
LADY MACBETH: Your servants everHave theirs, themselves and what is theirs, in compt,To make their audit at your highness' pleasure,Still to return your own. | ||
| --The Tragedy of Macbeth, I, vi, 27–30. | ||
Auditing is an a posteriori technique for determining security violations. This chapter presents the notions of logging (recording of system events and actions) and auditing (analysis of these records). Auditing plays a major role in detection of security violations and in postmortem analysis to determine precisely what happened and how. This makes an effective auditing subsystem a key security component of any system.
The development of techniques for auditing computer systems sprang from the need to trace access to sensitive or important information stored on computer systems as well as access to the computer systems themselves. Anderson [27] first proposed the use of audit trails to monitor threats. The use of existing audit records suggested the development of simple tools that would check for unauthorized access to systems and files. The premise—that the logging mechanism was in place and active—required that the logs be augmented with additional information, but Anderson did not propose modification of the basic structure of the system's logging design, the implication being that redesign of the security monitoring mechanism was beyond the scope of the study.
Definition 24–1. Logging is the recording of events or statistics to provide information about system use and performance.
Definition 24–2. Auditing is the analysis of log records to present information about the system in a clear and understandable manner.
With respect to computer security, logs provide a mechanism for analyzing the system security state, either to determine if a requested action will put the system in a nonsecure state or to determine the sequence of events leading to the system being in a nonsecure (compromised) state. If the log records all events that cause state transitions, as well as the previous and new values of the objects that are changed, the system state can be reconstructed at any time. Even if only a subset of this information is recorded, one might be able to eliminate some possible causes of a security problem; what remains provides a valuable starting point for further analysis.
Gligor [397] suggests other uses for the auditing mechanism. It allows systems analysts to review patterns of usage in order to evaluate the effectiveness of protection mechanisms. These patterns can be used to establish expected patterns of resource usage, which are critical for some intrusion detection systems. (See Chapter 25, “Intrusion Detection.”) Auditing mechanisms must record any use of privileges. A security control that would restrict an ordinary user may not restrict the empowered user. Finally, audit mechanisms deter attacks because of the record and the analysis, thereby providing assurance that any violation of security policies will be detected.
Two distinct but related problems arise: which information to log and which information to audit. The decision of which events and actions should be audited requires a knowledge of the security policy of the system, what attempts to violate that policy involve, and how such attempts can be detected. The question of how such attempts can be detected raises the question of what should be logged: what commands must an attacker use to (attempt to) violate the security policy, what system calls must be made, who must issue the commands or system calls and in what order, what objects must be altered, and so forth. Logging of all events implicitly provides all this information; the problem is how to discern which parts of the information are relevant, which is the problem of determining what to audit.
An auditing system consists of three components: the logger, the analyzer, and the notifier. These components collect data, analyze it, and report the results.
Logging mechanisms record information. The type and quantity of information are dictated by system or program configuration parameters. The mechanisms may record information in binary or human-readable form or transmit it directly to an analysis mechanism (see Section 24.2.2). A log-viewing tool is usually provided if the logs are recorded in binary form, so a user can examine the raw data or manipulate it using text-processing tools.
An analyzer takes a log as input and analyzes it. The results of the analysis may lead to changes in the data being recorded, to detection of some event or problem, or both.
A single, well-unified logging process is an essential component of computer security mechanisms [132]. The design of the logging subsystem is an integral part of the overall system design. The auditing mechanism, which builds on the data from the logging subsystem, analyzes information related to the security state of the system and determines if specific actions have occurred or if certain states have been entered.
The goals of the auditing process determine what information is logged [60]. In general, the auditors desire to detect violations of policy. Let Ai be the set of possible actions on a system. The security policy provides a set of constraints pi that the design must meet in order for the system to be secure. This implies that the functions that could cause those constraints to fail must be audited.
Represent constraints as “action ⇒ condition.” Implication requires that the action be true (which means that the action occurred, in this context) before any valid conclusion about the condition can be deduced. Although this notation is unusual, it allows us simply to list constraints against which records can be audited. If the record's action is a “read,” for example, and the constraint's action is a “write,” then the constraint clearly holds. Furthermore, the goal of the auditing is to determine if the policy has been violated (causing a breach of security), so the result (success or failure) of the operation should match the satisfaction of the constraint. That is, if the constraint is true, the result is irrelevant, but if the constraint is false and the operation is successful, a security violation has occurred.
The example models above showed that analyzing the specific rules and axioms of a model reveal specific requirements for logging enough information to detect security violations. Interestingly enough, one need not assume that the system begins in a secure (or valid) state because all the models assert that the rules above are necessary but not sufficient for secure operation and auditing tests necessity. That is, if the auditing of the logs above shows a security violation, the system is not secure; but if it shows no violation, the system may still not be secure because if the initial state of the system is nonsecure, the result will (most likely) be a nonsecure state. Hence, if one desires to use auditing to detect that the system is not secure rather than detect actions that violate security, one needs also to capture the initial state of the system. In all cases, this means recording at start time the information that would be logged on changes in the state.
The examples above discussed logging requirements quite generically. The discussion of the Bell-LaPadula Model asserted specific types of data to be recorded during a “write.” In an implementation, instantiating “write” may embody other system-specific operations (“append,” “create directory,” and so on). Moreover, the notion of a “write” may be quite subtle—for example, it may include alteration of protection modes, setting the system clock, and so forth. How this affects other entities is less clear, but typically it involves the use of covert channels (see Section 17.3) to write (send) information. These channels also must be modeled.
Naming also affects the implementation of logging criteria. Typically, objects have multiple names by which they can be accessed. However, if the criteria involve the entity, the system must log all constrained actions with that entity regardless of the name used. For example, each UNIX file has at least two representations: first, the usual one (accessed through the file system), and second, the low-level one (composed of disk blocks and an inode and accessed through the raw disk device). Logging all accesses to a particular file requires that the system log accesses through both representations. Systems generally do not provide logging and auditing at the disk block level (owing to performance). However, this means that UNIX systems generally cannot log all accesses to a given file.
One critical issue is how to log: what data should be placed in the log file, and how it should be expressed, to allow an audit to draw conclusions that can be justified through reference to the log. This enables the analyst to display the reasoning behind the conclusions of the audit. The problem is that many systems log data ambiguously or do not present enough context to determine to what the elements of the log entry refer.
This example demonstrates that a single log entry may not contain all the information about a particular action. The context of the entry conveys information. An analysis engine benefits from analyzing the context as well as the entries.
Flack and Atallah [357] suggest using a grammar-based approach to specifying log content. The grammar, expressed using a notation such as BNF, forces the designer to specify the syntax and semantic content of the log. Because the grammar of the log is completely specified, writing tools to extract information from the log requires development of a parser using the stated grammar. The analyzer can then process log entries using this grammar.
Flack and Atallah point out that most current log entries are not specified using grammars. They examined BSM's description and entries (see Section 24.5.2) and found some ambiguities. For example, one BSM entry has two optional text fields followed by two mandatory text fields. The documentation does not specify how to interpret a sequence of three text fields in this context, so it is unclear which of the two optional text fields is present. They developed a BSM grammar that treats the optional fields as either both present or both absent, so three text fields generate a parse error. Any ambiguous log entries will thereby generate the exception. The analyst can then examine the log entry and best determine how to handle the situation.
A site may consider a set of information confidential. Logs may contain some of this information. If the site wishes to make logs available, it must delete the confidential information.
Definition 24–3. Let U be a set of users. The policy P defines a set of information C(U) that members of U are not allowed to see. Then the log L is sanitized with respect to P and U when all instances of information in C(U) are deleted from L.
Confidentiality policies may impact logs in two distinct ways. First, P may forbid the information to leave the site. For example, the log may contain file names that give indications of proprietary projects or enable an industrial spy to determine the IP addresses of machines containing sensitive information. In this case, the unsanitized logs are available to the site administrators. Second, P may forbid the information to leave the system. In this case, the goal is to prevent the system administration from spying on the users. For example, if the Crashing Computer Company rents time on Denise's Distributed System, the CCC may not want the administrators of the system to determine what they are doing. Privacy considerations also affect the policy. Laws may allow the system administration to monitor users only when they have reason to believe that users are attacking the system or engaging in illegal activities. When they do look at the logs, the site must protect the privacy of other users so that the investigators cannot determine what activities the unsuspected users are engaged in.
The distinction controls the organization of the logging. Figure 24-1 shows where the sanitizers are applied. The top figure shows a sanitizer that removes information from an existing log file before the analysts examine it. This protects company confidentiality because the external viewers are denied information that the company wishes to keep confidential. It does not protect users' privacy because the site administration has access to the unsanitized log. The bottom figure shows a configuration in which users' privacy is protected, because the data is sanitized before it is written to the log. The system administrators cannot determine the true value of the sanitized data because it is never written to the log file. If they must be able to recover the data at some future point (to satisfy a court order, for example), the sanitizer can use cryptography to protect the data by encrypting it or by using a cryptographic scheme allowing a reidentifier to reassemble the unsanitized data.
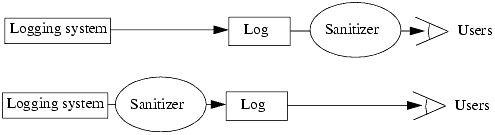
Figure 24-1. The different types of sanitization. The top figure shows logs being sanitized for external viewing. The bottom figure shows logs being sanitized for privacy of users. In this case, the sanitizer may save information in a separate log that enables the reconstruction of the omitted information. Cryptographic techniques enforce separation of privilege, so multiple administrators must agree to view the unsanitized logs.
This suggests two different types of sanitization.
Definition 24–4. An anonymizing sanitizer deletes information in such a way that it cannot be reconstructed by either the recipient or the originator of the data in the log. A pseudonymizing sanitizer deletes information in such a way that the originator of the log can reconstruct the deleted information.
These issues affect the design of the log. The sanitizer must preserve information and relationships relevant to the analysis of the data in the log. Otherwise, the analyzers may miss information that would enable them to detect attacks.
Biskup and Flegel [120] point out that one need not sanitize data that is not collected. Therefore, if a log is to be sanitized to provide anonymity, the simplest technique is simply not to collect the data. However, pseudonymity requires that the data be collected. Two techniques provide the hiding ability.
Suppose the policy allows site administrative personnel to view the data but others to see only the sanitized log. The first step is to determine a set of pseudonyms that preserve the relationships that are relevant to the analysis. The sanitizer replaces the data with the pseudonyms and maintains a table mapping pseudonyms to actual values (similar to a Cypherpunk remailer; see Definition 14–6). Because all site administrators have access to this table, any of them could reconstruct the actual log.
The second technique is appropriate when the policy requires that some set of individuals, not including the system administrators, be able to see the unsanitized data (for example, law enforcement officers or intrusion analysts at a remote site) [120]. The unsanitized data cannot be stored in the clear on the system because the system security officers could then obtain the unsanitized data. One approach is to use a random enciphering key to encipher each sensitive datum and treat the decryption key as the representation of the datum. Then a secret sharing scheme such as Shamir's (see Section 15.3.2) allows the shadows of the decryption key to be split among as many people (or entities) as desired. Using a (t,n)-threshold scheme allows any t of n recipients to reconstruct the decryption key and reverse the pseudonymity.
Application logs consist of entries made by applications. These entries typically use high-level abstractions, such as
su: bishop to root on /dev/ttyp0 smtp: delivery failed; could not connect to abcxy.net:25
These entries describe the problems (or results) encountered at the application layer. These logs usually do not include detailed information about the system calls that are made, the results that are returned, or the sequence of events leading up to the log entry.
System logs consist of entries of kernel events. These entries do not include high-level information. They report system calls and events. The first part of a system log corresponding to the su line above on a FreeBSD system is as follows.
3876 ktrace CALL execve(0xbfbff0c0,0xbfbff5cc,0xbfbff5d8) 3876 ktrace NAMI "/usr/bin/su" 3876 ktrace NAMI "/usr/libexec/ld-elf.so.1" 3876 su RET execve 0 3876 su CALL __sysctl(0xbfbff47c,0x2,0x2805c928,0xbfbff478,0,0) 3876 su RET __sysctl 0 3876 su CALL mmap(0,0x8000,0x3,0x1002,0xffffffff,0,0,0) 3876 su RET mmap 671473664/0x2805e000 3876 su CALL geteuid 3876 su RET geteuid 0 3876 su CALL getuid 3876 su RET getuid 0 3876 su CALL getegid
The system log consists of 1,879 lines detailing the system calls (the “CALL” lines), their return values (“RET”), file name lookups (“NAMI”), file I/O (including the data read or written), and any other actions requiring the kernel.
The difference in the two logs is their focus. If the audit is to focus on application events, such as failures to provide correct passwords (the su entry) or failures to deliver letters (the SMTP entry), an application log provides a simple way of recording the events for analysis. If system events such as file accesses or memory mapping affect the outcome of the auditing, then system logging is appropriate. In some cases, audits using both logs can uncover the system events leading up to an application event.
The advantage of system logs is the completeness of the information recorded. Rather than indicating that a configuration file could not be accessed, the system level log will identify the particular file, the type of access, and the reason for the failure. This leads to large log files that may require special handling. If a log overflows, the system can turn off logging, begin overwriting the least recent log entries, or shut down the system. Many systems allow the auditor to specify the types of information, or the specific system events, to be logged. By a judicious choice of which events to log, the danger of logs overflowing can be minimized.
The advantage of application logs is the level of abstraction. The applications provide the auditor with data that has undergone some interpretation before being entered. For example, rather than identifying a particular file as inaccessible, an application log should indicate the reason for accessing the file:
appx: cannot open config file appx.cf for reading: no such file
The correlation problem relates system and application logs. Given a system log composed of events from one execution of an application, and the corresponding application log, how can one determine which system log entries correspond to entries in the application log, and vice versa? This issue identifies the need to understand what an application level failure means at a system level and what application failures are caused by system level problems. The point is that the application logs are abstractions of system level events interpreted by the application in view of the previous application level events. By understanding the events at both the system and application levels, the auditor can learn about the causes of failures and determine if they are the results of attempts to breach system security.
The design of an effective auditing subsystem is straightforward when one is aware of all possible policy violations and can detect them. Unfortunately, this is rarely the case. Most security breaches arise on existing systems that were not designed with security considerations in mind. In this case, auditing may have two different goals. The first goal is to detect any violations of a stated policy; the second is to detect actions that are known to be part of an attempt to breach security.
The difference is subtle but important. The first goal focuses on the policy and, as with the a priori design of an auditing subsystem, records (attempted) actions that violate the policy. The set of such actions may not be known in advance. The second goal focuses on specific actions that the managers of the system have determined indicate behavior that poses a threat to system security. Thus, one approaches the first goal by examining the desired policy, whereas one approaches the second goal by examining the actions (attacks) that pose the threat.
Implementation of this type of auditing is similar to the auditing subsystem design discussed in Section 24.3. The idea is to determine whether or not a state violates the policy. Unlike mechanisms designed into the system, the auditing mechanisms must be integrated into the existing system. Analysts must analyze the system to determine what actions and settings are consistent with the policy. They then design mechanisms for checking that the actions and settings are in fact consistent with the policy. There are two ways to proceed: state-based auditing and transition-based auditing.
The designer can opt for a state-based approach, in which states of the system are analyzed to determine if a policy violation exists.
Definition 24–5. A state-based logging mechanism records information about a system's state. A state-based auditing mechanism determines whether or not a state of the system is unauthorized.
Typically, a state-based auditing mechanism is built on a state-based logging system. There is a tacit assumption that a state-based logging mechanism can take a snapshot of the system. More generally, the state-based logging mechanism must obtain a consistent state. Algorithms such as Chandy-Lamport [179] can supply a consistent state for distributed resources, but obtaining a state for nondistributed resources requires the resources to be quiescent while the state is obtained. On most systems in which multiple resources supply components of the state, this is infeasible.
Consider a set of resources on a system. Each resource supplies a component (called an attribute) of the state. Hence, state-based auditing mechanisms analyze attributes of the state. Let the state si be a vector (ci0 ... cin), where cij ∊ C is an attribute of the state. If the system is quiescent, then the audit analyzes (ci0 ... cin). We call this consistent static analysis. However, if the system is not quiescent, then the audit analyzes (ci0cj1 ... ckn). Here, the “state” is a vector of attributes of different states and does not correspond to any particular state. Although the intent is to examine a single state, the audit actually examines attributes from multiple states. This type of analysis is called inconsistent static analysis.
The designer can opt for a transition-based approach, in which actions that could violate the policy are checked to determine if they do indeed cause violations.
Definition 24–6. A transition-based logging mechanism records information about an action on a system. A transition-based auditing mechanism examines the current state of the system and the proposed transition (command) to determine if the result will place the system in an unauthorized state.
An important observation is that transition-based logging may not be sufficient to enable a transition-based auditing mechanism to determine if the system will enter an unauthorized state. Specifically, if the system begins in a state that violates policy, a transition-based auditing mechanism will not detect the security problem if the transition alone was analyzed and determined not to move the system from a secure state to a nonsecure state. For this reason, transition-based logging is used only when specific transitions always require an examination (as in the example of changes of privilege) or when some state analysis is also performed.
In many cases, the security policy is not stated explicitly. However, certain behaviors are considered to be “nonsecure.” For example, an attack that floods a network to the point that it is not usable, or accessing of a computer by an unauthorized person, would violate the implicit security policy. Under these conditions, analysts can determine specific sequences of commands, or properties of states, that indicate a security violation and look for that violation.
EXAMPLE: Daniels and Spafford [255] present an analysis of the Land attack [222], which causes a denial of service by causing the target of the attack to hang or to respond very slowly. This attack is built on an exchange that begins a TCP connection.
When a TCP connection begins, the source sends a SYN packet to the destination. This packet contains a sequence number s. The destination receives the packet and returns a SYN/ACK packet containing the acknowledgment number s + 1 and a second sequence number t. The source receives this packet and replies with the acknowledgment number t + 1. Figure 24-2 illustrates this exchange, called a three-way handshake.

Figure 24-2. The TCP three-way handshake. The SYN packet is a TCP packet with sequence number s (or t) and the SYN flag set. Likewise, the ACK packet is a TCP packet with acknowledgment number s + 1 (or t + 1) and the ACK flag set. The middle message is a single TCP packet with both SYN and ACK flags set.
The Land attack arises from an ambiguity of the TCP specification [511]. When the source and destination differ, or the TCP port numbers of the source and destination differ, the two sequence numbers s and t are from different processes. But what happens if the source and destination addresses and ports are the same? The TCP specification is ambiguous.
Consider what happens in the three-way handshake in this case. The target host receives a SYN packet with sequence number s. It responds with a SYN/ACK packet containing sequence number t and acknowledgment number s + 1. At this point, the internal state of the connection in that host is that the next acknowledgment number will be t + 1. Because the source and destination addresses and ports are the same, the packet returns to the host. The host checks the packet and finds that the acknowledgment number (s + 1) is incorrect. At this point, the TCP specification suggests two different ways to handle the situation.
According to one part of the specification,[1] the connection should send a reset (RST). If this is done, it terminates the connection and the attack fails.
According to a different part of the specification,[2] the host should reply with an empty packet with the current sequence number and the expected acknowledgment number. Hence, the host sends a packet with sequence number t + 1 and acknowledgment number s + 1. Naturally, it receives that packet. It checks that the acknowledgment number is correct, and—again—it is not. Repeating the sequence causes the same packet to be generated, resulting in an infinite loop. If the host has disabled interrupts during this part, the system hangs. Otherwise, it runs very slowly, servicing interrupts but doing little else. The denial of service attack is now successful.
Detecting this attack requires that the initial Land packet be detected. The characteristic of this packet is that the source and destination addresses and port numbers are the same. So, the logging requirement is to record that information. The audit requirement is to report any packets for which the following condition holds.
source address = destination address and
source port number = destination port number
Different systems approach logging in different ways. Most systems log all events by default and allow the system administrator to disable the logging of specific events. This leads to bloated logs.
In this section, we present examples of information that systems record and give some details of the auditing mechanisms.
Systems designed with security in mind have auditing mechanisms integrated with the system design and implementation. Typically, these systems provide a language or interface that allows system managers to configure the system to report specific events or to monitor accesses by a particular subject or to a particular object. This is controlled at the audit subsystem so that irrelevant actions or accesses are not recorded.
Auditing subsystems for systems not designed with security in mind are generally for purposes of accounting. Although these subsystems can be used to check for egregious security violations, they rarely record the level of detail or the types of events that enable security officers to determine if security has been violated. The level of detail needed is typically provided by an added subsystem.
The difference between designing a logging and auditing mechanism for an existing file system protocol and designing a logging and auditing mechanism for a new file system protocol illuminates the differences between a priori and a posteriori audit design. This section compares and contrasts the design of an audit mechanism for NFS and the design of a new file system intended to provide logging and auditing.
A bit of background first. Many sites allow computers and users to share file systems, so that one computer (called a client host) requests access to the file system of another computer (a server host). The server host responds by exporting a directory of its file system; the client host imports this information and arranges its own file system so that the imported directory (called the server host's mount point) appears as a directory in the client host's file system (this directory is called the client host's mount point).
Audit Analysis of the NFS Version 2 Protocol[3]
Consider a site connected to the Internet. It runs a local area network (LAN) with several UNIX systems sharing file systems using the Network File System [981] protocol. What should be logged?
We first review the NFS protocol. When a client host wishes to mount a server's file system, its kernel contacts the server host's MOUNT server with the request. The MOUNT server first checks that the client is authorized to mount the requested file system and how the client will mount the requested system. If the client is authorized to mount the file system, the MOUNT server returns a file handle naming the mount point of the server's file system. The client kernel then creates an entry in its file system corresponding to the server's mount point. In addition, either the client host or the server host may restrict the type of accesses to the networked file system. If the server host sets the restrictions, the programs on the server host that implement NFS will enforce the restrictions. If the client host sets the restrictions, the client kernel will enforce the restrictions and the server programs will be unaware that any restrictions have been set.
When a client process wishes to access a file, it attempts to open the file as though the file were on a local file system. When the client kernel reaches the client host's mount point in the path, the client kernel sends the file handle of the server host's mount point (which it obtained during the mount) to resolve the next component (name) of the path to the server host's NFS server using a LOOKUP request. If the resolution succeeds, this server returns the requested file handle. The client kernel then requests attributes of the component (a GETATTR request), and the NFS server supplies them. If the file is a directory, the client kernel iterates (passing the directory's file handle and the next component of the path in a LOOKUP request and using the obtained file handle to get the attributes in a GETATTR request) until it obtains a file handle corresponding to the desired file object. The kernel returns control to the calling process, which can then manipulate the file by name or descriptor; the kernel translates these manipulations into NFS requests, which are sent to the server host's NFS server.
Because NFS is a stateless protocol, the NFS servers do not keep track of which files are in use. The file handle is a capability. Furthermore, many versions of NFS require the kernel to present the requests,[4] although some accept requests from any user. In all cases, the server programs can identify the user making the request by examining the contents of the underlying messages.
The site policy drives the logging and auditing requirements because we are capturing events relevant to violations of that policy. In our example, the site wishes to regulate sharing of file systems among all systems on its LAN (with individual restrictions enforced through the NFS mechanism). All imported file systems are supposed to be as secure as the local file systems. Therefore, the policy is as follows.
P1. | NFS servers will respond only to authorized clients. The site authorizes only local hosts to act as clients. Under this policy, the site administrators could allow hosts not on the LAN to become clients, and so the policy could be less restrictive than the statement above suggests. |
P2. | The UNIX access controls regulate access to the server's exported file system. Once a client has imported a server host's file system, the client host's processes may access that file system as if it were local. In particular, accessing a file requires search permission on all the ancestor directories (both local and imported). An important ramification is the effect of the UNIX policy on file type. Only the local superuser can create device (block and character special) files locally, so users should not be able to create device files on any imported file system (or change an existing file's attributes to make it a device file). However, this policy does not restrict a client host from importing a file system that has device files. |
P3. | No client host can access a nonexported file system. This means that exporting a file system allows clients to access files at or below the server host's mount point. Exporting a file system does not mean that a client host can access any file on the server host; the client can access only exported files. These policies produce several constraints. |
C1. | File access granted ⇒ client is authorized to import file system, user can search all parent directories and can access file as requested, and file is descendant of server host's file system mount point. |
C2. | Device file created or file type changed to device ⇒ user has UID of 0. |
C3. | Possession of a file handle ⇒ file handle issued to that user. Because the MOUNT and NFS server processes issue file handles when a user successfully accesses a file, possession of a file handle implies that the user could access the file. If another user acquires the file handle without accessing either server, that user might access files without authorization. |
C4. | Operation succeeds ⇒ a similar operation local to the client would succeed. This follows from the second policy rule. Because an ordinary user cannot mount a file system locally, the MOUNT operation should fail if the requesting user is not a superuser. |
These constraints follow immediately from the three policy rules.
A transition from a secure to a nonsecure state can occur only when an NFS-related command is issued. Figure 24-3 lists the NFS commands that a client may issue. One set takes no arguments and performs no actions; these commands do not affect the security state of the system. A second set takes file handles as arguments (as well as other arguments) and returns data (including status information). The third set also takes file handles as arguments and returns file handles as results.

Figure 24-3. NFS operations. In the Arguments and Action columns, “fh” is “file handle,” “fn” is “file name,” “dh” is “directory handle” (effectively, a file handle), “attrib” is “file attributes,” “off” is “offset” (which need not be a byte count; it is positioning information), “ct” is “count,” “link” is “direct alias,” and “slink” is “indirect alias.”
Those operations that take file handles as arguments require that the auditor validate the constraint. When a server issues a file handle, the file handle, the user to whom it is issued, and the client to which it is sent must be recorded.
L1. | When a file handle is issued, the server must record the file handle, the user (UID and GID) to whom it is issued, and the client host making the request. |
The semantics of the UNIX file system say that access using a path name requires that the user be able to search each directory. However, once a file has been opened, access to the file requires the file descriptor and is not affected by the search permissions of parent directories. From the operation arguments, file handles seem to refer to open objects. For example, SYMLINK creates a symbolic link, which is effectively a write to a directory object; the argument to SYMLINK is the directory's handle. Hence, file handles resemble descriptors more than path names, so the auditor need not verify access permission whenever a user supplies a file handle. The only issue is whether the server issued the file handle to the user performing the operation.
L2. | When a file handle is supplied as an argument, the server must record the file handle and the user (UID and GID). |
A file handle allows its possessor to access the file to which the handle refers. Any operation that generates a file handle must record the user and relevant permissions for the object in question. For example, on a LOOKUP, recording the search permissions of the containing directory enables the auditor to determine if the user should have had access to the named file. On a CREATE, recording the write permissions of the containing directory indicates whether the use could legitimately write to the containing directory.
L3. | When a file handle is issued, the server must record the relevant attributes of any containing object. |
Finally, whether the operation succeeds or fails, the system must record the operation's status so that the auditor can verify the result.
L4. | Record the results of each operation. |
Because each operation performs a different function, we consider the audit criteria of each operation separately. We illustrate the process for mount and lookup and leave the rest as an exercise for the reader.
Constraints C1 and C4 define the audit criteria for MOUNT.
A1. | Check that the MOUNT server denies all requests by unauthorized client hosts or users to import a file system that the server host exports. |
(“Unauthorized users” refers specifically to those users who could not perform the operation locally.) This means that the MOUNT server must record L3 and L4 . Constraints C1 and C3 give the audit criteria for LOOKUP.
A2. | Check that the file handle comes from a client host and a user to which it was issued. |
A3. | Check that the directory has the file system mount point as an ancestor and that the user has search permission on the directory. |
The check for the client being authorized to import the file system (in C1) is implicit in A3 because if the client host is not authorized to import the file system, the client host will not obtain the file handle for the server host's mount point. Performing this audit requires logging of L2, L3 (the relevant attributes being owner, group, type, and permission), and L4. Audit criterion A3 requires recording of the name of the file being looked up; from this and the file handle, the auditor can reconstruct the ancestors of the file.
L5. | Record the name of the file argument in the LOOKUP operation. |
Given the logs and the auditing checks, an analyst can easily determine if the policy has been violated. This is a transition-based mechanism because checks are performed during the actions and not during an evaluation of the current state of the system.
LAFS [1035] takes a different approach. LAFS is a file system that records user level actions taken on files. A policy language allows an auditor to automate checks for violations of policy.
The LAFS file system is implemented as an extension of an existing file system, NFS, in the prototype. A user creates a directory using the lmkdir command and then attaches it to LAFS with the lattach command. For example, if the file policy contains a policy for LAFS, the commands
lmkdir /usr/home/xyzzy/project policy lattach /usr/home/xyzzy/project /lafs/xyzzy/project
attach the directory and its contents to LAFS. All references to the files through LAFS will be logged.
LAFS consists of three main components, along with a name server and a file manager. The configuration assistant, which interacts with the name server and protection mechanisms of the underlying file system, sets up the required protection modes. This part is invoked when a file hierarchy is placed under LAFS (using lattach) and by the LAFS name server. The audit logger logs accesses to the file. The LAFS file manager invokes it whenever a process accesses the file. This allows LAFS to log accesses by LAFS-unaware applications. It in turn invokes the file manager of the underlying file system. At no point does the LAFS file manager perform access checking; that is left to the underlying file system. The policy checker validates policies and checks that logs conform to the policy.
A goal of LAFS is to avoid modifying applications to enable the logging. This allows users to use existing applications rather than having to develop new ones. The interface is therefore a set of three “virtual” files associated with each file in the LAFS hierarchy. The file src.c is a regular file. The file src.c%log contains a log of all accesses to src.c. The file src.c%policy contains a description of the access control policy for the file src.c. Accessing the virtual file src.c%audit triggers an audit in which the accesses of src.c are compared with the policy for the file. Any accesses not conforming to the policy are listed. The virtual files do not appear in file listings; the LAFS interface recognizes the extensions and provides the required access.
The policy language is simple yet powerful. It consists of a sequence of lines in the %policy files of the form
action:date&time:file:user:application:operation:status
For example, the following line says that users may not play the game wumpus from 9 A.M. to 5 P.M. The status field is omitted, because the policy checker is to report any attempts to play wumpus whether they succeed or not.
prohibit:0900-1700:*:*:wumpus:exec
The following lines describe a policy for controlling accesses to source code files in a project under development.
allow:*:Makefile:*:make:read allow:*:Makefile:Owner:makedepend:write allow:*:*.o,*.out:Owner,Group:gcc,ld:write allow:-010929:*.c,*.h:Owner:emacs,vi,ed:write allow:010930-:RCS/:librarian:rcs,co,ci:write
The first line allows the make program to read the Makefile on behalf of any user on the system. The second line allows the owner of the Makefile (indicated by the distinguished user “Owner”) to change the Makefile by running the command makedepend (which adds dependencies among source code). The owner, or anyone in the group, of an object file can re-create the object file. Line 4 allows the owner of the source code to modify the source files using the emacs editor, the vi editor, or the ed editor, provided that the modification occurs before September 29, 2001. The last line allows the user “librarian” to write into the directory RCS using the rcs, co, and ci commands on any date from September 30, 2001, on. The purpose of this line is to allow the librarian to commit source code changes. The preceding line requires that all such changes be made before September 30, so (presumably) the project code is to be frozen on September 30, 2001.
As users access files, LAFS logs the accesses in a human-readable format, and when the user accesses the appropriate %audit file, the audit reports all violations of the relevant policy.
The NFS auditing mechanism and the LAFS have important similarities. In both cases, a security policy controls access, and the goal of both mechanisms is to detect and report attempted violations of the policy. Both have auditing mechanisms built into the file system.
The differences are also crucial. LAFS is “stacked” on top of NFS, so if a file is not bound to LAFS, no accesses to it are logged or audited. With the modifications of NFS, an attacker could avoid being audited only by not using NFS. (This is a typical problem with security mechanisms layered on top of existing protocols or other mechanisms.) The auditing mechanisms in NFS are at a lower layer than those in LAFS (because of the stacking). However, LAFS allows users to specify policies for sets of files and to perform audits. The analysis of NFS above is not as flexible.
There, a site sets the policy for NFS. Users cannot define their own policies. Thus, the NFS auditing mechanism will examine all file accesses, whereas LAFS may not. This affects not only auditing but also performance because if only a few files need to be audited, much of the effort by the NFS mechanisms is unnecessary. Finally, modifying NFS for auditing requires changes in several privileged daemons, whereas adding LAFS requires no modifications to existing system daemons and a kernel.
Which scheme to use depends on several factors, such as the ability to modify the NFS daemons. The NFS auditing modifications and LAFS can work together, the NFS modifications being for the low-level system checking and LAFS for user level auditing.
In addition to running audit mechanisms to analyze log files, auditors sometimes look through the log files themselves. The audit mechanisms may miss information or irregularities in the log that a knowledgeable auditor can detect. Furthermore, the audit mechanisms may be unsophisticated. By examining the logs directly, the auditors may uncover evidence of previously unknown patterns of misuse and attack. Finally, few systems provide a fully integrated suite of logs. Most have several different log files, each for a different set of applications or kernel events. The logs are usually ordered by timestamp and do not show relations other than the time of day and the program (process) creating the entry. For example, a log typically does not indicate two different programs making a sequence of accesses to a particular file.
The goal of an audit browsing tool is to present log information in a form that is easy for the analyst to understand and use. Specifically, the tool must indicate associations between log entries that are of interest to the analyst. Hoagland, Wee, and Levitt [473] identify six basic browsing techniques.
Text display shows the logs in a textual format. The format may be fixed, or it may be defined by the analyst through postprocessing. The auditor may search for events based on name, time, or some other attribute; however, the attribute must be recorded in the log file. This method does not indicate relationships among events, entries, and entities.
Hypertext display shows the logs as a set of hypertext documents with associated log entries linked by hypertext constructs. This allows the auditor to follow relationships between entries and entities by following the links. The browser can include additional information about entities as well. The disadvantage is that the view of the log information is local because the browser does not highlight global relationships in a manner that is clear and easy to understand.
Relational database browsing requires that the logs be stored in a relational database. The auditor then issues queries to the database, and the database performs the correlations and associations before it replies to the query. The advantage of this method is that the database performs the correlations and can do so after the logs have been preprocessed. That is, the auditor need not know in advance what associations are of interest. The disadvantage is that the representation of the output to the query is usually textual. Furthermore, some preprocessing is required because the elements of the logs must be separated to provide the information for the database. The expected queries imply how this is to be done. This may limit the associations between entities and events that the database can exhibit.
Replay presents the events of interest in temporal order. It highlights temporal relationships. For example, if three logs are replayed on a single screen, the temporal order of the events in the log will be intermingled and the order of occurrence across the logs will clearly indicate the order of the events in a way that the analyst can see.
Graphing provides a visual representation of the contents of logs. Typically, nodes represent entities such as processes and files, and edges represent associations. The associations indicate relationships between various entities. For example, processes may have incoming edges from their parents and outgoing edges to their children. The process hierarchy then becomes clear. One problem with this technique is the size of the drawing. If the area in which the graph is drawn is too small, the information may be unreadable. Reducing the logs to eliminate some information ameliorates this problem. The graph may also represent high-level entities (such as groups of processes or file systems) and their relationships, and the auditor can expand the high-level entities in order to examine relationships within the components of those entities.
Slicing obtains a minimum set of log events and objects that affect a given object. This comes from the traditional notion of slicing [1036], a program debugging technique that extracts a minimum set of statements that affect a given variable. Its advantage is that it focuses attention on the sequence of events, and related objects, that affect some entity. Its disadvantage, like that of hypertext browsing, is the locality of the technique.
Audit browsing tools emphasize associations that are of interest to the auditor. Hence, their configurations depend on the goals of the audit.
Developing a visual interface to logs is as much an art as a science. The science lies in determining what to display; the art lies in the graphics used to express the desired relationships and entities. The human should be able to grasp the relevant parts of the log quickly and to pursue lines of inquiry quickly and easily.
Logging is the collection of information; auditing is its analysis. Auditing consists of analysis, which is the study of information gleaned from the log entries, and notification, which is the reporting of the results of the study (and possibly the taking of appropriate actions).
Designing an audit system requires that the goals of the audit be well formed. Typically, the security policy defines these goals. The audit mechanism reports attempts to violate the constraints imposed by the security policy, such as a subject's attempt to write to a lower-level object. Several considerations affect the auditing. For example, names in the logs must be resolvable to an object. The logs must be well structured to allow unambiguous and consistent parsing. They may need to be sanitized before or after analysis. Application logs reflect actions of the application; system logs reflect events within the operating system.
Auditing mechanisms should be designed into the system. These mechanisms may also be added after the system is completed. In this case, the mechanism may report violations of a defined security policy or may report actions that are considered to be security threats (whether a security policy is defined precisely or not).
A mechanism enabling auditors to browse the logs aids in the analysis. Such a browser helps auditors locate problems that they have not thought of and may speed the analysis of problems that other audit mechanisms have reported.
The sanitization of logs is an important research topic. The key issues are the preservation of relationships needed to perform a useful audit and the protection of sensitive data. The former requires a careful analysis of the goals of the audit and the security policy involved. In real situations, the policy is often not explicit. The audit system itself looks for known violations of the policy. In this case, the analysts are attempting to discover previously unknown methods of attack. If the audit detects violations of a known policy, then the analysts need to determine the sequence of events leading up to the breach. In either case, the analyst may not know what information he is looking for until he has done considerable analysis, at which point the required data may have been sanitized and the original data may be unavailable. But if information about the relationship of sanitized data is left in the log, someone may be able to deduce confidential information. Whether or not this dilemma can be resolved and, if not, how to sanitize the logs to best meet the needs of the analysts and the people being protected are open questions.
Correlation of logs is another open problem. The first type of correlation is development of a general method that maps a set of system log entries to the corresponding application log entries. Conversely, an analyst may want to map a single application log entry to a set of system log entries to determine what happens at the lower (system) level. A second type of correlation involves ordering of logs from systems spread over a network. If the clocks are synchronized, the log entries may be placed in temporal order. If not, Lamport's clock algorithm [607] provides a partial ordering of the entries, provided that the sends and receives between systems are logged. However, Lamport's scheme assumes either that the systems communicate directly with one another or that the logs of all intermediate systems record sends and receives and be available to the analyst. How to correlate the events when this information is not available, or when the logs do not record sends and receives, is an open problem.
Audit browsing techniques are in their infancy. Like other user interface mechanisms, audit browsing mechanisms take advantage of human psychology and cognitive abilities. How best to use these mechanisms to enable people to study logs and draw conclusions, or to determine where to focus the analysis, is an open question, and another one is how to create or determine associations of entities on the fly as the interest of the human analyst shifts from one set of data to another.
Papers about systems designed with security in mind discuss the auditing mechanism and the rationale behind it, usually pointing to the relevant requirements. Sibert [920] discusses auditing in the SunOS MLS system. Rao [831] discusses auditing in an avionics system. Banning and her colleagues [60] discuss auditing of distributed systems. Shieh and Gligor [913] discuss auditing of covert channels.
Interfaces to the logging mechanism control how data can be logged and, once logged, accessed. The POSIX group has defined an interface for UNIX-like systems [813]. The Clio logging service [352] provides an interface that mimics append-only files. The S4 service [978] uses journaling techniques to secure logs even if the system has been compromised.
Various techniques based on artificial intelligence have been used to analyze logs [469, 629, 930, 993]. Data mining techniques show great promise [456]. Jajodia, Gadia, Bhargava, and Sibley [518] discuss a database model that makes past and current log records available for analysis.
Holley and Millar [480] discuss approaches to auditing an online real-time computer system. Markantonakis [658] discusses the application of smart card logs, and Markantonakis and Xenitellis [659] present an implementation.
Fisch, White, and Pooch [353] discuss sanitization of network traffic logs.
Sajaniemi [862] discusses a technique for visualizing an audit of a spreadsheet. Takada and Koike [987] present a visual interface for logs used to detect intruders. Shneiderman [917] discusses human-computer interfaces in general.
1: | Extend the example of deriving required logging information to the full Bell-LaPadula Model with both security levels and compartments. |
2: | In the example of deriving required logging information for the Chinese Wall model, it is stated that the time must be logged. Why? Can something else be logged to achieve the same purpose? |
3: | The Windows NT logger allows the system administrator to define events to be entered into the security log. In the example, the system administrator configured the logger to record process execution and termination. What other events might the system administrator wish to record? |
4: | Suppose a notifier sends e-mail to the system administrator when a successful compromise of that system is detected. What are the drawbacks of this approach? How would you notify the appropriate user? |
5: | Describe a set of constraints for the Clark-Wilson model that lead to a description of the conditions that an audit mechanism should detect. Give these conditions. |
6: | Why is adherence to the principle of complete mediation (see Section 13.2.4) a necessity for logging of file accesses? |
7: | A network monitor records the following information while recording a network connection.
Which type of information should the monitor check to see if it must sanitize the data to conceal the names of the users and the names and addresses of the computers involved? |
8: | Fisch, White, and Pooch [353] define four levels of log sanitization.
Discuss the level of anonymity of each level of sanitization. Which level could be automated, and to what degree would human oversight be required? |
9: | Prove or disprove that state-based logging and transition-based logging are equivalent if and only if the state of the system at the first transition is recorded. |
10: | Suppose a remote host begins the TCP three-way handshake with the local host but never sends the final ACK. This is called a half-open connection. The local host waits for some short time and then purges the information from its network tables. If a remote host makes so many half-open connections that the local host cannot accept connections from other hosts, the remote host has launched a syn flood attack (See Section 26.4 for more details.) Derive logging and auditing requirements to detect such an attack. |
11: | What are the logging and auditing requirements for the NFS operations MKDIR and WRITE? |
12: | In the LAFS file system, what does the following policy line say? prohibit:0800-1700:*:root:solitaire:exec:ok What is the effect of specifying the status field? |
13: | Write a program that will slice a log file with respect to a given object. Your program should take an object identifier (such as a process or file name) and a log file as input. Your program should print the minimum set of statements that affect the object, either directly or indirectly. |