
Chapter 6. Building Real-Time Data Pipelines
Technologies and Architecture to Enable Real-Time Data Pipelines
Today’s applications thrive using both real-time and historical data for fast, accurate insights. Historical data provides the background for building an initial algorithm to score real-time data as it streams into an application.
To enable real-time machine learning (ML), you will need a modern data processing architecture that takes advantage of technologies available for ingestion, analysis, and visualization. Such topics are discussed with greater depth in the book The Path to Predictive Analytics and Machine Learning (O’Reilly, 2016); however, the overview provided in the sections that follow offers sufficient background to understand the concepts of the next several chapters.
Building any real-time application requires infrastructure and technologies that accommodate ultra-fast data capture and processing. These high-performance technologies share the following characteristics:
-
In-memory data storage for high-speed ingest
-
Distributed architecture for horizontal scalability
-
Queryable for instantaneous, interactive data exploration.
Figure 6-1 illustrates these characteristics.

Figure 6-1. Characteristics of real-time technologies
High-Throughput Messaging Systems
The initial input for most real-time applications begins by capturing data at its source and using a high-throughput message bus to ensure that every data point is recorded in its correct place. Data can come from a variety of sources, including logs, web events, sensor data, user interactions, financial market streams, and mobile applications.
High-throughput messaging technologies like Apache Kafka are ideal for consuming streaming data at its source. Apache Kafka can handle terabytes of messages, and its effective use of memory, combined with commit log on disk, provides ideal performance for real-time pipelines and durability in the event of server failure.
Data Transformation
The next piece of a real-time data pipeline is the transformation tier. Data transformation takes raw data from a message bus, and transforms the data to a more accessible format for easier analysis. Transformers serve a number of purposes, including data enrichment, aggregation, and scoring for ML.
Similar to our message bus, it’s important that you use technologies that are fast and scalable to allow for real-time data processing. Apache Python and Apache Spark are used often for data transformation and are ideal for obtaining real-time performance.
When building real-time data pipelines, the job of the transformation is to extract data from the message bus (Apache Kafka), filter down to a smaller dataset, run enrichment operations, augment data, and then push that refined dataset to an operational data warehouse. You can create pipelines by using standard SQL queries. Example 6-1 describes a pipeline used to load Twitter messages for a sentiment analysis application.
Example 6-1. Creating a real-time data pipeline from Kafka
sql> CREATE PIPELINE twitter_pipeline AS -> LOAD DATA KAFKA "public-kafka.compute.com:9092/tweets-json" -> INTO TABLE tweets -> (id, tweet); Query OK, (0.89 sec) sql> START PIPELINE twitter_pipeline; Query OK, (0.01 sec) sql> SELECT text FROM tweets ORDER BY id DESC LIMIT 5G
Technologies such as Apache Spark do not include a persistent datastore; this requires that you implement an operational datastore to manage that process, which we describe in the next step of our data pipeline.
Operational Datastore
To make use of both real-time and historical data for ML, data must be saved into a permanent datastore. Although you can use unstructured systems such as Hadoop Distributed File System (HDFS) or Amazon S3 for historical data persistence, neither offers the performance for delivering real-time analytics.
This is where an operational datastore comes into play. A memory-optimized data warehouse provides both persistence for real-time and historical data as well as the ability to query streaming data in a single system. By combining transactions and analytics, data is rapidly ingested from our transformation tier and saved to a datastore. This supplies your application with the most recent data available, which you can use to power real-time dashboards, predictive analytics, and ML applications.
Data Processing Requirements
For a database management system to meet the requirements for real-time ML, a variety of criteria must be met. The following sections explore some of these criteria.
Memory Optimization
For real-time performance, in-memory data processing is a must. Taking advantage of memory for compute allows reads and writes to occur at rapid pace. In-memory operations are also necessary for real-time analysis because no purely disk-based system can deliver the input/output (I/O) required for real-time operations.
Access to Real-Time and Historical Data
Converging traditional online transaction processing (OLTP) and online analytical processing (OLAP) systems requires the ability to compare real-time data to statistical models and aggregations of historical data. To do so, a datastore must accommodate two types of workloads (without compromising on latency): high-throughput operational transactions and fast analytical queries.
Compiled Query Execution Plans
Reducing disk I/O allows queries to execute so rapidly that dynamic SQL interpretation can become a bottleneck. To address this, some datastores use a caching layer on top of their relational database management system (RDBMS). However, this leads to cache invalidation issues resulting in minimal, if any, performance benefit. Executing a query directly in memory, against the live dataset, maintains query performance with assured data consistency, as depicted in Figure 6-2.
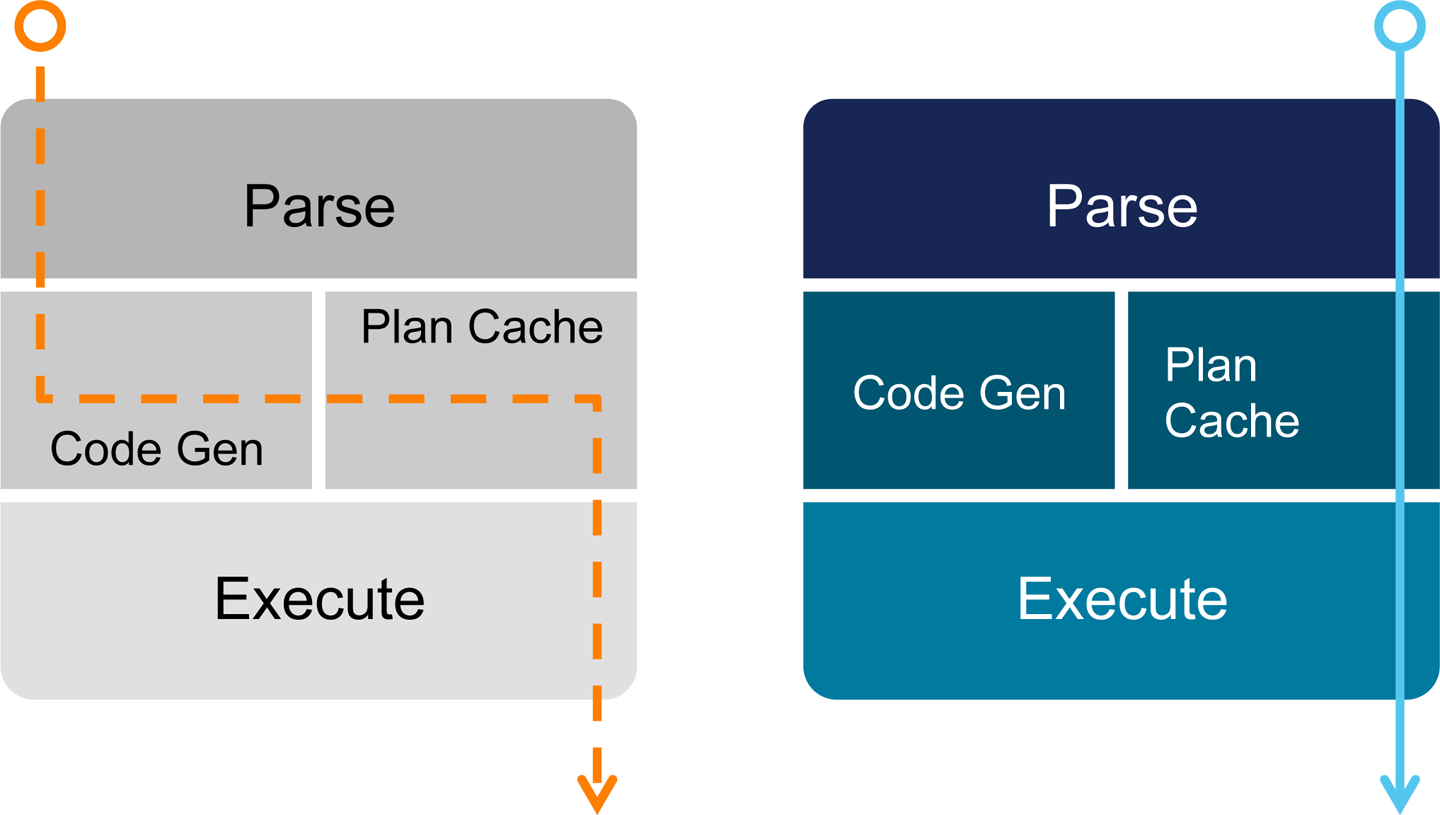
Figure 6-2. Compiled query execution plans
Multiversion Concurrency Control
You can achieve the high throughput necessary for a real-time ML engine through lock-free data structures and multiversion concurrency control (MVCC). MVCC enables data to be accessed simultaneously, avoiding locking on both reads and writes.
Fault Tolerance and ACID Compliance
Fault tolerance and Atomicity, Consistency, Isolation, and Durability (ACID) compliance are prerequisites for any operational data system, given that loss of data is unacceptable. A datastore should also support redundancy in the cluster and cross-datacenter replication for disaster recovery to ensure that data is never lost.
Benefits from Batch to Real-Time Learning
Historically, analytic computing and ML approaches have been constrained to batch processing to work around the limitations of Extract, Transfer, and Load (ETL) pipelines and traditional data warehouses. Such architectures restrict performance and limit the amount of data required for successful modeling.
Even though not every application requires real-time data, virtually every industry requires real-time solutions. For example, in real estate, transactions do not necessarily need to be logged to the millisecond. However, when every real estate transaction is logged to an operational datastore and a company wants to provide ad hoc access to that data, a real-time solution is likely required.
Here are a few benefits that real-time data pipelines offer:
- Consistency with existing models
-
By using existing models and bringing them into a real-time workflow, companies can maintain consistency of modeling.
- Speed to production
-
Using existing models means more rapid deployment and an existing knowledge base around those models.
- Immediate familiarity with real-time streaming and analytics
-
By not changing models, but changing the speed, companies can gain immediate familiarity with modern data pipelines.
- Harness the power of distributed systems
-
Pipelines built with Kafka, Spark, and MemSQL harness the power of distributed systems and let companies benefit from the flexibility and performance of such systems. For example, companies can use readily available industry standard servers, or cloud instances to set up new data pipelines.
- Cost savings
-
Most important, these real-time pipelines facilitate dramatic cost savings. In the case of energy companies drilling for reserves, they need to determine the health and efficiency of the drilling operation. Push a drill bit too far and it will break, costing millions to replace and lost time for the overall rig. Retire a drill bit too early and money is left on the table. Going to a real-time model lets companies make use of assets to their full extent without pushing too far to cause breakage or a disruption to rig operations.