
XPath applications
XPath data model
Location expressions
All XML processing depends upon the idea of addressing. In order to do something with data you must be able to locate it. To start with, you need to be able to actually find the XML document on the Web. Once you have it, you need to be able to find the information that you need within the document.
The Web has a uniform solution for the first part. The XML document is called a resource and Uniform Resource Identifiers are the Web’s way of addressing resources. The most popular form of Uniform Resource Identifier is the ubiquitous Uniform Resource Locator (URL).
The standard way to locate information within an XML document is through a language known as the XML Path Language or XPath. XPath can be used to refer to textual data, elements, attributes and other information in an XML document.
As we have seen, both XSLT and XSDL make use of XPath for addressing.
It is only possible to construct an address – any address – given a model, For instance the US postal system is composed of a model of states containing cities containing streets with house numbers. To some degree the model falls naturally out of the geography of the country but it is mostly artificial. State and city boundaries are not exactly visible from an airplane. We give new houses street numbers so that they can be addressed within the postal system’s model.
Relational databases also have a model that revolves around tables, records, columns, foreign keys and so forth. This “relational model” is the basis for the SQL query language. Just as SQL depends on the relational model, XPath depends on a formal model of the logical structure and data in an XML document.
You may wonder if XML really needs a formal model. It seems so simple: elements within elements, attributes of elements and so forth. It is simple but there are details that need to be standardized in order for addresses to behave in a reliable fashion. The tricky part is that there are many ways of representing what might seem to be the “same” information. We can represent a less-than symbol in at least four ways:
a predefined entity reference:
<a CDATA section:
<![CDATA[<]]>a decimal Unicode character reference:
<a hex Unicode character reference:
<
We could also reference a text entity that embeds a CDATA section and a text entity that embeds another text entity that embeds a character reference, etc. In a query you would not want to explicitly search for the less-than symbol in all of these variations. It would be easier to have a processor that could magically normalize them to a single model. Every XPath-based query engine needs to get exactly the same data model from any particular XML document.
The XPath data model views a document as a tree of nodes, or node tree. Most nodes correspond to document components, such as elements and attributes.
It is very common to think of XML documents as being either families (elements have child elements, parent elements and so forth) or trees (roots, branches and leaves). This is natural: trees and families are both hierarchical in nature, just as XML documents are. XPath uses both metaphors but tends to lean more heavily on the familial one.[1]
XPath uses genealogical taxonomy to describe the hierarchical makeup of an XML document, referring to children, descendants, parents and ancestors. The parent is the element that contains the element under discussion. The list of ancestors includes the parent, the parent’s parent and so forth. A list of descendants includes children, children’s children and so forth.
As there is no culture-independent way to talk about the first ancestor, XPath calls it the “root”. The root is not an element. It is a logical construct that holds the document element and any comments and processing instructions that precede and follow it.
Trees in computer science are very rarely (if ever) illustrated as a natural tree is drawn, with the root at the bottom and the branches and leaves growing upward. Far more typically, trees are depicted with the root at the top just as family trees are. This is probably due to the nature of our writing systems and the way we have learned to read.[2] Accordingly, this chapter refers to stepping “down” the tree towards the leaf-like ends and “up” the tree towards the root as the tree is depicted in Figure 24-1. One day we will genetically engineer trees to grow this way and nature will be in harmony with technology.
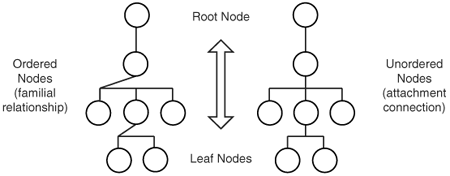
A node tree is built by an XPath processor after parsing an XML document like that in Example 24-1.
Example 24-1. Sample document
<?xml version="1.0"?> <!--start--> <part-list><part-name nbr="A12">bolt</part-name> <part-name nbr="B45">washer</part-name><warning type="ignore"/> <!--end of list--><?cursor blinking?> </part-list> <!--end of file-->
In constructing the node tree, the boundaries and contents of “important” constructs are preserved, while other constructs are discarded. For example, entity references to both internal and external entities are expanded and character references are resolved. The boundaries of CDATA sections are discarded. Characters within the section are treated as character data.
The node tree constructed from the document in Example 24-1 is shown in Figure 24-2. In the following sections, we describe the components of node trees and how they are used in addressing. You may want to refer back to this diagram from time to time as we do so.
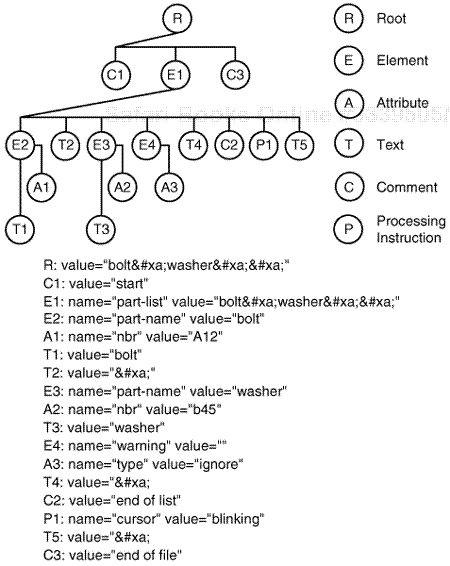
The XPath data model describes seven types of nodes used to construct the node tree representing any XML document. We are interested primarily in the root, element, attribute and text node types, but will briefly discuss the others.
For each node type, XPath defines a way to compute a string-value (labeled “value” in Figure 24-2). Some node types also have a “name”.
The top of the hierarchy that represents the XML document is the root node.
It is important to remember that in the XPath data model the root of the tree representing an XML document is not the document (or root) element of the document. A root node is different from a root element. The root node contains the root element.
The nodes that are children of the root node represent the document element and the comments and processing instructions found before and after the document element.
Every element in an XML document is represented in the node tree as an element node. Each element has a parent node. Usually an element’s parent is another element but the document element has as its parent the root node.
Element nodes can have as their children other element nodes, text nodes, comment nodes and processing instruction nodes.
An element node also exhibits properties, such as its name, its attributes and information about its active namespaces.
Element nodes in documents with DTDs may have unique identifiers. These allow us to address element nodes by name. IDs are described in 15.3.3.2, “ID and IDREF attributes”, on page 361.
The string-value of an element node is the concatenation of the string-values of all text node descendants of the element node in the document order. You can think of it as all of the data with none of the markup, organized into one long character string.
The XML Recommendation describes character data as all text that is not markup. In other words it is the textual data content of the document and it does not include data in attribute values, processing instructions and comments.
XPath does not care how a character was originally represented. The string “<>” in an XML document is simply “<>” from the data model’s point of view. The same goes for “<>” and “<![CDATA[<>]]>”. The characters represented by any of these will be grouped with the data characters that precede and follow them and called a “text node.” The individual characters of the text node are not considered its children: they are just part of its value. Text nodes do not have any children.[3]
Remember that whitespace is significant. A text node might contain nothing else. In Figure 24-2, for example, nodes T2, T4, and T5 contain line feed characters, represented by hexadecimal character references.[4]
If an element has attributes then these are represented as attribute nodes. These nodes are not considered children of the element node. They are more like cousins who live in the guest house.
An attribute node exhibits name, string-value, and namespace URI properties. Defaulted attributes are reported as having the default values. The data model does not record whether they were explicitly specified or merely defaulted. No node is created for an unspecified attribute that had an #IMPLIED default value declared. Attribute nodes are also not created for attributes used as namespace declarations.
Note that an XML processor is not required to read an external DTD unless it is validating the document. This means that detection of ID attributes and default attribute values is not mandatory.
Namespace nodes keep track of the set of namespace prefix/URI pairs that are in effect at a particular point in a document. Like attribute nodes, namespace nodes are attached to element nodes and are not in any particular order.
Each comment and processing instruction in the XML document is instantiated as a comment or processing instruction node in the node tree. The string-value property accesses the content of these constructs, as you can see in Figure 24-2.
An instance of the XPath language is called an expression. XPath expressions can involve a variety of operations on different kinds of operands. In this chapter we will focus on two operand types: function calls and location paths.
A location path is the most important kind of expression in the XPath notation. Its syntax is similar to the familiar path expressions used in URLs and in Unix and Windows systems to locate directories and files.[5]
A location path has a starting point, which XPath calls its context node. In a file system path, it might be a computer, a disk drive, or a directory. In an XPath location path it could be, for example, the document element node or some other element node.
The purpose of the location path is to select nodes from the document by locating the desired nodes relative to the initial context node.
Arguably, the simplest location path is “/”. This selects the root node (not the document element node).
We can extend this location path to select the document element node instead of the root node. “/mydoc” will select a document element node named “mydoc”. The name of an element node is the element-type name of the element it represents.
Note
From now on, as long as we are discussing node trees, we’ll often just say “element” instead of “element node”.
We have taken a step “down” the tree. We can take another step: “/mydoc/section”. This will select every section element that is a child of the mydoc element.
Each slash-separated (/) path component is a step.
Any amount of whitespace can be present between the parts of a location path. Steps can be written across a number of lines or spaced apart to be more legible to a reader.
So far we have seen how to build single and multi-level location paths based on element-type names. However, the type name is not the only thing that is interesting about an element. For example, we might want to filter out elements that have (or do not have) particular attributes with particular values. Or we may be interested in the first or seventh element, or just the even-numbered ones.
We can express these constraints with qualifiers called predicates. Any step can be qualified. The location path in Example 24-2, for example, selects the seventh paragraph from each section with a security attribute whose string-value is “public”.
Note that we use the word select carefully. We could say that the expression returns certain nodes but that might put a picture in your head of nodes being ripped out of the tree and handed to you: “Here are your nodes!”
Rather, what you get back is a set of locations – pointers to the nodes. Imagine the result of a location path as a set of arrows pointing into the node tree, saying: “Your nodes are here!”
The context node keeps changing as we step down the path. As each step is evaluated, the result is a set of nodes – in XPath talk, a node-set. The node-set could have one or more nodes, or it could be empty.
The next step is then evaluated for each member of that node-set. That is, each member is used as the context node for one of the evaluations of the next step. The node-sets selected by each of those evaluations are combined (except for any duplicates) to produce the result node-set.
Consider what happens in Example 24-2.
The XPath processor first evaluates the “
/”. The root node becomes the initial context node.Next it looks for every child of the context node with the name “
mydoc”. There will be only one member of that node-set because XML allows only a single root element. It becomes the context node for the next step, which is evaluated only once.Next the processor looks for all of the
sectionchildren in the context of themydocelement that have the appropriate attribute value and returns their node-set. The next step will be evaluated once for each selectedsectionnode, which is the context node for that evaluation.We’re almost done. The processor looks for the seventh
paraseveral times, once for eachsectionin the node-set. It puts the selectedparanodes together into the final node-set and returns a set of pointers to them: “Your nodes are here!”.
The initial context does not always have to be the root node of the document. It depends on the environment or application. Whatever application (e.g. database or browser) or specification (e.g. XSLT or XPointer) is using XPath must specify the starting context.
In XSLT there is always a concept of the current node. That node is the context node for location paths that appear in XSLT transforms. In XPointer, the starting context is always the root node of the particular document, selected by its URI. In some sort of document database, we might be allowed to do a query across thousands of documents. The root node of each document would become the context node in turn. XPath itself does not have a concept of working with multiple documents but it can be used in a system that does.
In addition to the current node, an application could specify some other details of the context: it could supply some values for variables and functions that can be used in the XPath expression. It could also include namespace information that can be used to interpret prefixed names in a location path.
But wait. That’s not all! Up to now we’ve always stepped down the tree, to a child element. But we can also step up the tree instead of down and step many levels instead of one.
We can step in directions that are neither up nor down but more like sideways. For example we can step from elements to attributes and from attributes to elements.
We can also step from an element directly to a child of a child of a child (a descendant).
These different ways of stepping are called axes.
For example, the descendant axis (abbreviated //) can potentially step down all the levels of the tree. The location path “/mydoc//footnote” would select all footnotes in the current document, no matter how many levels deep they occur.
The parent axis uses an abbreviated syntax (..) that is similar to that for going up a directory in a file system. For instance we could select all of the elements containing a footnote like this: “/mydoc//footnote/..”.
The attribute axis (abbreviated “@”) steps into the attribute nodes of an element.
The namespace axis is used for namespace information associated with an element node.
There are a number of less commonly used axes as well. You can find out more about them in the XPath specification.
The attribute and namespace axes each have only one type of node, which is (necessarily!) its principal node type.
The other axes, however, have element as the principal node type but have comment, processing instruction, and text node types as well. We’ll refer to such an axis as a content axis and its nodes as content nodes.
A step normally selects nodes of the principal type. In the case of content axes, a node test can be used to select another type. For example, the node test text() selects text nodes.
We’ve now seen enough of the basics to take a formal look at the parts of a location step. There are three:
An axis, which specifies the tree relationship between the context node and the nodes selected by the location step. Our examples so far have used the child axis.
A node test, which specifies the node type of the nodes selected by the location step. The default type is element, unless the axis is one that can’t have element nodes.
Zero or more predicates, which use arbitrary expressions to further refine the set of nodes selected by the location step. The expressions are full-blown XPath expressions and can include function calls and location paths. In Example 24-2 the first predicate is a location path and the second uses an abbreviation for the
position()function.
In this tutorial, we’ve only been using abbreviated forms of the XPath syntax, in which common constructs can often be omitted or expressed more concisely. Example 24-3 shows the unabbreviated form of Example 24-2. Note the addition of explicit axis names (child and attribute) and the position() function call.
Example 24-3. Unabbreviated form of Example 24-2
/child::mydoc/child::section[attribute::security="public"]
/child::para[position()=7]
In the remainder of the chapter, we’ll take a closer look at each of the three parts: node tests, axes, and predicates.
Some node tests are useful in all axes; others only in content axes.
Node tests for all axes are:
*
any node of the principal type; i.e., element, attribute, or namespace.[6]
node()
any node of any type
Node tests solely for content axes are:
text()
any text node
comment()
any comment node
processing-instruction()
any processing-instruction node, regardless of its target name
processing-instruction(target-name)
any processing-instruction node with the specified target name
Here are some examples of node tests used in a content axis:
processing-instruction(cursor)
all nodes created from a processing instruction with the target name “
cursor”
part-nbr
all nodes created from an element with the element-type name
part-nbr
text()
all text nodes (contrast below)
text
all nodes created from an element with the element-type name
text
*
all nodes created from elements, irrespective of the element-type name
node()
all nodes created from elements (irrespective of the element-type name), contiguous character data, comments or processing instructions (irrespective of the target name)
The most important axes are described here.
The default axis is the child axis. That means that if you ask for “/section/para” you are looking for a para in a section. If you ask merely for “para” you are looking for the para element children of the context node, whatever it is.
When using the symbol “@” before either an XML name or the node test “*”, one is referring to the attribute axis of the context node.
The attribute nodes are attached to an element node but the nodes are not ordered. There is no “first” or “third” attribute of an element.
Attribute nodes have a string-value that is the attribute value, and a name that is the attribute name.
Some examples of abbreviated references to attribute nodes attached to the context node are:
@type
an attribute node whose name is “
type”
@*
all attributes of the context node, irrespective of the attribute name
We can use the double-slash “//” abbreviation in a location path to refer to the descendant axis. This axis includes not only children of the context node, but also all other nodes that are descendants of the context node.
This is a very powerful feature. We could combine this with the wildcard node test, for example, to select all elements in a document, other than the document element, no matter how deep they are: “/doc//*”.
Some examples:
/mydoc//part-nbr
all element nodes with the element-type name
part-nbrthat are descendants of themydocdocument element; that is, all of thepart-nbrelements in the document
/mydoc//@type
all attribute nodes named
typeattached to any descendant element of themydocdocument element; i.e., all of thetypeattributes in the document
/mydoc//*
all elements that are descendants of the
mydocdocument element; i.e., every element in the document except themydocelement itself
/mydoc//comment()
all comment nodes that are descendants of the
mydocdocument element
/mydoc//text()
all of the text nodes that are descendants of the
mydocdocument element; i.e., all of the character data in the document!
We do not have to start descendant expressions with the document element. If we want to start somewhere farther into the document we can use “//” in any step anywhere in the location path.
We could also begin with “//”. A location path that starts with “//” is interpreted as starting at the root and searching all descendants of it, including the document element.
The self axis is unique in that it has only one node: the context node. This axis can solve an important problem.
For instance in an XSLT transformation we might want to search for all descendants of the current node. If we begin with “//” the address will start at the root. We need a way to refer specifically to the current node.
A convenient way to do this is with an abbreviation: a period (.) stands for the context node.[7]
So “.//footnote” would locate all footnote descendants of the context node.
The parent axis (..) of a content node selects its parent, as the axis name suggests. For a namespace or attribute node, however, it selects the node’s attached element.
You could therefore search an entire document for a particular attribute and then find out what element it is attached to: “//@confidential/..”. You could go on to find out about the element’s parent (and the parent’s parent, etc.): “//@confidential/../..”.
There is also a way of searching for an ancestor by name, but it does not have an abbreviated syntax. For example, “ancestor::section” would look for the ancestor(s) of the context node that are named “section”.
This location path locates the titles of sections that contain images: “//image/ancestor::section/title”.
Here are some examples of location paths using features we have covered so far:
item
itemelement nodes that are children of the context node
item/para
paraelement nodes that are children ofitemelement nodes that are children of the context node; in other words, thoseparagrandchildren of the context node whose parent is anitem
//para
paraelement nodes that are descendants of the root node; in other words, all theparaelement nodes in the entire document
//item/para
paraelement nodes that are children of allitemelement nodes in the entire document
//ordered-list//para
paraelement nodes that are descendants of allordered-listelement nodes in the entire document
ordered-list//para/@security
securityattribute nodes attached to allparaelement nodes that are descendants of allordered-listelement nodes that are children of the context node
*/@*
attribute nodes attached to all element nodes that are children of the context node
../@*
attribute nodes attached to the parent or attached node of the context node
.//para
paraelement nodes that are descendants of the context node
.//comment()
comment nodes that are descendants of the context node
It is often important to filter nodes out of a node-set. We might filter out nodes that lack a particular attribute or subelement. We might filter out all but the first node. This sort of filtering is done in XPath through predicates. A predicate is an expression that is applied to each node. If it evaluates as false, the tested node is filtered out.
We’ll discuss some common types of predicate expressions, then look at some examples.
A location path expression can be used as a predicate. It evaluates to true if it selects any nodes at all. It is false if it does not select any nodes. So Example 24-4 would select all paragraphs that have a footnote child.
Recall that the evaluation of a step in the path results in a node-set, each member of which is a context node for an evaluation of the next step.[8]
One by one, each member of the result node-set, which in this case is every paragraph in the document, would get a chance to be the context node. It would either be selected or filtered out, depending on whether it contained any footnotes. Every paragraph would get its bright shining moment in the sun when it could be “.”.[9]
A number of predicates can be chained together. Only nodes that pass all of the filters are passed on to the next step in the location path. For example, “//para[footnote][@important]” selects all paragraphs with important attributes and footnote children.
Like other location paths, those in predicates can have multiple steps with their own predicates. Consider the complex one in Example 24-5. It looks for sections with author child elements with qualifications child elements that have both professional and affordable attributes.
Not all predicates are location path expressions. Sometimes you do not want to test for the existence of some node. You might instead want to test whether an attribute has some particular value. That is different from testing whether the attribute exists or not.
Testing an attribute’s value is simple: “@type='ordered'” tests whether the context node has a type attribute with value “ordered”.
In XPath, every node type has a string-value. The value of an element node that is the context node, for example, is the concatenation of the string-values from the expression: “.//text()”. In other words, it is all of the character data content anywhere within the element and its descendants.
So we can test the data content of a section’s title child element with “section[title='Doo-wop']” and both of the sections in Example 24-6 would match.
There is more to the context in which an expression is evaluated than just the context node. Among the other things is the node’s context position, which is returned by a function call: position()=number.
In practice, an abbreviation, consisting of the number alone, is invariably used. A number expression is evaluated as true if the number is the same as the context position.
Context position can be a tricky concept to grasp because it is, well, context-sensitive. However, it is easy to understand for the most common types of steps.
In a step down the child axis (a/b) the context position is the position of the child node in the parent node. So “doc/section[5]” is the fifth section in a doc. In a step down the descendant axis (a//b[5]) it still refers to the position of the child node in its parent node, not its numerical order in the list of matching nodes.
XPath also has a function called “last()”. We can use it to generate the number for the last node in a context: “a//b[last()]”. We can also combine that with some simple arithmetic to get the next-to-last node: “a//b[last()-1]”.
Here are some examples, using the predicate types that we’ve discussed:
item[3]
third
itemelement child of the context node
item[@type]/para
paraelement children ofitemelements that exhibit atypeattribute and are children of the context node
//list[@type='ordered']/item[1]/para[1]
first
paraelement child of the firstitemelement child of any list element that exhibits atypeattribute with the string-value “ordered”
//ordered-list[item[@type]/para[2]]//para
paraelements descended from anyordered-listelement that has anitemchild that exhibits atypeattribute and has at least twoparaelement children (whew!)
This last example is illustrated in Figure 24-3.
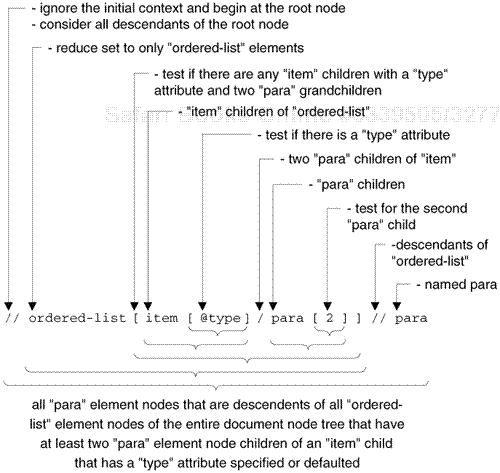
The XPath spec includes numerous other examples of using predicates. XPath is a powerful expression language, including operators and functions that operate on node-sets, numbers, strings, and booleans.
The most common high-level expression in XPath is the location path, which we have explored in some detail. And, as we have seen, a location path can also be used at lower levels - as a predicate expression, for example.
Another form of expression that returns a node-set is a function call to the id(string) function. The main use of the function is to select the element node whose ID is the same as the string. For example, “id('final')”. selects the element node whose unique identifier is “final”.
An ID function and a location path can be used in the same expression. One way is to create the union of the two, as in Example 24-7. The result node-set is the element whose ID is “final”, plus all para elements descended from ordered-list elements.
Another way to combine the two is to use the ID function as the initial context node of a location path, to create a path expression like that in Example 24-8. It locates the title child of the element whose ID is “A12345”.
Instead of a literal string, the argument could be a node whose string-value would be used, as in “id(@IDREF)”. This expression locates the element referenced by the IDREF attribute of the context node.
XPath is an extremely powerful language for addressing an XML document. Although it has depths that we could not address even in a “tad tougher” tutorial, we have covered all of the most common features.
Hint

For the complete details on XPath, we recommend Definitive XSLT and XPath by G. Ken Holman of Crane Softwrights Ltd., http://www.CraneSoftwrights.com. We also thank Ken for his expert contributions to this chapter.
[1] Politicians take note: in this case, family values win out over environmentalism!
[2] To do: rotate all tree diagrams for Japanese edition of this book!
[3] As the word “text” means something different in XPath from its meaning in the XML Recommendation, we try always to say “text node”, even when the context is clear, reserving “text” as a noun for its normal meaning.
[5] There is an illustrated tutorial on path expressions in Chapter 17, “XPath primer”, on page 384.
[6] The asterisk cannot be used as a prefix ("*ara") or suffix ("ara*") as it is in some regular-expression languages.
[7] This “dot-convention” also comes from the file system metaphor. Unix and Windows use “.” to mean the current directory.
[8] In other words, Example 24-4 is really an abbreviation for “//para[./footnote]”.
[9] Unfortunately, the moment is brief and the price of failure is exclusion from the selection set.