
In this recipe, we will introduce multithreaded rendering techniques and implement a simple benchmark application to analyze the performance of using multiple deferred contexts. We will render the same model multiple times, comparing the results between varying numbers of deferred contexts and the immediate context. We will introduce additional CPU processing overhead to compare GPU-bound and CPU-bound frame times.
We can begin with any completed rendering loop and apply the techniques presented in this recipe to it. However, for the purpose of this recipe, we will assume a starting point based upon the finished result from the Animating bones recipe in Chapter 4, Animating Meshes with Vertex Skinning.
In order to support multithreaded rendering, it is necessary to pass the DeviceContext deferred context instance that will receive the rendering commands for the renderer. We will implement support for starting a new thread for each deferred context and split the recording of rendering tasks between them.
- The first change we will make to our renderer(s) is that we want it to support executing commands on a deferred context. So that a renderer can use the provided context, we will use the following
Renderoverride ofCommon.RendererBase:public void Render(SharpDX.Direct3D11.DeviceContext context) { if (Show) DoRender(context); } - Within appropriate renderer classes (for example,
MeshRenderer.cs), we will change to theRendererBase.DoRendermethod override that accepts aDeviceContextparameter.protected override void DoRender(DeviceContext context) { ... SNIP – previous DoRender() code } - Within the
D3DAppclass, we need code for initializing the requested number of deferred contextDeviceContextinstances. This might look similar to the following code snippet:DeviceContext[] contextList; int threadCount = 2; contextList = new DeviceContext[threadCount]; if (threadCount == 1) { // Use the immediate context if only 1 thread contextList[0] = this.DeviceManager .Direct3DDevice.ImmediateContext; } else { for (var i = 0; i < threadCount; i++) { contextList[i] = ToDispose(new DeviceContext( this.DeviceManager.Direct3DDevice));InitializeContext(contextList[i]);} } - Within the previous code snippet, we are initializing the pipeline state for each new deferred context with a call to a new function named
InitializeContext. Before the new context can be used forDrawcalls, it must at least have a viewport and render target assigned. The following code snippet shows an example for representing this function in our simplistic, example-rendering framework:protected void InitializeContext(DeviceContext context) { // Tell the IA what the vertices will look like context.InputAssembler.InputLayout = vertexLayout; // Set the constant buffers for vertex shader stage context.VertexShader.SetConstantBuffer(0, perObjectBuffer); context.VertexShader.SetConstantBuffer(1, perFrameBuffer); context.VertexShader.SetConstantBuffer(2, perMaterialBuffer); context.VertexShader.SetConstantBuffer(3, perArmatureBuffer); // Set the default vertex shader to run context.VertexShader.Set(vertexShader); // Set our pixel shader constant buffers context.PixelShader .SetConstantBuffer(1, perFrameBuffer); context.PixelShader .SetConstantBuffer(2, perMaterialBuffer); // Set the default pixel shader to run context.PixelShader.Set(blinnPhongShader); // Set our depth stencil state context.OutputMerger .DepthStencilState = depthStencilState; // Set viewport context.Rasterizer.SetViewports(this.DeviceManager .Direct3DContext.Rasterizer.GetViewports()); // Set render targets context.OutputMerger.SetTargets(this.DepthStencilView, this.RenderTargetView); } - In order to test the performance benefits or costs of multithreaded rendering within
D3DApp.Run, we need to load a number of additional copies of a mesh (or perhaps load one very large scene). For loading the same model multiple times, let's create a grid of models using the same mesh and separate them by theirMesh.Extentproperty. The following code snippet can load simple or complex scenes and apply aWorldmatrix to theMeshRendererinstances, laying them out in a grid:// Create and initialize the mesh renderer var loadedMesh = Common.Mesh.LoadFromFile("Character.cmo"); List<MeshRenderer> meshes = new List<MeshRenderer>(); int meshRows = 10; int meshColumns = 10; // Create duplicates of mesh separated by the extent var minExtent = (from mesh in loadedMesh orderby new { mesh.Extent.Min.X, mesh.Extent.Min.Z } select mesh.Extent).First(); var maxExtent = (from mesh in loadedMesh orderby new { mesh.Extent.Max.X, mesh.Extent.Max.Z } descending select mesh.Extent).First(); var extentDiff = (maxExtent.Max - minExtent.Min); // X-axis for (int x = -(meshColumns/2); x < (meshColumns/2); x++) { // Z-axis for (int z = -(meshRows/2); z < (meshRows/2); z++) { var meshGroup = (from mesh in loadedMesh select ToDispose(new MeshRenderer(mesh))).ToList(); // Reposition based on width/depth of combined extent foreach (var m in meshGroup) { m.World.TranslationVector = new Vector3( m.Mesh.Extent.Center.X + extentDiff.X * x, m.Mesh.Extent.Min.Y, m.Mesh.Extent.Center.Z + extentDiff.Z * z); } meshes.AddRange(meshGroup); } } // Initialize each mesh renderer meshes.ForEach(m => m.Initialize(this));Note
To analyze the performance accurately, it is necessary to either disable the animation or pause on a particular frame. This is because the frames later in the animation will apply additional CPU load due to the increased number of bone matrix transformations that are necessary causing the frame times to increase and decrease at different times during the animation. It is also critical to run a release build.
We are now ready to update our rendering loop for multithreaded rendering.
- At the start of the rendering loop in
D3DApp.Run, we will retrieve the immediate context and the first context within thecontextListarray.// Retrieve immediate context var immediateContext = DeviceManager.Direct3DDevice .ImmediateContext; // Note: the context at index 0 is always executed first var context = contextList[0]; - All the operations within the main render loop are now taking place on the first device context within the
contextListarray, such as the following call to clear the render target:// Clear render target view context.ClearRenderTargetView(RenderTargetView, background);
- Towards the end of the render loop, where we normally call the
Rendermethod of our renderers, we will create aSystem.Threading.Tasks.Taskinstance for each render context, which will perform the render logic and then record itsSharpDX.Direct3D11.CommandListvalue.Task[] renderTasks = new Task[contextList.Length]; CommandList[] commands = new CommandList[contextList.Length]; for (var i = 0; i < contextList.Length; i++) { // Must store value of iterator in another variable // otherwise all threads will end up using the last // context. var contextIndex = i; renderTasks[i] = Task.Run(() => { // Retrieve render context for thread var renderContext = contextList[contextIndex]; // TODO: regular render logic goes here // Create the command list if (contextList[contextIndex].TypeInfo == DeviceContextType.Deferred) { commands[contextIndex] = contextList[contextIndex].FinishCommandList(true); } }); } // Wait for all the tasks to complete Task.WaitAll(renderTasks); - Next, we need to replay command lists on the immediate context. We are applying them in the order in which they are located within the
contextListarray.// Replay the command lists on the immediate context for (var i = 0; i < contextList.Length; i++) { if (contextList[i].TypeInfo == DeviceContextType.Deferred && commands[i] != null) { immediateContext.ExecuteCommandList(commands[i], false); commands[i].Dispose(); commands[i] = null; } } - The following code snippet shows an example of the logic that belongs to the preceding rendering task's loop. The only difference compared to our regular rendering process is that we are only rendering a portion of the available meshes for the current context, optionally simulating the additional CPU load, and we are calling the
MeshRenderer.Rendermethod with a context.// Retrieve appropriate context var renderContext = contextList[contextIndex]; // Create viewProjection matrix var viewProjection = Matrix.Multiply(viewMatrix, projectionMatrix); // Determine the meshes to render for this context int batchSize = (int)Math.Floor((double)meshes.Count / contextList.Length); int startIndex = batchSize * contextIndex; int endIndex = Math.Min(startIndex + batchSize, meshes.Count - 1); // If the last context include remaining meshes due to // the rounding above. if (contextIndex == contextList.Length - 1) endIndex = meshes.Count - 1; // Loop over the meshes for this context and render them var perObject = new ConstantBuffers.PerObject(); for (var i = startIndex; i <= endIndex; i++) { // Simulate additional CPU load for (var j = 0; j < additionalCPULoad; j++) { viewProjection = Matrix.Multiply(viewMatrix, projectionMatrix); } var m = meshes[i]; // Update perObject constant buffer perObject.World = m.World * worldMatrix; perObject.WorldInverseTranspose = Matrix.Transpose( Matrix.Invert(perObject.World)); perObject.WorldViewProjection = perObject.World * viewProjection; perObject.Transpose(); renderContext.UpdateSubresource(ref perObject, perObjectBuffer); // Provide the material and armature constant buffer m.PerArmatureBuffer = perArmatureBuffer; m.PerMaterialBuffer = perMaterialBuffer; // Render the mesh using the provided DeviceContext m.Render(renderContext); } - The following screenshot shows an example by running at a frame time of 8.2 ms with seven deferred contexts and threads. By comparison, rendering only on the immediate context on the same hardware configuration results in a frame time of 24.8 ms.
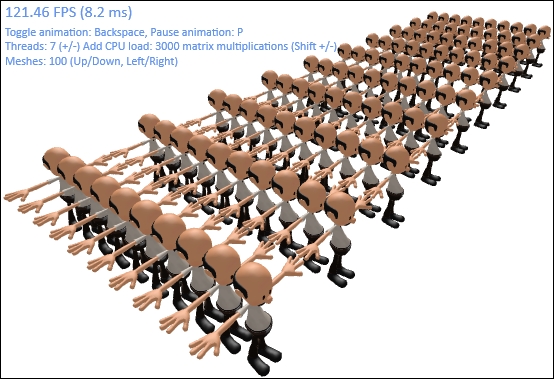
Multithreaded rendering benchmark application running with 100 meshes, seven threads and deferred context instances, and an additional 3,000 matrix multiplications performed per mesh.
A deferred context allows for a sequence of commands and state changes to be recorded and then packaged up into a command buffer for later execution on the Direct3D device's immediate context. We have implemented a method of creating a number of deferred contexts, starting with a new thread for each context and then splitting the load of rendering meshes across them. Our renderers are then able to use the deferred context to submit Direct3D commands by using the provided context instead of retrieving the device.ImmediateContext property directly. We implement this by calling the Render(DeviceContext context) function to support circumstances where the same instance of the renderer needs to be rendered multiple times in different threads. Before playing back the command lists on the immediate context, we first wait for all the threads to complete.
The process is outlined in the following diagram:
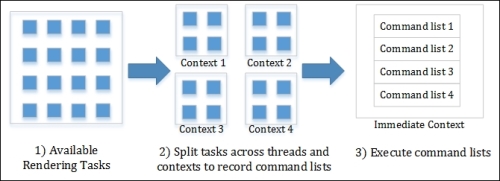
Rendering across multiple deferred contexts
While setting up the deferred context, it is necessary to configure the pipeline state as you would for the immediate context. The deferred context begins with a default state, the equivalent of when the DeviceContext.ClearState method is called. When we create the SharpDX.Direct3D11.CommandList instance via a call to the DeviceContext.FinishComandList(bool restoreState) instance, we are passing in the true value so that the context's state remains as we have set it; otherwise, it reverts to its default state. Conversely, the immediateContext.ExecuteCommandList method is passed a false value because we don't need to preserve the immediate context state.
Note
Passing true to either DeviceContext.FinishCommandList or DeviceContext.ExecuteCommandList can potentially degrade the performance by introducing avoidable and inefficient state transitions. In order to throw away the current state, we need to call something similar to the InitializeContext method for each deferred context on every frame (or rendering pass).
Each context can have a different state applied depending on its purpose; in fact, this might be a convenient way of separating pipeline states for your rendering logic, for example, a deferred context with a different render target for shadow mapping, another for a lighting pass, and so on. Another example may be of a deferred context that is to be used only for preparing compute shaders in which there may be no need to set a viewport and render a target.
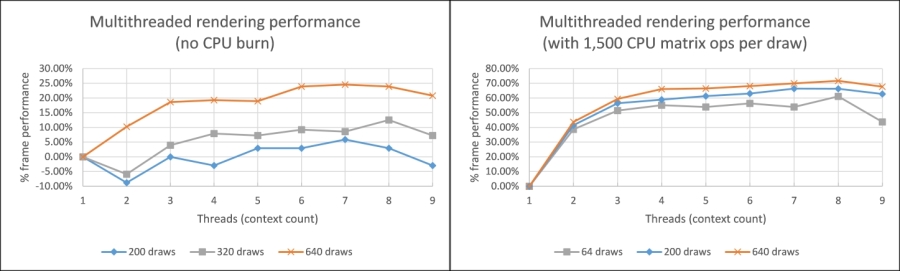
Multithreaded rendering performance as compared to single threaded (higher is better). Results with an AMD® Radeon HD 7950 on an Intel® i7-3770K.
By applying both GPU and CPU load, we are better able to identify where multithreaded rendering might be beneficial. After reviewing the preceding graphs, it is apparent that unless a certain amount of CPU load is present, there is only a small improvement in frame times; in some cases, we even see a decrease in performance. The frame times have been calculated using a 100-frame simple moving average.
Another important feature of multithreading support in Direct3D 11 is that it also includes the creation of Direct3D resources on multiple threads. This does not involve using immediate or deferred contexts and is instead a feature of the Direct3D 11 device class. By creating resources on multiple threads, we can decrease the initialization time of our Direct3D applications, and importantly, for Windows 8, we are able to load and compile our resources asynchronously.
To identify the areas where multithreaded rendering has the most impact, it may be necessary to employ the use of performance profilers or implement an in-application frame profiler.
GPUView is a CPU/GPU profiler included with the Windows Performance Toolkit; an overview of using this profiling tool is available at http://graphics.stanford.edu/~mdfisher/GPUView.html. The default install location for this tool on Windows 8 is C:Program Files (x86)Windows Kits8.0Windows Performance Toolkitgpuview.
To check whether multithreading is supported at the hardware/driver level, we can use the following function:
// Determine if the hardware driver supports CommandLists
// If not, the Direct3D framework will emulate support.
bool createResourcesConcurrently;
bool nativeCommandListSupport;
device.CheckThreadingSupport(out createResourcesConcurrently, out nativeCommandListSupport);The CheckThreadingSupport function wraps the native API ID3D11Device::CheckFeatureSupport method, returning two Boolean values and indicating whether the driver natively supports the creation of resources simultaneously on multiple threads or command lists. If not supported, the Direct3D 11 API will emulate the behavior, albeit with potentially smaller performance gains.
- The Loading and compiling resources asynchronously recipe in Chapter 11, Integrating Direct3D with XAML and Windows 8.1