
HIPPOLYTA: How chance Moonshine is gone beforeThisbe comes back and finds her lover?THESEUS: She will find him by starlight. Hereshe comes; and her passion ends the play. | ||
| --A Midsummer Night's Dream, V, i, 320–323. | ||
System managers must protect computer systems from attack. The mechanisms and techniques discussed throughout this book help protect systems, data, and resources. However, nothing is perfect. Even the best protected systems must be monitored to detect successful (and unsuccessful) attempts to breach security. This chapter discusses automated systems for detecting intrusions and looks at responses to attacks.
Computer systems that are not under attack exhibit several characteristics.
The actions of users and processes generally conform to a statistically predictable pattern. A user who does only word processing when using the computer is unlikely to perform a system maintenance function.
The actions of users and processes do not include sequences of commands to subvert the security policy of the system. In theory, any such sequence is excluded; in practice, only sequences known to subvert the system can be detected.
The actions of processes conform to a set of specifications describing actions that the processes are allowed to do (or not allowed to do).
Denning [270] hypothesized that systems under attack fail to meet at least one of these characteristics.
The characteristics listed above guide the detection of intrusions. Once the province of the technologically sophisticated, attacks against systems have been automated. So a sophisticated attack need not be the work of a sophisticated attacker.
Definition 25–1. An attack tool is an automated script designed to violate a security policy.
Attack tools do not change the nature of intrusion detection fundamentally. They do eliminate many errors arising from incorrect installation and perform routine steps to clean up detritus of the attack, but they cannot eliminate all traces.
Denning [270] suggests automation of the intrusion detection process. Her specific hypothesis is that exploiting vulnerabilities requires an abnormal use of normal commands or instructions, so security violations can be detected by looking for abnormalities. Her model is very general and includes abnormalities such as deviation from usual actions (anomaly detection), execution of actions that lead to break-ins (misuse detection), and actions inconsistent with the specifications of privileged programs (specification-based detection).
Systems that do this are called intrusion detection systems (IDS). Their goals are fourfold[4]:
Detect a wide variety of intrusions. Intrusions from within the site, as well as those from outside the site, are of interest. Furthermore, both known and previously unknown attacks should be detected. This suggests a mechanism for learning or adapting to new types of attacks or to changes in normal user activity.
Detect intrusions in a timely fashion. “Timely” here need not be in real time. Often it suffices to discover an intrusion within a short period of time. Real-time intrusion detection raises issues of responsiveness. If every command and action must be analyzed before it can be executed, only a very simple analysis can be done before the computer (or network) being monitored becomes unusable. On the other hand, in all but a few rare cases, determining that an intrusion took place a year ago is probably useless.
Present the analysis in a simple, easy-to-understand format. Ideally, this should be a light that glows green for no detected intrusions and that changes to red when an attack is detected. Unfortunately, intrusions are rarely this clear-cut, so intrusion detection mechanisms must present more complex data to a site security officer. The security officer determines what action (if any) to take. Because intrusion detection mechanisms may monitor many systems (not just one), the user interface is of critical importance. This leads to the next requirement.
Be accurate. A false positive occurs when an intrusion detection system reports an attack, but no attack is underway. False positives reduce confidence in the correctness of the results as well as increase the amount of work involved. However, false negatives (occurring when an intrusion detection system fails to report an onging attack) are worse, because the purpose of an intrusion detection system is to report attacks. The goal of an intrusion detection system is to minimize both types of errors.
Formalizing this type of analysis provides a statistical and analytical basis for monitoring a system for intrusions. Three types of analyses—anomaly detection, misuse (or signature) detection, and specification detection—look for violations of the three characteristics in Section 25.1. Before discussing these types of analyses, let us consider a model of an intrusion detection system.
Intrusion detection systems determine if actions constitute intrusions on the basis of one or more models of intrusion. A model classifies a sequence of states or actions, or a characterization of states or actions, as “good” (no intrusions) or “bad” (possible intrusions). Anomaly models use a statistical characterization, and actions or states that are statistically unusual are classified as “bad.” Misuse models compare actions or states with sequences known to indicate intrusions, or sequences believed to indicate intrusions, and classify those sequences as “bad.” Specification-based models classify states that violate the specifications as “bad.” The models may be adaptive models that alter their behavior on the basis of system states and actions, or they may be static models that are initialized from collected data and do not change as the system runs.
In this section we examine representative models of each class. In practice, models are often combined, and intrusion detection systems use a mixture of two or three different types of models.
Anomaly detection uses the assumption that unexpected behavior is evidence of an intrusion. Implicit is the belief that some set of metrics can characterize the expected behavior of a user or a process. Each metric relates a subject and an object.
Definition 25–2. Anomaly detection analyzes a set of characteristics of the system and compares their behavior with a set of expected values. It reports when the computed statistics do not match the expected measurements.
Denning identifies three different statistical models.
The first model uses a threshold metric. A minimum of m and a maximum of n events are expected to occur (for some event and some values m and n). If, over a specific period of time, fewer than m or more than n events occur, the behavior is deemed anomalous.
Determining the threshold complicates use of this model. The threshold must take into account differing levels of sophistication and characteristics of the users. For example, if n were set to 3 in the example above for a system in France, and the primary users of that system were in the United States, the difference in the keyboards would result in a large number of false alarms. But if the system were located in the United States, setting n to 3 would be more reasonable. One approach is to combine this approach with the other two models to adapt the thresholds to observed or predicted behavior.
The second model uses statistical moments. The analyzer knows the mean and standard deviation (first two moments) and possibly other measures of correlation (higher moments). If values fall outside the expected interval for that moment, the behavior that the values represent is deemed anomalous. Because the profile, or description of the system, may evolve over time, anomaly-based intrusion detection systems take these changes into account by aging (or weighting) data or altering the statistical rule base on which they make decisions.
The statistical moments model provides more flexibility than the threshold model. Administrators can tune it to discriminate better than the threshold model. But with flexibility comes complexity. In particular, an explicit assumption is that the behavior of processes, and users, can be statistically modeled. If this behavior matches a statistical distribution (such as a Gaussian or normal distribution), determining the parameters requires experimental data that can be obtained from the system. But if not, the analysts must use other techniques, such as clustering, to determine the characteristics, the moments, and the values that indicate abnormal behavior. Section 25.3.1.1 discusses one such technique. An additional problem is the difficulty of computing these moments in real time.
Denning's third model is a Markov model. Examine a system at some particular point in time. Events preceding that time have put the system into a particular state. When the next event occurs, the system transitions into a new state. Over time, a set of probabilities of transition can be developed. When an event occurs that causes a transition that has a low probability, the event is deemed anomalous. This model suggests that a notion of “state,” or past history, can be used to detect anomalies. The anomalies are now no longer based on statistics of the occurrence of individual events, but on sequences of events. This approach heralded misuse detection and was used to develop effective anomaly detection mechanisms.
Teng, Chen, and Lu used this approach in Digital Equipment Corporation's TIM research system [993]. Their scheme used an artificial intelligence technique called time-based inductive learning. The system is given a type of event to be predicted. It develops a set of temporally related conditions that predict the time that the event will occur with respect to the set.
The effectiveness of Markov-based models depends on the adequacy of the data used to establish the model. This data (called training data) is obtained experimentally, usually from populations that are believed to be normal (not anomalous). For example, TIM could obtain data by monitoring a corporate system to establish the relevant events and their sequence. Hofmeyr, Forrest, and Somayaji obtained traces of system calls from processes running in a normal environment. If this training data accurately reflects the environment in which the intrusion detection system is to run, the model will work well, but if the training data does not correspond to the environment, the Markov model will produce false alarms and miss abnormal behaviors. In particular, unless the training data covers all possible normal uses of the system in the environment, the intrusion detection mechanism will issue false reports of abnormalities.
Central to the notion of anomaly detection is the idea of being able to detect “outliers” or values that do not match, or fall within, a set of “reasonable values.” These outliers are the anomalies, but characterizing a value as abnormal implies that there is a method for characterizing “normal” values. This method is statistical modeling. For example, IDES builds its anomaly detection scheme on the assumption that values of events have a Gaussian distribution. If the distribution is Gaussian, the model works well. If it is not, the model will not match the events, and either too many anomalous events will occur (a high false positive rate) or anomalous events will be missed (a high false negative rate). The former will overwhelm the security officers with data and possibly cause them to miss truly anomalous behavior. The latter will simply not report events that should be reported. Experience indicates, however, that the distribution is typically not Gaussian.
Lankewicz and Benard [616] considered the use of nonparametric statistical techniques—that is, statistical models that do not assume any a priori distribution of events. The technique they used is called clustering analysis and requires some set of data to be available (this data is obtained by monitoring the system for some period of time). The data is then grouped into subsets, or clusters, based on some property (called a feature). Instead of analyzing individual data points, the clusters are analyzed. This greatly reduces the amount of data analyzed, at the cost of some preprocessing time (to cluster the data). This approach is sensitive to the features and the statistical definitions of clustering.
EXAMPLE: Suppose an intrusion detection system bases anomaly detection on the number of reads and writes that a process does. Figure 25-1 shows a sample of the relevant data for a system. Rather than deal with six data points, we cluster them. (In practice, the data sample would be many thousands of values.)

Figure 25-1. Clustering. The relevant measure, CPU time, is clustered in two ways. The first uses intervals of 25th percentiles, and the second uses the 50th percentile.
Our first clustering scheme is to group the data into four clusters. The first cluster contains all entries whose CPU times fall into the first 25th percentile of the data; the second, the entries whose CPU times fall into the second 25th percentile of the data; and so forth. Using this grouping, we have four clusters, with only one value in the last quartile. This could be selected as an anomalous cluster.
Our second clustering reduces the number of clusters to two, divided into those events with CPU times above the 50th percentile, and those with the CPU times below it. Here, the two clusters contain three values each, so no conclusions about anomalies can be drawn.
As this example shows, determining how to cluster the data can be tricky. Even more difficult is determining which features are meaningful. For example, the CPU time used may show anomalies but may not indicate violations of the security policy, but the number of I/O requests may indicate a violation if the data falls into a particular cluster. To overcome this problem, systems using clustering require training data in which the anomalous data indicating intrusions is marked. The feature selection program will use this data to derive features and build clusters that will reflect the anomalous data (to some degree of accuracy).
In some contexts, the term “misuse” refers to an attack by an insider or authorized user. In the context of intrusion detection systems, it means “rule-based detection.”
Definition 25–3. Misuse detection determines whether a sequence of instructions being executed is known to violate the site security policy being executed. If so, it reports a potential intrusion.
Modeling of misuse requires a knowledge of system vulnerabilities or potential vulnerabilities that attackers attempt to exploit. The intrusion detection system incorporates this knowledge into a rule set. When data is passed to the intrusion detection system, it applies the rule set to the data to determine if any sequences of data match any of the rules. If so, it reports that a possible intrusion is underway.
Misuse-based intrusion detection systems often use expert systems to analyze the data and apply the rule set. These systems cannot detect attacks that are unknown to the developers of the rule set. Previously unknown attacks, or even variations of known attacks, can be difficult to detect. Later intrusion detection systems used adaptive methods involving neural networks and Petri nets to improve their detection abilities.
EXAMPLE: Kumar and Spafford [601] have adapted colored Petri nets to detect both attack signatures and the actions following previously unknown attacks in their system Intrusion Detection In Our Time (IDIOT). They define an event as a change in the system state. The observation that an “event can represent a single action by a user or system, or it can represent a series of actions resulting in a single, observable record”[5] is key. They have developed a model of attacks on the UNIX operating system based on temporal ordering of events. Their model classified attacks in five ways.
Existence; the attack creates a file or some other entity at some time.
Sequence; the attack causes several events to occur sequentially.
Partial order; the attack causes two or more sequences of events, and the events form a partial order under the temporal relation.
Duration; something exists for an interval of time.
Interval; two events occur exactly n units of time apart.
In these attacks, the sequence of events may be interlaced with other events. Regular expressions and attribute- and context-free grammars cannot easily capture this. Hence, Kumar and Spafford use colored Petri nets. Each signature corresponds to an automaton called a Colored Petri Automaton (CPA). The nodes represent tokens; the edges represent transitions. The final state of each signature is the compromised state. Each automaton may have multiple start states (see Figure 25-2). At the beginning, a token is placed in each node corresponding to a start state. As events transition the states, the tokens move from one node along the appropriate edge to the next node.
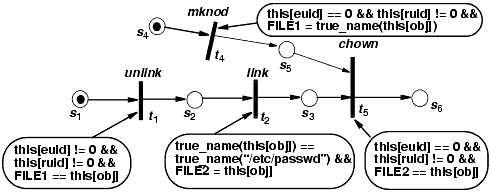
Figure 25-2. The mkdir attack on pages 667–668 described using a Colored Petri Automaton. The circles represent states, and the thick bars represent the commands causing transitions.
Associated with each transition is a set of expressions protected by (possibly empty) guards. The expressions dictate assignments to variables when the transition is taken, and the guards determine whether or not conditions hold for the transitions to be taken. In a guard or expression, the function “this” instantiates itself to the attributes of the last event. In Figure 25-2, the guard for transition t4 requires that the UID of the process executing the mknod be 0 but that root not be running it (this[euid] == 0 && this[ruid] != 0). If it is, the variable FILE1 is bound to the true name of the object being created, and the transition is made. Similarly, the guard for transition t1 (the unlink) requires that the UID of the process not be 0 and that FILE1 be instantiated and be the same as the name of the object being unlinked (FILE1 == true_name(this[obj])). If both hold, the token is moved to s2, which represents transitioning of the system into a new state.
When transition t5 occurs, it merges the two branches into one. FILE2 obtains its value from the s1-s2-s3 branch, but the restrictions on the user IDs come from the s4-s5 branch. If those conditions are met, the transition t5 occurs, the tokens merge at node s6, and the system enters the corresponding (compromised) state.
This model has two important features. The first is the ability to add new signatures dynamically. The partially matched signatures need not be cleared and rematched; existing representations of the CPAs maintain their states. Furthermore, the patterns can be prioritized by ordering the CPAs. Even more, sequences that are known to be likely to occur (perhaps because they were recently published) can be prioritized by appropriately ordering the initial branches of the CPAs.
IDIOT monitors audit logs looking for a sequence of events that correspond to an attack. An alternative point of view is to ignore the actual states and focus on the commands that change them. Researchers at the University of California at Santa Barbara have built several systems that analyze the results of commands to breach a security policy.
EXAMPLE: STAT [508] views a computer as being in a particular state, and commands move it from one state to another. The effect of the command is to cause a state transition. Ilgun, Kemmerer, and Porras use this to model attacks. Ilgun developed the first STAT prototype, called USTAT.
Although the notion of “state” encompasses all data stored on the computer, down to the level of caches and registers, the architects of STAT noted that they needed to track only those portions of the state that affected security. For example, suppose that a process is running as the superuser (UID 0) without authorization. The system has been compromised. But rather than detect the compromised state, STAT looks at the manner in which the user obtained the special privileges. This focuses on transitions. All compromises may be described in this way—that is, a process goes from a limited state to a state in which some other right is acquired. The key to STAT is to find how this can happen.
Associated with each state is a set of assertions. Consider an attack on a UNIX system in which an attacker renames a setuid to root shell script so its name begins with “–”. The user executes it. Because some shells have a bug that makes any invocation of the shell beginning with “–” interactive, the attacker gets superuser privileges.
ln target –s –s
The state transition diagram is
The state diagram is now augmented to capture the result of the attack by placing postconditions under the state. Let USER be the user's effective UID. The transition of the process into a state where it has superuser privileges means that the effective UID is no longer that of the user:
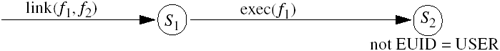
Finally, the state diagram needs to establish conditions under which the state s1 can be entered. In order to enter that state, the new file name must start with “–” and cannot be owned by USER (otherwise, the user could not acquire additional privileges). Furthermore, it must be a script, it must be setuid, and USER must be able to execute the file. This leads to:
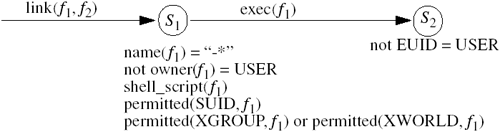
USTAT uses records generated by BSM to obtain system information. A preprocessor extracts events of interest and maps them into USTAT's internal representation. It also removes events in which the attempted system calls failed (because such events do not change the system state).
It then uses an inference engine to determine when a state transition compromising a system occurs. The system has a fact base of seven types of transitions. The first type lists files that no unprivileged user should be able to access (read or write). The second type lists files that no unprivileged user should be able to write to. The third and fourth types list executable programs that are authorized to read from files in the first list and write to files in the second list, repectively. The fifth type lists files that are common places for Trojan horses and should not be deleted nor overwritten. The sixth type lists system directories that users should not be able to write to, and the last type lists UNIX files with multiple names. A rule set uses these types of transitions to constrain the actions that should be reported.
The inference engine constructs a series of state table entries corresponding to the transitions. Consider the attack described above, and suppose that the rule base consists of the one state transition rule above. Initially, the table appears as follows:
S1 | S2 | |
1 |
because there is one state transition rule with two states. After the first command (the ln), all five preconditions of state S1 are satisfied, so the system creates a new row to represent this:
S1 | S2 | |
1 | ||
2 | X |
The first row will be used if another file is created with the same properties as those in the state transition diagram. The second row asserts that a process has already done so. The attacker now executes the file –x and, because the EUID of the process is no longer that of the user, the system enters S2. The matrix is not augmented, but the violation is noted. The row remains present until something negates the preconditions on S1 (such as the file not being a shell script or not being setuid).
The load that USTAT places on a system does not increase as the system load increases, because USTAT reopens log files repeatedly to read new records. Nevertheless, its approach is interesting because, unlike other intrusion detection mechanisms, it focuses on the changes of state rather than on the existing state.
One important feature for intrusion detection systems is an interface into which new users and/or maintainers can add new rules or data. Ranum's Network Flight Recorder is a classic example of how this can be done well.
Anomaly detection has been called the art of looking for unusual states. Misuse detection, similarly, is the art of looking for states known to be bad. Specification detection takes the opposite approach; it looks for states known not to be good, and when the system enters such a state, it reports a possible intrusion.
Definition 25–4. Specification-based detection determines whether or not a sequence of instructions violates a specification of how a program, or system, should execute. If so, it reports a potential intrusion.
For security purposes, only those programs that in some way change the protection state of the system need to be specified and checked. For example, because the policy editor in Windows NT changes security-related settings, it needs to have an associated specification.
Specification-based detection relies on traces, or sequences, of events [582].
Definition 25–5. A system trace is a sequence of events t0, t1, …, ti, ti+1, … during the execution of a system of processes. Event ti occurs at time C(ti), and this imposes a total ordering on the events.
Contrast this with the notion of trace in Chapter 8, “Noninterference and Policy Composition.” This definition uses events as elements of the sequence, whereas the definition in Chapter 8 uses inputs and outputs as elements of the sequence.
Definition 25–6. A subtrace of a trace T = t0, t1, …, ti, ti+1, …, tn is a sequence of events t0', …, tk', where t0', …, tk' is a subsequence of t0, t1, …, ti, ti+1, …, tn.
For example, if U is the system trace for the system, and V is a system trace for one process in that system, then V will be a subtrace of U.
Definition 25–7. A trace T = t0, …, tm+n is the merge of two traces U and V if and only if there are two subtraces u1, …, um and v0, …, vn of T such that U = u1, …, um and V = v0, …, vn.
When a distributed process executes, its trace is the merged trace of its components. The merge of traces U and V is written T = U ⊕ V.
Definition 25–8. A filter p is a function that maps a trace T to a subtrace T' such that, for all events ti in T', p(ti) is true.
The filter allows the monitoring to weed out events that are of no interest.
Definition 25–9. An execution trace of a subject s is the sequence of operations performed by the processes making up the subject.
For example, if the subject s is composed of processes p, q, and r, with traces Tp, Tq, and Tr, respectively, then the trace of s is Ts = Tp ⊕ Tq ⊕ Tr.
A trace policy takes a set of selection expressions and applies them to the system trace of interest.
Specification-based intrusion detection is in its infancy. Among its appealing qualities are the formalization (at a relatively low level) of what should happen. This means that intrusions using unknown attacks will be detected. Balanced against this desirable feature is the extra effort needed to locate and analyze the programs that may cause security problems. The subtlety of this last point is brought home when one realizes that any program is a potential security threat when executed by a privileged user.
Reflecting on the differences between the three basic types of intrusion detection will clarify the nature of each type.
Some observations on misuse detection will provide a basis for what follows. Definition 25–3 characterizes misuse detection as detection of violations of a policy. The policy may be known (explicit) or implicit. In the former case, one uses the techniques described in Section 24.4.1 to develop the rules for the misuse detection system. In the latter case, one must describe the policy in terms of actions or states that are known to violate the policy, which calls on the techniques described in Section 24.4.2 to develop the relevant rules. This distinction, although subtle, is crucial. In the first case, the rules database is sufficient to detect all violations of policy because the policy itself was used to populate the rule set. In the second case, the rule set contains descriptions of states and/or actions that are known to violate the policy, but not all such states or actions. This kind of misuse detection system will not detect all violations of system policy.
Example 25-3. The PE-grammar for monitoring rdist (see [582], p. 181).
1.SPEC rdist <?, rdist, *, nobhill>
2. ENV User U = getuser();
3. ENV int PID = getpid();
4. ENV int FILECD[int];
5. ENV int PATHCD[str];
6. ENV str HOME = "/export/home/U.name"
7. SE: <rdist>
8. <rdist> -> <valid_op> <rdist> |.
9. <valid_op> -> open_r_worldread
| open_r_not_worldread
{ if !Created(F)
then violation(); fi; }
| open_rw
{ if !Dev(F)
then violation(); fi; }
| creat_file
{ if !(Inside(P, "/tmp") or Inside(P. HOME))
then violation(); fi;
FILECD[F.nodeid] = 1;
PATHCD[P] = F.nodeid';}
| creat_dir
{ if !(Inside(P, "/tmp") or Inside(P. HOME))
then violation(); fi;}
| symlink
{ if !(Inside(P, "/tmp") or Inside(P. HOME))
then violation(); fi; }
| chown
{ if !(Created(F) and M.newownerid = U)
then violation(); fi; }
| chmod
{ if !Created(F)
then violation(); fi; }
| rename
{ if !(PathCreated(P) and Inside(M.newpath, HOME))
then violation(); fi;}
10. END
Now consider the difference between misuse detection and anomaly detection. The former detects violations of a policy. The latter detects violations of expectation, which may (or may not) violate the policy. For example, TIM uses rules that it derives from logs to construct its Markov model. If the training data contain attacks, the Markov model will accept those attacks as normal. Hence, it is an anomaly detection mechanism. By way of contrast, IDIOT does not construct models from data on the fly. It contains a rule base of sequences that describe known attacks. Hence, it is a misuse detection mechanism.
The distinction between specification-based detection and misuse detection is also worth consideration. The former detects violations of per-program specifications, and makes an implicit assumption that if all programs adhere to their specifications, the site policy cannot be violated. The latter makes no such assumption, focusing instead on the overall site policy. Suppose an attacker could attack a system in such a way that no program violated its specifications but the combined effect of the execution of the programs during the attack did violate the site policy. Misuse intrusion detection might detect the attack (depending on the completeness of the rule set). Anomaly intrusion detection might also detect the attack (depending on the characterization of expected behavior). However, specification-based intrusion detection would not detect this attack. In essence, if the specification of a program is its “security policy,” specification-based detection is a local (per-program) form of misuse detection.
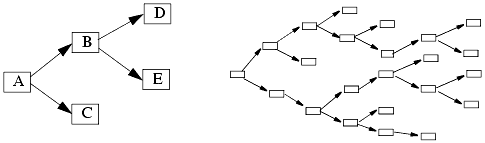
An intrusion detection system is also an automated auditing mechanism. Like auditing systems, it consists of three parts (see Section 24.2). The agent corresponds to the logger. It acquires information from a target (such as a computer system). The director corresponds to the analyzer. It analyzes the data from the agents as required (usually to determine if an attack is in progress or has occurred). The director then passes this information to the notifier, which determines whether, and how, to notify the requisite entity. The notifier may communicate with the agents to adjust the logging if appropriate. Figure 25-4 illustrates this.
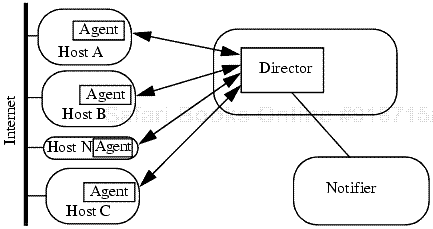
Figure 25-4. Architecture of an intrusion detection system. Hosts A, B, and C are general-purpose computers, and the agents monitor activity on them. Host N is designed for network monitoring, and its agent reports data gleaned from the Net to the director.
An agent obtains information from a data source (or set of data sources). The source may be a log file, another process, or a network. The information, once acquired, may be sent directly to the director. Usually, however, it is preprocessed into a specific format to save the director from having to do this. Also, the agent may discard information that it deems irrelevant.
The director may determine that it needs more information from a particular information source. In that case, the director can instruct the agent to collect additional data, or to process the data it collects differently. The director can use this to cut down on the amount of processing it must do, but can increase the level of information it receives when an attack is suspected.
An agent can obtain information from a single host, from a set of hosts (in which case it may also function as a director; see Section 25.4.2), or from a network. Let us consider the types of information that are available from each, and how they might be gathered.
Host-based agents usually use system and application logs to obtain records of events, and analyze them to determine what to pass to the director. The events to look for, and to analyze, are determined by the goals of the intrusion detection mechanism. The logs may be security-related logs (such as BSM and the Windows NT logs discussed in Chapter 24, “Auditing,”) or other logs such as accounting logs. Crosbie and Spafford [248] point out that the logs may even be virtual logs if the agent is put directly in the kernel. The agent then simply copies records that the kernel puts into the logs. This eliminates the need to convert from one log format to an internal representation. It also means that the agents are not portable among heterogeneous computers. There is also a drawback involving the granularity of information obtained, which we will discuss in Section 25.4.1.3.
A variant of host-based information gathering occurs when the agent generates its own information. Policy checkers do this. They analyze the state of the system, or of some objects in the system, and treat the results as a log (to reduce and forward). However, these agents are usually somewhat complex, and a fundamental rule of secure design is to keep software simple, usually by restricting its function to one task. This arrangement violates that rule. So, the policy checker usually logs its output, and the agent simply analyzes that log just as it would analyze any other log.
Network-based agents use a variety of devices and software to monitor network traffic. This technique provides information of a different flavor than host-based monitoring provides. It can detect network-oriented attacks, such as a denial of service attack introduced by flooding a network. It can monitor traffic for a large number of hosts. It can also examine the contents of the traffic itself (called content monitoring).
Network-based agents may use network sniffing to read the network traffic. In this case, a system provides the agent with access to all network traffic passing that host. If the medium is point-to-point (such as a token ring network), the agents must be distributed to obtain a complete view of the network messages. If the medium is a broadcast medium (such as Ethernet), typically only one computer needs to have the monitoring agent. Arranging the monitoring agents so as to minimize the number required to provide complete network coverage is a difficult problem. In general, the policy will focus on intruders entering the network rather than on insiders. In this case, if the network has a limited number of points of access, the agents need to monitor only the traffic through those points. If the computers controlling those entry points do extensive logging on the network traffic that they receive, the network-based information gathering is in effect reduced to host-based information gathering.
Monitoring of network traffic raises several significant issues. The critical issue is that the analysis software must ensure that the view of the network traffic is exactly the same as at all hosts for which the traffic is intended. Furthermore, if the traffic is end-to-end enciphered, monitoring the contents from the network is not possible.
The goal of an agent is to provide the director with information so that the director can report possible violations of the security policy (intrusions). An aggregate of information is needed. However, the information can be viewed at several levels.
The difference between application and system views (which is, essentially, a problem of layers of abstraction) affects what the agent can report to the director and what the director can conclude from analyzing the information. The agent, or the director, must either obtain information at the level of abstraction at which it looks for security problems or be able to map the information into an appropriate level.
The director itself reduces the incoming log entries to eliminate unnecessary and redundant records. It then uses an analysis engine to determine if an attack (or the precursor to an attack) is underway. The analysis engine may use any of, or a mixture of, several techniques to perform its analysis.
Because the functioning of the director is critical to the effectiveness of the intrusion detection system, it is usually run on a separate system. This allows the system to be dedicated to the director's activity. It has the side effect of keeping the specific rules and profiles unavailable to ordinary users. Then attackers lack the knowledge needed to evade the intrusion detection system by conforming to known profiles or using only techniques that the rules do not include.
The director must correlate information from multiple logs.
Many types of directors alter the set of rules that they use to make decisions. These adaptive directors alter the profiles, add (or delete) rules, and otherwise adapt to changes in the systems being monitored. Typical adaptive directors use aspects of machine learning or planning to determine how to alter their behavior.
Directors rarely use only one analysis technique, because different techniques highlight different aspects of intrusions. The results of each are combined, analyzed and reduced, and then used.
The notifier accepts information from the director and takes the appropriate action. In some cases, this is simply a notification to the system security officer that an attack is believed to be underway. In other cases, the notifier may take some action to respond to the attack.
Many intrusion detection systems use graphical interfaces. A well-designed graphics display allows the intrusion detection system to convey information in an easy-to-grasp image or set of images. It must allow users to determine what attacks are underway (ideally, with some notion of how likely it is that this is not a false alarm). This requires that the GUI be designed with a lack of clutter and unnecessary information.
EXAMPLE: The Graphical Intrusion Detection System (GrIDS) [963] uses a graph-oriented user interface to show the progress of attacks across multiple systems. The hosts are represented as nodes, and as an attack from one system to another is identified, the nodes are connected with edges labeled to show the progress of the attack. Figure 25-5 is an example of one of the user displays of GrIDS. It shows the progress of a worm attack as it progresses through a network.
The notifier may send electronic mail to the appropriate person or make entries into the appropriate log files.
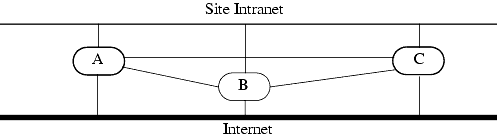
EXAMPLE: The Intrusion Detection and Isolation Protocol (IDIP) [887] provides a basis for coordinating intrusion detection systems residing on firewalls to block attacks over a network. Figure 25-6 shows a site with three firewalls monitoring traffic from the Internet. If intrusion detection systems on hosts A and B detect a coordinated attack, they can inform host C, which can then reject packets from the source(s) of the attack.
Incident response is a type of notification. In addition to any human-intelligible notifications, the intrusion detection system communicates with other entities to counteract the attack. Responses include disconnecting from the network, filtering packets from attacking hosts, increasing the level of logging, and instructing agents to forward information from additional sources.
An intrusion detection system can be organized in several ways. This section explores three such paradigms using research intrusion detection systems. The first system examined network traffic only. The second explored how to combine network and host sources. The third system distributed the director among multiple systems to enhance security and reliability.
The Network Security Monitor (NSM) [459] develops a profile of expected usage of a network and compares current usage with that profile. It also allows the definition of a set of signatures to look for specific sequences of network traffic that indicate attacks. It runs on a local area network and assumes a broadcast medium. The monitor measures network utilization and other characteristics and can be instructed to look at activity based on a user, a group of users, or a service. It reports anomalous behavior.
The NSM monitors the source, destination, and service of network traffic. It assigns a unique connection ID to each connection. The source, destination, and service are used as axes for a matrix. Each element of the matrix contains the number of packets sent over that connection for a specified period of time, and the sum of the data of those packets. NSM also generates expected connection data from the network. The data in the array is “masked” by the expected connection data, and any data not within the expected range is reported as an anomaly.
The developers of the NSM quickly found that too much data was being generated during the network analysis. To reduce the overhead, they constructed a hierarchy of elements of the matrix and generated expected connection data for those elements. If any group in the hierarchy showed anomalous data, the system security officer could ask the NSM to break it down into the underlying elements. The groups were constructed by folding axes of the matrix. For example, one group would be the set of traffic between two hosts for each service. It would have the elements { (A, B, SMTP), (A, B, FTP), … }, where A and B were host names. The next group would collapse the service names and simply group all traffic into source-destination pairs. At the highest level, traffic would be grouped into its source. The NSM would analyze the data at the source level. If it flagged an anomaly, the system security officer could have the NSM examine each component of the underlying group and determine which specific source-destination pair had the anomaly. From there, it could be broken into the specific service or services involved.
The NSM's use of a matrix allowed a simple signature-based scheme to look for known patterns of misuse. For example, repeated telnet connections that lasted only as long as the normal setup time would indicate a failed login attempt. A specific rule could look in the matrix for this occurrence (although, as the designers point out, these patterns can be hidden as one moves up the hierarchy).
The implementation of the NSM also allowed the analyst to write specific rules against which to compare network traffic. The rules initially used were to check for excessive logins, a single host communicating with 15 or more hosts, or any attempt to communicate with a nonexistent host.
The NSM provided a graphical user display to enable the system security officer to see at a glance the state of the network. Furthermore, the display manager was independent of the NSM matrix analyzer, so the latter could devote full time to the analysis of the data. The prototype system, deployed at the University of California at Davis, detected many attacks. As with all intrusion detection systems, it also reported false positives, such as alumni logging into accounts that had laid dormant for some time. But its capabilities revealed the need for and feasibility of monitoring the network as well as individual hosts.
The NSM is important for two reasons. First, it served as the basis for a large number of intrusion detection systems. Indeed, 11 years after its creation, it was still in use at many sites (although with an augmented set of signatures). Second, it proved that performing intrusion detection on networks was practical. As network traffic becomes enciphered, the ability to analyze the contents of the packets diminishes, but NSM did not look at the contents of the traffic. It performed traffic analysis. Hence, its methodology will continue to be effective even after widespread deployment of network encryption.
The Distributed Intrusion Detection System (DIDS) [940] combined the abilities of the NSM with intrusion detection monitoring of individual hosts. It sprang from the observation that neither network-based monitoring nor host-based monitoring was sufficient. An intruder attempting to log into a system through an account without a password would not be detected as malicious by a network monitor. Subsequent actions, however, might make a host-based monitor report that an intruder is present. Similarly, if an attacker tries to telnet to a system a few times, using a different login name each time, the host-based intrusion detection mechanism would not report a problem, but the network-based monitor could detect repeated failed login attempts.
DIDS used a centralized analysis engine (the DIDS director) and required that agents be placed on the systems being monitored as well as in a place to monitor the network traffic. The agents scanned logs for events of interest and reported them to the DIDS director. The DIDS director invoked an expert system that performed the analysis of the data. The expert system was a rule-based system that could make inferences about individual hosts and about the entire system (hosts and networks). It would then pass results to the user interface, which displayed them in a simple, easy-to-grasp manner for the system security officer.
One problem is the changing of identity as an intruder moves from host to host. An intruder might gain access to the first system as user alice, and then to the second system as user bob. The host-based mechanisms cannot know that alice and bob are the same user, so they cannot correlate the actions of those two user names. But the DIDS director would note that alice connected to the remote host and that bob logged in through that connection. The expert system would infer that they were the same user. To enable this type of correlation, each user was identified by a network identification number (NID). In the example above, because alice and bob are the same user, both would share a common NID.
The host agents and network agent provide insight into the problems distributed intrusion detection faces. The host logs are analyzed to extract entries of interest. In some cases, simple reduction is performed to determine if the records should be forwarded; for example, the host agents monitor the system for attacks using signatures. Summaries of these results go to the director. Other events are forwarded directly. To capture this, the DIDS model has host agents report events, which are the information contained in the log entries, and an action and domain (see Figure 25-7). Subjects (such as active processes) perform actions; domains characterize passive entities. Note that a process can be either a subject (as when it changes the protection mode of a file) or an object (as when it is terminated). An object is assigned to the highest-priority domain to which it belongs. For example, a file may be tagged as important. If the file contains authentication data and also is tagged, it will be reported as a tagged object. A hand-built table dictates which events are sent to the DIDS director based on the actions and domains associated with the events. Events associated with the NID are those with session_start actions, and execute actions with network domains. These actions are forwarded so that the DIDS director can update its system view accordingly.

Figure 25-7. DIDS actions and domains. The two left columns name the types of action; the right two, the types of domains. The domains are listed in order of priority, from top to bottom.
The network agent is a simplified version of the NSM. It provides the information described above.
The expert system, a component of the DIDS director, derives high-level intrusion information from the low-level data sent to it. The rule base comes from a hierarchical model of intrusion detection. That model supplies six layers in the reduction procedure.
At this lowest layer, the log records are all visible. They come from the host and the network agent, and from any other sources the DIDS director has.
Here, the events abstract relevant information from the log entries.
This layer defines a subject that captures all events associated with a single user. The NID is assigned to this subject. This layer defines the boundary between machine-dependent information and the abstraction of a user (subject) and associated events.
This layer adds contextual information. Specifically, temporal data such as wall clock time, and spacial data such as proximity to other events, are taken into account. If the user tries to log in at a time when that user has never tried to log in before, or if a series of failed logins follows commands to see who is using a system, the context makes the events suspicious.
This layer deals with network threats, which are combinations of events in context. A threat is abuse if the protection state of the system is changed (for example, making a protected file world-writable). A threat is misuse if it violates policy but does not change the state of the system (for example, copying a world-readable homework file, which is a clear violation of policy at most universities). A threat is a suspicious act if it does not violate policy but is of interest (for example, a finger probe may be a prelude to an attack).
This layer assigns a score, from 1 to 100, representing the security state of the network. This score is derived from the threats to the system developed in layer 5. This is a user convenience, because it enables the system security officer to notice problems quickly. Because the raw data (and intermediate data) used to derive the figure is present, the specifics can be provided quickly.
Within the expert system, each rule has an associated rule value. This value is used to calculate the score. The system security officer gives feedback to the expert system, and if false alarms occur, the expert system lowers the value associated with the rules leading to the false alarm.
A later system, GrIDS, extended DIDS to wide area networks. In addition to monitoring hosts and network traffic, the GrIDS directors could obtain data from network infrastructure systems (such as DNS servers). As mentioned earlier (see Figure 25-5), GrIDS deployed a hierarchy of directors, each one reducing data from its children (agents or other directors) and passing the information to its parent. GrIDS directors can be in different organizations. This leads to the ability to analyze incidents occurring over a wide area, and to coordinate responses.
In 1995, Crosbie and Spafford examined intrusion detection systems in light of fault tolerance [248]. They noted that an intrusion detection system that obtains information by monitoring systems and networks is a single point of failure. If the director fails, the IDS will not function. Their suggestion was to partition the intrusion detection system into multiple components that function independently of one another, yet communicate to correlate information.
Definition 25–10. An autonomous agent is a process that can act independently of the system of which it is a part.
Crosbie and Spafford suggested developing autonomous agents each of which performed one particular monitoring function. Each agent would have its own internal model, and when the agent detected a deviation from expected behavior, a match with a particular rule, or a violation of a specification, it would notify other agents. The agents would jointly determine whether the set of notifications were sufficient to constitute a reportable intrusion.
The beauty of this organization lies in the cooperation of the agents. No longer is there a single point of failure. If one agent is compromised, the others can continue to function. Furthermore, if an attacker compromises one agent, she has learned nothing about the other agents in the system or monitoring the network. Moreover, the director itself is distributed among the agents, so it cannot be attacked in the same way that an intrusion detection system with a director on a single host can be. Other advantages include the specialization of each agent. The agent can be crafted to monitor one resource, making the agent small and simple (and meeting the principle of economy of mechanism; see Section 13.2.3). The agents could also migrate through the local network and process data on multiple systems. Finally, this approach appears to be scalable to larger networks because of the distributed nature of the director.
The drawbacks of autonomous agents lie in the overhead of the communications needed. As the functionality of each agent is reduced, more agents are needed to monitor the system, with an attendant increase in communications overhead. Furthermore, the communications must be secured, as must the distributed computations.
Once an intrusion is detected, how can the system be protected? The field of intrusion response deals with this problem. Its goal is to handle the (attempted) attack in such a way that damage is minimized (as determined by the security policy). Some intrusion detection mechanisms may be augmented to thwart intrusions. Otherwise, the security officers must respond to the attack and attempt to repair any damage.
Ideally, intrusion attempts will be detected and stopped before they succeed. This typically involves closely monitoring the system (usually with an intrusion detection mechanism) and taking action to defeat the attack.
In the context of response, prevention requires that the attack be identified before it completes. The defenders then take measures to prevent the attack from completing. This may be done manually or automatically.
Amoroso [22] points out that multilevel secure systems are excellent places to implement jails, because they provide much greater degrees of confinement than do ordinary systems. The attacker is placed into a security compartment isolated from other compartments. The built-in security mechanisms are designed to limit the access of the subjects in the compartment, thereby confining the attacker.
More sophisticated host-based approaches may be integrated with intrusion detection mechanisms. Signature-based methods enable one to monitor transitions for potential attacks. Anomaly-based methods enable one to monitor relevant system characteristics for anomalies and to react when anomalies are detected in real time.
When an intrusion occurs, the security policy of the site has been violated. Handling the intrusion means restoring the system to comply with the site security policy and taking any actions against the attacker that the policy specifies. Intrusion handling consists of six phases [779].
Preparation for an attack. This step occurs before any attacks are detected. It establishes procedures and mechanisms for detecting and responding to attacks.
Identification of an attack. This triggers the remaining phases.
Containment (confinement) of the attack. This step limits the damage as much as possible.
Eradication of the attack. This step stops the attack and blocks further similar attacks.
Recovery from the attack. This step restores the system to a secure state (with respect to the site security policy).
Follow-up to the attack. This step involves taking action against the attacker, identifying problems in the handling of the incident, and recording lessons learned (or lessons not learned that should be learned).
In the following discussions, we focus on the containment, eradication, and follow-up phases.
Containing or confining an attack means limiting the access of the attacker to system resources. The protection domain of the attacker is reduced as much as possible. There are two approaches: passively monitoring the attack, and constraining access to prevent further damage to the system. In this context, “damage” refers to any action that causes the system to deviate from a “secure” state as defined by the site security policy.
Passive monitoring simply records the attacker's actions for later use. The monitors do not interfere with the attack in any way. This technique is marginally useful. It will reveal information about the attack and, possibly, the goals of the attacker. However, not only is the intruded system vulnerable throughout, the attacker could attack other systems.
The other approach, in which steps are taken to constrain the actions of the attacker, is considerably more difficult. The goal is to minimize the protection domain of the attacker while preventing the attacker from achieving her goal. But the system defenders may not know what the goal of the attacker is, and thus may misdirect the confinement so that the data or resources that the attacker seeks lie within the minimal protection domain of the attacker.
The document that Stoll wrote is an example of a honeypot. The file was carefully designed to entice the attacker to upload it but in fact contained false and meaningless information. This technique can be extended to systems and networks. Honeypots, sometimes called decoy servers, are servers that offer many targets for attackers. The targets are designed to entice attackers to take actions that indicate their goals. Honeypots are also instrumented and closely monitored. When a system detects an attack, it takes actions to shift the attacker onto a honeypot system. The defenders can then analyze the attack without disrupting legitimate work or systems. Two good examples are the Deception Tool Kit and the Honeynet Project.
Eradicating an attack means stopping the attack. The usual approach is to deny access to the system completely (such as by terminating the network connection) or to terminate the processes involved in the attack. An important aspect of eradication is to ensure that the attack does not immediately resume. This requires that attacks be blocked.
A common method for implementing blocking is to place wrappers around suspected targets. The wrappers implement various forms of access control. Wrappers can control access locally on systems or control network access.
Firewalls (see Section 26.3.1) are systems that sit between an organization's internal network and some other external network (such as the Internet). The firewall controls access from the external network to the internal network and vice versa. The advantage of firewalls is that they can filter network traffic before it reaches the target host. They can also redirect network connections as appropriate, or throttle traffic to limit the amount of traffic that flows into (or out of) the internal network.
An organization may have several firewalls on its perimeter, or several organizations may wish to coordinate their responses. The Intruder Detection and Isolation Protocol [887] provides a protocol for coordinated responses to attacks.
The IDIP protocol runs on a set of computer systems. A boundary controller is a system that can block connections from entering a perimeter. Typically, boundary controllers are firewalls or routers. A boundary controller and another system are neighbors if they are directly connected. If they send messages to one another, the messages go directly to their destination without traversing any other system. If two systems are not boundary controllers and can send messages to each other without the messages passing through a boundary controller, they are said to be in the same IDIP domain. This means that the boundary controllers form a perimeter for an IDIP domain.
When a connection passes through a member of an IDIP domain, the system monitors the connection for intrusion attempts. If one occurs, the system reports the attempt to its neighbors. The neighbors propagate information about the attack and proceed to trace the connection or datagrams to the appropriate boundary controllers. The boundary controllers can then coordinate their responses, usually by blocking the attack and notifying other boundary controllers to block the relevant communications.
EXAMPLE: Kahn and Zurko [535] discuss the use of IDIP to handle network flooding attacks, in which one or more sources spew large numbers of packets to a target. This effectively prevents legitimate traffic from being processed, either because the target is overwhelmed with processing the flooding packets or because the legitimate traffic cannot reach the destination (target).
Consider Figure 25-8. Suppose host f launches a flooding attack against host A along the path f, Z, Y, X, W, a, A. The flood effectively stops all traffic along that path. Host a detects the flood and begins blocking traffic for host A. It also notifies its neighbor W, a boundary controller. W detects traffic targeting A, suppresses it, and notifies its neighbor X. X detects the traffic targeting A, suppresses it, and notifies its neighbors Y and C. W then notices the traffic for A has stopped, and it eliminates its suppression. At this point, A, a, W, and b can again communicate freely, because the traffic formerly saturating the links has been eliminated by X. C detects no traffic for A and so does nothing. Y does detect the traffic, and suppresses it. X detects that the traffic going through it for A has stopped, and X eliminates its suppression. Y then communicates with Z, and Z detects and suppresses the traffic. Y also communicates with D, which detects no relevant traffic. This process continues until all traffic from f to A is suppressed.
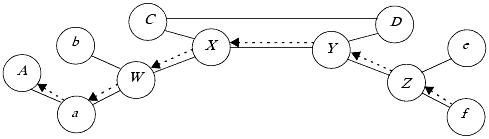
Figure 25-8. Example of IDIP. C, D, W, X, Y, and Z are boundary controllers. Host a runs the IDIP protocol but is not a boundary controller. The flooding attack follows the dashed arrows from f to A.
The IDIP protocol is flexible, because if multiple sources attempt to flood a host, the boundary controllers will block the traffic along each path that the sources use. Of course, if any path has no IDIP controllers, the traffic can flow freely along that path. Kahn and Zurko suggest that IDIP, or a similar protocol, should be widely deployed throughout the Internet to handle flooding attacks. They argue that economic and other incentives will encourage Internet Service Providers and other network providers to cooperate in suppressing distributed flooding attacks.
In the follow-up phase, the systems take some action external to the system against the attacker. The most common follow-up is to pursue some form of legal action, either criminal or civil. The requirements of the law vary among communities, and indeed vary within communities over time. So, for our purposes, we confine ourselves to the technical issue of tracing the attack through a network. Two techniques for tracing are thumbprinting and IP header marking.
Thumbprinting [460, 964] takes advantage of connections passing through several hosts. An attacker may go from one host, through many intermediate hosts, until he attacks his target. If one monitors the connections at any two hosts that the connections pass through, the contents of the connections will be the same (excluding data added at the lower layers). By comparing contents of connections passing through hosts, one can construct the chain of hosts making up the connections.
Staniford-Chen and Heberlein [964] list five characteristics of a good thumbprint.
The thumbprint should take as little space as possible, to minimize storage requirements at each site.
If two connections have different contents, the probability that their thumbprints are the same should be low. Notice that two connections with identical contents will have the same thumbprint. This is a consequence of the thumbprint being computed over the contents of the connection.
The thumbprint should be affected minimally by common errors in transmission. Thus, if traffic between two hosts often has some bits discarded, the thumbprints of the connections at both hosts should be close enough to identify them as belonging to the same connection. (Recall that thumbprints are computed passively, and that the thumbprinting program may not have access to the error correction features of TCP.)
Thumbprints should be additive so that two thumbprints over successive intervals can be combined into a single thumbprint for the total interval.
Finally, thumbprints should cost little to compute and compare.
There are several possible sources of error (see Exercise 8).
An alternative approach is to ignore the contents of the packets and examine the headers. IP header marking does just this. A router places extra information into the IP header of each packet to indicate the path that the packet has taken. This information may be examined in order to to trace the packet's route back through the Internet [880].
The keys to IP header marking are selection of the packets to mark, and marking of the packets. Packet selection may be deterministic or probabilistic. Packet marking may be internal or expansive.
Deterministic packet selection means that packets are selected on the basis of a deterministic, nonrandom algorithm. For example, every second packet may have the router's IP address inserted as the marking. In general, deterministic packet selection is too expensive and unreliable. It is unreliable because an attacker can enter false data into the header area and prevent the marking (see Exercise 10). In probabilistic packet selection, packets are selected with some given probability.
Internal packet marking places the router's marking in the packet header without expanding it. For example, Dean, Franklin, and Stubblefield [263] have identified several bits in an IPv4 header that could be used for marking. Expansive packet marking means that the packet header is expanded to include extra space for the marking.
EXAMPLE: Doeppner, Klein, and Koyfman [305] suggest a probabilistic, expansive packet marking scheme. They propose adding space (“slots”) for s markings. The probability that a packet will be marked is p. The following algorithm describes how the router handles an incoming packet.
/* generate random number between 0, 1 */ x = random(0, 1); /* stamp the packet appropriately */ if x < s * p then slot[x/p] = router's stamp;
Note that the slot into which the router's marking is placed depends on the random number generated.
The markings can enable one to trace certain attacks back to their sources. As an example, consider the SYN flood attack [255], in which an attacker generates a large number of TCP SYN packets (see Section 26.4). The target receives them and sends the SYN/ACK packet in the second step of the three-way handshake (see Section 24.4.2). The attacker never sends the third packet, so the connection is pending until it times out. At that point, the target grabs the next incoming SYN packet and repeats the cycle. Because the attacker is flooding the target with SYN packets, the probability of any other host's SYN packet initiating the three-way handshake is very low. The attack therefore denies service to all other hosts.
Consider the network in Figure 25-9. Host E experiences a SYN flood. The administrators identify 3,150 packets that could be a result of the attack. Of these packets, 600 have the route (A, B, D), 200 have the route (A, D), 150 have the route (B, D), 1,500 have the route (D), 400 have the route (A, C), and 300 have the route (C). Counting, there are 1,200 packets with A's mark, 750 with B's mark, 700 with C's mark, and 2,450 with D's mark. Assuming that the probability of marking is the same on each router, the number of packets that D received is more than three times as great as the number that B received. Thus, B is probably the source of the flooding.
Counterattacking, or attacking the attacker, takes two forms. The first form involves legal mechanisms, such as filing criminal complaints. This requires protecting a “chain of evidence” so that legal authorities can establish that the attack was real (in other words, that the attacked site did not invent evidence) and that the evidence can be used in court. The precise requirements of the law change over time and jurisdictions, so this first form of counterattacking lies outside the scope of this discussion. The second form is a technical attack, in which the goal is to damage the attacker seriously enough to stop the current attack and discourage future attacks. This approach has several important consequences that must be considered.
The counterattack may harm an innocent party. The attacker may be impersonating another site. In this case, the counterattack could damage a completely innocent party, putting the counterattackers in the same position as the original attackers. Alternately, the attackers may have broken into the site from which the attack was launched. Attacking that host does not solve the problem. It merely eliminates one base from which future attacks might be launched.
The counterattack may have side effects. For example, if the counterattack consists of flooding a specific target, the flood could block portions of the network that other parties need to transit, which would damage them.
The counterattack is antithetical to the shared use of a network. Networks exist to share data and resources and provide communication paths. By attacking, regardless of the reason, the attackers make networks less usable because they absorb resources and make threats more immediate. Hence, sites must protect themselves by limiting the sharing and communication on the network beyond what is needed for their safe operation.
The counterattack may be legally actionable. If an attacker can be prosecuted or sued, it seems reasonable to assume that one who responds to the attack by counterattacking can also be prosecuted or sued, especially if other innocent parties are damaged by the counterattack.
Under exceptional circumstances, counterattacking may be appropriate. In general, it should be avoided, and legal avenues of prosecution (either civil or criminal) should be pursued. Improving defenses will also hinder attacks. The efforts used to develop and launch counterattacks could be spent far more effectively in that way.
Intrusion detection is a form of auditing that looks for break-ins and attacks. Automated methods aid in this process, although it can be done manually. There are three basic models of intrusion detection.
Anomaly detection looks for unexpected behavior. A baseline of expected actions or characteristics of processes, users, or groups of users is developed. Whenever something deviates from that baseline, it is reported as a possible intrusion. In some cases, the profiles are changed over time. In this way, the expected behavior of users is updated as their actual behavior changes over time.
Misuse detection looks for sequences of events known to indicate attacks. A rule set (or database) of attacks provides the requisite information. Ideally, an expert system will use the rule set to detect previously unknown attacks (but efforts of this type have been singularly unsuccessful). Both state-based and transition-based techniques capture the sequence of events in attacks.
Specification-based detection looks for actions outside the specifications of key programs. Each program has a set of rules specifying what actions it is allowed to take. If the program tries to take any other action, the intrusion detection mechanism reports a probable intrusion. This method requires that specifications for programs be written.
Intrusion detection systems are auditing engines, so models of auditing systems can describe their architecture. The director, or analysis engine, may be centralized or distributed, and may be hierarchical or fragmented. Each organization has advantages and disadvantages, but for wide area networks, a distributed director provides the greatest flexibility and power. Information may be gathered from hosts, from the network, from both, or from other directors.
When an intrusion occurs, some response is appropriate. If the intrusion attempt is detected before the attack is successful, the system can take action to prevent the attack from succeeding. Otherwise, the intrusion must be handled. Among the steps involved are confinement of the attack to limit its effectiveness, eradication to eliminate the attacking processes or connections, and follow-up to take action against the attacker as well as learn from the attack.
Models of intrusion detection are being studied. In particular, techniques for developing profiles of expected behavior that allow deviations to be quickly determined would improve the state of anomaly detection, such as mechanisms that learn program or user behavior or mechanisms allowing for rapid adaptation of profiles. The acme of misuse detection would be to develop methods of detecting previously unseen attacks. Research on attack taxonomies and attack languages provides a better understanding of how attacks work. Vulnerabilities analysis is another approach that is compatible with research on attacks.
The architecture of a wide area intrusion detection system is critical to successful deployment. Technical problems abound. Should the director be distributed or centralized? Should intrusion detection systems be organized hierarchically? How can existing security tools be integrated into an intrusion detection system? Cooperation among intrusion detection systems would allow different organizations to work together to detect, ameliorate, and possibly trace attacks. Several techniques for enabling communication among such systems are under study.
Related to communication is the data processing required to analyze large amounts of data from distributed agents and directors. Intrusion detection agents can gather large amounts of data, and when this data is combined with output from other agents, storing, sending, and processing the data becomes difficult. The layering methodology GrIDS lessens the amount of raw data that the higher-level directors need, but at lower levels the problem persists. Unless the hierarchy involves few directors, the problem can exist even when the abstractions are used. Data mining may be useful for this problem.
If end-to-end encryption becomes pervasive, intrusion detection techniques that rely on analysis of unencrypted network traffic will become less useful, and intrusion detection mechanisms will move to the endpoints. Similarly, if link level encryption becomes widely used, intrusion detection will take place at the intermediate hosts. How this will impact the organization, efficiency, and effectiveness of intrusion detection systems is not fully understood.
The most technically exacting area of research is testing of intrusion detection systems. Determining the rate of false negatives is difficult unless the data has been thoroughly analyzed before the test by people other than the designers (and, even then, the analysts may miss attacks). Furthermore, comparison of intrusion detection systems requires an understanding of the policies that each intrusion detection system assumes, as well as development of a basis for comparison. These areas will grow in importance as the need to determine efficiency with respect to various metrics increases.
Privacy issues pervade intrusion detection. In particular, how does one ensure that the data being analyzed does not reveal information about nonattackers? The data can be sanitized, but sanitization risks elimination of data that the intrusion detection system needs in order to detect intrusions. Moreover, if different organizations decide to cooperate, how can each organization sanitize the data that it wishes to keep private? Although the heart of these questions is nontechnical, their resolution is central to maintaining people's trust in the system and the security mechanisms. The technologies used to protect individuals and organizations raise sublime technical questions.
In order to pursue culprits, a site must have evidence that will satisfy a court or a jury that a tort (or crime) has been committed and that the accused is guilty, but the legal rules for collecting and handling evidence must be followed if the evidence is to be admissible in court. An area of active research is the development of intrusion detection systems, methodologies, and procedures that will supply evidence of this caliber.
Several books describe intrusion detection in detail. Bace [52] provides a wonderful overview with much historical information. Amoroso [22] presents a technical introduction. Northcutt [780] gives a practitioner's overview. Cooper, Northcutt, Fearnow, and Frederick [233] discuss intrusion detection and analysis, again from a practitioner's viewpoint. Proctor [821] presents both managerial and technical information.
Helman and Liepins [466] discuss the statistical foundations of intrusion detection. Immunological approaches to intrusion detection distinguish between normal and abnormal program behavior [291, 366, 368, 949]. Other approaches abound [264, 611, 620, 705]. Sekar, Bowen, and Segal [902] discuss the use of specification-based detection for automated response at the system call level. Badger discusses the relationship among wrappers, reference monitors, and trusted systems [53].
Several papers have been written about testing of intrusion detection systems [313, 377, 638, 639, 677, 823]. Axelsson [49] discusses the relationship between false positives and false negatives. Ptacek and Newsham [822] discuss how attackers might evade detection. Securing of mobile agents arises in many contexts [423, 1011].
Techniques for response are varied. Some are technical [339, 1067], whereas others are procedural and legal and involve special response teams [15, 356, 382, 507, 1010].
Sobirey, Fischer-Hübner, and Rannenberg raise the issue of privacy in an intrusion detection context [945]. Others have analyzed this problem and suggested approaches [120, 646].
1: | You have been hired as the security officer for Compute Computers, Inc. Your boss asks you to determine the number of erroneous login attempts that should be allowed before a user's account is locked. She is concerned that too many employees are being locked out of their accounts unnecessarily, but is equally concerned that attackers may be able to guess passwords. How would you determine an appropriate value for the threshhold? |
2: | Why should the administrator (or the superuser) account never be locked regardless of how many incorrect login attempts are made? What should be done instead to alert the staff to the attempted intrusion, and how could the chances of such an attack succeeding be minimized? |
3: | Consider the trace-based approach to anomaly-based intrusion detection. An intrusion detection analyst reports that a particular pattern of system usage results in processes with “low entropy,” meaning that there is little uncertainty about how the system processes behave. How well would a cluster-based analysis mechanism for anomaly-based intrusion detection work with this system? Justify your answer. |
4: | Use a Colored Petri Automaton (see Section 25.3.2) to describe the xterm attack discussed in Section 23.3.1. |
5: | One view of intrusion detection systems is that they should be of value to an analyst trying to disprove that an intrusion has taken place. Insurance companies and lawyers, for example, would find such evidence invaluable in assessing liability. Consider the following scenario. A system has both classified and unclassified documents in it. Someone is accused of using a word processing program to save an unclassified copy of a classified document. Discuss if, and how, each of the three forms of intrusion detection mechanisms could be used to disprove this accusation. |
6: | GrIDS uses a hierarchy of directors to analyze data. Each director performs some checks, then creates a higher-level abstraction of the data to pass to the next director in the hierarchy. AAFID distributes the directors over multiple agents. Discuss how the distributed director architecture of AAFID could be combined with the hierarchical structure of the directors of GrIDS. What advantages would there be in distributing the hierarchical directors? What disadvantages would there be? |
7: | As encryption conceals the contents of network messages, the ability of intrusion detection systems to read those packets decreases. Some have speculated that all intrusion detection will become host-based once all network packets have been encrypted. Do you agree? Justify your answer. In particular, if you agree, explain why no information of value can be gleaned from the network; if you disagree, describe the information of interest. |
8: | This exercise asks you to consider sources of errors in thumbprints (see Section 25.6.2.3). Recall that a thumbprint is computed from the contents of a connection over some interval of time. Consider clocks on two different computers. Initially, they are synchronized. After some period of time has passed, the clocks will show different times. This is called clock skew.
|
9: | Consider how enciphering of connections would affect thumbprinting.
|
10: | This exercise examines deterministic packet selection (see Section 25.6.2.3). Assume that the packet header contains spaces for routers to enter their IP addresses.
|
11: | Consider the “counterworm” in the example on that begins on page 764.
|
[1] Rootkit continues to evolve both in doctored programs and in sophistication. At the time of publication, some versions used dynamically loadable kernel modules.
[2] If a kernel module is involved, any program using this interface will also return bogus information. Programs that read directly from memory or the disk will not.
[3] Unless the network device is in promiscuous mode, the network sniffer can record only packets intended for the host on which the sniffer resides.
[4] Intrusion detection systems may simply log traffic for later analysis. In this case, they are logging engines rather than intrusion detection mechanisms (see Section 24.2.1).