
Chapter 4 Metadata in DW 2.0
One of the essential ingredients of the DW 2.0 architecture is metadata. Unlike first-generation data warehouses where metadata either was not present or was an afterthought, metadata is one of the cornerstones of the DW 2.0 data warehouse.
There are many reasons metadata is so important. Metadata is important to the developer, who must align his/her efforts with work that has been done previously. It is important to the maintenance technician, who must deal with day-to-day issues of keeping the data warehouse in order. It is perhaps most important to the end user, who needs to find out what the possibilities are for new analysis.
The best way to understand the value of metadata in DW 2.0 is to see it as acting like a card catalog in a large public library. How is information found in the public library? Do people walk in and look for a book by passing from one row of books to the next? Of course people can do that. But it is a colossal waste of time. A much more rational way to locate what you are looking for in a library is to go directly to the card catalog. Compared to manually searching through every book in the library, searching a card catalog is immensely faster.
Once the book that is desired is located in the catalog, the reader can walk directly to where the book is stored. In doing so, vast amounts of time are saved in the location of information.
Metadata in DW 2.0 plays essentially the same role as the card catalog in the library. Metadata allows the analyst to look across the organization and to see what analysis has already been done.
REUSABILITY OF DATA AND ANALYSIS
Consider the end user. End users sit on the sidelines and feel the need for information. This need for information may come from a management directive, from a corporate mandate, or simply from the end user’s own curiosity. However it comes, the end user ponders how to approach the analysis. Metadata is the logical place to which to turn. Metadata enables the analyst to determine what data is available. Once the analyst has identified the most likely place to start, the analyst can then proceed to access the data.
Without metadata, the analyst has a really hard time identifying the possible sources of data. The analyst may be familiar with some sources of data, but it is questionable whether he/she is aware of all of the possibilities. In this case, the existence of metadata may save huge amounts of unnecessary work.
Similarly, the end user can use metadata to determine if an analysis has already been done. Answering a question may be as simple as looking at what someone else has done. Without metadata, the end-user analyst will never know what has already been done.
For these reasons, then (and plenty more!), metadata is a very important component of the DW 2.0 architecture.
METADATA IN DW 2.0
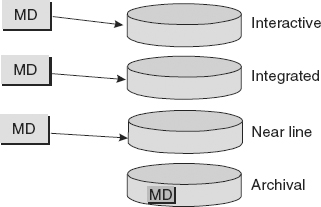
Metadata has a special role and implementation in DW 2.0. Separate metadata is required for each sector of DW 2.0. There is metadata for the Interactive Sector, metadata for the Integrated Sector, metadata for the Near Line Sector, and metadata for the Archival Sector.
The metadata for the Archival Sector is different from the other metadata, because Archival Sector metadata is placed directly in the archival data. The reason for this is to ensure that over time the metadata is not separated or lost from the base data that it describes.
Figure 4.1 depicts the general location of metadata in the DW 2.0 architecture.
There is a general architecture for metadata in DW 2.0. There are actually two parallel metadata structures—one for the unstructured environment and one for the structured environment. Figure 4.2 shows the high level of structure of DW 2.0 metadata.

For unstructured data, there are really two types of metadata—enterprise and local. The enterprise metadata is also referred to as general metadata, and the local metadata is referred to as specific metadata.
For structured metadata, there are three levels—enterprise, local, and business or technical. There is an important relationship between these different kinds of metadata. The best place to start to explain these relationships is the local level.
Local metadata is a good place to start, because most people have the most familiarity with that type of metadata. Local metadata exists in many places and in many forms. It exists inside ETL processes. It exists inside a DBMS directory. It exists inside a business intelligence universe.
Local metadata is metadata that exists inside a tool that is useful for describing the metadata immediate to the tool. For example, ETL metadata is about data sources and targets and the transformations that take place as data is passed from source to target. DBMS directory metadata is typically about tables, attributes, and indexes. Business intelligence (BI) universe metadata is about data used in analytical processing. There are many more forms of local metadata other than these common sources.
Figure 4.3 depicts examples of local metadata.
Local metadata is stored in a tool or technology that is central to the usage of the local metadata. Enterprise metadata, on the other hand, is stored in a locale that is central to all of the tools and all of the processes that exist within the DW 2.0 environment.
Figure 4.4 shows that enterprise metadata is stored for each sector of the DW 2.0 environment in a repository.


In this figure it is seen that sitting above each sector of DW 2.0 is a collection of enterprise metadata, and that all of the enterprise metadata taken together forms a repository. Actually, all of the sectors except the Archival Sector have their metadata stored in a repository.
ACTIVE REPOSITORY/PASSIVE REPOSITORY
There are two basic types of metadata repositories—active and passive. An active repository is one in which the metadata interacts in an ongoing manner with the development and query activities of the system. A passive repository is one in which the metadata does not interact in any direct manner with the development and/or the query activities of the end user.
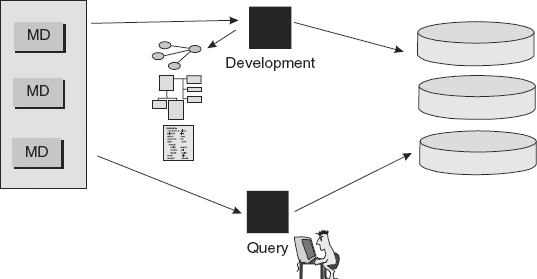
Figure 4.5 depicts a passive metadata repository.
The passive repository is the least desirable option, because end-user and developer activity is independent of the metadata repository. Any work that becomes optional quickly becomes work that is not done at all, because most organizations are compelled to minimize the amount of work, reduce costs, and meet deadlines. The passive metadata repository quickly assumes the same position as documentation. In the time-honored fashion of developers, documentation simply does not get done.
If by some miracle the passive metadata repository does get built, it is soon out of date as changes to the system are not reflected in the passive repository.
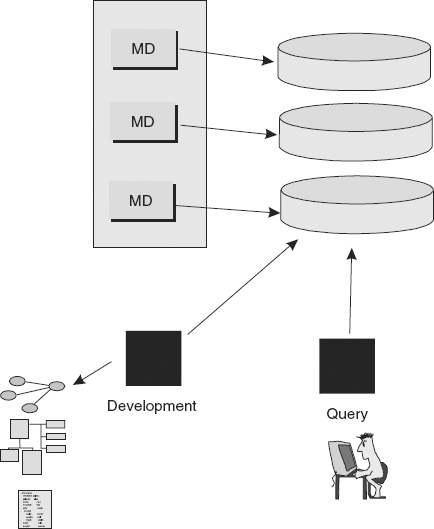
THE ACTIVE REPOSITORY
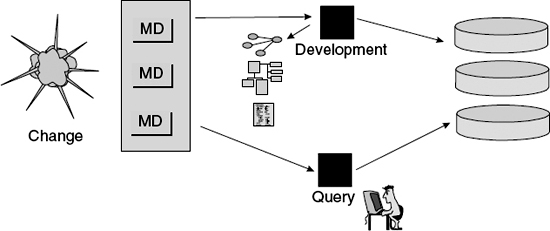
The other style of metadata repository is the active repository. The active repository is the place where enterprise metadata is kept when the metadata is actively used during the development process and for data-querying activities. Figure 4.6 shows an active metadata repository.
This figure illustrates that the development process and the query process are intimately intertwined with the metadata repository. When a change needs to be made to the data model, when the most current description of the data is needed, or when the source of data is needed, these activities and more rely on the active repository as their foundation.
ENTERPRISE METADATA
The enterprise active metadata repository is used when a query needs to be made against a table, when the relationship between the local and the global needs to be examined, or when the analyst just wishes to see what the data possibilities are.
Enterprise metadata has many different relationships with local metadata. One such relationship is semantics. In a semantics relationship, the enterprise describes a global term for the corporation. Then the local usage of that term is described, along with a pointer to the local system where the term is found. For example, suppose there is an enterprise term “revenue” and three local systems that refer to that term. In one local system the term is the same—” revenue.” In another local system, the term is “money,” and in another the term is “funds.” These three different words mean the same thing in the example enterprise. Enterprise metadata is an excellent way to ensure that the terms are consistently recognized and interpreted as the synonyms they are in the enterprise’s dialect.
Metadata provides a way to unite vocabularies at the enterprise level and the local level. This capability is illustrated in Figure 4.7.
But semantic relationships are hardly the only type of enterprise/local relationship that can be found in the metadata of the DW 2.0 environment.
Another key type of data relationship commonly found in organizations is that of enterprise subject area definitions. Figure 4.8 shows one such definition.
This figure shows a major subject area, Customer, defined at the enterprise level. The different places at the local level where information about Customer is found are shown. One local system has name and address information about a Customer. Another local system has age and buying preference information about a Customer. Yet another local system maintains Customer income, education, and Social Security number.

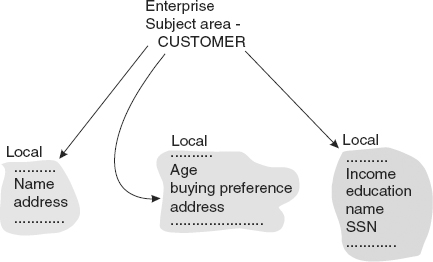
The enterprise metadata level can be used to identify where the local systems have supporting data for major business subjects.
METADATA AND THE SYSTEM OF RECORD
Metadata can also be used to define the system of record for the enterprise’s data subjects and their data attributes. In the system of record, the definitive source for a unit of data is declared. Figure 4.9 shows that the system of record for each element of data may be identified. It is not unusual for there to be more than one system of record for various data attributes of a major subject of the enterprise.
It is noteworthy that in the three preceding examples, there is some overlap between the definitions of data and relations defined between the local level of metadata and the enterprise level of metadata. However, there are some dissimilarities as well. The differences between the relationships that have been described are subtle. This level of subtlety can be represented by enterprise metadata and its relationship with local metadata in the DW 2.0 environment.
But there are other metadata relationships that are also important in the DW 2.0 environment. For example, there are two distinct types of metadata in the local level of metadata—business and technical.
Business metadata is information about the data that is useful to and found in the jargon of the business person. Technical metadata is information about the data that is useful to and found in the jargon of the technician. An example of business metadata might be the definition of “revenue” as “money or instruments paid for services or products.” An example of technical metadata might be the attribute definition “REV-DESIGNATED PIC 9999.99” contained in a table named “ABC.”


Figure 4.10 shows that the local level of metadata has its own subdivisions for business and technical metadata.
Unstructured data in DW 2.0 has its own metadata. The metadata for the unstructured environment is very different from the metadata for the structured environment. Taxonomies are an example of metadata for the unstructured environment.
TAXONOMY
Simply stated, a taxonomy is a detailed subdivision of a larger subject. A taxonomy has a detailed breakdown of the components of a given subject. Glossaries and ontologies are related to taxonomies.
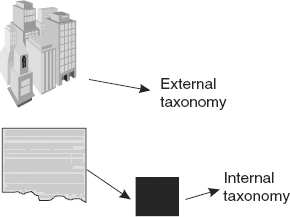
Two basic types of taxonomies are found in the unstructured DW 2.0 environment—internal and external. Internal taxonomies are constructed using only the words and phrases found in the text itself. For example, suppose the text in question is a series of contracts. The taxonomies for a group of contracts might well contain major themes, such as contract, terms, length of agreement, and payments. The internal taxonomy is a declaration of the major subject areas found within the text of unstructured data itself. Sometimes internal taxonomies are called “themes” of a text.
The other type of taxonomy found in the unstructured DW 2.0 environment is external. An external taxonomy can come from anywhere. An external taxonomy is something that is developed entirely from the “real world.” Examples of some external taxonomies include
There may or may not be a relationship between an external taxonomy and a body of unstructured data. For example, suppose the external taxonomy major league baseball is compared to some unstructured contract text. Unless the contracts are for baseball players, there most likely is little or no overlap between the contracts and major league baseball. In contrast, suppose the body of text is a collection of emails authorizing corporate expenditures and the external taxonomy is Sarbanes Oxley. In this case there would indeed be major overlap between the taxonomy and the body of unstructured data.
INTERNAL TAXONOMIES/EXTERNAL TAXONOMIES
Figure 4.11 shows that there are two different kinds of taxonomies.
There are many different forms of unstructured metadata. Figure 4.12 illustrates just a sampling of the different kinds of unstructured metadata.

Some other types of metadata that are common to the unstructured environment include:
METADATA IN THE ARCHIVAL SECTOR
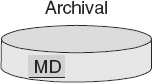
There is one anomaly in the DW 2.0 environment when it comes to metadata, and that is the metadata that is associated with the Archival Sector. The metadata that is associated with archival processing is stored with the archival data itself. The reason for storing the archival metadata with the archival data is that it is assumed that the metadata will be lost over time if it is collocated with its associated archival content data. Of course, it is possible to store a separate set of metadata with the archival environment, but the first place where historical metadata is most often sought and likely to be most useful is with the archival data itself.
Figure 4.13 suggests that archival data should contain its own metadata.
MAINTAINING METADATA
One of the biggest challenges associated with metadata is not the initial creation of the metadata environment, but rather the ongoing maintenance of the metadata environment. Change is a constant and it affects metadata just as much as it does everything else.
Figure 4.14 shows that change occurs and that when the environment is an active metadata environment it is easier to keep up with change than in a passive environment.
It is much too easy to just ignore change with a passive metadata environment. Change occurs and the associated alterations to passive metadata tend to be put off. Then one day, someone wakes up and sees that normal, routine changes have not been reflected in the metadata environment for a long time, resulting in a passive metadata that is so far out of sync with the present that it is virtually useless, often coincidentally when it is most needed.
With an active metadata repository, changes need to be reflected regularly in the metadata to keep up with the normal evolution and maintenance of existing systems. Whenever the systems are changed, the metadata must be changed as well.
Using metadata is just as important as the storing and periodic update of metadata. Although there are many ways to use metadata, perhaps the most effective way is at the point of end-user interface—the point at which the end user is doing interactive processing.
USING METADATA—AN EXAMPLE
For an example of the usage of DW 2.0 metadata, consider the following scenario. An airline agent—P. Bruton—pulls up a screen with the flight details for a client—Bill Inmon.
Figure 4.15 shows the screen that she has pulled up.
P. Bruton is not familiar with the reservations made by Tiki Airlines. She sees a data field on the screen that interests her. She highlights the CONNECTIONS field on the Tiki Airlines screen, as shown in Figure 4.16.


Next, P. Bruton hits a Function key, and the popup menu shown in Figure 4.17 appears. The menu asks her to identify what aspect of CONNECTIONS she wants to see. The options on the menu are “AKA” (also known as), “definition,” “formula,” “where used,” and “owned by.” P. Bruton selects the definitions option.
Figure 4.17 shows the menu of types of metadata that are available.


Now the system goes and searches its metadata information for a definition of CONNECTIONS. Upon finding the definition, the system displays a message showing the definition of CONNECTIONS.
Figure 4.18 shows the display of a metadata definition in an interactive mode.
Note that the accessing of metadata never entailed leaving the original screen. The display of metadata was done on top of an analytical process. The metadata was displayed interactively and became part of the analytical process.
FROM THE END-USER PERSPECTIVE
There are many purposes served by metadata in DW 2.0. Metadata serves to interconnect the different sectors of data. It serves as documentation for the environment. It serves as a road map for adding to the DW 2.0 environment. But the most important role metadata plays is as a guide to the contents and relationships of data found in DW 2.0.
It is the end user who needs a guide to the data and relationships that are found in DW 2.0. When the end user has a guide to what data already exists in the DW 2.0 environment, there is the possibility of the reuse of data. Stated differently, when there is no metadata in DW 2.0, the end user always has to invent every new analysis from scratch. The end user is incapable of seeing what analytical work has been done before. Therefore everything must be new.
The problem with every analysis being new is that in many cases the wheel gets to be reinvented over and over. But with metadata there is no need to reinvent the wheel. One analyst can build on the work of another analyst.
From the standpoint of the business user, there is another important role for metadata and that role is in showing the heritage of data. In many cases in which an analyst considers using a unit of data as part of an analysis, the business user needs to know where the data came from and how it was calculated. It is metadata that provides this very important function in DW 2.0.
There is yet another important role played by metadata in the eyes of the business user. On occasion there is a need for compliance of data. There is Sarbanes Oxley and there is Basel II. Metadata provides the key to the audit trail that is so vital to compliance in the analytical environment.
There are then some very pragmatic reasons metadata plays such an important role in the eyes of the business user in DW 2.0.
SUMMARY
Metadata is the key to reusability of data and analysis. Metadata enables the analyst to determine what has already been built. Without metadata, the analyst has a hard time finding out what infrastructure is already in place.
There are four levels of metadata:
There is metadata for both the structured and the unstructured DW 2.0 environments. A metadata repository can be either active or passive. As a rule, an active metadata repository is much more desirable and useful than a passive metadata repository. When development and analysis are used interactively with a metadata repository, the repository is considered to be active.
The system of record of data warehouse data is ideally defined in a metadata repository.
Unstructured metadata consists of taxonomies, glossaries, and ontologies. The forms of metadata may be internal or external.
Archival metadata is stored directly in the archival environment. By colocating the metadata with the physical storage of archival data it describes, a time capsule of data can be created.