
15. Client-side Security
“Protection is not a principle, but an expedient.”
—BENJAMIN DISRAELI
HANSARD
In Chapter 11 we discussed a number of reasons why there can be no such thing as perfect security on the client side. This problem stems from the fact that the client machine is completely untrusted. No matter what kind of solution you devise to keep the secrets in your code safe, there must necessarily be a way for someone to compromise your work completely.
This is not to say that there’s no point to client-side protection. There is definite value in raising the bar, as long as the security activity keeps enough people out to make it worth your while. However, deciding how much to invest in this theoretically impossible problem is difficult.
Consider the computer game community, in which software “crackers” are most active, producing pirated versions of popular software. Some game manufacturers have gone through a lot of trouble to design anti-tampering measures. However, every time game designers go through an extraordinary effort to come up with a new way to protect their software, the crackers go to similar lengths to figure out how to break it. This is reminiscent of a Cold War arms race.
The cracker community is filled with people whose motivations may not be understood by most software developers and architects. For example, a lot of people in the gaming world crack for prestige, despite the fact that few of them use their real names on-line. If a particular target title is well protected and is thus quite a challenge to break, then it’s even more prestigious to create a pirated copy. More prestige of this sort can be attained by being the first person to crack a new game program. Yet more status comes with finding a crack on the same day that the original software is released. And ultimate on the prestige scale is to put the crack out before the original even comes out.
Developers and producers of games spend plenty of time worrying about the cracker community and how they may undermine a revenue stream. Although the Software Piracy Association (SPA) provides very large, scary-looking numbers for revenue lost as a result of software piracy, the reality is much less grim than their numbers suggest. The numbers on which the SPA bases its reports reflect the estimated total value of all pirated copies of software. That is, if the SPA believes there are 1,000 bootlegged copies of Fred’s Software running in the world, and the package sells for $10,000 a seat, then they would estimate a $10 million loss. However, much pirated software doesn’t actually cost the vendor anything. Why? Because people who steal software would most likely not be willing to pay for a copy if they couldn’t steal it. We believe that most of the cracker community is this way. Crackers are generally not willing to pay for software.
However, we see at least two types of software piracy that do cost vendors money. The first is piracy by organized crime rings. Organized criminals pirate software and resell it at a lower price point than the original vendor. Most of these piracy organizations are based in Asia (and tend to operate in the Asian market exclusively). A more limited amount of organized piracy goes on in the United States and Europe. This type of piracy really does cost software vendors significant amounts of money each year. However, once these pirates have been able to duplicate a program for easy resale, there is often little that can be done to make a dent in their business.
The other type of software piracy that hurts vendors is casual piracy. When a user can simply pop a data CD into a CD-R drive, then lots of people are bound to pirate something just for convenience sake. For example, many corporate offices have a policy against software piracy. If people have a legitimate need to own a copy of Microsoft Office, all they need to do is ask. Their company will get it for them. However, it may take time (or filling out some form) to get in a new copy. It’s just easier to go down a few cubes to find someone who already has it, and install that copy. Having a CD key helps a little bit, but not very much. The only time it helps is when people don’t have access to the key (something we believe is pretty infrequent). Even if your company keeps its keys locked up and out of the reach of employees, it is usually possible to copy a key out of a running version of the software.
Yet another category of piracy is worth discussing. This category involves a competitor taking your code (probably in binary form) and reverse engineering it to get at your proprietary algorithms. The only realistic protection against such piracy is the judicial system. This is almost certainly the most cost-effective solution available to you (even with lawyers’ fees being what they are). Although we tend to agree with the sentiment that there have been a large number of bogus software patents issued, such patents are often crucial from a business perspective. And sometimes they need to be enforced in court. Similarly, though, we think that laws that prohibit the reverse engineering of software are quite unfortunate (especially if you’re concerned about the security or reliability of software), because such laws can be used to legitimate ends to protect against illegal competition.
Some may decide that better protection from prying eyes is crucial for their product. The goal of the attacker might not be piracy per se, it may just be tampering with the software for other nefarious ends. For example, when iD Software released the source code to Quake I, they had a very large problem with people modifying Quake clients to give them an unfair advantage in network play. Cheaters would give themselves supernatural aim, or give themselves extra warning when people were getting close. Note that these kinds of problems are just as big an issue for closed-source software as they are for open source because, as we have said, people can still reverse engineer and modify clients.
In these kinds of situations, the goal becomes to raise the bar high enough that only a few people are capable of tampering. Moreover, we wish to make the attacker’s job difficult enough that even fewer people find it worth the effort.
As usual, there are a number of tradeoffs in this kind of code protection security. The biggest is usability. Although it may be nice to stop piracy, doing so usually means making the life of your legitimate users more difficult. Typing in a license key isn’t too much of an inconvenience, but it doesn’t provide much security. If you add code to bind software to a single machine, you will have a system that raises the bar high enough to keep casual pirates out, yet greatly inconveniences legitimate users who need to move the software from one computer to another.
Another common tradeoff involves performance. Techniques like code obfuscation tend to add extra code to your program. Even if that code never runs, it still takes up space in memory, which can result in degraded virtual memory performance.
We feel that, in most cases, client-side protection technologies tend to get in the way of the user too much to be useful. Such technologies tend to be fragile. Many can break if the user tries to make a change to the environment in which the software operates. For example, some software, including Microsoft Office XP, is machine locked, checking the configuration of a machine and trying to detect when it changes “too much.” If you are a hardware fan, and keep swapping around motherboards and parts, the product probably will cause you to reactivate your software—a major hassle. After a few major hardware upgrades, Microsoft may suspect you of piracy!
All in all, software protection schemes tend to annoy users, particularly copy protection and license management. In keeping users from doing illegal things, such schemes often end up preventing people from doing valid things, such as running the same piece of software on a desktop and a laptop.
Additionally, hiding license information in obscure places really annoys technical users who don’t like to have applications scribbling in places where they shouldn’t be. Applications that “phone home” are detected by personal firewalls (which a lot of people run), potentially preventing the application from calling home, and possibly leading to bad publicity when the fact is exposed. The most popular commercial license management scheme, FlexLM has been hacked repeatedly and, according to Peter Guttman,
... from talking to people who have done it it isn’t that hard to get around (this wasn’t even commercial pirates or hardcore warez kiddies, just average programmers who were annoyed at something which FlexLM forced on them for no good reason they could see).
We seriously considered not including this chapter in our book, because we feel strongly that the technologies discussed are rarely worth using. However, we do recognize that these kinds of ideas are ones that companies often wish to implement. Plus, it is your decision to make: You need to weigh the potential advantages and disadvantages as you see them, and make your own decision. Just recognize that there are many significant problems associated with these technologies, and you should pursue any of these solutions with the utmost of caution.
Copy Protection Schemes
Even though license keys don’t really raise the security bar significantly, many companies resort to providing license keys for software. License keys provide somewhat of a psychological deterrent even if they are technically deficient. The theory is that if you just “borrow” a CD, you may subconsciously understand what you are doing is wrong if you have to type in a unique license key.
A related strategy that is similarly effective is to try to force software to run largely off the distribution CD. In this way, casual users must explicitly copy the CD to run it at home and so forth. This makes users more conscious of the fact that they’re illegally running software. It is technically easy to implement this protection scheme. Instead of reading files off a CD drive as if it were any other file system, deal with the drive at the device driver level, raising the technical stakes for an attacker.
License keys are slightly harder to implement. The basic idea is to create a set of keys in such a way that very few arbitrarily chosen strings are actually valid. We’d also like to make it so that valid strings are not something that people can easily construct.
A good basic strategy is to use encryption to create valid keys. We start with a counter plus a fixed string and turn it into a compact binary representation. Then we encrypt the binary representation, and convert the binary to a printable key. When a user types in a license key, we decrypt it and check the string for validity.
This strategy leaves you open to an attacker being able to “mint” license keys by finding the encryption key in the binary. Usually this is not much of a concern. We are not trying to raise the bar in the face of determined attackers or habitual software pirates. If it wasn’t possible to “mint” keys, such people would just swap working keys, unless you add more complex checking. In this case, we are only trying to deter the casual pirate. If you do want to prevent key minting, you can use digital signatures as license keys (discussed in the next section).
A simple license scheme is straightforward. The biggest issue to tackle is encoding and decoding. First we must decide what character set to use for keys. We can use the base64 alphabet, which would allow for easy translation to and from binary. Unfortunately, this is hard for some users. People will type in the wrong character (because of typos or easily confused characters) relatively often. The most common problem is likely to be ignoring the case sensitivity of the license. It would be nice to use all the roman letters and all ten digits. That yields a 36-character alphabet. However, computationally it is best for the size of our alphabet to be exactly a power of two in size. Thus, we should trim four characters out. We recommend getting rid of L, 1, O, and 0, because they’re the four characters most prone to typos of the standard 36. This leaves us with a good-size alphabet.
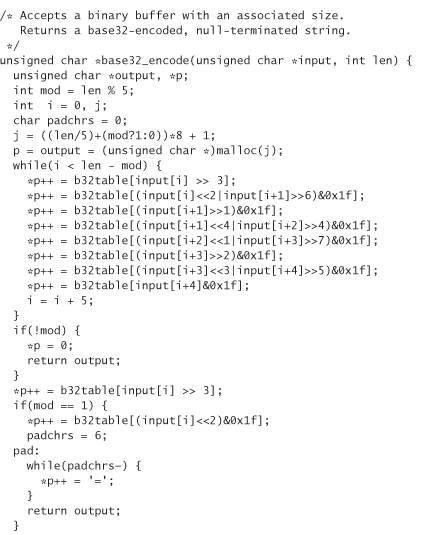
The following includes the code for converting data into this 32-character set and back. Although the encoding always converts text into numbers or capital letters, it treats lowercase letters as uppercase letters when converting back to binary.
We call this encoding base32 encoding, because it’s quite similar to base64 encoding. Note that we actually have a 33-character set because we also use = to denote padding. The way we encode data is to break them up into 5-byte chunks. Each chunk is encoded into 8 base32 characters. If we don’t have a multiple of 5 bytes (which we won’t for this application), we need to perform padding. Note that this library allocates its own memory using malloc. You need to free the memory explicitly when you’re done with it:






The identifying string that we are going to encrypt should be a unique identifier. It would be okay to use some text that uniquely identifies the program down to the version (we want to have different keys for each version, so that users can’t use old keys to unlock new software). However, we want to prevent attackers who have read this book from guessing the string we use, enabling them to build automatic license key generators more easily. Therefore, we opt to use a high-quality, random binary string. Let’s use 16 bytes total (otherwise, the license key risks being too long in terms of end user annoyance). We reserve 4 bytes for our counter, and generate 12 bytes randomly. These 12 bytes get hard coded into our license key generation software. They are also hard coded into the actual application, which needs them to be able to validate license keys. We also need an encryption key. For this, we shall use a different hard-coded value, also generated from a high-quality source. The encryption key also needs to live in the client software, to validate license keys.1
1. It’s unfortunate that the word “key” is overloaded here; however, in each case, “key” is the widely used terminology.
Now we’re ready to create valid license keys. Each valid license key is a counter concatenated with the fixed binary string, then is encrypted and converted to base32. When encrypting, we should use CBC mode, and we should make sure to place the counter at the front of our string.
Note that 16 bytes doesn’t exactly map evenly to base32 blocks. When we base32 encode, we get 26 encoded characters, with 6 characters of padding. Let’s avoid reporting the pad as part of the key.
Here’s a program that generates the first 256 valid license keys, using the OpenSSL version of Blowfish for encryption:

Checking the license key for validity is easy. We add padding back to the license key (6 characters worth), decode the base32 string, decrypt the binary with the stored encryption key, and check to see that the last 12 bytes are equal to our stored binary string. If it is, the license key is valid.
License Files
One thing that we may wish to do is generate licenses that are dependent on user-specific information, such as a user’s name. We may also like to be able to ship a single version of software, and enable particular features for those who paid for them. To support this kind of operation, we can use a digital signature of license data to validate the accuracy of that data. The way this works is by sending users a digitally signed license file that the software can validate. DSA is good for this task because it produces smaller signatures than RSA.
The public key associated with the signing key is embedded into each copy of the software product and is used to verify that no one has tampered with the license file. The private key is necessary to generate valid signatures of license files; the public key only validates the signatures. Therefore, this scheme thwarts automatic license generators, but is still susceptible to reverse-engineering attacks.
Before adding the digital signature, a license file may be as simple as the following:
Owner: Bill Gates
Company: Microsoft Corporation
Issue Date: November 24, 2000
Once we have placed proper licensing information in a file, we digitally sign the file (often base64 encoded). The digital signature is often considered a “license key.”
There are many ways to get all the licensing information into the system. One technique is to have the user type everything into the application, including personal data as well as the “license key.” In such a case, you should consider silently stripping white space and punctuation from license text, both when generating a signature and when validating it. This avoids many unnecessary headaches when end users decide to use tabs instead of spaces and so forth. As an alternative, we can just distribute the license as a file, which must be placed somewhere where the program knows how to find it.
To validate the license information, we need to embed the public key associated with the signing key into our software. We read the license information from wherever it lives, and feed it into the signature validation algorithm. If the check succeeds, we know that the data in the license information is correct (barring a successful attack).
Most software performs these checks every time the software is run. In this way, if users get a new license, it’s no big deal. Plus, we may want to license shareware software for only a short period of time. We could add the date the software was installed to the license information, and create a license when the software first runs. In this way we can “expire” the license by checking a system date. A classic way around license expiration of this sort is changing the system clock so the software believes it has not yet expired. Early Netscape users frequently resorted to this technique before browsers became free.
To fix this problem, you can keep a registry entry or some other persistent data that stores the initial date the software was run, the last date the software was run, and a MAC of the two dates. In this way, you will be able to detect any drastic changes in the clock.
The next kind of attack involves deleting the key, or uninstalling and reinstalling the program. To make this attack less effective, you can hide the MAC information somewhere on the file system that won’t be removed on uninstall. Then the attacker is forced to find out about that file. If an attacker does find the file, you have to come up with your own ideas for further protection. Leaving such extra data around is a huge hassle to legitimate users who actually want to wipe every trace of your software off their system. If you actually remove everything at uninstall time, then an attacker can easily find out where you hide your secrets. As we said, please think through the consequences of such schemes carefully before adopting them.
Thwarting the Casual Pirate
The biggest bang for the buck available in protecting software from piracy involves raising the bar high enough to prevent casual software piracy. Because it is, in the theoretical sense, not possible to make something copyproof (although some unscrupulous vendors still claim to be able to do this),2 our scheme simply raises the bar high enough so that it’s not trivially easy to copy software. For the most part, vendors haven’t really implemented the sort of copy protection we present later. Note that the license management schemes we present earlier in the chapter don’t either! Defeating our earlier schemes is as easy as copying legitimate license information from one machine to another and being done with it. There’s a fairly easy way to raise the bar higher though. The basic idea is to include machine-specific information when calculating the license. It’s best to gather this information from the software customer, asking questions about the machine on which they will be running. Then, the program validates those things at runtime by gathering the appropriate data and validating the license.
2. Note that we do believe that it may be possible to raise the bar high enough so that it would take many worker-years to break software. If this is possible, it’s certainly not easy to do.
There are all sorts of things you can check. You can’t really check anything that can’t be forged by a determined adversary, of course; nevertheless, this strategy is usually enough to thwart casual piracy. Simply check for two or three different things that are appropriate for your product, such as how much memory the machine has. If your application is made to run on a broadband network, you can check the hardware address of the Ethernet card. On a UNIX box, you can check the name reported by the hostname command, or the inode number of the license file, which changes when the license file is copied.
Note that this technique is very obtrusive, and often thwarts legitimate use. It often prevents honest users from modifying their machine configuration too significantly. For example, if the owner of the software needs to move the software to another machine (perhaps because of hardware failure, for example), he or she would have to get a new license.
A related approach for Internet-enabled applications is to include callbacks to a central server that keeps track of which license keys have been used. The problem here is that privacy advocates will (legitimately) worry about invasion-of-privacy issues. Plus, there is a huge usability hassle on the part of the legitimate user. Beyond the fact that the user must have access to an Internet connection (which would make working on an airplane pretty hard), the user also has an overly difficult time when it becomes necessary to reinstall the software for any reason. One option for solving this problem is to allow the install, but just keep track of who uses which license key, and then try to detect things that look suspicious statistically, and follow up on them legally. Another issue that crops up is that your code needs to take into account firewalls that put significant restrictions on outgoing traffic (see Chapter 16).
Other License Features
A scheme popular in high-end applications is to set up a license server that is responsible for doling out resources. For example, a university may buy a site license for your product that allows them to have 50 concurrent users. However, they may want the software installed on several thousand machines. The clients on the network need to be coordinated to enforce this policy.
This model can be implemented as an extension of our signature-based license scheme. In this case, we place a server on the university’s network to issue licenses. Licenses would have an expiration date, which would be relatively short. When the license is about to expire, the software goes out and gets another license. In this way, if a client crashes, the server is able to reclaim licenses periodically. The client exits if it ever notices that it doesn’t have a license that is currently valid.
If you need the flexibility that a license server can provide you, and have heeded all our caveats, then you should consider moving to an off-the-shelf solution instead of building something from scratch. We’re not aware of an open-source solution, although the existence of one would be greatly ironic, although still useful. There are plenty of commercial license packages. The most widely used is FlexLM.
During risk assessment, it is a good idea to expect that any license system will be compromised, and plan accordingly. One advantage of FlexLM is that it tries very hard to be a moving target, so that cracks that work against a particular software version cannot necessarily work against the next version. Most of the power of FlexLM, according to their marketing, is that they provide anti-tampering mechanisms. Although we do not know the details of their anti-tampering mechanisms, we do discuss some such mechanisms later.
Other Copy Protection Schemes
A copy protection scheme popular in game software is to issue challenges that require the documentation to answer the challenge. At its best, such a scheme requires the attacker to copy an entire manual, which can potentially be very large. This type of scheme is fairly outdated, because it is now common for most game documentation to be available in electronic format, and it is trivially easy to copy. The other problem is that even if you rely on printed manuals, the manuals only need to be scanned into a computer once, then the scheme is broken worldwide.
In the typical challenge-based license scheme, an attacker has several strategies that usually work with some effort. Problems shared by all documentation-based challenge/response systems result in attacks that include the following:
1. Replace the license management code with code that always allows operations.
2. Replace all calls to a license management system with successful returns.
3. Skip over the license management code altogether.
In fact, these problems exist with the license-based schemes discussed earlier. Tamperproofing, which we discuss later, can help thwart these problems.
Another common copy protection strategy is to use CDs to store a key in such a way that the typical CD writer won’t duplicate the key. This sort of approach is available in Macrovision’s product SafeDisk. It suffers from the same sorts of problems as the previous schemes we’ve discussed, although Macrovision appears to have added many anti-tampering measures.
One of the more effective copy protection schemes is a dongle. Dongles are pieces of hardware that are designed to connect externally to a computer’s serial port. They have some very basic computational power. An application using a dongle is set up to check the dongle strategically during execution. For example, the software can issue a challenge to the dongle that the dongle must answer. More often, a bit of important code is off-loaded to the dongle. For the program to run properly, the code in the dongle needs to be properly executed.
The dongle strategy is superior to most license schemes because the attacker can’t try for the “easy” hacks that circumvent the copy protection. The new goal of an attacker in this situation is to reproduce the code from the dongle in software.
The most difficult issue with respect to dongles is figuring out what code to place in the dongle. There are often serious size limits, plus the processing power of the dongle is also severely limited. In addition, figuring out what the dongle is doing by inspection is not exactly intractable. Although hardware tamperproofing is good enough to keep most attackers from disassembling the dongle and figuring out its innards, inferring the innards by merely observing the inputs and outputs along with the context of the calling software is often possible.
The more code you can off-load to tamperproofed hardware, the better off you will be in terms of security, because the average software attacker is far less likely to be a good hardware hacker. Ultimately, the best dongle would be one in which the entire application runs on the dongle. In this case, why not just sell a special purpose computer?
Needless to say, dongles are a fairly expensive solution, and are incredibly burdensome on the end user. In fact, Peter Gutmann says that dongles are “loathed to an unbelievable level by anyone who’s ever had to use them.” Our experience concurs.
A method very similar to dongles is remote execution. In this scheme, each client requires its own credentials that enable it to authenticate to a remote server. Part or all of the application must be run on the remote server, only if authentication succeeds. Remote execution is certainly cheaper than dongles, but it is also even more inconvenient for the end user because it requires an on-line component. Plus, it requires the software vendor to do credential management and maintain servers with high availability.
Authenticating Untrusted Clients
One common requirement that goes slightly beyond what we’ve covered so far involves preventing attackers from being able to create their own replacement clients without having to reverse engineer or patch the code. Often, an attacker can figure out a protocol by closely observing valid client/server communication on the network for a long enough period of time. What is required is some sort of way to authenticate the client to the server that necessarily requires us to keep data in the client away from the watchful eyes of potential attackers.
The naïve use of public key encryption to authenticate the client does not raise much of a bar because the attacker probably knows the public key algorithm, and can probably find the key in a straightforward manner. Embedding a shared secret key in the client suffers from the exact same problem.
The only real solution to this problem is to go ahead and use authentication, but to use advanced obfuscation techniques to make the key material as difficult as possible to recover. A free tool called mkkey automatically obfuscates RSA private keys so that they can be embedded into clients for authentication purposes. It works by unrolling the key and the mathematical operations on it into a large series of primitive mathematical operations, then moving a lot of code around. The mkkey tool was developed to prevent client-side cheating at Netrek, an on-line game based loosely around Star Trek.
Every time the Netrek developers want to release a new version of their client, they run mkkey, which generates the code for them to link into their client. Once again, the code performs RSA operations in an obfuscated manner. By necessity, Netrek has a different key pair for each updated version of the client produced.
The mkkey tool is available as part of the Netrek RES-RSA package. We provide references to this software on our book’s companion Web site.
The mkkey tool makes figuring out the private key being used in the client quite difficult. If we were trying to write our own client as an attacker, we probably wouldn’t attack this code by trying to extract the private key. Instead we would try to isolate the set of functions that constitute the protection and replace all the code except for those functions.
Tamperproofing
Putting in place a good infrastructure for copy protection such as some of the license management schemes described earlier is certainly possible. However, most of these schemes rely on making the actual executable difficult to analyze and to modify. We lump such defensive methods together under the term tamperproofing. Anything that makes the attacker’s job harder to modify a program successfully without the program failing is a tamperproofing method.
One simple example involves scattering license management software throughout the application. You should duplicate checks instead of relying on a central license management library. Otherwise, the attacker need only follow your code’s execution to the license management module, then figure out how to modify that single piece of code. It’s better to force the attacker to perform the same kind of hack multiple times, especially if you make subtle changes to keep such attackers busy. As with most measures for intellectual property protection, such efforts tend to make code significantly harder to support and maintain.
One well-known aspect of tamperproofing is obfuscation. Obfuscation is the art of making code unreadable. We treat this issue separately later. In this section we limit our discussion to other strategies for keeping people from viewing or modifying our code.
Hardware is one of the more effective ways to achieve tamperproofing. However, it isn’t very practical in the real world, mainly because it’s prohibitively expensive. If this solution is economically feasible for you, we highly recommend it. The reason why hardware is one of the best solutions is largely because software tamperproofing is so hard. Even hardware-based tamperproofing can be defeated by attackers with sufficient expertise and resources.
Antidebugger Measures
Most of the time, tamperproof hardware is not practical. Thus we end up relying on software solutions. For this reason, the most important tool in a software cracker’s tool kit is a debugger. Our goal should be to make it as hard to “debug” a deployed copy of our software as possible. Debuggers necessarily cause programs to behave differently from their undebugged behavior. We can take advantage of this behavior to try to thwart the debugger attack.
One feature of debuggers that we can leverage (a technique first introduced to us by Radim Bacinschi) is that they tend to reset the processor instruction cache on every operation. The instruction cache contains the next few instructions to execute, so that they are readily available in a timely manner and don’t have to be fetched as they are needed.
Under normal operation, the instruction cache doesn’t get completely wiped on every operation. It only gets wiped when a jump happens. This is done because the cached instructions are no longer to be executed.3 We can write assembly code that takes advantage of this fact, causing many debuggers to crash. What we’ll do is write code that changes instructions that should definitely be in the processor cache. If we’re not running under the debugger, doing this has no effect, because the change doesn’t cause the cache to refresh. But under a debugger, we can make things break.
3. Some architectures can do “speculative fetching” of instructions to perform some intelligent caching, even in the presence of jump instructions.
When running under a debugger, our change is immediately reflected, causing us to execute the changed version of the code. We can then have the changed version do something likely to cause a crash, such as force a premature return. Of course, this technique only works in environments in which we can modify the code segment.
Here’s some assembly code for the x86 architecture that shows an example of this technique:
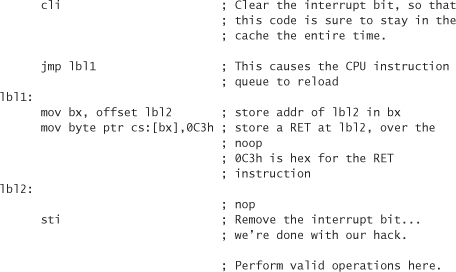
We should try to be a bit stealthier than we are in the previous code. If an attacker knows this trick, our technique can be found automatically with some simple pattern matching. For example, we should definitely replace the noop with a valid operation.
Note that in the previous example, if we run the modified code a second time, even the nondebugged version may crash. We can cleverly avoid this problem by later replacing the original instruction. If we’re more clever, we may change the code to something that will crash the first time, but will be correct the second time through.
There are other antidebugger measures you can implement. One straightforward thing to do is to check the currently running processes to see if a known debugger is running and behaving oddly if it is. On some architectures, you can also take advantage of the fact that break points are usually implemented by causing an interrupt in place of an actual instruction. You can mask the interrupt yourself, and then butcher your code as we did (this is often easy to circumvent, however). Additionally, you can write code that decrypts and reencrypts itself on an instruction-by-instruction basis using the x86 trace capabilities, or (and this one is really simple) put the stack on top of the code so that when the CPU hits a break point and dumps stuff to the stack, it trashes the code being debugged.
Checksums
Another good antitampering device is to compute checksums of data and routines that may be subject to tampering. This can be done by precomputing a checksum over a piece of memory, and then dynamically comparing against that value. This can be done in C. We give an example with a very simple checksum routine that XORs consecutive bytes:

The problem with such checksums is that by protecting important code, you potentially reveal the existence of code that an attacker may not have discovered otherwise. Even if you throw in a lot of debugger pitfalls, an attacker can eventually remove them all. Once this happens, we must assume that the attacker can watch everything we do. Therefore, if we compute checksums on a function, we must assume the attacker can watch us and tell that we’re computing a checksum.
The best solution to this problem is to rely on obfuscation. One trick is to use lots of checksums: Have them check each other and have them be interdependent. If you use enough checksums, you can drown potential attackers in a sea of things through which they need to wade. Again, this doesn’t make a system unbreakable, but it should sharply increase the amount of time it takes for someone to break your code.
Another trick is to have other parts of your program replace critical sections of code, just in case an attacker has modified them. For example, an attacker may replace a guard with noops, just to find the guard has mysteriously returned at runtime. You can also replace some of the code being guarded. This makes your code more difficult for an attacker to follow. The more complex your code gets, the higher you’ve placed the bar that an attacker must jump. This trades off (badly) against software maintenance, of course.
Responding To Misuse
When you detect that someone is using software without permission, or when you detect that someone is tampering, the worst thing you can possibly do is error or exit immediately. Doing so can reveal to an attacker where your tamper detection code is located. We’d like to put as much distance as possible between the tamper detection code and the place where we deal with the tampering. Ultimately, it should be difficult to find the tamper detection code by tracing the control of the code back a few steps. Similarly, we’d like to make it difficult to trace back to the detection code by looking at the memory accessed around the crash, and then looking at the last few times that variable was accessed.
One approach is to introduce bugs into parts of a program that are not immediately executed, but are bound to execute eventually. However, if an attacker can’t be tricked into thinking that an actual bug was tickled in the program, then the attacker should be able to see what data caused the crash, then run the program again, watching for all accesses to that code.
One of the best ways to avoid this data flow problem (at least partially) is to take the reverse approach. Instead of adding subtle bugs, leave in some of the more subtle bugs that actually exist in your code, and have your tamperproofing code repair those bugs, if and only if no tampering is detected. In this way, a data flow to the crash location only exists when the program can’t detect tampering. For example, you may take a variable that is used near the end of your program’s execution and leave it uninitialized. Then, sometime later, you run a checksum on your obvious license management code. Then, in some other routine, you run a checksum on your checksum code. If the second checksum succeeds, then you go ahead and initialize the variable. Otherwise, the program will probably crash near the end of its run, because the license management software is modified. However, you hope to force the attacker to locate both checksums if the attacker wants to break your program. If you add a bug that only gets tickled approximately one third of the time, the more likely result is that the attacker will think your code is genuinely broken, and won’t realize what really happened.
Of course, if an attacker suspects that you played this trick, then his or her next step is to look through the code for all accesses to the variable you left uninitialized. There are a couple of tricks you can play to make this step of the attack more difficult.
First, you can “accidentally” initialize the variable to a correct value by overwriting a buffer in memory that is juxtaposed to that variable. You can either do this when you determine that there has been no tampering, or you could delay it. For example, let’s say that you leave the variable Z uninitialized, and the array A sits in memory so that A[length(A)] is Z. Let’s also say that you, at some point in the program, copy array B into A, and that you have a variable L that contains the length of B, which is solely used for the exit condition on your copy loop:
for(i=0;i<L;i++) {
A[i] = B[i];
}
If we were to place the correct value for Z’s initialization in the space immediately after B, then we could cause the program to behave correctly by adding 1 to L when we determine that a particular part of the program was not tampered with. This kind of indirection will likely take an attacker some time and effort to identify and understand.
A similar technique is to access the variable you’re leaving uninitialized through pointer indirection. Offset another variable by a known, fixed quantity.
These techniques are very dangerous, however. You may very likely end up with an endless series of technical support calls from people whose software isn’t working properly. For example, we have heard rumors that AutoDesk did something similar some years ago and barely survived the avalanche of calls from people reporting that their software was broken.
Decoys
In the previous section we discussed how you should fail as far from your detection code as possible. This is not always true. One good thing to do is to add decoy license checks to your program that are valid, but easy to find. These checks can give a suitable error message immediately when they detect someone using the software in the wrong way. With this strategy, you can give the attacker fair warning, and you may also trick the attacker into thinking your protection is more naive than it really is.
You can use checksums on this decoy code as well. If the decoy is removed or changed, then you introduce subtle bugs to the program, as discussed earlier. Another approach is to keep two separate copies of license data. One can be stored plainly on disk and the other can be inserted into the middle of one of your data files.
Code Obfuscation
Many technologists treat compiled programs as a black box into which no one can peer. For most people, this turns out to be true, because they wouldn’t be able to take a binary file and make sense of the contents. However, there are plenty of people who can figure out machine code. There are even more people who are competent enough to be able to use a disassembler, and still more who can run a decompiler and make sense of the results.
If you’re concerned about these kinds of attacks, then you should consider obfuscation techniques to hide your secrets. Of course, given enough effort, it is always possible to reverse engineer programs. The goal of obfuscation is to make such reverse engineering difficult enough that any potential attacker gives up before breaking your code.
If you’re developing in a language like Java, then you have even more to worry about, because the JVM format tends to retain much more data than the average C program. Although Windows binaries also tend to retain quite a lot of information by default, at least you can strip out symbols—meaning, your variable and function names all disappear (commands like strip are available to do this). In Java, the linking depends on symbolic names, so you can’t strip information like this at all. The best you can do is choose names that have no meaning.
Automated tools for code obfuscation exist, but none of them does complex enough transformations to stop anyone who really knows her way around a binary. In reality, such tools do little more than remove symbol information from a binary, or mangle all the names they can get away with mangling (in the case of Java). These techniques are somewhat effective (the first more so than the second), but definitely don’t raise the bar so high that you’ll need to wonder whether people will be capable of defeating them. (They will.) High-quality code obfuscation is a relatively unstudied topic. Only as of the late 1990s has it become a serious topic of interest to academicians. We predict that within a few years there will be several decent products available.
The biggest problem with high-quality code obfuscation today is that it makes programs hard to maintain, because any transformations you make have to be applied by hand. Usually, you’re not going to want to maintain obfuscated code, and there is every reason to keep a clean source tree around. However, every time you want to release a modified version of your code, you have to reapply any sophisticated obfuscations you want (which is likely to require great attention to detail). This is difficult enough, but it’s even worse, because applying obfuscations by hand is an error-prone activity and you’re likely to add bugs.
Another problem is that as code obfuscation becomes more widely practiced, the attacker community may potentially start developing deobfuscation tools. These tools will be quite challenging to build, but are certainly not beyond the realm of possibility (especially when the stakes are high). So try to keep in mind whether someone could automatically undo any obfuscations you add once they figure out what you’re doing.
Basic Obfuscation Techniques
There are several simple tricks that can make your code more difficult to comprehend:
1. Add code that never executes, or that does nothing. If you add code that never executes, you need to keep it from being obvious that it never executes. One thing to do is to take calculations and make them far more complex than they need to be. Another thing to do is to use mathematical identities or other special information to construct conditions that always evaluate to either true or false.4 The idea is that a person or program trying to deobfuscate your code will not be able to figure out that the condition should always evaluate the same way. You have to come up with your own conditions though. If we supplied a list, then people would know what to look for!
4. This in itself is code that does essentially nothing. You can add such conditions to loop conditions, and so on, for more complexity. If you overuse this trick, however, clever attackers will start to see right through it and will ignore the extra conditions.
2. Move code around. Spread related functions as far apart as possible. Inline functions, group a few statements together into a function without the statements encapsulating anything. Copy and rename the same function, instead of calling it from multiple places.5 Combine multiple functions into a single function that has some extra logic to make sure it calls the right block of code depending on how it got called. If an algorithm specifies that you do some operation A and then do B, move B as far from A as possible by putting other, unrelated tasks in between.
5. Go to some effort to make the copies look somewhat different.
3. Encode your data oddly. Picking strings directly out of memory is easy if you don’t take efforts to stop it (making the use of the strings command on binaries is a standard attacker technique). Convert everything to a strange character set, and only make strings printable when necessary. Or, encrypt all your data in memory, using a set of keys that are spread throughout your program.
Note that most of these tricks involve adding code or data to your program that are bound to slow down execution, sometimes a lot. Make sure that you are aware of how much of a speed hit you’re taking. Additionally, note that these techniques amount to applying poor programming techniques. If you’re interested in pursuing this topic further, despite our caveats, see [Collberg, 1997].
Encrypting Program Parts
Another decent obfuscation technique is to encrypt parts of your program. The sort of encryption we’re talking about isn’t generally of the same caliber as the encryption we’ve previously discussed. This is because real encryption algorithms provide too much of a speed hit for too little additional protection. In this case, our biggest problem is that if we have an encryption key, we have to leave it somewhere that the program (and thus an attacker) can read it.
Our basic strategy is to select parts of our program that we’d like to encrypt. For the sake of this discussion, let’s encrypt parts of the code itself. However, encrypting your program’s data is also a useful technique. Let’s encrypt single functions at a time. The binary will store encrypted functions, along with a procedure to decrypt those functions. First we look at the encryption and decryption functions.
The functions we use in the following code are incredibly simple (and weak, cryptographically speaking). They don’t encrypt using a key at all. They just take an address and the length in bytes of the code on which we wish to operate. This example is here solely for educational purposes. Don’t use this exact idea in your own code! If you can afford the hit, use a few rounds of a real encryption function instead.
Here, our encrypt function does an XOR for each byte with a variable that gets updated after each XOR operation, and the decrypt function does the inverse:

We embed these calls into our code so that we can encrypt and decrypt parts of our program on the fly. We don’t actually make any calls to this code yet. First we need to identify functions we want to encrypt, and figure out how big they are. The best way to do that is with a debugger. Disassembling the function usually tells you the size of the function in bytes. For example, if we disassemble a function, we’ll get some output that ends in something like
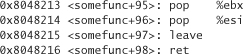
The ret instruction is only 1 byte, so we can conclude that we should encrypt 99 bytes if we wanted to encrypt our somefunc routine.
Next, we add calls to decrypt and encrypt when appropriate. Remember, the code should start encrypted, but it isn’t there yet, so our code will no longer run properly at this point. When we compile this time, we need to tell the compiler to make the text segment (the part of the binary where executable code lives) writable to the program proper. By default, it’s usually read-only. With the gcc compiler you can do this by passing the –N flag in at the command line.
We don’t run the code. Instead, we take the binary, and open it up in a hex editor. We find the functions we need to encrypt, and encrypt them by hand. One simple way to find the function is to look at the memory address given to us in a debugger, get to that memory in the debugger, and then use an editor to pattern match for the right hex values.6 Here’s an example using the gdb debugger:
6. Often, the debugger starts numbering from a different location than a hex editor (which usually starts from 0).

Now we can search for the previous sequence of hex values in a hex editor, and encrypt manually, and then we’re done. The modified binary should work just fine, assuming we didn’t make any mistakes from the last time we ran the program, of course.
This technique can be used fairly liberally, but it is rather labor intensive the way we have spelled it out. It’s not really slow if you only do it over a handful of functions. And remember, it’s good to misdirect attackers by encrypting plenty of unimportant parts of your program. The biggest drawback to this technique is that it makes your functions implicitly non-threadsafe, because you don’t want multiple threads dealing with encryption and decryption of the same program section.
Conclusion
Protecting your intellectual property in software is impossible, but there are methods you can apply to raise the bar for an attacker.
There is no solution that is 100% guaranteed to be effective. Thus, a reasonable goal is to make the effort required to produce a “cracked” version of software bigger than the expected payoff of breaking the code. A good way to approach this goal is to apply a number of different techniques judiciously.
By the way, you should assume that your attacker has also read this book. If you are serious about protecting your software, you really must do better than the tricks we’ve laid out in this chapter. Implement some of our tricks, but devise your own using ours as inspiration. Anything new that you do should, at the very least, give attackers a few headaches.