
1.6 A More Detailed Look at Phases of a Compiler
We have already seen that a compiler has the following phases:
- Pre-processing
- Scanner – Lexical Analysis
- Parser – Syntax Analysis
- Mapper – Semantic Analysis
- Code Generation
- Assembler
- Optimization (spread over several phases)
- Error Checking (spread over several phases)
A compiler generates intermediate files between these phases, to communicate output of one phase as input to the next (see Fig. 1.14).
We now discuss each phase of a compiler in some details.
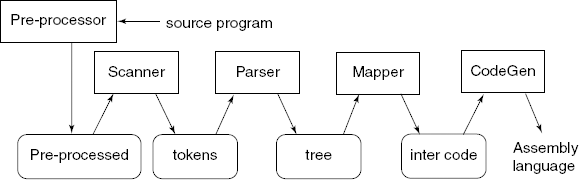
1.6.1 Lexical Analyzer - Scanner
Does lexical analysis, by doing the following:
- Analyze individual character sequences and find language tokens, like NUMBER, IDENTIFIER, OPERATOR, etc. Usually, these tokens are internally denoted by small integers, e.g. 257 for NUMBER, 258 for IDENTIFIER, 259 for OPERATOR, etc.
- Send a stream of pairs (token-type, value) for each language construct, to the Parser.
- Lexical tokens are generally defined as regular expressions (RE), for example:
NUMBER = [+ |−]d*[.]d+ - Usually based on a finite-state machine (FSM) model.
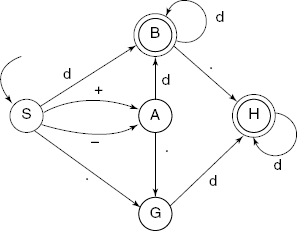
Refer to Appendix A for more details. Figure 1.15 shows FSM for the example RE given above.
See the example lexical analyzer code scanner.c given below.
/*----------------scanner.c--------------*/
#include <ctype.h>
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int token;
next(){
token = getchar();
}
error(char *s){
printf(“
error: %s
”, s);
for(next(); token != ‘
’; next());
}
func0(){
next();
if(isdigit(token))
func2();
else {
if((token == ‘+’) || (token == ‘-’))
func1();
else {
if(token == ‘.’)
func3();
else
error(“NAN”);
}
}
}
func1(){
next();
if(isdigit(token))
func2();
else {
if(token == ‘.’)
func3();
else
error(“Digit or . expected”);
}
}
func2(){
next();
if(isdigit(token))
func2();
else {
if(token == ‘.’)
func4();
else
func5();
}
}
func3(){
next();
if(isdigit(token))
func4();
else
error(“Digit expected”);
}
func4(){
next();
if(isdigit(token))
func4();
else
func5();
}
func5(){
if(token == ‘
’) {
printf(“
NUMBER
”);
} else
error(“invalid”);
} main(){
while(1){
func0();
}
}
This Scanner code is for the finite-state machine shown in Fig. 1.15.
1.6.2 SyntaxAnalyzer – Parser
Does syntax analysis, by doing the following:
- Analyze the stream of (tokens, value) pairs and find language syntactic constructs, like ASSIGNMENT, IF-THEN-ELSE, WHILE, FOR, etc.
- Make a syntax tree for each identified construct.
- Detect syntax errors while doing the above.
Most of the programming languages are designed to be context-free languages (CFL). A pushdown automaton, i.e. an FSM + stack is an acceptor for these types of languages. See Appendix A for details.
Consider the following example grammar:
S –> E#
E –> T { + T }
T –> F { * F }
F –> 1p E rp | n
This grammar generates a language consisting of arithmetic expressions like
n n+n n*n n+n*n n*n+n (n+n)*n (n+n)*(n+n) … …
where ‘n’ represents a number token and ‘lp’and ‘rp’, respectively, represent left and right parentheses tokens coming from the Scanner.
The code for a simplified example parser, parser.c, for the above grammar is given below. This type of parser is called a recursive-descent parser, whose design is discussed in Chapter 4.
/*--------------parser.c----------------------*/
#include <stdio.h>
#include <string.h>
int err, t;
char str[82];
error(int i){
err = 1;
printf(“error number %d
”, i);
mungetc();
while(mgetch() != ‘
’);
mungetc();
}
nextsymbol(){
int c;
c = mgetch();
mungetc();
return(c);
}
pE(){
pT();
while(nextsymbol() == ‘+’) {
pplus();
pT();
}
}
pT(){
pF();
while(nextsymbol() == ‘*’) {
past();
pF();
}
}
pF(){
switch(nextsymbol()) {
case ‘(’:{
p1p();
pE();
prp();
break;
}
case ‘a’:{
pa();
break;
}
default: error(10);
}
}
pa(){
if(symbol)) != ‘a’)
error(1);
}
p1p(){
if(symbol() != ‘(’)
error(2);
}
prp(){
if(symbol() != ‘)’)
error(3);
}
pplus(){
if(symbol() != ‘+’)
error(4);
}
past(){
if(symbol)) != ‘*’)
error(5);
}
symbol(){
int c;
c = mgetch();
return(c);
}
mgetch(){
char c;
t++;
c = str[t];
return) (c >= ‘a’ & & c <= ‘z’)?’a’:c);
}
mungetc(){
t--;
}
main(){
int c;
while(1) {
err = 0;
t = -1;
fgets(str,82,stdin);
printf(“
%s”, str);
pE();
c = mgetch();
if(c == ‘
’) {
if(!err) {
printf(“
ACCEPTED
”);
} else {
printf(“
REJECTED
”);
t = -1;
fgets(str,82,stdin);
printf(“
%s”, str);
err = 0;
}
}
}
}
Note that this simplified parser does not generate the syntax tree, it only detects correctness of syntax.
1.6.3 Semantic Analyzer – Mapper
It converts or maps syntax trees for each construct into a sequence of intermediate language statements.
For example, source:
d = a * (b + c);
The syntax tree generated by the Parser may look like as shown in Fig. 1.16.
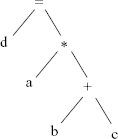
The (unoptimized) intermediate language code may look like
load b
add c
store t1
load a
mult t1
store t2
load t2
store d
1.6.4 Code Generation and Machine-dependent Optimization
From the intermediate code, assembly language statements can be generated. Instead of temporaries (t1, t2, etc.) in memory, CPU registers may be assigned.
Code Optimization
In the example intermediate code, several possibilities are there:
- unnecessary stores and loads
- sequence of statements
A better intermediate code could be:
load b
add c
mult a
store d
1.6.5 Optimization
What we have done above is Optimization. There are two types of optimization – machine-independent and machine-dependent optimizations. There are several possibilities of optimization:
- register allocation,
- taking invariant code outside loops,
- operator rank reduction (e.g. add instead of mult),
- constant expression calculation (e.g. a = 3.142 * 56, RHS done at compile time),
- removal of dead code,
- rolling out a loop, etc.
Several types and levels of optimization are available in GNU C compiler, as briefly indicated in Section. 1.7.
1.6.6 How to Develop Optimized Code?
- First get your code working completely error-free without any optimization.
- You should put the code to be optimized (i.e. most time-consuming functions) in a separate source file.
- Be aware of general nature of the optimization (code changes) introduced by different switches.
- Start with lowest level of optimization (-O only), get the assembly output (use -S switch).
- Carefully inspect it; does it do your job still, the way you wanted?
- If yes, apply next higher level of optimization and repeat.