
Chapter 19 DW 2.0 and unstructured data
It is estimated that more than 80% of the data that exists in corporations is unstructured text. Unfortunately the technology that runs on computers today is dedicated to handling structured, repeatable data. The result is that there is valuable information that is not being used for decision making in the corporation. The useful information found in text is not a big part of the decision-making process.
DW 2.0 AND UNSTRUCTURED DATA
The DW 2.0 architecture for the next generation of data warehousing recognizes that there is valuable information in unstructured textual information. DW 2.0 recognizes that quite a bit of work must be done to the text to make it fit for analytical processing.
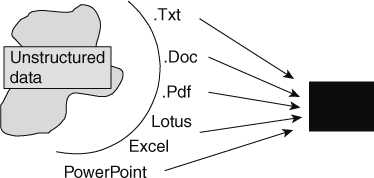
The starting point is the document itself. Figure 19.1 shows that text comes in all sorts of forms, such as emails, documents, medical records, contracts, spreadsheets, and voice transcriptions.
READING TEXT
The first step in the process of preparing unstructured data for analytical processing is to read the text. The text resides in a wide variety of formats. The formats may need to be read in as input.
Figure 19.2 depicts the reading of unstructured source texts.
After the original source text has been read, the next step is to prepare the data for entry into a data base. This textual preparation is an involved process. There are several good reasons text must be processed:

WHERETO DO TEXTUAL ANALYTICAL PROCESSING
At this point an important strategic decision is about to be made. That decision is where to do textual analytical processing. There are essentially two alternatives. One alternative is to do it at the place where unstructured text resides—in the unstructured environment. The other alternative is to do it in the structured environment. To do textual analytics in the structured environment requires that the unstructured text be read, integrated, and processed and then placed in the structured environment.
There is no question that reading, integrating, and processing textual unstructured data is an arduous task. But once the unstructured text has been processed, and once it is placed inside the structured environment, an entire world of opportunity opens up. Once unstructured data has been integrated and placed in the structured environment, there is the possibility of using standard analytical technology.
Organizations have already spent millions of dollars on the training of staff and users for the purpose of creating an analytical environment inside the world of structured technology. In the structured environment there already is data base technology, business intelligence, ETL, statistical processing, and so forth. It simply makes sense that the existing analytical environment be used—as is. All that is required is the ability to read and integrate textual information. And for that purpose there is textual ETL.
So choosing the environment in which to do textual analytical processing is easy. The structured environment is the place where analytical processing is best done.
INTEGRATING TEXT
The process of “integrating” text prior to placing it in a data base has many different facets. A number of steps are involved in preparing text for incorporation into a data base and subsequent analytical use as part of a DW 2.0 data warehouse. The key tasks that must be performed to groom unstructured data for the data warehouse are:
A description of each of these different facets of unstructured data grooming follows.
SIMPLE EDITING
The first step in the preparation of unstructured text for analytical processing is to do simple editing on case, punctuation, and font. The reason this simple type of editing is important is that future analytical searches do not need to be impeded by discrepancies in typography. For example, if a search is done for “bill inmon,” the search needs to find “Bill Inmon,” even though the first letters of the two words in the text are in uppercase. Figure 19.3 illustrates the elimination of case, font, and punctuation from unstructured text as it is prepared for analytical processing.
STOP WORDS
The next step is to eliminate stop words. A stop word is a word that is useful for the lubrication or flow of language, but is not a useful or meaningful part of the message. Some typical stop words are
Figure 19.4 depicts the elimination of stop words.


SYNONYM REPLACEMENT
Another optional step in the process of textual integration is the creation of synonym substitutes. Synonym replacements are used to rationalize text from different terminologies into a single terminology. Synonym replacement involves substituting one standard word for all words with the same meaning. Consistent use of a single terminology can be a major step in the direction of ensuring reliable, repeatable queries against unstructured data after it is incorporated into the data warehouse. Figure 19.5 illustrates synonym replacement.
SYNONYM CONCATENATION
Synonym concatenation is an alternative to synonym replacement. In synonym concatenation, instead of replacing synonyms with a chosen standard word, the standard word is inserted next to, or concatenated with, all occurrences of other words that have the same meaning, its synonyms. Figure 19.6 illustrates synonym concatenation.
HOMOGRAPHIC RESOLUTION
Homographic resolution is the reverse of synonym concatenation and synonym replacement. Homographic resolution is used to clarify words or phrases that can mean more than one thing. The actual thing that the word means replaces or overlays the word or phrase appearing in the text. Figure 19.7 illustrates homographic resolution.



CREATING THEMES
One of the interesting and useful things that is done with the text after it has been integrated is to produce a “cluster” of the text. Clustering text produces “themes.” In the clustering of text, words and phrases are logically grouped together based on the number of occurrences of the words and their proximity to each other.

Clustering can also lead to the creation of a glossary or taxonomy. The glossary or taxonomy is called an “internal glossary” or an “internal taxonomy,” because it is created from the text that has been entered into the system. Figure 19.8 shows the clustering of text and the themes that are produced.
EXTERNAL GLOSSARIES/TAXONOMIES
Whereas internal glossaries or taxonomies are useful, external glossaries and taxonomies are also useful. External glossaries and taxonomies can come from anywhere—books, indexes, the Internet, and so forth. External glossaries and taxonomies can represent anything. External glossaries and taxonomies can be used to superimpose a structure over text. Text can be read into the system, and a comparison can be made to determine whether the text belongs to or is otherwise related to an external glossary or taxonomy.
Figure 19.9 illustrates some external glossaries/taxonomies.

STEMMING
Stemming is another step in the integration of text and the preparation of text for textual analytics. Text is stemmed when it is reduced to its Greek or Latin root. Stemming is important if the foundations of words are to be recognized. Stated differently, if words are compared literally, related words will not be clustered together as they should be. Figure 19.10 shows some words and their stems.

ALTERNATE SPELLINGS
If searches are to be done effectively, the need for and practice of alternative spellings must be accommodated. Some words have alternative spellings and many names have alternative spellings. As an example of the utility of accommodating alternative spellings, suppose the name “Osama Bin Laden” is being searched. It would be a shame to miss a reference to “Usama Bin Laden” because the name is spelled differently. Figure 19.11 illustrates why different spellings of the same thing must be recognized.

TEXT ACROSS LANGUAGES
Another useful feature of textual analytics is that of the ability to operate in multiple languages. Figure 19.12 shows different languages.

DIRECT SEARCHES
Yet another important feature of textual analytics is that of the ability to support different types of searches. The integration of text needs to set the stage for this feature. One type of search that needs to be supported is the direct search. A direct search is typified by Yahoo or Google. An argument is passed to the search engine and the search engine looks for any occurrence of the search argument. Figure 19.13 depicts a direct search.
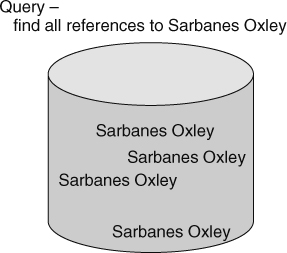
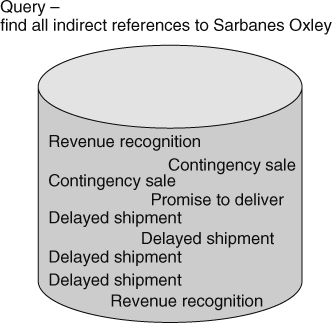
INDIRECT SEARCHES
Another kind of search is the indirect search. Whereas search arguments are also passed to the search engine, in an indirect search, there is no search made on the argument itself. Instead, the search is based on whatever relates to the argument. For example, Figure 19.14 depicts an indirect search on “Sarbanes Oxley.” The search does not look for “Sarbanes Oxley.” Instead the search looks for text relating to Sarbanes Oxley.
TERMINOLOGY
There is a major problem in the handling of text for the purpose of analytical processing. That problem is the handling of terminology. Terminology exists as a problem because language is spoken in terminology. Consider the human body. For any part of the human body there may be as many as 20 different ways of referring to that part. One doctor uses one set of terminology. Another doctor uses another set of terminology. A nurse uses another set of terminology. These professionals are all talking about the same thing. However, these people are speaking different languages.
If analytical processing is ever to be done on text, there must be a resolution of terminology. The final data base of textual words and phrases must be stored at both the specific and the generic level. The final textual data base on which textual analytics is done must contain the original specific word that the doctor or nurse used, and the textual data base must also contain the generic term that will be understood across the entire community of analysts.
If an organization does not solve the issues of terminology, it simply is impossible to do effective textual analytic processing.
SEMISTRUCTURED DATA/VALUE = NAME DATA
Unstructured data comes in all sorts of flavors. The simplest form unstructured data comes in is that of text in a document. Where there is text in a document, the words and phrases have no order or structure. An unstructured document is just that—an unstructured document.
But there are other forms of textual documents. In some cases the author of the document has given an inferred structure to the document. A simple example of an inferred structure inside a document is that of a recipe book. Inside a recipe book are many recipes. There is one document. But inside the document there are implied beginnings and endings. One recipe ends and another begins.
There often is a need to map the implied structure of the book onto the textual analytical data base. In some cases this is a very easy and obvious thing to do. In other cases it is not obvious at all as to how to do the mapping.
Another form of unstructured data that needs to be treated specially in a DW 2.0 environment is a form that can be called a VALUE = NAME form of data. To understand this form of unstructured data, consider a handful of resumes. On each resume is found common information, such as name, address, education, salary, and so forth. It is quite useful to be able to understand what kind of data in the unstructured data is being considered. In other words, for “name—Bill Inmon,” it is convenient for the system to recognize that “name” is an important field and that “Bill Inmon” is the person being named. This capability means that text can be read and words can be picked up symbolically, not literally. The ability to sense symbolic words is very important in the building of a textual analytics data base.
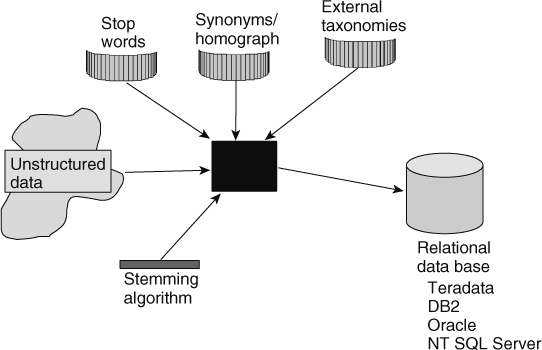
THE TECHNOLOGY NEEDED TO PREPARE THE DATA
The technology that accomplishes the integration of unstructured text is commonly called textual ETL technology and is depicted at a high level in Figure 19.15.
THE RELATIONAL DATA BASE
When the unstructured text is ready for analytical processing, the text is placed in a relational data base. The relational data base may then be accessed and analyzed by many different tools, such as business intelligence tools.
Figure 19.16 shows the usage of business intelligence against unstructured data.
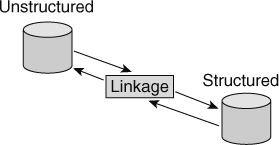
STRUCTURED/UNSTRUCTURED LINKAGE
After the unstructured relational data base is created, it is then linked to the structured data bases, forming a DW 2.0 foundation for the organization.
Figure 19.17 depicts the creation of the linkage between the two types of data bases.
FROM THE PERSPECTIVE OF THE BUSINESS USER
If there is any data the business user is close to it is unstructured textual data. Unstructured textual data makes up the daily commerce of the life of the end user. Therefore the end user is highly involved when it comes to the inclusion of unstructured textual data in the DW 2.0 environment.
The business user is involved with specification of stop words. He/she is involved with terminology and with what languages are to be used in DW 2.0. The end user is involved with stemming—whether it is useful or not. The end user is involved with the sources of unstructured textual data—email, reports, contracts, and so forth.
In short the business user is heavily involved in all aspects of the capture, preparation, and entry of unstructured textual data into the DW 2.0 environment.
In general the business user has only a passive involvement in the design of the structured aspects of DW 2.0. But the reverse is true for the unstructured textual aspects of DW 2.0. For example, the business user is heavily involved in the specifications for the textual ETL transformations.
SUMMARY
Unstructured data is an important component of the DW 2.0 data warehouse.
Unstructured data must be read in and integrated into the DW 2.0 environment. The process of unstructured data integration includes but is not limited to the following:
After the gathering and integration of textual data have occurred, the stage is set for the creation of a relational data base for the purpose of supporting analytical processing. After integration the textual data is placed in a relational format and a relational data base is created. Then the relational data base is ready for business intelligence processing. Finally, the unstructured relational data base is linked with the structured data base in the DW 2.0 data warehouse.