
Chapter 28
Using Appropriate Data Sources to Support an Investigation
This chapter covers the following topics related to Objective 4.3 (Given an incident, utilize appropriate data sources to support an investigation) of the CompTIA Security+ SY0-601 certification exam:
Vulnerability scan output
SIEM dashboards
Sensor
Sensitivity
Trends
Alerts
Correlation
Log Files
Network
System
Application
Security
Web
DNS
Authentication
Dump files
VoIP and call managers
Session Initiation Protocol (SIP) traffic
syslog/rsyslog/syslog-ng
journalctl
NXLog
Bandwidth monitors
Metadata
Email
Mobile
Web
File
NetFlow/sFlow
NetFlow
sFlow
IPFIX
Protocol analyzer output
Long before an incident takes place, an organization should be running baseline network inventory scans and discovery, running vulnerability scans, and collecting and saving logs from systems. All an attacker needs is one vulnerability to get a foothold in your network. That is why at a minimum, you should scan your network at least once a month and patch or remediate identified vulnerabilities immediately. Some compliance requirements require you to scan your network quarterly; however, that is not often enough and should be part of your bigger security commitment. You can’t adequately defend your network until you have conducted a security assessment to identify critical assets and know where on your network they are located.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz enables you to assess whether you should read this entire chapter thoroughly or jump to the “Chapter Review Activities” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 28-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 28-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions |
|---|---|
Vulnerability Scan Output |
1–2 |
SIEM Dashboards |
3–4 |
Log Files |
5–6 |
syslog/rsyslog/syslog-ng |
7 |
journalctl |
8 |
NXLog |
9 |
Bandwidth Monitors |
10 |
Metadata |
11 |
NetFlow/sFlow |
12 |
Protocol Analyzer Output |
13 |
Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you correctly guess skews your self-assessment results and might provide you with a false sense of security.
1. Which is one of the benefits of storing historical vulnerability scans?
Previous scans compared with current scans can provide insight into what has changed.
Historical scans are required for department leads to understand bandwidth issues and plan for upgrades.
Historical scans can be a good data source to feed into your disaster recovery management system.
None of these answers are correct.
2. Which devices on a given network should a vulnerability scanner scan?
Laptops and workstations
Multifunction printers
Routers and switches
All of these answers are correct.
3. When is the best time to implement a SIEM sensor on your corporate networks that support critical assets?
During the incident to capture as much evidence as possible
Before the incident to capture as much evidence as possible
After the incident to capture as much evidence as possible
All of these answers are correct.
4. When you are tuning sensitivity of the SIEM for collecting and alerting on suspect data, what is the risk of an alert being missed because of poor tuning?
Configurations enhance the usability of the SIEM.
The SIEM collects all of the potential incident data required.
A breach can go unnoticed for months.
A breach is alerted and recognized immediately.
5. Which log files that you store in a read-only mode can help with your incident response investigation?
Windows server logs
Linux server logs
Routers and switch log files and logging
All of these answers are correct.
6. Which Session Initiation Protocol is used to establish, maintain, and tear down a call session?
MGCP
RS232
H.323
SIP
7. You need to log data from remote Linux-based applications and devices. Which of the following are your best options? (Select all that apply.)
syslog
rsyslog
syslog-ng
Event Viewer
8. Which journalctl command allows you to search through Linux log files and select a specific time window, date, and time?
journalctl time select
sh journalctl file “filename” -select “datatime””
journalctl -since YYYY-MM-DD HH:MM:SS
journalctl -date -filename
9. Which of the following is used for centralized logging across various platforms and supports a myriad of different log types and formats?
NXLog
Application log
Security log
System log
10. Which of the following can map out historical trends for capacity planning and quickly identify abnormal usage and top talkers?
Metadata
Dnsenum
Bandwidth monitors
DNSSEC
11. Which type of data does not seem to have any relevance or bearing on an investigation by itself but when combined with additional context is valuable?
Metadata
RFC data
Syslog
SIEM data
12. How does NetFlow create flow sessions from unidirectional sets of packets?
Unidirectional flows are sent to dynamic collectors.
NetFlow uses flows from stateless packets to build an aggregation of flow records.
NetFlow statefully tracks flows or sessions, aggregating packets associated with each flow into flow records.
None of these answers are correct.
13. What tool can you use to capture network traffic and perform analysis of the captured data to identify potential malicious activity or problems with network traffic?
systemd
TTL
Metadata scanner
Protocol analyzer
Foundation Topics
Vulnerability Scan Output
If there were no vulnerabilities within a network or computer system, there would be nothing to exploit, and the network attack surface would be greatly reduced. However, software vulnerabilities always exist and will continue to, because applications are developed by people, and people make mistakes, all of which can allow attackers to compromise networks. Running regular vulnerability scans is just the first step in your defensive posture. A network scan should include all devices with an IP address (workstations, laptops, printers and multifunction printers, IoT devices, routers, switches, hubs, IDS/IPS, servers, wireless networks, and firewalls) and all the software running on them. You should run both authenticated and unauthenticated scans. Each provides insight into vulnerabilities found in services running on your network, open ports on devices that could allow malicious apps to run or communicate on them, and configurations or issues that affect security.
The vulnerability scan reports should be saved for at least 24 months, but certain regulations and industries require longer retention times. Some systems enable you to save these reports and compare month over month to show your cybersecurity posture and improvements. Historical vulnerability scans can also provide significant insight after an incident. By comparing previous scans with the most recent, you can also look for variances in devices and systems that may have been changed. In turn, you should make reimaging these devices a top priority. A change can be anything from additional TCP/UDP ports being shown as open to the detection of unauthorized software, scheduled events, or unrecognized outbound communications.
Figure 28-1 shows basic vulnerability scan results from my internal network 1.1.100.0/24 showing two certificate issues as medium-level threats. Vulnerability reports are perfect for engaging several departments in your organization to get them involved and responsible for the overall posture.
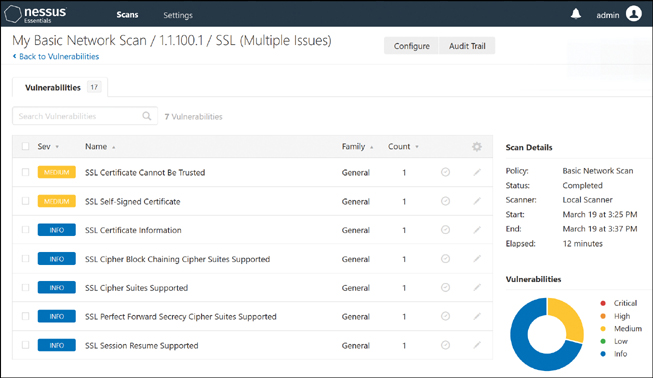
FIGURE 28-1 Vulnerability Scan Report
SIEM Dashboards
Security Information and Event Management (SIEM) software works by collecting logs and event data generated by an organization’s application, security devices, and host systems and bringing it together into a single centralized platform, allowing companies to identify threats in real time. SIEM gathers data from antivirus events, firewall logs, and other locations; it then sorts this data into categories. When the SIEM identifies a threat through network security monitoring, it generates an alert and defines a threat level based on predetermined rules.
In Figure 28-2 the SIEM dashboard provides a quick reference to the top threats that require security analyst attention. Alarms by Day Past 30 Days enables you to trend your performance on threats. Top Classification shows types of active attacks in the last nine hours. Top Host (Origin) shows who is attacking and from where, as well as hosts impacted by attacks.
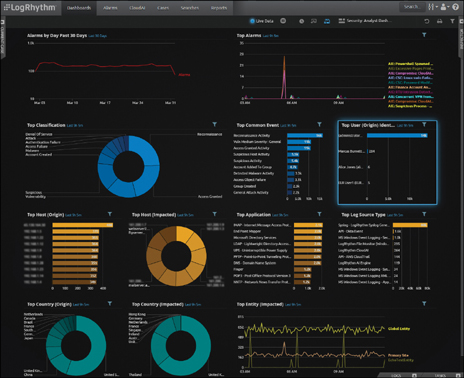
FIGURE 28-2 SIEM Dashboard
TIP
SIEMs normalize and aggregate collected data. Log aggregation is the process by which SIEM systems combine similar events to reduce event volume.
Sensors
SIEM sensors collect network traffic and provide advanced threat detection, anomaly detections, log collection, and more. Active network sensors probe and query application scanners and devices on the network for current or existing asset information. Network event sensors provide situational awareness of unauthorized events that take place on the network. Sensors also collect and report installed software information and versions from devices, including patch level. Software and application scanners can be utilized to identify approved and unapproved software installed on devices that may be found through scans. Sensors should be used before and after an incident. Sensor placement around the network allows for greater visibility and can aid in forensic investigation by quickly identifying the breadth of the spread.
Sensitivity
SIEMs have the capability to tune sensitivity to what is considered suspect behavior or suspicious files (risk-based prioritization) to help reduce or increase the amount of data/matches and therefore the number of notifications. During an investigation, the more data, the better. On SIEMs and sensors that store lots of data, adjusting the sensitivity to what is considered suspect becomes much easier and can help pinpoint suspect zero. Because of the sensitivity of some company and government data, they are more likely to run the SIEM scans and sensors locally, with little to no external access. More modern hybrid SIEMs with artificial intelligence and machine learning (AI/ML) capabilities can offload some of the more advanced capabilities to these cloud-based services. In this case, a secure tunnel can be established, and only suspect files can be interrogated offsite.
Trends
At the most basic level, SIEMs should enable alerting of suspect traffic, user activity, and files, as well as correlation of data, including multiple sources. They also should allow input of third-party threat intelligence, automatic uses cases, machine learning, and multiple statistical models to be applied to users and network traffic. You should expect to see trend data and more deepening of automatic expert analysis, more automated incident response capabilities, and convergence of network traffic analysis and endpoint detection and response.
Note
A SIEM dashboard contains multiple views that allow you to visualize and monitor patterns and trends. The intent of a SIEM dashboard is to give you one pane of glass to view your network’s or system’s status and condition.
Alerts
Alerts provide a purpose for those who monitor SIEMs. When all of the information is flowing into your SIEM, you can track important statistics, identify exceptions, and automate functions like alerting and sending notifications via email, text, or phone, if certain thresholds are met, such as a user logging in with a certain ID or someone accessing certain company assets. Alerting is one of the most important features of a SIEM, and you should take care in how you configure and review alert capabilities.
Correlation
Data correlation allows you to take data and logs from disparate systems, such as Windows server events, firewall logs, VPN connections, and RAS devices, and bring them all together. Because this data is all formatted differently, the SIEM data correlation function allows you to tie these logs together to see exactly what took place during that event.
Log Files
Log files from every system in your network are important. Most devices are capable of sending syslog data of some sort. The log data you collect from your systems and devices might seem pretty mundane; however, these logs could contain the precise evidence needed to investigate and successfully prosecute a crime. For log data to stand up in court as admissible evidence, you must put into place and operate with chain of custody in mind and take special precautions on how you collect, handle, and store the data. Many regulations such as PCI DSS, HIPAA, and SOX require the use of logs and log management. When set up properly and with the appropriate due care, logs can provide an immutable fingerprint of system and user activity. In many cases, the logs tell a story as to what really happened in an incident. They can tell what systems were involved, how the systems and people behaved, what information was accessed, who accessed it, and precisely when these activities took place. Log files should be saved to a write once read many (WORM) device like DVD write once (DVD-R) media.
Figure 28-3 shows syslog messages sent from network devices and servers. Notice that the mail server is running postfix/smpd, letting you know this is a Linux host and that it rejected a connection from a host because it could not retrieve its entity information. There are several free visual syslog servers including one from SolarWinds.
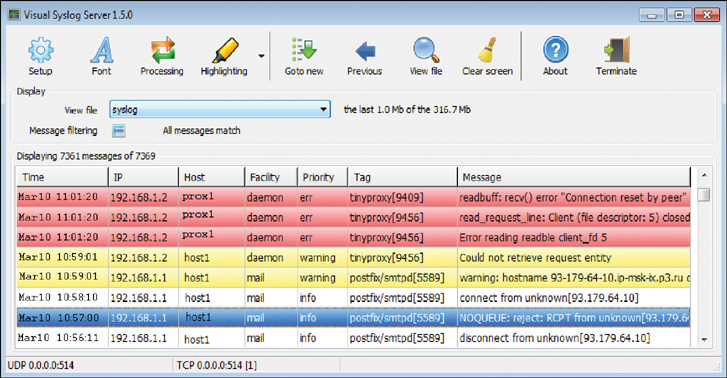
FIGURE 28-3 Visual Syslog Messages
Network
Logging and logfiles for networking devices should have detailed date and time stamps down to the second. You should configure these devices with a common secure Network Time Protocol (NTP) time provider and configure logging to be sent to a separate secure syslog server with limited access. At certain times, logs and logfiles may be available only on the device itself. In those cases, you should ensure access is controlled and logged. These log files may be the key to solving an intrusion or other event.
Every network device—from firewalls to routers to switches to wireless access points—logs slightly differently and at different levels. You should determine what types of logs from these systems you require. Logging everything is not only taxing for the devices but also inundates your logging server. You should take the time to learn the appropriate syntax to set up logging properly for the specific platform. Transit network devices are of particular interest because they are located between your network and your partners, vendors, or some offsite locations. Transit network devices contain syslog data, debugs, and messages that provide additional insight and context during a security incident. This insight aids in determining the validity and extent of an attack.
Within the context of a security incident, investigators can use syslog messages to understand communication relationships, timing, and, in some cases, the attackers’ motives and/or tools. The events become part of the larger picture when used in conjunction with other forms of network monitoring that may already be in place. Depending on the device, the logs have a different format and layout, and they provide different information. For example, you can configure logging on a Cisco ASA through the ASDM software for managing ASA firewalls. To do so, you enable Facility 23, timestamp logging, and ensure you have debug-trace logging disabled.
Figure 28-4 shows a real-time log viewer from the ASA ASDM management software. As you can see, the logs are from the ASA firewall, showing that the firewall intercepted a DNS reply for a host on the outside interface and providing both IP addresses. This information allows you to dig deeper in the Syslog Details window.

FIGURE 28-4 Real-Time Log Viewer
RAW syslog messages from devices look similar to the syslog details shown in Figure 28-4, although using Linux command-line utilities or GUI-based tools is usually best. One of the reasons logging to SIEMS is so helpful is that it can understand the context of what is being received and has the ability to correlate, deduplicate, and provide a clear picture of the event.
System
System logging is all about the capabilities of the specific system you are trying to obtain logs from. Each system that has logs also refers to specific system messages that contain log records for the operating system events. Many of them show how system processes and drivers were loaded, and errors during loading or any failures since. Windows provides a few areas to obtain logs, such as the Event Viewer. You can use it to collect .evt and .evtx files from other Windows-based machines. You can even sort by event ID and perform filtering and exporting. The Windows Admin Center can provide events from Event Viewer as well and allows you to export them.
Linux hosts log files are mostly contained in the /var/log directory. You should make it a regular process to collect these logs and store them as you would with other devices. Application, system, and security logs should be stored off-host when possible. Monitoring system logs provides proactive monitoring and helps you build a complete picture if or when an incident occurs: knowing which systems were accessed and when, what files were accessed, which applications were installed, and whether the integrity of the system was compromised and how.
Figure 28-5 shows the Windows Event Viewer where you can clearly see the event ID, level of logging, and type of message. Here, four types of messages are displayed: Warning, Critical, Information, and Error. Information messages are typically those from the operating system letting you know that it performed some action like allowing a process to start. Errors are generated by failures of processes to start. Critical messages indicate some serious failure; in this case, the Event Viewer assumes the system did not shut down properly. Warning messages are normal; Windows handles all of these events and recovers without any user intervention.

FIGURE 28-5 Event Viewer
The system log records error messages, warnings, and other information generated from the Windows operating system. It provides a wealth of information on what is going on with the system. System log records can also help you determine if, when, or where a user attempted to log in and failed, what user ID was used, and what IP address it came from.
Application
Logging hosts end to end from services, events, or systems to applications gives you near end-to-end visibility. Application logging and the process for implementation, management, and reporting need to be configured and reviewed before, during, and after an incident. You should parse, partition, and analyze all logs and data generated by the application. Logging for critical process information about user, system, and web application behavior can help incident responders build a better understanding of the breadth and depth of an attack. Application logs provide information related to applications run on the local system, how they are performing, and any attempts to utilize the application. Depending on the level of logging, the logs can determine whether users exposed an unknown flaw in the application programming or whether they attempted to escalate privilege or modify data they were not intended to have access to.
Security
Both successful and failed login events are relevant to logging and help build the investigation’s scope. Security event–specific logs from systems, devices, and applications allow you to focus on main event types. They help guide the investigation and allow the team to quickly get the organization to the breadth of the breach, attribution, and recovery. Computer forensics processes use log file data in finding electronic evidence for criminal investigations. Companies should follow best practices to help ensure log data and log management practices properly support forensic investigations.
The security log in the Windows Event Viewer provides information related to the success and failure of login attempts and information related to other audited events, as shown in Figure 28-6.
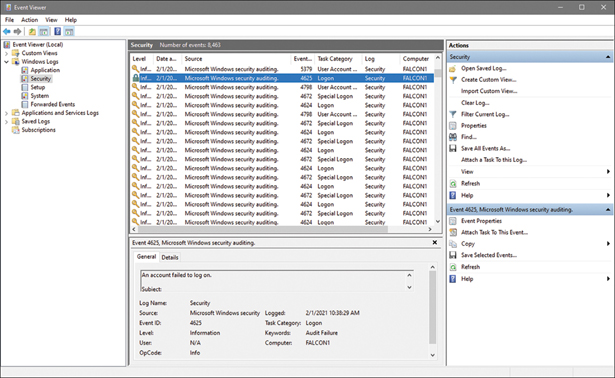
FIGURE 28-6 Security Log Event Viewer
Note
Windows Event Viewer logs are stored in %SystemRoot%System32WinevtLogs.
Web
Log files provide a precise view of the behavior of the server as well as critical information about when, how, and by whom a server is being accessed. This kind of information can help incident responders and investigators unfold the chain of events that may have led to a particular activity. For example, the most common web servers are IIS, Nginx, and Apache. These servers provide log files such as access.log and error.log. The access.log records all requests for files made by visitors. For example, if a visitor requests www.example.com/main.php, an entry is added in the log file showing what the visitor requested. The log files provide investigators with an IP address, date, and time, as well as requested files. In the absence of that log file, you might have never known that someone discovered and ran a secret or restricted script you have on your website that dumps the database.
Analyzing logs from web servers such as Apache, Nginx, and IIS can provide important insight into the website and web application quality and availability. Web server logs are usually access logs, common error logs, custom logs, and W3C logs. W3C logs are used mainly by web servers to log web-related events, including web logs. The log format for an Apache access log file is as follows:
LogFormat "%h %1 %u %t \%r" %>s %b" common
Logs can be an extremely important aspect of your web environment. They provide additional data that’s useful for security, debugging purposes, informational purposes, and more.
If a request was made to a website using the log format, the resulting log would look similar to the following.
127.0.0.1 - chris [26/Feb/2021:10:34:12 -0700] "GET /sample-image.png HTTP/2" 200 1479
Figure 28-7 shows a web server’s log file, where users are requesting specific pages. Based on the GET requests and 404 messages, the user is requesting files that do not exist, and this could be an attacker looking for potential files to exploit or an outdated webpage somewhere making a reference to files that have been since removed.

FIGURE 28-7 Web Server Log File
DNS
The Domain Name System (DNS) provides a hierarchy of names for computers and services on the Internet or other networks. Its most noteworthy function is the translation of domain names such as example.com into IP addresses. DNS is required for the Internet to function, operates on a global scale, and is massively distributed. Authoritative DNS servers run a service called BIND that normally accepts messages on UDP port 53. BIND performs the DNS role acting as an authoritative name server for domains and also acts as a recursive resolver in the network. The DNS protocol has two message types: queries and replies. Both use the same format. These messages are used to transfer resource records (RRs). An RR contains a name, a time-to-live (TTL), a class (normally IN), a type, and a value.
There are nearly a dozen different types of logs that are of particular interest. Obtaining and including them in your investigation can help build a full picture. Investigating any transfers or lookups and any queries prior to the attack can help identify a source IP address. DNS servers can and should be configured for file integrity monitoring systemwide. Figure 28-8 demonstrates how to use the tail command to view the /named/security.log, showing a DNS client request and DNS A record being approved for entry.

FIGURE 28-8 Security.log
The following are common DNS record types:
Address mapping record (A record): Also known as a DNS host record, stores a hostname and its corresponding IPv4 address. When you request google.com, it provides you with an associated IP address.
IP version 6 address record (AAAA record): Stores a hostname and its corresponding IPv6 address.
The Domain Name System Security Extensions (DNSSEC) protocol was developed to strengthen DNS through the use of digital signatures and public key cryptography. It protects against attacks by providing a validation path for records.
The DNS enumeration tool called dnsenum enumerates DNS by finding DNS servers and DNS records such as mail exchange servers, domain name servers, and the address records for a domain. You can use nslookup and dig to troubleshoot DNS servers and resolve name resolution issues by querying a DNS server to check whether the correct information is in the zone database. For Windows, you use nslookup to check which DNS servers are being used, and you use dig, which stands for Domain Information Groper, on Mac and Linux-based systems.
Several log aggregators for DNS Bind, such as Men & Mice Logeater, can provide query statistics that are formatted to make it easy to understand loads and issues on DNS servers. These tools are also capable of grouping error messages, even with DNSSEC.
Authentication
One of the primary logs that should be used in any incident response or forensic investigation is the authentication log. Well-written applications also log authentication approved and failure events. By reviewing authentication failures, you can see password guessing and crackers at work. If you were to search even deeper and correlate which users logged in and authenticated and when they did so, then compare with valid user locations and the systems they were actually on, and filter on those suspect differences, you could build a picture of which systems the attackers gained access to and what activity was performed. To view authentication pass/fail attempts on Linux, you navigate to the /var/log/ folder and locate the auth.log file, where you can use cat or more on the file. Receiving an Open response means that someone logged on. In Figure 28-9, the wrong password was entered, which shows up as an authentication failure. The figure also shows that the session opened for user root, which indicates a successful login attempt.
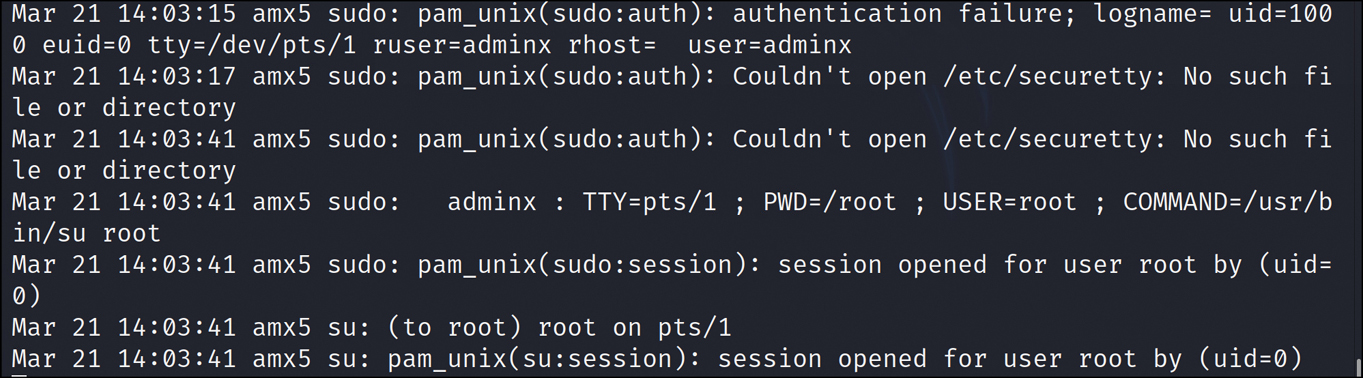
FIGURE 28-9 Authentication Log
Dump Files
Everyone has seen the blue screen of death. Once it is initiated on a Windows system, it creates a dump file that is sent to %systemroot%Minidump. These dump files contain information that was in memory on the system right before it died. This information includes applications, processes, and activities, including commands run before the crash. All of these indicators can help you build a picture of what an attacker was doing on the system before it crashed. In many cases, you can see programs the attacker was running, and what is even more helpful is that the image can contain evidence before the attacker had an opportunity to clean up. Tracking the specific programs and commands used by a would-be attacker helps create an attacker profile.
To access the dump file, first you need to enable the setting to write debugging information. As shown in Figure 28-10, you can select Small Memory Dump, which makes it easier to read with standard tools. After this setting is enabled, if you have a crash, you can easily find the file in %systemroot%Minidump.
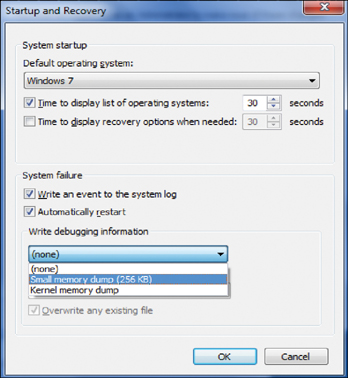
FIGURE 28-10 Enabling the Setting to Write Debugging Information
As you can see in Figure 28-11, on your Windows host, if your system crashed or you initiated a dump file, you see a MEMORY.DMP file under c:/windows/Minidump/. Using a tool called Bluescreen View, you can dive deeper into the reason for the failure. In this case, it’s obvious that the problem was a driver because IRQ_NOT_LESS indicates a card or driver conflict.
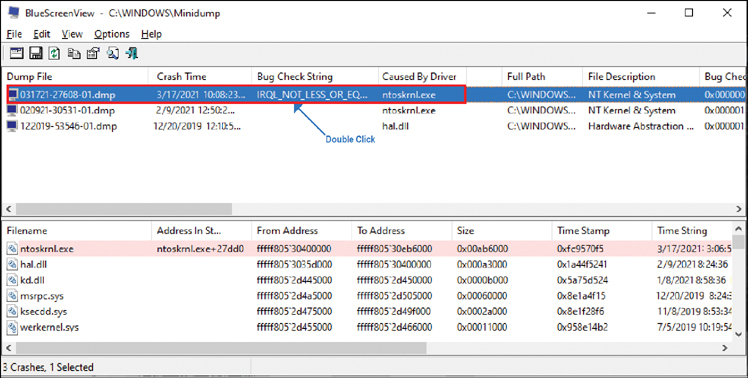
FIGURE 28-11 Viewing Dump File Information
VoIP and Call Managers
The popularity of Voice over Internet Protocol (VoIP) is increasing as the cost savings and ease of use are realized by a wide range of large and small company users. VoIP technology also is an attractive platform to criminals. The reason is that call managers and VoIP systems are global telephony services, so it is difficult to verify the user’s location and identification. The security of placing such calls is also appealing to criminals; they can make calls and use systems as pivot points to attack other systems.
As shown in Figure 28-12, the logging and logs from these systems can provide the context of attacker calls made, including source and destination of IP addresses, as well as any systems connected to. Several tools on Call Manager allow you to view calls and troubleshoot. The Real-Time Monitoring Tool (RTMT) provides access to the syslog viewer. Ideally, you can configure RTMT to send all logs to a remote syslog server, which ensures the attacker isn’t able to modify logs that may indicate the intrusion.

FIGURE 28-12 Call Manager Logs
If you have Call Detail Records (CDR) enabled, you can go to CDR > Search > By User/Phone Number/Sip URL and select Next. Input the extension in the Phone Number/SIP URL field and click the Add button. Then select the time and date range and click Find, export in CSV, and save to an XLS; then you can filter your data.
Session Initiation Protocol Traffic
Session Initiation Protocol (SIP) is a signaling protocol used to establish, maintain, and tear down a call when terminated. SIP allows the calling parties called user agents (UAs) to locate one another using the network, which allows user agents to be registered and invite other UAs to join in an Internet multimedia call called a session. SIP devices are typically routers connected to the telco or to the Internet; these devices should be configured to send detailed time-stamped logs to a syslog server. Routers can be used as pivot devices to gain additional access to the network; therefore, hardening the routers is important. Combining logs from these devices with other logs collected from call systems allows the investigator to build a picture of what attackers were doing, who they were contacting, and what systems they compromised. Depending on your SIP provider and what system you are using to process SIP calls, your logging can be different. Most SIP providers include tools that provide reporting from call diagrams to failed attempts and even alerting. Figure 28-13 shows some sample SIP logs.
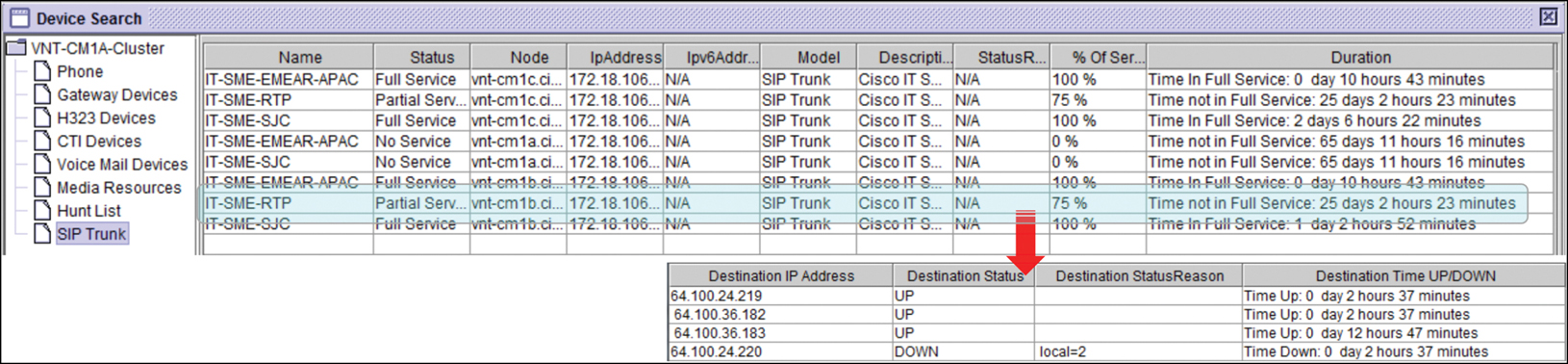
FIGURE 28-13 SIP Logs
syslog/rsyslog/syslog-ng
The system logging service syslog was created in the 1980s to provide logging for systems. The syslog-ng is an advancement to syslog that added many enhanced features, such as content-based filtering, direct logging to a database, using TCP for transport, and TLS for encryption. All of these improvements are important for protecting information being sent from systems and devices. The rocket-fast syslog server, or rsyslog, was created in 2004, extending the syslog protocol with buffered operation and Reliable Event Logging Protocol (RELP) support.
Logging to an external system is a very important aspect of maintaining chain of custody; it also ensures the logs of the attacked device are not tampered with because they are stored off-system. Although syslog is a decades-old standard for message logging, it is still extensively used. It is available on most network devices (such as routers, switches, and firewalls), as well as printers and Linux-based systems. Over a network, a syslog server listens for and then logs data messages coming from the syslog client.
Some Debian-based Linux systems such as Ubuntu store global system activity and startup messages in /var/log/syslog.
rsyslog and syslog-ng are similar because they build on syslog capabilities by adding support for advanced filtering, configuration, and output. syslog-ng is considered next-gen, a free and open-source implementation of the syslog protocol for Linux systems. It extends the original syslogd model with content-based filtering, rich filtering capabilities, and flexible configuration options. It also adds important features to syslog, such as using TCP for transport. syslog-ng started from scratch, with a different configuration format, whereas rsyslog was originally a fork of syslogd, supporting and extending its syntax. syslog-ng provides the capability for many third-party tools to interface and manipulate data, including Grafana, splunk, logzilla, and others. They provide a web interface and allow you to perform robust searches using correlation and advanced queries, as well as provide many other open-source options for viewing and manipulating log files.
Figure 28-14 shows the command-line help interface for syslog-ng.
FIGURE 28-14 syslog-ng Command-Line Help Interface
journalctl
journalctl is a Linux command-line tool used for viewing logs that are collected by systemd. These logs are collected in a central repository for easy display, review, and reporting. The log records are well indexed and structured in a way that enables you to easily analyze and manipulate the large log records. A number of filtering options enable users to sift through large sets of log entries to find specific data fields, messages, alerts, and errors that are specific to certain applications, users, services, and applications. To run journalctl on a Debian distribution, you need to install systemd, apt-get install systemd. Figure 28-15 illustrates the journalctl reviewing log files from this system showing log start date and the version of Linux. This is what a raw log format looks like.
FIGURE 28-15 Journalctl Raw Log Format
To access the man (full manual) page, you enter man systemd.journal-fields.
To access logs for a specific time window, you type journalctl -since ”‘2019-03-11 15:05:00”’. The time format is YYYY-MM-DD HH:MM:SS.
As you can see, journalctl is a valuable tool you can use to collect logs and investigate a Linux system as well as other syslog records/files to sort through mountains of data to help you find the proverbial needle in a haystack. This tool enables you to query and display logs from journald, which is the logging service for Linux-based systems that stores log data in binary format. With journald, you cannot log to remote locations; however, there are several mechanisms to forward logs to syslog when necessary.
Note
The man page for using Journalctl is located at www.freedesktop.org/software/systemd/man/journalctl.html.
NXLog
NXLog is used for centralized logging across various platforms and supports a plethora of different log types and formats. NXLog is available in two versions: the Community Edition and the Enterprise Edition. Enterprise Edition features are platform support for Linux, Windows, Android, AIX, Solaris, and macOS. NXLog can accept event logs from TCP, UDP, files, databases, and various other sources in different formats such as syslog or Windows event logs. NXLog can process high volumes of event logs from many different sources. Log processing includes rewriting, correlating, alerting, filtering, pattern matching, log file rotation buffering, and prioritized processing. NXLogs can store or forward event logs in a number of supported formats.
To use NXLog on Windows, you must make sure you use the appropriate x86 version and use an MMC snap-in (such as gpedit.msc).
On Debian Linux type operating systems like Ubuntu, you download the appropriate .deb file and install. To start NXLog on Linux, you enter service nxlog start.
Many investigators use NXLog to uncover supportable evidence, enabling you to build a near complete picture of the status of the host. Because it can prioritize certain critical log messages, it ensures those attacker messages make it to NXLog (central log collection). A common requirement is to detect conditions when there are no log messages coming from a source. This usually indicates a problem, such as network connectivity issues, a server that is down, an unresponsive application, or an attacker cleaning up. The absence of logs can also be a good reason to investigate.
The solution to this problem is to use statistical counters and scheduled checks. The NXLog input module can update a statistical counter configured to calculate events per hour. In the same input module, a schedule block checks the value of the statistical counter periodically. When the event rate drops below a certain limit, an action can be executed, such as sending out an alert message. In Figure 28-16, the Windows entry for nxlog.log shows the startup of NXLog and the IP address and port being used.

FIGURE 28-16 The nxlog.log File Provides Insight into the Startup
Bandwidth Monitors
A bandwidth monitor tracks bandwidth use over all areas of the network, including devices, applications, servers, WAN, and Internet links, and that information will assist you in keeping an eye on inbound and outbound bandwidth within your network and help you identify which hosts are using the most bandwidth. One benefit of deploying bandwidth monitors is that they map out historical trends for capacity planning. With bandwidth monitors, you can quickly identify abnormal bandwidth usage, top talkers, and unique communications, all useful in finding infected systems that may be exfiltrating data or scanning the network looking to spread to other hosts. Bandwidth monitors provide critical information before, during, and after investigations. Incident responders can use this baseline information to determine when the attacked host started to overcommunicate outbound or to spread internally. The historical information is key to determining “normal” for the attacked network and host, what is normal communication for that specific host, and what is normal for the network in general. There are several developers of bandwidth monitors, and some devices have built-in bandwidth logging and monitoring.
In Figure 28-17, the SolarWinds monitor shows several problem devices, including which stations are using the most bandwidth, where they are going, and how much traffic (both in megabytes and in percentage). Several baseline items show how normal traffic should look as compared to what is currently happening.

FIGURE 28-17 Bandwidth Monitoring
Metadata
Metadata is created from every activity you perform, whether it’s on a personal computer or online, every email, web search, and social or public application and interaction. Metadata is defined as “data that provides information about other data.” There are many distinct types of metadata. On its own, it may have little or no relevance to the investigation. However, when placed with other types of data and sources, the result could bring you steps closer in your investigation. Metadata security is the practice and policies designed to protect an organization from security risks posed by unauthorized access to the organization’s metadata. Even metadata from Microsoft Word documents contains the names of authors and modifiers, dates of creation, and changes and file size. Metadata risk is the potential for disclosure of private information, usually unknowingly, because this metadata is hidden from plain view and users may be unaware of it. This information may be something those outside your company shouldn’t have access to.
There are several types of metadata you should be aware of. The first is descriptive metadata, which refers to elements like titles, dates, and keywords. For instance, when you download a video file, it contains descriptive metadata describing what the video is about as well as the name and date. Descriptive metadata is used with books, providing book titles, author names, dates, pages, and key data locations.
In addition to descriptive metadata, structural metadata provides information concerning a specific object or resource. Digital media (film on DVD, for example) is a perfect example. Each section has a certain length of film running time. In a broader sense, structural metadata records information on how a particular object or resource might be sorted.
Preservation metadata provides information that strengthens the entire process of making a digital file (object). This includes vital details required for a system to communicate or interact with a specific file and upholds the integrity of a digital file or object. A common pattern involved is the Preservation Metadata Implementation Strategies (PREMIS) mode that brings forth common factors to preservation and maintenance, including actions taken on a digital file or the rights attached to it.
Use metadata is data that is sorted each time a user accesses and uses a specific piece of digital data. Use metadata is gathered in a clear and direct attempt to make potentially helpful predictions about a user’s future behavior. This type of metadata can be used to understand fluctuations in data that have no pattern when there is really a pattern beneath the data.
There are even more types of metadata, including provenance. This means that it’s most relevant when something changes or is duplicated frequently, such as in the digital realm where there are frequent changes. Administrative metadata informs users what types of instructions, rules, and restrictions are placed on a file. This information helps administrators limit access to files based on user qualifications.
Cell phones have a ton of metadata, from the pictures you take that provide GPS coordinates, to the date and time of the photo, the language, camera type, flash setting, and more. From the coordinates of the tweet or Instagram image you just sent, to metadata from emails, and public and private social media applications you use, to airline tickets and rental car details, your phone is literally a treasure trove of information.
Figure 28-18 shows a Microsoft Word file. By right-clicking and looking at the properties under Details, you can see the title, authors, subject, tags, and comments. Notice the Remove Properties and Personal Information link, which allows you to remove certain personal information.
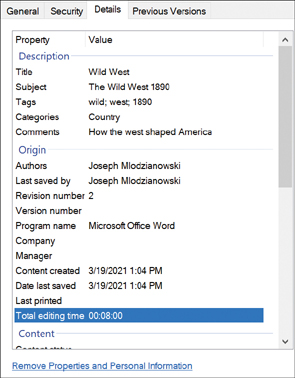
FIGURE 28-18 Metadata in a Microsoft Word File
Figure 28-19 shows an email header’s metadata about an email message received from Hulu at hulumail.com. As you can see, this message provides email addresses for the server (Google server), how the email was handed off, and the path it took to get to my Gmail account (gmail email mx.google.com) server. So, grab some popcorn and look through the email headers to see what else you can find of interest.

FIGURE 28-19 Full Headers from a Gmail Email
Note
Metadata has proven itself to be very useful in regards to investigations, and practically everything digital contains metadata including files, images, and email.
There is a ton of metadata in emails, specifically in the headers. Email is quite trivial to spoof and/or trick users into clicking on. Once attackers have a foothold in a network, they can turn any host into a spammer. There is a lot you can learn from these emails and those that might be used in spear phishing executives of the company.
The header is a section of code that contains information about where the email came from and how the message reached its destination. A header contains the originator’s email address and/or the computer that the perpetrator/sender was using, the browser used, and the IP address, which is sometimes conveniently identified as the Originating IP. With this information, you can trace the email to the Internet service provider (ISP) with the date and time of the email using the sender’s computer’s IP address.
There are two types of email headers. There are partial headers that you see when you normally open your email. The partial headers are the most important to your daily tasks. Such headers are the From Address, To Address, Subject, Date and Time, Reply-To Address, CC, and BCC. And then there are full headers; these are simply more technical information than you normally see when you check your email. They are required to complete a full forensic investigation. Figure 28-19 shows only a small part of full headers; full headers allow you to forensically follow the patch from the sender to the receiver.
Email is responsible for over 85 percent of successful company intrusions, so you should ensure you have detailed logging enabled.
Mobile
Mobile devices are essentially people’s lives now. We pay our bills, chat with friends, interact on social media platforms, perform online banking, and much more. Using a mobile device to obtain metadata can provide a significant advantage to the incident response team. If the phone received a text message, IM, email, or other type of communication and it was suspect zero, detailed mobile forensic applications can export and provide these files in an investigative form. Beyond that, you can use the metadata from the device to see if any precipitating activity led to the attack/breach.
Web
Web pages are a consistent source of metadata. While not usually visible, it’s in the keywords and phrases that describe the contents of the page. Most of this metadata is picked up and used by search engines to index a site. Search engine optimization (SEO) practices are those that take advantage of meta tags, such as keywords, phrases, page titles, and more. During an incident, investigators should review all web page metadata content to see if it was removed or modified. There have been incidents where attackers change this data to replace it with vulgar, adult, or malware links or words. Then it gets picked up by search engines and scored low or hostile, which makes the company website unavailable to browsers and search engines because of the ratings.
File
Certain applications add attributes to the files they create or edit. Accessing this metadata can be an important step in finding who created the files, what application was used, the host system operating system, and much more. For any file you have on your computer, simply right-click on it, select Properties, and then select Details. What you see then is all metadata, and most of it is not readily visible to the user.
NetFlow/sFlow
NetFlow and sFlow are technologies that can aid in gathering additional information about network, user, and application traffic that can be used to build a better understanding of network, user, and application flow.
NetFlow
NetFlow is a session flow protocol that collects and analyzes network traffic data that can be used to help you understand which applications, users, and protocols might be consuming the most network bandwidth or if a denial-of-service (DoS) activity is taking place and who the actors are. A “flow” is a unidirectional set of packets sharing common session attributes, such as source and destination, IP, TCP/UDP ports, and type of service. NetFlow statefully tracks flows or sessions, aggregating packets associated with each flow into flow records, which are bidirectional flows.
The export of NetFlow records depends on timers. It may take up to 30 minutes to export flows. If NetFlow is deployed on a compromised network, the flow sensors and flow tools can aid in the investigation by providing details of the communication between the attacker and the investigated device, as well as the tactics, techniques, and procedures (TTPs) of the attacker. This is another tool in the incident response team’s toolchest that provides valuable information.
Because NetFlow is a protocol developed by Cisco, it is deployed on Cisco routers and switches that are configured to send flow data ultimately to a NetFlow collector. As of this writing, the latest version of NetFlow is NetFlow v9. NetFlow collects packets via router interfaces, which are then provided to a NetFlow collector. A NetFlow application can then analyze the data, which is useful for incident investigations for intrusion analysis. Figure 28-20 shows NetFlow traffic details. As you can see, it is full of rich and useful information, including application usage, most accessed locations of your network devices, the type of traffic, web browsing, database access, and DNS—all very useful for detecting an attack or network issue.
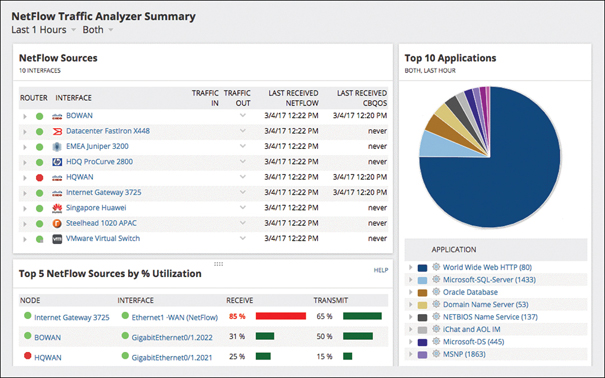
FIGURE 28-20 NetFlow Report
sFlow
Often network engineers look at sFlow as the successor to NetFlow; however, there are places to deploy specific tools for specific outcomes. sFlow can monitor Layer 2 to Layer 7 headers. sFlow stands for Sampled Flow, where packets are being sampled instead of flows. The goal of packet sampling and filtering is to forward only certain packets. sFlow datagrams are continuously sent across the network in real time. In terms of visibility, sFlow is good at massive DoS attack detection because the sampled network patterns are sent on the fly to the sFlow collector. sFlows are only an approximation of the real traffic because sampled packets do not reflect all network traffic. As a result, sFlow lacks the accuracy that is provided by NetFlow.
sFlow can provide the incident response team with much more insight into network Layers 2–7, which includes the packet header, MPLS labels, VLANs, MAC address, and all of the Layer 3–4 information from NetFlow, providing additional context to the investigation and visibility at more layers. sFlow is used for network monitoring. However, sFlow samples packets and can provide analysis to identify unauthorized network activity and quickly identify attacks, as well as investigate DDoS attacks.
In Figure 28-21, an sFlow trend shows that traffic slows at each interval, allowing you to quickly identify abnormal traffic and investigate those items.
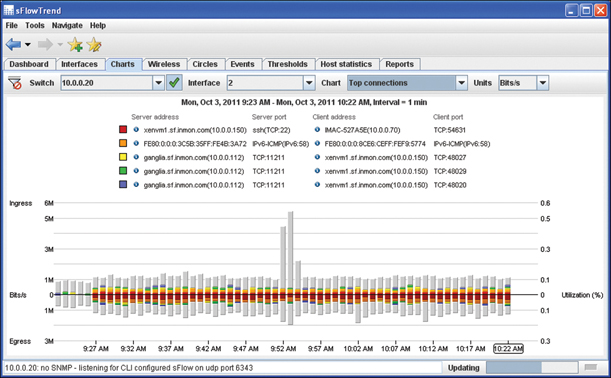
FIGURE 28-21 sFlow Trend Report
IPFIX
Internet Protocol Flow Information Export (IPFIX) is a standard for exporting the information about network flows from devices. Defined in RFC 5982, IPFIX is derived from NetFlow v9. IPFIX has a metering process that generates flow records collecting data packets at an observation point, filters them, and aggregates information about these packets. Flow records are encapsulated by Layer 4 protocols (SCTP, UDP, or TCP) to a collector. IPFIX can be used to export any traffic information from L2 to L7 to a flow collector. IPFIX tracks IP actions across the network. When it collects data packets from across the network, the exporter organizes and sends the compiled information to a collector. In IPFIX, exporters can transport data to multiple collectors, which is known as a many-to-many relationship. Exporters send information sets via IPFIX messages.
IPFIX is a flexible protocol that supports variable-length fields. One major advantage IPFIX has over NetFlow is in the collection process of the data packets, where users can organize and analyze the data using IPFIX. Users are able to customize their requests, so the system completes only specified tasks, such as organizing information or doing basic data analysis. IPFIX is also capable of integrating more information into its exporting process.
When you look at individual host flow ratios, TCP flags, host reputation, and DNS and compare trend data, this flow data can be very effective at detecting malware. NetFlow and IPFIX can be leveraged to study network behaviors over time. Any communication considered abnormal can trigger events that increase indexes, which can trigger alarms and notification. From there, investigators can take over, and with the information collected from IPFIX, they can get a picture of what happened and how.
Figure 28-22 shows the robust data available. IPFIX enables variable-length strings, allows a vendor to be specified, and is an enabler technology that allows vendors to export any performance details they can provide.
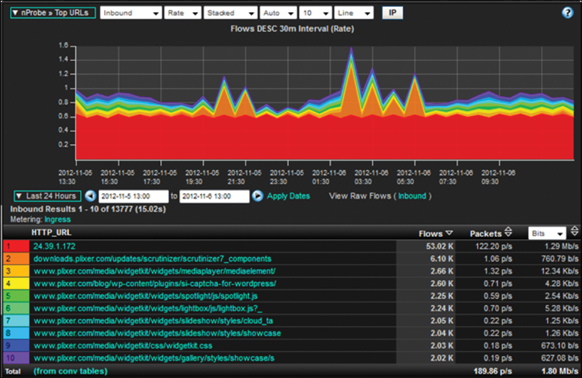
FIGURE 28-22 IPFIX Report
Note
IPFIX is based on a NetFlow implementation and serves as an industry standard for the export of flow information from all kinds of network devices. It is an IEFT protocol created out of the need to facilitate measurement, billing, and accounting services. You can find more information about IPFIX at https://tools.ietf.org/html/rfc7011.
Protocol Analyzer Output
Protocol analyzers primarily allow network engineers and security teams to capture network traffic and perform analysis of the captured data to identify potential malicious activity or problems with network traffic. The network traffic data can be observed in real time for troubleshooting purposes, monitored by an alerting tool such as a SIEM to identify active network threats, and/or retained to perform forensic analysis. Generally, there are two categories of protocol analyzers.
Ad hoc protocol analysis tools like Wireshark are used to troubleshoot or analyze a specific issue. Although these tools are best focused on analysis for a specific protocol or host, they are not suitable for monitoring an entire network for an extended period.
A number of enterprise analysis tools are more well suited for monitoring your entire corporate infrastructure around the clock. Well-known monitoring solutions such as Paessler PRTG, SolarWinds, Manage Engine, and Atera provide holistic monitoring of protocol traffic, database health, application availability, server uptime, and other collection points. The output from these analyzers can be fed into certain SIEMs and other security tools to not only alert of an attack but also provide proactive notifications using algorithms that can observe the steps taken before an attack.
A protocol analyzer is a tool for monitoring and analyzing capture signals as they traverse communication channels, such as satellite, computer bus, leased line, the Internet, and many other mediums. Figure 28-23 shows a 1480A physical device that is connected via USB to a computer and software that decodes the communication; this one is by International Test Instruments Corporation. This protocol analyzer can capture and decode even low-level bus communication protocols.
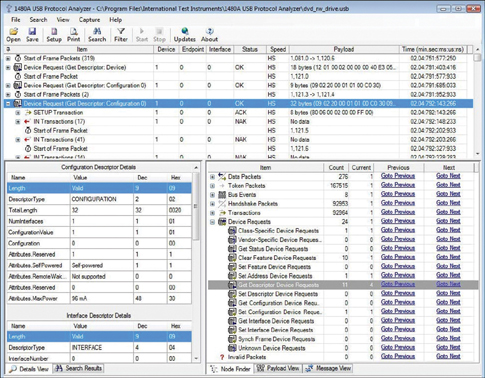
FIGURE 28-23 Protocol Analyzer Report
Chapter Review Activities
Use the features in this section to study and review the topics in this chapter.
Review Key Topics
Review the most important topics in the chapter, noted with the Key Topic icon in the outer margin of the page. Table 28-2 lists a reference of these key topics and the page number on which each is found.
Table 28-2 Key Topics for Chapter 28
Key Topic Element |
Description |
Page Number |
|---|---|---|
Paragraph |
Vulnerability scan output |
785 |
Section |
SIEM Dashboards |
786 |
Section |
Sensors |
787 |
Section |
Sensitivity |
788 |
Section |
Trends |
788 |
Section |
Alerts |
788 |
Section |
Correlation |
788 |
Paragraph |
Log files |
789 |
Section |
Network |
790 |
Section |
System |
791 |
Section |
Application |
792 |
Section |
Security |
793 |
Section |
Web |
794 |
Section |
DNS |
795 |
Section |
Authentication |
796 |
Section |
Dump Files |
797 |
Section |
VoIP and Call Managers |
799 |
Section |
Session Initiation Protocol Traffic |
800 |
Paragraph |
syslog/rsyslog/syslog-ng |
800 |
Paragraph |
journalctl |
802 |
Paragraph |
NXLog |
803 |
Section |
Bandwidth Monitors |
804 |
Section |
Metadata |
805 |
Section |
NetFlow/sFlow |
809 |
Section |
IPFIX |
811 |
Paragraph |
Protocol analyzers |
813 |
Define Key Terms
Define the following key terms from this chapter, and check your answers in the glossary:
Security Information and Event Management (SIEM)
Review Questions
Answer the following review questions. Check your answers with the answer key in Appendix A.
1. What is an indicator of a host on your network being compromised?
2. How does a SIEM use data correlation to help with discovering what took place during an incident?
3. Application logging can help an investigator by building a picture of what ________ looks like.
4. There are nearly a dozen logs available from DNS. They include which two message types?
5. What platform would cybercriminals use to make nearly anonymous calls?