message is too small, there is no wraparound because of the modulus, which in turn permits recovery of the key. (Of interest only for digital signatures, of course, but the point stands.) Indeed, in a paper entitled, “Twenty Years of Attacks Against the RSA Cryptosystem” [Boneh, 1999], Dan Boneh states:
Although twenty years of research have led to a number of fascinating attacks, none of them is devastating. They mostly illustrate the dangers of improper use of RSA. Indeed, securely implementing RSA is a nontrivial task.
Similar, but more severe problems exist in the Digital Signature Algorithm (DSA). In March 2001, it was revealed that OpenPGP had misused DSA in such a way that signing keys could be recovered under certain conditions. Similar problems exist in many protocols built around DSA.
Another common problem that comes from a poor understanding of cryptographic primitives is reusing keys for stream ciphers (or similar block cipher modes) across sessions. With stream ciphers, it is important never to use the same key multiple times. A stream cipher generally takes a key and uses it to create a stream of key material (a key stream). If you stop using a key stream, then reuse the same key, you will get an identical key stream, which leaves you vulnerable to attack.
If at all possible, you should stick with well-scrutinized protocols for your needs, such as SSL and Kerberos. Similarly, you should use well-scrutinized implementations of these protocols, because implementation errors are quite common themselves.
Data Integrity
One of the biggest fallacies in applying cryptography is the thought that encryption provides data integrity. This is not true. If you merely encrypt a data stream, an attacker may change it to his heart’s content. In some cases this only turns the data into garbage (under the assumption that the attacker does not know the key, of course). Nonetheless, turning data to garbage can have a devastating effect if you’re not handling the error condition sufficiently.
Many people try fixing the problem by sticking a known quantity at the end of a data stream, or periodically throughout the data stream. This is insufficient. In electronic code book (ECB) mode (see Appendix A for a brief overview of cipher modes), each block is independent, thus making the end quantity irrelevant. In cipher block chaining (CBC) mode, modifications to the ciphertext don’t necessarily impact the end of the stream. Additionally, there are often quite usable cut-and-paste attacks against CBC, unless a keyed MAC such as HMAC (the keyed-Hash Message Authentication Code) is used.
Stream ciphers and block ciphers in output feedback (OFB), cipher feedback (CFB), or counter mode also have bad problems with data integrity. Generally, plaintext is combined with a stream of pseudo-random data via an XOR operation. If an attacker knows that a specific section of the ciphertext decrypts to a specific value, then there is usually an easy way to modify the data to any same-size value the attacker wishes.
Any time you use encryption, you should use a MAC for message integrity. Additionally, you must make sure that you gracefully handle those cases in which a message integrity check fails. Such issues are difficult enough that it is best to stick with well-scrutinized protocols such as SSL. For more information about data integrity problems in encryption, see [Bellovin, 1996] and [Bellovin, 1998].
Export Laws
Traditionally, the United States has been quite hard on strong cryptography, only allowing free export of things that cryptographers consider weak. Many developers believe this is still the way the world is. We’re happy to say that if you’re a resident of the United States, this is not the way things work anymore.
If you are a free software developer, you are allowed to release software with strong cryptography in it for use outside the United States. You need to notify the US government that you are releasing such software, and let them know where on the Internet it can be found. The preferred way to do this is by mailing [email protected]. Your mail is logged for the world to see, and it is forwarded to the proper persons in the government ([email protected]). Note that you cannot deliberately give your software to someone in a foreign terrorist nation, but you need take no specific countermeasures to prevent such a person from downloading your code from your Web site.
If you’re not a free software developer, there are still hoops you must jump through to export your software. However, we’re told it’s just a matter of bureaucracy, and not meant to be a serious impediment. Prior to early 2000, it was almost impossible to get permission to export strong cryptography. However, we’re not lawyers, so we cannot tell you with absolute certainty the procedures you should go through to export commercial software.
There are some sneaky ways to get past the legal hurdles on strong cryptography. Some companies do a reasonable job. They don’t export cryptography, so that they don’t have to do the paperwork. Instead, they import it. They either develop the cryptographic software outside the country, or get someone outside the country to add cryptography to their software. This sort of solution is probably not feasible for everybody. A more practical approach is to design your software to work with no cryptography, but also to interoperate easily with off-the-shelf, freely available cryptographic packages (packages that are available to people outside the United States, of course). People can download the cryptographic package and drop it into your application themselves. This approach is fairly common, with some packages even providing detailed instructions regarding how to download and install the appropriate cryptographic package along with the software distribution.
Common Cryptographic Libraries
We’ve already established that we should probably use the libraries of other people in our implementations. (Remember, don’t roll your own cryptography!) The next question to ask is, Which libraries should we be using? There are several widely used libraries, each with their relative advantages and disadvantages. Here we look at the comparative advantages of the more popular of the available libraries with which we have experience. Note that even when a library is free for any use, you should ensure that there are no intellectual property issues hanging over the particular algorithm you choose to use. For example, IDEA (International Data Encryption Algorithm) is widely implemented (mainly because of its widespread adoption in PGP), but is not free for commercial use, even if you get it from a free library.
Keep in mind that unlike the rest of the material in this book, the following material does not age well. If you’re reading this book much beyond 2002, you need to check our Web site for updated information on cryptographic libraries.
Cryptlib
Our personal choice for the best all-around library is Peter Gutmann’s Cryptlib. This library is robust, well written, and efficient. The biggest drawback is that it’s only free for noncommercial use, although the commercial prices are quite reasonable. Moreover, Cryptlib is far easier to use than other libraries. Its interface solves most of the problems with misusing cryptographic algorithms that we discussed earlier.
Target language. The Cryptlib API is for the C programming language, and is cross platform. On Windows machines, Cryptlib supports Delphi and most other languages through ActiveX.
Symmetric algorithms. As of this writing, Cryptlib implements a standard set of important symmetric algorithms, including Blowfish, Triple DES, IDEA, RC4, and RC5. It is expected to support AES (Rijndael) as soon as the standard is finalized.
Hash algorithms. Cryptlib implements a common set of hash functions, including SHA-1, RIPEMD-160, and MD5. Like most libraries, Cryptlib doesn’t yet implement the new SHA algorithms (SHA-256, SHA-384, and SHA-512). The author is waiting for the standards surrounding them to be finalized.
MACs. Cryptlib implements the popular HMAC for SHA-1, RIPEMD-160, and MD5.
Public key algorithms. Cryptlib implements all common public key algorithms, including RSA, El Gamal, Diffie-Hellman, and DSA.
Quality and efficiency. Cryptlib is widely regarded to be a robust, well-written, and highly efficient cryptographic library. Most of its critical functions are written in hand-optimized assembly on key platforms. It is also fully reentrant, so it works well in multithread environments.
Documentation. Cryptlib is extensively documented. The documentation is clear and easy to use.
Ease of use. Cryptlib is almost certainly the easiest to use cryptographic library we’ve seen. It provides great high-level functionality that hides most of the details for common operations. However, there’s still a low-level interface for programmers who need to do it themselves. The author tries to discourage people from using those interfaces:
... because it’s too easy for people to get them wrong (“If RC4 were a child’s toy, it’d be recalled as too dangerous”). If people want S/MIME they should use the S/MIME interface, if they want certificates they should use the cert management interface, for secure sessions use the SSH or SSL interface, for timestamping use the timestamping interface, etc.... The major design philosophy behind the code, is to give users the ability to build secure apps without needing to spend several years learning crypto. Even if it only included RSA, 3DES, and SHA-1 (and nothing else) it wouldn’t make much difference, because the important point is that anybody should be able to employ them without too much effort, not that you give users a choice of 400 essentially identical algorithms to play with.
Extras. Cryptlib comes with extensive support libraries, including digital certificate management, and password and key management. It also comes with good support for cryptographic acceleration hardware and smart cards. One thing generally expected from commercial libraries that is not available in Cryptlib is elliptic curve cryptography (ECC) support, which can speed up public key operations. However, this feature is expected to appear in the near future.
Cost. Cryptlib is free for noncommercial use. Additionally, if you are a commercial organization and don’t really intend to use Cryptlib in a product that will make a significant amount of money, you can generally use it for free as well, although check the license. Even for commercial use in real products, Cryptlib is quite reasonably priced.
Availability. Cryptlib is available for download in zip format from its official Web site, http://www.cs.auckland.ac.nz/~pgut001/cryptlib/. If you are interested in commercial use, there is pricing information on that site as well. For sales information, contact [email protected].
OpenSSL
OpenSSL is probably the most popular choice of the freely available encryption libraries. It was originally written by Eric A. Young and was called SSLeay. This is a solid package that also provides encrypted sockets through SSL. Its biggest drawback is a serious lack of documentation.
Target language. OpenSSL’s primary API is for the C programming language. However, the OpenSSL package comes with a command-line program that allows developers to perform a wide variety of encryption operations through shell scripts. This makes OpenSSL something that can be used with relative ease from most programming languages. There are also good bindings for OpenSSL to other programming languages, such as the amkCrypt package for Python (http://www.amk.ca/python/code/crypto.html).
Symmetric algorithms. OpenSSL implements a standard set of important symmetric algorithms, including Blowfish, Triple DES, IDEA, RC4, and RC5. The next major version is expected to support AES.
Hash algorithms. OpenSSL implements a common set of hash functions, including SHA-1, RIPEMD-160, and MD5. Like most libraries, OpenSSL doesn’t yet implement the new SHA algorithms (SHA-256, SHA-384, and SHA-512).
MACs. OpenSSL implements HMAC for all its supported hash algorithms.
Public key algorithms. OpenSSL implements RSA, Diffie-Hellman, and the DSA signature algorithm.
Quality and efficiency. OpenSSL is good, but a bit messy under the hood. Like Cryptlib, there is some hand-tuned assembly on key platforms. However, the user-level code tends not to be as efficient as that of Cryptlib. OpenSSL is probably not the best suited for embedded environments (or other situations in which you are memory constrained) because the library has a fairly large footprint. It’s fairly difficult, but not impossible, to carve out only the pieces needed on a particular project. The library can be reentrant if used properly, with some exceptions.
Documentation. OpenSSL has a limited amount of manpage-style documentation. Many algorithms are currently undocumented, and several interfaces are poorly documented. This situation has been improving over time, but slowly.
Ease of use. The standard interfaces are somewhat complex, but the EVP (“envelope”) interface makes programming fairly straightforward. Unfortunately, the internals have some organizational issues that can impact ease of use. For example, OpenSSL is not thread safe, unless you set two callbacks. If you naively try to use standard interfaces in a threaded application, then your code will probably crash.
Extras. OpenSSL provides a full-featured SSL implementation. However, the SSL implementation is quite complex to use properly. When possible, we recommend using an external wrapper around OpenSSL, such as Stunnel (discussed later).
Cost. OpenSSL is distributed under a free software license.
Availability. OpenSSL is freely available from http://www.openssl.org.
Crypto++
Crypto++ is a library that takes pride in completeness. Every significant cryptographic algorithm is here. However, there is no documentation whatsoever.
Target language. Crypto++ is a C++ library that takes full advantage of C++ features. One issue here is that many compilers are not able to build this library. For example, if using gcc, you need version 2.95 or higher.
Symmetric algorithms. Crypto++ supports any well-known symmetric encryption algorithm you could want to use, including AES.
Hash algorithms. Crypto++ supports any well-known hash algorithm you could want to use, including the new SHA family of hashes, SHA-256, SHA-384, and SHA-512.
MACs. Crypto++ supports several different MACs, including HMAC, DMAC, and XOR-MAC.
Public key algorithms. Crypto++ implements all common public key algorithms, including RSA, El Gamal, Diffie-Hellman, and DSA.
Quality and efficiency. The implementation seems good. Often, other people’s implementations of algorithms are taken directly, and modified for C++. Compared with most other libraries, Crypto++ is not as tuned for performance, especially in UNIX environments (although it does seem to be faster than OpenSSL for many things). On Windows 2000, it performs significantly better than in a Linux environment running on the same machine.
One excellent feature of Crypto++ is that it can automatically run benchmarks of every algorithm for you. It is easy to determine whether Crypto++ is efficient enough for your needs on a particular architecture.
Documentation. Crypto++ is almost completely undocumented. The entire API must be learned from reading the source code. If you’re not a good C++ programmer, you will probably find it difficult. If you are, you should find it fairly easy. Nonetheless, the lack of documentation is a significant barrier to using this library.
Ease of use. Once the Crypto++ API is understood, it is quite easy to use in the hands of a good C++ programmer. It does require a solid understanding of genericity in C++.
Extras. Crypto++ has many things not often found, such as a wide array of algorithms, and full support for ECC, which can substantially speed up public key operations.
Cost. Crypto++ is free for any use.
Availability. The Crypto++ distribution is available off the homepage, located at http://www.eskimo.com/~weidai/cryptlib.html.
BSAFE
The BSAFE library is from RSA Security, the people who developed the RSA encryption algorithm, the MD5 message digest algorithm, and the symmetric ciphers RC4, RC5, and RC6. This library is perhaps the most widely deployed commercial library available, mainly because of people buying it so that they could have legitimate use of algorithms created by RSA.
Target language. There are versions of BSAFE for C and Java.
Symmetric algorithms. BSAFE includes the DES family of algorithms, RC2, RC4, RC5, RC6, and AES.
Hash algorithms. Here, BSAFE only provides MD2, MD5, and SHA-1. The newer members of the SHA family are not available.
MACs. BSAFE provides HMAC.
Public key algorithms. BSAFE implements RSA, Diffie-Hellman, and DSA, along with a complete set of extensions for ECC.
Quality and efficiency. By all reports, as of version 5, this library is extremely efficient and is of high quality. Previously, it was generally regarded as not very good or efficient.
Documentation. BSAFE comes with the extensive documentation you would expect from a pricey commercial library.
Ease of use. BSAFE seems to be average in terms of ease of use. That is, you should have no difficulty using the library.
Extras. BSAFE comes with many extras, depending on which particular product you buy. At the very least, you receive an extensive library, including ECC, calls for sensitive memory control, and good support for key management. More expensive versions have plenty of additional extras, including SSL implementations.
Cost. RSA did not answer our requests for pricing information. Consequently, we asked several people who have been interested in using BSAFE. According to those sources, RSA asks for a fraction of revenue generated by products that use BSAFE. We have heard that they aim for 6%, but some people have successfully gotten them to settle for as little as 3%. Your best chance at getting definitive information is by contacting RSA yourself.
Availability. BSAFE is available by contacting RSA Security. Their Web site is http://www.rsasecurity.com. Their sales address is [email protected].
Cryptix
Cryptix is a popular open-source cryptography package for Java. It is quite full-featured, but is notoriously difficult to use. Part of this is because of the lack of documentation. Also at fault is probably the Java Crypto API, which is significantly more complex than it could be.
Target language. Cryptix is a Java library. There is an old version of the library available for Perl, but it is currently unsupported.
Symmetric algorithms. Cryptix provides a solid array of symmetric algorithms, including AES.
Hash algorithms. Cryptix currently provides a reasonable set of hash algorithms, including MD5, SHA-1, and RIPEMD-160. It does not currently support the new family of SHA functions.
MACs. Cryptix provides an implementation of HMAC.
Public key algorithms. Cryptix implements all common public key algorithms, including RSA, Diffie-Hellman, and DSA. El Gamal is only available in their JCE (Java Cryptography Extension) package, which is currently only available in prerelease.
Quality and efficiency. Although a well-designed library, Cryptix isn’t well-known for its speed. A significant factor here is that Cryptix is implemented solely in Java. Public key operations are particularly painful. If speed is a factor, but Java is a requirement for your application as a whole, you may wish to build a JNI (Java Noting Interface) wrapper for a good C-based library, or look for commercial solutions (such as BSAFE). Note that a JNI wrapper does require you to build a different version for each platform.
Documentation. Cryptix comes with full documentation of the API generated from JavaDOC. This strategy is good once a programmer is familiar with the API, but the documentation is quite inadequate for most programmers who have never used the library.
Ease of use. The lack of documentation and the overall complexity of the Java Crypto API make Cryptix fairly difficult to implement. One of the authors (Viega) has had students use Cryptix in Java-based projects. Not only are there incessant complaints about the documentation, but also approximately half the students fail to get public key cryptography working without significant help.
Extras. Cryptix doesn’t provide much in addition to basic cryptographic primitives. Several extensions are being developed, though, including a library for ECC.
Cost. Cryptix is free software. The authors only ask that copyright notices be perpetuated.
Availability. Cryptix is available from its Web site http://www.cryptix.com.
Other libraries worth mentioning are commercial products from Baltimore and Network Associates (the PGPsdk). Both, by all reports, produce quite excellent products. Although PGPsdk is quite impressive, most notably from an efficiency standpoint, its pricing structure is unreasonable—a significant percentage of all revenue made by products using their library. We have no personal experience with Baltimore’s products.
Programming with Cryptography
Throughout the remainder of this book we use OpenSSL on and off for any code that requires cryptography. Although we prefer Cryptlib for ease of development, we provide examples for OpenSSL because we want to provide code that anyone can use in any application. Unfortunately, the Cryptlib license makes this impossible. OpenSSL is the most widely deployed, totally free library available, and there is support for the library available for many programming languages (see this book’s companion Web site for links).
In OpenSSL, there are individual interfaces for each supported algorithm. However, it is both possible and preferable to use a more generic interface to these facilities. The primary advantages of this are that developers can easily switch algorithms, and still have only a single, small interface to master. This unified interface is called the EVP interface, where EVP is an abbreviation for “envelope.” To use the EVP interface we include the EVP header file. Assuming well-located header files, the only thing that needs to be included is <openssl/evp.h>. To link to the OpenSSL cryptographic subsystem, we link to the library libcrypto.a. Generally, this library is installed in /usr/local/lib and may or may not be in the default library path.
Encryption
The following is a simple program using OpenSSL that creates a symmetric key, encrypts a fixed message with that key, then decrypts the message. Let’s dissect the program, starting at its entry point:


The variable ctx is a cipher “context.” When we perform encryption and decryption operations, we may end up making many calls over a period of time. Even encrypting a single message one time is never a single call. A context encapsulates all of the state that needs to be passed between calls. The notion of a context allows us to start encrypting a second stream of data before we have finished encrypting the first. The context encapsulates the state of what is conceptually an encryption object.
The EVP_CIPHER type encapsulates information about the cipher we want to use. When we instantiate a value of this type, we specify the cipher we want to use and the mode in which we wish to use it. For this example, we use Blowfish in CBC mode, specified by the function EVP_bf_cbc(). When we set the cipher variable, we’re not actually telling the OpenSSL library to use Blowfish. We tell the cipher context to use Blowfish shortly.
There are many ciphers at our disposal, as listed in Table 11-1.

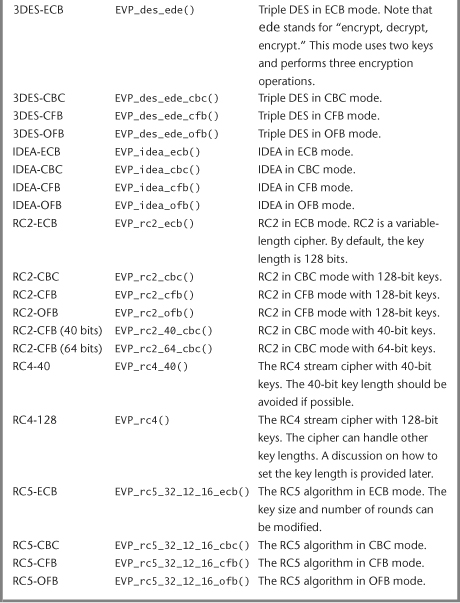
Now we need to initialize the encryption context. To do this we must say which algorithm we wish to use and pass it an initialization vector (IV). The IV can be public information. It’s essential that you give the same IV to the decryption context that was given to the context used to encrypt the message. A good recommendation is to use data from a PRNG as an IV. An easy solution is to use the last block of ciphertext from the previous message. Nonetheless, to keep our examples simple, let’s use an IV that is all zeros.1 Notice that our IV is declared to be large enough to accommodate any cipher in the OpenSSL library. In some circumstances, you can get away with setting the IV to null, but we recommend against it.
1. Many argue that because IVs are public, they aren’t very security relevant. However, they can be quite useful in thwarting dictionary-style attacks.
When initializing the context, we must also specify the key to be used for encryption. In this application, we generate a random key by reading a sufficient number of bytes from /dev/random. This strategy only works on Linux systems. See Chapter 10 for more information on generating high-quality key material.
Note that when initializing the key, we initialize enough key material to handle any cipher. Also note that when using DES and its variants, several of the bits are designed to be parity bits to ensure key integrity. By default, OpenSSL (as well as many other libraries) ignores these bits, making them meaningless. For this reason, reading random bytes into the key is acceptable.
To initialize the context, we call EVP_EncryptInit(). This function takes a pointer to the context object to initialize, the cipher to use, the key (an unsigned char *), and the IV (also an unsigned char *).
If the cipher has additional parameters, we can specify them with additional function calls. We must make all function calls before we actually begin encrypting data. For example, we can change the key length for ciphers that support it using EVP_CIPHER_CTX_set_key_length(). This function takes a pointer to a context object, and a new key length. Additional, cipher-specific parameters can be set with the function EVP_CIPHER_CTX_ctrl().
When we have initialized the cipher, we can turn our attention to encrypting data with it. The first thing to note is that we’re required to allocate our own storage for ciphertext. We must take into consideration the fact that the last block of data is padded.2 The maximum padding is equal to the block size of the cipher (the unit on which the cipher operates). To be conservative, we should use the OpenSSL maximum key length to represent the most bytes that could be added resulting from padding generically. Therefore, we should always allocate the length of the plaintext, plus EVP_MAX_KEY_LENGTH to be safe.
2. OpenSSL currently provides no mechanism for turning off padding. If your data are properly block aligned, you can “forget” to call EVP_EncryptFinal() to forgo padding. The decrypting entity needs to skip the call to EVP_DecryptFinal() as well.
When we encrypt, we get incremental output. That output can also be decrypted incrementally. The incremental output we receive always consists of entire blocks. Any partial blocks are held in the internal state of the context, waiting for the next update. We encrypt with EVP_EncryptUpdate, which has this behavior. When we wish to finish, the leftover needs to be encrypted and the result needs to be padded. For this we call EVP_EncryptFinal.
EVP_EncryptUpdate takes a pointer to a context, a pointer to a preallocated output buffer, a pointer to an integer to which the number of bytes encrypted in this operation is written, the data to be encrypted (partial data are acceptable), and the length of the data to be encrypted. We can call this command as many times as we like. Here, we keep track of how much data get encrypted, so we can easily decrypt the data. Note that we must keep track of lengths carefully, and avoid strlen() unless we know data are null terminated. In particular, the output of OpenSSL encryption routines are binary, and may have nulls in them (or any other character for that matter).
Note that EVP_EncryptUpdate does not append data to the end of a buffer. If you use a single string for your result, and you encrypt incrementally, you must index to the right place every single time.
When we’re done encrypting, we call EVP_EncryptFinal, which takes a pointer to the context, a pointer that denotes where to store the remainder of the ciphertext, and a pointer to an integer that receives the number of bytes written. Notice that we don’t get to encrypt additional data with this call. It only finishes the encryption for the data we have given to EVP_EncryptUpdate.
Decrypting the result is just as straightforward. We first need to reinitialize the context object for decryption. The parameters to the initialization function, EVP_DecryptInit, are exactly the same as for encryption. As with encrypting, there is a special call we must use to make sure we’ve completely recovered the final block of output—EVP_DecryptFinal. Otherwise, we use EVP_DecryptUpdate to decrypt data. Note that we have to allocate the space for the results again.
EVP_DecryptUpdate takes a context pointer, a location to dump the current data, a pointer to an integer that receives the number of bytes decrypted, a pointer to the ciphertext to decrypt, and the length of the ciphertext.
EVP_DecryptFinal takes a context pointer, a location to place data, and a pointer to an integer that receives the number of bytes decrypted. By the time you call this function, you should have no new ciphertext to input.
EVP_DecryptUpdate and EVP_DecryptFinal can fail. Unless you know with absolute certainty that your data remain untampered, you should always check the return value. Even if these functions return successfully, note that an attacker may still have tampered with the encrypted data stream.
Hashing
Performing hashing is easy in OpenSSL using the EVP interface. Much as is the case with encryption, there’s a context object when hashing. You can continually add data to a running hash. The reported value is not calculated until all data have been added.
We initialize a hashing context of type EVP_MD_CTX by calling EVP_DigestInit(). This function takes only two parameters: a pointer to the context and the algorithm to use. Table 11-2 presents the algorithms that are available:
Table 11-2 Available Algorithms

We recommend against using MD4 and MD5. MD4 is known to be broken, and MD5 has serious weaknesses that indicate it may be completely broken soon [Dobbertin, 1996]. Even MD2, which has fared better against cryptanalysis than MD4 and MD5, should probably be avoided, because 128-bits is on the small side for a message digest algorithm.
To hash data, we pass a pointer to the context, the data, and the length of the data to EVP_DigestUpdate(). When we’re done adding data to be hashed, we call EVP_DigestFinal() to get the results. We pass in a context pointer, a buffer, and a pointer to an integer, which receives the length of the digest.
Here’s an example of hashing a simple message:

Public Key Encryption
Although OpenSSL makes symmetric encryption and hashing quite easy, public key encryption is still difficult. The EVP interface provides functionality for this, but it is more complex than the other interfaces, and not nearly as well documented. The following code listing is the subject of our discussion for this section:
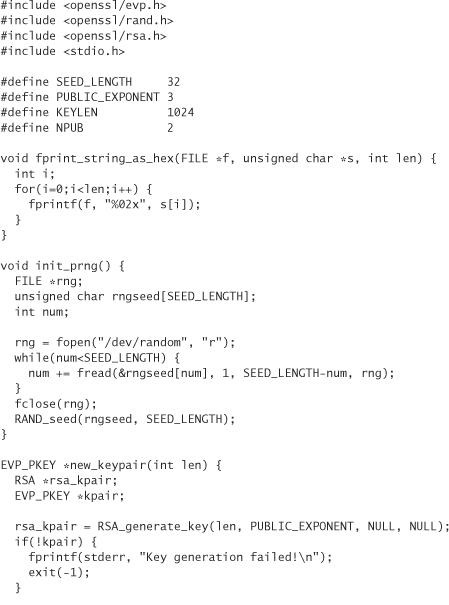



This code generates three public keys. We encrypt a message to two of the public keys, and then sign the message using the third public key. Finally, we validate the signature, then decrypt the message for each key originally used in the encryption process.
Public key cryptography is rarely used without symmetric cryptography. The EVP public key encryption interface that we’re using (the Seal interface) automates the hybrid aspect.3 We specify a set of keys with which we wish to communicate. The library automatically generates session keys for us, encrypts those session keys using public key cryptography (the only choice with this interface is RSA encryption), then encrypts the data using a symmetric cipher that we specify.
3. The notion of “Sealing” is supposed to be likened to sealing an envelope. Here, the public key encryption is an envelope around the actual data stream.
The Open interface does the inverse operation. Given a public key, it decrypts the session key, then uses that session key to decrypt the stream of data using the symmetric cipher.
The first thing we do is seed OpenSSL’s random number generator. OpenSSL uses it to generate both the public/private key pairs for our application and the one-time session keys. The OpenSSL random number generator is only a cryptographic random number generator; it requires the user to provide a securely chosen seed. We use /dev/random for that seed. See Chapter 10 for more information on random number generation.
When we’ve seeded the random number generator, we turn our attention to generating the key pairs. Unfortunately, OpenSSL wants us to use data objects of type EVP_PKEY, but provides no easy way for generating keys of this type. We provide a function new_keypair that does the necessary magic. This returns a preallocated EVP_PKEY instance. Note that, unlike the other interfaces in OpenSSL, the public key-related data structures are instantiated by making calls to the library that performs the actual memory allocation.
When we have our keys, we can encrypt our message. We can send the message to multiple recipients. We specify an array of keys to which we wish to encrypt the message. Actually, what happens is that we encrypt the symmetric session key once for each public key. Then, we encrypt the message itself only a single time.
To initialize the encryption, we must call EVP_SealInit. It takes a pointer to a context, a cipher to use, an array of buffers in which encrypted symmetric keys are stored, an array of integers in which the length of each encrypted symmetric key is stored, an IV, an array of pointers to public keys, and an integer stating how many public keys are in the array.
When we call EVP_SealInit, the symmetric key is generated, and our array of buffers is filled with the proper public key-encrypted symmetric keys. To determine how long a buffer should be to store a particular symmetric key, we pass the key to EVP_PKEY_size, which returns an upper bound. Note that different sizes for the public key result in different sizes for the encrypted symmetric keys.
Now, we call EVP_SealUpdate and EVP_SealFinal in the exact same way we called EVP_EncryptUpdate and EVP_EncryptFinal earlier. They do the same thing at this point; the public key cryptography has already been performed.
When it comes time to simulate the receiver and decrypt all these messages, we use the EVP Open interface. We must use this interface once for each user receiving enveloped data. EVP_OpenInit is responsible for initializing the symmetric encryption context. This includes retrieving the proper symmetric key, which was public key encrypted. When we’ve called EVP_OpenInit, we can then call EVP_OpenUpdate and EVP_OpenFinal, just as if they were EVP_DecryptUpdate and EVP_DecryptFinal (they are doing the same thing at that point).
EVP_OpenInit takes a pointer to a symmetric encryption context, the symmetric algorithm used to encrypt the data, the encrypted symmetric key for the intended recipient, the length of the encrypted symmetric key, the IV, and the RSA key pair that should be used to decrypt the session key.
Between the encryption and the decryption, we digitally sign the data using a third RSA key pair. The way digital signatures work is by private key encrypting a hash of the data to be signed. Anyone with the public key can validate who encrypted the hash. The signing process is done with the EVP Sign interface. EVP_SignInit and EVP_SignUpdate work just like EVP_DigestInit and EVP_DigestUpdate, taking the exact same parameters. When the data for the hash have been read in, we need to generate a signature, not a hash. The EVP_SignFinal method takes a pointer to the digest context being used to sign, a buffer into which the signature should be placed, a pointer to the integer that holds the signature’s length, and the key pair to use when signing the digest. To calculate the maximum length of the signature in bytes, we call EVP_PKEY_size, passing in the key pair that is used for signing.
Before validating the signature, we remove all of the private information from the key. You need to go through these steps any time you want to distribute a public key in this format. The function that removes this information is lobotomize_key().
The process for verifying a signature is similar to creating it. EVP_VerifyInit and EVP_VerifyUpdate calculate a hash, and work just like the corresponding methods in the EVP Digest interface. The EVP_VerifyFinal method takes a pointer to the digest context, the signature to verify, the length of that signature, and the public key of the person we think generated the signature. This call returns a positive integer if the signature corresponds to the key and the data.
Threading
OpenSSL doesn’t work with multithreaded programs out of the box. You need to provide two calls to help the OpenSSL API; otherwise, your programs will probably crash. Unfortunately, writing these calls is quite complex. The OpenSSL library comes with working example code for Windows, Solaris, and Pthreads (which is found on most Linux systems). The example code is in crypto/threads/mttest.c, and is quite involved. We recommend using their code with as few modifications as possible if you need to use OpenSSL in a multithreaded environment.
Cookie Encryption
In Chapter 12 we discuss the need for protecting data stored in cookies. We say that the best way to protect such data is to encrypt the cookies, or to protect them with a MAC. Let’s say that we have a string we’d like to keep on a user’s browser in a form that can’t be read. Let’s keep a symmetric key on the server that we use to encrypt the cookie before placing it in the client browser. When we retrieve the cookie, we decrypt it.
We’d also like to be able to detect when the user has tampered with the cookie. The best strategy is to use two cookies. The first is an encrypted version of our string. The second is a MAC, which serves as a secure checksum for the encrypted string.
Cookies are implemented by writing out MIME headers in an HTTP response. To send our cookie in plaintext, we would add the header
![]()
The next time the user hits a file on our server under the specified path (in this case, any file), we receive the following in the request (assuming cookies are turned on in the browser):
Cookie: mystring=our_string_here
One problem with encrypting cookies is that we’re quite limited in the character set that can go into them, but encryption output is always binary. The MAC output has similar issues. We need to be able to encode binary data in such a way that we can place the result in a cookie.
A good way to do this is to use base64 encoding. This encoding scheme takes binary data and encodes them as printable ASCII. The 64 principal characters are the uppercase and lowercase letters, the digits, the forward slash and the plus sign. The equal sign is used for padding. We provide a base64 library on this book’s companion Web site.
Using that library, we can easily compose a proper header:
![]()
We still need to compute a MAC, so that we can easily detect when the encrypted string has been modified. Here’s a program that computes a MAC of a fixed string using the HMAC algorithm, reading the secret MAC key from /dev/random:

This interface for HMAC is quite straightforward. It works exactly like the EVP Digest interface, except that the initializer gets passed a different type of context, a key, and the length of that key. Note that an attacker cannot forge this MAC without having access to the secret MAC key.
More Uses for Cryptographic Hashes
Cryptographic hashes have a wide variety of uses. One that we saw in Chapter 10 allowed us to hide statistical patterns in data. This trick is often used when turning a password or pass phrase into a key for symmetric cryptography (see Chapter 13). Sometimes the derived key is used directly for communication. Another common trick is to use a hash to protect an RSA private key, so that the RSA key is not vulnerable to being read directly off a disk. Generally, the key size is less than or equal to the hash size. If the hash is larger, it is truncated.
Another clever use of cryptographic hashes is in resource metering. Consider an electronic mail server that wants to meter its use by parties that it cannot necessarily authenticate. For example, an attacker may be able to spoof IP addresses, and flood the server with thousands of fake messages that appear to be coming from different machines. One approach to this problem is to require an electronic payment before processing the message. The payment does not have to be digital cash; it can be in computational resources. That is, before allowing someone to send mail, the server requires a client to compute something that is expensive to calculate but easy to validate.
One prominent idea in this domain is “hash cash” (see our Web site for a link). The server presents a client with a “challenge,” which is a large, randomly generated string (it should probably encode 128 bits of random data), along with a preset number n. Before being allowed to use resources, the client must produce a new string that starts with the randomly generated string. The new string, when hashed, must have the same initial n bits as the hash of the challenge string. This is called an n-bit collision. Assuming the cryptographic strength of the hash function, the client can only generate a collision by iterating a set of strings, hashing each string, and testing it. The server can easily validate the collision. It need only perform a single hash.
If you can force clients to spend even a second’s worth of computational resources, then you have limited the number of messages that client can send in a day to 86,400 messages. You can adjust the amount of resources a client must spend by asking for a larger collision.
The biggest problem with hash cash is that some machines compute collisions more quickly than others. If you’re worried about an attack, you should ask for a collision that protects you against the worst attack you would reasonably expect to see.
On a Pentium III-866 running Red Hat Linux, the expected time to find a collision using SHA-1 as the hash function is presented in Table 11-3.
Table 11-3 Expected Time to Collision
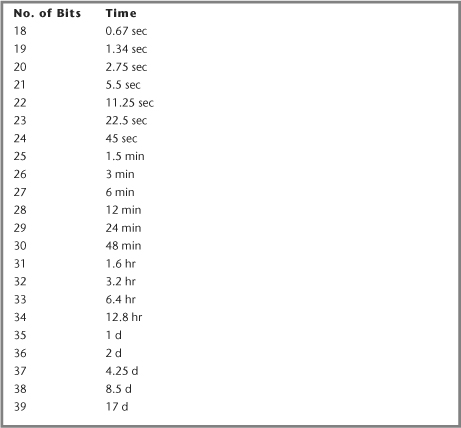
To take into account machines that can compute hashes even faster, we may ask for a larger hash than we need. For example, if we want to limit realistically a single source to 50 messages a minute, we may ask for a 21-bit collision, even though a Pentium III-866 would only be able to send out ten messages a minute, and less-powerful machines may be able to send out even less.
SSL and TLS (Transport Layer Security)
Cryptography is most commonly used as a building block in network-based protocols. However, cryptographic protocols tend to be just as hard to design as good cryptographic algorithms. Many protocols built on great cryptographic primitives have turned out to be quite broken. Therefore, we recommend that you avoid writing your own protocols if at all possible. Instead, look for preexisting protocols that may meet your needs, and try to find well-tested implementations of those protocols. One of the most widely used cryptographic protocols is SSL, which will soon give way to TLS.
SSL and TLS are protocols for secure network connections. TLS is the most recent version of the SSL protocol, being a slightly changed version of SSL version 3. The goal of SSL and TLS (which we collectively refer to as SSL from here forward) is to provide transparent encryption over a network. That is, we’d like to be able to run protocols that generally are unencrypted, such as HTTP and NNTP (Network News Transfer Protocol), and encrypt them, while avoiding major changes to the code.
The authentication strategy is host based. An end user authenticates a remote server, not an application or a user on the remote server. This authentication is done with public key technology. However, public key technology is worthless if you cannot trust the public key given to you. For example, if you were to connect to Amazon.com and let it self-report its public key so that you can communicate with it, how do you know if you get the correct public key?4
4. Although we don’t discuss it, SSL allows for client authentication. However, this is seldom used in the real world because of the difficulties of managing the certificate infrastructure.
The SSL answer to this problem is to use a trusted third party, called a certificate authority (CA). The CA will sign Amazon’s public key, along with other data (in total, the certificate). We validate the CA’s signature to determine the authenticity of the certificate we are presented.
How do we validate the signature of the CA? The answer is that we need to hard code a well-known certificate for the CA into our program for each CA we trust. CAs generally perform some minimal background checks on people buying keys. However, as Matt Blaze has said, “A commercial CA will protect you from anyone whose money it refuses to take,” and that’s a fairly accurate description of the situation. For example, in early 2001, Verisign signed several keys purportedly from Microsoft Corporation, even though they turned out not to be.
You can set yourself up as a CA, but that’s its own nightmare. First, people won’t be able to use your services unless your CA is known by everyone’s client software. Second, CAs tend to involve lots of administrative overhead. It is often more reasonable to stick with established public key infrastructures (PKIs), such as Verisign’s.
Ideally, SSL would feel just like regular old sockets, except that they’d be encrypted. In reality, things are a lot more complex than that. In particular, if you want to embed OpenSSL into your application, it’s quite a lot of work to do fairly simple things. Example SSL client/server applications using the OpenSSL library come with the package. We recommend you look at ssl/s3_clnt.c and ssl/s3_srvr.c when you need to use OpenSSL.5 Use this code as a skeleton for your own, instead of trying to build something from scratch (which is a feat). A much easier approach is to code your application as a regular socket application without encryption, and then add SSL through a “tunneling” mechanism. For example, let’s say that you wish to run an SSL-enabled server on port 4000. You would run an unencrypted service on port 4000 on local host (not visible outside the current machine). An external tunneling program binds to port 4000 on the external interface, and speaks SSL to the remote client. It decrypts everything, and talks to your server in the clear. The disadvantage of this approach is that local users have access to the unencrypted port. Nonetheless, we find this is often the best way to implement SSL. Later, we show you how to use one such free package.
5. Covering the OpenSSL API for SSL connections is too lengthy a topic for us to take on here, especially considering that other APIs have many significant differences.
As a developer, your biggest concerns with SSL are the parts of an implementation that aren’t transparent. Fortunately, there is a pretty short laundry list of things you need to do to make sure you use SSL libraries properly:
1. Do not use SSL version 2 unless absolutely necessary for compatibility. It has fundamental security flaws.
2. Provide the SSL library with a list of CAs, and provide certificates for each CA. Otherwise, you’ll be relying on self-reported keys, which offers little security.
3. When you validate a certificate, you are simply verifying that a known CA signed it. You have not validated anything, unless you compare the information in the certificate with the information you expected to get. Most people forget to take this crucial step in their own systems. Although Web browsers can check to make sure the certificate matches the domain name advertised, it can’t know whether the user is really on the site she wanted to view (silent redirections are pretty common because of outsourcing of merchant services). Therefore, the security of SSL in Web browsers is completely dependent on users checking to make sure the secure link is with the intended site. In practice, nobody does this. As a result, Web-based SSL connections are usually trivial to attack using tool sets like dsniff.
4. You need high-quality random number generation, both on the client and the server. Netscape has fallen prey to this problem in the past. (See Chapter 10 for more information on this topic.)
5. Compromise of the server key is essentially an unrecoverable situation. The SSL protocol specification has a notion of a Certificate Revocation List (CRL). CRLs are supposed to specify lists of certificates that are no longer valid, usually because they have been stolen. However, this feature is largely unimplemented, and where it is implemented, it is usually turned off by default, for performance reasons. Of course, if someone steals your certificate, you can get a new one. However, this does not solve your problem. If an attacker has your old private key, he can use it, and always appear to be you. The vulnerability lasts until the original credentials expire. Similarly, the practical solution to the problem of the forged Microsoft certificates mentioned earlier is to wait for the certificates to expire (although some updated client software contains information about the bogus certificates).
In the final analysis, SSL tends to give developers and organizations a false sense of security. Each of the issues mentioned earlier are significant, and are often not easily solved. For example, attacks like dsniff’s man-in-the-middle attack (see Appendix A) probably work against 98% of all SSL connections made, if not more. You need to be super careful with your implementation.
Stunnel
Stunnel (a link is available on our Web site) is a free SSL tunneling package that requires OpenSSL. Once we have installed Stunnel, using it to protect a server is quite easy. For example, we can SSL-enable an IMAP (Internet Message Access protocol) server by having it bind to local host, and then run Stunnel on the external IP address (assuming an IMAP server is already running, and that 192.168.100.1 is the external IP):
stunnel –d 192.168.100.1:imap2 -r 127.0.0.1:imap2
Clients can use Stunnel to connect to servers. However, it is a little bit more work. First, you must spawn Stunnel as an external process. The easiest way is by using a safe alternative to the standard popen() call (one can be found on this book’s companion Web site). To build a client that connects to the previous SSL-enabled IMAP server, we run Stunnel with the following command-line arguments:
stunnel –c –r 192.168.100.1:imap2 –A /etc/ca_certs –v 3
The last two options are not strictly necessary. The client connects regardless. However, if we leave off these options, the client does not perform sufficient validation on the server certificate, leaving the client open to a man-in-the-middle attack. The v argument specifies the level of validation. The default is 0, which is okay for a server that has other means of authenticating clients. However, levels 1 and 2 are little better. Level 1 optionally checks to see whether a server certificate is valid. Level 2 requires a valid server certificate but does not check to see whether the certificate has been signed by a trusted authority, such as Verisign.
The A argument specifies a file that must contain a list of trusted certificates. For a server certificate to be accepted, it must either be in the file specified by the A argument, or a certificate used to sign the presented certificate must be in the specified file.
The problem with this approach, as we’ve previously mentioned, comes when you use a large CA. For example, it is good to ensure that a particular certificate is signed by Verisign. However, how do you ensure that the certificate is from the site to which you wish to connect? Unfortunately, as of this writing, Stunnel doesn’t allow the calling program access to the validated certificate information. Therefore, you are limited to four options:
1. Hope that no one performs a man-in-the-middle attack (a bad idea).
2. Hard code the certificates for every possible server on the client side.
3. Run your own CA, so you can dynamically add trusted servers.
4. Use SSL in the application instead of using an external tunnel, so you can perform programmatic checks.
This book’s companion Web site provides links to current certificates from prominent CAs. It also links to resources on how to run your own CA.
One-Time Pads
Cryptography is sometimes far more an art than a science. For example, how secure is AES? Because its keys are at least 128 bits, we can throw around the number 2128. In reality, no one knows how secure AES is, because it is incredibly difficult to prove security guarantees for algorithms. Basically, the problem is that it is hard to prove that there are no potential attacks that could be launched on an algorithm. It’s difficult enough considering that new cryptographic attacks are still being discovered today. It is even more difficult considering that we’d like to prove that a cipher can withstand any future attacks as well, including ones that will not be discovered for centuries.
In practice, ciphers that are in popular use and that are believed to be secure may or may not be. They’re believed to be secure because no one has broken them yet, not because they’re known to be secure. That’s why cryptographers are more likely to recommend ciphers that have been extensively scrutinized, as opposed to newer or proprietary cryptographic algorithms. The hope is that if a whole lot of smart minds couldn’t break it, then it’s more likely to be secure. The more minds on a problem, the more likely we are to trust the algorithm. We end up talking about the “best-case” security properties of an algorithm. With symmetric key ciphers, the best case is generally related to the size of the key space, unless there’s known to be a better attack than trying every possible key until one unlocks the data. Therefore, all symmetric key algorithms can be broken given enough time (although we hope that no one ever has that much time).
Public key algorithms are actually a bit easier on the mathematician in terms of being able to prove their security properties, because they tend to be based on well-defined mathematical problems. By contrast, symmetric algorithms tend to be an ad hoc collection of substitutions and permutations that are much more difficult to analyze in context. For example, assuming a perfect implementation, it’s known that the difficulty of breaking the RSA algorithm is strongly tied to the difficulty of being able to factor very large numbers. Mathematicians believe that factoring large numbers cannot be computed in reasonable time. Unfortunately, to date, no one has been able to prove the level of difficulty of factorization.
Even if factorization was known to be hard enough (and assuming no other problems), there is still some theoretical limit at which RSA would be breakable, just as is the case with symmetric algorithms. For example, if you could wait around for the lifetime of the universe and then some, you could definitely crack RSA keys.
It may seem that perfect data secrecy is not possible, given lots of time. Yet oddly enough, there is a perfect encryption algorithm: the one-time pad. Even stranger, the algorithm is incredibly simple. For each plaintext message, there is a secret key that is generated randomly. The key is exactly as long as the plaintext message. The ciphertext is created by XOR-ing the plaintext with the key.
For example, let’s say that we want to encrypt the message “One-time pads are cool.” This message is encoded in 8-bit ASCII. The hexadecimal representation is
4f 6e 65 20 74 69 6d 65 20 70 61 64 73 20 61 72 65 20 63 6f 6f 6c 2e
Let’s say our random key is the following:
9d 90 93 e7 4f f7 31 d8 2d 0d 22 71 b6 78 12 9d 60 74 68 46 6c c0 07
After XOR-ing, we would have the following ciphertext:
d2 fe f6 c7 3b 9e 5c bd 0d 7d 43 15 c5 58 73 ef 05 54 0b 29 03 ac 29
Because every single bit in our plaintext is encoded by a single unique bit in the key, there is no duplicate information that a cryptographer could use in an attack. Because the key was randomly chosen, it is just as likely to be the previous stream as it is to be
86 96 93 e7 49 f7 33 c9 2d 1f 26 72 ac 36 00 cf 64 20 2b 46 6d c9 07
which would decrypt to “The riot begins at one.” Because of the one-to-one correspondence of bits, the cryptanalyst just can’t gain any information that would point to any one decryption as more likely.
The following C code can be used to encrypt and decrypt using a onetime pad. The plaintext is modified in place, and thus must be writable:

One-time pads sound so good that you may be surprised to find out that they’re only rarely encountered in the field. There are several reasons why this is the case.
First, it’s difficult to distribute keys securely, especially when they have to be as long as a message. For example, if you want to send 12 gigabytes of data to a friend over an untrusted medium, you would need to have a key that is 12 gigabytes long.
Second, and more important, the cipher requires numbers that absolutely cannot be guessed. Unfortunately, rand() and its ilk are completely out of the question, because they’re utterly predictable. It’s not easy to generate that much randomness, especially at high bandwidths. For example, if you need 12 gigabytes of random data, it takes an incredibly long time to get it from /dev/random. A hardware source of randomness is far more practical.
You might ask, why not use /dev/urandom, because it spits out numbers as fast as it can? The problem is that it generates numbers quickly using a cryptographic mechanism. You’re effectively reducing the strength of the encryption from unbreakable to something that is probably no more difficult to break than the best symmetric key algorithm available.
This problem has always plagued one-time pads. Using the text of War and Peace as a pad is a bad idea. Because the key isn’t random, the ciphertext won’t be random. One technique used was the same one favored by lotteries to this day. Numbered balls were put into a chamber, and air blew the balls around. An operator would use this chamber to create two identical pads. For the first character on the pad, the operator would reach into the chamber without looking and extract one ball. The number on that ball was recorded on both pads, then the ball was returned to the chamber. Then, the process was repeated.
Even techniques like that weren’t very practical in the real world. The difficulty of generating and distributing pads was a major reason why there were hundreds of less secure cryptographic codes used during World War II.
One-time pads have a gaggle of additional problems when used in the field. First, the pad must be synchronized between two communicating parties to avoid race conditions. Consider when Alice would send a message to Bob at about the same time Bob sent a message to Alice. They may both use the same key for encryption. If each party followed the algorithm precisely, then neither would have the right pad available to decrypt the message.
Worse, encrypting two messages with the same key compromises the security of the algorithm. If someone were to guess that two messages were encrypted using the same pad, that person may be able to recover both of the original messages. The risk is very real. Many years ago, Soviet spies were known to reuse pads, and motivated cryptographers did notice, breaking messages that the communicating parties probably believed were perfectly secret.
To solve the problem, it would make sense to give Alice and Bob two one-time pads. One set of pads would be for messages from Alice to Bob, and the other for messages from Bob to Alice. Now, as long as pads were not reused, and as long as pads were destroyed after use so that no one could compromise used pads, everything would be secure.
There is still another problem, one of data integrity. Let’s say that Alice sent a message to Bob at 10:00 AM, then a message at 1:00 PM, and finally a message at 5:00 PM. If the 10:00 AM message never arrived because the messenger was shot, it would be very difficult for Bob to decrypt the later messages. It wouldn’t be impossible, but it would be a major inconvenience, because Bob would have to guess where in the pad to start when trying to decode the 1:00 PM message. One way to solve the problem would be to number the messages and to use only one pad per message. Another solution would be to have one pad per day; then, only one day of communications could be disturbed at a time.
The lessons learned by World War II cryptographers are quite valuable to developers today. The most important lesson is that one-time pads aren’t very convenient. In practice, it is usually worth the risk to trade perfect secrecy for usability.
They’re also easy to get wrong. Remember that the pads must be used once and only once, thus the “one time” in the name. Plus, the data must be absolutely unpredictable.
In practice, most people aren’t willing to exchange huge keys in a secure manner. It would also be horrible to have missing data somewhere in a large data stream. If the stream could be missing anywhere from 1 byte to 1 gigabyte, resynchronization won’t be all that feasible. However, if after all the caveats, one-time pads still sound like a good idea to you, we recommend the following strategy:
1. Get high-quality random output, as discussed in Chapter 10.
2. Store those bits on two CDs, until you fill the CDs. Both CDs should be identical.
3. Securely distribute and use the CDs.
4. Make sure new CDs are available for when more data are needed. Reusing the same CD can lead to compromise.
5. Destroy the CDs when done.
Be careful, because most products claiming to be based on one-time pads are usually insecure rip-offs. See the “Snake Oil” FAQ, which we mirror on this book’s companion Web site.
Conclusion
In this chapter we’ve given you a flavor for what it takes to apply cryptography in the real world. Currently, SSL is the most important technology for on-line security, and it comes with a host of problems. At its heart, SSL is geared toward a large, distributed population of users. There are other cryptographic libraries that, although less frequently used, may better meet your needs. In particular, Kerberos is a fairly popular technology for providing strong authentication for small- to medium-size organizations. Kerberos has the advantages that it has free implementations and relies completely on symmetric cryptography (this can be good, but the management hassle increases dramatically as the number of users goes up). In the past, it was infrequently used. However, Windows 2000 makes extensive use of it. Kerberos is large enough that we do not cover it here. For a nice, concise overview of Kerberos, see Kerberos: A Network Authentication System by Brian Tung [Tung, 1999].