
8.6 Threaded Code
This Intermediate form of the program is derived from the fact that it is possible, for many High Level languages, to express and optimize the translated form of the program as a sequence of CALLs to certain primitive functions. Just as a thread strings beads together, the “thread” of control flow strings these functions together to achieve the intent of the source program.
The threaded code works in semi-interpretive mode and is amenable to machine-independent optimization. It is the basis for implementation of languages like FORTH, PostScript, GhostScript, Java Bytecode, .NET bytecode, etc. It was also used in the FORTRAN and COBOL compilers on PDP-11 and VAX-11 machines.
There are several ways in which a threaded code can be implemented. We discuss below the most well-known among them. First, we see how the idea of a threaded code arises.
8.6.1 Subroutine Threaded Code
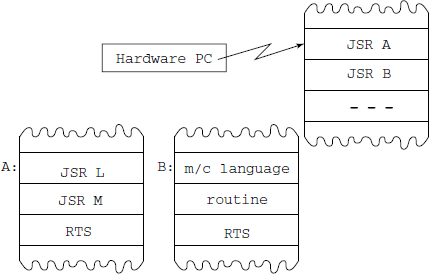
This is how a program translated from a typical High Level language into machine language would work (see Fig. 8.9). The execution is controlled by three operations:
NEXT: Execute next instruction:
fetch instruction from (PC)
PC++
execute the fetched instruction
CALL: Jump-to-subroutine A instruction (JSR):
push PC on stack
PC = address of subr A
do NEXT
RETURN: Return-from-subroutine (RTS):
PC = pop(stack)
do NEXT
Note that the hardware stack, which is generally present in all modern CPUs, is used to save PC values during a subroutine CALL.
Somebody thought: “why not remove the JSR op-code? It will save bytes. Keep only the subroutine addresses” that leads us to the Direct Threaded code.
8.6.2 Direct Threaded Code
See Fig. 8.10. The three critical operations are implemented as follows:
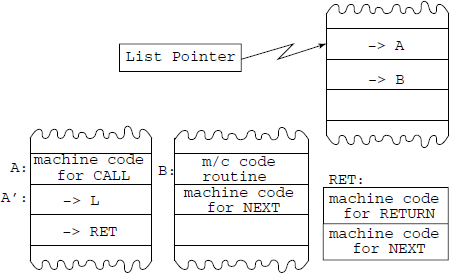
NEXT: Execute next list item as a machine code:
TMP = Mem(LP)
increament LP to next item
JMP (TMP)
CALL: Call a subroutine A:
push LP to stack
LP = beginning of list-subroutine of A, A’
do NEXT
RET: Return from list-subroutine:
LP = TOS
do NEXT
We strongly advise you to see that you understand these three operations and convince yourself that they work for both list-subroutines and machine language subroutines.
8.6.3 Indirect Threaded Code
Indirect Threaded code is preferred on machines which have indirect addressing available at low cost (i.e., only a few clock cycles), as it gives a somewhat more compact code compared to the Direct Threaded code (see Fig. 8.11).
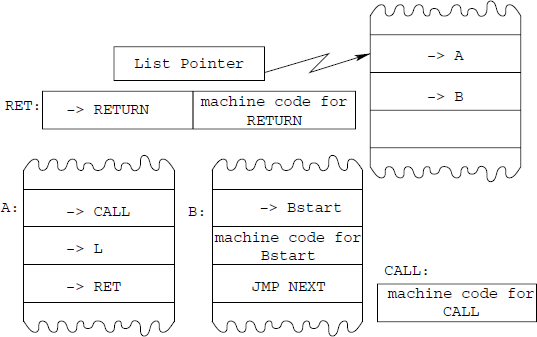
The three critical operations are implemented as follows:
NEXT: Execute next list item as a machine code:
TMP = Mem(LP)
increament LP to next item
CODE-TMP = Mem(TMP)
JMP (CODE-TMP)
CALL: Call a subroutine A:
push LP to stack
increment TMP to next item
LP = TMP
do NEXT
RET: Return from list-subroutine:
LP = TOS
do NEXT
8.6.4 Token Threaded Code
Direct Threaded code cannot be simply transported from one machine to another, because it contains the code addresses that vary from machine to machine. Token threaded code uses a fixed virtual machine instruction encoding, allowing code portability at the price of a table lookup (that maps the instruction token to its code address) in each NEXT. Indirect threading and token threading are orthogonal, so they can be combined into indirect token threading (with an even slower NEXT). Usually, the token is a single byte, which allows up to 255 basic “op-codes” in the virtual machine.
8.6.5 Implementation of Threaded Code on Motorola 68000
We present here a typical implementation of Direct Threaded code on Motorola 68000 machine. The machine registers used are as follows:
PC: Normal hardware PC
SP: (A7) Return-stack pointer
PSP: (A6) Parameter stack pointer
LP: (A5) List-pointer
TMP: (A4) Temporary storage
The three critical operations are implemented as follows. Note that they are stored in the memory in the order shown, which makes for a very compact code.
RET: MOVE.W (A7)+, A5
NEXT: MOVE.W (A5)+, A4
JMP (A4)
CALL: MOVE.W A5, −(A7)
ADD.W 16, A5
MOVE.W (A5)+, A4
JMP (A4)
8.6.6 Implementation of Threaded Code on Intel x86 Machines
Here is a typical implementation of Direct Threaded code on Intel x86 series machines. The machine registers used are as follows:
PC: Normal hardware PC
SP: (EBP) Return-stack pointer
PSP: (ESP) Parameter stack pointer
LP: (ESI) List-pointer
The three critical operations are implemented as follows, in the order as stored in the memory.
CALL:LEA EBP, −4(EBP)
MOVW (EBP), ESI
ADDW EAX, 4
MOVW ESI, EAX
NEXT:LODS
JMP *(EAX)
RET:MOV ESP, (EBP)
LEA EBP, 4(EBP)
LODS
JMP *(EAX)