
Linux offers many advantages, but one feature in particular has allowed it to penetrate the corporate market: It can instantly transform inexpensive PCs into full-fledged Web or intranet servers. If you're planning to deploy Linux in a Web setting, this chapter is for you. It focuses exclusively on securing Web hosts and covers these topics:
Securing your Web host begins even before installation, when you make your first crucial decision: which type of Web host you're building. The three most common types are
Intranet Web hosts—Hosts without Internet connectivity, typically connected to a local area network.
Private or extranet Web hosts—Hosts that have Internet connectivity but provide services only to a very limited clientele.
Public or sacrificial Web hosts—Garden-variety Web hosts that users known and unknown can access publicly, 24 hours a day, on the Internet.
Each host type demands a slightly different approach. In an intranet environment, for example, you may provide network services that you'd never allow on a public Web server, and they would pose less risk.
Default Linux installations include many services that your Web host can probably do without, including:
File Transfer Protocol (FTP)
fingerNetwork File System (NFS)
Other RPC services
Server Message Block (SMB) protocol
R services
You must decide which services to provide by weighing their utility, their benefits, and the risks they pose. Let's briefly address these services now.
File Transfer Protocol (FTP) is the standard method of transferring files from one system to another. In intranet and private Web hosts, you may well decide to provide FTP services as a convenient means of file distribution and acceptance. Or you might provide FTP to offer users an alternate avenue though which to retrieve information that is otherwise available via HTTP.
For public Web servers, though, you should probably pass on public FTP. Open anonymous FTP poses various security risks and is a big headache. For example:
If attackers compromise your FTP server, they can gain privileged access to the host's remaining resources.
Attackers can sometimes use external FTP to "hop" your firewall.
On public FTP servers with writeable directories, attackers can perform irritating but effective disk saturation attacks by filling your disks with junk.
Bozos can use your FTP to store contraband, such as stolen or cracked software (warez) or obscene materials prohibited by law.
If your organization must provide public FTP services, dedicate a box specifically for this purpose. Isolate that box (prohibit trust relationships to other machines), strip it to the essentials, and take these steps:
Place the FTP directories on their own file system (perhaps in a
chrootenvironment).Deny users
chmod,overwrite,delete, orrenameprivileges. See Chapter 11, "FTP Security."
fingerd (the finger server) reports
personal information on specified users, including username, real name, shell, directory, and office telephone number (if available).
finger is nonessential and can expose your system to unwanted intelligence-gathering activity. Dan Farmer and Wietse Venema discuss the benefits that finger offers to crackers in their paper "Improving the Security of Your Site by Breaking Into It":
As every finger devotee knows, fingering "@", "0", and "", as well as common names, such as root, bin, ftp, system, guest, demo, manager, etc., can reveal interesting information. What that information is depends on the version of finger that your target is running, but the most notable are account names, along with their home directories and the host that they last logged in from.
(From "Improving the Security of Your Site by Breaking Into It," Dan Farmer and Wietse Venema, http://www.mindrape.org/papers/improve_by_breakin.html .)
Crackers can use this information to track your staff's movements and even identify levels of trust within your organization and network. At a bare minimum, attackers can build user lists and establish other possible avenues of attack.
To appreciate your potential level of exposure, consider this output, pulled from a finger server at moria.bu.edu:
allysony Allyson Yarbrough qterm 73 csa (BABB022-0B96AX01.BU.E ann317 Ann Lam netscap 35 csa (PUB6-XT19.BU.EDU:0.0) annie77 Nhi Au emacs-1 38 csa (PUB3-XT30.BU.EDU:0.0) april jeannie lu tin *43 csa (sonic.synnet.com) artdodge Adam Bradley pico 40 csb (cs-xt6.bu.edu:0.0) barford Paul Barford pine *1* csb (exeter) best Azer Bestavros tcsh 28 csb (sphinx:0.0) best Azer Bestavros tcsh 0 sphinx (:0.0) bhatti bhatti ghulam tin 33 csa (mail.evare.com) brianm Brian Mancuso bash 19 csa (gateway-all.itg.net) budd Phil Budne tcsh *5* csa (philbudne.ne.mediaone carter Bob Carter rlogin 11 csb (liquid.bellcore.com)
The first thing you'll
notice is that several users are logged in not from dialup accounts, but from workstations with static IP addresses or hostnames (sonic.synet.com, mail.evare.com, liquid.bellcore.com, and so on). Determined attackers will take note of this: If they can't gain unlawful access to your host directly, they might be able to compromise one of these other hosts.
For example, consider the situation depicted above. Since users on external hosts already have valid accounts on moria, they provide attackers a convenient avenue of entry. Attackers can log in to moria under legitimate usernames and conduct fishing expeditions without raising suspicion.
Also, by examining the output, attackers can quickly determine that moria supports X sessions (cs-xt6.bu.edu:0:0) and supports at least basic r services for selected users and hosts (liquid.bellcore.com). This is precisely the type of information you're trying to keep under wraps. So, unless you have a very good reason for it, do not run fingerd on your
Web host.
Network File System (NFS) provides distributed file and directory access and allows users from remote hosts to mount your file systems from afar. On the remote user's machine, your exported file systems act and appear as though they are local. NFS services vaguely resemble file and directory sharing in the Windows and MacOS worlds.
In internal networks, you might well use NFS for convenience. For example, by using NFS, you can share out a central directory hierarchy containing essential tools to all workstations of a particular class. Or you can use NFS to share out user home directories. This will ensure that users have access to their files even when they log in to different machines. Hence, user bozo can log in to linux1.samshack.net, linux2.samshack.net, or scounix.samshack.net and still have an identical /home directory.
If you're using NFS on an internal Web server, take at least these steps:
Consider creating a separate partition for file systems that you intend to export, and enable the
nosuidoption.Export file systems read-only whenever possible.
Limit
portmapperaccess to trusted hosts. To do so, addportmapperand your approved host list to/etc/hosts.allow. After you've done that, addportmapperto/etc/hosts.denyand specifyALL.Never export your root file system.
Your NFS server is configured by default to deny access to remote users logged in as root. Do not change this.
Otherwise, unless you absolutely have to, don't run NFS on a public Web server. (The benefits here outweigh the risk by a wide margin.)
Additional RPC services that you should disable are rpc.rusersd (the rusers server), rpc.rwalld (the rwall server), and rstatd (the system statistics daemon).
ruserd can expose
you to unwanted intelligence-gathering activity, producing results similar to finger output. For example, I pulled a host query on Santa Clara University in California (host –l –v –t any scu.edu) to generate a list of possible targets. Here's a snippet of the results:
Bookstore-Switch.scu.edu 83659 IN A 129.210.84.250 gw3svr.scu.edu 83659 IN A 129.210.8.28 832Market-Switch.scu.edu 83659 IN A 129.210.36.253 852Market-Switch.scu.edu 83659 IN A 129.210.37.253 862Market-Switch.scu.edu 83659 IN A 129.210.38.253 Performing-arts-router.scu.edu 83659 IN A 129.210.216.254 FineArts-Router.scu.edu 83659 IN A 129.210.24.254 DonohoeSvr.scu.edu 83659 IN A 129.210.116.248 ebiz.scu.edu 83659 IN A 129.210.46.109 pcalin.scu.edu 83659 IN A 129.210.18.160 IT-SUPPORT-SVR.scu.edu 83659 IN A 129.210.208.12 LeaveySvr.scu.edu 83659 IN A 129.210.104.248 it.scu.edu 83659 IN A 129.210.8.57 www.it.scu.edu 83659 IN CNAME scuish.SCU.EDU sunrise.scu.edu 83659 IN A 129.210.17.17
I picked through this list—which was revealing in itself because of how scu.edu administrators
named their hosts and hardware—and chose this entry:
sunrise.scu.edu 83659 IN A 129.210.17.17
sunrise seemed like a good choice. I guessed that it was a host (not network hardware) and probably a SPARC. I ran a rusers query on it (rusers –l sunrise.scu.edu), and this is what I received:
qli sunrise.scu.edu:pts/0 Jun 12 08:03 26:55 (sunrise) hwen sunrise.scu.edu:pts/14 Jun 4 09:51 44:47 (godzilla.taec.co) vli sunrise.scu.edu:pts/1 Jun 12 18:34 5:49 (205.158.38.36) qli sunrise.scu.edu:pts/19 Jun 9 13:50 8:29 (sunrise)
As you can see, rusersd provides the same basic information as fingerd (minus user directories, real names, and last login), and for that reason, you should
disable it. To do so, comment it out in inetd.conf.
rstatd also
provides interesting information, including statistics on the CPU, virtual memory, network uptime, and hard drive. Although exposure of this data may not pose a significant threat, there's no good reason to provide it on a publicly accessible Web host. I recommend that you disable rstatd. To do so, comment it out
in inetd.conf.
rwalld processes rwall requests
and allows remote users to send messages to all users on the network. (rwall is the networked version of wall.) It serves no purpose on a public Web host and may allow bozos to jam up terminals with nonsensical text. I recommend that you disable rwalld. To do so, comment
it out in inetd.conf.
The R services (rshd, rlogin, rwhod, and rexec) provide varying degrees of command
execution on, or interaction with, remote hosts, and they're quite convenient in closed network environments. However, they have no place on a public Web server. Let's briefly run through each one and what it does.
rshd (the Remote Shell server) allows
remote command execution. The client program (rsh) connects and requests a shell on the specified remote host. There, rshd opens the shell and executes user-supplied commands. For example, suppose you wanted a directory listing of / on the remote host linux3. If linux3 was running rshd, you could issue this command:
rsh linux "ls –l /"
rshd services are not suitable for publicly available Web servers. To disable rshd, comment
it out in inetd.conf.
rlogin is much like
telnet. In fact, once you log in using rlogin, things will work exactly as if you were using telnet. The difference is this: rlogin is designed to automate logins between machines that trust one another. For example, suppose your network had three machines:
linux1.mycompany.com linux2.mycompany.com linux3.mycompany.com
Suppose further that you had an account under the username hacker on all three machines. If you used telnet to log in to linux1, linux2, or linux3, you'd have to enter a username and password every time. To avoid this, use rlogin instead, like this:
rlogin linux1
Because linux1 already knows you, it logs you in immediately without bothering to ask for a username or password. rlogin only works this way if your username is known and you have an .rhosts entry. If not, rlogin will still ask for a username and password.
Providing rlogin services is fine in intranet environments or closed networks, but they aren't essential on a public Web host. To remove rlogind (the rlogin server), remove it from (or comment it out in) inetd.conf. Also, as an extra measure, you might want to remove /etc/hosts.equiv and do
a disk-wide removal of any .rhosts files.
rexec services are
somewhat antiquated but still available on Linux. rexec offers remote command execution, much like rsh. The chief difference is that users must supply a password to execute commands with rexec. However, even with this level of protection, I would still recommend disabling rexecd (the rexec server) on public Web hosts. To do so, comment
out rexecd in inetd.conf.
rwho is the networked
version of who, which is a utility that reports information on currently logged users. Here's an example of a simple who query's output:
NAME LINE TIME mikal ttyq0 Jun 14 02:51
Or, here's a more advanced who query's output, which shows not simply the currently logged user's username and tty, but also his last command:
NAME LINE TIME IDLE PID COMMENTS . system boot Jun 14 02:38 . run-level 2 Jun 14 02:38 2 0 S mikal ftp1253 Jun 14 02:44 1253 id=ftp0 term=0 exit=0 mikal + ttyq0 Jun 14 02:51 . 1497
rwhod (the rwho server) serves such information to remote rwho clients. This utility (much like rusers) can expose sensitive information and help crackers build user lists and usage time- tables. I recommend that you disable rwhod. To do so, comment
it out in inetd.conf.
Next, let's quickly cover additional services that might be running if you didn't personally perform the installation, or if others have previously administered your Linux Web host.
Here's a common scenario: Your organization has been using a Linux box for development for several months. Suddenly, you're informed that the box should be converted to a Web or intranet host. Under these conditions, you should perform a reinstallation. However, if you don't, you may have to disable several services that, although perfectly acceptable on a standalone or internal server, could pose security risks on a Web server.
Table 14.1 addresses those services and what they do, and offers some quick background and suggestions on each one.
Table 14.1. Other Network Services and Daemons
If you're unsure of which services your Web host is running, try scanning the system from port 0 to port 65000. This will reveal many (but not all) running services. (To learn more about network scanning, please see Chapter 8, "Scanners." )
Finally, note that when you disable services, your changes won't go live until you
restart inetd and httpd.
In all likelihood, you'll run several services that could open security holes. For example, it would be difficult to establish and maintain a Web host without providing FTP services to at least internal users. Hence, you'll need to apply host-based access control to those services.
You do this using a toolkit called TCP Wrappers, which offers pattern-matching-based access control to remote services. You can use this to allow or deny services to specified users.
The TCP Wrappers
toolkit offers you wide latitude and functionally resembles a mixture of firewall and intrusion detection tools. Built into the TCP Wrappers system is an extensive access control language, hosts_access, through which you can not only allow and deny access, but also trigger various events
when TCP Wrappers detects certain activity. Learn more about TCP Wrappers in Chapter 18, "Linux and Firewalls."
After slimming down your Web host's services, your next step is to establish access control and authentication on your Web server. That's what this section is all about.
Apache is the Web server, httpd, on most modern Linux distributions.
Application:
httpd
Required:
Apache
Config files:
access.conf, httpd.conf, srm.conf
Security history: Like any mature distribution, Apache has had security bugs in the past. However, the current release is quite stable. To examine Apache's security history, go to http://bugs.apache.org/index. There you'll find an exceptionally comprehensive bug tracking system, with a search engine that provides indexing by bug type, module, version, and severity (critical, serious, or non-critical).
Notes: Apache 1.3.4, released in January 1999, handles all directives in a single, unified file named httpd.conf-dist.
Originally a replacement for (and improvement on) the National Center for Supercomputer Applications' httpd, Apache is the world's most popular HTTP server
and provides many built-in security mechanisms, including
Host-based network access control
Control over if and where local users can run CGI scripts
Control over if and how local users can override your settings
Apache provides
host-based network access control via access.conf. Depending on your Linux distribution, access.conf might be located in several directories, but the most likely is /etc/httpd/apache/conf/.
Here's a standard access.conf from a default installation:
# access.conf: Global access configuration # Online docs at http://www.apache.org/ # This file defines server settings which affect which types of # services are allowed, and in what circumstances. # Each directory to which Apache has access, can be configured # with respect # to which services and features are allowed and/or disabled in that # directory (and its subdirectories). # Originally by Rob McCool # First, we configure the "default" to be a very restrictive set of # permissions. <Directory /> Options None AllowOverride None </Directory> # Note that from this point forward you must specifically allow # particular features to be enabled - so if something's not working as # you might expect, make sure that you have specifically enabled it # below. # This should be changed to whatever you set DocumentRoot to. <Directory /home/httpd/html> # This may also be "None", "All", or any combination of "Indexes", # "Includes", "FollowSymLinks", "ExecCGI", or "MultiViews". # Note that "MultiViews" must be named *explicitly* --- "Options All" # doesn't give it to you. # Options Indexes FollowSymLinks Options None # This controls which options the .htaccess files in directories can # override. Can also be "All", or any combination of "Options", # "FileInfo", "AuthConfig", and "Limit" AllowOverride None # Controls who can get stuff from this server. order allow,deny allow from all </Directory> # /usr/local/etc/httpd/cgi-bin should be changed to whatever your # ScriptAliased CGI directory exists, if you have that configured. #<Directory /usr/local/etc/httpd/cgi-bin> <Directory /home/httpd/cgi-bin> AllowOverride None #Options None Options ExecCGI </Directory> # Allow server status reports, with the URL of # http://servername/server-status # Change the ".your_domain.com" to match your domain to enable. #<Location /server-status> #SetHandler server-status #order deny,allow #deny from all #allow from .your_domain.com #</Location> # There have been reports of people trying to abuse an old bug from # pre-1.1 days. This bug involved a CGI script distributed as a part # of Apache. By uncommenting these lines you can redirect these attacks # to a logging script on phf.apache.org. Or, you can record them # yourself, using the script # support/phf_abuse_log.cgi. #<Location /cgi-bin/phf*> #deny from all #ErrorDocument 403 http://phf.apache.org/phf_abuse_log.cgi #</Location> # You may place any other directories or locations you wish to have # access information for after this one.
To establish rules for applying network access control, concentrate your efforts on directives in this section:
# Controls who can get stuff from this server. order allow,deny allow from all
The directives offer three avenues of control:
allow—Theallowdirective controls which hosts (if any) can connect and offers you four choices:all,none, orlist(wherelistis a list of approved hosts).deny—Thedenydirective controls which hosts (if any) cannot connect and offers you three choices:all,none, orlist(again, wherelistis a list of unapproved hosts).order—Theorderdirective controls the order in which theallow/denyrules are applied and offers three choices:allow, deny,deny, allow, ormutual-failure. (mutual-failureis a special option that specifies that a connection must pass bothallowanddenyrules.)
Using these directives in concert, you can apply access control in several ways:
Inclusively—Here, you explicitly name all authorized hosts.
Exclusively—Here, you explicitly name all unauthorized hosts.
Inclusively and exclusively—Here, you mix and match.
Suppose your
host was linux1.mydom.net and you wanted to restrict all outside traffic. Your access control section might look like this:
order deny, allow allow from linux1.nycom.net deny from all
Here, on evaluation of a connect request, the server first processes denials and rejects everyone. Next, it checks for approved hosts and finds linux1.mycom.net. In this scenario, only connection requests from linux1.mycom.net are allowed.
Of course, this scenario is a bit too restrictive. Chances are, you'd like to allow at least a few machines in your domain to connect. If so, you could make the rules slightly more liberal using a host list, like this:
order deny, allow allow from linux1.mydom.net linux2.mydom.net linux3.mydom.net deny from all
In this new scenario, not only can linux1.mycom.net connect, but linux2.mycom.net and linux3.mycom.net can too. However, other machines in your domain are left out in the cold. (For example, the server will reject connections from fiji.mycom.net and hawaii.mycom.net.)
Or perhaps you aim to allow all connections initiated from your domain, and reject only those coming from foreign networks. To do so, you could configure the access control directives like this:
order deny, allow allow from mydom.net deny from all
Here, any machine in the mydom.net domain can connect. However, note that wherever possible, you should use IP addresses instead of hostnames to designate
hosts and networks. This will guard against DNS spoofing.
Note
In DNS spoofing, the cracker compromises the DNS server and explicitly alters the hostname-IP address tables. These changes are written into the translation table databases on the DNS server. Thus, when a client requests a lookup, he or she is given a bogus address; this address would be the IP address of a machine completely under the cracker's control.
Here's an example that limits connections to those initiated by the host www.deltanet.com :
order deny, allow allow from 199.171.190.25 deny from all
And here's a more general ruleset that limits connections to those initiated from Deltanet's network:
order deny, allow allow from 199.171.190 deny from all
But these are inclusive schemes, where you explicitly name all hosts or networks that can connect. You need not rely on inclusive schemes alone. You can also use exclusive schemes to screen out just one host (or a few of them) using
the deny directive.
Suppose you wanted
to block connections from hackers.annoying.net but still allow connections from everyone else. You might set up your directives like this:
order deny, allow allow from all deny from hackers.annoying.net
This would block hackers.annoying.net
only and grant other hosts open access. Of course, in practice this would probably be an unrealistic approach. The folks on hackers likely also have accounts on other machines within annoying.net. Therefore, you might be forced to block the entire domain, like
this:
order deny, allow allow from all deny from annoying.net
This would block any host coming from annoying.net. And if you later encountered problems from users on hackers from still other domains, you could simply add the new "bad" domains to the list, like this:
order allow, deny allow from all deny from annoying.net hackers.really-annoying.net hackers.knuckelheads.net
But things aren't always that cut-and-dried. Sometimes you need to limit access to a single domain and even refuse connections from machines within it. For
this, you must use the mutual-failure option.
Suppose that you're
running Apache in an intranet environment where your main network is ourcompany.net. Your aim is to provide Web access to all hosts but accounts.ourcompany.net and shipping.ourcompany.net. The easiest way is to establish a ruleset like this:
order mutual-failure allow from ourcompany.net deny from accounts.ourcompany.net shipping.ourcompany.net
The mutual-failure directive forces a test where incoming hosts must meet both allow and deny rules. Here, all hosts in ourcompany.net are granted access
except accounts and shipping.
Except for
network access control functions in access.conf, Apache installs with optimal security settings. In fact, these settings are stringent enough that you may have to change some of them.
As you tailor your Apache configuration to suit your needs and you learn more about it, you may be tempted to enable many useful options that are disabled by default. Table 14.2 lists these options and what they do.
Table 14.2. Various Options in access.conf
These options, and the way you configure them, can raise security issues. Let's briefly cover those now.
Not long after the Web emerged, it became apparent that, although hypertext allowed users to navigate through documents (or between them), it provided little interactivity. Users couldn't manipulate data or search through it.
In response, developers created various programs that could interact with Web servers to produce rudimentary indexing. And as the demand for this functionality increased, so did the need for a standard by which such gateway programs could be written. The result was the Common Gateway Interface (CGI).
CGI is a standard that specifies how Web servers use external applications to pass dynamic information to Web clients. CGI is platform- and language-neutral, so as long as you have the necessary compiler or interpreter, you can write gateway programs in any language. This includes but is not limited to the following:
BASIC
C/C++
Perl
Python
REXX
TCL
The shell languages (
sh,csh,bash,ksh,ash,zsh, etc.)
Typical CGI tasks include performing database lookups, displaying statistics, and running WHOIS or FINGER queries through a Web interface. (Although technically, you could perform almost any network-based query using CGI.)
Apache allows you to control whether CGI programs can be executed and who can execute them. To add CGI execution permission, enable the ExecCGI option
in access.conf, like this:
Options ExecCGI
Does enabling CGI execution pose any risk? Yes, because although you may observe safe programming practices, your users might not. They could inadvertently write CGI programs that weaken system security. Hence, enabling CGI execution is sometimes more trouble than it is worth. Frankly, you may find yourself reviewing your users' code, looking for possible holes.
If you can avoid granting CGI execution, do it.
Note
You can also restrict CGI execution to a specific directory. This way, you can install and execute CGI scripts but your users can't. Some ISPs do this and mandate that users submit their scripts for examination. If the scripts seem safe, the ISP will house them in the approved directory. To restrict CGI to a particular directory, use the ScriptAlias directive to define your desired directory.
Linux supports symbolic links, which are small files that point to the location of other files. When accessed, a symbolic link behaves as though the user accessed the real, referenced file.
For example, suppose your home directory was /home/hacker and you frequently accessed a file named /home/jack/accounting/reports/1999/returns.txt. Instead of typing that long path each time you needed access, you could create a symbolic link, like this:
ln –s /home/jack/accounting/reports/1999/returns.txt returns.txt
This would place a symbolic link named reports.txt in your home directory. From then on, you could access reports.txt locally. This is quite convenient.
Apache supports an option called FollowSymLinks that allows remote users to follow symbolic links in the current directory simply by clicking on their hyperlinks. This has serious security implications because local users can inadvertently (or even maliciously) link to internal system files and thus "break the barrier," allowing remote users to jump over the virtual barrier that separates the Web space from the main file
system hierarchy. Do not enable the FollowSymLinks option.
Apache supports Server Side Includes (SSI), a system that allows Webmasters to include on-the-fly information in HTML documents without actually writing CGI programs.
SSI does this using HTML-based directives, which are commands that you can embed in HTML documents. When Web clients request such documents, the server parses and executes those commands.
Here's an example using the config timefmt directive that reports the time and date:
<html> The current date and time is: <!--#config timefmt="%B %e %Y"--> </html>
When a Web browser calls this document, the server will capture the local host's date and time and then output the following:
The current date and time is: Monday, 14-Jun-99 11:47:37 PST
This is quite convenient and much easier than writing a Perl script (which might have to parse other data) to do the same:
#!/usr/local/bin/perl
if ($ENV{'REQUEST_METHOD'} eq 'POST')
{
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
@pairs = split(/&/, $buffer);
foreach $pair (@pairs)
{
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
$value =~ tr/,/ /;
$contents{$name} = $value;
}
}
print "Content-type: text/html
";
$mydate='/usr/bin/date';
print "<html>";
print "The current date and time is $mydate
";";
print "</html>";
Similarly, SSI allows you to cleanly include additional HTML documents in the final output. For example, suppose you have a Web page that reports daily hacker news, like the one in Figure 14.1.
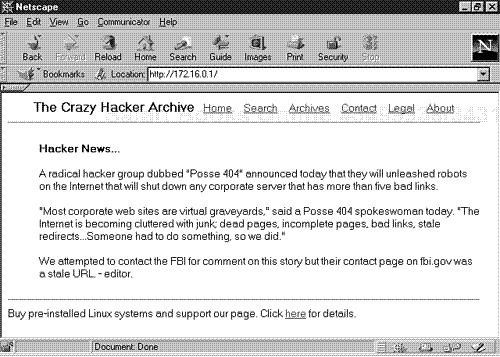
The header and footer
are static, and it's really only the news that changes. Hence, you could create a special file for dynamic news, news.html, and allow your reporters to add their stories to it as they receive them. Meanwhile, backstage, you might employ a script like this:
open(HEADER, "header.html");
while(<HEADER>) {
print;
}
close(HEADER);
open(NEWS, "news.html");
while(<NEWS>) {
print;
}
close(NEWS);
open(FOOTER, "footer.html");
while(<FOOTER>) {
print;
}
close(FOOTER);
The script displays the header, the updated news file, and the footer in sequence. The end result is that you never have to edit or rewrite the header or footer, and all fresh edits to news.html are always automatically displayed. But this seems like an awful lot of work, especially when you could just add this SSI directive to your home page source to
achieve precisely the same result:
<!--#include file="news.html"-->
Because SSIs are so convenient, you might be persuaded to enable them. I recommend that you don't because they can pose security risks. For example, the exec cmd directive allows you to specify systems commands within your source, like this:
<!--#exec cmd=" ls –l /"--> (This would output a directory listing).
This could open your server to possible attack. For instance, suppose your Web page also has a form that takes user input. An attacker could download the HTML source, insert malicious exec commands, and then submit the form. Your server would process the form and unwittingly execute the commands assigned to exec.
For this reason, if you do intend to allow SSIs, at least restrict them to file inclusion and display functions only.
One option you shouldn't enable is directory indexing. This is when Apache sends a directory listing if no default page is found. In a moment, I'll demonstrate why this is undesirable. But first, let's examine how directory indexing works.
It's an unfortunate fact of life that you cannot control how others construct hyperlinks to your server pages. In a perfect world, all Webmasters would use fully qualified URLs, like this:
This URL contains all possible variables:
The protocol (
http)The server's base address
www.ourcompany.netThe port that
httpdis listening on (8080)The directory path (
/)The desired document (
index.html)
Alas, few Webmasters, amateur or professional, take the time to construct URLs this way. Instead, they're more apt to do something like this:
http://www.ourcompany.net/
As you can see, some key variables are missing. This initially doesn't seem problematic because your Web host will sort it out. After receiving the connection request, it will find httpd, which in turn will call the Web
server's / directory.
By default, your Web server looks for a file named index.html in the requested directory. With directory indexing, if the Web server cannot find index.html, it sends
a directory listing instead. Please see Figure 14.2.
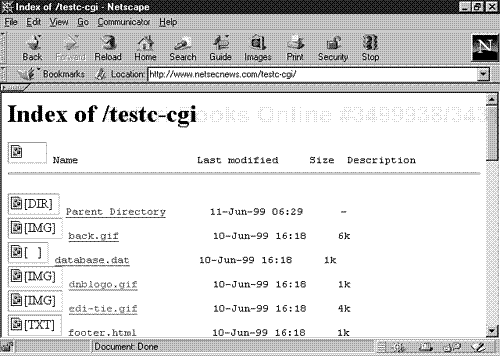
This is undesirable because remote users can browse your file list. Therefore, unless you're hosting an archive where you intend to provide file browsing, do not enable directory listing.
Beyond the measures discussed previously, you can also add additional password protection and access control at the directory level with htpasswd, and allow your users to do the same on a per-directory basis.
The prevailing tool for password-protecting Web directories is Rob McCool's htpasswd.
Application:
htpasswd
Required:
htpasswd and Apache
Config files:
.htpasswd, .htaccess, .htgroup
Security history:
htpasswd has no relevant security history. However, Apache 1.2 had a buffer overflow in cfg_getline(), a function used to read various files, including the htpasswd access files (.htpasswd and .htaccess). This allowed users without access to the Web server UID to obtain such access. You should have a more recent Apache release, but
if not, upgrade.
Notes: None
The htpasswd system offers access control at the user and group levels via three configuration files. Each file fulfills a different function in the authentication process:
.htpasswd—The password database. It stores username and password pairs..htpasswdvaguely resembles/etc/passwdin this respect. When users request access to the protected Web directory, the server prompts them for a username and password. The server then compares these user-supplied values to those stored in.htpasswd..htpasswdis mandatory..htgroup—Thehtpasswdgroups file. It stores group membership information, and in this respect it vaguely resembles/etc/group..htgroupis optional; you only need it if you implement group access control..htaccess—Thehtpasswdaccess file. It stores access rules (allow,deny), the location of configuration files, the authentication method, and so on..htaccessis mandatory.
The following examples show how to implement simple user-based and more complex group-based HTTP authentication.
In this example, you'll password-protect Web directories belonging to a user named Nicole, located in and beneath /home/Nicole/public_html. Because group
authentication is not involved, you need only take two steps:
Create a new
.htpasswddatabaseCreate a new .
htaccessfile
To create a new .htpasswd password database, issue the htpasswd command plus the -c switch, the password filename, and the username, like this:
$ /usr/sbin/htpasswd -c .htpasswd nicole
Note
Depending on your
installation, you may find htpasswd utility in different directories. Two common locations are /home/httpd/bin and /usr/sbin.
The preceding
command tells htpasswd to create a new htpasswd database, .htpasswd, with a user entry for user nicole. In response, htpasswd will prompt you for the new user's password:
Adding password for nicole. New password:
Finally, when you enter the new password, htpasswd will prompt you to confirm it:
Re-type new password:
If the two passwords match, htpasswd will commit this information to .htpasswd, a plain-text file broken into two comma-delimited fields, the username and the encrypted password:
nicole:fG7Gk0K2Isa6s
This new .htpasswd file is your password database. The next step is to create your .htaccess
file.
The .htaccess file stores your access rules and various configuration information. To create it, you can use any plain-text editor.
Here's the .htaccess file
for Nicole's Web directory:
AuthUserFile /home/Nicole/public_html/.htpasswd AuthGroupFile /dev/null AuthName Nicole AuthType Basic <Limit GET POST> require user nicole </Limit>
The file consists of five main directives and their corresponding values:
AuthUserFile—Points to the location of the.htpasswddatabase. Note that when you setAuthUserFile, you must specify the full path to.htpasswd. For instance, in the preceding example, the path is/home/Nicole/public_html, not/~Nicole/public_html.AuthGroupFile—Points to the location of your group access file, normally.htgroup. In this first example, a group file wasn't necessary, so I set theAuthGroupFiledirective value to/dev/null.AuthName—Stores a user-defined text string to display when the authentication dialog box appears. When users request access, they're confronted by a username/password prompt. The caption requests that they "Enter username forAuthNameathostname." Although the server fills in thehostnamevariable, you must specify theAuthNamevariable's value. If you leave it blank, the dialog will display a message like "Enter username for——atwww.myhost.net."AuthType—Identifies the authentication method. In the preceding example, I specified basic authentication, the most commonly used type. Note that although basic authentication provides effective password protection, it does not protect against eavesdropping. That's because in basic authentication, passwords are sent in uuencoded format. More on this later.Limit—Controls which users are allowed access, what type of access they can obtain (such asGET,PUT, andPOST), and the order in which these rules are evaluated.
The Limit directive's
four internal directives offer refined access control:
require—Specifies which users or groups can access the password-protected directory. Valid choices are explicitly named users, explicitly named user groups, or any valid user who appears in.htpasswd. In the example file, I used therequiredirective to limit access to usernicole(require user nicole).allow—Controls which hosts can access the password-protected directory. Syntax isallow fromhost1host2host3, and you can specify these hosts by hostname, IP address, or partial IP addresses.deny—Specifies which hosts are prohibited from accessing the password-protected directory. Syntax isdeny fromhost1host2host3. Here, too, you can specify hosts by their fully qualified hostnames, IP addresses, or partial IP addresses.order—Controls the order in which the server will evaluate access rules. Syntax isdeny, allow(deny rules are processed first) orallow, deny(allow rules are processed first).
If you look at the sample file again, it will now make more sense:
AuthUserFile /home/Nicole/public_html/.htpasswd AuthGroupFile /dev/null AuthName Nicole AuthType Basic <Limit GET POST> require user nicole </Limit>
The file specifies that no group access is allowed, that the authentication is type Basic, and that only user nicole's login and password will be accepted for comparison with the password database's values.
When users connect to Nicole's site, the server locates .htpasswd and notifies the client that authentication is required. In response, the Web browser displays
a password dialog box. Please see Figure 14.3.
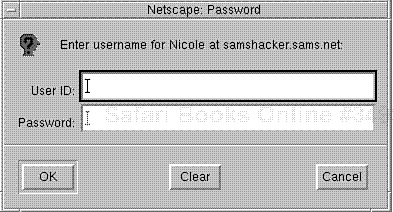
If the user supplies an incorrect username or password, the server rejects his authentication attempt and offers him another opportunity. Please see Figure 14.4.
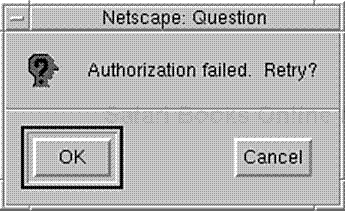
This method is quite effective for password-protecting a single directory hierarchy for a single user. Now, let's address group access.
Setting up group authentication is just slightly more complicated. For this, you must
create an .htgroup file. In this example, let's stick with Nicole's site, located in /home/Nicole/ public_html/.
Let's assume that you want to grant users larry, moe, and curly access to Nicole's site. First, you need to designate a group, which you'll fittingly call stooges. Here's a corresponding .htgroup file:
stooges: larry moe curly
The file is broken into two fields. The first identifies the group, and the second holds your user list. Once you've created .htgroup, you must edit .htaccess and specify .htgroup's location:
AuthUserFile /home/Nicole/public_html/.htpasswd
AuthGroupFile /home/Nicole/public_html/.htgroup
AuthName Nicole
AuthType Basic
<Limit GET POST>
require user nicole
</Limit>
And finally, you must
specify access rules for group stooges:
AuthUserFile /home/Nicole/public_html/.htpasswd AuthGroupFile /home/Nicole/public_html/.htgroup AuthName Nicole AuthType Basic <Limit GET POST> require group stooges </Limit>
When should you use group-based authentication? Here's an example on a microscopic scale: Suppose you password-protect /public_html and allow users larry, moe, and curly to access it. Suppose further that beneath /public_html, you create a special directory named /reports and you want to restrict access to larry and moe only. You could create two groups, as depicted in Figure 14.5.
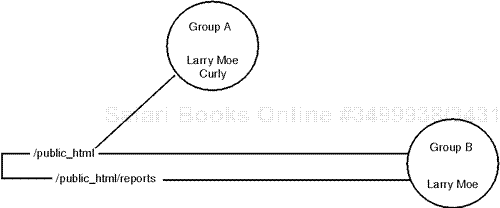
All members of Group A and Group B can access /public_html. However, only larry and moe from Group B can access /public_html/reports.
In reality, if you were dealing with only three users, you could create new .htpasswd and .htaccess files in /public_html/reports and allow any valid user appearing in /public_html/reports/.htpasswd (larry or moe or both). However, when you have several hundred users and multiple directories and subdirectories to restrict, group-based authentication is quite
convenient.
Basic HTTP authentication is a great quick fix for password-protecting Web directories, but it does have weaknesses:
htpasswdprotects against strictly outside approaches. It does not protect local Web directories from local users who can access such directories directly, via the file system or through other services, without using a Web client.By default, the
htpasswdsystem provides no password lockout mechanism and therefore invites sustained, reiterative, or brute-force attacks. Attackers can try as many usernames and passwords as they like. To try a brute-force attack, get BeastMaster'sbrute_Web, located at http://sunshine.sunshine.ro/FUN/New/hacking/brute_Web.c . (Note thatbrute_Webrequires a dictionary file.)
Also, basic HTTP authentication methods are well known. Therefore, when you're employing HTTP authentication on public Web hosts, I strongly recommend that you do not store .htpasswd files in the directories they
protect. If you do, authorized users will be able to download the file and run password-cracking tools against it. This is the Web equivalent of someone grabbing /etc/passwd.
But basic HTTP authentication's greatest weakness by far is that passwords are sent in encoded but not encrypted format. Hence, attackers can sniff authentication traffic.
Note
To sniff your own HTTP authentication traffic, get Web_sniff by
BeastMaster V from Rootshell. It was specifically
designed to capture and decode basic HTTP authentication passwords on-the-fly. Find it at
http://bob.urs2.net/computer_security/C%20source%20code/Web_sniff.c
.
If you're concerned about electronic eavesdropping, you can opt out of basic HTTP authentication for something more industrial-strength: cryptographic authentication.
Currently, above
and beyond Basic type authentication, Apache supports digest-based cryptographic authentication using MD5. MD5 belongs to a family of one-way hash functions called message digest
algorithms and was originally defined in RFC 1321:
The algorithm [MD5] takes as input a message of arbitrary length and produces as output a 128-bit "fingerprint" or "message digest" of the input. It is conjectured that it is computationally infeasible to produce two messages having the same message digest, or to produce any message having a given prespecified target message digest. The MD5 algorithm is intended for digital signature applications, where a large file must be "compressed" in a secure manner before being encrypted with a private (secret) key under a public-key cryptosystem such as RSA.
(RFC 1321 is located at http://www.thefrog.com/source/rfc1321.txt .)
MD5 has been most often used to ascertain file integrity (or whether someone has tampered with files). When you run a file through MD5, the fingerprint emerges as a unique 32-character value, like this:
2d50b2bffb537cc4e637dd1f07a187f4
Many UNIX software distribution sites use MD5 to generate digital fingerprints for their distributions. As you browse their directories, you can examine the original digital fingerprint of each file. A typical directory listing would look like this:
MD5 (wn-1.17.8.tar.gz) = 2f52aadd1defeda5bad91da8efc0f980 MD5 (wn-1.17.7.tar.gz) = b92916d83f377b143360f068df6d8116 MD5 (wn-1.17.6.tar.gz) = 18d02b9f24a49dee239a78ecfaf9c6fa MD5 (wn-1.17.5.tar.gz) = 0cf8f8d0145bb7678abcc518f0cb39e9 MD5 (wn-1.17.4.tar.gz) = 4afe7c522ebe0377269da0c7f26ef6b8 MD5 (wn-1.17.3.tar.gz) = aaf3c2b1c4eaa3ebb37e8227e3327856 MD5 (wn-1.17.2.tar.gz) = 9b29eaa366d4f4dc6de6489e1e844fb9 MD5 (wn-1.17.1.tar.gz) = 91759da54792f1cab743a034542107d0 MD5 (wn-1.17.0.tar.gz) = 32f6eb7f69b4bdc64a163bf744923b41
If you download a file from such a server and later determine that the digital fingerprint differs from its reported original, something is amiss.
Because MD5 offers high assurance, developers have incorporated it into many network applications. MD5 authentication over HTTP has actually been available ever since NCSA httpd was the prevailing Web server. Let's look at MD5 digest authentication now.
You can add MD5 authentication
using the htdigest tool.
Application:
htdigest
Required:
htdigest and Apache
Config files:
.htdigest
Security history:
htdigest has no relevant security history.
Notes: None
htdigest works in a similar fashion as htpasswd. To create a new digest database, .htdigest, issue the following command:
htdigest -c .htdigest [realm] [username]
Note
The
realm
variable is your AuthName from .htpasswd.
Next, edit .htacess and
specify .htdigest's location:
AuthUserFile /home/Nicole/public_html/.htpasswd
AuthGroupFile /home/Nicole/public_html/.htgroup
AuthDigestFile /home/Nicole/public_html/.htdigest
AuthName Nicole
AuthType Basic
<Limit GET POST>
require user nicole
</Limit>
And finally, specify the new authentication type:
AuthUserFile /home/Nicole/public_html/.htpasswd
AuthGroupFile /home/Nicole/public_html/.htgroup
AuthDigestFile /home/Nicole/public_html/.htdigest
AuthName Nicole
AuthType Digest
<Limit GET POST>
require user nicole
</Limit>
After you complete these steps, all further authentication will be digest-based. This will at least ensure that even if attackers come armed with sniffers, they won't be able to harvest any passwords.
Another method of
bolstering Web security is to run a chroot Web environment. To do so, use the chroot program.
Application:
chroot
Required:
chroot
Config files: None
Security history: None
chroot allows you to change the root directory. That is, you can designate a "new" root directory hierarchy where your Web will reside. In this directory hierarchy, you create a miniature Linux file system. This environment is sometimes called a "jail" because even if attackers do manage to exploit some weakness in your Web system, their leveraged access cannot bleed over into the main file system.
You create a chroot environment
in five steps:
Create a user/owner for this Web tree.
Create a group for this Web tree.
Create the Web tree's directory.
chrootthe Web server root to that directory.Create a miniature directory system there.
All of these steps are simple except for the last one. For example, assume that the owner is webowner and the group is webgroup. To create the root directory, webjail, and set permissions and ownership, you'd issue these commands:
mkdir /webjail chown -R webowner:webgroup /webjail chmod -R 775 /webjail
Next, log in as webowner and create the directory hierarchy. Here, you must carefully consider what programs and functions you want to support. At a minimum, you'll need a /bin directory with one shell and some staple system commands (ls, mv, grep, cat, cp, and so on). But that's not all. If you intend to run any CGI programs, you'll need to include Perl, which
would entail /bin/perl and /usr/lib/perl.
After you decide which programs and functions you want to support, create the appropriate directories and copy over the files. Note that you may have to duplicate the directory structure, precisely because some utilities have hard links hard-coded into their source.
When you're finished, issue the following command:
chroot /webjail httpd
Establishing a chroot Web environment is not easy and takes considerable research. The following online documents can guide you through the most
difficult choices.
Web Server Wiles '98 (Part One), Peter Galvin and Carole Fennelly. Although the authors wrote specifically for Solaris, they take you through the essential steps of establishing a
chrootenvironment ( http://www.sunworld.com/sunworldonline/swol-05-1998/ swol-05-security.html ).Web Server Setup, [email protected]. This document describes in detail how to establish a restricted Web environment ( http://csel.cs.colorado.edu/udp/admin/apache.html ).
A
chrootExample, Denice Deatrich. This document is quite comprehensive and covers many subtle problems you may encounter while establishing achrootWeb environment ( http://www.me-tf.postech.ac.kr/NCSA-HTTPd/docs/tutorials/chroot-example.html ).The World Wide Web Security FAQ, Lincoln Stein ( http://onlineinstitute.com/cgi/wwwsf2.html ).
Finally, I wanted to address a seldom-treated issue that's relevant if you're employing your Linux Web server in electronic commerce: accreditation. In enterprise or electronic commerce environments, you may need verification that your business, process, and transactional processes are secure. Your trading partners might even make this a requisite.
One route is to have your system assessed by a recognized body of professionals (after you've secured it). When your system is assessed this way, it's ultimately given a certificate of assurance. This next section identifies several bodies that offer certification.
Coopers&Lybrand L.L.P., Resource Protection Services
One Sylvan Way
Parsippany, NJ 07054 USA
Phone: (800) 639-7576
Email: [email protected]
Coopers&Lybrand's Resource Protection Services group is composed of the Information Technology Security Services (ITSS) and Business Continuity Planning (BCP) services. Their professionals provide a full range of security and BCP solutions, including security implementation services, electronic commerce and cryptography services, technical security analysis and design, penetration testing, security management services, and business continuity planning using their trademarked CALIBER Methodology.
The ITSS branch specializes in testing and certification in the following areas:
American Institute of Certified Public Accountants
1211 Avenue of the Americas
New York, NY 10036-8775
Phone: (212) 596-6200
Fax: (212) 596-6213
The American Institute of Certified Public Accountants (AICPA) offers the WebTrust certification system. In this process, CPAs trained in information security assess your network for the following:
Transaction integrity
Encryption and secure communications
Best security practices
Your successful certification results in a VeriSign security certificate and the WebTrust seal of approval. This notifies customers that CPAs have evaluated your business practices and controls and determined that they are in conformity with WebTrust Principles and Criteria for Business-to-Consumer Electronic Commerce.
The WebTrust system is similar to CPA certification of your firm's assets, profits, and losses. The certification comes with the signature and assurance of a trained professional licensed in his given area of expertise.
International Computer Security Association
ICSA, Inc. Corporate Headquarters
1200 Walnut Bottom Road
Carlisle, PA 17013-7635
Phone: (717) 258-1816
Email: [email protected]
URL: http://www.icsa.com/
The International Computer Security Association (formerly the National Computer Security Association) is the world's largest provider of computer security assurance services. Their mission is to better public confidence in computer security through a program of products and services certification.
Besides certifying products, ICSA also provides network assurance and certification. This is done through their TruSecure program. TruSecure is a service in which ICSA tests and certifies your Web servers, firewalls, and network at an operational level.
Upon completing the certification process, your company will receive a seal of approval
from ICSA.COM certifying your network.
Troy Systems
3701 Pender Drive, Suite 500
Fairfax, VA 22030
Phone: (703) 218-5300
Fax: (703) 218-5301
Email: [email protected]
URL: http://www.troy.com
Troy Systems' Information Systems Security supports government and commercial clients with security planning, risk management, security test and evaluation, vulnerability testing, technical countermeasures, disaster recovery, contingency planning, Internet/intranet security, training and awareness, and certification and accreditation.
Troy Systems services some major governmental agencies. For example, they recently secured a contract with the U.S. Army Medical Information Systems and Services Agency.
Beyond the steps described in this chapter, the best step you can take to secure your Web server is to become intimately familiar with Apache's configuration options. For this, I recommend that you obtain a copy of Apache: The Definitive Guide, Second Edition, by Ben and Peter Laurie, from O'Reilly and Associates.
Also, Web server security is inextricably linked not simply to where your CGI programs reside, but also to whether you wrote them in a secure manner. Hence, if you intend to provide CGI functionality, check Chapter 16, "Secure Web Development," for secure programming techniques. Nothing spoils a secure server like insecure CGI programs.