
I am, in point of fact, a particularly haughty and exclusive person, of pre-Adamite ancestral descent. You will understand this when I tell you that I can trace my ancestry back to a protoplasmal primordial atomic globule. | ||
| --Gilbert and Sullivan, The Mikado | ||
The quick tour (Chapter 1) described briefly how a class can be extended, or subclassed, and how an object of an extended class can be used wherever the original class is required. The term for this capability is polymorphism, meaning that an object of a given class can have multiple forms, either as its own class or as any class it extends. The new class is a subclass or extended class of the class it extends; the class that is extended is its superclass.
The collection of methods and fields that are accessible from outside a class, together with the description of how those members are expected to behave, is often referred to as the class's contract. The contract is what the class designer has promised that the class will do. Class extension provides two forms of inheritance:
inheritance of contract or type, whereby the subclass acquires the type of the superclass and so can be used polymorphically wherever the superclass could be used; and
inheritance of implementation, whereby the subclass acquires the implementation of the superclass in terms of its accessible fields and methods.
Class extension can be used for a number of purposes. It is most commonly used for specialization—where the extended class defines new behavior and so becomes a specialized version of its superclass. Class extension may involve changing only the implementation of an inherited method, perhaps to make it more efficient. Whenever you extend a class, you create a new class with an expanded contract. You do not, however, change the part of the contract you inherit from the class you extended. Changing the way that the superclass's contract is implemented is reasonable, but you should never change the implementation in a way that violates that contract.
The ability to extend classes interacts with the access control mechanisms to expand the notion of contract that a class presents. Each class can present two different contracts—one for users of the class and one for extenders of the class. Both of these contracts must be carefully designed.
With class extension, inheritance of contract and inheritance of implementation always occur together. However, you can define new types independent of implementation by using interfaces. You can also reuse existing implementations, without affecting type, by manually using composition and forwarding. Interfaces and composition are discussed in Chapter 4.
Class extension that involves generic classes has its own special rules concerning redefining members, overriding, and overloading. These rules are discussed in detail in Chapter 11. In this chapter, generic types are not considered.
To demonstrate subclassing, we start with a basic attribute class designed to store name–value pairs. Attribute names are human-readable strings, such as “color” or “location.” Attribute values are determined by the kind of attribute; for example, a “location” may have a string value representing a street address, or it may be a set of integer values representing latitude and longitude.
public class Attr {
private final String name;
private Object value = null;
public Attr(String name) {
this.name = name;
}
public Attr(String name, Object value) {
this.name = name;
this.value = value;
}
public String getName() {
return name;
}
public Object getValue() {
return value;
}
public Object setValue(Object newValue) {
Object oldVal = value;
value = newValue;
return oldVal;
}
public String toString() {
return name + "='" + value + "'";
}
}
An attribute must have a name, so each Attr constructor requires a name parameter. The name must be immutable (and so is marked final) because it may be used, for example, as a key into a hashtable or sorted list. In such a case, if the name field were modified, the attribute object would become “lost” because it would be filed under the old name, not the modified one. Attributes can have any type of value, so the value is stored in a variable of type Object. The value can be changed at any time. Both name and value are private members so that they can be accessed only via the appropriate methods. This ensures that the contract of Attr is always honored and allows the designer of Attr the freedom to change implementation details in the future without affecting clients of the class.
Every class you have seen so far is an extended class, whether or not it is declared as such. A class such as Attr that does not explicitly extend another class implicitly extends the Object class. Object is at the root of the class hierarchy. The Object class declares methods that are implemented by all objects—such as the toString method you saw in Chapter 2. Variables of type Object can refer to any object, whether it is a class instance or an array. The Object class itself is described in more detail on page 99.
The next class extends the notion of attribute to store color attributes, which might be strings that name or describe colors. Color descriptions might be color names like “red” or “ecru” that must be looked up in a table, or numeric values that can be decoded to produce a standard, more efficient color representation we call ScreenColor (assumed to be defined elsewhere). Decoding a description into a ScreenColor object is expensive enough that you would like to do it only once. So we extend the Attr class to create a ColorAttr class to support a method to retrieve a decoded ScreenColor object. We implement it so the decoding is done only once:
class ColorAttr extends Attr {
private ScreenColor myColor; // the decoded color
public ColorAttr(String name, Object value) {
super(name, value);
decodeColor();
}
public ColorAttr(String name) {
this(name, "transparent");
}
public ColorAttr(String name, ScreenColor value) {
super(name, value.toString());
myColor = value;
}
public Object setValue(Object newValue) {
// do the superclass's setValue work first
Object retval = super.setValue(newValue);
decodeColor();
return retval;
}
/** Set value to ScreenColor, not description */
public ScreenColor setValue(ScreenColor newValue) {
// do the superclass's setValue work first
super.setValue(newValue.toString());
ScreenColor oldValue = myColor;
myColor = newValue;
return oldValue;
}
/** Return decoded ScreenColor object */
public ScreenColor getColor() {
return myColor;
}
/** set ScreenColor from description in getValue */
protected void decodeColor() {
if (getValue() == null)
myColor = null;
else
myColor = new ScreenColor(getValue());
}
}
We first create a new ColorAttr class that extends the Attr class. The ColorAttr class does everything the Attr class does and adds new behavior. Therefore, the Attr class is the superclass of ColorAttr, and ColorAttr is a subclass of Attr. The class hierarchy for these classes looks like this, going bottom-up from subclass to superclass:
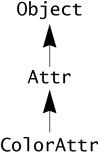
The extended ColorAttr class does three primary things:
It provides three constructors: two to mirror its superclass and one to directly accept a
ScreenColorobject.It both overrides and overloads the
setValuemethod of its superclass so that it can set the color object when the value is changed.It provides a new
getColormethod to return a value that is the color description decoded into aScreenColorobject.
We look at the intricacies of the construction process and the effect of inheritance on the different class members over the next few sections.
Note the use of the protected access modifier on the decodeColor method. By making this method protected it can be accessed in the current class or in a subclass but is not externally visible. We look in detail at what protected access really means on page 93.
Exercise 3.1: Starting with the Vehicle class from the exercises in Chapter 2, create an extended class called PassengerVehicle to add a capability for counting the number of seats available in the car and the number currently occupied. Provide a new main method in PassengerVehicle to create a few of these objects and print them out.
An object of an extended class contains state variables (fields) that are inherited from the superclass as well as state variables defined locally within the class. To construct an object of the extended class, you must correctly initialize both sets of state variables. The extended class's constructor can deal with its own state but only the superclass knows how to correctly initialize its state such that its contract is honored. The extended class's constructors must delegate construction of the inherited state by either implicitly or explicitly invoking a superclass constructor.
A constructor in the extended class can directly invoke one of the superclass's constructors using another kind of explicit constructor invocation: the superclass constructor invocation, which uses the super construct. This is shown in the first constructor of the ColorAttr class:
public ColorAttr(String name, Object value) {
super(name, value);
decodeColor();
}
This constructor passes the name and value up to the corresponding two-argument superclass constructor. It then invokes its own decodeColor method to make myColor hold a reference to the correct ScreenColor object.
You can defer the choice of which superclass constructor to use by explicitly invoking one of your class's own constructors using this instead of super, as shown in the second constructor of ColorAttr.
public ColorAttr(String name) {
this(name, "transparent");
}
We chose to ensure that every color attribute has a color. If a color value is not supplied we provide a default of "transparent", hence the one-argument constructor invokes the two-argument constructor using a default argument.
If you do not invoke a superclass constructor or one of your own constructors as your constructor's first executable statement, the superclass's no-arg constructor is automatically invoked before any statements of the new constructor are executed. That is, your constructor is treated as if
super();
were its first statement. If the superclass doesn't have a no-arg constructor, you must explicitly invoke another constructor.
The third constructor of ColorAttr enables the programmer creating a new ColorAttr object to specify the ScreenColor object itself.
public ColorAttr(String name, ScreenColor value) {
super(name, value.toString());
myColor = value;
}
The first two constructors must convert their parameters to ScreenColor objects using the decodeColor method, and that presumably has some overhead. When the programmer already has a ScreenColor object to provide as a value, you want to avoid the overhead of that conversion. This is an example of providing a constructor that adds efficiency, not capability.
In this example, ColorAttr has constructors with the same signatures as its superclass's constructors. This arrangement is by no means required. Sometimes part of an extended class's benefit is to provide useful parameters to the superclass constructors based on few or no parameters of its own constructor. It is common to have an extended class that has no constructor signatures in common with its superclass.
Constructors are not methods and are not inherited. If the superclass defines a number of constructors and an extended class wishes to have constructors of the same form, then the extended class must explicitly declare each constructor, even if all that constructor does is invoke the superclass constructor of the same form.
When an object is created, memory is allocated for all its fields, including those inherited from superclasses, and those fields are set to default initial values for their respective types (zero for all numeric types, false for boolean, 'u0000' for char, and null for object references). After this, construction has three phases:
Invoke a superclass's constructor.
Initialize the fields using their initializers and any initialization blocks.
Execute the body of the constructor.
First the implicit or explicit superclass constructor invocation is executed. If an explicit this constructor invocation is used then the chain of such invocations is followed until an implicit or explicit superclass constructor invocation is found. That superclass constructor is then invoked. The superclass constructor is executed in the same three phases; this process is applied recursively, terminating when the constructor for Object is reached because there is no superclass constructor at that point. Any expressions evaluated as part of an explicit constructor invocation are not permitted to refer to any of the members of the current object.
In the second stage all the field initializers and initialization blocks are executed in the order in which they are declared. At this stage references to other members of the current object are permitted, provided they have already been declared.
Finally, the actual statements of the constructor body are executed. If that constructor was invoked explicitly, then upon completion, control returns to the constructor that invoked it, and executes the rest of its body. This process repeats until the body of the constructor used in the new construct has been executed.
If an exception is thrown during the construction process, the new expression terminates by throwing that exception—no reference to the new object is returned. Because an explicit constructor invocation must be the first statement in a constructor body, it is impossible to catch an exception thrown by another constructor. (If you were allowed to catch such exceptions it would be possible to construct objects with invalid initial states.)
Here is an example you can trace to illustrate the different stages of construction:
class X {
protected int xMask = 0x00ff;
protected int fullMask;
public X() {
fullMask = xMask;
}
public int mask(int orig) {
return (orig & fullMask);
}
}
class Y extends X {
protected int yMask = 0xff00;
public Y() {
fullMask |= yMask;
}
}
If you create an object of type Y and follow the construction step by step, here are the values of the fields after each step:
Step | What Happens |
|
|
|
|---|---|---|---|---|
0 | Fields set to default values |
|
|
|
1 |
|
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
4 |
|
|
|
|
5 |
|
|
|
|
6 |
|
|
|
|
7 |
|
|
|
|
Understanding this ordering is important when you invoke methods during construction. When you invoke a method, you always get the implementation of that method for the actual type of the object. If the method uses fields of the actual type, they may not have been initialized yet. During step 5, if the constructor X invoked mask, it would use a fullMask value of 0x00ff, not 0xffff. This is true even though a later invocation of mask—after the object was completely constructed—would use 0xffff.
Also, imagine that class Y overrides mask with an implementation that explicitly uses the yMask field in its calculations. If the constructor for X used the mask method, it would actually invoke Y's mask method, and at that point yMask would be 0 instead of the expected 0xff00.
Methods you invoke during the construction phase of an object must be designed with these factors in mind. Your constructors should avoid invoking overridable methods—methods that are not private, static, or final. If you do invoke such methods, clearly list them in your documentation to alert anyone wanting to override these methods of their potential unusual use.
Exercise 3.2: Type in the classes X and Y as shown previously, and add print statements to trace the values of the masks. Add a main method and run it to see the results. (Hint: Use the printf method—shown in Chapter 1—with a format specifier of %x to print integers in hexadecimal format.)
Exercise 3.3: If it were critical to set up these masks using the values from the extended class during construction, how could you work around these problems?
When you extend a class you can both add new members to a class and redefine existing members. Exactly what effect redefining an inherited member has depends on the kind of member. You'll learn about field and method members here, but we defer discussion of nested members until Chapter 5.
In our new ColorAttr class we have both overridden and overloaded the instance method setValue:
Overloading a method is what you have already learned: providing more than one method with the same name but with different signatures to distinguish them.
Overriding a method means replacing the superclass's implementation of a method with one of your own. The signatures must be identical—but the return type can vary in a particular way, as discussed below.
Overloading an inherited method simply means that you have added a new method, with the same name as, but a different signature from, an inherited method. In ColorAttr we have gone from having one setValue method to having two overloaded forms of the method.
public Object setValue(Object newValue) {
// ...
}
public ScreenColor setValue(ScreenColor newValue) {
// ...
}
This is no different from having overloaded forms of a method declared in the same class.
Overriding a method means that you have replaced its implementation so that when the method is invoked on an object of the subclass, it is the subclass's version of the method that gets invoked. In the ColorAttr class, we overrode the Attr class's setValue(Object) by providing a new setValue(Object) method in the ColorAttr class that uses the super keyword to invoke the superclass's implementation and then invokes decodeColor. The super reference can be used in method invocations to access methods from the superclass that are overridden in this class. You'll learn about super in detail on page 89.
When you're overriding methods, the signature must be the same as in the superclass—if they differ then it is an overload, not an override. The return type of an overriding method is allowed to vary in a specific way: If the return type is a reference type then the overriding method can declare a return type that is a subtype of that declared by the superclass method. Because a reference to a superclass can always hold a reference to an instance of a subclass, this variation is perfectly safe—it is referred to as being a covariant return type. We'll see a good example of this when we look at object cloning on page 101. If the return type is a primitive type, then the return type of the overriding method must be identical to that of the superclass method. It is an error if two methods differ only in return type and the compiler will reject your class.
For overriding in a varargs method, as with overloading (see page 60), a sequence parameter of type T... is treated the same as a parameter of type T[]. This means that an overriding method can “convert” the last array parameter to a sequence, without changing the signature of the method. This allows clients of the subclass to invoke that method with a variable number of arguments. Defining an overriding method that replaces a sequence with an array is allowed, but is strongly discouraged. This is confusing and not useful, so don't do it.[1]
The overriding methods have their own access specifiers. A subclass can change the access of a superclass's methods, but only to provide more access. A method declared protected in the superclass can be redeclared protected (the usual thing to do) or declared public, but it cannot be declared private or have package access. Making a method less accessible than it was in a superclass would violate the contract of the superclass, because an instance of the subclass would not be usable in place of a superclass instance.
The overriding method is also allowed to change other method modifiers. The synchronized, native, and strictfp modifiers can be freely varied because they are implementation concerns, as are any annotations—see Chapter 15. The overriding method can be final but obviously the method it is overriding cannot—see “Marking Methods and Classes final” on page 96 for the implications of final methods. An instance method cannot have the same signature as an inherited static method, and vice versa. The overriding method can, however, be made abstract, even though the superclass method was not—see “Abstract Classes and Methods” on page 97.
A subclass can change whether a parameter in an overriding method is final; a final modifier for a parameter is not part of the method signature—it is an implementation detail. Also, the overriding method's throws clause can be different from that of the superclass method's as long as every exception type listed in the overriding method is the same as or a subtype of the exceptions listed in the superclass's method. That is, each type in the overriding method's throws clause must be polymorphically compatible with at least one of the types listed in the throws clause of the supertype's method. This means that the throws clause of an overriding method can have fewer types listed than the method in the superclass, or more specific types, or both. The overriding method can even have no throws clause, which means that it results in no checked exceptions. Exceptions and throws clauses are described in detail in Chapter 12.
Fields cannot be overridden; they can only be hidden. If you declare a field in your class with the same name (regardless of type) as one in your superclass, that other field still exists, but it can no longer be accessed directly by its simple name. You must use super or another reference of your superclass's type to access it. We show you an example in the next section.
When a method accesses an object's member that has been redefined in a subclass, to which member will the method refer—the superclass member or the subclass member? The answer to that depends on the kind of member, its accessibility, and how you refer to it.
When you invoke a method through an object reference, the actual class of the object governs which implementation is used. When you access a field, the declared type of the reference is used. The following example will help explain:
class SuperShow {
public String str = "SuperStr";
public void show() {
System.out.println("Super.show: " + str);
}
}
class ExtendShow extends SuperShow {
public String str = "ExtendStr";
public void show() {
System.out.println("Extend.show: " + str);
}
public static void main(String[] args) {
ExtendShow ext = new ExtendShow();
SuperShow sup = ext;
sup.show();
ext.show();
System.out.println("sup.str = " + sup.str);
System.out.println("ext.str = " + ext.str);
}
}
There is only one object, but we have two variables containing references to it: One variable has type SuperShow (the superclass) and the other variable has type ExtendedShow (the actual class). Here is the output of the example when run:
For the show method, the behavior is as you expect: The actual class of the object, not the type of the reference, governs which version of the method is called. When you have an ExtendShow object, invoking show always calls ExtendShow's show even if you access it through a reference declared with the type SuperShow. This occurs whether show is invoked externally (as in the example) or internally within another method of either ExtendShow or SuperShow.
For the str field, the type of the reference, not the actual class of the object, determines which class's field is accessed. In fact, each ExtendShow object has two String fields, both called str, one of which is hidden by ExtendShow's own, different field called str:
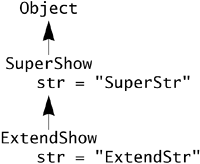
The field that gets accessed is determined at compile time based on the type of the reference used to access it.
Inside a method, such as show, a reference to a field always refers to the field declared in the class in which the method is declared, or else to an inherited field if there is no declaration in that class. So in SuperShow.show the reference to str is to SuperShow.str, whereas in ExtendShow.show the reference to str is to ExtendShow.str.
You've already seen that method overriding enables you to extend existing code by reusing it with objects of expanded, specialized functionality not foreseen by the inventor of the original code. But where fields are concerned, it is hard to think of cases in which hiding them is a useful feature.
If an existing method had a parameter of type SuperShow and accessed str with that object's reference, it would always get SuperShow.str even if the method were actually handed an object of type ExtendShow. If the classes were designed to use a method instead of a field to access the string, the overriding method would be invoked in such a case and the ExtendShow.str could be returned. This hiding behavior is often another reason to prefer defining classes with private data accessed only by methods, which are overridden, not hidden.
Hiding fields is allowed because implementors of existing superclasses must be free to add new public or protected fields without breaking subclasses. If the language forbade using the same field name in a superclass and a subclass, adding a new field to an existing superclass could potentially break any subclasses already using those names.
If adding new fields to existing superclasses would break some unknown number of subclasses, you'd be effectively immobilized, unable to add public or protected fields to a superclass. Purists might well argue that classes should have only private data, but you get to decide on your style.
A method can be overridden only if it is accessible. If the method is not accessible then it is not inherited, and if it is not inherited it can't be overridden. For example, a private method is not accessible outside its own class. If a subclass defines a method that coincidentally has the same signature and return type as the superclass's private method, they are completely unrelated—the subclass method does not override the superclass's private method.
What does this mean in practice? An external invocation of the subclass method (assuming it is accessible outside its class) results in the subclass implementation being invoked. This is normal behavior. But notice that in the superclass, any invocations of the private method result in the superclass's implementation of the method being invoked, not any like-named method in a subclass. In short, invocations of private methods always invoke the implementation of the method declared in the current class.
When a method is inaccessible because the superclass and subclass are in different packages things are more complicated. We defer a discussion of this until Chapter 18.
Static members within a class—whether fields or methods—cannot be overridden, they are always hidden. The fact that they are hidden has little effect, however—each static field or method should always be accessed via the name of its declaring class, hence the fact that it gets hidden by a declaration in a subclass is of little consequence. If a reference is used to access a static member then, as with instance fields, static members are always accessed based on the declared type of the reference, not the type of the object referred to.
The super keyword is available in all non-static methods of a class. In field access and method invocation, super acts as a reference to the current object as an instance of its superclass. Using super is the only case in which the type of the reference governs selection of the method implementation to be used. An invocation of super.method always uses the implementation of method the superclass defines (or inherits). It does not use any overriding implementation of that method further down the class hierarchy. Here is an example that shows super in action:
class Base {
/** return the class name */
protected String name() {
return "Base";
}
}
class More extends Base {
protected String name() {
return "More";
}
protected void printName() {
Base sref = (Base) this;
System.out.println("this.name() = " + this.name());
System.out.println("sref.name() = " + sref.name());
System.out.println("super.name() = " + super.name());
}
}
Although sref and super both refer to the same object using the type Base, only super will ignore the real class of the object to use the superclass's implementation of name. The reference sref will act the same way this acts, selecting an implementation of name based on the actual class of the object. Here is the output of printName:
The Java programming language is strongly typed, which means that it checks for type compatibility at compile time in most cases—preventing incompatible assignments by forbidding anything questionable. Now that you understand the basic type relationship defined by subclasses and superclasses, we can revisit a few details regarding the compatibility of reference types within assignments (implicit or explicit) and conversion between types. The full rules for how and when type conversions are applied, for both reference and primitive types, are discussed in “Type Conversions” on page 216.
When you assign the value of an expression to a variable, either as part of an initializer, assignment statement, or implicitly when an argument value is assigned to a method parameter, the type of the expression must be compatible with the type of the variable. For reference types this means that the type of the expression must be the same type as, or a subtype of, the declared type of the variable—or can be converted to such a type. For example, any method that expects an Attr object as a parameter will accept a ColorAttr object because ColorAttr is a subtype of Attr. This is called assignment compatibility.[2] But the converse is not true—you cannot assign an Attr object to a variable of type ColorAttr, or pass an Attr object as an argument when a ColorAttr is expected.
The same rule applies for the expression used on a return statement within a method. The type of the expression must be assignment compatible with the declared return type of the method.
The null object reference is a special case in that it is assignment compatible with all reference types, including array types—a reference variable of any type can be assigned null.
The types higher up the type hierarchy are said to be wider, or less specific, than the types lower down the hierarchy. The lower types are said to be narrower, or more specific, than their supertypes. When you are expecting a supertype and receive a subtype, a widening conversion takes place. Such a conversion causes the subtype object to be treated as an instance of the supertype and can be checked at compile time. No action is needed by the programmer in a widening conversion. Going the other way—taking a reference to a supertype and converting it to a reference to a subtype—is known as a narrowing conversion. Narrowing conversions must be explicitly requested using the cast operator.
A variable, or an expression, of primitive type can be automatically converted to a reference type using an instance of the wrapper class corresponding to that primitive type—such as an int value becoming an Integer object. Conversely, a reference to a wrapper object can be converted to the primitive value that is being wrapped. These primitive–to–wrapper conversions (termed boxing conversions) are discussed in Chapter 8. The existence of the boxing conversions means that a variable of type Object can be assigned the value of any expression that you can form in the Java programming language.
The type compatibility of an expression in a given context (assignment, argument-passing, operand, etc.) is affected by different type conversions that can be applied manually or automatically, depending on that context. Widening and boxing conversions are examples of type conversions that will be automatically applied in some contexts. The different type conversions that exist and the contexts in which they are applied are discussed in “Type Conversions” on page 216. If an expression requires multiple conversions, or if there is no applicable automatic conversion (as in the case of a narrowing conversion), then you must tell the compiler what conversion to apply by using the cast operator.
A cast is used to tell the compiler that an expression should be treated as having the type specified by the cast—and when applied to primitive types can also affect the value of the expression. A cast consists of a type name within parentheses, applied to an expression. In the previous example we used a widening cast in printName to convert the type of this to its superclass type:
Base sref = (Base) this;
This cast was unnecessary but emphasized that we really wanted the current object to be treated as an instance of its superclass. If we then try to assign sref back to a reference of the narrower More type, an explicit cast is essential:
More mref = (More) sref;
Even though we know the object referred to is of the right type, the compiler still requires an explicit cast.
A widening conversion is also known as an upcast because it casts from one type to another further up the type hierarchy—it is also a safe cast because it is always valid. A narrowing conversion is also known as a downcast because it casts from one type to another, further down the inheritance hierarchy—it is also an unsafe cast because it may not be valid.
When a cast is used to request a conversion, the compiler does not assume that the conversion is correct. If the compiler can tell that is cast is correct, then it can apply the cast. If the compiler can tell that a cast is incorrect then a compile time error can occur. If the compiler cannot ascertain that the cast is correct at compile time, then a run time check will be performed. If the run time check fails because the cast is incorrect, then a ClassCastException is thrown.
You can test the class of an object by using the instanceof operator, which evaluates to true if the expression on its left is a reference type that is assignment compatible with the type name on its right, and false otherwise. Because null is not an instance of any type instanceof for null always returns false. Using instanceof you can safely downcast a reference, knowing that no exception will be thrown. For example:
if (sref instanceof More)
mref = (More) sref;
Note that we still have to apply the cast—that's to convince the compiler that we really meant to use the object as a subclass instance.
Type testing with instanceof is particularly useful when a method doesn't require an object of a more extended type but if passed such an object it can make use of the extended functionality. For example, a sort method may accept a general List type as an argument, but if it actually receives a SortedList then it doesn't have to do anything:
public static void sort(List list) {
if (list instanceof SortedList)
return;
// else sort the list ...
}
We noted briefly that making a class member protected means it can be accessed by classes that extend that class, but that is loose language. More precisely, beyond being accessible within the class itself and to code within the same package (see Chapter 18), a protected member can also be accessed from a class through object references that are of at least the same type as the class—that is, references of the class's type or one its subtypes. An example will make this easier to understand.
Consider a linked-list implementation of a queue, class SingleLinkQueue, with methods add and remove for storing an object at the tail of the queue and removing the object from the head of the queue, respectively. The nodes of the queue are made up of Cell objects that have a reference to the next cell in the queue and a reference to the object stored in the current cell.
class Cell {
private Cell next;
private Object element;
public Cell(Object element) {
this.element = element;
}
public Cell(Object element, Cell next) {
this.element = element;
this.next = next;
}
public Object getElement() {
return element;
}
public void setElement(Object element) {
this.element = element;
}
public Cell getNext() {
return next;
}
public void setNext(Cell next) {
this.next = next;
}
}
A queue then consists of a reference to the head and tail cells and the implementation of add and remove.
public class SingleLinkQueue {
protected Cell head;
protected Cell tail;
public void add(Object item) {/* ... */}
public Object remove() {/* ... */}
}
We make the head and tail references protected so that extended classes can manipulate the linked-list cells directly, rather than having to use add and remove—which would involve wrapping and unwrapping the elements each time.
One group decides that it needs a priority queue in which items are stored in a specific order rather than always being inserted at the tail. So it defines a PriorityQueue class in another package that extends SingleLinkQueue and overrides add to insert the object in the right place. The PriorityQueue class's implementation of add can access the head and tail fields inherited from SingleLinkQueue—the code is in a subclass of SingleLinkQueue and the type of the object reference used (this) is the same as that subclass, namely PriorityQueue, so access to the protected members is allowed. This is what you would expect.
The group designing the priority queue needs an additional feature—it wants to be able to merge two priority queues. In a merge operation the target queue ends up with the elements of both queues, while the queue with which it was merged becomes empty. The merge operation starts like this:
public void merge(PriorityQueue q) {
Cell first = q.head;
// ...
}
We are not accessing the protected member of the current object, but the protected member of an object passed as an argument. This is allowed because the class attempting the access is PriorityQueue and the type of the reference q is also PriorityQueue. If q were a subclass of PriorityQueue this access would also be valid.
Later the group determines that there is a new requirement: It wants to be able to merge a SingleLinkQueue with a PriorityQueue. So it defines an overloaded version of merge that starts like this:
public void merge(SingleLinkQueue q) {
Cell first = q.head;
// ...
}
But this code won't compile.
The problem is that the class attempting to access the protected member is PriorityQueue while the type of the reference to the object being accessed is SingleLinkQueue. SingleLinkQueue is not the same as, nor a subclass of, PriorityQueue, so the access is not allowed. Although each PriorityQueue is a SingleLinkQueue, not every SingleLinkQueue is a PriorityQueue.
The reasoning behind the restriction is this: Each subclass inherits the contract of the superclass and expands that contract in some way. Suppose that one subclass, as part of its expanded contract, places constraints on the values of protected members of the superclass. If a different subclass could access the protected members of objects of the first subclass then it could manipulate them in a way that would break the first subclass's contract—and this should not be permissible.
Protected static members can be accessed in any extended class. If head were a static field, any method (static or not) in PriorityQueue could access it. This is allowed because a subclass can't modify the contract of its static members because it can only hide them, not override them—hence, there is no danger of another class violating that contract.
Members declared protected are also available to any code within the package of the class. If these different queue classes were in the same package, they could access one another's head and tail fields, as could any unrelated type in that package. Classes in the same package are assumed to be fairly trustworthy and not to violate each other's contracts—see Chapter 18. In the list “private, package, protected, public,” each access level adds to the kinds of code to which a member is accessible.
Marking a method final means that no extended class can override the method to change its behavior. In other words, this is the final version of that method. Entire classes can also be marked final:
A class marked final cannot be extended by any other class, and all the methods of a final class are themselves effectively final.
Final classes and methods can improve security. If a class is final, nobody can declare a class that extends it, and therefore nobody can violate its contract. If a method is final, you can rely on its implementation details (unless it invokes non-final methods, of course). You could use final, for example, on a validatePassword method to ensure that it does what it is advertised to do instead of being overridden to always return true. Or you can mark as final the class that contains the method so that it can never be extended to confuse the implementation of validatePassword.
Marking a method or class final is a serious restriction on the use of the class. If you make a method final, you should really intend that its behavior be completely fixed. You restrict the flexibility of your class for other programmers who might want to use it as a base from which to add functionality to their code. Marking an entire class final prevents anyone else from extending your class, limiting its usefulness to others. If you make anything final, be sure that you want to create these restrictions.
In many cases, you can achieve the security of marking a whole class final by leaving the class extensible and instead marking each method in the class as final. In this way, you can rely on the behavior of those methods while still allowing extensions that can add functionality without overriding methods. Of course, fields that the final methods rely on should be final or private, or else an extended class could change behavior by changing those fields.
Another ramification of final is that it simplifies optimizations. When a non-final method is invoked, the runtime system determines the actual class of the object, binds the method invocation to the correct implementation of the method for that type, and then invokes that implementation. But if, for example, the getName method was final in the Attr class and you had a reference to an object of type Attr or any extended type, it can take fewer steps to invoke the method. In the simplest case, such as getName, an invocation can be replaced with the actual body of the method. This mechanism is known as inlining. An inlined method makes the following two statements perform the same:
Although the two statements are equally efficient, a getName method allows the name field to be read-only and gives you the benefits of abstraction, allowing you to change the implementation.
The same optimizations can be applied to private and static methods, because they too cannot be overridden.
Some type checks become faster with final classes. In fact, many type checks become compile time checks, and errors can be caught earlier. If the compiler encounters a reference to a final class, it knows that the object referred to is exactly that type. The entire class hierarchy for that class is known, so the compiler can check whether any use is valid or invalid. With a non-final reference, some checks can happen only at run time.
Exercise 3.4: Which methods (if any) of Vehicle and PassengerVehicle might reasonably be made final?
An extremely useful feature of object-oriented programming is the concept of the abstract class. Using abstract classes, you can declare classes that define only part of an implementation, leaving extended classes to provide specific implementation of some or all of the methods. The opposite of abstract is concrete—a class that has only concrete methods, including implementations of any abstract methods inherited from superclasses, is a concrete class.
Abstract classes are helpful when some of the behavior is defined for most or all objects of a given type, but other behavior makes sense only for particular classes and not for a general superclass. Such a class is declared abstract, and each method not implemented in the class is also marked abstract. (If you need to define some methods but you don't need to provide any implementation, you probably want to use interfaces, which are described in Chapter 4.)
For example, suppose you want to create a benchmarking harness to provide an infrastructure for writing benchmarked code. The class implementation could understand how to drive and measure a benchmark, but it couldn't know in advance which benchmark would be run. Most abstract classes fit a pattern in which a class's particular area of expertise requires someone else to provide a missing piece—this is commonly known as the “Template Method” pattern. In many cases the expertise methods are good candidates for being final so that the expertise cannot be compromised in any way. In this benchmarking example, the missing piece is code that needs to be benchmarked. Here is what such a class might look like:
abstract class Benchmark {
abstract void benchmark();
public final long repeat(int count) {
long start = System.nanoTime();
for (int i = 0; i < count; i++)
benchmark();
return (System.nanoTime() - start);
}
}
Any class with any abstract methods must be declared abstract. This redundancy helps the reader quickly see that the class is abstract without scanning to see whether any method in the class is declared abstract.
The repeat method provides the benchmarking expertise. It can time a run of count repetitions of the benchmark. The method System.nanoTime returns a timestamp in nanoseconds—see page 665. By subtracting the starting time from the finishing time you get an approximation of the time spent executing the benchmark. If the timing needs become more complex (perhaps measuring the time of each run and computing statistics about the variations), this method can be enhanced without affecting any extended class's implementation of its specialized benchmark code.
The abstract method benchmark must be implemented by each subclass that is not abstract itself. This is why it has no implementation in this class, just a declaration. Here is an example of a simple Benchmark extension:
class MethodBenchmark extends Benchmark {
/** Do nothing, just return. */
void benchmark() {
}
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
long time = new MethodBenchmark().repeat(count);
System.out.println(count + " methods in " +
time + " nanoseconds");
}
}
This class times how long it takes to invoke an empty method benchmark, plus the loop overhead. You can now time method invocations by running the application MethodBenchmark with the number of times to repeat the test. The count is taken from the program arguments and decoded using the Integer class's parseInt method on the argument string, as described in “String Conversions” on page 316.
Any class can override methods from its superclass to declare them abstract, turning a concrete method into an abstract one at that point in the type tree. This technique is useful, for example, when a class's default implementation is invalid for a part of the class hierarchy.
You cannot create an object of an abstract class because there would be no valid implementation for some methods that might well be invoked.
Exercise 3.5: Write a new extended class that benchmarks something else, such as how long it takes to run a loop from zero to some passed-in parameter.
Exercise 3.6: Change Vehicle so that it has an EnergySource object reference, which is associated with the Vehicle in its constructor. EnergySource must be an abstract class, because a GasTank object's measure of fullness will differ from that of a Battery object. Put an abstractempty method in EnergySource and implement it in GasTank and Battery classes. Add a start method to Vehicle that ensures that the energy source isn't empty.
The Object class is the root of the class hierarchy. Every class directly or indirectly extends Object and so a variable of type Object can refer to any object, whether a class instance or an array. For example, the Attr class can hold an attribute of any type, so its value field was declared to be of type Object. Such a class cannot hold primitive types directly, but can hold references to the associated wrapper class—see Chapter 8.
The Object class defines a number of methods that are inherited by all objects. These methods fall into two categories: general utility methods and methods that support threads. Thread support is covered in Chapter 14. This section describes the utility methods and how they affect classes. The utility methods are:
public booleanequals(Object obj)Compares the receiving object and the object referenced by
objfor equality, returningtrueif they have the same value andfalseif they don't. If you want to determine whether two references refer to the same object, you can compare them using==and!=. Theequalsmethod is concerned with value equality. The default implementation ofequalsinObjectassumes that an object is equal only to itself, by testing ifthis ==obj.
public inthashCode()Returns a hash code for this object. Each object has a hash code for use in hashtables. The default implementation returns a value that is usually different for different objects. It is used when storing objects in hashed collections, as described in Chapter 21.
protected Objectclone()throws CloneNotSupportedExceptionReturns a clone of this object. A clone is a new object that is a copy of the object on which
cloneis invoked. Cloning is discussed in the next section.
public final Class<?>getClass()Returns the type token that represents the class of this object. For each class
Tthere is a type tokenClass<T>(read as “class of T”) that is an instance of the generic classClassdescribed in “The Class Class” on page 399. When invoked on an instance ofObjectthis method will return an instance ofClass<Object>; when invoked on an instance ofAttrit will return an instance ofClass<Attr>, and so forth.
protected voidfinalize()throws ThrowableFinalizes the object during garbage collection. This method is discussed in detail in “Finalization” on page 449.
public StringtoString()Returns a string representation of the object. The
toStringmethod is implicitly invoked whenever an object reference is used within a string concatenation expression as an operand of the+operator. TheObjectversion oftoStringconstructs a string containing the class name of the object, an@character, and a hexadecimal representation of the instance's hash code.
Both the hashCode and equals methods should be overridden if you want to provide a notion of equality different from the default implementation provided in the Object class. The default is that any two different objects are not equal and their hash codes are usually distinct.
If your class has a notion of equality in which two different objects can be equal, those two objects must return the same value from hashCode. The mechanism used by hashed collections relies on equals returning true when it finds a key of the same value in the table. For example, the String class overrides equals to return true if the two String objects have the same contents. It also overrides hashCode to return a hash based on the contents of the String so that two strings with the same contents have the same hashCode.
The term identity is used for reference equality: If two references are identical, then == between the two will be true. The term equivalence describes value equality—objects that may or may not be identical, but for which equals will return true. So one can say that the default implementation of equals is that equivalence is the same as identity. A class that defines a broader notion of equality can have objects that are not identical be equivalent by overriding equals to return true based on the states of the objects rather than their identities.
Some hashtables, such as java.util.IdentityHashMap, are concerned with identity of objects, not equivalence. If you need to write such a hashtable, you want hash codes corresponding to the identity of objects, not their states. The method System.identityHashCode returns the same value that the Object class's implementation of hashCode would return for an object if it were not overridden. If you simply use hashCode on the objects you are storing, you might get a hash code based on equivalence, not on identity, which could be far less efficient.
Exercise 3.7: Override equals and hashCode for ColorAttr.
The Object.clone method helps you write clone methods for your own classes. A clone method returns a new object whose initial state is a copy of the current state of the object on which clone was invoked. Subsequent changes to the new clone object should not affect the state of the original object.
There are three important factors in writing a clone method:
The empty
Cloneableinterface, which you must implement to provide aclonemethod that can be used to clone an object.[3]The
clonemethod implemented by theObjectclass, which performs a simple clone by copying all fields of the original object to the new object. This method works for many classes but may need to be supplemented by an overriding method.The
CloneNotSupportedException, which can be used to signal that a class'sclonemethod shouldn't have been invoked.
A given class can have one of four different attitudes toward clone:
Support
clone. Such a class implementsCloneableand declares itsclonemethod to throw no exceptions.Conditionally support
clone. Such a class might be a collection class that can be cloned in principle but cannot successfully be cloned unless its contents can be cloned. This kind of class will implementCloneable, but will let itsclonemethod pass through anyCloneNotSupportedExceptionit may receive from other objects it tries to clone. Or a class may have the ability to be cloned itself but not require that all subclasses also have the ability to be cloned.Allow subclasses to support
clonebut don't publicly support it. Such a class doesn't implementCloneable, but if the default implementation ofcloneisn't correct, the class provides a protectedcloneimplementation that clones its fields correctly.Forbid
clone. Such a class does not implementCloneableand provides aclonemethod that always throwsCloneNotSupportedException.
Object.clone checks whether the object on which it was invoked implements the Cloneable interface and throws CloneNotSupportedException if it does not. Otherwise, Object.clone creates a new object of exactly the same type as the original object on which clone is invoked and initializes the fields of the new, cloned object to have the same values as the fields of the original object. When Object.clone is finished, it returns a reference to the new object.
The simplest way to make a class that can be cloned is to declare that it implements the Cloneable interface, and override the clone method, redeclaring it to be public:
public class MyClass extends HerClass implements Cloneable {
public MyClass clone()
throws CloneNotSupportedException {
return (MyClass) super.clone();
}
// ...
}
Any other code can now make a clone of a MyClass object. In this simple case, all fields of MyClass will be assigned by Object.clone into the new object that is returned. Note that the overriding implementation declares that it returns an instance of MyClass, not Object, utilizing the ability to specify a covariant return type—this saves the calling code from having to supply a cast, but we have to supply it internally when returning the value from super.clone().
The clone method in Object has a throwsCloneNotSupportedException declaration. This means a class can declare that it can be cloned, but a subclass can decide that it can't be cloned. Such a subclass would implement the Cloneable interface because it extends a class that does so, but the subclass could not, in fact, be cloned. The extended class would make this known by overriding clone to always throw CloneNotSupportedException and documenting that it does so. Be careful—this means that you cannot determine whether a class can be cloned by a run time check to see whether the class implements Cloneable. Some classes that can't be cloned will be forced to signal this condition by throwing an exception.
Objects of most classes can be cloned in principle. Even if your class does not support the Cloneable interface, you should ensure that its clone method is correct. In many classes, the default implementation of clone will be wrong because it duplicates a reference to an object that shouldn't be shared. In such cases, clone should be overridden to behave correctly. The default implementation assigns each field from the source to the same field in the destination object.
If, for example, an object has a reference to an array, a clone of one of the objects will refer to the same array. If the array holds read-only data, such a shared reference is probably fine. But if it is a list of objects that should be distinct for each of your objects, you probably don't want the clone's manipulation of its own list to affect the list of the original source object, or vice versa.
Here is an example of the problem. Suppose you have a simple integer stack class:
public class IntegerStack implements Cloneable { // dangerous
private int[] buffer;
private int top;
public IntegerStack(int maxContents) {
buffer = new int[maxContents];
top = -1;
}
public void push(int val) {
buffer[++top] = val;
}
public int pop() {
return buffer[top--];
}
public IntegerStack clone() {
try {
return (IntegerStack) super.clone();
} catch (CloneNotSupportedException e) {
// Cannot happen -- we support clone
throw new InternalError(e.toString());
}
}
// ...
}
Here we override clone to make it public, but we use the default implementation from the Object class.
Now let's look at some code that creates an IntegerStack object, puts some data onto the stack, and then clones it:
IntegerStack first = new IntegerStack(2); first.push(2); first.push(9); IntegerStack second = first.clone();
With the default clone method, the data in memory will look something like this:
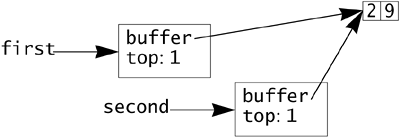
Now consider what happens when future code invokes first.pop(), followed by first.push(17). The top element in the stack first will change from 9 to 17, which is expected. The programmer will probably be surprised, however, to see that the top element of second will also change to 17 because there is only one array that is shared by the two stacks.
The solution is to override clone to make a copy of the array:
public IntegerStack clone() {
try {
IntegerStack nObj = (IntegerStack) super.clone();
nObj.buffer = buffer.clone();
return nObj;
} catch (CloneNotSupportedException e) {
// Cannot happen -- we support
// clone, and so do arrays
throw new InternalError(e.toString());
}
}
First the clone method invokes super.clone. This invocation is very important because the superclass may be working around its own problem of shared objects. If you do not invoke the superclass's method, you solve your own cloning problem but you may create another one. Furthermore, super.clone will eventually invoke the method Object.clone, which creates an object of the correct type. If the IntegerStack implementation of clone used new to create an IntegerStack object, it would be incorrect for any object that extended IntegerStack. The extended class's invocation of super.clone would give it an IntegerStack object, not an object of the correct, extended type. The return value of super.clone is then cast to an IntegerStack reference.
Object.clone initializes each field in the new clone object by assigning it the value from the same field of the object being cloned. You then need only write special code to deal with fields for which copying the value is incorrect. IntegerStack.clone doesn't need to copy the top field, because it is already correct from the “copy values” default. It must, however, make a copy of the buffer array, which is done by cloning the array—all arrays can be cloned, with clone returning a reference of the same type as the array reference on which clone was invoked.
With the specialized clone method in place, the example code now creates memory that looks like this:
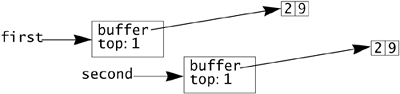
Cloning is an alternative form of construction but is not recognized as construction by the system. This means that you have to be wary of using blank finals (see page 46) that can be set only in constructors. If the value of the final field should be a copy of the value in the object being cloned, then there is no problem since Object.clone will achieve this. If copying the value is not appropriate for the field then it cannot be declared final. In this example, the buffer array is immutable for the life of the object, but it can't be declared final because its value needs to be explicitly set in clone.
If the object that should not be shared between the clone and the original, is not an array, that object should support copying in some way. That may mean that the object itself supports clone, or that it has a copy constructor that allows a duplicate object to be created. For example, the String class does not support clone but it does have a copy constructor that creates a new String with the same contents as the String passed to the constructor. The issues when writing copy constructors are the same as those for writing clone—you must decide when a simple field copy is sufficient and when more specific action is required. One advantage the copy constructor has is that it can deal with final fields in situations where clone cannot.
Sometimes making clone work correctly is not worth the trouble, and some classes should not support clone. In such cases, you should define a clone method that throws CloneNotSupportedException so that objects with bad state will never be created by an unsuspecting subclass that uses clone.
You can declare that all subclasses of a class must support clone properly by overriding your class's clone method with one that drops the declaration of CloneNotSupportedException. Subclasses implementing the clone method cannot throw CloneNotSupportedException, because methods in a subclass cannot add an exception to a method. In the same way, if your class makes clone public, all extended classes must also have public clone methods, because a subclass cannot make a method less visible than it was in its superclass.
The default implementation of clone provides what is known as a shallow clone or copy—it simply performs a field by field copy. A deep clone would clone each object referred to by a field and each entry in an array. This would apply recursively and so deep cloning an object would clone all of the objects reachable from that object. In general, clone is overridden to perform a deeper clone whenever a shallow clone is not appropriate—such as in the IntegerStack example.
The object serialization mechanism (see page 549) allows you to write entire object graphs to a stream of bytes and, using that generated stream of bytes, create an equivalent copy of the original object graphs. Serialization can provide a way to make deeper copies than those provided by Object.clone.
Exercise 3.8: Make Vehicle and PassengerVehicle into Cloneable types. Which of the four described attitudes should each class take toward cloning? Is the simple copying done by Object.clone correct for the clone methods of these classes?
Exercise 3.9: Write a Garage class whose objects can hold up to some number of Vehicle objects in an array. Make Garage a Cloneable type, and write a proper clone method for it. Write a Garage.main method to test it.
Exercise 3.10: Make your LinkedList class (from the exercises in Chapter 2) Cloneable, with clone returning a new list that refers to the same values as the original list, not clones of the values. In other words, changes to one list should not affect the other list, but changes to the objects referenced by the list would be visible in both lists.
The ability to write extended classes is a large part of the benefits of object-oriented programming. When you extend a class to add new functionality, you create what is commonly termed an IsA relationship—the extension creates a new kind of object that “is a” kind of the original class. The IsA relationship is quite different from a HasA relationship, in which one object uses another object to store state or do work—it “has a” reference to that other object.
Let's look at an example. Consider a Point class that represents a point in two-dimensional space by an (x, y) pair. You might extend Point to create, say, a Pixel class to represent a colored point on a screen. A Pixel IsA Point: anything that is true of a simple Point would also be true of a Pixel. The Pixel class might add mechanisms to represent the color of the pixel or a reference to an object that represents the screen on which the pixel is drawn. As a point in a two-dimensional space (the plane of a display) with an extension to the contract (it has color and a screen), a Pixel IsA Point.
On the other hand, a circle is not a point. Although a circle can be described by a point and a radius, a point has uses that no circle would have. For example, if you had a method to place the center of a rectangle at a particular point, would it really make sense to pass in a circle? A circle HasA center that IsA point, but a circle IsNotA point with a radius, and therefore should not be a subclass of Point.
There are times when the correct choice is not obvious and for which different choices will be correct depending on the application. In the end, applications must run and make sense.
Getting IsA versus HasA relationships correct is both subtle and potentially critical. For example, one obvious and common way to design an employee database using object-oriented tools is to use an Employee class that has the properties all persons share (such as name and employee number) and extend it to classes for particular kinds of employees, such as Manager, Engineer, and FileClerk.
This design fails in real-world situations, in which one person operates simultaneously in more than one role. For example, an engineer might be an acting manager in a group and must now appear in two guises. As another example, a teaching assistant is often both a student and a staff member at a university.
A more flexible design would create a Role class and extend it to create classes for roles such as Manager. You would then change the design of the Employee class to have a set of Role objects. A person could now be associated with an ever-changing set of roles in the organization. We have changed from saying that a manager IsAn employee to saying that manager IsA role, and that an employee can HaveA manager's role as well as other roles.
If the wrong initial choice is made, changing deployed systems will be hard because changes could require major alterations in code. For example, methods in the first employee database design would no doubt rely on the fact that a Manager object could be used as an Employee. This would no longer be true if we had to change to the role-based design, and all the original code would break.
The Attr class is an example of a well-designed class—it follows the design principles that you learned in Chapter 2. The fields of the class are private and accessible only through accessor methods, thereby protecting them from modifications that violate the class's contract. The Attr class presents a clean interface to users of the class and at the same time decouples itself from those classes to allow its own implementation to change in the future.
Given that ColorAttr extends Attr, should we have designed Attr differently to make it more suitable for extension? Should the name and value fields have been protected, instead of private, so that a subclass could access them directly? Such decisions require careful thought and consideration of both the benefits and consequences. Making the Attr fields protected would not benefit a subclass because all of the actions that can be performed on those fields can be done via the public methods that Attr provides. On the other hand, making the fields protected would prevent any future modifications to the implementation of Attr because subclasses could depend on the existence and type of those fields, as well as direct access to them. So in this case, Attr's current design is suited for extension as well as for general use.
In our linked-list queue class, SingleLinkQueue, we did make the head and tail fields protected. In that case there was a great performance benefit in allowing the subclass to directly access cells of the linked list—it would be impractical to implement the override of add in PriorityQueue if the only tools available to use were the original add and remove methods. The low-level nature of the SingleLinkQueue class also means that we are not concerned about locking in implementation details—it is after all a linked-list implementation of a queue and that doesn't really leave much scope for change. If we had written a more general queue class that just happened to be using a linked-list implementation, then it would be a different story.
A non-final class has two interfaces. The public interface is for programmers using your class. The protected interface is for programmers extending your class. Do not casually make fields of your classes protected: Both interfaces are real contracts, and both should be designed carefully.
Suppose you want to provide a benchmarking harness for comparing varieties of sorting algorithms. Some things can be said of all sorting algorithm benchmarks: They all have data on which they must operate; that data must support an ordering mechanism; and the number of comparisons and swaps they require to do their work is an important factor in the benchmark.
You can write an abstract class that helps you with these features, but you cannot write a general-purpose sort method—the actual operations of sorting are determined by each extended class. Here is a SortDouble class that sorts arrays of double values, tracking the number of swaps, comparisons, and tests required in a SortMetrics class we define later:
abstract class SortDouble {
private double[] values;
private final SortMetrics curMetrics = new SortMetrics();
/** Invoked to do the full sort */
public final SortMetrics sort(double[] data) {
values = data;
curMetrics.init();
doSort();
return getMetrics();
}
public final SortMetrics getMetrics() {
return curMetrics.clone();
}
/** For extended classes to know the number of elements*/
protected final int getDataLength() {
return values.length;
}
/** For extended classes to probe elements */
protected final double probe(int i) {
curMetrics.probeCnt++;
return values[i];
}
/** For extended classes to compare elements */
protected final int compare(int i, int j) {
curMetrics.compareCnt++;
double d1 = values[i];
double d2 = values[j];
if (d1 == d2)
return 0;
else
return (d1 < d2 ? -1 : 1);
}
/** For extended classes to swap elements */
protected final void swap(int i, int j) {
curMetrics.swapCnt++;
double tmp = values[i];
values[i] = values[j];
values[j] = tmp;
}
/** Extended classes implement this -- used by sort */
protected abstract void doSort();
}
This class defines fields to hold the array being sorted (values) and a reference to a metrics object (curMetrics) to track the measured operations. To ensure that these counts are correct, SortDouble provides routines to be used by extended sorting classes when they need to examine data or perform comparisons and swaps.
When you design a class, you can decide whether to trust its extended classes. The SortDouble class is designed not to trust them, and that is generally the best way to design classes for others to extend. A guarded design not only prevents malicious use, it also prevents bugs.
SortDouble carefully restricts access to each member to the appropriate level. It uses final on all its non-abstract methods. These factors are all part of the contract of the SortDouble class, which includes protecting the measurement of the sort algorithm from tampering. Making the methods final ensures that no extended class overrides these methods to change behavior, and also allows the compiler and runtime system to make them as efficient as possible.
SortMetrics objects describe the cost of a particular sorting run. The class has three public fields. Its only task is to communicate data, so there is no need to hide that data behind accessor methods. SortDouble.getMetrics returns a copy of the data so that it doesn't give out a reference to its internal data. This prevents both the code that creates SortDouble objects and the code in the extended classes from changing the data. Here is the SortMetrics class:
final class SortMetrics implements Cloneable {
public long probeCnt, // simple data probes
compareCnt, // comparing two elements
swapCnt; // swapping two elements
public void init() {
probeCnt = swapCnt = compareCnt = 0;
}
public String toString() {
return probeCnt + " probes " +
compareCnt + " compares " +
swapCnt + " swaps";
}
/** This class supports clone */
public SortMetrics clone() {
try {
// default mechanism works
return (SortMetrics) super.clone();
} catch (CloneNotSupportedException e) {
// can't happen: this and Object both clone
throw new InternalError(e.toString());
}
}
}
The following class extends SortDouble. The SimpleSortDouble class implements doSort with a very slow but simple sort algorithm (a “selection sort”) whose primary advantage is that it is easy to code and easy to understand:
class SimpleSortDouble extends SortDouble {
protected void doSort() {
for (int i = 0; i < getDataLength(); i++) {
for (int j = i + 1; j < getDataLength(); j++) {
if (compare(i, j) > 0)
swap(i, j);
}
}
}
}
Now we can write a test harness for sort algorithms that must be changed only slightly to test a new sort algorithm. Here it is shown as a driver for testing the class SimpleSortDouble:
public class TestSort {
static double[] testData = {
0.3, 1.3e-2, 7.9, 3.17
};
public static void main(String[] args) {
SortDouble bsort = new SimpleSortDouble();
SortMetrics metrics = bsort.sort(testData);
System.out.println("Metrics: " + metrics);
for (int i = 0; i < testData.length; i++)
System.out.println(" " + testData[i]);
}
}
The main method shows how code that drives a test works: It creates an object of a class extended from SortDouble, provides it with the data to be sorted, and invokes sort. The sort method stores the data, initializes the metrics, and then invokes the abstract method doSort. Each extended class implements doSort to do its sorting, invoking getDataLength, compare, and swap when it needs to. When doSort returns, the counts reflect the number of each operation performed. To test a different algorithm, you can simply change the class name after the new. Here is what one run of TestSort looks like:
Now with these classes as examples, let us return to the issue of designing a class to be extended. We carefully designed the protected interface of SortDouble to allow extended classes more intimate access to the data in the object but only to things we want them to manipulate. The access for each part of the class design has been carefully chosen:
public—. The
publicpart of the class is designed for use by the code that tests how expensive the sorting algorithm is. An example of testing code is inTestSort.main. This code provides the data to be sorted and gets the results of the test. For the test code, the metrics are read-only. The publicsortmethod we provide for the test code ensures that the metrics are initialized before they are used.Making the actual
doSortmethodprotectedforces the test code to invoke it indirectly by the publicsortmethod; thus, we guarantee that the metrics are always initialized and so avoid another possible error.To the test code, the only available functionality of the class is to drive a test of a particular sorting algorithm and provide the results. We used methods and access protection to hide the rest of the class, which should not be exposed to the testing code.
protected—. The
protectedpart of the class is designed for use by the sorting code to produce a properly metered sort. Theprotectedcontract lets the sorting algorithm examine and modify the data to produce a sorted list by whatever means the sort desires. It also gives the sorting algorithm a context in which it will be properly driven so that it can be measured. This context is thedoSortmethod.The extended class is not considered trustworthy, and that is why it can access the data only indirectly, through methods that have access to the data. For example, to hide a comparison by avoiding
compare, the sort would have to useprobeto find out what is in the array. Because calls toprobeare also metered, this would, in the end, hide nothing.In addition,
getMetricsreturns a clone of the actual metrics, so a sorting implementation cannot modify the values.private—. The class keeps private to itself data that should be hidden from the outside—namely, the data being sorted and the metrics. Outside code cannot access these fields, directly or indirectly.
Recall that to prevent intentional cheating and accidental misuse, SortDouble is designed not to trust its extended classes. For example, if SortDouble.values (the array being sorted) were protected instead of private, we could eliminate the probe method because sort algorithms normally count only comparisons and swaps. But if we eliminated it, the programmer writing an extended class could avoid using swap to swap data. The results would be invalid in ways that might be hard to notice. Counting probes and declaring the array private preclude some bugs as well as intentionally devious programming.
If a class is not designed to be extended, it often will be misused by subclasses. If your class will have subclasses, you should design its protected parts carefully. The end result may be to have no protected members if extended classes need no special access. If you do not design the protected part of your class, the class should have no protected members, making subclasses rely on its public contract.
Exercise 3.11: Find at least one security hole in SortDouble that would let a sorting algorithm cheat on its metrics without getting caught. Fix the security hole. Assume that the sorting algorithm author doesn't get to write main.
Exercise 3.12: Write a general-purpose SortHarness class that can sort any object type. How would you provide a way to represent ordering for the objects in a general way, given that you cannot use < to compare them?
A new class can extend exactly one superclass, a model known as single inheritance. Extending a class means that the new class inherits not only its superclass's contract but also its superclass's implementation. Some object-oriented languages employ multiple inheritance, in which a new class can have two or more superclasses.
Multiple inheritance is useful when you want a new class to combine multiple contracts and inherit some, or all, of the implementation of those contracts. But when there is more than one superclass, problems arise when a superclass's behavior is inherited in two ways. Assume, for a moment, the following type tree:
This is commonly called diamond inheritance, and there is nothing wrong with it. Many legitimate designs show this structure. The problems exist in the inheritance of implementation, when W's implementation stores some state. If class W had, for example, a public field named goggin, and if you had a reference to an object of type Z called zref, what would zref.goggin refer to? It might refer to X's copy of goggin, or it might refer to Y's copy, or X and Y might share a single copy of goggin because Z is really only a W once even though it is both an X and a Y. Resolving such issues is non-trivial and complicates the design and use of class hierarchies. To avoid such issues, the Java programming language uses the single-inheritance model of object-oriented programming.
Single inheritance precludes some useful and correct designs. The problems of multiple inheritance arise from multiple inheritance of implementation, but in many cases multiple inheritance is used to inherit a number of abstract contracts and perhaps one concrete implementation. Providing a means to inherit an abstract contract without inheriting an implementation allows the typing benefits of multiple inheritance without the problems of multiple implementation inheritance. The inheritance of an abstract contract is termed interface inheritance. The Java pro gramming language supports interface inheritance by allowing you to declare an interface type—the subject of the next chapter.
When we are planning for posterity, we ought to remember that virtue is not hereditary. | ||
| --Thomas Paine | ||
[1] In the JDK 5.0 release the javac compiler issues a (somewhat misleading) warning in both cases. It is expected that the warning when converting to a sequence will be removed. It is possible that in a future release converting from a sequence to an array will be an error.
[2] There is a slight difference between direct assignment and parameter passing—see the discussion on page 218.
[3] Cloneable should have been spelled Clonable, but the misspelling was realized too late to be fixed.