
Chapter 10. Real-Time Machine Learning Use Cases
Overview of Use Cases
Real-time data warehouses help companies take advantage of modern technology and are critical to the growth of machine learning (ML), big data, and artificial intelligence (AI). Companies looking to stay current need a data warehouse to support them.
Choosing the Correct Data Warehouse
If your company is looking to benefit from ML and needs data analytics in real time, choosing the correct data warehouse is critical to success. When deciding which data warehouse is best for your workload, here are a series of questions to ask yourself:
-
Do you need to ingest data quickly?
-
Do you need to run fast queries?
-
Do you need to have concurrent workloads?
The use cases discussed in this chapter highlight how the combination of these needs lead to amazing business results.
Energy Sector
In this section, you will learn about two different companies in the energy sector and the work they’re doing to drive equipment efficiency and pass along savings to customers.
Goal: Anomaly Detection for the Internet of Things
At a leading independent energy company during its drilling explorations, drill operators are constantly making decisions for where, when, and in what direction to adjust, with the goal of decreasing the time it takes to drill a well.
Approach: Real-Time Sensor Data to Manage Risk
Each drill bit on a drilling rig can cost millions of dollars, and the entire operation can cost millions per day, operating over the course of several months. As a result, there is a delicate balance between pushing the equipment far enough to get the full value from it, but not pushing it too hard and breaking it too soon. To better manage this operation, the company needed to combine multiple data types and third-party sources, including geospatial and weather data, into one solution, as illustrated in Figure 10-1.
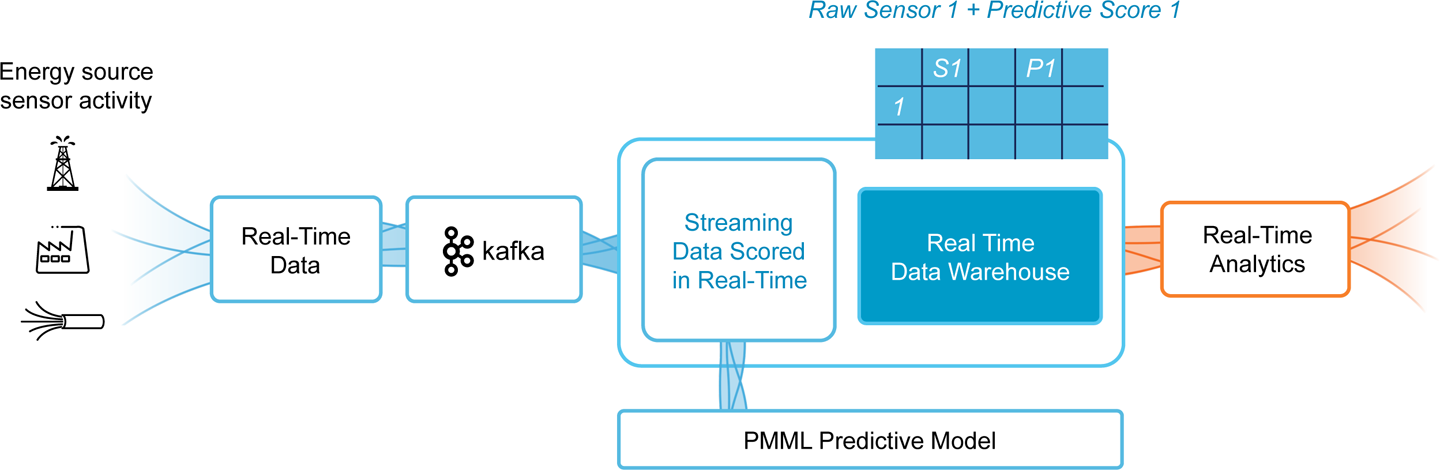
Figure 10-1. Sample real-time sensor pipeline in the energy sector
Goal: Take Control of Metering Equipment
Smart gas and electric meters produce huge volumes of data. A leading gas and electric utility needed to better manage meter readings and provide analytics to its data teams.
Approach: Use Predictive Analytics to Drive Efficiencies
The company had more than 200,000 meter readings per second load into its database while users simultaneously processed queries against that data. Additionally, it had millions of meters sending between 10 and 30 sensor readings every hour, leading to billions of rows of data. Just an initial part of a year contained more than 72 billion meter reads, which measured up to six terabytes of raw data.
To handle this amount of data, the company needed an affordable analytics platform to meet its goals and support data scientists using predictive analytics.
Implementation Outcomes
This leading independent energy production company was able to save millions of dollars based on high data ingest from its equipment, receiving about a half a million data points per second.
The gas and electric utility was able to compress its data by 10 times and reduce its storage on disk. The query time against the data dropped from 20 hours to 20 seconds.
Thorn
Thorn is a nonprofit that focuses on defending children from sexual exploitation on the internet.
Goal: Use Technology to Help End Child Sexual Exploitation
To achieve the goal of ending childhood sexual exploitation, Thorn realized it needed to create a digital defense to solve this growing problem.
Approach: ML Image Recognition to Identify Victims
Currently, roughly 100,000 ads of children are posted online daily. Matching these images to missing child photos is akin to finding a needle in a haystack. To comb through these images, Thorn implemented the use of ML and facial recognition technology.
The technology allowed the nonprofit to develop a point map of a given face, with thousands of points, and use those points to assign a searchable number sequence to the face. This process lets the technology individually classify the image and match it to a larger database of images, as shown in Figure 10-2.

Figure 10-2. Facial-mapping diagram
To solve this problem, Thorn took advantage of the Dot Product function within its database as well as Intel’s AVX2 SIMD instruction set to quickly analyze the points on a given face.
Implementation Outcomes
This process allowed Thorn to reduce the time it took to make a positive photo match from minutes down to milliseconds (see Figure 10-3).
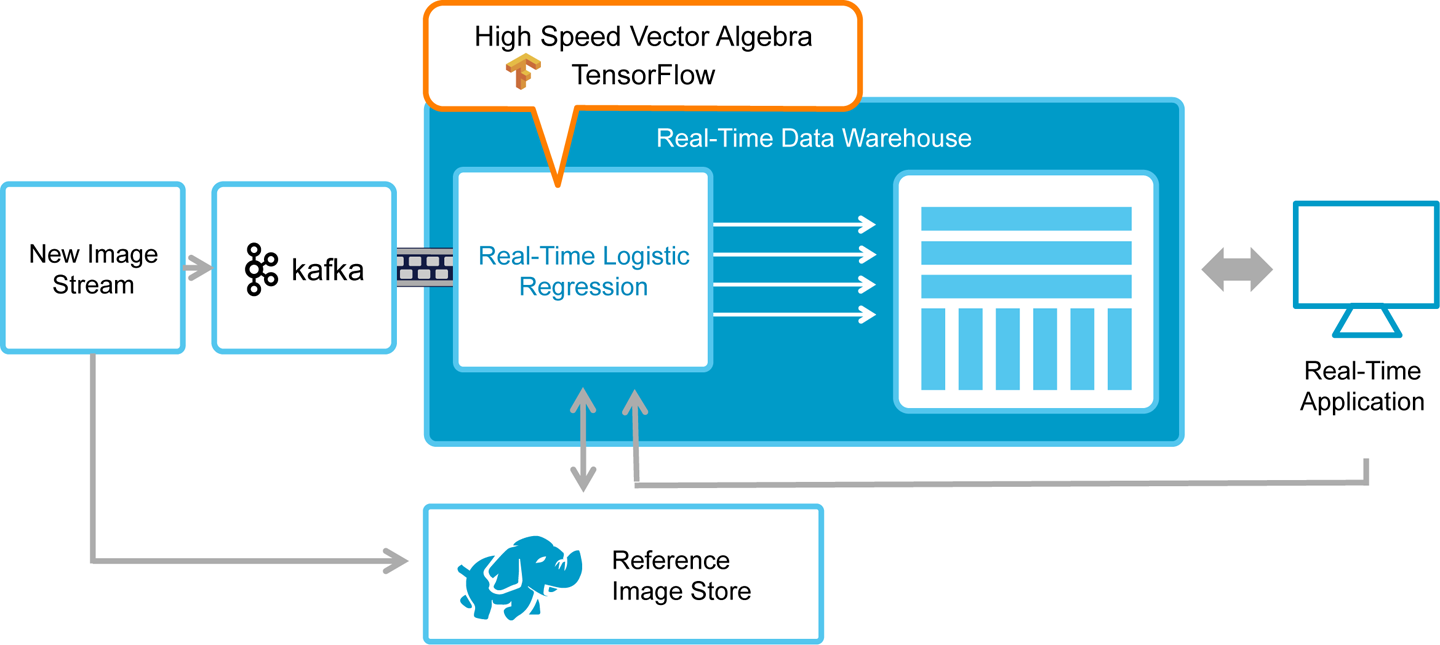
Figure 10-3. Reference architecture for building image recognition pipelines
Tapjoy
Tapjoy is a mobile advertising company that works with mobile applications to drive revenue.
Goal: Determine the Best Ads to Serve Based on Previous Behavior and Segmentation
Tapjoy helps address app economics, given that mobile application developers want to pay on installations of the applications, as opposed to advertising impressions. This is where Tapjoy comes in. It uses technology to deliver the best ad to the person using the application.
Approach: Real-Time Ad Optimization to Boost Revenue
Tapjoy wanted a solution that could combine many functions and eliminate the need for unnecessary processes. The original architecture would have required streaming from Kafka and Spark to update the application numbers—conversion rate, spending history, and total views. As the application grew, this process became more complicated with the addition of new features. One downside to this model was that streaming failed, which was problematic because the data needs to be real time and it’s difficult to catch up when streaming stops working. To fix this problem, most companies would add a Lambda process. However, none of that architecture is easy to maintain or scale.
The team needed a better way. With the proper data warehouse, they were able to put raw data in, with the condition that the data could be rapidly ingested, and do the aggregation and serve it out, as depicted in Figure 10-4.
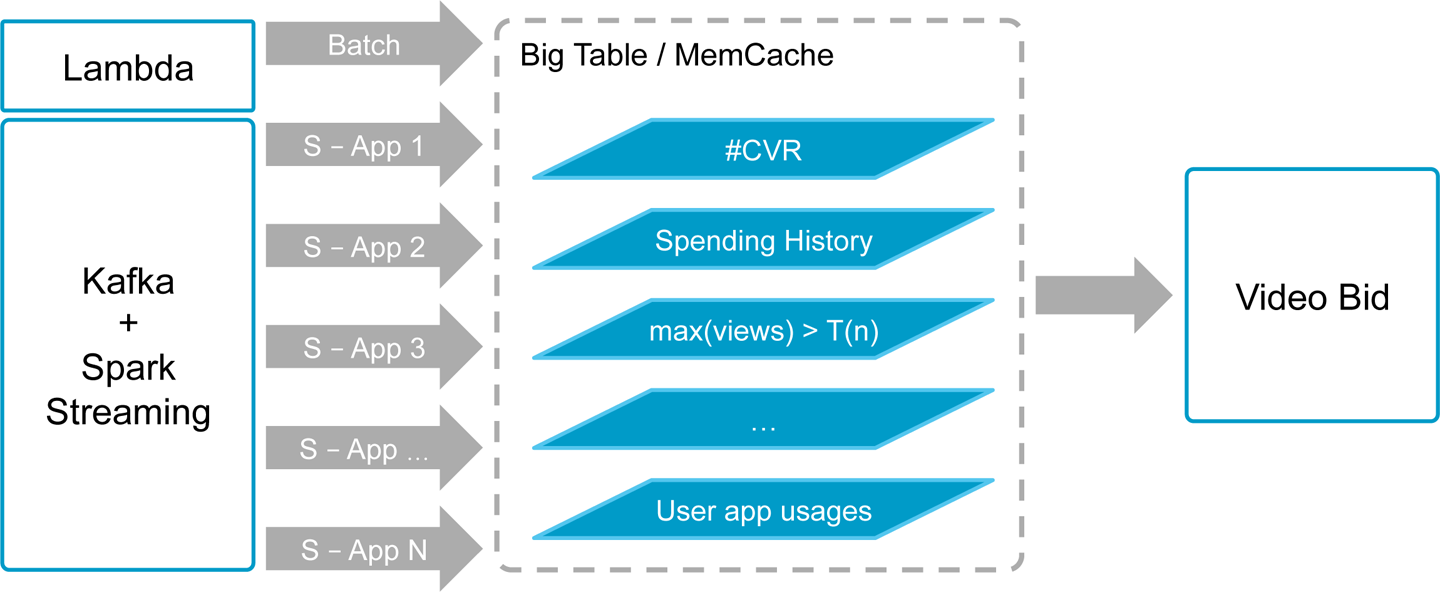
Figure 10-4. Reference architecture for building ad request pipelines
Implementation Outcomes
The new configuration allowed Tapjoy to run a query 217,000 times per minute on the device level, and achieve an average response time of .766 milliseconds. This is about two terabytes of data over 30 days. Additionally, the Tapjoy team learned that it could use a real-time data warehouse to support a variety of different tasks to reduce its tech stack footprint, which you can see in Figure 10-5.
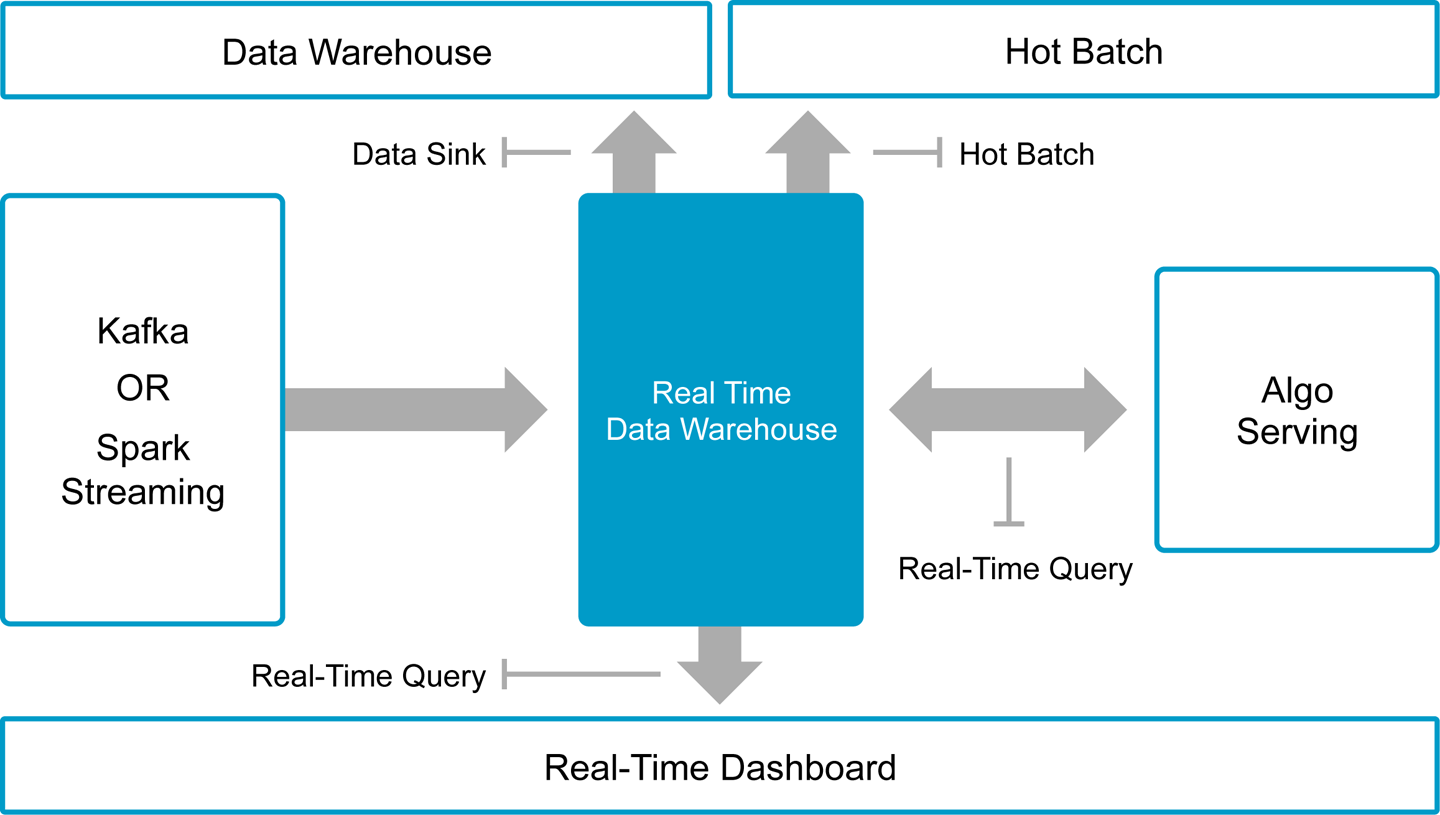
Figure 10-5. Example of uses for data warehouses
Reference Architecture
If you’re looking to do real-time ML, Figure 10-6 gives a snapshot of what the architecture could look like.
First you begin with raw data. Then, you need to ingest that data into the data warehouse. You could use applications such as Kafka or Spark to transform the data. Or use Hadoop or Amazon S3 to handle your historical data.
After you’ve ingested the data, you can analyze it and manipulate it with tools such as Looker and Tableau. Figure 10-6 provides an overview of the environment.
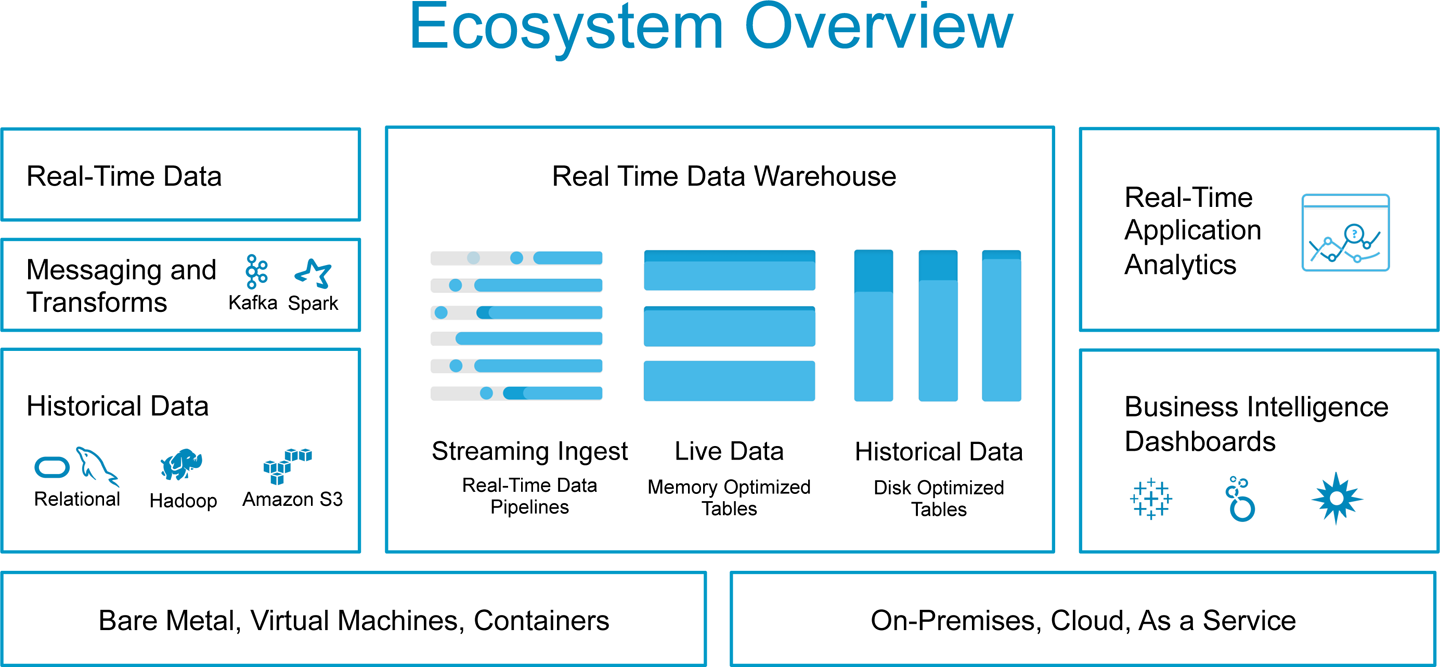
Figure 10-6. Reference architecture for data warehouse ecosystems
Datasets and Sample Queries
To begin transforming data, you can check out the following free datasets available online: