
CHAPTER 4
Risk Metrics
This chapter presents the following topics:
• Review effectiveness of existing security controls
• Reverse-engineer/deconstruct existing solutions
• Creation, collection, and analysis of metrics
• Prototype and test multiple solutions
• Create benchmarks and compare to baselines
• Analyze and interpret trend data to anticipate cyber defense needs
• Analyze security solution metrics and attributes to ensure they meet business needs
• Use judgment to solve problems where the most secure solution is not feasible
In some environments, security is a must. In such cases, it doesn’t matter what it costs, how long it takes, or what needs to be implemented, security is the top priority. However, most businesses don’t operate that way, and security officers are increasingly being asked to justify security expenditures. Questions such as “What’s the ROI for that solution?” are increasingly being asked of security professionals. As the CISO (or any other senior security position), you’re going to be expected to answer those questions. More agile business processes are requiring creative, flexible solutions. Fifteen years ago, few dreamed that one day portable computing devices roughly the size of a magazine would support e-mail, word processing, spreadsheets, and web browsing. Now it’s possible to carry millions of printed pages worth of data around on a USB stick that masquerades as a pen. Adapting to this rapidly changing IT environment and the threats within it requires the application of tools and techniques security professionals didn’t really need to worry about 15 years ago.
Review Effectiveness of Existing Security Controls
The effectiveness of a security program is often measured in binary terms as in “did we have a breach or not?” Although that certainly is a measurement one should consider when examining the effectiveness of a security program, it’s not the only thing you should be looking at. Examining the effectiveness of any large security program can seem like a daunting task, and quite often it’s something people think only auditors do. Reviewing your current security program can help you identify areas that need improvement, areas that need additional spending or attention, and so on. Although creating an exhaustive review checklist is beyond the scope of this chapter, let’s consider a few areas that should be reviewed and discuss the types of items that should be examined:
• User training Your security would be perfect if it weren’t for those pesky users, right? The fact is that users need to be taught what to do, and your user training program provides that opportunity. Do you know how well your user training program is working? Have you tested how many users responded to phishing attempts? Do the users know whom to contact if they think their system is infected? What’s the average length for passwords in use? How many passwords are easily cracked? Make sure these questions can be answered if you want your end-user training program to be successful.
• IDS/IPS alarms How many alarms does your IDS/IPS installation produce each day? How many of those are false positives? How are false positives screened? Some administrators get frustrated with the number of false positives and may overreact by dialing back the aggressiveness of the IDS/IPS. Although this will reduce false positives, it will also lead to the worse outcome of more false negatives.
• Firewall rules How many connection attempts are your firewalls blocking? Which ports are filtered on inbound connections? Which ports are filtered or monitored for outbound connections?
• Vulnerability testing What is currently being tested? How often? What is done with the findings? Are findings being addressed? If so, how long is it taking to address findings? How often are scans being performed?
• Policies and procedures Are they being reviewed at least annually? How often are exceptions to policies and procedures required? Are updates needed to existing documents? Are employees told about updates? Are they reviewing applicable policies and procedures on an annual basis?
As you can see, reviewing the effectiveness of an existing security program should be answering more than “what are we doing?”—it should be answering the “how well are we doing it?” type of questions. Although that can be a difficult thing to do, it will be worthwhile.

EXAM TIP Reviewing the effectiveness of your organization’s security program is a necessary step to help identify areas for improvement.
Gap Analysis
In a security context, a gap analysis helps determine the differences from an organization’s present state of security to its recommended or desired state. Whether motivated by compliance laws, an organization’s security policies, or just good ol’ security common sense, a gap analysis is a great way to measure the efficacy of existing security controls. Since changes are always being introduced into the business environment, security gaps will inevitably open and widen with time. Once the gaps are determined, mitigations must be prescribed to close them.
For example, your environment requires all Windows 10 computers to have passwords of at least eight characters. Yet, your security gap analysis identified many systems under-performing this minimum requirement. You propose to close the security gap by creating a configuration baseline using Microsoft’s System Center Configuration Manager to enforce the use of eight-character-minimum passwords.
To ensure a systematic approach to gap analyses, take a look at the gap analysis approach shown here:
• Information security standards Utilize existing information security standards such as ISO 18028-5, 27002, NIST SP 800-65, and ISACA’s COBIT 5.0, which provide direct or indirect coverage of gap analysis best practices.
• Define the scope A gap analysis may need to be trimmed to include separate location-based or smaller-sized gap analysis projects.
• Review security documents This includes current policies, standards, procedures, and guidelines.
• Executive approval Any kind of security review would greatly benefit from upper-management’s approval to remove business-related obstacles.
• Security questionnaire This will help gather required technical, business, and people-related information regarding current security practices and controls.
• Identify gaps Enumerate all technologies, security practices, and controls to identify any gaps with network appliances such as firewalls, IDSs/IPSs, routers, switches, or weaknesses with cryptographic ciphers, ACLs, wireless networking, staff training, physical security, security policies, business continuity, disaster recovery, and incident response procedures.
• Gap analysis report Publish a gap analysis report containing all security gaps discovered in the previous step. Implement any last-minute mitigations before committing to a final gap analysis report.
• Mitigation plan After the gap analysis report is published, develop a comprehensive remediation plan to address all gaps. Address the most critical gaps first and then work your way downward.
Conduct a Lessons-Learned/After-Action Review
Eventually bad things will happen regardless of how well you plan or how many precautions you take. When things do happen, there’s often a great deal of scrambling, finger-pointing, voices raised, and chaos. While you are dealing with the situation, you often learn things that were overlooked in your procedures, such as steps that take much longer than you planned for, phone numbers that have not been updated, cables or plugs you didn’t think you needed, and so on. When the situation is over and things start to settle back down, your organization has a great opportunity to conduct a lessons-learned/after-action review.
EXAM TIP Lessons-learned/after-action reviews are not just post-incident activities. Any complex, potentially repeatable process can be improved through such reviews.
A lessons-learned/after-action review is a careful analysis of what happened, why it happened, and what can be done differently or more effectively next time. The review should include everyone with a role in that event—the larger the event, the more people involved in the review. If you are part of a large organization and the incident was a major breach that became public knowledge, the review could encompass 50 or more participants, with representatives from legal to HR to public relations. In most cases, the review will likely only involve a handful of people, but if you do find yourself in charge of performing a lessons-learned review with a large number of people, consider breaking the review up into areas and holding multiple meetings that focus on each area of the incident. Lawyers don’t really care what steps your administrators took to rewrite ACLs on the firewalls, and your administrators may not care who crafted the press release (if one was required). One thing to remember when creating multiple groupings for after-action reports is that it’s often necessary to have a high-level meeting with all the senior officials from each area involved.
You should also keep in mind there’s really a small window of opportunity for holding lessons-learned/after-action reviews. Individual memories will start to fade immediately after the incident, especially if those involved have to work for 20+ hours straight to resolve the issue. Schedule and conduct your reviews as soon as you can after the incident. The reviews should be structured—follow the chronology of the incident where you can and systematically step through the entire incident so you can examine each area. It helps to record the sessions or have a dedicated note taker whose only job is to capture the lessons learned or recommendations for improvement. Keep the review as objective as possible—have participants stick to facts whenever possible. If emotions run high and people start looking for a scapegoat, you lose the opportunity to collect actionable information. If your organization is heavily into processes and procedures, lessons-learned/after-action reviews are a great time to go over those processes and procedures. Did they work as intended? What was missing? What was wrong? How should they be updated? It also helps to have a neutral party conduct or, at least, participate in the review—someone from your organization with no vested interest who can keep the review moving forward and on task.
Reverse-Engineer/Deconstruct Existing Solutions
Sometimes the hardest thing for a security professional to do is to think like a hacker. Oftentimes we get so wrapped up in locking down, restricting, and patching that we forget to take a second to look at our solutions from the opposite perspective. If you step back and think about it, the most important question you can ask yourself is likely to be, “How would I defeat this security solution?”
EXAM TIP Reverse-engineering or deconstructing existing security solutions is an excellent way to identify entry points and weaknesses. If you can break down your own systems and correct the issues you find, you will be that much more effective against actual attackers.
You’ve probably heard the term reverse-engineer applied to things such as malware (taking it apart to see what it does and how it works), but how often have you thought about reverse-engineering your own security solutions? It might be difficult for you to do if you helped design, construct, and implement the solution, but if you’ve inherited systems or security solutions, it shouldn’t be as difficult. Here are a few steps to help get you started:
• Look at what the system does. What does the system you’re examining actually do? What inputs does it take? What are the outputs?
• Determine how the solution impacts network traffic. Assuming the solution does interact with traffic, how does it do this? What types of traffic will it let in? What does it block? Does it matter which direction the traffic is flowing?
• Encryption. How does the system handle encrypted traffic? Does it handle encrypted traffic at all? Or does it just pass encrypted traffic through without looking at it?
• Determine what the system tells you about itself. Does it have services running? Does it have banners on those services? Can you connect to the system remotely?
• Communication. Is the system a single entity or a group of resources? If it’s a group, do they communicate? Can you tell how they communicate? If you try and interfere with the communications, what happens?
• Reactive capabilities. Although it’s bit trickier to test without actually generating some suspicious/malicious traffic, does the system have any capability to react to traffic that you generate? Does it block your source address after a port scan? Does it block your source address after multiple port scans? Does it block your source address after multiple failed login attempts? Does it block your activity after SQL injection attempts? Do you get blocked after attempting to execute DoS attacks?
If you can take an objective look at your system and how it functions, you should be better able to understand its possible weaknesses (and correct them).
Perhaps we should take this process one step further by creating an attack tree/plan for a penetration test? Imagine you are being asked to perform a penetration test on your organization or another organization. To perform a thorough test, you need to understand the environment you’ll be examining. What are the entry points? How many network links are there? Are there wireless access points? Are there dedicated links to other organizations? Remote sites?
The chances of you (as a tester) getting a detailed map and a full description of the environment—including firewalls in use, use or lack of IDS/IPS, and so on—are slim to none (unless you are performing the test against your own organization and already have access to those items, or you’re conducting a white-box penetration test). If you try to look at your organization from a purely external perspective, you can start to piece together bits of information to build your own picture. IP blocks can be pulled from DNS and Whois records. Perhaps you can drive or walk around the facility looking for access points. When you’ve built your own “picture” of what you think the entry points are, you can start to build out a testing plan. External IPs you’ve uncovered can be scanned and probed. Tracing to those IPs may give you an idea of where the firewall is. Walking the firewall will help you determine what services are allowed through. Finding the e-mail servers may allow you to attempt a phishing attack (if permitted). Reverse-engineering the solution in that case is really just an attempt to “discover” how your organization works and connects so that you can then flip that around and try to find a way to break in through one of those paths.
Creation, Collection, and Analysis of Metrics
It is frequently said that it is impossible to manage something you cannot measure accurately. In that respect, security is no different from most other industries—eventually it all boils down to numbers. Whether its customer service departments worrying about resolution rates, car manufacturers concerned with number of units manufactured, drive-thru restaurants clocking the speed of service per customer, or security professionals reviewing the number of IDS/IPS false positives/negatives over a given period, metrics tells an important story. Metrics allow us to measure the qualities (or lack thereof) of a system that contribute to its security state. What we’re interested in is creating, collecting, and analyzing any metrics that inform us about short-term and long-term trends in our overall security posture. Although specifics of such metrics will be discussed in more detail in the upcoming sections on key performance indicators (KPIs) and key risk indicators (KRIs), gathering security-related metrics can provide numerous benefits to an organization, including the following:
• Advises resource allocation Metrics can simultaneously guide experts on what security adjustments need to be made, while also easing executive buy-in if additional purchases are required.
• Communicates security performance If the benchmark metrics are equal to or better than the baselines, then we know we’re meeting or exceeding our goals.
• Determines compliance adherence It is easier to demonstrate compliance when you have hard numbers to back you up.
• Determines the efficacy of security controls Although reviewing existing security controls is great, looking at key metrics will help us truly understand the effectiveness of such controls.
• Enables benchmark/baseline comparisons To know whether our security progress is trending upward or downward, we need to know what the baseline measuring stick is. Then we conduct additional benchmark measurements to compare with the baselines. The comparison will help determine the direction of our progress.
• Enhances accountability Compliance and noncompliance with security/IT systems can occur at the executive, administrative, and user levels. By measuring key metrics, we’ll be able to determine whom to hold accountable for positive and negative actions at all levels of the organization.
• Identifies problems One of the critical benefits of metrics is to identify real and potential issues long before they cause significant damage to the business. By discovering issues early, mitigations can be implemented well in advance.
• Supports intelligent business decisions Decision-makers need accurate and concise metrics in order to make intelligent decisions that can affect the security of the organization. Think of traffic lights as an example of business intelligence indicators. The simplicity of traffic lights helps inform millions of drivers each day to make intelligent driving decisions. Metrics might use graphics with brief quantitative and qualitative summaries to “back up” the graphic.
• Triggers improvements to performance The goal of creating, collecting, and analyzing metrics is simply to use information to improve the security of the organization. All of the preceding bullet points aggregate into that one overarching goal.
As with many security initiatives, there’s no need to reinvent the wheel. Take advantage of the information provided by security standards and frameworks. According to the standard ISO/IEC 27004, “Information Security Management—Monitoring, Measurement, Analysis and Evaluation,” you would implement the following steps to measure the effectiveness of information security controls:
1. Select processes and objects for measurement.
2. Determine baselines.
3. Collect data.
4. Develop a measurement method.
5. Interpret measured values.
6. Communicate measurement values.
The next section goes into the specifics of creating, collecting, and analyzing metrics through the usage of KPIs and KRIs.
KPIs
Key performance indicators (KPIs) are quantifiable metrics used to evaluate the success of technologies, processes, or people meeting an organization’s performance goals. One example of a goal might be to reduce IT risk to an acceptable level. Since we’re discussing KPIs in security terms as opposed to business terms, focus on upward/downward trends in security-related activities as opposed to big-picture business outcomes such as revenue, profits, expenses, and so on. Although the types of security metrics can vary across industries and organizations, there are certain security metrics worth gathering, including the following:
• Incident response time to detection (TTD) How long did it take for the organization to detect a real or potential security incident?
• Incident response time to remediation (TTR) How long did it take for the organization to eradicate the incident after it was detected?
• Malware instances identified How many unique and repeat instances of malware have been detected?
• Number of lost or stolen devices How many technological assets have been lost or stolen?
• Number of SSL/TLS certificate issues How many certificates were misconfigured, expired, suspended, revoked, or fraudulently used?
• Number of vulnerabilities identified per device, OS, and application How many vulnerabilities have been reported on each device type, OS, and application?
• Passwords cracked How many passwords have been successfully guessed, stolen, or cracked?
• Patch latency How many days elapsed between patches published versus patches installed?
• Security issues identified during audits How many insignificant, minor, or major security issues have been identified during in-house and third-party audits?
• Unplanned downtime How many seconds, minutes, and hours of unplanned downtime did we have on a weekly, monthly, quarterly, and annual basis?
KPIs are at their most effective when they are presented graphically, pleasing to the eye, and aggregated onto business intelligence dashboards much like the various gauges located on your car’s dashboard. Decision-makers and security professionals should be able to immediately understand the trend implications of the KPI and make a decision shortly thereafter.
KRIs
Key risk indicators (KRIs) measure the amount of risk an activity brings to an organization. In other words, are certain activities indicating that increased risk exposures are happening or likely to happen? Shown next are well-known key risk indicators that organizations may want to measure:
• Mean time between failure (MTBF) Are hard drive failures happening more frequently since switching hard drive brands?
• Mean time to repair (MTTR) Are printer repairs taking longer since switching printer consulting companies?
• Network availability Has unplanned network downtime occurred more since the replacement of a crucial firewall device?
• Percentage of critical systems missing patches Is this percentage too high due to downsizing the number of IT personnel?
• Percentage of IT projects delayed Is this percentage too high due to upper management’s failure to hold the IT manager accountable?
• Percentage of IT projects in excess of budget Is this percentage too high due to the IT staff having an inadequate budget?
• Percentage of end users who failed e-mail phishing test Is this percentage too high due to poor end-user security training?

NOTE If you’re confused about the difference between KPIs and KRIs, think of KPIs as a measure of how well things are going now whereas KRIs can help measure how badly things might turn out in the future.
Prototype and Test Multiple Solutions
Developing, purchasing, or implementing a security solution for an enterprise is a complex and oftentimes daunting task. Does the product do what you want it to do? Does it work with the other systems and applications you have in place? How will it affect network performance? What kind of false positive rate will you see? Oftentimes the only way to really find out what works (and how well it works) is to develop a prototype or conduct a run-off with multiple solutions.
The ideal place to start prototyping and testing is within a lab environment. You’ll never be able to completely simulate your enterprise network, but with the use of virtualization and traffic generators, you can at least create a decent starting point for analysis and testing. Implement your candidate security solutions in the lab and then develop test scenarios to examine how well they operate, whether they interfere with business operations, whether they impact traffic flow, and so on. You won’t be able to completely rule out any potential issues that pop up in the production environment, but you should be able to get a clear feeling for which product is best suited to your organization if you’re evaluating it against several others in the lab. If you are evaluating multiple solutions, just be sure to run each of them through the same set of tests. Evaluating different solutions in different scenarios won’t give you a clear comparison.
If your business lacks the staff or technological resources to prototype security solutions on-premises, consider using a cloud-hosted sandboxing provider. These providers offer isolated, secure, and accessible online environments for customers to install and test various security solutions, including the following:
• Virtual machines
• Virtual routers
• Virtual switches
• Virtual firewalls
• Operating systems
• Third-party applications
• In-house custom code
You may want to try out malware analysis or perform quality assurance testing of software patches inside of department-specific virtual machines.
NOTE Prototyping security solutions is very useful. Having the opportunity to search for vulnerabilities in an early prototype can reveal serious issues that would be extremely expensive to fix in a finished product.
A lab environment is also a great place to start examining how a combination of tools and techniques can address different security needs. Are there issues with SQL injection attacks on your e-commerce site? Experiment with content filters in the lab using development systems. Want to see what impact a particular packet filter has? Run it in the lab first and measure.
When you’ve tested your solution in the lab or have narrowed down your possible solutions from many to a few, or even a single candidate, then it’s time to test it in the production environment. This can be tricky, but when done correctly, it’s probably the best way to truly validate whether a candidate solution will work for your organization. When implementing a security solution in the production environment for the first time, you’ll want to coordinate the effort well—maintenance windows, low traffic times, backup links, and so on. Make sure you have a fallback plan and methods for inserting/removing the solution being tested rapidly.
Create Benchmarks and Compare to Baselines
Baselines are a captured point of reference used as a comparison for future changes. Such points of reference are valuable in information security because they help us to know if our security controls are trending in the right or wrong direction. Once established and agreed upon, baselines will serve as the measuring stick against which all future measurements are compared. As for the “future measurements,” those are known as benchmarks. Benchmarks are the subsequent measurements that are compared to baselines.
EXAM TIP In other words, benchmarks are simply point-in-time measurements that are only focused on that particular point in time, whereas baselines are point-in-time measurements to which future measurements will be compared.
It is through taking various benchmark measurements that baselines can be established. After all, if multiple benchmark measurements aren’t taken, then it cannot be known what the baseline is. Benchmarks can be a set of performance criteria, a set of conditions, an established and measured process, and so on. Benchmarks have obvious usage for web server response times, backups, batch processing routines, and so on. But how are they useful for security? Just as benchmarks can help you identify performance issues, they can also help identify potential security issues. Let’s examine a few possibilities where benchmarks could be useful from a security perspective.
Let’s start with an obvious area—network performance. Most network engineers keep at least a casual eye on the throughput of their routers and switches. They’ll monitor peak flow, average flow, dropped packets, and so on. From a security perspective, that same data can help you identify scans, probes, or data exfiltration attempts. Spikes in incoming traffic flow or spikes on certain protocols/ports could indicate scanning activity. A huge spike in traffic is most likely a DDoS. Outbound traffic spike at 3 A.M.? Could be data exfiltration. The point is, if you know what level of traffic is “normal”—or the baseline—for any given timeframe, then traffic above or below that level could be indicative of an issue.
System performance is also another area where monitoring and comparisons to benchmarks could be useful from a security perspective. Spikes in CPU utilization, disk I/O, or increases in application response time could indicate scans, overflow attacks, or other malicious activity. If you know what “normal” looks like, anything well above or well below that threshold could indicate a problem worth investigating. Figure 4-1 shows a fairly simple CPU utilization graph. In this simple graph we see a large spike in CPU usage that is way out of the norm for that system. The question we would need to answer is, what caused that spike? Is there a legitimate reason for the spike, such as a major patching effort or service pack? Did a batch process run? Or did something else cause that CPU spike?
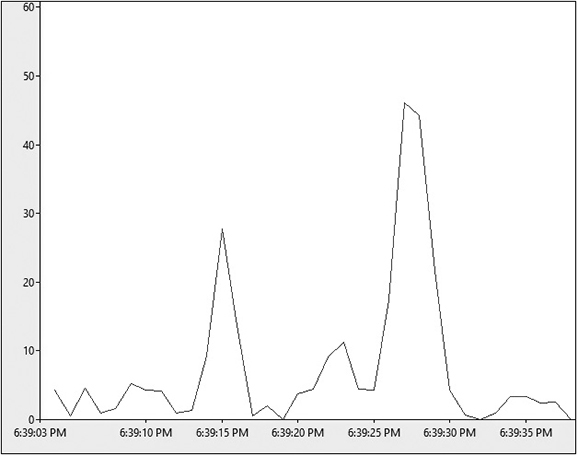
Figure 4-1 CPU utilization example
EXAM TIP Focus on why benchmarks might be useful from a security perspective—they can be great indicators when something is “off” or not quite right. But you need to have those initial baselines to compare readings and realize when something is off.
If you stretch the definition of benchmark a bit, you can even consider things such as file checksums as indicators. If you checksum the binaries on a system to create a “known, good” benchmark, then unexpected deviations are likely indicators of a serious problem. Benchmarks have been used to measure and evaluate system performance for years—it doesn’t take a lot of work to start using them for security as well.
The term benchmark has also been applied by some in the security field to configuration standards, best practices, and recommendations. Even checklists have been referred to as “benchmarks” by some, but you definitely have to stretch the definition of “benchmark” to consider them benchmarks, unless you’re using them as an audit-type measurement. For example, if the “benchmark” you are using is describing how to securely configure an Apache web server, then you can “measure” all the things you did to secure your system against the supplied checklist or recommended steps. With this broad of a definition, almost any security checklist, best practice, or list of recommendations could be used as a “benchmark” and you could measure your “performance” or compliance against it.
Analyze and Interpret Trend Data to Anticipate Cyber Defense Needs
If you’ve been running a firewall or IDS/IPS for any length of time, chances are you have a mountain of log files. Log files are great for incident response, finding out where an attack came from, and noting the types of traffic flowing in and out of your network. Log files are also great for analysis and trending activities; something many security analysts don’t have the time or don’t take the time to do.
Cyber-attacks typically don’t pop up out of the blue. Sure, sometimes an attack will start pounding on your firewall or web server with no advance warning, but generally there are signs and indicators leading up to an attack. You may see port scans looking for specific ports. You may see probes for SQL injection vulnerabilities on web servers. That “doorknob-rattling” type of activity can be analyzed to spot trends. Do you see more port-scanning activity on weekends? Weekdays after 3 P.M. local time? Do you always get a spike in traffic after a major vulnerability announcement? If you can start spotting trends and patterns in your data, you can start using that data to mount a proactive defense.
NOTE Trend data is a powerful tool for security professionals. Learn to use it to help you anticipate where and when your defenses might need to be augmented.
Start analyzing trend data to anticipate the need for cyber defense aids. Are scanning activities starting to overwhelm your older firewall? Do you need to bring on additional personnel on patch Tuesdays? Can you route traffic or split it between defensive systems? If you can start spotting trends and preparing for them rather than reacting to them, you should be able to secure your organization in a more effective manner. Most security analysts find it easier to consolidate their data using a consolidation tool such as Splunk (www.splunk.com), as seen in Figure 4-2. Using consolidation tools that can provide a graphical representation of the data you are analyzing can be extremely useful when sifting through mounds of data.

Figure 4-2 Timeline graph generated using Splunk
Analyze Security Solution Metrics and Attributes to Ensure They Meet Business Needs
Security solutions must first and foremost protect the business, but they must also avoid having a negative impact on your organization. A firewall that blocks all incoming probes on restricted ports is great, but if it can only handle 256 KBps of traffic, it won’t meet the needs of your organization. As with most any other product, security solutions need to be examined to ensure they meet the current and future needs of your organization. This section takes a look at various security solution metrics such as performance, latency, scalability, capability, usability, maintainability, availability, recoverability, return on investment, and total cost of ownership.
Performance
In computer terms, performance is the amount of work a hardware or software component can perform in a given period of time. This can also be stretched to include the work performed by people and processes. When researching potential security solutions, it pays to first enumerate your performance criteria. What throughput must the solution be able to maintain? How many active connections must it support? How many packets per second? Does it need to support Gigabit? Ten Gigabit? When you’re shopping for potential solutions, it helps to determine what you absolutely need to have in terms of coverage and performance and then add a safety margin of 25 percent or more to the performance requirements. That extra buffer may allow your organization to keep using that solution a bit longer because its performance may still be sufficient for your organization long past the time when an “exact fit” solution would be. The extra performance buffer can also help protect your organization should you be targeted with a DDoS.
Latency
Another critical factor to consider is the latency introduced by a particular security solution or set of solutions. Latency is that amount of time delay a system introduces as data passes through it (typically expressed in milliseconds). Latency can be a critical issue for any network traffic and is especially critical in audio/video transmission or real-time processing applications. Passing network traffic through any security device, such as a firewall, will introduce latency. After all, latency cannot be avoided.
EXAM TIP Latency is not always considered when security solutions are examined, but it should be. The introduction of additional latency due to security solutions can have a very detrimental impact on voice and video services.
In Figure 4-3 we see that traffic passing between a user and a server farm experiences a 100 ms delay every time a packet passes through the firewall between the user and the server farm. The question you must answer is, how much latency can your network traffic tolerate? When examining different security solutions, pay attention to the expected latency introduced for different types of traffic under different conditions. For example, does the solution introduce an average of 50 ms at light load but 250 ms at heavy load? Defining your maximum tolerance for latency will likely help drive your selection of security solutions.

Figure 4-3 Simple example of latency introduced by firewall
Scalability
Scalability refers to the capacity of a technology or solution to be changed in size or scale. It is important for security solutions to be able to “grow” without difficulty to accommodate the growth requirements of more users/more traffic. Many solutions (especially hardware solutions) are sold by “size” and accommodate a certain number of connections and an anticipated amount of traffic. When considering the scalability of solutions, consider the following questions:
• What happens when your organization doubles in size?
• What happens when the organization adds three more B2B links?
• Can the solution you’ve chosen be expanded with interface modules?
• Does the solution have add-on capabilities?
• Do you need to switch it out for new hardware and software? If a switch-out is necessary, how much of your current configuration can you migrate to the new platform (rules, settings, and so on)?
• Can you add additional elements to your current solution that will work with the components you already have in place?
No discussion on scalability would be complete without mentioning its chief proponent—cloud computing. Unlike most organizations, which use IT infrastructures for the support of products and services, a cloud computing provider’s infrastructure is the product and service. With cloud products like Microsoft Azure totaling over a million servers worldwide, with bandwidth up to 1.6 Pbps per region, cloud computing solutions provide virtually limitless scalability potential. Such a high-scalability ceiling will consistently guarantee that increases in resource demand will be met with increases in resource supply.
To summarize, the wise security professional purchases what is needed at the moment, but definitely keeps the future in mind.
Capability
Capability refers to the ability of a solution to carry out its intended task. What does the security solution you’re considering actually do? What capabilities does it have to protect/secure your organization? For a firewall, this typically consists of filtering network traffic (in and out). For an IDS/IPS, this typically consists of examining traffic, identifying malicious activity, and potentially reacting to the traffic it sees through resets or temporary firewall rules to block additional traffic from “bad” sources. The thing to really consider is what capabilities does your organization actually need? Do you need an IDS/IPS that blocks offending IP addresses? If you are an e-commerce site, this could be a very bad thing because you could end up blocking potential customers NAT’d behind the same IP address as a single troublemaker. How about logging? Do you need a system that captures just summary information? Just packet headers? The first 5KB of a TCP conversation? In order to effectively select the right security solution for your organization, you’ll need to determine and document the capabilities your organization needs from a security solution.
Usability
Usability describes the degree to which something is easy to use and applicable to a given scenario. The most powerful and capable security system in the world is worthless if your staff doesn’t understand it and can’t use it. We don’t often pay enough attention to the usability aspect of security systems. We get caught up in statistics such as packets per second and number of signatures, and we tend to forget that the interface to the human element can be the most critical element of that security solution. You need to determine how and where the system will be used and managed. Does it require a console application to be installed on user workstations? Can more than one person monitor/manage the system at the same time? How does it display logs and alarm data? How configurable is the interface? Are communications between clients and servers performed in a secure manner? How much training is required before someone is “proficient” with that system? What level of staff is required to operate the system? All of these issues are important—a great security solution can quickly turn into a subpar security system if your staff is not able to effectively use it.
EXAM TIP The usability of a solution is affected by competing characteristics such as the security and functionalities of that solution. As a general principle, if you increase any one of the three characteristics, it inversely reduces the other two. That is why secure operating systems tend to be less usable, and more usable operating systems tend to be less secure.
Maintainability
Maintainability refers to the frequency and duration of successfully updating a solution. Sooner or later every system requires some maintenance. Whether it’s installing patches, clearing out old alarms and log data, or upgrading signatures, most security systems have specific maintenance tasks that need to be performed on a regular basis. The areas to examine are how much maintenance is required, how much effort those tasks take, and how often they need to be performed. A system that requires a great deal of maintenance and monitoring may be a great solution, but the additional manpower cost may make it a poor choice for your organization. You will also want to consider how long a solution will last before it becomes outdated or unmanageable. Is there a projected end of life for the solution? When will a replacement be needed?
Availability
Availability refers to the amount of time a solution is available for use. It is often expressed in terms of the number of seconds, minutes, and hours of unplanned downtown in weekly, monthly, quarterly, and yearly periods. Availability is crucial because a security system that breaks down is almost as bad as not having a security system at all. Most hardware-based or appliance security solutions use enterprise-level components, right? It’s your job to find out. Take a long hard look at the security solutions being offered. What is the weakest component in each of them? Is it a hard drive? Compact flash? Most components will have a mean time between failure (MTBF) rating. (Figure 4-4 shows how the MTBF rating is calculated.)

Figure 4-4 Formula for calculating MTBF
It’s reasonable to assume that the weakest component (the item with the lowest MTBF in the system) is the most likely to fail. What is the MTBF in the solutions you are examining? How bad is a failure of that component for the overall system? Does it result in a degraded capacity or a total outage? And what happens when there is a failure? What is the mean time to recovery (MTTR)? How quickly can the system be brought back online? How quickly can you restore your settings and configuration? Does a failure require a hardware swap? A visit from a service tech? What are the high availability options?
To offset the cost, complexity, and responsibility of maintaining high-availability solutions, organizations are increasingly gravitating toward cloud computing. Availability is one of the most attractive qualities of cloud computing. Cloud computing providers maintain service level agreements (SLAs) that promise minimum service levels for each element of their services (such as availability), in addition to accommodations when failing to meet those levels. For example, Amazon’s AWS promises a respectable monthly uptime percentage of at least 99.99 percent, which amounts to about 4.38 minutes of unplanned downtime per month, or 52.60 minutes per year. If the cloud provider fails to deliver on expectations, they compensate the customer in some manner—typically in the form of service credits.
Although cloud computing solutions will help transfer some of the risk away from the customer, the customer will still retain some risk. For example, when an end user’s data suddenly disappears from Apple iCloud, which party is liable? Is it the end user? Apple? Or one of the various iCloud hosting providers (which, over the years, have included Microsoft Azure, Amazon AWS, and Google Cloud Platform)? Don’t make assumptions about responsibilities—find out. Make sure you understand all of the services and expectations defined in the cloud provider’s SLA. Ask the provider plenty of questions so that you know where the responsibility lines are drawn in various situations and failures.
Most organizations cannot achieve availability on the scale of cloud computing without considerable expense and difficulty; therefore, you can expect cloud computing solutions to increasingly meet the demands of organizations and customers far into the future.
A security solution can do a lot to protect you, but only when it’s actually working. When designing or examining your security system, you will need to examine the MTBF and MTTR of every component in your system. For the most critical components, such as firewalls, you should carefully consider how an outage will affect your overall security solution. The mitigation may be a hot spare, high-availability options, alternate communication paths, and so on. A hardware or software failure can be bad, especially when it’s a security system that fails, but it doesn’t have to be catastrophic for your organization.
EXAM TIP Understand the difference between MTBF and MTTR. MTBF is a measure of how long before similar components failed under typical use. MTTR is a measure of how long it takes before something can be restored to normal functionality.
Recoverability
Recoverability refers to the likelihood that a solution can be returned to its normal working condition within a realistic time period. Unlike maintainability—which is concerned about updating a solution that isn’t broken and is measured using MTBF and MTTR—recoverability focuses on restoring a device that is in a failed or nonworking condition and is measured in terms of recovery time objectives (RTOs) and recovery point objectives (RPOs). For more information about recoverability, see the business continuity and disaster recovery sections covered in Chapter 3.
Cost Benefit Analysis (ROI, TCO)
Let’s face it, security solutions can be expensive. Getting broken into and having customers’ credit cards/medical records/personal information stolen is expensive, too, but the mere threat of this happening is often not enough to justify the cost to prevent it from happening. C-level staff increasingly ask, “How likely is this to happen?” and “What’s the cost if we get hit once? Twice?” Security may be a cost of doing business, but increasingly the question that needs to be answered is, at how much cost?
To help address those questions, CISOs are turning toward methods C-level staff and most MBA graduates understand—ROI and TCO. Return on investment (ROI) is essentially the efficiency of an investment. The “return” or benefit of the investment (minus the cost) is divided by the cost of the investment (see Figure 4-5). This formula works fairly well for manufacturing processes because any increase in productivity will likely generate a positive ROI—but what about security spending? How does one see a “return” from purchasing a new firewall? Or deploying an IPS? It is a bit trickier to show an ROI with security solutions, but it can be done. The obvious case is where spending helps reduce headcount or manpower costs—a new log consolidation tool allows one person to do the work of two people. In other cases, we will need to look at risk analysis calculations for soft numbers that can be used in ROI calculations. Let’s use a simple example—let’s say the risk of a break-in is 100 percent with no security and the cost of said break-in would be $500,000. Let’s say a firewall costing $50,000 would reduce that risk by 80 percent (theoretically providing $400,000 of risk mitigation). So for $50,000, we could achieve $400,000 of risk mitigation. In theory we’re “saving” $350,000 by purchasing the firewall. That’s an extremely simplistic example, but you get the idea. Take a few minutes to google “security ROI” and you’ll see entire papers written on calculating ROI for security products.

Figure 4-5 Simple ROI formula
So, what about total cost of ownership (TCO)? Much like owning a car, purchasing a security product isn’t a one-time expense. Cars have fuel, insurance, and maintenance costs; security products usually have maintenance agreements, require someone to operate and manage them, upgrades, and so on. Calculating the TCO of a security product involves factoring in all the expected costs over the life cycle of that product. Some are simple to calculate, such as purchase price and maintenance contracts, but the hardest to calculate is often the largest number that factors into TCO—personnel. A security tool doesn’t run completely on its own—in almost every case, there’s a human sitting at a keyboard interacting with the security tool. The challenge is trying to estimate how many people will be needed to operate and maintain that tool. How many hours will it take? How much does that type of person get paid? What types of training classes will they need?
EXAM TIP It’s difficult to calculate a straight ROI for security expenditures—you’ll have to rely on risk, expected loss, and risk mitigation for your calculations in most cases.
Use Judgment to Solve Problems Where the Most Secure Solution Is Not Feasible
At some point in your career, you’ll be asked to make a decision and solve a problem where there is no clear “right” answer. You might be selecting the next firewall platform for your small business or you may be deciding whom to lay off in a 500-person IT shop. The best you can do during those times is to collect as much information as you can, weigh each alternative carefully, factor in what’s best for your organization in the long term, and then make your decision.
Good judgment comes with experience—some people seem to be born with a knack for making good decisions, but for most people being able to solve a difficult problem or resolve a difficult situation is a learned skill. Even when there doesn’t seem to be a single clear path ahead, you can often figure out what is best for your organization by carefully weighing each option in front of you. When making a difficult decision or solving a difficult problem, you should do the following:
• Collect as much information as you can.
• Determine the cost of each choice.
• Determine the impact of each solution.
• Determine who will be affected by the choice.
• Figure out if one solution is better in the short term and another better in the long run.
Don’t rush your decision—take the time to gather as much information as you can. When you’ve collected what you can, step back and analyze what is in front of you. How does each solution solve your problem? Can you combine parts from each solution and create a better solution? Weigh each solution—it may help you to actually create a set of grading criteria to better analyze each solution if you have the time. At the end of the day, you’re going to have to make a decision, and one factor may weigh more heavily than all the others in influencing your decision (the long-term impact/benefit the solution has on/for your organization).
Chapter Review
In this chapter we covered the analysis of risk metric scenarios to secure the enterprise. It began with a discussion on reviewing the effectiveness of existing security controls. The key to this endeavor is the performing of gap analyses to help compare the current security state to the desired security state. Whereas that takes place prior to an incident, the lessons-learned and after-action reports take place after a reported breach. Organizations must not only recover from breaches but also learn valuable lessons on what was done wrong, what could have been done better, and what will be done better going forward.
The next section talked about reverse-engineering/deconstructing existing solutions by putting yourself in the attacker’s shoes and asking/answering various questions about attacking security solutions. Through reverse-engineering, security professionals can identify security gaps that they may have ignored due to thinking offensively instead of defensively.
The section that followed discussed the creation, collection, and analysis of metrics, including key performance indicators and key risk indicators. These measurements help organizations quantify the current and future trends of the organization’s security state, and what the organization must do to correct negative trends.
The next section talked about prototyping and testing multiple solutions. Before committing security changes into the production environment, it often helps to test proposed changes in a quality assurance environment to demonstrate proof of concept. After succeeding in the test environment, security changes can be scheduled for delivery into the production environment.
We followed that up with a discussion on creating benchmarks and comparing them to baselines. A baseline is a measurement of an acceptable level of normal performance, whereas a benchmark helps to measure our compliance or deviation from said baseline.
Analyzing and interpreting trend data to anticipate cyber defense needs was the next section. Combing through IDS/IPS and firewall logs will help you to identify attack trends that you can react to before a serious breach occurs.
We then talked about analyzing security solution metrics and attributes to ensure they meet business needs. This included coverage of performance, latency, scalability, capability, usability, maintainability, recoverability, and ROI and TCO. These are all measurements of the qualities of metrics that positively or negatively affect security outcomes.
The final section touched on using judgment to solve problems where the most secure solution is not feasible. Sometimes the best solution is not practical or possible to implement; therefore, we must exercise our judgment on how to work around the security deficit. Collecting information about alternatives and determining the pros and cons of each choice will help us to make a sound decision.
Quick Tips
The following tips should serve as a brief review of the topics covered in more detail throughout the chapter.
Review Effectiveness of Existing Security Controls
• Reviewing your current security program can help you identify areas that need improvement, areas that need additional spending or attention, and what changes you’ll implement to address the needs.
• Reviewing end-user training, IDS/IPS alarms, firewall rules, vulnerability testing, and policies and procedures to determine how well you are performing these activities will help identity areas for improvement.
• A gap analysis helps determine the differences between an organization’s present state of security to its recommended or desired state.
• A gap analysis is a great way to measure the efficacy of existing security controls.
• Bad things will happen regardless of how well you plan or how many precautions you take.
• A lessons-learned/after-action review is a careful analysis of what happened, why it happened, and what can be done differently or more effectively next time.
• There is a small window of opportunity for holding lessons-learned/after-action reviews.
• Lessons-learned/after-action reviews are not just post-incident activities. Any complex, potentially repeatable process can be improved through such reviews.
Reverse-Engineer/Deconstruct Existing Solutions
• Rather than thinking about how to defend organizational assets, consider how a hacker might attack them.
• Reverse-engineering or deconstructing existing security solutions is an excellent way to identify entry points and weaknesses. If you can break down your own systems and correct the issues you find, you will be that much more effective against actual attackers.
• Deconstruct what the system does, how the solution impacts network traffic, and how it handles encryption, communications, and reactive capabilities in order to learn the weaknesses that need protection.
Creation, Collection, and Analysis of Metrics
• It is difficult to manage things that cannot be measured accurately.
• Metrics allow you to measure the qualities (or lack thereof) of a system that contribute to its security state.
• Create, collect, and analyze any metrics that inform you about short-term and long-term trends in your overall security posture.
• Key performance indicators (KPIs) are quantifiable metrics used to evaluate the success of technology, processes, or people meeting an organization’s performance goals.
• Key risk indicators (KRIs) measure the amount of risk an activity brings to an organization.
• Think of KPIs as a measure of how well things are going now, whereas KRIs can help measure how badly things might turn out in the future.
Prototype and Test Multiple Solutions
• The ideal place to start prototyping and testing is within a lab environment.
• You’ll never be able to completely simulate your enterprise network, but with the use of virtualization and traffic generators, you can at least create a decent starting point for analysis and testing.
• Prototyping security solutions is very useful. Having the opportunity to search for vulnerabilities in an early prototype can reveal serious issues that would be extremely expensive to fix in a finished product.
• A lab environment is a great place to start examining how a combination of tools and techniques can address different security needs.
• When you’ve tested your solution in the lab or have narrowed down your possible solutions from many to a few, or even a single candidate, then it’s time to test it in the production environment.
• Make sure you have a fallback plan and methods for inserting/removing the solution being tested rapidly.
Create Benchmarks and Compare to Baselines
• A baseline is a captured point of reference used as a comparison for future changes.
• Baselines are valuable in information security because they help you to know if your security controls are trending in the right or wrong direction.
• A benchmark is a subsequent measurement that is compared to a baseline.
• The term “benchmark” has also been applied by some in the security field to configuration standards, best practices, and recommendations.
Analyze and Interpret Trend Data to Anticipate Cyber Defense Needs
• Log files are great for incident response, finding out where an attack came from, and noting the types of traffic flowing in and out of your network.
• Log files are also great for analysis and trending activities—something many security analysts don’t have the time or don’t take the time to do.
• Trend data is a powerful tool for security professionals. Learn to use it to help you anticipate where and when your defenses might need to be augmented.
Analyze Security Solution Metrics and Attributes to Ensure They Meet Business Needs
• Security solutions must first and foremost protect the business, but they must also avoid having a negative impact on your organization.
• Performance is the amount of work a hardware or software component can perform in a given period of time.
• Latency is that amount of time delay a system introduces as data passes through it (typically expressed in milliseconds).
• Scalability refers to the capacity of a technology or solution to be changed in size or scale.
• Capability refers to the ability of a solution to carry out its intended task.
• Usability describes the degree to which something is easy to use and applicable to a given scenario.
• Maintainability refers to the frequency and duration of successfully updating a solution.
• Availability refers to the amount of time a solution is available for use.
• Recoverability refers to the likelihood that a solution can be returned to its normal working condition within a realistic time period.
• Security may be a cost of doing business, but increasingly the question that needs to be answered is, at how much cost?
• Return on investment (ROI) is essentially the efficiency of an investment.
• Calculating the total cost of ownership (TCO) of a security product involves factoring in all the expected costs over the life cycle of that product.
Use Judgment to Solve Problems Where the Most Secure Solution Is Not Feasible
• You’ll eventually be asked to make a decision and solve a problem where there is no clear “right” answer.
• The best you can do during those times is to collect as much information as you can, weigh each alternative carefully, factor in what’s best for your organization in the long term, and then make your decision.
Questions
The following questions will help you measure your understanding of the material presented in this chapter. Read all the choices carefully because there might be more than one correct answer. Choose all correct answers for each question.
1. A benchmark is an example of which of the following?
A. A set of expectations
B. Only useful for batch routine measurements
C. A point of reference for measurement
D. Used to encrypt backup files
2. Which of the following could indicate a potential security problem?
A. Spike in outbound network traffic at odd times
B. Increase in CPU utilization on Internet-facing systems
C. Increased logins during weekend or evening hours
D. All of the above
3. In which situation or location would prototyping be most appropriate?
A. In a lab environment
B. After products have been released to the public
C. In the production environment
D. With second or subsequent releases of a product
4. From a security perspective, prototyping could help you in which way?
A. Identifying issues in production environments
B. Identifying potential vulnerabilities in early versions of products
C. Spotting data exfiltration attacks
D. Targeting botnets on wireless networks
5. What does ROI stand for?
A. Real occurrence of incidents
B. Return on investment
C. Rate of incident
D. Rate of inclusion
6. Total cost of ownership (TCO) should include which of the following?
A. Cost of hardware
B. Cost of maintenance contracts
C. Cost of personnel
D. All of the above
7. Which of the following tools can assist you in analyzing large data sets for trends?
A. Sniffers
B. Prototypes
C. Log consolidation tools such as Splunk
D. Cost analysis platforms
8. Reviewing the effectiveness of your existing security programs can help you:
A. Identify areas that need improvement
B. Identify areas where additional effort is needed
C. Measure impact of user training
D. All of the above
9. Reverse-engineering an existing security solution is a good way to:
A. Determine the TCO of the system
B. Identify entry points and weaknesses
C. Discover trends in network traffic
D. Validate mitigation approaches
10. Which of the following areas should you examine when performing reverse-engineering:
A. Communication paths
B. Reactive capabilities
C. Impact on network traffic
D. All of the above
11. Specifying performance of a security solution means:
A. Specifying packets per second and throughput that must be supported
B. Determining the MTTR of the solution
C. Validating the TCO of the solution
D. Counting the types and number of attacks contained in the signature database
12. Latency is:
A. The total cost of a security system, including personnel costs
B. Measurement of the overall throughput of a security system
C. A desirable trait of any distributed solution
D. The amount of time delay a system introduces as data passes through it
13. Which of the following would be most important when considering the scalability of a security solution?
A. Support for future versions
B. Cost of maintenance contracts
C. Ability to accommodate more users and more traffic
D. Ability to analyze encrypted traffic
14. Which of the following is not an important factor to consider when examining the usability of a security solution?
A. Configurability of the user interface
B. Amount of training required to use the product effectively
C. Throughput under ideal conditions
D. Type of interface used to display data to user
15. A lessons-learned/after-action review is an analysis of:
A. What happened
B. Why it happened
C. What can be done differently or more effectively next time
D. All of the above
16. When making a difficult decision where there is no clear “right” answer, you should:
A. Gather as much data as possible
B. Determine the cost and impact of each alternative
C. Analyze all the collected data
D. All of the above
17. Network traffic analysis can help you:
A. Really understand the traffic passing through your network
B. Reveal problems in your organization’s accounting policies
C. Pinpoint sources of data corruption
D. Verify the MTTF of network components
Answers
1. C. A benchmark is a point of reference for measurement. It could be a set of performance criteria, a set of conditions, an established and measured process, and so on.
2. D. Any of these could indicate a potential security problem. If you have an established set of benchmarks (reference points), deviations from the “norm” could indicate a potential security problem.
3. A. Prototyping is typically done in a test environment.
4. B. Prototyping can help you identify potential vulnerabilities in early versions of products.
5. B. ROI is return on investment, also known as the efficiency of an investment.
6. D. When calculating total cost of ownership, you should always include all the expenses associated with an item, including the cost of hardware, the cost of any maintenance agreements, and the cost of the personnel to run/maintain the system.
7. C. Log consolidation tools such as Splunk can assist you in analyzing large data sets for attack trends.
8. D. Reviewing the effectiveness of your existing security programs can help you identify areas that need improvement, identify areas where additional effort is needed, and measure the impact of user-training programs.
9. B. Reverse-engineering existing solutions is a good way to identify entry points and weaknesses in your network.
10. D. Communications paths, reactive capabilities, and impact on network traffic are all areas you should examine when reverse-engineering existing security solutions.
11. A. In the examples listed, specifying the performance of a security solution means specifying packets per second and the throughput that must be supported.
12. D. Latency is the amount of time delay a system introduces as data passes through it.
13. C. The ability to accommodate more users and more traffic is the most important item in the list when considering the scalability of a security solution.
14. C. Throughput under ideal conditions is a performance consideration, not a usability consideration.
15. D. A lessons-learned/after-action review is a careful analysis of what happened, why it happened, what could be done to prevent it, and what can be done differently or more effectively next time.
16. D. When making a difficult decision where there is no clear “right” answer, you should gather as much data as possible, determine the cost and impact of each alternative, and analyze all the collected data.
17. A. Network traffic analysis can help you understand what is really going on within your network.