
Chapter 16. Applying the Appropriate Incident Response Procedure
This chapter covers the following topics related to Objective 4.2 (Given a scenario, apply the appropriate incident response procedure) of the CompTIA Cybersecurity Analyst (CySA+) CS0-002 certification exam:
• Preparation: Describes steps required to be ready for an incident, including training, testing, and documentation of procedures
• Detection and analysis: Covers detection methods and analysis, exploring topics such as characteristics contributing to severity level classification, downtime, recovery time, data integrity, economic impact, system process criticality, reverse engineering, and data correlation
• Containment: Identifies methods used to separate and confine the damage, including segmentation and isolation
• Eradication and recovery: Defines activities that return the network to normal, including vulnerability mitigation, sanitization, reconstruction/reimaging, secure disposal, patching, restoration or permissions, reconstitution of resources, restoration of capabilities and services, and verification of logging/communication to security monitoring
• Post-incident activities: Identifies operations that should follow incident recovery, including evidence retention, lessons learned report, change control process, incident response plan update, incident summary report, IoC generation, and monitoring
When a security incident occurs, there are usually several possible responses. Choosing the correct response and appropriately applying that response is a critical part of the process. This second chapter devoted to the incident response process presents the many considerations that go into making the correct decisions regarding response.
“Do I Know This Already?” Quiz
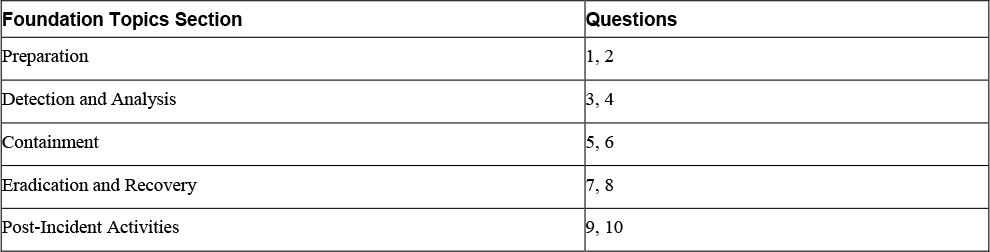
The “Do I Know This Already?” quiz enables you to assess whether you should read the entire chapter. If you miss no more than one of these ten self-assessment questions, you might want to skip ahead to the “Exam Preparation Tasks” section. Table 16-1 lists the major headings in this chapter and the “Do I Know This Already?” quiz questions covering the material in those headings so that you can assess your knowledge of these specific areas. The answers to the “Do I Know This Already?” quiz appear in Appendix A.
Table 16-1 “Do I Know This Already?” Foundation Topics Section-to-Question Mapping
1. Which of the following is the first step in the incident response process?
a. Containment
b. Eradication and recovery
c. Preparation
d. Detection
2. Which of the following groups should receive technical training on configuring and maintaining security controls?
a. High-level management
b. Middle management
c. Technical staff
d. Employees
3. Which of the following characteristics of an incident is a function of how widespread the incident is?
a. Scope
b. Downtime
c. Data integrity
d. Indicator of compromise
4. Which of the following is the average time required to repair a single resource or function?
a. RPO
b. MTD
c. MTTR
d. RTO
5. Which of the following processes involves limiting the scope of an incident by leveraging existing segments of the network as barriers to prevent the spread to other segments?
a. Isolation
b. Segmentation
c. Containerization
d. Partitioning
6. How do you isolate a device at Layer 2 without removing it from the network?
a. Port security
b. Isolation
c. Secured memory
d. Processor encryption
7. Which of the following includes removing data from the media so that it cannot be reconstructed using normal file recovery techniques and tools?
a. Destruction
b. Clearing
c. Purging
d. Buffering
8. Which of the following refers to removing all traces of a threat by overwriting the drive multiple times to ensure that the threat is removed?
a. Destruction
b. Clearing
c. Purging
d. Sanitization
9. Which of the following refers to behaviors and activities that precede or accompany a security incident?
a. IoCs
b. NOCs
c. IONs
d. SOCs
10. Which of the following is the first document that should be drafted after recovery from an incident?
a. Incident summary report
b. Incident response plan
c. Lessons learned report
d. IoC document
Foundation Topics
Preparation
When security incidents occur, the quality of the response is directly related to the amount and the quality of the preparation. Responders should be well prepared and equipped with all the tools they need to provide a robust response. Several key activities must be carried out to ensure this is the case.
Training
The terms security awareness training, security training, and security education are often used interchangeably, but they are actually three different things. Basically, security awareness training is the what, security training is the how, and security education is the why. Security awareness training reinforces the fact that valuable resources must be protected by implementing security measures. Security training teaches personnel the skills they need to perform their jobs in a secure manner. Organizations often combine security awareness training and security training and label it as “security awareness training” for simplicity; the combined training improves user awareness of security and ensures that users can be held accountable for their actions. Security education is more independent, targeted at security professionals who require security expertise to act as in-house experts for managing the security programs.
Security awareness training should be developed based on the audience. In addition, trainers must understand the corporate culture and how it will affect security. The audiences you need to consider when designing training include high-level management, middle management, technical personnel, and other staff.
For high-level management, the security awareness training must provide a clear understanding of potential risks and threats, effects of security issues on organizational reputation and financial standing, and any applicable laws and regulations that pertain to the organization’s security program. Middle management training should discuss policies, standards, baselines, guidelines, and procedures, particularly how these components map to individual departments. Also, middle management must understand their responsibilities regarding security. Technical staff should receive technical training on configuring and maintaining security controls, including how to recognize an attack when it occurs. In addition, technical staff should be encouraged to pursue industry certifications and higher education degrees. Other staff need to understand their responsibilities regarding security so that they perform their day-to-day tasks in a secure manner. With these staff, providing real-world examples to emphasize proper security procedures is effective.
Personnel should sign a document that indicates they have completed the training and understand all the topics. Although the initial training should occur when personnel are hired, security awareness training should be considered a continuous process, with future training sessions occurring at least annually.
Testing
After incident response processes have been developed as described in Chapter 15, “The Incident Response Process,” responders should test the process to ensure it is effective. In Chapter 20, “Applying Security Concepts in Support of Organizational Risk Mitigation,” you’ll learn about exercises that can be performed that help to test your response to a live attack (red team/blue team/white team exercises and tabletop exercises). The results of tests along with the feedback from live events can help to inform the lesson learned report, described later in this chapter.
Documentation of Procedures
Incident response procedures should be clearly documented. While many incident response plan templates can be found online (and even the outline of this chapter is organized by one set of procedures), a generally accepted incident response plan is shown in Figure 16-1 and described in the list that follows.


Figure 16-1 Incident Response Process
Step 1. Detect: The first step is to detect the incident. The worst sort of incident is one that goes unnoticed.
Step 2. Respond: The response to the incident should be appropriate for the type of incident. A denial of service (DoS) attack against a web server would require a quicker and different response than a missing mouse in the server room. Establish standard responses and response times ahead of time.
Step 3. Report: All incidents should be reported within a time frame that reflects the seriousness of the incident. In many cases, establishing a list of incident types and the person to contact when each type of incident occurs is helpful. Attention to detail at this early stage, while time-sensitive information is still available, is critical.
Step 4. Recover: Recovery involves a reaction designed to make the network or system affected functional again. Exactly what that means depends on the circumstances and the recovery measures available. For example, if fault-tolerance measures are in place, the recovery might consist of simply allowing one server in a cluster to fail over to another. In other cases, it could mean restoring the server from a recent backup. The main goal of this step is to make all resources available again.
Step 5. Remediate: This step involves eliminating any residual danger or damage to the network that still might exist. For example, in the case of a virus outbreak, it could mean scanning all systems to root out any additional affected machines. These measures are designed to make a more detailed mitigation when time allows.
Step 6. Review: Finally, you need to review each incident to discover what can be learned from it. Changes to procedures might be called for. Share lessons learned with all personnel who might encounter the same type of incident again. Complete documentation and analysis are the goals of this step.
The actual investigation of an incident occurs during the respond, report, and recover steps. Following appropriate forensic and digital investigation processes during an investigation can ensure that evidence is preserved.
You responses will benefit from using standard forms that prompt for the collection of all relevant information that can lead to a better and more consistent response process over time. Some examples of commonly used forms are as follows:
• Incident form: This form is used to describe the incident in detail. It should include sections to record complementary metal oxide semiconductor (CMOS), hard drive information, image archive details, analysis platform information, and other details. The best approach is to obtain a template and customize it to your needs.
• Call list/escalation list: First responders to an incident should have contact information for all individuals who might need to be alerted during the investigation. This list should also indicate under what circumstance these individuals should be contacted to avoid unnecessary alerts and to keep the process moving in an organized manner.
Detection and Analysis
Once evidence from an incident has been collected, it must be analyzed and classified as to its severity so that more critical incidents can be dealt with first and less critical incidents later.
Characteristics Contributing to Severity Level Classification
To properly prioritize incidents, each must be classified with respect to the scope of the incident and the types of data that have been put at risk. Scope is more than just how widespread the incident is, and the types of data classifications may be more varied than you expect. The following sections discuss the factors that contribute to incident severity and prioritization.
The scope determines the impact and is a function of how widespread the incident is and the potential economic and intangible impacts it could have on the business. Five common factors are used to measure scope. They are covered in the following sections.
Downtime and Recovery Time
One of the issues that must be considered is the potential amount of downtime the incident could inflict and the time it will take to recover from the incident. If a proper business continuity plan (BCP) has been created, you will have collected information about each asset that will help classify incidents that affect each asset.
As part of determining how critical an asset is, you need to understand the following terms:
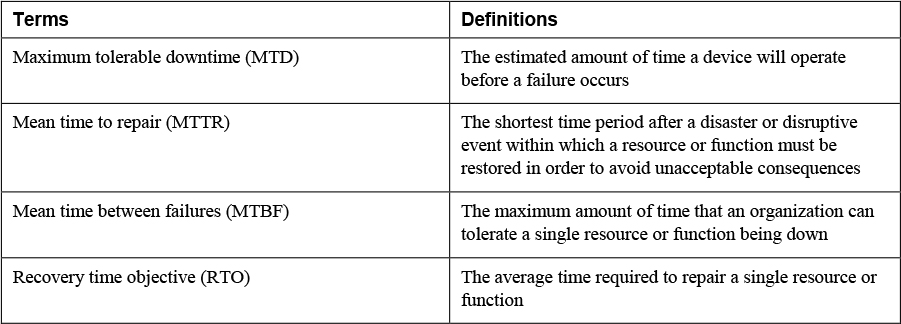
• Maximum tolerable downtime (MTD): This is the maximum amount of time that an organization can tolerate a single resource or function being down. This is also referred to as maximum period time of disruption (MPTD).
• Mean time to repair (MTTR): This is the average time required to repair a single resource or function when a disaster or disruption occurs.
• Mean time between failures (MTBF): This is the estimated amount of time a device will operate before a failure occurs. This amount is calculated by the device vendor. System reliability is increased by a higher MTBF and lower MTTR.
• Recovery time objective (RTO): This is the shortest time period after a disaster or disruptive event within which a resource or function must be restored in order to avoid unacceptable consequences. RTO assumes that an acceptable period of downtime exists. RTO should be smaller than MTD.
• Work recovery time (WRT): This is the difference between RTO and MTD, which is the remaining time that is left over after the RTO before reaching the MTD.
• Recovery point objective (RPO): This is the point in time to which the disrupted resource or function must be returned.
Each organization must develop its own documented criticality levels. The following is a good example of organizational resource and function criticality levels:
• Critical: Critical resources are those resources that are most vital to the organization’s operation and should be restored within minutes or hours of the disaster or disruptive event.
• Urgent: Urgent resources should be restored within 24 hours but are not considered as important as critical resources.
• Important: Important resources should be restored within 72 hours but are not considered as important as critical or urgent resources.
• Normal: Normal resources should be restored within 7 days but are not considered as important as critical, urgent, or important resources.
• Nonessential: Nonessential resources should be restored within 30 days.
Data Integrity
Data integrity refers to the correctness, completeness, and soundness of the data. One of the goals of integrity services is to protect the integrity of data or at least to provide a means of discovering when data has been corrupted or has undergone an unauthorized change. One of the challenges with data integrity attacks is that the effects might not be detected for years—until there is a reason to question the data. Identifying the compromise of data integrity can be made easier by using file-hashing algorithms and tools to check seldom-used but sensitive files for unauthorized changes after an incident. These tools can be run to quickly identify files that have been altered. They can help you get a better assessment of the scope of the data corruption.
Economic
The economic impact of an incident is driven mainly by the value of the assets involved. Determining those values can be difficult, especially for intangible assets such as plans, designs, and recipes. Tangible assets include computers, facilities, supplies, and personnel. Intangible assets include intellectual property, data, and organizational reputation. The value of an asset should be considered with respect to the asset owner’s view. The following considerations can be used to determine an asset’s value:
• Value to owner
• Work required to develop or obtain the asset
• Costs to maintain the asset
• Damage that would result if the asset were lost
• Cost that competitors would pay for the asset
• Penalties that would result if the asset were lost
After determining the value of assets, you should determine the vulnerabilities and threats to each asset.
System Process Criticality
Some assets are not actually information but systems that provide access to information. When these system or groups of systems provide access to data required to continue to do business, they are called critical systems. While it is somewhat simpler to arrive at a value for physical assets such as servers, routers, switches, and other devices, in cases where these systems provide access to critical data or are required to continue a business-critical process, their value is more than the replacement cost of the hardware. The assigned value should be increased to reflect its importance in providing access to data or its role in continuing a critical process.
Reverse Engineering
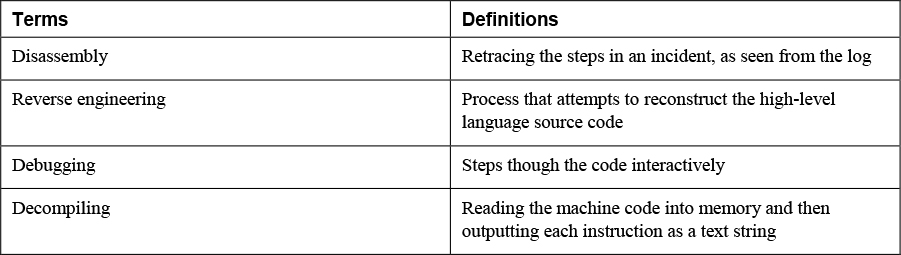
Reverse engineering can refer to retracing the steps in an incident, as seen from the logs in the affected devices or in logs of infrastructure devices that may have been involved in transferring information to and from the devices. This can help you understand the sequence of events. When unknown malware is involved, the term reverse engineering may refer to an analysis of the malware’s actions to determine a removal technique. This is the approach to zero-day attacks in which no known fix is yet available from anti-malware vendors. With respect to reverse engineering malware, this process refers to extracting the code from the binary executable to identify how it was programmed and what it does. There are three ways the binary malware file can be made readable:
• Disassembly: This refers to reading the machine code into memory and then outputting each instruction as a text string. Analyzing this output requires a very high level of skill and special software tools.
• Decompiling: This process attempts to reconstruct the high-level language source code.
• Debugging: This process steps though the code interactively. There are two kinds of debuggers:
• Kernel debugger: This type of debugger operates at ring 0 (essentially the driver level) and has direct access to the kernel.
• Usermode debugger: This type of debugger has access to only the usermode space of the operating system. Most of the time, this is enough, but not always. In the case of rootkits or even super-advanced protection schemes, it is preferable to step into a kernel mode debugger instead because usermode in such situations is untrustworthy.
Data Correlation
Data correlation is the process of locating variables in the information that seem to be related. For example, say that every time there is a spike in SYN packets, you seem to have a DoS attack. When you apply these processes to the data in security logs of devices, it helps you identify correlations that help you identify issues and attacks. A good example of such a system is a security information event management (SIEM) system. These systems collect the logs, analyze the logs, and, through the use of aggregation and correlation, help you identify attacks and trends. SIEM systems are covered in more detail in Chapter 11, “Analyzing Data as Part of Security Monitoring Activities.”
Containment
Just as the first step when an injury occurs is to stop the bleeding, after a security incident occurs, the first priority is to contain the threat to minimize the damage. There are a number of containment techniques. Not all of them are available to you or advisable in all situations. One of the benefits of proper containment is that it gives you time to develop a good remediation strategy.
Segmentation
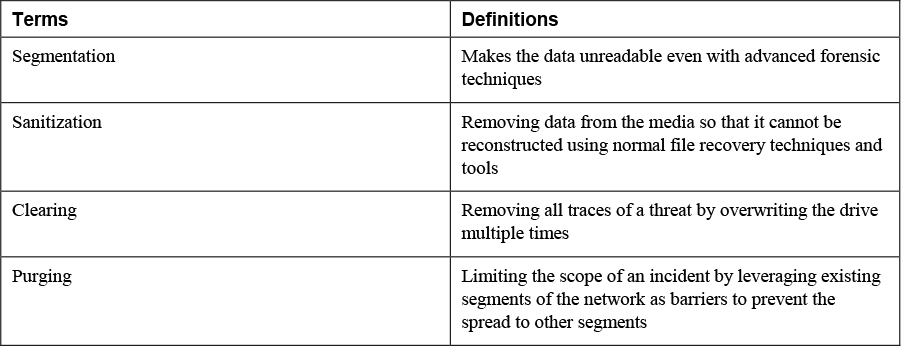
The segmentation process involves limiting the scope of an incident by leveraging existing segments of the network as barriers to prevent the spread to other segments. These segments could be defined at either Layer 3 or Layer 2 of the OSI reference model.
When you segment at Layer 3, you are creating barriers based on IP subnets. These are either physical LANs or VLANs. Creating barriers at this level involves deploying access control lists (ACLs) on the routers to prevent traffic from moving from one subnet to another. While it is possible to simply shut down a router interface, in some scenarios that is not advisable because the interface is used to reach more subnets than the one where the threat exists.
Segmenting at Layer 2 can be done in several ways:
• You can create VLANs, which create segmentation at both Layer 2 and Layer 3.
• You can create private VLANs (PVLANs), which segment an existing VLAN at Layer 2.
• You can use port security to isolate a device at Layer 2 without removing it from the network.
In some cases, it might be advisable to use segmentation at the perimeter of the network (for example, stopping the outbound communication from an infected machine or blocking inbound traffic).
Isolation
Isolation typically is implemented by either blocking all traffic to and from a device or devices or by shutting down device interfaces. This approach works well for a single compromised system but becomes cumbersome when multiple devices are involved. In that case, segmentation may be a more advisable approach. If a new device can be set up to perform the role of the compromised device, the team may leave the device running to analyze the end result of the threat on the isolated host.
Another form of isolation, process isolation is a technique whereby all processes (work being performed by the processor) are executed using memory dedicated to each process. This prevents processes from accessing the memory of other processes, which can help to mitigate attacks that do so.
Eradication and Recovery
After the threat has been contained, the next step is to remove or eradicate the threat. In some cases the compromised device can be cleaned without a format of the hard drive, while in many other cases this must be done to completely remove the threat. This section looks at some removal approaches.
Vulnerability Mitigation
Once the specific vulnerability has been identified, it must be mitigated. This mitigation will in large part be driven by the type of issue with which you are presented. In some cases the proper response will be to format the hard drive of the affected system and reimage it. In other cases the mitigation may be a change in policies, when a weakness is revealed that results from the way the organization operates. Let’s look at some common mitigations.
Sanitization
Sanitization refers to removing all traces of a threat by overwriting the drive multiple times to ensure that the threat is removed. This works well for mechanical hard disk drives, but solid-state drives present a challenge in that they cannot be overwritten. Most solid-state drive vendors provide sanitization commands that can be used to erase the data on the drive. Security professionals should research these commands to ensure that they are effective.
Note
NIST Special Publication 800-88 Rev. 1 is an example of a government guideline for proper media sanitization, as are the IRS guidelines for proper media sanitization:
• https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-88r1.pdf
• https://www.irs.gov/privacy-disclosure/media-sanitization-guidelines
Reconstruction/Reimaging
Once a device has been sanitized, the system must be rebuilt. This can be done by reinstalling the operating system, applying all system updates, reinstalling the anti-malware software, and implementing any organization security settings. Then, any needed applications must be installed and configured. If the device is a server that is running some service on behalf of the network (for example, DNS or DHCP), that service must be reconfigured as well. All this is not only a lot of work, it is time-consuming. A better approach is to maintain standard images of the various device types in the network so that you can use these images to stand up a device quickly. To make this approach even more seamless, having a backup image of the same device eliminates the need to reconfigure everything you might have to reconfigure when using standard images.
Secure Disposal
In some instances, you may decide to dispose of a compromised device (or its storage drive) rather than attempt to sanitize and reuse the device. In that case, you want to dispose of it in a secure manner. In the case of secure disposal, an organization must consider certain issues, including the following:
• Does removal or replacement introduce any security holes in the network?
• How can the system be terminated in an orderly fashion to avoid disrupting business continuity?
• How should any residual data left on any systems be removed?
• Are there any legal or regulatory issues that would guide the destruction of data?
Whenever data is erased or removed from a storage media, residual data can be left behind. This can allow data to be reconstructed when the organization disposes of the media, and unauthorized individuals or groups may be able to gain access to the data. When considering data remanence, security professionals must understand three countermeasures:
• Clearing: Clearing includes removing data from the media so that it cannot be reconstructed using normal file recovery techniques and tools. With this method, the data is recoverable only using special forensic techniques.
• Purging: Also referred to as sanitization, purging makes the data unreadable even with advanced forensic techniques. With this technique, data should be unrecoverable.
• Destruction: Destruction involves destroying the media on which the data resides. Degaussing, another destruction technique, exposes the media to a powerful, alternating magnetic field, removing any previously written data and leaving the media in a magnetically randomized (blank) state. Physical destruction involves physically breaking the media apart or chemically altering it.
Patching
In many cases, a threat or an attack is made possible by missing security patches. You should update or at least check for updates for a variety of components. This includes all patches for the operating system, updates for any applications that are running, and updates to all anti-malware software that is installed. While you are at it, check for any firmware update the device may require. This is especially true of hardware security devices such as firewalls, IDSs, and IPSs. If any routers or switches are compromised, check for software and firmware updates.
Restoration of Permissions
Many times an attacker compromises a device by altering the permissions, either in the local database or in entries related to the device in the directory service server. All permissions should undergo a review to ensure that all are in the appropriate state. The appropriate state may not be the state they were in before the event. Sometimes you may discover that although permissions were not set in a dangerous way prior to an event, they are not correct. Make sure to check the configuration database to ensure that settings match prescribed settings. You should also make changes to the permissions based on lessons learned during an event. In that case, ensure that the new settings undergo a change control review and that any approved changes are reflected in the configuration database.
Reconstitution of Resources
In many incidents, resources may be deleted or stolen. In other cases, the process of sanitizing the device causes the loss of information resources. These resources should be recovered from backup. One key process that can minimize data loss is to shorten the time between backups for critical resources. This results in a recovery point objective (RPO) that includes more recent data. RPO is discussed in more detail earlier in this chapter.
Restoration of Capabilities and Services
During the incident response, it might be necessary to disrupt some of the normal business processes to help contain the issue or to assist in remediation. It is also possible that the attack has rendered some services and capabilities unavailable. Once an effective response has been mounted, these systems and services must be restored to full functionality. As shortening the backup time can help to reduce the effects of data loss, fault-tolerant measures can be effective in preventing the loss of critical services.
Verification of Logging/Communication to Security Monitoring
To ensure that you will have good security data going forward, you need to ensure that all logs related to security are collecting data. Pay special attention to the manner in which the logs react when full. With some settings, the log begins to overwrite older entries with new entries. With other settings, the service stops collecting events when the log is full. Security log entries need to be preserved. This may require manual archiving of the logs and subsequent clearing of the logs. Some logs make this possible automatically, whereas others require a script. If all else fails, check the log often to assess its state.
Many organizations send all security logs to a central location. This could be a Syslog server, or it could be a SIEM system. These systems not only collect all the logs, they use the information to make inferences about possible attacks. Having access to all logs allows the system to correlate all the data from all responding devices.
Regardless of whether you are logging to a Syslog server or a SIEM system, you should verify that all communications between the devices and the central server are occurring without a hitch. This is especially true if you had to rebuild the system manually rather than restore from an image, as there would be more opportunity for human error in the rebuilding of the device.
Post-Incident Activities
Once the incident has been contained and removed and the recovery process is complete, there is still work to be done. Much of it, as you might expect, is paperwork, but this paperwork is critical to enhancing the response to the next incident. Let’s look at some of these post-incident activities that should take place.
Evidence Retention
If the incident involved a security breach and the incident response process gathered evidence to prove an illegal act or a violation of policy, the evidence must be stored securely until it is presented in court or is used to confront the violating employee. Computer investigations require different procedures than regular investigations because the time frame for the computer investigator is compressed, and an expert might be required to assist in the investigation. Also, computer information is intangible and often requires extra care to ensure that the data is retained in its original format. Finally, the evidence in a computer crime is difficult to gather.
After a decision has been made to investigate a computer crime, you should follow standardized procedures, including the following:
• Identify what type of system is to be seized.
• Identify the search and seizure team members.
• Determine the risk of the suspect destroying evidence.
After law enforcement has been informed of a computer crime, the constraints on the organization’s investigator are increased. Turning over an investigation to law enforcement to ensure that evidence is preserved properly might be necessary.
When investigating a computer crime, evidentiary rules must be addressed. Computer evidence should prove a fact that is material to the case and must be reliable. The chain of custody must be maintained. Computer evidence is less likely to be admitted in court as evidence if the process for producing it is not documented.
Lessons Learned Report
The first document that should be drafted is a lessons learned report, which briefly lists and discusses what was learned about how and why the incident occurred and how to prevent it from occurring again. This report should be compiled during a formal meeting shortly after recovery from the incident. This report provides valuable information that can be used to drive improvement in the security posture of the organization. This report might answer questions such as the following:
• What went right, and what went wrong?
• How can we improve?
• What needs to be changed?
• What was the cost of the incident?
Change Control Process
The lessons learned report may generate a number of changes that should be made to the network infrastructure. All these changes, regardless of how necessary they are, should go through the standard change control process. They should be submitted to the change control board, examined for unforeseen consequences, and studied for proper integration into the current environment. Only after gaining approval should they be implemented. You may find it helpful to create a “fast track” for assessment in your change management system for changes such as these when time is of the essence. For more details regarding change control processes, refer to Chapter 8, “Security Solutions for Infrastructure Management.”
Incident Response Plan Update
The lessons learned exercise may also uncover flaws in your IR plan. If this is the case, you should update the plan appropriately to reflect the needed procedure changes. When this is complete, ensure that all software and hard copy versions of the plan have been updated so everyone is working from the same document when the next event occurs.
Incident Summary Report
All stakeholders should receive a document that summarizes the incident. It should not have an excessive amount of highly technical language in it, and it should be written so nontechnical readers can understand the major points of the incident. The following are some of the highlights that should be included in an incident summary report:
• When the problem was first detected and by whom
• The scope of the incident
• How it was contained and eradicated
• Work performed during recovery
• Areas where the response was effective
• Areas that need improvement
Indicator of Compromise (IoC) Generation
Indicators of compromise (IoCs) are behaviors and activities that precede or accompany a security incident. In Chapter 17, “Analyzing Potential Indicators of Compromise,” you will learn what some of these indicators are and what they may tell you. You should always record or generate the IOCs that you find related to the incident. This information may be used to detect the same sort of incident later, before it advances to the point of a breach.
Monitoring
As previously discussed, it is important to ensure that all security surveillance tools (IDS, IPS, SIEM, firewalls) are back online and recording activities and reporting as they should be, as discussed in Chapter 11. Moreover, even after you have taken all steps described thus far, consider using a vulnerability scanner to scan the devices or the network of devices that were affected. Make sure before you do so that you have updated the scanner so it can recognize the latest vulnerabilities and threats. This will help catch any lingering vulnerabilities that may still be present.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have several choices for exam preparation: the exercises here, Chapter 22, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
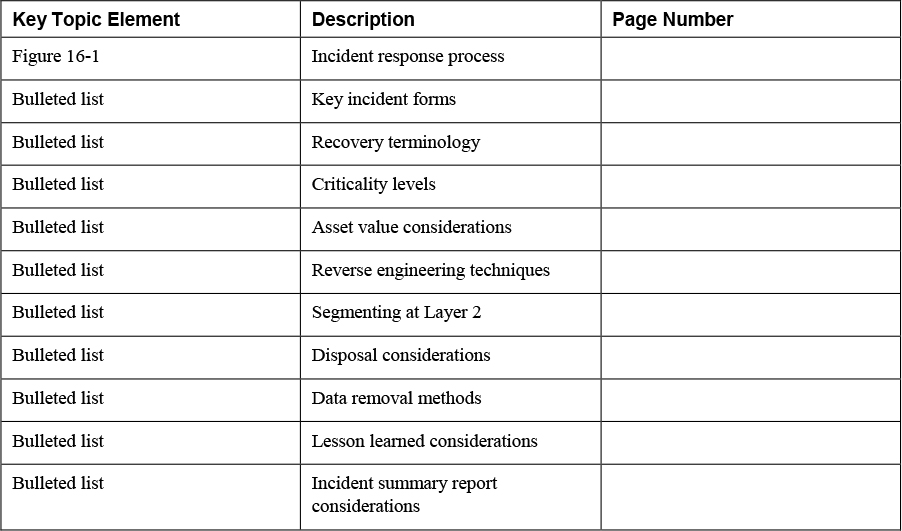
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 16-2 lists a reference of these key topics and the page numbers on which each is found.
Table 16-2 Key Topics for Chapter 16
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
maximum tolerable downtime (MTD)
mean time between failures (MTBF)
recovery point objective (RPO)
indicator of compromise (IoC)
Review Questions
1. When security incidents occur, the quality of the response is directly related to the amount of and quality of the ____________.
2. List the steps, in order, of the incident response process.
3. Match the following terms with their definitions.
4. ____________________ involves eliminating any residual danger or damage to the network that still might exist.
5. List at least two considerations that can be used to determine an asset’s value.
6. Match the following terms with their definitions.
7. The _______________________ should indicate under what circumstance individuals should be contacted to avoid unnecessary alerts and to keep the process moving in an organized manner.
8. List at least one way the binary malware file can be made readable.
9. Match the following terms with their definitions.
10. ______________________ are behaviors and activities that precede or accompany a security incident.