
Chapter 11
Multiscale Analysis of Complex Networks
In the previous two chapters, we discussed frequency analysis of complex network data using the graph Fourier transform (GFT). Being a global transform, the GFT has the capability of capturing global variations in a graph signal; however, it fails to identify the local vatiations. In classical signal processing, wavelet transforms have been extensively used for extracting local as well as global information from the data. Wavelets have the capability to simultaneously localize a signal content in both time and frequency that allows us to extract information from the data at various scales. Similarly, wavelet-like transforms for network data give us a means to analyze the network data at various scales. Various methods have been developed to design localized, multiscale transforms for analyzing data defined on complex networks. This chapter presents these multiscale techniques for complex network data analysis.
11.1 Introduction
Multiscale transforms provide us a means to analyze data at different scales (levels of resolution). In classical signal processing, multiscale transforms have been extremely useful in a number of applications such as compression, denoising, identification of transient points in discrete-time signals, and images. Wavelets have been most popular among multiresolution techniques. An extremely popular usage of wavelet to compress images is JPEG 2000 [196], which uses wavelet transform for data compression. Therefore, multiscale techniques may prove to be phenomenal in analyzing network data as well.
The GFT defined in Chapter 10 is a powerful tool to analyze data defined on complex networks. However, being a global transform, it has certain limitations and drawbacks too. For example, it is highly sensitive to changes in network structures, since a small change (addition or deletion of a few nodes or edges) in the network topology may result in very different eigenvalues and eigenvectors of the graph Laplacian. Moreover, GFT fails to provide any information regarding where in the network topology particular frequency components are present. Although windowed graph Fourier transform gives the answer to where in the network topology particular frequency components are present, it does not localize the signal content in the frequency domain.
In classical signal processing, various techniques are available for wavelet analysis of signals. For continuous time signals, wavelets at different scales are constructed by translating and scaling a single mother wavelet. There also exist second-generation wavelets [197], which are not necessarily composed of either shifts or dilations of some single function. Nevertheless, the wavelets are localized and indexed across a range of scales and locations within scales, have zero integral, and share some common characteristics in their definition. Moreover, for discrete-time signals, there exist discrete wavelet transforms [198] that can be implemented through filterbanks [199] or lifting-based schemes [200].
In the past decade, various techniques have been developed that allow localized multiscale analysis of complex network data. These techniques include the Crovella and Kolaczyk wavelet transform (CKWT) [201], random transform [202], lifting-based wavelets [203], [204], [205], spectral graph wavelet transform (SGWT) [206], two-channel wavelet filter banks [193], and diffusion wavelets [207]. These different approaches derive analogy from different classical multiresolution schemes. For example, SGWT derives analogy from the classical continuous-time wavelet transform, whereas lifting-based wavelets and two-channel wavelet filter banks are the analogues of classical discrete-time wavelet transforms. Although the classical continuous wavelets are time invariant, the graph wavelets are not space invariant due to irregular structure of the underlying graph.
Similar to classical wavelet transform, a graph wavelet transform aims to localize graph signal contents in both the vertex as well as the spectral domains. As described in previous chapters, translation and scaling of graph signals are not straightforward operations. Therefore, the concepts of classical wavelet transforms, where wavelets are constructed by translating and scaling a single mother wavelet, cannot be extended directly in graph settings. Moreover, two-channel wavelet filter banks require downsampling of graph signals, which is not a simple operation. However, these difficulties can be overcome by using the GFT. In the next section, various existing techniques for designing wavelets on graphs are presented.
11.2 Multiscale Transforms for Complex Network Data
Multiple techniques exist for multiscale analysis of complex network data. Multiscale transforms can be designed in both vertex as well as spectral domains. In vertex domain designs, spatial features such as hop distance are used. On the other hand, in spectral domain designs, spectral features of graphs such as low and high frequencies are utilized to define multiple scales. Figure 11.1 shows different multiscale transforms for complex network data under the two categories. In vertex domain designs, the spatial features of complex networks are explored, whereas in spectral domain designs, the eigendecomposition of one of the network matrices is used.
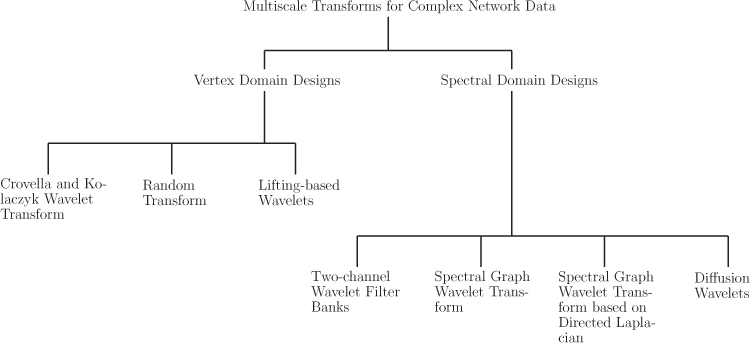
Figure 11.1. Classification of multiscale transforms for data defined on complex networks
11.2.1 Vertex Domain Designs
Vertex domain designs of graph wavelets utilize spatial features of graphs to construct wavelets at multiple scales. The spatial features can be connectivity of the nodes in a graph or shortest distance between two nodes. The CKWT [201], random transforms [202], lifting-based wavelets [203], [204], [205], and tree wavelets [208], [209] fall under this category of wavelet designs.
In CKWT, the wavelet is constructed based on k-hop distance such that the value of wavelet centered at node i on node j depends only on shortest path distance between nodes i and j. CKWT is designed for unweighted graphs, but inverse transform has not been mentioned.
Random transform [202] was proposed to analyze sensor network data at multiple resolutions.
Lifting-based wavelet transform [203], [204], [205] splits the nodes of a graph into two sets: even and odd nodes. Then, as in standard lifting, data on the nodes of one parity are used to predict/update those of the other. By construction, these transforms are invertible; that is, the graph signal can be found from the transform coefficients.
11.2.2 Spectral Domain Designs
Spectral domain designs of multiscale transforms utilize spectral properties—the eigenvalues and eigenvectors of one of the graph matrices—to derive wavelets at multiple scales. Examples in this category of wavelet designs include SGWT [206], two-channel wavelet filter banks [193], and diffusion wavelets [207].
SGWT is defined by deriving an analogy from the continuous wavelet transform, where wavelets at various scales are derived by translating and dilating a mother wavelet. On the other hand, two-channel wavelet filter banks are analogous to classical discrete wavelet transforms. Diffusion wavelets are orthonormal and use diffusion as a scaling tool for multiscale analysis. In diffusion wavelets, the wavelet construction is based on compressed representations of powers of a diffusion operator. In contrast to diffusion wavelets, SGWT gives precise analogy to classical continuous wavelet transform, gives highly redundant transform, and offers finer control over the selection of wavelet scales. In addition, fast algorithms exist for SGWT computation.
11.3 Crovella and Kolaczyk Wavelet Transform
In 2002, Crovella and Kolaczyk developed a class of wavelets on graphs for spatial traffic analysis in computer networks [201]. Their work was one of the initial attempts to generalize the traditional wavelet transform to graph signals. The CKWT is an example of vertex domain wavelet design on graphs. It utilizes only a single network metric, shortest path distance or geodesic distance, for computing wavelets on networks. The motivation behind the development of CKWT was to form highly summarized views of traffic in a network. CKWT can be used to gain insight into a network’s global traffic response to a link failure and to localize the extent of a failure event within the network.
11.3.1 CK Wavelets
A Crovella and Kolaczyk (CK) wavelet at scale j and centered at node i is an N × 1 vector ψCKWTji
Let us define ?(i,h)
The wavelet ψCKWTji
for some constants {ajh}h=0,1,... ,j satisfying ∑jh=0ajh=0
Computation of Coefficients ajh
To compute the coefficients ajh, a continuous-time wavelet ψ(t) supported on the unit interval [0, 1) is used. This continuous-time wavelet function must have zero mean, that is, ∫10ψ(t)dt=0
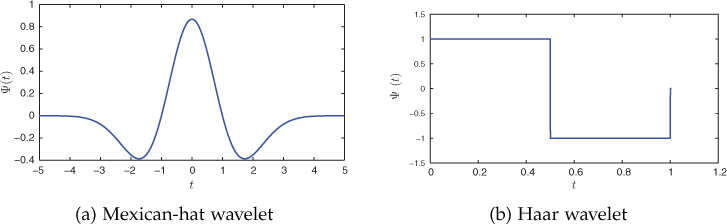
Figure 11.2. Continuous-time Mexican-hat and Haar wavelets
where Ijh = [h/(j + 1), (h + 1)/(j + 1)] is one of the equal-length subintervals over [0,1].
11.3.2 Wavelet Transform
The wavelets defined above can be used to represent a graph signal in the transform domain. These transform coefficients can be utilized to analyze graph signals more closely. The CKWT of a graph signal f at scale j and node i is given by
These coefficients for a graph signal at different scales can be utilized to extract useful information, for example, the spread of the graph signal localized to a particular node.
11.3.3 Wavelet Properties
The properties of wavelets in the CKWT scheme are listed here.
A CK wavelet has zero mean, that is, ∑Nk=1ψCKWTji(k)=0
∑Nk=1ψCKWTji(k)=0 , where ψCKWTjiψCKWTji is a graph wavelet at scale j and centered at vertex i.A CK wavelet at scale j and centered at vertex i
i (ψCKWTjiψCKWTji ) has constant value at the nodes that are equidistant from center node i. That is, ψCKWTji(k)=ψCKWTji(l)ψCKWTji(k)=ψCKWTji(l) , if d?(i,k)=d?(i,l)≤jdG(i,k)=dG(i,l)≤j . This property of symmetricity can be visualized from an example graph shown in Figure 11.3. A wavelet centered at node 1 will have equal values at nodes 2, 3 and 4 that are at one-hop distance from the center node 1. Also, the wavelet has equal values at nodes 5, 6, 7, and 8, which are at two-hop distance from the center node.A CK wavelet at scale j and centered at vertex i
i (ψCKWTjiψCKWTji ) has zero value at the nodes that are not within j-hops from center node i. That is, ψCKWTji(k)=0ψCKWTji(k)=0 , if d?(i,k)=d?(i,l)≤jdG(i,k)=dG(i,l)≤j .
11.3.4 Examples
Consider the network shown in Figure 11.3. Assuming the Haar wavelet shown in Figure 11.2(b) as ψ(t), Table 11.1 presents the coefficients ajh for various values of j and h.

Figure 11.3. Illustration of symmetricity property of a graph wavelet in CKWT scheme
Table 11.1. Computing ajh for the network shown in Figure 11.3 (assuming ψ(t) as Haar wavelet)
j |
h |
Ijh |
ajh |
1 |
0 1 |
[0,12] [12,1] |
1 −1 |
2 |
0 1 2 |
[0,13] [0,13][13,23] [23,1] |
1 0 −1 |
Having found the values of coefficients ajh, we can compute wavelets centered at the desired node using Equation (11.3.1). For example, CK wavelets centered at node 1 and scales j = 1, 2 are
ψCKWT11=[1−1/3−1/3−1/30000],ψCKWT21=[1000−1/4−1/4−1/4−1/4].
11.3.5 Advantages and Disadvantages
CKWT was one of the first methods that provide multiscale analysis on graphs. CK wavelets are easy to implement. The wavelets are symmetric about the center node and have zero mean. However, CKWT is limited to undirected and unweighted graphs. Being designed in the vertex domain, it does not provide vertex-frequency interpretation as in classical wavelet transforms. Moreover, CKWT is not invertible and, therefore, cannot be used for applications such as compression and denoising.
11.4 Random Transform
Wang and Ramachandran [202] proposed random transform for multiresolution representation of sensor network data. Under their framework, two bases were proposed that allow us to obtain averages or detect anomalies at different resolutions corresponding to the neighborhood hop size. The framework is motivated by the classical wavelet functions consisting of averages and differences. Multiresolution analysis is performed through basis functions that have finite support over the network. These functions can be scaled to different resolutions, corresponding to different neighborhood sizes.
The two different basis functions under this framework are weighted average basis functions and weighted difference basis functions. A weighted average basis function at scale h and centered at node i is represented by ψhi. It computes the weighted average on the h-hop neighborhood of node i, giving more weight to the value at node i. Let ∂?(i,h)
(11.4.1) ψhi(j)={adi,hifj∈?(i,h)i,(1−a)+adi,hifj=i,0otherwise,
where 0<a<12
A weighted difference basis function at scale j and centered at node i is represented as φhi. It computes the weighted difference of the value at node i and the values at its h-hop neighbors. It is given by
(11.4.2) ϕhi(j)={−bdi,hifj∈?(i,h)i,(1+b)−bdi,hifj=i,0otherwise,
where b > 0 is a constant.
The set of weighted average basis functions at scale h can be represented in matrix form as Ψh = [ψh1, ψh2,... ,ψhN], and the set of weighted average basis functions at scale h can be represented in matrix form as Φh = [φh1, φh2,... ,φhN]. It is worth noting that for any non-negative integer value of h∈ℕ
By changing the scale h, we can compute basis functions with different support on the graph, and subsequently these basis functions can be utilized to analyze data, such as sensor network data, at multiple resolutions. Intuitively, this approach defines a two-channel wavelet filter bank on the graph consisting of two types of linear filters: (i) approximation filters (given by Equation (11.4.1)) and (ii) detail filters (given by Equation (11.4.2)).
11.4.1 Advantages and Disadvantages
The transform bases defined in this approach are very simple to compute. However, this approach is limited to undirected and unweighted graphs. Also, these transforms are oversampled and produce output of the size twice that of the input.
11.5 Lifting-Based Wavelets
Lifting-based wavelet transforms [203], [204], [205] are constructed by splitting the nodes into two disjoint sets of even and odd nodes. Then, odd data is predicted using even data, and subsequently, even data is updated using predicted odd data. The block diagram of one-step lifting-based transform is shown in Figure 11.4, where fe and fo, respectively, are the even and odd parts of the input graph signal f, ??
In standard lifting, a discrete-time signal is first split into two sequences: even sequence and odd sequence. Similarly, in order to apply the lifting-based transform to an arbitrary graph signal, we need to split the nodes ?
11.5.1 Splitting of a Graph into Even and Odd Nodes
A good splitting of a graph into two disjoint sets of nodes must minimize the number of conflicts (i.e., the percentage of direct neighbors in the graph that have same parity). The splitting of a graph is a graph coloring problem (two color) that minimizes the number of conflicts. For this purpose, a conservative fixed-probability (CFP) colorer algorithm can be used. The CFP colorer algorithm solves the corresponding two-color graph coloring problem (2-GCP) so as to minimize the conflicts.
Let us consider that the algorithm results in m number of odd nodes and n number of even nodes, where m + n = N. The graph signal f and the adjacency matrix of the graph ?
where submatrix So is the adjacency matrix of the subgraph containing odd nodes and Se is the adjacency matrix of the subgraph containing even nodes. These matrices contain edges which have conflicts, since they connect nodes of the same parity. The block matrices P and Up contain edges which do not have conflicts. The matrices P and Up are used to design prediction and update filters, respectively, for lifting-based transform. Note that a good even-odd splitting of a graph should minimize the edge information present in the matrices So and Se (thus minimizing the number of conflicts).
11.5.2 Lifting-Based Transform
After splitting of the nodes into even and odd sets, prediction and update steps are performed. A block diagram of the lifting operation is shown in Figure 11.4. Odd data is predicted from the even data using a prediction filter ??

Figure 11.4. Block diagram of lifting-based transform
The lifting-based transform outputs two vectors f1 and d1 for an input graph signal f. The vector f1 is analogous to the approximation sequence of standard lifting transform and the vector d1 is analogous to the detail sequence of standard lifting transform. The lifting-based wavelet transform on a graph can be performed by using the following equations:
where ??
The lifting-based transform is invertible by its construction. The inverse transform can be calculated using the following equations:
Depending on the application, we can perform multiple lifting operations on the updated set of even nodes. Starting from scale j = 1, one-step lifting results in the even set of nodes ?1
11.6 Two-Channel Graph Wavelet Filter Banks
Two-channel graph wavelet filter banks [193] are analogous to filter bank implementation of classical discrete wavelet transforms. Design of two-channel wavelet filter banks falls under the spectral domain design category as it involves spectral decomposition of the graph Laplacian matrix. Analogous to classical two-channel filter banks (see Appendix B.4), two-channel wavelet filter banks on graphs decompose a graph signal into a low-pass (smooth) graph signal and a high-pass (detail) graph signal component and, thus, decompose the graph signal into multiple resolutions.
As discussed in Chapter 8 (Section 8.5.6), bipartite graphs exhibit a spectral folding phenomenon, which allows one to design perfect reconstruction wavelet graph filter banks known as graph quadrature mirror filter banks (graph-QMFs) for bipartite graphs. Moreover, for arbitrary graphs, two-channel filter banks are constructed in cascade, along a series of bipartite subgraphs of the original graph.
In the discussion of two-channel graph wavelet filter banks, the normalized form of Laplacian ?norm=?−12??12
A two-channel graph filter bank constitutes downsamplers and upsamplers. Therefore, first we discuss downsampling and upsampling operations over graphs.
11.6.1 Downsampling and Upsampling in Graphs
The downsampling and upsampling blocks are fundamental in two-channel graph wavelet filter banks. Downsampling and upsampling operations for discrete-time signals are discussed in Appendix B.3.1. A classical downsampler discards alternate samples, whereas an upsampler inserts zeros in between two samples. However, in graph settings, these operations are not straightforward: there is no interpretation of alternate samples for a graph signal. Therefore, a different approach is required to define the operations of downsampling and upsampling for graph signals.
To downsample a graph signal, first we need to find a set of nodes ℋ
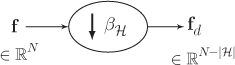
Figure 11.5. A downsampler for graph signals
An upsampler characterized by βℋ
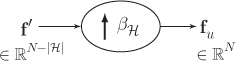
Figure 11.6. An upsampler for graph signals
A cascaded block consisting of a downsampler followed by an upsampler is shown in Figure 11.7. This cascaded structure is common in graph filter banks. Overall, it performs downsample then upsample (DU) operation. Let us define a downsampling matrix ?βℋ=diag{βℋ(n)}

Figure 11.7. A downsampler and an upsampler in cascade
where IN is an N × N identity matrix and
DU Operation in Spectral Domain
Let u0, u1,... , uN−1 be the eigenvectors of the (normalized) Laplacian matrix of the graph ?
Since ?βℋ
In this equation, observe that the first term is the GFT coefficient of the input graph signal at the corresponding frequency λl, whereas the second term is the deformation component. Let us represent the deformed harmonic at frequency λℓ as ?dℓ=?βℋ?ℓ
where ˆfd(λℓ)=?T?dℓ
In simple form, the spectrum of the DU graph signal can be written as
where
is the deformed spectrum of signal f. Note that ?d=?βℋ?
Example 11.6.1
This example illustrates the DU operation. Consider the bipartite graph shown in Figure 11.8(a). The eigenvalues of the normalized graph Laplacian are shown in Figure 11.8(b). Now consider a signal f = [−2, 3, −2, 5, 1, −3, 1]T defined on the graph. Let us assume that we downsample the signal by discarding a set of nodes ℋ={5,6,7}
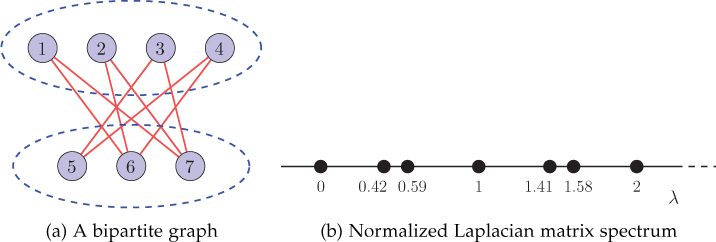
Figure 11.8. A bipartite graph and its normalized Laplacian matrix spectrum
The matrices containing the graph Fourier basis U and the deformed graph Fourier basis ?d=?βℋ?
?=[0.35360.353600.707100.35360.35360.35360.35360−0.707100.35360.35360.3536−0.3536−0.50000−0.5000−0.35360.35360.3536−0.35360.500000.5000−0.35360.35360.3536−0.61240000.6124−0.35360.43300.25000.50000−0.5000−0.2500−0.43300.43300.2500−0.500000.5000−0.2500−0.4330]
and
(11.3.9) ?d=[0.35360.353600.707100.35360.35360.35360.35360−0.707100.35360.35360.3536−0.3536−0.50000−0.5000−0.35360.35360.3536−0.35360.500000.5000−0.35360.3536−0.35360.6124000−0.61240.3536−0.4330−0.2500−0.500000.50000.25000.4330−0.4330−0.25000.50000−0.50000.25000.4330].
The spectrum of signal f and the spectrum of its DU version fdu are plotted in Figures 11.9(a) and (b), respectively. Since the underlying graph is bipartite, notice that the spectrum ^?du
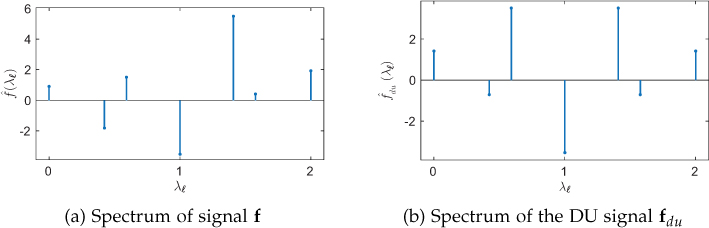
Figure 11.9. Spectra of signal f defined on the bipartite graph shown in Figure 11.8(a) and its DU version
Downsampling in Bipartite Graphs and Spectral Folding
As described in Chapter 2, a bipartite graph ?
As discussed in Chapter 8, the spectrum of normalized Laplacian for bipartite graphs is symmetric about 1. This symmetry property is responsible for the phenomenon of spectral folding in bipartite graphs: if uℓ is an eigenvector of Lnorm corresponding to the eigenvalue λ ℓ, then the deformed eigenvector ?dℓ=?β?ℓ
Using Equations (11.6.5) and (11.6.6), for bipartite graphs, we can write
The above equation can be interpreted as follows. In the spectral domain, the result of a DU operation over a bipartite graph is the average of the original graph signal and an aliasing term which is the folded version of original signal with respect to λ = 1.
11.6.2 Two-Channel Graph Wavelet Filter Banks
A two-channel graph filter bank consists of the following blocks: an analysis graph filter bank, downsamplers, upsamplers, and a synthesis graph filter bank. A block diagram of a two-channel graph wavelet filter bank is shown in Figure 11.10. An analysis graph filter bank is a set of graph-filters H0 and H1 with a common input. It splits the input graph signal into sub-band graph signals. The filter H0 is a low-pass filter, whereas H1 is a high-pass filter. Thus, the analysis graph filter bank decomposes a graph signal in two sub-bands: low frequency sub-band and high frequency sub-band. On the other hand, a synthesis graph filter bank is a set of graph-filters G0 and G1 with a summed output. It combines multiple sub-band graph signals to produce a single output.
A two-channel graph wavelet filter bank decomposes a graph signal (?∈ℝN
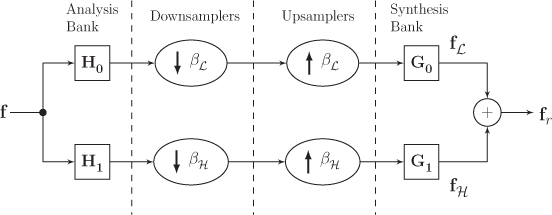
Figure 11.10. Two channel filter bank on graph
The reconstructed signal is the sum of these two signal components:
(11.6.12) ??=?ℒ+?ℋ=[12?0(?N+?βℒ)?0+12?1(?N+?βℋ)?1]?=[12(?0?0+?1?1)⏟Term 1+12(?0?βℒ?0+?1?βℋ?1)⏟Term 2]?.
In the above equation, Term 1 is the equivalent operator for the system without the DU operation. Term 2 is an aliasing term that comes from the DU operation. For perfect reconstruction, Term 2 should be zero and Term 1 should be an identity matrix. Therefore, perfect reconstruction is possible if
where c is a scalar constant, and
In case of bipartite graphs, consider βℒ=β and βℋ=−β. Then, for a bipartite graph, the condition given by Equation (11.6.14) can be rewritten as
The above conditions are incorporated for designing a graph-QMF, which is described next.
11.6.3 Graph Quadrature-Mirror Filterbanks
Section 11.6.1 explained that the DU operation in bipartite graphs exhibits a spectral folding phenomenon. By utilizing this phenomenon, a perfect reconstruction filter bank—the graph-QMF—is designed. Incorporating the spectral folding phenomenon in bipartite graphs, the two conditions for perfect reconstruction (given by Equations (11.6.13) and (11.6.15)) can be represented in spectral domain as
and
Here, g0, g1, h0, and h1 are kernels (in spectral domain) corresponding to the filters G0, G1, H0, and H1, respectively. One possible choice for the filter kernels is [193]
for any arbitrary kernel h0(λ ℓ).
Therefore, for a bipartite graph ? with its two partitions as ℋ and ℒ, with a downsampling function β=βℋ in a two-channel filter bank, as shown in Figure 11.10, the filter kernels given by Equation (11.6.18) guarantee perfect reconstruction for any arbitrary kernel h0(λℓ).
11.6.4 Multidimensional Separable Wavelet Filter Banks for Arbitrary Graphs
Graph-QMFs, discussed above, are applicable to only bipartite graphs. For applying graph-QMF design to an arbitrary graph, the graph is decomposed into a number of bipartite subgraphs. Subsequently, graph-QMFs can be constructed on each bipartite subgraph that leads to multidimensional separable wavelet filter banks on graphs. The underlying graph G is decomposed into a set of K bipartite subgraphs using an iterative decomposition scheme. These bipartite subgraphs are represented as ℬi=(ℒi,ℋi,ℰi), where i = 1, 2, . . . , K. In this scheme, at each iteration stage i, the bipartite subgraph ℬi covers the same vertex set, ℒi∪ℋi=?, and Ei consists of all the links in ℰ−∪i−1k=1ℰk that connect vertices in ℒi to vertices in ℋi. After this decomposition, a two-channel wavelet filter bank is implemented in K number of stages, such that filtering and downsampling operations in each stage i are restricted to the links in the ith bipartite subgraph ℬi.
Once the set of bipartite subgraphs is obtained, graph-QMFs can be implemented for each of these subgraphs in a cascaded manner. At every stage, filtering operations are done along one dimension using only the edges that belong to the corresponding bipartite subgraph. This approach is a separable approach in the sense that results of the transform in one stage are used in the next stage. Figure 11.11 shows a 2-D two-channel filterbank. Here, a graph is decomposed into two bipartite subgraphs ℬ1 and ℬ2. In the first stage, edges of subgraph ℬ1 are utilized, and at the second stage, edges of subgraph ℬ2 are utilized.
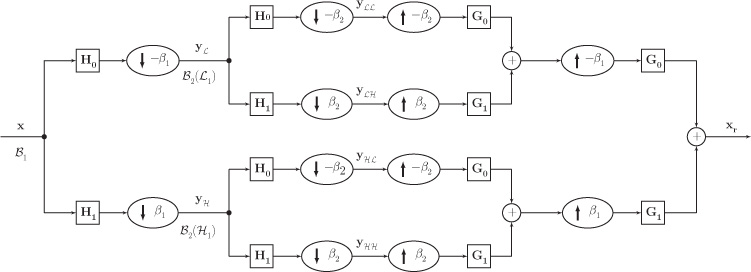
Figure 11.11. Two channel filter bank on an arbitrary graph
11.7 Spectral Graph Wavelet Transform
SGWT [206] gives precise analogy to the continuous wavelet transform. In classical continuous wavelet transform (CWT), wavelets at different scales and locations are constructed by scaling and translating a single mother wavelet ψ. The wavelet at scale s and location a is given by ψs,a(x)=1sψ(x−as). By defining the scaling operation in the Fourier domain, the wavelet can be written as1
1. See Appendix B.6 for details on continuous-time wavelets.
Note that scaling ψ by 1/s corresponds to scaling ˆψ with s and the modulation term e−jωa comes from localization of the wavelet at location a. Thus, a wavelet can be interpreted as an inverse Fourier transform of the scaled and modulated band-pass filter ˆψ.
Analogous to the Fourier representation of classical continuous wavelets, spectral graph wavelets are constructed based on a kernel g defined in the graph Fourier domain. Kernel g behaves as a band-pass filter; that is, it satisfies g(0) = 0 and limx→∞ g(x) = 0. The spectral graph waveletψt,n, at scale t and centered at node n, is defined through spectral decomposition of the graph Laplacian matrix L (symmetric) as
Here, in comparison to the classical wavelet described by Equation (11.7.1), frequency ω is replaced with the eigenvalues of the graph Laplacian λℓ. Furthermore, translating (or localizing) a wavelet to node n corresponds to a multiplication by u*ℓ(n), replacing e−jωa, replacing e− jωa. In addition, g acts as a scaled bandpass filter, replacing ˆψ of Equation 11.7.1. One important point to note here is that the spectral wavelets are continuous in scale but discrete in space. The filter kernel function g is defined as a real-valued continuous function defined on ℝ+ and sampled at the discrete frequency values of (λℓ) ℓ=0,... ,N−1. In practical scenarios, to have a finite number of scales, the continuous scaling parameter t is also sampled; that is, a total of J scales are considered: {tj}j=1,... ,J.
11.7.1 Matrix Form of SGWT
Let U(m,:) represent the mth row of the matrix U and ?T(:,n) be the nth column of the matrix UT, where U is the matrix with eigenvectors of the graph Laplacian as its columns. We can write Equation (11.7.2) equivalently as
where Gt = diag[g(tλ0), g(tλ1),... , g(tλN−1)] is a diagonal matrix with the diagonal entries as values of the scaled band-pass filter sampled at the graph frequencies. Therefore, the wavelet (column) vector at scale t and centered at node n is
Hence, the wavelet basis at scale t, which is the collection of N number of wavelets (each wavelet centered at a particular node of the graph), can be written as
Now, the wavelet coefficient at scale t and centered at node n of a graph signal f can be calculated as
SGWT can be computed efficiently using the fast Chebyshev polynomial approximation algorithm [206], which avoids full eigendecomposition of the graph Laplacian matrix.
11.7.2 Wavelet Generating Kernels
Spectral graph wavelets require a filter kernel whose scaled versions are used to construct wavelets at various scales. An example kernel g can be defined as
where x is the distance from origin (zero frequency), α and β are integer parameters of the band-pass filter g, x1 and x2 determine transition regions, and p(x) is a 3-D cubic spline that ensures continuity in g. One possible choice of these parameters can be α = β = 2, x1 = 1, x2 = 2, and p(x) = −5 + 11x − 6x2 + x3.
A total of J logarithmically equally spaced discrete wavelet scales can be selected for practical purposes: t1,... , tJ, where tJ is the minimum scale. Considering λmin = |λmax|/K, where λmax is the eigenvalue of L with the largest magnitude and K is a design parameter, we set tJ = x2/|λmax| and t1 = x2/λmin.
Kernels for different scales with parameters |λmax| = 7.8830, α = β = 2, x1 = 1, x2 = 2, K = 20, and J = 4, are shown in Figure 11.12. Figure 11.12(a) shows original kernel (t = 1). Kernels at scales t = 5.0742, t = 1.8693, t = 0.6887, and t = 0.2537 are shown in Figures 11.12(b), (c), (d) and (e), respectively. One can clearly observe that kernels become increasingly confined to low frequencies with the increase in scale t.
11.7.3 An Example of SGWT
Wavelets are demonstrated at various scales for an arbitrary network, shown in Figure 11.13. Corresponding to the kernels shown in Figure 11.12, the wavelets are shown in Figure 11.14. A total of J = 4 logarithmically equally spaced discrete wavelet scales has been selected, and the parameters are λmax = 7.8830, K = 20, λmin = λmax/K = 0.3942, x1 = 1, x2 = 2, α = β = 2, t4 = x2/|λmax| = 0.2537 and t1 = x2/λmin = 5.0742. It can be seen that at small scales (small t), the filter g(tλ) is stretched out and lets through high-frequency modes essential for better localization. The corresponding wavelets, as shown in Figures 11.14(a) and 11.14(b), extend only to their close neighborhood in the graph. However, at large scales (large t), the filter function is compressed around low-frequency modes, as shown in Figures 11.12(a) and 11.12(b), and corresponding wavelets are largely spread over the graph, as shown in Figures 11.14(c) and 11.14(d). Another representation of the wavelets plotted in Figure 11.14 is shown in Figure 11.15

Figure 11.12. Kernels at various scales. As the scale t increases, the kernel becomes increasingly confined to low frequencies.

Figure 11.13. An arbitrary network
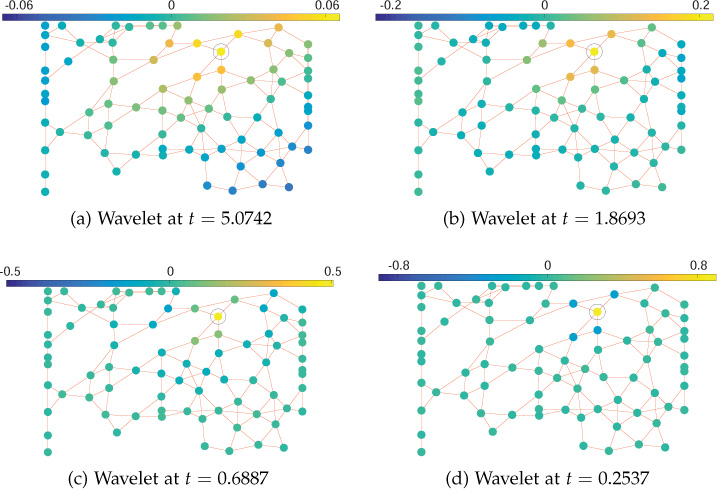
Figure 11.14. Wavelets at various scales for an arbitrary network. Wavelets are centered around the circled node.
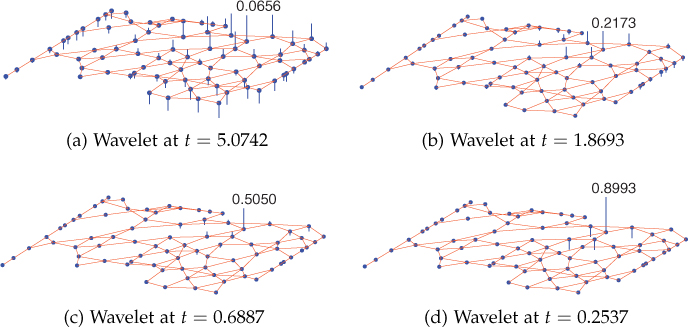
Figure 11.15. Another representation of the wavelets plotted in Figure 11.14
SGWT has been used in various applications, including mobility inference [210] and community mining [211]. SGWT can be used in the analysis of network dynamics for capturing and quantifying the changes as well.
11.7.4 Advantages and Disadvantages
SGWT is applicable to weighted graphs and also provides inverse transform. It provides precise analogy to the classical wavelet transforms and provides finer control over the scales.
However, SGWT is not applicable to directed graphs. Also, SGWT is highly sensitive to network topology: a small change in network topology can alter the wavelets significantly. This is because the eigenvalues and eigenvectors of the graph Laplacian are highly sensitive to the network topology.
11.8 Spectral Graph Wavelet Transform Based on Directed Laplacian
This section presents SGWT based on directed Laplacian (SGWTDL), extending SGWT presented in [206] to directed graphs. As discussed in Section 10.5.5, natural frequency interpretation is achieved with spectral decomposition of the (directed) graph Laplacian. Therefore, the concept of SGWT can be extended to directed graphs easily. This extension is known as SGWTDL. GFT, presented in Section 10.5.5, is utilized to define scaling in the spectral domain. In the definition of SGWTDL, it is assumed that the graph Laplacian matrix is diagonalizable as in Equation (10.5.11). The ability of SGWTDL to achieve localization in the vertex and frequency domains is demonstrated with examples.
11.8.1 Wavelets
By utilizing spectral decomposition of the graph Laplacian (Equation (10.5.8)), Equation (11.7.5) is extended to directed graphs so that the wavelet basis at scale t can be written as
where V is the graph Fourier basis described in Section 10.5.5, Gt = diag[g(tλ0), g(tλ1),... , g(tλN−1)], and g(tλℓ) is the value (real) of scaled 2-D generating kernel at graph frequency λℓ (complex). Therefore, wavelet at scale t and centered at node n is
where ?n is an N-dimensional column vector having unit value only at the nth entry and zero elsewhere. Furthermore, the wavelet transform coefficient of a graph signal f at scale t and node n can be calculated as
11.8.2 Wavelet Generating Kernel
Because of the complex nature of frequencies in the case of directed graphs, a wavelet generating kernel is a real-valued function of a complex variable, in contrast to a real-valued function of a real variable in the undirected graph case. In addition, generating kernels are circularly symmetric functions because eigenvalues with equal absolute values correspond to a single frequency. The band-pass filter kernel g, discussed in Section 11.7, can be extended to the complex frequency plane.
where r=√x2+y2 is the distance from origin (zero frequency), α and β are integer parameters of the band-pass filter g, r1 and r2 determine transition regions, and p(r) is a 3-D cubic spline surface that ensures continuity in g. The parameters used are same as in [206]: α = β = 2, r1 = 1, r2 = 2, and p(r) = −5 + 11r − 6r2 + r3.
A total of J logarithmically equally spaced discrete wavelet scales can be selected for practical purposes: t1,... , tJ, where tJ is the minimum scale. Considering λmin = |λmax|/K, where λmax is the eigenvalue of L with the largest magnitude and K is a design parameter, the wavelet scales can be set as tJ = r2/|λmax| and t1 = r2/λmin.
Kernels for different scales with parameters |λmax| = 2.2871, α = β = 2, r1 = 1, r2 = 2, K = 20, and J = 4 are shown in Figure 11.16. The four scales have been chosen such that they are logarithmically equally spaced between tJ = x2/|λmax| and t1 = x2/λmin. One can clearly observe that kernels become increasingly confined to low frequencies with the increase in scale t.
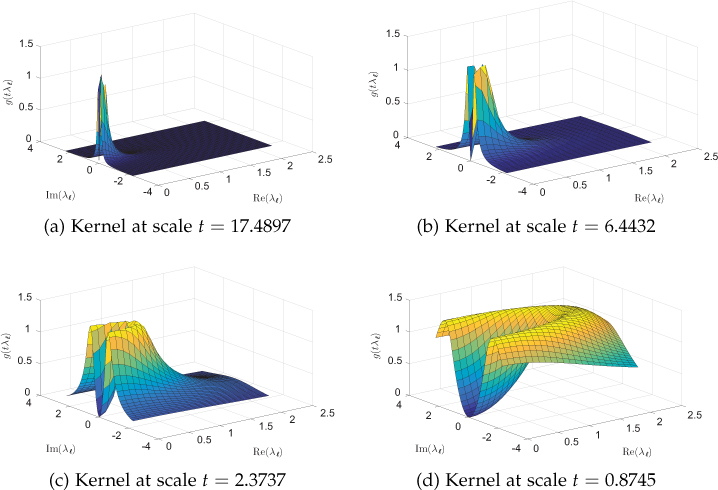
Figure 11.16. Kernels at different scales. As the scale t increases, kernels become increasingly confined to low frequencies. Only the positive real-half of the frequency plane is shown for ease of visualization.
11.8.3 Examples
Figure 11.17 shows wavelets on a 20-node directed graph at different scales and centered at the circled node. The generating kernel given by Equation (11.8.4) is used. It can be observed that the “spread” of wavelets decreases with scale, since the generating kernel lets in only high frequencies at small scales.
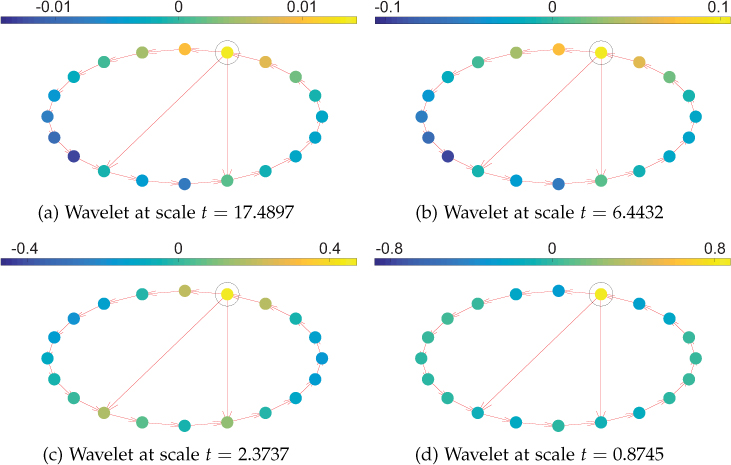
Figure 11.17. Wavelets on directed ring graph. Wavelets at different scales centered at the circled node. As the scale t decreases (high frequencies dominate), the wavelet spread also decreases.
As a second example, a directed weighted graph is constructed from the undirected Minnesota road network. The original road network is made directed by arbitrarily assigning directed weights to some of the edges (22 edges) of the undirected network. Figure 11.18 shows wavelets on this directed network. It can be observed that the spread of the wavelets decreases as scales decrease.
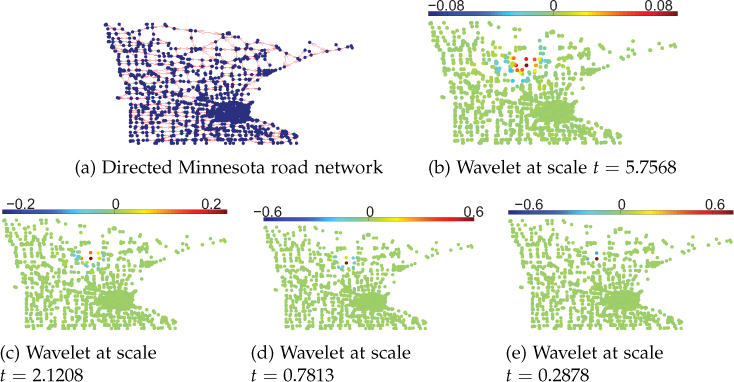
Figure 11.18. Wavelets at different scales centered at the circled node. As the scale t decreases (high frequencies dominate), the wavelet spread also decreases.
11.9 Diffusion Wavelets
Diffusion wavelets [207] on a graph are based on compressed representations of powers of a diffusion matrix specific to the graph. A diffusion matrix can be the random walk or the Laplacian matrix. The framework also allows graph compression; that is, it produces coarser versions of the graph as well. Usually the increasing power of the diffusion operator T produces lower-rank matrices and thereby allows compression.
Diffusion wavelets not only produce wavelets on complex networks but also produce coarser versions of a complex network, allowing multiscale analysis of complex networks. The graphs (complex networks) encountered in the present time are very large. Usually the finest-scale information contained in a graph is noisy. Therefore, a graph at the finest scale is not always the most informative for a specific task. By compressing graphs at multiple scale, we can reduce the size of a graph in a meaningful way. Compressing a graph means to produce coarser and coarser graphs that replicate the original graph at different levels of resolution. The framework of diffusion wavelets provides a means to compress a graph.
The diffusion operator T utilized in this scheme is the random walk matrix, ?=?12??−12, where D is the degree matrix and W is the weight matrix of the graph. Note that the dyadic power of T are utilized. The powers T2j (for j > 0) describe the behavior of the diffusion at different scales. As the power of T is increased, the spectrum shift toward zero; that is, more and more eigenvalues tend to be small. In other words, high powers of T are low rank and, therefore, it allows compression by efficiently representing them on an appropriate basis. It is important to note the consistency in the compression in the diffusion operator is defined such that one step of the random walk at scale j corresponds to 2j+1 steps of the original random walk. The basis functions used here are not the eigenvectors of the diffusion operator T, but are the localized basis functions obtained from the QR decomposition. The reason behind not using the eigenvectors as the basis is that they are global over the graph and, therefore, are unable to give any local information.
The localized basis functions at each resolution level are orthogonalized and downsampled appropriately to transform sets of orthonormal basis functions through a variation of the Gram-Schmidt orthonormalization (GSM) scheme. Although this local GSM method orthogonalizes the basis functions (filters) into well localized bump functions in the spatial domain, it does not provide guarantees on the size of the support of the filters it constructs.
11.9.1 Advantages and Disadvantages
One of the biggest advantages of the diffusion wavelet scheme is that besides producing wavelets at different scales, it also produces compressed (coarser) version of graphs. In addition, the basis functions are orthonormal and, therefore, allow signal reconstruction from the transform coefficients.
While an orthogonal transform is desirable for many applications, for example, signal compression, the use of the orthogonalization procedure complicates the construction of the transform. Moreover, the relation between the diffusion operator T and the resulting wavelets is not directly evident.
11.10 Open Research Issues
• Most of the techniques for multiscale analysis are limited to undirected graphs. Development of new techniques that are computationally efficient and applicable to directed graphs is an open research problem.
• Two-channel wavelet filter banks guarantee perfect reconstruction for bipartite graphs only. For artibtary graphs, it requires the original graph to be decomposed into a series of separable bipartite subgraphs. However, this decomposition is not unique, and the question remains open about which decomposition is better than other methods.
• M-channel filter banks on graphs have been developed in [194] and [195]. However, perfect reconstruction is guaranteed only for a class of graphs with certain conditions. Development of filter banks on arbitrary graphs that achieve perfect reconstruction is an interesting area to investigate.
• Although SGWT closely resembles the classical countinuous-time wavelet transform, the wavelets in this scheme do not follow the shift-invariance property as do classical wavelets. Graph wavelets with the shift-invariance property might be an interesting problem to investigate.
• Properties of SGWTDL have not been studied, nor has the inverse transform been presented. Also, the effect of edge directivity has not been investigated.
• All of the multiscale transforms presented in the chapter utilize only the underlying graph structure and do not take the properties of the signal into consideration. For images and multidimensional regular signals, a number of wavelet transforms exist that take signal properties into consideration [212]. Constructing signal-adaptive wavelets on graphs is a challenging area of research. Some efforts in this direction can be found in [213].
11.11 Summary
The chapter presented different transforms for analyzing complex network data at multiple resolutions (scales). These techniques involve wavelet-like transform that make multiscale analysis possible. The multiscale analysis methods can be very useful in the complex network domain, as they are in the classical domain of discrete-time and image signals. Multiscale transforms can be designed in the vertex as well as the spectral domains. Transform designed in the vertex domain, such as CKWT, random transforms, and lifting-based wavelet transforms, were discussed in detail. Spectral domain designs, including SGWT, two-channel wavelet filter banks, and diffusion wavelets, were also presented. Different transforms have their own merits and demerits in terms of simplicity, applicability, and complexity. However, the approaches developed so far are still not mature enough to counter the extremely huge complex networks containing millions of nodes that generate data almost continuously. With the current inclination of research in the field, we can expect much more efficient multiresolution techniques in near future.
Exercises
Consider the graph ? shown in Figure 11.19.
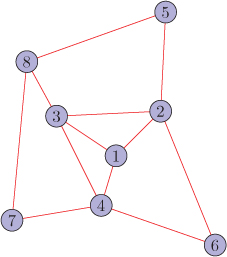
Figure 11.19. Graph G
The non-zero eigenvalues of the graph Laplacian are 1.1464, 2.1337, 5.4424, 17.2775. Moreover, the eigenvector matrix of the Laplacian is
?=[0.44720.18400.21890.54770.64670.4472−0.8860−0.0467−0.10360.04630.44720.26850.5663−0.6370−0.03780.44720.12970.05290.4604−0.75400.44720.3039−0.7914−0.26750.0987]
1. For the graph shown in Figure 11.20, compute CK wavelets centered at node 2 at all possible scales. Assume Haar wavelet as ψ(t). Also verify the properties of the CK wavelets listed in Section 11.3.3.
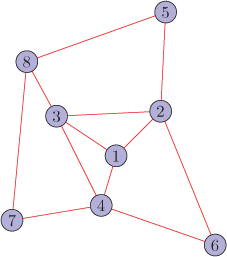
Figure 11.20. Graph for Problem 1
2. In Example 11.6.1, assume that nodes 1, 2, 3, and 4 are discarded. Write down the deformed graph Fourier basis and plot the spectrum of DU signal.
3. Consider the graph shown in Figure 11.21(a).
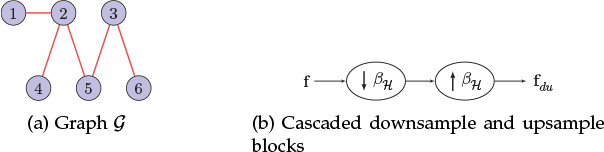
Figure 11.21. Graph and DU blocks (Problem 3)
(a) Is the graph bipartite? If yes, write down the nodes belonging to the two sections of the graph and denote them as ℋ and ℒ.
(b) Explain the spectral folding phenomenon exhibited by the graph ?.
(c) For the cascaded downsample upsample block shown in Figure 11.21(b), find the downsampling matrix. Compute the DU output for an input graph signal f = [4, −7, 1, −2, 3]T.
(d) Represent the GFT coefficients of the output DU graph signal in terms of input and deformed spectral coefficients.
4. Consider the same graph as in Problem 3 if the output signal to the block diagram shown in Figure 11.22 is fout = [−2, −1, 3, 9, 0]T. Compute the input signal fin.
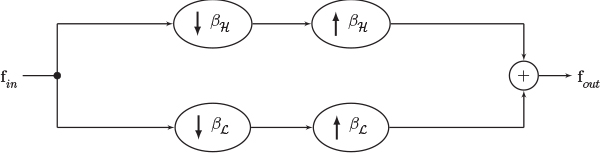
Figure 11.22. Block diagram for Problem 4
5. In Figure 11.10, assume that the filter H0 is charaterized in spectral domain as
Assuming that the underlying structure for the input signal f is a bipartite graph, plot the kernels in the spectral domain for the filters H1, G0, and G1 so that perfect reconstruction condition is satisfied.
Considering a signal f = [−2, 1, 9, 0, 4, −5]T defined on the graph G shown in Figure 11.21(a), find the signals at the output of each block in Figure 11.10 and verify that perfect reconstruction is achieved.
6. For the graph shown in Figure 11.19, compute the wavelets centered at node 1 and at scales t = 2, 10, and 40. Use the same kernel given by Equation (11.7.7). Comment on the wavelets at different scales.
![]() 7. This problem is about detecting anomalous nodes in a sensor network. Using GSPBox, create a 60-node random sensor network and define a signal f on the graph as
7. This problem is about detecting anomalous nodes in a sensor network. Using GSPBox, create a 60-node random sensor network and define a signal f on the graph as
where c = 0.1 is a constant and d(i, j) is the distance between nodes i and j (can be found using Dijkstra’s shortest path algorithm). This signal can be thought of as temperature values in a geographical area, since the variations in temperature values are not high if the sensors are placed densely. Now introduce some anomaly in the graph signal by making the temperature values zero for sensors 18 and 39.
In Problem 12 of Chapter 10, the anomaly can be detected using GFT; however, one could not locate the anomalous nodes. Use SGWT to find the anomalous nodes from the temperature data you created. Write down the step-by-step procedure and explain why your procedure works.
8. This problem is about quantifying spread of a graph signal. The spread of a graph signal can be defined in the vertex as well as the spectral domains. In the vertex domain, the spread of a signal f lying on a graph G about a node vi is defined as
where Pvi = diag{d(vi, v1), d(vi, v2),... d(vi, vN} is a diagonal matrix with d(vi, vj) being geodesic distance between nodes vi and vj. Moreover, the overall graph spread (or simply graph spread) is the minimum of the graph spreads about all the nodes, that is,
The spectral spread of a graph signal f is defined as
where L is the Laplacian matrix of the graph.
Based on the graph and spectral spread definitions, answer the following:
(a) Prove that
where ˆf(λℓ) is the GFT coefficient at frequency λℓ.
(b) Write an expression for spectral spread of the eigenvectors of the graph Laplacian. What is the relation between the spread of the eigenvectors?
(c) For the graph shown in Figure 11.19, find graph spreads of the eignevectors of the Laplacian matrix. Can you find a relation between the graph and spectral spreads of the eigenvectors?
(d) Compute the graph and spectral spreads for an impuse signal δi.
9. Based on the definitions of spread in Problem 8, compute the graph and spectral spreads of the wavelets found in Problem 6. Comment on the graph and spectral spreads of the wavelets at different scales.