
Chapter 3. The Data Warehouse Has Changed
The Birth of the Data Warehouse
Decades ago, organizations used transactional databases to run analytics. This resulted in significant stress and hand-wringing by database administrators, who struggled to maintain performance of the application while providing worthwhile insights on the data. New techniques arose, including setting up preaggregated roll-ups or online analytical processing (OLAP) cubes during off-hours in order to accelerate report query performance. The approach was notoriously difficult to maintain and refreshed sporadically, either weekly or monthly, leaving business users in the dark on up-to-date analytics.
New Performance, Limited Flexibility
In the mid-1990s, the introduction of appliance-based data warehouse solutions (Figure 3-1) helped mitigate the performance issues for more up-to-date analytics while offloading the query load on transactional systems. These appliance solutions were optimized transactional databases using column store engines and specialized hardware. Several data warehouse solutions sprang up from Oracle, IBM Netezza, Microsoft, SAP, Teradata, and HP Vertica. However, over time, new challenges arose for appliance-based systems, such as the following:
- Usability
-
Each environment required specialty hardware and software services to set up, configure, and tune.
- Cost
-
Initial investments were high, along with adding capacity for new data sources or general growth. Adding new capacity often resulted in days or weeks of an outage to restructure and tune the environment.
- Single-box scalability
-
Query performance designed for a single-box configuration resulted in top-end limitations and costly data reshuffling for large data volumes or heavy user concurrency.
- Batch ingestion
-
Data ingestion was designed for nightly updates during off hours, affecting the analytics on the most recent data.
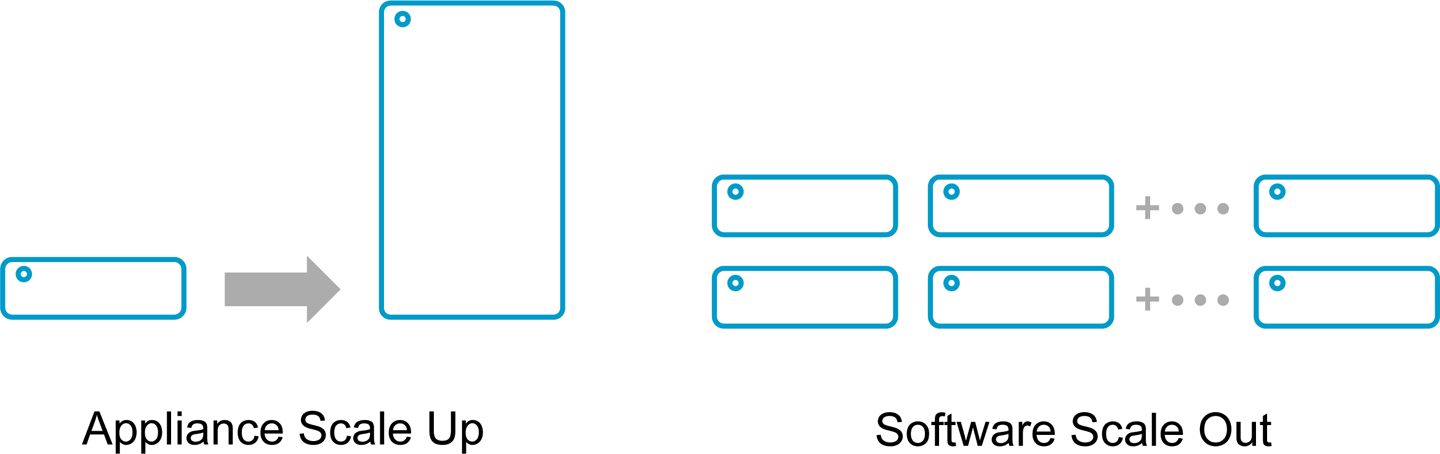
Figure 3-1. Database scale-up versus scale-out architecture
The Emergence of the Data Lake
Applications quickly evolved to collect large volumes and velocity of data driven by web and mobile technologies. These new web-scale applications tracked customer interactions, machine events, social interactions, and more. The appliance data warehouse was unable to keep up with this class of application, which resulted in new data lake technologies based on schema-less frameworks such as, Hadoop, HDFS, and NoSQL distributed storage systems. The benefit of these systems was the ability to store all of your data in one place.
Several analytic limitations occurred with data-lake solutions, including poor query performance and complexity for getting sophisticated insights out of an unstructured data environment. Although SQL query layers were introduced to help simplify access to the data, the underlying data structure was not designed for fast query response to sophisticated analytic queries. It was designed to ingest a lot of variable data as quickly as possible utilizing commodity scale-out hardware.
A New Class of Data Warehousing
A new class of data warehouse has emerged to address the changes in data while simplifying the setup, management, and data accessibility. Most of these new data warehouses are cloud-only solutions designed to accelerate deployment and simplify manageability. It’s based on previous generation engines, and takes advantage of columnstore table formats and industry-standard hardware.
Notable improvements to prior solutions include easy scalability for changing workloads, along with pay-as-you-go pricing. Additional innovations include the separation of storage from query compute to minimize data movement and optimization for machine utilization, as illustrated in Figure 3-2. Pricing is often tied to queries by rows scanned or the amount of time the query engine is available to the user. The new cloud data warehouses are designed for offline or ad hoc analytics for which sporadic use by a select group of analysts requires the spin up and down of system resources.
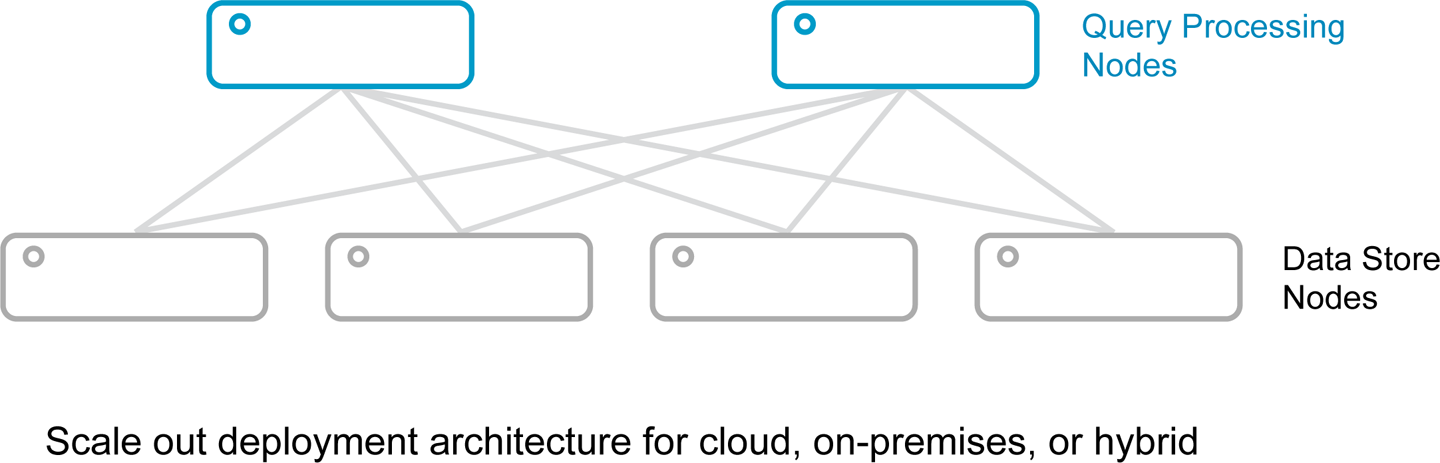
Figure 3-2. Modern distributed architecture for scalability
Notable limitations to the new class of cloud-only data warehouses are related to on-premises data analysis, optimizations for 24/7 operational analytics, and large-scale concurrency. Operational analytics can monitor and respond to a live business process requiring a continuous stream of data with subsecond query latency. Often the analysis is widely available across the enterprise or customer base, placing additional stress on the data warehouse that has been designed for sporadic, ad hoc usage.