
5. Guiding Principles for Software Security
“We shall not cease from exploration
And the end of all our exploring
Will be to arrive where we started
And know the place for the first time”
—T. S. ELIOT
LITTLE GIDDING
We hope we’ve been able to impress on you the fact that software security is hard. One of the biggest challenges is that some important new flaws tend to defy all known patterns completely. Following a checklist approach based on looking for known problems and avoiding well-marked pitfalls is not an optimal strategy. For a good example we need to look no further than cryptography, where it is relatively easy to construct a new algorithm that resists the best known attacks on well-understood algorithms but that is still broken. New algorithms that seem good in light of known cryptographic problems end up in the dustbin all the time. That’s because protecting against unknown attacks is a far greater challenge than protecting against hackneyed rote attacks. One major factor is that there is plenty of room for new attacks to emerge, and every few years a significant one does. Another major factor is that keeping up with known problems is difficult, because there are so many of them.
Mobile code security teaches us the same lesson in a different way. Java attack applets may fall into generic types to some extent: type confusion attacks, type safety verification attacks, class-loading attacks, and so on. But there is no algorithmic (or even heuristic) way of describing known attacks in such a way that a “scanner” could be built to find new ones. New categories of attacks as well as surprising new twists on broad categories like class-loading attacks are discovered fairly consistently. Anticipating exactly how these attacks will work is impossible.
By now we know that it is not practical to protect against every type of attack possible anyway. We have to approach software security as an exercise in risk management. An approach that works very well is to make use of a set of guiding principles when designing and building software. Good guiding principles tend to improve the security outlook even in the face of unknown future attacks. This strategy helps to alleviate the “attack-of-the-day” problem so reminiscent of the “coding-to-the-tests” problem in software development. Checklists may have their place, but they are not as good as guiding principles.
In this chapter we present ten principles for building secure software. The goal of these principles is to identify and to highlight the most important objectives you should keep in mind when designing and building a secure system. Following these principles should help you avoid lots of common security problems. Of course, this set of principles will not be able to cover every possible new flaw lurking in the future. We don’t pretend that any set of principles could by itself solve the software security problem. We’re simply laying out a good “90/10” strategy: Avoid 90% of the potential problems by following these ten simple guidelines:
Some caveats are in order. No list of principles like the one just presented is ever perfect. There is no guarantee that if you follow these principles your software will be secure. Not only do our principles present an incomplete picture, but they also sometimes conflict with each other. As with any complex set of principles, there are often subtle tradeoffs involved. For example, the defense-in-depth principle suggests that you build redundancy into your systems, whereas the simplicity principle advises that you avoid unnecessary code.
Clearly, application of these ten principles must be sensitive to context. A mature software risk management approach provides the sort of data required to apply the principles intelligently.
Principle 1: Secure the Weakest Link
Security practitioners often point out that security is a chain. And just as a chain is only as strong as the weakest link, a software security system is only as secure as its weakest component. Bad guys will attack the weakest parts of your system because they are the parts most likely to be easily broken. (Often, the weakest part of your system will be administrators, users, or technical support people who fall prey to social engineering.)
It’s probably no surprise to you that attackers tend to go after low-hanging fruit. If a malicious hacker targets your system for whatever reason, they’re going to follow the path of least resistance. This means they’ll try to attack the parts of the system that look the weakest, and not the parts that look the strongest. (Of course, even if they spend an equal effort on all parts of your system, they’re far more likely to find exploitable problems in the parts of your system most in need of help.)
A similar sort of logic pervades the physical security world. There’s generally more money in a bank than a convenience store, but which one is more likely to be held up? The convenience store, because banks tend to have much stronger security precautions. Convenience stores are a much easier target. Of course the payoff for successfully robbing a convenience store is much lower than knocking off a bank, but it is probably a lot easier to get away from the convenience store crime scene. To stretch our analogy a bit, you want to look for and better defend the convenience stores in your software system.
Consider cryptography. Cryptography is seldom the weakest part of a software system. Even if a system uses SSL-1 with 512-bit RSA keys and 40-bit RC4 keys (which is, by the way, considered an incredibly weak system all around), an attacker can probably find much easier ways to break the system than attacking the cryptography. Even though this system is definitely breakable through a concerted cryptographic attack, successfully carrying out the attack requires a large computational effort and some knowledge of cryptography.
Let’s say the bad guy in question wants access to secret data being sent from point A to point B over the network (traffic protected by SSL-1). A clever attacker will target one of the end points, try to find a flaw like a buffer overflow, and then look at the data before they get encrypted, or after they get decrypted. Attacking the data while they are encrypted is just too much work. All the cryptography in the world can’t help you if there’s an exploitable buffer overflow, and buffer overflows abound in code written in C.
For this reason, although cryptographic key lengths can certainly have an impact on the security of a system, they aren’t all that important in most systems, in which there exist much bigger and more obvious targets.
For similar reasons, attackers don’t attack a firewall unless there’s a well-known vulnerability in the firewall itself (something all too common, unfortunately). Instead, they’ll try to break the applications that are visible through the firewall, because these applications tend to be much easier targets. New development tricks and protocols like Simple Object Access Protocol (SOAP), a system for tunneling traffic through port 80, make our observation even more relevant. It’s not about the firewall; it’s about what is listening on the other side of the firewall.
Identifying the weakest component of a system falls directly out of a good risk analysis. Given good risk analysis data, addressing the most serious risk first, instead of a risk that may be easiest to mitigate, is always prudent. Security resources should be doled out according to risk. Deal with one or two major problems, and move on to the remaining ones in order of severity.
Of course, this strategy can be applied forever, because 100% security is never attainable. There is a clear need for some stopping point. It is okay to stop addressing risks when all components appear to be within the threshold of acceptable risk. The notion of acceptability depends on the business proposition.
Sometimes it’s not the software that is the weakest link in your system; sometimes it’s the surrounding infrastructure. For example, consider social engineering, an attack in which a bad guy uses social manipulation to break into a system. In a typical scenario, a service center gets a call from a sincere-sounding user, who talks the service professional out of a password that should never be given away. This sort of attack is easy to carry out, because customer service representatives don’t like to deal with stress. If they are faced with a customer who seems to be really mad about not being able to get into their account, they may not want to aggravate the situation by asking questions to authenticate the remote user. They instead are tempted just to change the password to something new and be done with it.
To do this right, the representative should verify that the caller is in fact the user in question who needs a password change. Even if they do ask questions to authenticate the person on the other end of the phone, what are they going to ask? Birth date? Social Security number? Mother’s maiden name? All of that information is easy for a bad guy to get if they know their target. This problem is a common one and it is incredibly difficult to solve.
One good strategy is to limit the capabilities of technical support as much as possible (remember, less functionality means less security exposure). For example, you may choose to make it impossible for a user to change a password. If a user forgets his or her password, then the solution is to create another account. Of course, that particular example is not always an appropriate solution, because it is a real inconvenience for users. Relying on caller ID is a better scheme, but that doesn’t always work either. That is, caller ID isn’t available everywhere. Moreover, perhaps the user is on the road, or the attacker can convince a customer service representative that they are the user on the road.
The following somewhat elaborate scheme presents a reasonable solution. Before deploying the system, a large list of questions is composed (say, no fewer than 400 questions). Each question should be generic enough that any one person should be able to answer it. However, the answer to any single question should be pretty difficult to guess (unless you are the right person). When the user creates an account, we select 20 questions from the list and ask the user to answer six of them for which the user has answers and is most likely to give the same answer if asked again in two years. Here are some sample questions:
• What is the name of the celebrity you think you most resemble, and the one you would most like to resemble?
• What was your most satisfying accomplishment in your high school years?
• List the first names of any significant others you had in high school.
• Whose birth was the first birth that was significant to you, be it a person or animal?
• Who is the person you were most interested in but you never expressed your interest to (your biggest secret crush)?
When someone forgets their password and calls technical support, technical support refers the user to a Web page (that’s all they are given the power to do). The user is provided with three questions from the list of six, and must answer two correctly. If they answer two correctly, then we do the following:
• Give them a list of ten questions, and ask them to answer three more.
• Let them set a new password.
We should probably only allow a user to authenticate in this way a small handful of times (say, three).
The result of this scheme is that users can get done what they need to get done when they forget their passwords, but technical support is protected from social engineering attacks. We’re thus fixing the weakest link in a system.
All of our asides aside, good security practice dictates an approach that identifies and strengthens weak links until an acceptable level of risk is achieved.
Principle 2: Practice Defense in Depth
The idea behind defense in depth is to manage risk with diverse defensive strategies, so that if one layer of defense turns out to be inadequate, another layer of defense hopefully prevents a full breach. This principle is well-known, even beyond the security community. For example, it is a famous principle for programming language design:
Have a series of defenses so that if an error isn’t caught by one, it will probably be caught by another. [MacLennan, 1987]
Let’s go back to our example of bank security. Why is the typical bank more secure than the typical convenience store? Because there are many redundant security measures protecting the bank, and the more measures there are, the more secure the place is.
Security cameras alone are a deterrent for some. But if people don’t care about the cameras, then a security guard is there to defend the bank physically with a gun. Two security guards provide even more protection. But if both security guards get shot by masked bandits, then at least there’s still a wall of bulletproof glass and electronically locked doors to protect the tellers from the robbers. Of course if the robbers happen to kick in the doors, or guess the code for the door, at least they can only get at the teller registers, because the bank has a vault protecting the really valuable stuff. Hopefully, the vault is protected by several locks and cannot be opened without two individuals who are rarely at the bank at the same time. And as for the teller registers, they can be protected by having dye-emitting bills stored at the bottom, for distribution during a robbery.
Of course, having all these security measures does not ensure that the bank is never successfully robbed. Bank robberies do happen, even at banks with this much security. Nonetheless, it’s pretty obvious that the sum total of all these defenses results in a far more effective security system than any one defense alone.
The defense-in-depth principle may seem somewhat contradictory to the “secure-the-weakest-link” principle because we are essentially saying that defenses taken as a whole can be stronger than the weakest link. However, there is no contradiction. The principle “secure the weakest link” applies when components have security functionality that does not overlap. But when it comes to redundant security measures, it is indeed possible that the sum protection offered is far greater than the protection offered by any single component.
A good real-world example where defense in depth can be useful, but is rarely applied, is in the protection of data that travel between various server components in enterprise systems. Most companies throw up a corporate-wide firewall to keep intruders out. Then they assume that the firewall is good enough, and let their application server talk to their database in the clear. Assuming that the data in question are important, what happens if an attacker manages to penetrate the firewall? If the data are also encrypted, then the attacker won’t be able to get at them without breaking the encryption, or (more likely) without breaking into one of the servers that stores the data in an unencrypted form. If we throw up another firewall, just around the application this time, then we can protect ourselves from people who can get inside the corporate firewall. Now they’d have to find a flaw in some service that our application’s subnetwork explicitly exposes, something we’re in a good position to control.
Defense in depth is especially powerful when each layer works in concert with the others.
Principle 3: Fail Securely
Any sufficiently complex system has failure modes. Failure is unavoidable and should be planned for. What is avoidable are security problems related to failure. The problem is that when many systems fail in any way, they exhibit insecure behavior. In such systems, attackers only need to cause the right kind of failure or wait for the right kind of failure to happen. Then they can go to town.
The best real-world example we know is one that bridges the real world and the electronic world—credit card authentication. Big credit card companies such as Visa and MasterCard spend lots of money on authentication technologies to prevent credit card fraud. Most notably, whenever you go into a store and make a purchase, the vendor swipes your card through a device that calls up the credit card company. The credit card company checks to see if the card is known to be stolen. More amazingly, the credit card company analyzes the requested purchase in context of your recent purchases and compares the patterns to the overall spending trends. If their engine senses anything suspicious, the transaction is denied. (Sometimes the trend analysis is performed off-line and the owner of a suspect card gets a call later.)
This scheme appears to be remarkably impressive from a security point of view; that is, until you note what happens when something goes wrong. What happens if the line to the credit card company is down? Is the vendor required to say, “I’m sorry, our phone line is down”? No. The credit card company still gives out manual machines that take an imprint of your card, which the vendor can send to the credit card company for reimbursement later. An attacker need only cut the phone line before ducking into a 7-11.
There used to be some security in the manual system, but it’s largely gone now. Before computer networks, a customer was supposed to be asked for identification to make sure the card matches a license or some other ID. Now, people rarely get asked for identification when making purchases1; we rely on the computer instead. The credit card company can live with authenticating a purchase or two before a card is reported stolen; it’s an acceptable risk. Another precaution was that if your number appeared on a periodically updated paper list of bad cards in the area, the card would be confiscated. Also, the vendor would check your signature. These techniques aren’t really necessary anymore, as long as the electronic system is working. If it somehow breaks down, then, at a bare minimum, those techniques need to come back into play. In practice, they tend not to, though. Failure is fortunately so uncommon in credit card systems that there is no justification for asking vendors to remember complex procedures when it does happen. This means that when the system fails, the behavior of the system is less secure than usual. How difficult is it to make the system fail?
1. In fact, we have been told that Visa prohibits merchants who accept Visa cards from requesting additional identification, at least in the United States.
Why do credit card companies use such a brain-dead fallback scheme? The answer is that the credit card companies are good at risk management. They can eat a fairly large amount of fraud, as long as they keep making money hand over fist. They also know that the cost of deterring this kind of fraud would not be justified, because the amount of fraud is relatively low. (There are a lot of factors considered in this decision, including business costs and public relations issues.)2
2. The policy used by the credit card companies definitely ignores the principle of “fail securely,” but it must be said that credit card companies have done an excellent job in performing risk management. They know exactly which risks they should ignore and which risks they should address.
Plenty of other examples are to be found in the digital world. Often, the insecure failure problem occurs because of a desire to support legacy versions of software that were not secure. For example, let’s say that the original version of your software was broken and did not use encryption to protect sensitive data at all. Now you want to fix the problem, but you have a large user base. In addition, you have deployed many servers that probably won’t be upgraded for a long time. The newer, smarter clients and servers need to interoperate with older clients that don’t use the new protocols. You’d like to force old users to upgrade, but you didn’t plan for that. Legacy users aren’t expected to be such a big part of the user base that it really matters anyway. What do you do? Have clients and servers examine the first message they get from the other, and figure out what’s going on from there. If we are talking to an old piece of software, then we don’t perform encryption.
Unfortunately, a wily hacker can force two new clients to think each other is an old client by tampering with data as they traverse the network (a form of the man-in-the-middle attack). Worse yet, there’s no way to get rid of the problem while still supporting full (two-way) backward compatibility.
A good solution to this problem is to design a forced upgrade path from the very beginning. One way is to make sure that the client can detect that the server is no longer supporting it. If the client can securely retrieve patches, it is forced to do so. Otherwise, it tells the user that a new copy must be obtained manually. Unfortunately, it’s important to have this sort of solution in place from the very beginning; that is, unless you don’t mind alienating early adopters.
We discussed a problem in Chapter 3 that exists in most implementations of Java’s RMI. When a client and server wish to communicate over RMI, but the server wants to use SSL or some other protocol other than “no encryption,” the client may not support the protocol the server would like to use. When this is the case, the client generally downloads the proper socket implementation from the server at runtime. This constitutes a big security hole because the server has yet to be authenticated at the time that the encryption interface is downloaded. This means an attacker can pretend to be the server, installing a malicious socket implementation on each client, even when the client already had proper SSL classes installed. The problem is that if the client fails to establish a secure connection with the default libraries (a failure), it establishes a connection using whatever protocol an untrusted entity gives it, thereby extending trust when it should not be extended.
If your software has to fail, make sure it does so securely!
Principle 4: Follow the Principle of Least Privilege
The principle of least privilege states that only the minimum access necessary to perform an operation should be granted, and that access should be granted only for the minimum amount of time necessary. (This principle was introduced in [Saltzer, 1975].)
When you give out access to parts of a system, there is always some risk that the privileges associated with that access will be abused. For example, let’s say you are to go on vacation and you give a friend the key to your home, just to feed pets, collect mail, and so forth. Although you may trust the friend, there is always the possibility that there will be a party in your house without your consent, or that something else will happen that you don’t like. Regardless of whether you trust your friend, there’s really no need to put yourself at risk by giving more access than necessary. For example, if you don’t have pets, but only need a friend to pick up the mail on occasion, you should relinquish only the mailbox key. Although your friend may find a good way to abuse that privilege, at least you don’t have to worry about the possibility of additional abuse. If you give out the house key unnecessarily, all that changes.
Similarly, if you do get a house sitter while you’re on vacation, you aren’t likely to let that person keep your keys when you’re not on vacation. If you do, you’re setting yourself up for additional risk. Whenever a key to your house is out of your control, there’s a risk of that key getting duplicated. If there’s a key outside your control, and you’re not home, then there’s the risk that the key is being used to enter your house. Any length of time that someone has your key and is not being supervised by you constitutes a window of time in which you are vulnerable to an attack. You want to keep such windows of vulnerability as short as possible—to minimize your risks.
Another good real-world example appears in the security clearance system of the US government; in particular, with the notion of “need to know.” If you have clearance to see any secret document whatsoever, you still can’t demand to see any secret document that you know exists. If you could, it would be very easy to abuse the security clearance level. Instead, people are only allowed to access documents that are relevant to whatever task they are supposed to perform.
Some of the most famous violations of the principle of least privilege exist in UNIX systems. For example, in UNIX systems, root privileges are necessary to bind a program to a port number less than 1024.3 For example, to run a mail server on port 25, the traditional SMTP (Simple Mail Transport Protocol) port, a program needs the privileges of the root user. However, once a program has set up shop on port 25, there is no compelling need for it ever to use root privileges again.4 A security-conscious program relinquishes root privileges as soon as possible, and lets the operating system know that it should never require those privileges again during this execution (see Chapter 8 for a discussion of privileges). One large problem with many e-mail servers is that they don’t give up their root permissions once they grab the mail port. (Sendmail is a classic example.) Therefore, if someone ever finds a way to trick such a mail server into doing something nefarious, he or she will be able to get root. If a malicious attacker were to find a suitable stack overflow in Sendmail (see Chapter 7), that overflow could be used to trick the program into running arbitrary code as root. Given root permission, anything valid that the attacker tries will succeed. The problem of relinquishing privilege is especially bad in Java because there is no operating system-independent way to give up permissions.
3. This restriction is a remnant from the research days of the Internet, when hosts on the Internet were all considered trusted. It was the user-level software and the end user who were untrusted.
4. This is actually made more complicated by the fact that most systems use a central mailbox directory. As a side effect of this design, either the SMTP server or some program it invokes must have root privileges. Many SMTP servers can store mailboxes in more secure formats. For example, we’re fond of Postfix.
Another common scenario involves a programmer who may wish to access some sort of data object, but only needs to read from the object. Let’s say the programmer actually requests more privileges than necessary, for whatever reason. Programmers do this to make life easier. For example, one might say, “Someday I might need to write to this object, and it would suck to have to go back and change this request.” Insecure defaults may lead to a violation here too. For example, there are several calls in the Windows API for accessing objects that grant all access if you pass 0 as an argument. To get something more restrictive, you’d need to pass a bunch of flags (OR’d together). Many programmers just stick with the default, as long as it works, because it’s easiest.
This problem is starting to become common in security policies that ship with products intended to run in a restricted environment. Some vendors offer applications that work as Java applets. Applets usually constitute mobile code, which a Web browser treats with suspicion by default. Such code is run in a sandbox, where the behavior of the applet is restricted based on a security policy that a user sets. Vendors rarely practice the principle of least privilege when they suggest a policy to use with their code, because doing so would take a lot of effort on their part. It’s far easier just to ship a policy that says: Let my code do anything at all. People generally install vendor-supplied security policies—maybe because they trust the vendor or maybe because it’s too much of a hassle to figure out what security policy does the best job of minimizing the privileges that must be granted to the vendor’s application.
Laziness often works against the principle of least privilege. Don’t let this happen in your code.
Principle 5: Compartmentalize
The principle of least privilege works a lot better if the basic access structure building block is not “all or nothing.” Let’s say you go on vacation again, and you once again need a pet sitter. You’d like to confine the pet sitter to the garage, where you’ll leave your pets while you’re gone. If you don’t have a garage with a separate lock, then you have to give the pet sitter access to the entire house, even though such access is otherwise unnecessary.
The basic idea behind compartmentalization is to minimize the amount of damage that can be done to a system by breaking up the system into as few units as possible while still isolating code that has security privileges. This same principle explains why submarines are built with many different chambers, each separately sealed. If a breach in the hull causes one chamber to fill with water, the other chambers are not affected. The rest of the ship can keep its integrity, and people can survive by making their way to parts of the submarine that are not flooded. Unfortunately, this design doesn’t always work, as the Karst disaster shows.
Another common example of the compartmentalization principle shows up in prison design. Prison designers try hard to minimize the ability for large groups of convicted criminals to get together. Prisoners don’t bunk in barracks, they bunk in cells that accommodate two people. Even when they do congregate, say in a mess hall, that’s the time and place where other security measures are increased to help make up for the large rise in risk.
In the computer world, it’s a lot easier to point out examples of poor compartmentalization than it is to find good examples. The classic example of how not to do it is the standard UNIX privilege model, in which interesting operations work on an all-or-nothing basis. If you have root privileges, you can do anything you want anywhere on the system. If you don’t have root access, there are significant restrictions. As we mentioned, you can’t bind to ports under 1024 without root access. Similarly, you can’t access many operating system resources directly (for example, you have to go through a device driver to write to a disk; you can’t deal with it directly).5
5. Of course, the reason many of these operations require root permission is that they give root access fairly directly. Thus, any lesser permission suitable here is actually equivalent to root. Maybe that’s a flaw too, but it’s at a more subtle level. There were some early attempts to limit things. For example, in seventh edition UNIX, most commands were owned by bin, not root, so you didn’t need to be root to update them. But root would run them, which meant that if they were booby-trapped, the attacker with bin privileges would then get root privileges. Separation of privilege is a good idea, but it’s a lot harder than it looks.
Given a device driver, if an attacker exploits a buffer overflow in the code, the attacker can make raw writes to disk and mess with any data in the kernel’s memory. There are no protection mechanisms to prevent this. Therefore, it is not possible to support a log file on a local hard disk that can never be erased, so that you can keep accurate audit information until the time of a break-in. Attackers will always be able to circumvent any driver you install, no matter how well it mediates access to the underlying device.
On most platforms, it is not possible to protect one part of the operating system from others. If one part is compromised, then everything is hosed. Very few operating systems do compartmentalize. Trusted Solaris is a well-known one, but it is unwieldy. In those operating systems with compartmentalization, operating system functionality is broken up into a set of roles. Roles map to entities in the system that need to provide particular functionality. One role might be a LogWriter role, which would map to any client that needs to save secure logs. This role would be associated with a set of privileges. For example, a LogWriter may have permission to append to its own log files, but never to erase from any log file. Perhaps only a special utility program is given access to the LogManager role, which would have complete access to all the logs. Standard programs would not have access to this role. Even if an attacker breaks a program, and ends up in the operating system, the attacker still won’t be able to mess with the log files unless the log management program gets broken too.
Complicated “trusted” operating systems are not all that common. One reason is that this kind of functionality is difficult to implement and hard to manage. Problems like dealing with memory protection inside the operating system provide challenges that have solutions, but not ones that are simple to effect.
The compartmentalization principle must be used in moderation. If you segregate each little bit of functionality, then your system will become completely unmanageable.
Principle 6: Keep It Simple
The KISS mantra is pervasive: Keep It Simple, Stupid! This motto applies just as well to security as it does everywhere else. Complexity increases the risk of problems. Avoid complexity and avoid problems.
The most obvious implication is that software design and implementation should be as straightforward as possible. Complex design is never easy to understand, and is therefore more likely to include subtle problems that will be missed during analysis. Complex code tends to be harder to maintain as well. And most important, complex software tends to be far more buggy. We don’t think this comes as a big surprise to anyone.
Consider reusing components whenever possible, as long as the components to be reused are believed to be of good quality. The more successful use that a particular component has seen, the more intent you should be on not rewriting it. This consideration particularly holds true for cryptographic libraries. Why would anyone want to reimplement AES or SHA-1, when there are several widely used libraries available? Well-used libraries are much more likely to be robust than something put together in-house, because people are more likely to have noticed implementation problems.6 Experience builds assurance, especially when the experiences are positive. Of course, there is always the possibility of problems even in widely used components, but it’s reasonable to suspect that there’s less risk involved in the known quantity, all other things being equal (although, please refer back to Chapter 4 for several caveats).
6. Subtle implementation flaws may very well seem to work if both ends are using the same library. Trying to get different implementations of an algorithm to interoperate tends to weed out more problems.
It also stands to reason that adding bells and whistles tends to violate the simplicity principle. True enough. But what if the bells and whistles are security features? When we discussed defense in depth, we said that we wanted redundancy. Here, we seem to be arguing the opposite. We previously said, Don’t put all your eggs in one basket. Now we’re saying, Be wary of having multiple baskets. Both notions make sense, even though they’re obviously at odds with each other.
The key to unraveling this paradox is to strike a balance that is right for each particular project. When adding redundant features, the idea is to improve the apparent security of the system. When enough redundancy has been added to address the security level desired, then extra redundancy is not necessary. In practice, a second layer of defense is usually a good idea, but a third layer should be carefully considered.
Despite its obvious face value, the simplicity principle has its subtleties. Building as simple a system as possible while still meeting security requirements is not always easy. An on-line trading system without encryption is certainly simpler than an otherwise equivalent one that includes cryptography, but there’s no way that it’s more secure.
Simplicity can often be improved by funneling all security-critical operations through a small number of choke points in a system. The idea behind a choke point is to create a small, easily controlled interface through which control must pass. This is one way to avoid spreading security code throughout a system. In addition, it is far easier to monitor user behavior and input if all users are forced into a few small channels. This is the idea behind having only a few entrances at sports stadiums. If there were too many entrances, collecting tickets would be harder and more staff would be required to do the same quality job.
One important thing about choke points is that there should be no secret ways around them. Harking back to our example, if a stadium has an unsecured chain-link fence, you can be sure that people without tickets will climb it. Providing “hidden” administrative functionality or “raw” interfaces to your functionality that are available to savvy attackers can easily backfire. There have been plenty of examples when a hidden administrative backdoor could be used by a knowledgeable intruder, such as a backdoor in the Dansie shopping cart or a backdoor in Microsoft FrontPage, both discovered in the same month (April 2000). The FrontPage backdoor became somewhat famous because of a hidden encryption key that read, Netscape engineers are weenies!
Another not-so-obvious but important aspect of simplicity is usability. Anyone who needs to use a system should be able to get the best security it has to offer easily, and should not be able to introduce insecurities without thinking carefully about it. Even then, they should have to bend over backward. Usability applies both to the people who use a program and to the people who have to maintain its code base, or program against its API.
Many people seem to think they’ve got an intuitive grasp on what is easy to use, but usability tests tend to prove them wrong. This may be okay for generic functionality, because a given product may be cool enough that ease of use isn’t a real concern. When it comes to security, though, usability becomes more important than ever.
Strangely enough, there’s an entire science of usability. All software designers should read two books in this field: The Design of Everyday Things [Norman, 1989] and Usability Engineering [Nielson, 1993]. This space is too small to give adequate coverage to the topic. However, we can give you some tips, as they apply directly to security:
1. The user will not read documentation. If the user needs to do anything special to get the full benefits of the security you provide, then the user is unlikely to receive those benefits. Therefore, you should provide security by default. A user should not need to know anything about security or have to do anything in particular to be able to use your solution securely. Of course, because security is a relative term, you have to make some decisions regarding the security requirements of your users.
Consider enterprise application servers that have encryption turned off by default. Such functionality is usually turned on with a menu option on an administrative tool somewhere. However, even if a system administrator stops to think about security, it’s likely that person will think, They certainly have encryption on by default.
2. Talk to users to determine their security requirements. As Jakob Nielson likes to say, corporate vice presidents are not users. You shouldn’t assume that you know what people need. Go directly to the source [Nielson 1993]. Try to provide users with more security than they think they need.
3. Realize that users aren’t always right. Most users aren’t well informed about security. They may not understand many security issues, so try to anticipate their needs. Don’t give them security dialogs that they can ignore. Err on the side of security. If your assessment of their needs provides more security than theirs, use yours (actually, try to provide more security than you think they need in either case).
As an example, think about a system such as a Web portal, where one service you provide is stock quotes. Your users may never think there’s a good reason to secure that kind of stuff at all. After all, stock quotes are for public consumption. But there is a good reason: An attacker could tamper with the quotes users get. Users may decide to buy or sell something based on bogus information, and lose their shirt. Sure, you don’t have to encrypt the data; you can use a MAC (see Appendix A). However, most users are unlikely to anticipate this risk.
4. Users are lazy. They’re so lazy, that they won’t actually stop to consider security, even when you throw up a dialog box that says WARNING! in big, bright red letters. To the user, dialog boxes are an annoyance if they keep the user from what he or she wants to do. For example, a lot of mobile code systems (such as Web-based ActiveX controls) pop up a dialog box, telling you who signed the code and asking you if you really want to trust that signer. Do you think anyone actually reads that stuff? Nope. Users just want to see the program advertised run, and will take the path of least resistance, without considering the consequences. In the real world, the dialog box is just a big annoyance. As Ed Felten says, “Given the choice between dancing pigs and security, users will pick dancing pigs every time.”
Keeping it simple is important in many domains, including security.
Principle 7: Promote Privacy
Many users consider privacy a security concern. Try not to do anything that may compromise the privacy of the user. Be as diligent as possible in protecting any personal information a user does give your program. You’ve probably heard horror stories about malicious hackers accessing entire customer databases through broken Web servers. It’s also common to hear about attackers being able to hijack other user’s shopping sessions, and thus get at private information. Try really hard to avoid the privacy doghouse. There is often no quicker way to lose customer respect than to abuse user privacy.
One of the things privacy most often trades off against is usability. For example, most systems are better off forgetting about credit card numbers as soon as they are used. That way, even if the Web server is compromised, there is not anything interesting stored there long term. Users hate that solution, though, because it means they have to type in their credit card information every time they want to buy something. A more secure approach would make the convenience of “one-click shopping” impossible.
The only acceptable solution in this case is to store the credit card information, but be really careful about it. We should never show the user any credit card number, even the one that belongs to the user, in case someone manages to get access they shouldn’t have. A common solution is to show a partial credit card number with most of the digits blacked out. Although not perfect, this compromise is often acceptable.7
7. One problem with this blacking-out system is that some people show the first 12 digits and hide the last four, whereas others hide the first 12 and show the last four, together showing the entire thing!
A better idea may be to ask for the issuing bank, never showing any part of the actual number once it has been captured. The next time the user wants to select a credit card, it can be done by reference to the bank. If a number needs to be changed because there is a new card, it can be entered directly.
On the server side, the credit card number should be encrypted before being stored in a database. Keep the key for the credit card number on a different machine (this requires decrypting and encrypting on a machine other than the one on which the database lives). In this way, if the database gets compromised, then the attacker still needs to find the key, which requires breaking into another machine. This raises the bar.
User privacy isn’t the only kind of privacy. Malicious hackers tend to launch attacks based on information easily collected from a target system. Services running on a target machine tend to give out lots of information about themselves that can help the attacker figure out how to break in. For example, the TELNET service often supplies the operating system name and version:
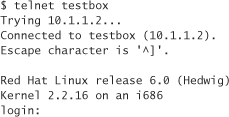
There is no reason to give out any more information than necessary. First, a firewall should block unnecessary services, so that an attacker can get no information from them. Second, regardless of whether you are protected by a firewall (defense in depth, remember?), remove as much publicly provided versioning information from your software as possible. For the previous example, the TELNET login can be made not to advertise the operating system.
In fact, why not lie about this sort of information? It doesn’t hurt to send a potential attacker on a wild goose chase by advertising a Linux box as a Solaris machine. Remote Solaris exploits don’t tend to work against a Linux box. The attacker may give up in frustration long before figuring out that the service was set up to lie. (Of course, lies like this make it harder to audit your own configuration.)
Leaving any sort of information around about a system can help potential attackers. Deterring an attacker through misinformation can work. If you’re using AES as an encryption algorithm, does it hurt to claim to be using Twofish? Both algorithms are believed to provide similar levels of cryptographic security, so there’s probably no harm done.
Attackers collecting information from a software environment can make use of all sorts of subtle information. For example, known idiosyncrasies of different Web server software can quickly tell a bad guy what software a company runs, even if the software is modified not to report its version. Usually, it’s impossible to close up every such information channel in a system. This type of problem is probably the most difficult security issue to identify and remove from a system. When it comes to privacy, the best strategy is to try to identify the most likely information channels, and use them to your advantage, by sending potential attackers on a wild goose chase.
Promote privacy for your users, for your systems, and for your code.
Principle 8: Remember That Hiding Secrets Is Hard
Security is often about keeping secrets. Users don’t want their personal data leaked. Keys must be kept secret to avoid eavesdropping and tampering. Top-secret algorithms need to be protected from competitors. These kinds of requirements are almost always high on the list, but turn out to be far more difficult to meet than the average user may suspect.
Many people make an implicit assumption that secrets in a binary are likely to stay secret, maybe because it seems very difficult to extract secrets from a binary. It is true that binaries are complex. However, as we discussed in Chapter 4, keeping the “secrets” secret in a binary is incredibly difficult. One problem is that some attackers are surprisingly good at reverse engineering binaries. They can pull a binary apart and figure out what it does. The transparent binary problem is why copy protection schemes for software tend not to work. Skilled youths will circumvent any protection that a company tries to hard code into their software, and will release “cracked” copies. For years, there was an arms race and an associated escalation in techniques of both sides. Vendors would try harder to keep people from finding the secrets to “unlock” software, and the software crackers would try harder to break the software. For the most part, the crackers won. Cracks for interesting software like DVD viewers or audio players tend to show up on the same day that the software is officially released, and sometimes sooner.
It may appear that software running server side on a dedicated network could keep secrets safe, but that’s not necessarily the case. Avoid trusting even a dedicated network if possible. Think through a scenario in which some unanticipated flaw lets an intruder steal your software. This actually happened to id software right before they released the first version of Quake.
Even the most secure networks are often amenable to insider attacks. Several studies show that the most common threat to companies is the insider attack, in which a disgruntled employee abuses access. Sometimes the employee isn’t even disgruntled. Maybe he just takes his job home, and a friend goes prodding around where he or she shouldn’t. Think about the fact that many companies are not able to protect their firewall-guarded software from a malicious janitor. If someone is really intent on getting to software through illegal means, it can probably be done. When we point out the possibility of an insider attack to clients, we often hear, “That won’t happen to us. We trust our employees.” But relying on this reasoning is dangerous even though 95% of the people we talk to say the same thing. Given that most attacks are perpetrated by insiders, there’s a large logical gap here, suggesting that most of the people who believe they can trust their employees must be wrong. Remember that employees may like your environment, but when it comes down to it, most of them have a business relationship with your company, not a personal relationship. The moral here is that it pays to be paranoid.
The infamous FBI spy Richard P. Hanssen carried out the ultimate insider attack against US classified networks for more than 15 years. Hanssen was assigned to the FBI counterintelligence squad in 1985, around the same time he became a traitor to his country. During some of that time, he had root privileges on a UNIX system. The really disturbing thing is that Hanssen created code (in C and Pascal) that was (is?) used to carry out various communications functions in the FBI. Apparently, he wrote code used by agents in the field to cable back to the home office. We sincerely hope that any and all code used in such critical functions is carefully checked before it becomes widely used. If not, the possibility that a Trojan horse is installed in the FBI communication system is extremely high. Any and all code that was ever touched by Hanssen needs to be checked. In fact, Hanssen sounds like the type of person who may even be able to create hard-to-detect distributed attacks that use covert channels to leak information.
Software is a powerful tool, both for good and evil. Because most people treat software as magic and never actually look at its inner workings, the potential for serious misuse and abuse is a very real risk.
Keeping secrets is hard, and it is almost always a source of security risk.
Principle 9: Be Reluctant to Trust
People commonly hide secrets in client code, assuming those secrets will be safe. The problem with putting secrets in client code is that talented end users will be able to abuse the client and steal all its secrets. Instead of making assumptions that need to hold true, you should be reluctant to extend trust. Servers should be designed not to trust clients, and vice versa, because both clients and servers get hacked. A reluctance to trust can help with compartmentalization.
For example, although shrink-wrapped software can certainly help keep designs and implementations simple, how can any off-the-shelf component be trusted to be secure? Were the developers security experts? Even if they were well versed in software security, are they also infallible? There are hundreds of products from security vendors with gaping security holes. Ironically, many developers, architects, and managers in the security tool business don’t actually know very much about writing secure code themselves. Many security products introduce more risk than they address.
Trust is often extended far too easily in the area of customer support. Social engineering attacks are thus easy to launch against unsuspecting customer support agents who have a proclivity to trust because it makes their jobs easier.
“Following the herd” has similar problems. Just because a particular security feature is an emerging standard doesn’t mean it actually makes any sense. And even if competitors are not following good security practices, you should still consider good security practices yourself. For example, we often hear people deny a need to encrypt sensitive data because their competitors aren’t encrypting their data. This argument holds up only as long as customers are not hacked. Once they are, they will look to blame someone for not being duly diligent about security.
Skepticism is always good, especially when it comes to security vendors. Security vendors all too often spread suspect or downright false data to sell their products. Most snake oil peddlers work by spreading FUD: fear, uncertainty, and doubt. Many common warning signs can help identify security quacks. One of our favorites is the advertising of “million-bit keys” for a secret key encryption algorithm. Mathematics tells us that 256 bits will likely be a big enough symmetric key to protect messages through the lifetime of the universe, assuming the algorithm using the key is of high quality. People advertising more know too little about the theory of cryptography to sell worthwhile security products. Before making a security buy decision, make sure to do lots of research. One good place to start is the “Snake Oil” FAQ, available at http://www.interhack.net/people/cmcurtin/snake-oil-faq.html.
Sometimes it is prudent not to trust even yourself. It is all too easy to be shortsighted when it comes to your own ideas and your own code. Although everyone wants to be perfect, it is often wise to admit that nobody is, and periodically get some objective, high-quality outside eyes to review what you’re doing.
One final point to remember is that trust is transitive. Once you dole out some trust, you often implicitly extend it to anyone the trusted entity may trust. For this reason, trusted programs should not invoke untrusted programs, ever. It is also good to be careful when determining whether a program should be trusted or not. See Chapter 12 for a complete discussion.
When you spread trust, be careful.
Principle 10: Use Your Community Resources
Although it’s not a good idea to follow the herd blindly, there is something to be said for strength in numbers. Repeated use without failure promotes trust. Public scrutiny does as well.
For example, in the cryptography field it is considered a bad idea to trust any algorithm that isn’t public knowledge and hasn’t been widely scrutinized. There’s no real solid mathematical proof of the security of most cryptographic algorithms. They’re trusted only when a large enough number of smart people have spent a lot of time trying to break them, and all fail to make substantial progress.
Many developers find it exciting to write their own cryptographic algorithms, sometimes banking on the fact that if they are weak, security by obscurity will help them. Repeatedly, these sorts of hopes are dashed on the rocks (for two examples, recall the Netscape and E*Trade breaks mentioned earlier). The argument generally goes that a secret algorithm is better than a publicly known one. We’ve already discussed why it is not a good idea to expect any algorithm to stay secret for very long. The RC2 and RC4 encryption algorithms, for example, were supposed to be RSA Security trade secrets. However, they were both ultimately reverse engineered and posted anonymously to the Internet.
In any case, cryptographers design their algorithms so that knowledge of the algorithm is unimportant to its security properties. Good cryptographic algorithms work because they rely on keeping a small piece of data secret (the key), not because the algorithm itself is secret. That is, the only thing a user needs to keep private is the key. If a user can do that, and the algorithm is actually good (and the key is long enough), then even an attacker intimately familiar with the algorithm will be unable to break the cryptography (given reasonable computational resources).
Similarly, it’s far better to trust security libraries that have been widely used and widely scrutinized. Of course, they may contain bugs that haven’t been found, but at least it is possible to leverage the experience of others.
This principle only applies if you have reason to believe that the community is doing its part to promote the security of the components you want to use. As we discussed at length in Chapter 4, one common fallacy is to believe that open-source software is highly likely to be secure, because source availability leads to people performing security audits. There’s strong evidence to suggest that source availability doesn’t provide the strong incentive for people to review source code and design that many would like to believe exists. For example, many security bugs in widely used pieces of free software have gone unnoticed for years. In the case of the most popular FTP (File Transfer Protocol) server around, several security bugs went unnoticed for more than a decade!
Conclusion
The ten principles discussed in this chapter address many common security problems when properly applied. Of course, no guidelines are ever perfect. The good ideas here must be carefully applied.