
Chapter 8. Security Solutions for Infrastructure Management
This chapter covers the following topics related to Objective 2.1 (Given a scenario, apply security solutions for infrastructure management) of the CompTIA Cybersecurity Analyst (CySA+) CS0-002 certification exam:
• Cloud vs. on-premises: Discusses the two main infrastructure models: cloud vs. on-premises
• Asset management: Covers issues surrounding asset management including asset tagging
• Segmentation: Describes physical and virtual segmentation, jumpboxes, and system isolation with an air gap
• Network architecture: Covers physical, software-defined, virtual private cloud (VPC), virtual private network (VPN), and serverless architectures
• Change management: Discusses the formal change management processes
• Virtualization: Focuses on virtual desktop infrastructure (VDI)
• Containerization: Discusses an alternate form of virtualization
• Identity and access management: Explores privilege management, multifactor authentication (MFA), single sign-on (SSO), federation, role-based access control, attribute-based access control, mandatory access control, and manual review
• Cloud access security broker (CASB): Discusses the role of CASBs
• Honeypot: Covers placement and use of honeypots
• Monitoring and logging: Explains monitoring and logging processes
• Encryption: Introduces important types of encryption
• Certificate management: Discusses issues critical to managing certificates
• Active defense: Discusses defensive strategy in the cybersecurity arena
Over the years, security solutions have been adopted, discredited, and replaced as technology changes. Cybersecurity professionals must know and understand the pros and cons of various approaches to protect the infrastructure. This chapter examines both old and new solutions.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz enables you to assess whether you should read the entire chapter. If you miss no more than one of these 14 self-assessment questions, you might want to skip ahead to the “Exam Preparation Tasks” section. Table 8-1 lists the major headings in this chapter and the “Do I Know This Already?” quiz questions covering the material in those headings so that you can assess your knowledge of these specific areas. The answers to the “Do I Know This Already?” quiz appear in Appendix A.
Table 8-1 “Do I Know This Already?” Foundation Topics Section-to-Question Mapping

1. Which statement is false with respect to multitenancy in a cloud?
a. It can lead to allowing another tenant or attacker to see others’ data or to assume the identity of other clients.
b. It prevents residual data of former tenants from being exposed in storage space assigned to new tenants.
c. Users may lose access due to inadequate redundancy and fault-tolerance measures.
d. Shared ownership of data with the customer can limit the legal liability of the provider.
2. Which of the following involves marking a video, photo, or other digital media with a GPS location?
a. TAXII
b. Geotagging
c. Geofencing
d. RFID
3. Which of the following is a network logically separate from the other networks where resources that will be accessed from the outside world are made available to only those that are authenticated?
a. Intranet
b. DMZ
c. Extranet
d. Internet
4. Which of the following terms refers to any device exposed directly to the Internet or to any untrusted network?
a. Screened subnet
b. Three-legged firewall
c. Bastion host
d. Screened host
5. Which statement is false regarding the change management process?
a. All changes should be formally requested.
b. Each request should be approved as quickly as possible.
c. Prior to formal approval, all costs and effects of the methods of implementation should be reviewed.
d. After they’re approved, the change steps should be developed.
6. Which of the following is installed on hardware and is considered as “bare metal”?
a. Type 1 hypervisor
b. VMware Workstation
c. Type 2 hypervisor
d. Oracle VirtualBox
7. Which of the following is a technique in which the kernel allows for multiple isolated user space instances?
a. Containerization
b. Segmentation
c. Affinity
d. Secure boot
8. Which of the following authentication factors represents something a person is?
a. Knowledge factor
b. Ownership factor
c. Characteristic factor
d. Location factor
9. Which of the following is a software layer that operates as a gatekeeper between an organization’s on-premises network and the provider’s cloud environment?
a. Virtual router
b. CASB
c. Honeypot
d. Black hole
10. Which of the following is the key purpose of a honeypot?
a. Loss minimization
b. Information gathering
c. Confusion
d. Retaliation
11. Which of the following relates to logon and information security continuous monitoring?
a. IEEE 802.ac
b. IOC/IEC 27017
c. NIST SP 800-137
d. FIPS
12. Which of the following cryptographic techniques provides the best method of ensuring integrity and determines if data has been altered?
a. Encryption
b. Hashing
c. Digital signature
d. Certificate pinning
13. Which of the following PKI components verifies the requestor’s identity and registers the requestor?
a. TA
b. CA
c. RA
d. BA
14. Which of the following is a new approach to security that is offensive in nature rather than defensive?
a. Hunt teaming
b. White teaming
c. Blue teaming
d. APT
Foundation Topics
Cloud vs. On-premises
Accompanying the movement to virtualization is a movement toward the placement of resources in a cloud environment. While the cloud allows users to access the resources from anywhere they can get Internet access, it presents a security landscape that differs from the security landscape of your on-premises resources. For one thing, a public cloud solution relies on the security practices of the provider.
These are the biggest risks you face when placing resources in a public cloud:

• Multitenancy can lead to the following:
• Allowing another tenant or attacker to see others’ data or to assume the identity of other clients
• Residual data of former tenants exposed in storage space assigned to new tenants
• The use of virtualization in cloud environments leads to the same issues covered later in this chapter in the section “Virtualization.”
• Mechanisms for authentication and authorization may be improper or inadequate.
• Users may lose access due to inadequate redundancy and fault-tolerance measures.
• Shared ownership of data with the customer can limit the legal liability of the provider.
• The provider may use data improperly (such as data mining).
• Data jurisdiction is an issue: Where does the data actually reside, and what laws affect it, based on its location?
Cloud Mitigations
Over time, best practices have emerged to address both cloud and on-premises environments. With regard to cloud it is incumbent on the customer to take an active role in ensuring security, including
• Understand you share responsibility for security with the vendor
• Ask, don’t assume, with regard to detailed security questions
• Deploy an identity and access management solution that supports cloud
• Train your staff
• Establish and enforce cloud security policies
• Consider a third-party partner if you don’t have the skill sets to protect yourself
Asset Management
Asset management and inventory control across the technology life cycle are critical to ensuring that assets are not stolen or lost and that data on assets is not compromised in any way. Asset management and inventory control are two related areas. Asset management involves tracking the devices that an organization owns, and inventory control involves tracking and containing inventory. All organizations should implement asset management, but not all organizations need to implement inventory control.
Asset Tagging
Asset tagging is the process of placing physical identification numbers of some sort on all assets. This can be a simple as a small label that identifies the asset and the owner, as shown in Figure 8-1.

Figure 8-1 Asset Tag
Asset tagging can also be a part of more robust asset-tracking system when implemented in such a way that the device can be tracked and located at any point in time. Let’s delve into the details of such systems.
Device-Tracking Technologies
Device-tracking technologies allow organizations to determine the location of a device and also often allow the organization to retrieve the device. However, if the device cannot be retrieved, it may be necessary to wipe the device to ensure that the data on the device cannot be accessed by unauthorized users. As a security practitioner, you should stress to your organization the need to implement device-tracking technologies and remote-wiping capabilities.
Geolocation/GPS Location
Device-tracking technologies include geolocation, or Global Positioning System (GPS) location. With this technology, location and time information about an asset can be tracked, provided that the appropriate feature is enabled on the device. For most mobile devices, the geolocation or GPS location feature can be enhanced through the use of Wi-Fi networks. A security practitioner must ensure that the organization enacts mobile device security policies that include the mandatory use of GPS location features. In addition, it will be necessary to set up appropriate accounts that allow personnel to use the vendor’s online service for device location. Finally, remote-locking and remote-wiping features should be seriously considered, particularly if the mobile devices contain confidential or private information.
Object-Tracking and Object-Containment Technologies
Object-tracking and object-containment technologies are primarily concerned with ensuring that inventory remains within a predefined location or area. Object-tracking technologies allow organizations to determine the location of inventory. Object-containment technologies alert personnel within the organization if inventory has left the perimeter of the predefined location or area.
For most organizations, object-tracking and object-containment technologies are used only for inventory assets above a certain value. For example, most retail stores implement object-containment technologies for high-priced electronics devices and jewelry. However, some organizations implement these technologies for all inventory, particularly in large warehouse environments.
Technologies used in this area include geotagging/geofencing and RFID.
Geotagging/Geofencing
Geotagging involves marking a video, photo, or other digital media with a GPS location. This feature has received criticism recently because attackers can use it to pinpoint personal information, such as the location of a person’s home. However, for organizations, geotagging can be used to create location-based news and media feeds. In the retail industry, geotagging can be helpful for allowing customers to locate a store where a specific piece of merchandise is available.
Geofencing uses the GPS to define geographical boundaries. A geofence is a virtual barrier, and alerts can occur when inventory enters or exits the boundary. Geofencing is used in retail management, transportation management, human resources management, law enforcement, and other areas.
RFID
Radio frequency identification (RFID) uses radio frequency chips and readers to manage inventory. The chips are placed on individual pieces or pallets of inventory. RFID readers are placed throughout the location to communicate with the chips. Identification and location information are collected as part of the RFID communication. Organizations can customize the information that is stored on an RFID chip to suit their needs.
Two types of RFID systems can be deployed: active reader/passive tag (ARPT) and active reader/active tag (ARAT). In an ARPT system, the active reader transmits signals and receives replies from passive tags. In an ARAT system, active tags are woken with signals from the active reader.
RFID chips can be read only if they are within a certain proximity of the RFID reader. A recent implementation of RFID chips is the Walt Disney MagicBand, which is issued to visitors at Disney resorts and theme parks. The band verifies park admission and allows visitors to reserve attraction restaurant times and pay for purchases in the resort.
Different RFID systems are available for different wireless frequencies. If your organization decides to implement RFID, it is important that you fully research the advantages and disadvantages of different frequencies.
Segmentation
One of the best ways to protect sensitive resources is to utilize network segmentation. When you segment a network, you create security zones that are separated from one another by devices such as firewalls and routers that can be used to control the flow of traffic between the zones.
Physical
Physical segmentation is a tried and true method of segmentation. While there is no limit to the number of zones you can create in general, most networks have the zone types discussed in the following sections.
LAN
Let’s talk about what makes a local-area network (LAN) local. Although classically we think of a LAN as a network located in one location, such as a single office, referring to a LAN as a group of systems that are connected with a fast connection is more correct. For purposes of this discussion, that is any connection over 10 Mbps. This might not seem very fast to you, but it is fast compared to a wide-area network (WAN). Even a T1 connection is only 1.544 Mbps. Using this as our yardstick, if a single campus network has a WAN connection between two buildings, then the two networks are considered two LANs rather than a single LAN. In most cases, however, networks in a single campus are typically not connected with a WAN connection, which is why usually you hear a LAN defined as a network in a single location.
Intranet
Within the boundaries of a single LAN, there can be subdivisions for security purposes. The LAN might be divided into an intranet and an extranet. The intranet is the internal network of the enterprise. It is considered a trusted network and typically houses any sensitive information and systems and should receive maximum protection with firewalls and strong authentication mechanisms.
Extranet
An extranet is a network logically separate from the intranet where resources that will be accessed from the outside world are made available to authorized, authenticated third parties. Access might be granted to customers, or business partners. All traffic between the extranet and the intranet should be closely monitored and securely controlled. Nothing of a sensitive nature should be placed in the extranet.
DMZ
Like an extranet, a demilitarized zone (DMZ) is a network logically separate from the intranet where resources that will be accessed from the outside world are made available. The difference is that usually an extranet contains resources available only to certain entities from the outside world, and access is secured with authentication, whereas a DMZ usually contains resources available to everyone from the outside world, without authentication. A DMZ might contain web servers, email servers, or DNS servers. Figure 8-2 shows the relationship between intranet, extranet, Internet, and DMZ networks.

Figure 8-2 Network Segmentation
Virtual
While all the network segmentation components discussed thus far separate networks physically with devices such as routers and firewalls, a virtual local-area network (VLAN) separates them logically. Enterprise-level switches are capable of creating VLANs. These are logical subdivisions of a switch that segregates ports from one another as if they were in different LANs. VLANs can also span multiple switches, meaning that devices connected to switches in different parts of a network can be placed in the same VLAN, regardless of physical location.
A VLAN adds a layer of separation between sensitive devices and the rest of the network. For example, if only two devices should be able to connect to the HR server, the two devices and the HR server could be placed in a VLAN separate from the other VLANs. Traffic between VLANs can only occur through a router. Routers can be used to implement access control lists (ACLs) that control the traffic allowed between VLANs. Figure 8-3 shows an example of a network with VLANs.

Figure 8-3 VLANs
VLANs can be used to address threats that exist within a network, such as the following:
• DoS attacks: When you place devices with sensitive information in a separate VLAN, they are shielded from both Layer 2 and Layer 3 DoS attacks from devices that are not in that VLAN. Because many of these attacks use network broadcasts, if they are in a separate VLAN, they will not receive broadcasts unless they originate from the same VLAN.
• Unauthorized access: While permissions should be used to secure resources on sensitive devices, placing those devices in a secure VLAN allows you to deploy ACLs on the router to allow only authorized users to connect to the device.
Jumpbox
A jumpbox, or jump server, is a server that is used to access devices that have been placed in a secure network zone such as a DMZ. The server would span the two networks to provide access from an administrative desktop to the managed device. Secure Shell (SSH) tunneling is common as the de facto method of access. Administrators can use multiple zone-specific jumpboxes to access what they need, and lateral access between servers is prevented by whitelists. This helps prevent the types of breaches suffered by both Target and Home Depot, in which lateral access was used to move from one compromised device to other servers. Figure 8-4 shows a jumpbox (jump server) arrangement.

Figure 8-4 Jumpboxes
A jumpbox arrangement can avoid the following issues:
• Breaches that occur from lateral access
• Inappropriate administrative access of sensitive servers
System Isolation
While the safest device is one that is not connected to any networks, disconnecting devices is typically not a workable solution if you need to access the data on a system. However, there are some middle-ground solutions between total isolation and total access. Systems can be isolated from other systems through the control of communications with the device. An example of system isolation is through the use of Microsoft Server isolation. By leveraging Group Policy (GP) settings, you can require that all communication with isolated servers must be authenticated and protected (and optionally encrypted as well) by using IPsec. As Group Policy settings can only be applied to computers that are domain members, computers that are not domain members must be specified as exceptions to the rules controlling access to the device if they need access. Figure 8-5 shows the results of three different types of devices attempting to access an isolated server. The non-domain device (unmanaged) cannot connect, while the unmanaged device that has been excepted can, and the domain member that lies within the isolated domain can also.

Figure 8-5 Server Isolation
The device that is a domain member (Computer 1) with the proper Group Policy settings to establish an authenticated session is allowed access. The computer that is not a domain member but has been excepted is allowed an unauthenticated session. Finally, a device missing the proper GP settings to establish an authenticated session is not allowed access. This is just one example of how devices can be isolated.
Air Gap
In cases where data security concerns are extreme, it may even be advisable to protect the underlying system with an air gap. This means the device has no network connections and all access to the system must be done manually by adding and removing items such as updates and patches with a flash drive or other external device.
Any updates to the data on the device must be done manually, using external media. An example of when it might be appropriate to do so is in the case of a certificate authority (CA) root server. If a root CA is in some way compromised (broken into, hacked, stolen, or accessed by an unauthorized or malicious person), all the certificates that were issued by that CA are also compromised.
Network Architecture
Network architecture refers not only to the components that are arranged and connected to one another (physical architecture) but also to the communication paths the network uses (logical architecture). This section surveys security considerations for a number of different architectures that can be implemented both physically and virtually.
Physical
The physical network comprises the physical devices and their connections to one another. The physical network in many cases serves as an underlay or carrier for higher-level network processes and protocols.
Security practitioners must understand two main types of enterprise deployment diagrams:
• Logical deployment diagram: Shows the architecture, including the domain architecture, with the existing domain hierarchy, names, and addressing scheme; server roles; and trust relationships.
• Physical deployment diagram: Shows the details of physical communication links, such as cable length, grade, and wiring paths; servers, with computer name, IP address (if static), server role, and domain membership; device location, such as printer, hub, switch, modem, router, or bridge, as well as proxy location; communication links and the available bandwidth between sites; and the number of users, including mobile users, at each site.
A logical diagram usually contains less information than a physical diagram. While you can often create a logical diagram from a physical diagram, it is nearly impossible to create a physical diagram from a logical one.
Figure 8-6 shows an example of a logical network diagram.

Figure 8-6 Logical Network Diagram
As you can see, the logical network diagram shows only a few of the servers in the network, the services they provide, their IP addresses, and their DNS names. The relationships between the different servers are shown by the arrows between them. Figure 8-7 shows an example of a physical network diagram.

Figure 8-7 Physical Network Diagram
A physical network diagram gives much more information than a logical one, including the cabling used, the devices on the network, the pertinent information for each server, and other connection information.
Note
CySA+ firewall-related objectives including firewall logs, web application firewalls (WAFs), and implementing configuration changes to firewalls are covered later in the book in Chapter 11, “Analyzing Data as Part of Security Monitoring Activities.”
Firewall Architecture
Whereas the type of firewall speaks to the internal operation of the firewall, the architecture refers to the way in which firewalls are deployed in the network to form a system of protection. The following sections look at the various ways firewalls can be deployed.
Bastion Hosts
A bastion host may or may not be a firewall. The term actually refers to the position of any device. If the device is exposed directly to the Internet or to any untrusted network while screening the rest of the network from exposure, it is a bastion host. Some other examples of bastion hosts are FTP servers, DNS servers, web servers, and email servers. In any case where a host must be publicly accessible from the Internet, the device must be treated as a bastion host, and you should take the following measures to protect these machines:
• Disable or remove all unnecessary services, protocols, programs, and network ports.
• Use authentication services separate from those of the trusted hosts within the network.
• Remove as many utilities and system configuration tools as is practical.
• Install all appropriate service packs, hotfixes, and patches.
• Encrypt any local user account and password databases.
A bastion host can be located in the following locations:
• Behind the exterior and interior firewalls: Locating it here and keeping it separate from the interior network complicates the configuration but is safest.
• Behind the exterior firewall only: Perhaps the most common location for a bastion host is separated from the internal network; this is a less complicated configuration. Figure 8-8 shows an example in which there are two bastion hosts: the FTP/WWW server and the SMTP/DNS server.
• As both the exterior firewall and a bastion host: This setup exposes the host to the most danger.

Figure 8-8 Bastion Host in a Screened Subnet
Dual-Homed Firewalls
A dual-homed firewall has two network interfaces: one pointing to the internal network and another connected to the untrusted network. In many cases, routing between these interfaces is turned off. The firewall software allows or denies traffic between the two interfaces based on the firewall rules configured by the administrator. The following are some of the advantages of this setup:
• The configuration is simple.
• It is possible to perform IP masquerading (NAT).
• It is less costly than using two firewalls.
Disadvantages include the following:
• There is a single point of failure.
• It is not as secure as other options.
Figure 8-9 shows a dual-homed firewall (also called a dual-homed host) location.

Figure 8-9 Location of Dual-Homed Firewall
Multihomed Firewall
A firewall can be multihomed. One popular type of multihomed firewall is the three-legged firewall. In this configuration, there are three interfaces: one connected to the untrusted network, one connected to the internal network, and one connected to a DMZ. As mentioned earlier in this chapter, a DMZ is a protected network that contains systems needing a higher level of protection. The advantages of a three-legged firewall include the following:
• It offers cost savings on devices because you need only one firewall and not two or three.
• It is possible to perform IP masquerading (NAT) on the internal network while not doing so for the DMZ.
Among the disadvantages are the following:
• The complexity of the configuration is increased.
• There is a single point of failure.
The location of a three-legged firewall is shown in Figure 8-10.

Figure 8-10 Location of a Three-legged Firewall
Screened Host Firewalls
A screened host firewall is located between the final router and the internal network. The advantages to a screened host firewall solution include the following:
• It offers more flexibility than a dual-homed firewall because rules rather than an interface create the separation.
• Potential cost savings.
The disadvantages include the following:
• The configuration is more complex.
• It is easier to violate the policies than with dual-homed firewalls.
Figure 8-11 shows the location of a screened host firewall.

Figure 8-11 Location of a Screened Host Firewall
Screened Subnets
In a screened subnet, two firewalls are used, and traffic must be inspected at both firewalls before it can enter the internal network. The advantages of a screened subnet include the following:
• It offers the added security of two firewalls before the internal network.
• One firewall is placed before the DMZ, protecting the devices in the DMZ.
Disadvantages include the following:
• It is more costly than using either a dual-homed or three-legged firewall.
• Configuring two firewalls adds complexity.
Figure 8-12 shows the placement of the firewalls to create a screened subnet. The router is acting as the outside firewall, and the firewall appliance is the second firewall. In any situation where multiple firewalls are in use, such as an active/passive cluster of two firewalls, care should be taken to ensure that TCP sessions are not traversing one firewall while return traffic of the same session is traversing the other. When stateful filtering is being performed, the return traffic will be denied, which will break the user connection. In the real world, various firewall approaches are mixed and matched to meet requirements, and you may find elements of all these architectural concepts being applied to a specific situation.

Figure 8-12 Location of a Screened Subnet
Software-Defined Networking
In a network, three planes typically form the networking architecture:
• Control plane: This plane carries signaling traffic originating from or destined for a router. This is the information that allows routers to share information and build routing tables.
• Data plane: Also known as the forwarding plane, this plane carries user traffic.
• Management plane: This plane administers the router.
Software-defined networking (SDN) has been classically defined as the decoupling of the control plane and the data plane in networking. In a conventional network, these planes are implemented in the firmware of routers and switches. SDN implements the control plane in software, which enables programmatic access to it.
This definition has evolved over time to focus more on providing programmatic interfaces to networking equipment and less on the decoupling of the control and data planes. An example of this is the provision of application programming interfaces (APIs) by vendors into the multiple platforms they sell.
One advantage of SDN is that it enables very detailed access into, and control over, network elements. It allows IT organizations to replace a manual interface with a programmatic one that can enable the automation of configuration and policy management.
An example of the use of SDN is using software to centralize the control plane of multiple switches that normally operate independently. (While the control plane normally functions in hardware, with SDN it is performed in software.) Figure 8-13 illustrates this concept.

Figure 8-13 Centralized and Decentralized SDN
The advantages of SDN include the following:
• Mixing and matching solutions from different vendors is simple.
• SDN offers choice, speed, and agility in deployment.
The following are disadvantages of SDN:
• Loss of connectivity to the controller brings down the entire network.
• SDN can potentially allow attacks on the controller.
Virtual SAN
A virtual storage area network (VSAN) is a software-defined storage method that allows pooling of storage capabilities and instant and automatic provisioning of virtual machine storage. This is a method of software-defined storage (SDS). It usually includes dynamic tiering, QoS, caching, replication, and cloning. Data availability is ensured through the software, not by implementing redundant hardware. Administrators are able to define policies that allow the software to determine the best placement of data. By including intelligent data placement, software-based controllers, and software RAID, a VSAN can provide better data protection and availability than tradition hardware-only options.
Virtual Private Cloud (VPC)
In Chapter 6, “Threats and Vulnerabilities Associated with Operating in the Cloud,” you learned about cloud deployment models, one of which was the hybrid model. A type of hybrid model is the virtual private cloud (VPC) model. In this model, a public cloud provider isolates a specific portion of its public cloud infrastructure to be provisioned for private use. How does this differ from a standard private cloud? VPCs are private clouds sourced over a third-party vendor infrastructure rather than over an enterprise IT infrastructure. Figure 8-14 illustrates this architecture.

Figure 8-14 Virtual Private Cloud
Virtual Private Network (VPN)
A virtual private network (VPN) allows external devices to access an internal network by creating a tunnel over the Internet. Traffic that passes through the VPN tunnel is encrypted and protected. An example of a network with a VPN is shown in Figure 8-15. In a VPN deployment, only computers that have the VPN client and are able to authenticate will be able to connect to the internal resources through the VPN concentrator.

Figure 8-15 VPN
VPN connections use an untrusted carrier network but provide protection of the information through strong authentication protocols and encryption mechanisms. While we typically use the most untrusted network, the Internet, as the classic example, and most VPNs do travel through the Internet, a VPN can be used with interior networks as well whenever traffic needs to be protected from prying eyes.
In VPN operations, entire protocols wrap around other protocols when this process occurs. They include
• A LAN protocol (required)
• A remote access or line protocol (required)
• An authentication protocol (optional)
• An encryption protocol (optional)
A device that terminates multiple VPN connections is called a VPN concentrator. VPN concentrators incorporate the most advanced encryption and authentication techniques available.
In some instances, VLANs in a VPN solution may not be supported by the ISP if they are also using VLANs in their internal network. Choosing a provider that provisions Multiprotocol Label Switching (MPLS) connections can allow customers to establish VLANs to other sites. MPLS provides VPN services with address and routing separation between VPNs.
VPN connections can be used to provide remote access to teleworkers or traveling users (called remote-access VPNs) and can also be used to securely connect two locations (called site-to-site VPNs). The implementation process is conceptually different for these two VPN types. In a remote-access VPN, the tunnel that is created has as its endpoints the user’s computer and the VPN concentrator. In this case, only traffic traveling from the user computer to the VPN concentrator uses this tunnel. In the case of two office locations, the tunnel endpoints are the two VPN routers, one in each office. With this configuration, all traffic that goes between the offices uses the tunnel, regardless of the source or destination. The endpoints are defined during the creation of the VPN connection and thus must be set correctly according to the type of remote-access link being used.
Two protocols commonly used to create VPN connections are IPsec and SSL/TLS. The next section discusses these two protocols
IPsec
Internet Protocol Security (IPsec) is a suite of protocols used in various combinations to secure VPN connection. Although it provides other services it is an encryption protocol. Before we look at IPsec let’s look at several remote-access or line protocols (tunneling protocols) used to create VPN connections, including
• Point-to-Point Tunneling Protocol (PPTP): PPTP is a Microsoft protocol based on PPP. It uses built-in Microsoft Point-to-Point encryption and can use a number of authentication methods, including CHAP, MS-CHAP, and EAP-TLS. One shortcoming of PPTP is that it only works on IP-based networks. If a WAN connection that is not IP based is in use, L2TP must be used.
• Layer 2 Tunneling Protocol (L2TP): L2TP is a newer protocol that operates at Layer 2 of the OSI model. Like PPTP, L2TP can use various authentication mechanisms; however, L2TP does not provide any encryption. It is typically used with IPsec, which is a very strong encryption mechanism.
When using PPTP, the encryption is included, and the only remaining choice to be made is the authentication protocol. When using L2TP, both encryption and authentication protocols, if desired, must be added. IPsec can provide encryption, data integrity, and system-based authentication, which makes it a flexible and capable option. By implementing certain parts of the IPsec suite, you can either use these features or not.
Internet Protocol Security (IPsec) includes the following components:
• Authentication Header (AH): AH provides data integrity, data origin authentication, and protection from replay attacks.
• Encapsulating Security Payload (ESP): ESP provides all that AH does as well as data confidentiality.
• Internet Security Association and Key Management Protocol (ISAKMP): ISAKMP handles the creation of a security association (SA) for the session and the exchange of keys.
• Internet Key Exchange (IKEv2): Also sometimes referred to as IPsec Key Exchange, IKE provides the authentication material used to create the keys exchanged by ISAKMP during peer authentication. This was proposed to be performed by a protocol called Oakley that relied on the Diffie-Hellman algorithm, but Oakley has been superseded by IKEv2.
IPsec is a framework, which means it does not specify many of the components used with it. These components must be identified in the configuration, and they must match in order for the two ends to successfully create the required SA that must be in place before any data is transferred. The following selections must be made:
• The encryption algorithm, which encrypts the data
• The hashing algorithm, which ensures that the data has not been altered and verifies its origin
• The mode, which is either tunnel or transport
• The protocol, which can be AH, ESP, or both
All these settings must match on both ends of the connection. It is not possible for the systems to select these on the fly. They must be preconfigured correctly in order to match.
When configured in tunnel mode, the tunnel exists only between the two gateways, but all traffic that passes through the tunnel is protected. This is normally done to protect all traffic between two offices. The SA is between the gateways between the offices. This is the type of connection that would be called a site-to-site VPN.
The SA between the two endpoints is made up of the security parameter index (SPI) and the AH/ESP combination. The SPI, a value contained in each IPsec header, help the devices maintain the relationship between each SA (and there could be several happening at once) and the security parameters (also called the transform set) used for each SA.
Each session has a unique session value, which helps prevent
• Reverse engineering
• Content modification
• Factoring attacks (in which the attacker tries all the combinations of numbers that can be used with the algorithm to decrypt ciphertext)
With respect to authenticating the connection, the keys can be preshared or derived from a public key infrastructure (PKI). A PKI creates public/private key pairs that are associated with individual users and computers that use a certificate. These key pairs are used in the place of preshared keys in that case. Certificates that are not derived from a PKI can also be used.
In transport mode, the SA is either between two end stations or between an end station and a gateway or remote access server. In this mode, the tunnel extends from computer to computer or from computer to gateway. This is the type of connection that would be used for a remote-access VPN. This is but one application of IPsec.
When the communication is from gateway to gateway or host to gateway, either transport or tunnel mode may be used. If the communication is computer to computer, transport mode is required. When using transport mode from gateway to host, the gateway must operate as a host.
The most effective attack against an IPsec VPN is a man-in-the middle attack. In this attack, the attacker proceeds through the security negotiation phase until the key negotiation, when the victim reveals its identity. In a well-implemented system, the attacker fails when the attacker cannot likewise prove his identity.
SSL/TLS
Secure Sockets Layer (SSL)/Transport Layer Security (TLS) is another option for creating VPNs. Although SSL/TLS has largely been replaced by its successor, TLS, it is quite common to hear it still refereed to it as an SSL/TLS connection. It works at the application layer of the OSI model and is used mainly to protect HTTP traffic or web servers. Its functionality is embedded in most browsers, and its use typically requires no action on the part of the user. It is widely used to secure Internet transactions. It can be implemented in two ways:
• SSL/TLS portal VPN: In this case, a user has a single SSL/TLS connection for accessing multiple services on the web server. Once authenticated, the user is provided a page that acts as a portal to other services.
• SSL/TLS tunnel VPN: A user may use an SSL/TLS tunnel to access services on a server that is not a web server. This solution uses custom programming to provide access to non-web services through a web browser.
TLS and SSL/TLS are very similar but not the same. When configuring SSL/TLS, a session key length must be designated. The two options are 40-bit and 128-bit. Using self-signed certificates to authenticate the server’s public key prevents man-in-the-middle attacks.
SSL/TLS is often used to protect other protocols. Secure Copy Protocol (SCP), for example, uses SSL/TLS to secure file transfers between hosts. Table 8-2 lists some of the advantages and disadvantages of SSL/TLS.
Table 8-2 Advantages and Disadvantages of SSL/TLS

When placing the SSL/TLS gateway, you must consider a trade-off: The closer the gateway is to the edge of the network, the less encryption that needs to be performed in the LAN (and the less performance degradation), but the closer to the network edge it is placed, the farther the traffic travels through the LAN in the clear. The decision comes down to how much you trust your internal network.
The latest version of TLS is version 1.3, which provides access to advanced cipher suites that support elliptical curve cryptography and AEAD block cipher modes. TLS has been improved to support the following:
• Hash negotiation: Can negotiate any hash algorithm to be used as a built-in feature, and the default cipher pair MD5/SHA-1 has been replaced with SHA-256.
• Certificate hash or signature control: Can configure the certificate requester to accept only specified hash or signature algorithm pairs in the certification path.
• Suite B–compliant cipher suites: Two cipher suites have been added so that the use of TLS can be Suite B compliant:
• TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
• TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
Serverless
A serverless architecture is one in which servers are not located where applications are hosted. In this model, applications are hosted by a third-party service, eliminating the need for server software and hardware management by the developer. Applications are broken up into individual functions that can be invoked and scaled individually. Function as a Service (FaaS), another name for serverless architecture, was discussed in Chapter 6.
Change Management
All networks evolve, grow, and change over time. Companies and their processes also evolve and change, which is a good thing. But infrastructure change must be managed in a structured way so as to maintain a common sense of purpose about the changes. By following recommended steps in a formal change management process, change can be prevented from becoming the tail that wags the dog. The following are guidelines to include as a part of any change management policy:
• All changes should be formally requested.
• Each request should be analyzed to ensure it supports all goals and polices.
• Prior to formal approval, all costs and effects of the methods of implementation should be reviewed.
• After they’re approved, the change steps should be developed.
• During implementation, incremental testing should occur, relying on a predetermined fallback strategy if necessary.
• Complete documentation should be produced and submitted with a formal report to management.
One of the key benefits of following this change management method is the ability to make use of the documentation in future planning. Lessons learned can be applied, and even the process itself can be improved through analysis.
Virtualization
Multiple physical servers are increasingly being consolidated to a single physical device or hosted as virtual servers. It is even possible to have entire virtual networks residing on these hosts. While it may seem that these devices are safely contained on the physical devices, they are still vulnerable to attack. If a host is compromised or a hypervisor that manages virtualization is compromised, an attack on the virtual machines (VMs) could ensue.
Security Advantages and Disadvantages of Virtualization
Virtualization of servers has become a key part of reducing the physical footprint of data centers. The advantages include
• Reduced overall use of power in the data center
• Dynamic allocation of memory and CPU resources to the servers
• High availability provided by the ability to quickly bring up a replica server in the event of loss of the primary server
However, most of the same security issues that must be mitigated in the physical environment must also be addressed in the virtual network. In a virtual environment, instances of an operating system are virtual machines. A host system can contain many VMs. Software called a hypervisor manages the distribution of resources (CPU, memory, and disk) to the VMs. Figure 8-16 shows the relationship between the host machine, its physical resources, the resident VMs, and the virtual resources assigned to them.

Figure 8-16 Virtualization
Keep in mind that in any virtual environment, each virtual server that is hosted on the physical server must be configured with its own security mechanisms. These mechanisms include antivirus and anti-malware software and all the latest patches and security updates for all the software hosted on the virtual machine. Also, remember that all the virtual servers share the resources of the physical device.
When virtualization is hosted on a Linux machine, any sensitive application that must be installed on the host should be installed in a chroot environment. A chroot on Unix-based operating systems is an operation that changes the root directory for the current running process and its children. A program that is run in such a modified environment cannot name (and therefore normally cannot access) files outside the designated directory tree.
Type 1 vs. Type 2 Hypervisors
The hypervisor that manages the distribution of the physical server’s resources can be either Type 1 or Type 2:
• Type 1 hypervisor: A guest operating system runs on another level above the hypervisor. Examples of Type 1 hypervisors are Citrix XenServer, Microsoft Hyper-V, and VMware vSphere.
• Type 2 hypervisor: A Type 2 hypervisor runs within a conventional operating system environment. With the hypervisor layer as a distinct second software level, guest operating systems run at the third level above the hardware. VMware Workstation and Oracle VM VirtualBox exemplify Type 2 hypervisors.
Figure 8-17 shows a comparison of the two approaches.

Figure 8-17 Hypervisor Types
Virtualization Attacks and Vulnerabilities
Virtualization attacks and vulnerabilities fall into the following categories:
• VM escape: This type of attack occurs when a guest OS escapes from its VM encapsulation to interact directly with the hypervisor. This can allow access to all VMs and the host machine as well. Figure 8-18 illustrates an example of this attack.

Figure 8-18 VM Escape
• Unsecured VM migration: This type of attack occurs when a VM is migrated to a new host and security policies and configuration are not updated to reflect the change.
• Host and guest vulnerabilities: Host and guest interactions can magnify system vulnerabilities. The operating systems on both the host and the guest systems can suffer the same issues as those on all physical devices. For that reason, both guest and host operating systems should always have the latest security patches and should have antivirus and anti-malware software installed and up to date. All other principles of hardening the operating system should also be followed, including disabling unneeded services and disabling unneeded accounts.
• VM sprawl: More VMs create more failure points, and sprawl can cause problems even if no malice is involved. Sprawl occurs when the number of VMs grows over time to an unmanageable number. As this occurs, the ability of the administrator to keep up with them is slowly diminished.
• Hypervisor attack: This type of attack involves taking control of the hypervisor to gain access to the VMs and their data. While these attacks are rare due to the difficulty of directly accessing hypervisors, administrators should plan for them.
• Data remnants: Sensitive data inadvertently replicated in VMs as a result of cloud maintenance functions or remnant data left in terminated VMs needs to be protected. Also, if data is moved, residual data may be left behind, accessible to unauthorized users. Any remaining data in the old location should be shredded, but depending on the security practice, data remnants may remain. This can be a concern with confidential data in private clouds and any sensitive data in public clouds. Commercial products can deal with data remnants. For example, Blancco is a product that permanently removes data from PCs, servers, data center equipment, and smart phones. Data erased by Blancco cannot be recovered with any existing technology. Blancco also creates a report to price each erasure for compliance purposes.
Virtual Networks
A virtual infrastructure usually contains virtual switches that connect to the physical switches in the network. You should ensure that traffic from the physical network to the virtual network is tightly controlled. Remember that virtual machines run operating systems that are vulnerable to the same attacks as those on physical machines. Also, the same type of network attacks and scanning can be done if there is access to the virtual network.
Management Interface
Some vulnerability exists in the management interface to the hypervisor. The danger here is that this interface typically provides access to the entire virtual infrastructure. The following are some of the attacks through this interface:
• Privilege elevation: In some cases, the dangers of privilege elevation or escalation in a virtualized environment may be equal to or greater than those in a physical environment. When the hypervisor is performing its duty of handling calls between the guest operating system and the hardware, any flaws introduced to those calls could allow an attacker to escalate privileges in the guest operating system. An example of a flaw in VMware ESX Server, Workstation, Fusion, and View products could have led to escalation on the host. VMware reacted quickly to fix this flaw with a security update. The key to preventing privilege escalation is to make sure all virtualization products have the latest updates and patches.
• Live VM migration: One of the advantages of a virtualized environment is the ability of the system to migrate a VM from one host to another when needed, called a live migration. When VMs are on the network between secured perimeters, attackers can exploit the network vulnerability to gain unauthorized access to VMs. With access to the VM images, attackers can plant malicious code in the VM images to plant attacks on data centers that VMs travel between. Often the protocols used for the migration are not encrypted, making a man-in-the-middle attack in the VM possible while it is in transit, as shown in Figure 8-19. They key to preventing man-in-the middle attacks is encryption of the images where they are stored.

Figure 8-19 Man-in-the-Middle Attack
Vulnerabilities Associated with a Single Physical Server Hosting Multiple Companies’ Virtual Machines
In some virtualization deployments, a single physical server hosts multiple organizations’ VMs. All the VMs hosted on a single physical computer must share the resources of that physical server. If the physical server crashes or is compromised, all the organizations that have VMs on that physical server are affected. User access to the VMs should be properly configured, managed, and audited. Appropriate security controls, including antivirus, anti-malware, ACLs, and auditing, must be implemented on each of the VMs to ensure that each one is properly protected. Other risks to consider include physical server resource depletion, network resource performance, and traffic filtering between virtual machines.
Driven mainly by cost, many companies outsource to cloud providers computing jobs that require a large number of processor cycles for a short duration. This situation allows a company to avoid a large investment in computing resources that will be used for only a short time. Assuming that the provisioned resources are dedicated to a single company, the main vulnerability associated with on-demand provisioning is traces of proprietary data that can remain on the virtual machine and may be exploited.
Let’s look at an example. Say that a security architect is seeking to outsource company server resources to a commercial cloud service provider. The provider under consideration has a reputation for poorly controlling physical access to data centers and has been the victim of social engineering attacks. The service provider regularly assigns VMs from multiple clients to the same physical resource. When conducting the final risk assessment, the security architect should take into consideration the likelihood that a malicious user will obtain proprietary information by gaining local access to the hypervisor platform.
Vulnerabilities Associated with a Single Platform Hosting Multiple Companies’ Virtual Machines
In some virtualization deployments, a single platform hosts multiple organizations’ VMs. If all the servers that host VMs use the same platform, attackers will find it much easier to attack the other host servers once the platform is discovered. For example, if all physical servers use VMware to host VMs, any identified vulnerabilities for that platform could be used on all host computers. Other risks to consider include misconfigured platforms, separation of duties, and application of security policy to network interfaces. If an administrator wants to virtualize the company’s web servers, application servers, and database servers, the following should be done to secure the virtual host machines: only access hosts through a secure management interface and restrict physical and network access to the host console.
Virtual Desktop Infrastructure (VDI)
Virtual desktop infrastructure (VDI) hosts desktop operating systems within a virtual environment in a centralized server. Users access the desktops and run them from the server. There are three models for implementing VDI:
• Centralized model: All desktop instances are stored in a single server, which requires significant processing power on the server.
• Hosted model: Desktops are maintained by a service provider. This model eliminates capital cost and is instead considered operational cost.
• Remote virtual desktops model: An image is copied to the local machine, which means a constant network connection is unnecessary.
Figure 8-20 compares the remote virtual desktop models (also called streaming) with centralized VDI.

Figure 8-20 VDI Streaming and Centralized VDI
Terminal Services/Application Delivery Services
Just as operating systems can be provided on demand with technologies like VDI, applications can also be provided to users from a central location. Two models can be used to implement this:
• Server-based application virtualization (terminal services): In server-based application virtualization, an application runs on servers. Users receive the application environment display through a remote client protocol, such as Microsoft Remote Desktop Protocol (RDP) or Citrix Independent Computing Architecture (ICA). Examples of terminal services include Remote Desktop Services and Citrix Presentation Server.
• Client-based application virtualization (application streaming): In client-based application virtualization, the target application is packaged and streamed to the client PC. It has its own application computing environment that is isolated from the client OS and other applications. A representative example is Microsoft Application Virtualization (App-V).
Figure 8-21 compares these two approaches.

Figure 8-21 Application Streaming and Terminal Services
When using either of these technologies, you should force the use of encryption, set limits to the connection life, and strictly control access to the server. These measures can prevent eavesdropping on any sensitive information, especially the authentication process.
Containerization
A newer approach to server virtualization is referred to as container-based virtualization, also called operating system virtualization. Containerization is a technique in which the kernel allows for multiple isolated user space instances. The instances are known as containers, virtual private servers, or virtual environments.
In this model, the hypervisor is replaced with operating system–level virtualization. A virtual machine is not a complete operating system instance but rather a partial instance of the same operating system. The containers in Figure 8-22 are the darker boxes just above the host OS level. Container-based virtualization is used mostly in Linux environments, and examples are the commercial Parallels Virtuozzo and the open source OpenVZ project.

Figure 8-22 Container-based Virtualization
Identity and Access Management
This section describes how identity and access management (IAM) work, why IAM is important, and how IAM components and devices work together in an enterprise. Access control allows only authorized users, applications, devices, and systems to access enterprise resources and information. In includes facilities, support systems, information systems, network devices, and personnel. Security practitioners must use access controls to specify which users can access a resource, which resources can be accessed, which operations can be performed, and which actions will be monitored. Once again, the CIA triad is important in providing enterprise IAM. The three-step process used to set up a robust IAM system is covered in the following sections.
Identify Resources
This first step in the access control process involves defining all resources in the IT infrastructure by deciding which entities need to be protected. When defining these resources, you must also consider how the resources will be accessed. The following questions can be used as a starting point during resource identification:
• Will this information be accessed by members of the general public?
• Should access to this information be restricted to employees only?
• Should access to this information be restricted to a smaller subset of employees?
Keep in mind that data, applications, services, servers, and network devices are all considered resources. Resources are any organizational asset that users can access. In access control, resources are often referred to as objects.
Identify Users
After identifying the resources, an organization should identify the users who need access to the resources. A typical security professional must manage multiple levels of users who require access to organizational resources. During this step, only identifying the users is important. The level of access these users will be given will be analyzed further in the next step.
As part of this step, you must analyze and understand the users’ needs and then measure the validity of those needs against organizational needs, policies, legal issues, data sensitivity, and risk.
Remember that any access control strategy and the system deployed to enforce it should avoid complexity. The more complex an access control system is, the harder that system is to manage. In addition, anticipating security issues that could occur in more complex systems is much harder. As security professionals, we must balance the organization’s security needs and policies with the needs of the users. If a security mechanism that we implement causes too much difficulty for the user, the user might engage in practices that subvert the mechanisms that we implement. For example, if you implement a password policy that requires a very long, complex password, users might find remembering their passwords to be difficult. Users might then write their passwords on sticky notes that they then attach to their monitor or keyboard.
Identify Relationships Between Resources and Users
The final step in the access control process is to define the access control levels that need to be in place for each resource and the relationships between the resources and users. For example, if an organization has defined a web server as a resource, general employees might need a less restrictive level of access to the resource than the level given to the public and a more restrictive level of access to the resource than the level given to the web development staff. Access controls should be designed to support the business functionality of the resources that are being protected. Controlling the actions that can be performed for a specific resource based on a user’s role is vital.
Privilege Management
When users are given the ability to do something that typically only an administrator can do, they have been granted privileges and their account becomes a privileged account. The management of such accounts is called privilege management and must be conducted carefully because any privileges granted become tools that can be used against your organization if an account is compromised by a malicious individual.
An example of the use of privilege management is in the use of attribute certificates (ACs) to hold user privileges with the same object that authenticates them. So when Sally uses her certificates to authenticate, she receives privileges that are attributes of the certificate. This architecture is called a privilege management infrastructure.
Multifactor Authentication (MFA)
Identifying users and devices and determining the actions permitted by a user or device forms the foundation of access control models. While this paradigm has not changed since the beginning of network computing, the methods used to perform this important set of functions have changed greatly and continue to evolve. While simple usernames and passwords once served the function of access control, in today’s world, more sophisticated and secure methods are developing quickly. Not only are such simple systems no longer secure, the design of access credential systems today emphasizes ease of use. Multifactor authentication (MFA) is the use of more than a single factor, such as a password, to authenticate someone. This section covers multifactor authentication.
Authentication
To be able to access a resource, a user must prove her identity, provide the necessary credentials, and have the appropriate rights to perform the tasks she is completing. So there are two parts:
• Identification: In the first part of the process, a user professes an identity to an access control system.
• Authentication: The second part of the process involves validating a user with a unique identifier by providing the appropriate credentials.
When trying to differentiate between these two parts, security professionals should know that identification identifies the user, and authentication verifies that the identity provided by the user is valid. Authentication is usually implemented through a user password provided at login. The login process should validate the login after all the input data is supplied. The most popular forms of user identification include user IDs or user accounts, account numbers, and personal identification numbers (PINs).
Authentication Factors
Once the user identification method has been established, an organization must decide which authentication method to use. Authentication methods are divided into five broad categories:
• Knowledge factor authentication: Something a person knows
• Ownership factor authentication: Something a person has
• Characteristic factor authentication: Something a person is
• Location factor authentication: Somewhere a person is
• Action factor authentication: Something a person does
Authentication usually ensures that a user provides at least one factor from these categories, which is referred to as single-factor authentication. An example of this would be providing a username and password at login. Two-factor authentication ensures that the user provides two of the three factors. An example of two-factor authentication would be providing a username, password, and smart card at login. Three-factor authentication ensures that a user provides three factors. An example of three-factor authentication would be providing a username, password, smart card, and fingerprint at login. For authentication to be considered strong authentication, a user must provide factors from at least two different categories. (Note that the username is the identification factor, not an authentication factor.)
You should understand that providing multiple authentication factors from the same category is still considered single-factor authentication. For example, if a user provides a username, password, and the user’s mother’s maiden name, single-factor authentication is being used. In this example, the user is still only providing factors that are something a person knows.
Knowledge Factors
As previously described in brief, knowledge factor authentication is authentication that is provided based on something a person knows. This type of authentication is referred to as a Type I authentication factor. While the most popular form of authentication used by this category is password authentication, other knowledge factors can be used, including date of birth, mother’s maiden name, key combination, or PIN.
Ownership Factors
Ownership factor authentication is authentication that is provided based on something that a person has. This type of authentication is referred to as a Type II authentication factor. Ownership factors can include the following:
• Token devices: A token device is a handheld device that presents the authentication server with the one-time password. If the authentication method requires a token device, the user must be in physical possession of the device to authenticate. So although the token device provides a password to the authentication server, the token device is considered a Type II authentication factor because its use requires ownership of the device. A token device is usually implemented only in very secure environments because of the cost of deploying the token device. In addition, token-based solutions can experience problems because of the battery life span of the token device.
• Memory cards: A memory card is a swipe card that is issued to a valid user. The card contains user authentication information. When the card is swiped through a card reader, the information stored on the card is compared to the information that the user enters. If the information matches, the authentication server approves the login. If it does not match, authentication is denied. Because the card must be read by a card reader, each computer or access device must have its own card reader. In addition, the cards must be created and programmed. Both of these steps add complexity and cost to the authentication process. However, using memory cards is often worth the extra complexity and cost for the added security it provides, which is a definite benefit of this system. However, the data on the memory cards is not protected, and this is a weakness that organizations should consider before implementing this type of system. Memory-only cards are very easy to counterfeit.
• Smart cards: A smart card accepts, stores, and sends data but can hold more data than a memory card. Smart cards, often known as integrated circuit cards (ICCs), contain memory like memory cards but also contain embedded chips like bank or credit cards. Smart cards use card readers. However, the data on a smart card is used by the authentication server without user input. To protect against lost or stolen smart cards, most implementations require the user to input a secret PIN, meaning the user is actually providing both Type I (PIN) and Type II (smart card) authentication factors.
Characteristic Factors
Characteristic factor authentication is authentication that is provided based on something a person is. This type of authentication is referred to as a Type III authentication factor. Biometric technology is the technology that allows users to be authenticated based on physiological or behavioral characteristics. Physiological characteristics include any unique physical attribute of the user, including iris, retina, and fingerprints. Behavioral characteristics measure a person’s actions in a situation, including voice patterns and data entry characteristics.
Single Sign-On (SSO)
In an effort to make users more productive, several solutions have been developed to allow users to use a single password for all functions and to use these same credentials to access resources in external organizations. These concepts are called single sign-on (SSO) and identity verification based on federations. The following section looks at these concepts and their security issues.
In an SSO environment, a user enters his login credentials once and can access all resources in the network. The Open Group Security Forum has defined many objectives for an SSO system. Some of the objectives for the user sign-on interface and user account management include the following:
• The interface should be independent of the type of authentication information handled.
• The creation, deletion, and modification of user accounts should be supported.
• Support should be provided for a user to establish a default user profile.
• Accounts should be independent of any platform or operating system.
Note
To obtain more information about the Open Group’s Single Sign-On Standard, visit http://www.opengroup.org/security/sso_scope.htm.
SSO provides many advantages and disadvantages when it is implemented.
Advantages of an SSO system include the following:
• Users are able to use stronger passwords.
• User and password administration is simplified.
• Resource access is much faster.
• User login is more efficient.
• Users only need to remember the login credentials for only a single system.
Disadvantages of an SSO system include the following:
• After a user obtains system access through the initial SSO login, the user is able to access all resources to which he is granted access. Although this is also an advantage for the user (only one login needed), it is also considered a disadvantage because only one sign-on by an adversary can compromise all the systems that participate in the SSO network.
• If a user’s credentials are compromised, attackers will have access to all resources to which the user has access.
Although the discussion of SSO so far has been mainly about how it is used for networks and domains, SSO can also be implemented in web-based systems. Enterprise access management (EAM) provides access control management for web-based enterprise systems. Its functions include accommodation of a variety of authentication methods and role-based access control. SSO can be implemented in Kerberos, SESAME, and federated identity management environments. Security domains can then be established to assign SSO rights to resources.
Kerberos
Kerberos is an authentication protocol that uses a client/server model developed by MIT’s Project Athena. It is the default authentication model in the recent editions of Windows Server and is also used in Apple, Oracle, and Linux operating systems.
Kerberos is an SSO system that uses symmetric key cryptography. Kerberos provides confidentiality and integrity. Kerberos assumes that messaging, cabling, and client computers are not secure and are easily accessible. In a Kerberos exchange involving a message with an authenticator, the authenticator contains the client ID and a timestamp. Because a Kerberos ticket is valid for a certain time, the timestamp ensures the validity of the request.
In a Kerberos environment, the key distribution center (KDC) is the repository for all user and service secret keys. The process of authentication and subsequent access to resources is as follows:
1. The client sends a request to the authentication server (AS), which might or might not be the KDC.
2. The AS forwards the client credentials to the KDC.
3. The KDC authenticates clients to other entities on a network and facilitates communication using session keys. The KDC provides security to clients or principals, which are users, network services, and software. Each principal must have an account on the KDC.
4. The KDC issues a ticket-granting ticket (TGT) to the principal.
5. The principal sends the TGT to the ticket-granting service (TGS) when the principal needs to connect to another entity.
6. The TGS then transmits a ticket and session keys to the principal. The set of principles for which a single KDC is responsible is referred to as a realm.
Some advantages of implementing Kerberos include the following:
• User passwords do not need to be sent over the network.
• Both the client and server authenticate each other.
• The tickets passed between the server and client are timestamped and include lifetime information.
• The Kerberos protocol uses open Internet standards and is not limited to proprietary codes or authentication mechanisms.
Some disadvantages of implementing Kerberos include the following:
• KDC redundancy is required if providing fault tolerance is a requirement. The KDC is a single point of failure.
• The KDC must be scalable to ensure that performance of the system does not degrade.
• Session keys on the client machines can be compromised.
• Kerberos traffic needs to be encrypted to protect the information over the network.
• All systems participating in the Kerberos process must have synchronized clocks.
• Kerberos systems are susceptible to password-guessing attacks.
Figure 8-23 show the Kerberos ticketing process.

Figure 8-23 Kerberos Ticket-Issuing Process
Active Directory
Microsoft’s implementation of SSO is Active Directory (AD), which organizes directories into forests and trees. AD tools are used to manage and organize everything in an organization, including users and devices. This is where security is implemented, and its implementation is made more efficient through the use of Group Policy. AD is an example of a system based on the Lightweight Directory Access Protocol (LDAP). It uses the same authentication and authorization system used in Unix and Kerberos. This system authenticates a user once and then, through the use of a ticket system, allows the user to perform all actions and access all resources to which she has been given permission without the need to authenticate again. The steps in this process are shown in Figure 8-24. The user authenticates with the domain controller, which is performing several other roles as well. First, it is the key distribution center (KDC), which runs the authorization service (AS), which determines whether the user has the right or permission to access a remote service or resource in the network.

Figure 8-24 Kerberos Implementation in Active Directory
After the user has been authenticated (when she logs on once to the network), she is issued a ticket-granting ticket (TGT). This is used to later request session tickets, which are required to access resources. At any point that she later attempts to access a service or resource, she is redirected to the AS running on the KDC. Upon presenting her TGT, she is issued a session, or service, ticket for that resource. The user presents the service ticket, which is signed by the KDC, to the resource server for access. Because the resource server trusts the KDC, the user is granted access.
SESAME
The Secure European System for Applications in a Multivendor Environment (SESAME) project extended Kerberos’s functionality to fix Kerberos’s weaknesses. SESAME uses both symmetric and asymmetric cryptography to protect interchanged data. SESAME uses a trusted authentication server at each host. SESAME uses Privileged Attribute Certificates (PACs) instead of tickets. It incorporates two certificates: one for authentication and one for defining access privileges. The trusted authentication server is referred to as the Privileged Attribute Server (PAS), which performs roles similar to the KDC in Kerberos. SESAME can be integrated into a Kerberos system.
Federation
A federated identity is a portable identity that can be used across businesses and domains. In federated identity management, each organization that joins the federation agrees to enforce a common set of policies and standards. These policies and standards define how to provision and manage user identification, authentication, and authorization. Providing disparate authentication mechanisms with federated IDs has a lower up-front development cost than other methods, such as a PKI or attestation. Federated identity management uses two basic models for linking organizations within the federation:
• Cross-certification model: In this model, each organization certifies that every other organization is trusted. This trust is established when the organizations review each other’s standards. Each organization must verify and certify through due diligence that the other organizations meet or exceed standards. One disadvantage of cross-certification is that the number of trust relationships that must be managed can become problematic.
• Trusted third-party (or bridge) model: In this model, each organization subscribes to the standards of a third party. The third party manages verification, certification, and due diligence for all organizations. This is usually the best model for an organization that needs to establish federated identity management relationships with a large number of organizations.
Security issues with federations and their possible solutions include the following:
• Inconsistent security among partners: Federated partners need to establish minimum standards for the policies, mechanisms, and practices they use to secure their environments and information.
• Insufficient legal agreements among partners: Like any other business partnership, identity federation requires carefully drafted legal agreements.
A number of methods are used to securely transmit authentication data among partners. The following sections look at these protocols and services.
XACML
Extensible Access Control Markup Language (XACML) is a standard for an access control policy language using XML. It is covered in Chapter 7, “Implementing Controls to Mitigate Attacks and Software Vulnerabilities.”
SPML
Another open standard for exchanging authorization information between cooperating organizations is Service Provisioning Markup Language (SPML). It is an XML-based framework developed by the Organization for the Advancement of Structured Information Standards (OASIS), which is a nonprofit, international consortium that creates interoperable industry specifications based on public standards such as XML and SGML. The SPML architecture has three components:
• Request authority (RA): The entity that makes the provisioning request
• Provisioning service provider (PSP): The entity that responds to the RA requests
• Provisioning service target (PST): The entity that performs the provisioning
When a trust relationship has been established between two organizations with web-based services, one organization acts as the RA and the other acts as the PSP. The trust relationship uses Security Assertion Markup Language (SAML), discussed next, in a Simple Object Access Protocol (SOAP) header. The SOAP body transports the SPML requests/responses.
Figure 8-25 shows an example of how these SPML messages are used. In the diagram, a company has an agreement with a supplier to allow the supplier to access its provisioning system. When the supplier’s HR department adds a user, an SPML request is generated to the supplier’s provisioning system so the new user can use the system. Then the supplier’s provisioning system generates another SPML request to create the account in the customer provisioning system.

Figure 8-25 SPML
SAML
Security Assertion Markup Language (SAML) is a security attestation model built on XML and SOAP-based services that allows for the exchange of authentication and authorization data between systems and supports federated identity management. The major issue it attempts to address is SSO using a web browser. When authenticating over HTTP using SAML, an assertion ticket is issued to the authenticating user.
Remember that SSO enables a user to authenticate once to access multiple sets of data. SSO at the Internet level is usually accomplished with cookies, but extending the concept beyond the Internet has resulted in many proprietary approaches that are not interoperable. The goal of SAML is to create a standard for this process.
A consortium called the Liberty Alliance proposed an extension to the SAML standard called the Liberty Identity Federation Framework (ID-FF), which is proposed to be a standardized cross-domain SSO framework. It identifies a circle of trust, within which each participating domain is trusted to document the following about each user:
• The process used to identify a user
• The type of authentication system used
• Any policies associated with the resulting authentication credential
Each member entity is free to examine this information and determine whether to trust it. Liberty contributed ID-FF to OASIS. In March 2005, SAML v2.0 was announced as an OASIS standard. SAML v2.0 represents the convergence of Liberty ID-FF and other proprietary extensions.
In an unauthenticated SAMLv2 transaction, the browser asks the service provider (SP) for a resource. The SP provides the browser with an XHTML format. The browser asks the identity provider (IP) to validate the user and then provides the XHTML back to the SP for access. The <nameID> element in SAML can be provided as the X.509 subject name or by Kerberos principal name.
To prevent a third party from identifying a specific user as having previously accessed a service provider through an SSO operation, SAML uses transient identifiers (which are valid only for a single login session and are different each time the user authenticates again but stay the same as long as the user is authenticated).
SAML is a good solution in the following scenarios:
• When you need to provide SSO (when at least one actor or participant is an enterprise)
• When you need to provide access to a partner or customer application to your portal
• When you can provide a centralized identity source
OpenID
OpenID is an open standard and decentralized protocol by the nonprofit OpenID Foundation that allows users to be authenticated by certain cooperating sites. The cooperating sites are called relying parties (RPs). OpenID allows users to log in to multiple sites without having to register their information repeatedly. Users select an OpenID identity provider and use the accounts to log in to any website that accepts OpenID authentication.
While OpenID solves the same issue as SAML, an enterprise may find these advantages in using OpenID:
• It’s less complex than SAML.
• It’s been widely adopted by companies such as Google.
On the other hand, you should be aware of the following shortcomings of OpenID compared to SAML:
• With OpenID, auto-discovery of the identity provider must be configured per user.
• SAML has better performance.
SAML can initiate SSO from either the service provider or the identity provider, while OpenID can only be initiated from the service provider.
In February 2014, the third generation of OpenID, called OpenID Connect, was released. It is an authentication layer protocol that resides atop the OAuth 2.0 framework. It is designed to support native and mobile applications, and it defines methods of signing and encryption.
Here is an example of SAML in action:
1. A user logs in to Domain A, using a PKI certificate that is stored on a smart card protected by an eight-digit PIN.
2. The credential is cached by the authenticating server in Domain A.
3. Later, the user attempts to access a resource in Domain B. This initiates a request to the Domain A authenticating server to attest to the resource server in Domain B that the user is in fact who she claims to be.
Figure 8-26 illustrates the way the service provider obtains the identity information from the identity provider.

Figure 8-26 SAML
Shibboleth
Shibboleth is an open source project that provides single sign-on capabilities and allows sites to make informed authorization decisions for individual access of protected online resources in a privacy-preserving manner. Shibboleth allows the use of common credentials among sites that are a part of the federation. It is based on SAML. This system has two components:
• Identity providers: IPs supply the user information.
• Service providers: SPs consume this information before providing a service.
Role-Based Access Control
Role-based access control (RBAC) is commonly used in networks to simplify the process of assigning new users the permission required to perform a job role. In this arrangement, users are organized by job role into security groups, which are then granted the rights and permissions required to perform that job. Figure 8-27 illustrates this process. The role is implemented as a security group possessing the required rights and permissions, which are inherited by all security group or role members.

Figure 8-27 RBAC
This is not a perfect solution, however, and it carries several security issues. First, RBAC is only as successful as the organization policies designed to support it. Poor policies can result in the proliferation of unnecessary roles, creating an administrative nightmare for the person managing user access. This can lead to mistakes that reduce rather than enhance access security.
A related issue is that those managing user access may have an incomplete understanding of the process, and this can lead to a serious reduction in security. There can be additional costs to the organization to ensure proper training of these individuals. The key to making RBAC successful is proper alignment with policies and proper training of those implementing and maintaining the system.
Note
A security issue can be created when a user is fired or quits. In both cases, all access should be removed. Account reviews should be performed on a regular basis to catch any old accounts that are still active.
Attribute-Based Access Control
Attribute-based access control (ABAC) grants or denies user requests based on arbitrary attributes of the user and arbitrary attributes of the object, and environment conditions that may be globally recognized. NIST SP 800-162 was published to define and clarify ABAC.
According to NIST SP 800-162, ABAC is an access control method where subject requests to perform operations on objects are granted or denied based on assigned attributes of the subject, assigned attributes of the object, environment conditions, and a set of policies that are specified in terms of those attributes and conditions. An operation is the execution of a function at the request of a subject upon an object. Operations include read, write, edit, delete, copy, execute, and modify. A policy is the representation of rules or relationships that makes it possible to determine if a requested access should be allowed, given the values of the attributes of the subject, object, and possibly environment conditions. Environment conditions are the operational or situational context in which access requests occur. Environment conditions are detectable environmental characteristics, which are independent of subject or object, and may include the current time, day of the week, location of a user, or the current threat level.
Figure 8-28 shows a basic ABAC scenario according to NIST SP 800-162.

Figure 8-28 NIST SP 800-162 Basic ABAC Scenario
As specified in NIST SP 800-162, there are characteristics or attributes of a subject such as name, date of birth, home address, training record, and job function that may, either individually or when combined, comprise a unique identity that distinguishes that person from all others. These characteristics are often called subject attributes.
Like subjects, each object has a set of attributes that help describe and identify it. These traits are called object attributes (sometimes referred to as resource attributes). Object attributes are typically bound to their objects through reference, by embedding them within the object, or through some other means of assured association such as cryptographic binding.
ACLs and RBAC are in some ways special cases of ABAC in terms of the attributes used. ACLs work on the attribute of “identity.” RBAC works on the attribute of “role.” The key difference with ABAC is the concept of policies that express a complex Boolean rule set that can evaluate many different attributes. While it is possible to achieve ABAC objectives using ACLs or RBAC, demonstrating access control requirements compliance is difficult and costly due to the level of abstraction required between the access control requirements and the ACL or RBAC model. Another problem with ACL or RBAC models is that if the access control requirement is changed, it may be difficult to identify all the places where the ACL or RBAC implementation needs to be updated.
ABAC relies upon the assignment of attributes to subjects and objects, and the development of policy that contains the access rules. Each object within the system must be assigned specific object attributes that characterize the object. Some attributes pertain to the entire instance of an object, such as the owner. Other attributes may only apply to parts of the object.
Each subject that uses the system must be assigned specific attributes. Every object within the system must have at least one policy that defines the access rules for the allowable subjects, operations, and environment conditions to the object. This policy is normally derived from documented or procedural rules that describe the business processes and allowable actions within the organization. The rules that bind subject and object attributes indirectly specify privileges (i.e., which subjects can perform which operations on which objects). Allowable operation rules can be expressed through many forms of computational language such as
• A Boolean combination of attributes and conditions that satisfies the authorization for a specific operation
• A set of relations associating subject and object attributes and allowable operations
Once object attributes, subject attributes, and policies are established, objects can be protected using ABAC. Access control mechanisms mediate access to the objects by limiting access to allowable operations by allowable subjects. The access control mechanism assembles the policy, subject attributes, and object attributes, then renders and enforces a decision based on the logic provided in the policy. Access control mechanisms must be able to manage the process required to make and enforce the decision, including determining what policy to retrieve, which attributes to retrieve in what order, and where to retrieve attributes. The access control mechanism must then perform the computation necessary to render a decision.
The policies that can be implemented in an ABAC model are limited only to the degree imposed by the computational language and the richness of the available attributes. This flexibility enables the greatest breadth of subjects to access the greatest breadth of objects without having to specify individual relationships between each subject and each object.
While ABAC is an enabler of information sharing, the set of components required to implement ABAC gets more complex when deployed across an enterprise. At the enterprise level, the increased scale requires complex and sometimes independently established management capabilities necessary to ensure consistent sharing and use of policies and attributes and the controlled distribution and employment of access control mechanisms throughout the enterprise.
Mandatory Access Control
In mandatory access control (MAC), subject authorization is based on security labels. MAC is often described as prohibitive because it is based on a security label system. Under MAC, all that is not expressly permitted is forbidden. Only administrators can change the category of a resource.
Because of the importance of security in MAC, labeling is required. Data classification reflects the data’s sensitivity. In a MAC system, a clearance is a privilege to access a class of items that are organized by sensitivity. Each subject and object is given a security or sensitivity label. The security labels are hierarchical. For commercial organizations, the levels of security labels could be confidential, proprietary, corporate, sensitive, and public. For government or military institutions, the levels of security labels could be top secret, secret, confidential, and unclassified.
In MAC, the system makes access decisions when it compares a subject’s clearance level with an object’s security label. MAC access systems operate in different security modes at various times, based on variables such as sensitivity of data, the clearance level of the user, and the actions the user is authorized to take. These security modes are as follows:
• Dedicated security mode: A system is operating in dedicated security mode if it employs a single classification level. In this system, all users can access all data, but they must sign a nondisclosure agreement (NDA) and be formally approved for access on a need-to-know basis.
• System high security mode: In a system operating in system high security mode, all users have the same security clearance (as in the dedicated security mode), but they do not all possess a need-to-know clearance for all the information in the system. Consequently, although a user might have clearance to access an object, she still might be restricted if she does not have need-to-know clearance pertaining to the object.
• Compartmented security mode: In a compartmented security mode system, all users must possess the highest security clearance (as in both dedicated and system high security modes), but they must also have valid need-to-know clearance, a signed NDA, and formal approval for all information to which they have access. The objective is to ensure that the minimum number of people possible have access to information at each level or compartment.
• Multilevel security mode: When a system allows two or more classification levels of information to be processed at the same time, it is said to be operating in multilevel security mode. Users must have a signed NDA for all the information in the system and have access to subsets based on their clearance level and need-to-know and formal access approval. These systems involve the highest risk because information is processed at more than one level of security, even when all system users do not have appropriate clearances or a need-to-know for all information processed by the system. This is also sometimes called controlled security mode.
Manual Review
Users who have been assigned privileged accounts have been given the right to do things that could cause issues. Privileged accounts, regardless of the authentication method or architecture, must be monitored to ensure that these additional rights are not abused.
While there are products that automate the audit of privileged accounts, if all else fails a manual review must be done on a regular basis. This task should not be placed in the “when we have time” category. There’s never time.
Cloud Access Security Broker (CASB)
A cloud security broker, or cloud access security broker (CASB), is a software layer that operates as a gatekeeper between an organization’s on-premises network and the provider’s cloud environment. It can provide many services in this strategic position, as shown in Figure 8-29. Vendors in the CASB include McAfee and Netskope.

Figure 8-29 CASB
Honeypot
Honeypots are systems that are configured to be attractive to hackers and lure them into spending time attacking them while information is gathered about the attack. In some cases entire networks called honeynets are attractively configured for this purpose. These types of approaches should only be undertaken by companies with the skill to properly deploy and monitor them.
Care should be taken that the honeypots and honeynets do not provide direct connections to any important systems. This prevents providing a jumping-off point to other areas of the network. The ultimate purpose of these systems is to divert attention from more valuable resources and to gather as much information about an attack as possible. A tarpit is a type of honeypot designed to provide a very slow connection to the hacker so that the attack can be analyzed.
Monitoring and Logging
Monitoring and monitoring tools will be discussed in much more depth in several subsequent chapters, but it is important that we talk here about logging and monitoring in the context of infrastructure management.
Log Management
Typically, system, network, and security administrators are responsible for managing logging on their systems, performing regular analysis of their log data, documenting and reporting the results of their log management activities, and ensuring that log data is provided to the log management infrastructure in accordance with the organization’s policies. In addition, some of the organization’s security administrators act as log management infrastructure administrators, with responsibilities such as the following:
• Contact system-level administrators to get additional information regarding an event or to request investigation of a particular event.
• Identify changes needed to system logging configurations (for example, which entries and data fields are sent to the centralized log servers, what log format should be used) and inform system-level administrators of the necessary changes.
• Initiate responses to events, including incident handling and operational problems (for example, a failure of a log management infrastructure component).
• Ensure that old log data is archived to removable media and disposed of properly when it is no longer needed.
• Cooperate with requests from legal counsel, auditors, and others.
• Monitor the status of the log management infrastructure (for example, failures in logging software or log archival media, failures of local systems to transfer their log data) and initiate appropriate responses when problems occur.
• Test and implement upgrades and updates to the log management infrastructure’s components.
• Maintain the security of the log management infrastructure.
Organizations should develop policies that clearly define mandatory requirements and suggested recommendations for several aspects of log management, including the following: log generation, log transmission, log storage and disposal, and log analysis. Table 8-3 provides examples of logging configuration settings that an organization can use. The types of values defined in Table 8-3 should only be applied to the hosts and host components previously specified by the organization as ones that must or should be logging security-related events.
Table 8-3 Examples of Logging Configuration Settings

Audit Reduction Tools
Audit reduction tools are preprocessors designed to reduce the volume of audit records to facilitate manual review. They are discussed in Chapter 7.
NIST SP 800-137
According to NIST SP 800-137, information security continuous monitoring (ISCM) is defined as maintaining ongoing awareness of information security, vulnerabilities, and threats to support organizational risk management decisions. Organizations should take the following steps to establish, implement, and maintain ISCM:
1. Define an ISCM strategy based on risk tolerance that maintains clear visibility into assets, awareness of vulnerabilities, up-to-date threat information, and mission/business impacts.
2. Establish an ISCM program that includes metrics, status monitoring frequencies, control assessment frequencies, and an ISCM technical architecture.
3. Implement an ISCM program and collect the security-related information required for metrics, assessments, and reporting. Automate collection, analysis, and reporting of data where possible.
4. Analyze the data collected, report findings, and determine the appropriate responses. It may be necessary to collect additional information to clarify or supplement existing monitoring data.
5. Respond to findings with technical, management, and operational mitigating activities or acceptance, transference/sharing, or avoidance/rejection.
6. Review and update the monitoring program, adjusting the ISCM strategy and maturing measurement capabilities to increase visibility into assets and awareness of vulnerabilities, further enable data-driven control of the security of an organization’s information infrastructure, and increase organizational resilience.
Encryption
Protecting information with cryptography involves the deployment of a cryptosystem. A cryptosystem consists of software, protocols, algorithms, and keys. The strength of any cryptosystem comes from the algorithm and the length and secrecy of the key. For example, one method of making a cryptographic key more resistant to exhaustive attacks is to increase the key length. If the cryptosystem uses a weak key, it facilitates attacks against the algorithm.
While a cryptosystem supports the three core principles of the confidentiality, integrity, and availability (CIA) triad, cryptosystems directly provide authentication, confidentiality, integrity, authorization, and non-repudiation. The availability tenet of the CIA triad is supported by cryptosystems, meaning that implementing cryptography will help to ensure that an organization’s data remains available. However, cryptography does not directly ensure data availability, although it can be used to protect the data. Security services provided by cryptosystems include the following:
• Authentication: Cryptosystems provide authentication by being able to determine the sender’s identity and validity. Digital signatures verify the sender’s identity. Protecting the key ensures that only valid users can properly encrypt and decrypt the message.
• Confidentiality: Cryptosystems provide confidentiality by altering the original data in such a way as to ensure that the data cannot be read except by the valid recipient. Without the proper key, unauthorized users are unable to read the message.
• Integrity: Cryptosystems provide integrity by allowing valid recipients to verify that data has not been altered. Hash functions do not prevent data alteration but provide a means to determine whether data alteration has occurred.
• Authorization: Cryptosystems provide authorization by providing the key to a valid user after that user proves his identity through authentication. The key given to the user allows the user to access a resource.
• Non-repudiation: Non-repudiation in cryptosystems provides proof of the origin of data, thereby preventing the sender from denying that he sent the message and supporting data integrity. Public key cryptography and digital signatures provide non-repudiation.
• Key management: Key management in cryptography is essential to ensure that the cryptography provides confidentiality, integrity, and authentication. If a key is compromised, it can have serious consequences throughout an organization.
Cryptographic Types
Algorithms that are used in computer systems implement complex mathematical formulas when converting plaintext to ciphertext. The two main components to any encryption system are the key and the algorithm. In some encryption systems, the two communicating parties use the same key. In other encryption systems, the two communicating parties use different keys in the process, but the keys are related. This section discusses symmetric algorithms and asymmetric algorithms.
Symmetric Algorithms
Symmetric algorithms use a private or secret key that must remain secret between the two parties. Each party pair requires a separate private key. Therefore, a single user would need a unique secret key for every user with whom she communicates.
Consider an example where there are 10 unique users. Each user needs a separate private key to communicate with the other users. To calculate the number of keys that would be needed in this example, you would use the following formula:
number of users × (number of users – 1) / 2
Therefore, in this example, you would calculate 10 × (10 – 1) / 2 = 45 needed keys.
With symmetric algorithms, the encryption key must remain secure. To obtain the secret key, the users must find a secure out-of-band method for communicating the secret key, including courier or direct physical contact between the users. A special type of symmetric key called a session key encrypts messages between two users during one communication session. Symmetric algorithms can be referred to as single-key, secret-key, private-key, or shared-key cryptography. Symmetric systems provide confidentiality but not authentication or non-repudiation. If both users use the same key, determining where the message originated is impossible. Symmetric algorithms include AES, IDEA, Blowfish, Twofish, RC4/RC5/RC6, and CAST. Table 8-4 lists the strengths and weaknesses of symmetric algorithms.
Table 8-4 Symmetric Algorithm Strengths and Weaknesses

The two broad types of symmetric algorithms are stream-based ciphers and block ciphers. Initialization vectors (IVs) are an important part of block ciphers. These three components are discussed next.
Stream-based Ciphers
Stream-based ciphers perform encryption on a bit-by-bit basis and use keystream generators. The keystream generators create a bit stream that is XORed with the plaintext bits. The result of this XOR operation is the ciphertext.
A synchronous stream-based cipher depends only on the key, and an asynchronous stream cipher depends on the key and plaintext. The key ensures that the bit stream that is XORed to the plaintext is random.
Advantages of stream-based ciphers include the following:
• They generally have lower error propagation because encryption occurs on each bit.
• They are generally used more in hardware implementations.
• They use the same key for encryption and decryption.
• They are generally cheaper to implement than block ciphers.
Block Ciphers
Block ciphers perform encryption by breaking the message into fixed-length units. A message of 1024 bits could be divided into 16 blocks of 64 bits each. Each of those 16 blocks is processed by the algorithm formulas, resulting in a single block of ciphertext. Examples of block ciphers include IDEA, Blowfish, RC5, and RC6.
Advantages of block ciphers include the following:
• Implementation of block ciphers is easier than stream-based cipher implementation.
• They are generally less susceptible to security issues.
• They are generally used more in software implementations.
Table 8-5 lists the key facts about each symmetric algorithm.
Table 8-5 Symmetric Algorithms Key Facts

The Block ciphers mentioned earlier use initialization vectors (IVs) to ensure that patterns are not produced during encryption. These IVs provide this service by using random values with the algorithms. Without using IVs, a repeated phrase within a plaintext message could result in the same ciphertext. Attackers can possibly use these patterns to break the encryption.
Asymmetric Algorithms
Asymmetric algorithms use both a public key and a private or secret key. The public key is known by all parties, and the private key is known only by its owner. One of these keys encrypts the message, and the other decrypts the message. (Asymmetric algorithms are also referred to as dual-key or public-key cryptography.)
In asymmetric cryptography, determining a user’s private key is virtually impossible even if the public key is known, although both keys are mathematically related. However, if a user’s private key is discovered, the system can be compromised.
Asymmetric systems provide confidentiality, integrity, authentication, and non-repudiation. Because both users have one unique key that is part of the process, determining where the message originated is possible. If confidentiality is the primary concern for an organization, a message should be encrypted with the receiver’s public key, which is referred to as secure message format. If authentication is the primary concern for an organization, a message should be encrypted with the sender’s private key, which is referred to as open message format. When using open message format, the message can be decrypted by anyone with the public key.
Asymmetric algorithms include Diffie-Hellman, RSA, El Gamal, ECC, Knapsack, DSA, and Zero Knowledge Proof.
Table 8-6 lists the strengths and weaknesses of asymmetric algorithms.
Table 8-6 Asymmetric Algorithm Strengths and Weaknesses

Hybrid Encryption
Because both symmetric and asymmetric algorithms have weaknesses, solutions have been developed that use both types of algorithms in a hybrid cipher. By using both algorithm types, the cipher provides confidentiality, authentication, and non-repudiation.
The process for hybrid encryption is as follows:
1. The symmetric algorithm provides the keys used for encryption.
2. The symmetric keys are passed to the asymmetric algorithm, which encrypts the symmetric keys and automatically distributes them.
3. The message is encrypted with the symmetric key.
4. Both the message and the key are sent to the receiver.
5. The receiver decrypts the symmetric key and uses the symmetric key to decrypt the message.
An organization should use hybrid encryption if the parties do not have a shared secret key and large quantities of sensitive data must be transmitted.
Integrity is one of the three basic tenets of security. Message integrity ensures that a message has not been altered by using parity bits, cyclic redundancy checks (CRCs), or checksums.
The parity bit method adds an extra bit to the data. This parity bit simply indicates if the number of 1 bits is odd or even. The parity bit is 1 if the number of 1 bits is odd, and the parity bit is 0 if the number of 1 bits is even. The parity bit is set before the data is transmitted. When the data arrives, the parity bit is checked against the other data. If the parity bit doesn’t match the data sent, then an error is sent to the originator.
The CRC method uses polynomial division to determine the CRC value for a file. The CRC value is usually 16 or 32 bits long. Because CRC is very accurate, the CRC value does not match up if a single bit is incorrect.
The checksum method adds up the bytes of data being sent and then transmits that number to be checked later using the same method. The source adds up the values of the bytes and sends the data and its checksum. The receiving end receives the information, adds up the bytes in the same way the source did, and gets the checksum. The receiver then compares his checksum with the source’s checksum. If the values match, message integrity is intact. If the values do not match, the data should be re-sent or replaced. Checksums are also referred to as hash sums because they typically use hash functions for the computation.
Message integrity is provided by hash functions and message authentication code, as discussed next.
Hashing Functions
Hash functions are used to ensure integrity. This section discusses some of the most popular hash functions. Some of these might no longer be commonly used because more secure alternatives are available. Security professionals should be familiar with the following hash functions:
• One-way hash
• MD2/MD4/MD5/MD6
• SHA/SHA-2/SHA-3
A hash function takes a message of variable length and produces a fixed-length hash value. Hash values, also referred to as message digests, are calculated using the original message. If the receiver calculates a hash value that is the same, then the original message is intact. If the receiver calculates a hash value that is different, then the original message has been altered.
Using a given function H, the following equation must be true to ensure that the original message, M1, has not been altered or replaced with a new message, M2:
H(M1) < > H(M2)
One-way Hash
For a one-way hash to be effective, creating two different messages with the same hash value must be mathematically impossible. Given a hash value, discovering the original message from which the hash value was obtained must be mathematically impossible. A one-way hash algorithm is collision free if it provides protection against creating the same hash value from different messages.
Unlike symmetric and asymmetric algorithms, the hashing algorithm is publicly known. Hash functions are always performed in one direction. Using it in reverse is unnecessary.
However, one-way hash functions do have limitations. If an attacker intercepts a message that contains a hash value, the attacker can alter the original message to create a second, invalid message with a new hash value. If the attacker then sends the invalid message to the intended recipient, the intended recipient has no way of knowing that he received an incorrect message. When the receiver performs a hash value calculation, the invalid message looks valid because the invalid message was appended with the attacker’s new hash value, not the original message’s hash value.
To prevent the preceding scenario from occurring, the sender should use a message authentication code (MAC). Encrypting the hash function with a symmetric key algorithm generates a keyed MAC. The symmetric key does not encrypt the original message. It is used only to protect the hash value.
Figure 8-30 outlines the basic steps of a hash function.

Figure 8-30 Hash Function Process
Message Digest Algorithm
The MD2 message digest algorithm produces a 128-bit hash value. It performs 18 rounds of computations. Although MD2 is still in use today, it is much slower than MD4, MD5, and MD6.
The MD4 algorithm also produces a 128-bit hash value. However, it performs only three rounds of computations. Although MD4 is faster than MD2, its use has significantly declined because attacks against it have been so successful.
Like the other MD algorithms, the MD5 algorithm produces a 128-bit hash value. It performs four rounds of computations. It was originally created because of the issues with MD4, and it is more complex than MD4. However, MD5 is not collision free. For this reason, it should not be used for SSL/TLS certificates or digital signatures. The U.S. government requires the usage of SHA-2 instead of MD5. However, in commercial usage, many software vendors publish the MD5 hash value when they release software patches so customers can verify the software’s integrity after download.
The MD6 algorithm produces a variable hash value, performing a variable number of computations. Although it was originally introduced as a candidate for SHA-3, it was withdrawn because of early issues the algorithm had with differential attacks. MD6 has since been re-released with this issue fixed. However, that release was too late to be accepted as the NIST SHA-3 standard.
Secure Hash Algorithm
Secure Hash Algorithm (SHA) is a family of four algorithms published by NIST. SHA-0, originally referred to as simply SHA because there were no other “family members,” produces a 160-bit hash value after performing 80 rounds of computations on 512-bit blocks. SHA-0 was never very popular because collisions were discovered.
Like SHA-0, SHA-1 produces a 160-bit hash value after performing 80 rounds of computations on 512-bit blocks. SHA-1 corrected the flaw in SHA-0 that made it susceptible to attacks.
SHA-3, the latest version, is actually a family of hash functions, each of which provides different functional limits. The SHA-3 family is as follows:
• SHA3-224: Produces a 224-bit hash value after performing 24 rounds of computations on 1152-bit blocks
• SHA3-256: Produces a 256-bit hash value after performing 24 rounds of computations on 1088-bit blocks
• SHA-3-384: Produces a 384-bit hash value after performing 24 rounds of computations on 832-bit blocks
• SHA3-512: Produces a 512-bit hash value after performing 24 rounds of computations on 576-bit blocks
Keep in mind that SHA-1 and SHA-2 are still widely used today. SHA-3 was not developed because of some security flaw with the two previous standards but was instead proposed as an alternative hash function to the others.
Transport Encryption
Securing data at rest and data in transit leverages the respective strengths and weaknesses of symmetric and asymmetric algorithms. Applying the two types of algorithms is typically done as shown in Table 8-7.
Table 8-7 Applying Cryptography

Transport encryption ensures that data is protected when it is transmitted over a network or the Internet. Transport encryption protects against network sniffing attacks.
Security professionals should ensure that their enterprises are protected using transport encryption in addition to protecting data at rest. As an example, think of an enterprise that implements token and biometric authentication for all users, protected administrator accounts, transaction logging, full-disk encryption, server virtualization, port security, firewalls with ACLs, NIPS, and secured access points. None of these solutions provides any protection for data in transport. Transport encryption would be necessary in this environment to protect data. To provide this encryption, secure communication mechanisms should be used, including SSL/TLS, HTTP/HTTPS/SHTTP, SET, SSH, and IPsec.
SSL/TLS
Secure Sockets Layer (SSL) is a transport-layer protocol that provides encryption, server and client authentication, and message integrity. SSL/TLS was discussed earlier in this chapter.
HTTP/HTTPS/SHTTP
Hypertext Transfer Protocol (HTTP) is the protocol used on the Web to transmit website data between a web server and a web client. With each new address that is entered into the web browser, whether from initial user entry or by clicking a link on the page displayed, a new connection is established because HTTP is a stateless protocol.
HTTP Secure (HTTPS) is the implementation of HTTP running over the SSL/TLS protocol, which establishes a secure session using the server’s digital certificate. SSL/TLS keeps the session open using a secure channel. HTTPS websites always include the https:// designation at the beginning.
Although it sounds similar to HTTPS, Secure HTTP (S-HTTP) protects HTTP communication in a different manner. S-HTTP only encrypts a single communication message, not an entire session (or conversation). S-HTTP is not as commonly used as HTTPS.
SSH
Secure Shell (SSH) is an application and protocol that is used to remotely log in to another computer using a secure tunnel. After the secure channel is established after a session key is exchanged, all communication between the two computers is encrypted over the secure channel.
IPsec
Internet Protocol Security (IPsec) is a suite of protocols that establishes a secure channel between two devices. IPsec is commonly implemented over VPNs. IPsec was discussed earlier in this chapter.
Certificate Management
A public key infrastructure (PKI) includes systems, software, and communication protocols that distribute, manage, and control public key cryptography. A PKI publishes digital certificates. Because a PKI establishes trust within an environment, a PKI can certify that a public key is tied to an entity and verify that a public key is valid. Public keys are published through digital certificates.
The X.509 standard is a framework that enables authentication between networks and over the Internet. A PKI includes timestamping and certificate revocation to ensure that certificates are managed properly. A PKI provides confidentiality, message integrity, authentication, and non-repudiation.
The structure of a PKI includes certificate authorities, certificates, registration authorities, certificate revocation lists, cross-certification, and the Online Certificate Status Protocol (OCSP). This section discusses these PKI components as well as a few other PKI concepts.
Certificate Authority and Registration Authority
Any participant that requests a certificate must first go through the registration authority (RA), which verifies the requestor’s identity and registers the requestor. After the identity is verified, the RA passes the request to the certificate authority.
A certificate authority (CA) is the entity that creates and signs digital certificates, maintains the certificates, and revokes them when necessary. Every entity that wants to participate in the PKI must contact the CA and request a digital certificate. It is the ultimate authority for the authenticity for every participant in the PKI by signing each digital certificate. The certificate binds the identity of the participant to the public key.
There are different types of CAs. Organizations exist who provide a PKI as a payable service to companies who need them. An example is Verisign. Some organizations implement their own private CAs so that the organization can control all aspects of the PKI process. If an organization is large enough, it might need to provide a structure of Cas, with the root CA being the highest in the hierarchy.
Because more than one entity is often involved in the PKI certification process, certification path validation allows the participants to check the legitimacy of the certificates in the certification path.
Certificates
A digital certificate provides an entity, usually a user, with the credentials to prove its identity and associates that identity with a public key. At minimum, a digital certification must provide the serial number, the issuer, the subject (owner), and the public key.
An X.509 certificate complies with the X.509 standard. An X.509 certificate contains the following fields:
• Version
• Serial Number
• Algorithm ID
• Issuer
• Validity
• Subject
• Subject Public Key Info
• Public Key Algorithm
• Subject Public Key
• Issuer Unique Identifier (optional)
• Subject Unique Identifier (optional)
• Extensions (optional)
Verisign first introduced the following digital certificate classes:
• Class 1: Intended for use with email. These certificates get saved by web browsers.
• Class 2: For organizations that must provide proof of identity.
• Class 3: For servers and software signing in which independent verification and identity and authority checking is done by the issuing CA.
Certificate Revocation List
A certificate revocation list (CRL) is a list of digital certificates that a CA has revoked. To find out whether a digital certificate has been revoked, the browser must either check the CRL or the CA must push out the CRL values to clients. This can become quite daunting when you consider that the CRL contains every certificate that has ever been revoked.
One concept to keep in mind is the revocation request grace period. This period is the maximum amount of time between when the revocation request is received by the CA and when the revocation actually occurs. A shorter revocation period provides better security but often results in a higher implementation cost.
OCSP
The Online Certificate Status Protocol (OCSP) is an Internet protocol that obtains the revocation status of an X.509 digital certificate. OCSP is an alternative to the standard certificate revocation list (CRL) that is used by many PKIs. OCSP automatically validates the certificates and reports back the status of the digital certificate by accessing the CRL on the CA.
PKI Steps
The steps involved in requesting a digital certificate are as follow:
1. A user requests a digital certificate, and the RA receives the request.
2. The RA requests identifying information from the requestor.
3. After the required information is received, the RA forwards the certificate request to the CA.
4. The CA creates a digital certificate for the requestor. The requestor’s public key and identity information are included as part of the certificate.
5. The user receives the certificate.
After the user has a certificate, she is ready to communicate with other trusted entities. The process for communication between entities is as follows:
1. User 1 requests User 2’s public key from the certificate repository.
2. The repository sends User 2’s digital certificate to User 1.
3. User 1 verifies the certificate and extracts User 2’s public key.
4. User 1 encrypts the session key with User 2’s public key and sends the encrypted session key and User 1’s certificate to User 2.
5. User 2 receives User 1’s certificate and verifies the certificate with a trusted CA.
After this certificate exchange and verification process occurs, the two entities are able to communicate using encryption.
Cross-Certification
Cross-certification establishes trust relationships between CAs so that the participating CAs can rely on the other participants’ digital certificates and public keys. It enables users to validate each other’s certificates when they are actually certified under different certification hierarchies. A CA for one organization can validate digital certificates from another organization’s CA when a cross-certification trust relationship exists.
Digital Signatures
A digital signature is a hash value encrypted with the sender’s private key. A digital signature provides authentication, non-repudiation, and integrity. A blind signature is a form of digital signature where the contents of the message are masked before it is signed.
Public key cryptography is used to create digital signatures. Users register their public keys with a certificate authority (CA), which distributes a certificate containing the user’s public key and the CA’s digital signature. The digital signature is computed by the user’s public key and validity period being combined with the certificate issuer and digital signature algorithm identifier.
The Digital Signature Standard (DSS) is a federal digital security standard that governs the Digital Security Algorithm (DSA). DSA generates a message digest of 160 bits. The U.S. federal government requires the use of DSA, RSA, or Elliptic Curve DSA (ECDSA) and SHA for digital signatures. DSA is slower than RSA and only provides digital signatures. RSA provides digital signatures, encryption, and secure symmetric key distribution.
When considering cryptography, keep the following facts in mind:
• Encryption provides confidentiality.
• Hashing provides integrity.
• Digital signatures provide authentication, non-repudiation, and integrity.
Active Defense
The importance of defense systems in network architecture is emphasized throughout this book. In the context of cybersecurity, the term active defense has more to do with process than architecture. Active defense is achieved by aligning your incident identification and incident response processes such that there is an element of automation built into your reaction to any specific issue. So what does that look like in the real world? One approach among several is called the Active Cyber Defense Cycle, illustrated in Figure 8-31.

Figure 8-31 Active Cyber Defense Cycle
While it may not be obvious from the graphic, one of the key characteristics of this approach is that there is an active response to the security issue. This departs from the classic approach of deploying passive defense mechanisms and relying on them to protect assets.
Hunt Teaming
Hunt teaming is a new approach to security that is offensive in nature rather than defensive, which has been the common approach of security teams in the past. Hunt teams work together to detect, identify, and understand advanced and determined threat actors. A hunt team is a costly investment on the part of an organization. They target the attackers. To use a bank analogy, when a bank robber compromises a door to rob a bank, defensive measures would say get a better door, while offensive measures (hunt teaming) would say eliminate the bank robber. These cyber guns-for-hire are another tool in the kit.
Hunt teaming also refers to a collection of techniques used by security personnel to bypass traditional security technologies to hunt down other attackers who may have used similar techniques to mount attacks that have already been identified, often by other companies. These techniques help in identifying any systems compromised using advanced malware that bypasses traditional security technologies, such as an intrusion detection system/intrusion prevention system (IDS/IPS) or an antivirus application. As part of hunt teaming, security professional could also obtain blacklists from sources like DShield (https://www.dshield.org/). These blacklists would then be compared to existing DNS entries to see if communication was occurring with systems on these blacklists that are known attackers.
Hunt teaming can also emulate prior attacks so that security professionals can better understand the enterprise’s existing vulnerabilities and get insight into how to remediate and prevent future incidents.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have several choices for exam preparation: the exercises here, Chapter 22, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 8-8 lists a reference of these key topics and the page numbers on which each is found.



Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
radio frequency identification (RFID)
virtual local-area network (VLAN)
virtual storage area network (SAN)
Point-to-Point Tunneling Protocol (PPTP)
Layer 2 Tunneling Protocol (L2TP)
Internet Protocol Security (IPsec)
Encapsulating Security Payload (ESP)
Internet Security Association and Key Management Protocol (ISAKMP)
Secure Sockets Layer/Transport Layer Security (SSL/TLS)
virtual desktop infrastructure (VDI)
multifactor authentication (MFA)
knowledge factor authentication
ownership factor authentication
characteristic factor authentication
Secure European System for Applications in a Multivendor Environment (SESAME)
Service Provisioning Markup Language (SPML)
Security Assertion Markup Language (SAML)
role-based access control (RBAC)
attribute-based access control (ABAC)
mandatory access control (MAC)
cloud access security broker (CASB)
public key infrastructure (PKI)
Online Certificate Status Protocol (OCSP)
certificate revocation list (CRL)
Review Questions
1. _____________________ is the process of placing physical identification numbers of some sort on all assets.
2. List at least two examples of segmentation.
3. Match the following terms with their definitions.

4. In a(n) _____________________, two firewalls are used, and traffic must be inspected at both firewalls before it can enter the internal network
5. List at least one of the network architecture planes.
6. Match the following terms with their definitions.

7. ____________________________ handles the creation of a security association for the session and the exchange of keys in IPsec.
8. List at least two advantages of SSL/TLS.
9. Match the following terms with their definitions.
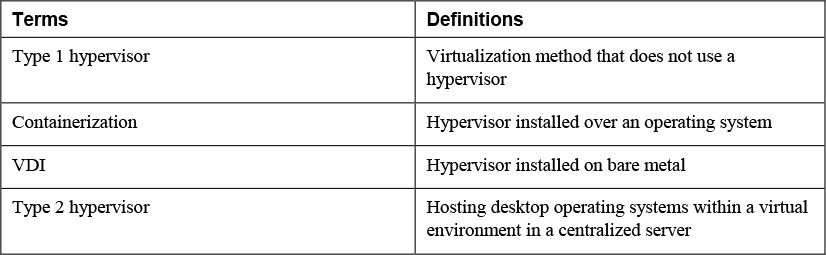
10. ______________________ are authentication factors that rely in something you have in your possession