
Chapter 13
Implementing Cybersecurity Resilience
This chapter covers the following topics related to Objective 2.5 (Given a scenario, implement cybersecurity resilience) of the CompTIA Security+ SY0-601 certification exam:
Redundancy
Geographic dispersal
Disk
Redundant array of inexpensive disks (RAID) levels
Multipath
Network
Load balancers
Network interface card (NIC) teaming
Power
Uninterruptible power supply (UPS)
Generator
Dual supply
Managed power distribution units (PDUs)
Replication
Storage area network
VM
On-premises vs. cloud
Backup types
Full
Incremental
Snapshot
Differential
Tape
Disk
Copy
Network-attached storage (NAS)
Storage area network (SAN)
Cloud
Image
Online vs. offline
Offsite storage
Distance considerations
Non-persistence
Revert to known state
Last known-good configuration
Live boot media
High availability
Scalability
Restoration order
Diversity
Technologies
Vendors
Crypto
Controls
Cybersecurity resilience is the capability of an organization to prepare, respond, and recover when cyber attacks happen. An organization has cybersecurity resilience when it can defend itself against these attacks, limit the effects of a security incident, and guarantee the continuity of its operation during and after the attacks. Organizations today are beginning to complement their cybersecurity strategies with cyber resilience. Although the main aim of cybersecurity is to protect information technology and systems, cyber resilience focuses more on making sure the business is delivered.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz enables you to assess whether you should read this entire chapter thoroughly or jump to the “Chapter Review Activities” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 13-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 13-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions |
|---|---|
Redundancy |
1–5 |
Replication |
6 |
On-premises vs. Cloud |
7 |
Backup Types |
8 |
Non-persistence |
9 |
High Availability |
10 |
Restoration Order |
11 |
Diversity |
12 |
Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you correctly guess skews your self-assessment results and might provide you with a false sense of security.
1. Which of the following is one of the primary goals of geographic dispersal of data and data processing?
Ensuring availability of data in the event of a disaster or regional issue, such as power outage
Reducing the cost of acquiring computer systems, servers, network infrastructure, and software used for information security
Ensuring the application infrastructure does not affect the underlying network
All of these answers are correct.
2. Which of the following describes the disk redundancy method of RAID 5?
It uses more hard disks and stripes data and parity over all hard disks.
It is a parity hard disk proportional to the log of HDD numbers.
It is a JBOD, otherwise known as just a bunch of drives.
It duplicates data from one hard disk to another; typically, it is two hard disks set up to copy data to both disks.
3. Which hard disk resilience mechanism uses two hard disks to provide redundancy and copies everything to both hard disks?
RAID 0
RAID 3
RAID 6
RAID 10
4. When a network interface card fails in a server, a secondary NIC continues transmitting traffic uninterrupted. What mechanism allows this feature to operate?
Redundant NIC
NIC teaming
NIC failover
Mirrored NIC
5. Which high-availability power mechanism provides an additional power supply that can share or split the power load?
Redundant supervisor modules
Redundant power supplies
Dual hard disks
RAID 5 power sources
6. SAN-connected servers utilize a special fiber interface card called what?
Network interface card (NIC)
Host bus adapter (HBA)
Storage area network device (SAND)
Data beam fiber (DBF) card
7. You can host services in your own data center or in the cloud. What is considered a cloud-based service?
Azure Active Directory (AD)
Novell NDS Services
Outlook 2010
Data Center Hosted SAP
8. Which backup method provides connected backup storage anywhere in the world with private/public remote storage?
Incremental offline
Intermittent even days
Local backup session
Cloud-based backup
Tape backup to mainframe
9. You can now back up your organization’s critical data to the cloud, including all your desktop computers and servers. What is one downside to hosting all your backups in the cloud?
Restoral is available only during the work week.
They require a special VPN connection to each device.
Accessing them may be slow depending on your Internet connection.
Backups are rotated every 30 days.
10. What is the uptime measurement of available time for a highly available system, knowing that no system can be up forever?
95.99 percent
100 percent
90 percent
99.999 percent
11. Your company just had a catastrophic failure, and the entire data center and campus are down. After you establish your chain of command, what is the first service or system you need to bring up in order to start recovery?
Video telecom VTC systems and bridges
Desktop computers in network operations center
Active Directory and LDAP to authorized users
Network connectivity
12. An organization can add many levels of diversity to enhance its systems and network resilience. Which components will help? (Select all that apply.)
Redundant Pathed Facility Power
Network interface card (NIC) teaming
Supplier and supply chain contracts
Security cameras at all junctions
Foundation Topics
Redundancy
When systems are not designed or configured with redundancy in mind, a single point of failure can bring an entire company to its knees. High availability is provided through redundant systems and fault tolerance. If the primary method used to store data, transfer information, or perform other operations fails, then a secondary method is used to continue providing services. Redundancy ensures that systems are always available in one way or another, and with minimal downtime. Several key elements are used in the redundancy process:
Geographical dispersal: Placing valuable data assets around the city, state, country, or world can provide an extra level of protection.
Disk redundancy: Various levels of disk redundancy exist to reduce data loss from disk failure.
Network redundancy: Networks deliver data to users during component failures.
Power: Power resilience provides power via multiple sources.
Geographic Dispersal
We live in a connected world, with employees, contractors, servers, data, and connected resources dispersed throughout the world. This dispersal is essential for a company with a global presence (marketing); it also lends itself to resilience. Local issues are likely to be isolated, allowing the rest of the workforce to continue operating as normal. Companies that have workforces dispersed in remote locations throughout the world have adopted and learned to utilize technology to connect people and resources. To implement geographical dispersal within your company for compute resources, you can set up a computing environment, such as a data center or resource center, in another location at least fifty miles away from the main compute campus, data center. You also should consider placing resources closer to groups of users who might be in another city or country. By way of a wide-area network, you can configure resources that are local to the users to respond first, thereby providing resilience and resource dispersal.
Disk Redundancy
Disk redundancy is simply writing data to two or more disks at the same time. Having the same data stored on separate disks enables you to recover the data in the event of a disk failure without resorting to expensive or time-consuming data recovery techniques. Implementing disk redundancy starts with selecting the appropriate level of RAID and a controller that is capable of performing RAID functions at various levels. Newer servers have RAID-capable controllers, thus allowing you to develop a RAID strategy and implement the appropriate level of RAID.
Redundant Array of Inexpensive Disks
Redundant Array of Inexpensive Disks (RAID) 1 and RAID 5 are the most common approaches to disk redundancy. RAID is a group of disks or solid-state drives (SSDs) that increases performance or provides fault tolerance or both. RAID uses two or more physical drives and a RAID controller, which is plugged into a motherboard that does not have RAID circuits. Today, most motherboards have built-in RAID, but not necessarily every RAID level of configuration is available. In the past, RAID was also accomplished through software only, but was much slower. Table 13-2 lists a few of the most common levels of RAID and their safeguards, configurations, and protections. Implementing the appropriate RAID level begins with an overall corporate strategy.
Table 13-2 Common RAID Levels and Characteristics
Raid Level |
Description |
Data Reliability/Speed |
Protection |
|---|---|---|---|
0—Striping |
Disk striping; divides data across a set of hard disks. |
Is lower than a single disk; enables writes and reads to be done more quickly. |
Very low; if a disk fails, you could lose all your data. |
1—Mirroring |
Duplicates data from one hard disk to another, typically two hard disks. |
Provides redundancy of all data because it is duplicated; is much slower. |
A complete copy of data is on both hard disks. |
5—Striping with parity |
Uses more hard disks and stripes data and parity over all hard disks. |
Provides higher performance; quickly writes data to all disks. |
Data is protected by the parity writes. |
6—Striping with dual parity |
Similar to RAID 5; includes a second parity distributed across hard disks. |
Provides slower storage system performance; provides best protection. |
Dual parity protects against loss of two hard disks. |
10—Mirroring a striped set of disks |
Similar to RAID 1 and RAID 0 where you start with a striped set of disks and then mirror them. |
Provides higher performance and fault tolerance than other RAID levels. |
It requires more disks. |
Tip
To obtain more data on RAID, see https://datatracker.ietf.org/wg/raidmib/about/.
RAID 0 Striping
RAID 0 striping provides no fault tolerance or redundancy; the failure of one drive will cause the entire array to fail. As a result of having data striped across x number of disks, the failure will be a total loss of data. RAID 0 is normally used to increase performance and provide additional space (larger than a single drive) because RAID 0 appears as a single disk to the user. To implement RAID 0, you need to boot your computer to the BIOS and look for Disks and Settings for RAID (see Figure 13-1). There, you select the RAID level. In the example shown here, the ASUS motherboard has a built-in RAID controller like most modern motherboards do (see Figure 13-2). In this case, you select Create a RAID Volume, enter the name of the RAID set, select the RAID level, and select the disks to be part of the RAID set. Then you select Create Volume. Be warned that this will delete all data on all disks.
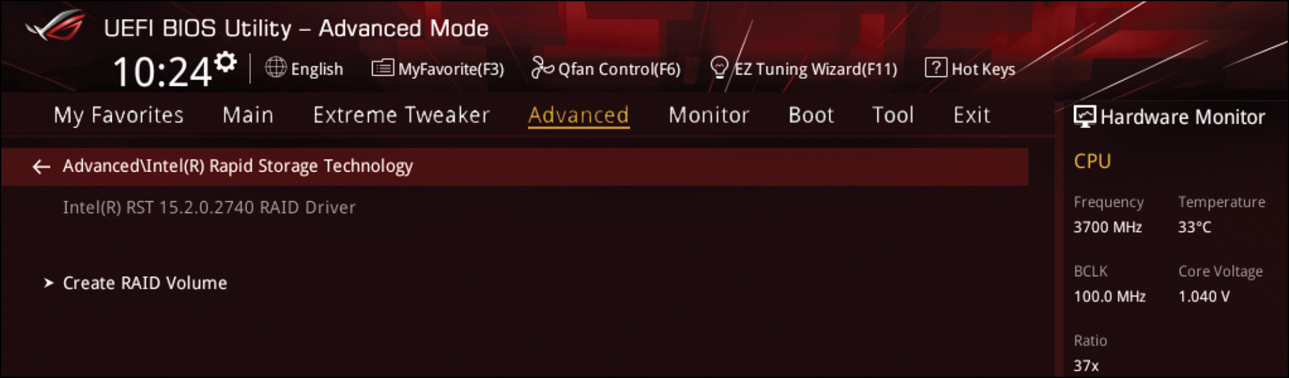
FIGURE 13-1 Bios RAID Controller
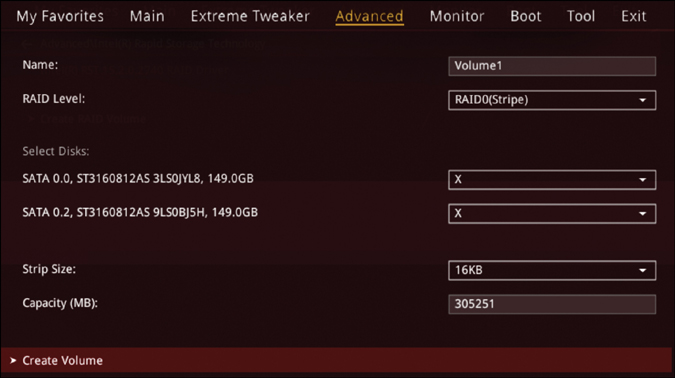
FIGURE 13-2 Creating a Volume
Your motherboard might be different. In fact, different ASUS models are slightly different in layout and configuration, but the steps are virtually the same.
RAID 1—Mirror
RAID 1—Mirror is exactly that—one or more disks with an additional disk to act as a mirror image for each disk. A classic RAID 1 mirrored disk pair contains two disks. The configuration offers no striping, no parity, and no spanning disks across multiple sets. Because all disks are mirrored, you need to match disk sizes to obtain the most benefit. The smallest disk in a mirror set is the largest the array can be. The performance of the RAID 1 array depends on the drive array, controller, slowest disk speed, and I/O load. Typically, you will see slightly slower speeds than a single drive. To configure RAID 1, you follow the steps described for Figure 13-1 and Figure 13-2, and select RAID 1 Mirror for the RAID level.
RAID 5—Striping with Parity
RAID 5—Striping with Parity consists of block-level striping with distributed parity among all drives. RAID 5 requires at least three disks and can suffer only a single drive failure before data becomes corrupted. The disk parity can be distributed in three different ways; only more expensive controllers allow you to select which method. The default sequence of data blocks is written left to right or right to left on the disk array of disks 0–X, also called Left Asynchronous RAID 5. Performance of RAID 5 is increased because all RAID members participate in the servicing of write requests. To configure and implement RAID 5, you follow the steps outlined for Figure 13-1 and Figure 13-2 and select RAID 5 Striping with Parity for the RAID level, of course taking into account your specific motherboard capabilities.
RAID 6—Striping with Double Parity
RAID 6—Striping with Double Parity consists of block-level striping with two parity blocks distributed across all member disks. Similar to RAID 5, there are different capabilities for how data is striped over the disk. None of them provide any greater performance over the other, and RAID 6 takes a performance penalty during read operations but is similar in the write speeds. You can suffer the loss of two disks using RAID 6 and still remain operational. To configure RAID 6, you follow the steps outlined for Figure 13-1 and Figure 13-2 and select RAID 6 for the RAID level. Also, note that higher-end server motherboards and controllers typically only have this RAID level capability.
RAID 10—Stripe and Mirror
RAID 10—Stripe and Mirror is the combination of creating a stripe and then mirroring it. RAID 10 is often called RAID 1 + 0 and array of mirrors, which may be two- or three-way mirrors. This configuration requires a minimum of four drives, and performance-wise it beats all RAID levels with better throughput and lower latency, except for RAID 0. To configure RAID 10, you need to consult your server manufacturer’s guide on creating RAID 10 arrays.
Multipath
Storage multipath involves the establishment of multiple physical routes; for example, multipath I/O defines more than one physical path between the CPU in a computer and its mass-storage devices through the buses, controllers, and bridge devices connecting them. Storage area networks (SANs), covered later in this chapter, are primary examples of storage multipaths. When building a SAN, you create two paths from the server to the SAN switch, providing control from the SAN switch to the storage controller all the way to the disk.
Network Resilience
Network resilience involves more than just redundancy; it enables service operations in the face of outages, faults, and challenges. Threats and challenges for services can range from simple misconfiguration to large-scale natural disasters to targeted attacks. Network availability can be handled from multiple network cards, load balancers, and redundant network hardware. You can implement network resilience in multiple ways, as mentioned previously, such as having multiple network cards in each server, using load balancers to offload traffic to hosts that are less busy, and adding in layers of redundant networking components like switches and routers that are configured in high-availability configurations.
Load Balancers
There are several types of load balancers. Network load balancers automatically distribute incoming traffic across multiple network paths. This capability increases the availability of your network during component outages, misconfigurations, attacks, and hardware failures. Most network load balancers utilize routing protocols to help make path decisions during a network overload or network failure. A load balancer spreads out the network load to various switches, routers, and servers. Server load balancers distribute the traffic load based on specific selected algorithms to each of the servers in a group. Load balancers are typically placed in front of a group of servers to evenly distribute the load among them.
In network load balancing, when a router learns multiple routes to a specific network via routing protocols such as RIP, EIGRP, and OSPF, it installs the route with the lowest administrative distance in the routing table. If the router receives and installs multiple paths with the same administrative distance and cost to a destination, load balancing of network traffic will occur.
To mitigate risks associated with failures of load balancers themselves, you can deploy two servers in an active/active or active/passive configuration. In active/active, traffic is split between the two servers typically in a round-robin fashion. In active/passive configuration, all traffic is sent to the active server, and the passive server is automatically promoted to active status if the current active server fails or is taken down for maintenance.
Network Interface Card (NIC) Teaming
Network interface card (NIC) teaming allows you to group server network cards to increase throughput, improve performance, and provide path diversity and fault tolerance in the event of a single network adapter, cable, or path failure. NIC teaming is typically done via the system’s motherboard/supervisor or via the cards themselves. Note that software NIC teaming is extremely inefficient and is generally not used any longer. NIC teaming allows a NIC to be grouped with multiple physical NICs, forming a logical network device known as a bond. This bond provides for fault tolerance and load balancing. To implement NIC teaming, typically the server motherboard with built-in NIC cards has a separate utility to configure the specific capability and mode.
Power Resilience
Power resilience is about ensuring a business, data center, or system has a reliable, regular supply of energy and contingency measures in place in the event of a power failure or fluctuations. Faults can include power surges, weather, natural disasters, accidents, and equipment failure.
Uninterruptible Power Supply (UPS)
An uninterruptible power supply or uninterruptible power source (UPS) is an electrical device that provides emergency power to a load when the input power source or main power fails. A UPS differs from an auxiliary or emergency power system or standby generator in that it will provide near-instantaneous protection from input power interruptions by supplying energy stored in batteries or supercapacitors. A UPS will allow you enough time to properly and safely power down equipment until power is fully restored. A UPS has a limited run time due to the storage capability of batteries and is meant to be a temporary solution—in most cases, enough time to properly shut down resources. Some newer UPSs and servers are aware of each other, and when power fails, a signal is sent to the server asking it to properly shut down.
Note
UPSs are used to protect electronic equipment and provide immediate emergency power in case of complete power failure.
Generators
A generator provides power to spaces and devices during complete power loss, blackouts, or in areas where standard electrical service isn’t available. Generators range from 800 watts to over 500,000 watts, and there are different types of generators for every deployment requirement. Generators convert mechanical or chemical energy into electrical energy. They do this by capturing the power of motion and turning it into electrical energy by forcing electrons from the external source through an electrical circuit. The formula to figure out your required size generator is (Running wattage × 3) + Starting wattage = Total wattage needed. As mentioned previously, implementing a corporate generator strategy requires preplanning, sizing and capacity planning, and ensuring you build a sufficient platform to house the generators, fuel supply, and power transfer equipment.
Dual Supply
Dual supply is often confused with dual power supplies, where two power supplies are provided to a device, such as a server. For example, two power supplies with a single source provide power potential to the server, usually from a single “main circuit.” If one power supply fails, the other power supply continues to provide power. Dual supply power is more complicated. Most facilities receive power from a single power company, single supply path, and single substation. For a substantial price, a company can request a design and buildout of a two-pathed independent power source solution. Dual supply power provides the ultimate in protection from power outages, and rarely fails. Figure 13-3 shows how dual supply power can provide resilience. Depending on the distance, one or two substations can provide power to the facility.
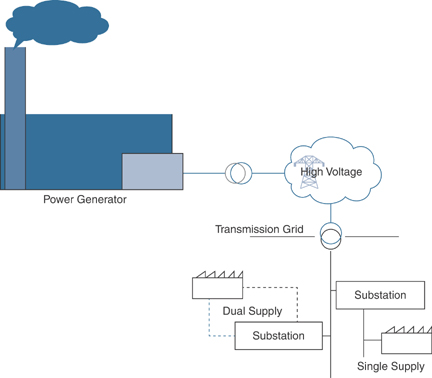
FIGURE 13-3 Resilience Through Dual Supply Power
Dual supply power mitigates the failure of a single substation or power feed that might be susceptible to a car hitting a light pole or a backhoe digging up a power cable.
Managed Power Distribution Units (PDUs)
A managed power distribution unit (PDU) is essentially a power strip with multiple outputs designed to distribute electric power to critical equipment. It is specifically designed to deliver power to racks of computers and networking equipment located within a data center. Certain PDUs have features that allow them to take power from two different power sources, known as A power and B power. Data centers face challenges in power consumption, protection, and management solutions, but PDUs provide monitoring capabilities to improve efficiency, uptime, and growth. There are two main categories of PDUs: basic PDUs and intelligent (networked) PDUs (or iPDUs). Intelligent PDUs normally have an intelligence module that allows them to be remotely managed and monitored, such as the ability to view power metering information, power outlet on/off control, alarms, and sensors and to improve the power quality and provide load balancing.
Replication
When systems are not designed or configured with redundancy in mind, they create a single point of failure; nowadays, many components of the modern data center provide capabilities that allow for replication, from storage area networks to virtual machines (VMs) that support those systems.
Storage Area Network
Storage area networks (SANs) are the most common storage networking architecture used by enterprises for business-critical applications that need to deliver high throughput and low latency. By storing data in centralized shared storage, SANs enable organizations to apply consistent methodologies and tools for security, data protection, and disaster recovery.
SANs are designed to remove single points of failure, making them highly available and resilient. A well-designed SAN can easily withstand multiple component or device failures. SAN-to-SAN replication (or synchronization) provides a fast no-impact high-performance backup of your all the data.
With replication, you could have a SAN in one data center; then you could send data to another SAN in a different data center location. You can back up very large volumes of data very quickly using SAN technology, and you can also transfer that data to a secondary location independently of your snapshot schedule. This approach is more efficient because traditional backup windows can take a very long time and impact the performance of your system. When everything is kept on the SAN, backups can be done very fast, and data can be copied in the background, so it’s not impacting the performance of your systems. Figure 13-4 shows how a SAN accomplishes its high availability with dual paths.

FIGURE 13-4 Storage Area Network
In Figure 13-4, SAN-connected servers contain special fiber interface cards called host bus adapters (HBAs) that are configured as HBA1 and HBA2. The fiber is then connected to a SAN switch, which in turn connects to a SAN storage array. These two paths ensure diverse and high-availability paths to the server and the SAN storage.
Virtual Machines
A virtual machine (VM) is a computer file, typically called an image, that behaves like an actual computer. It runs in a window, much like any other program, giving end users the same experience on a virtual machine as they would have on the host operating system itself. The virtual machine is sandboxed from the rest of the system, meaning that the software inside a virtual machine can’t escape or tamper with the computer itself. Multiple virtual machines can run simultaneously on the same physical computer, typically a server. For servers, the multiple operating systems run side by side with a piece of software called a hypervisor to manage them.
Each virtual machine provides its own “abstracted” virtual hardware, including CPUs, memory, hard drives, network interfaces, and other devices. The virtual hardware is then mapped to the real hardware on the physical machine, which saves costs by reducing the need for physical hardware systems, along with the associated maintenance costs, and reduces power and cooling demand.
To ensure the availability of your virtual machines, you can enable replication. Several different types of VM replication give you different restore points, including a near real-time VM replication option that immediately copies the data as it is being written to the VM, giving you a close-to-exact copy of the VM in near real-time. A more point-in-time replication option occurs on a scheduled basis. For example, if you replicate your VM once an hour, you can either have it automatically start when the protected VM fails or manually start when you want it to be turned on. Typically, you configure replication between data centers and the “vmotion,” a virtual machine from one physical system to another system in the secondary data center.
Tip
A hypervisor controls the virtual machines much like the supervisor of a switch: It controls distribution of the abstracted devices of a VM.
On-premises vs. Cloud
On-premises or cloud-based vulnerabilities will follow poorly configured and deployed assets from servers to networking equipment. If shortcuts are taken and best practices are not followed, your company may experience a cyber attack that will affect your equipment no matter where it lives. On-premises and cloud-based are simply terms that describe where systems store data. Many of the same vulnerabilities that affect on-premises systems also affect cloud-based systems.
On-premises redundancy provides rapid recovery from small and localized events, such as a server failure, rack failure, or single-source power failure. However, when more catastrophic events occur, on-premises recovery can take an extremely long time. Locating and replacing damaged equipment and locating operational space to stage a recovery add to the delayed recovery of the company’s business operations.
Cloud-based redundancy allows the enterprise to recover in a moderate to rapid manner, depending on the deployment of resources. For example, if the company’s users are all stored or managed in a cloud-based directory service like Azure Active Directory (AD), recovery of users and rights to local assets can take place more quickly. If the company’s primary assets are mostly cloud based, such as email, databases, and enterprise resource planning (ERP), then the outage is rather confined. In this case, the company need only move to a suitable facility and connect its users to the cloud or have employees work from home.
Cloud-based failures could extend the company’s recovery times by days, if not weeks; therefore, it is prudent for the company to regularly back up its cloud-based assets. But there is never any guarantee that a specific cloud provider will be around tomorrow.
Backup Types
There is nothing more important to an organization than its data. Without it, most companies would cease to exist. If a company does not take proper precautions to back up its data and that data is damaged or destroyed, the company may no longer be able to operate. Backing up critical data is one of the highest priorities a company can undertake. Table 13-3 displays the backup types and how they provide protection. The most common types are full backup, differential, and incremental. A company only having backups in the cloud puts those backups at risk if the provider has geographical outages or goes out of business; or if the provider gets compromised, the backups could be transferred to the attacker and ransomed or deleted/destroyed.
Table 13-3 Backup Type Benefits and Drawbacks
Type |
Benefits |
Drawbacks |
|---|---|---|
Full |
Provides full copy of data set. Provides the best protection. |
Time-consuming to restore. Requires lots of storage. |
Incremental |
Takes less time and storage space. |
Time-consuming to restore. Requires all backups in the backup chain to restore. |
Snapshot |
Creates fast backups of specific times. |
May take more space to restore each snapshot in order. |
Differential |
Takes a shorter restore time than incremental. |
Can grow to be much bigger in size than incremental. |
Tape |
Offers the best protection for catastrophic disasters if proper rotation and offsite storage are employed. |
Is costly, very slow to recover and restore; requires specific order. |
Disk |
Provides one of the fastest and most complete backup and restore capabilities. |
Is costly. |
Copy |
Provides quick backup. |
Doesn’t copy in-use files; not complete. |
Is PC connected or network connected and shared among many; provides readily available storage. |
Is very slow, reliant on the connected PC and/or the network speed and availability. |
|
Cloud |
Provides connected backup storage anywhere in the world with private/public cloud storage. |
Is slow to back up, slow to restore, and dependent on network availability. |
Image |
Provides the most complete type of backup, including the entire operating system and all other files. Can be directly connected, NAS, SAN, or cloud based. |
Requires a large amount of storage. |
Online storage is readily available, whereas offline storage provides safety from potential hackers and viruses. |
Online backups and storage are costly. Offline storage requires physically connecting or turning on specific devices. |
|
Is typically rotated because tapes are stored in an offsite facility. |
Can delay the recovery process. |
|
Distance considerations |
Provides geographical diversity if backed up over long distances. |
Can take a long time to recover backups that are located geographically far away, depending on bandwidth and facility availability. |
When you’re backing up data to the cloud, a large concern is who owns the data, what privacy laws and regulations apply, and whether data is stored across borders.
Figure 13-5 illustrates the most common backup types, which are further described in the sections that follow.
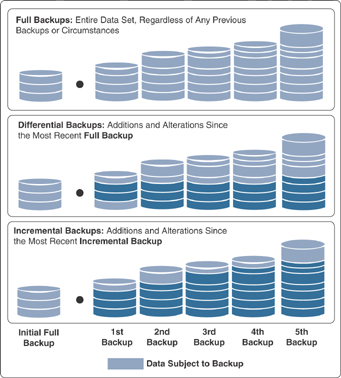
FIGURE 13-5 Backup Types
Full Backup
A full backup is the most complete type of backup where you make a complete copy of all the selected data. This includes files, folders, applications, hard drives, and more. The highlight of a full backup is the minimal time required to restore data; however, because everything is backed up at one time, it takes longer to back up compared to other types of backups. Most businesses tend to run a full backup and occasionally follow it up with a differential or incremental backup. This approach reduces the burden on the storage space, increasing backup speed.
Differential Backup
A differential backup is in between a full and an incremental backup. This type of backup involves backing up data that was created or changed since the last full backup. A full backup is done initially, and then subsequent backups are run to include all the changes made to the files and folders. It lets you restore data faster than a full backup because it requires only two backup components: the initial full backup and the latest differential backup.
A differential backup works like this:
Day 1: Schedule a full backup.
Day 2: Schedule a differential backup. It covers all the changes that took place between Day 1 and Day 2.
Day 3: Schedule a differential backup. It makes a copy of all the data that has changed from Day 2 (this includes the full backup on Day 1 + differential backup) and Day 3.
Incremental Backup
The full backup is first; then succeeding backups store only changes that were made to the previous backup. An incremental backup requires space to store only the changes (increments), which enables fast backups.
Non-persistence
Non-persistent data is that which is not available after fully closing the application or turning off the system. Non-persistent desktops have a short existence under natural conditions. They are known as a many-to-one ratio, meaning that they are shared among end users, but no changes are saved. Non-persistent storage is typically short-lived storage used for logs and diagnostics. Non-persistent capabilities, such as those in bootable distributions, allow you to boot up a full operating system and perform tasks, browse, and operate, and then when the machine is powered down, everything changed or modified is gone.
In revert to known state the desired outcome is to take a system back to a prior moment in time or state of existence. In the process, typically changes implemented since that known “good” point in time are removed, usually to start at a point and time before a problem or issue arose; the purpose is to reset a device to a stable and secure setting. Revert to known state examples include Cisco’s Configuration Rollback, VMware snapshot, Windows Steady State, Linux Systemback, and Mac’s Time Machine.
Last known good configuration, or LKGC for short, returns the configuration of a system back to just before a problem started. You can undo recent changes that caused a problem or error or that weakened security. In Windows 7 and 8 computers, you can fix driver and configuration issues by selecting F8. In Windows 10, Microsoft disabled this capability; however, you can still enter Safe Mode (a last good configuration alternative) in the Windows Recovery Advanced Options.
Note
For more information, see https://softwarekeep.com/help-center/how-to-boot-windows-10-into-the-last-known-good-configuration.
Live boot media is a lightweight bootable image on a USB flash drive or external hard disk drive containing a full operating system that can be booted to. The added benefit of writable storage is that it allows customizations to the booted operating system. Live USBs can be used in embedded systems for system administration, data recovery, or test driving an operating system, and can persistently save settings and install software packages on the USB device.
High Availability
High availability (HA) is a characteristic of a system that aims to ensure an agreed-upon level of operational performance, usually uptime, for a higher-than-normal period. Modernization has resulted in an increased reliance on these systems, hence the need to make them available at all times. Availability refers to the ability of users to obtain a service or good or to access the system—whether to submit new work, update or alter existing work, or collect the results of previous work. Three principles of system design in reliability engineering can help achieve high availability:
Elimination of single points of failure: This means adding or building redundancy into the system so that failure of a component does not mean failure of the entire system.
Reliable crossover: In redundant systems, the crossover point itself tends to become a single point of failure. Reliable systems must provide for reliable crossover.
Detection of failures as they occur: If the preceding two principles are observed, a user may never see a failure, but the maintenance activity is a must.
High availability is measured as the available time of a system being reachable. Assuming 100 percent is never failing, HA is the widely held but difficult-to-achieve standard of availability of a system or service known as “five nines,” or 99.999 percent available. Availability percentage is measured as follows:
Availability = (minutes in a month − minutes of downtime) * 100/minutes in a month
For example, if there is a service-level agreement for five nines, the end user can expect that the service will be unavailable for 26.3 seconds per month and 5 minutes and 15 seconds per year.
Scalability is the property of a system to handle a growing amount of work by adding resources to the system. In terms of systems, it must be able to scale to number of users and workloads.
Restoration Order
Prior to a disaster, a company should run through an exercise called disaster recovery planning (DRP). From here, you can build a plan that will include all systems you plan to restore during the recovery process and in which order. Certain systems are required to be online prior to anything else; typically, they are networking and authentication services, like the physical network connectivity, and Active Directory. You can build a table similar to the sample shown in Table 13-4 to ensure everyone on the team is on the same page. That way, any replacements or new resources who were not involved in DRP planning or testing will be able to understand how things come together.
Table 13-4 Disaster Recovery Order
Process |
Priority |
System |
|---|---|---|
Connectivity |
Restoring specific networks that include administrative networks. |
Routers, switches, and networking infrastructure; Internet; telco services. |
Authentication |
Performing logical layout of systems and interdependencies. |
Active Directory and authentication services. |
Phone systems |
Restoring phones (a very high priority). |
Requirements for emergency response, health and safety, E911 (Enhanced 911), and support. |
CRM/SAP/HRM |
Restoring systems that enable the corporation to perform operations and provide continuity. |
Ordering systems, online sales and marketing systems, human resources. |
Other resources |
Continue to build this out. |
List all your important systems and put them in order. |
Diversity
One of the best ways to ensure availability is through diversity and redundancy. The more diverse the redundancy, the more fault tolerant the systems and network. You can minimize the business impact of a cyber attack on your organization by providing diversity in the manner you build and deploy your network and systems.
Technologies
Diversity with technology starts with utilizing different methods to accomplish similar tasks. For example, you can provide network resilience by utilizing a routing protocol and a load balancer. Although these are two completely different methods to provide resilience, they provide diversity that helps a company recover from a failure. By adding two network cards to a server, you can utilize diverse paths.
Vendors
Diversity in vendors provides resilience in your supply chain, and having relationships with multiple vendors ensures that your procurement process won’t break down if one of your vendors experiences an attack or disaster, or it goes out of business. Employing multiple vendors allows you to obtain the best price when sourcing but also ensures access to products when they may be in short supply.
Crypto
Cryptography (encryption) should be utilized as often as possible. For example, your backups should be encrypted with a strong encryption method. This way, if they are stolen, the attacker will not have access to the data. Windows servers and workstations can encrypt hard disks (storage). Any link that leaves your organization should be encrypted to ensure your communications are private. Encryption should be utilized and implemented with every application and system your organization uses.
Controls
The control systems in your building include the HVAC system, elevators, lighting, and other building controls you take for granted while at work. Control systems are purposely designed with diversity and high availability in mind so that you aren’t stuck on an elevator, do not lose lighting, or are unable to exit a building during a power failure. These feats are accomplished by running dual-diverse path cables to each component, having redundant controllers, and using automation so that if power does fail, the elevator is automatically taken to the ground floor with the doors open and locked.
Tip
Control systems are unique in that they manage and monitor mission-critical systems such as lights, power, generators, and data centers.
Chapter Review Activities
Use the features in this section to study and review the topics in this chapter.
Review Key Topics
Review the most important topics in the chapter, noted with the Key Topic icon in the outer margin of the page. Table 13-5 lists a reference of these key topics and the page number on which each is found.
Table 13-5 Key Topics for Chapter 13
Key Topic Element |
Description |
Page Number |
|---|---|---|
Paragraph |
Redundancy through geographic dispersal |
315 |
Section |
Redundant Array of Inexpensive Disks |
316 |
Paragraph |
Redundancy through storage multipath |
319 |
Section |
Load Balancers |
319 |
Section |
Uninterruptible Power Supply (UPS) |
320 |
Section |
Generators |
321 |
Section |
Dual Supply |
321 |
Section |
Managed Power Distribution Units (PDUs) |
322 |
Section |
Storage Area Network |
323 |
Section |
Virtual Machines |
324 |
Section |
On-premises vs. Cloud |
325 |
Backup Type Benefits and Drawbacks |
326 |
|
List |
Non-persistent capabilities |
329 |
Section |
High Availability |
329 |
Disaster Recovery Order |
330 |
|
Section |
Diversity |
331 |
Define Key Terms
Define the following key terms from this chapter, and check your answers in the glossary:
Redundant Array of Inexpensive Disks
network interface card (NIC) teaming
managed power distribution unit (PDU)
Review Questions
1. What is geographical dispersal?
2. What is disk redundancy?
3. What is a UPS?
4. What is replication?
5. What is reverting to known state?