
Appendix A. Cryptography Basics
“Seven years ago I wrote another book: Applied Cryptography. In it I described a mathematical utopia: algorithms that would keep your deepest secrets safe for millennia, protocols that could perform the most fantastical electronic interactions—unregulated gambling, undetectable authentication, anonymous cash—safely and securely. In my vision cryptography was the great technological equalizer; anyone with a cheap (and getting cheaper every year) computer could have the same security as the largest government. In the second edition of the same book, written two years later, I went so far as to write: ‘It is insufficient to protect ourselves with laws; we need to protect ourselves with mathematics.’ It’s just not true. Cryptography can’t do any of that.”
—BRUCE SCHNEIER
SECRETS & LIES [SCHNEIER, 2000]
Cryptography is a huge area with many interesting facets and subtle issues. There is no way we can provide this topic the full justice it deserves in this small space. To do so would require an entire book. The good news is that several good books devoted to cryptography are available. We highly recommend Bruce Schneier’s Applied Cryptography [Schneier, 1996], which has the advantage of being fairly complete and is aimed at all audiences, including people with little or no experience in cryptography. Not only does Bruce’s book go into more detail than you can get here, it also covers esoteric algorithms that we’re not going to cover. For example, if you want to implement a protocol for secure voting—one in which no outsider can figure out who you voted for, and no one can forge a vote—Bruce’s book will tell you how to do it. We won’t. We’re only going to discuss the most important, commonly encountered stuff here, for those who would rather have a single, stand-alone reference. The material we cover provides you with the essential background information necessary to understand our use of cryptography in this book, particularly that in Chapter 11.
We set the stage by providing some background on cryptography. We discuss the goals that cryptographic systems are designed to meet. Then we talk about what sorts of things can go wrong in these systems. Next we talk about the two primary classes of cryptographic algorithms: symmetric (secret key) cryptography and public key cryptography. Finally, we discuss a handful of other common cryptographic algorithms and their applications, including cryptographic hash algorithms and digital signatures.
The Ultimate Goals of Cryptography
There are four different types of security that cryptographic algorithms can help provide:
1. Confidentiality. Ensuring confidentiality of data amounts to ensuring that only authorized parties are able to understand the data. Note that we’re not trying to keep unauthorized parties from knowing there is some data (perhaps going by on the wire). In fact, they can even copy it all as long as they can’t understand it. In most cases, sensitive data must be transferred over an insecure medium, such as a computer network, and at the same time remain confidential. Only authorized people are allowed access to understand.
Usually the term authorized is loosely defined to imply that anyone who has a particular secret (usually a cryptographic key, which is some small piece of data used as an input to an encryption algorithm) is allowed to decode the data and thus understand it. In a perfect world, we could make a list of who we want to be able to read a particular piece of data, and no one else in the world would ever be able to read it. In practice, confidentiality is supplied through encryption. A message is scrambled using some special information and a specialized cryptographic algorithm. The original message in its preencrypted form is called the plaintext. After encryption, the scrambled version of the message is called ciphertext. Cryptographic algorithms themselves are often called ciphers. Usually, only people with secret information are able to unscramble (decrypt) the message. By using cryptography, software developers can keep data confidential.
2. Authentication. Data authentication ensures that whoever supplies or accesses sensitive data is an authorized party. Usually this involves having some sort of password or key that is used to prove who you are. In a perfect world, we would always be able to tell with absolute certainty who we are communicating with. We would never have to worry about lost or stolen passwords or keeping keys secret. There are several practical ways to provide authentication. Having possession of a secret key that can be authenticated via standard cryptographic techniques is one standard way. We discuss common approaches to the authentication problem, including digital signature systems.
3. Integrity. Data integrity is maintained only if authorized parties are allowed to modify data. In the case of messages going over a network, the ultimate goal is to be sure that when a message arrives, it is the same message that was originally sent. That is, the message has not been altered en route. Data integrity mechanisms usually work by detecting if a message has been altered. Cryptographic hashes (nonreversable transformations) are checksums of a sort that allow us to guarantee data integrity. Generic encryption can also usually be used to ensure data integrity.
4. Nonrepudiation. In communication, data nonrepudiation involves two notions. First, the sender should be able to prove that the intended recipient actually received a sent message. Second, the recipient should be able to prove that the alleged sender actually sent the message in question. Absolute nonrepudiation is fairly difficult to demonstrate in practice, because it is very difficult to show that a person’s cryptographic credentials have not been compromised. Additionally, it can be difficult to prove whether a message was received by the machine or the intended target.
In a perfect world, cryptography would provide a total, unbreakable solution for each of the four central characteristics. But the real world tends not to be so perfect. In fact, weaknesses are often uncovered in commonly used cryptographic algorithms. And misuse of good cryptographic algorithms themselves is also all too common. There is even a science of breaking cryptographic algorithms called cryptanalysis.
All this trouble aside, one important thing to understand is that well-applied cryptography is powerful stuff. In practice, the cryptographic part of a system is the most difficult part of a system to attack directly. Other aspects of a system’s software tend to be far easier to attack, as we discussed in Chapter 5.
For example, if we use a 128-bit key (with a symmetric algorithm), there are enough possible keys that, even with a government’s resources, your keys should be safe well beyond your lifetime, barring unforeseen advances in quantum computing, or unforeseen breaks in the cryptographic algorithms being used, because there are 2128 possible keys. Even the fastest computer cannot try all possible keys quickly enough to break a real system. Most security experts believe that 256-bit keys offer enough security to keep data protected until the end of the universe.
Attackers don’t often try the direct “try-each-key-out” approach, even with fairly weak cryptographic systems (such as RC4 with 40-bit keys), mostly because there are usually much easier ways to attack a system. Security is a chain. One weak link is all it takes break the chain. Used properly, cryptography is quite a strong link. Of course a link alone doesn’t provide much of a chain. In other words, by itself, cryptography is not security. It is often easier for an attacker to hack your machine and steal your plaintext before it is encrypted or after it is decrypted. There are so many security flaws in current software that the direct attack on a host is often the best bet. Even prominent cryptographer Bruce Schneier agrees with this position now, as his quote at the beginning of this appendix attests.
Attacks on Cryptography
In this section we discuss the most common classes of attacks on cryptographic systems. Understanding the things that can go wrong is important in helping you evaluate any cryptographic algorithms you may wish to use.
Known cipher text attacks. In this attack, the cryptanalyst has an encrypted version of a message (or multiple messages encrypted by the same algorithm) called ciphertext. The ciphertext message is manipulated in an attempt to reconstruct the original plaintext, and hopefully to determine the cryptographic key needed to decrypt the message (and subsequent messages). One common version of a known ciphertext attack is the brute-force attack, in which each possible key is used to decrypt the ciphertext. After each key is attempted, the ciphertext is examined to see whether it seems to be a valid message. Given 264 possible keys that may have been used to encrypt a message, the expected number of keys that must be examined before finding the actual key is 263 (we expect to find a key by this method after trying about half the keys, on average). The problem with a known ciphertext attack is that there must be some way of knowing that the decryption was correct. This is not impossible, but it requires advance analysis, and is rare. See [Bellovin, 1997] for more details.
Known plaintext attacks. In this attack, the cryptanalyst has both the ciphertext of a message and the associated plaintext for that message (or part of the message), and tries to figure out the cryptographic key that decrypts the cyphertext to the known plaintext. When that key is known, perhaps future messages will be decipherable as well. Brute force is commonly used with known plaintext, so that one can tell when the correct key is found.
Chosen plaintext attacks. This type of attack is similar to a known plaintext attack, but the cryptanalyst is able to watch as a particular piece of plaintext (chosen by the analyst) is encrypted. If the cryptanalyst can use feedback from previous messages to construct new messages and see how those are encrypted, this becomes known as an adaptive/chosen plaintext attack.
Chosen ciphertext attacks. In this attack, the cryptanalyst has some way of choosing encrypted messages and seeing their decrypted version. The goal is to determine the key used to decrypt the message.
Related-key attacks. In this attack, the cryptanalyst uses knowledge about the relationship of different keys and their associated outputs to guess the key used to encrypt something.
Side-channel attacks. Sometimes seemingly incidental information can be determined from the execution of the encryption or decryption that gives hints as to the key in use.
For example, if there is a predictable relationship between the time it takes to encode a particular string and the key used to encode it, then a cryptanalyst may be able to greatly reduce the number of keys she would have to examine in a brute-force attack. This sort of attack usually requires known ciphertext and chosen plaintext.
One particularly effective example of side-channel attacks is DPA—an attack on smart cards and other small processors. The idea is to keep track of power consumption during a controlled cryptographic computation (say, a DES operation). In simple forms of power analysis, the power curve of the computation leaks key material so badly it is visible with a special tool. More sophisticated chips require some statistics to recover key material. For more, see Paul Kocher’s work at Cryptography Research (http://www.cryptography.com).
There are also plenty of attacks that are not really mathematical in nature. Instead, they rely on nefarious means to obtain a key. Examples include theft and bribery. Theft and bribery are certainly quite effective, and are often very easy to carry out. Also, never underestimate the utility of a social engineering attack. The famous criminal hacker Kevin Mitnick testified to Congress that this is often the easiest way to break a system.
Types of Cryptography
There are many different types of cryptography that you may want to use in your applications. Which one you use depends on your needs. Using more than one type of cryptography in a single application is often appropriate. We ignore cryptography that isn’t considered modern. It’s definitely in your best interests not to use traditional algorithms, as opposed to modern ciphers. Additionally, there are far better sources for such information, such as [Khan, 1996].
Symmetric Cryptography
Symmetric algorithms for cryptography are primarily intended for data confidentiality, and as a side effect, data integrity. They use a single key shared by two communicating parties in their computation. The shared key must remain secret to ensure the confidentiality of the encrypted text.
In a symmetric cipher, the same key is used both to encrypt and to decrypt a plaintext message. The message and the key are provided as input to the encryption algorithm, producing ciphertext that can safely be transmitted over an insecure medium (like, say, the Internet). On the other side, the decryption algorithm (which is necessarily closely related to the encryption algorithm) takes the ciphertext and the same secret key as its inputs and produces the original message. A high-level overview of symmetric algorithms is shown in Figure A-1.
Figure A-1 Symmetric cryptographic algorithms use secret key pairs between communicating entities.
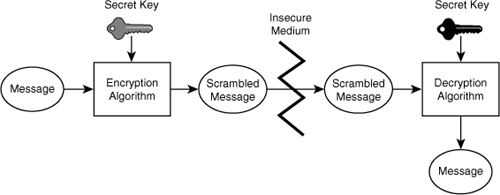
Because both parties in a symmetric cipher communication must possess the same key, and because the key must remain secret, special arrangements need to be made to distribute the secret key securely. It must remain secret at all costs, or the algorithm loses all of its power. One reasonable way to distribute a secret key is to put a copy of it on a floppy disk, and to deliver it to the person with whom you wish to communicate securely. The vulnerability inherent in this method of key distribution is the biggest disadvantage of symmetric algorithms. Lose the disk, and all bets are off.
Some well-known protocols exist for distributing a symmetric key over an insecure medium (Diffie-Hellman is a good example). However, when using these protocols, one must be aware of the requirement for good authentication. Securely exchanging keys with a remote server is certainly possible, but there may be no confirmation (unless you require it) that you are sending key to the correct entity. Perhaps counterintuitively, the most common way keys are exchanged for symmetric ciphers is through public key cryptography (discussed later).1
1. In fact, Diffie-Hellman is a type of public key cryptography that provides key exchange, but no authentication.
Types of Symmetric Algorithms
There are two main categories of symmetric algorithms: block ciphers and stream ciphers. Block ciphers break up a message into constant-size blocks (most often, blocks of 64 bits or 128 bits). The size of the output is usually the same size as the plaintext. If a plaintext message isn’t perfectly aligned with the block size (that is, a whole number factor of the block size), it is usually padded to an appropriate size by appending dummy data. The encryption algorithm itself is most often responsible for any padding operation. In contrast to block ciphers, stream ciphers encrypt a single bit at a time (at least conceptually). Stream ciphers tend to be much faster than block ciphers, but most of the well-known and well-studied symmetric algorithms in common use are block ciphers.
In the easiest to understand block cipher, each block of data is encrypted separately (this type of cipher is said to work in ECB mode). Be forewarned that this obvious approach presents some security risks. For example, suppose that every block of 64 bits in a data file is encrypted separately. Every time the 64-bit plaintext string “security” (assume 8 bits per character) gets encrypted, it encrypts to the exact same ciphertext string. If an attacker sees the plaintext for a sample message, and the message happens to include the word “security” perfectly aligned on a 64-bit boundary, subsequently, every message with “security” so aligned is immediately apparent to an attacker.
Information like the way a specific word is encoded can help an attacker immensely, depending on the circumstances. In one attack, a bad guy can modify encrypted data without any knowledge of the key used to encrypt the information by inserting previously recorded blocks into a new message. To delve a bit more deeply, consider a money payment system in which deposits are sent in a strictly encrypted block cipher format. In our example, the first 128 bits represent the account number in which to deposit the money, and the rest of the message encodes the amount of the deposit, the time at which the message was sent, and perhaps some other information. If an attacker knows that the first 128 bits represent the account number, and if the attacker also happens to know that a target account number encrypts to a particular string, the attacker can modify messages in transit to divert a deposit into the target account. The attack works by replacing the real account number in its encrypted format with the attacker’s own account number (also in encrypted form).
Stream ciphers suffer a similar problem that is generally fixed only by using a MAC. However, block ciphers can be used in such a way as to mitigate the risk we outlined earlier. There are several different strategies that avoid the problem. For example, in CBC mode, blocks are still encrypted one at a time, but the initial state for each block is dependent on the ciphertext of the previous block before being encrypted.
CBC mode is the default mode for many block ciphers. There are many other useful cipher modes. Another mode, called counter mode, uses an arbitrary but reproducible sequence of numbers as an additional input to the cryptographic algorithm. The particular sequence doesn’t matter very much. Usually a pseudorandom sequence seeded with the clock time is more than sufficient. The counter is then mixed with the plaintext before encrypting. In any such approach, the counter cannot repeat, ever, if security is to be maintained. Counter mode effectively turns a block cipher into a stream cipher. Two more modes capable of the same feat are OFB mode, which is actually more commonly used than counter mode, and CFB mode. Using any of these modes in a block cipher helps mitigate the risks incurred when the same plaintext block appears in multiple places in a message (or across multiple messages) by ensuring that the corresponding ciphertext blocks are different.
In most cases, several of the modes we have discussed are built right into an algorithm implementation, and it’s possible to choose which mode to use in your particular application. We usually recommend against using ECB mode, but beyond that general advice, picking a mode depends on circumstances. Each mode tends to have its own security implications. CBC presents a reasonable solution, except that attackers can add gibberish to the end of an encrypted message, or introduce it into the middle of a message. A problem like this can be avoided with two preventative measures. First, make sure you know where your messages end. Encode that information at the start of your message, or make it implicit in your protocol. Make sure the receiving end checks the length information before proceeding. Second, add a cryptographic checksum to the data, so that you can detect cases in which the middle of a message has been modified (see the Section entitled Cryptographic Hashing Algorithms). These precautions help mitigate message-tampering problems.2
2. According to Bruce Schneier, really long messages may still make picking out possible patterns possible, but a risky message would have to be at least 34 GB in the case of a 64-bit block before this would even start to become an issue.
Spending some research time to determine which mode is best for your particular application is a good idea, especially because each mode has different efficiency and fault-tolerance considerations. An excellent discussion of the pros and cons of each common block cipher mode is available in Chapter 9 of Schneier’s Applied Cryptography [Schneier, 1996].
Security of Symmetric Algorithms
If we discount the problem of keeping secret keys secret, the security of symmetric block ciphers depends on two major factors. The first and most important factor is the quality of the algorithm. The second factor, of far less importance, is the length of the key used.3
3. Note that block size can also be a factor. Sixty-four-bit blocks may not be secure enough, but 128-bit blocks should be more than adequate.
The research community has done lots of work on developing secure symmetric ciphers. However, demonstrating how secure a cipher is remains an extremely hard problem. No practical cryptographic algorithm is completely secure.4 Information about the original plaintext that can be located without possessing the key is always revealed in the ciphertext. An attacker’s challenge is to be able to recognize the leaking information.
4. There is one perfect encryption algorithm called a one-time pad. It tends not to be very practical. We discussed it in Chapter 12.
One important goal of any cryptographic algorithm is to make cryptanalysis extremely difficult (other important goals include speed and memory minimization). Unfortunately, this is something very difficult to do. It’s not impossible for good cryptographers to design an algorithm resilient to all known forms of attack. However, it is far more difficult to design against types of attacks that are completely unknown. Many people believe, but no one outside the classified community knows for sure, that the NSA has developed sophisticated attacks against general block ciphers that they have not shared with the rest of the world. Also, there is no telling what sorts of attacks against any algorithm will be discovered in the coming years. The best that cryptanalysts can do is analyze ciphers relative to known attacks, and judge them that way.
When it comes to key length, 128 bits is generally considered more than adequate for messages that need to be protected for a typical human life span (assuming no other attacks can be mounted against the algorithm except a brute-force attack, of course). One hundred twelve bits is also considered adequate. To be safe against partial attacks on a cipher, you may wish to consider 256 bits, which is believed to be secure enough that a computer made of all the matter in the universe computing for the entire lifetime of the universe would have an infinitesimal probability of finding a key by brute force. At the opposite end of the spectrum, 64 bits is considered too small a key for high-security applications. According to Schneier, in 1995 someone willing to spend $100 billion could break a 64-bit key in under a minute [Schneier, 1996]. Reasonable computational resources can break such a key in just a couple of days [Gilmore, 1998]. Forty bits is considered only marginally better than no security at all.
Symmetric algorithms are in widespread use, and have been studied extensively by scientists. There are literally hundreds of such algorithms, a few of them good, some of them bad. The most commonly used symmetric algorithm is DES, which stands for Data Encryption Standard. DES was created by IBM (and partners), under the guidance of the NSA. For many years, DES has been a US government standard. DES is a block cipher that uses 56-bit keys.5 Many modern ciphers have been patterned after DES, but few have stood up well to cryptanalysis, as DES has. The main problem with DES is the very short key length, which is completely inadequate in this day and age.
5. The key is actually 64 bits, but 8 of the key bits are parity bits. Because the parity bits are a function of other bits of the key, they provide no added cryptographic security, meaning DES keys are effectively 56 bits.
It is possible to adapt DES with its short key length to be more secure, but this can’t be done arbitrarily. One idea that many people try involves applying DES twice—something known as double encryption. In such a scheme, a message is encrypted once using one key, then encrypted again (ciphertext to modified ciphertext) using a second key. A very subtle form of attack turns out to render this kind of double encryption not much better than single encryption. In fact, with certain types of ciphers, multiple encryption has been proved to be no better than single encryption.
Although double encryption isn’t very effective, it turns out that triple encryption is about as effective as one might naively expect double encryption to be. For example, 56-bit DES, when triple encrypted, yields 112 bits of strength, which is believed to be more than adequate for any application. Triple-encrypted DES (otherwise known as Triple DES, and often seen written as 3DES) is a popular modern symmetric block algorithm.
Triple DES is not a panacea though. One problem with Triple DES is speed, or lack thereof. Partially because of the speed issue, NIST (part of the US Department of Commerce) initiated a competition for the AES in 1999. NIST chose a winner in October 2000, and as of this writing, is close to ratifying it as a standard. The winning algorithm, called Rijndael, was created by Joan Daemen and Vincent Rijmen. Because of the difficulty of pronouncing the algorithm’s name, most people call it AES.
One risk of the AES competition is that all the algorithms are relatively new. No amount of scrutiny in the short lifetime of the candidate algorithms can compare with the intense scrutiny that has been placed on DES over the years. In truth, it is very likely that Rijndael will be at least as good an algorithm (for use over the next 50 years) as DES has been since its introduction, despite a relatively short lifetime.
Although Triple DES does have some performance issues, for the time being it is a highly recommended solution. A big advantage to this algorithm is that it is free for any use. There are several good implementations of DES that are easily downloaded off the Internet (we link to encryption packages on this book’s companion Web site, and discuss several in Chapter 11). AES is also free for any use, with several free implementations. It is also much faster than DES. However, as of this writing, it’s still not present in many of the popular encryption libraries, mainly because of the fact that the NIST standard hasn’t been completely finalized. Undoubtedly, it will make its way into libraries at that time, which we expect to be soon.
Plenty of commercial symmetric algorithms are also available. Because these algorithms are proprietary, they tend not to be as well analyzed, at least publicly. However, some proprietary algorithms are believed to offer excellent security, and they run quite efficiently to boot. Nonetheless, for most applications, we see no overwhelming reason to recommend anything other than the standard for most applications—Triple DES or AES.
One problem with a symmetric key solution is the requirement that each pair of communicating agents needs a unique key. This presents a key management nightmare in a situation with lots of users. Every unique pair of communicating entities needs a unique key! As a way around this problem, some designers turn to key derivation algorithms. The idea is to use a master key to derive a unique key for each communicating pair. Most often, key derivation uses some unique user identification information (such as user serial number) to transform the master key. The inherent risk in this scheme is obvious. If the master key is compromised, all bets are off. In fact, if even one derived key can be cracked, this may provide enough information to attack the master key, depending on the derivation algorithm.6 Regardless of this risk, many systems rely on symmetric algorithms with key derivation to control cryptographic costs. Before you do this, you should, of course, perform a risk analysis.
6. Hash functions tend to make good key derivation algorithms.
In a related practice, designers often make use of session keys instead of using the same symmetric key for all encrypted communication between two agents. As in the previously derived key, the idea is to use a master key for each communicating pair (perhaps itself derived from a global master key) to derive a session key. In case the session key is compromised, the system can continue to be useful. Once again, the idea of session key derivation from a master communicating-pair key presents risks to the entire system. Much work has been done to build practical solutions for this problem. For example, Kerberos is an excellent technology for symmetric key management.
Public Key Cryptography
As we mentioned in the previous section, one of the biggest problems with symmetric cryptography is the key distribution problem. The problem is figuring out how to exchange a secret key securely with a remote party over an insecure medium. Public key cryptography attempts to circumvent the key exchange problem completely. In a public key system, a pair of keys is used for cryptographic operations (instead of copies of one single key). One of the two keys is made available publicly, and is called the public key. This key can be given away freely, put on a Web page, broadcast, and so forth. A public key is used to encrypt messages. The second key, unlike the first, must remain secret. It is called the private key and it is used to decrypt messages. The security of the private key is as important as key security in a symmetric algorithm. The essential difference between the algorithmic approaches is that in public key cryptography, the private key never needs to be shared with anyone (thus alleviating the key distribution problem).
In a public key system, a message is encrypted by the sender using the public key of the receiver. Barring a weakness in the algorithm, and assuming the algorithm is implemented and used properly (a large assumption; see Chapter 11), the only person who should be able to decrypt a message encrypted in this way is the person who possesses the associated private key. This system is analogous to a mailbox into which everyone can place mail. In this analogy, no one can easily retrieve mail from the box unless they possess the secret (carefully guarded) key that opens the box.
Figure A-2 gives a graphical overview of public key cryptography, showing what happens when Alice sends a message to Bob.
Figure A-2 A high-level view of public key cryptography. Note the asymmetric pairs of keys.
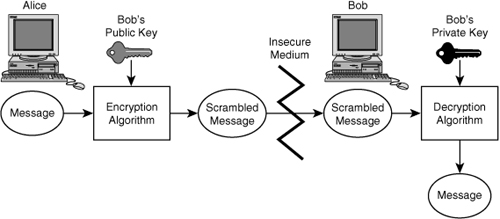
The Achilles’ heel of public key algorithms is that encryption and decryption of messages tend to be incredibly slow relative to symmetric key algorithms. In general, software implementations of public key algorithms tend to be approximately 100 times slower than DES. For this reason, encrypting large messages in a timely manner using public key cryptography is generally not considered practical.
Fortunately, encrypting small messages does seem to fit within acceptable bounds. As a result, people tend to mix the symmetric and public key algorithms together in practice. In such a mix, most communication is carried out with a relatively fast symmetric algorithm. But the high-risk part, that is, exchanging the symmetric key, makes use of a public key algorithm. As we alluded to earlier, this is a reasonable way to avoid the key distribution problem. It also addresses the key derivation risks cited at the end of the symmetric key section (at least for platforms with reasonable computational resources). Given a solid way to distribute keys in a reasonable time, there is little reason to turn to key derivation and take on the associated risks. SSL is a good example of a system that uses hybrid cryptography.
The most famous public key algorithm is the RSA algorithm. The general idea behind RSA starts with picking two large prime numbers, p and q. These numbers remain secret, but you can publish their product, n, along with some additional information. The published information is used to encrypt a message. As a result of the mathematics involved, only someone who knows p and q can decrypt the message in any reasonable amount of time. Usually p and q are all exceptionally large prime numbers (hundreds to thousands of bits).
The security of the RSA algorithm is believed to be equivalent to the difficulty of factoring n to get p and q. Factoring large numbers is believed to be very difficult to do, although this generally accepted claim has never been proved conclusively. Nonetheless, RSA has stood up well to public scrutiny for almost 20 years, so people have gained faith in it.7
7. However, it is notoriously difficult to get a high-quality implementation that doesn’t end up introducing subtle security vulnerabilities. For this reason you should be sure to use well-regarded implementations, and definitely avoid reimplementing this algorithm yourself.
Many people intuitively believe that there are a small number of very large primes, and go on to reason that there are likely to be many problems with the RSA system. Why couldn’t an attacker simply create a database of all possible keys? Each possible key could be tried in a brute-force attack. The bad news is that this sort of attack is possible. The good news is that there are far more prime numbers than most people suspect. There are approximately 10151 primes of length up to 512 bits, which means there are enough primes of as many as 512 bits to assign every atom in the universe 1074 prime numbers without ever repeating one of those primes.
In RSA, security is mostly dependent on how difficult the composite of two prime numbers is to factor. Recall that in a symmetric cryptosystem we said that 256-bit keys are believed to be large enough to provide security for any application through the end of time. With RSA and other public key cryptosystems, the same heuristic does not apply! In fact, it is very difficult to say what a good public key system length will be in 50 years, never mind any farther down the road. A 256-bit number represents far fewer possible RSA keys than 2256, because not every number is prime. So the size of the space is considerably smaller for a brute-force attack. In the end, comparing public key length to symmetric key length directly is like comparing apples and oranges.
One major concern is our inability to predict what kinds of advances researchers will make in factoring technology. Many years ago, it was believed no one would ever have the resources necessary to factor a 128-bit number. Now anyone willing to spend just a few months and a few million dollars can factor a 512-bit number. As a good security skeptic, you should use no less than a 2,048-bit key for data requiring long-term security. That is, use 2,048 bits if your data need to remain secure for long periods of time (ten or more years). Keys that are 1,024 bits are appropriate for most uses for the time being. However, if you’re reading this in 2005, you should check more recent sources to make sure that 1,024-bit keys are still considered sufficient for practical uses, because they may not be!
What’s the drawback of using a very long key? The problem is that with public key cryptography, the longer the key, the longer it takes to encrypt using it. Although you may be well served with a huge (say 100,000-bit) key, you are really not likely to want to wait around long enough to encrypt a single message.
One common misconception is that RSA can’t be used because it is patented. This used to be true, but the patent expired in September 2000 and cannot be renewed. There are other public key algorithms that are protected by patent and modifications to RSA that may also be protected. One of the most notable technologies is ECC, which speeds up traditional public key algorithms, but has not been studied as extensively from a mathematical perspective as RSA.
Other free algorithms do exist. The El Gamal cryptosystem is a good example, based on a different mathematical problem also believed to be hard. Similarly, you could use a combination of Diffie-Hellman key exchange and DSA to get the same practical functionality most people expect from RSA.
Public key cryptosystems are susceptible to chosen plaintext attacks, especially when there are only a small number of possible messages that can be sent (as constrained by a program design, for example). Symmetric algorithms tend to be much more resilient to such attacks. The good news is, in a mixed algorithm approach such as the one we described earlier, you are only using public key cryptography to encrypt a session key, so you have little to worry about.
Another type of attack that is fairly easy to launch against most public key cryptosystems is a “man-in-the-middle” attack (see Figure A-3). Once again, consider a situation in which Bob and Alice wish to communicate. Imagine that Mallory is able to intercept the exchange of public keys. Mallory sends Alice his own key, but misrepresents it as Bob’s key. He also sends Bob his own key, misrepresenting it as Alice’s key. Mallory now intercepts all traffic between Alice and Bob. If Alice sends a message to Bob in the compromised system, she’s actually encrypting the message using Mallory’s public key, even though she thinks she is using Bob’s. Mallory gets the message, decrypts it, and stores it, so he can read it later. He then encrypts the message using Bob’s public key, and sends it on to Bob. Bob gets the message, and is able to decode it, unaware that it really came from Mallory, and not from Alice.
Figure A-3 A man-in-the-middle attack.
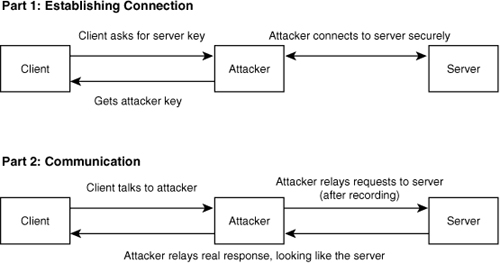
The primary problem here is that Alice has no way of ensuring that the key she obtained actually belongs to Bob. There are several ways to get around this problem, but they tend to involve the presence of a PKI. In a generic PKI, a trusted third party signs valid keys. The public key for that trusted third party is widely available (usually encoded into a Web browser), and can be used to validate a certificate.
The PKI strategy works well using a somewhat complex protocol. However, there are some drawbacks. First, how can anyone be sure that he or she can trust the so-called trusted authority? Second, what if someone is able to defraud the authority (say, by hacking their site)? Defrauding is apparently pretty easy. In March 2001, Microsoft let it be known that two false keys with their name on them had been issued. Finally, a certificate that is signed by a trusted CA is not necessarily the certificate from the site that the client expected to contact. We discuss this problem more in Chapter 11.
One of the largest CAs is a company called Verisign. Verisign helps spread trust around by performing limited background checks on people before deciding to trust them and issue a public key identity (in the model, a person who wants to be trusted pays for this trust). The problem is that the identity checking in the early days was on the lax side. Soon after Verisign introduced their services, some people began registering false identities. For example, we are told that several people registered identities as Bill Gates. Perhaps the best way to circumvent these problems is to exchange keys in person, or through any medium that you do trust completely (sometimes the phone is sufficient if you know the party well by voice).
Beyond the issue of lax identity verification lies a user issue. The problem is that, in practice, people often don’t bother to check the results given by the trusted third party. This problem is extremely widespread, especially in the use of “secure” Web sites.
Here’s a common scenario. Say you want to buy some books from Amazon.com. When you go to check out using Netscape, you notice that the little lock icon in the left-hand corner of the browser switches from “unlocked” to “locked,” indicating that you are talking to Amazon.com over an encrypted channel. Or are you? Not necessarily. The lock just indicates that you’re talking to someone over an encrypted channel. You can find out who the trusted third party claims to be by clicking on the lock, then clicking on “View Certificate.” If you’re not being attacked with a man-in-the-middle attack (like Web spoofing), you will see Amazon.com’s information displayed in the certificate window. However, if a man-in-the-middle attack is taking place, or if some second party is completely spoofing Amazon.com’s look and feel, and you’re not really talking to Amazon.com at all, you will see different information. By bothering to check, you can be pretty sure whether you’re talking to the party with which you intended to communicate. Unfortunately, in practice most people never check this information! They just see the lock and feel good about it. If you don’t check the certificate, you can’t have any assurance as to the security.
This problem permeates practical implementations of public key cryptography. For example, many users of SSL (which is a public key-based library used in both Netscape and many other applications) suffer from the “not-checking-who-you’re-connected-to” problem. People get a warm fuzzy because they’re using SSL to encrypt data, but they don’t realize that the validation problem exists.
Unless an application has a method of distributing public keys in which you have high confidence (such as personal delivery), it is never a good idea to trust blindly that you have a correct public key. If you really need high security, don’t go for the passive Netscape solution in which data from the trusted authority are only available on request (by clicking on the icon). Put the information right in the user’s face. Sure it’s another dialog box, and a hassle for the user, but hopefully the user will understand the importance of checking the dialog box, and won’t just get rid of it without reading it. Even if that happens, you’ve at least made a good effort on your end. We firmly believe any man-in-the-middle attacks made against Netscape are more the responsibility of Netscape than the end user, because Netscape doesn’t make a good effort to get users to validate the party with whom they’re communicating. If there was an “in-your-face” dialog, then the responsibility would shift to the user, in our opinion. Dismissing the dialog box without reading it is something the user does at his own risk.
By the way, man-in-the-middle attacks are incredibly easy to launch against SSL. There are tools such as dsniff that can readily automate the attack.
Cryptographic Hashing Algorithms
In our treatment of cryptography thus far, we touch on both common forms of cryptographic algorithms (public key cryptosystems, such as RSA, and symmetric algorithms, such as DES). These are the traditional means used to address the data confidentiality problem. We also discuss the importance of using well-understood algorithms instead of rolling your own, and introduce the risks commonly encountered when implementing cryptography in an application. Now we turn to common approaches for data integrity and authentication, starting with hashing algorithms.
Hashing algorithms are one-way functions. That is, they take a plaintext string and transform it into a small piece of ciphertext that cannot be used to reconstruct the original plaintext. Clearly, some data need to be lost in the transformation for this sort of function to work.
One-way functions may not sound immediately useful because you can’t get the plaintext back out of a one-way computed ciphertext. Why would you want to compute a cipher that you can’t undo? Of course functions that are almost one way are pretty useful, because all public key functions are, at their essence, one-way functions with “trapdoors.” Good candidate functions for public key cryptography are those that are easy to compute in one direction, but very difficult to compute in the other direction unless you know some secret. Thus we find public key algorithms based on factoring and other hard mathematical problems.
As it turns out, true one-way functions are useful too. These functions are often called hash functions, and the result of such a function is commonly called a cryptographic hash value, cryptographic checksum, cryptographic fingerprint, or message digest. Such functions play a major role in many cryptographic protocols.
The idea is to take a piece of plaintext and convert it to a piece of (usually smaller) ciphertext in a way that is irreversible. Most of the time, there are infinitely many different strings that can produce the exact same hash value. However, with a good cryptographic hashing function, finding two intelligible strings that hash to the same value should be extremely difficult in practice. Another property of a good hash function is that the output does not reflect the input in any discernible way.
Hash functions usually output constant-size digests. There are many algorithms that produce very small digests. However, the security of the algorithm rests largely on the size of the resulting digest. We recommend selecting an algorithm that provides a digest size of no fewer than 160 bits. SHA-1, which gives a 160-bit hash, is a reasonable hashing function to use. The more modern SHA algorithms—SHA-256, SHA-384, and SHA-512—are potentially better choices for high-security needs (as is Tiger), but aren’t yet widely available, and have yet to receive significant analysis from the cryptographic community.
Hash functions can be used to ensure data integrity, much like a traditional checksum. If you publicly release a regular cryptographic hash for a document, anyone can verify the hash, assuming he or she knows the hash algorithm. Most hash algorithms that people use in practice are published and well understood. Again, let us remind you that using proprietary cryptographic algorithms, including hash functions, is usually a bad idea.
Consider the case of a software package distributed over the Internet. Software packages available through FTP were, in the recent past, associated with checksums. The idea was to download the software, then run a program to calculate your version of the checksum. The self-calculated checksum could then be compared with the checksum available on the FTP site to make sure the two matched and to ensure data integrity (of sorts) over the wire. The problem is that this old-fashioned approach is not cryptographically sound. For one thing, with many checksum techniques, modifying the program to download maliciously, while causing the modified program to yield the exact same checksum, is possible. For another, a Trojan horse version of a software package can easily be published on an FTP site with its associated (poorly protected) checksum. Cryptographic hash functions can be used as drop-in replacements for old-style checksum algorithms. They have the advantage of making tampering with posted code more difficult.
Be forewarned, there is still a problem with this distribution scheme. What if you, as the software consumer, somehow download the wrong checksum? For example, let’s say that we distribute the xyzzy software package. One night, some cracker breaks into the distribution machine and replaces the xyzzy software with a slightly modified version including a malicious Trojan horse. The attacker also replaces our publicly distributed hash with the hash of the Trojan horse copy of the release. Now, when some innocent user downloads the target software package, a malicious copy arrives. The victim also downloads a cryptographic checksum and tests it against the software package. It checks out, and the malicious code appears safe for use. Obviously, the hash alone is not a complete solution if we can’t guarantee that the hash itself has not been modified. In short, we need a way to authenticate the hash.
There are two possible situations that arise when we consider the authentication problem. We may want everyone to be able to validate the hash. If so, we can use digital signatures based on PKI, as discussed later, or we may want to restrict who can validate the hash. For example, say we send an anonymous letter to the sci.crypt newsgroup posting the full source code to a proprietary encryption algorithm, but we want only a single closest friend to be able to verify that we posted the message. We can use a MAC to achieve these results.
MACs work by leveraging a shared secret key, one copy of which is used on the recipient end. This key can be used to authenticate the data in question. The sender must possess the other copy of the secret key. There are several ways a MAC can work. They generally involve a hash of the text, and then several hashes of the resulting hash and the secret key.8 If you don’t have the secret key, there is no way that you can confirm the data are unaltered. Another, more computationally expensive approach is to compute the hash like normal, then encrypt the hash using a symmetric algorithm (like DES). To authenticate the hash, it must first be decrypted.9
8. You should not try to design your own MAC. Good MACs are driven by proved security properties. Instead, use a well-trusted MAC such as HMAC.
9. There are many constructions for MACs that do not depend on cryptographic hashing. See Bruce Schneier’s Applied Cryptography [Schneier, 1996] for more details.
MACs are useful in lots of other situations too. If you need to perform basic message authentication without resorting to encryption (perhaps for efficiency reasons), MACs are the right tool for the job. Even when you are using encryption already, MACs are an excellent way to ensure that the encrypted bit stream is not maliciously modified in transit.
If designed carefully, a good MAC can help solve other common protocol problems. One widespread problem with many protocols is evidenced during what is called a playback attack (or a capture/replay attack). Say we send a request to our bank, asking for a transfer of $50 into John Doe’s banking account from ours. If John Doe intercepts that communication, he can later send an exact duplicate of the message to the bank! In some cases the bank may believe we sent two valid requests!
Playback attacks turn out to be a widespread problem in many real-world systems. Fortunately, they can be mitigated with clever use of MACs. In our previous bank transfer example, assume we use a primitive MAC that hashes the request along with a secret key. To thwart playback we can make sure that the hash never comes out the same. One of the best ways is to use an ever-increasing counter (a sequence number) as part of the message to be “MAC-ed.” The remote host need only keep track of the last sequence number it serviced, and make sure that it never services a request older than the next expected sequence number. This is a common approach.
In many cases authentication may not really be an issue. For example, consider using a cryptographic hash to authenticate users logging in to a machine from the console. When the user enters a password for the first time in many systems, the password itself is never actually stored. Instead, a cryptographic hash of the password is stored. This is because most users feel better if they believe system administrators can’t retrieve their password at will. Assuming the operating system can be trusted (which is a laughably big assumption, of course!), we can assume our database of cryptographically hashed passwords is correct. When the user tries to log in, and types in a password, the login program hashes it, and compares the newly hashed password with the stored hash. If the two are equal, we assume the user typed in the right password, and login proceeds.
Unfortunately, architects and developers sometimes assume that the security of the authentication mechanism isn’t really a problem, when in reality it is. For example, consider the TELNET protocol. Most TELNET servers take a username password as input. They then hash the password, or perform some similar transformation, and compare the result with a local database. The problem is that with the TELNET protocol, the password goes over the network in the clear. Anyone who can listen on a network line (with a packet sniffer) can discover the password. TELNET authentication provides a very low bar for potential attackers to clear. Many well-known protocols have a similarly broken authentication mechanism, including most versions of FTP, POP3, and IMAP.
There are, of course, many other important security considerations surrounding the implementation of password authentication systems. This problem is a big enough topic that we discuss it extensively in Chapter 13.
Other Attacks on Cryptographic Hashes
Any good cryptographic hashing algorithm should make finding a duplicate hash for an alternative plaintext difficult, even given a known message and its associated message hash. Searching for a collision on purpose amounts to a brute-force attack, and is usually fairly difficult. This is especially true if the attacker wants the second plaintext document to be something other than a string of gibberish.
There’s another attack on cryptographic hashes that is much easier to carry out than the average brute-force attack. Consider the following scenario: Alice shows Bob a document and a cryptographic hash to validate the document in which Alice agrees to pay Bob $5 per widget. Bob doesn’t want to store the document on his server, so he just stores the cryptographic hash. Alice would like to pay only $1 per widget, so she would like to create a second document that gives the same hash value as the $5 one, then go to court, claiming that Bob overbilled her. When she gets to court, Bob presents a hash value, believing that Alice’s document will not hash to that value, because it isn’t the original document she showed him. If her attack is successful, Alice will be able to demonstrate that the document she has does indeed hash to the value Bob stored, and the courts will rule in her favor.
But how? Alice uses what is called a birthday attack. In this attack, she creates two documents: one with the $5-per-widget price and the other with the $1-per-widget price. Then, in each document, she identifies n places where a cosmetic change can be made (for example, places where a space could be replaced with a tab). A good value of n is usually one more than half the bit length of the resulting hash output (so n = m/2+1 if we assign m to the bit length of the hash output). For a 64-bit hash algorithm, she would select 33 places in each document. She then iterates through the different permutations of each document, creating and storing a hash value. Generally, she will expect to find two documents that hash to the same value after hashing approximately 2m/2 messages. This is much more efficient than a brute-force attack, in which the expected number of messages she would have to hash is 2m–1. If it would take Alice a million years to perform a successful brute-force attack, she could probably perform a successful birthday attack in less than a week. As a result, Bob should demand that Alice use an algorithm that gives a digest size for which she cannot perform a birthday attack in any reasonable time.
To get the same security against birthday attacks as is typically desired against brute-force attacks given a symmetric cipher with key length p, you should pick a hash algorithm that gives a digest of size p*2. Therefore, for applications that require very high levels of security, it is a good idea to demand hash algorithms that yield message digests that are 256 bits, or even 512 bits.
What’s a Good Hash Algorithm to Use?
We do not recommend using anything weaker than SHA-1. In particular, MD4 and MD5 should never be used for new applications. MD4 and MD5 have some known weaknesses, and should not be used for new applications. Legacy applications should even try to migrate from MD-4. SHA-1 is a good algorithm, as is RIPEMD-160, which has a slightly more conservative design than SHA-1. Both these algorithms have 160-bit digest sizes. This equates to approximately an 80-bit symmetric key, which is a bit small for long-term comfort, although currently sufficient for most applications. If you’re willing to trust algorithms that are fairly new, Tiger, SHA-256, and SHA-512 all look well designed, and are quite promising.
Digital Signatures
A digital signature is analogous to a traditional handwritten signature. The idea is to be able to “sign” digital documents in such a way that it is as easy to demonstrate who made the signature as it is with a physical signature. Digital signatures must be at least as good as handwritten signatures at meeting the main goals of signatures:
1. A signature should be proof of authenticity. Its existence on a document should be able to convince people that the person whose signature appears on the document signed the document deliberately.
2. A signature should be impossible to forge. As a result, the person who signed the document should not be able to claim this signature is not theirs.
3. After the document is signed, it should be impossible to alter the document without detection, so that the signature can be invalidated.
4. It should be impossible to transplant the signature to another document.
Even with handwritten signatures, these ideals are merely conceptual, and don’t really reflect reality. For example, forging ink signatures is possible, even though few people are skilled enough to do it. However, signatures tend not to be abused all that often, and thus hold up in court very well. All in all, ink signatures are a “good-enough” solution.
To quote Matt Blaze, “physical signatures are weakly bound to the document but strongly bound to the individual; digital signatures are strongly bound to the document and weakly bound to the individual. This fact often amazes people, because they figure such a signature is akin to the “signature” files that people often place at the bottom of e-mail messages (usually a bunch of ASCII). If this were what digital signatures were like, then they wouldn’t be very useful at all. It would be far too easy to copy a signature out of one file and append it directly to another file for a “perfect forgery.” It would also be possible to modify a document easily after it was supposedly signed, and no one would be the wiser. Thankfully, digital signatures are completely different.
Most digital signature systems use a combination of public key cryptography and cryptographic hash algorithms. As we have explained, public key cryptographic systems are usually used to encrypt a message using the receiver’s public key, which the receiver then decrypts with the corresponding private key. The other way works too. That is, a private key can be used to encrypt a message that can only be decrypted using the corresponding public key. If a person keeps his or her private key completely private (which isn’t necessarily a great assumption, because someone who has broken into your machine can get your key after you use it), being able to decrypt a message using the corresponding public key then constitutes proof that the person in question encrypted the original message. Determining whether a signature is trustworthy is usually done through a PKI.
Digital signatures are not just useful for signing documents; they’re useful for almost all authentication needs. For example, they are often used in conjunction with encryption to achieve both data privacy and data authentication.
A digital signature for a document is usually constructed by cryptographically hashing the document, then encrypting the hash using a private key. The resulting ciphertext is called the signature. Anyone can validate the signature by hashing the document themselves, and then decrypting the signature (using either a public key or a shared secret key), and comparing the two hashes. If the two hashes are equal, then the signature is considered validated (assuming the person doing the validation believes the public key they used really belongs to you).
Note that the signature need not be stored with the document. Also, the signature applies to any exact digital replica of the document. The signature can also be replicated, but there is no way to apply it to other documents, because the resulting hash would not match the decrypted hash.
The one problem with digital signatures is nonrepudiation. People can always claim their key was stolen. Nonetheless, digital signatures are widely accepted as legal alternatives to a physical signature, because they come at least as close to meeting the ideals presented here as do physical signatures. The US Congress passed the Millennium Digital Commerce Act in 2000 which states:
Industry has developed several electronic signature technologies for use in electronic transactions, and the public policies of the United States should serve to promote a dynamic marketplace within which these technologies can compete. Consistent with this Act, States should permit the use and development of any authentication technologies that are appropriate as practicable as between private parties and in use with State agencies.
One problem is that the verbiage of the Act is a bit too lenient for our tastes. It says, “The term ‘electronic signature’ means an electronic sound, symbol, or process attached to or logically associated with a record and executed or adopted by a person with the intent to sign the record.” This means that regular old ASCII “signatures” such as
(signed) John Viega
are perfectly legal.
Most public key algorithms including RSA and El Gamal can easily be extended to support digital signatures. In fact, a good software package that supports one of these algorithms should also support digital signatures. Try to use built-in primitives instead of building your own construction out of an encryption algorithm and a hash function.
Conclusion
Cryptography is a huge field. We won’t even pretend to cover it completely in this book. For anything you can’t get here and in Chapter 11, we highly recommend Schneier’s Applied Cryptography [Schneier, 1996].
As we previously mentioned, there are plenty of cool things you can do with cryptography that Bruce talks about, but we won’t have the space to discuss. For example, he discusses how you may create your own digital certified mail system. He also discusses how to split up a cryptographic secret in such a way that you can distribute parts to n people, and the secret will only be revealed when m of those n people pool their resources. It’s definitely worth perusing his book, if just to fill your head with the myriad possibilities cryptography has to offer.