
8
Intermediate Code
What you will learn in this chapter
- What is Intermediate Code and why do we need it?
- What are different commonly used forms of Intermediate Code?
- How to build a Parse tree in memory?
- What are Polish and Reverse Polish Notation (RPN)?
- How to generate RPN from a parse tree?
- What is N-tuple notation?
- How to generate N-tuples?
- What is an Abstract Syntax Tree (AST)?
- How to generate an AST for a given source code?
- What are Virtual Machines?
- An introduction to PASCAL P-code
- An introduction to Java Bytecode
- What are Threaded codes and what are their variants?
- Implementation of Threaded code interpreter on Motorola 68000 and Intel x86 series machines
- Introduction to SECD and WAM virtual machines
- Real-life: Intermediate codes used in GNU GCC
Key Words
Intermediate codes, reverse Polish notation (RPN), N-tuple notation, abstract syntax tree (AST), virtual machines, P-code, bytecode, threaded codes, SECD, WAM, GNU GCC
The translation of a High Level language program into its machine executable version is performed via a sequence of transformations, which we can roughly divide into two groups – analysis and synthesis steps. Each transformation outputs the program representation in a particular format or language. Especially, the boundary between the analysis and the synthesis parts is usually formed by representation in the form of an Intermediate language (see Fig. 8.1).
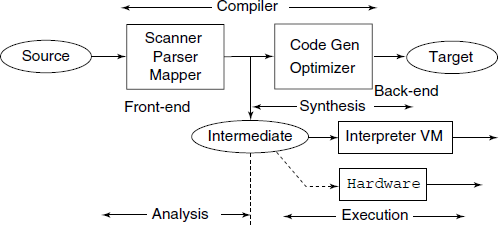
Fig. 8.1 Intermediate language form of the program being translated links the analysis and the synthesis parts
The Intermediate language form of the program is useful in many ways:
- Certain types of optimizations can be done more easily on this form of the program.
- It can be used as a possible target language and used for interpretive execution, as used in Java (Bytecode), PASCAL (P-code, see Section 8.5.1), FORTH (see Section 8.6), etc. Such an implementation structure provides a more secure language (Java) or compact translation (FORTH).
- Two versions of the compiler can be built:
- a check-out or debugging compiler, which executes the user program via an interpreter (also called a virtual machine) of the Intermediate code, for a quick partial compilation and execution, run-time error diagnostics, execution tracing, etc.
- an optimizing compiler, which operates further on the Intermediate code, does various forms of optimizations and generate a machine native code. This code will become production version of the program.
Note that the high-level language specification, which in fact is defined by the compiler, remains essentially the same in both ways of using the compiler.
- If the selected Intermediate form is machine independent, then the compiler is more portable.
- Ideally, for n languages and m machine architectures, total code writing effort will be O(n + m) and not O(nm) (see Fig. 8.2).
- Disadvantage: The interpretive execution will be less efficient compared to direct translation to the native machine language. This disadvantage is adequately offset by numerous advantages listed above.
- We should also note that in real-life a High Level language implementation is almost always a judicious mix of the pure compilation and interpretation schemes.
- Apart from the two major ways in which the Intermediate form is used – as a step in full translation to the target language and as language for interpretive execution – a third possibility has come up in recent years. Can we not design and build a hardware (CPU) whose machine language itself is the Intermediate form? At least partial success with Java has been achieved, which can lead to Java machines.
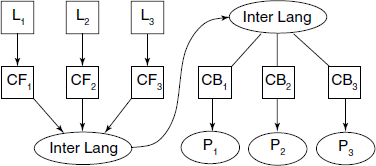
We keep the three possible uses of the Intermediate form in mind, while discussing it in detail.
Although C itself is used as an Intermediate language by some high-level languages (Eiffel, Sather, Esterel) which do not output object or machine code, but output C code only, to be submitted to
a C compiler, which then outputs finished object or machine code, we restrict ourselves to more traditional intermediate codes.
We now discuss several possible Intermediate forms of the program. We also indicate how to generate the intermediate code for some of them. For that purpose we use the following example grammar, given in yacc input format.
program : ‘P’ stmt-list ‘.’ ;
stmt-list : stmt
| stmt ‘;’ stmt-list ;
stmt : expr | if | while | let ;
if : ‘I’ ‘(’ expr ‘)’ stmt-list ‘E’
| ‘I’ ‘(’ expr ‘)’ stmt-list ‘:’ stmt-list ‘E’;
while : ‘W’ ‘(’ expr ‘)’ stmt-list ‘Z’ ;
let : ‘L’ ‘a’ ‘=’ expr ;
expr : term | term ‘+’ expr ;
term : factor | factor ‘*’ term ;
factor : ‘(’ expr ‘)’ | a ;
Note that in order to have almost trivial Scanner, we have used single-character “keywords”. Also, we do not distinguish between numerical constants and variables – all are represented by ‘a’. A close look at the grammar will tell you that we can build a recursive-descent parser for this grammar, which in fact is an extension of grammar given in Sections 1.6.2 and 2.2.2. First, we see how to get a parse tree out of the parser.