
ANTIPHOLUS OF SYRACUSE: To me she speaks; she moves me for her theme!What, was I married to her in my dream?Or sleep I now and think I hear all this?What error drives our eyes and ears amiss?Until I know this sure uncertainty,I'll entertain the offer'd fallacy | ||
| --The Comedy of Errors, II, ii, 185–190. | ||
Authentication is the binding of an identity to a principal. Network-based authentication mechanisms require a principal to authenticate to a single system, either local or remote. The authentication is then propagated. This chapter explores the question of authentication to a single system.
Subjects act on behalf of some other, external entity. The identity of that entity controls the actions that its associated subjects may take. Hence, the subjects must bind to the identity of that external entity.
Definition 12–1. Authentication is the binding of an identity to a subject.
The external entity must provide information to enable the system to confirm its identity. This information comes from one (or more) of the following.
What the entity knows (such as passwords or secret information)
What the entity has (such as a badge or card)
What the entity is (such as fingerprints or retinal characteristics)
Where the entity is (such as in front of a particular terminal)
The authentication process consists of obtaining the authentication information from an entity, analyzing the data, and determining if it is associated with that entity. This means that the computer must store some information about the entity. It also suggests that mechanisms for managing the data are required. We represent these requirements in an authentication system [113] consisting of five components.
The set A of authentication information is the set of specific information with which entities prove their identities.
The set C of complementary information is the set of information that the system stores and uses to validate the authentication information.
The set F of complementation functions that generate the complementary information from the authentication information. That is, for f ∊ F, f: A → C.
The set L of authentication functions that verify identity. That is, for l ∊ L, l: A × C→{ true, false }.
The set S of selection functions that enable an entity to create or alter the authentication and complementary information.
Passwords are an example of an authentication mechanism based on what people know: the user supplies a password, and the computer validates it. If the password is the one associated with the user, that user's identity is authenticated. If not, the password is rejected and the authentication fails.
Definition 12–2. A password is information associated with an entity that confirms the entity's identity.
The simplest password is some sequence of characters. In this case, the password space is the set of all sequences of characters that can be passwords.
The set of complementary information may contain more, or fewer, elements than A, depending on the nature of the complementation function. Originally, most systems stored passwords in protected files. However, the contents of such files might be accidentally exposed. Morris and Thompson [731] recount an amusing example in which a Multics system editor swapped pointers to the temporary files being used to edit the password file and the message of the day file (printed whenever a user logged in); the result was that whenever a user logged in, the cleartext password file was printed.
The solution is to use a one-way hash function to hash the password into a complement [1046].
The goal of an authentication system is to ensure that entities are correctly identified. If one entity can guess another's password, then the guesser can impersonate the other. The authentication model provides a systematic way to analyze this problem. The goal is to find an a ∊ A such that, for f ∊ F, f(a) = c ∊ C and c is associated with a particular entity (or any entity). Because one can determine whether a is associated with an entity only by computing f(a) or by authenticating via l(a), we have two approaches for protecting the passwords, used simultaneously.
Hide enough information so that one of a, c, or f cannot be found.
Prevent access to the authentication functions L.
Each of these approaches leads to different types of attacks and defenses.
The simplest attack against a password-based system is to guess passwords.
Definition 12–3. A dictionary attack is the guessing of a password by repeated trial and error.
The name of this attack comes from the list of words (a “dictionary”) used for guesses. The dictionary may be a set of strings in random order or (more usually) a set of strings in decreasing order of probability of selection.
If the complementary information and complementation functions are available, the dictionary attack takes each guess g and computes f(g) for each f ∊ F. If f(g) corresponds to the complementary information for entity E, then g authenticates E under f. This is a dictionary attack type 1. If either the complementary information or the complementation functions are unavailable, the authentication functions l ∊ L may be used. If the guess g results in l returning true, g is the correct password. This is a dictionary attack type 2.
The issue of efficiency controls how well an authentication system withstands dictionary attacks.
Password guessing requires either the set of complementation functions and complementary information or access to the authentication functions. In both approaches, the goal of the defenders is to maximize the time needed to guess the password. A generalization of Anderson's Formula [25] provides the fundamental basis.
Let P be the probability that an attacker guesses a password in a specified period of time. Let G be the number of guesses that can be tested in one time unit. Let T be the number of time units during which guessing occurs. Let N be the number of possible passwords. Then ![]() .
.
EXAMPLE: Let R be the number of bytes per minute that can be sent over a communication line, let E be the number of characters exchanged when logging in, let S be the length of the password, and let A be the number of characters in the alphabet from which the characters of the password are drawn. The number of possible passwords is N = AS, and the number of guesses per minute is G = R/E. If the period of guessing extends M months, this time in minutes is T = 4.32 × 104 M. Then 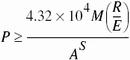 , or
, or ![]() , the original statement of Anderson's Formula.
, the original statement of Anderson's Formula.
EXAMPLE: Let passwords be composed of characters drawn from an alphabet of 96 characters. Assume that 104 guesses can be tested each second. We wish the probability of a successful guess to be 0.5 over a 365-day period. What is the minimum password length that will give us this probability?
From the formulas above, we want ![]() . Thus, we must choose an integer S such that
. Thus, we must choose an integer S such that 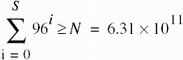 . This holds when S ≥ 6. So, to meet the desired conditions, passwords of at least length 6 must be required.
. This holds when S ≥ 6. So, to meet the desired conditions, passwords of at least length 6 must be required.
Several assumptions underlie these examples. First, the time required to test a password is constant. Second, all passwords are equally likely to be selected. The first assumption is reasonable, because the algorithms used to validate passwords are fixed, and either the algorithms are independent of the password's length or the variation is negligible. The second assumption is a function of the password selection mechanism. We will now elaborate on these mechanisms.
The following theorem from probability theory states a maximum on the expected time to guess a password.
Theorem 12–1. Let the expected time required to guess a password be T. Then T is a maximum when the selection of any of a set of possible passwords is equiprobable.
Proof. See Exercise 1.
Theorem 12–1 guides selection of passwords in the abstract. In practice, several other factors mediate the result. For example, passwords selected at random include very short passwords. Attackers try short passwords as initial guesses (because there are few enough of them so that all can be tried). This suggests that certain classes of passwords should be eliminated from the space of legal passwords P. The danger, of course, is that by eliminating those classes, the size of P becomes small enough for an exhaustive search.
Complicating these considerations is the quality of the random (or pseudorandom) number generator. If the period of the password generator is too small, the size of P allows every potential password to be tested. This situation can be obvious, although more often it is not.
Human factors also play a role in this problem. Psychological studies have shown that humans can repeat with perfect accuracy about eight meaningful items, such as digits, letters, or words [231]. If random passwords are eight characters long, humans can remember one such password. So a person who is assigned two random passwords must write them down. Although most authorities consider this to be poor practice, the vulnerabilities of written passwords depend on where a written password is kept. If it is kept in a visible or easily accessed place (such as taped to a terminal or a keyboard or pinned to a bulletin board), writing down the password indeed compromises system security. However, if wallets and purses are rarely stolen by thieves with access to the computer systems, writing a password down and keeping it in a wallet or purse is often acceptable.
Michele Crabb describes a clever method of obscuring the written password [243]. Let X be the set of all strings over some alphabet. A site chooses some simple transformation algorithm t: X → A. Elements of X are distributed on pieces of paper. Before being used as passwords, they must be transformed by applying t. Typically, t is very simple; it must be memorized, and it must be changed periodically.
This scheme is most often used when system administrators need to remember many different passwords to access many different systems. Then, even if the paper is lost, the systems will not be compromised.
A compromise between using random, unmemorizable passwords and writing passwords down is to use pronounceable passwords. Gasser [386] did a detailed study of such passwords for the Multics system and concluded that they were viable on that system.
Pronounceable passwords are based on the unit of sound called a phoneme. In English, phonemes for constructing passwords are represented by the character sequences cv, vc, cvc, or vcv, where v is a vowel and c a consonant.
The advantage of pronounceable passwords is that fewer phonemes need to be used to reach some limit, so that the user must memorize “chunks” of characters rather than the individual characters themselves. In effect, each phoneme is mapped into a distinct character, and the number of such characters is the number of legal phonemes. In general, this means that the number of pronounceable passwords of length n is considerably lower than the number of random passwords of length n. Hence, a type 1 dictionary attack is expected to take less time for pronounceable passwords than for random passwords.
Assume that passwords are to be at most eight characters long. Were these passwords generated at random from a set of 96 printable characters, there would be 7.3 × 1015 possible passwords. But if there are 440 possible phonemes, generating passwords with up to six phonemes produces approximately the same number of possible passwords. One can easily generalize this from phonemes to words, with similar results.
One way to alleviate this problem is through key crunching [417].
Definition 12–4. Let n and k be two integers, with n ≥ k. Key crunching is the hashing of a string of length n or less to another string of length k or less.
Conventional hash functions, such as MD5 and SHA-1, are used for key crunching.
Rather than selecting passwords for users, one can constrain what passwords users are allowed to select. This technique, called proactive password selection [114], enables users to propose passwords they can remember, but rejects any that are deemed too easy to guess.
The set of passwords that are easy to guess is derived from experience coupled with specific site information and prior studies [472, 731, 736, 954]. Klein's study [573] is very comprehensive. He took 15,000 password hashes and used a set of dictionaries to guess passwords. Figure 12-1 summarizes his results. Some categories of passwords that researchers have found easy to guess are as follows.
Passwords based on account names
Account name followed by a number
Account name surrounded by delimiters
Passwords based on user names
Initials repeated 0 or more times
All letters lower-or uppercase
Name reversed
First initial followed by last name reversed
Passwords based on computer names
Dictionary words
Reversed dictionary words
Dictionary words with some or all letters capitalized
Reversed dictionary words with some or all letters capitalized
Dictionary words with arbitrary letters turned into control characters
Dictionary words with any of the following changes: a → 2 or 4, e → 3, h → 4, i → 1, l → 1, o → 0, s → 5 or $, z → 5.
Conjugations or declensions of dictionary words
Patterns from the keyboard
Passwords shorter than six characters
Passwords containing only digits
Passwords containing only uppercase or lowercase letters, or letters and numbers, or letters and punctuation
Passwords that look like license plate numbers
Acronyms (such as “DPMA,” “IFIPTC11,” “ACM,” “IEEE,” “USA,” and so on)
Passwords used in the past
Concatenations of dictionary words
Dictionary words preceded or followed by digits, punctuation marks, or spaces
Dictionary words with all vowels deleted
Dictionary words with white spaces deleted
Passwords with too many characters in common with the previous (current) password
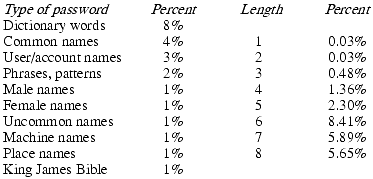
Figure 12-1. Results of Klein's password guessing experiments. The percentages are from 15,000 potential passwords selected from approximately 50 different sites.
Good passwords can be constructed in several ways. A password containing at least one digit, one letter, one punctuation symbol, and one control character is usually quite strong. A second technique is to pick a verse from an obscure poem (or an obscure verse from a well-known poem) and pick the characters for the string from its letters.
Definition 12–5. A proactive password checker is software that enforces specific restrictions on the selection of new passwords.
Proactive password checkers must meet several criteria [118]:
It must always be invoked. Otherwise, users could bypass the proactive mechanism.
It must be able to reject any password in a set of easily guessed passwords (such as in the list above).
It must discriminate on a per-user basis. For example, “^AHeidiu'” (^A being control-a) is a reasonable password (modulo Exercise 5) for most people, but not for the author, whose oldest daughter is named “Heidi Tinúviel.”
It must discriminate on a per-site basis. For example, “^DHMC^DCNH” is a reasonable password at most places, but not at the Dartmouth Hitchcock Medical Center at Dartmouth College, New Hampshire.
It should have a pattern-matching facility. Many common passwords, such as “aaaaa,” are not in dictionaries but are easily guessed. A pattern-matching language makes detecting these patterns simple. For example, in one pattern-matching language, the pattern “^(.)1*$” will detect all strings composed of a single character repeated one or more times.
It should be able to execute subprograms and accept or reject passwords based on the results. This allows the program to handle spellings that are not in dictionaries. For example, most computer dictionaries do not contain the word “waters” (because it is the plural of a word, “water,” in that dictionary). A spelling checker would recognize “waters” as a word. Hence, the program should be able to run a spelling checker on proposed passwords, to detect conjugations and declensions of words in the dictionary.
The tests should be easy to set up, so administrators do not erroneously allow easily guessed passwords to be accepted.
Both these methods are excellent techniques for reducing the space required to represent a dictionary. However, they do not meet all the requirements of a proactive password checker and should be seen as part of such a program rather than as sufficient on their own.
EXAMPLE: A “little language” designed for proactive password checking [115] was based on these requirements. The language includes functions for checking whether or not words are in a dictionary (a task that could easily use the techniques of OPUS or Ganesan and Davies). It also included pattern matching and the ability to run subprograms, as well as the ability to compare passwords against previously chosen passwords.
The keyword set sets the values of variables. For example,
set gecos "Matt Bishop, 3085 EU-II"
assigns the variable gecos to the value Matt Bishop, 3085 EU-II. Pattern assignment is available through setpat:
setpat "$gecos" "^([^,]), (.*)$" name office
This matches the pattern with the value of gecos (obtained by prefixing a “$” to the variable name). The strings matched by the subpatterns in “(” and “)” are assigned to the variables name and office (so name is Matt Bishop and office is 3085 EU-II). Equality and inequality operators work as string operators. All integers are translated to strings before any operations take place. Other functions are available; see Figure 12-2 for some examples.

The basic component of the little language is the password test block:
test length("$p") < 6
true "Your password contains fewer than 6 characters."
endtest
This block says to compare the length of the proposed password, stored in the variable p earlier, and compare it with 6 (the test). If the test is true (that is, if the password is less than six characters long), the message in the second line is printed and the password is rejected. As another example, the test
infile("/usr/dict/words", "$p")
is true if the value of p is a string in the file “/usr/dict/words.” The test
!inprog("spell", "$p", "$p")
is true if the output of the program spell, given the value of p as input, produces that same value as output. Because spell prints all misspelled input words, if the input and output match, then the value of p is not a correctly spelled word.
The language contains many other functions, including one for testing for catenated words and another for hashing passwords using the UNIX password hashing function.
As discussed earlier, reusable passwords are quite susceptible to dictionary attacks of type 1. The goal of random passwords, pronounceable passwords, and proactive password checking is to maximize the time needed to guess passwords.
If a type 1 dictionary attack is aimed at finding any user's password (as opposed to a particular user's password), a technique known as salting increases the amount of work required [731]. Salting makes the choice of complementation function a function of randomly selected data. Ideally, the random data is different for each user. Then, to determine if the string s is the password for any of a set of n users, the attacker must perform n complementations, each of which generates a different complement. Thus, salting increases the work by the order of the number of users.
If the actual complements, or the complementation functions, are not publicly available, the only way to try to guess a password is to use the authentication function systems provide for authorized users to log in. Although this sounds difficult, the patience of some attackers is amazing. One group of attackers guessed passwords in this manner for more than two weeks before gaining access to one target system.
Unlike a type 1 dictionary attack, this attack cannot be prevented, because the authentication functions must be available to enable legitimate users to access the system. The computer has no way of distinguishing between authorized and unauthorized users except by knowledge of the password.
Defending against such attacks requires that the authentication functions be made difficult for attackers to use, or that the authentication functions be made to react in unusual ways. Four types of techniques are common.
Techniques of the first type are collectively called backoff techniques. The most common, exponential backoff, begins when a user attempts to authenticate and fails. Let x be a parameter selected by the system administrator. The system waits x0 = 1 second before reprompting for the name and authentication data. If the user fails again, the system reprompts after x1 = x seconds. After n failures, the system waits xn–1 seconds. Other backoff techniques use arithmetic series rather than geometric series (reprompting immediately, then waiting x seconds, then waiting 2x seconds, and so forth).
Techniques of the second type involve disconnection. After some number of failed authentication attempts, the connection is broken and the user must reestablish it. This technique is most effective when connection setup requires a substantial amount of time, such as redialing a telephone number. It is less effective when connections are quick, such as over a network.
Techniques of the third type use disabling. If n consecutive attempts to log in to an account fail, the account is disabled until a security manager can reenable it. This prevents an attacker from trying too many passwords. It also alerts security personnel to an attempted attack. They can take appropriate action to counter the threat.
One should consider carefully whether to disable accounts and which accounts to disable. A (possibly apocryphal) story concerns one of the first UNIX vendors to implement account disabling. No accounts were exempt. An attacker broke into a user account, and then attempted to log in as root three times. The system disabled that account. The system administrators had to reboot the system to regain root access.
The final, fourth type of technique is called jailing. The unauthenticated user is given access to a limited part of the system and is gulled into believing that he or she has full access. The jail then records the attacker's actions. This technique is used to determine what the attacker wants or simply to waste the attacker's time.
One form of the jailing technique is to plant bogus data on a running system, so that after breaking in the attacker will grab the data. (This technique, called honeypots, is often used in intrusion detection. See Section 25.6.2.1, “Containment.”) Clifford Stoll used this technique to help trap an attacker who penetrated computers at the Lawrence Berkeley Laboratory. The time required to download the bogus file was sufficient to allow an international team to trace the attacker through the international telephone system [973, 975].
Guessing of passwords requires that access to the complement, the complementation functions, and the authentication functions be obtained. If none of these have changed by the time the password is guessed, then the attacker can use the password to access the system.
Consider the last sentence's conditional clause. The techniques discussed in Section 12.2 attempt to negate the part saying “the password is guessed” by making that task difficult. The other part of the conditional clause, “if none of these have changed,” provides a different approach: ensure that, by the time a password is guessed, it is no longer valid.
Definition 12–6. Password aging is the requirement that a password be changed after some period of time has passed or after some event has occurred.
Assume that the expected time to guess a password is 180 days. Then changing the password more frequently than every 180 days will, in theory, reduce the probability that an attacker can guess a password that is still being used. In practice, aging by itself ensures little, because the estimated time to guess a password is an average; it balances those passwords that can be easily guessed against those that cannot. If users can choose passwords that are easy to guess, the estimation of the expected time must look for a minimum, not an average. Hence, password aging works best in conjunction with other mechanisms such as the ones discussed in this chapter.
There are problems involved in implementing password aging. The first is forcing users to change to a different password. The second is providing notice of the need to change and a user-friendly method of changing passwords.
Password aging is useless if a user can simply change the current password to the same thing. One technique to prevent this is to record the n previous passwords. When a user changes a password, the proposed password is compared with these n previous ones. If there is a match, the proposed password is rejected. The problem with this mechanism is that users can change passwords n times very quickly, and then change them back to the original passwords. This defeats the goal of password aging.
An alternative approach is based on time. In this implementation, the user must change the password to one other than the current password. The password cannot be changed for a minimum period of time. This prevents the rapid cycling of passwords. However, it also prevents the user from changing the password should it be compromised within that time period.
If passwords are selected by users, the manner in which users are reminded to change their passwords is crucial. Users must be given time to think of good passwords or must have their password choices checked. Grampp and Morris [415] point out that, although there is no formal statistical evidence to support it, they have found that the easiest passwords to guess are on systems that do not give adequate notice of upcoming password expirations.
Passwords have the fundamental problem that they are reusable. If an attacker sees a password, she can later replay the password. The system cannot distinguish between the attacker and the legitimate user, and allows access. An alternative is to authenticate in such a way that the transmitted password changes each time. Then, if an attacker replays a previously used password, the system will reject it.
Definition 12–7. Let user U desire to authenticate himself to system S. Let U and S have an agreed-on secret function f. A challenge-response authentication system is one in which S sends a random message m (the challenge) to U, and U replies with the transformation r = f(m) (the response). S validates r by computing it separately.
Challenge-response algorithms are similar to the IFF (identification—friend or foe) techniques that military airplanes use to identify allies and enemies.
Definition 12–8. Let there be a challenge-response authentication system in which the function f is the secret. Then f is called a pass algorithm.
Under this definition, no cryptographic keys or other secret information may be input to f. The algorithm computing f is itself the secret.
The ultimate form of password aging occurs when a password is valid for exactly one use. In some sense, challenge-response mechanisms use one-time passwords. Think of the response as the password. As the challenges for successive authentications differ, the responses differ. Hence, the acceptability of each response (password) is invalidated after each use.
Definition 12–9. A one-time password is a password that is invalidated as soon as it is used.
A mechanism that uses one-time passwords is also a challenge-response mechanism. The challenge is the number of the authentication attempt; the response is the one-time password.
The problems in any one-time password scheme are the generation of random passwords and the synchronization of the user and the system. The former problem is solved by using a cryptographic hash function or enciphering function such as the DES, and the latter by having the system inform the user which password it expects—for example, by having all the user's passwords numbered and the system providing the number of the one-time password it expects.
One-time passwords are considerably simpler with hardware support because the passwords need not be printed on paper or some other medium.
Hardware support comes in two forms: a program for a general-purpose computer and special-purpose hardware support. Both perform the same functions.
The first type of hardware device, informally called a token, provides mechanisms for hashing or enciphering information. With this type of device, the system sends a challenge. The user enters it into the device. The device returns the appropriate response. Some devices require the user to enter a personal identification number or password, which is used as a cryptographic key or is combined with the challenge to produce the response.
The second type of hardware device is temporally based. Every 60 seconds, it displays a different number. The numbers range from 0 to 10n – 1, inclusive. A similar device is attached to the computer. It knows what number the device for each registered user should display. To authenticate, the user provides his login name. The system requests a password. The user then enters the number shown on the hardware device, followed by a fixed (reusable) password. The system validates that the number is the one expected for the user at that time and that the reusable portion of the password is correct.
Whether or not a challenge-response technique is vulnerable to a dictionary attack of type 1 depends on the nature of the challenge and the response. In general, if the attacker knows the challenge and the response, a dictionary attack proceeds as for a reusable password system.
In practice, it is not necessary to know the value of r. Most challenges are composed of random data combined with public data that an attacker can determine.
Bellovin and Merritt [77] propose a technique, called encrypted key exchange, that defeats dictionary attacks of type 1. Basically, it ensures that random challenges are never sent in the clear. Because the challenges are random, and unknown to the attacker, the attacker cannot verify when she has correctly deciphered them. Hence, the dictionary attack is infeasible.
The protocol assumes that Alice shares a secret password with Bob.
Alice uses the shared password s to encipher a randomly selected public key p for a public key system. Alice then forwards this key, along with her name, to Bob.
Bob determines the public key using the shared password, generates a random secret key k, enciphers it with p, enciphers the result with s, and sends it to Alice.
Alice deciphers the message to get k. Now both Bob and Alice share a randomly generated secret key. At this point, the challenge-response phase of the protocol begins.
Alice generates a random challenge RA, enciphers it using k, and sends Ek(RA) to Bob.
Bob uses k to decipher RA. He then generates a random challenge RB and enciphers both with k to produce Ek(RARB). He sends this to Alice.
Alice deciphers the message, validates RA, and determines RB. She enciphers it using k and sends the message Ek(RB) back to Bob.
Bob deciphers the message and verifies RB.
At this point, both Alice and Bob know that they are sharing the same random key k. To see that this system is immune to dictionary attacks of type 1, look at each exchange. Because the data sent in each exchange is randomly selected and never visible to the attacker in plaintext form, the attacker cannot know when she has correctly deciphered the message.
Identification by physical characteristics is as old as humanity. Recognizing people by their voices or appearance, and impersonating people by assuming their appearance, was widely known in classical times. Efforts to find physical characteristics that uniquely identify people include the Bertillion cranial maps, fingerprints, and DNA sampling. Using such a feature to identify people for a computer would ideally eliminate errors in authentication.
Biometrics is the automated measurement of biological or behavioral features that identify a person [713]. When a user is given an account, the system administration takes a set of measurements that identify that user to an acceptable degree of error. Whenever the user accesses the system, the biometric authentication mechanism verifies the identity. Lawton [618] points out that this is considerably easier than identifying the user because no searching is required. A comparison to the known data for the claimed user's identity will either verify or reject the claim. Common characteristics are fingerprints, voice characteristics, eyes, facial features, and keystroke dynamics.
Fingerprints can be scanned optically, but the cameras needed are bulky. A capacitative technique uses the differences in electrical charges of the whorls on the finger to detect those parts of the finger touching a chip and those raised. The data is converted into a graph in which ridges are represented by vertices and vertices corresponding to adjacent ridges are connected. Each vertex has a number approximating the length of the corresponding ridge. At this point, determining matches becomes a problem of graph matching [515]. This problem is similar to the classical graph isomorphism problem, but because of imprecision in measurements, the graph generated from the fingerprint may have different numbers of edges and vertices. Thus, the matching algorithm is an approximation.
Authentication by voice, also called speaker verification or speaker recognition, involves recognition of a speaker's voice characteristics [169] or verbal information verification [626, 627]. The former uses statistical techniques to test the hypothesis that the speaker's identity is as claimed. The system is first trained on fixed pass-phrases or phonemes that can be combined. To authenticate, either the speaker says the pass-phrase or repeats a word (or set of words) composed of the learned phonemes. Verbal information verification deals with the contents of utterances. The system asks a set of questions such as “What is your mother's maiden name?” and “In which city were you born?” It then checks that the answers spoken are the same as the answers recorded in its database. The key difference is that speaker verification techniques are speaker-dependent, but verbal information verification techniques are speaker-independent, relying only on the content of the answers [628].
Authentication by eye characteristics uses the iris and the retina. Patterns within the iris are unique for each person. Hence, one verification approach is to compare the patterns statistically and ask whether the differences are random [258]. A second approach is to correlate the images using statistical tests to see if they match [1045]. Retinal scans rely on the uniqueness of the patterns made by blood vessels at the back of the eye. This requires a laser beaming onto the retina, which is highly intrusive. This method is typically used only in the most secure facilities [618].
Face recognition consists of several steps. First, the face is located. If the user places her face in a predetermined position (for example, by resting her chin on a support), the problem becomes somewhat easier. However, facial features such as hair and glasses may make the recognition harder. Techniques for doing this include the use of neural networks [803] and templates [1068]. The resulting image is then compared with the relevant image in the database. The correlation is affected by the differences in the lighting between the current image and the reference image, by distortion, by “noise,” and by the view of the face. The correlation mechanism must be “trained.” Several different methods of correlation have been used, with varying degrees of success [726]. An alternative approach is to focus on the facial features such as the distance between the nose and the chin, and the angle of the line drawn from one to the other [867].
Keystroke dynamics requires a signature based on keystroke intervals, keystroke pressure, keystroke duration, and where the key is struck (on the edge or in the middle). This signature is believed to be unique in the same way that written signatures are unique [531]. Keystroke recognition can be both static and dynamic. Static recognition is done once, at authentication time, and usually involves typing of a fixed or known string [152, 727]. Once authentication has been completed, an attacker can capture the connection (or take over the terminal) without detection. Dynamic recognition is done throughout the session, so the aforementioned attack is not feasible. However, the signature must be chosen so that variations within an individual's session do not cause the authentication to fail. For example, keystroke intervals may vary widely, and the dynamic recognition mechanism must take this into account. The statistics gathered from a user's typing are then run through statistical tests (which may discard some data as invalid, depending on the technique used) that account for acceptable variance in the data.
Several researchers have combined some of the techniques decribed above to improve the accuracy of biometric authentication. Dieckmann, Plankensteiner, and Wagner [292] combined voice sounds and lip motion with the facial image. Duc, Bigun, Bigun, Maire, and Fischer [311] describe a “supervisor module” for melding voice and face recognition with a success rate of 99.5%. The results indicate that a higher degree of accuracy can be attained than when only a single characteristic is used.
Because biometrics measures characteristics of the individual, people are tempted to believe that attackers cannot pose as authorized users on systems that use biometrics. Two assumptions underlie this belief. The first is that the biometric device is accurate in the environment in which it is used. For example, if a fingerprint scanner is under observation, having it scan a mask of another person's finger would be detected. But if it is not under observation, such a trick might not be detected and the unauthorized user might gain access. The second assumption is that the transmission from the biometric device to the computer's analysis process is tamperproof. Otherwise, one could record a legitimate authentication and replay it later to gain access. Exercise 13 explores this in more detail.
Denning and MacDoran [276] suggest an innovative approach to authentication. They reason that if a user claims to be Anna, who is at that moment working in a bank in California but is also logging in from Russia at the same time, the user is impersonating Anna. Their scheme is based on the Global Positioning System (GPS), which can pinpoint a location to within a few meters. The physical location of an entity is described by a location signature derived from the GPS satellites. Each location (to within a few meters) and time (to within a few milliseconds) is unique, and hence form a location signature. This signature is transmitted to authenticate the user. The host also has a location signature sensor (LSS) and obtains a similar signature for the user. If the signatures disagree, the authentication fails.
This technique relies on special-purpose hardware. If the LSS is stolen, the thief would have to log in from an authorized geographic location. Because the signature is generated from GPS data, which changes with respect to time, location, and a variety of vagaries resulting from the nature of the electromagnetic waves used to establish position, any such signature would be unique and could not be forged. Moreover, if intercepted, it could not be replayed except within the window of temporal uniqueness.
This technique can also restrict the locations from which an authorized user can access the system.
Authentication methods can be combined, or multiple methods can be used.
Techniques using multiple methods assign one or more authentication methods to each entity. The entity must authenticate using the specific method, or methods, chosen. The specific authentication methods vary from system to system, but in all cases the multiple layers of authentication require an attacker to know more, or possess more, than is required to spoof a single layer.
Authentication consists of an entity, the user, trying to convince a different entity, the verifier, of the user's identity. The user does so by claiming to know some information, to possess something, to have some particular set of physical characteristics, or to be in a specific location. The verifier has some method of validating the claim, possibly with auxiliary equipment.
Passwords are the most basic authentication mechanism. They are vulnerable to guessing unless precautions ensure that there is a large enough set of possible passwords and that each potential password in the set is equally likely to be selected. Challenge-response techniques allow the system to vary the password and are less vulnerable to compromise because the password is never transmitted in the clear. One-time passwords, an example of this technique, are particularly effective against guessing attacks because even if a password is guessed, it may not be reused.
Some forms of authentication require hardware support. A cryptographic key is embedded in the device. The verifier transmits a challenge. The user computes a response using the hardware device and transmits it to the verifier. The verifier then validates the signature.
Biometrics measures physical characteristics of the user. These characteristics are sent to the verifier, which validates them. Critical to the successful use of biometric measurements is the understanding that they are simply passwords (although very complex ones) and must be protected in the same way that passwords must be protected.
Location requires the verifier to determine the location of the user. If the location is not as it should be, the verifier rejects the claim.
In practice, some combination of these methods is used. The specific methods, and their ordering, depend on the resources available to the verifier and the user, the strength of the authentication required, and external factors such as laws and customs.
Because of human factors such as writing passwords down or choosing passwords that are easy to remember, much research focuses on making authentication schemes difficult to break but easy to use. Using noncharacter password schemes (such as graphical motion) appears to be promising. Research into techniques and the psychology underlying them may improve this situation. Further, given the multiplicity of passwords, storing them in a form that a user can easily access but that an attacker cannot access is another important issue.
Authentication protocols involve passwords, often as cryptographic keys. Protocols that prevent dictionary attacks of type 1 make attacks of authentication schemes more difficult. Research into provably secure protocols, which cannot be broken, and into probabilistic authentication protocols (such as zero-knowledge proofs) will harden authentication even more. Considerable effort is being made to minimize the time and storage requirements of these protocols, as well as to maximize their robustness in the face of attacks.
Biometrics enables systems to authenticate users based on physical characteristics. Because fingerprints uniquely identify people, they should make excellent authenticators. Research into mechanisms for recording biometric data under varying conditions is critical to the success of authentication using biometrics. For example, if voiceprints are used, the mechanisms must correctly identify an individual even if that individual has a bad cold.
Single system sign-on is a mechanism whereby a user logs on once and has access to all systems and resources within the organizational unit. This requires compatibility among a wide variety of authentication mechanisms, and development of mechanisms for integrating a wide variety of systems into a single sign-on organization is an area of active research.
Discussions of the strength of the UNIX password scheme provide insight into how gracefully authentication schemes age. Bishop [109] and Feldmeier and Karn [344] discuss attacks on the UNIX scheme. Su and Bishop use a Connection Machine in a dictionary attack [979]; Kedem and Ishihara use a PixelFlow SIMD computer [556]. Leong and Tham [621] discuss specific password-cracking hardware. Manber [656] discusses a salting scheme. Bergadano, Crispo, and Ruffo discuss techniques for compressing dictionaries for use with proactive password checkers [81, 82].
The U.S. Department of Defense has issued specific guidelines for password selection and management [284]. Jermyn, Mayer, Monrose, Reiter, and Rubin use the graphical capabilities of many systems to generate passwords [523]. Rubin presents an alternative one-time password scheme [854].
Many network-oriented protocols are challenge-response protocols. Seberry and Pieprzyk [897] and Schneier [888] discuss network-oriented authentication in depth. Chapter 10, “Key Management,” discusses some of these protocols.
Itoi and Honeyman [517] have developed a version of PAM for Windows NT.