
Forward Error Correction
Channel Coding
Retransmission
Implementation Considerations
Although it is clearly important to be able to conceal the effects of transmission errors, it is better if those errors can be avoided or corrected. This chapter presents techniques that the sender can use to help receivers recover from packet loss and other transmission errors.
The techniques used to correct transmission errors fall into two basic categories: forward error correction and retransmission.80 Forward error correction relies on additional data added by the sender to a media stream, which receivers can then use to correct errors with a certain probability. Retransmission, on the other hand, relies on explicit requests for additional copies of particular packets.
The choice between retransmission and forward error correction depends on the application and on the network characteristics. The details and trade-offs of the different approaches are discussed in more detail in this chapter.
Forward error correction (FEC) algorithms transform a bit stream to make it robust for transmission. The transformation generates a larger bit stream intended for transmission across a lossy medium or network. The additional information in the transformed bit stream allows receivers to exactly reconstruct the original bit stream in the presence of transmission errors. Forward error correction algorithms are notably employed in digital broadcasting systems, such as mobile telephony and space communication systems, and in storage systems, such as compact discs, computer hard disks, and memory. Because the Internet is a lossy medium, and because media applications are sensitive to loss, FEC schemes have been proposed and standardized for RTP applications. These schemes offer both exact and approximate reconstruction of the bit stream, depending on the amount and type of FEC used, and on the nature of the loss.
When an RTP sender uses FEC, it must decide on the amount of FEC to add, on the basis of the loss characteristics of the network. One way of doing this is to look at the RTCP receiver report packets it is getting back, and use the loss fraction statistics to decide on the amount of redundant data to include with the media stream.
In theory, by varying the encoding of the media, it is possible to guarantee that a certain fraction of losses can be corrected. In practice, several factors indicate that FEC can provide only probabilistic repair. Key among those is the fact that adding FEC increases the bandwidth of a stream. This increase in bandwidth limits the amount of FEC that can be added on the basis of the available network capacity, and it may also have adverse effects if loss is caused by congestion. In particular, adding bandwidth to the stream may increase congestion, worsening the loss that the FEC was supposed to correct. This issue is discussed further in the section titled At the Sender, under Implementation Considerations, later in this chapter, as well as in Chapter 10, Congestion Control.
Note that although the amount of FEC can be varied in response to reception quality reports, there is typically no feedback about individual packet loss events, and no guarantee that all losses are corrected. The aim is to reduce the residual loss rate to something acceptable, then to let error concealment take care of any remaining loss.
If FEC is to work properly, the loss rate must be bounded, and losses must occur in particular patterns. For example, it is clear that an FEC scheme designed to correct 5% loss will not correct all losses if 10% of packets are missing. Less obviously, it might be able to correct 5% loss only if the losses are of nonconsecutive packets.
The key advantage of FEC is that it can scale to very large groups, or groups where no feedback is possible.54 The amount of redundant data added depends on the average loss rate and on the loss pattern, both of which are independent of the number of receivers. The disadvantage is that the amount of FEC added depends on the average loss rate. A receiver with below-average loss will receive redundant data, which wastes capacity and must be discarded. One with above-average loss will be unable to correct all the errors and will have to rely on concealment. If the loss rates for different receivers are very heterogeneous, it will not be possible to satisfy them all with a single FEC stream (layered coding may help; see Chapter 10, Congestion Control).
Another disadvantage is that FEC may add delay because repair cannot happen until the FEC packets arrive. If FEC packets are sent a long time after the data they protect, then a receiver may have to choose between playing damaged data quickly or waiting for the FEC to arrive and potentially increasing the end-to-end delay. This is primarily an issue with interactive applications, in which it is important to have low delay.
Many FEC schemes exist, and several have been adopted as part of the RTP framework. We will first review some techniques that operate independently of the media format—parity FEC and Reed–Solomon encoding—before studying those specific to particular audio and video formats.
One of the simplest error detection/correction codes is the parity code. The parity operation can be described mathematically as an exclusive-or (XOR) of the bit stream. The XOR operation is a bitwise logic operation, defined for two inputs in this way:
0 XOR 0 = 0 1 XOR 0 = 1 0 XOR 1 = 1 1 XOR 1 = 0
The operation may easily be extended to more than two inputs because XOR is associative:
A XOR B XOR C = (A XOR B) XOR C = A XOR (B XOR C)
Changing a single input to the XOR operation will cause the output to change, allowing a single parity bit to detect any single error. This capability is of limited value by itself, but when multiple parity bits are included, it becomes possible to detect and correct multiple errors.
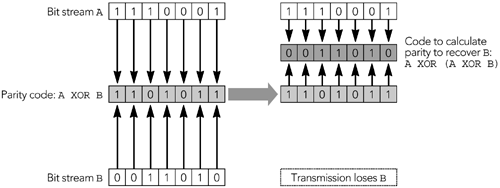
To make parity useful to a system using RTP-over-UDP/IP—in which the dominant error is packet loss, not bit corruption—it is necessary to send the parity bits in a separate packet to the data they are protecting. If there are enough parity bits, they can be used to recover the complete contents of a lost packet. The property that makes this possible is that
A XOR B XOR B = A
for any values of A and B.
If we somehow transmit the three pieces of information A, B, and A XOR B separately, we need only receive two of the three pieces to recover the values of A and B. Figure 9.1 shows an example in which a group of seven lost bits is recovered via this process, but it works for bit streams of any length. The process may be directly applied to RTP packets, treating an entire packet as a bit stream and calculating parity packets that are the XOR of original data packets, and that can be used to recover from loss.
The standard for parity FEC applied to RTP streams is defined by RFC 2733.32 The aim of this standard is to define a generic FEC scheme for RTP packets that can operate with any payload type and that is backward-compatible with receivers that do not understand FEC. It does this by calculating FEC packets from the original RTP data packets; these FEC packets are then sent as a separate RTP stream, which may be used to repair loss in the original data, as shown in Figure 9.2.
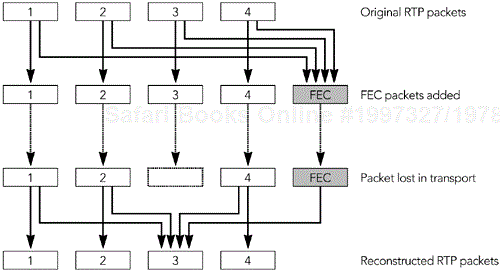
Figure 9.2. Repair Using Parity FEC (From C. Perkins, O. Hodson, and V. Hardman, “A Survey of Packet Loss Recovery Techniques for Streaming Media,” IEEE Network Magazine, September/October 1998. © 1998 IEEE.)
The format of an FEC packet, shown in Figure 9.3, has three parts to it: the standard RTP header, a payload-specific FEC header, and the payload data itself. With the exception of some fields of the RTP header, the FEC packet is generated from the data packets it is protecting. It is the result of applying the parity operation to the data packets.
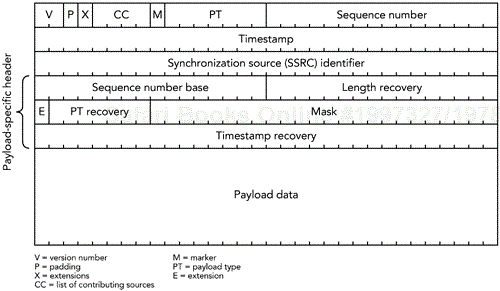
The fields of the RTP header are used as detailed here:
The version number, payload type, sequence number, and timestamp are assigned in the usual manner. The payload type is dynamically assigned, according to the RTP profile in use; the sequence number increases by one for each FEC packet sent; and the timestamp is set to the value of the RTP media clock at the instant the FEC packet is transmitted. (The timestamp is unlikely to be equal to the timestamp of the surrounding RTP packets.) As a result, the timestamps in FEC packets increase monotonically, independently of the FEC scheme.
The SSRC (synchronization source) value is the same as the SSRC of the original data packets.
The padding, extension, CC, and marker bits are calculated as the XOR of the equivalent bits in the original data packets. This allows those fields to be recovered if the original packets are lost.
The CSRC (contributing source) list and header extension are never present, independent of the values of the CC field and X bit. If they are present in the original data packets, they are included as part of the payload section of the FEC packet (after the FEC payload header).
The payload header protects the fields of the original RTP headers that are not protected in the RTP header of the FEC packet. These are the six fields of the payload header:
Sequence number base. The minimum sequence number of the original packets composing this FEC packet.
Length recovery. The XOR of the lengths of the original data packets. The lengths are calculated as the total length of the payload data, CSRC list, header extension, and padding of the original packets. This calculation allows the FEC procedure to be applied even when the lengths of the media packets are not identical.
Extension (E). An indicator of the presence of additional fields in the FEC payload header. It is usually set to zero, indicating that no extension is present (the ULP format, described later in this chapter, uses the extension field to indicate the presence of additional layered FEC).
Payload type (PT) recovery. The XOR of the payload type fields of the original data packets.
Mask. A bit mask indicating which of the packets following the sequence number base are included in the parity FEC operation. If bit i in the mask is set to 1, the original data packet with sequence number N + i is associated with this FEC packet, where N is the sequence number base. The least significant bit corresponds to i = 0, and the most significant to i = 23, allowing for the parity FEC to be calculated over up to 24 packets, which may be nonconsecutive.
Timestamp recovery. The XOR of the timestamps of the original data packets.
The payload data is derived as the XOR of the CSRC list (if present), header extension (if present), and payload data of the packets to be protected. If the data packets are different lengths, the XOR is calculated as if the short packets were padded out to match the length of the largest (the contents of the padding bits are unimportant, as long as the same values are used each time a particular packet is processed; it is probably easiest to use all zero bits).
The number of FEC packets and how they are generated depend on the FEC scheme employed by the sender. The payload format places relatively few restrictions on the mapping process: Packets from a group of up to 24 consecutive original packets are input to the parity operation, and each may be used in the generation of multiple FEC packets.
The sequence number base and mask in the payload header are used to indicate which packets were used to generate each FEC packet; there is no need for additional signaling. Accordingly, the packets used in the FEC operation can change during an RTP session, perhaps in response to the reception quality information contained in RTCP RR packets. The ability of the FEC operation to change gives the sender much flexibility: The sender can adapt the amount of FEC in use according to network conditions and be certain that the receivers will still be able to use the FEC for recovery.
A sender is expected to generate an appropriate number of FEC packets in real time, as the original data packets are sent. There is no single correct approach for choosing the amount of FEC to add because the choice depends on the loss characteristics of the network, and the standard does not mandate a particular scheme. Following are some possible choices:
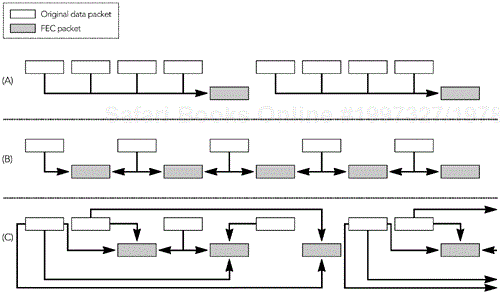
The simplest approach is to send one FEC packet for every n – 1 data packets, as shown in Figure 9.4A, allowing recovery provided that there is at most one loss for every n packets. This FEC scheme has low overhead, is easy to compute, and is easy to adapt (because the fraction of packets that are FEC packets directly corresponds to the loss fraction reported in RTCP RR packets).
If the probability that a packet is lost is uniform, this approach works well; however, bursts of consecutive loss cannot be recovered. If bursts of loss are common—as in the public Internet—the parity can be calculated across widely spaced packets, rather than over adjacent packets, resulting in more robust protection. The result is a scheme that works well for streaming but has a large delay, making it unsuitable for interactive applications.
A more robust scheme, but one with significantly higher overhead, is to send an FEC packet between each pair of data packets, as shown in Figure 9.4B. This approach allows the receiver to correct every single packet loss, and many double losses. The bandwidth overhead of this approach is high, but the amount of delay added is relatively small, making it more suitable for interactive applications.
Higher-order schemes allow recovery from more consecutive losses. For example, Figure 9.4C shows a scheme that can recover from loss of up to three consecutive packets. Because of the need to calculate FEC over multiple packets, the delay introduced is relatively high, so these schemes are unlikely to be suitable for interactive use. They can be useful in streaming applications, though.
To make parity FEC backward-compatible, it is essential that older receivers do not see the FEC packets. Thus the packets are usually sent as a separate RTP stream, on a different UDP port but to the same destination address. For example, consider a session in which the original RTP data packets use static payload type 0 (G.711 µ-law) and are sent on port 49170, with RTCP on port 49171. The FEC packets could be sent on port 49172, with their corresponding RTCP on port 49173. The FEC packets use a dynamic payload type—for example, 122. This scenario could be described in SDP like this:
v=0 o=hamming 2890844526 2890842807 IN IP4 128.16.64.32 s=FEC Seminar c=IN IP4 10.1.76.48/127 t=0 0 m=audio 49170 RTP/AVP 0 122 a=rtpmap:122 parityfec/8000 a=fmtp:122 49172 IN IP4 10.1.76.48/127
An alternative—described in the section titled Audio Redundancy Coding later in this chapter—is to transport parity FEC packets as if they were a redundant encoding of the media.
At the receiver the FEC packets and the original data packets are received. If no data packets are lost, the parity FEC can be ignored. In the event of loss, the FEC packets can be combined with the remaining data packets, allowing the receiver to recover lost packets.
There are two stages to the recovery process. First, it is necessary to determine which of the original data packets and the FEC packets must be combined in order to recover a missing packet. After this is done, the second step is to reconstruct the data.
Any suitable algorithm can be used to determine which packets must be combined. RFC 2733 gives an example, which operates as shown here:
When an FEC packet is received, the sequence number base and mask fields are checked to determine which packets it protects. If all those packets have been received, the FEC packet is redundant and is discarded. If some of those packets are missing, and they have sequence numbers smaller than the highest received sequence number, recovery is attempted; if recovery is successful, the FEC packet is discarded and the recovered packet is stored into the playout buffer. Otherwise the FEC packet is stored for possible later use.
When a data packet is received, any stored FEC packets are checked to see whether the new data packet makes recovery possible. If so, after recovery the FEC packet is discarded and the recovered packet entered into the playout buffer.
Recovered packets are treated as if they were received packets, possibly triggering further recovery attempts.
Eventually, all FEC packets will be used or discarded as redundant, and all recoverable lost packets will be reconstructed.
The algorithm relies on an ability to determine whether a particular set of data packets and FEC packets makes it possible to recover from a loss. Making the determination requires looking at the set of packets referenced by an FEC packet; if only one is missing, it can be recovered. The recovery process is similar to that used to generate the FEC data. The parity (XOR) operation is conducted on the equivalent fields in the data packets and the FEC packets; the result is the original data packet.
In more detail, this is the recovery process:
The SSRC of the recovered packet is set to the SSRC of the other packets.
The padding, header extension, CC, and marker bits of the recovered packet are generated as the XOR of the same fields in the original and FEC packets.
The sequence number of the recovered packet is known from the gap in the original sequence numbers (that is, there is no need to recover it, because it is directly known).
The payload type of the recovered packet is generated as the XOR of the payload type fields in the original packets, and the payload type recovery field of the FEC packets. The timestamp is recovered in the same manner.
The length of the payload is calculated as the XOR of lengths of the original packets and the length recovery field of the FEC packets.
The CSRC lists (if present), header extension (if present), and payload of the recovered packet are calculated as the XOR of those fields in the original packets, plus the payload of the FEC packets (because the FEC packet never contains a CSRC list or header extension itself, and it carries the protected version of the original fields as part of its payload).
The result is an exact reconstruction of the missing packet, bitwise identical to the original. There is no partial recovery with the RFC 2733 FEC scheme. If there are sufficient FEC packets, the lost packet can be perfectly recovered; if not, nothing can be saved.
Although some payload formats must be recovered exactly, there are other formats in which some parts of the data are more important than others. In these cases it is sometimes possible to get most of the effect while recovering only part of the packet. For example, some audio codecs have a minimum number of bits that need to be recovered to provide intelligible speech, with additional bits that are not essential but improve the audio quality if they can be recovered. A recovery scheme that recovers only the minimum data will be lower in quality than one that recovers the complete packet, but it may have significantly less overhead.
Alternatively, it is possible to protect the entire packet against some degree of packet loss but give the most important part of the packet a greater degree of protection. In this case the entire packet is recovered with some probability, but the important parts have a higher chance of recovery.
Schemes such as these are known as unequal layered protection (ULP) codes. At the time of this writing, there is no standard for ULP codes applied to RTP. However, there is ongoing work in the IETF to define an extension to the parity FEC codes in RFC 2733, which will provide this function.47 This work is incomplete, and the final standard may be slightly different from that described here.
The extension provides for layered coding, with each layer protecting a certain portion of the packet. Each layer may have a different length, up to the length of the longest packet in the group. Layers are arranged so that multiple layers protect the start of the packet, with later parts being protected by fewer layers. This arrangement makes it more likely that the start of the packet can be recovered.
The proposed RTP payload format for ULP based on parity FEC is shown in Figure 9.5. The start of the payload header is identical to that of RFC 2733, but the extension bit is set, and additional payload headers follow to describe the layered FEC operation. The payload data section of the packet contains the protected data for each layer, in order.
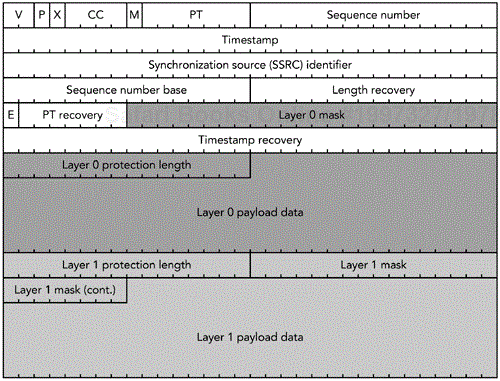
The operation of the ULP-based parity FEC format is similar to that of the standard parity FEC format, except that the FEC for each layer is computed over only part of the packet (rather than the entire packet). Each layer must protect the packets protected by the lower layers, making the amount of FEC protecting the lower layers cumulative with the number of layers. Each FEC packet can potentially contain data for all layers, stacked one after the other in the payload section of the packet. The FEC for the lowest layer appears in all FEC packets; higher layers appear in a subset of the packets, depending on the FEC operation. There is only one FEC stream, independent of the number of layers of protection.
Recovery operates on a per-layer basis, with each layer potentially allowing recovery of part of the packet. The algorithm for recovery of each layer is identical to that of the standard parity FEC format. Each layer is recovered in turn, starting with the base layer, until all possible recovery operations have been performed.
The use of ULP is not appropriate for all payload formats, because for it to work, the decoder must be able to process partial packets. When such partial data is useful, ULP can provide a significant gain in quality, with less overhead than complete FEC protection requires.
Reed–Solomon codes98 are an alternative to parity codes that offer protection with less bandwidth overhead, at the expense of additional complexity. In particular, they offer good protection against burst loss, where conventional parity codes are less efficient.
Reed–Solomon encoding involves treating each block of data as the coefficient of a polynomial equation. The equation is evaluated over all possible inputs in a certain number base, resulting in the FEC data to be transmitted. Often the procedure operates per octet, making implementation simpler. A full treatment is outside the scope of this book, but the encoding procedure is actually relatively straightforward, and there are optimized decoding algorithms.
Despite advantages of Reed–Solomon codes compared to parity codes, there is no standard for their use with RTP. Both equal and unequal FEC48 using Reed–Solomon codes has generated some interest, and a standard is expected to be developed in the future.
The error correction schemes we have discussed so far are independent of the media format being used. However, it is also possible to correct errors in a media-specific way, an approach that can often lead to improved performance.
The first media-specific error correction scheme defined for RTP was audio redundancy coding, specified in RFC 2198.10,77 The motivation for this coding scheme was interactive voice telecon-ferences, in which it is more important to repair lost packets quickly than it is to repair them exactly. Accordingly, each packet contains both an original frame of audio data and a redundant copy of a preceding frame, in a more heavily compressed format. The coding scheme is illustrated in Figure 9.6.
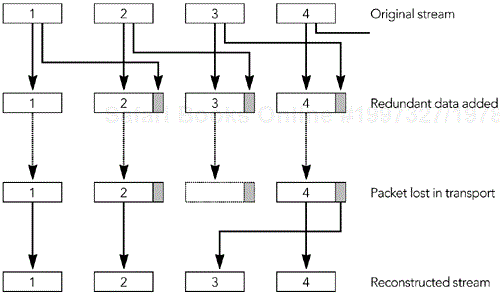
Figure 9.6. Audio Redundancy Coding (From C. Perkins, O. Hodson, and V. Hardman, “A Survey of Packet Loss Recovery Techniques for Streaming Media,” IEEE Network Magazine, September/October 1998. © 1998 IEEE.)
When receiving a redundant audio stream, the receiver can use the redundant copies to fill in any gaps in the original data stream. Because the redundant copy is typically more heavily compressed than the primary, the repair will not be exact, but it is perceptually better than a gap in the stream.
The redundant audio payload format is shown in Figure 9.7. The RTP header has the standard values, and the payload type is a dynamic payload type representing redundant audio.
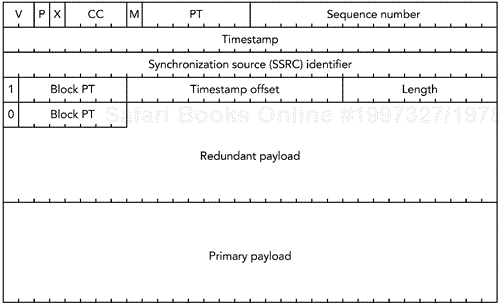
The payload header contains four octets for each redundant encoding of the data, plus a final octet indicating the payload type of the original media. The four-octet payload header for each redundant encoding contains several fields:
A single bit indicating whether this is a redundant encoding or the primary encoding.
The payload type of the redundant encoding.
The length of the redundant encoding in octets, stored as a 10-bit unsigned integer.
A timestamp offset, stored as a 14-bit unsigned integer. This value is subtracted from the timestamp of the packet, to indicate the original playout time of the redundant data.
The final payload header is a single octet, consisting of one bit to indicate that this is the last header, and the seven-bit payload type of the primary data. The payload header is followed immediately by the data blocks, stored in the same order as the headers. There is no padding or other delimiter between the data blocks, and they are typically not 32-bit aligned (although they are octet aligned).
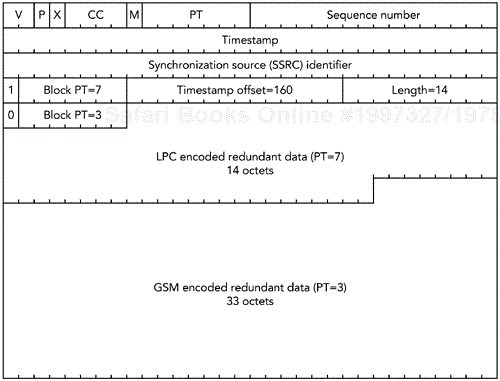
For example, if the primary encoding is GSM sent with one frame—20 milliseconds—per packet, and the redundant encoding is a low-rate LPC codec sent with one packet delay, a complete redundant audio packet would be as shown in Figure 9.8. Note that the timestamp offset is 160 because 160 ticks of an 8kHz clock represent a 20-millisecond offset (8,000 ticks per second × 0.020 seconds = 160 ticks).
The format allows the redundant copy to be delayed more than one packet, as a means of countering burst loss at the expense of additional delay. For example, if bursts of two consecutive packet losses are common, the redundant copy may be sent two packets after the original.
The choice of redundant encoding used should reflect the bandwidth requirements of those encodings. The redundant encoding is expected to use significantly less bandwidth than the primary encoding—the exception being the case in which the primary has a very low bandwidth and a high processing requirement, in which case a copy of the primary may be used as the redundancy. The redundant encoding shouldn't have a higher bandwidth than the primary.
It is also possible to send multiple redundant data blocks in each packet, allowing each packet to repair multiple loss events. The use of multiple levels of redundancy is rarely necessary because in practice you can often achieve similar protection with lower overhead by delaying the redundancy. If multiple levels of redundancy are used, however, the bandwidth required by each level is expected to be significantly less than that of the preceding level.
The redundant audio format is signaled in SDP as in the following example:
m=audio 1234 RTP/AVP 121 0 5 a=rtpmap:121 red/8000/1 a=fmtp:121 0/5
In this case the redundant audio uses dynamic payload type 121, with the primary and secondary encoding being payload type 0 (PCM µ-law) and 5 (DVI).
It is also possible to use dynamic payload types as the primary or secondary encoding—for example:
m=audio 1234 RTP/AVP 121 0 122 a=rtpmap:121 red/8000/1 a=fmtp:121 0/122 a=rtpmap:122 g729/8000/1
in which the primary is PCM µ-law and the secondary is G.729 using dynamic payload type 122.
Note that the payload types of the primary and secondary encoding appear in both the m= and a=fmtp: lines of the SDP fragment. Thus the receiver must be prepared to receive both redundant and nonredundant audio using these codecs, both of which are necessary because the first and last packets sent in a talk spurt may be nonredundant.
Implementations of redundant audio are not consistent in the way they handle the first and last packets in a talk spurt. The first packet cannot be sent with a secondary encoding, because there is no preceding data: Some implementations send it using the primary payload format, and others use the redundant audio format, with the secondary encoding having zero length. Likewise, it is difficult to send a redundant copy of the last packet because there is nothing with which to piggyback it: Most implementations have no way of recovering the last packet, but it may be possible to send a nonredundant packet with just the secondary encoding.
Although redundant audio encoding can provide exact repair—if the redundant copy is identical to the primary—it is more likely for the redundant encoding to have a lower bandwidth, and hence lower quality, and to provide only approximate repair.
The payload format for redundant audio also does not preserve the complete RTP headers for each of the redundant encodings. In particular, the RTP marker bit and CSRC list are not preserved. Loss of the marker bit does not cause undue problems, because even if the marker bit were transmitted with the redundant information, there would still be the possibility of its loss, so applications would still have to be written with this in mind. Likewise, because the CSRC list in an audio stream is expected to change relatively infrequently, it is recommended that applications requiring this information assume that the CSRC data in the RTP header may be applied to the reconstructed redundant data.
The redundant audio payload format was designed primarily for audio teleconferencing. To some extent it performs that job very well; however, advances in codec technology since the format was defined mean that the overhead of the payload format is perhaps too high now.
For example, the original paper proposing redundant audio suggested the use of PCM-encoded audio—160 octets per frame—as the primary, with LPC encoding as the secondary. In this case, the five octets of payload header constitute an acceptable overhead. However, if the primary is G.729 with ten octets per frame, the overhead of the payload header may be considered unacceptable.
In addition to audio teleconferencing, in which adoption of redundant audio has been somewhat limited, redundant audio is used in two scenarios: with parity FEC and with DTMF tones.
The parity FEC format described previously requires the FEC data to be sent separately from the original data packets. A common way of doing this is to send the FEC as an additional RTP stream on a different port; however, an alternative is to treat it as a redundant encoding of the media and piggyback it onto the original media using the redundant audio format. This approach reduces the overhead of the FEC, but it means that the receivers have to understand the redundant audio format, reducing the backward compatibility.
The RTP payload format for DTMF tones and other telephone events34 suggests the use of redundant encodings because these tones need to be delivered reliably (for example, telephone voice menu systems in which selection is made via DTMF touch tones would be even more annoying if the tones were not reliably recognized). Encoding multiple redundant copies of each tone makes it possible to achieve very high levels of reliability for the tones, even in the presence of packet loss.
Forward error correction, which relies on the addition of information to the media stream to provide protection against packet loss, is one form of channel coding. The media stream can be matched to the loss characteristics of a particular network path in other ways as well, some of which are discussed in the following sections.
Most packet loss in the public Internet is caused by congestion in the network. However, as noted in Chapter 2, Voice and Video Communication over Packet Networks, in some classes of network—for example, wireless—noncongestive loss and packet corruption are common. Although discarding packets with corrupted bits is appropriate in many cases, some RTP payload formats can make use of corrupted data (for example, the AMR audio codecs41). You can make use of partially corrupt RTP packets either by disabling the UDP checksum (if IPv4 is used) or by using a transport with a partial checksum.
When using RTP with a standard UDP/IPv4 stack, it is possible to disable the UDP checksum entirely (for example, using sysctlnet.inet.udp.checksum=0 on UNIX machines supporting sysctl, or using the UDP_NOCHECKSUM socket option with Winsock2). Disabling the UDP checksum has the advantage that packets with corrupted payload data are delivered to the application, allowing some part of the data to be salvaged. The disadvantage is that the packet header may be corrupted, resulting in packets being misdirected or otherwise made unusable.
A better approach is to use a transport with a partial checksum, such as UDP Lite.53 This is a work in progress that extends UDP to allow the checksum to cover only part of the packet, rather than all or none of it. For example, the checksum could cover just the RTP/UDP/IP headers, or the headers and the first part of the payload. With a partial checksum, the transport can discard packets in which the headers—or other important parts of the payload—are corrupted, yet pass those that have errors only in the unimportant parts of the payload.
The first RTP payload format to make significant use of partial checksum was the AMR audio codec.41 This is the codec selected for many third-generation cellular telephony systems, and hence the designers of its RTP payload format placed high priority on robustness to bit errors. Each frame of the codec bit stream is split into class A bits, which are vital for decoding, and class B and C bits, which improve quality if they are received, but are not vital. One or more frames of AMR output are placed into each RTP packet, with the option of using a partial checksum that covers the RTP/UDP/IP headers and class A bits, while the other bits are left unprotected. This lack of protection allows an application to ignore errors in the class B and class C bits, rather than discarding the packets. In Figure 9.9, for example, the shaded bits are not protected by a checksum. This approach appears to offer little advantage, because there are relatively few unprotected bits, but when header compression (see Chapter 11) is used, the IP/UDP/RTP headers and checksum are reduced to only four octets, increasing the gain due to the partial checksum.
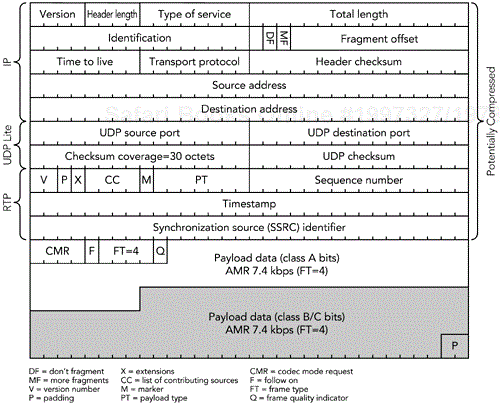
The AMR payload format also supports interleaving and redundant transmission, for increased robustness. The result is a very robust format that copes well with the bit corruption that is common in cellular networks.
Partial checksums are not a general-purpose tool, because they don't improve performance in networks in which packet loss is due to congestion. As wireless networks become more common, however, it is expected that future payload formats will also make use of partial checksums.
Many payload formats rely on interframe coding, in which it is not possible to decode a frame without using data sent in previous frames. Interfame coding is most often used in video codecs, in which motion vectors allow panning of the image, or motion of parts of the image, to occur without resending the parts of the preceding frame that have moved. Interframe coding is vital to achieving good compression efficiency, but it amplifies the effects of packet loss (clearly, if a frame depends on the packet that is lost, that frame cannot be decoded).
One solution to making interframe encodings more robust to packet loss is reference picture selection, as used in some variants of H.263 and MPEG-4. This is another form of channel coding, in which if a frame on which others are predicted is lost, future frames are recoded on the basis of another frame that was received (see Figure 9.10). This process saves significant bandwidth compared to sending the next frame with no interframe compression (only intraframe compression).
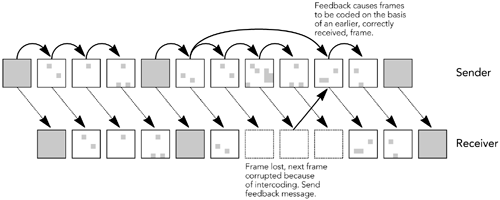
To change the reference picture, it is necessary for the receiver to report individual packet losses to the sender. Mechanisms for feedback are discussed in the next section in the context of retransmission; the same techniques can be used for reference picture selection with minor modification. Work on a standard for the use of reference picture selection in RTP is ongoing, as part of the retransmission profile discussed next.
Losses may also be recovered if the receivers send feedback to the sender, asking it to retransmit packets lost in transit. Retransmission is a natural approach to error correction, and it works well in some scenarios. It is, however, not without problems that can limit its applicability. Retransmission is not a part of standard RTP; however, an RTP profile is under development44 that provides an RTCP-based framework for retransmission requests and other immediate feedback.
Because RTP includes a feedback channel—RTCP—for reception reports and other data, it is natural to use that channel for retransmission requests too. Two steps are required: Packet formats need to be defined for retransmission requests, and the timing rules must be modified to allow immediate feedback.
The profile for retransmission-based feedback defines two additional RTCP packet types, representing positive and negative acknowledgments. The most common type is expected to be negative acknowledgments, reporting that a particular set of packets was lost. A positive acknowledgment reports that packets were correctly received.
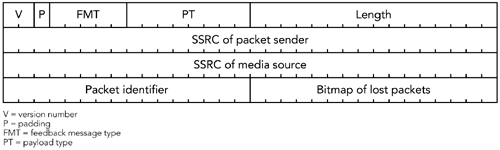
The format of a negative acknowledgment (NACK) is shown in Figure 9.11. The NACK contains a packet identifier representing a lost packet, and a bitmap showing which of the following 16 packets were lost, with a value of 1 indicating loss. The sender should not assume that a receiver has received a packet just because the corresponding position in the bit mask is set to zero; all it knows is that the receiver has not reported the packet lost at this time. On receiving a NACK, the sender is expected to retransmit the packets marked as missing, although it is under no obligation to do so.
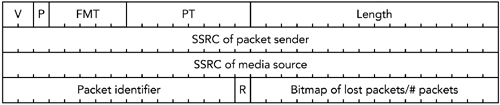
The format of a positive acknowledgment (ACK) is shown in Figure 9.12. The ACK contains a packet identifier representing a correctly received packet, and either a bitmap or a count of the following packets. If the R bit is set to 1, the final field is a count of the number of correctly received packets following the packet identifier. If the R bit is set to zero, the final field is a bitmap showing which of the following 15 packets were also received. The two options allow both long runs of ACKs with few losses (R = 1) and occasional ACKs interspersed with loss (R = 0) to be signaled efficiently.
The choice between ACK and NACK depends on the repair algorithm in use, and on the desired semantics. An ACK signals that some packets were received; the sender may assume others were lost. On the other hand, a NACK signals loss of some packets but provides no information about the rest (for example, a receiver may send a NACK when an important packet is lost but silently ignore the loss of unimportant data).
Feedback packets are sent as part of a compound RTCP packet, in the same way as all other RTCP packets. They are placed last in the compound packet, after the SR/RR and SDES items. (See Chapter 5, RTP Control Protocol, for a review of RTCP packet formats.)
The standard definition of RTCP has strict timing rules, which specify when a packet can be sent and limit the bandwidth consumption of RTCP. The retransmission profile modifies these rules to allow feedback packets to be sent earlier than normal, at the expense of delaying the following packet. The result is a short-term violation of the bandwidth limit, although the longer-term RTCP transmission rate remains the same. The modified timing rules can be summarized as follows:
When no feedback messages need to be sent, RTCP packets are sent according to the standard timing rules, except that the 5-second minimum interval between RTCP reports is not enforced (the reduced minimum discussed in the section titled Reporting Interval in Chapter 5, RTP Control Protocol, should be used instead).
If a receiver wants to send feedback before the regularly scheduled RTCP transmission time, it should wait for a short, random dither interval and check whether it has already seen a corresponding feedback message from another receiver. If so, it must refrain from sending and follow the regular RTCP schedule. If the receiver does not see a similar feedback message from any other receiver, and if it has not sent feedback during this reporting interval, it may send the feedback message as part of a compound RTCP packet.
If feedback is sent, the next scheduled RTCP packet transmission time is reconsidered on the basis of twice the standard interval. The receiver may not send any more feedback until the reconsidered packet has been sent (that is, it may send a feedback packet once for each regular RTCP report).
The dither interval is chosen on the basis of the group size and the RTCP bandwidth. If the session has only two participants, the dither interval is set to zero; otherwise, it is set to half of the round-trip time between sender and receiver, multiplied by the number of members (if the round-trip time is unknown, it is set to half of the RTCP reporting interval).
The algorithm for choosing the dither interval allows each receiver to send feedback almost immediately for small sessions. As the number of receivers increases, the rate at which each can send retransmission requests is reduced, but the chance that another receiver will see the same loss and send the same feedback increases.
The RTP retransmission profile allows feedback to be sent at a higher rate than standard RTCP, but it still imposes some limitations on allowable send times. Depending on the group size, bandwidth available, data rate, packet loss probability, and desired reporting granularity, an application will operate in one of three modes—immediate, early, and regular—which are illustrated in Figure 9.13.
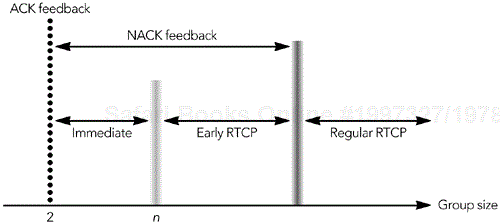
In immediate feedback mode, there is sufficient bandwidth to send feedback for each event of interest. In early feedback mode, there is not enough bandwidth to provide feedback on all events, and the receiver has to report on a subset of the possible events. Performance is best in immediate mode. As an application moves into early feedback mode, it begins to rely on statistical sampling of the loss and gives only approximate feedback to the sender. The boundary between immediate and early modes, indicated by group size n in Figure 9.13, varies depending on the data rate, group size, and fraction of senders.
In both immediate and early modes, only NACK packets are allowed. If the session has only two participants, ACK mode can be used. In ACK mode, positive acknowledgments of each event are sent, providing more detailed feedback to the sender (for example, ACK mode might allow a video application to acknowledge each complete frame, enabling reference picture selection to operate efficiently). Again, the bandwidth limitations of the retransmission profile must be respected.
The main factor that limits the applicability of retransmission is feedback delay. It takes at least one round-trip time for the retransmission request to reach the sender and for the retransmitted packet to reach the receiver. This delay can affect interactive applications because the time taken for a retransmission may exceed the acceptable delay bounds. For streaming, and other applications in which the delay bounds are less strict, retransmission can be effective.69
Retransmission allows a receiver to request repair of only those packets that are lost, and allows it to accept loss of some packets. The result can be very efficient repair, given the right circumstances. But retransmission becomes inefficient in certain cases, such as these:
Each retransmission request uses some bandwidth. When the loss rate is low, the bandwidth used by the requests is low, but as losses become more common, the amount of bandwidth consumed by requests increases.
If the group is large and many receivers see the same loss, they may all request retransmissions at once. Many requests use a lot of bandwidth, and the implosion of requests may overwhelm the sender.
If the group is large and each receiver sees a different loss, the sender will have to retransmit most packets even though each receiver lost only a small fraction of the packets.
Retransmission works best when groups are small and the loss rate is relatively low. When the number of receivers, or the loss rate, increases, requesting retransmission of lost packets rapidly becomes inefficient. Eventually, a cutoff is reached beyond which the use of forward error correction is more effective.
For example, Handley has observed122 multicast groups in which most packets are lost by at least one receiver. The result could be a retransmission request for almost every packet, which would require tremendous overhead. If forward error correction is used, each FEC packet repairs multiple losses, and the amount of repair data that has to be sent is much lower.
The retransmitted packet does not have to be identical to the original. This flexibility allows retransmission to be used in cases when it might otherwise be inefficient, because the sender can respond to requests by sending an FEC packet, rather than another copy of the original.85 The fact that the retransmitted and original packets do not have to be identical may also allow a single retransmission to repair many losses.
If error correction is used, an RTP implementation can be made significantly more robust to the adverse effects of IP networks. These techniques come at a price, though: The implementation becomes somewhat more complex, with the receiver needing a more sophisticated playout buffer algorithm, and the sender needing logic to decide how much recovery data to include and when to discard that data.
Use of these error correction techniques requires that the application have a more sophisticated playout buffer and channel-coding framework than it might otherwise need. In particular, it needs to incorporate FEC and/or retransmission delay into its playout point calculation, and it needs to allow for the presence of repair data in playout buffers.
When calculating the playout point for the media, a receiver has to allow sufficient time for the recovery data to arrive. This may mean delaying the playout of audio/video beyond its natural time, depending on the time needed to receive the recovery data, and the desired playout point of the media.
For example, an interactive voice telephony application might want to operate with a short jitter buffer and a playout delay of only one or two packets' worth of audio. If the sender uses a parity FEC scheme such as that shown in Figure 9.2, in which an FEC packet is sent after every four data packets, the FEC data will be useless because it will arrive after the application has played out the original data it was protecting.
How does an application know when recovery data is going to arrive? In some cases the configuration of the repair is fixed and can be signaled in advance, allowing the receiver to size its playout buffers. Either the signaling can be implicit (for example, RFC 2198 redundancy in which the sender can insert zero-length redundant data into the first few packets of an audio stream, allowing the receiver to know that real redundancy data will follow in later packets), or it can be explicit as part of session setup (for example, included in the SDP during a SIP invitation).
Unfortunately, advance signaling is not always possible, because the repair scheme can change dynamically, or because the repair time cannot be known in advance (for example, when retransmission is used, the receiver has to measure the round-trip time to the sender). In such cases it is the responsibility of the receiver to adapt to make the best use of any repair data it receives, by either delaying media playout or discarding repair data that arrives late. Generally the receiver must make such adaptation without the help of the sender, relying instead on its own knowledge of the application scenario.
A receiver will need to buffer arriving repair data, along with the original media packets. How this is done depends on the form of repair: Some schemes are weakly coupled with the original media, and a generic channel-coding layer can be used; others are tightly coupled to the media and must be integrated with the codec.
Examples of weak coupling include parity FEC and retransmission in which repairs can be made by a general-purpose layer, with no knowledge of the contents of the packets. The reason is that the repair operates on the RTP packets, rather than on the media data itself.
In other cases the repair operation is tightly coupled with the media codec. For example, the AMR payload format41 includes support for partial checksums and redundant transmission. Unlike the audio redundancy defined in RFC 2198, this form of redundant transmission has no separate header and is specific to AMR: Each packet contains multiple frames, overlapping in time with the following packet. In this case the AMR packetization code must be aware of the overlap, and it must ensure that the frames are correctly added to the playout buffer (and that duplicates are discarded). Another example is the reference picture selection available in MPEG-4 and some modes of H.263, in which the channel coding depends on the shared state between encoder and decoder.
When error correction is in use, the sender is also required to buffer media data longer than it normally would. The amount of buffering depends on the correction technique in use: An FEC scheme requires the sender to hold on to enough data to generate the FEC packets; a retransmission scheme requires the sender to hold on to the data until it is sure that the receivers will no longer request retransmission.
The sender has an advantage over the receiver when it comes to buffering because it knows the details of the repair scheme used and can size its buffers appropriately. This is obviously the case when FEC is being used, but it is also true if retransmission is in use (because RTCP allows the sender to calculate the round-trip time to each receiver).
The sender must also be aware of how its media stream is affecting the network. Most techniques discussed in this chapter add additional information to a media stream, which can then be used to repair loss. This approach necessarily increases the data rate of the stream. If the loss were due to network congestion—which is the common case in the public Internet—then this increase in data rate could lead to a worsening of the congestion, and could actually increase the packet loss rate. To avoid these problems, error correction has to be tied to congestion control, which is the subject of Chapter 10.
In this chapter we have discussed various ways in which errors due to packet loss can be corrected. The schemes in use today include various types of forward error correction and channel coding, as well as retransmission of lost packets.
When used correctly, error correction provides a significant benefit to the perceived quality of a media stream, and it can make the difference between a system being usable or not. If used incorrectly, however, it can lead to a worsening of the problems it was intended to solve, and it can cause significant network problems. The issue of congestion control—adapting the amount of data sent to match the network capacity, as discussed in more detail in Chapter 10, Congestion Control—forms an essential counterpoint to the use of error correction.
One thing that should be clear from this chapter is that error correction usually works by adding some redundancy to a media stream, which can be used to repair lost data. This mode of operation is somewhat at odds with the goal of media compression, which seeks to remove redundancy from the stream. There is a trade-off to be made between compression and error tolerance: At some stage, extra effort spent compressing a media stream is counterproductive, and it is better to use the inherent redundancy for error resilience. Of course, the point at which that line is passed depends on the network, the codec, and the application.