
Chapter 11. Analyzing Data as Part of Security Monitoring Activities
This chapter covers the following topics related to Objective 3.1 (Given a scenario, analyze data as part of security monitoring activities) of the CompTIA Cybersecurity Analyst (CySA+) CS0-002 certification exam:
• Heuristics: Discusses how the heuristics process works
• Trend analysis: Covers the use of trend data
• Endpoint: Topics include malware, memory, system and application behavior, file system, and user and entity behavior analytics (UEBA)
• Network: Covers URL and DNS analysis, flow analysis, and packet and protocol analysis
• Log review: Includes event logs, Syslog, firewall logs, web application firewall (WAF), proxy, and intrusion detection system (IDS)/intrusion prevention system (IPS)
• Impact analysis: Compares organization impact vs. localized impact and immediate vs. total impact
• Security information and event management (SIEM) review: Discusses rule writing, known-bad Internet Protocol (IP) and the dashboard
• Query writing: Explains string search, scripting, and piping
• E-mail analysis: Examines malicious payload, DomainKeys Identified Mail (DKIM), Domain-based Message Authentication, Reporting, and Conformance (DMARC), Sender Policy Framework (SPF), phishing, forwarding, digital signature, e-mail signature block, embedded links, impersonation, and header
Security monitoring activities generate a significant (maybe even overwhelming) amount of data. Identifying what is relevant and what is not requires that you not only understand the various data formats that you encounter, but also recognize data types and activities that indicate malicious activity. This chapter explores the data analysis process.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz enables you to assess whether you should read the entire chapter. If you miss no more than one of these nine self-assessment questions, you might want to skip ahead to the “Exam Preparation Tasks” section. Table 11-1 lists the major headings in this chapter and the “Do I Know This Already?” quiz questions covering the material in those headings so that you can assess your knowledge of these specific areas. The answers to the “Do I Know This Already?” quiz appear in Appendix A.
Table 11-1 “Do I Know This Already?” Foundation Topics Section-to-Question Mapping
1. Which of the following determines the susceptibility of a system to a particular threat or risk using decision rules or weighing methods?
a. Heuristics
b. Trend analysis
c. SPF
d. Regression analysis
2. Which of the following is not an example of utilizing trend analysis?
a. An increase in the use of a SQL server, indicating the need to increase resources on the server
b. The identification of threats based on behavior that typically accompanies such threats
c. A cessation in traffic bound for a server providing legacy services, indicating a need to decommission the server
d. An increase in password resets, indicating a need to revise the password policy
3. Which of the following discusses implementing endpoint protection platforms (EPPs)?
a. IEC 270017
b. FIPS 120
c. NIST SP 800-128
d. PCI DSS
4. Which of the following is a free online service for testing and analyzing URLs, helping with identification of malicious content on websites?
a. URLVoid
b. URLSec
c. SOA
d. urlQuery
5. Which of the following is a protocol that can be used to collect logs from devices and store them in a central location?
a. Syslog
b. DNSSec
c. URLQuery
d. SMTP
6. When you are determining what role the quality of the response played in the severity of the issue, what type of analysis are you performing?
a. Trend analysis
b. Impact analysis
c. Log analysis
d. reverse engineering
7. Which type of SIEM rule is typically used in worm/malware outbreak scenarios?
a. Cause and effect
b. Trending
c. Transitive or tracking
d. Single event
8. Which of the following is used to look within a log file or data stream and locate any instances of a combination of characters?
a. Script
b. Pipe
c. Transitive search
d. String search
9. Which of the following enables you to verify the source of an e-mail by providing a method for validating a domain name identity that is associated with a message through cryptographic authentication?
a. DKIM
b. DNSSec
c. IPsec
d. AES
Foundation Topics
Heuristics
When analyzing security data, sometimes it is difficult to see the forest for the trees. Using scripts, algorithms, and other processes to assist in looking for the information that really matters makes the job much easier and ultimately more successful.
Heuristics is a type of analysis that determines the susceptibility of a system to a particular threat/risk by using decision rules or weighing methods. Decision rules are preset to allow the system to make decisions, and weighing rules are used within the decision rules to enable the system to make value judgements among options. Heuristics is often utilized by antivirus software to identify threats that signature analysis can’t discover because the threats either are too new to have been analyzed (called zero-day threats) or are multipronged attacks that are constructed in such a way that existing signatures do not identify them.
Many IDS/IPS solutions also can use heuristics to identify threats.
Trend Analysis
In many cases, the sheer amount of security data that is generated by the various devices located throughout our environments makes it difficult to see what is going on. When this same raw data is presented to us in some sort of visual format, it becomes somewhat easier to discern patterns and trends. Aggregating the data and graphing it makes spotting a trend much easier.
Trend analysis focuses on the long-term direction in the increase or decrease in a particular type of traffic or in a particular behavior in the network. Some examples include the following:
• An increase in the use of a SQL server, indicating the need to increase resources on the server
• A cessation in traffic bound for a server providing legacy services, indicating a need to decommission the server
• An increase in password resets, indicating a need to revise the password policy
Many vulnerability scanning tools include a preconfigured filter for scan results that both organizes vulnerabilities found by severity and charts the trend (up or down) for each severity level.
For example, suppose you were interested in getting a handle on the relative breakdown of security events between your Windows devices and your Linux devices. Most tools that handle this sort of thing can not only aggregate all events of a certain type but graph them over time. Figure 11-1 shows examples of such graphs.

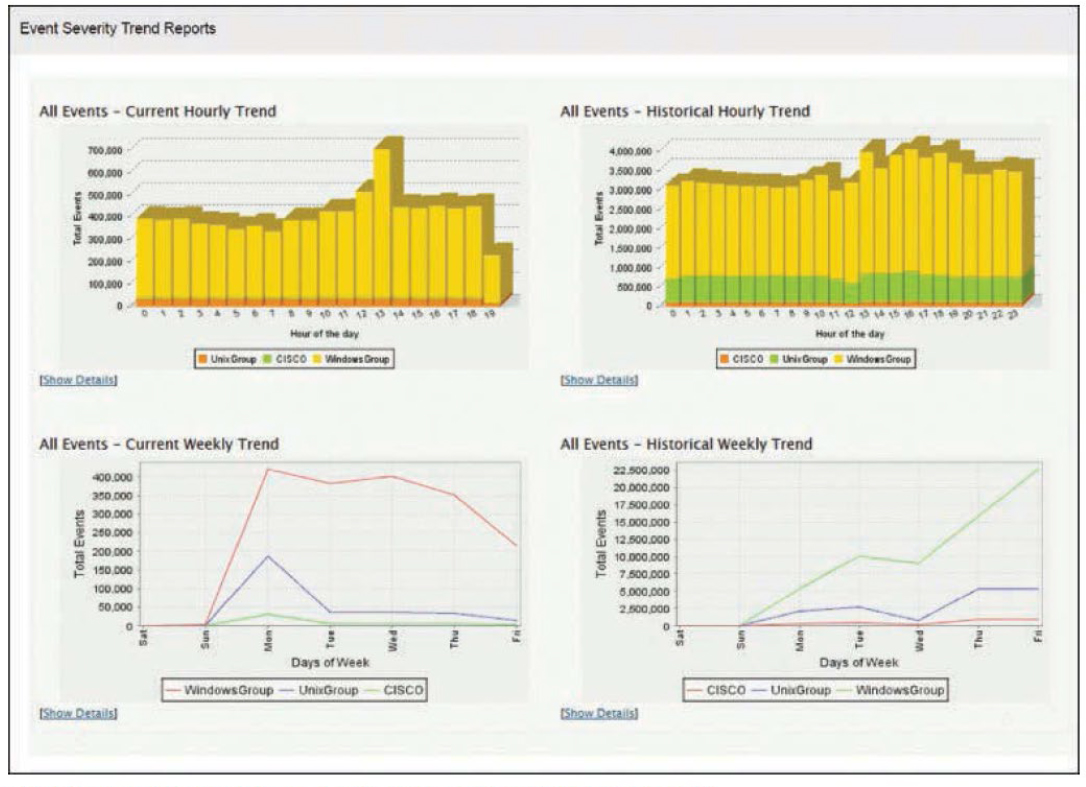
Figure 11-1 Trend Analysis
Endpoint
Many of the dangers to our environments come through the endpoints. Endpoint security is a field of security that attempts to protect individual endpoints in a network by staying in constant contact with these individual endpoints from a central location. It typically works on a client/server model in that each endpoints has software that communicates with the software on the central server. The functionality provided can vary.
In its simplest form, endpoint security includes monitoring and automatic updating and configuration of security patches and personal firewall settings. In more advanced systems, endpoint security might include examination of the system each time it connects to the network. This examination would ensure that all security patches are up to date. In even more advanced scenarios, endpoint security could automatically provide remediation to the computer by installing missing security patches. In either case, the computer would not be allowed to connect to the network until the problem is resolved, either manually or automatically. Other measures include using device or drive encryption, enabling remote management capabilities (such as remote wipe and remote locate), and implementing device ownership policies and agreements so that the organization can manage or seize the device.
Endpoint security can mitigate issues such as the following:
• Malware of all types
• Data exfiltration
NIST SP 800-128 discusses implementing endpoint protection platforms (EPPs). According to NIST SP 800-128, endpoints (that is, laptops, desktops, mobile devices) are a fundamental part of any organizational system. Endpoints are an important source of connecting end users to networks and systems, and are also a major source of vulnerabilities and a frequent target of attackers looking to penetrate a network. User behavior is difficult to control and hard to predict, and user actions, whether it is clicking on a link that executes malware or changing a security setting to improve the usability of the endpoint, frequently allow exploitation of vulnerabilities. Commercial vendors offer a variety of products to improve security at the “endpoints” of a network. These EPPs include the following:
• Anti-malware: Anti-malware applications are part of the common secure configurations for system components. Anti-malware software employs a wide range of signatures and detection schemes, automatically updates signatures, disallows modification by users, runs scans on a frequently scheduled basis, has an auto-protect feature set to scan automatically when a user action is performed (for example, opening or copying a file), and may provide protection from zero-day attacks. For platforms for which anti-malware software is not available, other forms of anti-malware such as rootkit detectors may be employed.
• Personal firewalls: Personal firewalls provide a wide range of protection for host machines including restriction on ports and services, control against malicious programs executing on the host, control of removable devices such as USB devices, and auditing and logging capability.
• Host-based intrusion detection and prevention system (IDPS): Host-based IDPS is an application that monitors the characteristics of a single host and the events occurring within that host to identify and stop suspicious activity. This is distinguished from network-based IDPS, which is an intrusion detection and prevention system that monitors network traffic for particular network segments or devices and analyzes the network and application protocol activity to identify and stop suspicious activity.
• Restrict the use of mobile code: Organizations should exercise caution in allowing the use of mobile code such as ActiveX, Java, and JavaScript. An attacker can easily attach a script to a URL in a web page or e-mail that, when clicked, executes malicious code within the computer’s browser.
Security professionals may also want to read NIST SP 800-111, which provides guidance to storage encryption technologies for end-user devices. In addition, NIST provides checklists for implementing different operating systems according to the U.S. Government Configuration Baseline (USGCB).
Malware
Malicious software (or malware) is any software that harms a computer, deletes data, or takes actions the user did not authorize. It includes a wide array of malware types, including ones you have probably heard of such as viruses, and many you might not have heard of, but of which you should be aware. The malware that you need to understand includes the following:
• Virus
• Boot sector virus
• Parasitic virus
• Stealth virus
• Polymorphic virus
• Macro virus
• Multipartite virus
• Worm
• Trojan horse
• Logic bomb
• Spyware/adware
• Botnet
• Rootkit
• Ransomware
Virus
A virus is a self-replicating program that infects software. It uses a host application to reproduce and deliver its payload and typically attaches itself to a file. It differs from a worm in that it usually requires some action on the part of the user to help it spread to other computers. The following list briefly describes various virus types:
• Boot sector: This type of virus infects the boot sector of a computer and either overwrites files or installs code into the sector so that the virus initiates at startup.
• Parasitic: This type of virus attaches itself to a file, usually an executable file, and then delivers the payload when the program is used.
• Stealth: This type of virus hides the modifications that it is making to the system to help avoid detection.
• Polymorphic: This type of virus makes copies of itself, and then makes changes to those copies. It does this in hopes of avoiding detection from antivirus software.
• Macro: This type of virus infects programs written in Word, Basic, Visual Basic, or VBScript that are used to automate functions. Macro viruses infect Microsoft Office files and are easy to create because the underlying language is simple and intuitive to apply. They are especially dangerous in that they infect the operating system itself. They also can be transported between different operating systems because the languages are platform independent.
• Multipartite: Originally, these viruses could infect both program files and boot sectors. This term now means that the virus can infect more than one type of object or can infect in more than one way.
• File or system infector: File infectors infect program files, and system infectors infect system program files.
• Companion: This type of virus does not physically touch the target file. It is also referred to as a spawn virus.
• E-mail: This type of virus specifically uses an e-mail system to spread itself because it is aware of the e-mail system functions. Knowledge of the functions allows this type of virus to take advantage of all e-mail system capabilities.
• Script: This type of virus is a stand-alone file that can be executed by an interpreter.
Worm
A worm is a type of malware that can spread without the assistance of the user. It is a small program that, like a virus, is used to deliver a payload. One way to help mitigate the effects of worms is to place limits on sharing, writing, and executing programs.
Trojan Horse
A Trojan horse is a program or rogue application that appears to or is purported to do one thing but actually does another when executed. For example, what appears to be a screensaver program might really be a Trojan horse. When the user unwittingly uses the program, it executes its payload, which could be to delete files or create backdoors. Backdoors are alternative ways to access the computer undetected in the future.
One type of Trojan targets and attempts to access and make use of smart cards. A countermeasure to prevent this attack is to use “single-access device driver” architecture. Using this approach, the operating system allows only one application to have access to the serial device (and thus the smart card) at any given time. Another way to prevent the attack is by using a smart card that enforces a “one private key usage per PIN entry” policy model. In this model, the user must enter her PIN every single time the private key is used, and therefore the Trojan horse would not have access to the key.
Logic Bomb
A logic bomb is a type of malware that executes when a particular event takes place. For example, that event could be a time of day or a specific date or it could be the first time you open notepad.exe. Some logic bombs execute when forensics are being undertaken, and in that case the bomb might delete all digital evidence.
Spyware/Adware
Adware doesn’t actually steal anything, but it tracks your Internet usage in an attempt to tailor ads and junk e-mail to your interests. Spyware also tracks your activities and can also gather personal information that could lead to identity theft. In some cases, spyware can even direct the computer to install software and change settings.
Botnet
A bot is a type of malware that installs itself on large numbers of computers through infected e-mails, downloads from websites, Trojan horses, and shared media. After it’s installed, the bot has the ability to connect back to the hacker’s computer. After that, the hacker’s server controls all the bots located on these machines. At a set time, the hacker might direct the bots to take some action, such as direct all the machines to send out spam messages, mount a DoS attack, or perform phishing or any number of malicious acts. The collection of computers that act together is called a botnet, and the individual computers are called zombies. The attacker that manages the botnet is often referred to as the botmaster. Figure 11-2 shows this relationship.
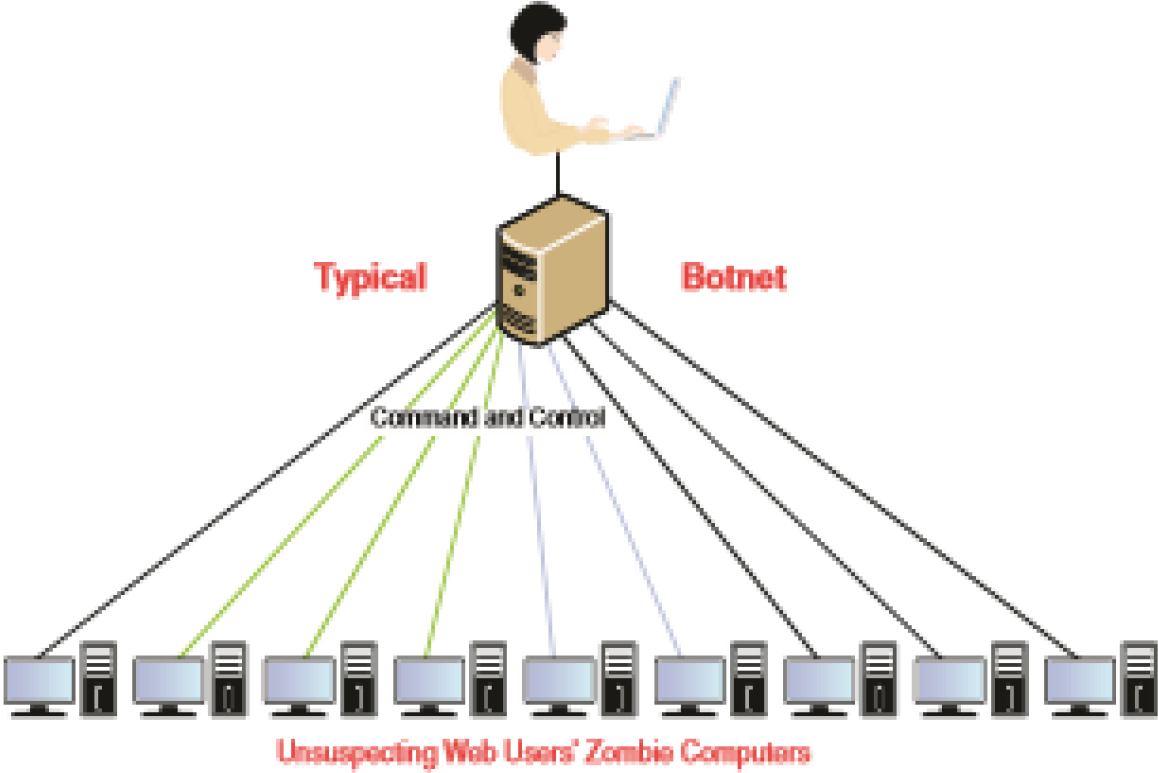
Figure 11-2 Botnet
Rootkit
A rootkit is a set of tools that a hacker can use on a computer after he has managed to gain access and elevate his privileges to administrator. It gets its name from the root account, the most powerful account in Unix-based operating systems. The rootkit tools might include a backdoor for the hacker to access. This is one of the hardest types of malware to remove, and in many cases only a reformat of the hard drive will completely remove it. The following are some of the actions a rootkit can take:
• Install a backdoor
• Remove all entries from the security log (log scrubbing)
• Replace default tools with compromised versions (Trojaned programs)
• Make malicious kernel changes
Ransomware
Ransomware is malware that prevents or limits users from accessing their systems. It is called ransomware because it forces its victims to pay a ransom through certain online payment methods to be given access to their systems again or to get their data back.
Reverse Engineering
Reverse engineering is a term that has been around for some time. Generically, it means taking something apart to discover how it works and perhaps to replicate it. In cybersecurity, it is used to analyze both hardware and software and for various other reasons, such as to do the following:
• Discover how malware functions
• Determine whether malware is present in software
• Locate software bugs
• Locate security problems in hardware
The following sections look at the role of reverse engineering in cybersecurity analysis.
Isolation/Sandboxing
When conducting reverse engineering, how can you analyze malware without suffering the effects of the malware? The answer is to place the malware where you can safely probe and analyze it. This is done by isolating, or sandboxing, the malware. This process is covered more fully in the “Sandboxing” section of Chapter 12, “Implementing Configuration Changes to Existing Controls to Improve Security.”
Software/Malware
Software of any type can be checked for integrity to ensure that it has not been altered since its release. Checking for integrity is one of the ways you can tell when a file has been corrupted (or perhaps replaced entirely) with malware. Two main methods are used in this process:
• Fingerprinting/hashing: Fingerprinting, or hashing, is the process of using a hashing algorithm to reduce a large document or file to a character string that can be used to verify the integrity of the file (that is, whether the file has changed in any way). To be useful, a hash value must have been computed at a time when the software or file was known to have integrity (for example, at release time). At any time thereafter, the software file can be checked for integrity by calculating a new hash value and comparing it to the value from the initial calculation. If the character strings do not match, a change has been made to the software.
Fingerprinting/hashing has been used for some time to verify the integrity of software downloads from vendors. The vendor provides the hash value and specifies the hash algorithm, and the customer recalculates the hash value after the download. If the result matches the value from the vendor, the customer knows the software has integrity and is safe.
Anti-malware products also use this process to identify malware. The problem is that malware creators know this, and so they are constantly making small changes to malicious code to enable the code to escape detection through the use of hashes or signatures. When they make a small change, anti-malware products can no longer identify the malware, and they won’t be able to until a new hash or signature is created by the anti-malware vendor. For this reason, some vendors are beginning to use “fuzzy” hashing, which looks for hash values that are similar but not exact matches.
• Decomposition: Decomposition is the process of breaking something down to discover how it works. When applied to software, it is the process of discovering how the software works, perhaps who created it, and, in some cases, how to prevent the software from performing malicious activity.
When used to assess malware, decomposition can be done two ways: statically and dynamically. When static or manual analysis is used, it takes hours per file and uses tools called disassemblers. Advanced expertise is required. Time is often wasted on repetitive sample unpacking and indicator extraction tasks.
With dynamic analysis tools, an automated static analysis engine is used to identify, de-archive, de-obfuscate, and unpack the underlying object structure. Then proactive threat indicators (PTIs) are extracted from the unpacked files. A rules engine classifies the results to calculate the threat level and to route the extracted files for further analysis. Finally, the extracted files are repaired to enable further extraction or analysis with a sandbox, decompiler, or debugger. While the end result may be the same, these tools are much faster and require less skill than manual or static analysis.
Reverse Engineering Tools
When examples of zero-day malware have been safely sandboxed and must be analyzed or when a host has been compromised and has been safely isolated and you would like to identify details of the breach to be better prepared for the future, reverse engineering tools are indicated. The Infosec Institute recommends the following as the top reverse engineering tools for cybersecurity professionals (as of January 2019):
• Apktool: This third-party tool for reverse engineering can decode resources to nearly original form and re-create them after making some adjustments.
• dex2jar: This lightweight API is designed to read the Dalvik Executable (.dex/.odex) format. It is used with Android and Java .class files.
• diStorm3: This tool is lightweight, easy to use, and has a fast decomposer library. It disassembles instructions in 16-, 32-, and 64-bit modes. It is also the fastest disassembler library. The source code is very clean, readable, portable, and platform independent.
• edb-debugger: This is the Linux equivalent of the famous OllyDbg debugger on the Windows platform. One of the main goals of this debugger is modularity.
• Jad Debugger: This is the most popular Java decompiler ever written. It is a command-line utility written in C++.
• Javasnoop: This Aspect Security tool allows security testers to test the security of Java applications easily.
• OllyDbg: This is a 32-bit, assembler-level analyzing debugger for Microsoft Windows. Emphasis on binary code analysis makes it particularly useful in cases where the source is unavailable.
• Valgrind: This suite is for debugging and profiling Linux programs
Memory
A computing system needs somewhere to store information, both on a long-term basis and a short-term basis. There are two types of storage locations: memory, for temporary storage needs, and long-term storage media. Information can be accessed much faster from memory than from long-term storage, which is why the most recently used instructions or information is typically kept in cache memory for short period of time, which ensures the second and subsequent accesses will be faster than returning to long-term memory. Computers can have both random-access memory (RAM) and read-only memory (ROM). RAM is volatile, meaning the information must continually be refreshed and will be lost if the system shuts down.
Memory Protection
In an information system, memory and storage are the most important resources. Damaged or corrupt data in memory can cause the system to stop functioning. Data in memory can be disclosed and therefore must be protected. Memory does not isolate running processes and threads from data. Security professionals must use processor states, layering, process isolation, abstraction, hardware segmentation, and data hiding to help keep data isolated.
Most processors support two processor states: supervisor state (or kernel mode) and problem state (or user mode). In supervisor state, the highest privilege level on the system is used so that the processor can access all the system hardware and data. In problem state, the processor limits access to system hardware and data. Processes running in supervisor state are isolated from the processes that are not running in that state; supervisor-state processes should be limited to only core operating system functions.
A security professional can use layering to organize programming into separate functions that interact in a hierarchical manner. In most cases, each layer only has access to the layers directly above and below it. Ring protection is the most common implementation of layering, with the inner ring (ring 0) being the most privileged ring and the outer ring (ring 3) being the lowest privileged. The OS kernel usually runs on ring 0, and user applications usually run on ring 3.
A security professional can isolate processes by providing memory address spaces for each process. Other processes are unable to access address space allotted to another process. Naming distinctions and virtual mapping are used as part of process isolation.
Hardware segmentation works like process isolation. It prevents access to information that belongs to a higher security level. However, hardware segmentation enforces the policies using physical hardware controls rather than the operating system’s logical process isolation. Hardware segmentation is rare and is usually restricted to governmental use, although some organizations may choose to use this method to protect private or confidential data. Data hiding prevents data at one security level from being seen by processes operating at other security levels.
Secured Memory
Memory can be divided into multiple partitions. Based on the nature of data in a partition, the partition can be designated as a security-sensitive or a non-security-sensitive partition. In a security breach (such as tamper detection), the contents of a security-sensitive partition can be erased by the controller itself, while the contents of the non-security-sensitive partition can remain unchanged (see Figure 11-3).
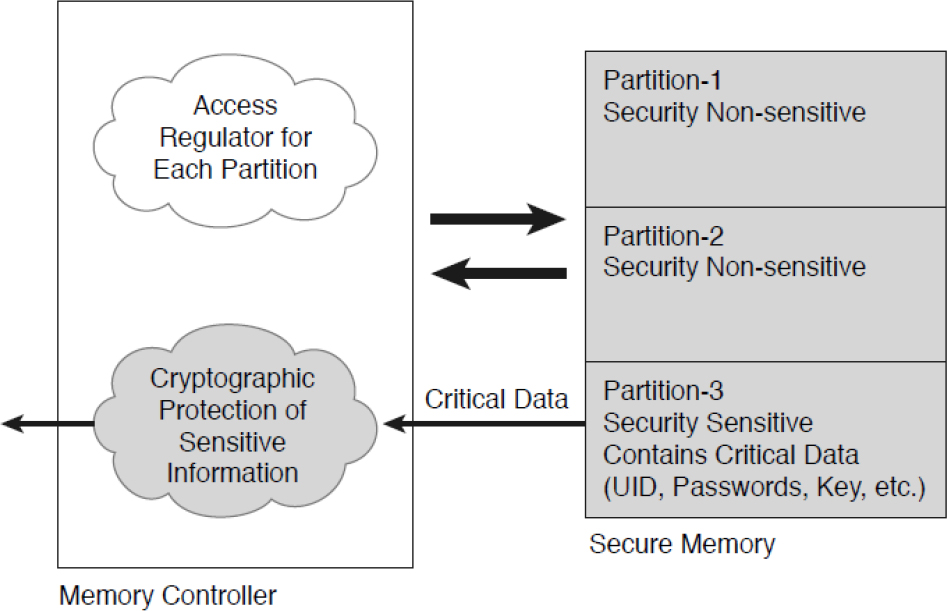
Figure 11-3 Secure Memory
Runtime Data Integrity Check
The runtime data integrity check process ensures the integrity of the peripheral memory contents during runtime execution. The secure booting sequence generates a hash value of the contents of individual memory blocks stored in secured memory. In the runtime mode, the integrity checker reads the contents of a memory block, waits for a specified period, and then reads the contents of another memory block. In the process, the checker also computes the hash values of the memory blocks and compares them with the contents of the reference file generated during boot time. In the event of a mismatch between two hash values, the checker reports a security intrusion to a central unit that decides the action to be taken based on the security policy, as shown in Figure 11-4.
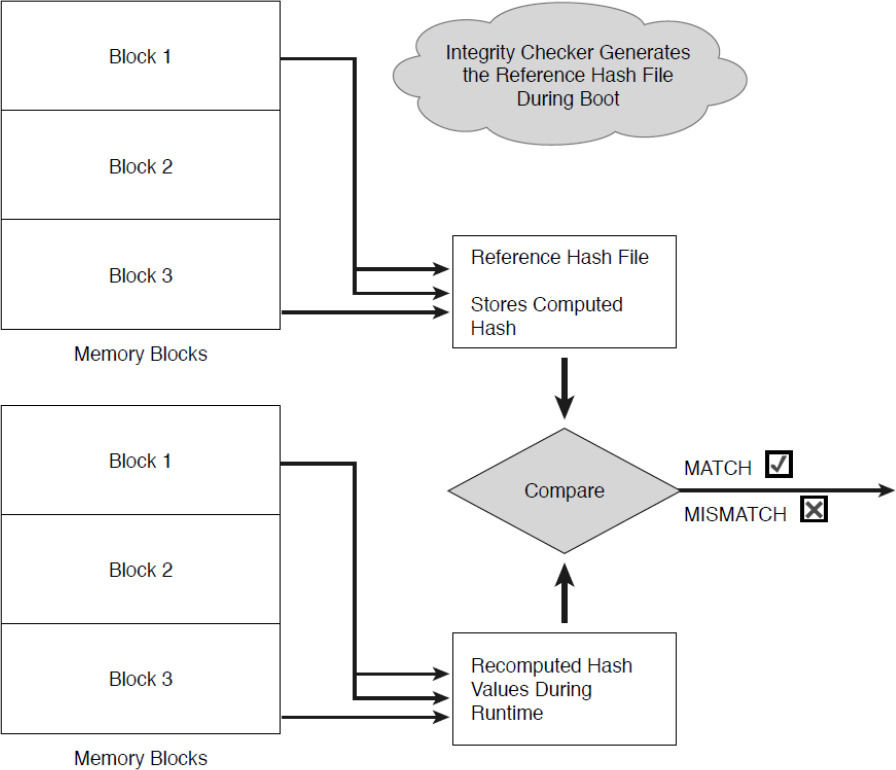
Figure 11-4 Runtime Data Integrity Check
Memory Dumping, Runtime Debugging
Many penetration testing tools perform an operation called a core dump or memory dump. Applications store information in memory, and this information can include sensitive data, passwords, usernames, and encryption keys. Hackers can use memory-reading tools to analyze the entire memory content used by an application. Any vulnerability testing should take this into consideration and utilize the same tools to identify any issues in the memory of an application. The following are some examples of memory-reading tools:
• Memdump: This free tool runs on Windows, Linux, and Solaris. It simply creates a bit-by-bit copy of the volatile memory on a system.
• KnTTools: This memory acquisition and analysis tool used with Windows systems captures physical memory and stores it to a removable drive or sends it over the network to be archived on a separate machine.
• FATKit: This popular memory forensics tool automates the process of extracting interesting data from volatile memory. FATKit helps an analyst visualize the objects it finds to help in understanding the data that the tool was able to find.
Runtime debugging, on the other hand, is the process of using a programming tool to not only identify syntactic problems in code but also discover weaknesses that can lead to memory leaks and buffer overflows. Runtime debugging tools operate by examining and monitoring the use of memory. These tools are specific to the language in which the code was written. Table 11-2 shows examples of runtime debugging tools and the operating systems and languages for which they can be used.
Table 11-2 Runtime Debugging tools
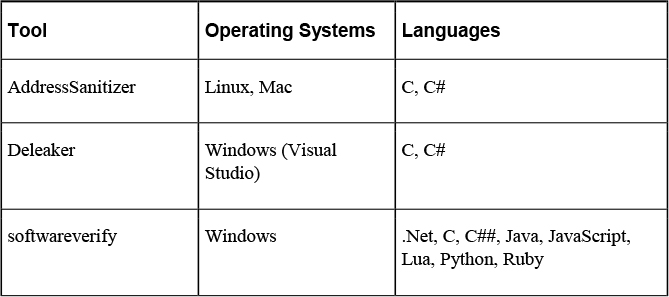
Memory dumping can help determine what a hacker might be able to learn if she were able to cause a memory dump. Runtime debugging would be the correct approach for discovering syntactic problems in an application’s code or to identify other issues, such as memory leaks or potential buffer overflows.
System and Application Behavior
Sometimes an application or system will provide evidence that something is not quite right. With proper interpretation, these behaviors can be used to alert one of the presence of malware or an ongoing attack. It is useful to know what behavior is normal and what is not.
Known-good Behavior
Describing abnormal behavior is perhaps simpler than describing normal behavior, but it is possible to develop a performance baseline for a system that can be used to identity operations that fall outside of the normal. A baseline is a reference point that is defined and captured to be used as a future reference. While capturing baselines is important, using baselines to assess the security state is just as important. Even the most comprehensive baselines are useless if they are never used.
Baselines alone, however, cannot help you if you do not have current benchmarks for comparison. A benchmark, which is a point of reference later used for comparison, captures the same data as a baseline and can even be used as a new baseline should the need arise. A benchmark is compared to the baseline to determine whether any security or performance issues exist. Also, security professionals should keep in mind that monitoring performance and capturing baselines and benchmarks will affect the performance of the systems being monitored.
Capturing both a baseline and a benchmark at the appropriate time is important. Baselines should be captured when a system is properly configured and fully updated. Also, baselines should be assessed over a longer period of time, such as a week or a month rather than just a day or an hour. When updates occur, new baselines should be captured and compared to the previous baselines. At that time, adopting new baselines on the most recent data might be necessary.
Let’s look at an example. Suppose that your company’s security and performance network has a baseline for each day of the week. When the baselines were first captured, you noticed that much more authentication occurs on Thursdays than on any other day of the week. You were concerned about this until you discovered that members of the sales team work remotely on all days but Thursday and rarely log in to the authentication system when they are not working in the office. For their remote work, members of the sales team use their laptops and log in to the VPN only when remotely submitting orders. On Thursday, the entire sales team comes into the office and works on local computers, ensuring that orders are being processed and fulfilled as needed. The spike in authentication traffic on Thursday is fully explained by the sales team’s visit. On the other hand, if you later notice a spike in VPN traffic on Thursdays, you should be concerned because the sales team is working in the office on Thursdays and will not be using the VPN.
For software developers, understanding baselines and benchmarks also involves understanding thresholds, which ensure that security issues do not progress beyond a configured level. If software developers must develop measures to notify system administrators prior to a security incident occurring, the best method is to configure the software to send an alert, alarm, or e-mail message when specific incidents pass the threshold.
Security professionals should capture baselines over different times of day and days of the week to ensure that they can properly recognize when possible issues occur. In addition, security professionals should ensure that they are comparing benchmarks to the appropriate baseline. Comparing a benchmark from a Monday at 9 a.m. to a baseline from a Saturday at 9 a.m. may not allow you to properly assess the situation. Once you identify problem areas, you should develop a possible solution to any issue that you discover.
Anomalous Behavior
When an application is behaving strangely and not operating normally, it could be that the application needs to be reinstalled or that it has been compromised by malware in some way. While all applications occasionally have issues, persistent issues or issues that are typically not seen or have never been seen could indicate a compromised application:
• Introduction of new accounts: Some applications have their own account database. In that case, you may find accounts that didn’t previously exist in the database, which should be a cause for alarm and investigation. Many application compromises create accounts with administrative access for the use of a malicious individual or for the processes operating on his behalf.
• Unexpected output: When the output from a program is not what is normally expected and when dialog boxes are altered or the order in which the boxes are displayed is not correct, it is an indication that the application has been altered. Reports of strange output should be investigated.
• Unexpected outbound communication: Any unexpected outbound traffic should be investigated, regardless of whether it was discovered as a result of network monitoring or as a result of monitoring the host or application. With regard to the application, it can mean that data is being transmitted back to the malicious individual.
• Service interruption: When an application stops functioning with no apparent problem, or when an application cannot seem to communicate in the case of a distributed application, it can be a sign of a compromised application. Any such interruptions that cannot be traced to an application, host, or network failure should be investigated.
• Memory overflows: Memory overflow occurs when an application uses more memory than the operating system has assigned to it. In some cases, it simply causes the system to run slowly, as the application uses more and more memory. In other cases, the issue is more serious. When it is a buffer overflow, the intent may be to crash the system or execute commands.
Exploit Techniques
Endpoints such as desktops, laptops, printers, and smartphones account for the highest percentage of devices on the network. They are therefore common targets. These devices are subject to a number of security issues, as discussed in the following sections.
Social Engineering Threats
Social engineering attacks occur when attackers use believable language to exploit user gullibility to obtain user credentials or some other confidential information. Social engineering threats that you should understand include phishing/pharming, shoulder surfing, identity theft, and dumpster diving. The best countermeasure against social engineering threats is to provide user security awareness training. This training should be required and must occur on a regular basis because social engineering techniques evolve constantly. The following are the most common social engineering threats:
• Phishing/pharming: Phishing is a social engineering attack using email in which attackers try to learn personal information, including credit card information and financial data. This type of attack is usually carried out by implementing a fake website that very closely resembles a legitimate website. Users enter data, including credentials, on the fake website, allowing the attackers to capture any information entered. Spear phishing is a phishing attack carried out against a specific target by learning about the target’s habits and likes. Spear phishing attacks take longer to carry out than phishing attacks because of the information that must be gathered.
Pharming is similar to phishing, but pharming actually pollutes the contents of a computer’s DNS cache so that requests to a legitimate site are actually routed to an alternate site.
Caution users against using any links embedded in e-mail messages, even if a message appears to have come from a legitimate entity. Users should also review the address bar any time they access a site where their personal information is required, to ensure that the site is correct and that SSL is being used, which is indicated by an HTTPS designation at the beginning of the URL address.
• Shoulder surfing: Occurs when an attacker watches a user enter login or other confidential data. Encourage users to always be aware of who is observing their actions. Implementing privacy screens helps ensure that data entry cannot be recorded.
• Identity theft: Occurs when someone obtains personal information, including driver’s license number, bank account number, and Social Security number, and uses that information to assume an identity of the individual whose information was stolen. After the identity is assumed, the attack can go in any direction. In most cases, attackers open financial accounts in the users name. Attackers also can gain access to the user’s valid accounts.
• Dumpster diving: Occurs when attackers examine garbage contents to obtain confidential information. This includes personnel information, account login information, network diagrams, and organizational financial data. Organizations should implement policies for shredding documents that contain this information.
Rogue Endpoints
As if keeping up with the devices you manage is not enough, you also have to concern yourself with the possibility of rogue devices in the networks. Rogue endpoints are devices that are present that you do not control or manage. In some cases, these devices are benign, as in the case of a user bringing his son’s laptop to work and putting it on the network. In other cases, rogue endpoints are placed by malicious individuals.
Rogue Access Points
Rogue access points are APs that you do not control and manage. There are two types: those that are connected to your wired infrastructure and those that are not. The ones that are connected to your wired network present a danger to your wired and wireless networks. They may be placed there by your own users without your knowledge, or they may be purposefully put there by a hacker to gain access to the wired network. In either case, they allow access to your wired network. Wireless intrusion prevention system (WIPS) devices can be used to locate rogue access points and alert administrators to their presence. Wireless site surveys can also be conducted to detect such threats.
Servers
While servers represent a less significant number of devices than endpoints, they usually contain the critical and sensitive assets and perform mission-critical services for the network. Therefore, these devices receive the lion’s share of attention from malicious individuals. The following are some issues that can impact any device but that are most commonly directed at servers:
• DoS/DDoS: A denial-of-service (DoS) attack occurs when attackers flood a device with enough requests to degrade the performance of the targeted device. Some popular DoS attacks include SYN floods and teardrop attacks. A distributed DoS (DDoS) attack is a DoS attack that is carried out from multiple attack locations. Vulnerable devices are infected with software agents called zombies. The vulnerable devices become a botnet, which then carries out the attack. Because of the distributed nature of the attack, identifying all the attacking bots is virtually impossible. The botnet also helps hide the original source of the attack.
• Buffer overflow: Buffers are portions of system memory that are used to store information. A buffer overflow occurs when the amount of data that is submitted to an application is larger than the buffer can handle. Typically, this type of attack is possible because of poorly written application or operating system code, and it can result in an injection of malicious code. To protect against this issue, organizations should ensure that all operating systems and applications are updated with the latest service packs and patches. In addition, programmers should properly test all applications to check for overflow conditions. Finally, programmers should use input validation to ensure that the data submitted is not too large for the buffer.
• Mobile code: Mobile code is any software that is transmitted across a network to be executed on a local system. Examples of mobile code include Java applets, JavaScript code, and ActiveX controls. Mobile code includes security controls, Java implements sandboxes, and ActiveX uses digital code signatures. Malicious mobile code can be used to bypass access controls. Organizations should ensure that users understand the security concerns related to malicious mobile code. Users should only download mobile code from legitimate sites and vendors.
• Emanations: Emanations are electromagnetic signals that are emitted by an electronic device. Attackers can target certain devices or transmission media to eavesdrop on communication without having physical access to the device or medium. The TEMPEST program, initiated by the United States and United Kingdom, researches ways to limit emanations and standardizes the technologies used. Any equipment that meets TEMPEST standards suppresses signal emanations using shielding material. Devices that meet TEMPEST standards usually implement an outer barrier or coating, called a Faraday cage or Faraday shield. TEMPEST devices are most often used in government, military, and law enforcement settings.
• Backdoor/trapdoor: A backdoor, or trapdoor, is a mechanism implemented in many devices or applications that gives the user who uses the backdoor unlimited access to the device or application. Privileged backdoor accounts are the most common type of backdoor in use today. Most established vendors no longer release devices or applications with this security issue. You should be aware of any known backdoors in the devices or applications you manage.
Services
Services that run on both servers and workstations have identities in the security system. They possess accounts called system or service accounts that are built in, and they log on when they operate, just as users do. They also possess privileges and rights, and this is why security issues come up with these accounts. These accounts typically possess many more privileges than they actually need to perform the service. The security issue is that if a malicious individual or process were able to gain control of the service, her/its rights would be significant.
Therefore, it is important to apply the concept of least privilege to these services by identifying the rights the services need and limiting the services to only those rights. A common practice has been to create a user account for the service that possesses only the rights required and set the service to log on using that account. You can do this in Windows by accessing the Log On tab in the Properties dialog box of the service, as shown in Figure 11-5. In this example, the Remote Desktop Service is set to log on as a Network Service account. To limit this account, you can create a new account either in the local machine or in Active Directory, give the account the proper permissions, and then click the Browse button, locate the account, and select it.
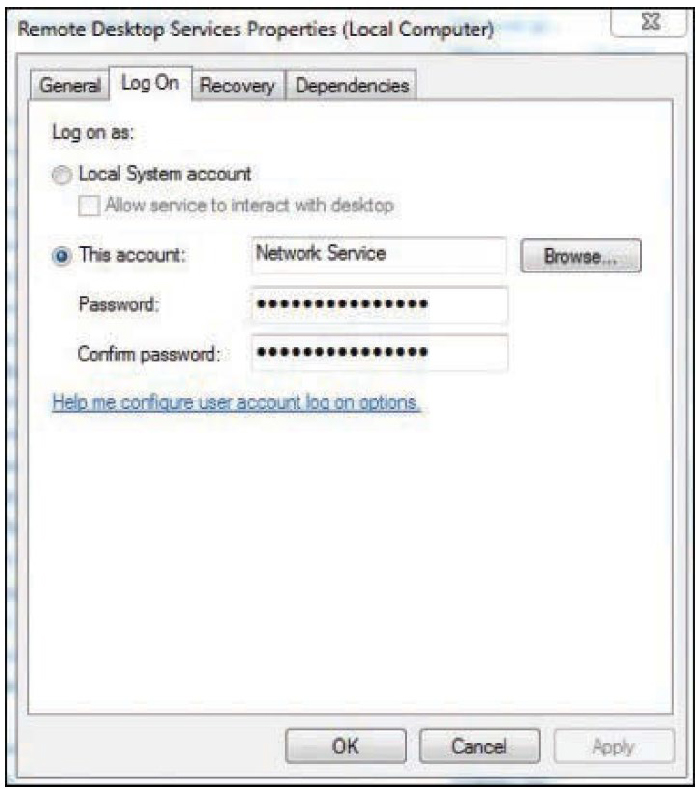
Figure 11-5 Log On Tab
While this is a good approach, it involves some complications. First is the difficulty of managing the account password. If the domain in which the system resides has a policy that requires a password change after 30 days and you don’t change the service account password, the service will stop running.
Another complication involves the use of domain accounts. While setting a service account as a domain account eliminates the need to create an account for the service locally on each server that runs the service, it introduces a larger security risk. If that single domain service account were compromised, the account would provide access to all servers running the service.
Fortunately, with Windows Server 2008 R2 and later systems like Windows Server 2016 and Windows Server 2019, Microsoft introduced the concept of managed service accounts. Unlike with regular domain accounts, in which administrators must reset passwords manually, the network passwords for these accounts are reset automatically. Windows Server 2012 R2 introduced the concept of group managed accounts, which allow servers to share the same managed service account; this was not possible with Server 2008 R2. The account password is managed by Windows Server domain controllers and can be retrieved by multiple Windows Server systems in an Active Directory environment.
File System
The file system can present some opportunities for mischief. One of the prime targets are database servers. In many ways, the database is the Holy Grail for an attacker. It is typically where the sensitive information resides. When considering database security, you need to understand the following terms:
• Inference: Inference occurs when someone has access to information at one level that allows her to infer information about another level. The main mitigation technique for inference is polyinstantiation, which is the development of a detailed version of an object from another object using different values in the new object. It prevents low-level database users from inferring the existence of higher-level data.
• Aggregation: Aggregation is defined as the assembling or compilation of units of information at one sensitivity level and having the resultant totality of data being of a higher sensitivity level than the individual components. So you might think of aggregation as a different way of achieving the same goal as inference, which is to learn information about data on a level to which one does not have access.
• Contamination: Contamination is the intermingling or mixing of data of one sensitivity or need-to-know level with that of another. Proper implementation of security levels is the best defense against these problems.
• Data mining warehouse: A data mining warehouse is a repository of information from heterogeneous databases. It allows for multiple sources of data to not only be stored in one place but to be organized in such a way that redundancy of data is reduced (called data normalizing). More sophisticated data mining tools are used to manipulate the data to discover relationships that may not have been apparent before. Along with the benefits they provide, they also offer more security challenges.
File Integrity Monitoring
Many times, malicious software and malicious individuals make unauthorized changes to files. In many cases these files are data files, and in other cases they are system files. While alterations to data files are undesirable, changes to system files can compromise an entire system.
The solution is file integrity software that generates a hash value of each system file and verifies that hash value at regular intervals. This entire process is automated, and in some cases a corrupted system file will automatically be replaced when discovered.
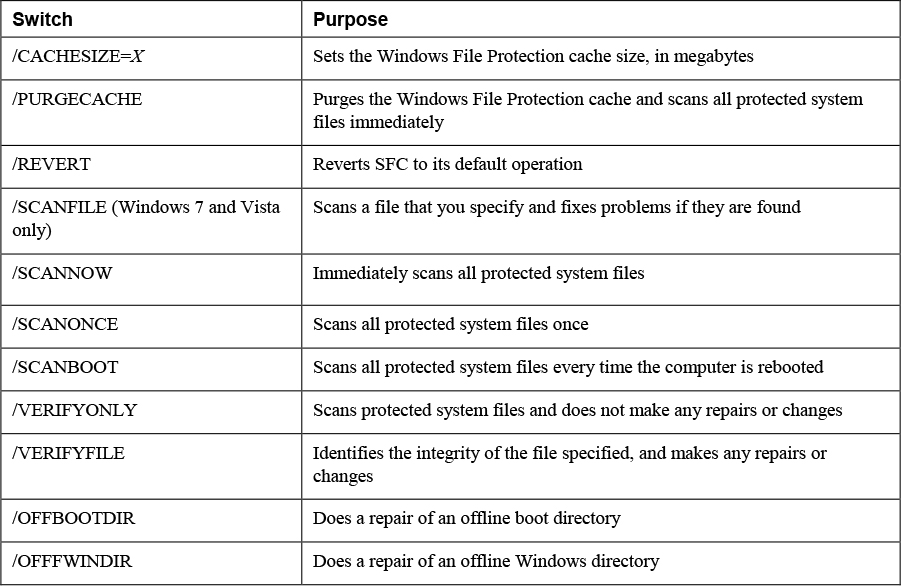
While there are third-party tools such as Tripwire that do this, Windows offers System File Checker (SFC) to do the same thing. SFC is a command-line utility that checks and verifies the versions of system files on a computer. If system files are corrupted, SFC replaces the corrupted files with correct versions. The syntax for the SFC command is as follows:
SFC [switch]
The switches vary a bit between different versions of Windows. Table 11-3 lists the most common ones available for SFC.
Table 11-3 SFC Switches
User and Entity Behavior Analytics (UEBA)
Behavioral analysis is another term for anomaly analysis. It also observes network behaviors for anomalies. It can be implemented using combinations of the scanning types already covered, including NetFlow, protocol, and packet analysis to create a baseline and subsequently report departures from the traffic metrics found in the baseline. One of the newer advances in this field is the development of user and entity behavior analytics (UEBA). This type of analysis focuses on user activities. Combining behavior analysis with machine learning, UEBA enhances the ability to determine which particular users are behaving oddly. An example would be a hacker who has stolen credentials of a user and is identified by the system because he is not performing the same activities that the user would perform.
Network
Sometimes our focus is not on endpoints or on individual application behavior, but on network activity. Let’s look at some types of analysis that relate to network traffic.
Uniform Resource Locator (URL) and Domain Name System (DNS) Analysis
Malicious individuals can make use of both DNS records and URLs to redirect network traffic in a way that benefits them.
Also, some techniques used to shorten URLs (to make them less likely to malfunction) have resulted in the following:
• Allowing spammers to sidestep spam filters as domain names like TinyURL are automatically trusted
• Preventing educated users from checking for suspect URLs by obfuscating the actual website URL
• Redirecting users to phishing sites to capture sensitive personal information
• Redirecting users to malicious sites loaded with drive-by droppers, just waiting to download malware
Tools that can be used to analyze URLs include the following:
• urlQuery is a free online service for testing and analyzing URLs, helping with identification of malicious content on websites.
• URLVoid is a free service developed by NoVirusThanks Company Srl that allows users to scan a website address (such as google.com or youtube.com) with multiple website reputation engines and domain blacklists to facilitate the detection of possible dangerous websites.
DNS Analysis
DNS provides a hierarchical naming system for computers, services, and any resources connected to the Internet or a private network. You should enable Domain Name System Security Extensions (DNSSEC) to ensure that a DNS server is authenticated before the transfer of DNS information begins between the DNS server and client. Transaction Signature (TSIG) is a cryptographic mechanism used with DNSSEC that allows a DNS server to automatically update client resource records if their IP addresses or hostnames change. The TSIG record is used to validate a DNS client.
As a security measure, you can configure internal DNS servers to communicate only with root servers. When you configure internal DNS servers to communicate only with root servers, the internal DNS servers are prevented from communicating with any other external DNS servers.
The Start of Authority (SOA) contains the information regarding a DNS zone’s authoritative server. A DNS record’s Time to Live (TTL) determines how long a DNS record will live before it needs to be refreshed. When a record’s TTL expires, the record is removed from the DNS cache. Poisoning the DNS cache involves adding false records to the DNS zone. If you use a longer TTL, the resource record is read less frequently and therefore is less likely to be poisoned.
Let’s look at a security issue that involves DNS. Suppose an IT administrator installs new DNS name servers that host the company mail exchanger (MX) records and resolve the web server’s public address. To secure the zone transfer between the DNS servers, the administrator uses only server ACLs. However, any secondary DNS servers would still be susceptible to IP spoofing attacks.
Another scenario could occur when a security team determines that someone from outside the organization has obtained sensitive information about the internal organization by querying the company’s external DNS server. The security manager should address the problem by implementing a split DNS server, allowing the external DNS server to contain only information about domains that the outside world should be aware of and enabling the internal DNS server to maintain authoritative records for internal systems.
Domain Generation Algorithm
A domain generation algorithm (DGA) is used by attackers to periodically generate large numbers of domain names that can be used as rendezvous points with their command and control servers. Detection efforts consist of using cumbersome blacklists that must be updated often. Figure 11-6 illustrates the use of a DGA.
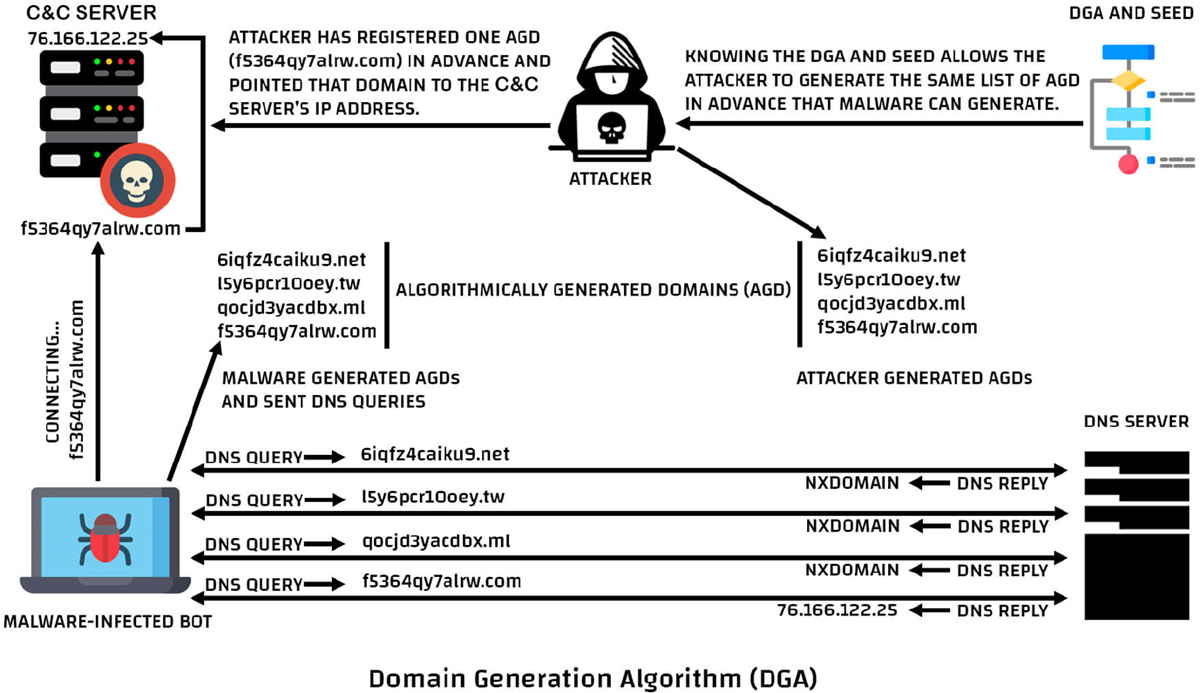
Figure 11-6 Domain Generation Algorithm
Flow Analysis
To protect data during transmission, security practitioners should identify confidential and private information. Once this data has been properly identified, the following flow analysis steps should occur:
Step 1. Determine which applications and services access the information.
Step 2. Document where the information is stored.
Step 3. Document which security controls protect the stored information.
Step 4. Determine how the information is transmitted.
Step 5. Analyze whether authentication is used when accessing the information. If it is, determine whether the authentication information is securely transmitted. If it is not, determine whether authentication can be used.
Step 6. Analyze enterprise password policies, including password length, password complexity, and password expiration.
Step 7. Determine whether encryption is used to transmit data. If it is, ensure that the level of encryption is appropriate and that the encryption algorithm is adequate. If it is not, determine whether encryption can be used.
Step 8. Ensure that the encryption keys are protected.
Security practitioners should adhere to the defense-in-depth principle to ensure that the CIA of data is ensured across its entire life cycle. Applications and services should be analyzed to determine whether more secure alternatives can be used or whether inadequate security controls are deployed. Data at rest may require encryption to provide full protection and appropriate ACLs to ensure that only authorized users have access. For data transmission, secure protocols and encryption should be employed to prevent unauthorized users from being able to intercept and read data. The most secure level of authentication possible should be used in the enterprise. Appropriate password and account policies can protect against possible password attacks.
Finally, security practitioners should ensure that confidential and private information is isolated from other information, including locating the information on separate physical servers and isolating data using virtual LANs (VLANs). Disable all unnecessary services, protocols, and accounts on all devices. Make sure that all firmware, operating systems, and applications are kept up to date, based on vendor recommendations and releases.
When new technologies are deployed based on the changing business needs of the organization, security practitioners should be diligent to ensure that they understand all the security implications and issues with the new technology. Deploying a new technology before proper security analysis has occurred can result in security breaches that affect more than just the newly deployed technology. Remember that changes are inevitable! How you analyze and plan for these changes is what will set you apart from other security professionals.
NetFlow Analysis
NetFlow is a technology developed by Cisco that is supported by all major vendors and can be used to collect and subsequently export IP traffic accounting information. The traffic information is exported using UDP packets to a NetFlow analyzer, which can organize the information in useful ways. It exports records of individual one-way transmissions called flows. When NetFlow is configured on a router interface, all packets that are part of the same flow share the following characteristics:
• Source MAC address
• Destination MAC address
• IP source address
• IP destination address
• Source port
• Destination port
• Layer 3 protocol type
• Class of service
• Router or switch interface
Figure 11-7 shows the types of questions that can be answered by using the NetFlow information.
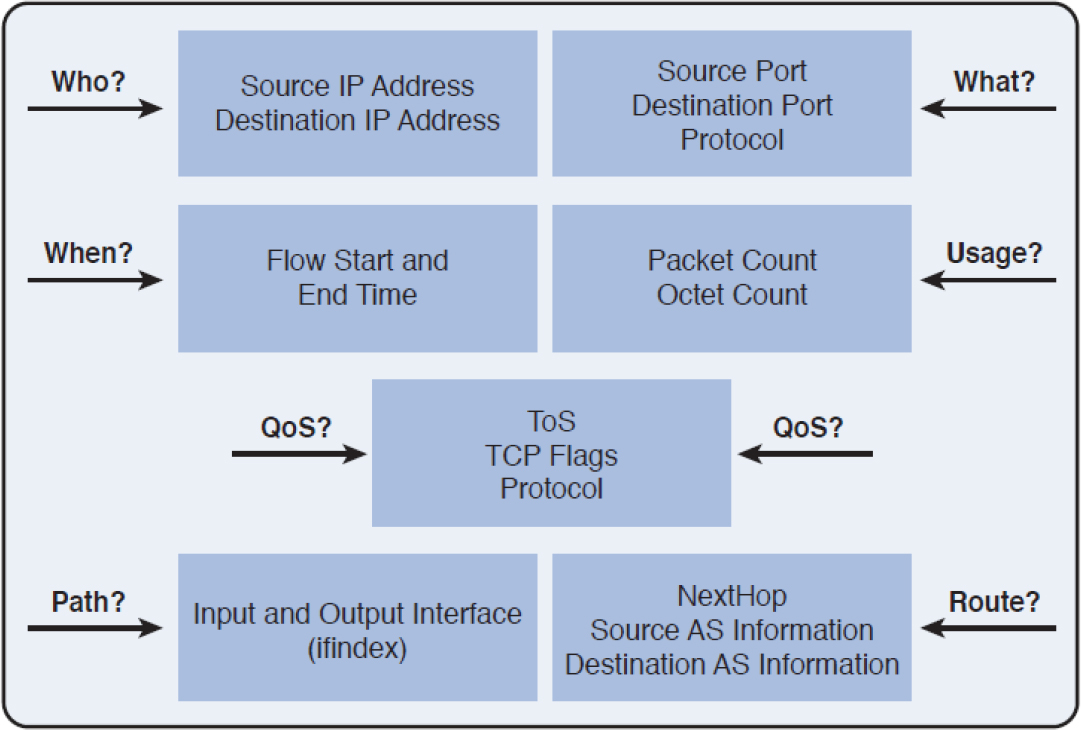
Figure 11-7 Using NetFlow Data
When the flow information is received by the analyzer, it is organized and can then be used to identify the following:
• The top protocols in use
• The top talkers in the network
• Traffic patterns throughout the day
In the example in Figure 11-8, the SolarWinds NetFlow Traffic Analyzer displays the top talking endpoints over the past hour.
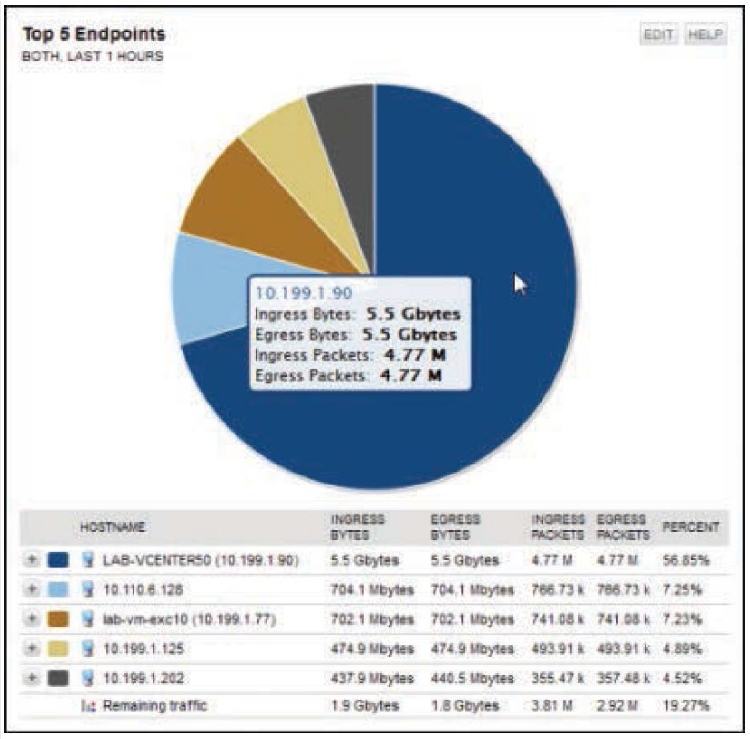
Figure 11-8 NetFlow Data
There a number of tools that can be used to perform flow analysis. Many of these tools are discussed in the next section.
Packet and Protocol Analysis
Point-in-time analysis captures data over a specified period of time and thus provides a snapshot of the situation at that point in time or across the specified time period. The types of analysis described in this section involve capturing the information and then analyzing it. Although these types of analysis all require different tools or processes, they all follow this paradigm.
Packet Analysis
Packet analysis examines an entire packet, including the payload. Its subset, protocol analysis, described next, is concerned only with the information in the header of the packet. In many cases, payload analysis is done when issues cannot be resolved by observing the header. While the header is only concerned with the information used to get the packet from its source to its destination, the payload is the actual data being communicated. When performance issues are occurring, and there is no sign of issues in the header, looking into the payload may reveal error messages related to the application in use that do not present in the header. From a security standpoint, examining the payload can reveal data that is unencrypted that should be encrypted. It also can reveal sensitive information that should not be leaving the network. Finally, some attacks can be recognized by examining the application commands and requests within the payload.
Protocol Analysis
As you just learned, protocol analysis is a subset of packet analysis, and it involves examining information in the header of a packet. Protocol analyzers examine these headers for information such as the protocol in use and details involving the communication process, such as source and destination IP addresses and source and destination MAC addresses. From a security standpoint, these headers can also be used to determine whether the communication rules of the protocol are being followed.
Malware
The handling of malware was covered earlier in this chapter and is covered further in Chapter 12.
Log Review
While automated systems can certainly make log review easier, these tools are not available to all cybersecurity analysts, and they do not always catch everything. In some cases, manual log review must still be done. The following sections look at how log analysis is performed in the typical logs that relate to security.
Event Logs
Event logs can include security events, but other types of event logs exist as well. Figure 11-9 shows the Windows System log, which includes operating system events. The view has been filtered to show only error events. Error messages indicate that something did not work, warnings indicate a lesser issue, and informational events are normal operations.
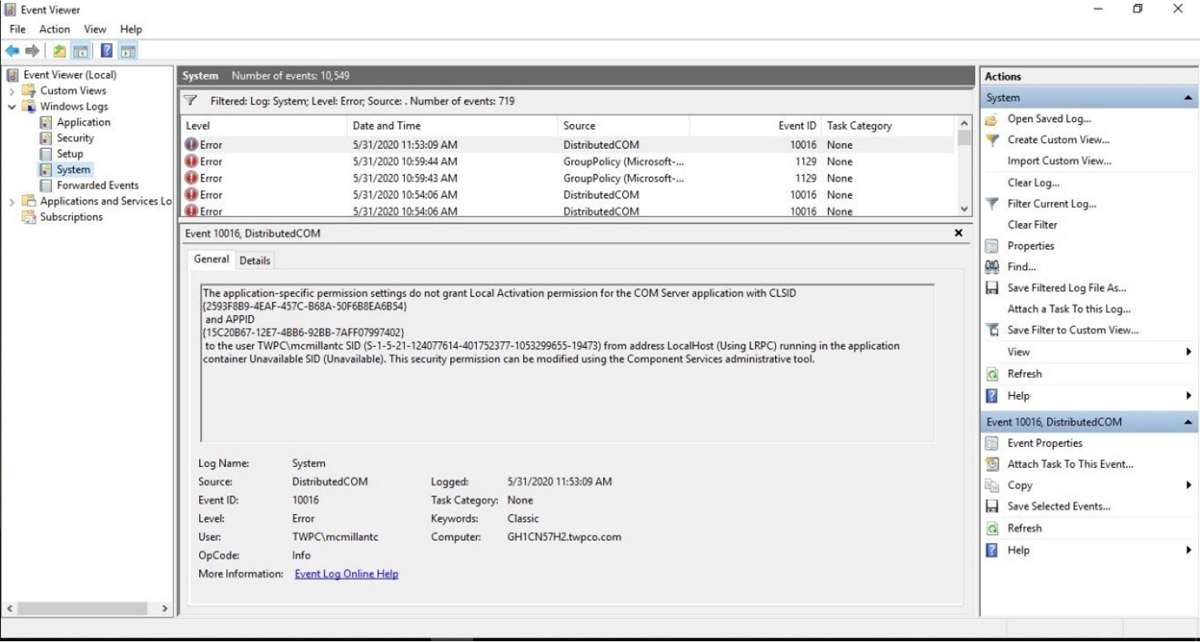
Figure 11-9 System Log in Event Viewer
System logs record regular system events, including operating system and service events. Audit and security logs record successful and failed attempts to perform certain actions and require that security professionals specifically configure the actions that are audited. Organizations should establish policies regarding the collection, storage, and security of these logs. In most cases, the logs can be configured to trigger alerts when certain events occur. In addition, these logs must be periodically and systematically reviewed. Cybersecurity analysts should be trained on how to use these logs to detect when incidents have occurred. Having all the information in the world is no help if personnel do not have the appropriate skills to analyze it.
For large enterprises, the amount of log data that needs to be analyzed can be quite large. For this reason, many organizations implement a SIEM device, which provides an automated solution for analyzing events and deciding where the attention needs to be given.
Suppose an intrusion detection system (IDS) logged an attack attempt from a remote IP address. One week later, the attacker successfully compromised the network. In this case, it is likely that no one was reviewing the IDS event logs. Consider another example of insufficient logging and mechanisms for review. Say that an organization did not know its internal financial databases were compromised until the attacker published sensitive portions of the database on several popular attacker websites. The organization was unable to determine when, how, or who conducted the attacks but rebuilt, restored, and updated the compromised database server to continue operations. If the organization is unable to determine these specifics, it needs to look at the configuration of its system, audit, and security logs.
Syslog
Syslog is a protocol that can be used to collect logs from devices and store them in a central location called a Syslog server. Syslog provides a simple framework for log entry generation, storage, and transfer that any OS, security software, or application could use if designed to do so. Many log sources either use Syslog as their native logging format or offer features that allow their logging formats to be converted to Syslog format.
Syslog messages all follow the same format because they have, for the most part, been standardized. The Syslog packet size is limited to 1024 bytes and carries the following information:
• Facility: The source of the message. The source can be the operating system, the process, or an application.
• Severity: Rated using the following scale:
• 0 Emergency: System is unusable.
• 1 Alert: Action must be taken immediately.
• 2 Critical: Critical conditions.
• 3 Error: Error conditions.
• 4 Warning: Warning conditions.
• 5 Notice: Normal but significant conditions.
• 6 Informational: Informational messages.
• 7 Debug: Debug-level messages.
• Source: The log from which this entry came.
• Action: The action taken on the packet.
• Source: The source IP address and port number.
• Destination: The destination IP address and port number.
Each Syslog message has only three parts. The first part specifies the facility and severity as numeric values. The second part of the message contains a timestamp and the hostname or IP address of the source of the log. The third part is the actual log message, with content as shown here:
seq no:timestamp: %facility-severity-MNEMONIC:description
In the following sample Syslog message, generated by a Cisco router, no sequence number is present (it must be enabled), the timestamp shows 47 seconds since the log was cleared, the facility is LINK (an interface), the severity is 3, the type of event is UP/DOWN, and the description is “Interface GigabitEthernet0/2, changed state to up”:
00:00:47: %LINK-3-UPDOWN: Interface GigabitEthernet0/2, changed state to up
This example is a locally generated message on the router and not one sent to a Syslog server. When a message is sent to the Syslog server, it also includes the IP address of the device sending the message to the Syslog server. Figure 11-10 shows some output from a Syslog server that includes this additional information.
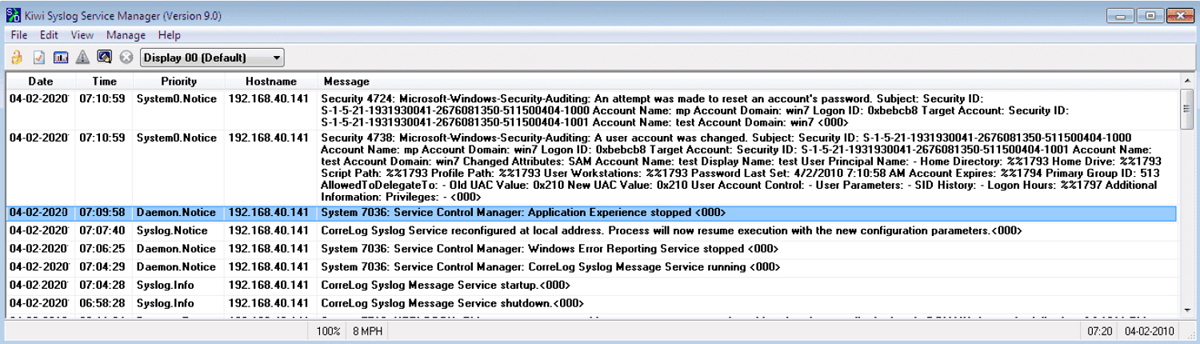
Figure 11-10 Syslog Server
The following is a standard Syslog message, and its parts are explained in Table 11-4:
*May 1 23:02:27.143: %SEC-6-IPACCESSLOGP: list ACL-IPv4-E0/0-IN permitted tcp 192.168.1.3(1026) -> 192.168.2.1(80), 1 packet
Table 11-4 Parts of a Standard Syslog Message

No standard fields are defined within the message content; it is intended to be human readable, and not easily machine parsable. This provides very high flexibility for log generators, which can place whatever information they deem important within the content field, but it makes automated analysis of the log data very challenging. A single source may use many different formats for its log message content, so an analysis program needs to be familiar with each format and should be able to extract the meaning of the data from the fields of each format. This problem becomes much more challenging when log messages are generated by many sources. It might not be feasible to understand the meaning of all log messages, and analysis might be limited to keyword and pattern searches. Some organizations design their Syslog infrastructures so that similar types of messages are grouped together or assigned similar codes, which can make log analysis automation easier to perform.
As log security has become a greater concern, several implementations of Syslog have been created that place a greater emphasis on security. Most have been based on IETF’s RFC 3195, which was designed specifically to improve the security of Syslog. Implementations based on this standard can support log confidentiality, integrity, and availability through several features, including reliable log delivery, transmission confidentiality protection, and transmission integrity protection and authentication.
While Syslog message formats differ based on the device and the type of message, this is a typical format of security-related message.
Kiwi Syslog Server
Kiwi Syslog Server is log management software that provides centralized storage of log data and SNMP data from hosts and appliances, based on Windows or Linux. While Kiwi combines the functions of SNMP collector and log manager, it lacks many of the features found in other systems; however, it is very economical.
Firewall Logs
Examining a firewall log can be somewhat daunting at first. But if you understand the basic layout and know what certain acronyms stand for, you can usually find your way around a firewall log. The following are some examples of common firewalls.
Windows Defender
Windows operating system include the Windows Defender Firewall. The default path for the log is %windir%system32logfilesfirewallpfirewall.log. Figure 11-11 shows the Windows Defender Firewall with Advanced Security interface.
Figure 11-11 Windows Defender Interface
Cisco Check Point
A Check Point log (Cisco) follows this format:
Time | Action | Firewall | Interface | Product| Source | Source Port | Destination | Service | Protocol | Translation | Rule
Note
These fields are used when allowing or denying traffic. Other actions, such as a change in an object, use different fields that are beyond the scope of this discussion.
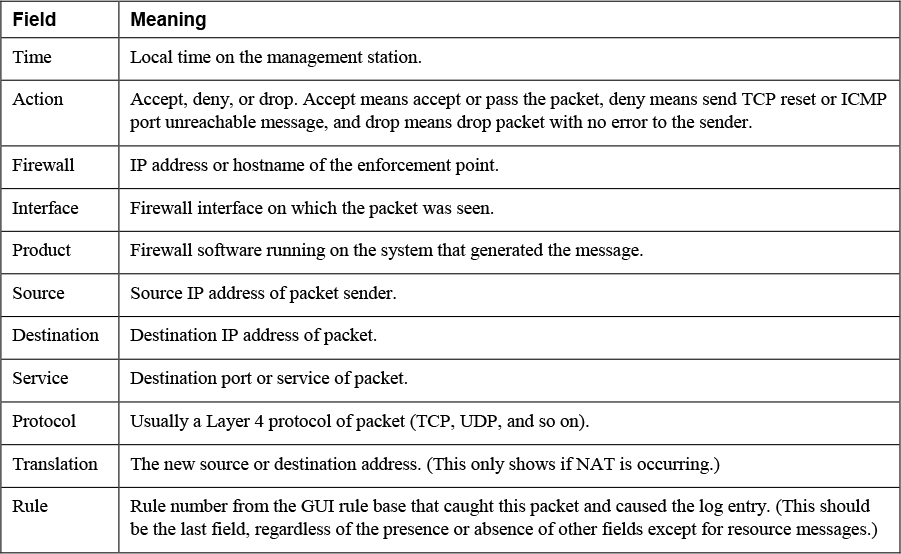
Table 11-5 shows the meaning of each field.
Table 11-5 Check Point Firewall Fields
This is what a line from the log might look like:
14:55:20 accept bd.pearson.com >eth1 product VPN-1 & Firewall-1 src 10.5.5.1 s_port 4523 dst xx.xxx.10.2 service http proto tcp xlatesrc xxx.xxx.146.12 rule 15
This is a log entry for permitted HTTP traffic sourced from inside (eth1) with NAT. Table 11-6 describes the meanings of the fields.
Table 11-6 Firewall Log Entry Field Meanings

While other logs may be slightly different, if you understand the examples shown here, you should be able to figure them out pretty quickly.
Web Application Firewall (WAF)
A web application firewall (WAF) applies rule sets to an HTTP conversation and examines all web input before processing.. These rule sets cover common attack types to which these session types are susceptible. Among the common attacks they address are cross-site scripting and SQL injections. A WAF can be implemented as an appliance or as a server plug-in. In appliance form, a WAF is typically placed directly behind the firewall and in front of the web server farm; Figure 11-12 shows an example.
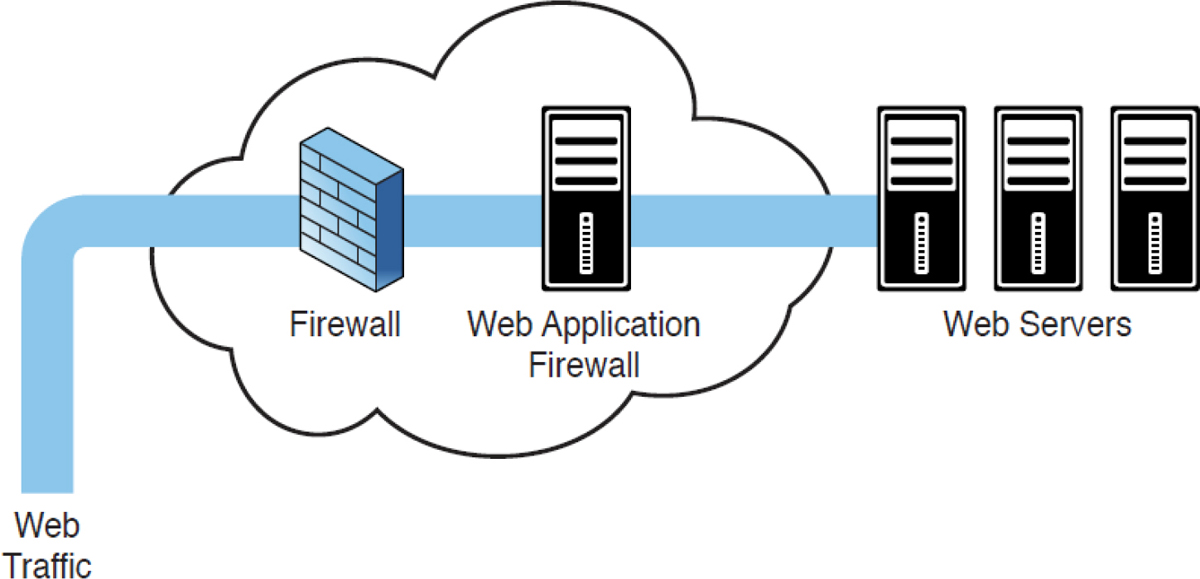
Figure 11-12 Placement of a WAF
While all traffic is usually funneled inline through the device, some solutions monitor a port and operate out-of-band. Table 11-7 lists the pros and cons of these two approaches. Finally, WAFs can be installed directly on the web servers themselves. The security issues involved with WAFs include the following:
• The IT infrastructure becomes more complex.
• Training on the WAF must be provided with each new release of the web application.
• Testing procedures may change with each release.
• False positives may occur and can have a significant business impact.
• Troubleshooting becomes more complex.
• The WAF terminating the application session can potentially have an effect on the web application.
Table 11-7 Advantages and Disadvantages of WAF Placement Options

An example pf a WAF log file is shown in Figure 11-13. In it you can see a number of entries regarding a detected threat attempting code tampering.
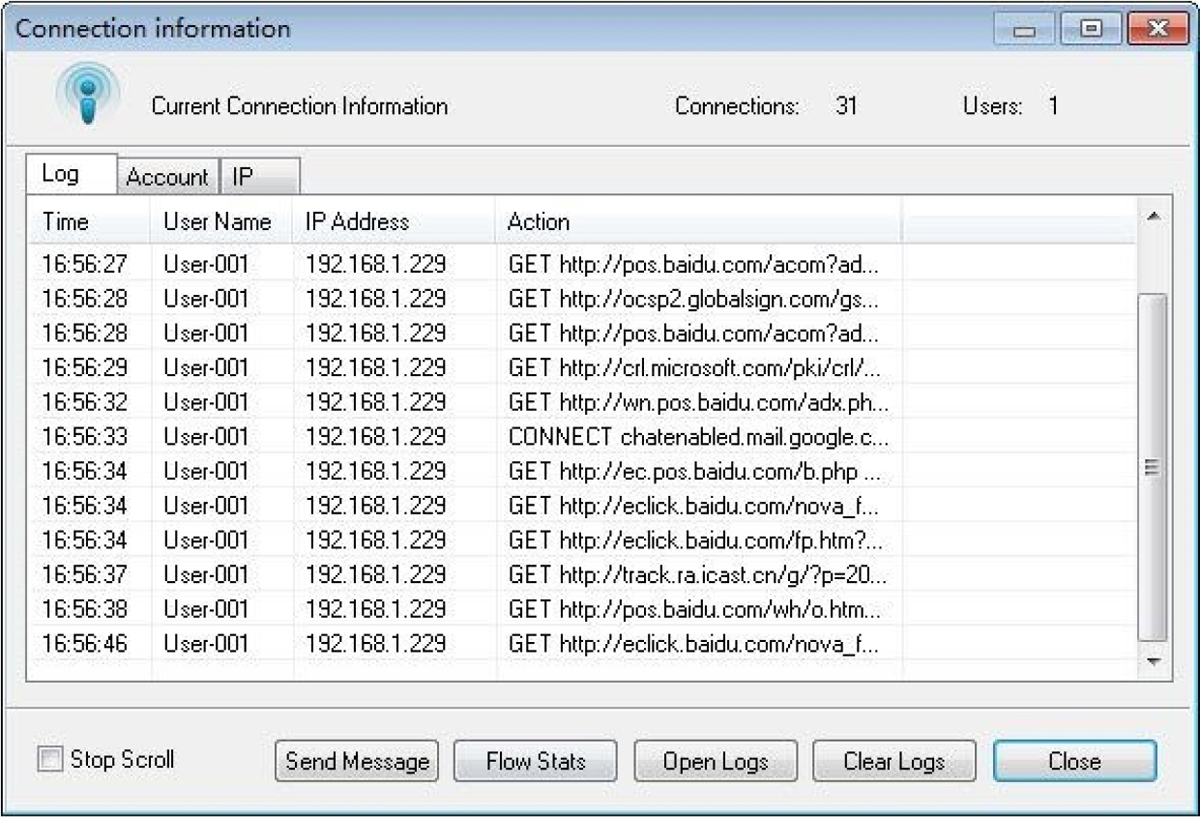
Figure 11-13 WAF Log File
Proxy
Proxy servers can be appliances, or they can be software that is installed on a server operating system. These servers act like a proxy firewall in that they create the web connection between systems on their behalf, but they can typically allow and disallow traffic on a more granular basis. For example, a proxy server may allow the Sales group to go to certain websites while not allowing the Data Entry group access to those same sites. The functionality extends beyond HTTP to other traffic types, such as FTP traffic.
Proxy servers can provide an additional beneficial function called web caching. When a proxy server is configured to provide web caching, it saves a copy of all web pages that have been delivered to internal computers in a web cache. If any user requests the same page later, the proxy server has a local copy and need not spend the time and effort to retrieve it from the Internet. This greatly improves web performance for frequently requested page.
Figure 11-14 shows a view of a proxy server log. This is from the Proxy Server CCProxy for Internet Monitoring. This view shows who is connected and what they are doing.
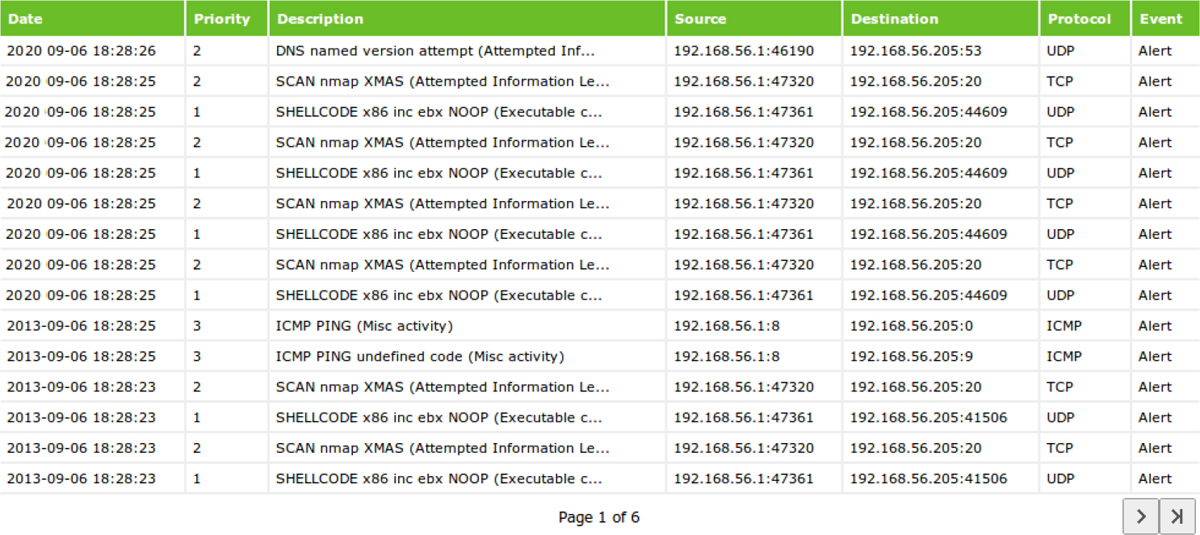
Figure 11-14 Proxy Server Log
Intrusion Detection System (IDS)/Intrusion Prevention System (IPS)
An intrusion detection system (IDS) creates a log of every event that occurs. An intrusion prevention system (IPS) goes one step further and can take actions to stop an intrusion. Figure 11-15 shows output from an IDS. In the output, you can see that for each intrusion attempt, the source and destination IP addresses and port numbers are shown, along with a description of the type of intrusion. In this case, all the alerts have been generated by the same source IP address. Because this is a private IP address, it is coming from inside your network. It could be a malicious individual, or it could be a compromised host under the control of external forces. As a cybersecurity analyst, you should either block that IP address or investigate to find out who has that IP address.
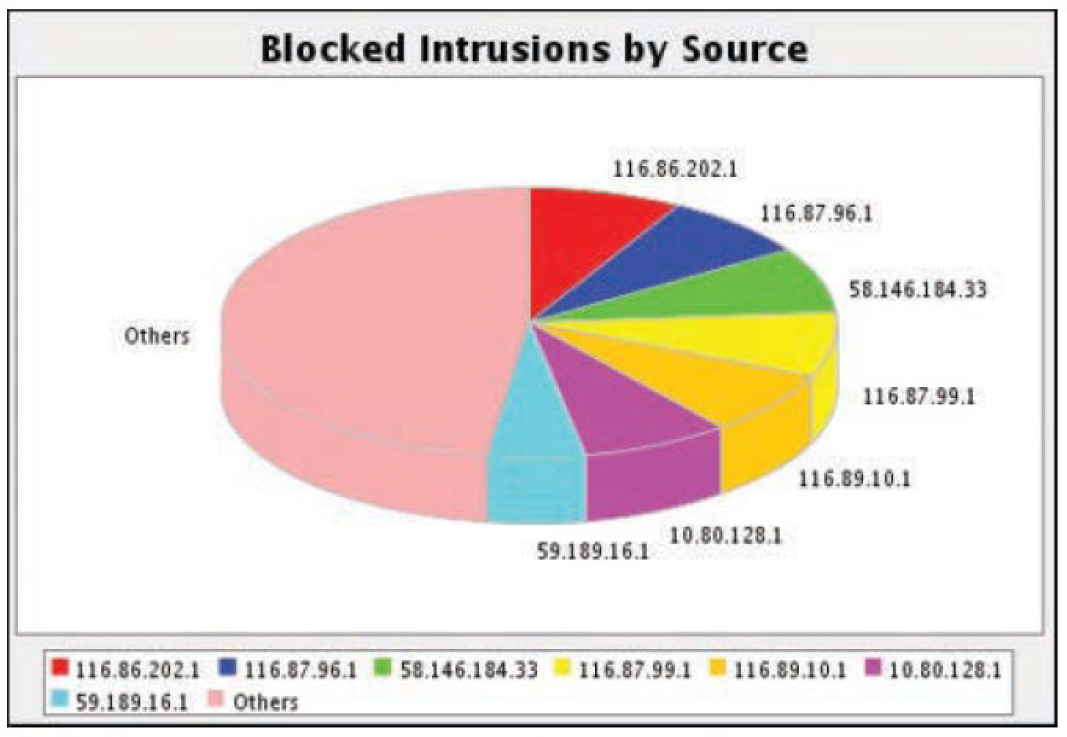
Figure 11-15 IDS Log
While the logs are helpful, one of the real values of an IDS is its ability to present the data it collects in meaningful ways in reports. For example, Figure 11-16 shows a pie chart created to show the intrusion attempts and the IP addresses from which the intrusions were sourced.
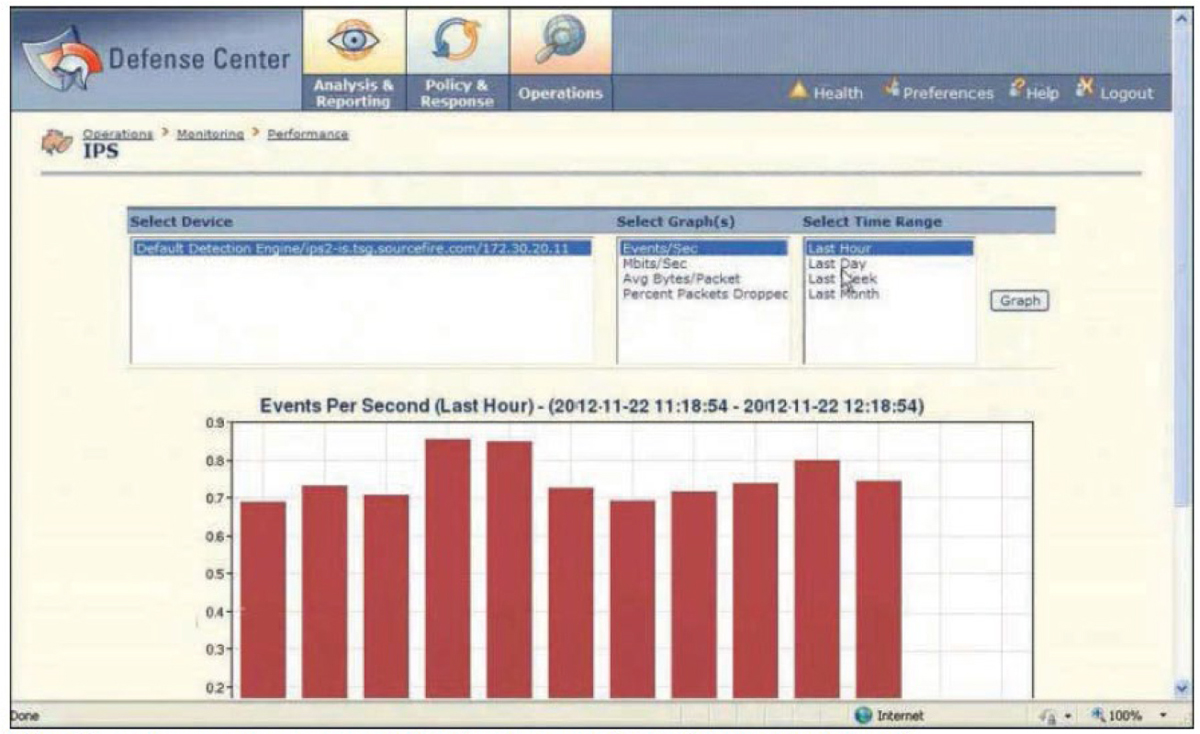
Figure 11-16 IDS Report Showing Blocked Intrusions by Sources
Sourcefire
Sourcefire (now owned by Cisco) created products based on Snort (covered in the next section). The devices Sourcefire created were branded as Firepower appliances. These products were next-generation IPSs (NGIPSs) that provided network visibility into hosts, operating systems, applications, services, protocols, users, content, network behavior, and network attacks and malware. Sourcefire also included integrated application control, malware protection, and URL filtering. Figure 11-17 shows the Sourcefire Defense Center displaying the numbers of events in the last hour in a graph. All the services provided by these products are now incorporated into Cisco firewall products. For more information on Sourcefire, see https://www.cisco.com/c/en/us/services/acquisitions/sourcefire.html.
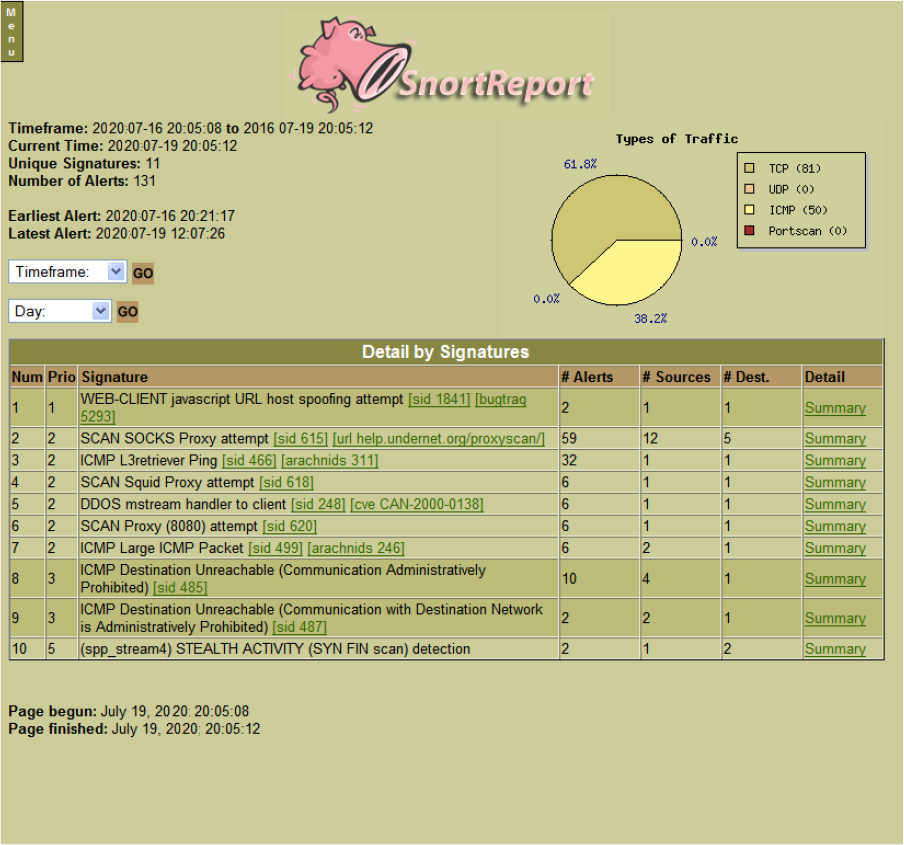
Figure 11-17 Sourcefire
Snort
Snort is an open source NIDS on which Sourcefire products are based. It can be installed on Fedora, CentOS, FreeBSD, and Windows. The installation files are free, but you need a subscription to keep rule sets up to data. Figure 11-18 shows a Snort report that has organized the traffic in the pie chart by protocol. It also lists all events detected by various signatures that have been installed. If you scan through the list, you can see attacks such as URL host spoofing, oversized packets, and, in row 10, a SYN FIN scan.
Figure 11-18 Snort
Zeek
Zeek is another open source NIDS. It is only supported on Unix/Linux platforms. It is not as user friendly as Snort in that configuring it requires more expertise. Like with many other open source products, it is supported by a nonprofit organization called the Software Freedom Conservancy.
HIPS
A host-based IPS (HIPS) monitors traffic on a single system. Its primary responsibility is to protect the system on which it is installed. HIPSs typically work closely with anti-malware products and host firewall products. They generally monitor the interaction of sites and applications with the operating system and stop any malicious activity or, in some cases, ask the user to approve changes that the application or site would like to make to the system. An example of a HIPS is SafenSoft SysWatch.
Impact Analysis
When the inevitable security event occurs, especially if it results in a successful attack, the impact of the event must be determined. Impact analysis must be performed on several levels to yield useful information. In Chapter 15, “The Incident Response Process,” and Chapter 16, “Applying the Appropriate Incident Response Procedure,” you will learn more about the incident response process, but for now understand that the purpose of an impact analysis is to
• Identify what systems were impacted
• Determine what role the quality of the response played in the severity of the issue
• For the future, associate the attack type with the systems that were impacted
Organization Impact vs. Localized Impact
Always identify the boundaries of the attack or issue if possible. This may result in a set of impacts that affected one small area or environment while another set of issues may have impacted a larger area. Defining those boundaries helps you to anticipate the scope of a similar attack of that type in the future.
You might find yourself in a scenario where one office or LAN is affected while others are not affected (localized). Even when that is the case, it could result in a wider organizational impact. For example, if a local office hosts all the database servers and the attack is local to that office, it could mean database issues for the entire organization.
Immediate Impact vs. Total Impact
While many attacks cause an immediate issue, some attacks (especially some of the more serious) take weeks and months to reveal their damage. When attacks occur, be aware of such a lag in the effect and ensure that you continue to gather information that can be correlated with previous attacks. The immediate impact is what you see that alerts you, but the total impact might not be known for weeks.
Security Information and Event Management (SIEM) Review
For large enterprises, the amount of log data that needs to be analyzed can be quite large. For this reason, many organizations implement security information and event management (SIEM), which provides an automated solution for analyzing events and deciding where the attention needs to be given. Most SIEM products support two ways of collecting logs from log generators:
• Agentless: With this type of collection, the SIEM server receives data from the individual hosts without needing to have any special software installed on those hosts. Some servers pull logs from the hosts, which is usually done by having the server authenticate to each host and retrieve its logs regularly. In other cases, the hosts push their logs to the server, which usually involves each host authenticating to the server and transferring its logs regularly. Regardless of whether the logs are pushed or pulled, the server then performs event filtering and aggregation and log normalization and analysis on the collected logs.
• Agent-based: With this type of collection, an agent program is installed on the host to perform event filtering and aggregation and log normalization for a particular type of log. The host then transmits the normalized log data to a SIEM server, usually on a real-time or near-real-time basis, for analysis and storage. Multiple agents may need to be installed if a host has multiple types of logs of interest. Some SIEM products also offer agents for generic formats such as Syslog and SNMP. A generic agent is used primarily to get log data from a source for which a format-specific agent and an agentless method are not available. Some products also allow administrators to create custom agents to handle unsupported log sources.
There are advantages and disadvantages to each method. The primary advantage of the agentless approach is that agents do not need to be installed, configured, and maintained on each logging host. The primary disadvantage is the lack of filtering and aggregation at the individual host level, which can cause significantly larger amounts of data to be transferred over networks and increase the amount of time it takes to filter and analyze the logs. Another potential disadvantage of the agentless method is that the SIEM server may need credentials for authenticating to each logging host. In some cases, only one of the two methods is feasible; for example, there might be no way to remotely collect logs from a particular host without installing an agent onto it.
Rule Writing
One of the key issues to a successful SIEM implementation is the same issue you face with your firewall, IDS, and IPS implementations: how to capture useful and actionable information while reducing the amount of irrelevant data (noise) from the collection process. Moreover, you want to reduce the number of errors[md]false positives and false negatives[md]the SIEM system makes. To review these error types, see Chapter 3, “Vulnerability Management Activities.”
The key to reducing the amount of irrelevant data (noise) and the number of errors is to write rules that guide the system in making decisions. Rules are classified by the rule type. Some example rule types are
• Single event rule: If condition A happens, trigger an action.
• Many-to-one or one-to-many rules: If condition A happens, several scenarios are in play.
• Cause-and-effect rules: If condition A matches and leads to condition B, take an action. Example: “Password-guessing failure followed by successful login” type scenarios.
• Transitive rules or tracking rules: Here, the target in the first event (N malware infection) becomes the source in the second event (malware infection of another machine). This is typically used in worm/malware outbreak scenarios.
• Trending rules: Track several conditions over a time period, based on thresholds. This happens in DoS or DDoS scenarios.
Known-Bad Internet Protocol (IP)
Many SIEM solutions include the capability to recognize IP addresses and domain names from which malicious traffic has been sourced in the past. IP, URL, and domain reputation data is derived from the aggregated information of all the customers of the SIEM solution. The system then prioritizes response efforts by identifying known bad actors and infected sites.
This reputational data has another use as well. If your organization’s IP addresses or domains appear in a blacklist, a hacker forum, chances are that one or more of these systems have been compromised, and compromise of public systems like web servers can be just the tip of the iceberg, requiring further investigation.
Dashboard
SIEM products usually include support for several dozen types of log sources, such as OSs, security software, application servers (for example, web servers and e-mail servers), and even physical security control devices such as badge readers. For each supported log source type, except for generic formats such as Syslog, the SIEM products typically know how to categorize the most important logged fields. This significantly improves the normalization, analysis, and correlation of log data over that performed by software with a less granular understanding of specific log sources and formats. Also, the SIEM software can perform event reduction by disregarding data fields that are not significant to computer security, potentially reducing the SIEM software’s network bandwidth and data storage usage. Figure 11-19 shows output from a SIEM system. Notice the various types of events that have been recorded.
Figure 11-19 SIEM Output
The tool in Figure 11-19 shows the name or category within which each alert falls (Name column), the attacker’s address, if captured, the target IP address, and the priority of the alert (Priority column, denoted by color). Given this output, the suspicious FTP traffic (high priority) need to be investigated. While only three are shown on this page, if you look at the top-right corner, you can see that there are a total of 83 alerts with high priority, many of which are likely to be suspicious e-mail attachments.
The following are examples of product dashboards:
• ArcSight: ArcSight, owned by HP, sells SIEM systems that collect security log data from security technologies, operating systems, applications, and other log sources and analyze that data for signs of compromise, attacks, or other malicious activity. The solution comes in a number of models, based on the number of events the system can process per second and the number of devices supported. The selection of the model is important to ensure that the device is not overwhelmed trying to access the traffic. This solution also can generate compliance reports for HIPAA, SOX, and PCI DSS. For more information, see https://www.microfocus.com/en-us/products/siem-log-management/overview.
• QRadar: The IBM SIEM solution, QRadar, purports to help eliminate noise by applying advanced analytics to chain multiple incidents together and identify security offenses requiring action. Purchase also permits access to the IBM Security App Exchange for threat collaboration and management. For information, see https://www.ibm.com/security/security-intelligence/qradar.
• Splunk: Splunk is a SIEM system that can be deployed as a premises-based or cloud-based solution. The data it captures can be analyzed using searches written in Splunk Search Processing Language (SPL). Splunk uses machine-driven data imported by connectors or add-ons. For example, the Splunk add-on for Oracle Database allows a Splunk software administrator to collect and ingest data from an Oracle database server. See more at https://www.splunk.com/en_us/cyber-security.html.
• AlienVault/OSSIM: AlienVault (now AT&T Cybersecurity) produces both commercial and open source SIEM systems. Open Source Security Information Management (OSSIM) is the open source version, and the commercially available AlienVault Unified Security Management (USM) goes beyond traditional SIEM software with all-in-one security essentials and integrated threat intelligence. Figure 11-20 shows the Executive view of the AlienVault USM console. See more at https://cybersecurity.att.com/?utm_source=bing&utm_medium=cpc&utm_term=kwd-28340254695:loc-190&utm_campaign=140645415&source=EBPS0000000PSM00P&WT.srch=1&wtExtndSource=&wtpdsrchprg=AT%26T%20ABS&wtpdsrchgp=ABS_SEARCH&wtPaidSearchTerm=alienvault&wtpdsrchpcmt=alienvault&kid=kwd-28340254695:loc-190&cid=140645415&msclkid=b2f3090f87611f60019e57f75d673cfd&utm_source=bing&utm_medium=cpc&utm_campaign=ACS_BRAND-NA-MSN-SE&utm_term=alienvault&utm_content=AlienVault&gclid=CMjYvOeKpeoCFQpbgQodo70GlQ&gclsrc=ds.
Figure 11-20 AlienVault
Query Writing
Queries are simply questions formed and used to locate data that matches specific characteristics. Query writing is the process of forming a query that locates the information for which you are looking. Properly formed queries can help you to locate the security needle in the haystack when it comes to analyzing log data. We’ve already discussed the vast amount of information that can be collected by SIEM and other types of systems.
Sigma is an open standard for writing rules that allow you to describe searches on log data in generic form. These rules can be converted and applied to many log management or SIEM systems and can even be used with grep on the command line. The following is an example of a rule written using Sigma. The rule is named sigmac and its target is splunk. It’s looking for an event with an ID of 11.
$ python3 sigmac -t splunk ../rules/windows/sysmon/sysmon_quarkspw_filedump.yml (EventID="11" TargetFileName="*AppDataLocalTempSAM-*.dmp*")
String Search
String searches are used to look within a log file or data stream and locate any instances of that string. A string can be any combination of letters, numbers, and other characters. String searches are used to locate malware and to locate strings that are used in attacks or typically accompany an attack.
String searches can be performed by using either search algorithms or regular expressions, but many audit tools such as SIEM (and many sniffers as well) offer GUI tools that allow you to form the search by choosing from options. Figure 11-21 shows a simple search formed in Splunk to filter out all but items including either of two strings, visudo or usermod.
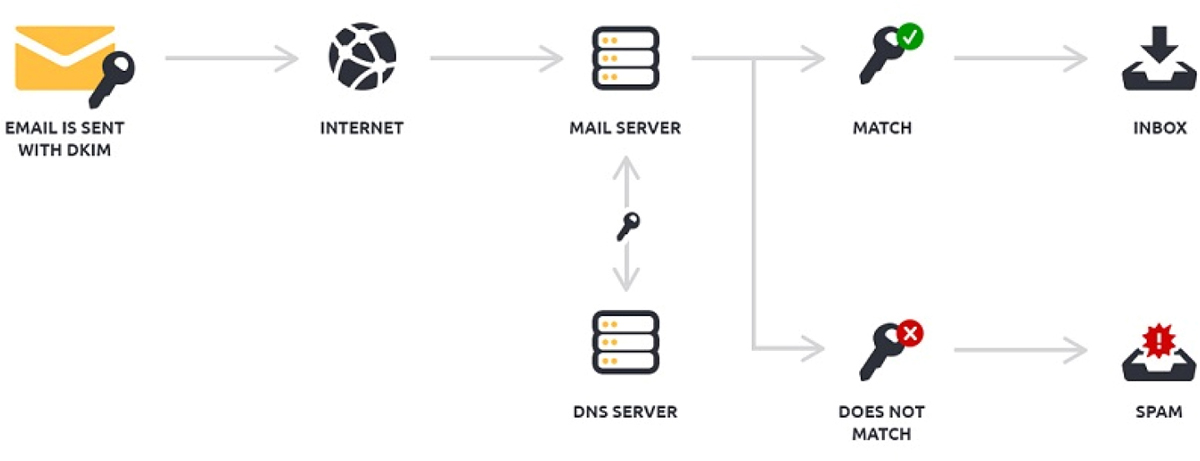
Figure 11-21 String Search in Splunk
Script
Scripts can be used to combine and orchestrate functions or to automate responses. A simple example is the following script that tests for the presence of lowercase letters in passwords and responds when no lowercase letter is present:
chop=$(echo "$password" | sed -E 's/[[:lower:]]//g') echo "chopped to $chop" if [ "$password" == "$chop" ] ; then echo "Fail: You haven't used any lowercase letters." Fi
Piping
Piping is the process of sending the output of one function to another function as its input. Piping is used in scripting to link together functions and orchestrate their operation. The symbol | denotes a pipe. For example, in the following Linux command, by piping the output of the cat filename command to the less command, the less command alters the display of the output:
cat filename | less
Normally the output would be displayed scrolled all the way to the end of the file. The less command prevents that from occurring.
Anther use of piping is to search for a set of items and then use a second function to search within that set or to perform some process on that output.
E-mail Analysis
One of the most popular avenues for attacks is a tool we all must use every day, e-mail. This section covers several attacks that use e-mail as the vehicle. In most cases the best way to prevent these attacks is user training and awareness, because many of these attacks are based upon poor security practices on the part of the user. Email analysis is a part of security monitoring.
E-mail Spoofing
E-mail spoofing is the process of sending an e-mail that appears to come from one source when it really comes from another. It is made possible by altering the fields of e-mail headers such as From, Return Path, and Reply-to. Its purpose is to convince the receiver to trust the message and reply to it with some sensitive information that the receiver would not have shared unless it was a trusted message.
Often this is one step in an attack designed to harvest usernames and passwords for banking or financial sites. This attack can be mitigated in several ways. One is SMTP authentication, which when enabled, disallows the sending of an e-mail by a user that cannot authenticate with the sending server.
Malicious Payload
E-mail is a frequent carrier of malware; in fact, e-mail is the most common vehicle for infecting computers with malware. You should employ malware scanning software on both the client machines and the e-mail server. Despite taking this measure, malware can still get through, and it is imperative to educate users to follow safe e-mail handling procedures (such as not opening attachments from unknown sources). Training users is critical.
DomainKeys Identified Mail (DKIM)
DomainKeys Identified Mail (DKIM) allows you to verify the source of an e-mail. It provides a method for validating a domain name identity that is associated with a message through cryptographic authentication. Figure 11-22 shows the process. As you can see, the e-mail server verifies the domain name (actually what’s called the DKIM signature) with the DNS server first before delivering the e-mail.

Figure 11-22 DKIM Process
Sender Policy Framework (SPF)
Another possible mitigation technique is to implement a Sender Policy Framework (SPF). An SPF is an e-mail validation system that works by using DNS to determine whether an e-mail sent by someone has been sent by a host sanctioned by that domain’s administrator. If it can’t be validated, it is not delivered to the recipient’s box.
Domain-based Message Authentication, Reporting, and Conformance (DMARC)
Domain-based Message Authentication, Reporting, and Conformance (DMARC) is an e-mail authentication and reporting protocol that improves e-mail security within federal agencies. All federal agencies are required to implement this standard, which improves e-mail security. Protocols (SPF, DKIM) authenticate e-mails to ensure they are coming from a valid source. A DMARC policy allows a sender’s domain to indicate that its e-mails are protected by SPF and/or DKIM, and tells a receiver what to do if neither of those authentication methods passes[md]such as to reject the message or quarantine it. Figure 11-23 illustrates a workflow whereby DMARC implements both SPF and DKIM, along with a virus filter.

Figure 11-23 DMARC
Phishing
Phishing is a social engineering attack in which attackers try to learn personal information, including credit card information and financial data. This type of attack is usually carried out by implementing a fake website that very closely resembles a legitimate website. Users enter data, including credentials, on the fake website, allowing the attackers to capture any information entered.
As a part of assessing your environment, you should send out phishing e-mails to assess the willing ness of your users to respond. A high number of successes indicates that users need training to prevent successful phishing attacks.
Spear Phishing
Spear phishing is the process of foisting a phishing attack on a specific person rather than a random set of people. The attack might be made more convincing by learning details about the person through social media that the e-mail might reference to boost its appearance of legitimacy. Spear phishing is carried out against a specific target by learning about the target’s habits and likes. Spear phishing attacks take longer to carry out than phishing attacks because of the information that must be gathered.
Whaling
Just as spear phishing is a subset of phishing, whaling is a subset of spear phishing. It targets a single person, and in the case of whaling, that person is someone of significance or importance. It might be a CEO, COO, or CTO, for example. The attack is based on the assumption that these people have more sensitive information to divulge.
Note
Pharming is similar to phishing, but pharming actually pollutes the contents of a computer’s DNS cache so that requests to a legitimate site are actually routed to an alternate site.
Caution users against using any links embedded in e-mail messages, even if a message appears to have come from a legitimate entity. Users should also review the address bar any time they access a site where their personal information is required, to ensure that the site is correct and that SSL/TLS is being used, which is indicated by an HTTPS designation at the beginning of the URL address.
Forwarding
No one enjoys the way our e-mail boxes fill every day with unsolicited e-mails, usually trying to sell us something. In many cases we cause ourselves to receive this e-mail by not paying close attention to all the details when we buy something or visit a site. When e-mail is sent out on a mass basis that is not requested, it is called spam.
Spam is more than an annoyance because it can clog e-mail boxes and cause e-mail servers to spend resources delivering it. Sending spam is illegal, so many spammers try to hide the source of the spam by relaying or forwarding through other corporations’ e-mail servers. Not only does this practice hide the e-mail’s true source, but it can cause the relaying company to get in trouble.
Today’s e-mail servers have the ability to deny relaying to any e-mail servers that you do not specify. This can prevent your e-mail system from being used as a spamming mechanism. This type of relaying should be disallowed on your e-mail servers. In addition, spam filters can be implemented on personal e-mail, such as web-based e-mail clients.
Digital Signature
A digital signature added to an e-mail is a hash value encrypted with the sender’s private key. A digital signature provides authentication, non-repudiation, and integrity. A blind signature is a form of digital signature where the contents of the message are masked before it is signed. The process for creating a digital signature is as follows:
1. The signer obtains a hash value for the data to be signed.
2. The signer encrypts the hash value using her private key.
3. The signer attaches the encrypted hash and a copy of her public key in a certificate to the data and sends the message to the receiver.
The process for verifying the digital signature is as follows:
1. The receiver separates the data, encrypted hash, and certificate.
2. The receiver obtains the hash value of the data.
3. The receiver verifies that the public key is still valid by using the PKI.
4. The receiver decrypts the encrypted hash value using the public key.
5. The receiver compares the two hash values. If the values are the same, the message has not been changed.
Public key cryptography, discussed in Chapter 8, “Security Solutions for Infrastructure Management,” is used to create digital signatures. Users register their public keys with a certificate authority (CA), which distributes a certificate containing the user’s public key and the CA’s digital signature. The digital signature is computed by the user’s public key and validity period being combined with the certificate issuer and digital signature algorithm identifier.
The Digital Signature Standard (DSS) is a U.S. federal government digital security standard that governs the Digital Security Algorithm (DSA). DSA generates a message digest of 160 bits. The U.S. federal government requires the use of DSA, RSA, or Elliptic Curve DSA (ECDSA) and SHA for digital signatures. DSA is slower than RSA and provides only digital signatures. RSA provides digital signatures, encryption, and secure symmetric key distribution. In a review of cryptography, keep the following facts in mind:
• Encryption provides confidentiality.
• Hashing provides integrity.
• Digital signatures provide authentication, non-repudiation, and integrity.
E-mail Signature Block
An e-mail signature block is a set of information, such as name, e-mail address, company title, and credentials, that usually appears at the end of an e-mail. Many organizations choose to determine the layout of the signature block and its contents to achieve consistency in how the company appears to the outside world. Another reason for this, however, is to prevent the disclosure of information that could be used at some point in time for an attack.
It is also important to control what users can put in these signature blocks to ensure that users do not inadvertently create a legal obligation on the part of the organization.
Embedded Links
Many times, e-mails are received that have embedded links in them. These links may appear to lead to one site based on the text you see on the page but if you scroll over the link (revealing what is called an embedded link) the actual site to which you will be directed will be shown and they may be completely different. There’s not much you can do to prevent users from clicking on these links other than train them to review the embedded links in e-mails before accessing them.
Impersonation
Impersonation is the process of acting as another entity and is done to gain unauthorized access to resources or networks. It can be done by adopting another’s IP address, MAC address, or user account. It can also be done at the e-mail level. E-mail can be spoofed by altering the SMTP header of the e-mail. This allows the e-mail to appear to come from another source.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have several choices for exam preparation: the exercises here, Chapter 22, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep Software Online.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 11-8 lists a reference of these key topics and the page numbers on which each is found.
Table 11-8 Key Topics in Chapter 11
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
denial-of-service (DoS) attack
user and entity behavior analytics (UEBA)
domain generation algorithm (DGA)
web application firewall (WAF)
intrusion detection system (IDS)
intrusion prevention system (IPS)
security information and event management (SIEM)
DomainKeys Identified Mail (DKIM)
Domain-based Message Authentication Reporting and Conformance (DMARC)
Review Questions
1. ActiveX, Java, and JavaScript are examples of _______________.
2. List and define at least two types of viruses.
3. Match the following terms with their definitions.
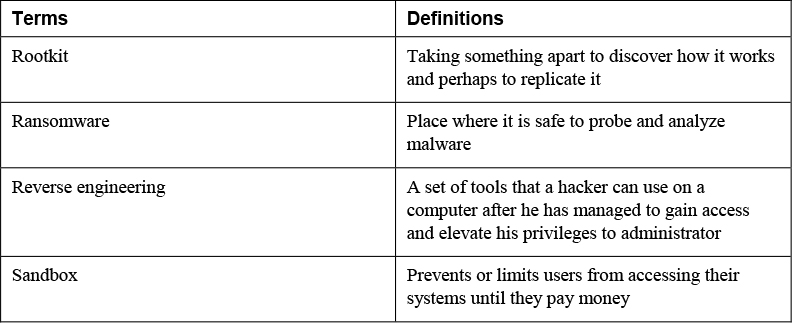
4. ____________________ is a partition designated as security-sensitive.
5. List and define at least two forms of social engineering.
6. Match the following terms with their definitions.
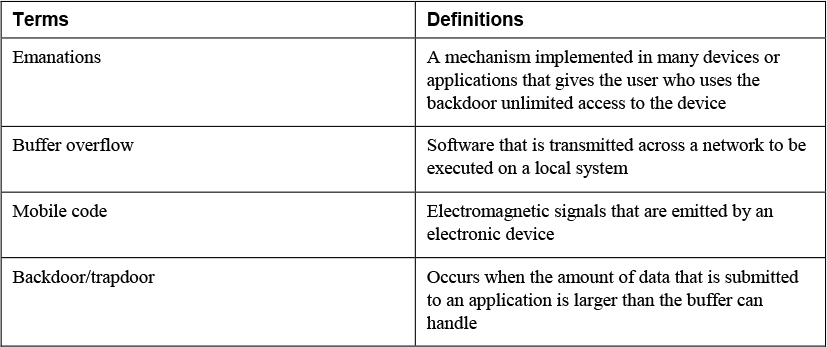
7. ______________________________ is a technology developed by Cisco that is supported by all major vendors and can be used to collect and subsequently export IP traffic accounting information.
8. List at least two parts of a Syslog message.
9. Match the following terms with their definitions.
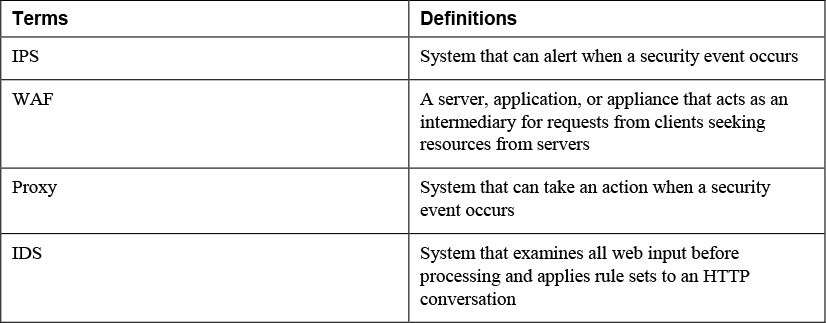
10. ______________________ enables you to verify the source of an e-mail.