
11
Time Variant Solution Definition
Equally important in the difficulties of Time Variance are those aspects of Time Variance that cause, and do not cause, a performance degradation. In Chapter 10, the explanation of difficulties inherent in Time Variant data did not include any confusion about time, time intervals, hierarchies, hierarchy relationships, or any other aspect of relational data or a data warehouse. That being the case, the concept of a data warehouse built on an RDBMS platform is still a sturdy architecture and has not diminished in strength or flexibility due to any concerns about Time Variant data. So, we don’t need to solve the RDBMS problem, the data warehouse problem, the relational hierarchy problem, or any other such problems that do not exist. Locally, a single data warehouse implementation may contain its own self-inflicted difficulties. But, as a general concept and design, the data warehouse continues to be strong and flexible. So, if nothing is broken and there’s nothing to fix, what problem is solved by the Time Variant Solution Design?
Time Variant Problem Reprise
Chapter 10 showed the root cause and manifestation of the Time Variant problem. The root cause is the inability of an RDBMS to join on data it does not have. A transaction occurs at a single point in time. A dimension persists for an interval of time. When attempting to join a transaction row to a dimension row, an RDBMS is peculiarly unequipped to join those two rows. Specifically, the only relational key between a Dimension_ID/Date and Dimension_ID/Interval is the Dimension_ID. Having been half-equipped to perform such a join, the relational approach is to perform the available join on Dimension_ID and then complete the join using a WHERE clause using the statement “WHERE Date between Interval_Begin and Interval_End.” This approach causes an RDBMS to assemble a superset of rows and then retain only those rows that satisfy the statement “WHERE Date between Interval_Begin and Interval_End.”
The manifestation of this approach is shown in Figure 10.2. For every join to every dimension table every possible row becomes a multiplicative explosion of rows. For that reason, a Time Variant relational data warehouse quickly hits a wall. When the cardinality of a data warehouse, either in depth or breadth, exceeds the capacity of an RDBMS to handle the multiplicative explosion of rows, then that Time Variant data warehouse will cease to perform satisfactorily. The phrase “a brick” was used to describe such a data warehouse.
The Goal of This Time Variant Solution Design
The goal of this Time Variant Solution Design is to prevent the multiplicative explosion of data. Figure 11.1 shows how this goal, once achieved, will work for the RDBMS.
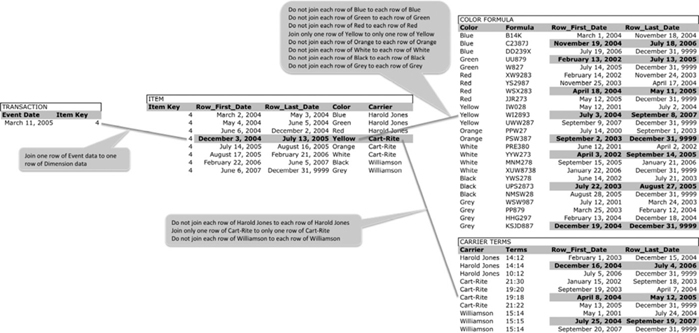
FIGURE 11.1
The goal of this Time Variant Solution Design.
The join between the Transaction and Item tables reduces from eight pairs of joined rows to one pair of joined rows. By removing extraneous pairs of joined rows from the join between the Item and Color_Formula tables, completely removing all pairs of rows joined on the colors Blue, Green, Red, Orange, White, Black, and Grey, and reducing the pairs of rows joined on the color Yellow from three to one, the pairs of joined rows reduces from twenty-six to one. By removing extraneous pairs of joined rows from the join between the Item and Carrier_Terms tables, completely removing all pairs of rows joined on the carriers Harold Jones and Williamson, and reducing the pairs of rows joined on the carrier Cart-Rite from three to one, the pairs of joined rows reduces from eleven to one. Taken together, those three joins alone reduce the number of pairs of joined rows from forty-five to three, which is a reduction by a factor of fifteen. That means that if in this example we can completely remove the multiplicative explosion of data by joining on only those rows that satisfy the conditions of the Time Variant join, the RDBMS will be required to handle one-fifteenth the volume of data it was previously required to handle.
The tuple construct of temporal databases also attempts to optimize joins within and between Time Variant data. By managing the Time Variant intersections of fact table rows, dimension table rows, and dates, temporal databases also avoid the superset of joined pairs of rows in Figure 10.2. Having never implemented a temporal database, I have no evidence in favor of, or against, temporal databases. Temporal databases may perform Time Variant joins and queries faster and more efficiently than the Time Variant Solution Design outlined in this chapter. Regardless, from researching temporal databases, I can see that temporal databases are designed to limit database activity to only those rows that apply to the query at hand, in its Time Variant context. However, temporal databases are also a departure from the relational database structure and query language of generally available relational databases. As such, I’m not yet convinced the path to the goal is in temporal databases. For those reasons, the Time Variant Solution Definition outlined in this chapter is focused solely on achieving the goal displayed in Figure 11.1 via the Time Variant Solution Design. As such, the concepts and constructs of temporal databases are not included in the remainder of this chapter. This exclusion of temporal databases is neither an implicit nor an explicit statement about temporal databases. Rather, the inclusion of the Time Variant Solution Design, to the exclusion of all other designs, only means that the Time Variant Solution Design is the singular focus of this chapter.
One Row at a Time
The question is so simple, the answer so obvious, that it seems a trick question. When a dimension table has five million rows, and you want to join to one and only one of those five million rows, what is the fastest and most efficient way to retrieve that one and only one row? The answer is simple. Give each of those five million rows a unique identifier. Each row has one and only one unique identifier. Each unique identifier has one and only one row. It is a one-to-one relation: one row equals one unique identifier, and one unique identifier equals one row. A unique identifier can never be associated with any other row, and a row can never be associated with any other unique identifier. If a row ceases to exist, the unique identifier ceases to exist. If a unique identifier ceases to exist, the row ceases to exist.
Now, given that construct in a dimension table that has five million rows, and you want to join to one and only one of those five million rows, what is the fastest and most efficient way to retrieve that one and only one row? The answer is simple. Include a WHERE clause statement that says “WHERE unique_identifier = 12345.” Such a WHERE clause will return one and only one row. No additional logic is required. No superset is required. The RDBMS does not bring five million rows into memory. Instead, the RDBMS brings only one row into memory. The goal has been achieved and we can all congratulate ourselves and call it a day...almost.
We don’t query a data warehouse one table at a time. No, we query multiple tables simultaneously. When a transaction table joins to a dimension table that has five million rows, and you want to join each individual transaction row to one and only one of those five million dimension rows, what is the fastest and most efficient way to join the transaction and dimension tables such that each row of the transaction table joins to one and only one row of the dimension table? The answer is simple, and the same as before. Give each of those five million dimension rows a unique identifier. Embed that unique identifier in each row of the transaction table. Then, when each row of the transaction table is joined to the dimension table, each individual row of the transaction table will join with one and only one row of the dimension table. A query that joins the transaction and dimension tables will use that unique identifier to perform the join (i.e., Table_A JOIN Table_B on Table_A.Foreign_Key = Table_B.Unique_Identifier). No additional logic is required. No superset is required. The RDBMS does not bring five million dimension rows into memory. Instead, the RDBMS brings only one dimension row into memory for every transaction row. The goal has been achieved and we can all congratulate ourselves and call it a day...almost.
We don’t query a data warehouse one dimension at a time. No, we query multiple dimension tables simultaneously. This allows a query to include a parent hierarchy or a type code lookup in conjunction with a dimension table. When a dimension table joins to another dimension table that has five thousand rows, and you want to join each individual dimension row to one and only one of those five thousand dimension rows, what is the fastest and most efficient way to join the two dimension tables such that each row of the first dimension table joins to one and only one row of the second dimension table? The answer is simple, and the same as before. Give each of those five thousand dimension rows a unique identifier. Embed that unique identifier in each row of the first dimension table. Then, when each row of the first dimension table is joined to the second dimension table, each individual row of the first dimension table will join with one and only one row of the second dimension table. The query that joins the two dimension tables will use that unique identifier to perform the join (i.e., Table_A JOIN Table_B on Table_A.Foreign_Key = Table_B.Unique_Identifier). No additional logic is required. No superset is required. The RDBMS does not bring five thousand dimension rows from the second table into memory for every row of the first dimension table. Instead, the RDBMS brings only one dimension row from the second dimension table into memory for every row from the first dimension table. The goal has been achieved and we can all congratulate ourselves and call it a day. True, assuming we can come back tomorrow and replicate this method throughout the data warehouse.
To that end, let’s try to generalize what we have learned. We have learned that the fastest and most efficient method to find a row in a table is by providing each row in that table with its own unique identifier. Now we can retrieve a single row from that table, either through a direct query or through an indirect join, via the unique identifier for that row in that table. The optimal path to a single row in a table, therefore, is through a unique identifier. A query can reference the unique identifier directly or indirectly. Regardless, the fastest and most efficient path to a single row is its unique identifier.
Not a Surrogate Key
At this point, some readers are one page-turn away from tossing this book into a fireplace. If a fireplace is not handy, no doubt some readers will build a fire for the sole purpose of burning this book. Why? Those readers who have a strong preference against surrogate keys may perceive this Time Variant Solution Design to be a surrogate key design by another name. That perception is a misperception but is also understandable. A unique identifier may have the look and feel of a surrogate key. However, a unique identifier does not have the purpose of a surrogate key.
Surrogate keys in a data warehouse are intended to resolve relational integrity issues caused by key collision or key confusion. Regardless, surrogate keys have been mangled and abused in many data warehouses. Some data warehouse designers prefer to avoid surrogate keys altogether simply so they can avoid the pitfalls of surrogate keys. The unique identifier in the Time Variant Solution Design is not intended to resolve relational integrity issues. The unique identifier in the Time Variant Solution Design is intended to efficiently identify a specific row in a table, which is displayed in Figure 11.1.
If a unique identifier simultaneously identifies a specific row in a table and resolves relational integrity issues, that paired coupling of features is a bonus. In that case, the unique identifier should be treated two ways, first as a unique identifier of a specific row and second as a surrogate key. These are two totally separate functions. All the data in a data warehouse is delivered by an ETL application. The functions of a unique identifier are delivered by an ETL application, which will be discussed in Chapter 13. The functions of a surrogate key are also delivered by an ETL application. You cannot simply assume that an ETL application that delivers unique identifiers also delivers surrogate keys because the concept of a unique identifier matches your implementation of surrogate keys. Such an assumption will eventually cause data quality issues as the reality of surrogate keys and the reality of unique identifiers in your data warehouse diverge into two different meanings. If you must, you probably can deliver a unique identifier and a surrogate key in the same data element. But, in doing so, the ETL application that delivers that data, and the data quality application that assesses that data, must embed the functional meaning of surrogate keys and unique identifiers into the data it delivers.
A unique identifier, therefore, is not necessarily a surrogate key. In your data warehouse implementation both the unique identifier function and the surrogate key function may be performed by the same data element; alternatively, your data warehouse may use unique identifiers with no hint of the use of surrogate keys. Surrogate keys are mentioned here only to clarify that unique identifiers and surrogate keys may be similar but are functionally different in their use and meaning within a data warehouse. So, like ducks and geese, they may look like each other, walk like each other, and fly like each other, but they are two different things.
Instance Key
The name given to the data element that serves the function of a unique identifier is Instance Key. Any one of a number of names would suffice. But, for the purposes of this explanation of this Time Variant Solution Definition, the name for the unique identifier is Instance Key. An Instance Key can take one of two forms—Simple Instance Key and Compound Instance Key. A Simple Instance Key requires only one data value to uniquely identify a row of data within a table. A Compound Instance Key requires more than one data value to uniquely identify a row of data within a table.
A Simple Instance Key, illustrated in Figure 11.2, uses a single data value to identify an individual row in a table. The simplest and cleanest method for a Simple Instance Key is a sequential numeric data element that begins with the number 1 for the first row and then increments by 1 thereafter for each additional row. A Simple Instance Key can be used when you know beyond any doubt that the number of rows in the table containing a Simple Instance Key will never exceed the positive range of the numeric data type of the Simple Instance Key. For example, the Integer data type typically has a maximum value of 2,147,483,647. If you know beyond any doubt that a dimension table, including a row for every update, will never exceed two billion rows, then you could define a Simple Instance Key for that dimension table, with the Instance Key defined as an Integer data type. A Simple Instance Key does not cause the key already assigned to an entity (i.e., the Entity Key) to become superfluous. Instead, the Entity Key and the Instance Key can exist side by side without any interruption in both keys serving their individual respective purposes.
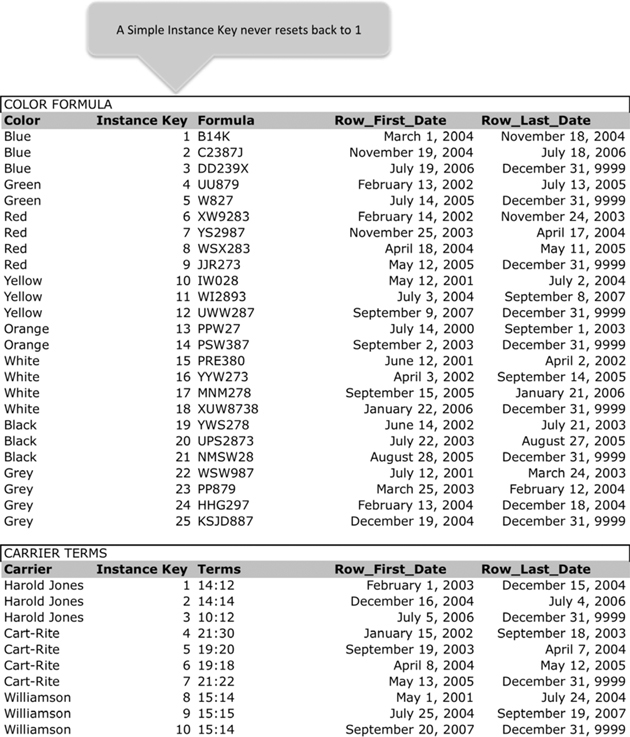
FIGURE 11.2
Simple Instance Key.
A Compound Instance Key, illustrated in Figure 11.3, uses a compound key to uniquely identify each individual row of a table. That compound key is made of the Entity Key, which is the key already assigned to an entity, and a sequential numeric Instance Key. A Compound Instance Key resets back to the value 1 for each entity within a table. The first Instance Key value for each and every individual entity is the number 1. The last Instance Key value for each and every individual entity is the number of rows assigned to each individual entity. For example, if the entity A has thirty-two rows, the Instance Key value for the first row is 1 and the Instance Key value for the last row is 32; if the entity B has 862 rows, the Instance Key value for the first row is 1 and the Instance Key value for the last row is 862. When joining to a table with a Compound Instance Key, likewise with any table having a compound key, the join must include the Entity Key and the Instance Key, because the combination of the Entity Key and Instance Key is required to uniquely identify an individual row.
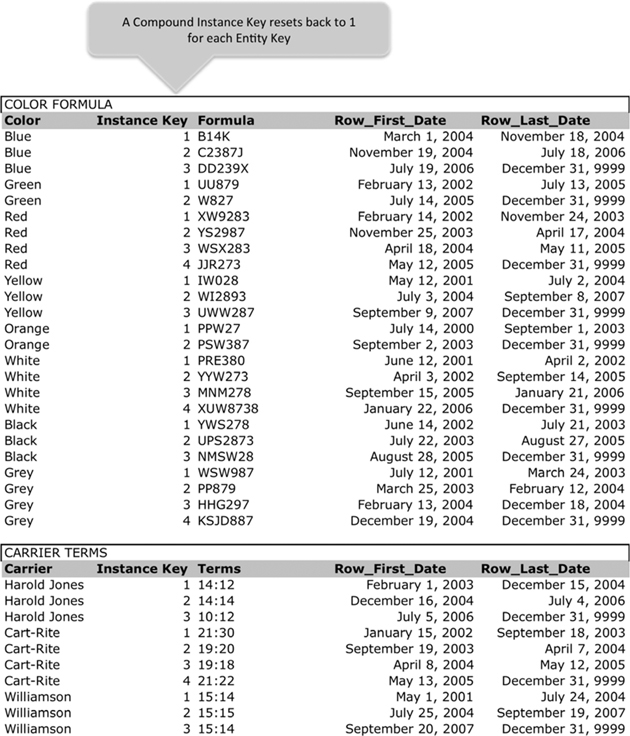
FIGURE 11.3
Compound Instance Key.
Join to a simple Instance Key
A join to a Simple Instance Key is achieved by embedding the Instance Key value as a foreign key. The example in Figure 11.4 shows a Transaction table that joins to a dimension table named Item. That join is achieved by embedding the Item_Instance_Key as an attribute in the Transaction table. The Item_Instance_Key, which in this example has the value 4, joins to one and only one row in the Item table. That one row can be identified by the Instance_Key value equal to 4.
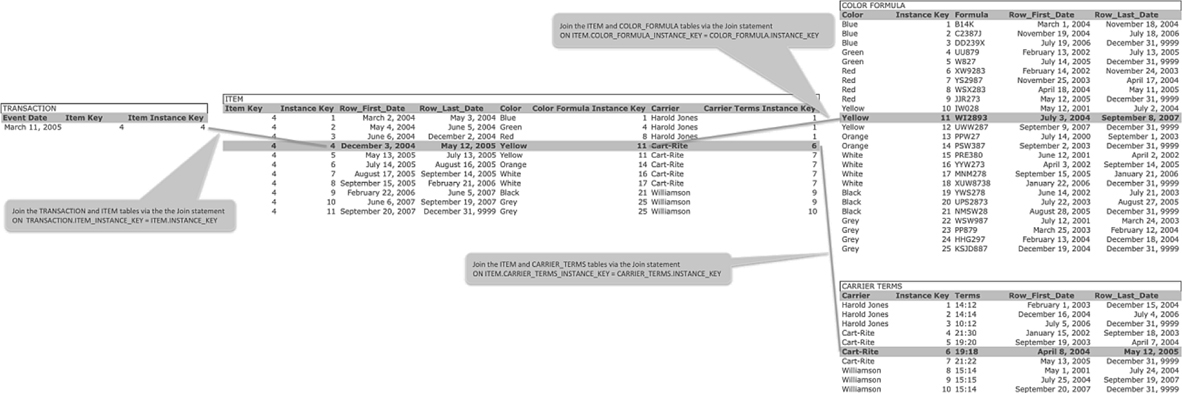
FIGURE 11.4
Transaction and Simple Instance Key.
The Item row identified by the Instance_Key value equal to 4 has two foreign keys: Color_Formula_Instance_Key and Carrier_Terms_Instance_Key. The Color_Formula_Instance_Key value 11 joins the Item table to one and only one row in the Color Formula table. That one row in the Color Formula table is identified by the Instance Key value 11. The Carrier_Terms_Instance_Key value 6 joins the Item table to one and only one row in the Carrier Terms table. That one row in the Carrier Terms table is identified by the Instance Key value 6. In this way, the use of a Simple Instance Key satisfies the Time Variant requirement in that each row of the Transaction table joins to one and only one row of the Item table. Each row of the Item table joins to one and only one row of the Color Formula and Carrier Terms tables. When joining these tables, the RDBMS no longer need join a multitude of rows that will not be in the final result set. Instead, the RDBMS can join only those rows that will be in the final result set.
Join to a Compound Instance Key
A join to a Compound Instance Key is achieved by embedding the Entity Key and Instance Key values as foreign keys. The example in Figure 11.5 shows a Transaction table that joins to a dimension table named Item. That join is achieved by embedding the Item_Key and Item_Instance_Key as attributes in the Transaction table. The Item_Key, which has the value 4, and the Item_Instance_Key, which also has the value 4, join to one and only one row in the Item table. That one row can be identified by the Item_Key value equal to 4 and the Instance_Key value equal to 4.
The Item row identified by the Item_Key value equal to 4 and the Instance_Key value equal to 4 has two compound foreign keys: Color & Color_Formula_Instance_Key and Carrier & Carrier_Terms_Instance_Key. The Color value “Yellow” and Color_Formula_Instance_Key value 2 join the Item table to one and only one row in the Color Formula table. That one row in the Color Formula table is identified by the Color value “Yellow” and the Instance Key value 2. The Carrier value “Cart-Rite” and Carrier_Terms_Instance_Key value 3 join the Item table to one and only one row in the Carrier Terms table. That one row in the Carrier Terms table is identified by the Carrier value “Cart-Rite” and the Instance Key value 3. In this way, the use of a Compound Instance Key satisfies the Time Variant requirement in that each row of the Transaction table joins to one and only one row of the Item table. Each row of the Item table joins to one and only one row of the Color Formula and Carrier Terms tables. When joining these tables, the RDBMS no longer need join a multitude of rows that will not be in the final result set. Instead, the RDBMS can join only those rows that will be in the final result set.
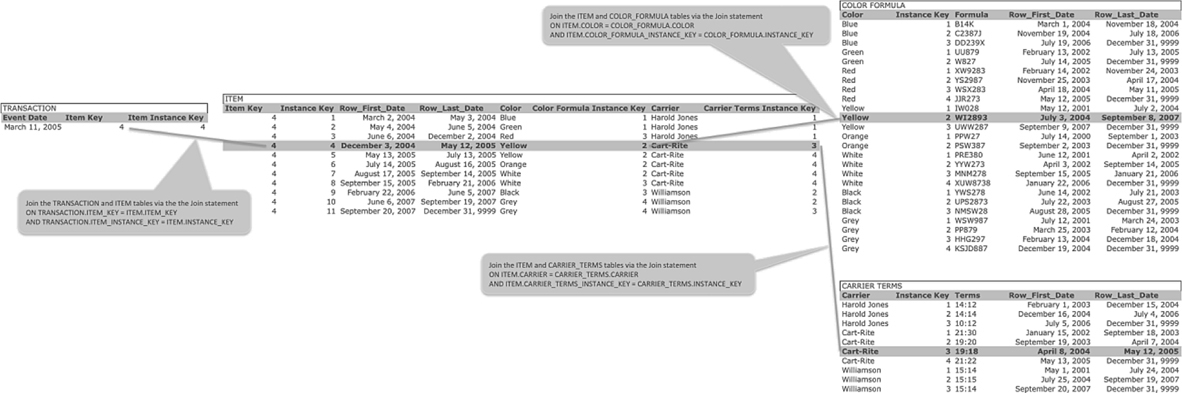
FIGURE 11.5
Transaction and Compound Instance Key.
Cascading Instance Keys
The ex.4 also demonstrates a peculiarity of this Time Variant Solution Design. Notice in the Item table the rows identified by the Instance Key values 4 and 5 have the same attributes. The Item table rows identified by the Instance Key values 7 and 8 and the values 10 and 11 also seem to display the same attributes, yet have an incremented Item Instance Key. So, the obvious question is why. Why did the Item table increment to Instance Key 5, even though no attributes in the Item table changed? The answer is that an attribute of the Cart-Rite entity in the Carrier Terms table changed. The attribute change in the Carrier Terms table for the Cart-Rite entity caused the Carrier Terms table to increment to the next Instance Key. Coincidentally, the Item table was referencing the Cart-Rite entity in the Carrier Terms table when the Cart-Rite entity incremented to the next Instance Key. So, the Item table incorporated the new Carrier Terms Instance Key, and in the process, incremented to the next Instance Key for the Item table. Likewise, an incremented Item Instance Key was caused by the incremented Color Instance Key for the White entity in the Color Formula table. At that time the Item table was referencing the White entity of the Color Formula table. The formula for the color White changed, which caused the Color Formula table to increment to the next Color Formula Instance Key. The new Color Formula Instance Key was incorporated into the Item table, which resulted in a new Item Instance Key. The Item Instance Key 11 is also caused by a change in the Williamson entity of the Carrier Terms table. The Williamson entity of the Carrier Terms table incremented to a new Instance Key when the Terms changed. The new Carrier Instance Key for the Williamson entity cascaded down into the Item table, causing the Item table to increment to a new Item Instance Key.
The example in Figure 11.5 demonstrates the same behavior. Simple Instance Keys and Compound Instance Keys both cascade Instance Keys with identical behavior. The general rule is that any increment in the Instance Key of a table cascades to any other table that references that table, causing an increment in the Instance Key of the referring table. A table at the top of a hierarchy structure will not experience the effect of cascading Instance Keys because a table at the top of a hierarchy structure refers to no hierarchical parents. A table at the bottom of a hierarchy structure, however, will experience significant effects from cascading Instance Keys because a table at the bottom of a hierarchy references hierarchical parents that also have hierarchical parents (and probably grandparents) of their own. A table, such as the Item table in Figure 11.4 and Figure 11.5, that refers to multiple hierarchical parents will experience cascading Instance Keys from both hierarchical parent tables.
This is the point at which this Time Variant Solution Design initially seems somewhat counterintuitive. The insertion of additional rows in a hierarchically lower table because a hierarchically higher table experienced updates seems to defy common sense. But then, a good example of why this construct succeeds can be found in the automotive insurance industry. For an example of the automotive insurance industry, we can consider a fictitious young boy named Harold.
Harold/16 years of age—At the age of 16 years, Harold receives his driver’s license. His automotive insurance company requires a very high insurance premium because Harold is 16 years of age; all 16-year-old boys are considered a very high risk.
Harold/24 years of age—At the age of 24 years, Harold graduates from college. His automotive insurance company reduces his insurance premium because Harold is 24 year of age and has a college degree; all 24-year-old young men with a college degree are considered a moderate risk.
Harold/35 years of age—At the age of 35 years, Harold is married and has his first child. His automotive insurance company extends its lowest possible insurance premium because Harold is 35 years of age and has a child; all 35-year-old men with a child are considered a minimal risk.
Is there a difference between Harold/16, Harold/24, and Harold/35? Yes, there is a difference. The difference is that Harold/16 is a member of a high-risk group, whereas Harold/24 is a member of a moderate-risk group and Harold/35 is a member of a low-risk group. Are Harold/16, Harold/24, and Harold/35 the same person? Yes, of course they are all Harold. However, they are different manifestations of the one person known as Harold. Those different manifestations of Harold are Harold at different times of his life. Likewise, the incremented Instance Keys for the entities Cart-Rite, White, and Williamson mean the data is representing different manifestations of the entities Cart-Rite, White, and Williamson. In that way, Cart_Rite/3 is indeed different from Cart_Rite/4. You have to go to Cart_Rite’s table, the Carrier Terms table, to find that difference. In the same way, White/2 is different from White/3, and Williamson/2 is different from Williamson/3. The Instance Keys uniquely identify the manifestations of an entity in a table. Any other table that references that entity also references a manifestation of that entity, which is identified by an Instance Key.
This is the effect of time in a data warehouse. Data modeling standard practices consider the relationship between entities with the assumption that such entity relations persist through time. If a hierarchical parent could gain and lose its relation to a hierarchical child from one day to the next, a data modeler would recognize such a condition as an error in the data model and try again. If a data model is constructed correctly, two related entities will always be related. Their relation exists today and will exist tomorrow. As such, entity relations in a data model are built with the expectation that entity relations exist at all times. Therefore, entity relations in a data model do not need to incorporate a third element (i.e., time) into their relation. However, when in a Time Variant data warehouse we add the element of time, relations between entities are affected by time. That time effect is captured in the form of Instances. That is the major difference in this Time Variant Solution Design. This Time Variant Solution Design uses Instance Keys to capture the effect of time, rather than using dates and intervals to capture the effect of time. Through the use of Instance Keys in a primary key/foreign key relation, this Time Variant Solution Design simultaneously captures the effect of time and resolves the performance problems caused by the multiplicative explosion of time variant data.
which tables use instance keys?
Every row of every table has some aspect of time. The transactions in a fact table occurred at a time. The entities in a dimension table began at a time and ended at a time. So, which of the multitude of tables in a data warehouse should include Instance Keys? The answer is any table wherein the data can be in effect over an interval, or span, of time. Transactions and events in a fact table typically occur at, or are realized as of, a single moment in time. Transactions and events that are associated with only a single moment in time do not need an Instance Key to further identify that moment in time. Entities, properties, and attributes in a dimension table typically remain in effect for a period of days, weeks, months, or years. Entities, properties, and attributes need an Instance Key to identify their existence in that interval of time in a way that can be captured in a relation between tables.
There is always an exception to the rule. Somewhere, a data warehouse has a dimension table that is specific to a single moment in time. Somewhere, another data warehouse has a fact table that has transactions that span days, weeks, months, or years. So, we cannot define the use of Instance Keys as a method dedicated solely to dimension tables, and never fact tables, in a data warehouse. If you’re looking at the data model of your data warehouse wondering which tables need Instance Keys, you can probably look for dates that identify the beginning and ending of the effective span of time. If a table has such dates, that table will require an Instance Key. If a table has a time value that indicates only a moment in time, that table does not need an Instance Key.
Type 1 Time Variance
The Time Variant Solution Design has thus far dealt solely with Type 2 Time Variance. Type 2 Time Variance places all transactions and events in their original historical context. This Time Variant Solution Design also includes a solution for Type 1 Time Variance. The difference between Type 1 and Type 2 Time Variance is, therefore, the historic context in time. Type 2 Time Variance achieves the historic context by the inclusion of all history rows, each of which is uniquely identified by Instance Keys, either Simple or Compound. Type 1 Time Variance can also be achieved by reversing both those features. In Figure 11.6, the history rows are removed, retaining only those rows that are the most recent for each entity. The notations in Figure 11.6 also show that all joins are achieved by way of the entity keys.

FIGURE 11.6
Transaction and Type 1 Time Variance with Simple Instance Keys.
The tables in Figure 11.6 avoid the multiplicative explosion of rows by retaining only one row for each entity. In Chapter 10, the joins using entity keys caused the multiplicative explosion of rows because the dimension tables had multiple rows for the same entity key. The dimension tables in Figure 11.6, however, have only one row for each entity key. So, you could say the tables in Figure 11.6 also experience the multiplicative explosion of rows, and the multiplicative factor is the number of rows per entity, which would be a factor of 1.
Also notice that the dimension tables in Figure 11.6 retain their Instance Keys. The inclusion of the instance keys facilitates a data quality assessment of the parity between the Type 2 and Type 1 tables. The ability to match the entity keys, instance keys, and attributes for each entity in each dimension table in the Type 1 and Type 2 sets of data increases the level of confidence in the parity between the two sets of data, as compared to matching only the entity keys and attributes.
The tables in Figure 11.7 are very similar to the tables in Figure 11.6. The one difference is the instance keys. The instance keys in Figure 11.7 are based on rows from a dimension table that was built using Compound Instance Keys. The resulting data is the same. The only difference is the key structure that returned that data. The data from the Type 2 tables in Figure 11.4 and Figure 11.5 associated the transaction with a yellow item delivered by Cart-Rite. However, the data from the Type 1 tables in Figure 11.6 and Figure 11.7 associated the transaction with a gray item delivered by Williamson. Which answer is correct? They are both correct...for their respective time variant context.
Type 1 and Type 2 Combined
A data warehouse can incorporate both forms of time variance. The existence of the Type 1 time variant dimension tables does not preclude the existence of Type 2 time variant dimension tables. A transaction or dimension table is able to join to them both, as can be seen in Figures 11.4, 11.5, 11.6, and 11.7. So, there really is no reason to choose one form of time variance at the exclusion of the other.
Figure 11.8 shows a single transaction table (in the middle of the figure) that joins to Type 2 dimension tables (in the top of the figure) and Type 1 dimension tables (in the bottom of the figure). This approach leverages a single set of transaction, or fact, tables that can join to both Type 1 dimension tables and Type 2 dimension tables.

FIGURE 11.7
Transaction and Type 1 Time Variance with Compound Instance Keys.
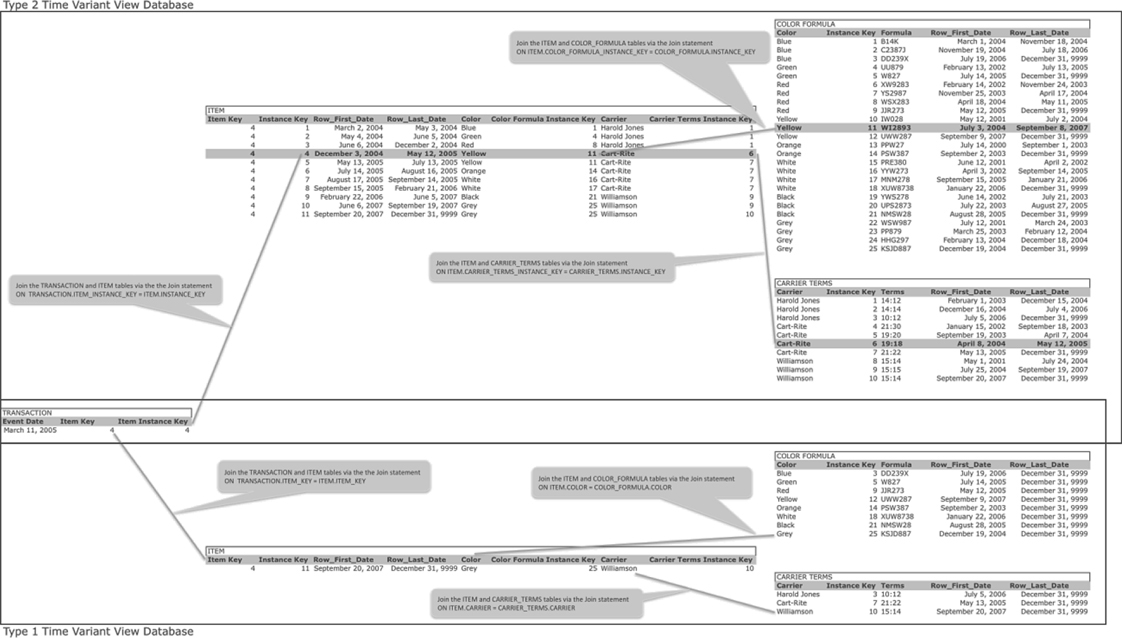
FIGURE 11.8
Transaction and Type 1 and 2 Time Variance with Simple Instance Keys.
The only caveat here is the possibility to cause confusion. When joining the Transaction table to the Item table, which Item table do I join to the Transaction table? The answer, which will be discussed in further detail in Chapter 12, is to use three databases. The first database holds only the transaction, or fact, tables. The second database holds the Type 1 dimension tables and views to the transaction, or fact, tables. In that Type 1 database, the Transaction table can join to only one Item table because the Type 1 database has only one Item table. The third database holds the Type 2 dimension tables and views to the transaction, or fact, tables. In that Type 2 database, the Transaction table can join to only one Item table because the Type 2 database has only one Item table. So, if you want to view the data warehouse in the Type 1 time variant context, you query the Type 1 database; if you want to view the data warehouse in the Type 2 time variant context, you query the Type 2 database.
Figure 11.9 shows the combination of Type 1 and Type 2 databases, using Compound Instance Keys to uniquely identify the Type 2 dimension rows. The dimension rows in Figure 11.8 used Simple Instance Keys to uniquely identify every dimension row. The combination of Type 1 and Type 2 dimension tables works equally well with Simple Instance Keys and Compound Instance Keys. Both forms of combined time variance avoid the multiplicative explosion of rows that is the root cause of the performance degradation associated with a time variant data warehouse. Data warehouse customers who wish to see enterprise transactions in their historical context can query the Type 2 database. Data warehouse customers who wish to see enterprise transactions in the present context of the enterprise can query the Type 1 database. The query language used to query both databases is the standard relational SQL. By using this Time Variant Solution Design, a data warehouse can simultaneously deliver Type 1 and Type 2 time variant data, without the performance degradation associated with time variance via date logic.
Summary Tables
Transaction tables contain data from individual transactions. For a shipping company a Transaction table could hold all the shipping orders, deliveries, and confirmations. For a restaurant a Transaction table could contain all the dining orders. For a retail company a Transaction table could contain all the sales details that occurred. Granular detailed data is a valuable asset to a data warehouse, unless you need a weekly sales report. When you need to know how many pounds of potatoes sold every week for the past two years, granular transaction data about the individual sale of potatoes only causes the data warehouse RDBMS to work harder to provide a weekly sales report. For that reason, the most obvious performance optimization for a data warehouse is Summary tables.
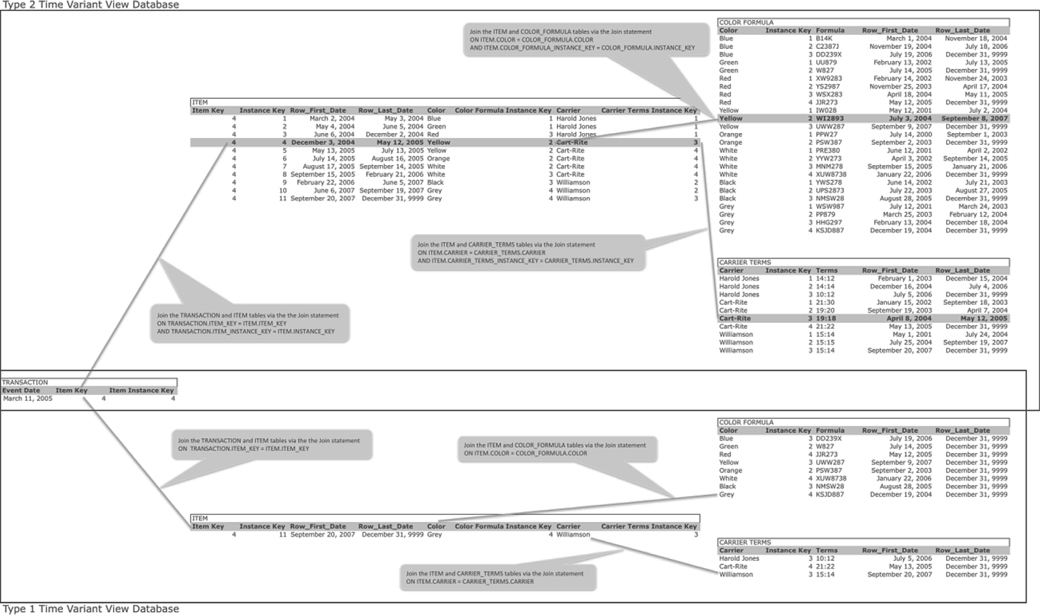
FIGURE 11.9
Transaction and Type 1 & 2 Time Variance With Compound Instance Keys.
Summary tables hold the result set of an Insert/Select query that sums the additive quantitative portions of a Transaction table. A summation query also includes a GROUP BY statement. The GROUP BY statement defines the level of granularity of the Summary table. If the summation query groups retail locations by a geographic area (i.e., region), then the geographic granularity of the Summary table will be the region, whereas the geographic granularity of the Transaction table was the retail location. If the summation query groups products by a hierarchy (i.e., department), then the hierarchical granularity of the Summary table will be the department, whereas the hierarchical granularity of the Transaction table was the individual product.
Summary tables can, and often are, a summation of time. All the transactions that occurred during a day can be summarized to the level of granularity of a day (i.e., day-level summary), week (i.e., week-level summary), or any other time cycle within the enterprise. The time period of a Summary table may, or may not, override the time variance of the data included in the Summary table. If, for example, a Summary table is defined as a week-level summary, that table would summarize all the transactions that occurred from Sunday through Saturday. Suppose a product in those transactions was blue on Sunday, green on Monday, red on Tuesday, yellow on Wednesday, black on Thursday, white on Friday, and mauve on Saturday. So for the week-level summary of transactions including that product, what is the color of that product for the week? Is it the first color? Is it the last color?
The answer is based on the time variance of the Summary table. If the Summary table is a Type 1 Summary table, then all dimensions will be represented by their Entity Key. The product in question, which seems to change color daily, will be represented by its Entity Key. What is its color? It is the color it is right now. Because it is a Type 1 Summary table, by definition the Type 1 dimensions can represent only their properties and attributes in effect now.
If, however, the Summary table is a Type 2 Summary table, then all the dimensions will be represented by their Instance Key. The product in question, which seems to change color daily, will be represented by all its Instance Keys—all seven of them, one for each color. Because it is a Type 2 Summary table, by definition the Type 2 dimensions can represent their properties and attributes in effect at the time of the original transaction or event. Even when summed up by the week all the “green” rows sum together, all the “red” rows sum together, all the “yellow” rows sum together, and so on.
The result is that a Type 1 Summary table will have one row for each GROUP BY key including the Entity_Key, regardless of the time variant changes in the dimensions referenced by the GROUP BY statement, which included the Entity_Key. However, a Type 2 Summary table for the same GROUP BY key including the Instance_Key will have one row for each time variant change in the dimensions referenced by the GROUP BY statement, which included the Instance_Key.
ETL Cycles
ETL cycles are the frequency, or schedule, by which the ETL jobs run. If the ETL jobs run once a day, then the ETL cycle is the day. If the ETL jobs run once a week, then the ETL cycle is the week. The ETL cycle determines how often the data warehouse “sees” the enterprise. If the enterprise changes the color of a product nine times every day, and the ETL application for a data warehouse extracts the color of that product only once in a day, then the data warehouse will be aware of only one color update per day. The other eight color updates per day will never be seen in the data warehouse. In that example the ETL cycle is a day.
The ETL cycle determines the smallest possible interval of time in a dimension table. For example, if the ETL cycle runs once per day at 5:00 a.m., then the smallest interval of time for that dimension table is the day (e.g., 5:00 a.m. today through 5:00 a.m. tomorrow). So, if the ETL cycle for the color of a product runs at 5:00 a.m. every day, then the smallest time interval for the product color table would be a 24-hour day. So, the Instance Key value 1357 would indicate that the color of the product was blue from Sunday 5:00 a.m. through Monday 5:00 a.m. The time interval indicated by an Instance Key in that table, therefore, would be Sunday 5:00 a.m. through Monday 5:00 a.m., which is a day. In that example, the Instance Key represents a day.
If an ETL application extracts data once per week on Tuesday morning at 8:00 a.m., then the ETL cycle would be from Tuesday 8:00 a.m. through the following Tuesday 8:00 a.m. The smallest interval of time for which a dimension update could exist in that data warehouse would be from Tuesday 8:00 a.m. through the following Tuesday 8:00 a.m. The Instance Key for that dimension table would indicate the time period Tuesday 8:00 a.m. through the following Tuesday 8:00 a.m.
If an ETL application extracts data once per month on the fifth of the month, then the ETL cycle would be from the fifth of the month through the fifth of the following month. The smallest interval of time for which a dimension update could exist in that data warehouse would be from the fifth of the month through the fifth of the following month. The Instance Key for that dimension table would indicate the time period the fifth of the month through the fifth of the following month.
Therefore, the ETL cycle determines the smallest time interval that can be represented by an Instance Key. So, if you want the Instance Keys to represent dates, then ETL cycle must run once per day. If you want the Instance Keys to represent weeks, then the ETL cycle must run once per week. Time-based Summary tables can summarize at a time hierarchy level equal to the time interval represented by the Instance Keys. However, time-based Summary tables cannot summarize at a level more granular than the time interval represented by the Instance Keys.
Instance Keys
The time interval between ETL cycles is the time interval represented by an Instance Key. In that way, the ETL cycle defines the periodicity of the Instance Keys. If the ETL cycle occurs every twenty-four hours, and an update with an incremented Instance Key occurs every twenty-four hours, then the interval represented by each Instance Key is twenty-four hours. That means that all rows in a Transaction table representing that twenty-four hour period will share the same Instance Key.
A time variant data warehouse works best when the entire data warehouse shares the same ETL Cycle, and therefore, the same periodicity. A shared common periodicity avoids difficult time variant conversions and the same relational integrity issues that arise in the presence of differing time frames. By defining the periodicity of the ETL cycle and Instance Keys, a data warehouse is able to be time variant in a single consistent unit of time. The unit of time chosen for a specific data warehouse is a judgment decision based on the transactions and activity within the enterprise.
Real Time and Time Variance
At first glance, Real Time and Time Variance would seem to go hand in hand. They are both about time, and they both have a wow factor of 9+. So, they should go together, right? Actually, no, Real Time and Time Variance do not go together.
The goal of Time Variance is to synchronize enterprise events in the past with the state of the enterprise at that moment in the past. A time variant data warehouse will be able to synchronize events on July 21, 2001, with the state of the enterprise on July 21, 2001. Time Variance adds value by increasing the span of time during which transactions and dimensions can be synchronized. The reason Time Variance is so difficult is that there is so much history to synchronize. Looking back in time, the history begins yesterday and continues as far as the enterprise can see.
Real Time, on the other hand, could be renamed as Right Now. The focus of Real Time is the “right now” time frame. Real Time is not focused on the five, ten, or fifteen years leading up to today. Instead, Real Time is focused on today. That being the case, the “time” in Real Time is right now, whereas the “time” in Time Variant is all of history. These two time frames contrast drastically with each other.
The enterprise knows the properties and attributes of a product today. The enterprise also knows the properties and attributes of that same product as of yesterday. So, time variant data about transactions and dimensions that occurred today, or yesterday, do not add much value. However, a data warehouse that can synchronize enterprise transactions and dimensions for the past five, ten, or fifteen years adds value through its time variant data. As such, time variant data about today’s transactions is not as helpful as time variant data about transactions from the past fifteen years.
The distinction between time variant data for the past fifteen years and real-time data for the past fifteen hours is the distinction between strategic and tactical data. Strategic data provides the big picture, far distant horizon, and holistic perspective of the enterprise. Tactical data provides the current, up-to-the minute, “right now” perspective of the enterprise. Strategic data can identify trends and patterns that can only be seen by looking at multiple years of data. Tactical data can tell you the state of the enterprise right now, this minute, which has changed since you began reading this paragraph...see, it changed again.
If that tactical, “right now” time frame is your requirement, then you need an operational data store. An operational data store is both. It is operational. It is a data store. An operational data store provides an interface into the operational data of a single business unit. The data is grained at the lowest level available in the operational system. The data retention period is very short, possibly as short as days, or as long as weeks. The ETL process for an operational data store updates the data frequently—if not real time, then near real time. The lowest-level granularity, short retention period, frequent updates, and single business unit focus all together indicate the tactical nature of an operational data store.
The operational data store is explained in Chapter 5 of Building and Maintaining a Data Warehouse. The architectural considerations that lead to the creation of an operational data store are similar to the distinction between a delivery truck and an ice cream truck. They both serve their individual purposes very well. They do not, however, serve both purposes simultaneously well at all. For that reason, real-time up-to-the-minute data is best presented in an operational data store, while long-range time variant data is best presented in a data warehouse.
First Time Variant Subject Area
Your first time variant data warehouse subject area should be small...smaller than that...still smaller. That is because your first time variant subject area will include the initial creation of all things time variant: tables, keys, ETL, views, BI reports, data quality, metadata. The scope of your first time variant subject area will be more about time variance than about the subject area. Unfortunately, you don’t get to under-deliver the subject area. So, the safest plan is to convert a reasonably small subject area that is already mature in the data warehouse. Your ability to recognize mistakes will be improved when you’re looking at data you can recognize. For that reason, begin with a subject area with which you are experienced. This will initially seem counterintuitive. However, for that first time variant subject area the new deliverable is time variance. Delivering a time variant version of a mature subject area allows you to focus more on the time variant structures and infrastructures. For the second time variant subject area, all those structures and infrastructures will already be in place.