
Chapter 7
Data and Application Security Issues
THE CISSP EXAM TOPICS COVERED IN THIS CHAPTER INCLUDE:
- Application Development Security
- Understand and apply security in the system life cycle
- Systems Development Life Cycle (SDLC); maturity models; operation and maintenance; change management
- Understand the application environment and security controls
- Security of the application environment; security issues of programming languages; security issues in source code (e.g., buffer overflow); configuration management
- Assess the effectiveness of application security
- Auditing and logging; Corrective actions
- Understand and apply security in the system life cycle
- Operations Security
- Understand configuration management concepts (e.g., versioning, baselining)
All too often, security administrators are unaware of system vulnerabilities caused by applications with security flaws (either intentional or unintentional). Security professionals often have a background in system administration and don’t have an in-depth understanding of the application development process and therefore of application security. This can be a critical oversight. As you will learn in Chapter 14, “Auditing and Monitoring,” organization insiders (in other words, employees, contractors, and trusted visitors) are the most likely candidates to commit computer crimes. Security administrators must be aware of all threats to ensure that adequate checks and balances exist to protect against a malicious insider or application vulnerability.
In this chapter, we examine some of the common threats that applications pose to both traditional and distributed computing environments. Next, we explore how to protect data. Finally, we take a look at some of the systems development controls that can help ensure the accuracy, reliability, and integrity of internal application development processes.
As technology marches on, application environments are becoming much more complex than they were in the days of simple stand-alone DOS systems running precompiled code. To understand the application environment and security controls, you need to evaluate the variety of different situations that software will encounter. Organizations are now faced with challenges that arise from connecting their systems to networks of all shapes and sizes (from the office LAN to the global Internet) as well as from distributed computing environments. These challenges come in the form of malicious code, denial-of-service attacks, application attacks, and other security risks. In the following sections, we’ll take a brief look at a few of these issues.
Local/Nondistributed Environment
In a traditional, nondistributed computing environment, individual computer systems store and execute programs to perform functions for the local user. These functions generally involve networked applications that provide access to remote resources, such as web servers and remote file servers, as well as perform other interactive networked activities, such as the transmission and reception of electronic mail. The key characteristic of a nondistributed system is that all user-executed code is stored on the local machine (or on a file system accessible to that machine, such as a file server on the machine’s LAN) and executed using processors on that machine.
The threats that face local/nondistributed computing environments are some of the more common malicious code objects that you are most likely already familiar with, at least in passing. The following sections contain brief descriptions of those objects from an application security standpoint. We cover them in greater detail in Chapter 8, “Malicious Code and Application Attacks.”
Viruses
Viruses are the oldest form of malicious code objects that plague cyberspace. Once they are in a system, they attach themselves to legitimate operating system and user files and applications and usually perform some sort of undesirable action, ranging from the somewhat innocuous display of an annoying message on the screen to the more malicious destruction of the entire local file system.
Before the advent of networked computing, viruses spread from system to system through infected media. For example, suppose a user’s hard drive is infected with a virus. That user might then format a floppy disk and inadvertently transfer the virus to it along with some data files. When the user inserts the disk into another system and reads the data, that system would also become infected with the virus. The virus might then get spread to several other users, who go on to share it with even more users in an exponential fashion.
![]()
Macro viruses were among the most insidious viruses out there. They’re extremely easy to write and took advantage of some of the advanced features of modern productivity applications to significantly broaden their reach. Today, office applications are set by default to disable the use of macros that haven’t been digitally signed by a trusted author.
In this day and age, more and more computers are connected to some type of network and have at least an indirect connection to the Internet. This greatly increases the number of mechanisms that can transport viruses from system to system and expands the potential magnitude of these infections to epidemic proportions. After all, an email macro virus that can automatically propagate itself to every contact in your address book can inflict far more widespread damage than a boot sector virus that requires the sharing of physical storage media to transmit infection. The majority of viruses today are designed to create large botnets. While they historically were designed to cause damage to the infected machine, and many still do this today, most viruses lie hidden as zombies or clones waiting for direction from the botnet controllers. These topics are covered in more detail in Chapter 8.
Trojan Horses
During the Trojan War, the Greek military used a false horse filled with soldiers to gain access to the fortified city of Troy. The Trojans fell prey to this deception because they believed the horse to be a generous gift and were unaware of its insidious cargo. Modern computer users face a similar threat from today’s electronic version of the Trojan horse. A Trojan horse is a malicious code object that appears to be a benevolent program—such as a game or simple utility. When a user executes the application, it performs the “cover” functions, as advertised; however, electronic Trojan horses also carry a secret payload. While the computer user is using the cover program, the Trojan horse performs some sort of malicious action—such as opening a security hole in the system for hackers to exploit, tampering with data, or installing keystroke-monitoring software.
Logic Bombs
Logic bombs are malicious code objects that lie dormant until events occur that satisfy one or more logical conditions. At that time, they spring into action, delivering their malicious payload to unsuspecting computer users. They are often planted by disgruntled employees or other individuals who want to harm an organization but for one reason or another want to delay the malicious activity for a period. Many simple logic bombs operate based solely upon the system date or time. For example, an employee who was terminated might set a logic bomb to destroy critical business data on the first anniversary of their termination. Other logic bombs operate using more complex criteria. For example, a programmer who fears termination might plant a logic bomb that alters payroll information after the programmer’s account is locked out of the system.
Worms
Worms are an interesting type of malicious code that greatly resemble viruses, with one major distinction. Like viruses, worms spread from system to system bearing some type of malicious payload. However, whereas viruses require some type of user action to propagate, worms are self-replicating. They remain resident in memory and exploit one or more networking vulnerabilities to spread from system to system under their own power. Obviously, this allows for much greater propagation and can result in a denial-of-service attack against entire networks. Indeed, the famous Internet Worm launched by Robert Tappan Morris in November 1988 (we present the technical details of this worm in Chapter 8) actually crippled the entire Internet for several days.
Distributed Environment
The previous sections discussed how the advent of networked computing facilitated the rapid spread of malicious code objects between computing systems. The following sections examine how distributed computing (an offshoot of networked computing) introduces a variety of new malicious code threats that information system security practitioners must understand and protect their systems against.
Essentially, distributed computing allows a single user to harness the computing power of one or more remote systems to achieve a single goal. A common example of this is the client/server interaction that takes place when a computer user browses the World Wide Web. The client uses a web browser, such as Microsoft Internet Explorer or Mozilla Firefox, to request information from a remote server. The remote server’s web hosting software then receives and processes the request. In many cases, the web server fulfills the request by retrieving an HTML file from the local file system and transmitting it to the remote client. In the case of dynamically generated web pages, that request might involve generating custom content tailored to the needs of the individual user (real-time account information is a good example of this). In effect, the web user is causing remote server(s) to perform actions on their behalf.
Agents
Agents (also known as bots) are intelligent code objects that perform actions on behalf of a user. Agents typically take initial instructions from the user and then carry on their activity in an unattended manner for a predetermined period of time, until certain conditions are met, or for an indefinite period.
The most common type of intelligent agent in use today is the web bot. These agents continuously crawl a variety of websites retrieving and processing data on behalf of the user. For example, a user interested in finding a low airfare between two cities might use an intelligent agent to scour a variety of airline and travel websites and continuously check fare prices. Whenever the agent detects a fare lower than previous fares, it might send the user an email message, text message, or other notification of the cheaper travel opportunity. More adventurous bot programmers might even provide the agent with credit card information and instruct it to actually order a ticket when the fare reaches a certain level.
![]()
Stop Orders as User Agents
If you invest in the stock market, you’re probably familiar with another type of user agent: stop orders. These allow investors to place predefined orders instructing their broker (or, more realistically, their broker’s computer system) to make trades on the investor’s behalf when certain conditions occur.
Stop orders may be used to limit an investor’s loss on a stock. Suppose you buy shares of Acme Corporation at $30 and wish to ensure that you don’t lose more than 50 percent of your initial investment. You might place a stop loss order at $15, which instructs your broker to sell your stock at the current market price if the share price ever falls below $15.
Similarly, you can use stop orders to lock in profits. In the previous example, the investor might target a 20 percent profit by placing a stop order to execute whenever the stock price exceeds $36.
The popularity of online auctions has created another market for intelligent agents: auction sniping. Agents using this strategy log into an auction website seconds before an auction closes to place a last-minute bid on behalf of a buyer. Buyers use sniping in an attempt to ward off last-minute bidding wars.
Although agents can be useful computing objects, they also introduce a variety of new security concerns that must be addressed. For example, what if a hacker programs an agent to continuously probe a network for security holes and report vulnerable systems in real time? How about a malicious individual who uses a number of agents to flood a website with bogus requests, thereby mounting a denial-of-service attack against that site? Or perhaps a commercially available agent accepts credit card information from a user and then transmits it to a hacker at the same time that it places a legitimate purchase.
Applets
Recall that agents are code objects sent from a user’s system to query and process data stored on remote systems. Applets perform the opposite function; these code objects are sent from a server to a client to perform some action. In fact, applets are actually self-contained miniature programs that execute independently of the server that sent them.
Imagine a web server that offers a variety of financial tools to web users. One of these tools might be a mortgage calculator that processes a user’s financial information and provides a monthly mortgage payment based upon the loan’s principal and term and the borrower’s credit information. Instead of processing this data and returning the results to the client system, the remote web server might send to the local system an applet that enables it to perform those calculations itself. This provides a number of benefits to both the remote server and the end user:
- The processing burden is shifted to the client, freeing up resources on the web server to process requests from more users.
- The client is able to produce data using local resources rather than waiting for a response from the remote server. In many cases, this results in a quicker response to changes in the input data.
- In a properly programmed applet, the web server does not receive any data provided to the applet as input, therefore maintaining the security and privacy of the user’s financial data.
However, just as with agents, applets introduce a number of security concerns. They allow a remote system to send code to the local system for execution. Security administrators must take steps to ensure that code sent to systems on their network is safe and properly screened for malicious activity. Also, unless the code is analyzed line by line, the end user can never be certain that the applet doesn’t contain a Trojan horse component. For example, the mortgage calculator might indeed transmit sensitive financial information to the web server without the end user’s knowledge or consent.
The following sections explore two common applet types: Java applets and ActiveX controls.
Java Applets
Java is a platform-independent programming language developed by Sun Microsystems. Most programming languages use compilers that produce applications custom-tailored to run under a specific operating system. This requires the use of multiple compilers to produce different versions of a single application for each platform it must support. Java overcomes this limitation by inserting the Java Virtual Machine (JVM) into the picture. Each system that runs Java code downloads the version of the JVM supported by its operating system. The JVM then takes the Java code and translates it into a format executable by that specific system. The great benefit of this arrangement is that code can be shared between operating systems without modification. Java applets are simply short Java programs transmitted over the Internet to perform operations on a remote system.
Security was of paramount concern during the design of the Java platform, and Sun’s development team created the “sandbox” concept to place privilege restrictions on Java code. The sandbox isolates Java code objects from the rest of the operating system and enforces strict rules about the resources those objects can access. For example, the sandbox would prohibit a Java applet from retrieving information from areas of memory not specifically allocated to it, preventing the applet from stealing that information.
ActiveX Controls
ActiveX controls are Microsoft’s answer to Sun’s Java applets. They operate in a similar fashion, but they are implemented using any one of a variety of languages, including Visual Basic, C, C++, and Java. There are two key distinctions between Java applets and ActiveX controls. First, ActiveX controls use proprietary Microsoft technology and, therefore, can execute only on systems running Microsoft browsers. Second, ActiveX controls are not subject to the sandbox restrictions placed on Java applets. They have full access to the Windows operating environment and can perform a number of privileged actions. Therefore, you must take special precautions when deciding which ActiveX controls to download and execute. Some security administrators have taken the somewhat harsh position of prohibiting the download of any ActiveX content from all but a select handful of trusted sites.
Object Request Brokers
To facilitate the growing trend toward distributed computing, the Object Management Group (OMG) set out to develop a common standard for developers around the world. Their work, known as the Common Object Request Broker Architecture (CORBA), has resulted in an international standard (sanctioned by the International Organization for Standardization) for distributed computing. It defines the sequence of interactions between client and server shown in Figure 7.1.
FIGURE 7.1 CORBA
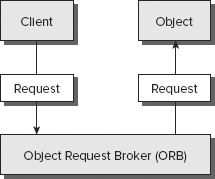
In this model, clients do not need specific knowledge of a server’s location or technical details to interact with it. They simply pass their request for a particular object to a local Object Request Broker (ORB) using a well-defined interface. These interfaces are created using the OMG’s Interface Definition Language (IDL). The ORB, in turn, invokes the appropriate object, keeping the implementation details transparent to the original client.
![]()
Object Request Brokers (ORBs) are an offshoot of object-oriented programming, a topic discussed later in this chapter.
![]()
The discussion of CORBA and ORBs presented here is, by necessity, an oversimplification designed to provide security professionals with an overview of the process. CORBA extends well beyond the model presented in Figure 7.1 to facilitate ORB-to-ORB interaction, load balancing, fault tolerance, and a number of other features. If you’re interested in learning more about CORBA, the OMG has an excellent tutorial on its website at www.omg.org/gettingstarted/corbafaq.htm.
Microsoft Component Models
The driving force behind OMG’s efforts to implement CORBA was the desire to create a common standard that enabled non-vendor-specific interaction. However, as such things often go, Microsoft decided to develop its own proprietary standards for object management: COM and DCOM.
The Component Object Model (COM) is Microsoft’s standard architecture for the use of components within a process or between processes running on the same system. It works across the range of Microsoft products, from development environments to the Office productivity suite. In fact, Office’s object linking and embedding (OLE) model that allows users to create documents that utilize components from different applications uses the COM architecture.
Although COM is restricted to local system interactions, the Distributed Component Object Model (DCOM) extends the concept to cover distributed computing environments. It replaces COM’s interprocess communications capability with an ability to interact with the network stack and invoke objects located on remote systems.
![]()
Although DCOM and CORBA are competing component architectures, Microsoft and OMG agreed to allow some interoperability between ORBs utilizing different models.
Microsoft created the .NET Framework as a replacement to DCOM. The .NET Framework provides a Common Language Infrastructure (CLI) as the core foundation for all compiled languages. .NET developers may use Visual Basic .NET, C#, J#, or any of a number of other languages that provide .NET support.
Databases and Data Warehousing
Almost every modern organization maintains some sort of database that contains information critical to operations—be it customer contact information, order-tracking data, human resource and benefits information, or sensitive trade secrets. It’s likely that many of these databases contain personal information that users hold secret, such as credit card usage activity, travel habits, grocery store purchases, and telephone records. Because of the growing reliance on database systems, information security professionals must ensure that adequate security controls exist to protect them against unauthorized access, tampering, or destruction of data.
In the following sections, we’ll discuss database management system (DBMS) architecture, the various types of DBMSs, and their features. Then we’ll discuss database security features, polyinstantiation, ODBS, aggregation, inference, and data mining. They’re loaded sections, so pay attention.
Database Management System (DBMS) Architecture
Although there are a variety of database management system (DBMS) architectures available today, the vast majority of contemporary systems implement a technology known as relational database management systems (RDBMSs). For this reason, the following sections focus primarily on relational databases. However, first we’ll discuss two other important DBMS architectures: hierarchical and distributed.
Hierarchical and Distributed Databases
A hierarchical data model combines records and fields that are related in a logical tree structure. This results in a “one-to-many” data model, where each node may have zero, one, or many children but only one parent. An example of a hierarchical data model appears in Figure 7.2.
FIGURE 7.2 Hierarchical data model
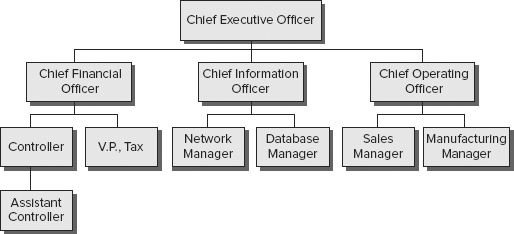
The hierarchical model in Figure 7.2 is a corporate organization chart. Notice that the “one-to-many” data model holds true in this example. Each employee has only one manager (the “one” in “one-to-many”), but each manager may have one or more (the “many”) employees. Other examples of hierarchical data models include the NCAA March Madness bracket system and the hierarchical distribution of Domain Name System (DNS) records used on the Internet. Hierarchical databases store data in this type of hierarchical fashion and are useful for specialized applications that fit the model. For example, biologists might use a hierarchical database to store data on specimens according to the kingdom/phylum/class/order/family/genus/species hierarchical model used in that field.
The distributed data model has data stored in more than one database, but those databases are logically connected. The user perceives the database as a single entity, even though it comprises numerous parts interconnected over a network. Each field can have numerous children as well as numerous parents. Thus, the data mapping relationship for distributed databases is many-to-many.
Relational Databases
A relational database consists of flat two-dimensional tables made up of rows and columns. In fact, each table looks very similar to a spreadsheet file. The row and column structure provides for one-to-one data mapping relationships. The main building block of the relational database is the table (also known as a relation). Each table contains a set of related records. For example, a sales database might contain the following tables:
- Customers table that contains contact information for all the organization’s clients
- Sales Reps table that contains identity information on the organization’s sales force
- Orders table that contains records of orders placed by each customer
Object-Oriented Programming and Databases
Object-relational databases combine relational databases with the power of object-oriented programming. True object-oriented databases (OODBs) benefit from ease of code reuse, ease of troubleshooting analysis, and reduced overall maintenance. OODBs are also better suited for supporting complex applications involving multimedia, CAD, video, graphics, and expert systems than other types of databases.
Each of these tables contains a number of attributes, or fields. Each attribute corresponds to a column in the table. For example, the Customers table might contain columns for the company name, address, city, state, zip code, and telephone number. Each customer would have its own record, or tuple, represented by a row in the table. The number of rows in the relation is referred to as cardinality, and the number of columns is the degree. The domain of a relation is the set of allowable values that the attribute can take. Figure 7.3 shows an example of a Customers table from a relational database.
FIGURE 7.3 Customers table from a relational database

In this example, the table has a cardinality of three (corresponding to the three rows in the table) and a degree of eight (corresponding to the eight columns). It’s common for the cardinality of a table to change during the course of normal business, such as when a sales rep adds new customers. The degree of a table normally does not change frequently and usually requires database administrator intervention.
![]()
To remember the concept of cardinality, think of a deck of cards on a desk, with each card (the first four letters of this term) being a row. To remember the concept of degree, think of a wall thermometer as a column (in other words, the temperature in degrees as measured on a thermometer).
Relationships between the tables are defined to identify related records. In this example, a relationship exists between the Customers table and the Sales Reps table because each customer is assigned a sales representative and because each sales representative is assigned to one or more customers. This relationship is reflected by the Sales Rep column in the Customer table, shown in Figure 7.3. The values in this column refer to a Sales Rep ID field contained in the Sales Rep table (not shown). Additionally, a relationship would probably exist between the Customers table and the Orders table because each order must be associated with a customer and each customer is associated with one or more product orders. The Orders table (not shown) would likely contain a Customer field that contained one of the Customer ID values shown in Figure 7.3.
Records are identified using a variety of keys. Quite simply, keys are a subset of the fields of a table used to uniquely identify records. They are also used to join tables together when you wish to cross-reference information. You should be familiar with three types of keys:
Candidate keys Subsets of attributes that can be used to uniquely identify any record in a table. No two records in the same table will ever contain the same values for all attributes composing a candidate key. Each table may have one or more candidate keys, which are chosen from column headings.
Primary keys Selected from the set of candidate keys for a table to be used to uniquely identify the records in a table. Each table has only one primary key, selected by the database designer from the set of candidate keys. The RDBMS enforces the uniqueness of primary keys by disallowing the insertion of multiple records with the same primary key. In the Customers table shown in Figure 7.3, the Customer ID would likely be the primary key.
Foreign keys Used to enforce relationships between two tables, also known as referential integrity. Referential integrity ensures that if one table contains a foreign key, it corresponds to a still-existing primary key in the other table in the relationship. It makes certain that no record/tuple/row contains a reference to a primary key of a nonexistent record/tuple/row. In the example described earlier, the Sales Rep field shown in Figure 7.3 is a foreign key referencing the primary key of the Sales Reps table.
All relational databases use a standard language, the Structured Query Language (SQL), to provide users with a consistent interface for the storage, retrieval, and modification of data and for administrative control of the DBMS. Each DBMS vendor implements a slightly different version of SQL (like Microsoft’s Transact-SQL and Oracle’s PL/SQL), but all support a core feature set. SQL’s primary security feature is its granularity of authorization. This means that SQL allows you to set permissions at a very fine level of detail. You can limit user access by the table, row, column, or even the individual cell in some cases.
Database Normalization
Database developers strive to create well-organized and efficient databases. To assist with this effort, they’ve defined several levels of database organization known as normal forms. The process of bringing a database table into compliance with normal forms is known as normalization.
Although a number of normal forms exist, the three most common are first normal form (1NF), second normal form (2NF), and third normal form (3NF). Each of these forms adds requirements to reduce redundancy in the tables, eliminating misplaced data and performing a number of other housekeeping tasks. The normal forms are cumulative; in other words, to be in 2NF, a table must first be 1NF compliant. Before making a table 3NF compliant, it must first be in 2NF.
The details of normalizing a database table are beyond the scope of the CISSP exam, but several web resources can help you understand the requirements of the normal forms in greater detail. For example, refer to the article “Database Normalization” at http://databases.about.com/od/specificproducts/a/normalization.htm. You can also read the book SQL Server 2008 for Dummies (Wiley, 2008) for an introduction to database design.
SQL provides the complete functionality necessary for administrators, developers, and end users to interact with the database. In fact, the graphical database interfaces popular today merely wrap some extra bells and whistles around a standard SQL interface to the DBMS. SQL itself is divided into two distinct components: the Data Definition Language (DDL), which allows for the creation and modification of the database’s structure (known as the schema), and the Data Manipulation Language (DML), which allows users to interact with the data contained within that schema.
Database Transactions
Relational databases support the explicit and implicit use of transactions to ensure data integrity. Each transaction is a discrete set of SQL instructions that will either succeed or fail as a group. It’s not possible for one part of a transaction to succeed while another part fails. Consider the example of a transfer between two accounts at a bank. You might use the following SQL code to first add $250 to account 1001 and then subtract $250 from account 2002:
BEGIN TRANSACTION
UPDATE accounts
SET balance = balance + 250
WHERE account_number = 1001;
UPDATE accounts
SET balance = balance - 250
WHERE account_number = 2002
END TRANSACTION
Imagine a case where these two statements were not executed as part of a transaction but were instead executed separately. If the database failed during the moment between completion of the first transaction and completion of the second transaction, $250 would have been added to account 1001, but there would be no corresponding deduction from account 2002. The $250 would have appeared out of thin air! Flipping the order of the two statements wouldn’t help—this would cause $250 to disappear into thin air if interrupted! This simple example underscores the importance of transaction-oriented processing.
When a transaction successfully completes, it is said to be committed to the database and cannot be undone. Transaction committing may be explicit, using SQL’s COMMIT command, or it can be implicit if the end of the transaction is successfully reached. If a transaction must be aborted, it can be rolled back explicitly using the ROLLBACK command or implicitly if there is a hardware or software failure. When a transaction is rolled back, the database restores itself to the condition it was in before the transaction began.
All database transactions have four required characteristics: atomicity, consistency, isolation, and durability. Together, these attributes are known as the ACID model, which is a critical concept in the development of database management systems. Let’s take a brief look at each of these requirements:
Atomicity Database transactions must be atomic—that is, they must be an “all-or-nothing” affair. If any part of the transaction fails, the entire transaction must be rolled back as if it never occurred.
Consistency All transactions must begin operating in an environment that is consistent with all of the database’s rules (for example, all records have a unique primary key). When the transaction is complete, the database must again be consistent with the rules, regardless of whether those rules were violated during the processing of the transaction itself. No other transaction should ever be able to utilize any inconsistent data that might be generated during the execution of another transaction.
Isolation The isolation principle requires that transactions operate separately from each other. If a database receives two SQL transactions that modify the same data, one transaction must be completed in its entirety before the other transaction is allowed to modify the same data. This prevents one transaction from working with invalid data generated as an intermediate step by another transaction.
Durability Database transactions must be durable. That is, once they are committed to the database, they must be preserved. Databases ensure durability through the use of backup mechanisms, such as transaction logs.
In the following sections, we’ll discuss a variety of specific security issues of concern to database developers and administrators.
Security for Multilevel Databases
As you learned in Chapter 5, “Security Management Concepts and Principles,” many organizations use data classification schemes to enforce access control restrictions based upon the security labels assigned to data objects and individual users. When mandated by an organization’s security policy, this classification concept must also be extended to the organization’s databases.
Multilevel security databases contain information at a number of different classification levels. They must verify the labels assigned to users and, in response to user requests, provide only information that’s appropriate. However, this concept becomes somewhat more complicated when considering security for a database.
When multilevel security is required, it’s essential that administrators and developers strive to keep data with different security requirements separate. Mixing data with different classification levels and/or need-to-know requirements is known as database contamination and is a significant security challenge. Often, administrators will deploy a trusted front end to add multilevel security to a legacy or insecure DBMS.
![]()
Restricting Access with Views
Another way to implement multilevel security in a database is through the use of database views. Views are simply SQL statements that present data to the user as if they were tables themselves. They may be used to collate data from multiple tables, aggregate individual records, or restrict a user’s access to a limited subset of database attributes and/or records.
Views are stored in the database as SQL commands rather than as tables of data. This dramatically reduces the space requirements of the database and allows views to violate the rules of normalization that apply to tables. However, retrieving data from a complex view can take significantly longer than retrieving it from a table because the DBMS may need to perform calculations to determine the value of certain attributes for each record.
Because views are so flexible, many database administrators use them as a security tool—allowing users to interact only with limited views rather than with the raw tables of data underlying them.
Concurrency
Concurrency, or edit control, is a preventative security mechanism that endeavors to make certain that the information stored in the database is always correct or at least has its integrity and availability protected. This feature can be employed whether the database is multilevel or single level. Concurrency uses a “lock” feature to allow one user to make changes but deny other users access to view or make changes to data elements at the same time. Then, after the changes have been made, an “unlock” feature restores the ability of other users to access the data they need. In some instances, administrators will use concurrency with auditing mechanisms to track document and/or field changes. When this recorded data is reviewed, concurrency becomes a detective control.
Other Security Mechanisms
Administrators can deploy several other security mechanisms when using a DBMS. These features are relatively easy to implement and are common in the industry. The mechanisms related to semantic integrity, for instance, are common security features of a DBMS. Semantic integrity ensures that user actions don’t violate any structural rules. It also checks that all stored data types are within valid domain ranges, ensures that only logical values exist, and confirms that the system complies with any and all uniqueness constraints.
Administrators may employ time and date stamps to maintain data integrity and availability. Time and date stamps often appear in distributed database systems. When a time stamp is placed on all change transactions and those changes are distributed or replicated to the other database members, all changes are applied to all members, but they are implemented in correct chronological order.
Another common security feature of DBMS is that objects can be controlled granularly within the database; this can also improve security control. Content-dependent access control is an example of granular object control. Content-dependent access control focuses on control based upon the contents or payload of the object being accessed. Since decisions must be made on an object-by-object basis, content-dependent control increases processing overhead. Another form of granular control is cell suppression. Cell suppression is the concept of hiding or imposing more security restrictions on individual database fields or cells.
Context-dependent access control is often discussed alongside content-dependent access control because of the similarity of their names. Context-dependent access control evaluates the big picture to make its access control decisions. The key factor in context-dependent access control is how each object or packet or field relates to the overall activity or communication. Any single element may look innocuous by itself, but in a larger context that element may be revealed to be benign or malign.
Administrators may employ database partitioning to subvert aggregation, inferencing, and contamination vulnerabilities, which are discussed later in this chapter. Database partitioning is the process of splitting a single database into multiple parts, each with a unique and distinct security level or type of content.
Polyinstantiation occurs when two or more rows in the same relational database table appear to have identical primary key elements but contain different data for use at differing classification levels. It is often used as a defense against some types of inference attacks (we’ll discuss inference in just a moment).
Consider a database table containing the location of various naval ships on patrol. Normally, this database contains the exact position of each ship stored at the secret classification level. However, one particular ship, the USS UpToNoGood, is on an undercover mission to a top-secret location. Military commanders do not want anyone to know that the ship deviated from its normal patrol. If the database administrators simply change the classification of the UpToNoGood’s location to top secret, a user with a secret clearance would know that something unusual was going on when they couldn’t query the location of the ship. However, if polyinstantiation is used, two records could be inserted into the table. The first one, classified at the top-secret level, would reflect the true location of the ship and be available only to users with the appropriate top-secret security clearance. The second record, classified at the secret level, would indicate that the ship was on routine patrol and would be returned to users with a secret clearance.
Finally, administrators can insert false or misleading data into a DBMS in order to redirect or thwart information confidentiality attacks. This is a concept known as noise and perturbation. You must be extremely careful when using this technique to ensure that noise inserted into the database does not affect business operations.
ODBC
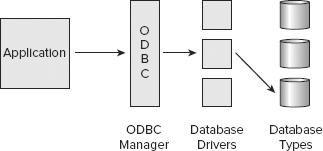
Open Database Connectivity (ODBC) is a database feature that allows applications to communicate with different types of databases without having to be directly programmed for interaction with each type. ODBC acts as a proxy between applications and back-end database drivers, giving application programmers greater freedom in creating solutions without having to worry about the back-end database system. Figure 7.4 illustrates the relationship between ODBC and a back-end database system.
FIGURE 7.4 ODBC as the interface between applications and a back-end database system
Aggregation
SQL provides a number of functions that combine records from one or more tables to produce potentially useful information. This process is called aggregation. Aggregation is not without its security vulnerabilities. Aggregation attacks are used to collect numerous low-level security items or low-value items and combine them together to create something of a higher security level or value. Some of the functions, known as the aggregate functions, are listed here:
COUNT( ) Returns the number of records that meet specified criteria
MIN( ) Returns the record with the smallest value for the specified attribute or combination of attributes
MAX( ) Returns the record with the largest value for the specified attribute or combination of attributes
SUM( ) Returns the summation of the values of the specified attribute or combination of attributes across all affected records
AVG( ) Returns the average value of the specified attribute or combination of attributes across all affected records
These functions, although extremely useful, also pose a risk to the security of information in a database. For example, suppose a low-level military records clerk is responsible for updating records of personnel and equipment as they are transferred from base to base. As part of his duties, this clerk may be granted the database permissions necessary to query and update personnel tables.
The military might not consider an individual transfer request (in other words, Sergeant Jones is being moved from Base X to Base Y) to be classified information. The records clerk has access to that information, as he needs it to process Sergeant Jones’s transfer. However, with access to aggregate functions, the records clerk might be able to count the number of troops assigned to each military base around the world. These force levels are often closely guarded military secrets, but the low-ranking records clerk was able to deduce them by using aggregate functions across a large number of unclassified records.
Inference
The database security issues posed by inference attacks are very similar to those posed by the threat of data aggregation. As with aggregation, inference attacks involve the combination of several pieces of nonsensitive information used to gain access to information that should be classified at a higher level. However, inference makes use of the human mind’s deductive capacity rather than the raw mathematical ability of modern database platforms.
A commonly cited example of an inference attack is that of the accounting clerk at a large corporation who is allowed to retrieve the total amount the company spends on salaries for use in a top-level report but is not allowed to access the salaries of individual employees. The accounting clerk often has to prepare those reports with effective dates in the past and so is allowed to access the total salary amounts for any day in the past year. Say, for example, that this clerk must also know the hiring and termination dates of various employees and has access to this information. This opens the door for an inference attack. If an employee was the only person hired on a specific date, the accounting clerk can now retrieve the total salary amount on that date and the day before and deduce the salary of that particular employee—sensitive information that the user would not be permitted to access directly.
As with aggregation, the best defense against inference attacks is to maintain constant vigilance over the permissions granted to individual users. Furthermore, intentional blurring of data may be used to prevent the inference of sensitive information. For example, if the accounting clerk were able to retrieve only salary information rounded to the nearest million, they would probably not be able to gain any useful information about individual employees. Finally, you can use database partitioning (discussed earlier in this chapter) to help subvert these attacks.
For this reason, it’s especially important for database security administrators to strictly control access to aggregate functions and adequately assess the potential information they may reveal to unauthorized individuals.
Data Mining
Many organizations use large databases, known as data warehouses, to store large amounts of information from a variety of databases for use with specialized analysis techniques. These data warehouses often contain detailed historical information not normally stored in production databases because of storage limitations or data security concerns.
A data dictionary is commonly used for storing critical information about data, including usage, type, sources, relationships, and formats. DBMS software reads the data dictionary to determine access rights for users attempting to access data.
Data mining techniques allow analysts to comb through these data warehouses and look for potential correlated information amid the historical data. For example, an analyst might discover that the demand for lightbulbs always increases in the winter months and then use this information when planning pricing and promotion strategies. Data mining techniques result in the development of data models that may be used to predict future activity.
The activity of data mining produces metadata. Metadata is data about data or information about data. Metadata is not exclusively the result of data mining operations; other functions or services can produce metadata as well. Think of metadata from a data mining operation as a concentration of data. It can also be a superset, a subset, or a representation of a larger data set. Metadata can be the important, significant, relevant, abnormal, or aberrant elements from a data set.
One common security example of metadata is that of a security incident report. A incident report is the metadata extracted from a data warehouse of audit logs through the use of a security auditing data mining tool. In most cases, metadata is of a greater value or sensitivity (due to disclosure) than the bulk of data in the warehouse. Thus, metadata is stored in a more secure container known as the data mart.
![]()
You may also hear data mining referred to as Knowledge Discovery in Databases (KDD). It is closely related to the fields of machine learning and artificial intelligence.
Data warehouses and data mining are significant to security professionals for two reasons. First, as previously mentioned, data warehouses contain large amounts of potentially sensitive information vulnerable to aggregation and inference attacks, and security practitioners must ensure that adequate access controls and other security measures are in place to safeguard this data. Second, data mining can actually be used as a security tool when it’s used to develop baselines for statistical anomaly–based intrusion detection systems (see Chapter 2, “Attacks and Monitoring,” for more information on the various types and functionality of intrusion detection systems).
![]()
Data Mining for Anomaly Detection
With several colleagues, Mike Chapple, one of this book’s authors, recently published a paper titled “Authentication Anomaly Detection” that explored the usefulness of data mining techniques to explore authentication logs from a virtual private network (VPN). In the study, they used expectation maximization (EM) clustering, a data mining technique, to develop models of normal user behavior based upon a user’s affiliation with the organization, the distance between the data center and their physical location, the day of the week, the hour of the day, and other attributes.
After developing the models through data mining, they applied them to future activity and identified user connection attempts that didn’t look “normal,” as defined by the model. Using this approach, they identified several unauthorized uses of the VPN.
Database management systems have helped harness the power of data and gain some modicum of control over who can access it and the actions they can perform on it. However, security professionals must keep in mind that DBMS security covers access to information through only the traditional “front-door” channels. Data is also processed through a computer’s storage resources—both memory and physical media. Precautions must be in place to ensure that these basic resources are protected against security vulnerabilities as well. After all, you would never incur a lot of time and expense to secure the front door of your home and then leave the back door wide open, would you?
Types of Storage
Modern computing systems use several types of storage to maintain system and user data. The systems strike a balance between the various storage types to satisfy an organization’s computing requirements. There are several common storage types:
Primary (or “real”) memory Consists of the main memory resources directly available to a system’s CPU. Primary memory normally consists of volatile random access memory (RAM) and is usually the most high-performance storage resource available to a system.
Secondary storage Consists of more inexpensive, nonvolatile storage resources available to a system for long-term use. Typical secondary storage resources include magnetic and optical media, such as tapes, disks, hard drives, flash drives, and CD/DVD storage.
Virtual memory Allows a system to simulate additional primary memory resources through the use of secondary storage. For example, a system low on expensive RAM might make a portion of the hard disk available for direct CPU addressing.
Virtual storage Allows a system to simulate secondary storage resources through the use of primary storage. The most common example of virtual storage is the RAM disk that presents itself to the operating system as a secondary storage device but is actually implemented in volatile RAM. This provides an extremely fast file system for use in various applications but provides no recovery capability.
Random access storage Allows the operating system to request contents from any point within the media. RAM and hard drives are examples of random access storage resources.
Sequential access storage Requires scanning through the entire media from the beginning to reach a specific address. A magnetic tape is a common example of a sequential access storage resource.
Volatile storage Loses its contents when power is removed from the resource. RAM is the most common type of volatile storage resource.
Nonvolatile storage Does not depend upon the presence of power to maintain its contents. Magnetic/optical media and nonvolatile RAM (NVRAM) are typical examples of nonvolatile storage resources.
Storage Threats
Information security professionals should be aware of two main threats posed against data storage systems. First, the threat of illegitimate access to storage resources exists no matter what type of storage is in use. If administrators do not implement adequate file system access controls, an intruder might stumble across sensitive data simply by browsing the file system. In more sensitive environments, administrators should also protect against attacks that involve bypassing operating system controls and directly accessing the physical storage media to retrieve data. This is best accomplished through the use of an encrypted file system, which is accessible only through the primary operating system. Furthermore, systems that operate in a multilevel security environment should provide adequate controls to ensure that shared memory and storage resources provide fail-safe controls so that data from one classification level is not readable at a lower classification level.
Covert channel attacks pose the second primary threat against data storage resources. Covert storage channels allow the transmission of sensitive data between classification levels through the direct or indirect manipulation of shared storage media. This may be as simple as writing sensitive data to an inadvertently shared portion of memory or physical storage. More complex covert storage channels might be used to manipulate the amount of free space available on a disk or the size of a file to covertly convey information between security levels. For more information on covert channel analysis, see Chapter 12, “Principles of Security Models.”
Since the advent of computing, engineers and scientists have worked toward developing systems capable of performing routine actions that would bore a human and consume a significant amount of time. The majority of the achievements in this area focused on relieving the burden of computationally intensive tasks. However, researchers have also made giant strides toward developing systems that have an “artificial intelligence” that can simulate (to some extent) the purely human power of reasoning.
The following sections examine two types of knowledge-based artificial intelligence systems: expert systems and neural networks. We’ll also take a look at their potential applications to computer security problems.
Expert Systems
Expert systems seek to embody the accumulated knowledge of experts on a particular subject and apply it in a consistent fashion to future decisions. Several studies have shown that expert systems, when properly developed and implemented, often make better decisions than some of their human counterparts when faced with routine decisions.
Every expert system has two main components. The knowledge base contains the rules known by an expert system. The knowledge base seeks to codify the knowledge of human experts in a series of “if/then” statements. Let’s consider a simple expert system designed to help homeowners decide whether they should evacuate an area when a hurricane threatens. The knowledge base might contain the following statements (these statements are for example only):
- If the hurricane is a Category 4 storm or higher, then flood waters normally reach a height of 20 feet above sea level.
- If the hurricane has winds in excess of 120 miles per hour (mph), then wood-frame structures will fail.
- If it is late in the hurricane season, then hurricanes tend to get stronger as they approach the coast.
In an actual expert system, the knowledge base would contain hundreds or thousands of assertions such as those just listed.
The second major component of an expert system—the inference engine—analyzes information in the knowledge base to arrive at the appropriate decision. The expert system user utilizes some sort of user interface to provide the inference engine with details about the current situation, and the inference engine uses a combination of logical reasoning and fuzzy logic techniques to draw a conclusion based upon past experience. Continuing with the hurricane example, a user might inform the expert system that a Category 4 hurricane is approaching the coast with wind speeds averaging 140 mph. The inference engine would then analyze information in the knowledge base and make an evacuation recommendation based upon that past knowledge.
Expert systems are not infallible—they’re only as good as the data in the knowledge base and the decision-making algorithms implemented in the inference engine. However, they have one major advantage in stressful situations—their decisions do not involve judgment clouded by emotion. Expert systems can play an important role in analyzing situations such as emergency events, stock trading, and other scenarios in which emotional investment sometimes gets in the way of a logical decision. For this reason, many lending institutions now utilize expert systems to make credit decisions instead of relying upon loan officers who might say to themselves, “Well, Jim hasn’t paid his bills on time, but he seems like a perfectly nice guy.”
Fuzzy Logic
As previously mentioned, inference engines commonly use a technique known as fuzzy logic. This technique is designed to more closely approximate human thought patterns than the rigid mathematics of set theory or algebraic approaches that utilize “black-and-white” categorizations of data. Fuzzy logic replaces them with blurred boundaries, allowing the algorithm to think in the “shades of gray” that dominate human thought. Fuzzy logic as used by an expert system has four steps or phases: fuzzification, inference, composition, and defuzzification.
For example, consider the task of determining whether a website is undergoing a denial-of-service attack. Traditional mathematical techniques may create basic rules, such as “If we have more than 1,000 connections per second, we are under attack.” Fuzzy logic, on the other hand, might define a blurred boundary, saying that 1,000 connections per second represents an 80 percent chance of an attack, while 10,000 connections per second represents a 95 percent chance and 100 connections per second represents a 5 percent chance. The interpretation of these probabilities is left to the analyst.
Neural Networks
In neural networks, chains of computational units are used in an attempt to imitate the biological reasoning process of the human mind. In an expert system, a series of rules is stored in a knowledge base, whereas in a neural network, a long chain of computational decisions that feed into each other and eventually sum to produce the desired output is set up.
Keep in mind that no neural network designed to date comes close to having the reasoning power of the human mind. Nevertheless, neural networks show great potential to advance the artificial intelligence field beyond its current state. Benefits of neural networks include linearity, input-output mapping, and adaptivity. These benefits are evident in the implementations of neural networks for voice recognition, face recognition, weather prediction, and the exploration of models of thinking and consciousness.
Typical neural networks involve many layers of summation, each of which requires weighting information to reflect the relative importance of the calculation in the overall decision-making process. These weights must be custom-tailored for each type of decision the neural network is expected to make. This is accomplished through the use of a training period during which the network is provided with inputs for which the proper decision is known. The algorithm then works backward from these decisions to determine the proper weights for each node in the computational chain. This activity is known as the Delta rule or learning rule. Through the use of the Delta rule, neural networks are able to learn from experience.
Decision Support Systems
A decision support system (DSS) is a knowledge-based application that analyzes business data and presents it in such a way as to make business decisions easier for users. It is considered more of an informational application than an operational application. Often a DSS is employed by knowledge workers (such as help desk or customer support personnel) and by sales services (such as phone operators). This type of application may present information in a graphical manner to link concepts and content and guide the script of the operator. Often a DSS is backed by an expert system controlling a database.
Security Applications
Both expert systems and neural networks have great applications in the field of computer security. One of the major advantages offered by these systems is their capability to rapidly make consistent decisions. One of the major problems in computer security is the inability of system administrators to consistently and thoroughly analyze massive amounts of log and audit trail data to look for anomalies. It seems like a match made in heaven!
One successful application of this technology to the computer security arena is the Next-Generation Intrusion Detection Expert System (NIDES) developed by Philip Porras and his team at the Information and Computing Sciences System Design Laboratory of SRI International. This system provides an inference engine and knowledge base that draws information from a variety of audit logs across a network and provides notification to security administrators when the activity of an individual user varies from their standard usage profile.
Many organizations use custom-developed hardware and software systems to achieve flexible operational goals. As you will learn in Chapter 8 and Chapter 12, these custom solutions can present great security vulnerabilities as a result of malicious and/or careless developers who create trap doors, buffer-overflow vulnerabilities, or other weaknesses that can leave a system open to exploitation by malicious individuals.
To protect against these vulnerabilities, it’s vital to introduce security concerns into the entire systems development life cycle. An organized, methodical process helps ensure that solutions meet functional requirements as well as security guidelines. The following sections explore the spectrum of systems development activities with an eye toward security concerns that should be foremost on the mind of any information security professional engaged in solutions development.
Software Development
Security should be a consideration at every stage of a system’s development, including the software development process. Programmers should strive to build security into every application they develop, with greater levels of security provided to critical applications and those that process sensitive information. It’s extremely important to consider the security implications of a software development project from the early stages because it’s much easier to build security into a system than it is to add security onto an existing system.
Assurance
To ensure that the security control mechanisms built into a new application properly implement the security policy throughout the life cycle of the system, administrators use assurance procedures. Assurance procedures are simply formalized processes by which trust is built into the life cycle of a system. The Trusted Computer System Evaluation Criteria (TCSEC) Orange Book refers to this process as life cycle assurance. We’ll discuss this further in Chapter 13, “Administrative Management.”
Avoiding System Failure
No matter how advanced your development team, your systems will likely fail at some point in time. You should plan for this type of failure when you put the software and hardware controls in place, ensuring that the system will respond appropriately. You can employ many methods to avoid failure, including using limit checks and creating fail-safe or fail-open procedures. Let’s talk about these in more detail.
Limit Checks
Environmental controls and hardware devices cannot prevent problems created by poor program coding. It is important to have proper software development and coding practices to ensure that security is a priority during product development. Limit checks are a technique for managing data types, data formats, and data length when accepting input from a user or another application. Limit checks ensure that data does not fall outside the range of allowable values. For example, when creating a database that contains the age of individuals, a limit check might restrict the possible values so that they must be greater than 0 and less than 130. Depending on the application, you may also need to include sequence checks to ensure that data input is properly ordered. Limit checks are a form of input validation—checking to ensure that user input meets the requirements of the application.
![]()
In most organizations, security professionals come from a system administration background and don’t have professional experience in software development. If your background doesn’t include this type of experience, don’t let that stop you from learning about it and educating your organization’s developers on the importance of secure coding.
Fail-Secure and Fail-Open
In spite of the best efforts of programmers, product designers, and project managers, developed applications will be used in unexpected ways. Some of these conditions will cause failures. Since failures are unpredictable, programmers should design into their code a general sense of how to respond to and handle failures.
There are two basic choices when planning for system failure, fail-secure (also called fail-safe) or fail-open:
- The fail-secure failure state puts the system into a high level of security (and possibly even disables it entirely) until an administrator can diagnose the problem and restore the system to normal operation.
- The fail-open state allows users to bypass failed security controls, erring on the side of permissiveness.
In the vast majority of environments, fail-secure is the appropriate failure state because it prevents unauthorized access to information and resources.
Software should revert to a fail-secure condition. This may mean closing just the application or possibly stopping the operation of the entire host system. An example of such failure response is seen in the Windows OS with the appearance of the infamous Blue Screen of Death (BSOD), indicating the occurrence of a STOP error. A STOP error occurs when an undesirable activity occurs in spite of the OS’s efforts to prevent it. This could include an application gaining direct access to hardware, an attempt to bypass a security access check, or one process interfering with the memory space of another. Once one of these conditions occurs, the environment is no longer trustworthy. So, rather than continuing to support an unreliable and insecure operating environment, the OS initiates a STOP error as its fail-secure response.
Once a fail-secure operation occurs, the programmer should consider the activities that occur afterward. The options are to remain in a fail-secure state or to automatically reboot the system. The former option requires an administrator to manually reboot the system and oversee the process. This action can be enforced by using a boot password. The latter option does not require human intervention for the system to restore itself to a functioning state, but it has its own unique issues. First, it is subject to initial program load (IPL) vulnerabilities (for more information on IPL, review Chapter 14). Second, it must restrict the system to reboot into a nonprivileged state. In other words, the system should not reboot and perform an automatic logon; instead, it should prompt the user for authorized access credentials.
![]()
In limited circumstances, it may be appropriate to implement a fail-open failure state. This is sometimes appropriate for lower-layer components of a multilayered security system. Fail-open systems should be used with extreme caution. Before deploying a system using this failure mode, clearly validate the business requirement for this move. If it is justified, ensure that adequate alternative controls are in place to protect the organization’s resources should the system fail. It’s extremely rare that you’d want all your security controls to utilize a fail-open approach.
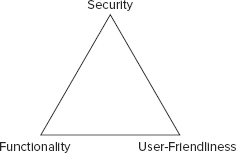
Even when security is properly designed and embedded in software, that security is often disabled in order to support easier installation. Thus, it is common for the IT administrator to have the responsibility of turning on and configuring security to match the needs of their specific environment. Maintaining security is often a trade-off with user-friendliness and functionality, as you can see from Figure 7.5. Additionally, as you add or increase security, you will also increase costs, increase administrative overhead, and reduce productivity/throughput.
FIGURE 7.5 Security vs. user-friendliness vs. functionality
Programming Languages
As you probably know, software developers use programming languages to develop software code. You might not know that several types of languages can be used simultaneously by the same system. This section takes a brief look at the different types of programming languages and the security implications of each.
Computers understand binary code. They speak a language of 1s and 0s, and that’s it! The instructions that a computer follows consist of a long series of binary digits in a language known as machine language. Each CPU chipset has its own machine language, and it’s virtually impossible for a human being to decipher anything but the simplest machine language code without the assistance of specialized software. Assembly language is a higher-level alternative that uses mnemonics to represent the basic instruction set of a CPU but still requires hardware-specific knowledge of a relatively obscure language. It also requires a large amount of tedious programming; a task as simple as adding two numbers together could take five or six lines of assembly code!
Programmers don’t want to write their code in either machine language or assembly language. They prefer to use high-level languages, such as C++, Java, and Visual Basic. These languages allow programmers to write instructions that better approximate human communication, decrease the length of time needed to craft an application, possibly decrease the number of programmers needed on a project, and also allow some portability between different operating systems and hardware platforms. Once programmers are ready to execute their programs, two options are available to them, depending upon the language they’ve chosen.
Some languages (such as C++, Java, and FORTRAN) are compiled languages. When using a compiled language, the programmer uses a tool known as a compiler to convert the higher-level language into an executable file designed for use on a specific operating system. This executable is then distributed to end users who may use it as they see fit. Generally speaking, it’s not possible to view or modify the software instructions in an executable file.
Other languages (such as JavaScript and VBScript) are interpreted languages. When these languages are used, the programmer distributes the source code, which contains instructions in the higher-level language. End users then use an interpreter to execute that source code on their system. They’re able to view the original instructions written by the programmer.
Each approach has security advantages and disadvantages. Compiled code is generally less prone to manipulation by a third party. However, it’s also easier for a malicious (or unskilled) programmer to embed back doors and other security flaws in the code and escape detection because the original instructions can’t be viewed by the end user. Interpreted code, however, is less prone to the insertion of malicious code by the original programmer because the end user may view the code and check it for accuracy. On the other hand, everyone who touches the software has the ability to modify the programmer’s original instructions and possibly embed malicious code in the interpreted software.
Generational Languages
For the CISSP exam, you should also be familiar with the programming language generations, which are defined as follows:
- First-generation languages (1GL) include all machine languages.
- Second-generation languages (2GL) include all assembly languages.
- Third-generation languages (3GL) include all compiled languages.
- Fourth-generation languages (4GL) attempt to approximate natural languages and include SQL which is used by databases.
- Fifth-generation languages (5GL) allow programmers to create code using visual interfaces.
Object-Oriented Programming
Many modern programming languages, such as C++, Java, and the .NET languages, support the concept of object-oriented programming (OOP). Older programming styles, such as functional programming, focused on the flow of the program itself and attempted to model the desired behavior as a series of steps. Object-oriented programming focuses on the objects involved in an interaction. You can think of it as a group of objects that can be requested to perform certain operations or exhibit certain behaviors. Objects work together to provide a system’s functionality or capabilities. OOP has the potential to be more reliable and able to reduce the propagation of program change errors. As a type of programming method, it is better suited to modeling or mimicking the real world. For example, a banking program might have three object classes that correspond to accounts, account holders, and employees. When a new account is added to the system, a new instance, or copy, of the appropriate object is created to contain the details of that account.
Each object in the OOP model has methods that correspond to specific actions that can be taken on the object. For example, the account object can have methods to add funds, deduct funds, close the account, and transfer ownership.
Objects can also be subclasses of other objects and inherit methods from their parent class. For example, the account object may have subclasses that correspond to specific types of accounts, such as savings, checking, mortgages, and auto loans. The subclasses can use all the methods of the parent class and have additional class-specific methods. For example, the checking object might have a method called write_check(), whereas the other subclasses do not.
Computer-Aided Software Engineering (CASE)
The advent of object-oriented programming has reinvigorated a movement toward applying traditional engineering design principles to the software engineering field. One part of that movement has been toward the use of computer-aided software engineering (CASE) tools to help developers, managers, and customers interact through the various stages of the software development life cycle.
One popular CASE tool, Middle CASE, is used in the design and analysis phase of software engineering to help create screen and report layouts.
From a security point of view, object-oriented programming provides a black-box approach to abstraction. Users need to know the details of an object’s interface (generally the inputs, outputs, and actions that correspond to each of the object’s methods) but don’t necessarily need to know the inner workings of the object to use it effectively. To provide the desired characteristics of object-oriented systems, the objects are encapsulated (self-contained), and they can be accessed only through specific messages (in other words, input). Objects can also exhibit the substitution property, which allows different objects providing compatible operations to be substituted for each other.
Here is a list of common object-oriented programming terms you might come across in your work:
Message A message is a communication to or input of an object.
Method A method is internal code that defines the actions an object performs in response to a message.
Behavior The results or output exhibited by an object is a behavior. Behaviors are the results of a message being processed through a method.
Class A collection of the common methods from a set of objects that defines the behavior of those objects is a class.
Instance Objects are instances of or examples of classes that contain their method.
Inheritance Inheritance occurs when methods from a class (parent or superclass) are inherited by another subclass (child).
Delegation Delegation is the forwarding of a request by an object to another object or delegate. An object delegates if it does not have a method to handle the message.
Polymorphism A polymorphism is the characteristic of an object that allows it to respond with different behaviors to the same message or method because of changes in external conditions.
Cohesiveness An object is highly cohesive if it can perform a task with little or no help from others. Highly cohesive objects are not as dependent upon other objects as objects that are less cohesive. Highly cohesive objects are often better. Objects that have high cohesion perform tasks alone and have low coupling.
Coupling Coupling is the level of interaction between objects. Lower coupling means less interaction. Lower coupling provides better software design because objects are more independent. Lower coupling is easier to troubleshoot and update. Objects that have low cohesion require lots of assistance from other objects to perform tasks and have high coupling.
Systems Development Life Cycle
Security is most effective if it is planned and managed throughout the life cycle of a system or application. Administrators employ project management to keep a development project on target and moving toward the goal of a completed product. Often project management is structured using life cycle models to direct the development process. Using formalized life cycle models helps ensure good coding practices and the embedding of security in every stage of product development.
All systems development processes should have several activities in common. Although they may not necessarily share the same names, these core activities are essential to the development of sound, secure systems:
- Conceptual definition
- Functional requirements determination
- Protection specifications development
- Design review
- Code review walk-through
- System test review
- Maintenance
The section “Life Cycle Models” later in this chapter examines two life cycle models and shows how these activities are applied in real-world software engineering environments.
![]()
It’s important to note at this point that the terminology used in systems development life cycles varies from model to model and from publication to publication. Don’t spend too much time worrying about the exact terms used in this book or any of the other literature you may come across. When taking the CISSP examination, it’s much more important that you have an understanding of how the process works and the fundamental principles underlying the development of secure systems.
Conceptual Definition
The conceptual definition phase of systems development involves creating the basic concept statement for a system. Simply put, it’s a simple statement agreed upon by all interested stakeholders (the developers, customers, and management) that states the purpose of the project as well as the general system requirements. The conceptual definition is a very high-level statement of purpose and should not be longer than one or two paragraphs. If you were reading a detailed summary of the project, you might expect to see the concept statement as an abstract or introduction that enables an outsider to gain a top-level understanding of the project in a short period of time.
It’s very helpful to refer to the concept statement at all phases of the systems development process. Often, the intricate details of the development process tend to obscure the overarching goal of the project. Simply reading the concept statement periodically can assist in refocusing a team of developers.
Functional Requirements Determination
Once all stakeholders have agreed upon the concept statement, it’s time for the development team to sit down and begin the functional requirements process. In this phase, specific system functionalities are listed, and developers begin to think about how the parts of the system should interoperate to meet the functional requirements. The deliverable from this phase of development is a functional requirements document that lists the specific system requirements.
As with the concept statement, it’s important to ensure that all stakeholders agree on the functional requirements document before work progresses to the next level. When it’s finally completed, the document shouldn’t be simply placed on a shelf to gather dust—the entire development team should constantly refer to this document during all phases to ensure that the project is on track. In the final stages of testing and evaluation, the project managers should use this document as a checklist to ensure that all functional requirements are met.
Protection Specifications Development
Security-conscious organizations also ensure that adequate protections are designed into every system from the earliest stages of development. It’s often very useful to have a protection specifications development phase in your life cycle model. This phase takes place soon after the development of functional requirements and often continues as the design and design review phases progress.
During the development of protection specifications, it’s important to analyze the system from a number of security perspectives. First, adequate access controls must be designed into every system to ensure that only authorized users are allowed to access the system and that they are not permitted to exceed their level of authorization. Second, the system must maintain the confidentiality of vital data through the use of appropriate encryption and data protection technologies. Next, the system should provide both an audit trail to enforce individual accountability and a detective mechanism for illegitimate activity. Finally, depending upon the criticality of the system, availability and fault-tolerance issues should be addressed as corrective actions.
Keep in mind that designing security into a system is not a one-shot process and it must be done proactively. All too often, systems are designed without security planning, and then developers attempt to retrofit the system with appropriate security mechanisms. Unfortunately, these mechanisms are an afterthought and do not fully integrate with the system’s design, which leaves gaping security vulnerabilities. Also, the security requirements should be revisited each time a significant change is made to the design specification. If a major component of the system changes, it’s very likely that the security requirements will change as well.
Design Review
Once the functional and protection specifications are complete, let the system designers do their thing! In this often-lengthy process, the designers determine exactly how the various parts of the system will interoperate and how the modular system structure will be laid out. Also, during this phase, the design management team commonly sets specific tasks for various teams and lays out initial timelines for the completion of coding milestones.
After the design team completes the formal design documents, a review meeting with the stakeholders should be held to ensure that everyone is in agreement that the process is still on track for the successful development of a system with the desired functionality.
Code Review Walk-Through
Once the stakeholders have given the software design their blessing, it’s time for the software developers to start writing code. Project managers should schedule several code review walk-though meetings at various milestones throughout the coding process. These technical meetings usually involve only development personnel who sit down with a copy of the code for a specific module and walk through it, looking for problems in logical flow or other design/security flaws. The meetings play an instrumental role in ensuring that the code produced by the various development teams performs according to specification.
System Test Review
After many code reviews and a lot of long nights, there will come a point at which a developer puts in that final semicolon and declares the system complete. As any seasoned software engineer knows, the system is never complete. Now it’s time to begin the system test review phase. Initially, most organizations perform the initial system tests using development personnel to seek out any obvious errors. Once this phase is complete, a series of beta test deployments takes place to ensure that customers agree that the system meets all functional requirements and performs according to the original specification. As with any critical development process, it’s important that you maintain a copy of the written system test plan and test results for future review.
Maintenance
Once a system is operational, a variety of maintenance tasks are necessary to ensure continued operation in the face of changing operational, data processing, storage, and environmental requirements. It’s essential that you have a skilled support team in place to handle any routine or unexpected maintenance. It’s also important that any changes to the code be handled through a formalized change request/control process, as described in Chapter 5.
Life Cycle Models
One of the major complaints you’ll hear from practitioners of the more established engineering disciplines (such as civil, mechanical, and electrical engineering) is that software engineering is not an engineering discipline at all. In fact, they contend, it’s simply a combination of chaotic processes that somehow manage to scrape out workable solutions from time to time. Indeed, some of the “software engineering” that takes place in today’s development environments is nothing but bootstrap coding held together by “duct tape and chicken wire.”
However, the adoption of more formalized life cycle management processes is seen in mainstream software engineering as the industry matures. After all, it’s hardly fair to compare the processes of an age-old discipline such as civil engineering to those of an industry that’s barely a few decades old. In the 1970s and 1980s, pioneers like Winston Royce and Barry Boehm proposed several software development life cycle (SDLC) models to help guide the practice toward formalized processes. In 1991, the Software Engineering Institute introduced the Capability Maturity Model, which described the process organizations undertake as they move toward incorporating solid engineering principles into their software development processes. In the following sections, we’ll take a look at the work produced by these studies. Having a management model in place should improve the resultant products. However, if the SDLC methodology is inadequate, the project may fail to meet business and user needs. Thus, it is important to verify that the SDLC model is properly implemented and is appropriate for your environment. Furthermore, one of the initial steps of implementing an SDLC should include management approval.
Waterfall Model
Originally developed by Winston Royce in 1970, the waterfall model seeks to view the systems development life cycle as a series of iterative activities. As shown in Figure 7.6, the traditional waterfall model has seven stages of development. As each stage is completed, the project moves into the next phase. As illustrated by the backward arrows, the modern waterfall model does allow development to return to the previous phase to correct defects discovered during the subsequent phase. This is often known as the feedback loop characteristic of the waterfall model.
FIGURE 7.6 The waterfall life cycle model
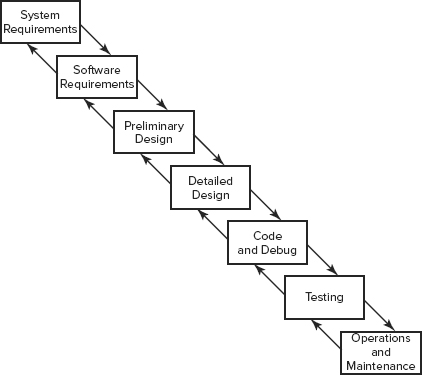
The waterfall model was one of the first comprehensive attempts to model the software development process while taking into account the necessity of returning to previous phases to correct system faults. However, one of the major criticisms of this model is that it allows the developers to step back only one phase in the process. It does not make provisions for the discovery of errors at a later phase in the development cycle.
![]()
The waterfall model was improved by adding validation and verification steps to each phase. Verification evaluates the product against specifications, while validation evaluates how well the product satisfies real-world requirements. The improved model was labeled the modified waterfall model. However, it did not gain widespread use before the spiral model dominated the project management scene.
Spiral Model
In 1988, Barry Boehm of TRW proposed an alternative life cycle model that allows for multiple iterations of a waterfall-style process. Figure 7.7 illustrates this model. Because the spiral model encapsulates a number of iterations of another model (the waterfall model), it is known as a metamodel, or a “model of models.”
FIGURE 7.7 The spiral life cycle model
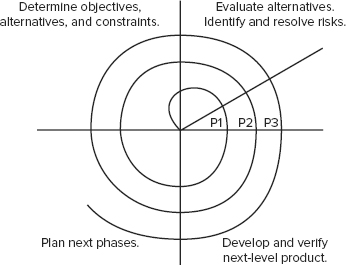
Notice that each “loop” of the spiral results in the development of a new system prototype (represented by P1, P2, and P3 in the illustration). Theoretically, system developers would apply the entire waterfall process to the development of each prototype, thereby incrementally working toward a mature system that incorporates all the functional requirements in a fully validated fashion. Boehm’s spiral model provides a solution to the major criticism of the waterfall model—it allows developers to return to the planning stages as changing technical demands and customer requirements necessitate the evolution of a system.
Agile Software Development
More recently, the agile model of software development has gained popularity within the software engineering community. Beginning in the mid-1990s, developers began to embrace approaches to software development that eschewed the rigid models of the past in favor of approaches that placed an emphasis on the needs of the customer and on quickly developing new functionality that meets those needs in an iterative fashion.
Seventeen pioneers of the agile development approach got together in 2001 and produced a document, titled the “Agile Manifesto,” that states the core philosophy of the agile approach:
“We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
“That is, while there is value in the items on the right, we value the items on the left more.”
The Agile Manifesto, available at http://agilemanifesto.org/, also defines 12 principles that underlie the philosophy:
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
4. Business people and developers must work together daily throughout the project.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
7. Working software is the primary measure of progress.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
9. Continuous attention to technical excellence and good design enhances agility.
10. Simplicity—the art of maximizing the amount of work not done—is essential.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
12. At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
The agile development approach is quickly gaining momentum in the software community and has many variants, including Scrum, Agile Unified Process (AUP), the Dynamic Systems Development Model (DSDM), and Extreme Programming (XP).
Software Capability Maturity Model
The Software Engineering Institute (SEI) at Carnegie Mellon University introduced the Capability Maturity Model for Software also known as the Software Capability Maturity Model (abbreviated as SW-CMM, CMM, or SCMM), which contends that all organizations engaged in software development move through a variety of maturity phases in sequential fashion. The SW-CMM describes the principles and practices underlying software process maturity. It is intended to help software organizations improve the maturity and quality of their software processes by implementing an evolutionary path from ad hoc, chaotic processes to mature, disciplined software processes. The idea behind the SW-CMM is that the quality of software depends on the quality of its development process.
The stages of the SW-CMM are as follows:
Level 1: Initial In this phase, you’ll often find hard-working people charging ahead in a disorganized fashion. There is usually little or no defined software development process.
Level 2: Repeatable In this phase, basic life cycle management processes are introduced. Reuse of code in an organized fashion begins to enter the picture, and repeatable results are expected from similar projects. SEI defines the key process areas for this level as Requirements Management, Software Project Planning, Software Project Tracking and Oversight, Software Subcontract Management, Software Quality Assurance, and Software Configuration Management.
Level 3: Defined In this phase, software developers operate according to a set of formal, documented software development processes. All development projects take place within the constraints of the new standardized management model. SEI defines the key process areas for this level as Organization Process Focus, Organization Process Definition, Training Program, Integrated Software Management, Software Product Engineering, Intergroup Coordination, and Peer Reviews.
Level 4: Managed In this phase, management of the software process proceeds to the next level. Quantitative measures are utilized to gain a detailed understanding of the development process. SEI defines the key process areas for this level as Quantitative Process Management and Software Quality Management.
Level 5: Optimizing In the optimized organization, a process of continuous improvement occurs. Sophisticated software development processes are in place that ensure that feedback from one phase reaches to the previous phase to improve future results. SEI defines the key process areas for this level as Defect Prevention, Technology Change Management, and Process Change Management.
For more information on the Capability Maturity Model for Software, visit the Software Engineering Institute’s website at www.sei.cmu.edu.
IDEAL Model
The Software Engineering Institute also developed the IDEAL model for software development, which implements many of the SW-CMM attributes. The IDEAL model, illustrated in Figure 7.8, has five phases:
I: Initiating In the initiating phase of the IDEAL model, the business reasons behind the change are outlined, support is built for the initiative, and the appropriate infrastructure is put in place.
D: Diagnosing During the diagnosing phase, engineers analyze the current state of the organization and make general recommendations for change.
E: Establishing In the establishing phase, the organization takes the general recommendations from the diagnosing phase and develops a specific plan of action that helps achieve those changes.
A: Acting In the acting phase, it’s time to stop “talking the talk” and “walk the walk.” The organization develops solutions and then tests, refines, and implements them.
L: Learning As with any quality improvement process, the organization must continuously analyze its efforts to determine whether it has achieved the desired goals and, when necessary, propose new actions to put the organization back on course.
FIGURE 7.8 The IDEAL model
SW-CMM and IDEAL Model Memorization
To help you remember the initial letters of each of the 10 level names of the SW-CMM and IDEAL models (II DR ED AM LO), imagine yourself sitting on the couch in a psychiatrist’s office saying, “I . . . I, Dr. Ed, am lo(w).” If you can remember that phrase, then you can extract the 10 initial letters of the level names. If you write the letters out into two columns, you can reconstruct the level names in order of the two systems. The left column is the IDEAL model, and the right represents the levels of the SW-CMM.
| Initiating | Initiating |
| Diagnosing | Repeatable |
| Establishing | Defined |
| Acting | Managed |
| Learning | Optimized |
Gantt Charts and PERT
A Gantt chart is a type of bar chart that shows the interrelationships over time between projects and schedules. It provides a graphical illustration of a schedule that helps to plan, coordinate, and track specific tasks in a project. Figure 7.9 shows an example of a Gantt chart.
FIGURE 7.9 A Gantt chart
Program Evaluation Review Technique (PERT) is a project-scheduling tool used to judge the size of a software product in development and calculate the standard deviation (SD) for risk assessment. PERT relates the estimated lowest possible size, the most likely size, and the highest possible size of each component. PERT is used to direct improvements to project management and software coding in order to produce more efficient software. As the capabilities of programming and management improve, the actual produced size of software should be smaller.
Change Control and Configuration Management
Once software has been released into a production environment, users will inevitably request the addition of new features, correction of bugs, and other modifications to the code. Just as the organization developed a regimented process for developing software, they must also put a procedure in place to manage changes in an organized fashion.
![]()
Change Control as a Security Tool
Change control plays an important role when monitoring systems in the controlled environment of a data center. One of the authors recently worked with an organization that used change control as an essential component of its efforts to detect unauthorized changes to computing systems.
In Chapter 8, you’ll learn how tools for monitoring file integrity, such as Tripwire, allow you to monitor a system for changes. This organization used Tripwire to monitor hundreds of production servers. However, the organization quickly found itself overwhelmed by file modification alerts resulting from normal activity. The author worked with them to tune the Tripwire-monitoring policies and integrate them with change control. Now all Tripwire alerts go to a centralized monitoring center where administrators correlate them with approved changes. System administrators receive an alert only if the security team identifies a change that does not appear to correlate with an approved change request.
This approach greatly reduced the time spent by administrators reviewing file integrity reports and improved the usefulness of the tool to security administrators.
The change control process has three basic components:
Request control The request control process provides an organized framework within which users can request modifications, managers can conduct cost/benefit analysis, and developers can prioritize tasks.
Change control The change control process is used by developers to re-create the situation encountered by the user and analyze the appropriate changes to remedy the situation. It also provides an organized framework within which multiple developers can create and test a solution prior to rolling it out into a production environment. Change control includes conforming to quality control restrictions, developing tools for update or change deployment, properly documenting any coded changes, and restricting the effects of new code to minimize diminishment of security.
Release control Once the changes are finalized, they must be approved for release through the release control procedure. An essential step of the release control process is to double-check and ensure that any code inserted as a programming aid during the change process (such as debugging code and/or back doors) is removed before releasing the new software to production. Release control should also include acceptance testing to ensure that any alterations to end user work tasks are understood and functional.
In addition to the change control process, security administrators should be aware of the importance of configuration management. This process is used to control the version(s) of software used throughout an organization and formally track and control changes to the software configuration. It has four main components:
Configuration identification During the configuration identification process, administrators document the configuration of covered software products throughout the organization.
Configuration control The configuration control process ensures that changes to software versions are made in accordance with the change control and configuration management policies. Updates can be made only from authorized distributions in accordance with those policies.
Configuration status accounting Formalized procedures are used to keep track of all authorized changes that take place.
Configuration Audit A periodic configuration audit should be conducted to ensure that the actual production environment is consistent with the accounting records and that no unauthorized configuration changes have taken place.
Together, change control and configuration management techniques form an important part of the software engineer’s arsenal and protect the organization from development-related security issues.
Software Testing
As part of the development process, your organization should thoroughly test any software before distributing it internally (or releasing it to market). The best time to address testing is as the modules are designed. In other words, the mechanisms you use to test a product and the data sets you use to explore that product should be designed in parallel with the product itself. Your programming team should develop special test suites of data that exercise all paths of the software to the fullest extent possible and know the correct resulting outputs beforehand. This extensive test suite process is known as a reasonableness check. Furthermore, while conducting stress tests, you should check how the product handles normal and valid input data, incorrect types, out-of-range values, and other bounds and/or conditions. Live workloads provide the best stress testing possible. However, you should not use live or actual field data for testing, especially in the early development stages, since a flaw or error could result in the violation of integrity or confidentiality of the test data.
When testing software, you should apply the same rules of separation of duties that you do for other aspects of your organization. In other words, you should assign the testing of your software to someone other than the programmer(s) who developed the code to avoid a conflict of interest and assure a more successful finished product. When a third party tests your software, you have a greater likelihood of receiving an objective and nonbiased examination. The third-party test allows for a broader and more thorough test and prevents the bias and inclinations of the programmers from affecting the results of the test.
You can utilize three testing methods or ideologies for software testing:
White-box testing White-box testing examines the internal logical structures of a program and steps through the code line by line, analyzing the program for potential errors.
Black-box testing Black-box testing examines the program from a user perspective by providing a wide variety of input scenarios and inspecting the output. Black-box testers do not have access to the internal code. Final acceptance testing that occurs prior to system delivery is a common example of black-box testing.
Gray-box testing Gray-box testing combines the two approaches and is a popular approach to software validation. In this approach, testers approach the software from a user perspective, analyzing inputs and outputs. They also have access to the source code and use it to help design their tests. They do not, however, analyze the inner workings of the program during their testing.
Proper software test implementation is a key element in the project development process. Many of the common mistakes and oversights often found in commercial and in-house software can be eliminated. Keep the test plan and results as part of the system’s permanent documentation.
Security Control Architecture
All secure systems implement some sort of security control architecture. At the hardware and operating system levels, controls should ensure enforcement of basic security principles. The following sections examine several basic control principles that should be enforced in a secure computing environment.
Process Isolation
Process isolation is one of the fundamental security procedures put into place during system design. Process isolation mechanisms (whether part of the operating system or part of the hardware itself) ensure that each process has its own isolated memory space for storage of data and the actual executing application code itself. This guarantees that processes cannot access each other’s reserved memory areas and protects against confidentiality violations or intentional/unintentional modification of data by an unauthorized process. Hardware segmentation is a technique that implements process isolation at the hardware level by enforcing memory access constraints.
Protection Rings
The ring-oriented protection scheme provides for several modes of system operation, thereby facilitating secure operation by restricting processes to running in the appropriate security ring. Figure 7.10 shows the four-layer ring protection scheme supported by Intel microprocessors.
FIGURE 7.10 Ring protection scheme
In this scheme, each of the rings has a separate and distinct function:
Level 0 Represents the ring where the operating system itself resides. This ring contains the security kernel—the core set of operating system services that handles all user/application requests for access to system resources. The kernel also implements the reference monitor, an operating system component that validates all user requests for access to resources against an access control scheme. Processes running at Level 0 are often said to be running in supervisory mode, also called privileged mode. Level 0 processes have full control of all system resources, so it’s essential to ensure that they are fully verified and validated before implementation.
Levels 1 and 2 Contain device drivers and other operating system services that provide higher-level interfaces to system resources. However, in practice, most operating systems do not implement either one of these layers.
Level 3 Represents the security layer where user applications and processes reside. This layer is commonly referred to as user mode, or protected mode, and applications running here are not permitted direct access to system resources. In fact, when an application running in protected mode attempts to access an unauthorized resource, a General Protection Fault (GPF) occurs.
![]()
The security kernel and reference monitor are extremely important computer security topics that must be understood by any information security practitioner. These topics commonly appear on the CISSP exam.
The reference monitor component (present at Level 0) is an extremely important element of any operating system offering multilevel secure services. This concept was first formally described in the Department of Defense Trusted Computer System Evaluation Criteria (commonly referred to as the Orange Book because of the color of its cover). The DoD set forth the following three requirements for an operational reference monitor:
- It must be tamperproof.
- It must always be invoked when a program or user requests access to resources.
- It must be small enough to be subject to analysis and tests, the completeness of which can be assured.
Abstraction
Abstraction is a valuable tool drawn from the object-oriented software development model that can be extrapolated to apply to the design of all types of information systems. In effect, abstraction states that a thorough understanding of a system’s operational details is not often necessary to perform day-to-day activities. For example, a system developer might need to know that a certain procedure, when invoked, writes information to disk, but it’s not necessary for the developer to understand the underlying principles that enable the data to be written to disk or the exact format that the disk procedures use to store and retrieve data. The process of developing increasingly sophisticated objects that draw upon the abstracted methods of lower-level objects is known as encapsulation. The deliberate concealment of lower levels of functionality from higher-level processes is known as data hiding or information hiding.
Security Modes
In a secure environment, information systems are configured to process information in one of four security modes. These modes are set out by the Department of Defense in CSC-STD-003-85 (the “light yellow book”) as follows:
- Systems running in compartmented security mode may process two or more types of compartmented information. All system users must have an appropriate clearance to access all information processed by the system but do not necessarily have a need to know all of the information in the system. Compartments are subcategories or compartments within the different classification levels, and extreme care is taken to preserve the information within the different compartments. The system may be classified at the secret level but contain five different compartments, all classified secret. If a user has the need to know about only two of the five different compartments to do their job, that user can access the system but can access only the two compartments.
- Systems running in dedicated security mode are authorized to process only a specific classification level at a time, and all system users must have clearance and a need to know that information.
- Systems running in multilevel security mode are authorized to process information at more than one level of security even when all system users do not have appropriate clearances or a need to know for all information processed by the system.
- Systems running in system-high security mode are authorized to process only information that all system users are cleared to read and have a valid need to know. These systems are not trusted to maintain separation between security levels, and all information processed by these systems must be handled as if it were classified at the same level as the most highly classified information processed by the system.
Service-Level Agreements
Using service-level agreements (SLAs) is an increasingly popular way to ensure that organizations providing services to internal and/or external customers maintain an appropriate level of service agreed upon by both the service provider and the vendor. It’s a wise move to put SLAs in place for any data circuits, applications, information processing systems, databases, or other critical components that are vital to your organization’s continued viability. The following issues are commonly addressed in SLAs:
- System uptime (as a percentage of overall operating time)
- Maximum consecutive downtime (in seconds/minutes/and so on)
- Peak load
- Average load
- Responsibility for diagnostics
- Failover time (if redundancy is in place)
Service-level agreements also often commonly include financial and other contractual remedies that kick in if the agreement is not maintained. For example, if a critical circuit is down for more than 15 minutes, the service provider might agree to waive all charges on that circuit for one week.
Data is quickly becoming the most valuable resource many organizations possess. Therefore, it’s critical that information security practitioners understand the necessity of safeguarding the data itself and the systems and applications that assist in the processing of that data. Protections against malicious code, database vulnerabilities, and system/application development flaws must be implemented in every technology-aware organization.
Malicious code objects pose a threat to the computing resources of organizations. In the nondistributed environment, such threats include viruses, logic bombs, Trojan horses, and worms. Chapter 8 delves more deeply into specific types of malicious code objects as well as other attacks commonly used by hackers. We’ll also explore some effective defense mechanisms to safeguard your network against their insidious effects.
By this point, you no doubt recognize the importance of placing adequate access controls and audit trails on these valuable information resources. Database security is a rapidly growing field; if databases play a major role in your security duties, take the time to sit down with database administrators, courses, and textbooks and learn the underlying theory. It’s a valuable investment.
Finally, there are various controls that can be put into place during the system and application development process to ensure that the end product of these processes is compatible with operation in a secure environment. Such controls include process isolation, hardware segmentation abstraction, and contractual arrangements, such as service level agreements (SLA). Security should always be introduced in the early planning phases of any development project and continually monitored throughout the design, development, deployment, and maintenance phases of production.
Understand the application threats present in a local/nondistributed environment. Describe the functioning of viruses, worms, Trojan horses, and logic bombs. Understand the impact each type of threat may have on a system and the methods they use to propagate.
Understand the application threats unique to distributed computing environments. Know the basic functioning of agents and the impact they may have on computer/network security. Understand the functionality behind Java applets and ActiveX controls and be able to determine the appropriate security controls for a given computing environment.
Explain the basic architecture of a relational database management system (RDBMS). Know the structure of relational databases. Be able to explain the function of tables (relations), rows (records/tuples), and columns (fields/attributes). Know how relationships are defined between tables.
Understand the various types of keys used to identify information stored in a database. You should be familiar with the basic types of keys. Understand that each table has one or more candidate keys that are chosen from a column heading in a database and that uniquely identify rows within a table. The database designer selects one candidate key as the primary key for the table. Foreign keys are used to enforce referential integrity between tables participating in a relationship.
Recognize the various common forms of DBMS safeguards. The common DBMS safeguards include concurrency, edit control, semantic integrity mechanisms, use of time and date stamps, granular control of objects, content-dependent access control, context-dependent access control, cell suppression, database partitioning, noise, perturbation, and polyinstantiation.
Explain the database security threats posed by aggregation and inference. Aggregation utilizes specialized database functions to draw conclusions about a large amount of data based on individual records. Access to these functions should be restricted if aggregate information is considered more sensitive than the individual records. Inference occurs when database users can deduce sensitive facts from less-sensitive information.
Know the various types of storage. Explain the differences between primary memory and virtual memory, secondary storage and virtual storage, random access storage and sequential access storage, and volatile storage and nonvolatile storage.
Explain how expert systems function. Expert systems consist of two main components: a knowledge base that contains a series of “if/then” rules and an inference engine that uses that information to draw conclusions about other data.
Describe the functioning of neural networks. Neural networks simulate the functioning of the human mind to a limited extent by arranging a series of layered calculations to solve problems. Neural networks require extensive training on a particular problem before they are able to offer solutions.
Understand the models of systems development. Know that the waterfall model describes a sequential development process that results in the development of a finished product. Developers may step back only one phase in the process if errors are discovered. The spiral model uses several iterations of the waterfall model to produce a number of fully specified and tested prototypes. Agile development models place an emphasis on the needs of the customer and quickly developing new functionality that meets those needs in an iterative fashion.
Describe software development maturity models. Know that maturity models help software organizations improve the maturity and quality of their software processes by implementing an evolutionary path from ad hoc, chaotic processes to mature, disciplined software processes. Describe the SW-CMM and IDEAL models.
Understand the importance of change and configuration management Know the three basic components of change control—request control, change control, and release control—and how they contribute to security. Explain how configuration management controls the versions of software used in an organization.
Explain the ring protection scheme. Understand the four rings of the ring protection scheme and the activities that typically occur within each ring. Know that most operating systems only implement Level 0 (privileged or supervisory mode) and Level 3 (protected or user mode).
Describe the function of the security kernel and reference monitor. The security kernel is the core set of operating system services that handles user requests for access to system resources. The reference monitor is a portion of the security kernel that validates user requests against the system’s access control mechanisms.
Understand the importance of testing. Software testing should be designed as part of the development process. Testing should be used as a management tool to improve the design, development, and production processes.
Understand the four security modes approved by the Department of Defense. Know the differences between compartmented security mode, dedicated security mode, multilevel security mode, and system-high security mode. Understand the different types of classified information that can be processed in each mode and the types of users that can access each system.
1. How does a worm travel from system to system?
2. Describe three benefits of using applets instead of server-side code for web applications.
3. What are the three requirements for an operational reference monitor in a secure computing system?
4. What operating systems are capable of processing ActiveX controls posted on a website?
5. What type of key is selected by the database developer to uniquely identify data within a relational database table?
6. What database security technique appears to permit the insertion of multiple rows sharing the same uniquely identifying information?
7. What type of storage is commonly referred to as a RAM disk?
8. How far backward does the waterfall model allow developers to travel when a development flaw is discovered?
1. Worms travel from system to system under their own power by exploiting flaws in networking software.
2. The processing burden is shifted from the server to the client, allowing the web server to handle a greater number of simultaneous requests. The client uses local resources to process the data, usually resulting in a quicker response. The privacy of client data is protected because information does not need to be transmitted to the web server.
3. It must be tamperproof, it must always be invoked, and it must be small enough to be subject to analysis and tests, the completeness of which can be assured.
4. Microsoft Windows platforms only.
5. Primary key.
6. Polyinstantiation.
7. Virtual storage.
8. One phase.
1. Which one of the following malicious code objects might be inserted in an application by a disgruntled software developer with the purpose of destroying system data after the developer’s account has been deleted (presumably following their termination)?
A. Virus
B. Worm
C. Trojan horse
D. Logic bomb
2. What term is used to describe code objects that act on behalf of a user while operating in an unattended manner?
A. Agent
B. Worm
C. Applet
D. Browser
3. Which form of DBMS primarily supports the establishment of treelike relationships?
A. Relational
B. Hierarchical
C. Mandatory
D. Distributed
4. Which of the following characteristics can be used to differentiate worms from viruses?
A. Worms infect a system by overwriting data in the master boot record of a storage device.
B. Worms always spread from system to system without user intervention.
C. Worms always carry a malicious payload that impacts infected systems.
D. All of the above.
5. What programming language(s) can be used to develop ActiveX controls for use on an Internet site?
A. Visual Basic
B. C
C. Java
D. All of the above
6. What form of access control is concerned with the data stored by a field rather than any other issue?
A. Content-dependent
B. Context-dependent
C. Semantic integrity mechanisms
D. Perturbation
7. Which one of the following key types is used to enforce referential integrity between database tables?
A. Candidate key
B. Primary key
C. Foreign key
D. Super key
8. Richard believes that a database user is misusing his privileges to gain information about the company’s overall business trends by issuing queries that combine data from a large number of records. What process is the database user taking advantage of?
A. Inference
B. Contamination
C. Polyinstantiation
D. Aggregation
9. What database technique can be used to prevent unauthorized users from determining classified information by noticing the absence of information normally available to them?
A. Inference
B. Manipulation
C. Polyinstantiation
D. Aggregation
10. Which one of the following terms cannot be used to describe the main RAM of a typical computer system?
A. Volatile
B. Sequential access
C. Real memory
D. Primary memory
11. What type of information is used to form the basis of an expert system’s decision-making process?
A. A series of weighted layered computations
B. Combined input from a number of human experts, weighted according to past performance
C. A series of “if/then” rules codified in a knowledge base
D. A biological decision-making process that simulates the reasoning process used by the human mind
12. Which one of the following intrusion detection systems makes use of an expert to detect anomalous user activity?
A. PIX
B. IDIOT
C. AAFID
D. NIDES
13. Which of the following acts as a proxy between two different systems to support interaction and simplify the work of programmers?
A. SDLC
B. ODBC
C. DSS
D. Abstraction
14. Which software development life cycle model allows for multiple iterations of the development process, resulting in multiple prototypes, each produced according to a complete design and testing process?
A. Software Capability Maturity Model
B. Waterfall model
C. Development cycle
D. Spiral model
15. In systems utilizing a ring protection scheme, at what level does the security kernel reside?
A. Level 0
B. Level 1
C. Level 2
D. Level 3
16. Which database security risk occurs when data from a higher classification level is mixed with data from a lower classification level?
A. Aggregation
B. Inference
C. Contamination
D. Polyinstantiation
17. Machine language is an example of a_________ -generation language.
A. First
B. Second
C. Third
D. Fifth
18. Which one of the following is not part of the change control process?
A. Request control
B. Release control
C. Configuration audit
D. Change control
19. What transaction management principle ensures that two transactions do not interfere with each other as they operate on the same data?
A. Atomicity
B. Consistency
C. Isolation
D. Durability
20. Which subset of the Structured Query Language is used to create and modify the database schema?
A. Data Definition Language
B. Data Structure Language
C. Database Schema Language
D. Database Manipulation Language
1. D. Logic bombs are malicious code objects programmed to lie dormant until certain logical conditions, such as a certain date, time, system event, or other criteria, are met. At that time, they spring into action, triggering their malicious payload.
2. A. Intelligent agents are code objects programmed to perform certain operations on behalf of a user in their absence. They are also often referred to as bots.
3. B. A hierarchical DBMS supports one-to-many relationships, often expressed in a tree structure.
4. B. The major difference between viruses and worms is that worms are self-replicating, whereas viruses require user intervention to spread from system to system. Infection of the master boot record is a characteristic of a subclass of viruses known as MBR viruses. Both viruses and worms are capable of carrying malicious payloads.
5. D. Microsoft’s ActiveX technology supports a number of programming languages, including Visual Basic, C, C++, and Java. On the other hand, only the Java language can be used to write Java applets.
6. A. Content-dependent access control is focused on the internal data of each field.
7. C. Foreign keys are used to enforce referential integrity constraints between tables that participate in a relationship.
8. D. In this case, the process the database user is taking advantage of is aggregation. Aggregation attacks involve the use of specialized database functions to combine information from a large number of database records to reveal information that may be more sensitive than the information in individual records would reveal.
9. C. Polyinstantiation allows the insertion of multiple records that appear to have the same primary key values into a database at different classification levels.
10. B. Random access memory (RAM) allows for the direct addressing of any point within the resource. A sequential access storage medium, such as a magnetic tape, requires scanning through the entire media from the beginning to reach a specific address.
11. C. Expert systems utilize a knowledge base consisting of a series of “if/then” statements to form decisions based upon the previous experience of human experts.
12. D. The Next-Generation Intrusion Detection Expert System (NIDES) is an expert system–based intrusion detection system. PIX is a firewall, and IDIOT and AAFID are intrusion detection systems that do not utilize expert systems.
13. B. ODBC acts as a proxy between applications and the back-end DBMS.
14. D. The spiral model allows developers to repeat iterations of another life cycle model (such as the waterfall model) to produce a number of fully tested prototypes.
15. A. The security kernel and reference monitor reside at Level 0 in the ring protection scheme, where they have unrestricted access to all system resources.
16. C. Contamination is the mixing of data from a higher classification level and/or need-to-know requirement with data from a lower classification level and/or need-to-know requirement.
17. A. Machine languages are considered first-generation languages.
18. C. Configuration audit is part of the configuration management process rather than the change control process.
19. C. The isolation principle states that two transactions operating on the same data must be temporarily separated from each other such that one does not interfere with the other.
20. A. The Data Definition Language (DDL) is used to make modifications to a relational database’s schema.