
So far in this part of the book, we have discussed how to drive different kinds of use cases from requirements to code. Testing is an integral part of this work and should not be perceived as a separate activity done at the end. In fact, design is not complete until you know how to test your design elements. Likewise, implementation (coding) is not complete until the actual tests pass. When testing each element, you often need to somehow control the execution of the element being tested to follow the execution path stipulated by the test scenario. You also need to instrument (i.e., check and collect information about) the execution to determine that the behavior of the element is indeed correct. Use-case test slices help you localize such control and instrumentation extensions, which can be easily removed when you have completed executing tests. More importantly, when use cases of different kinds are kept separate, the system is much easier to test and defects are more readily isolated.
Testing should not be seen as the final border to cross before releasing the system to users. Testing should occur throughout the project life cycle, from requirements to code. In fact, whatever you do, you are not done until you have verified (and validated) that you did what you wanted to do. This applies not just to coding, but to design, requirements, and basically every task. You need to clarify the acceptance criteria for everything you do, and progress is measured with respect to meeting these acceptance criteria. Thus, test cases have to be identified before a single line of code is written, not after the code is written. This is because unless implementation passes the tests, implementation is not complete. Having tests identified and specified up front is crucial to an objective evaluation of the progress of the system. When a developer says she has completed 70 percent of the code, it has to be 70 percent working—that is, she passes 70 percent of the test identified. Anything else, such as saying, “Seventy percent of the code written,” when testing has not yet been completed, is potentially misleading.
You must identify test cases early. But writing test cases that you know will definitely pass is not useful. You should always attempt to write test cases for parts of the system that may fail. Why write tests for parts you know will pass?
The test-first design principle emphasizes this even further—you write test cases for parts of the system that have yet to be implemented. Of course, they will fail—they have not been implemented yet! So, you start to implement parts of the system to pass this test case. You then write a test case for another part of the system that has yet to be implemented. This test case will fail too, so you code parts of the system to pass this test case. The cycle repeats and each time, you write test cases for parts of the system that have yet to be implemented and thereafter implement them according to the test case. In this way, testing is very much part of coding rather than a separate activity or an afterthought. Testing thus becomes more meaningful. In addition, since you are always thinking about test cases that will fail the system, your system will be robust to a wide variety of scenarios.
One of the critiques about test-first design is that you might write the wrong tests and then design to pass the wrong tests. So, you need to anchor the test cases to something useful, something important. This anchor is in the form of use cases. From use cases, you derive a good initial set of test cases through which you apply the test-first-driven design.
Use cases are also specified using the same test-first principle, but with a difference—you base your use cases on stakeholder concerns, specifically on what each actor needs to do with the system and the variations the stakeholder wants the system to handle. You begin with an empty use case and start to specify the basic flow. You explore with the stakeholder another scenario that the use case has yet to handle, and then you specify an alternate flow to handle that scenario. This repeats until you have adequately explored your stakeholders’ concerns for each use case. Thus, you have an advantage with applying use cases, because use cases are written in a manner that facilitates testing. They should be written in that way—a use case that is not a good test case is not a good use case; more specifically, good test cases start with good use cases. This is because each use case systematically leads to many test cases. So, use cases provide a framework for you to organize and structure test cases. The use-case technique is quite helpful in getting stakeholders and end users, not just the developers and testers, to think in terms of test cases. This certainly promotes a better common understanding between team members on the acceptable behaviors of the system.
The fact that you have been able to keep use cases separate means that the system is much easier to test. Each use-case module is a unit of analysis, design, implementation, and testing. You test a use-case module separately from other use-case modules. Thus, you have test cases for: application use cases, infrastructure use cases, platform specifics, and so on. In this way, you can isolate defects quickly. Thus, use-case-driven development is indeed about testing first and testing early.
In Part II, we discussed in fairly good detail how you capture stakeholder concerns in use-case specifications. You have much to gain by getting use cases right at the beginning of the project. This is because test cases are derived from and organized around use cases.
However, you have to take note that use cases are not test cases. Use-case specifications are written for stakeholders to help explore and clarify their concerns. Test-case specifications are for testers and are significantly more detailed and much wider in coverage than use-case specifications. Test cases evaluate the behavior of a use-case implementation against its specification. Test cases can be identified to evaluate the behavior of a single use-case instance or multiple use-case instances, as we demonstrate in this section.
Let’s look at how you can identify test cases for each use case. A use case is specified in terms of flow of events—basic flows and alternative flows. Figure 16-1 depicts the different paths for the Reserve Room use case.
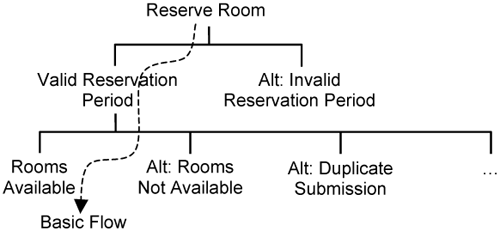
Figure 16-1 shows various execution paths from the instantiation of the Reserve Room use case until its termination. The basic flow is depicted by the dashed arrow, and the alternate flows are depicted with labels prefixed by Alt.
Each path through a use-case specification is a use-case scenario. It chains various flows together into a single sequence. It describes the desired behavior of one use-case instance. You evaluate the implementation of a use case against use-case scenarios. Since there are many different flows, you have many different use-case scenarios. You have at least one use-case scenario per flow of events. That is, each use-case flow of events must appear within at least one use-case scenario.
For each use-case scenario, you identify the actual test cases (with test data, test environment, etc.) for that use-case scenario.
Earlier in the book, we discussed identifying variables that drive the variations in use-case flows of events. For example, the Reserve Room use case is subject to different customer types (individual, corporate, etc.), different reservation periods (reservation periods in weekdays, across weekends, during peak seasons, etc.), and so on, as shown in 16-2.
In Figure 16-2, each axis represents a variable, and each item on an axis represents a variation for that variable. During use-case modeling, you usually identify these variables, enumerate their values, and determine how the use case deals with each variation. However, when you identify test cases, you must explore their possible intersections of the variables and identify test cases for each intersection.
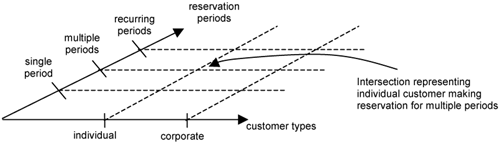
Use-case variables are useful for organizing alternate flows, as discussed in Part II. They are also useful for systematically exploring the test space—the total possible test cases for the use case. This test space will be large. Although it is important to test, you should not overtest. The meaning of overtest varies among systems—a life-critical system should be tested much more rigorously than a Hello-World application. Your tests should be driven by what is critical to the system.
You should also identify test cases that evaluate the behaviors of multiple use cases. For example, you might want to have a test case that executes a Reserve Room instance, followed by a Check In Customer use-case instance, and then a Check Out Customer use-case instance. This constitutes what is known as business-cycle testing, which is extremely important for validating how well the system supports business operations.
In real life, when using the system, use cases get instantiated concurrently, as the actor instance might be processing multiple customer requests at the same time. You can identify such test cases by first brainstorming business scenarios with the stakeholder, determining which use cases are involved, and then defining the test cases.
You definitely need to test the infrastructure and platform specifics. One way to do so is to combine them with application use cases, as shown in Table 16-1.
Table 16-1. Test Cases That Facilitate Defect Isolation
Test Case | Reserve Room | Handle Authorization | Use-Case Distribution | Outcome |
|---|---|---|---|---|
Test Case 1 | Yes | No | No | Pass |
Test Case 2 | Yes | Yes | No | Fail |
Test Case 3 | Yes | No | Yes | Pass |
Table 16-1 depicts three test cases, each using a combination of an application use case (i.e., the Reserve Room use case) and some infrastructure use cases. As you can see, the test cases are identified to deliberately help locate the possible existence of defects. For example, Test Case 2 fails, indicating that there is a defect in the Handle Authorization use case. If every test case for an application use case involves every single infrastructure use case, then it will not be easy to isolate the defect—you will need to resort to low-level tracing and debugging. However, by carefully designing your test cases, you can indeed reduce such efforts. This is the benefit of keeping use cases separate.
You should also have test cases that evaluate the performance of the system. For such test cases, you must combine the application use cases with the infrastructure use cases. For these tests, the use cases should already have been working. The focus of these tests is on timing issues and system configuration issues such as the number of threads you are using and the size of the memory pools.
You analyze different usage loads, such as the number of users making reservations, checking reservations, checking in, and checking out. From these usage models, you formulate performance test cases. These cases can be designed to evaluate such questions as the following:
What is the response time, and what is the time to service a request when the system is subject to a certain workload (i.e., number of requests per second)?
What is the maximum workload when the response time exceeds acceptable values? For example, what is the number of concurrent users the system can accept before the response time for each user exceeds 2 seconds?
You can run these tests with or without infrastructure or platform specifics composed. This facilitates the isolation of bottlenecks. Again, this is the benefit of keeping concerns separate—it is so much easier to isolate problems and fix them.
If you are still in the architectural iterations, the measurements you have at this moment are only for a very early stage of the system—not the final system. Still, these measurements are useful. You can use them to project the actual ones in the final system. In this way, you can evaluate whether your chosen architecture is feasible to build the rest of the system.
If, for example, the performance characteristics of the architecture might already be approaching the acceptable limits, you can predict that after incorporating the remainder of the system, the performance characteristics will not be acceptable. It is much better that you know such issues at the beginning of the project than later. This gives you ample time to find a better solution.
Use cases are also useful for identifying unit tests—tests for each element in the design model. Although you like to have a good test coverage, it is not practical to achieve complete coverage. You could not possibly test every single class. Instead, you choose a subset of classes to be tested more thoroughly than others. So, how do you determine which classes should be subject to unit testing, and also which operations should you focus more on? To find these classes, go back to the use-case realization. Figure 16-3 depicts the realization for the Reserve Room use case during design. These are Plain Old Java Objects (POJOs).
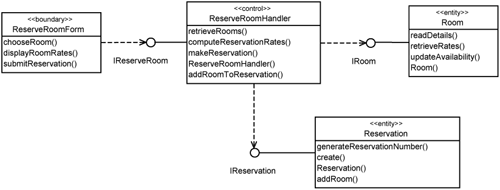
You should at least test the control class (i.e., The ReserveRoomHandler in this case) because it coordinates the other classes to realize the use case. You might also wish to test the boundary class (i.e., the ReserveRoomForm) as well, because it is the facade through which the Web presentation must access the POJO elements. Since the ReserveRoomForm does not involve any Web presentation elements, it is possible to conduct unit testing without worrying about changes in the user interface.
The entity classes here need not be tested because they are just dummy classes—they do not access the actual datastore. The classes that do access the datastore are data access objects (DAOs), which we discussed in Chapter 15, “Separating Platform Specifics with Platform-Specific Use-Case Slices.” The entity classes, however, are excellent mock objects when it comes to testing. Even for the DAOs, they can be tested as part of testing the control classes.
Boundary classes to external systems are also good candidates for mock objects since the boundary classes contain now platform specifics. We discuss mock objects in a moment, but the truth of the matter is that the use case driven approach together with the separation of platform specifics from minimum design provides a systematic approach to finding mock objects.
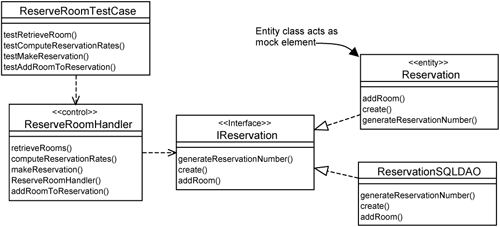
The test cases you implement for the POJOs are also applicable even after you incorporate the platform specifics. Let’s consider the control class for the ReserveRoomHandler. When you incorporate EJB distribution (see Chapter 15), you introduce a business delegate, ReserveRoomDelegate, which makes a call over the network and eventually to the ReserveRoomHandler. Both the ReserveRoomHandler and ReserveRoomDelegate conform to the same interface. This means that you can use the same test case for both classes, illustrated in Figure 16-4.
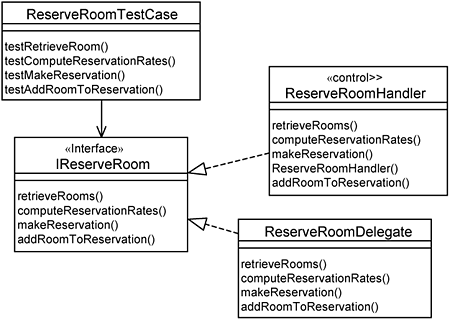
In Figure 16-4, we have a test case class named ReserveRoomTestCase. This class contains operations to test the realization of the IReserveRoom interface, which can be either the ReserveRoomHandler or the ReserveRoomDelegate. This is advantageous because you have a single test implementation to verify behaviors with or without distribution.
Now that you have a set of test cases, you can start to design and implement them. When designing tests, you must be very clear on what the element under test (EUT) is. The EUT can be as simple as just an operation in a class, a set of operations in a set of classes, or a set of classes that realize a use case. The EUT defines the subset of the system being tested. All other parts of the system are part of the EUT’s execution environment.
For instance, if you want to test the Reserve Room use case, specifically the operation makeReservation(), in the ReserveRoomHandler class, then the makeReservation() operation would be the EUT. A partial description of this operation is shown as a state chart in Figure 16-5. Suppose you want to develop the test case for a successful reservation. The dashed line in 16-5 depicts the execution path that you are interested in.
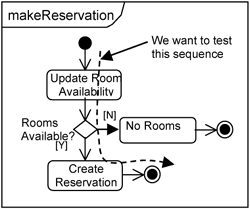
Test design and implementation is about forcing the behavior of the EUT to follow the desired execution path so that we can verify that the EUT does indeed behave as desired. There are two major considerations when designing and implementing tests: control and instrumentation.
Control means forcing the EUT to follow the desired execution path defined in the test case. In addition, the EUT must reproduce the same behavior every time you execute the test case. If, on the other hand, you cannot control the execution or are unable to reproduce the same execution conditions, then you might get different outcomes. In this case, it would be impossible to verify the behavior of the EUT. The consequence is that you will not really be sure if the EUT works.
You can control the execution of the EUT in several ways. You can use parameters passed into the operations being tested, or you can set the global variables accessed by the EUT. This is relatively simple, since you are testing the EUT from its interfaces.
However, in many cases, the EUT requires the support of other elements. These elements might be developed by a different team or might be nondeterministic and extremely difficult to control. In this case, you might want to replace the supporting elements with mock elements. Mock elements substitute the actual supporting elements during testing. This is useful under the following conditions:
The actual supporting elements have not been developed. For example, you have yet to decide how to integrate with an external system. In this case, to test the realization of the use case without the external system, you need a mock element in place of the external system.
Setting up the actual supporting elements for testing takes a long time. It might not be easy to set up the relational database for each test case you need to execute and reset the database after each test. In this case, you might create a mock element to replace the DAOs. If you follow our approach, the entity classes become natural candidates for such mock elements.
The behavior of the actual supporting element is nondeterministic. The supporting element involves sending messages over the network, and the network response is not deterministic. In this case, you can replace it with a mock element that simply provides a delay and returns a fixed result.
Figure 16-6 shows the classes needed to test the ReserveRoomHandler class. The ReserveRoomTestCase is the class that tests the ReserveRoomHandler class. The ReserveRoomHandler needs the ReservationSQLDAO to function. However, we do not use the ReservationSQLDAO for testing because the database setup might take up time. Instead, we use the Reservation entity class as a mock element.
In addition to controlling the execution of the EUT, you must be able to extract (instrument) information about the execution state and outputs of the EUT. This can be achieved through checking return values and values set on global variables.
If the EUT makes calls to the other elements, you might want to check the actual parameters being passed to these elements. You can use the mock objects to perform these checks as well.
If you add control and instrumentation code into the EUT directly, you experience tangling—you have both EUT code and testing (control and instrumentation) code all mixed up together. Application and testing are two different concerns, and hence you must keep them separate. To keep the control and instrumentation code separate from the EUT, you can define a separate slice that overlays on the EUT. In addition, you need a test infrastructure mechanism to manage tests and store test results for further analysis.
Let’s design the test infrastructure. This is done in much the same way as analyzing and designing use cases, discussed in preceding chapters. You begin by identifying needed classes and determining how their instances interact. Thereafter, you allocate the behaviors to use-case slices.
To model the test infrastructure as a pattern, we identify the participating classes as parameters, which we denote using brackets: 〈〉. A 〈TestManager〉 executes one or more 〈TestCase〉 instances. Each 〈TestCase〉 invokes operations on some 〈EUT〉. The 〈EUT〉 itself may depend on other classes that are not within the scope of testing. We refer to these classes as supporting classes. If the supporting classes have not been developed yet, or you want to keep them separate, you replace them with mock elements: you substitute the supporting classes with a mock element. The mock element is parameterized as 〈MockElement〉.
Now that the classes (more specifically, template parameters) have been identified, you describe the interaction between their instances. A typical interaction sequence (i.e., basic low) between their instances is depicted in Figure 16-7.
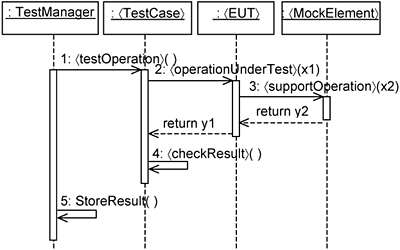
In Figure 16-7, we want to test operation 〈operationUnderTest〉 on the 〈EUT〉 instance. The 〈TestCase〉 invokes this operation via 〈testOperation〉. The 〈TestManager〉 is responsible for managing test cases, executing them, and storing the results. As part of the executing 〈operationUnderTest〉, the 〈EUT〉 might need support from other instances. This is provided by the 〈MockElement〉. For example, an operation might be invoked to perform some computation needed by 〈operationUnderTest〉.
Merely checking the return value of 〈operationUnderTest〉 is not sufficient. You must also check that the operation 〈supportOperation〉 in the 〈MockElement〉 instance is indeed invoked and that the parameter passed in (i.e., x2) is of the correct value. In addition, you must control the return value (i.e., y2) from the 〈MockElement〉 instance. The use of the variables x1, x2, y1, and y2 are summarized in Table 16-2.
Table 16-2. Test Data and Verification
Variable | Type | Purpose in testing |
|---|---|---|
x1 | Operation parameter | Test data |
x2 | Operation parameter | Test verification |
y2 | Operation return value | Test data |
y1 | Operation return value | Test verification |
The test data for the test case in Figure 16-7 are x1 and y2, and test verification is performed by checking the values of x2 and y1. 〈TestCase〉 and 〈MockElement〉 need to output the test data and perform the test verification accordingly.
Now that we have described the interaction between the participating parameters, we proceed to keep the test infrastructure separate from the test case and the test case separate from the use-case slice being tested. This yields the following three slices, shown in Figure 16-8:
The use-case design slice, which contains the elements being tested.
The test-case slice, which contains the specifics of a test case.
The test infrastructure slice, which contains elements that are common across test cases.
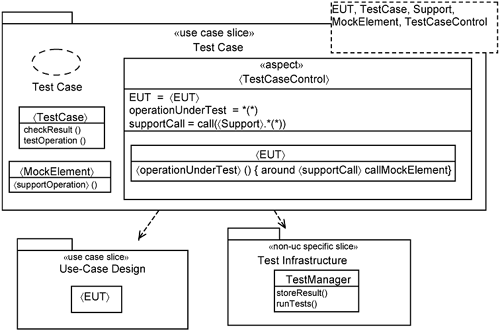
The use-case design slice contains the elements being tested. Collectively, these elements are represented by 〈EUT〉. They can be boundary, control, or entity classes.
The test infrastructure is a non-use-case-specific slice. It contains the TestManager, which manages and runs various test cases. It is responsible for storing test results. If the test infrastructure provides the ability to do performance tests, then the TestManager must be responsible for generating threads to run test cases in parallel. This requires further design and refinement of the TestManager class.
The test-case slice contains the specifics of a test case. It contains the 〈TestCase〉 and one or more 〈MockElement〉s, depending on how many supporting elements are needed. There is also a 〈TestCaseControl〉 aspect to control the behavior of the 〈EUT〉. Figure 16-7 shows the use of an operation extension to introduce the 〈MockElement〉. The operation extension declaration is as follows:
〈operationUnderTest〉 () { around 〈supportCall〉 callMockElement}
In essence, when the operationUnderTest() makes a call to an operation in 〈Support〉, it is replaced by a corresponding call to the 〈MockElement〉. Both 〈TestCase〉 and 〈MockElement〉 are responsible for conducting test verification where appropriate.
Now that you have established a test infrastructure and a template for designing test cases, you can apply it to test a specific use case. To do so, you must substitute the parameters in the test-case slice template. You also must work out the test data and test values needed during the execution of the test case.
Figure 16-9 illustrates the application of the test-case slice template to test the Reserve Room use-case slice. In this case, the 〈EUT〉 is the ReserveRoomHandler, and the 〈Support〉 class is the RoomSQLDAO class. Hence, the RoomSQLDAO class is replaced with a Room entity class.
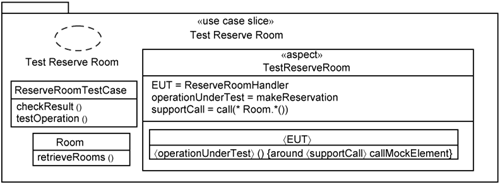
The mock element in this case is a Room class. Recall that in Chapter 15, we use a DAOFactory class to determine if an entity instance should be used or a DAO should be used. Thus, instead of using an operation extension as shown in Figure 16-9, you can also use the DAOFactory to introduce a mock element. Both approaches—using operation extensions and factory classes—are possible. The benefit of aspects is that since you are able to intercept calls to each operation, you have the option to substitute an operation instead of an entire object.
What we have shown in Figure 16-9 is only one test case and one operation being tested. In general, for each use case, there are many operations being tested and accordingly many test cases. You must apply the test case template many times.
For each operation or sequence of operations being tested, you must also identify the test data values and the test verification values. These values are usually stored in a data file, and you can easily execute more tests by providing more test data.
To recap, testing should not be seen as a final stage of development. In fact, it should be one of the first things to do in every project. Test cases are an effective means of defining the completion criteria for development—a developer’s job is not complete until the test cases pass.
You must systematically identify test cases for the system. Use cases help you identify and organize test cases systematically. You identify a set of test cases for each use case separately. This is important, since you can easily localize the presence of defects and bottlenecks. Furthermore, with test-case slices, you can keep test control and implementation separate from the use-case slice being tested. This is quite powerful because you can remove test codes from the production system after you are done with testing and leave the production system intact. With all these benefits, your approach to testing the system is streamlined significantly. You can test first, test early.