
1.5 Phases of a Compiler
Most of the modern compilers have the following phases:
- Pre-processing: Usually, this phase is implemented as a macro processor, with its own macro language. It provides for file inclusion, conditional compilation control of segments of the source code, definition of literals, “pragma” commands to the compiler, etc.
- Lexical analysis: (Scanner) – checks for correct use of the input character set, identifies language atoms and tags them as the type of atom, e.g. NUMBER, IDENTIFIER, OPERATION.
- Syntax analysis: (Parser) – processes output of the Scanner, detects syntactic constructs and types of statements, generates a parse tree.
- Semantic analysis: (Mapper) – processes the parse trees, detects the “meaning” of statements and generates an intermediate code.
- Code Generation: Processes the intermediate code to generate the “machine code” for the target machine. Or alternately, works as pseudo-code interpreter to execute the intermediate code directly (e.g. Perl, Java, Python). In that case it may be called a Virtual Machine (VM).
- Error checking: (Spread throughout the compiler) – various kinds of error checking, appropriate for a particular phase, are done in each phase.
- Optimization: (Spread among several phases) – two kinds of optimizations are done – machine-dependent and machine-independent.
- A compiler can also be thought of as divided into two logical parts (see Fig. 1.11):
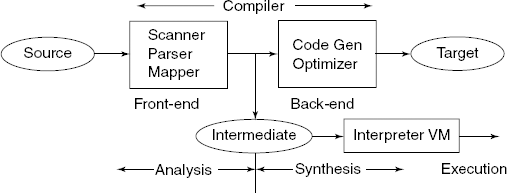
Front-end of compiler: Consisting of pre-processing, lexical, syntax and semantic phases. This is the part which does the analysis of the input code.
Back-end of compiler: Code generation, Optimization phases. This is the part which does the synthesis of the output or target code.
On the basis of this concept of two parts of a compiler, we can envision several situations for a compiler development project. We may be required to develop compilers for:
- single source language, single target language (1 × 1);
- multi-source language, single target language (m × 1);
- single source language, multi-target language (1 × n);
- multi-source language, multi-target language (m × n).
In the 1 × 1 case, we need to develop only one compiler, with one front-end and one back-end. For cases m × 1 and 1 × n, we have to develop m and n compilers, respectively. Instead, we really need to develop only m front-ends and one back-end for m × 1 case. Similarly, we really need to develop one front-end and only n back-end for 1 × n case (see Fig. 1.12).
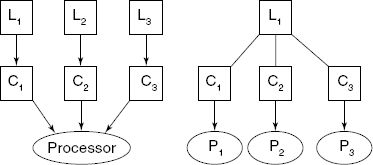
Fig. 1.12 Multiple source, single target (m × 1) and single source, multi-target (1 × n) cases. L Source language, C Compiler, P Processor
The real impact of this idea will be realized in the case of m × n, as shown in Fig. 1.13. Instead of developing m × n compilers, we need to develop only m front-ends and n back-ends, to fabricate a total of m × n compilers.
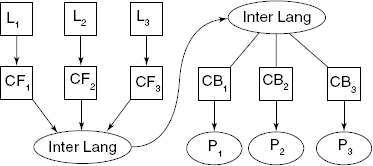
An example of implementation of this idea is the GNU C compiler, some preliminary details of which are given in Section 1.7.