
Chapter 9. Software Assurance Best Practices
This chapter covers the following topics related to Objective 2.2 (Explain software assurance best practices) of the CompTIA Cybersecurity Analyst (CySA+) CS0-002 certification exam:
• Platforms: Reviews software platforms, including mobile, web application, client/server, embedded, System-on-Chip (SoC), and firmware
• Software development life cycle (SDLC) integration: Explains the formal process specified by the SDLC
• DevSecOps: Discusses the DevSecOps framework
• Software assessment methods: Covers user acceptance testing, stress test application, security regression testing, and code review
• Secure coding best practices: Examines input validation, output encoding, session management, authentication, data protection, parameterized queries, static analysis tools, dynamic analysis tools, formal methods for verification of critical software, and service-oriented architecture
• Static analysis tools: Covers tools and methods for performing static analysis
• Dynamic analysis tools: Discusses tools used to test the software as it is running
• Formal methods for verification of critical software: Discusses more structured methods of analysis
• Service-oriented architecture: Reviews Security Assertions Markup Language (SAML), Simple Object Access Protocol (SOAP), and Representational State Transfer (REST) and introduces microservices
Many organizations create software either for customers or for their own internal use. When software is developed, the earlier in the process security is considered, the less it will cost to secure the software. It is best for software to be secure by design. Secure coding standards are practices that, if followed throughout the software development life cycle, help reduce the attack surface of an application. Standards are developed through a broad-based community effort for common programming languages. This chapter looks at application security, the type of testing to conduct, and secure coding best practices from several well-known organizations that publish guidance in this area.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz enables you to assess whether you should read the entire chapter. If you miss no more than one of these nine self-assessment questions, you might want to skip ahead to the “Exam Preparation Tasks” section. Table 9-1 lists the major headings in this chapter and the “Do I Know This Already?” quiz questions covering the material in those headings so that you can assess your knowledge of these specific areas. The answers to the “Do I Know This Already?” quiz appear in Appendix A.
Table 9-1 “Do I Know This Already?” Foundation Topics Section-to-Question Mapping

1. Which of the following is software designed to exert a measure of control over mobile devices?
a. IoT
b. BYOD
c. MDM
d. COPE
2. Which of the following is the first step in the SDLC?
a. Design
b. Plan/initiate project
c. Release/maintain
d. Develop
3. Which of the following is not one of the three main actors in traditional DevOps?
a. Operations
b. Security
c. QA
d. Production
4. Which of the following is done to verify functionality after making a change to the software?
a. User acceptance testing
b. Regression testing
c. Fuzz testing
d. Code review
5. Which of the following is done to prevent the inclusion of dangerous character types that might be inserted by malicious individuals?
a. Input validation
b. Blacklisting
c. Output encoding
d. Fuzzing
6. Which form of code review looks at runtime information while the software is in a static state?
a. Lexical analysis
b. Data flow analysis
c. Control flow graph
d. Taint analysis
7. Which of the following uses external agents to run scripted transactions against an application?
a. RUM
b. Synthetic transaction monitoring
c. Fuzzing
d. SCCP
8. Which of the following levels of formal methods would be the most appropriate in high-integrity systems involving safety or security?
a. Level 0
b. Level 1
c. Level 2
d. Level 3
9. Which of the following is a client/server model for interacting with content on remote systems, typically using HTTP?
a. SOAP
b. SAML
c. OpenId
d. REST
Foundation Topics
Platforms
All software must run on an underlying platform that supplies the software with the resources required to perform and connections to the underlying hardware with which it must interact. This section provides an overview of some common platforms for which software is written.
Mobile
You learned a lot about the issues with mobile as a platform in Chapter 5, “Threats and Vulnerabilities Associated with Specialized Technology.” Let’s look at some additional issues with this platform.
Containerization
One of the issues with allowing the use of personal devices in a bring your own device (BYOD) initiative is the possible mixing of sensitive corporate data with the personal data of the user. Containerization is a newer feature of most mobile device management (MDM) software that creates an encrypted “container” to hold and quarantine corporate data separately from that of the user’s data. This allows for MDM policies to be applied only to that container and not the rest of the device.
Configuration Profiles and Payloads
MDM configuration profiles are used to control the use of devices; when these profiles are applied to the devices, they make changes to settings such as the passcode settings, Wi-Fi passwords, virtual private network (VPN) configurations, and more. Profiles also can restrict items that are available to the user, such as the camera. The individual settings, called payloads, may be organized into categories in some implementations. For example, there may be a payload category for basic settings, such as a required passcode, and other payload categories, such as e-mail settings, Internet, and so on.
Personally Owned, Corporate Enabled
When a personally owned, corporate-enabled (POCE) policy is in use, the organization’s users purchase their own devices but allow the devices to be managed by corporate tools such as MDM software.
Corporate-Owned, Personally Enabled
Corporate-owned, personally enabled (COPE) is a strategy in which an organization purchases mobile devices and users manage those devices. Organizations can often monitor and control the users’ activity to a larger degree than with personally owned devices. Besides using these devices for business purposes, employees can use the devices for personal activities, such as accessing social media sites, using e-mail, and making calls. COPE also gives the company more power in terms of policing and protecting devices. Organizations should create explicit policies that define the allowed and disallowed activities on COPE devices.
Application Wrapping
Another technique to protect mobile devices and the data they contain is application wrapping. Application wrappers (implemented as policies) enable administrators to set policies that allow employees with mobile devices to safely download an app, typically from an internal store. Policy elements can include elements such as whether user authentication is required for a specific app and whether data associated with the app can be stored on the device.
Application, Content, and Data Management
In addition to the previously discussed containerization method of securing data and applications, MDM solutions can use other methods as well, such as conditional access, which defines policies that control access to corporate data based on conditions of the connection, including user, location, device state, application sensitivity, and real-time risk. Moreover, these policies can be granular enough to control certain actions within an application, such as preventing cut and paste. Finally, more secure control of sharing is possible, allowing for the control and tracking of what happens after a file has been accessed, with the ability to prevent copying, printing, and other actions that help control sharing with unauthorized users.
Remote Wiping
Remote wipes are instructions sent remotely to a mobile device that erase all the data, typically used when a device is lost or stolen. In the case of the iPhone, this feature is closely connected to the locater application Find My iPhone. Android phones do not come with an official remote wipe. You can, however, install an Android app called Lost Android that will do this. Once the app is installed, it works in the same way as the iPhone remote wipe. Android Device Manager provides almost identical functionality to the iPhone. Remote wipe is a function that comes with MDM software, and consent to remote wipe should be required of any user who uses a mobile device in either a BYOD or COPE environment.
SCEP
Simple Certificate Enrollment Protocol (SCEP) provisions certificates to network devices, including mobile devices. Because SCEP includes no provision for authenticating the identity of the requester, two different authorization mechanisms are used for the initial enrollment:

• Manual: The requester is required to wait after submission for the certificate authority (CA) operator or certificate officer to approve the request.
• Preshared secret: The SCEP server creates a “challenge password” that must be somehow delivered out-of-band to the requester and then included with the submission back to the server.
Security issues with SCEP include the fact that when the preshared secret method is used, the challenge password is used for authorization to submit a certificate request. It is not used for authentication of the device.
NIST SP 800-163 Rev 1
NIST SP 800-163 Rev 1, Vetting the Security of Mobile Applications, was written to help organizations do the following:
• Understand the process for vetting the security of mobile applications
• Plan for the implementation of an app vetting process
• Develop app security requirements
• Understand the types of app vulnerabilities and the testing methods used to detect those vulnerabilities
• Determine whether an app is acceptable for deployment on the organization’s mobile devices
To provide software assurance for apps, organizations should develop security requirements that specify, for example, how data used by an app should be secured, the environment in which an app will be deployed, and the acceptable level of risk for an app. To help ensure that an app conforms to such requirements, a process for evaluating the security of apps should be performed.
The NIST SP 800-163 Rev 1 process us as follows:
1. Application vetting process: A sequence of activities performed by an organization to determine whether a mobile app conforms to the organization’s app security requirements. This process is shown in Figure 9-1.

Figure 9-1 App Vetting Process
2. Application intake process: Begins when an app is received for analysis. This process is typically performed manually by an organization administrator or automatically by an app vetting system. The app intake process has two primary inputs: the app under consideration (required) and additional testing artifacts, such as reports from previous app vetting results (optional).
3. Application testing process: Begins after an app has been registered and preprocessed and is forwarded to one or more test tools. A test tool is a software tool or service that tests an app for the presence of software vulnerabilities.
4. Application approval/rejection process: Begins after a vulnerability and risk report is generated by a test tool and made available to one or more security analysts. A security analyst (or analyst) inspects vulnerability reports and risk assessments from one or more test tools to ensure that an app meets all general app security requirements.
5. Results submission process: Begins after the final app approval/rejection report is finalized by the authorizing official and artifacts are prepared for submission to the requesting source.
6. App re-vetting process: From the perspective of a security analyst, updates and threats they are designed to meet can force the evaluation of updated apps to be treated as wholly new pieces of software. Depending on the risk tolerance of an organization, this can make the re-vetting of mobile apps critical for certain apps.
Web Application
Despite all efforts to design a secure web architecture, attacks against web-based systems still occur and still succeed. This section examines some of the more common types of attacks, including maintenance hooks, time-of-check/time-of-use attacks, and web-based attacks.
Maintenance Hooks
From the perspective of software development, a maintenance hook is a set of instructions built into the code that allows someone who knows about the so-called backdoor to use the instructions to connect to view and edit the code without using the normal access controls. In many cases maintenance hooks are placed there to make it easier for the vendor to provide support to the customer. In other cases they are placed there to assist in testing and tracking the activities of the product and are never removed later.
Note
The term maintenance account is often confused with maintenance hook. A maintenance account is a backdoor account created by programmers to give someone full permissions in a particular application or operating system. A maintenance account can usually be deleted or disabled easily, but a true maintenance hook is often a hidden part of the programming and much harder to disable. Both of these can cause security issues because many attackers try the documented maintenance hooks and maintenance accounts first. You would be surprised at the number of computers attacked on a daily basis because these two security issues are left unaddressed.
Regardless of how the maintenance hooks got into the code, they can present a major security issue if they become known to hackers who can use them to access the system. Countermeasures on the part of the customer to mitigate the danger are as follows:
• Use a host-based IDS to record any attempt to access the system using one of these hooks.
• Encrypt all sensitive information contained in the system.
• Implement auditing to supplement the IDS.
The best solution is for the vendor to remove all maintenance hooks before the product goes into production. Code reviews should be performed to identify and remove these hooks.
Time-of-Check/Time-of-Use Attacks
Time-of-check/time-of-use attacks attempt to take advantage of the sequence of events that occurs as the system completes common tasks. It relies on knowledge of the dependencies present when a specific series of events occurs in multiprocessing systems. By attempting to insert himself between events and introduce changes, the hacker can gain control of the result. A term often used as a synonym for a time-of-check/time-of-use attack is race condition, which is actually a different attack. In this attack, the hacker inserts himself between instructions, introduces changes, and alters the order of execution of the instructions, thereby altering the outcome. Countermeasures to these attacks are to make critical sets of instructions atomic, which means that they either execute in order and in entirety or the changes they make are rolled back or prevented. It is also best for the system to lock access to certain items it uses or touches when carrying out these sets of instructions.
Cross-Site Request Forgery (CSRF)
Chapter 7, “Implementing Controls to Mitigate Attacks and Software Vulnerabilities,” described cross-site scripting (XSS) attacks. A similar attack is the cross-site request forgery (CSRF), which causes an end user to execute unwanted actions on a web application in which she is currently authenticated. Unlike with XSS, in CSRF, the attacker exploits the website’s trust of the browser rather than the other way around. The website thinks that the request came from the user’s browser and was actually made by the user. However, the request was planted in the user’s browser. It usually gets there when a user follows a URL that already contains the code to be injected. This type of attack is shown in Figure 9-2.

Figure 9-2 CSRF
The following measures help prevent CSRF vulnerabilities in web applications:
• Using techniques such as URLEncode and HTMLEncode, encode all output based on input parameters for special characters to prevent malicious scripts from executing.
• Filter input parameters based on special characters (those that enable malicious scripts to execute).
• Filter output based on input parameters for special characters.
Click-Jacking
A hacker using a click-jacking attack crafts a transparent page or frame over a legitimate-looking page that entices the user to click something. When the user does click, he is really clicking on a different URL. In many cases, the site or application may entice the user to enter credentials that could be used later by the attacker. This type of attack is shown in Figure 9-3.

Figure 9-3 Click-jacking
Client/Server
When a web application is developed, one of the decisions the developers need to make is which information will be processed on the server and which information will be processed on the browser of the client. Figure 9-4 shows client-side processing, and Figure 9-5 shows server-side processing. Many web designers like processing to occur on the client side, which taxes the web server less and allows it to serve more users. Others shudder at the idea of sending to the client all the processing code—and possibly information that could be useful in attacking the server. Modern web development should be concerned with finding the right balance between server-side and client-side implementation. In some cases performance might outweigh security and vice versa.

Figure 9-4 Client-Side Processing

Figure 9-5 Server-Side Processing
Embedded
An embedded system is a computer system with a dedicated function within a larger system, often with real-time computing constraints. It is embedded as part of the device, often including hardware and mechanical parts. Embedded systems control many devices in common use today and include systems embedded in cars, HVAC systems, security alarms, and even lighting systems. Machine-to-machine (M2M) communication, the Internet of Things (IoT), and remotely controlled industrial systems have increased the number of connected devices and simultaneously made these devices targets.
Because embedded systems are usually placed within another device without input from a security professional, security is not even built into the device. So while allowing the device to communicate over the Internet with a diagnostic system provides a great service to the consumer, oftentimes the manufacturer has not considered that a hacker can then reverse communication and take over the device with the embedded system. As of this writing, reports have surfaced of individuals being able to take control of vehicles using their embedded systems. Manufacturers have released patches that address such issues, but not all vehicle owners have applied or even know about the patches.
As M2M and IoT increase in popularity, security professionals can expect to see a rise in incidents like this. A security professional is expected to understand the vulnerabilities these systems present and how to put controls in place to reduce an organization’s risk.
Hardware/Embedded Device Analysis
Hardware/embedded device analysis involves using the tools and firmware provided with devices to determine the actions that were performed on and by the device. The techniques used to analyze the hardware/embedded device vary based on the device. In most cases, the device vendor can provide advice on the best technique to use depending on what information you need. Log analysis, operating system analysis, and memory inspections are some of the general techniques used.
Hardware/embedded device analysis is used when mobile devices are analyzed. For performing this type of analysis, NIST makes the following recommendations:
• Any analysis should not change the data contained on the device or media.
• Only competent investigators should access the original data and must explain all actions they took.
• Audit trails or other records must be created and preserved during all steps of the investigation.
• The lead investigator is responsible for ensuring that all these procedures are followed.
• All activities regarding digital evidence, including its seizure, access to it, its storage, or its transfer, must be documented, preserved, and available for review.
In Chapter 18, “Utilizing Basic Digital Forensics Techniques,” you will learn more about forensics.
System-on-Chip (SoC)
A System-on-Chip (SoC) is an integrated circuit that includes all components of a computer or another electronic system. SoCs can be built around a microcontroller or a microprocessor (the type found in mobile phones). Specialized SoCs are also designed for specific applications. Secure SoCs provide the key functionalities described in the following sections.
Secure Booting
Secure booting is a series of authentication processes performed on the hardware and software used in the boot chain. Secure booting starts from a trusted entity (also called the anchor point). The chip hardware booting sequence and BootROM are the trusted entities, and they are fabricated in silicon. Hence, it is next to impossible to change the hardware (trusted entity) and still have a functional SoC. The process of authenticating each successive stage is performed to create a chain of trust, as depicted in Figure 9-6.

Figure 9-6 Secure Boot
Central Security Breach Response
The security breach response unit monitors security intrusions. In the event that intrusions are reported by hardware detectors (such as voltage, frequency, and temperature monitors), the response unit moves the state of the SoC to nonsecure, which is characterized by certain restrictions that differentiate it from the secure state. Any further security breach reported to the response unit takes the SoC to the fail state (that is, a nonfunctional state). The SoC remains in the fail state until a power-on-reset is issued. See Figure 9-7.

Figure 9-7 Central Security Breach Response
Firmware
Firmware is software that is stored on an erasable programmable read-only memory (EPROM) or electrically erasable PROM (EEPROM) chip within a device. While updates to firmware may become necessary, they are infrequent. Firmware can exist as the basic input/output system (BIOS) on a computer or device.
Hardware devices, such as routers and printers, require some processing power to complete their tasks. This software is also contained in the firmware chips located within the devices. Like with computers, this firmware is often installed on EEPROM to allow it to be updated. Again, security professionals should ensure that updates are only obtained from the device vendor and that the updates have not been changed in any manner.
Firmware updates might be some of the more neglected but important tasks that technicians perform. Many subscribe to the principle “if it ain’t broke, don’t fix it.” The problem with this approach is that in many cases firmware updates are not designed to add functionality or fix something that doesn’t work exactly right; rather, in many cases, they address security issues. Computers contain a lot of firmware, all of which is potentially vulnerable to hacking[md]everything from USB keyboards and webcams to graphics and sound cards. Even computer batteries have firmware. A simple Google search for “firmware vulnerabilities” turns up pages and pages of results that detail various vulnerabilities too numerous to mention. While it is not important to understand each and every firmware vulnerability, it is important to realize that firmware attacks are on the new frontier, and the only way to protect yourself is to keep up with the updates.
Software Development Life Cycle (SDLC) Integration
The goal of the software development life cycle (SDLC) is to provide a predictable framework of procedures designed to identify all requirements with regard to functionality, cost, reliability, and delivery schedule and ensure that each is met in the final solution. This section breaks down the steps in the SDLC, listed next, and describes how each step contributes to this ultimate goal. Keep in mind that steps in the SDLC can vary based on the provider, and this is but one popular example.
Step 1. Plan/initiate project
Step 2. Gather requirements
Step 3. Design
Step 4. Develop
Step 5. Test/validate
Step 6. Release/maintain
Step 7. Certify/accredit
Step 8. Perform change management and configuration management/replacement
Step 1: Plan/Initiate Project
In the plan/initiate step of the software development life cycle, the organization decides to initiate a new software development project and formally plans the project. Security professionals should be involved in this phase to determine if information involved in the project requires protection and if the application needs to be safeguarded separately from the data it processes. Security professionals need to analyze the expected results of the new application to determine if the resultant data has a higher value to the organization and, therefore, requires higher protection.
Any information that is handled by the application needs a value assigned by its owner, and any special regulatory or compliance requirements need to be documented. For example, healthcare information is regulated by several federal laws and must be protected. The classification of all input and output data of the application needs to be documented, and the appropriate application controls should be documented to ensure that the input and output data are protected.
Data transmission must also be analyzed to determine the types of networks used. All data sources must be analyzed as well. Finally, the effect of the application on organizational operations and culture needs to be analyzed.
Step 2: Gather Requirements
In the gather requirements step of the software development life cycle, both the functionality and the security requirements of the solution are identified. These requirements could be derived from a variety of sources, such as evaluating competitor products for a commercial product or surveying the needs of users for an internal solution. In some cases, these requirements could come from a direct request from a current customer.
From a security perspective, an organization must identify potential vulnerabilities and threats. When this assessment is performed, the intended purpose of the software and the expected environment must be considered. Moreover, the sensitivity of the data that will be generated or handled by the solution must be assessed. Assigning a privacy impact rating to the data to help guide measures intended to protect the data from exposure might be useful.
Step 3: Design
In the design step of the software development life cycle, an organization develops a detailed description of how the software will satisfy all functional and security goals. It involves mapping the internal behavior and operations of the software to specific requirements to identify any requirements that have not been met prior to implementation and testing.
During this process, the state of the application is determined in every phase of its activities. The state of the application refers to its functional and security posture during each operation it performs. Therefore, all possible operations must be identified to ensure that the software never enters an insecure state or acts in an unpredictable way.
Identifying the attack surface is also a part of this analysis. The attack surface describes what is available to be leveraged by an attacker. The amount of attack surface might change at various states of the application, but at no time should the attack surface provided violate the security needs identified in the gather requirements stage.
Step 4: Develop
The develop step is where the code or instructions that make the software work is written. The emphasis of this phase is strict adherence to secure coding practices. Some models that can help promote secure coding are covered later in this chapter, in the section “Application Security Frameworks.”
Many security issues with software are created through insecure coding practices, such as lack of input validation or data type checks. Security professionals must identify these issues in a code review that attempts to assume all possible attack scenarios and their impacts on the code. Not identifying these issues can lead to attacks such as buffer overflows and injection and to other error conditions.
Step 5: Test/Validate
In the test/validate step, several types of testing should occur, including identifying both functional errors and security issues. The auditing method that assesses the extent of the system testing and identifies specific program logic that has not been tested is called the test data method. This method tests not only expected or valid input but also invalid and unexpected values to assess the behavior of the software in both instances. An active attempt should be made to attack the software, including attempts at buffer overflows and denial-of-service (DoS) attacks. Some types of testing performed at this time are
• Verification testing: Determines whether the original design specifications have been met
• Validation testing: Takes a higher-level view and determines whether the original purpose of the software has been achieved
Step 6: Release/Maintain
The release/maintenance step includes the implementation of the software into the live environment and the continued monitoring of its operation. At this point, as the software begins to interface with other elements of the network, finding additional functional and security problems is not unusual.
In many cases vulnerabilities are discovered in the live environments for which no current fix or patch exists. This is referred to as a zero-day vulnerability. Ideally, the supporting development staff should discover such vulnerabilities before those looking to exploit them do.
Step 7: Certify/Accredit
The Certification step is the process of evaluating software for its security effectiveness with regard to the customer’s needs. Ratings can certainly be an input to this but are not the only consideration. Accreditation is the formal acceptance of the adequacy of a system’s overall security by management. Provisional accreditation is given for a specific amount of time and lists applications, system, or accreditation documentation required changes. Full accreditation grants accreditation without any required changes. Provisional accreditation becomes full accreditation once all the changes are completed, analyzed, and approved by the certifying body.
Step 8: Change Management and Configuration Management/Replacement
After a solution is deployed in the live environment, additional changes will inevitably need to be made to the software due to security issues. In some cases, the software might be altered to enhance or increase its functionality. In any case, changes must be handled through a formal change and configuration management process.
The purpose of this step is to ensure that all changes to the configuration of and to the source code itself are approved by the proper personnel and are implemented in a safe and logical manner. This process should always ensure continued functionality in the live environment, and changes should be documented fully, including all changes to hardware and software.
In some cases, it may be necessary to completely replace applications or systems. While some failures may be fixed with enhancements or changes, a failure may occur that can be solved only by completely replacing the application.
DevSecOps
DevSecOps is a development concept that grew out of the DevOps approach to software development. Let’s first review DevOps.
DevOps
Traditionally, three main actors in the software development process[md]development (Dev), quality assurance (QA), and operations (Ops)[md]performed their functions separately, or operated in “silos.” Work would go from Dev to QA to Ops, in a linear fashion, as shown in Figure 9-8.

Figure 9-8 Traditional Development
This often led to delays, finger-pointing, and multiple iterations through the linear cycle due to an overall lac k of cooperation between the units.
DevOps aims at shorter development cycles, increased deployment frequency, and more dependable releases, in close alignment with business objectives. It encourages the three units to work together through all phases of the development process. Figure 9-9 shows a Venn diagram that represents this idea.

Figure 9-9 DevOps
While DevOps was created to develop a better working relationship between development, QA, and operations, encouraging a sense of shared responsibility for successful functionality, DevSecOps simply endeavors to bring the security group into the tent as well and create a shared sense of responsibility in all three groups with regard to security. As depicted in Figure 9-10, the entire DevSecOps process is wrapped in security, implying that security must be addressed at every development step.

Figure 9-10 DevSecOps
Software Assessment Methods
During the testing phase of the SDLC, various different assessment methods can be used. Among them are user acceptance testing, stress testing applications, security regression testing, and code review. The following sections dig into how these assessment methods operate.
User Acceptance Testing
While it is important to make web applications secure, in some cases security features make an application unusable from the user perspective. User acceptance testing (UAT) is designed to ensure that this does not occur. Keep the following guidelines in mind when designing user acceptance testing:
• Perform the testing in an environment that mirrors the live environment.
• Identify real-world use cases for execution.
• Select UAT staff from various internal departments.
Stress Test Application
While the goal of many types of testing is locating security issues, the goal of stress testing is to determine the workload that the application can withstand. These tests should be performed in a certain way and should always have defined objectives before testing begins. You will find many models for stress testing, but one suggested order of activities is as follows:
Step 1. Identify test objectives in terms of the desired outcomes of the testing activity.
Step 2. Identify key scenario(s)[md]the cases that need to be stress tested (for example, test login, test searching, test checkout).
Step 3. Identify the workload that you want to apply (for example, simulate 300 users).
Step 4. Identify the metrics you want to collect and what form these metrics will take (for example, time to complete login, time to complete search).
Step 5. Create test cases. Define steps for running a single test, as well as your expected results (for example, Step 1: Select a product; Step 2: Add to cart; Step 3: Check out).
Step 6. Simulate load by using test tools (for example, attempt 300 sessions).
Step 7. Analyze results.
Security Regression Testing
Regression testing is done to verify functionality after making a change to the software. Security regression testing is a subset of regression testing that validates that changes have not reduced the security of the application or opened new weaknesses. This testing should be performed by a different group than the group that implemented the change. It can occur in any part of the development process and includes the following types:
• Unit regression: This type tests the code as a single unit. Interactions and dependencies are not tested.
• Partial regression: With this type, new code is made to interact with other parts of older existing code.
• Complete regression: This type is the final step in regression testing and performs testing on all units.
Code Review
Code review is the systematic investigation of the code for security and functional problems. It can take many forms, from simple peer review to formal code review. There are two main types of code review:
• Formal review: This is an extremely thorough, line-by-line inspection, usually performed by multiple participants using multiple phases. This is the most time-consuming type of code review but the most effective at finding defects.
• Lightweight review: This type of code review is much more cursory than a formal review. It is usually done as a normal part of the development process. It can happen in several forms:
• Pair programming: Two coders work side by side, checking one another’s work as they go.
• E-mail review: Code is e-mailed around to colleagues for them to review when time permits.
• Over the shoulder: Coworkers review the code while the author explains his or her reasoning.
• Tool-assisted: Using automated testing tools is perhaps the most efficient method.
Security Testing
• Black-box testing, or zero-knowledge testing: The team is provided with no knowledge regarding the organization’s application. The team can use any means at its disposal to obtain information about the organization’s application. This is also referred to as closed testing.
• White-box testing: The team goes into the process with a deep understanding of the application or system. Using this knowledge, the team builds test cases to exercise each path, input field, and processing routine.
• Gray-box testing: The team is provided more information than in black-box testing, while not as much as in white-box testing. Gray-box testing has the advantage of being nonintrusive while maintaining the boundary between developer and tester. On the other hand, it may uncover some of the problems that might be discovered with white-box testing.
Table 9-2 compares black-box, gray-box, and white-box testing
Table 9-2 Comparing Black-Box, Gray-Box, and White-Box Testing
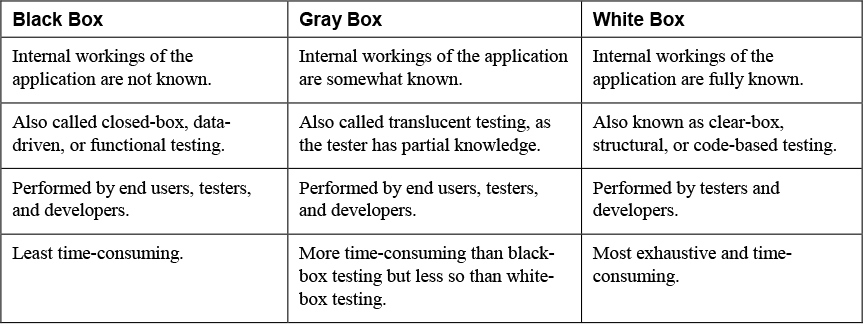
While code review is most typically performed on in-house applications, it may be warranted in other scenarios as well. For example, say that you are contracting with a third party to develop a web application to process credit cards. Considering the sensitive nature of the application, it would not be unusual for you to request your own code review to assess the security of the product.
In many cases, more than one tool should be used in testing an application. For example, an online banking application that has had its source code updated should undergo both penetration testing with accounts of varying privilege levels and a code review of the critical models to ensure that defects do not exist.
Code Review Process
Code review varies from organization to organization. Fagan inspections are the most formal code reviews that can occur and should adhere to the following process:
1. Plan
2. Overview
3. Prepare
4. Inspect
5. Rework
6. Follow-up
Most organizations do not strictly adhere to the Fagan inspection process. Each organization should adopt a code review process fitting for its business requirements. The more restrictive the environment, the more formal the code review process should be.
Secure Coding Best Practices
Earlier this chapter covered software development security best practices. In addition to those best practices, developers should follow the secure coding best practices covered in the following sections.
Input Validation
Many attacks arise because a web application has not validated the data entered by the user (or hacker). Input validation is the process of checking all input for issues such as proper format and proper length. In many cases, these validators use either the blacklisting of characters or patterns or the whitelisting of characters or patterns. Blacklisting looks for characters or patterns to block. It can be prone to preventing legitimate requests. Whitelisting looks for allowable characters or patterns and allows only those. Input validation tools fall into several categories:
• Cloud-based services
• Open source tools
• Proprietary commercial products
Because these tools vary in the amount of skill required, the choice should be made based on the skill sets represented on the cybersecurity team. A fancy tool that no one knows how to use is not an effective tool.
Output Encoding
Encoding is the process of changing data into another form using code. When this process is applied to output, it is done to prevent the inclusion of dangerous character types that might be inserted by malicious individuals. When processing untrusted user input for (web) applications, filter the input and encode the output. That is the most widely given advice to prevent (server-side) injections. Some common types of output encoding include the following:
• URL encoding: A method to encode information in a Uniform Resource Identifier. There’s a set of reserved characters, which have special meaning, and a set of unreserved, or safe characters, which are safe to use. If a character is reserved, then the character is encoded using the percent (%) sign, followed by its hexadecimal digits.
• Unicode: A standard for encoding, representing and handling characters in most (if not all) languages. Best known is the UTF-8 character encoding standard, which is a variable-length encoding (1, 2, 3, or 4 units of 8 bits, hence the name UTF-8).
Session Management
Session management ensures that any instance of identification and authentication to a resource is managed properly. This includes managing desktop sessions and remote sessions.
Desktop sessions should be managed through a variety of mechanisms. Screensavers allow computers to be locked if left idle for a certain period of time. To reactivate a computer, the user must log back in. Screensavers are a timeout mechanism, and other timeout features may also be used, such as shutting down or placing a computer in hibernation after a certain period. Session or logon limitations allow organizations to configure how many concurrent sessions a user can have. Schedule limitations allow organizations to configure the time during which a user can access a computer.
Remote sessions usually incorporate some of the same mechanisms as desktop sessions. However, remote sessions do not occur at the computer itself. Rather, they are carried out over a network connection. Remote sessions should always use secure connection protocols. In addition, if users will be remotely connecting only from certain computers, the organization may want to implement some type of rule-based access control that allows only certain connections.
Authentication
If you have no authentication, you have no security and no accountability. This section covers some authentication topics.
Context-based Authentication
Context-based authentication is a form of authentication that takes multiple factors or attributes into consideration before authenticating and authorizing an entity. So rather than simply rely on the presentation of proper credentials, the system looks at other factors when making the access decision, such as time of day or location of the subject. Context-based security solves many issues suffered by non-context-based systems. The following are some of the key solutions it provides:
• Helps prevent account takeovers made possible by simple password systems
• Helps prevent many attacks made possible by the increasing use of personal mobile devices
• Helps prevent many attacks made possible by the user’s location
Context-based systems can take a number of factors into consideration when a user requests access to a resource. In combination, these attributes can create a complex set of security rules that can help prevent vulnerabilities that password systems may be powerless to detect or stop. The following sections look at some of these attributes.
Time
Cybersecurity professionals have for quite some time been able to prevent access to a network entirely by configuring login hours in a user’s account profile. However, they have not been able to prevent access to individual resources on a time-of-day basis until recently. For example, you might want to allow Joe to access the sensitive Sales folder during the hours of 9 a.m. to 5 p.m. but deny him access to that folder during other hours. Or you might configure the system so that when Joe accesses resources after certain hours, he is required to give another password or credential (a process often called step-up authentication) or perhaps even have a text code sent to his e-mail address that must be provided to allow this access.
Location
At one time, cybersecurity professionals knew that all the network users were safely in the office and behind a secure perimeter created and defended with every tool possible. That is no longer the case. Users now access your network from home, wireless hotspots, hotel rooms, and all sorts of other locations that are less than secure. When you design authentication, you can consider the physical location of the source of an access request. A scenario for this might be that Alice is allowed to access the Sales folder at any time from the office, but only from 9 a.m. to 5 p.m. from her home and never from elsewhere.
Authentication systems can also use location to identify requests to authenticate and access a resource from two different locations in a very short amount of time, one of which could be fraudulent. Finally, these systems can sometimes make real-time assessments of threat levels in the region where a request originates.
Frequency
A context-based system can make access decisions based on the frequency with which the requests are made. Because multiple requests to log in coming very quickly can indicate a password-cracking attack, the system can use this information to deny access. It also can indicate that an automated process or malware, rather than an individual, is attempting this operation.
Behavioral
It is possible for authentication systems to track the behavior of an individual over time and use this information to detect when an entity is performing actions that, while within the rights of the entity, differ from the normal activity of the entity. This could be an indication that the account has been compromised.
The real strength of an authentication system lies in the way you can combine the attributes just discussed to create very granular policies such as the following: Gene can access the Sales folder from 9 a.m. to 5 p.m. if he is in the office and is using his desktop device, but can access the folder only from 10 a.m. to 3 p.m. if he is using his smartphone in the office, and cannot access the folder at all from 9 a.m. to 5 p.m. if he is outside the office.
The main security issue is that the complexity of the rule creation can lead to mistakes that actually reduce security. A complete understanding of the system is required, and special training should be provided to anyone managing the system. Other security issues include privacy issues, such as user concerns about the potential misuse of information used to make contextual decisions. These concerns can usually be addressed through proper training about the power of context-based security.
Network Authentication Methods
One of the protocol choices that must be made in creating a remote access solution is the authentication protocol. The following are some of the most important of those protocols:
• Password Authentication Protocol (PAP): PAP provides authentication, but the credentials are sent in cleartext and can be read with a sniffer.
• Challenge Handshake Authentication Protocol (CHAP): CHAP solves the cleartext problem by operating without sending the credentials across the link. The server sends the client a set of random text called a challenge. The client encrypts the text with the password and sends it back. The server then decrypts it with the same password and compares the result with what was sent originally. If the results match, the server can be assured that the user or system possesses the correct password without ever needing to send it across the untrusted network. Microsoft has created its own variant of CHAP:
• MS-CHAP v1: This is the first version of a variant of CHAP by Microsoft. This protocol works only with Microsoft devices, and while it stores the password more securely than CHAP, like any other password-based system, it is susceptible to brute-force and dictionary attacks.
• MS-CHAP v2: This update to MS-CHAP provides stronger encryption keys and mutual authentication, and it uses different keys for sending and receiving.
• Extensible Authentication Protocol (EAP): EAP is not a single protocol but a framework for port-based access control that uses the same three components that are used in RADIUS. A wide variety of EAP implementations can use all sorts of authentication mechanisms, including certificates, a public key infrastructure (PKI), and even simple passwords:
• EAP-MD5-CHAP: This variant of EAP uses the CHAP challenge process, but the challenges and responses are sent as EAP messages. It allows the use of passwords.
• EAP-TLS: This form of EAP requires a PKI because it requires certificates on both the server and clients. It is, however, immune to password-based attacks as it does not use passwords.
• EAP-TTLS: This form of EAP requires a certificate on the server only. The client uses a password, but the password is sent within a protected EAP message. It is, however, susceptible to password-based attacks.
Table 9-3 compares the authentication protocols described here.
Table 9-3 Authentication Protocols

IEEE 802.1X
IEEE 802.1X is a standard that defines a framework for centralized port-based authentication. It can be applied to both wireless and wired networks and uses three components:
• Supplicant: The user or device requesting access to the network
• Authenticator: The device through which the supplicant is attempting to access the network
• Authentication server: The centralized device that performs authentication
The role of the authenticator can be performed by a wide variety of network access devices, including remote-access servers (both dial-up and VPN), switches, and wireless access points. The role of the authentication server can be performed by a Remote Authentication Dial-in User Service (RADIUS) or Terminal Access Controller Access-Control System Plus (TACACS+) server. The authenticator requests credentials from the supplicant and, upon receiving those credentials, relays them to the authentication server, where they are validated. Upon successful verification, the authenticator is notified to open the port for the supplicant to allow network access. This process is illustrated in Figure 9-11.

Figure 9-11 IEEE 802.1X
While RADIUS and TACACS+ perform the same roles, they have different characteristics. These differences must be considered in the choice of a method. Keep in mind also that while RADUIS is a standard, TACACS+ is Cisco proprietary. Table 9-4 compares them.
Table 9-4 RADIUS and TACACs+

Biometric Considerations
When considering biometric technologies, security professionals should understand the following terms:
• Enrollment time: The process of obtaining the sample that is used by the biometric system. This process requires actions that must be repeated several times.
• Feature extraction: The approach to obtaining biometric information from a collected sample of a user’s physiological or behavioral characteristics.
• Accuracy: The most important characteristic of biometric systems, it is how correct the overall readings will be.
• Throughput rate: The rate at which the biometric system can scan characteristics and complete the analysis to permit or deny access. The acceptable rate is 6[nd]10 subjects per minute. A single user should be able to complete the process in 5[nd]10 seconds.
• Acceptability: Describes the likelihood that users will accept and follow the system.
• False rejection rate (FRR): A measurement of the percentage of valid users that will be falsely rejected by the system. This is called a Type I error.
• False acceptance rate (FAR): A measurement of the percentage of invalid users that will be falsely accepted by the system. This is called a Type II error. Type II errors are more dangerous than Type I errors.
• Crossover error rate (CER): The point at which FRR equals FAR. Expressed as a percentage, this is the most important metric.
When analyzing biometric systems, security professionals often refer to a Zephyr chart that illustrates the comparative strengths and weaknesses of biometric systems. However, you should also consider how effective each biometric system is and its level of user acceptance. The following is a list of the more popular biometric methods ranked by effectiveness, with the most effective being first:
1. Iris scan
2. Retina scan
3. Fingerprint
4. Hand print
5. Hand geometry
6. Voice pattern
7. Keystroke pattern
8. Signature dynamics
The following is a list of the more popular biometric methods ranked by user acceptance, with the methods that are ranked more popular by users being first:
1. Voice pattern
2. Keystroke pattern
3. Signature dynamics
4. Hand geometry
5. Hand print
6. Fingerprint
7. Iris scan
8. Retina scan
When considering FAR, FRR, and CER, smaller values are better. FAR errors are more dangerous than FRR errors. Security professionals can use the CER for comparative analysis when helping their organization decide which system to implement. For example, voice print systems usually have higher CERs than iris scans, hand geometry, or fingerprints.
Figure 9-12 shows the biometric enrollment and authentication process.

Figure 9-12 Biometric Enrollment and Authentication Process
Certificate-Based Authentication
The security of an authentication system can be raised significantly if the system is certificate based rather than password or PIN based. A digital certificate provides an entity[md]usually a user[md]with the credentials to prove its identity and associates that identity with a public key. At minimum, a digital certificate must provide the serial number, the issuer, the subject (owner), and the public key.
Using certificate-based authentication requires the deployment of a public key infrastructure (PKI). PKIs include systems, software, and communication protocols that distribute, manage, and control public key cryptography. A PKI publishes digital certificates. Because a PKI establishes trust within an environment, a PKI can certify that a public key is tied to an entity and verify that a public key is valid. Public keys are published through digital certificates.
In some situations, it may be necessary to trust another organization’s certificates or vice versa. Cross-certification establishes trust relationships between certificate authorities so that the participating CAs can rely on the other participants’ digital certificates and public keys. It enables users to validate each other’s certificates when they are actually certified under different certification hierarchies. A CA for one organization can validate digital certificates from another organization’s CA when a cross-certification trust relationship exists.
Data Protection
At this point, the criticality of protecting sensitive data transferred by software should be quite clear. Sensitive data in this context includes usernames, passwords, encryption keys, and paths that applications need to function but that would cause harm if discovered. Determining the proper method of securing this information is critical and not easy. In the case of passwords, a generally accepted rule is to not hard-code passwords (although this was not always the case). Instead, passwords should be protected using encryption when they are included in application code. This makes them difficult to change, reverse, or discover.
Parameterized Queries
There are two types of queries, parameterized and nonparameterized. The difference between the two is that parameterized queries require input values or parameters and nonparameterized queries do not. The most important reason to use parameterized queries is to avoid SQL injection attacks. The following are some guidelines:
• Use parameterized queries in ASP.NET and prepared statements in Java to perform escaping of dangerous characters before the SQL statement is passed to the database.
• To prevent command injection attacks in SQL queries, use parameterized APIs (or manually quote the strings if parameterized APIs are unavailable).
Static Analysis Tools
Static analysis refers to testing or examining software when it is not running. The most common type of static analysis is code review. Code review is the systematic investigation of the code for security and functional problems. It can take many forms, from simple peer review to formal code review. Code review was covered earlier in this chapter. More on static analysis was covered in Chapter 4.
Dynamic Analysis Tools
Dynamic analysis is testing performed on software while it is running. This testing can be performed manually or by using automated testing tools. There are two general approaches to dynamic analysis, which were covered in Chapter 4 but are worth reviewing:
• Synthetic transaction monitoring: A type of proactive monitoring, often preferred for websites and applications. It provides insight into the application’s availability and performance, warning of any potential issue before users experience any degradation in application behavior. It uses external agents to run scripted transactions against an application. For example, Microsoft’s System Center Operations Manager (SCOM) uses synthetic transactions to monitor databases, websites, and TCP port usage.
• Real user monitoring (RUM): A type of passive monitoring that captures and analyzes every transaction of every application or website user. Unlike synthetic monitoring, which attempts to gain performance insights by regularly testing synthetic interactions, RUM cuts through the guesswork by analyzing exactly how your users are interacting with the application.
Formal Methods for Verification of Critical Software
Formal code review is an extremely thorough, line-by-line inspection, usually performed by multiple participants using multiple phases. This is the most time-consuming type of code review but the most effective at finding defects.
Formal methods can be used at a number of levels:
• Level 0: Formal specification may be undertaken and then a program developed from this informally. The least formal method. This is the least expensive to undertake.
• Level 1: Formal development and formal verification may be used to produce a program in a more formal manner. For example, proofs of properties or refinement from the specification to a program may be undertaken. This may be most appropriate in high-integrity systems involving safety or security.
• Level 2: Theorem provers may be used to undertake fully formal machine-checked proofs. This can be very expensive and is only practically worthwhile if the cost of mistakes is extremely high (e.g., in critical parts of microprocessor design).
Service-Oriented Architecture
A newer approach to providing a distributed computing model is service-oriented architecture (SOA). It operates on the theory of providing web-based communication functionality without each application requiring redundant code to be written per application. SOA is considered a software assurance best practice because it uses standardized interfaces and components called service brokers to facilitate communication among web-based applications. Let’s look at some implementations.
Security Assertions Markup Language (SAML)
Security Assertion Markup Language (SAML) is a security attestation model built on XML and SOAP-based services that allows for the exchange of authentication and authorization data between systems and supports federated identity management. SAML is covered in depth in Chapter 8, “Security Solutions for Infrastructure Management.”
Simple Object Access Protocol (SOAP)
Simple Object Access Protocol (SOAP) is a protocol specification for exchanging structured information in the implementation of web services in computer networks. The SOAP specification defines a messaging framework which consists of
• The SOAP processing model: Defines the rules for processing a SOAP message
• The SOAP extensibility model: Defines the concepts of SOAP features and SOAP modules
• The SOAP binding framework: Describes the rules for defining a binding to an underlying protocol that can be used for exchanging SOAP messages between SOAP nodes
• The SOAP message: Defines the structure of a SOAP message
One of the disadvantages of SOAP is the verbosity of its operation. This has led many developers to use the REST architecture, discussed next, instead. From a security perspective, while the SOAP body can be partially or completely encrypted, the SOAP header is not encrypted and allows intermediaries to view the header data.
Representational State Transfer (REST)
Representational State Transfer (REST) is a client/server model for interacting with content on remote systems, typically using HTTP. It involves accessing and modifying existing content and also adding content to a system in a particular way. REST does not require a specific message format during HTTP resource exchanges. It is up to a RESTful web service to choose which formats are supported. RESTful services are services that do not violate required restraints. XML and JavaScript Object Notation (JSON) are two of the most popular formats used by RESTful web services.
JSON is a simple text-based message format that is often used with RESTful web services. Like XML, it is designed to be readable, and this can help when debugging and testing. JSON is derived from JavaScript and, therefore, is very popular as a data format in web applications. REST/JSON has several advantages over SOAP/XML:
• Size: REST/JSON is a lot smaller and less bloated than SOAP/XML. Therefore, much less data is passed over the network, which is particularly important for mobile devices.
• Efficiency: REST/JSON makes it easier to parse data, thereby making it easier to extract and convert the data. As a result, it requires much less from the client’s CPU.
• Caching: REST/JSON provides improved response times and server loading due to support from caching.
• Implementation: REST/JSON interfaces are much easier than SOAP/XML to design and implement.
SOAP/XML is generally preferred in transactional services such as banking services.
Microservices
An SOA microservice is a self-contained piece of business functionality with clear interfaces, not a layer in a monolithic application. It is a variant of the SOA structural style and arranges an application as a collection of these loosely coupled services. The focus is on building single-function modules with well-defined interfaces and operations. Figure 9-13 shows the microservices architecture in comparison with a typical monolithic structure.

Figure 9-13 Microservices
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have several choices for exam preparation: the exercises here, Chapter 22, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 9-5 lists a reference of these key topics and the page numbers on which each is found.
Table 9-5 Key Topics in Chapter 9

Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
corporate-owned, personally enabled (COPE)
Simple Certificate Enrollment Protocol (SCEP)
cross-site request forgery (CSRF)
software development life cycle (SDLC)
service-oriented architecture (SOA)
Security Assertions Markup Language (SAML)
Simple Object Access Protocol (SOAP)
Representational State Transfer (REST)
Review Questions
1. ____________________ is a strategy in which an organization purchases mobile devices for users and users manage those devices.
2. List at least one step in the NIST SP 800-163 Rev 1 process.
3. Match the terms on the left with their definitions on the right.

4. _______________ is a client/server model for interacting with content on remote systems, typically using HTTP.
5. List at least two advantage of REST/JSON over SOAP/XML.
6. Match the terms on the left with their definitions on the right.

7. __________________________ determines the workload that the application can withstand.
8. List at least two forms of code review.
9. Match the terms on the left with their definitions on the right.

10. ___________________ is a method to encode information in a Uniform Resource Identifier. ++++