
Chapter 1
Cybersecurity Fundamentals
This chapter covers the following topics:
Introduction to Cybersecurity: Cybersecurity programs recognize that organizations must be vigilant, resilient, and ready to protect and defend every ingress and egress connection as well as organizational data wherever it is stored, transmitted, or processed. In this chapter, you will learn concepts of cybersecurity and information security.
Defining What Are Threats, Vulnerabilities, and Exploits: Describe the difference between cybersecurity threats, vulnerabilities, and exploits.
Exploring Common Threats: Describe and understand the most common cybersecurity threats.
Common Software and Hardware Vulnerabilities: Describe and understand the most common software and hardware vulnerabilities.
Confidentiality, Integrity, and Availability: The CIA triad is a concept that was created to define security policies to protect assets. The idea is that confidentiality, integrity and availability should be guaranteed in any system that is considered secured.
Cloud Security Threats: Learn about different cloud security threats and how cloud computing has changed traditional IT and is introducing several security challenges and benefits at the same time.
IoT Security Threats: The proliferation of connected devices is introducing major cybersecurity risks in today’s environment.
An Introduction to Digital Forensics and Incident Response: You will learn the concepts of digital forensics and incident response (DFIR) and cybersecurity operations.
This chapter starts by introducing you to different cybersecurity concepts that are foundational for any individual starting a career in cybersecurity or network security. You will learn the difference between cybersecurity threats, vulnerabilities, and exploits. You will also explore the most common cybersecurity threats, as well as common software and hardware vulnerabilities. You will learn the details about the CIA triad—confidentiality, integrity, and availability. In this chapter, you will learn about different cloud security and IoT security threats. This chapter concludes with an introduction to DFIR and security operations.
The following SCOR 350-701 exam objectives are covered in this chapter:
1.1 Explain common threats against on-premises and cloud environments
1.1.a On-premises: viruses, trojans, DoS/DDoS attacks, phishing, rootkits, man-in-the-middle attacks, SQL injection, cross-site scripting, malware
1.1.b Cloud: data breaches, insecure APIs, DoS/DDoS, compromised credentials
1.2 Compare common security vulnerabilities such as software bugs, weak and/or hardcoded passwords, SQL injection, missing encryption, buffer overflow, path traversal, cross-site scripting/forgery
1.5 Describe security intelligence authoring, sharing, and consumption
1.6 Explain the role of the endpoint in protecting humans from phishing and social engineering attacks
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter thoroughly or jump to the “Exam Preparation Tasks” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 1-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Q&A Sections.”
Table 1-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions |
Introduction to Cybersecurity |
1 |
Defining What Are Threats, Vulnerabilities, and Exploits |
2–6 |
Common Software and Hardware Vulnerabilities |
7–10 |
Confidentiality, Integrity, and Availability |
11–13 |
Cloud Security Threats |
14–15 |
IoT Security Threats |
16–17 |
An Introduction to Digital Forensics and Incident Response |
18 |
1. Which of the following is a collection of industry standards and best practices to help organizations manage cybersecurity risks?
MITRE
NIST Cybersecurity Framework
ISO Cybersecurity Framework
CERT/cc
2. _________ is any potential danger to an asset.
Vulnerability
Threat
Exploit
None of these answers is correct.
3. A ___________ is a weakness in the system design, implementation, software, or code, or the lack of a mechanism.
Vulnerability
Threat
Exploit
None of these answers are correct.
4. Which of the following is a piece of software, a tool, a technique, or a process that takes advantage of a vulnerability that leads to access, privilege escalation, loss of integrity, or denial of service on a computer system?
Exploit
Reverse shell
Searchsploit
None of these answers is correct.
5. Which of the following is referred to as the knowledge about an existing or emerging threat to assets, including networks and systems?
Exploits
Vulnerabilities
Threat assessment
Threat intelligence
6. Which of the following are examples of malware attack and propagation mechanisms?
Master boot record infection
File infector
Macro infector
All of these answers are correct.
7. Vulnerabilities are typically identified by a ___________.?
CVE
CVSS
PSIRT
None of these answers is correct.
8. SQL injection attacks can be divided into which of the following categories?
Blind SQL injection
Out-of-band SQL injection
In-band SQL injection
None of these answers is correct.
All of these answers are correct.
9. Which of the following is a type of vulnerability where the flaw is in a web application but the attack is against an end user (client)?
XXE
HTML injection
SQL injection
XSS
10. Which of the following is a way for an attacker to perform a session hijack attack?
Predicting session tokens
Session sniffing
Man-in-the-middle attack
Man-in-the-browser attack
All of these answers are correct.
11. A denial-of-service attack impacts which of the following?
Integrity
Availability
Confidentiality
None of these answers is correct.
12. Which of the following are examples of security mechanisms designed to preserve confidentiality?
Logical and physical access controls
Encryption
Controlled traffic routing
All of these answers are correct.
13. An attacker is able to manipulate the configuration of a router by stealing the administrator credential. This attack impacts which of the following?
Integrity
Session keys
Encryption
None of these answers is correct.
14. Which of the following is a cloud deployment model?
Public cloud
Community cloud
Private cloud
All of these answers are correct.
15. Which of the following cloud models include all phases of the system development life cycle (SDLC) and can use application programming interfaces (APIs), website portals, or gateway software?
SaaS
PaaS
SDLC containers
None of these answers is correct.
16. Which of the following is not a communications protocol used in IoT environments?
Zigbee
INSTEON
LoRaWAN
802.1X
17. Which of the following is an example of tools and methods to hack IoT devices?
UART debuggers
JTAG analyzers
IDA
Ghidra
All of these answers are correct.
18. Which of the following is an adverse event that threatens business security and/or disrupts service?
An incident
An IPS alert
A DLP alert
A SIEM alert
Foundation Topics
Introduction to Cybersecurity
We live in an interconnected world where both individual and collective actions have the potential to result in inspiring goodness or tragic harm. The objective of cybersecurity is to protect each of us, our economy, our critical infrastructure, and our country from the harm that can result from inadvertent or intentional misuse, compromise, or destruction of information and information systems.
Cybersecurity risk includes not only the risk of a data breach but also the risk of the entire organization being undermined via business activities that rely on digitization and accessibility. As a result, learning how to develop an adequate cybersecurity program is crucial for any organization. Cybersecurity can no longer be something that you delegate to the information technology (IT) team. Everyone needs to be involved, including the board of directors.
Cybersecurity vs. Information Security (InfoSec)
Many individuals confuse traditional information security with cybersecurity. In the past, information security programs and policies were designed to protect the confidentiality, integrity, and availability of data within the confines of an organization. Unfortunately, this is no longer sufficient. Organizations are rarely self-contained, and the price of interconnectivity is exposure to attack. Every organization, regardless of size or geographic location, is a potential target. Cybersecurity is the process of protecting information by preventing, detecting, and responding to attacks.
Cybersecurity programs recognize that organizations must be vigilant, resilient, and ready to protect and defend every ingress and egress connection as well as organizational data wherever it is stored, transmitted, or processed. Cybersecurity programs and policies expand and build upon traditional information security programs, but also include the following:
Cyber risk management and oversight
Threat intelligence and information sharing
Third-party organization, software, and hardware dependency management
Incident response and resiliency
The NIST Cybersecurity Framework
The National Institute of Standards and Technology (NIST) is a well-known organization that is part of the U.S. Department of Commerce. NIST is a nonregulatory federal agency within the U.S. Commerce Department’s Technology Administration. NIST’s mission is to develop and promote measurement, standards, and technology to enhance productivity, facilitate trade, and improve quality of life. The Computer Security Division (CSD) is one of seven divisions within NIST’s Information Technology Laboratory. NIST’s Cybersecurity Framework is a collection of industry standards and best practices to help organizations manage cybersecurity risks. This framework is created in collaboration among the United States government, corporations, and individuals. The NIST Cybersecurity Framework can be accessed at https://www.nist.gov/cyberframework.
The NIST Cybersecurity Framework is developed with a common taxonomy, and one of the main goals is to address and manage cybersecurity risk in a cost-effective way to protect critical infrastructure. Although designed for a specific constituency, the requirements can serve as a security blueprint for any organization.
Additional NIST Guidance and Documents
Currently, there are more than 500 NIST information security–related documents. This number includes FIPS, the SP 800 series, information, Information Technology Laboratory (ITL) bulletins, and NIST interagency reports (NIST IR):
Federal Information Processing Standards (FIPS): This is the official publication series for standards and guidelines.
Special Publication (SP) 800 series: This series reports on ITL research, guidelines, and outreach efforts in information system security and its collaborative activities with industry, government, and academic organizations. SP 800 series documents can be downloaded from https://csrc.nist.gov/publications/sp800.
Special Publication (SP) 1800 series: This series focuses on cybersecurity practices and guidelines. SP 1800 series document can be downloaded from https://csrc.nist.gov/publications/sp1800.
NIST Internal or Interagency Reports (NISTIR): These reports focus on research findings, including background information for FIPS and SPs.
ITL bulletins: Each bulletin presents an in-depth discussion of a single topic of significant interest to the information systems community. Bulletins are issued on an as-needed basis.
From access controls to wireless security, the NIST publications are truly a treasure trove of valuable and practical guidance.
The International Organization for Standardization (ISO)
ISO is a network of the national standards institutes of more than 160 countries. ISO has developed more than 13,000 international standards on a variety of subjects, ranging from country codes to passenger safety.
The ISO/IEC 27000 series (also known as the ISMS Family of Standards, or ISO27k for short) comprises information security standards published jointly by the ISO and the International Electrotechnical Commission (IEC).
The first six documents in the ISO/IEC 27000 series provide recommendations for “establishing, implementing, operating, monitoring, reviewing, maintaining, and improving an Information Security Management System”:
ISO 27001 is the specification for an Information Security Management System (ISMS).
ISO 27002 describes the Code of Practice for information security management.
ISO 27003 provides detailed implementation guidance.
ISO 27004 outlines how an organization can monitor and measure security using metrics.
ISO 27005 defines the high-level risk management approach recommended by ISO.
ISO 27006 outlines the requirements for organizations that will measure ISO 27000 compliance for certification.
In all, there are more than 20 documents in the series, and several more are still under development. The framework is applicable to public and private organizations of all sizes. According to the ISO website, “the ISO standard gives recommendations for information security management for use by those who are responsible for initiating, implementing or maintaining security in their organization. It is intended to provide a common basis for developing organizational security standards and effective security management practice and to provide confidence in inter-organizational dealings.”
Defining What Are Threats, Vulnerabilities, and Exploits
In the following sections you will learn about the characteristics of threats, vulnerabilities, and exploits.
What Is a Threat?
A threat is any potential danger to an asset. If a vulnerability exists but has not yet been exploited—or, more importantly, it is not yet publicly known—the threat is latent and not yet realized. If someone is actively launching an attack against your system and successfully accesses something or compromises your security against an asset, the threat is realized. The entity that takes advantage of the vulnerability is known as the malicious actor, and the path used by this actor to perform the attack is known as the threat agent or threat vector.
What Is a Vulnerability?
A vulnerability is a weakness in the system design, implementation, software, or code, or the lack of a mechanism. A specific vulnerability might manifest as anything from a weakness in system design to the implementation of an operational procedure. The correct implementation of safeguards and security countermeasures could mitigate a vulnerability and reduce the risk of exploitation.
Vulnerabilities and weaknesses are common, mainly because there isn’t any perfect software or code in existence. Some vulnerabilities have limited impact and are easily mitigated; however, many have broader implications.
Vulnerabilities can be found in each of the following:
Applications: Software and applications come with tons of functionality. Applications might be configured for usability rather than for security. Applications might be in need of a patch or update that may or may not be available. Attackers targeting applications have a target-rich environment to examine. Just think of all the applications running on your home or work computer.
Operating systems: Operating system software is loaded on workstations and servers. Attackers can search for vulnerabilities in operating systems that have not been patched or updated.
Hardware: Vulnerabilities can also be found in hardware. Mitigation of a hardware vulnerability might require patches to microcode (firmware) as well as the operating system or other system software. Good examples of well-known hardware-based vulnerabilities are Spectre and Meltdown. These vulnerabilities take advantage of a feature called “speculative execution” common to most modern processor architectures.
Misconfiguration: The configuration file and configuration setup for the device or software may be misconfigured or may be deployed in an unsecure state. This might be open ports, vulnerable services, or misconfigured network devices. Just consider wireless networking. Can you detect any wireless devices in your neighborhood that have encryption turned off?
Shrinkwrap software: This is the application or executable file that is run on a workstation or server. When installed on a device, it can have tons of functionality or sample scripts or code available.
Vendors, security researchers, and vulnerability coordination centers typically assign vulnerabilities an identifier that’s disclosed to the public. This identifier is known as the Common Vulnerabilities and Exposures (CVE). CVE is an industry-wide standard. CVE is sponsored by US-CERT, the office of Cybersecurity and Communications at the U.S. Department of Homeland Security. Operating as DHS’s Federally Funded Research and Development Center (FFRDC), MITRE has copyrighted the CVE list for the benefit of the community in order to ensure it remains a free and open standard, as well as to legally protect the ongoing use of it and any resulting content by government, vendors, and/or users. MITRE maintains the CVE list and its public website, manages the CVE Compatibility Program, oversees the CVE Naming Authorities (CNAs), and provides impartial technical guidance to the CVE Editorial Board throughout the process to ensure CVE serves the public interest.
The goal of CVE is to make it easier to share data across tools, vulnerability repositories, and security services.
More information about CVE is available at http://cve.mitre.org.
What Is an Exploit?
An exploit refers to a piece of software, a tool, a technique, or a process that takes advantage of a vulnerability that leads to access, privilege escalation, loss of integrity, or denial of service on a computer system. Exploits are dangerous because all software has vulnerabilities; hackers and perpetrators know that there are vulnerabilities and seek to take advantage of them. Although most organizations attempt to find and fix vulnerabilities, some organizations lack sufficient funds for securing their networks. Sometimes no one may even know the vulnerability exists, and it is exploited. That is known as a zero-day exploit. Even when you do know there is a problem, you are burdened with the fact that a window exists between when a vulnerability is disclosed and when a patch is available to prevent the exploit. The more critical the server, the slower it is usually patched. Management might be afraid of interrupting the server or afraid that the patch might affect stability or performance. Finally, the time required to deploy and install the software patch on production servers and workstations exposes an organization’s IT infrastructure to an additional period of risk.
There are several places where people trade exploits for malicious intent. The most prevalent is the “dark web.” The dark web (or darknet) is an overlay of networks and systems that use the Internet but require specific software and configurations to access it. The dark web is just a small part of the “deep web.” The deep web is a collection of information and systems on the Internet that is not indexed by web search engines. Often people incorrectly confuse the term deep web with dark web.
Not all exploits are shared for malicious intent. For example, many security researchers share proof-of-concept (POC) exploits in public sites such as The Exploit Database (or Exploit-DB) and GitHub. The Exploit Database is a site maintained by Offensive Security where security researchers and other individuals post exploits for known vulnerabilities. The Exploit Database can be accessed at https://www.exploit-db.com. Figure 1-1 shows different publicly available exploits in the Exploit Database.
There is a command-line tool called searchsploit that allows you to download a copy of the Exploit Database so that you can use it on the go. Figure 1-2 shows an example of how you can use searchsploit to search for specific exploits. In the example illustrated in Figure 1-2, searchsploit is used to search for exploits related to SMB vulnerabilities.
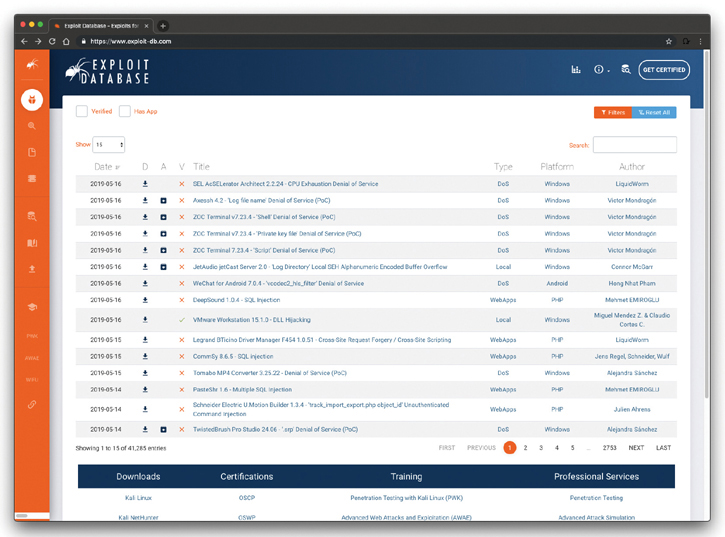
Figure 1-1 The Exploit Database (Exploit-DB)

Figure 1-2 Using Searchsploit
Risk, Assets, Threats, and Vulnerabilities
As with any new technology topic, to better understand the security field, you must learn the terminology that is used. To be a security professional, you need to understand the relationship between risk, threats, assets, and vulnerabilities.
Risk is the probability or likelihood of the occurrence or realization of a threat. There are three basic elements of risk: assets, threats, and vulnerabilities. To deal with risk, the U.S. federal government has adopted a risk management framework (RMF). The RMF process is based on the key concepts of mission- and risk-based, cost-effective, and enterprise information system security. NIST Special Publication 800-37, “Guide for Applying the Risk Management Framework to Federal Information Systems,” transforms the traditional Certification and Accreditation (C&A) process into the six-step Risk Management Framework (RMF). Let’s look at the various components associated with risk, which include assets, threats, and vulnerabilities.
An asset is any item of economic value owned by an individual or corporation. Assets can be real—such as routers, servers, hard drives, and laptops—or assets can be virtual, such as formulas, databases, spreadsheets, trade secrets, and processing time. Regardless of the type of asset discussed, if the asset is lost, damaged, or compromised, there can be an economic cost to the organization.
A threat sets the stage for risk and is any agent, condition, or circumstance that could potentially cause harm, loss, or damage, or compromise an IT asset or data asset. From a security professional’s perspective, threats can be categorized as events that can affect the confidentiality, integrity, or availability of the organization’s assets. These threats can result in destruction, disclosure, modification, corruption of data, or denial of service. Examples of the types of threats an organization can face include the following:
Natural disasters, weather, and catastrophic damage: Hurricanes, storms, weather outages, fire, flood, earthquakes, and other natural events compose an ongoing threat.
Hacker attacks: An insider or outsider who is unauthorized and purposely attacks an organization’s infrastructure, components, systems, or data.
Cyberattack: Attacks that target critical national infrastructures such as water plants, electric plants, gas plants, oil refineries, gasoline refineries, nuclear power plants, waste management plants, and so on. Stuxnet is an example of one such tool designed for just such a purpose.
Viruses and malware: An entire category of software tools that are malicious and are designed to damage or destroy a system or data.
Disclosure of confidential information: Anytime a disclosure of confidential information occurs, it can be a critical threat to an organization if such disclosure causes loss of revenue, causes potential liabilities, or provides a competitive advantage to an adversary. For instance, if your organization experiences a breach and detailed customer information is exposed (for example, personally identifiable information [PII]), such a breach could have potential liabilities and loss of trust from your customers. Another example is when a threat actor steals source code or design documents and sells them to your competitors.
Denial of service (DoS) or distributed DoS (DDoS) attacks: An attack against availability that is designed to bring the network, or access to a particular TCP/IP host/server, to its knees by flooding it with useless traffic. Today, most DoS attacks are launched via botnets, whereas in the past tools such as the Ping of Death or Teardrop may have been used. Like malware, hackers constantly develop new tools so that Storm and Mariposa, for example, are replaced with other, more current threats.
Defining Threat Actors
Threat actors are the individuals (or group of individuals) who perform an attack or are responsible for a security incident that impacts or has the potential of impacting an organization or individual. There are several types of threat actors:
Script kiddies: People who use existing “scripts” or tools to hack into computers and networks. They lack the expertise to write their own scripts.
Organized crime groups: Their main purpose is to steal information, scam people, and make money.
State sponsors and governments: These agents are interested in stealing data, including intellectual property and research-and-development data from major manufacturers, government agencies, and defense contractors.
Hacktivists: People who carry out cybersecurity attacks aimed at promoting a social or political cause.
Terrorist groups: These groups are motivated by political or religious beliefs.
Originally, the term hacker was used for a computer enthusiast. A hacker was a person who enjoyed understanding the internal workings of a system, computer, and computer network and who would continue to hack until he understood everything about the system. Over time, the popular press began to describe hackers as individuals who broke into computers with malicious intent. The industry responded by developing the word cracker, which is short for a criminal hacker. The term cracker was developed to describe individuals who seek to compromise the security of a system without permission from an authorized party. With all this confusion over how to distinguish the good guys from the bad guys, the term ethical hacker was coined. An ethical hacker is an individual who performs security tests and other vulnerability-assessment activities to help organizations secure their infrastructures. Sometimes ethical hackers are referred to as white hat hackers.
Hacker motives and intentions vary. Some hackers are strictly legitimate, whereas others routinely break the law. Let’s look at some common categories:
White hat hackers: These individuals perform ethical hacking to help secure companies and organizations. Their belief is that you must examine your network in the same manner as a criminal hacker to better understand its vulnerabilities.
Black hat hackers: These individuals perform illegal activities, such as organized crime.
Gray hat hackers: These individuals usually follow the law but sometimes venture over to the darker side of black hat hacking. It would be unethical to employ these individuals to perform security duties for your organization because you are never quite clear where they stand.
Understanding What Threat Intelligence Is
Threat intelligence is referred to as the knowledge about an existing or emerging threat to assets, including networks and systems. Threat intelligence includes context, mechanisms, indicators of compromise (IoCs), implications, and actionable advice. Threat intelligence is referred to as the information about the observables, indicators of compromise (IoCs) intent, and capabilities of internal and external threat actors and their attacks. Threat intelligence includes specifics on the tactics, techniques, and procedures of these adversaries. Threat intelligence’s primary purpose is to inform business decisions regarding the risks and implications associated with threats.
Converting these definitions into common language could translate to threat intelligence being evidence-based knowledge of the capabilities of internal and external threat actors. This type of data can be beneficial for the security operations center (SOC) of any organization. Threat intelligence extends cybersecurity awareness beyond the internal network by consuming intelligence from other sources Internet-wide related to possible threats to you or your organization. For instance, you can learn about threats that have impacted different external organizations. Subsequently, you can proactively prepare rather than react once the threat is seen against your network. Providing an enrichment data feed is one service that threat intelligence platforms would typically provide.
Figure 1-3 shows a five-step threat intelligence process for evaluating threat intelligence sources and information.

Figure 1-3 The Threat Intelligence Process
Many different threat intelligence platforms and services are available in the market nowadays. Cyber threat intelligence focuses on providing actionable information on adversaries, including IoCs. Threat intelligence feeds help you prioritize signals from internal systems against unknown threats. Cyber threat intelligence allows you to bring more focus to cybersecurity investigation because instead of blindly looking for “new” and “abnormal” events, you can search for specific IoCs, IP addresses, URLs, or exploit patterns.
A number of standards are being developed for disseminating threat intelligence information. The following are a few examples:
Structured Threat Information eXpression (STIX): An express language designed for sharing of cyber-attack information. STIX details can contain data such as the IP addresses or domain names of command-and-control servers (often referred to C2 or CnC), malware hashes, and so on. STIX was originally developed by MITRE and is now maintained by OASIS. You can obtain more information at http://stixproject.github.io.
Trusted Automated eXchange of Indicator Information (TAXII): An open transport mechanism that standardizes the automated exchange of cyber-threat information. TAXII was originally developed by MITRE and is now maintained by OASIS. You can obtain more information at http://taxiiproject.github.io.
Cyber Observable eXpression (CybOX): A free standardized schema for specification, capture, characterization, and communication of events of stateful properties that are observable in the operational domain. CybOX was originally developed by MITRE and is now maintained by OASIS. You can obtain more information at https://cyboxproject.github.io.
Open Indicators of Compromise (OpenIOC): An open framework for sharing threat intelligence in a machine-digestible format. Learn more at http://www.openioc.org.
Open Command and Control (OpenC2): A language for the command and control of cyber-defense technologies. OpenC2 Forum was a community of cybersecurity stakeholders that was facilitated by the U.S. National Security Agency. OpenC2 is now an OASIS technical committee (TC) and specification. You can obtain more information at https://www.oasis-open.org/committees/tc_home.php?wg_abbrev=openc2.
It should be noted that many open source and non-security-focused sources can be leveraged for threat intelligence as well. Some examples of these sources are social media, forums, blogs, and vendor websites.
Viruses and Worms
One thing that makes viruses unique is that a virus typically needs a host program or file to infect. Viruses require some type of human interaction. A worm can travel from system to system without human interaction. When a worm executes, it can replicate again and infect even more systems. For example, a worm can email itself to everyone in your address book and then repeat this process again and again from each user’s computer it infects. That massive amount of traffic can lead to a denial of service very quickly.
Spyware is closely related to viruses and worms. Spyware is considered another type of malicious software. In many ways, spyware is similar to a Trojan because most users don’t know that the program has been installed, and the program hides itself in an obscure location. Spyware steals information from the user and also eats up bandwidth. If that’s not enough, spyware can also redirect your web traffic and flood you with annoying pop-ups. Many users view spyware as another type of virus.
This section covers a brief history of computer viruses, common types of viruses, and some of the most well-known virus attacks. Also, some tools used to create viruses and the best methods of prevention are discussed.
Types and Transmission Methods
Although viruses have a history that dates back to the 1980s, their means of infection has changed over the years. Viruses depend on people to spread them. Viruses require human activity, such as booting a computer, executing an autorun on digital media (for example, CD, DVD, USB sticks, external hard drives, and so on), or opening an email attachment. Malware propagates through the computer world in several basic ways:
Master boot record infection: This is the original method of attack. It works by attacking the master boot record of the hard drive.
BIOS infection: This could completely make the system inoperable or the device could hang before passing Power On Self-Test (POST).
File infection: This includes malware that relies on the user to execute the file. Extensions such as .com and .exe are usually used. Some form of social engineering is normally used to get the user to execute the program. Techniques include renaming the program or trying to mask the .exe extension and make it appear as a graphic (.jpg, .bmp, .png, .svg, and the like).
Macro infection: Macro viruses exploit scripting services installed on your computer. Manipulating and using macros in Microsoft Excel, Microsoft Word, and Microsoft PowerPoint documents have been very popular in the past.
Cluster: This type of virus can modify directory table entries so that it points a user or system process to the malware and not the actual program.
Multipartite: This style of virus can use more than one propagation method and targets both the boot sector and program files. One example is the NATAS (Satan spelled backward) virus.
After your computer is infected, the malware can do any number of things. Some spread quickly. This type of virus is known as a fast infection. Fast-infection viruses infect any file that they are capable of infecting. Others limit the rate of infection. This type of activity is known as sparse infection. Sparse infection means that the virus takes its time in infecting other files or spreading its damage. This technique is used to try to help the virus avoid infection. Some viruses forgo a life of living exclusively in files and load themselves into RAM, which is the only way that boot sector viruses can spread.
As the antivirus and security companies have developed better ways to detect malware, malware authors have fought back by trying to develop malware that is harder to detect. For example, in 2012, Flame was believed to be the most sophisticated malware to date. Flame has the ability to spread to other systems over a local network. It can record audio, screenshots, and keyboard activity, and it can turn infected computers into Bluetooth beacons that attempt to download contact information from nearby Bluetooth-enabled devices. Another technique that malware developers have attempted is polymorphism. A polymorphic virus can change its signature every time it replicates and infects a new file. This technique makes it much harder for the antivirus program to detect it. One of the biggest changes is that malware creators don’t massively spread viruses and other malware the way they used to. Much of the malware today is written for a specific target. By limiting the spread of the malware and targeting only a few victims, malware developers make finding out about the malware and creating a signature to detect it much harder for antivirus companies.
When is a virus not a virus? When is the virus just a hoax? A virus hoax is nothing more than a chain letter, meme, or email that encourages you to forward it to your friends to warn them of impending doom or some other notable event. To convince readers to forward the hoax, the email will contain some official-sounding information that could be mistaken as valid.
Malware Payloads
Malware must place their payload somewhere. They can always overwrite a portion of the infected file, but to do so would destroy it. Most malware writers want to avoid detection for as long as possible and might not have written the program to immediately destroy files. One way the malware writer can accomplish this is to place the malware code either at the beginning or the end of the infected file. Malware known as a prepender infects programs by placing its viral code at the beginning of the infected file, whereas an appender places its code at the end of the infected file. Both techniques leave the file intact, with the malicious code added to the beginning or the end of the file.
No matter the infection technique, all viruses have some basic common components, as detailed in the following list. For example, all viruses have a search routine and an infection routine.
Search routine: The search routine is responsible for locating new files, disk space, or RAM to infect. The search routine could include “profiling.” Profiling could be used to identify the environment and morph the malware to be more effective and potentially bypass detection.
Infection routine: The search routine is useless if the virus doesn’t have a way to take advantage of these findings. Therefore, the second component of a virus is an infection routine. This portion of the virus is responsible for copying the virus and attaching it to a suitable host. Malware could also use a re-infect/restart routine to further compromise the affected system.
Payload: Most viruses don’t stop here and also contain a payload. The purpose of the payload routine might be to erase the hard drive, display a message to the monitor, or possibly send the virus to 50 people in your address book. Payloads are not required, and without one, many people might never know that the virus even existed.
Antidetection routine: Many viruses might also have an antidetection routine. Its goal is to help make the virus more stealth-like and avoid detection.
Trigger routine: The goal of the trigger routine is to launch the payload at a given date and time. The trigger can be set to perform a given action at a given time.
Trojans
Trojans are programs that pretend to do one thing but, when loaded, actually perform another, more malicious act. Trojans gain their name from Homer’s epic tale The Iliad. To defeat their enemy, the Greeks built a giant wooden horse with a trapdoor in its belly. The Greeks tricked the Trojans into bringing the large wooden horse into the fortified city of Troy. However, unknown to the Trojans and under cover of darkness, the Greeks crawled out of the wooden horse, opened the city’s gate, and allowed the waiting soldiers into the city.
A software Trojan horse is based on this same concept. A user might think that a file looks harmless and is safe to run, but after the file is executed, it delivers a malicious payload. Trojans work because they typically present themselves as something you want, such as an email with a PDF, a Word document, or an Excel spreadsheet. Trojans work hard to hide their true purposes. The spoofed email might look like it’s from HR, and the attached file might purport to be a list of pending layoffs. The payload is executed if the attacker can get the victim to open the file or click the attachment. That payload might allow a hacker remote access to your system, start a keystroke logger to record your every keystroke, plant a backdoor on your system, cause a denial of service (DoS), or even disable your antivirus protection or software firewall.
Unlike a virus or worm, Trojans cannot spread themselves. They rely on the uninformed user.
Trojan Types
A few Trojan categories are command-shell Trojans, graphical user interface (GUI) Trojans, HTTP/HTTPS Trojans, document Trojans, defacement Trojans, botnet Trojans, Virtual Network Computing (VNC) Trojans, remote-access Trojans, data-hiding Trojans, banking Trojans, DoS Trojans, FTP Trojans, software-disabling Trojans, and covert-channel Trojans. In reality, it’s hard to place some Trojans into a single type because many have more than one function. To better understand what Trojans can do, refer to the following list, which outlines a few of these types:
Remote access: Remote-access Trojans (RATs) allow the attacker full control over the system. Poison Ivy is an example of this type of Trojan. Remote-access Trojans are usually set up as client/server programs so that the attacker can connect to the infected system and control it remotely.
Data hiding: The idea behind this type of Trojan is to hide a user’s data. This type of malware is also sometimes known as ransomware. This type of Trojan restricts access to the computer system that it infects, and it demands a ransom paid to the creator of the malware for the restriction to be removed.
E-banking: These Trojans (Zeus is one such example) intercept and use a victim’s banking information for financial gain. Usually, they function as a transaction authorization number (TAN) grabber, use HTML injection, or act as a form grabber. The sole purpose of these types of programs is financial gain.
Denial of service (DoS): These Trojans are designed to cause a DoS. They can be designed to knock out a specific service or to bring an entire system offline.
Proxy: These Trojans are designed to work as proxy programs that help a hacker hide and allow him to perform activities from the victim’s computer, not his own. After all, the farther away the hacker is from the crime, the harder it becomes to trace him.
FTP: These Trojans are specifically designed to work on port 21. They allow the hacker or others to upload, download, or move files at will on the victim’s machine.
Security-software disablers: These Trojans are designed to attack and kill antivirus or software firewalls. The goal of disabling these programs is to make it easier for the hacker to control the system.
Trojan Ports and Communication Methods
Trojans can communicate in several ways. Some use overt communications. These programs make no attempt to hide the transmission of data as it is moved on to or off of the victim’s computer. Most use covert communication channels. This means that the hacker goes to lengths to hide the transmission of data to and from the victim. Many Trojans that open covert channels also function as backdoors. A backdoor is any type of program that will allow a hacker to connect to a computer without going through the normal authentication process. If a hacker can get a backdoor program loaded on an internal device, the hacker can then come and go at will. Some of the programs spawn a connection on the victim’s computer connecting out to the hacker. The danger of this type of attack is the traffic moving from the inside out, which means from inside the organization to the outside Internet. This is usually the least restrictive because companies are usually more concerned about what comes in the network than they are about what leaves the network.
Trojan Goals
Not all Trojans were designed for the same purpose. Some are destructive and can destroy computer systems, whereas others seek only to steal specific pieces of information. Although not all of them make their presence known, Trojans are still dangerous because they represent a loss of confidentiality, integrity, and availability. Common targets of Trojans include the following:
Credit card data: Credit card data and banking information have become huge targets. After the hacker has this information, he can go on an online shopping spree or use the card to purchase services, such as domain name registration.
Electronic or digital wallets: Individuals can use an electronic device or online service that allows them to make electronic transactions. This includes buying goods online or using a smartphone to purchase something at a store. A digital wallet can also be a cryptocurrency wallet (such as Bitcoin, Ethereum, Litecoin, Ripple, and so on).
Passwords: Passwords are always a big target. Many of us are guilty of password reuse. Even if we are not, there is always the danger that a hacker can extract email passwords or other online account passwords.
Insider information: We have all had those moments in which we have said, “If only I had known this beforehand.” That’s what insider information is about. It can give the hacker critical information before it is made public or released.
Data storage: The goal of the Trojan might be nothing more than to use your system for storage space. That data could be movies, music, illegal software (warez), or even pornography.
Advanced persistent threat (APT): It could be that the hacker has targeted you as part of a nation-state attack or your company has been targeted because of its sensitive data. Two examples include Stuxnet and the APT attack against RSA in 2011. These attackers might spend significant time and expense to gain access to critical and sensitive resources.
Trojan Infection Mechanisms
After a hacker has written a Trojan, he will still need to spread it. The Internet has made this much easier than it used to be. There are a variety of ways to spread malware, including the following:
Peer-to-peer networks (P2P): Although users might think that they are getting the latest copy of a computer game or the Microsoft Office package, in reality, they might be getting much more. P2P networks and file-sharing sites such as The Pirate Bay are generally unmonitored and allow anyone to spread any programs they want, legitimate or not.
Instant messaging (IM): IM was not built with security controls. So, you never know the real contents of a file or program that someone has sent you. IM users are at great risk of becoming targets for Trojans and other types of malware.
Internet Relay Chat (IRC): IRC is full of individuals ready to attack the newbies who are enticed into downloading a free program or application.
Email attachments: Attachments are another common way to spread a Trojan. To get you to open them, these hackers might disguise the message to appear to be from a legitimate organization. The message might also offer you a valuable prize, a desired piece of software, or similar enticement to pique your interest. If you feel that you must investigate these attachments, save them first and then run an antivirus on them. Email attachments are the number-one means of malware propagation. You might investigate them as part of your information security job to protect network users.
Physical access: If a hacker has physical access to a victim’s system, he can just copy the Trojan horse to the hard drive (via a thumb drive). The hacker can even take the attack to the next level by creating a Trojan that is unique to the system or network. It might be a fake login screen that looks like the real one or even a fake database.
Browser and browser extension vulnerabilities: Many users don’t update their browsers as soon as updates are released. Web browsers often treat the content they receive as trusted. The truth is that nothing in a web page can be trusted to follow any guidelines. A website can send to your browser data that exploits a bug in a browser, violates computer security, and might load a Trojan.
SMS messages: SMS messages have been used by attackers to propagate malware to mobile devices and to perform other scams.
Impersonated mobile apps: Attackers can impersonate apps in mobile stores (for example, Google Play or Apple Store) to infect users. Attackers can perform visual impersonation to intentionally misrepresents apps in the eyes of the user. Attackers can do this to repackage the application and republish the app to the marketplace under a different author. This tactic has been used by attackers to take a paid app and republish it to the marketplace for less than its original price. However, in the context of mobile malware, the attacker uses similar tactics to distribute a malicious app to a wide user audience while minimizing the invested effort. If the attacker repackages a popular app and appends malware to it, the attacker can leverage the user’s trust of their favorite apps and successfully compromise the mobile device.
Watering hole: The idea is to infect a website the attacker knows the victim will visit. Then the attacker simply waits for the victim to visit the watering hole site so the system can become infected.
Freeware: Nothing in life is free, and that includes most software. Users are taking a big risk when they download freeware from an unknown source. Not only might the freeware contain a Trojan, but freeware also has become a favorite target for adware and spyware.
Effects of Trojans
The effects of Trojans can range from the benign to the extreme. Individuals whose systems become infected might never even know; most of the creators of this category of malware don’t want to be detected, so they go to great lengths to hide their activity and keep their actions hidden. After all, their goal is typically to “own the box.” If the victim becomes aware of the Trojan’s presence, the victim will take countermeasures that threaten the attacker’s ability to keep control of the computer. In some cases, programs seemingly open by themselves or the web browser opens pages the user didn’t request. However, because the hacker is in control of the computer, he can change its background, reboot the systems, or capture everything the victim types on the keyboard.
Distributing Malware
Technology changes, and that includes malware distribution. The fact is that malware detection is much more difficult today than in the past. Today, it is not uncommon for attackers to use multiple layers of techniques to obfuscate code, make malicious code undetectable from antivirus, and employ encryption to prevent others from examining malware. The result is that modern malware improves the attackers’ chances of compromising a computer without being detected. These techniques include wrappers, packers, droppers, and crypters.
Wrappers offer hackers a method to slip past a user’s normal defenses. A wrapper is a program used to combine two or more executables into a single packaged program. Wrappers are also referred to as binders, packagers, and EXE binders because they are the functional equivalent of binders for Windows Portable Executable files. Some wrappers only allow programs to be joined; others allow the binding together of three, four, five, or more programs. Basically, these programs perform like installation builders and setup programs. Besides allowing you to bind a program, wrappers add additional layers of obfuscation and encryption around the target file, essentially creating a new executable file.
Packers are similar to programs such as WinZip, Rar, and Tar because they compress files. However, whereas compression programs compress files to save space, packers do this to obfuscate the activity of the malware. The idea is to prevent anyone from viewing the malware’s code until it is placed in memory. Packers serve a second valuable goal to the attacker in that they work to bypass network security protection mechanisms, such as host-and network-based intrusion detection systems. The malware packer will decompress the program only when in memory, revealing the program’s original code only when executed. This is yet another attempt to bypass antimalware detection.
Droppers are software designed to install malware payloads on the victim’s system. Droppers try to avoid detection and evade security controls by using several methods to spread and install the malware payload.
Crypters function to encrypt or obscure the code. Some crypters obscure the contents of the Trojan by applying an encryption algorithm. Crypters can use anything from AES, RSA, to even Blowfish, or might use more basic obfuscation techniques such as XOR, Base64 encoding, or even ROT13. Again, these techniques are used to conceal the contents of the executable program, making it undetectable by antivirus and resistant to reverse-engineering efforts.
Ransomware
Over the past few years, ransomware has been used by criminals making money out of their victims and by hacktivists and nation-state attackers causing disruption. Ransomware can propagate like a worm or a virus but is designed to encrypt personal files on the victim’s hard drive until a ransom is paid to the attacker. Ransomware has been around for many years but made a comeback in recent years. The following are several examples of popular ransomware:
WannaCry
Pyeta
Nyeta
Sodinokibi
Bad Rabbit
Grandcrab
SamSam
CryptoLocker
CryptoDefense
CryptoWall
Spora
Ransomware can encrypt specific files in your system or all your files, in some cases including the master boot record of your hard disk drive.
Covert Communication
Distributing malware is just half the battle for the attacker. The attacker will need to have some way to exfiltrate data and to do so in a way that is not detected. If you look at the history of covert communications, you will see that the Trusted Computer System Evaluation Criteria (TCSEC) was one of the first documents to fully examine the concept of covert communications and attacks. TCSEC divides covert channel attacks into two broad categories:
Covert timing channel attacks: Timing attacks are difficult to detect because they are based on system times and function by altering a component or by modifying resource timing.
Covert storage channel attacks: Use one process to write data to a storage area and another process to read the data.
It is important to examine covert communication on a more focused scale because it will be examined here as a means of secretly passing information or data. For example, most everyone has seen a movie in which an informant signals the police that it’s time to bust the criminals. It could be that the informant lights a cigarette or simply tilts his hat. These small signals are meaningless to the average person who might be nearby, but for those who know what to look for, they are recognized as a legitimate signal.
In the world of hacking, covert communication is accomplished through a covert channel. A covert channel is a way of moving information through a communication channel or protocol in a manner in which it was not intended to be used. Covert channels are important for security professionals to understand. For the ethical hacker who performs attack and penetration assessments, such tools are important because hackers can use them to obtain an initial foothold into an otherwise secure network. For the network administrator, understanding how these tools work and their fingerprints can help her recognize potential entry points into the network. For the hacker, these are powerful tools that can potentially allow him control and access.
How do covert communications work? Well, the design of TCP/IP offers many opportunities for misuse. The primary protocols for covert communications include Internet Protocol (IP), Transmission Control Protocol (TCP), User Datagram Protocol (UDP), Internet Control Message Protocol (ICMP), and Domain Name Service (DNS).
The Internet layer offers several opportunities for hackers to tunnel traffic. Two commonly tunneled protocols are IPv6 and ICMP.
IPv6 is like all protocols in that it can be abused or manipulated to act as a covert channel. This is primarily possible because edge devices might not be configured to recognize IPv6 traffic even though most operating systems have support for IPv6 turned on. According to US-CERT, Windows misuse relies on several factors:
Incomplete or inconsistent support for IPv6
The IPv6 autoconfiguration capability
Malware designed to enable IPv6 support on susceptible hosts
Malicious application of traffic “tunneling,” a method of Internet data transmission in which the public Internet is used to relay private network data
There are plenty of tools to tunnel over IPv6, including 6tunnel, socat, nt6tunnel, and relay6. The best way to maintain security with IPv6 is to recognize that even devices supporting IPv6 may not be able to correctly analyze the IPv6 encapsulation of IPv4 packets.
The second protocol that might be tunneled at the Internet layer is Internet Control Message Protocol (ICMP). ICMP is specified by RFC 792 and is designed to provide error messaging, best path information, and diagnostic messages. One example of this is the ping command. It uses ICMP to test an Internet connection.
The transport layer offers attackers two protocols to use: TCP and UDP. TCP offers several fields that can be manipulated by an attacker, including the TCP Options field in the TCP header and the TCP Flag field. By design, TCP is a connection-oriented protocol that provides robust communication. The following steps outline the normal TCP process:
A three-step handshake: This ensures that both systems are ready to communicate.
Exchange of control information: During the setup, information is exchanged that specifies maximum segment size.
Sequence numbers: This indicates the amount and position of data being sent.
Acknowledgments: This indicates the next byte of data that is expected.
Four-step shutdown: This is a formal process of ending the session that allows for an orderly shutdown.
Although SYN packets occur only at the beginning of the session, ACKs may occur thousands of times. They confirm that data was received. That is why packet-filtering devices build their rules on SYN segments. It is an assumption on the firewall administrator’s part that ACKs occur only as part of an established session. It is much easier to configure, and it reduces workload. To bypass the SYN blocking rule, a hacker may attempt to use TCP ACK packets as a covert communication channel. Tools such as AckCmd serve this exact purpose.
UDP is stateless and, as such, may not be logged in firewall connections; some UDP-based applications such as DNS are typically allowed through the firewall and might not be watched closely by network and firewall administrators. UDP tunneling applications typically act in a client/server configuration. Also, some ports like UDP 53 are most likely open. This means it’s also open for attackers to use as a potential means to exfiltrate data. There are several UDP tunnel tools that you should check out, including the following:
UDP Tunnel: Also designed to tunnel TCP traffic over a UDP connection. You can find UDP Tunnel at https://code.google.com/p/udptunnel/.
dnscat: Another option for tunneling data over an open DNS connection. You can download the current version, dnscat2, at https://github.com/iagox86/dnscat2.
Application layer tunneling uses common applications that send data on allowed ports. For example, a hacker might tunnel a web session, port 80, through SSH port 22 or even through port 443. Because ports 22 and 443 both use encryption, it can be difficult to monitor the difference between a legitimate session and a covert channel.
HTTP might also be used. Netcat is one tool that can be used to set up a tunnel to exfiltrate data over HTTP. If HTTPS is the transport, it is difficult for the network administrator to inspect the outbound data. Cryptcat (http://cryptcat.sourceforge.net) can be used to send data over HTTPS.
Finally, even Domain Name System (DNS) can be used for application layer tunneling. DNS is a request/reply protocol. Its queries consist of a 12-byte fixed-size header followed by one or more questions. A DNS response is formatted in much the same way in that it has a header, followed by the original question, and then typically a single-answer resource record. The most straightforward way to manipulate DNS is by means of these request/replies. You can easily detect a spike in DNS traffic; however, many times attackers move data using DNS without being detected for days, weeks, or months. They schedule the DNS exfiltration packets in a way that makes it harder for a security analyst or automated tools to detect.
Keyloggers
Keystroke loggers (keyloggers) are software or hardware devices used to record everything a person types. Some of these programs can record every time a mouse is clicked, a website is visited, and a program is opened. Although not truly a covert communication tool, these devices do enable a hacker to covertly monitor everything a user does. Some of these devices secretly email all the amassed information to a predefined email address set up by the hacker.
The software version of this device is basically a shim, as it sits between the operating system and the keyboard. The hacker might send a victim a keystroke-logging program wrapped up in much the same way as a Trojan would be delivered. Once installed, the logger can operate in stealth mode, which means that it is hard to detect unless you know what you are looking for.
There are ways to make keyloggers completely invisible to the OS and to those examining the file system. To accomplish this, all the hacker has to do is use a hardware keylogger. These devices are usually installed while the user is away from his desk. Hardware keyloggers are completely undetectable except for their physical presence. Even then, they might be overlooked because they resemble an extension. Not many people pay close attention to the plugs on the back of their computer.
To stay on the right side of the law, employers who plan to use keyloggers should make sure that company policy outlines their use and how employees are to be informed. The CERT Division of the Software Engineering Institute (SEI) recommends a warning banner similar to the following: “This system is for the use of authorized personnel only. If you continue to access this system, you are explicitly consenting to monitoring.”
Keystroke recorders have been around for years. Hardware keyloggers can be wireless or wired. Wireless keyloggers can communicate via 802.11 or Bluetooth, and wired keyloggers must be retrieved to access the stored data. One such example of a wired keylogger is KeyGhost, a commercial device that is openly available worldwide from a New Zealand firm that goes by the name of KeyGhost Ltd (http://www.keyghost.com). The device looks like a small adapter on the cable connecting one’s keyboard to the computer. This device requires no external power, lasts indefinitely, and cannot be detected by any software.
Numerous software products that record all keystrokes are openly available on the Internet. You have to pay for some products, but others are free.
Spyware
Spyware is another form of malicious code that is similar to a Trojan. It is installed without your consent or knowledge, hidden from view, monitors your computer and Internet usage, and is configured to run in the background each time the computer starts. Spyware has grown to be a big problem. It is usually used for one of two purposes:
Surveillance: Used to determine your buying habits, discover your likes and dislikes, and report this demographic information to paying marketers.
Advertising: You’re targeted for advertising that the spyware vendor has been paid to deliver. For example, the maker of a rhinestone cell phone case might have paid the spyware vendor for 100,000 pop-up ads. If you have been infected, expect to receive more than your share of these unwanted pop-up ads.
Many times, spyware sites and vendors use droppers to covertly drop their spyware components to the victim’s computer. Basically, a dropper is just another name for a wrapper, because a dropper is a standalone program that drops different types of standalone malware to a system.
Spyware programs are similar to Trojans in that there are many ways to become infected. To force the spyware to restart each time the system boots, code is usually hidden in the Registry run keys, the Windows Startup folder, the Windows load= or run= lines found in the Win.ini file, or the Shell= line found in the Windows System.ini file. Spyware, like all malware, may also make changes to the hosts file. This is done to block the traffic to all the download or update servers of the well-known security vendors or to redirect traffic to servers of their choice by redirecting traffic to advertisement servers and replacing the advertisements with their own.
If you are dealing with systems that have had spyware installed, start by looking at the hosts file and the other locations discussed previously or use a spyware removal program. It’s good practice to use more than one antispyware program to find and remove as much spyware as possible.
Analyzing Malware
Malware analysis can be extremely complex. Although an in-depth look at this area of cybersecurity is beyond this book, you should have a basic understanding of how analysis is performed. There are two basic methods to analyze viruses and other malware:
Static analysis
Dynamic analysis
Static Analysis
Static analysis is concerned with the decompiling, reverse engineering, and analysis of malicious software. The field is an outgrowth of the field of computer virus research and malware intent determination. Consider examples such as Conficker, Stuxnet, Aurora, and the Black Hole Exploit Kit. Static analysis makes use of disassemblers and decompilers to format the data into a human-readable format. Several useful tools are listed here:
IDA Pro: An interactive disassembler that you can use for decompiling code. It’s particularly useful in situations in which the source code is not available, such as with malware. IDA Pro allows the user to see the source code and review the instructions that are being executed by the processor. IDA Pro uses advanced techniques to make that code more readable. You can download and obtain additional information about IDA Pro at https://www.hex-rays.com/products/ida/.
Evan’s Debugger (edb): A Linux cross-platform AArch32/x86/x86-64 debugger. You can download and obtain additional information about Evan’s Debugger at https://github.com/eteran/edb-debugger.
BinText: Another tool that is useful to the malware analyst. BinText is a text extractor that will be of particular interest to programmers. It can extract text from any kind of file and includes the ability to find plain ASCII text, Unicode (double-byte ANSI) text, and resource strings, providing useful information for each item in the optional “advanced” view mode. You can download and obtain additional information about BinText from the following URL: https://www.aldeid.com/wiki/BinText.
UPX: A packer, compression, and decompression tool. You can download and obtain additional information about UPX at https://upx.github.io.
OllyDbg: A debugger that allows for the analysis of binary code where source is unavailable. You can download and obtain additional information about OllyDbg at http://www.ollydbg.de.
Ghidra: A software reverse engineering tool developed by the U.S. National Security Agency (NSA) Research Directorate. Figure 1-4 shows an example of a file being reversed engineered using Ghidra. You can download and obtain additional information about Ghidra at https://ghidra-sre.org.
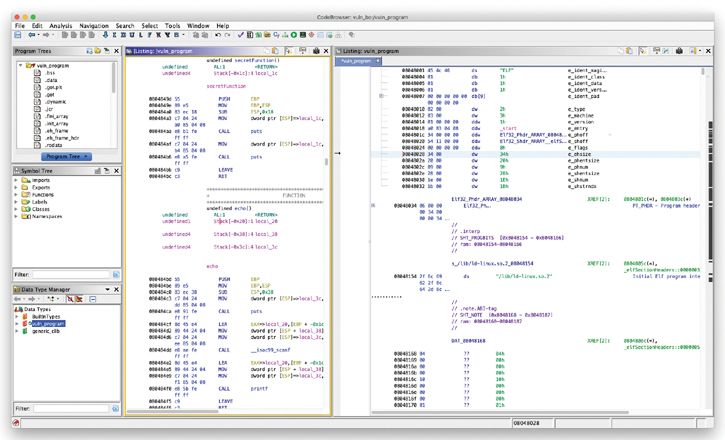
Figure 1-4 The Ghidra Reverse Engineering Toolkit
Dynamic Analysis
Dynamic analysis of malware and viruses is the second method that may be used. Dynamic analysis relates to the monitoring and analysis of computer activity and network traffic. This requires the ability to configure the network device for monitoring, look for unusual or suspicious activity, and try not to alert attackers. This approach requires the preparation of a testbed. Before you begin setting up a dynamic analysis lab, remember that the number-one goal is to keep the malware contained. If you allow the host system to become compromised, you have defeated the entire purpose of the exercise. Virtual systems share many resources with the host system and can quickly become compromised if the configuration is not handled correctly. Here are a few pointers for preventing malware from escaping the isolated environment to which it should be confined:
Install a virtual machine (VM).
Install a guest operating system on the VM.
Isolate the system from the guest VM.
Verify that all sharing and transfer of data is blocked between the host operating system and the virtual system.
Copy the malware over to the guest operating system and prepare for analysis.
Malware authors sometimes use anti-VM techniques to thwart attempts at analysis. If you try to run the malware in a VM, it might be designed not to execute. For example, one simple way is to get the MAC address; if the Organizationally Unique Identifier (OUI) matches a VM vendor, the malware will not execute.
The malware may also look to see whether there is an active network connection. If not, it may refuse to run. One tool to help overcome this barrier is FakeNet. FakeNet simulates a network connection so that malware interacting with a remote host continues to run. If you are forced to detect the malware by discovering where it has installed itself on the local system, there are some known areas to review:
Running processes
Device drivers
Windows services
Startup programs
Operating system files
Malware has to install itself somewhere, and by a careful analysis of the system, files, memory, and folders, you should be able to find it.
Several sites are available that can help analyze suspect malware. These online tools can provide a quick and easy analysis of files when reverse engineering and decompiling is not possible. Most of these sites are easy to use and offer a straightforward point-and-click interface. These sites generally operate as a sandbox. A sandbox is simply a standalone environment that allows you to safely view or execute the program while keeping it contained. A good example of sandbox services is the Cisco ThreatGrid. This great tool and service tracks changes made to the file system, Registry, memory, and network.
During a network security assessment, you may discover malware or other suspected code. You should have an incident response plan that addresses how to handle these situations. If you’re using only one antivirus product to scan for malware, you may be missing a lot. As you learned in the previous section, websites such as the Cisco Talos File Reputation Lookup site (https://www.talosintelligence.com/reputation) and VirusTotal (https://virustotal.com) allow you to upload files to verify if they may be known malware.
These tools and techniques listed offer some insight as to how static malware analysis is performed, but don’t expect malware writers to make the analysis of their code easy. Many techniques can be used to make disassembly challenging:
Encryption
Obfuscation
Encoding
Anti-VM
Anti-debugger
Common Software and Hardware Vulnerabilities
The number of disclosed vulnerabilities continues to rise. You can keep up with vulnerability disclosures by subscribing to vulnerability feeds and searching public repositories such as the National Vulnerability Database (NVD). The NVD can be accessed at https://nvd.nist.gov.
There are many different software and hardware vulnerabilities and related categories. The sections that follow include a few examples.
Injection Vulnerabilities
The following are examples of injection-based vulnerabilities:
SQL injection vulnerabilities
HTML injection vulnerabilities
Command injection vulnerabilities
Code injection vulnerabilities are exploited by forcing an application or a system to process invalid data. An attacker takes advantage of this type of vulnerability to inject code into a vulnerable system and change the course of execution. Successful exploitation can lead to the disclosure of sensitive information, manipulation of data, denial-of-service conditions, and more. Examples of code injection vulnerabilities include the following:
SQL injection
HTML script injection
Dynamic code evaluation
Object injection
Remote file inclusion
Uncontrolled format string
Shell injection
SQL Injection
SQL injection (SQLi) vulnerabilities can be catastrophic because they can allow an attacker to view, insert, delete, or modify records in a database. In an SQL injection attack, the attacker inserts, or injects, partial or complete SQL queries via the web application. The attacker injects SQL commands into input fields in an application or a URL in order to execute predefined SQL commands.
Web applications construct SQL statements involving SQL syntax invoked by the application mixed with user-supplied data, as shown in Figure 1-5.

Figure 1-5 An Explanation of an SQL Statement
The first portion of the SQL statement shown in Figure 1-5 is not shown to the user. Typically, the application sends this portion to the database behind the scenes. The second portion of the SQL statement is typically user input in a web form.
If an application does not sanitize user input, an attacker can supply crafted input in an attempt to make the original SQL statement execute further actions in the database. SQL injections can be done using user-supplied strings or numeric input. Figure 1-6 shows an example of a basic SQL injection attack.

Figure 1-6 Example of an SQL Injection Vulnerability
Figure 1-6 shows an intentionally vulnerable application (WebGoat) being used to demonstrate the effects of an SQL injection attack. When the string Snow’ OR 1=’1 is entered in the web form, it causes the application to display all records in the database table to the attacker.
One of the first steps when finding SQL injection vulnerabilities is to understand when the application interacts with a database. This is typically done with web authentication forms, search engines, and interactive sites such as e-commerce sites.
SQL injection attacks can be divided into the following categories:
In-band SQL injection: With this type of injection, the attacker obtains the data by using the same channel that is used to inject the SQL code. This is the most basic form of an SQL injection attack, where the data is dumped directly in a web application (or web page).
Out-of-band SQL injection: With this type of injection, the attacker retrieves data using a different channel. For example, an email, a text, or an instant message could be sent to the attacker with the results of the query. Alternatively, the attacker might be able to send the compromised data to another system.
Blind (or inferential) SQL injection: With this type of injection, the attacker does not make the application display or transfer any data; rather, the attacker is able to reconstruct the information by sending specific statements and discerning the behavior of the application and database.
To perform an SQL injection attack, an attacker must craft a syntactically correct SQL statement (query). The attacker may also take advantage of error messages coming back from the application and might be able to reconstruct the logic of the original query to understand how to execute the attack correctly. If the application hides the error details, the attacker might need to reverse engineer the logic of the original query.
HTML Injection
An HTML injection is a vulnerability that occurs when an unauthorized user is able to control an input point and able to inject arbitrary HTML code into a web application. Successful exploitation could lead to disclosure of a user’s session cookies; an attacker might do this to impersonate a victim or to modify the web page or application content seen by the victims.
HTML injection vulnerabilities can lead to cross-site scripting (XSS). You will learn details about the different types of XSS vulnerabilities and attacks later in this chapter.
Command Injection
A command injection is an attack in which an attacker tries to execute commands that he or she is not supposed to be able to execute on a system via a vulnerable application. Command injection attacks are possible when an application does not validate data supplied by the user (for example, data entered in web forms, cookies, HTTP headers, and other elements). The vulnerable system passes that data into a system shell.
With command injection, an attacker tries to send operating system commands so that the application can execute them with the privileges of the vulnerable application. Command injection is not the same as code execution and code injection, which involve exploiting a buffer overflow or similar vulnerability.
Authentication-based Vulnerabilities
An attacker can bypass authentication in vulnerable systems by using several methods.
The following are the most common ways to take advantage of authentication-based vulnerabilities in an affected system:
Credential brute forcing
Session hijacking
Redirecting
Exploiting default credentials
Exploiting weak credentials
Exploiting Kerberos vulnerabilities
Credential Brute Force Attacks and Password Cracking
In a credential brute-force attack, the attacker attempts to log in to an application or a system by trying different usernames and passwords. There are two major categories of brute-force attacks:
Online brute-force attacks: In this type of attack, the attacker actively tries to log in to the application directly by using many different combinations of credentials. Online brute-force attacks are easy to detect because you can easily inspect for large numbers of attempts by an attacker.
Offline brute-force attacks: In this type of attack, the attacker can gain access to encrypted data or hashed passwords. These attacks are more difficult to prevent and detect than online attacks. However, offline attacks require significantly more computation effort and resources from the attacker.
The strength of user and application credentials has a direct effect on the success of brute-force attacks. Weak credentials are one of the major causes of credential compromise. The more complex and the longer a password (credential), the better. An even better approach is to use multifactor authentication (MFA). The use of MFA significantly reduces the probability of success for these types of attacks.
An attacker may feed to an attacking system a word list containing thousands of words in order to crack passwords or associated credentials. The following site provides links to millions of real-world passwords: http://wordlists.h4cker.org.
Weak cryptographic algorithms (such as RC4, MD5, and DES) allow attackers to easily crack passwords.
Attackers can also use statistical analysis and rainbow tables against systems that improperly protect passwords with a one-way hashing function. A rainbow table is a precomputed table for reversing cryptographic hash functions and for cracking password hashes. Such tables can be used to accelerate the process of cracking password hashes.
For a list of publicly available rainbow tables, see http://project-rainbowcrack.com/table.htm.
In addition to weak encryption or hashing algorithms, poorly designed security protocols such as Wired Equivalent Privacy (WEP) introduce avenues of attack to compromise user and application credentials. Also, if hashed values are stored without being rendered unique first (that is, without a salt), it is possible to gain access to the values and perform a rainbow table attack.
An organization should implement techniques on systems and applications to throttle login attempts and prevent brute-force attacks. Those attempts should also be logged and audited.
Session Hijacking
There are several ways an attacker can perform a session hijack and several ways a session token may be compromised:
Predicting session tokens: This is why it is important to use non-predictable tokens.
Session sniffing: This can occur through collecting packets of unencrypted web sessions.
Man-in-the-middle attack: With this type of attack, the attacker sits in the path between the client and the web server.
Man-in-the-browser attack: This attack is similar in approach to a man-in-the-middle attack; however, in this case, a browser (or an extension or a plugin) is compromised and used to intercept and manipulate web sessions between the user and the web server.
If web applications do not validate and filter out invalid session ID values, they can potentially be used to exploit other web vulnerabilities, such as SQL injection (if the session IDs are stored on a relational database) or persistent XSS (if the session IDs are stored and reflected back afterward by the web application).
Default Credentials
A common adage in the security industry is, “Why do you need hackers if you have default passwords?” Many organizations and individuals leave infrastructure devices such as routers, switches, wireless access points, and even firewalls configured with default passwords.
Attackers can easily identify and access systems that use shared default passwords. It is extremely important to always change default manufacturer passwords and restrict network access to critical systems. A lot of manufacturers now require users to change the default passwords during initial setup, but some don’t.
Attackers can easily obtain default passwords and identify Internet-connected target systems. Passwords can be found in product documentation and compiled lists available on the Internet. An example is http://www.defaultpassword.com, but there are dozens of other sites that contain default passwords and configurations on the Internet. It is easy to identify devices that have default passwords and that are exposed to the Internet by using search engines such as Shodan (https://www.shodan.io).
Insecure Direct Object Reference Vulnerabilities
Insecure Direct Object Reference vulnerabilities can be exploited when web applications allow direct access to objects based on user input. Successful exploitation could allow attackers to bypass authorization and access resources that should be protected by the system (for example, database records and system files). This vulnerability occurs when an application does not sanitize user input and does not perform appropriate authorization checks.
An attacker can take advantage of Insecure Direct Object References vulnerabilities by modifying the value of a parameter used to directly point to an object. In order to exploit this type of vulnerability, an attacker needs to map out all locations in the application where user input is used to reference objects directly. Example 1-1 shows how the value of a parameter can be used directly to retrieve a database record.
Example 1-1 A URL Parameter Used Directly to Retrieve a Database Record
https://store.h4cker.org/buy?customerID=1245
In this example, the value of the customerID parameter is used as an index in a table of a database holding customer contacts. The application takes the value and queries the database to obtain the specific customer record. An attacker may be able to change the value 1245 to another value and retrieve another customer record.
In Example 1-2, the value of a parameter is used directly to execute an operation in the system.
Example 1-2 Direct Object Reference Example
https://store.h4cker.org/changepassd?user=omar
In Example 1-2, the value of the user parameter (omar) is used to have the system change the user’s password. An attacker can try other usernames and see if it is possible to modify the password of another user.
Mitigations for this type of vulnerability include input validation, the use of per-user or -session indirect object references, and access control checks to make sure the user is authorized for the requested object.
Cross-site Scripting (XSS)
Cross-site scripting (commonly known as XSS) vulnerabilities have become some of the most common web application vulnerabilities. XSS vulnerabilities are classified in three major categories:
Reflected XSS
Stored (persistent) XSS
DOM-based XSS
Attackers can use obfuscation techniques in XSS attacks by encoding tags or malicious portions of the script using Unicode so that the link or HTML content is disguised to the end user browsing the site.
Reflected XSS attacks (non-persistent XSS) occur when malicious code or scripts are injected by a vulnerable web application using any method that yields a response as part of a valid HTTP request. An example of a reflected XSS attack is a user being persuaded to follow a malicious link to a vulnerable server that injects (reflects) the malicious code back to the user’s browser. This causes the browser to execute the code or script. In this case, the vulnerable server is usually a known or trusted site.
Examples of methods of delivery for XSS exploits are phishing emails, messaging applications, and search engines.
Stored, or persistent, XSS attacks occur when the malicious code or script is permanently stored on a vulnerable or malicious server, using a database. These attacks are typically carried out on websites hosting blog posts (comment forms), web forums, and other permanent storage methods. An example of a stored XSS attack is a user requesting the stored information from the vulnerable or malicious server, which causes the injection of the requested malicious script into the victim’s browser. In this type of attack, the vulnerable server is usually a known or trusted site.
The Document Object Model (DOM) is a cross-platform and language-independent application programming interface that treats an HTML, XHTML, or XML document as a tree structure. DOM-based attacks are typically reflected XSS attacks that are triggered by sending a link with inputs that are reflected to the web browser. In DOM-based XSS attacks, the payload is never sent to the server. Instead, the payload is only processed by the web client (browser).
In a DOM-based XSS attack, the attacker sends a malicious URL to the victim, and after the victim clicks on the link, it may load a malicious website or a site that has a vulnerable DOM route handler. After the vulnerable site is rendered by the browser, the payload executes the attack in the user’s context on that site.
One of the effects of any type of XSS attack is that the victim typically does not realize that an attack has taken place. DOM-based applications use global variables to manage client-side information. Often developers create unsecured applications that put sensitive information in the DOM (for example, tokens, public profile URLs, private URLs for information access, cross-domain OAuth values, and even user credentials as variables). It is a best practice to avoid storing any sensitive information in the DOM when building web applications.
Successful exploitation could result in installation or execution of malicious code, account compromise, session cookie hijacking, revelation or modification of local files, or site redirection.
The results of XSS attacks are the same regardless of the vector. Even though XSS vulnerabilities are flaws in a web application, the attack typically targets the end user. You typically find XSS vulnerabilities in the following:
Search fields that echo a search string back to the user
HTTP headers
Input fields that echo user data
Error messages that return user-supplied text
Hidden fields that may include user input data
Applications (or websites) that display user-supplied data
Example 1-3 demonstrates an XSS test that can be performed from a browser’s address bar.
Example 1-3 XSS Test from a Browser’s Address Bar
javascript:alert("Omar_s_XSS test");
javascript:alert(document.cookie);
Example 1-4 demonstrates an XSS test that can be performed in a user input field in a web form.
Example 1-4 XSS Test from a Web Form
<script>alert("XSS Test")</script>
Cross-site Request Forgery
Cross-site request forgery (CSRF or XSRF) attacks occur when unauthorized commands are transmitted from a user who is trusted by the application. CSRF attacks are different from XSS attacks because they exploit the trust that an application has in a user’s browser. CSRF vulnerabilities are also referred to as “one-click attacks” or “session riding.”
CSRF attacks typically affect applications (or websites) that rely on a user’s identity. Attackers can trick the user’s browser into sending HTTP requests to a target website. An example of a CSRF attack is a user authenticated by the application by a cookie saved in the browser unwittingly sending an HTTP request to a site that trusts the user, subsequently triggering an unwanted action.
Cookie Manipulation Attacks
Cookie manipulation attacks are often referred to as stored DOM-based attacks (or vulnerabilities). Cookie manipulation is possible when vulnerable applications store user input and then embed that input in a response within a part of the DOM. This input is later processed in an unsafe manner by a client-side script. An attacker can use a JavaScript string (or other scripts) to trigger the DOM-based vulnerability. Such scripts can write controllable data into the value of a cookie.
An attacker can take advantage of stored DOM-based vulnerabilities to create a URL that sets an arbitrary value in a user’s cookie. The impact of a stored DOM-based vulnerability depends on the role that the cookie plays within the application.
Race Conditions
A race condition occurs when a system or an application attempts to perform two or more operations at the same time. However, due to the nature of such a system or application, the operations must be done in the proper sequence in order to be done correctly. When an attacker exploits such a vulnerability, he or she has a small window of time between when a security control takes effect and when the attack is performed. The attack complexity in race conditions is very high. In other words, race conditions are very difficult to exploit.
Race conditions are also referred to as time of check to time of use (TOCTOU) attacks. An example of a race condition is a security management system pushing a configuration to a security device (such as a firewall or an intrusion prevention system) such that the process rebuilds access control lists and rules from the system. An attacker might have a very small time window in which it could bypass those security controls until they take effect on the managed device.
Unprotected APIs
Application programming interfaces (APIs) are used everywhere today. A large number of modern applications use some type of APIs to allow other systems to interact with the application. Unfortunately, many APIs lack adequate controls and are difficult to monitor. The breadth and complexity of APIs also make it difficult to automate effective security testing. There are a few methods or technologies behind modern APIs:
Simple Object Access Protocol (SOAP): This standards-based web services access protocol was originally developed by Microsoft and has been used by numerous legacy applications for many years. SOAP exclusively uses XML to provide API services. XML-based specifications are governed by XML Schema Definition (XSD) documents. SOAP was originally created to replace older solutions such as the Distributed Component Object Model (DCOM) and Common Object Request Broker Architecture (CORBA). You can find the latest SOAP specifications at https://www.w3.org/TR/soap.
Representational State Transfer (REST): This API standard is easier to use than SOAP. It uses JSON instead of XML, and it uses standards such as Swagger and the OpenAPI Specification (https://www.openapis.org) for ease of documentation and to encourage adoption.
GraphQL: GraphQL is a query language for APIs that provides many developer tools. GraphQL is now used for many mobile applications and online dashboards. Many different languages support GraphQL. You can learn more about GraphQL at https://graphql.org/code.
SOAP and REST use the HTTP protocol; however, SOAP limits itself to a more strict set of API messaging patterns than REST.
An API often provides a roadmap that describes the underlying implementation of an application. API documentation can provide a great level of detail that can be very valuable to a security professional, as well to attackers. API documentation can include the following:
Swagger (OpenAPI): Swagger is a modern framework of API documentation and development that is the basis of the OpenAPI Specification (OAS). Additional information about Swagger can be obtained at https://swagger.io. The OAS specification is available at https://github.com/OAI/OpenAPI-Specification.
Web Services Description Language (WSDL) documents: WSDL is an XML-based language that is used to document the functionality of a web service. The WSDL specification can be accessed at https://www.w3.org/TR/wsdl20-primer.
Web Application Description Language (WADL) documents: WADL is an XML-based language for describing web applications. The WADL specification can be obtained from https://www.w3.org/Submission/wadl.
Return-to-LibC Attacks and Buffer Overflows
A “return-to-libc” (or ret2libc) attack typically starts with a buffer overflow. In this type of attack, a subroutine return address on a call stack is replaced by an address of a subroutine that is already present in the executable memory of the process. This is done to potentially bypass the no-execute (NX) bit feature and allow the attacker to inject his or her own code.
Operating systems that support non-executable stack help protect against code execution after a buffer overflow vulnerability is exploited. On the other hand, a non-executable stack cannot prevent a ret2libc attack because in this attack, only existing executable code is used. Another technique, called stack-smashing protection, can prevent or obstruct code execution exploitation because it can detect the corruption of the stack and can potentially “flush out” the compromised segment.
A technique called ASCII armoring can be used to mitigate ret2libc attacks. When you implement ASCII armoring, the address of every system library (such as libc) contains a NULL byte (0x00) that you insert in the first 0x01010101 bytes of memory. This is typically a few pages more than 16MB and is called the ASCII armor region because every address up to (but not including) this value contains at least one NULL byte. When this methodology is implemented, an attacker cannot place code containing those addresses using string manipulation functions such as strcpy().
Of course, this technique doesn’t protect the system if the attacker finds a way to overflow NULL bytes into the stack. A better approach is to use the address space layout randomization (ASLR) technique, which mitigates the attack on 64-bit systems. When you implement ASLR, the memory locations of functions are random. ASLR is not very effective in 32-bit systems, though, because only 16 bits are available for randomization, and an attacker can defeat such a system by using brute-force attacks.
OWASP Top 10
The Open Web Application Security Project (OWASP) is non-profit charitable organization that leads several industry-wide initiatives to promote the security of applications and software. They list the top 10 most common vulnerabilities against applications at their website at the following address:
https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project
Security Vulnerabilities in Open Source Software
Security vulnerability patching for commercial and open source software is one of the most important processes of any organization. An organization might use the following technologies and systems to maintain an appropriate vulnerability management program:
Vulnerability management software and scanners, such as Qualys, Nexpose, and Nessus
Software composition analysis tools, such as BlackDuck Hub, Synopsys Protecode (formerly known as AppCheck), FlexNet Code Insight (formerly known as Palamida), SourceClear, and WhiteSource
Security vulnerability feeds, such as MITRE’s CVE list, NIST’s National Vulnerability Database (NVD), VulnDB, and Recorded Future
Confidentiality, Integrity, and Availability
The elements of confidentiality, integrity, and availability are often described as the CIA model. It is easy to guess that the first thing that popped into your mind when you read those three letters was the United States Central Intelligence Agency. In the world of cybersecurity, these three letters represent something we strive to attain and protect. Confidentiality, integrity, and availability (CIA) are the unifying attributes of an information security program. Collectively referred to as the CIA triad or CIA security model, each attribute represents a fundamental objective of information security.
You may be wondering which is most important: confidentiality, integrity, or availability? The answer requires an organization to assess its mission, evaluate its services, and consider regulations and contractual agreements. As Figure 1-7 illustrates, organizations might consider all three components of the CIA triad equally important, in which case resources must be allocated proportionately.
What Is Confidentiality?
When you tell a friend something in confidence, you expect them to keep the information private and not share what you told them with anyone else without your permission. You also hope that they will never use this against you. Likewise, confidentiality is the requirement that private or confidential information not be disclosed to unauthorized individuals.
Figure 1-7 The CIA Triad
There are many attempts to define what confidentiality is. As an example, the ISO 2700 standard provides a good definition of confidentiality as “the property that information is not made available or disclosed to unauthorized individuals, entities, or processes.”
Confidentiality relies on three general concepts, as illustrated in Figure 1-8.
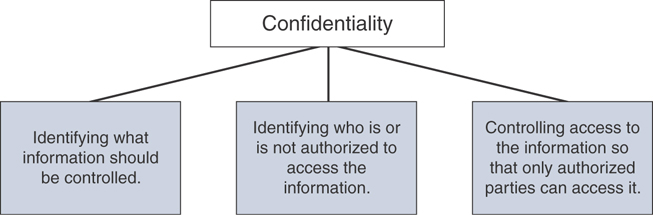
Figure 1-8 General Concepts of Confidentiality
There are several ways to protect the confidentiality of a system or its data; one of the most common is to use encryption. This includes encryption of data in transit with the use of site-to-site and remote access virtual private networks (VPNs) or by deploying server- and client-side encryption using Transport Layer Security (TLS).
Another important element of confidentiality is that all sensitive data needs to be controlled, audited, and monitored at all times. This is often done by encrypting data at rest. Here are some examples of sensitive data:
Social security numbers
Bank and credit card account information
Criminal records
Patient and health records
Trade secrets
Source code
Military secrets
Data often is protected by law, regulation, memorandum of agreement, contractual obligation, or management discretion. Examples include nonpublic personal information (NPPI) and personally identifiable information (PII), such as Social Security number, driver’s license or state-issued identification number, bank account or financial account numbers, payment card information (PCI), which is credit or debit cardholder information, and personal health information (PHI).
The following are examples of security mechanisms designed to preserve confidentiality:
Logical and physical access controls
Encryption (in motion and at rest)
Database views
Controlled traffic routing
Data classification is important when you’re deciding how to protect data. By having a good data classification methodology, you can enhance the way you secure your data across your network and systems.
Not only has the amount of information stored, processed, and transmitted on privately owned networks and the public Internet increased dramatically, so has the number of ways to potentially access the data. The Internet, its inherent weaknesses, and those willing (and able) to exploit vulnerabilities are the main reasons why protecting confidentiality has taken on a new urgency. The technology and accessibility we take for granted would have been considered magic just 10 years ago. The amazing speed at which we arrived here is also the reason we have such a gap in security. The race to market often means that security is sacrificed. So although it might seem that information security requirements are a bit extreme at times, it is really a reaction to the threat environment.
Because there is value in confidential information, it is often a target of cybercriminals. For instance, many breaches involve the theft of credit card information or other personal information useful for identity theft. Criminals look for and are prepared to exploit weaknesses in network designs, software, communication channels, and people to access confidential information. The opportunities are plentiful.
Criminals are not always outsiders. Insiders can be tempted to “make copies” of information they have access to for financial gain, notoriety, or to “make a statement.” The most recent threat to confidentiality is hacktivism, which is a combination of the terms “hack” and “activism.” Hacktivism has been described as the fusion of hacking and activism, politics, and technology. Hacktivist groups or collectives expose or hold hostage illegally obtained information to make a political statement or for revenge.
What Is Integrity?
Whenever the word integrity comes to mind, so does Brian De Palma’s classic 1987 film The Untouchables, starring Kevin Costner and Sean Connery. The film is about a group of police officers who could not be “bought off” by organized crime. They were incorruptible. Integrity is certainly one of the highest ideals of personal character. When we say someone has integrity, we mean she lives her life according to a code of ethics; she can be trusted to behave in certain ways in certain situations. It is interesting to note that those to whom we ascribe the quality of integrity can be trusted with our confidential information. As for information security, integrity has a very similar meaning. Integrity is basically the ability to make sure that a system and its data has not been altered or compromised. It ensures that the data is an accurate and unchanged representation of the original secure data. Integrity applies not only to data, but also to systems. For instance, if a threat actor changes the configuration of a server, firewall, router, switch, or any other infrastructure device, it is considered that he or she impacted the integrity of the system.
Data integrity is a requirement that information and programs are changed only in a specified and authorized manner. In other words, is the information the same as it was intended to be?
System integrity is a requirement that a system performs its intended function in an unimpaired manner, free from deliberate or inadvertent unauthorized manipulation of the system. Malware that corrupts some of the system files required to boot the computer is an example of deliberate unauthorized manipulation.
Errors and omissions are an important threat to data and system integrity. These errors are caused not only by data entry clerks processing hundreds of transactions per day, but also by all types of users who create and edit data and code. Even the most sophisticated programs cannot detect all types of input errors or omissions. In some cases, the error is the threat, such as a data entry error or a programming error that crashes a system. In other cases, the errors create vulnerabilities. Programming and development errors, often called “bugs,” can range in severity from benign to catastrophic.
To make this a bit more personal, let’s talk about medical and financial information. What if you are injured, unconscious, and taken to the emergency room of a hospital, and the doctors need to look up your health information? You would want it to be correct, wouldn’t you? Consider what might happen if you had an allergy to some very common treatment, and this critical information had been deleted from your medical records. Or think of your dismay if you check your bank balance after making a deposit and find that the funds have not been credited to your account!
Integrity and confidentiality are interrelated. If a user password is disclosed to the wrong person, that person could in turn manipulate, delete, or destroy data after gaining access to the system with the password he obtained. Many of the same vulnerabilities that threaten integrity also threaten confidentiality. Most notable, though, is human error. Safeguards that protect against the loss of integrity include access controls, such as encryption and digital signatures; process controls, such as code testing; monitoring controls, such as file integrity monitoring and log analysis; and behavioral controls, such as separation of duties, rotation of duties, and training.
What Is Availability?
The last component of the CIA triad is availability, which states that systems, applications, and data must be available to authorized users when needed and requested. The most common attack against availability is a denial-of-service (DoS) attack. User productivity can be greatly affected, and companies can lose a lot of money if data is not available. For example, if you are an online retailer or a cloud service provider and your ecommerce site or service is not available to your users, you could potentially lose current or future business, thus impacting revenue.
In fact, availability is generally one of the first security issues addressed by Internet service providers (ISPs). You might have heard the expressions “uptime” and “5-9s” (99.999% uptime). This means the systems that serve Internet connections, web pages, and other such services will be available to users who need them when they need them. Service providers frequently use service level agreements (SLAs) to assure their customers of a certain level of availability.
Just like confidentiality and integrity, we prize availability. Not all threats to availability could be malicious. For example, human error or a misconfigured server or infrastructure device can cause a network outage that will have a direct impact to availability. We are more vulnerable to availability threats than to the other components of the CIA triad. We are certain to face some of them. Safeguards that address availability include access controls, monitoring, data redundancy, resilient systems, virtualization, server clustering, environmental controls, continuity of operations planning, and incident response preparedness.
Talking About Availability, What Is a Denial-of-Service (DoS) Attack?
Denial-of-service (DoS) and distributed DoS (DDoS) attacks have been around for quite some time now, but there has been heightened awareness of them over the past few years. A DoS attack typically uses one system and one network connection to perform a denial-of-service condition to a targeted system, network, or resource. DDoS attacks use multiple computers and network connections that can be geographically dispersed (that is, distributed) to perform a denial-of-service condition against the victim.
DDoS attacks can generally be divided into the following three categories:
Direct DDoS attacks
Reflected DDoS attacks
Amplification DDoS attacks
Direct denial-of-service attacks occur when the source of the attack generates the packets, regardless of protocol, application, and so on, that are sent directly to the victim of the attack.
Figure 1-9 illustrates a direct denial-of-service attack.

Figure 1-9 Direct Denial-of-Service Attack
In Figure 1-9 the attacker launches a direct DoS to the victim (a web server) by sending numerous TCP SYN packets. This type of attack is aimed at flooding the victim with an overwhelming number of packets, oversaturating its connection bandwidth, or depleting the target’s system resources. This type of attack is also known as a “SYN flood attack.”
Reflected DDoS attacks occur when the sources of the attack are sent spoofed packets that appear to be from the victim, and then the sources become unwitting participants in the DDoS attacks by sending the response traffic back to the intended victim. UDP is often used as the transport mechanism because it is more easily spoofed due to the lack of a three-way handshake. For example, if the attacker (A) decides he wants to attack a victim (V), he will send packets (for example, Network Time Protocol [NTP] requests) to a source (S) that thinks these packets are legitimate. The source then responds to the NTP requests by sending the responses to the victim, who was never expecting these NTP packets from the source, as shown in Figure 1-10.
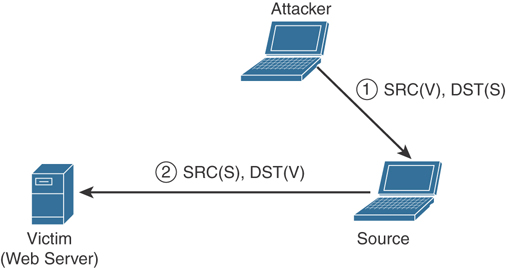
Figure 1-10 Reflected Denial-of-Service Attack
An amplification attack is a form of reflected attack in which the response traffic (sent by the unwitting participant) is made up of packets that are much larger than those that were initially sent by the attacker (spoofing the victim). An example is when DNS queries are sent, and the DNS responses are much larger in packet size than the initial query packets. The end result is that the victim’s machine gets flooded by large packets for which it never actually issued queries.
Another type of DoS is caused by exploiting vulnerabilities such as buffer overflows to cause a server or even network infrastructure device to crash, subsequently causing a denial-of-service condition.
Many attackers use botnets to launch DDoS attacks. A botnet is a collection of compromised machines that the attacker can manipulate from a command-and-control (often referred to as a C2 or CnC) system to participate in a DDoS, send spam emails, and perform other illicit activities. Figure 1-11 shows how a botnet is used by an attacker to launch a DDoS attack.
In Figure 1-11, the attacker sends instructions to compromised systems. These compromised systems can be end-user machines or IoT devices such as cameras, sensors, and so on.
Access Control Management
Access controls are security features that govern how users and processes communicate and interact with systems and resources. The objective of implementing access controls is to ensure that authorized users and processes are able to access information and resources while unauthorized users and processes are prevented from access to the same. Access control models refer to the active entity that requests access to an object or data as the subject and the passive entity being accessed or being acted upon as the object.
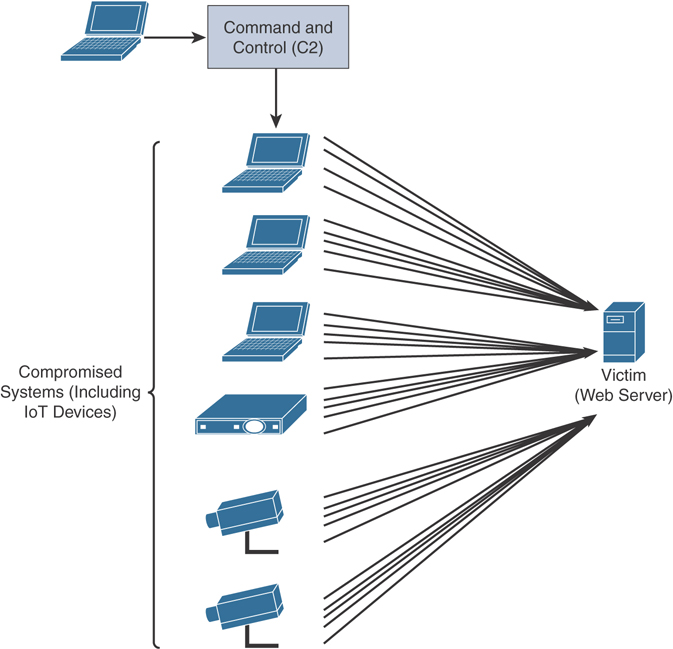
Figure 1-11 Example of a Botnet
An organization’s approach to access controls is referred to as its security posture. There are two fundamental approaches—open and secure. Open, also referred to as default allow, means that access not explicitly forbidden is permitted. Secure, also referred to as default deny, means that access not explicitly permitted is forbidden. Access decisions should consider the security principles of need to know and least privilege. Need to know means having a demonstrated and authorized reason for being granted access to information. Least privilege means granting subjects the minimum level of access required to perform their job or function.
Gaining access is a three-step process:
The object recognizes the subject. Identification is the process of the subject supplying an identifier such as a username to the object.
Providing proof that the subjects are who they say they are. Authentication is the process of the subject supplying verifiable credentials to the object.
Determining the actions a subject can take. Authorization is the process of assigning authenticated subjects the rights and permissions needed to carry out a specific operation.
Authentication credentials are called factors. There are three categories of factors:
Knowledge (something the user knows)
Possession (something a user has)
Inherence (something the user is)
Single-factor authentication is when only one factor is presented. Multifactor authentication is when two or more factors are presented. Multilayer authentication is when two or more of the same type of factor are presented. Out-of-band authentication requires communication over a channel that is distinct from the first factor. Data classification, regulatory requirement, the impact of unauthorized access, and the likelihood of a threat being exercised must all be considered when deciding on the level of authentication required.
Once authentication is complete, an authorization model defines how subjects access objects. Mandatory access controls (MACs) are defined by policy and cannot be modified by the information owner. Discretionary access controls (DACs) are defined by the owner of the object. Role-based access controls (RBACs, also called nondiscretionary) are access permissions based on a specific role or function. In a rule-based access controls environment, access is based on criteria independent of the user or group account, such as time of day or location.
Cloud Security Threats
Many organizations are moving to the cloud or deploying hybrid solutions to host their applications. Organizations moving to the cloud are almost always looking to transition from capital expenditure (CapEx) to operational expenditure (OpEx). Most of Fortune 500 companies operate in a multicloud environment. It is obvious that cloud computing security is more important than ever. Cloud computing security includes many of the same functionalities as traditional IT security. This includes protecting critical information from theft, data exfiltration, and deletion, as well as privacy.
The National Institute of Standards and Technology (NIST) authored Special Publication (SP) 800-145, “The NIST Definition of Cloud Computing,” to provide a standard set of definitions for the different aspects of cloud computing. The SP 800-145 document also compares the different cloud services and deployment strategies.
The advantages of using a cloud-based service include the following:
Distributed storage
Scalability
Resource pooling
Access from any location
Measured service
Automated management
According to NIST, the essential characteristics of cloud computing include the following:
On-demand self-service
Broad network access
Resource pooling
Rapid elasticity
Measured service
Cloud deployment models include the following:
Public cloud: Open for public use
Private cloud: Used just by the client organization on the premises (on-prem) or at a dedicated area in a cloud provider
Community cloud: Shared between several organizations
Hybrid cloud: Composed of two or more clouds (including on-prem services).
Cloud computing can be broken into the following three basic models:
Infrastructure as a Service (IaaS): IaaS describes a cloud solution where you are renting infrastructure. You purchase virtual power to execute your software as needed. This is much like running a virtual server on your own equipment, except you are now running a virtual server on a virtual disk. This model is similar to a utility company model because you pay for what you use.

Platform as a Service (PaaS): PaaS provides everything except applications. Services provided by this model include all phases of the system development life cycle (SDLC) and can use application programming interfaces (APIs), website portals, or gateway software. These solutions tend to be proprietary, which can cause problems if the customer moves away from the provider’s platform.
Software as a Service (SaaS): SaaS is designed to provide a complete packaged solution. The software is rented out to the user. The service is usually provided through some type of front end or web portal. While the end user is free to use the service from anywhere, the company pays a per-use fee.
Cloud Computing Issues and Concerns
There are many potential threats when organizations move to a cloud model. For example, although your data is in the cloud, it must reside in a physical location somewhere. Your cloud provider should agree in writing to provide the level of security required for your customers. The following are questions to ask a cloud provider before signing a contract for its services:
Who has access? Access control is a key concern because insider attacks are a huge risk. Anyone who has been approved to access the cloud is a potential hacker, so you want to know who has access and how they were screened. Even if it was not done with malice, an employee can leave, and then you find out that you don’t have the password, or the cloud service gets canceled because maybe the bill didn’t get paid.
What are your regulatory requirements? Organizations operating in the United States, Canada, or the European Union have many regulatory requirements that they must abide by (for example, ISO/IEC 27002, EU-U.S. Privacy Shield Framework, ITIL, and COBIT). You must ensure that your cloud provider can meet these requirements and is willing to undergo certification, accreditation, and review.
Do you have the right to audit? This particular item is no small matter in that the cloud provider should agree in writing to the terms of the audit. With cloud computing, maintaining compliance could become more difficult to achieve and even harder to demonstrate to auditors and assessors. Of the many regulations touching upon information technology, few were written with cloud computing in mind. Auditors and assessors might not be familiar with cloud computing generally or with a given cloud service in particular.
What type of training does the provider offer its employees? This is a rather important item to consider because people will always be the weakest link in security. Knowing how your provider trains its employees is an important item to review.
What type of data classification system does the provider use? Questions you should be concerned with here include what data classification standard is being used and whether the provider even uses data classification.
How is your data separated from other users’ data? Is the data on a shared server or a dedicated system? A dedicated server means that your information is the only thing on the server. With a shared server, the amount of disk space, processing power, bandwidth, and so on is limited because others are sharing this device. If it is shared, the data could potentially become comingled in some way.
Is encryption being used? Encryption should be discussed. Is it being used while the data is at rest and in transit? You will also want to know what type of encryption is being used. For example, there are big technical difference between DES and AES. For both of these algorithms, however, the basic questions are the same: Who maintains control of the encryption keys? Is the data encrypted at rest in the cloud? Is the data encrypted in transit, or is it encrypted at rest and in transit?
What are the service level agreement (SLA) terms? The SLA serves as a contracted level of guaranteed service between the cloud provider and the customer that specifies what level of services will be provided.
What is the long-term viability of the provider? How long has the cloud provider been in business, and what is its track record? If it goes out of business, what happens to your data? Will your data be returned and, if so, in what format?
Will the provider assume liability in the case of a breach? If a security incident occurs, what support will you receive from the cloud provider? While many providers promote their services as being unhackable, cloud-based services are an attractive target to hackers.
What is the disaster recovery/business continuity plan (DR/BCP)? Although you might not know the physical location of your services, it is physically located somewhere. All physical locations face threats such as fire, storms, natural disasters, and loss of power. In case of any of these events, how will the cloud provider respond, and what guarantee of continued services is it promising?
Even when you end a contract, you must ask what happens to the information after your contract with the cloud service provider ends.
Cloud Computing Attacks
Because cloud-based services are accessible via the Internet, they are open to any number of attacks. As more companies move to cloud computing, look for hackers to follow. Some of the potential attack vectors criminals might attempt include the following:
Session hijacking: This attack occurs when the attacker can sniff traffic and intercept traffic to take over a legitimate connection to a cloud service.
DNS attack: This form of attack tricks users into visiting a phishing site and giving up valid credentials.
Cross-site scripting (XSS): Used to steal cookies that can be exploited to gain access as an authenticated user to a cloud-based service.
SQL injection: This attack exploits vulnerable cloud-based applications that allow attackers to pass SQL commands to a database for execution.
Session riding: This term is often used to describe a cross-site request forgery attack. Attackers use this technique to transmit unauthorized commands by riding an active session by using an email or malicious link to trick users while they are currently logged in to a cloud service.
Distributed denial-of-service (DDoS) attack: Some security professionals have argued that the cloud is more vulnerable to DDoS attacks because it is shared by many users and organizations, which also makes any DDoS attack much more damaging.
Man-in-the-middle cryptographic attack: This attack is carried out when the attacker places himself in the communication path between two users. Anytime the attacker can do this, there is the possibility that he can intercept and modify communications.
Side-channel attack: An attacker could attempt to compromise the cloud by placing a malicious virtual machine in close proximity to a target cloud server and then launching a side-channel attack.
Authentication attack: Authentication is a weak point in hosted and virtual services and is frequently targeted. There are many ways to authenticate users, such as based on what a person knows, has, or is. The mechanisms used to secure the authentication process and the method of authentication used are frequent targets of attackers.
API attacks: Often APIs are configured insecurely. An attacker can take advantage of API misconfigurations to modify, delete, or append data in applications or systems in cloud environments.
Cloud Computing Security
Regardless of the model used, cloud security is the responsibility of both the client and the cloud provider. These details will need to be worked out before a cloud computing contract is signed. The contracts will vary depending on the given security requirements of the client. Considerations include disaster recovery, SLAs, data integrity, and encryption. For example, is encryption provided end to end or just at the cloud provider? Also, who manages the encryption keys: the cloud provider or the client? Overall, you want to ensure that the cloud provider has the same layers of security (logical, physical, and administrative) in place that you would have for services you control. You will learn details on how to secure cloud environments in Chapter 9, “Securing the Cloud.”
IoT Security Threats
The Internet of Things (IoT) includes any computing devices (mechanical and digital machines) that can transfer data over a network without requiring human-to-human or human-to-computer interaction—for example, sensors, home appliances, connected security cameras, wearables, and numerous other devices.
The capability of distributed intelligence in the network is a core architectural component of the IoT:
Data collection: Centralized data collection presents a few challenges for an IoT environment to be able to scale. For instance, managing millions of sensors in a smart grid network cannot efficiently be done using a centralized approach.
Network resource preservation: This is particularly important because network bandwidth may be limited, and centralized IoT device data collection leads to using a large amount of the network capabilities.
Closed-loop functioning: IoT environments often require reduced reaction times.
Fog computing is a concept of a distributed intelligence architecture designed to process data and events from IoT devices as close to the source as possible. The fog-edge device then sends the required data to the cloud. For example, a router might collect information from numerous sensors and then communicate to a cloud service or application for the processing of such data.
The following are some of the IoT security challenges and considerations:
Numerous IoT devices are inexpensive devices with little to no security capabilities.
IoT devices are typically constrained in memory and compute resources and do not support complex and evolving security and encryption algorithms.
Several IoT devices are deployed with no backup connectivity if the primary connection is lost.
Numerous IoT devices require secure remote management during and after deployment (onboarding).
IoT devices often require the management of multiparty networks. Governance of these networks is often a challenging task. For example, who will accept liability for a breach? Who is in charge of incident response? Who has provisioning access? Who has access to the data?
Crypto resilience is a challenge in many IoT environments. These embedded devices (such as smart meters) are designed to last decades without being replaced.
Physical protection is another challenge, because any IoT device could be stolen, moved, or tampered with.
Administrations should pay attention to how the IoT device authenticates to multiple networks securely.
IoT technologies like INSTEON, Zigbee, Z-Wave, LoRaWAN, and others were not designed with security in mind (however, they have improved significantly over the past few years).
IoT devices typically communicate to the cloud via a fog-edge device or directly to the cloud. Figure 1-12 shows several sensors are communicating to a fog-edge router, and subsequently the router communicates to the cloud.
Figure 1-12 Example of a Fog-Edge Device
Figure 1-13 shows how a smart thermostat communicates directly to the cloud using a RESTful API via a Transport Layer Security (TLS) connection. The IoT device (a smart thermostat in this example) sends data to the cloud, and an end user checks the temperature and manages the thermostat using a mobile application.
Figure 1-13 IoT, Cloud Applications, and APIs
In the example illustrated in Figure 1-13, securing the thermostat, the RESTful API, the cloud application, and the mobile application is easier said than done.
IoT Protocols
The following are some of the most popular IoT protocols:
Zigbee: One of the most popular protocols supported by many consumer IoT devices. Zigbee takes advantage of the underlying security services provided by the IEEE 802.15.4 MAC layer. The 802.15.4 MAC layer supports the AES algorithm with a 128-bit key for both encryption and decryption. Additional information about Zigbee can be obtained from the Zigbee Alliance at https://www.zigbee.org.
Bluetooth Low Energy (BLE) and Bluetooth Smart: BLE is an evolution of the Bluetooth protocol that is designed for enhanced battery life for IoT devices. Bluetooth Smart–enabled devices default to “sleep mode” and “wake up” only when needed. Both operate in the 2.4 GHz frequency range. Bluetooth Smart implements high-rate frequency-hopping spread spectrum and supports AES encryption. Additional information about BLE and Bluetooth Smart can be found at https://www.bluetooth.com.
Z-Wave: Another popular IoT communication protocol. It supports unicast, multicast, and broadcast communication. Z-Wave networks consist of controllers and slaves. Some Z-Wave devices can be both primary and secondary controllers. Primary controllers are allowed to add and remove nodes form the network. Z-Wave devices operate at a frequency of 908.42 MHz (North America) and 868.42 MHz (Europe) with data rates of 100Kbps over a range of about 30 meters. Additional information about Z-Wave can be obtained from the Z-Wave Alliance at https://z-wavealliance.org.
INSTEON: A protocol that allows IoT devices to communicate wirelessly and over the power lines. It provides support for dual-band, mesh, and peer-to-peer communication. Additional information about INSTEON can be found at https://www.insteon.com/technology/.
Long Range Wide Area Network (LoRaWAN): A networking protocol designed specifically for IoT implementations. LoRaWAN has three classes of endpoint devices: Class A (lowest power, bidirectional end devices), Class B (bidirectional end devices with deterministic downlink latency), and Class C (lowest latency, bidirectional end devices). Additional information about LoRaWAN can be found at the Lora Alliance at https://lora-alliance.org.
Wi-Fi: Still one of the most popular communication methods for IoT devices.
Low Rate Wireless Personal Area Networks (LRWPAN) and IPv6 over Low Power Wireless Personal Area Networks (6LoWPAN): IPv4 and IPv6 both play a role at various points within many IoT systems. IPv6 over Low Power Wireless Personal Area Networks (6LoWPAN) supports the use of IPv6 in the network-constrained IoT implementations. 6LoWPan was designed to support wireless Internet connectivity at lower data rates. 6LoWPAN builds upon the 802.15.4 Low Rate Wireless Personal Area Networks (LRWPAN) specification to create an adaptation layer that supports the use of IPv6.
Cellular Communication: Also a popular communication method for IoT devices, including connected cars, retail machines, sensors, and others. 4G and 5G are used to connect many IoT devices nowadays.
IoT devices often communicate to applications using REST and MQTT on top of lower-layer communication protocols. These messaging protocols provide the ability for both IoT clients and application servers to efficiently agree on data to exchange. The following are some of the most popular IoT messaging protocols:
MQTT
Constrained Application Protocol (CoAP)
Data Distribution Protocol (DDP)
Advanced Message Queuing Protocol (AMQP)
Extensible Messaging and Presence Protocol (XMPP)
Hacking IoT Implementations
Many of the tools and methodologies for hacking applications and network apply to IoT hacking; however, several specialized tools perform IoT hardware and software hacking.
The following are a few examples of tools and methods to hack IoT devices.
Hardware tools:
Multimeters
Oscilloscopes
Soldering tools
UART debuggers and tools
Universal interface tools like JTAG, SWD, I2C, and SPI tools
Logic analyzers
Reverse engineering tools, such as disassemblers and debuggers:
IDA
Binary Ninja
Radare2
Ghidra
Hopper
Wireless communication interfaces and tools:
Ubertooth One (for Bluetooth hacking)
Software-defined radio (SDR), such as HackRF and BladeRF, to perform assessments of Z-Wave and Zigbee implementations
An Introduction to Digital Forensics and Incident Response
Cybersecurity-related incidents have become not only more numerous and diverse, but also more damaging and disruptive. A single incident can cause the demise of an entire organization. In general terms, incident management is defined as a predictable response to damaging situations. It is vital that organizations have the practiced capability to respond quickly, minimize harm, comply with breach-related state laws and federal regulations, and maintain their composure in the face of an unsettling and unpleasant experience.
ISO/IEC 27002:2013 and NIST Incident Response Guidance
Section 16 of ISO 27002:2013, “Information Security Incident Management,” focuses on ensuring a consistent and effective approach to the management of information security incidents, including communication on security events and weaknesses.
Corresponding NIST guidance is provided in the following documents:
SP 800-61 Revision 2: “Computer Security Incident Handling Guide”
SP 800-83: “Guide to Malware Incident Prevention and Handling”
SP 800-86: “Guide to Integrating Forensic Techniques into Incident Response”
Incidents drain resources, can be very expensive, and can divert attention from the business of doing business. Keeping the number of incidents as low as possible should be an organizational priority. That means as much as possible identifying and remediating weaknesses and vulnerabilities before they are exploited. A sound approach to improving an organizational security posture and preventing incidents is to conduct periodic risk assessments of systems and applications. These assessments should determine what risks are posed by combinations of threats, threat sources, and vulnerabilities. Risks can be mitigated, transferred, or avoided until a reasonable overall level of acceptable risk is reached. However, it is important to realize that users will make mistakes, external events may be out of an organization’s control, and malicious intruders are motivated. Unfortunately, even the best prevention strategy isn’t always enough, which is why preparation is key.
Incident preparedness includes having policies, strategies, plans, and procedures. Organizations should create written guidelines, have supporting documentation prepared, train personnel, and engage in mock exercises. An actual incident is not the time to learn. Incident handlers must act quickly and make far-reaching decisions—often while dealing with uncertainty and incomplete information. They are under a great deal of stress. The more prepared they are, the better the chance that sound decisions will be made.
Computer security incident response is a critical component of information technology (IT) programs. The incident response process and incident handling activities can be very complex. To establish a successful incident response program, you must dedicate substantial planning and resources. Several industry resources were created to help organizations establish a computer security incident response program and learn how to handle cybersecurity incidents efficiently and effectively. One of the best resources available is NIST Special Publication 800-61, which can be obtained from the following URL:
http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf
NIST developed Special Publication 800-61 due to statutory responsibilities under the Federal Information Security Management Act (FISMA) of 2002, Public Law 107-347.
The benefits of having a practiced incident response capability include the following:
Calm and systematic response
Minimization of loss or damage
Protection of affected parties
Compliance with laws and regulations
Preservation of evidence
Integration of lessons learned
Lower future risk and exposure
What Is an Incident?
A cybersecurity incident is an adverse event that threatens business security and/or disrupts service. Sometimes confused with a disaster, an information security incident is related to loss of confidentiality, integrity, or availability (CIA), whereas a disaster is an event that results in widespread damage or destruction, loss of life, or drastic change to the environment. Examples of incidents include exposure of or modification of legally protected data, unauthorized access to intellectual property, or disruption of internal or external services. The starting point of incident management is to create an organization-specific definition of the term incident so that the scope of the term is clear. Declaration of an incident should trigger a mandatory response process.
Not all security incidents are the same. For example, a breach of personally identifiable information (PII) typically requires strict disclosure under many circumstances.
Before you learn the details about how to create a good incident response program within your organization, you must understand the difference between security “events” and security “incidents.” The following is from NIST Special Publication 800-61:
“An event is any observable occurrence in a system or network. Events include a user connecting to a file share, a server receiving a request for a web page, a user sending email, and a firewall blocking a connection attempt. Adverse events are events with a negative consequence, such as system crashes, packet floods, unauthorized use of system privileges, unauthorized access to sensitive data, and execution of malware that destroys data.”
According to the same document, “a computer security incident is a violation or imminent threat of violation of computer security policies, acceptable use policies, or standard security practices.”
The definition and criteria should be codified in policy. Incident management extends to third-party environments. Business partners and vendors should be contractually obligated to notify the organization if an actual or suspected incident occurs.
The following are a few examples of cybersecurity incidents:
Attacker sends a crafted packet to a router and causes a denial-of-service condition.
Attacker compromises a point-of-sale (POS) system and steals credit card information.
Attacker compromises a hospital database and steals thousands of health records.
Ransomware is installed in a critical server and all files are encrypted by the attacker.
False Positives, False Negatives, True Positives, and True Negatives
The term false positive is a broad term that describes a situation in which a security device triggers an alarm but there is no malicious activity or an actual attack taking place. In other words, false positives are “false alarms,” and they are also called “benign triggers.” False positives are problematic because by triggering unjustified alerts, they diminish the value and urgency of real alerts. If you have too many false positives to investigate, it becomes an operational nightmare, and you most definitely will overlook real security events.
There are also false negatives, which is the term used to describe a network intrusion device’s inability to detect true security events under certain circumstances. In other words, a malicious activity that is not detected by the security device.
A true positive is a successful identification of a security attack or a malicious event. A true negative is when the intrusion detection device identifies an activity as acceptable behavior and the activity is actually acceptable.
Traditional IDS and IPS devices need to be tuned to avoid false positives and false negatives. Next-generation IPSs do not need the same level of tuning compared to a traditional IPS. Also, you can obtain much deeper reports and functionality, including advanced malware protection and retrospective analysis to see what happened after an attack took place.
Traditional IDS and IPS devices also suffer from many evasion attacks. The following are some of the most common evasion techniques against traditional IDS and IPS devices:
Fragmentation: When the attacker evades the IPS box by sending fragmented packets.
Using low-bandwidth attacks: When the attacker uses techniques that use low bandwidth or a very small number of packets in order to evade the system.
Address spoofing/proxying: Using spoofed IP addresses or sources, as well as using intermediary systems such as proxies to evade inspection.
Pattern change evasion: Attackers may use polymorphic techniques to create unique attack patterns.
Encryption: Attackers can use encryption to hide their communication and information.
Incident Severity Levels
Not all incidents are equal in severity. Included in the incident definition should be severity levels based on the operational, reputational, and legal impact to the organization. Corresponding to the level should be required response times as well as minimum standards for internal notification.
A cybersecurity incident is any adverse event whereby some aspect of an information system or information itself is threatened. Incidents are classified by severity relative to the impact they have on an organization. This severity level is typically assigned by an incident manager or a cybersecurity investigator. How it is validated depends on the organizational structure and the incident response policy. Each level has a maximum response time and minimum internal notification requirements.
How Are Incidents Reported?
Incident reporting is best accomplished by implementing simple, easy-to-use mechanisms that can be used by all employees to report the discovery of an incident. Employees should be required to report all actual and suspected incidents. They should not be expected to assign a severity level, because the person who discovers an incident may not have the skill, knowledge, or training to properly assess the impact of the situation.
People frequently fail to report potential incidents because they are afraid of being wrong and looking foolish, they do not want to be seen as a complainer or whistleblower, or they simply don’t care enough and would prefer not to get involved. These objections must be countered by encouragement from management. Employees must be assured that even if they were to report a perceived incident that ended up being a false positive, they would not be ridiculed or met with annoyance. On the contrary, their willingness to get involved for the greater good of the company is exactly the type of behavior the company needs! They should be supported for their efforts and made to feel valued and appreciated for doing the right thing.
Digital forensic evidence is information in digital form found on a wide range of endpoint, server, and network devices—basically, any information that can be processed by a computing device or stored on other media. Evidence tendered in legal cases, such as criminal trials, is classified as witness testimony or direct evidence, or as indirect evidence in the form of an object, such as a physical document, the property owned by a person, and so forth.
Cybersecurity forensic evidence can take many forms, depending on the conditions of each case and the devices from which the evidence was collected. To prevent or minimize contamination of the suspect’s source device, you can use different tools, such as a piece of hardware called a write blocker, on the specific device so you can copy all the data (or an image of the system).
The imaging process is intended to copy all blocks of data from the computing device to the forensics professional evidentiary system. This is sometimes referred to as a “physical copy” of all data, as distinct from a logical copy, which copies only what a user would normally see. Logical copies do not capture all the data, and the process will alter some file metadata to the extent that its forensic value is greatly diminished, resulting in a possible legal challenge by the opposing legal team. Therefore, a full bit-for-bit copy is the preferred forensic process. The file created on the target device is called a forensic image file.
Chain of custody is the way you document and preserve evidence from the time that you started the cyber-forensics investigation to the time the evidence is presented in court. It is extremely important to be able to show clear documentation of the following:
How the evidence was collected
When it was collected
How it was transported
How is was tracked
How it was stored
Who had access to the evidence and how it was accessed
A method often used for evidence preservation is to work only with a copy of the evidence—in other words, you do not want to work directly with the evidence itself. This involves creating an image of any hard drive or any storage device. Additionally, you must prevent electronic static or other discharge from damaging or erasing evidentiary data. Special evidence bags that are antistatic should be used to store digital devices. It is very important that you prevent electrostatic discharge (ESD) and other electrical discharges from damaging your evidence. Some organizations even have cyber-forensic labs that control access to only authorized users and investigators. One method often used involves constructing what is called a Faraday cage. This “cage” is often built out of a mesh of conducting material that prevents electromagnetic energy from entering into or escaping from the cage. Also, this prevents devices from communicating via Wi-Fi or cellular signals.
What’s more, transporting the evidence to the forensics lab or any other place, including the courthouse, has to be done very carefully. It is critical that the chain of custody be maintained during this transport. When you transport the evidence, you should strive to secure it in a lockable container. It is also recommended that the responsible person stay with the evidence at all times during transportation.
What Is an Incident Response Program?
An incident response program is composed of policies, plans, procedures, and people. Incident response policies codify management directives. Incident response plans (IRPs) provide a well-defined, consistent, and organized approach for handling internal incidents as well as taking appropriate action when an external incident is traced back to the organization. Incident response procedures are detailed steps needed to implement the plan.
The Incident Response Plan
Having a good incident response plan and incident response process will help you minimize loss or theft of information and disruption of services caused by incidents. It will also help you enhance your incident response program by using lessons learned and information obtained during the security incident.
Section 2.3 of NIST Special Publication 800-61 Revision 2 goes over the incident response policies, plans, and procedures, including information on how to coordinate incidents and interact with outside parties. The policy elements described in NIST Special Publication 800-61 Revision 2 include the following:
Statement of management commitment
Purpose and objectives of the incident response policy
The scope of the incident response policy
Definition of computer security incidents and related terms
Organizational structure and definition of roles, responsibilities, and levels of authority
Prioritization or severity ratings of incidents
Performance measures
Reporting and contact forms
NIST’s incident response plan elements include the following:
Incident response plan’s mission
Strategies and goals of the incident response plan
Senior management approval of the incident response plan
Organizational approach to incident response
How the incident response team will communicate with the rest of the organization and with other organizations
Metrics for measuring the incident response capability and its effectiveness
Roadmap for maturing the incident response capability
How the program fits into the overall organization
NIST also defines standard operating procedures (SOPs) as “a delineation of the specific technical processes, techniques, checklists, and forms used by the incident response team. SOPs should be reasonably comprehensive and detailed to ensure that the priorities of the organization are reflected in response operations.”
The Incident Response Process
NIST Special Publication 800-61 goes over the major phases of the incident response process in detail. You should become familiar with that publication because it provides additional information that will help you succeed in your security operations center (SOC). The important key points are summarized here.
NIST defines the major phases of the incident response process as illustrated in Figure 1-14.
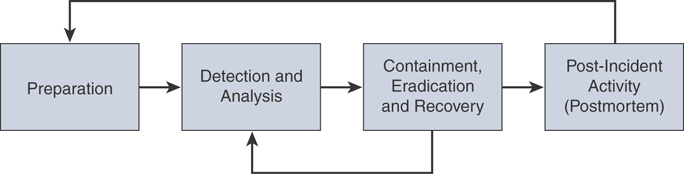
Figure 1-14 The Phases of the Incident Response Process
The preparation phase includes creating and training the incident response team, as well as deploying the necessary tools and resources to successfully investigate and resolve cybersecurity incidents. In this phase, the incident response team creates a set of controls based on the results of risk assessments. The preparation phase also includes the following tasks:
Creating processes for incident handler communications and the facilities that will host the security operation center (SOC) and incident response team
Making sure that the organization has appropriate incident analysis hardware and software as well as incident mitigation software
Creating risk assessment capabilities within the organization
Making sure the organization has appropriately deployed host security, network security, and malware prevention solutions
Developing user awareness training
The detection and analysis phase is one of the most challenging phases. Although some incidents are easy to detect (for example, a denial-of-service attack), many breaches and attacks are left undetected for weeks or even months. This is why detection might be the most difficult task in incident response. The typical network is full of “blind spots” where anomalous traffic goes undetected. Implementing analytics and correlation tools is critical to eliminating these network blind spots. As a result, the incident response team must react quickly to analyze and validate each incident. This is done by following a predefined process while documenting each step the analyst takes. NIST provides various recommendations for making incident analysis easier and more effective:
Profile networks and systems.
Understand normal behaviors.
Create a log retention policy.
Perform event correlation.
Maintain and use a knowledge base of information.
Use Internet search engines for research.
Run packet sniffers to collect additional data.
Filter the data.
Seek assistance from others.
Keep all host clocks synchronized.
Know the different types of attacks and attack vectors.
Develop processes and procedures to recognize the signs of an incident.
Understand the sources of precursors and indicators.
Create appropriate incident documentation capabilities and processes.
Create processes to effectively prioritize security incidents.
Create processes to effectively communicate incident information (internal and external communications).
The containment, eradication, and recovery phase includes the following activities:
Evidence gathering and handling
Identifying the attacking hosts
Choosing a containment strategy to effectively contain and eradicate the attack, as well as to successfully recover from it
NIST Special Publication 800-61 Revision 2 also defines the following criteria for determining the appropriate containment, eradication, and recovery strategy:
The potential damage to and theft of resources
The need for evidence preservation
Service availability (for example, network connectivity as well as services provided to external parties)
Time and resources needed to implement the strategy
Effectiveness of the strategy (for example, partial containment or full containment)
Duration of the solution (for example, emergency workaround to be removed in four hours, temporary workaround to be removed in two weeks, or permanent solution)
The post-incident activity phase includes lessons learned, how to use collected incident data, and evidence retention. NIST Special Publication 800-61 Revision 2 includes several questions that can be used as guidelines during the lessons learned meeting(s):
Exactly what happened, and at what times?
How well did the staff and management perform while dealing with the incident?
Were the documented procedures followed? Were they adequate?
What information was needed sooner?
Were any steps or actions taken that might have inhibited the recovery?
What would the staff and management do differently the next time a similar incident occurs?
How could information sharing with other organizations be improved?
What corrective actions can prevent similar incidents in the future?
What precursors or indicators should be watched for in the future to detect similar incidents?
What additional tools or resources are needed to detect, analyze, and mitigate future incidents?
Tabletop Exercises and Playbooks
Many organizations take advantage of tabletop (simulated) exercises to further test their capabilities. These tabletop exercises are an opportunity to practice and also perform gap analysis on their incident response processes and procedures. In addition, these exercises may allow them to create playbooks for incident response. Developing a playbook framework makes future analysis modular and extensible. A good playbook typically contains the following information:
Report identification
Objective statement
Result analysis
Data query/code
Analyst comments/notes
There are significant long-term advantages for having relevant and effective playbooks. When developing playbooks, focus on organization and clarity within your own framework. Having a playbook and detection logic is not enough. The playbook is only a proactive plan. Your plays must actually run to generate results, those results must be analyzed, and remedial actions must be taken for malicious events. This is why tabletop exercises are very important.
Tabletop exercises could be technical and also at the executive level. You can create technical simulations for your incident response team and also risk-based exercises for your executive and management staff. A simple methodology for an incident response tabletop exercise includes the following steps:
Preparation: Identify the audience, what you want to simulate, and how the exercise will take place.
Execution: Execute the simulation and record all findings to identify all areas for improvement in your program.
Report: Create a report and distribute it to all the respective stakeholders. Narrow your assessment to specific facets of incident response. You can compare the results with the existing incident response plans. You should also measure the coordination among different teams within the organization and/or external to the organization. Provide a good technical analysis and identify gaps.
Information Sharing and Coordination
During the investigation and resolution of a security incident, you might also need to communicate with outside parties regarding the incident. Examples include, but are not limited to, contacting law enforcement, fielding media inquiries, seeking external expertise, and working with Internet service providers (ISPs), the vendor of your hardware and software products, threat intelligence vendor feeds, coordination centers, and members of other incident response teams. You can also share relevant incident indicator of compromise (IoC) information and other observables with industry peers. A good example of information-sharing communities is the Financial Services Information Sharing and Analysis Center (FS-ISAC).
Your incident response plan should account for these types of interactions with outside entities. It should also include information about how to interact with your organization’s public relations (PR) department, legal department, and upper management. You should also get their buy-in when sharing information with outside parties to minimize the risk of information leakage. In other words, avoid leaking sensitive information regarding security incidents with unauthorized parties. These actions could potentially lead to additional disruption and financial loss. You should also maintain a list of all the contacts at those external entities, including a detailed list of all external communications for liability and evidentiary purposes.
Computer Security Incident Response Teams
There are different types of incident response teams. The most popular is the computer security incident response team (CSIRT). Others include the following:
Product security incident response team (PSIRT)
National CSIRT and computer emergency response team (CERT)
Coordination center
The incident response team of a security vendor and managed security service provider (MSSP)
The CSIRT is typically the team that works hand in hand with the information security teams (often called InfoSec). In smaller organizations, InfoSec and CSIRT functions may be combined and provided by the same team. In large organizations, the CSIRT focuses on the investigation of computer security incidents, whereas the InfoSec team is tasked with the implementation of security configurations, monitoring, and policies within the organization.
Establishing a CSIRT involves the following steps:
Step 1. Defining the CSIRT constituency
Step 2. Ensuring management and executive support
Step 3. Making sure that the proper budget is allocated
Step 4. Deciding where the CSIRT will reside within the organization’s hierarchy
Step 5. Determining whether the team will be central, distributed, or virtual
Step 6. Developing the process and policies for the CSIRT
It is important to recognize that every organization is different, and these steps can be accomplished in parallel or in sequence. However, defining the constituency of a CSIRT is certainly one of the first steps in the process. When defining the constituency of a CSIRT, one should answer the following questions:
Who will be the “customer” of the CSIRT?
What is the scope? Will the CSIRT cover only the organization or also entities external to the organization? For example, at Cisco, all internal infrastructure and Cisco’s websites and tools (that is, cisco.com) are the responsibility of the Cisco CSIRT, and any incident or vulnerability concerning a Cisco product or service is the responsibility of the Cisco PSIRT.
Will the CSIRT provide support for the complete organization or only for a specific area or segment? For example, an organization may have a CSIRT for traditional infrastructure and IT capabilities and a separate one dedicated to cloud security.
Will the CSIRT be responsible for part of the organization or all of it? If external entities will be included, how will they be selected?
Determining the value of a CSIRT can be challenging. One of the main questions that executives will ask is, what is the return on investment for having a CSIRT? The main goals of the CSIRT are to minimize risk, contain cyber damage, and save money by preventing incidents from happening—and when they do occur, to mitigate them efficiently. For example, the smaller the scope of the damage, the less money you need to spend to recover from a compromise (including brand reputation). Many studies in the past have covered the cost of security incidents and the cost of breaches. Also, the Ponemon Institute periodically publishes reports covering these costs. It is a good practice to review and calculate the “value add” of the CSIRT. This calculation can be used to determine when to invest more, not only in a CSIRT, but also in operational best practices. In some cases, an organization might even outsource some of the cybersecurity functions to a managed service provider, if the organization cannot afford or retain security talent.
Incident response teams must have several basic policies and procedures in place to operate satisfactorily, including the following:
Incident classification and handling
Information classification and protection
Information dissemination
Record retention and destruction
Acceptable usage of encryption
Engaging and cooperating with external groups (other IRTs, law enforcement, and so on)
Also, some additional policies or procedures can be defined, such as the following:
Hiring policy
Using an outsourcing organization to handle incidents
Working across multiple legal jurisdictions
Even more policies can be defined depending on the team’s circumstances. The important thing to remember is that not all policies need to be defined on the first day.
The following are great sources of information from the International Organization for Standardization/International Electrotechnical Commission (ISO/IEC) that you can leverage when you are conscripting your policy and procedure documents:
ISO/IEC 27001:2005: “Information Technology—Security Techniques—Information Security Management Systems—Requirements”
ISO/IEC 27002:2005: Information Technology—Security Techniques—Code of Practice for Information Security Management”
ISO/IEC 27005:2008: “Information Technology—Security techniques—Information Security Risk Management”
ISO/PAS 22399:2007: “Societal Security—Guidelines for Incident Preparedness and Operational Continuity Management”
ISO/IEC 27033: Information Technology—Security Techniques—Information Security Incident Management
CERT provides a good overview of the goals and responsibilities of a CSIRT at the following site: https://www.cert.org/incident-management/csirt-development/csirt-faq.cfm.
Product Security Incident Response Teams (PSIRTs)
Software and hardware vendors may have separate teams that handle the investigation, resolution, and disclosure of security vulnerabilities in their products and services. Typically, these teams are called product security incident response teams (PSIRTs). Before you can understand how a PSIRT operates, you must understand what constitutes security vulnerability.
The Common Vulnerability Scoring System (CVSS)
Each vulnerability represents a potential risk that threat actors can use to compromise your systems and your network. Each vulnerability carries an associated amount of risk with it. One of the most widely adopted standards to calculate the severity of a given vulnerability is the Common Vulnerability Scoring System (CVSS), which has three components: base, temporal, and environmental scores. Each component is presented as a score on a scale from 0 to 10.
CVSS is an industry standard maintained by the Forum of Incident Response and Security Teams (FIRST) that is used by many PSIRTs to convey information about the severity of vulnerabilities they disclose to their customers.
In CVSS, a vulnerability is evaluated under three aspects and a score is assigned to each of them:
The base group represents the intrinsic characteristics of a vulnerability that are constant over time and do not depend on a user-specific environment. This is the most important information and the only one that’s mandatory to obtain a vulnerability score.
The temporal group assesses the vulnerability as it changes over time.
The environmental group represents the characteristics of a vulnerability, taking into account the organizational environment.
The score for the base group is between 0 and 10, where 0 is the least severe and 10 is assigned to highly critical vulnerabilities. For example, a highly critical vulnerability could allow an attacker to remotely compromise a system and get full control. Additionally, the score comes in the form of a vector string that identifies each of the components used to make up the score.
The formula used to obtain the score takes into account various characteristics of the vulnerability and how the attacker is able to leverage these characteristics.
CVSSv3 defines several characteristics for the base, temporal, and environmental groups.
The base group defines Exploitability metrics that measure how the vulnerability can be exploited, as well as Impact metrics that measure the impact on confidentiality, integrity, and availability. In addition to these two metrics, a metric called Scope Change (S) is used to convey the impact on other systems that may be impacted by the vulnerability but do not contain the vulnerable code. For instance, if a router is susceptible to a denial-of-service vulnerability and experiences a crash after receiving a crafted packet from the attacker, the scope is changed, since the devices behind the router will also experience the denial-of-service condition. FIRST has additional examples at https://www.first.org/cvss/v3.1/examples.
The Exploitability metrics include the following:
Attack Vector (AV) represents the level of access an attacker needs to have to exploit a vulnerability. It can assume four values:
Network (N)
Adjacent (A)
Local (L)
Physical (P)
Attack Complexity (AC) represents the conditions beyond the attacker’s control that must exist in order to exploit the vulnerability. The values can be the following:
Low (L)
High (H)
Privileges Required (PR) represents the level of privileges an attacker must have to exploit the vulnerability. The values are as follows:
None (N)
Low (L)
High (H)
User Interaction (UI) captures whether a user interaction is needed to perform an attack. The values are as follows:
None (N)
Required (R)
Scope (S) captures the impact on systems other than the system being scored. The values are as follows:
Unchanged (U)
Changed (C)
The Impact metrics include the following:
Confidentiality (C) measures the degree of impact to the confidentiality of the system. It can assume the following values:
Low (L)
Medium (M)
High (H)
Integrity (I) measures the degree of impact to the integrity of the system. It can assume the following values:
Low (L)
Medium (M)
High (H)
Availability (A) measures the degree of impact to the availability of the system. It can assume the following values:
Low (L)
Medium (M)
High (H)
The temporal group includes three metrics:
Exploit Code Maturity (E), which measures whether or not public exploit is available
Remediation Level (RL), which indicates whether a fix or workaround is available
Report Confidence (RC), which indicates the degree of confidence in the existence of the vulnerability
The environmental group includes two main metrics:
Security Requirements (CR, IR, AR), which indicate the importance of confidentiality, integrity, and availability requirements for the system
Modified Base Metrics (MAV, MAC, MAPR, MUI, MS, MC, MI, MA), which allow the organization to tweak the base metrics based on specific characteristics of the environment
For example, a vulnerability that might allow a remote attacker to crash the system by sending crafted IP packets would have the following values for the base metrics:
Access Vector (AV) would be Network because the attacker can be anywhere and can send packets remotely.
Attack Complexity (AC) would be Low because it is trivial to generate malformed IP packets (for example, via the Scapy Python tool).
Privilege Required (PR) would be None because there are no privileges required by the attacker on the target system.
User Interaction (UI) would also be None because the attacker does not need to interact with any user of the system to carry out the attack.
Scope (S) would be Unchanged if the attack does not cause other systems to fail.
Confidentiality Impact (C) would be None because the primary impact is on the availability of the system.
Integrity Impact (I) would be None because the primary impact is on the availability of the system.
Availability Impact (A) would be High because the device could become completely unavailable while crashing and reloading.
Additional examples of CVSSv3 scoring are available at the FIRST website (https://www.first.org/cvss).
In numerous instances, security vulnerabilities are not exploited in isolation. Threat actors exploit more than one vulnerability “in a chain” to carry out their attack and compromise their victims. By leveraging different vulnerabilities in a chain, attackers can infiltrate progressively further into the system or network and gain more control over it. This is something that PSIRT teams must be aware of. Developers, security professionals, and users must be aware of this because chaining can change the order in which a vulnerability needs to be fixed or patched in the affected system. For instance, multiple low-severity vulnerabilities can become a severe one if they are combined.
Performing vulnerability chaining analysis is not a trivial task. Although several commercial companies claim that they can easily perform chaining analysis, in reality the methods and procedures that can be included as part of a chain vulnerability analysis are pretty much endless. PSIRT teams should utilize an approach that works for them to achieve the best end result.
Exploits cannot exist without a vulnerability. However, there isn’t always an exploit for a given vulnerability. Earlier in this chapter you were reminded of the definition of a vulnerability. As another reminder, an exploit is not a vulnerability. An exploit is a concrete manifestation, either a piece of software or a collection of reproducible steps, that leverages a given vulnerability to compromise an affected system.
In some cases, users call vulnerabilities without exploits “theoretical vulnerabilities.” One of the biggest challenges with “theoretical vulnerabilities” is that there are many smart people out there capable of exploiting them. If you do not know how to exploit a vulnerability today, it does not mean that someone else will not find a way in the future. In fact, someone else may already have found a way to exploit the vulnerability and perhaps is even selling the exploit of the vulnerability in underground markets without public knowledge.
PSIRT personnel should understand there is no such thing as an “entirely theoretical” vulnerability. Sure, having a working exploit can ease the reproducible steps and help to verify whether that same vulnerability is present in different systems. However, because an exploit may not come as part of a vulnerability, you should not completely deprioritize it.
A PSIRT can learn about a vulnerability in a product or service during internal testing or during the development phase. However, vulnerabilities can also be reported by external entities, such as security researchers, customers, and other vendors.
The dream of any vendor is to be able to find and patch all security vulnerabilities during the design and development phases. However, that is close to impossible. On the other hand, that is why a secure development life cycle (SDL) is extremely important for any organization that produces software and hardware. Cisco has an SDL program that is documented at the following URL:
www.cisco.com/c/en/us/about/security-center/security-programs/secure-development-lifecycle.html
Cisco defines its SDL as “a repeatable and measurable process we’ve designed to increase the resiliency and trustworthiness of our products.” Cisco’s SDL is part of Cisco Product Development Methodology (PDM) and ISO9000 compliance requirements. It includes, but is not limited to, the following:
Base product security requirements
Third-party software (TPS) security
Secure design
Secure coding
Secure analysis
Vulnerability testing
The goal of the SDL is to provide tools and processes that are designed to accelerate the product development methodology, by developing secure, resilient, and trustworthy systems. TPS security is one of the most important tasks for any organization. Most of today’s organizations use open source and third-party libraries. This approach creates two requirements for the product security team. The first is to know what TPS libraries are used, reused, and where. The second is to patch any vulnerabilities that affect such libraries or TPS components. For example, if a new vulnerability in OpenSSL is disclosed, what do you have to do? Can you quickly assess the impact of such a vulnerability in all your products?
If you include commercial TPS, is the vendor of such software transparently disclosing all the security vulnerabilities, including in its software? Nowadays, many organizations are including security vulnerability disclosure SLAs in their contracts with third-party vendors. This is very important because many TPS vulnerabilities (both commercial and open source) go unpatched for many months—or even years.
Many tools are available on the market today to enumerate all open source components used in a product. These tools either interrogate the product source code or scan binaries for the presence of TPS.
National CSIRTs and Computer Emergency Response Teams (CERTs)
Numerous countries have their own computer emergency response (or readiness) teams. Examples include the US-CERT (https://www.us-cert.gov), Indian Computer Emergency Response Team (http://www.cert-in.org.in), CERT Australia (https://cert.gov.au), and the Australian Computer Emergency Response Team (https://www.auscert.org.au/). The Forum of Incident Response and Security Teams (FIRST) website includes a list of all the national CERTs and other incident response teams at https://www.first.org/members/teams.
These national CERTs and CSIRTs aim to protect their citizens by providing security vulnerability information, security awareness training, best practices, and other information. For example, the following is the US-CERT mission posted at https://www.us-cert.gov/about-us:
“US-CERT’s critical mission activities include:
Providing cybersecurity protection to Federal civilian executive branch agencies through intrusion detection and prevention capabilities.
Developing timely and actionable information for distribution to federal departments and agencies; state, local, tribal and territorial (SLTT) governments; critical infrastructure owners and operators; private industry; and international organizations.
Responding to incidents and analyzing data about emerging cyber threats.
Collaborating with foreign governments and international entities to enhance the nation’s cybersecurity posture.”
Coordination Centers
Several organizations around the world also help with the coordination of security vulnerability disclosures to vendors, hardware and software providers, and security researchers.
One of the best examples is the CERT Division of the Software Engineering Institute (SEI). Their website can be accessed at cert.org, and their “About Us” page summarizes well their role and the role of many coordination centers alike:
“CERT Division of the Software Engineering Institute (SEI), we study and solve problems with widespread cybersecurity implications, research security vulnerabilities in software products, contribute to long-term changes in networked systems, and develop cutting-edge information and training to help improve cybersecurity.
“We are more than a research organization. Working with software vendors, we help resolve software vulnerabilities. We develop tools, products, and methods to help organizations conduct forensic examinations, analyze vulnerabilities, and monitor large-scale networks. We help organizations determine how effective their security-related practices are. And we share our work at conferences; in blogs, webinars, and podcasts; and through our many articles, technical reports, and white papers. We collaborate with high-level government organizations, such as the U.S. Department of Defense and the Department of Homeland Security (DHS); law enforcement, including the FBI; the intelligence community; and many industry organizations.
“Working together, DHS and the CERT Division meet mutually set goals in areas such as data collection and mining, statistics and trend analysis, computer and network security, incident management, insider threat, software assurance, and more. The results of this work include exercises, courses, and systems that were designed, implemented, and delivered to DHS and its customers as part of the SEI’s mission to transition SEI capabilities to the public and private sectors and improve the practice of cybersecurity.”
Incident Response Providers and Managed Security Service Providers (MSSPs)
Cisco, along with several other vendors, provides incident response and managed security services to its customers. These incident response teams and outsourced CSIRTs operate a bit differently because their task is to provide support to their customers. However, they practice the tasks outlined earlier in this chapter for incident response and CSIRTs.
Outsourcing has been a long practice for many companies, but the onset of the complexity of cybersecurity has allowed it to bloom and become bigger as the years go by in the world of incident response.
Key Incident Management Personnel
Key incident management personnel include incident response coordinators, designated incident handlers, incident response team members, and external advisors. In various organizations, they may have different titles, but the roles are essentially the same.
The incident response coordinator (IRC) is the central point of contact for all incidents. Incident reports are directed to the IRC. The IRC verifies and logs the incident. Based on predefined criteria, the IRC notifies appropriate personnel, including the designated incident handler (DIH). The IRC is a member of the incident response team (IRT) and is responsible for maintaining all non-evidence-based incident-related documentation.
DIHs are senior-level personnel who have the crisis management and communication skills, experience, knowledge, and stamina to manage an incident. DIHs are responsible for three critical tasks: incident declaration, liaison with executive management, and managing the IRT.
The IRT is a carefully selected and well-trained team of professionals that provides services throughout the incident life cycle. Depending on the size of the organization, there may be a single team or multiple teams, each with its own specialty. The IRT members generally represent a cross-section of functional areas, including senior management, information security, information technology (IT), operations, legal, compliance, HR, public affairs and media relations, customer service, and physical security. Some members may be expected to participate in every response effort, whereas others (such as compliance) may restrict involvement to relevant events. The team as directed by the DIH is responsible for further analysis, evidence handling and documentation, containment, eradication and recovery, notification (as required), and post-incident activities.
Tasks assigned to the IRT include but are not limited to the following:
Overall management of the incident
Triage and impact analysis to determine the extent of the situation
Development and implementation of containment and eradication strategies
Compliance with government and/or other regulations
Communication and follow-up with affected parties and/or individuals
Communication and follow-up with other external parties, including the board of directors, business partners, government regulators (including federal, state, and other administrators), law enforcement, representatives of the media, and so on, as needed
Root cause analysis and lessons learned
Revision of policies/procedures necessary to prevent any recurrence of the incident
Establishing a robust response capability ensures that the organization is prepared to respond to an incident swiftly and effectively. Responders should receive training specific to their individual and collective responsibilities. Recurring tests, drills, and challenging incident response exercises can make a huge difference in responder ability. Knowing what is expected decreases the pressure on the responders and reduces errors. It should be stressed that the objective of incident response exercises isn’t to get an “A” but rather to honestly evaluate the plan and procedures, to identify missing resources, and to learn to work together as a team.
Summary
This chapter started with an introduction to cybersecurity and then moved into defining what are threats, vulnerabilities, and exploits. You learned about different common threats that can affect any organization, individual, system, or network. This chapter also covered the most common software and hardware vulnerabilities such as cross-site scripting, cross-site request forgery, SQL injection, buffer overflows, and many others.
This chapter also defined what is confidentiality, integrity, and availability (the CIA triad). You also learned about different cloud and IoT security threats. At the end, this chapter provided an introduction to digital forensics and incident response.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 12, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topic icon in the outer margin of the page. Table 1-2 lists these key topics and the page numbers on which each is found.
Table 1-2 Key Topics for Chapter 1
Key Topic Element |
Description |
Page Number |
Paragraph |
Understand the difference between InfoSec and Cybersecurity |
|
Section |
What Is a Threat? |
|
Section |
What Is a Vulnerability? |
|
Section |
What Is an Exploit? |
|
List |
Understand the difference between a white hat, gray hat, and black hat hacker |
|
Section |
Understanding What Threat Intelligence Is |
|
Section |
Viruses and Worms |
|
Section |
Trojans |
|
Section |
Distributing Malware |
|
Section |
Ransomware |
|
Section |
Keyloggers |
|
Section |
Spyware |
|
Section |
SQL Injection |
|
Section |
Command Injection |
|
Section |
Authentication-based Vulnerabilities |
|
Section |
Cross-site Scripting (XSS) |
|
Section |
Cross-site Request Forgery |
|
Section |
OWASP Top 10 |
|
Paragraph |
The NIST Definition of Cloud Computing |
|
List |
Understand the different cloud models |
|
List |
Identifying common cloud computing security concerns |
|
List |
Identify cloud computing attacks |
|
Section |
IoT Protocols |
|
Section |
ISO/IEC 27002:2013 and NIST Incident Response Guidance |
|
Section |
What Is an Incident? |
|
Section |
False Positives, False Negatives, True Positives, and True Negatives |
|
Section |
The Incident Response Plan |
|
Section |
The Incident Response Process |
|
Section |
Information Sharing and Coordination |
|
Section |
Computer Security Incident Response Teams |
|
Section |
The Common Vulnerability Scoring System (CVSS) |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
Review Questions
1. Which of the following are standards being developed for disseminating threat intelligence information?
STIX
TAXII
CybOX
All of these answers are correct.
2. Which type of hacker is considered a good guy?
White hat
Black hat
Gray hat
All of these answers are correct.
3. Which of the following is not an example of ransomware?
WannaCry
Pyeta
Nyeta
Bad Rabbit
Ret2Libc
4. Which of the following is the way you document and preserve evidence from the time that you started the cyber-forensics investigation to the time the evidence is presented in court?
Chain of custody
Best evidence
Faraday
None of these answers is correct.
5. Software and hardware vendors may have separate teams that handle the investigation, resolution, and disclosure of security vulnerabilities in their products and services. Typically, these teams are called ________.
CSIRT
Coordination Center
PSIRT
MSSP
6. Which of the following are the three components in CVSS?
Base, temporal, and environmental groups
Base, temporary, and environmental groups
Basic, temporal, and environmental groups
Basic, temporary, and environmental groups
7. Which of the following are IoT technologies?
Z-Wave
INSTEON
LoRaWAN
A and B
A, B, and C
None of these answers is correct.
8. Which of the following is a type of cloud deployment model where the cloud environment is shared among different organizations?
Community cloud
IaaS
PaaS
None of these answers is correct.
9. ____________ attacks occur when the sources of the attack are sent spoofed packets that appear to be from the victim, and then the sources become unwitting participants in the DDoS attacks by sending the response traffic back to the intended victim.
Reflected DDoS
Direct DoS
Backtrack DoS
SYN flood
10. Which of the following is a nonprofit organization that leads several industry-wide initiatives to promote the security of applications and software?
CERT/cc
OWASP
AppSec
FIRST