
BOTTOM: Masters, I am to discourse wonders: butask me not what; for if I tell you, I am no trueAthenian. I will tell you every thing, right as itfell out. | ||
| --A Midsummer Night's Dream, IV, ii, 30–33. | ||
Although access controls can constrain the rights of a user, they cannot constrain the flow of information about a system. In particular, when a system has a security policy regulating information flow, the system must ensure that the information flows do not violate the constraints of the policy. Both compile-time mechanisms and runtime mechanisms support the checking of information flows. Several systems implementing these mechanisms demonstrate their effectiveness.
Information flow policies define the way information moves throughout a system. Typically, these policies are designed to preserve confidentiality of data or integrity of data. In the former, the policy's goal is to prevent information from flowing to a user not authorized to receive it. In the latter, information may flow only to processes that are no more trustworthy than the data.
Any confidentiality and integrity policy embodies an information flow policy.
Let x be a variable in a program. The notation x refers to the information flow class of x.
We now define precisely the notion of information flow. Intuitively, information flows from an object x to an object y if the application of a sequence of commands c causes the information initially in x to affect the information in y. We use the notion of entropy, or uncertainty (see Chapter 32, “Entropy and Uncertainty”), to formalize this concept.
Let c be a sequence of commands taking a system from state s to another state t. Let x and y be objects in the system. We assume that x exists when the system is in state s and has the value xs. We require that y exist in state t and have the value yt. If y exists in state s, it has value ys.
Definition 16–1. The command sequence c causes a flow of information from x to y if H(xs | yt) < H(xs | ys). If y does not exist in s, then H(xs | ys) = H(xs).
This definition states that information flows from the variable x to the variable y if the value of y after the commands allows one to deduce information about the value of x before the commands were run.
This definition views information flow in terms of the information that the value of y allows one to deduce about the value in x. For example, the statement
y := x;
reveals the value of x in the initial state, so H(xs | yt) = 0 (because given the value yt, there is no uncertainty in the value of xs). The statement
y := x / z;
reveals some information about x, but not as much as the first statement.
The final result of the sequence c must reveal information about the initial value of x for information to flow. The sequence
tmp := x; y := tmp;
has information flowing from x to y because the (unknown) value of x at the beginning of the sequence is revealed when the value of y is determined at the end of the sequence. However, no information flow occurs from tmp to x, because the initial value of tmp cannot be determined at the end of the sequence.
Definition 16–2. An implicit flow of information occurs when information flows from x to y without an explicit assignment of the form y := f(x), where f(x) is an arithmetic expression with the variable x.
The flow of information occurs, not because of an assignment of the value of x, but because of a flow of control based on the value of x. This demonstrates that analyzing programs for assignments to detect information flows is not enough. To detect all flows of information, implicit flows must be examined.
An information flow policy is a security policy that describes the authorized paths along which that information can flow. Part 3, “Policy,” discussed several models of information flow, including the Bell-LaPadula Model, nonlattice and nontransitive models of information flow, and nondeducibility and noninterference. Each model associates a label, representing a security class, with information and with entities containing that information. Each model has rules about the conditions under which information can move throughout the system.
In this chapter, we use the notation x ≤ y to mean that information can flow from an element of class x to an element of class y. Equivalently, this says that information with a label placing it in class x can flow into class y.
Earlier chapters usually assumed that the models of information flow policies were lattices. We first consider nonlattice information flow policies and how their structures affect the analysis of information flow. We then turn to compiler-based information flow mechanisms and runtime mechanisms. We conclude with a look at flow controls in practice.
Denning [267] identifies two requirements for information flow policies. Both are intuitive. Information should be able to flow freely among members of a single class, providing reflexivity. If members of one class can read information from a second class, they can save the information in objects belonging to the first class. Then, if members of a third class can read information from the first class, they can read the contents of those objects and, effectively, read information from the second class. This produces transitivity. The Bell-LaPadula Model exhibits both characteristics. For example, Cathy dom Betty, and Betty dom Anne, then Cathy dom Anne.
However, in some circumstances, transitivity is undesirable.
If information flow throughout a system is not transitive, then Denning's lattice model of information flow cannot represent the system. But such systems exist, as pointed out above. Lattices may not even model transitive systems.
We generalize the notion of a confidentiality policy. An information flow policy I is a triple I = (SCI, ≤I, joinI), where SCI is a set of security classes, ≤I is an ordering relation on the elements of SCI, and joinI combines two elements of SCI.
We now present a model of information flow that does not require transitivity and apply it to two cases in which the information flow relations do not form a lattice. In the first case, the relations are transitive; in the second, they are not.
Foley [362] presented a model of confinement flow. Assume that an object can change security classes; for example, a variable may take on the security classification of its data. Associate with each object x a security class x.
Definition 16–3. [362] The confinement flow model is a 4-tuple (I, O, confine, →) in which I = (SCI, ≤I, joinI) is a lattice-based information flow policy; O is a set of entities; →: O × O is a relation with (a, b) ∊ → if and only if information can flow from a to b; and, for each a ∊ O, confine(a) is a pair (aL, aU) ∊ SCI × SCI, with aL ≤ IaU, and the interpretation that for a ∊ O, if x ≤ aU, information can flow from x to a, and if aL ≤ x, information can flow from a to x.
This means that aL is the lowest classification of information allowed to flow out of a, and aU is the highest classification of information allowed to flow into a.
The security requirement for an information flow model requires that if information can flow from a to b, then b dominates a under the ordering relation of the lattice. For the confinement flow model, this becomes
(∀ a, b ∊ O)[ a → b ⇒ aL ≤I bU ]
This model exhibits weak tranquility. It also binds intervals of security classes, rather than a single security class (as in the Bell-LaPadula Model). The lattice of security classes induces a second lattice on these intervals (see Exercise 2).
Consider a company in which line managers report income to two different superiors—a business manager and an auditor. The auditor and the business manager are independent. Thus, information flows from the workers to the line managers, and from the line managers to the business manager and the auditor. This model is reflexive (because information can flow freely among entities in the same class) and transitive (because information can flow from the workers to the business manager and auditor). However, there is no way to combine the auditor and the business manager, because there is no “superior” in this system. Hence, the information flow relations do not form a lattice. Figure 16-1 captures this situation.
Definition 16–4. A quasi-ordered set Q = (SQ, ≤Q) is a set SQ and a relation ≤Q defined on SQ such that the relation is both reflexive and transitive.
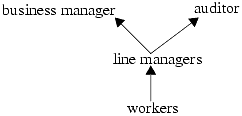
Figure 16-1. An example of a nonlattice information flow policy. Because the business manager and the auditor are independent, they have no least upper bound. Hence, the structure is not a lattice.
The company described above forms a quasi-ordered set. Handling the information flow now becomes a matter of defining a lattice that includes the quasi-ordered set. For all x ∊ SQ, let f(x) = { y | y ∊ SQ ∧ y ≤Q x }. Define the set SQP = { f(x) | x ∊ SQ } and the relation ≤QP = { (x, y) | x, y ∊ SQP ∧ x ⊆ y }. Then SQP is a partially ordered set under ≤QP. f preserves ordering, so x ≤Q y if and only if f(x) ≤ QP f(y).
Denning [267] describes how to turn a partially ordered set into a lattice. Add the sets SQ and Ø to the set SQP. Define ub(x, y) = { z | z ∊ SQP ∧ x ⊆ z ∧ y ⊆ z } (here, ub stands for “upper bound,” which contains all sets containing all elements of both x and y). Then define lub(x, y) = ∩ ub(x, y). Define the lower bound lb(x, y), and the greatest lower bound glb(x, y) similarly. The structure (SQP ∪ {SQ, Ø}, ≤QP) is now a lattice.
At this point, the information flow policy simply emulates that of the containing lattice.
Foley [362] has considered the problem of modeling nontransitive systems. He defines a procedure for building lattices from such systems. His procedure adds entities and relations to the model, but the procedure keeps the nontransitive relationships of the original entities and relations intact.
EXAMPLE: A government agency has the policy shown in Figure 16-2. It involves three types of entities: public relations officers (PRO), who need to know more than they can say publicly; analysts (A); and spymasters (S). The accesses of the three types of entities are confined to certain types of data, as follows.
confine(PRO) = [public, analysis]
confine(A) = [analysis, top-level]
confine(S) = [covert, top-level]
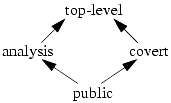
Figure 16-2. An example of a government agency information flow policy. Public information is available to all. All other types of information are restricted, with analysis data and covert data (about secret missions) being distinct types of data. Top-level data is synthesized from both covert and analysis data.
According to the confinement flow model, PRO ≤ A, A ≤ PRO, PRO ≤ S, A ≤ S, and S ≤ A. But covert data cannot flow to the public relations officers; S ≤ A and A ≤ PRO do not imply S ≤ PRO. The system is not transitive.
Government (and private) agencies often use procedures to insulate public relations officers from data that is not to be leaked. Although the agency may trust the public relations officers, people make mistakes, and what the officers don't know, they cannot accidentally blurt out. So the example is realistic.
Definition 16–5. Let R = (SCR, ≤R, joinR) represent a reflexive information flow policy. A dual mapping (lR(x), hR(x)) maps R to an ordered set P = (SP , ≤P):
lR: SCR → SP with lR(x) = { x }
hR: SCR → SP with hR(x) = { y | y ∊ SP ∧ y ≤R x }
The relation ≤P indicates “subset,” and the elements in SP are the set of subsets of SCR. The dual mapping is called order preserving if and only if
(∀a, b ∊ SCR) [a ≤R b ⇔ lR(a) ≤P hR(b) ]
The set SP formed by the dual mapping of a reflexive information flow policy is a (possibly improper) subset of the power set of SCR. It is a partially ordered set. Denning's procedure, discussed above, can transform this into a lattice. Hence, without loss of generality, we can assume that the set P = (SP , ≤P) is a lattice.
An order-preserving dual mapping preserves the ordering relation under the transformation. It also preserves nonorderings and hence nontransitivity. We now have:
Theorem 16–1. A dual mapping from a reflexive information flow policy R to an ordered set P is order-preserving.
Proof. Let R = (SCR, ≤R, joinR) be an information flow policy and let P = (SP , ≤P) be an ordered set. Let (lR(x), hR(x)) be the dual mapping from R to SP . Let a, b ∊ SCR.
(⇒) Let a ≤R b. By Definition 16–5, a ∊ lR(a) and a ∊ hR(b). Thus, lR(a) ⊆ hR(b), or lR(a) ≤P hR(b), as claimed.
(⇐) Let lR(a) ≤P hR(b). By Definition 16–5, lR(a) ⊆ hR(b). Because lR(a) = { a }, this means that a ∊ hR(b). Thus, a ∊ SP and a ≤R b, as claimed.
We can now interpret the information flow policy requirements. Let
confine(x) = [ xL, xU ]
and consider class y. Then information can flow from x to an element of y if and only if xL ≤R y, or lR(xL) ⊆ hR(y). Information can flow from an element of y to x if and only if y ≤RxU, or lR(y) ⊆ hR(xU).
Nonlattice policies can be embedded into lattices. Hence, analysis of information flows may proceed without loss of generality under the assumption that the information flow model is a lattice.
Compiler-based mechanisms check that information flows throughout a program are authorized. The mechanisms determine if the information flows in a program could violate a given information flow policy. This determination is not precise, in that secure paths of information flow may be marked as violating the policy; but it is secure, in that no unauthorized path along which information may flow will be undetected.
Definition 16–6. A set of statements is certified with respect to an information flow policy if the information flow within that set of statements does not violate the policy.
For our discussion, we assume that the allowed flows are supplied to the checking mechanisms through some external means, such as from a file. The specifications of allowed flows involve security classes of language constructs. The program involves variables, so some language construct must relate variables to security classes. One way is to assign each variable to exactly one security class. We opt for a more liberal approach, in which the language constructs specify the set of classes from which information may flow into the variable. For example,
x: integer class { A, B }
states that x is an integer variable and that data from security classes A and B may flow into x. Note that the classes are statically, not dynamically, assigned. Viewing the security classes as a lattice, this means that x's class must be at least the least upper bound of classes A and B—that is, lub{A, B} ≤ x.
Two distinguished classes, Low and High, represent the greatest lower bound and least upper bound, respectively, of the lattice. All constants are of class Low.
Information can be passed into or out of a procedure through parameters. We classify parameters as input parameters (through which data is passed into the procedure), output parameters (through which data is passed out of the procedure), and input/output parameters (through which data is passed into and out of the procedure).
(* input parameters are named is; output parameters, os; *) (* and input/output parameters, ios, with s a subscript *) proc something(i1, ..., ik; var o1, ..., om, io1, ..., ion); var l1, ..., lj; (* local variables *) begin S; (* body of procedure *) end;
The class of an input parameter is simply the class of the actual argument:
is: type class { is }
Because information can flow from any input parameter to any output parameter, the declaration must capture this:
os: type class { i1, ..., ik, io1, ..., iok }
(We implicitly assume that any output-only parameter is initialized in the procedure.) The input/output parameters are like output parameters, except that the initial value (as input) affects the allowed security classes:
ios: type class { i1, ..., ik, io1, ..., iok }
The declarations presented so far deal only with basic types, such as integers, characters, floating point numbers, and so forth. Nonscalar types, such as arrays, records (structures), and variant records (unions) also contain information. The rules for information flow classes for these data types are built on the scalar types.
Consider the array
a: array 1 .. 100 of int;
First, look at information flows out of an element a[i] of the array. In this case, information flows from a[i] and from i, the latter by virtue of the index indicating which element of the array to use. Information flows into a[i] affect only the value in a[i], and so do not affect the information in i. Thus, for information flows from a[i], the class involved is lub{ a[i], i }; for information flows into a[i], the class involved is a[i].
A program consists of several types of statements. Typically, they are
Assignment statements
Compound statements
Conditional statements
Iterative statements
Goto statements
Procedure calls
Function calls
Input/output statements.
We consider each of these types of statements separately, with two exceptions. Function calls can be modeled as procedure calls by treating the return value of the function as an output parameter of the procedure. Input/output statements can be modeled as assignment statements in which the value is assigned to (or assigned from) a file. Hence, we do not consider function calls and input/output statements separately.
An assignment statement has the form
y := f(x1, ..., xn)
where y and x1, ..., xn are variables and f is some function of those variables. Information flows from each of the xi's to y. Hence, the requirement for the information flow to be secure is
lub{x1, ..., xn} ≤ y
A compound statement has the form
begin S1; ... Sn; end;
where each of the Si's is a statement. If the information flow in each of the statements is secure, then the information flow in the compound statement is secure. Hence, the requirements for the information flow to be secure are
S1 secure
...
Sn secure
A conditional statement has the form
if f(x1, ..., xn) then S1; else S2; end;
where x1, …, xn are variables and f is some (boolean) function of those variables. Either S1 or S2 may be executed, depending on the value of f, so both must be secure. As discussed earlier, the selection of either S1 or S2 imparts information about the values of the variables x1, ..., xn, so information must be able to flow from those variables to any targets of assignments in S1 and S2. This is possible if and only if the lowest class of the targets dominates the highest class of the variables x1, ..., xn. Thus, the requirements for the information flow to be secure are
S1 secure
S2 secure
lub{x1, ..., xn} ≤ glb{ y | y is the target of an assignment in S1 and S2 }
As a degenerate case, if statement S2 is empty, it is trivially secure and has no assignments.
An iterative statement has the form
while f(x1, ..., xn) do S;
where x1, ..., xn are variables and f is some (boolean) function of those variables. Aside from the repetition, this is a conditional statement, so the requirements for information flow to be secure for a conditional statement apply here.
To handle the repetition, first note that the number of repetitions causes information to flow only through assignments to variables in S. The number of repetitions is controlled by the values in the variables x1, ..., xn, so information flows from those variables to the targets of assignments in S—but this is detected by the requirements for information flow of conditional statements.
However, if the program never leaves the iterative statement, statements after the loop will never be executed. In this case, information has flowed from the variables x1, ..., xn by the absence of execution. Hence, secure information flow also requires that the loop terminate.
Thus, the requirements for the information flow to be secure are
Iterative statement terminates
S secure
lub{x1, ..., xn} ≤ glb{ y | y is the target of an assignment in S }
A goto statement contains no assignments, so no explicit flows of information occur. Implicit flows may occur; analysis detects these flows.
Definition 16–7. A basic block is a sequence of statements in a program that has one entry point and one exit point.
Control within a basic block flows from the first line to the last. Analyzing the flow of control within a program is therefore equivalent to analyzing the flow of control among the program's basic blocks. Figure 16-3 shows the flow of control among the basic blocks of the body of the procedure transmatrix.
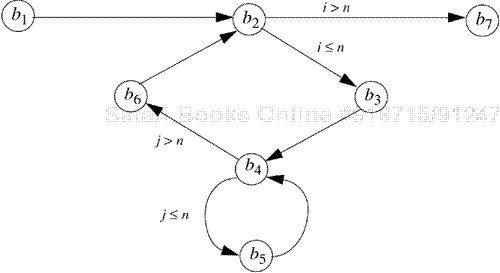
Figure 16-3. The control flow graph of the procedure transmatrix. The basic blocks are labeled b1 through b7.The conditions under which branches are taken are shown over the edges corresponding to the branches.
When a basic block has two exit paths, the block reveals information implicitly by the path along which control flows. When these paths converge later in the program, the (implicit) information flow derived from the exit path from the basic block becomes either explicit (through an assignment) or irrelevant. Hence, the class of the expression that causes a particular execution path to be selected affects the required classes of the blocks along the path up to the block at which the divergent paths converge.
Definition 16–8. An immediate forward dominator of a basic block b (written IFD(b)) is the first block that lies on all paths of execution that pass through b.
Computing the information flow requirement for the set of blocks along the path is now simply applying the logic for the conditional statement. Each block along the path is taken because of the value of an expression. Information flows from the variables of the expression into the set of variables assigned in the blocks. Let Bi be the set of blocks along an execution path from bi to IFD(bi), but excluding these endpoints. (See Exercise 6.) Let xi1, ..., xin be the set of variables in the expression that selects the execution path containing the blocks in Bi. The requirements for the program's information flows to be secure are
All statements in each basic block secure
lub{xi1, ..., xin} ≤ glb{ y | y is the target of an assignment in Bi }
A procedure call has the form
proc procname(i1, ..., im : int; var o1, ..., on : int); begin S; end;
where each of the ij's is an input parameter and each of the oj's is an input/output parameter. The information flow in the body S must be secure. As discussed earlier, information flow relationships may also exist between the input parameters and the output parameters. If so, these relationships are necessary for S to be secure. The actual parameters (those variables supplied in the call to the procedure) must also satisfy these relationships for the call to be secure. Let x1, ..., xm and y1, ..., yn be the actual input and input/output parameters, respectively. The requirements for the information flow to be secure are
S secure
For j = 1, ..., m and k = 1, ..., n, if ij ≤ ok then xj ≤ yk
For j = 1, ..., n and k = 1, ..., n, if oj ≤ ok then yj ≤ yk
Exceptions can cause information to flow.
If exceptions are handled explicitly, the compiler can detect problems such as this. Denning again supplies such a solution.
Denning also notes that infinite loops can cause information to flow in unexpected ways.
Of the many concurrency control mechanisms that are available, we choose to study information flow using semaphores [298]. Their operation is simple, and they can be used to express many higher-level constructs [148, 805]. The specific semaphore constructs are
wait(x): if x = 0 then block until x > 0; x := x - 1; signal(x): x := x + 1;
where x is a semaphore. As usual, the wait and the signal are indivisible; once either one has started, no other instruction will execute until the wait or signal finishes.
Reitman and his colleagues [34, 836] point out that concurrent mechanisms add information flows when values common to multiple processes cause specific actions. For example, in the block
begin wait(sem); x := x + 1; end;
the program blocks at the wait if sem is 0, and executes the next statement when sem is nonzero. The earlier certification requirement for compound statements is not sufficient because of the implied flow between sem and x. The certification requirements must take flows among local and shared variables (semaphores) into account.
Let the block be
begin S1; ... Sn; end;
Assume that each of the statements S1, ..., Sn is certified. Semaphores in the signal do not affect information flow in the program in which the signal occurs, because the signal statement does not block. But following a wait statement, which may block, information implicitly flows from the semaphore in the wait to the targets of successive assignments.
Let statement Si be a wait statement, and let shared(Si) be the set of shared variables that are read (so information flows from them). Let g(Si) be the greatest lower bound of the targets of assignments following Si. A requirement that the block be secure is that shared(Si) ≤ g(Si). Thus, the requirements for certification of a compound statement with concurrent constructs are
S1 secure
...
Sn secure
For i = 1, ..., n [ shared(Si) ≤ g(Si) ]
Loops are handled similarly. The only difference is in the last requirement, because after completion of one iteration of the loop, control may return to the beginning of the loop. Hence, a semaphore may affect assignments that precede the wait statement in which the semaphore is used. This simplifies the last condition in the compound statement requirement considerably. Information must be able to flow from all shared variables named in the loop to the targets of all assignments. Let shared(Si) be the set of shared variables read, and let t1, ..., tm be the targets of assignments in the loop. Then the certification conditions for the iterative statement
while f(x1, ..., xn) do S;
are
Iterative statement terminates
S secure
lub{x1, ..., xn} ≤ glb{ t1, ..., tm }
lub{shared(S1), ,,,, shared(Sn) } ≤ glb{ t1, ..., tm }
Finally, concurrent statements have no information flow among them per se. Any such flows occur because of semaphores and involve compound statements (discussed above). The certification conditions for the concurrent statement
cobegin S1; ... Sn; coend;
are
S1 secure
...
Sn secure
Denning and Denning [274], Andrews and Reitman [34], and others build their argument for security on the intuition that combining secure information flows produces a secure information flow, for some security policy. However, they never formally prove this intuition. Volpano, Irvine, and Smith [1023] express the semantics of the above-mentioned information on flow analysis as a set of types, and equate certification that a certain flow can occur to the correct use of types. In this context, checking for valid information flows is equivalent to checking that variable and expression types conform to the semantics imposed by the security policy.
Let x and y be two variables in the program. Let x's label dominate y's label. A set of information flow rules is sound if the value in x cannot affect the value in y during the execution of the program. (The astute reader will note that this is a form of noninterference; see Chapter 8.) Volpano, Irvine, and Smith use language-based techniques to prove that, given a type system equivalent to the certification rules discussed above, all programs without type errors have the noninterference property described above. Hence, the information flow certification rules of Denning and of Andrews and Reitman are sound.
The goal of an execution-based mechanism is to prevent an information flow that violates policy. Checking the flow requirements of explicit flows achieves this result for statements involving explicit flows. Before the assignment
y = f(x1, ..., xn)
is executed, the execution-based mechanism verifies that
lub(x1, ..., xn) ≤ y
If the condition is true, the assignment proceeds. If not, it fails. A naïve approach, then, is to check information flow conditions whenever an explicit flow occurs.
Implicit flows complicate checking.
Fenton explored this problem using a special abstract machine.
Fenton [345] created an abstract machine called the Data Mark Machine to study handling of implicit flows at execution time. Each variable in this machine had an associated security class, or tag. Fenton also included a tag for the program counter (PC).
The inclusion of the PC allowed Fenton to treat implicit flows as explicit flows, because branches are merely assignments to the PC. He defined the semantics of the Data Mark Machine. In the following discussion, skip means that the instruction is not executed, push(x, x) means to push the variable x and its security class x onto the program stack, and pop(x, x) means to pop the top value and security class off the program stack and assign them to x and x, respectively.
Fenton defined five instructions. The relationships between execution of the instructions and the classes of the variables are as follows.
The increment instruction
x := x + 1
is equivalent to
if PC ≤ x then x := x + 1; else skip
The conditional instruction
if x = 0 then goto n else x := x – 1
is equivalent to
if x = 0 then { push(PC, PC); PC = lub(PC, x); PC := n; } else { if PC ≤ x then { x := x – 1; } else skip }
This branches, and pushes the PC and its security class onto the program stack. (As is customary, the PC is incremented so that when it is popped, the instruction following the if statement is executed.) This captures the PC containing information from x (specifically, that x is 0) while following the goto.
The return
returnis equivalent to
pop(PC, PC);
This returns control to the statement following the last if statement. Because the flow of control would have arrived at this statement, the PC no longer contains information about x, and the old class can be restored.
The branch instruction
if' x = 0 then goto n else x := x – 1
is equivalent to
if x = 0 then { if x ≤ PC then { PC := n; } else skip } else { if PC ≤ x then { x := x – 1; } else skip }
This branches without saving the PC on the stack. If the branch occurs, the PC is in a higher security class than the conditional variable x, so adding information from x to the PC does not change the PC's security class.
The halt instruction
haltis equivalent to
if program stack empty then halt execution
The program stack being empty ensures that the user cannot obtain information by looking at the program stack after the program has halted (for example, to determine which if statement was last taken).
Fenton's machine handles errors by ignoring them. Suppose that, in the program above, y ≤ x. Then at the fifth step, the certification check fails (because PC = x). So, the assignment is skipped, and at the end y = 0 regardless of the value of x. But if the machine reports errors, the error message informing the user of the failure of the certification check means that the program has attempted to execute step 6. It could do so only if it had taken the branch in step 2, meaning that z = 0. If z = 0, then the else branch of statement 1 could not have been taken, meaning that x = 0 initially.
To prevent this type of deduction, Fenton's machine continues executing in the face of errors, but ignores the statement that would cause the violation. This satisfies the requirements. Aborting the program, or creating an exception visible to the user, would also cause information to flow against policy.
The problem with reporting of errors is that a user with lower clearance than the information causing the error can deduce the information from knowing that there has been an error. If the error is logged in such a way that the entries in the log, and the action of logging, are visible only to those who have adequate clearance, then no violation of policy occurs. But if the clearance of the user is sufficiently high, then the user can see the error without a violation of policy. Thus, the error can be logged for the system administrator (or other appropriate user), even if it cannot be displayed to the user who is running the program. Similar comments apply to any exception action, such as abnormal termination.
The classes of the variables in the examples above are fixed. Fenton's machine alters the class of the PC as the program runs. This suggests a notion of dynamic classes, wherein a variable can change its class. For explicit assignments, the change is straightforward. When the assignment
y := f(x1, ..., xn)
occurs, y's class is changed to lub(x1, …, xn). Again, implicit flows complicate matters.
Fenton's Data Mark Machine would detect the violation (see Exercise 7).
Denning [266] suggests an alternative approach. She raises the class of the targets of assignments in the conditionals and verifies the information flow requirements, even when the branch is not taken. Her method would raise z to x in the third statement (even when the conditional is false). The certification check at the fourth statement then would fail, because lub(Low, z) = x ≤ y is false.
Denning ([269], p. 285) credits Lampson with another mechanism. Lampson suggested changing classes only when explicit flows occur. But all flows force certification checks. For example, when x = 0, the third statement sets z to Low and then verifies x ≤ z (which is true if and only if x = Low).
Like the program-based information flow mechanisms discussed above, both special-purpose and general-purpose computer systems have information flow controls at the system level. File access controls, integrity controls, and other types of access controls are mechanisms that attempt to inhibit the flow of information within a system, or between systems.
The first example is a special-purpose computer that checks I/O operations between a host and a secondary storage unit. It can be easily adapted to other purposes. A mail guard for electronic mail moving between a classified network and an unclassified one follows. The goal of both mechanisms is to prevent the illicit flow of information from one system unit to another.
Hoffman and Davis [477] propose adding a processor, called a security pipeline interface (SPI), between a host and a destination. Data that the host writes to the destination first goes through the SPI, which can analyze the data, alter it, or delete it. But the SPI does not have access to the host's internal memory; it can only operate on the data being output. Furthermore, the host has no control over the SPI. Hoffman and Davis note that SPIs could be linked into a series of SPIs, or be run in parallel.
They suggest that the SPI could check for corrupted programs. A host requests a file from the main disk. An SPI lies on the path between the disk and the host (see Figure 16-4.) Associated with each file is a cryptographic checksum that is stored on a second disk connected to the first SPI. When the file reaches the first SPI, it computes the cryptographic checksum of the file and compares it with the checksum stored on the second disk. If the two match, it assumes that the file is uncorrupted. If not, the SPI requests a clean copy from the second disk, records the corruption in a log, and notifies the user, who can update the main disk.
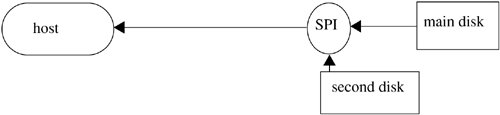
The information flow being restricted here is an integrity flow, rather than the confidentiality flow of the other examples. The inhibition is not to prevent the corrupt data from being seen, but to prevent the system from trusting it. This emphasizes that, although information flow is usually seen as a mechanism for maintaining confidentiality, its application in maintaining integrity is equally important.
Consider two networks, one of which has data classified SECRET[4] and the other of which is a public network. The authorities controlling the SECRET network need to allow electronic mail to go to the unclassified network. They do not want SECRET information to transit the unclassified network, of course. The Secure Network Server Mail Guard (SNSMG) [937] is a computer that sits between the two networks. It analyzes messages and, when needed, sanitizes or blocks them.
The SNSMG accepts messages from either network to be forwarded to the other. It then applies several filters to the message; the specific filters may depend on the source address, destination address, sender, recipient, and/or contents of the message. Examples of the functions of such filters are as follows.
Check that the sender of a message from the SECRET network is authorized to send messages to the unclassified network.
Scan any attachments to messages coming from the unclassified network to locate, and eliminate, any computer viruses.
Require all messages moving from the SECRET to the unclassified network to have a clearance label, and if the label is anything other than UNCLASS (unclassified), encipher the message before forwarding it to the unclassified network.
The SNSMG is a computer that runs two different message transfer agents (MTAs), one for the SECRET network and one for the unclassified network (see Figure 16-5). It uses an assured pipeline [785] to move messages from the MTA to the filter, and vice versa. In this pipeline, messages output from the SECRET network's MTA have type a, and messages output from the filters have a different type, type b. The unclassified network's MTA will accept as input only messages of type b. If a message somehow goes from the SECRET network's MTA to the unclassified network's MTA, the unclassified network's MTA will reject the message as being of the wrong type.
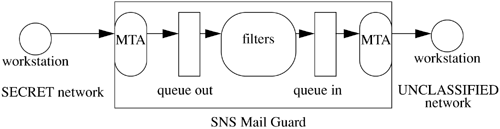
Figure 16-5. Secure Network Server Mail Guard. The SNSMG is processing a message from the SECRET network. The filters are part of a highly trusted system and perform checking and sanitizing of messages.
The SNSMG is an information flow enforcement mechanism. It ensures that information cannot flow from a higher security level to a lower one. It can perform other functions, such as restricting the flow of untrusted information from the unclassified network to the trusted, SECRET network. In this sense, the information flow is an integrity issue, not a confidentiality issue.
Two aspects of information flow are the amount of information flowing and the way in which it flows. Given the value of one variable, entropy measures the amount of information that one can deduce about a second variable. The flow can be explicit, as in the assignment of the value of one variable to another, or implicit, as in the antecedent of a conditional statement depending on the conditional expression.
Traditionally, models of information flow policies form lattices. Should the models not form lattices, they can be embedded in lattice structures. Hence, analysis of information flow assumes a lattice model.
A compiler-based mechanism assesses the flow of information in a program with respect to a given information flow policy. The mechanism either certifies that the program meets the policy or shows that it fails to meet the policy. It has been shown that if a set of statements meet the information flow policy, their combination (using higher-level language programming constructs) meets the information flow policy.
Execution-based mechanisms check flows at runtime. Unlike compiler-based mechanisms, execution-based mechanisms either allow the flow to occur (if the flow satisfies the information flow policy) or block it (if the flow violates the policy). Classifications of information may be static or dynamic.
Two example information flow control mechanisms, the Security Pipeline Interface and the Secure Network Server Mail Guard, provide information flow controls at the system level rather than at the program and program statement levels.
The declassification problem permeates information flow questions. The goal is to sanitize data so that it can move from a more confidential position to a less confidential one without revealing information that should be kept confidential. In the integrity sense, the goal is to accredit data as being more trustworthy than its current level. These problems arise in governmental and commercial systems. Augmenting existing models to handle this problem is complex, as suggested in Chapters 5 and 6.
Automated analysis of programs for information flows introduces problems of specification and proof. The primary problem is correct specification of the desired flows. Other problems include the user interface to such a tool (especially if the analysts are programmers and not experts in information flow or program proving methodologies); what assumptions are implicitly made; and how well the model captures the system being analyzed. In some cases, models introduce flows with no counterparts in the existing system. Detecting these flows is critical to a correct and meaningful analysis.
The cascade problem involves aggregation of authorized information flows to produce an unauthorized flow. It arises in networks of systems. The problem of removing such cascades is NP-complete. Efforts to approximate the solution must take into account the environment in which the problem arises.
The Decentralized Label Model [740] allows one to specify information flow policies on a per-entity basis. Formal models sometimes lead to reports of flows not present in the system; Eckmann [320] discusses these reports, as well as approaches to eliminating them. Guttmann draws lessons from the failure of an information flow analysis technique [430].
The cascade problem is identified in the Trusted Network Interpretation [286]. Numerous studies of this problem describe analyses and approaches [354, 709, 491]; the problem of correcting it with minimum cost is NP-complete [490].
Gendler-Fishman and Gudes [387] examine a compile-time flow control mechanism for object-oriented databases. McHugh and Good describe a flow analysis tool [678] for the language Gypsy. Greenwald et al. [424], Kocher [585], Sands [879], and Shore [919] discuss guards and other mechanisms for control of information flow.
A multithreaded environment adds to the complexity of constraints on information flow [935]. Some architectural characteristics can be used to enforce these constraints [514].
1: | Revisit the example for x := y + z in Section 16.1.1. Assume that x does not exist in state s. Confirm that information flows from y and z to x by computing H(ys | xt), H(ys), H(zs | xt), and H(zs) and showing that H(ys | xt) < H(ys) and H(zs | xt) < H(zs). |
2: | Let L = (SL, ≤L) be a lattice. Prove that the structure IL = (SIL, ≤IL), where each of the following is a lattice.
|
3: | Prove or disprove that the set P formed by the dual mapping of a reflexive information flow policy (as discussed in Definition 16–5) is a lattice. |
4: | Extend the semantics of the information flow security mechanism in Section 16.3.1 for records (structures). |
5: | Why can we omit the requirement lub{ i, b[i] } ≤ a[i] from the requirements for secure information flow in the example for iterative statements (see Section 16.3.2.4)? |
6: | In the flow certification requirement for the goto statement in Section 16.3.2.5, the set of blocks along an execution path from bi to IFD(bi) excludes these endpoints. Why are they excluded? |
7: | Prove that Fenton's Data Mark Machine described in Section 16.4.1 would detect the violation of policy in the execution time certification of the copy procedure. |
8: | Discuss how the Security Pipeline Interface in Section 16.5.1 can prevent information flows that violate a confidentiality model. (Hint: Think of scanning messages for confidential data and sanitizing or blocking that data.) |
[1] From Denning [269], p. 306.
[2] From Denning [269], Figure 5.7, p. 290.
[3] From Denning [269], Figure 5.5, p. 285.
[4] For this example, assume that the network has only one category, which we omit.