
The designers, program managers, and architects have designed a good, secure product, and the developers have written great code—now it’s time for the testers to keep everyone honest! It’s unfortunate, but many testers think they are the tail of the development process, cleaning up the mess left by developers. Nothing could be further from the truth; security testing is an important part of the overall process. In this chapter, I’ll describe the important role testers play when delivering secure products, including being part of the entire process—from the design phase to the ship phase. I’ll also discuss how testers should approach security testing—it’s different from normal testing. This is a pragmatic chapter, full of information you can really use rather than theories of security testing.
The information in this chapter is based on an analysis of over 100 security vulnerabilities across multiple applications and operating systems, including Microsoft Windows, Linux, UNIX, and MacOS. After analyzing the bugs, I spent time working out how each bug could be caught during testing, the essence of which is captured herein.
At the end of the chapter I describe a new technique for determining the relative attack surface of an application; this can be used to help drive the attack points of an application down.
I wasn’t being flippant when I said that testers keep everyone honest. With the possible exception of the people who support your product, testers have the final say as to whether your application ships. While we’re on that subject, if you do have dedicated support personnel and if they determine the product is so insecure that they cannot or will not support it, you have a problem that needs fixing. Listen to their issues and come to a realistic compromise about what’s best for the customer. Do not simply override the tester or support personnel and ship the product anyway—doing so is arrogance and folly.
The designers and the specifications might outline a secure design, the developers might be diligent and write secure code, but it’s the testing process that determines whether the product is secure in the real world. Because testing is time-consuming, laborious, and expensive, however, testing can find only so much. It’s therefore mandatory that you understand you cannot test security into a product; testing is one part of the overall security process.
Testers should also be involved in the design and threat-modeling process and review specifications for security problems. A set of "devious" tester eyes can often uncover potential problems before they become reality.
When the product’s testers determine how best to test the product, their test plans absolutely must include security testing, our next subject.
Important
If your test plans don’t include the words buffer overrun or security testing, you need to rectify the problem quickly.
Important
If you do not perform security testing for your application, someone else not working for your company will. I know you know what I mean!
Most testing is about proving that some feature works as specified in the functional specifications. If the feature deviates from its specification, a bug is filed, the bug is usually fixed, and the updated feature is retested. Testing security is often about checking that some feature appears to fail. What I mean is this: security testing involves demonstrating that the tester cannot spoof another user’s identity, that the tester cannot tamper with data, that enough evidence is collected to help mitigate repudiation issues, that the tester cannot view data he should not have access to, that the tester cannot deny service to other users, and that the tester cannot gain more privileges through malicious use of the product. As you can see, most security testing is about proving that defensive mechanisms work correctly, rather than proving that feature functionality works. In fact, part of security testing is to make the application being tested perform more tasks than it was designed to do. Think about it: code has a security flaw when it fulfills the attacker’s request, and no application should carry out an attacker’s bidding.
One could argue that functional testing includes security testing, because security is a feature of the product—refer to Chapter 2, if you missed that point! However, in this case functionality refers to the pure productivity aspects of the application.
Most people want to hear comments like, "Yes, the feature works as designed" rather than, "Cool, I got an access denied!" The latter is seen as a negative statement. Nevertheless, it is fundamental to the way a security tester operates. Good security testers are a rare breed—they thrive on breaking things, and they understand how attackers think.
I once interviewed a potential hire and asked him to explain why he’s a good tester. His reply, which clinched the job for him, was that he could break anything that opened a socket!
Important
Good security testers are also good testers who understand and implement important testing principles. Security testing, like all other testing, is by its nature subject to the tester’s experience, expertise, and creativity. Good security testers exhibit all three traits in abundance.
Tip
You should put yourself in a "blackhat" mindset by reviewing old security bugs at a resource such as http://www.securityfocus.com.
Building a security test plan can often be haphazard, and so the rest of this chapter outlines a rigorous and complete approach to security testing that offers better results. The process, derived in part from information in the threat model, is simple:
Decompose the application into its fundamental components.
Identify the component interfaces.
Rank the interfaces by potential vulnerability.
Ascertain the data structures used by each interface.
Find security problems by injecting mutated data.
Note
There are two aspects to using a threat model to build test plans. The first is to prove that the defensive mitigation techniques operate correctly and do indeed mitigate the identified threats. The second is to find other issues not represented in the threat model, which requires more work, but you must perform this extra level of testing.
Let’s look at each aspect of the process in detail.
Many people think threat models are purely a design tool. This is incorrect; they are tools that can aid all aspects of the development process, especially design and test. Three valuable items for testers come from a threat model: the list of components in the system, the threat types to each component (STRIDE), and the threat risk (DREAD or similar). I’ll discuss the last two items later in this chapter. But first let me say that the list of components is incredibly valuable. To build good tests, you need to know which components need testing. Also, the threat model helps give form to the process. Why duplicate the work when the inventory already exists in the threat model?
The next step is to determine the interfaces exposed by each component, which may or may not be exposed in the threat model. This is possibly the most critical step because exercising the interface code is how you find security bugs. The best place to find what interfaces are exposed by which components is in the functional specifications. Otherwise, ask the developers or read the code. Of course, if an interface is not documented, you should get it documented in the specifications.
Example interfacing and transport technologies include the following:
TCP and UDP sockets
Wireless data
NetBIOS
Mailslots
Dynamic Data Exchange (DDE)
Named Pipes
Shared memory
Other named objects—Named Pipes and shared memory are named objects—such as semaphores and mutexes
The Clipboard
Local procedure call (LPC) and remote procedure call (RPC) interfaces
COM methods, properties, and events
Parameters to ActiveX Controls and Applets (usually <OBJECT> tag arguments)
EXE and DLL functions
System traps and input/output controls (IOCTLs) for kernel-mode components
The registry
HTTP requests and responses
Simple Object Access Protocol (SOAP) requests
Remote API (RAPI), used by Pocket PCs
Console input
Command line arguments
Dialog boxes
Database access technologies, including OLE DB and ODBC
Database stored procedures
Store-and-forward interfaces, such as e-mail using SMTP, POP, or MAPI, or queuing technologies such as MSMQ
Environment (environment variables)
Files
Microphone
LDAP sources, such as Active Directory
Hardware devices, such as infrared using Infrared Data Association (IrDA), universal serial bus (USB), COM ports, FireWire (IEEE 1394), Bluetooth and so on
You need to prioritize which interfaces need testing first, simply because highly vulnerable interfaces should be tested thoroughly. The initial risk ranking should come from the threat model; however, the following process can add more granularity and accuracy for testing purposes. The process of determining the relative vulnerability of an interface is to use a simple point-based system. Add up all the points for each interface, based on the descriptions in Table 19-1, and list them starting with the highest number first. Those at the top of the list are most vulnerable to attack, might be susceptible to the most damage, and should be tested more thoroughly.
Table 19-1. Points to Attribute to Interface Characteristics
|
Interface Characteristic |
Points |
|---|---|
|
The process hosting the interface or function runs as a high-privileged account such as SYSTEM (Microsoft Windows NT and later) or root (UNIX and Linux systems) or some other account with administrative privileges. |
2 |
|
The interface handling the data is written in a higher-level language than C or C++, such as VB, C#, Perl and so on. |
-2 |
|
The interface handling the data is written in C or C++. |
1 |
|
The interface takes arbitrary-sized buffers or strings. |
1 |
|
The recipient buffer is stack-based. |
2 |
|
The interface has no or weak access control mechanisms. |
1 |
|
The interface or the resource has good, appropriate access control mechanisms. |
-2 |
|
The interface does not require authentication. |
1 |
|
The interface is, or could be, server-based. |
2 |
|
The feature is installed by default. |
1 |
|
The feature is running by default. |
1 |
|
The feature has already had security vulnerabilities. |
1 |
Note that if your list of interfaces is large and you determine that some interfaces cannot be tested adequately in the time frame you have set for the product, you should seriously consider removing the interface from the product and the feature behind the interface.
Important
If you can’t test it, you can’t ship it.
The next step is to determine the data accessed by each interface. Table 19-2 shows some example interface technologies and where the data comes from. This is the data you will modify to expose security bugs.
Table 19-2. Example Interface Technologies and Data Sources
|
Interface |
Data |
|---|---|
|
Sockets, RPC, Named Pipes, NetBIOS |
Data arriving over the network |
|
Files |
File contents |
|
Registry |
Registry key data |
|
Active Directory |
Nodes in the directory |
|
Environment |
Environment variables |
|
HTTP data |
HTTP headers, form entities, query strings, Multipurpose Internet Mail Extensions (MIME) parts, XML payloads, SOAP data and headers |
|
COM |
Method and property arguments |
|
Command line arguments |
Data in argv[] for C or C++ applications, data held in WScript.Arguments in Windows Scripting Host (WSH) applications, and the String[] args array in C# applications |
Now that we have a fully decomposed functional unit, a ranked list of interfaces used by the components, and the data used by the interfaces, we can start building test cases. But first, let’s look at the kinds of tests you can perform based on the STRIDE threat types in the threat model.
The STRIDE threat types in the threat model help you determine what kinds of tests to perform, and the threat risk allows you to prioritize your tests. The higher risk components should be tested first and tested the most thoroughly. In Table 4-10 in Chapter 4, I outlined some broad mitigation techniques for specific threat types. Now I want to explain some testing techniques to verify (or exploit!) the mitigation techniques. This list of testing techniques, which appears in Table 19-3, is by no means complete—you must think about new kinds of security tests for your application. As you learn more, document the new test methods and let others (and me!) know about them.
This table lists some general guidelines to help you formulate test plans based on the threat model. You should also determine whether attacks exist against components that you use but do not directly control, such as DLLs or class libraries. You should also include any of these scenarios in the threat model.
Table 19-3. Testing Threat Categories
|
Threat Type |
Testing Techniques |
|---|---|
|
Spoofing identity |
|
|
Tampering with data |
|
|
Repudiation |
|
|
Information disclosure |
|
|
Denial of service (DoS) |
DoS attacks are probably the easiest threats to test!
|
|
Elevation of privilege |
|
Important
Every threat in the threat model must have a test plan outlining one or more tests.
Important
Every test should have a note identifying what is the expected successful result of the test, as well as what should be observed to verify that the function being tested failed or not.
Other than basing tests on STRIDE, data mutation is another useful technique you can use to attack your application, and that’s our next subject.
The next step is to build test cases to exercise the interfaces by using data mutation. Data mutation involves perturbing the environment such that the code handling the data that enters an interface behaves in an insecure manner. I like to call data mutation "lyin’ and cheatin’" because your test scripts create bogus situations and fake data designed to make the code fail.
The easiest threats to test for are denial of service threats, which make the application fail. If your test code can make the application fail and issue an access violation, you’ve identified a DoS threat, especially if the application is a networked service. Data mutation is an excellent test mechanism for finding DoS vulnerabilities.
Important
The application has suffered a DoS attack if you can make a networked service fail with an access violation or some other exception. The development team should take these threats seriously, because they will have to fix the bug after the product ships if the defect is discovered.
Figure 19-1 shows techniques for perturbing an application’s environment.
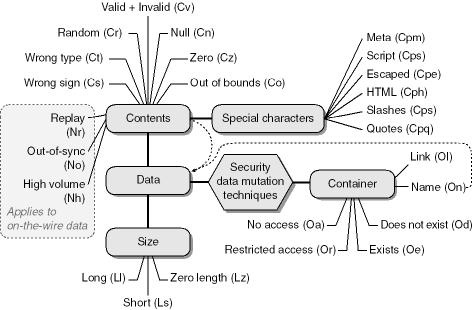
Figure 19-1. Techniques to perturb applications to reveal security vulnerabilities and reliability bugs.
When designing security tests, keep this diagram close at hand. It will help you determine which test conditions you need to create. Let’s look at each category.
Note
Be aware that two kinds of DoS attacks exist. The first, which is easy to test for, causes the application to stop running because of an access violation or similar event. In the second case, which is not easy to test for because it requires a great deal of hardware and preparation, an application fails slowly and response times get worse as the system is attacked by many machines in a distributed testing manner.
Data often exists in containers—for example, a file contains bytes of data. You can create security problems by perturbing the data in the container (the file contents) or the container (the file name). Changing the name of the container, in this case the filename, is changing the container but not the data itself. Generally, on-the-wire data does not have a container, unless you consider the network to be the container. I’ll leave that philosophical conundrum to you!
You can perturb a container in a number of ways. You can deny access (Oa) to the container; this is easily achieved by setting the Deny access control entry (ACE) on the object prior to running the test. Restricted access (Or) is somewhat similar to no access. For example, the application requires read and write access to the object in question, but an ACE on the object allows only read access. Some resources, such as files, can have their access restricted using other techniques. In Windows, files have attributes associated with them, such as read-only.
Another useful test relies on the application assuming the resource already exists (Oe) or not (Od). Imagine that your application requires that a registry key already exist—how does the application react if the key does not exist? Does it take on an insecure default?
Finally, how does the application react if the container exists but the name is different? A special name case, especially in UNIX, is the link problem. How does the application react if the name is valid but the name is actually a link to another file? Refer to Chapter 11, for more information about symbolic links and hard links in UNIX and Windows.
Note in Figure 19-1 the link from the container name to the data section. This link exists because you can do nasty things to container names, too, such as change the size of the name or the contents of the container name. For example, if the application expects a filename like Config.xml, what happens if you make the name overly long (shown in Figure 19-1 as Data-Size-Long, or Ll), such as Myreallybigconfig.xml, or too short (Data-Size-Small, or Ls), such as C.xml? What happens if you change the name of the file (that is, the contents of the container name) to something random (Data-Contents-Random, Cr), like rfQy6-J.87d?
Data has two characteristics: the nature of the contents and the size of the data. Each is a potential target and should be maliciously manipulated. Applications can take two types of input: correctly formed data and incorrectly formed data. Correctly formed data is just that—it’s the data your application expects. Such data rarely leads to the application raising errors and is of little interest to a security tester. Incorrectly formed data has numerous variations. Let’s spend some time looking at each in detail.
Random data (Cr) is a series of arbitrary bytes sent to the interface, or written to a data source, that is then read by the interface. In my experience, utterly incorrect data, although useful, does not help you find as many security holes as partially incorrect data, because many applications perform some degree of data input validation.
To create a buffer full of utterly random but printable data in Perl, you can use the following code:
srand time;
my $size = 256;
my @chars = (‘A’..’Z’, ’a’..’z’, 0..9, qw( ! @ # $ % ^ & * - + = ));
my $junk = join ("", @chars[ map{rand @chars } (1 .. $s ize)]);In C or C++, you can use CryptGenRandom to populate a user-supplied buffer with random bytes. Refer to Chapter 8, for example code that generates random data. If you want to use CryptGenRandom to create printable random data, use the following C++ code:
/*
PrintableRand.cpp
*/
#include "windows.h"
#include "wincrypt.h"
DWORD CreateRandomData(LPBYTE lpBuff, DWORD cbBuff, BOOL fPrintable) {
DWORD dwErr = 0;
HCRYPTPROV hProv = NULL;
if (CryptAcquireContext(&hProv, NULL, NULL,
PROV_RSA_FULL,
CRYPT_VERIFYCONTEXT) == FALSE)
return GetLastError();
ZeroMemory(lpBuff, cbBuff);
if (CryptGenRandom(hProv, cbBuff, lpBuff)) {
if (fPrintable) {
char *szValid="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789"
"~`!@#$%^&*()_- +={}[];:’<>,.?|\/";
DWORD cbValid = lstrlen(szValid);
//Convert each byte (0- 255) to a different byte
//from the list of valid characters above.
//There is a slight skew because strlen(szValid) is not
//an exact multiple of 255.
for (DWORD i=0; i<cbBuff; i++)
lpBuff[i] = szValid[lpBuff[i] % cbValid];
//Close off the string if it’s printable.
//The data is not zero- terminated if it’s not printable.
lpBuff[cbBuff-1] = ’�’;
}
} else {
dwErr = GetLastError();
}
if (hProv != NULL)
CryptReleaseContext(hProv, 0);
return dwErr;
}
void main(void) {
BYTE bBuff[16];
if (CreateRandomData(bBuff, sizeof bBuff, FALSE) == 0) {
//Cool, it worked!
}
}You can also find this sample code with the book’s sample files in the folder Secureco2Chapter19PrintableRand. The real benefit of using this kind of test—one that uses junk data—is to find certain buffer overrun types. The test is useful because you can simply increase the size of the buffer until the application fails or, if the code is robust, continues to execute correctly with no error. The following Perl code will build a buffer that continually increases in size:
# Note the use of ’_’ in $MAX below.
# I really like this method of using big numbers.
# They are more readable! 128_000 means 128,000.
# Cool, huh?
my $MAX = 128_000;
for (my $i=1; $i < $MAX; $i *= 2) {
my $junk = ’A’ x $i;
# Send $junk to the data source or interface.
}Important
Sometimes it’s difficult to determine whether a buffer overrun is really exploitable. Therefore, it’s better to be safe and just fix any crash caused by long data.
Probably the most well-known work on this kind of random data is a paper titled "Fuzz Revisited: A Re-examination of the Reliability of UNIX Utilities and Services" by Barton P. Miller, et al, which focuses on how certain applications react in the face of random input. The paper is available at http://citeseer.nj.nec.com/2176.html. The findings in the paper were somewhat alarming:
Even worse is that some of the bugs we reported in 1990 are still present in the code releases of 1995. The failure rate of utilities on the commercial versions of UNIX that we tested (from Sun, IBM, SGI, DEC and NEXT) ranged from 15–43%.
Chances are good that some of your code will also fail in the face of random garbage. Frankly, you should be concerned if the code does fail; it means you have very poor validation code. But although Fuzz testing is useful and should be part of your test plans, it won’t catch many classes of bugs. If random data is not so useful, what is? The answer is partially incorrect data.
Partially incorrect data is data that’s accurately formed but that might contain invalid values or different representations of valid values. There are a number of different partially incorrect data types:
Wrong sign (Cs)
Wrong type (Ct)
Null (Cn)
Zero (Cz)
Out of bounds (Co)
Valid + invalid (Cv)
Wrong sign (Cs) and wrong type (Ct) are self-explanatory. Depending on the application, zero could be 0 or '0'. (You should use both. If the application expects 0, try '0'—it’s still zero, but a different type [Ct].) Null is not the same as zero; in the database world, it means the data is missing. Out of bounds includes large numbers and ancient or future dates. Valid + invalid is interesting in that perfectly well-formed data has malformed data attached. For example, your application might require a valid date in the form 09-SEP-2002, but what if you provide 09-SEP-2002Jk17&61hhAn=_9jAMh? This is an example of adding random data to a valid date.
It takes more work to build such data because it requires better knowledge of the data structures used by the application. For example, if a Web application requires a specific (fictitious) header type, TIMESTAMP, setting the data expected in the header to random data is of some use, but it will not exercise the TIMESTAMP code path greatly if the code checks for certain values in the header data. Let’s say the code checks to verify that the timestamp is a numeric value and your test code sets the timestamp to a random series of bytes. Chances are good that the code will reject the request before much code is exercised. Hence, the following header is of little use:
TIMESTAMP: H7ahbsk(0kaaR
But the following header will exercise more code because the data is a valid number and will get past the initial validity-checking code:
TIMESTAMP: 09871662
This is especially true of RPC interfaces compiled using the /robust Microsoft Interface Definition Language (MIDL) compiler switch. If you send random data to an RPC interface compiled with this option, the packet won’t make it beyond the validation code in the server stub. The test is worthless. But if you can correctly build valid RPC packets with subtle changes, the packet might find its way into your code and you can therefore exercise your code and not MIDL-generated code.
Note
The /robust MIDL compiler switch does not mitigate all malformed data issues. Imagine an RPC function call that takes a zero-terminated string as an argument but your code expects that the data be numeric only. There is no way for the RPC marshaller to know this. Therefore, it’s up to you to test your interfaces appropriately by testing for wrong data types.
Let’s look at another example—a server listening on port 1777 requires a packed binary structure that looks like this in C++:
#define MAX_BLOB (128)
typedef enum {
ACTION_QUERY,
ACTION_GET_LAST_TIME,
ACTION_SYNC
} ACTION;
typedef struct {
ACTION actAction; // 2 bytes
short cbBlobSize; // 2 bytes
char bBlob[MAX_BLOB]; // 128 bytes
} ACTION_BLOB;However, if the code checks that actAction is 0, 1, or 2—which represent ACTION_QUERY, ACTION_GET_LAST_TIME, or ACTION_SYNC, respectively— and fails the request if the structure variable is not in that range, the test will not exercise much of the code when you send a series of 132 random bytes to the port. So, rather than sending 132 random bytes, you should create a test script that builds a correctly formed structure and populates actAction with a valid value but sets cbBlobSize and bBlob to random data. The following Perl script shows how to do this. This script is also available with the book’s sample files in the folder SecurecoChapter19.
# PackedStructure.pl
# This code opens a TCP socket to
# a server listening on port 1777;
# sets a query action;
# sends MAX_BLOB letter ’A’s to the port.
use IO::Socket;
my $MAX_BLOB = 128;
my $actAction = 0; # ACTION_QUERY
my $bBlob = ’A’ x $MAX_BLOB;
my $cbBlobSize = 128;
my $server = ’127.0.0.1’;
my $port = 1777;
if ($socks = IO::Socket::INET->new(Proto=>"tcp",
PeerAddr=>$server,
PeerPort => $port,
TimeOut => 5)) {
my $junk = pack "ssa128",$actAction,$cbBlobSize,$bB lob;
printf "Sending junk to $port (%d bytes)", length $ junk;
$socks->send($junk);
}Note
All the Perl samples in this chapter were created and executed using ActiveState Visual Perl 1.0 from http://www.activestate.com.
Note the use of the pack function. This Perl function takes a list of values and creates a byte stream by using rules defined by the template string. In this example, the template is "ssa128", which means two signed short integers (the letter s twice) and 128 arbitrary characters (the a128 value). The pack function supports many data types, including Unicode and UTF-8 strings, and little endian and big endian words. It’s a useful function indeed.
Note
The pack function is very useful if you want to use Perl to build test scripts to exercise binary data.
Before I move on to the next section, Figure 19-2 and Figure 19-3 outline some ways to build mutated XML data. I added these to give you some ideas, and the list is certainly not complete.

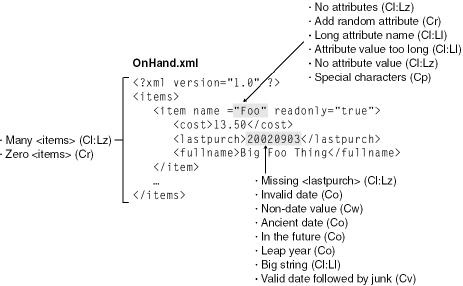
The real fun begins when you start to send overly large data structures (Ll). This is a wonderful way to test code that handles buffers, code that has in the past led to many serious buffer overrun security vulnerabilities.
You can have much more fun with the previous example Perl code because the structure includes a data member that determines the length of the buffer to follow. This is common indeed; many applications that support complex binary data have a data member that stores the size of the data to follow. To have some real fun with this, why not lie about the data size? (You should refer to the next chapter—Chapter 20—for information about analyzing data structures for security errors.) Look at the following single line change from the Perl code noted earlier:
my $cbBlobSize = 256; # Lie about blob size.
This code sets the data block size to 256 bytes. However, only 128 bytes is sent, and the server code assumes a maximum of MAX_BLOB (128) bytes. This might make the application fail with an access violation if it attempts to copy 256 bytes to a 128-byte buffer, when half of the 256 bytes is missing. Or you could send 256 bytes and set the blob size to 256 also. The code might copy the data verbatim, even though the buffer is only 128 bytes in size. Another useful trick is to set the blob size to a huge value, as in the following code, and see whether the server allocates the memory blindly. If you did this enough times, you could exhaust the server’s memory. Once again, this is another example of a great DoS attack.
my $cbBlobSize = 256_000; # Really lie about blob size.
I once reviewed an application that took usernames and passwords and cached them for 30 minutes, for performance reasons. The cache was an in-memory cache, not a file. However, there was a bug: if an attacker sent a bogus username and password, the server would cache the data and then reject the request because the credentials were invalid. However, it did not flush the cache for another 30 minutes. So an attacker could send thousands of elements of invalid data, and eventually the service would stop or slow to a crawl as it ran out of memory. The fix was simply not caching anything until credentials were validated. I also convinced the application team to reduce the cache time-out to 15 minutes.
If the code does fail, take special note of the value in the instruction pointer (EIP) register. If the register contains data from the buffer you provided—in this case, a series of As—the return address on the stack has been overwritten, making the buffer overrun exploitable.
Tip
A useful test case is to perturb file and registry data read by code that expects the data to be no greater than MAX_PATH bytes or Unicode characters in length. MAX_PATH, which is defined in many Windows header files, is set to 260.
Tip
You could consider that Unicode and ANSI characters are different data string types. Your test plans should use ANSI strings where Unicode is expected and vice versa.
You should also note another type data mutation exists, and that is to use special characters that either have special semantics (such as quotes [Cpq] and metacharacters [Cpm]) or are alternate representations of valid data (such as escaped data [Cpe]). Example metacharacters are shown in Table 19-4.
Table 19-4. Example Metacharacters
|
Character |
Comments |
|---|---|
|
// and /* and */ |
C++, C#, and C comment operators |
|
# |
Perl comment operator |
|
' |
Visual Basic comment operator |
|
<!-- and --> |
HTML and XML comment operators |
|
-- |
SQL comment operator |
|
; and : |
Command line command separation |
|
| |
Pipe redirection |
|
and or 0x0a and 0x0d |
Newline and carriage return |
|
|
Tab |
|
0x04 |
End of file |
|
0x7f |
Delete |
|
0x00 |
Null bytes |
|
< and > |
Tag delimiters and redirection |
|
* and ? |
Wildcard |
Other special cases exist that relate only to data on-the-wire: replayed data (Nr), out-of-sync data arrival (No), and data flooding or high volume (Nh). The first case can be quite serious. If you can replay a data packet or packets and gain access to some resource, or if you can make an application grant you access when it should not, you have a reasonably serious error that needs to be fixed. For example, if your application has some form of custom authentication that relies on a cookie, or some data held in a field that determines whether the client has authenticated itself, replaying the authentication data might grant others access to the service, unless the service takes steps to mitigate this.
Out-of-sync data involves sending data out of order. Rather than sending Data1, Data2, and Data3 in order, the test application sends them in an incorrect order, such as Data1, Data3, and Data2. This is especially useful if the application performs some security check on Data1, which allows Data2 and Data3 to enter the application unchecked. Some firewalls have been known to do this.
Finally, here’s one of the favorite attacks on the Internet: simply swamping the service with so much data, or so many requests, that it becomes overwhelmed and runs out of memory or some other restricted resource and fails. Performing such stress testing often requires a number of machines and multithreaded test tools. This somewhat rules out Perl (which has poor multithreaded support), leaving C/C++, .NET code, and specialized stress tools.
Tip
Do you want to find plenty of bugs quickly? Exercise the failure paths in the application being tested—because developers never do!
Another fruitful attack type is to write an evil client that initiates a transaction with a server and then fails to respond. Make sure you cover each phase of the conversation. Take a good look at Chapter 17, and create testing tools that exercise each of these failure modes.
Note
A useful tool for fault injection, especially if you’re not a tester who does much coding, is the Cenzic product named Hailstorm This tool allows a tester to construct arbitrarily complex data to send to various networking interfaces. It also supports data flooding. You can find more information about the tool at http://www.cenzic.com.
You need to set up application monitoring prior to running any test. Most notably, you should hook up a debugger to the machine in case the application breaks. Don’t forget to use Performance Monitor to track application memory and handle usage. If the application fails or memory counts or handle counts increase, attackers could also make the application fail, denying service to others.
Note
Other tools to use include Gflags.exe, available on the Windows 2000 and Windows .NET CDs, which allows you to set system heap options; Oh.exe, which shows handle usages; and dh.exe, which shows process heap usage. The second and third of these tools are available in the Windows 2000 and Windows .NET resource kits.
Important
If the application performs exception handling, you might not see any errors occur in the code unless you have a debugger attached. Why? When the error condition occurs, it is caught by the exception-handling code and the application continues operation. If a debugger is attached, the exception is passed to the debugger first.
Also, use the event log, because you might see errors appear there, especially if the application is a service. Many services are configured to restart on failure.
Now let’s turn our attention from testing techniques to technologies for security testing.
Finally, you need to build tools to test the interfaces to find flaws. There is a simple rule you should follow when choosing appropriate testing tools and technologies: use a tool that slips under the radar. Don’t use a tool that correctly formats the request for you, or you might not test the interface correctly. For example, don’t use Visual Basic to exercise low-level COM interfaces because the language will always correctly form strings and other data structures. The whole point of performing security testing by using fault injection is to create data that is invalid.
Note
If a security vulnerability is found in your code or in a competitor’s code by an external party and the external party makes exploit code available, use the code in your test plans. You should run the code as regularly as you run other test scripts. Vendors have been known to reintroduce security bugs in products, sometimes years after the original bug was fixed. A nasty Sendmail bug, known as the "pipe bomb," was reintroduced in IBM’s AIX 10.0 operating system several versions after it was originally fixed. Likewise, current vulnerability auditing tools will sometimes find problems—you certainly don’t want a widely used security tool crashing your application! Make these part of your test plan.
Also, consider alternate routes in the application that exhibit the same functionality. For example, many applications can be configured with administrative tools and programmatically with an object model. I’ve already discussed some ways to build mutated data. Now we need to look at how to get the data to the interfaces. In the next few sections, I’ll look at some ways to test various interface types.
I’ve already shown Perl-based test code that accesses a server’s socket and sends bogus data to the server. Perl is a great language to use for this because it has excellent socket support and gives you the ability to build arbitrarily complex binary data by using the pack function. You could certainly use C++, but if you do, I’d recommend you use a C++ class to handle the socket creation and maintenance. Your job is to create bogus data, not to worry about the lifetime of a socket. One example is the CSocket class in the Microsoft Foundation Classes (MFC). C# and Visual Basic .NET are also viable options. In fact, I prefer to use C# and the System.Net.Sockets namespace. You get ease of use, a rich socket class, memory management, and threading. Also, the TcpClient and TcpServer classes help by providing much of the plumbing for you.
To test HTTP-based server applications, once again I would use Perl or the .NET Framework for a number of reasons, including excellent socket support, HTTP support, and user-agent support. You can create a small Perl script or C# application that behaves like a browser, taking care of some of the various headers that are sent during a normal HTTP request. The following Perl sample code shows how to create an HTTP form request that contains invalid data in the form. The Name, Address, and Zip fields all contain long strings. The code sets a new header in the request, Timestamp, to a bogus value too.
# SmackPOST.pl
use HTTP::Request::Common qw(POST GET);
use LWP::UserAgent;
# Set the user agent string.
my $ua = LWP::UserAgent->new();
$ua->agent("HackZilla/v42.42 WindowsXP");
# Build the request.
my $url = "http://127.0.0.1/form.asp";
my $req = POST $url, [Name => ’A’ x 128,
Address => ’B’ x 256,
Zip => ’C’ x 128];
$req->push_header("Timestamp:" => ’1’ x 10);
my $res = $ua->request($req);
# Get the response.
# $err is the HTTP error and $_ holds the HTTP response data.
my $err = $res->status_line;
$_ = $res->as_string;
print " Error!" if (/Illegal Operation/ ig || $err != 200);This code is also available with the book’s sample files in the folder Secureco2Chapter19. As you can see, the code is small because it uses various Perl modules, Library for WWW access in Perl (LWP), and HTTP to perform most of the underlying work, while you get on with creating the malicious content.
Here’s another variation. In this case, the code exercises an ISAPI handler application, test.dll, by performing a GET operation, setting a large query string in the URL, and setting a custom header (bogushdr) handled by the application, made up of the letter H repeated 256 times, followed by carriage return and linefeed, which in turn is repeated 128 times. The following code is also available with the book’s sample files in the folder Secureco2Chapter19:
# SmackQueryString.pl
use LWP::UserAgent;
$bogushdr = (‘H’ x 256) . ’
’;
$hdr = new HTTP::Headers(Accept => ’text/plain’,
User-Agent => ’HackZilla/ 42.42’,
Test- Header => $bogushdr x 128);
$urlbase = ’http://localhost/test.dll?data=‘;
$data = ’A’ x 16_384;
$url = new URI::URL($urlbase . $data);
$req = new HTTP::Request(GET, $url, $hdr);
$ua = new LWP::UserAgent;
$resp = $ua->request($req);
if ($resp->is_success) {
print $resp->content;
}
else {
print $resp->message;
}When building such attack tools by using the .NET Framework, you can employ the WebClient, HttpGetClientProtocol or HttpPostClientProtocol classes. Like HTTP::Request::Common in Perl, these classes handle much of the low-level protocol work for you. The following C# example shows how to build such a client by using the WebClient class that creates a very large bogus header:
using System;
using System.Net;
using System.Text;
namespace NastyWebClient {
class NastyWebClientClass {
static void Main(string[] args) {
if (args.Length < 1) return;
string uri = args[0];
WebClient client = new WebClient();
client.Credentials = CredentialCache.DefaultCredentials;
client.Headers.Add
(@"IWonderIfThisWillCrash:" + new String(‘a’,32000));
client.Headers.Add
(@"User-agent: HackZilla/v42.42 WindowsXP");
try {
//Make request, and get response data
byte[] data = client.DownloadData(uri);
WebHeaderCollection header = client.ResponseHeaders;
bool isText = false;
for (int i=0; i < header.Count; i++) {
string headerHttp = header.GetKey(i);
string headerHttpData = header.Get(i);
Console.WriteLine
(headerHttp + ":" + headerHttpData);
if (headerHttp.ToLower().StartsWith
("content-type") &&
headerHttpData.ToLower().StartsWith("text"))
isText = true;
}
//Print the response if the response is text
if (isText) {
string download = Encoding.ASCII.GetString(data);
Console.WriteLine(download);
}
} catch (WebException e) {
Console.WriteLine(e.ToString());
}
}
}
}The buffer overrun in Microsoft Index Server 2.0, which led to the CodeRed worm and is outlined in "Unchecked Buffer in Index Server ISAPI Extension Could Enable Web Server Compromise" at http://www.microsoft.com/technet/security/bulletin/MS01-033.asp, could have been detected if this kind of test had been used. The following scripted URL will make an unpatched Index Server fail. Note the large string of As.
$url = ’http://localhost/nosuchfile.ida?’ . (‘A’ x 260) . ’=X’;
Perl includes a Named Pipe class, Win32::Pipe, but frankly, the code to write a simple named pipes client in C++ or managed code is small. And, if you’re using C++, you can call the appropriate ACL and impersonation functions when manipulating the pipe, which is important. You can also write a highly multithreaded test harness, which I’ll discuss in the next section.
To help you test, draw up a list of all methods, properties, events, and functions, as well as any return values of all the COM, DCOM, ActiveX, and RPC applications. The best source of information for this is not the functional specifications, which are often out of date, but the appropriate Interface Definition Language (IDL) files.
Assuming you have compiled the RPC server code by using the /robust compiler switch—refer to the RPC information in Chapter 16, if you need reminding why using this option is a good thing—you’ll gain little from attempting to send pure junk to the RPC interface, because the RPC and DCOM run times will reject the data unless it exactly matches the definition in the IDL file. In fact, if you do get a failure in the server-side RPC run time, please file a bug with Microsoft! So, you should instead exercise the function calls, methods, and properties by setting bogus data on each call from C++. After all, you’re trying to exercise your code, not the RPC run-time code. Follow the ideas laid out in Figure 19-1.
For low-level RPC and DCOM interfaces—that is, those exposed for C++ applications, rather than scripting languages—consider writing a highly multithreaded application, which you run on multiple computers, and stress each function or method to expose possible timing issues, race conditions, multithread design bugs, and memory or handle leaks.
If your application supports automation—that is, if the COM component supports the IDispatch interface—you can use C++ to set random data in the function calls themselves, or you can use any scripting language to set long data and special data types.
Remember that ActiveX controls can often be repurposed—that is, potentially instantiated from any Web page—unless they are tied to the originating domain. If you ship one or more ActiveX controls, consider the consequence of using the control beyond its original purpose.
ActiveX controls invoked through <OBJECT> tags can be tested in a way similar to testing other ActiveX controls. The only difference is that we create malformed data in the tag itself in an HTML file and then execute the HTML file. A number of buffer overruns have been found, and exploited, in ActiveX controls in <OBJECT> tags. Therefore, to test for these properly you should plan to exercise each property and method on the object.
An example of such an attack was found in the System Monitor ActiveX Control included with Microsoft Windows 2000, which had the name Sysmon.ocx and classid of C4D2D8E0-D1DD-11CE-940F-008029004347. The problem was in the control’s LogFileName parameter. A buffer overrun occurred if the length of the data entered was longer than 2000 characters, which could lead to remote code execution. Simply testing each parameter in the tag control would have found this bug. The following shows how you could test the LogFileName parameter:
<HTML> <BODY> <OBJECT ID="DISysMon" WIDTH="100%" HEIGHT="100%" CLASSID="CLSID:C4D2D8E0-D1DD-11CE-940F-008029004347"> <PARAM NAME="_Version" VALUE="195000"> <PARAM NAME="_ExtentX" VALUE="21000"> <PARAM NAME="_ExtentY" VALUE="16000"> <PARAM NAME="AmbientFont" VALUE="1"> <PARAM NAME="Appearance" VALUE="0"> <PARAM NAME="BackColor" VALUE="0"> <PARAM NAME="BackColorCtl" VALUE="-2147483633"> <PARAM NAME="BorderStyle" VALUE="1"> <PARAM NAME="CounterCount" VALUE="0"> <PARAM NAME="DisplayType" VALUE="3"> <PARAM NAME="ForeColor" VALUE="-1"> <PARAM NAME="GraphTitle" VALUE="Test"> <PARAM NAME="GridColor" VALUE="8421504"> <PARAM NAME="Highlight" VALUE="0"> <PARAM NAME="LegendColumnWidths" VALUE="-11 -12 -14 -12 -13 -13 -16"> <PARAM NAME="LegendSortColumn" VALUE="0"> <PARAM NAME="LegendSortDirection" VALUE="2097272"> <PARAM NAME="LogFileName" VALUE="aaaaaa ... more than 2,000 ’a’ ... aaaaaaa"> <PARAM NAME="LogViewStart" VALUE=""> <PARAM NAME="LogViewStop" VALUE=""> <PARAM NAME="ManualUpdate" VALUE="0"> <PARAM NAME="MaximumSamples" VALUE="100"> <PARAM NAME="MaximumScale" VALUE="100"> <PARAM NAME="MinimumScale" VALUE="0"> <PARAM NAME="MonitorDuplicateInstances" VALUE="1"> <PARAM NAME="ReadOnly" VALUE="0"> <PARAM NAME="ReportValueType" VALUE="4"> <PARAM NAME="SampleCount" VALUE="0"> <PARAM NAME="ShowHorizontalGrid" VALUE="1"> <PARAM NAME="ShowLegend" VALUE="1"> <PARAM NAME="ShowScaleLabels" VALUE="1"> <PARAM NAME="ShowToolbar" VALUE="1"> <PARAM NAME="ShowValueBar" VALUE="1"> <PARAM NAME="ShowVerticalGrid" VALUE="1"> <PARAM NAME="TimeBarColor" VALUE="255"> <PARAM NAME="UpdateInterval" VALUE="1"> <PARAM NAME="YAxisLabel" VALUE="Test"> </OBJECT> </BODY> </HTML>
To perform this type of test, you can enumerate all the properties (the <PARAM NAME> tags) in an array, as well as their valid data types; have the test code create an HTML file; output the valid HTML prolog code; mutate one or more parameters; output valid HTML epilog code; and then invoke the HTML file to see whether the ActiveX controls fails. The following C# test harness shows how to create the HTML test file that contains malformed data:
using System;
using System.Text;
using System.IO;
namespace WhackObject {
class Class1 {
static Random _rand;
static int getNum() {
return _rand.Next(-1000,1000);
}
static string getString() {
StringBuilder s = new StringBuilder();
for (int i = 0; i < _rand.Next(1,16000); i++)
s.Append("A");
return s.ToString();
}
static void Main(string[] args) {
_rand = new Random(unchecked((int)DateTime.Now.Ticks));
string CRLF = "
";
try {
string htmlFile = "test.html";
string prolog =
@"<HTML><BODY><OBJECT ID=‘DISysMon’ WIDTH=‘100%’ HEIGHT=‘100%’" +
"CLASSID=‘CLSID:C4D2D8E0-D1DD-11CE-940F-008029004347’>";
string epilog = @"</OBJECT></BODY></HTML>";
StreamWriter sw = new StreamWriter(htmlFile);
sw.Write(prolog + CRLF);
string [] numericArgs = {
"ForeColor","SampleCount",
"TimeBarColor","ReadOnly"};
string [] stringArgs = {
"LogFileName","YAxisLabel","XAxisLabel"};
for (int i=0; i < numericArgs.Length; i++)
sw.Write(@"<PARAM NAME={0} VALUE={1}>{2}",
numericArgs[i],getNum(),CRLF);
for (int j=0; j < stringArgs.Length; j++)
sw.Write(@"<PARAM NAME={0} VALUE={1}>{2}",
stringArgs[j],getString(),CRLF);
sw.Write(epilog + CRLF);
sw.Flush();
sw.Close();
} catch (IOException e){
Console.Write(e.ToString());
}
}
}
}Once you have created the file, it can be loaded into a browser to see if the control fails because of the data mutation.
Testing controls does not stop with parameters. You must also test all PARAMS, methods, events, and properties (because some properties can return other objects that should also be tested).
You should test the control in different zones if you are using Microsoft Internet Explorer as a test harness; controls can behave differently based on their zone or domain.
You need to test in a number of ways when handling files, depending on what your application does with a file. For example, if the application creates or manipulates a file or files, you should follow the ideas in Figure 19-1, such as setting invalid ACLs, precreating the file, and so on. The really interesting tests come when you create bogus data in the file and then force the application to load the file. The following simple Perl script creates a file named File.txt, which is read by Process.exe. However, the Perl script creates a file containing a series of 0 to 32,000 As and then loads the application.
my $FILE = "file.txt";
my $exe = "program.exe";
my @sizes = (0,256,512,1024,2048,32000);
foreach(@sizes) {
printf "Trying $_ bytes
";
open FILE, "> $FILE" or die "$!
";
print FILE ’A’ x $_;
close FILE;
# Note the use of backticks – like calling system().
‘$exe $FILE’;
}If you want to determine which files are used by an application, you should consider using FileMon from http://www.sysinternals.com.
More Information
Some other tools you need in your kit bag include Holodeck and Canned Heat from the Center for Software Engineering Research at the Florida Institute of Technology. More information is at http://se.fit.edu/projects. You should also pick up a copy of James A. Whittaker’s book, How to Break Software: A Practical Guide to Testing. Details are in the bibliography.
Registry applications are simple to test, using the Win32::Registry module in Perl. Once again, the code is short and simple. The following example sets a string value to 1000 As and then launches an application, which loads the key value:
use Win32::Registry;
my $reg;
$::HKEY_LOCAL_MACHINE->Create("SOFTWARE\AdvWorks\1.0\Config",$reg)
or die "$^E";
my $type = 1; # string
my $value = ’A’ x 1000;
$reg->SetValueEx("SomeData","",$type,$value);
$reg->Close();
‘process.exe’;Or, when using VBScript and the Windows Scripting Host, try
Set oShell = WScript.CreateObject("WScript.Shell")
strReg = "HKEY_LOCAL_MACHINESOFTWAREAdvWorks1.0ConfigNumericData"
oShell.RegWrite strReg, 32000, "REG_DWORD"
‘ Execute process.exe, 1=active window.
‘ True means waiting for app to complete.
iRet = oShell.Run("process.exe", 1, True)
WScript.Echo "process.exe returned " & iRetDon’t forget to clean up the registry between test passes. If you want to determine which registry keys are used by an application, consider using RegMon from http://www.sysinternals.com.
Important
You might not need to thoroughly test all securable objects—including files in NTFS file system (NTFS) partitions and the system registry—for security vulnerabilities if the ACLs in the objects allow only administrators to manipulate them. This is another reason for using good ACLs—they help reduce test cases. However, even if the data is writable only by administrators, it’s usually best if the application fails gracefully when it encounters invalid input.
No doubt you can guess how to test command line applications based on the previous two Perl examples. Simply build a large string and pass it to the application by using backticks, like so:
my $arg= ’A’ x 1000; ‘process.exe -p $args’; $? >>= 8; print "process.exe returned $?";
Of course, you should test all arguments with invalid data. And in each case the return value from the executable, held in the $? variable, should be checked to see whether the application failed. Note that the exit value from a process is really $? >>8, not the original $?.
The following sample code will exercise all arguments randomly and somewhat intelligently in that it knows the argument types. You should consider using this code as a test harness for your command line applications and adding new argument types and test cases to the handler functions. You can also find this code with the book’s sample files in the folder Secureco2Chapter19.
# ExerciseArgs.pl
# Change as you see fit.
my $exe = "process.exe";
my $iterations = 100;
# Possible option types
my $NUMERIC = 0;
my $ALPHANUM = 1;
my $PATH = 2;
# Hash of all options and types
# /p is a path, /i is numeric, and /n is alphanum.
my %opts = (
p => $PATH,
i => $NUMERIC,
n => $ALPHANUM);
# Do tests.
for (my $i = 0; $i < $iterations; $i++) {
print "Iteration $i";
# How many args to pick?
my $numargs = 1 + int rand scalar %opts;
print " ($numargs args) ";
# Build array of option names.
my @opts2 = ();
foreach (keys %opts) {
push @opts2, $_;
}
# Build args string.
my $args = "";
for (my $j = 0; $j < $numargs; $j++) {
my $whicharg = @opts2[int rand scalar @opts2];
my $type = $opts{$whicharg};
my $arg = "";
$arg = getTestNumeric() if $type == $NUMERIC;
$arg = getTestAlphaNum() if $type == $ALPHANUM;
$arg = getTestPath() if $type == $PATH;
# arg format is ’/’ argname ’:’ arg
# examples: /n:test and /n:42
$args = $args . " /" . $whicharg . ":$arg";
}
# Call the app with the args.
‘$exe $args’;
$? >>= 8;
printf "$exe returned $?
";
}
# Handler functions
# Return a numeric test result;
# 10% of the time, result is zero.
# Otherwise it’s a value between -32000 and 32000.
sub getTestNumeric {
return rand > .9
? 0
: (int rand 32000) - (int rand 32000);
}
# Return a random length string.
sub getTestAlphaNum {
return ’A’ x rand 32000;
}
# Return a path with multiple dirs, of multiple length.
sub getTestPath {
my $path="c:\";
for (my $i = 0; $i < rand 10; $i++) {
my $seg = ’a’ x rand 24;
$path = $path . $seg . "\";
}
return $path;
}In Windows, it’s rare for a buffer overrun in a command line argument to lead to serious security vulnerabilities, because the application runs under the identity of the user. But such a buffer overrun should be considered a code-quality bug. On UNIX and Linux, command line buffer overruns are a serious issue because applications can be configured by a root user to run as a different, higher-privileged identity, usually root, by setting the SUID (set user ID) flag. Hence, a buffer overrun in an application marked to run as root could have disastrous consequences even when the code is run by a normal user. One such example exists in Sun Microsystems’ Solaris 2.5, 2.6, 7, and 8 operating systems. A tool named Whodo, which is installed as setuid root, had a buffer overrun, which allowed an attacker to gain root privileges on Sun computers. Read about this issue at http://www.securityfocus.com/bid/2935.
As XML becomes an important payload, it’s important that code handling XML payloads is tested thoroughly. Following Figure 19-1, you can exercise XML payloads by making tags too large or too small or by making them from invalid characters. The same goes for the size of the XML payload itself—make it huge or nonexistent. Finally, you should focus on the data itself. Once again, follow the guidelines in Figure 19-1.
You can build malicious payloads by using Perl modules, .NET Framework classes, or the Microsoft XML document object model (DOM). The following example builds a simple XML payload by using JScript and HTML. I used HTML because it’s a trivial task to build the test code around the XML template. This code fragment is also available with the book’s sample files in the folder Secureco2Chapter19.
<!-- BuildXML.html -->
<XML ID="template">
<user>
<name/>
<title/>
<age/>
</user>
</XML>
<SCRIPT>
// Build long strings
// for use in the rest of the test application.
function createBigString(str, len) {
var str2 = new String();
for (var i = 0; i < len; i++)
str2 += str;
return str2;
}
var user = template.XMLDocument.documentElement;
user.childNodes.item(0).text = createBigString("A", 256);
user.childNodes.item(1).text = createBigString("B", 128);
user.childNodes.item(2).text = Math.round(Math.random() * 1000);
var oFS = new ActiveXObject("Scripting.FileSystemObject");
var oFile = oFS.CreateTextFile("c:\temp\user.xml");
oFile.WriteLine(user.xml);
oFile.Close();
</SCRIPT>View the XML file once you’ve created it and you’ll notice that it contains large data items for both name and title and that age is a random number. You could also build huge XML files containing thousands of entities.
If you want to send the XML file to a Web service for testing, consider using the XMLHTTP object. Rather than saving the XML data to a file, you can send it to the Web service with this code:
var oHTTP = new ActiveXObject("Microsoft.XMLHTTP");
oHTTP.Open("POST", "http://localhost/ PostData.htm", false);
oHTTP.send(user.XMLDocument);Building XML payloads by using the .NET Framework is trivial. The following sample C# code creates a large XML file made of bogus data. Note that getBogusISBN and getBogusDate are left as an exercise for the reader!
static void Main(string[] args) {
string file = @"c:1.xml";
XmlTextWriter x = new XmlTextWriter(file, Encoding.ASCII);
Build(ref x);
// Do something with the XML file.
}
static void Build(ref XmlTextWriter x) {
x.Indentation = 2;
x.Formatting = Formatting.Indented;
x.WriteStartDocument(true);
x.WriteStartElement("books", "");
for (int i = 0; i < new Random.Next(1000); i++) {
string s = new String(‘a’, new Random().Next(10000));
x.WriteStartElement("book", "");
x.WriteAttributeString("isbn", getBogusISBN());
x.WriteElementString("title", "", s);
x.WriteElementString("pubdate", "", getBogusDate());
x.WriteElementString("pages", "", s);
x.WriteEndElement();
}
x.WriteEndElement();
x.WriteEndDocument();
x.Close();
}Some in the industry claim that XML will lead to a new generation of security threats, especially in cases of XML containing script code. I think it’s too early to tell, but you’d better make sure your XML-based applications are well-written and secure, just in case! Check out one point of view at http://www.computerworld.com/rckey259/story/0,1199,NAV63_STO61979,00.html.
Essentially, a SOAP service is tested with the same concepts that are used to test XML and HTTP—SOAP is XML over HTTP, after all! The following sample Perl code shows how you can build an invalid SOAP request to launch at the unsuspecting SOAP service. This sample code is also available with the book’s sample files in the folder Secureco2Chapter19.
Note
SOAP can be used over other transports, such as SMTP and message queues, but HTTP is by far the most common protocol.
# TestSoap.pl
use HTTP::Request::Common qw(POST);
use LWP::UserAgent;
my $ua = LWP::UserAgent->new();
$ua->agent("SOAPWhack/1.0");
my $url = ’http://localhost/MySOAPHandler.dll’;
my $iterations = 10;
# Used by coinToss
my $HEADS = 0;
my $TAILS = 1;
open LOGFILE, ">>SOAPWhack.log" or die $!;
# Some SOAP actions - add your own, and junk too!
my @soapActions=(‘‘,’junk’,’foo.sdl’);
for (my $i = 1; $i <= $iterations; $i++) {
print "SOAPWhack: $i of $iterations
";
# Choose a random action.
my $soapAction = $soapActions[int rand scalar @soapActions];
$soapAction = ’S’ x int rand 256 if $soapAction eq ’junk’;
my $soapNamespace = "http://schemas.xmlsoap.org/soap/envelope/";
my $schemaInstance = "http://www.w3.org/2001/XMLSchema-instance";
my $xsd = "http://www.w3.org/XMLSchema";
my $soapEncoding = "http://schemas.xmlsoap.org/soap/encoding/";
my $spaces = coinToss() == $HEADS ? ’ ’ : ’ ’ x int rand 16384;
my $crlf = coinToss() == $HEADS ? ’
’ : ’
’ x int rand 256;
# Make a SOAP request.
my $soapRequest = POST $url;
$soapRequest- >push_header("SOAPAction" => $soapAction);
$soapRequest->content_type(‘text/xml’);
$soapRequest->content("<soap:Envelope " . $spaces .
" xmlns:soap="" . $soapNamespace .
"" xmlns:xsi="" . $schemaInstance .
"" xmlns:xsd="" . $xsd .
"" xmlns:soapenc="" . $soapEncoding .
""><soap:Body>" . $crlf .
"</soap:Body></soap:Envelope>");
# Perform the request.
my $soapResponse = $ua->request($soapRequest);
# Log the results.
print LOGFILE "[SOAP Request]";
print LOGFILE $soapRequest->as_string . "
";
print LOGFILE "[WSDL response]";
print LOGFILE $soapResponse->status_line . " ";
print LOGFILE $soapResponse->as_string . "
";
}
close LOGFILE;
sub coinToss {
return rand 10 > 5 ? $HEADS : $TAILS;
}Remember to apply the various mutation techniques outlined earlier in this chapter.
Finally, you could also use the .NET Framework class SoapHttpClientProtocol to build multithreaded test harnesses.
In Chapter 13, I discussed cross-site scripting (XSS) and the dangers of accepting user input. In this section, I’ll show you how to test whether your Web-based code is susceptible to some forms of scripting attacks. The methods here won’t catch all of them, so you should get some ideas, based on some attacks, from Chapter 13 to help build test scripts. Testing for some kinds of XSS issues is quite simple; testing for others is more complex.
More Information
Take a look at the excellent http://www.owasp.org for information about XSS issues.
If you look at what causes XSS problems—echoing user input—you’ll quickly realize how to test for them: force input strings on the Web application. First, identify all points of input into a Web application, such as fields, headers (including cookies), and query strings. Next, populate each identified input point with a constant string and send the request to the server. Finally, check the HTTP response to see whether the string is returned to the client. If it’s echoed back unchanged, you have a potential cross-site scripting bug that needs fixing. Refer to Chapter 13 for remedies. Note that this test does not mean you do have an XSS issue; it indicates that further analysis needed. Also, if you set the input string to a series of special characters, such as "<>>", and do not get the same data in the response, you know the Web page is performing some XSS filtering. Now you can check whether weaknesses or errors are in the processing.
Tip
Sometimes you may need to add one or more carriage returns/linefeeds (metacharacters [Cpm]) to the input—some Web sites don’t scan input across multiple lines.
The following Perl script works by creating input for a form and looking for the returned text from the Web page. If the output contains the injected text, you should investigate the page because the page might be susceptible to cross-site scripting vulnerabilities. The script then goes one step further to see whether any XSS processing is being performed by the server. Note that this code will not find all issues. The cross-site scripting vulnerability might not appear in the resulting page—it might appear a few pages away. So you need to test your application thoroughly.
# CSSInject.pl
use HTTP::Request::Common qw(POST GET);
use LWP::UserAgent;
my $url = "http://127.0.0.1/test.asp";
my $css = "xyzzy";
$_ = buildAndSendRequest($url,$css);
# If we see the injected script, we may have a problem.
if (index(lc $_, lc $css) != -1) {
print "Possible XSS issue in $url
";
# Do a bit more digging
my $css = "<>>";
$_ = buildAndSendRequest($url,$css);
if (index(lc $_, lc $css) != -1) {
print "Looks like no XSS process in $url
";
} else {
print "Looks like some XSS processing in $url
";
}
}
sub buildAndSendRequest {
my ($url, $css) = @_;
# Set the user agent string.
my $ua = LWP::UserAgent->new();
# Build the request.
$ua->agent("CSSInject/v1.42 WindowsXP");
my $req = POST $url, [Name => $css,
Address => $css,
Zip => $css];
my $res = $ua->request($req);
return $res->as_string;
}This sample code is also available with the book’s sample files in the folder Secureco2Chapter19.
More Information
Some issues outlined in "Malicious HTML Tags Embedded in Client Web Requests" at http://www.cert.org/advisories/CA-2000-02.html would have been detected using code like that in the listing just shown. A great XSS reference is "Cross-Site Scripting Overview" at http://www.microsoft.com/technet/itsolutions/security/topics/csoverv.asp.
So far, the focus has been on building test cases to attack servers. You should also consider creating rogue servers to stress-test client applications. The first way to do this is to make a special test version of the service you use and have it instrumented in such a way that it sends invalid data to the client. Just make sure you don’t ship this version to your clients! Another way is to build custom server applications that respond in ingenious and malicious ways to your client. In its simplest form, a server could accept requests from the client and send garbage back. The following example accepts any data from any client communicating with port 80 but sends junk back to the client. With some work, you could make this server code send slightly malformed data. This sample code is also available with the book’s sample files in the folder Secureco2Chapter19.
# TCPJunkServer.pl
use IO::Socket;
my $port = 80;
my $server = IO::Socket::INET->new(LocalPort => $port,
Type => SOCK_STREAM,
Reuse => 1,
Listen => 100)
or die "Unable to open port $port: $@
";
while ($client = $server->accept()) {
my $peerip = $client->peerhost();
my $peerport = $client->peerport();
my $size = int rand 16384;
my @chars = (‘A’..’Z’, ’a’..’z’, 0..9,
qw( ! @ # $ % ^ & * - + = ));
my $junk = join ("", @chars[ map{rand @chars } (1 . . $size)]);
print "Connection from $peerip:$peerport, ";
print "sending $size bytes of junk.
";
$client->send($junk);
}
close($server);Useful tests include testing for tampering with data bugs and information disclosure bugs. Should an attacker be able to change or view the data the application protects? For example, if an interface should be accessible only by an administrator, the expected result is an access denied error for all other user account types. The simplest way to build these test scripts is to build scripts as I have described earlier but to make the request a valid request. Don’t attempt any fault injection. Next make sure you’re logged on as a nonadministrator account. Or run a secondary logon console by using the RunAs command, log on as a user, and attempt to access the interface or data from the scripts. If you get an access denied error, the interface is performing as it should.
Unfortunately, many testers do not run these tests as a user. They run all their tests as an administrator, usually so that their functional tests don’t fail for security reasons. But that’s the whole purpose of security testing: to see whether you get an access denied error!
All the bugs outlined in "Tool Available for ‘Registry Permissions’ Vulnerability" at http://www.microsoft.com/technet/security/bulletin/MS00-095.asp and "OffloadModExpo Registry Permissions Vulnerability" at http://www.microsoft.com/technet/security/bulletin/MS00-024.asp would have been detected using the simple strategies just described.
Windows 2000 and later ship with security templates that define recommended lockdown computer configurations, a configuration more secure than the default settings. Many corporate clients deploy these policies to reduce the cost of maintaining client computers by preventing users from configuring too much of the system. Inexperienced users tinkering with their computers often leads to costly support problems.
Important
If your application has security settings, you must test every setting combination.
There is a downside to these templates: some applications fail to operate correctly when the security settings are anything but the defaults. Because so many clients are deploying these policies, as a tester you need to verify that your application works, or not, when the policies are used.
The templates included with Windows 2000 and later include those in Table 19-5.
Table 19-5. Windows 2000 Security Templates
|
Name |
Comments |
|---|---|
|
compatws |
This template applies default permissions to the Users group so that legacy applications are more likely to run. It assumes you’ve done a clean install of the operating system and the registry ACLs to an NTFS partition. The template relaxes ACLs for members of the Users group and empties the Power Users group. |
|
hisecdc |
This template assumes you’ve done a clean install of the operating system and the registry ACLs to an NTFS partition. The template includes securedc settings—see below—with Windows 2000–only enhancements. It empties the Power Users group. |
|
hisecws |
This template offers increased security settings over those of the securews template. It restricts Power User and Terminal Server user ACLs and empties the Power Users group. |
|
rootsec |
This template applies secure ACLs from the root of the boot partition down. |
|
securedc |
This template assumes you’ve done a clean install of the operating system and then sets appropriate registry and NTFS ACLs. |
|
securews |
This template assumes you’ve done a clean install of the operating system and then sets appropriate registry and NTFS ACLs. It also empties the Power Users group. |
|
setup security |
This template contains "out of the box" default security settings. |
At the very least you should configure one or more test computers to use the securews template if your code is client code and the securedc template for server code. You can deploy policy on a local test computer by using the following at the command line:
secedit /configure /cfg securews.inf /db securews.sdb /overwrite
Once a template is applied, run the application through the battery of functional tests to check whether the application fails. If it does, refer to "How to Determine Why Applications Fail" in Chapter 7, file a bug, and get the feature fixed.
Note
If you deploy the hisecdc or hisecws template on a computer, the computer can communicate only with other machines that have also had the relevant hisecdc or hisecws template applied. The hisecdc and hisecws templates require Server Message Block (SMB) packet signing. If a computer does not support SMB signing, all SMB traffic is disallowed.
When your tests find a defect, you can pat yourself on the back and start running your other test plans, right? No. You need go look for the bug’s variations. The process of identifying variations can be rewarding when a bug variation is discovered. Here’s a simple example. Let’s assume the application processes text IP addresses, such as 172.100.84.22, and your test plans note that a buffer overrun occurs if the first octet is not a number but rather a long string, such as aaaaaaaaaaaaaaaaaaaa.100.84.22. If there’s a bug in the code that processes the first octet, the chances are good the same bug exists when processing the other octets. Hence, when you discover this bug, you should update your test code to inject the following data:
aaaaaaaaaaaaaaaaaaaa.100.84.22 172.aaaaaaaaaaaaaaaaaaaa.84.22 172.100.aaaaaaaaaaaaaaaaaaaa.22 172.100.84.aaaaaaaaaaaaaaaaaaaa
A more methodical way to perform this kind of analysis is to follow these steps:
Reduce the attack.
What aspects of a flaw are superficial and can be eliminated from the test plan? Eliminate them and create the "base" exploit. In the previous example, the IP address might be part of another data structure that has no effect on the defect. It’s only the IP address we’re interested in.
Identify fundamental exploit variables.
Identify the individual parts of an exploit that can be modified to create new variations. The variables in an exploit are often easy to identify. In our example, the variables are the four IP octets.
Identify possible meaningfully distinct variable values.
It’s difficult to identify values that really are meaningfully distinct. The important variable values involved in a successful exploit are usually little-used or under-documented. A significant amount of time should be devoted to uncovering all the meaningfully distinct variable values. Ideally, this should involve analyzing existing documentation and source code or talking with the developers.
No two defects will ever have the same set of exploit variables with the exact same set of values. However, many exploits will have some common variables. This means the set of values for those variables can be saved and reused for other tests. In the previous example, it appears that any long string in an octet causes the failure. You should refer to Figure 19-1 to help determine valid and invalid variable types.
Test the full matrix of variables and variable values.
If you have properly identified all variables and all values, you now have all you need to construct a test of variations that isn’t covered by an existing test case. This leads to more complete test code, but even with broad test plans the test must code must be good quality, and that’s the next subject.
I’m sick of hearing comments like, "Oh, but it’s only test code." Bad test code is just about as bad as no test code and it’s worse if the test code is so bad that it convinces you that your code has no flaws. One bug I am overly familiar with resulted from a test case failing silently when a security violation was found. The application would fail during a test pass, but the code failed to catch the exception raised by the application, so it continued testing the application as though no security condition existed.
When writing test code, you should try to make it of ship quality, the sort of stuff you would be happy to give to a client. And let’s be honest: sometimes test code ends up being used by people other than the test organization, including third-party developers who build add-on functionality to the application, the sustained engineering teams, and people who might update the current version of the application once the developers move on to the next version.
When it comes to building secure distributed applications, no technology or feature is an island. A solution is the sum of its parts. Even the most detailed and well-considered design is insecure if one part of the solution is weak. As a tester, you need to find that weakest link, have it mitigated, and move on to the next-weakest link.
Tip
Keep in mind that sometimes two or more relatively secure components become insecure when combined!
People like numbers, especially numbers used to evaluate items. As humans, we seem to seek solace in comparative numbers. I’ve lost track of how many times I’ve been asked, "How much more secure is A compared to B?" Unfortunately, this king of comparison is often incredibly difficult, and this section does not seek to answer that question. Rather, it will help you determine how many items in an application can be attacked. The process is extremely simple:
Determine root attack vectors.
Determine bias for attack vectors.
Count the biased vectors in the product.
The result of this process is what’s called the relative attack surface quotient (RASQ). Let’s look at the process in a little more detail.
Applications are attacked in certain ways. For example, all operating systems are attacked through sockets, Windows PCs are attacked by virtue of weak ACLs, Linux and UNIX servers are attacked through setuid root applications, and database servers are attacked through stored procedures. You must determine how attackers will attack your application. This should come from—you guessed it—the threat model!
Next you must determine how bad an attack could be through the attack vector. For example, sockets are highly attacked points in an operating system, but weak registry ACLs are less attacked and attacks through them generally have less of a security impact. The bias should reflect the "badness" of each attack vector.
Finally, you must count the attack vectors in your application and apply the bias to each vector to arrive at the RASQ. Let’s look at an example: Windows. For Windows, I decided to count the attack vectors described in Table 19-6.
Table 19-6. Attack Vectors in Windows
|
Vector |
Bias |
Vector |
Bias |
|---|---|---|---|
|
Open sockets |
1.0 |
Active ISAPI filters |
1.0 |
|
Open RPC endpoints |
0.9 |
Dynamic Web pages |
0.6 |
|
Open named pipes |
0.8 |
Executable virtual directories |
1.0 |
|
Services |
0.4 |
Enabled accounts |
0.7 |
|
Services running by default |
0.8 |
Enabled accounts in admin group |
0.9 |
|
Services running as SYSTEM |
0.9 |
Null sessions to pipes and shares |
0.9 |
|
Active Web handlers |
1.0 |
Guest account enabled |
0.9 |
|
Weak ACLs in FS |
0.7 |
Weak ACLs in registry |
0.4 |
|
Weak ACLs on shares |
0.9 |
The result of comparing various versions of Windows by using this method is outlined in Figure 19-4.
You should be aware that you cannot use this method to compare different operating system types because each is attacked in different ways and has differing biases (but you can compare like operating systems). A comparison of, say, Linux and OS/400 is meaningless.
As a tester, you can use this method to determine whether your application has more points of attack than the previous version. A useful and recommended use of RASQ is to place a goal of reducing the RASQ of the version under development compared to the previous version. The developers can add as many new features as they like, so long as they still reduce the RASQ by, say, 5 percent.
Finally, this method is somewhat like function point analysis for security. It’s not foolproof, and it does not account for code quality. However, it is useful nonetheless.
In this chapter, I discussed the role of the security tester and how your job is not to prove that features work; rather, it is to determine how you can make features work in ways not anticipated by the developer. You should use the threat model to determine the components within the application that require test plans. The threat model also helps you understand how to attack the application components; use the STRIDE threat categories to decide what techniques to use to test that the threat is mitigated.
Data mutation is an incredibly useful way to force an application to fail. You should build data mutation routines for your application and use them to launch attacks at your application interfaces.
Finally, you can determine whether your application is becoming more or less susceptible to attack by measuring its attack surface. Build such a determination into the development process to make sure your application is becoming less susceptible to attack.