
Chapter 13
Fault Tolerance
One of the most significant ways in which servers differ from desktop computers has to do with the importance placed on fault tolerance. Fault tolerance means that a problem with software or hardware does not shut down the system, which minimizes the risk of data loss. To achieve fault tolerance, servers use technologies such as the following:
- Error correction for memory
- Self-monitoring of critical components such as memory, disk storage, and network connections
- Redundant memory, disk arrays, power supplies, and network connections
- Management of network hardware
Although many of these topics are covered in detail in other chapters, this chapter is designed to show you how these server technologies help you achieve a truly fault-tolerant network.
Fault-Tolerant Network Topologies
When setting up a network that must remain continuously accessible, one of the most important and often overlooked aspects to consider is the network topology.
Originally, Ethernet networks used a bus topology, which connected all devices to a common bus. If a single device on the bus failed, or if the ends of the network were improperly terminated, the network failed. 10BASE-T and faster networks that use UTP cables use a star topology, in which all devices connect to a central hub or switch. If a device other than the hub or switch fails, other devices can continue to connect to each other. However, if the hub or switch fails, the network fails.
To achieve a truly fault-tolerant network, you should consider one or more of these methods to provide redundant connections between devices on the network:
- Star topologies featuring teaming and failover connections between servers and backbone switches—These networks provide high-speed and redundant connections between servers and other network devices.
- The Hot Standby Router Protocol (HSRP, RFC 2281) and the newer Virtual Router Redundancy Protocol (VRRP, RFC 2338)—These protocols enable multiple routers to share a single virtual IP address and MAC address for fast recovery from router failure; these protocols also provide the benefit of load balancing.
These topologies and protocols support both copper and fiber-optic media, enabling usage in a wide variety of network situations. If you need to avoid network-related downtime, you should consider these solutions. The following sections provide more details about how these methods work and how to implement them in a new or existing network.
Mesh Configurations: Multiple Network Connections
A mesh configuration is designed to provide two or more direct links between networks or devices to create a redundant network of multiple interconnected sites. Because every site is directly connected to every other site, data can travel to any location on the network through a variety of routes that are configured within each site's routers.
To take full advantage of a mesh topology, each router should have multiple routes configured to each location. This allows for one of the lines to be taken down, due to disaster or scheduled maintenance, and still allow traffic to pass via an alternative route.
There are two types of mesh types: full mesh and partial mesh.
Note
If you are considering either a full or partial mesh network topology, you should determine which network nodes are of primary importance and which are secondary. You may decide to emphasize redundancy for primary nodes, in which case a partial mesh network or some other fault-tolerant design may make more sense (and cost far less money).
Full Mesh Networks
In a full mesh network, all network sites are directly connected to each other, as shown in Figure 13.1. This setup provides fault tolerance for every location, so if a line fails, no matter what one it is, all traffic will still be passed to its destination.
Figure 13.1 A full mesh network with all sites connected.
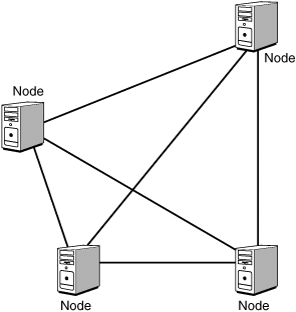
Although a full mesh configuration sounds like an ideal way to create a fault-tolerant network, it is not feasible in practice except, possibly, for very small networks. A full mesh network actually has several drawbacks, including the following:
- High initial hardware and cabling expenses
- Difficulties in scaling the network
A full mesh network requires at least two connections between each device on the network, with each connected to a different network. This type of configuration is known as dual-homed (two connections) or multihomed (three or more connections) and requires the addition of at least one network adapter to most clients (a few clients have two integrated network adapters). Many switches are required to provide redundant connections between the clients, and two network cables need to be run between each client or server—one each to different switches. The high initial cost of a full mesh network's additional hardware and cabling is magnified if the network needs more servers or clients.
A full mesh wide area network (WAN) is also very expensive due to the cost of the high-speed dedicated lines to connect the nodes. The larger the network gets, the more expensive a full mesh network is. As a result, a full mesh network design is not practical and is usually passed over in favor of a partial mesh network or other types of fault-tolerant network designs.
Partial Mesh Networks
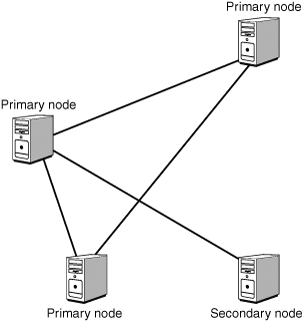
In a partial mesh network, all the critical sites are directly connected together, with the secondary sites connected using a star or ring topology, as shown in Figure 13.2. This setup is a little more common than full mesh because the cost of implementation is lower. This type of network has more points of failure, but if the secondary site is not critical, this is a good, cost-effective option for a network.
Figure 13.2 A partial mesh network with critical sites connected in a mesh topology and the secondary sites connected in a star topology.
Teaming and Failover
If a network adapter (that is, a NIC) fails in a server that has only one NIC, it loses connection with the entire network. If a multihomed server loses one NIC, it loses connection with the network segment serviced by that NIC. However, if teaming and failover have been implemented, a server can continue to connect to the network, even if one or more NICs have failed.
The following sections discuss how teaming and failover work to help create a fault-tolerant network.
Teaming
Teaming is the process of installing multiple NICs into a server or router and configuring them to work together in one of various ways. Teaming is controlled by the software on the network device that is using the teaming service. A team can include up to eight network ports in a server. This could be up to eight single-port network adapters (card-based or integrated) or a smaller number of multiport adapters.
Teaming can be used for fault tolerance, and it can also be used to improve network performance by allowing network traffic to be load balanced between all the network cards involved in the network team or to create a faster connection by aggregating the members of the team into a single logical connection. Because teaming can be used for a variety of purposes, you need to be familiar with the process of configuring a team. The following sections discuss how teaming is supported by some of the most popular server and network hardware vendors.
Teaming with Hewlett-Packard ProLiant Servers
Hewlett-Packard ProLiant servers offer a wide range of teaming options that vary by operating system. In addition to automatic teaming and failover, in which the server chooses the best method for keeping a connection alive, you can also choose dual-channel teaming. Dual-channel teaming allows for a team of network cards to be connected to two different switches. This method of teaming allows for a complete network switch failure to occur and the server or network device to stay online, without any downtime.
Switch-assisted load balancing is yet another option that is available for load balancing servers. This option is similar to the dual-channel option, but it allows you to have eight teams of eight network cards that all send and receive data simultaneously.
For automatic teaming and failover, as well as dynamic dual-channel load balancing or switch-assisted load balancing, you must use Windows 2000 Server or Windows Server 2003. Other teaming options are also available with these versions of Windows, as well as with other server operating systems, such as Windows NT 4.0, Red Hat and SUSE Linux Enterprise versions, Novell Netware 4.2 and greater, and various versions of SCO.
Tip
For more information about the teaming options and operating system support of Hewlett-Packard ProLiant servers, see http://h18004.www1.hp.com/products/servers/networking/teaming.html.
Teaming with Intel Advanced Network Services
Intel supports teaming through its Advanced Network Services (ANS) software, which is provided with Intel PRO Server adapters. ANS supports teaming and load balancing with Intel server-class Ethernet network adapters, Intel integrated Ethernet network adapters, and third-party network adapters. Note that at least one of the adapters in the team must be an Intel PRO add-on card or integrated network adapter. Intel ANS supports Windows 2000 Server, Windows Server 2003, and Linux. ANS teaming options include the following:
- Adapter fault tolerance (AFT)—Adapters configured for AFT provide automatic redundancy. If one fails, a backup adapter takes over and releases control back to the primary adapter when it comes back online. AFT works with standard switches.
- Adaptive load balancing—Adaptive load balancing provides load balancing among teamed adapters as well as fault tolerance with failover. It works with standard switches.
- Intel link aggregation (Cisco Fast EtherChannel Trunking or Gigabit EtherChannel Trunking)—Intel link aggregation provides faster throughput for teamed adapters as well as adapter fault tolerance and load balancing, but only when connected to switches that support the specific feature. It requires identical speed and duplex settings.
- IEEE 802.3ad dynamic link aggregation—IEEE 802.3ad dynamic link aggregation enables mixing of different speeds of Ethernet adapters for increased throughput, but it does not support fault tolerance. It requires a switch with IEEE 802.3ad support, and all adapters in a team to be assigned the same MAC address.
Tip
Intel provides a guide to using ANS with Linux at www.intel.com/support/network/adapter/1000/linux/ans.htm.
IBM provides a useful visual tutorial for the Intel PROSet network configuration utility and teaming wizard for Windows 2000 at www.307.ibm.com/pc/support/site.wss/document.do?lndocid=MIGR-40983.
Teaming with Broadcom Advanced Server Program
Broadcom, a leading vendor of server-class Ethernet adapters, provides the Broadcom Advanced Server Program (BASP) driver to enable Broadcom adapters to team with other Broadcom-based or third-party vendor network adapters. BASP supports Windows 2000 Server, Windows Server 2003, and Linux. BASP teaming options include the following:
- Smart load balancing—Smart load balancing provides load balancing among teamed adapters as well as fault tolerance with failover. It works with standard switches.
- IEEE 802.3ad dynamic link aggregation—IEEE 802.3ad dynamic link aggregation enables mixing of different speeds of Ethernet adapters for increased throughput, but it does not support fault tolerance. It requires a switch with IEEE 802.3ad support, and all adapters in a team to be assigned the same MAC address.
- Generic link aggregation (trunking)—This is a Broadcom protocol-independent version of IEEE 802.3ad aggregation with failover support.
Tip
For information on BASP, see the "Broadcom Ethernet FAQ's" page at www.broadcom.com/support/ethernet_nic/faq_drivers.php and whitepaper BCM570X: "Broadcom NetXtreme Gigabit Ethernet Teaming" at www.broadcom.com/collateral/wp/570X-WP100-R.pdf.
Failover
When you want to make sure that a server or another network device is constantly available, another technique, called failover, can also play an important role in your server network. A failover, which is automatic and transparent to the user, switches you to a backup device in the event of the failure of a server, database, router, or any other network device. You can use failover for emergency situations when you have a device failure or when you need to take a device down for routine maintenance.
Failover requires that you have a duplicate device that is connected and ready to be switched to in the event that the original hardware fails. This can be an expensive option to implement, but if your cost of being down is more than the cost of the redundant hardware, it is well worth it. You can implement many levels of failover, ranging from support for very minor components, such as a network card, to the extreme of having a backup device to everything on your network. Depending on your network's needs, you can decide the level of failover that is right for you.
As you learned in the previous sections, one of the features that NIC teaming supports is failover. Hewlett-Packard ProLiant servers support failover with most types of teaming (except for switch-assisted load balancing and 802.3ad dynamic teaming). With Intel ANS, you can select adapter fault tolerance or adaptive load balancing to set up failover support when teaming adapters. With Broadcom BASP, you can select smart load balancing or generic link aggregation to set up failover support when teaming adapters.
If you use routers that support the Virtual Router Redundancy Protocol (VRRP), you can configure two or more routers to provide redundancy and failover services.
However, failover should not be limited to NIC and router installations. Consider the following lists of devices that require failover support if you want to create a truly fault-tolerant network.
A company that relies on an Internet database should consider failover for the following:
- T1 or Internet connection, usually from two separate providers
- Smartjack
- Firewall
- Router with internal CSU/DSU
- Network switch
- Server
- Server network cards
- Database
A multisite company that relies on information sharing between locations should consider failover for the following:
- Point-to-point lines between each location, usually a T1 line but perhaps a fractional T1 or Frame Relay
- Smartjack
- Firewall
- Router with internal CSU/DSU
- Network switch
- Domain controller
- File server where the shared data resides
- Storage area network (SAN), if one is in use
A single-site company that desires failover only for LAN (not Internet) connections should consider failover for the following:
- Server network card
- Server power supply
- Server cooling fans
- Network switch
- SAN
- Database server (if applicable)
The individual components listed for a single-site company's server should also be considered for servers in large organizations.
![]() For more information about redundant power supplies, see "Redundant Power Supplies (RPSs)," p. 675.
For more information about redundant power supplies, see "Redundant Power Supplies (RPSs)," p. 675.
![]() For more information about implementing other types of hardware redundancy, see "Implementing Hardware Redundancy Options," p. 866.
For more information about implementing other types of hardware redundancy, see "Implementing Hardware Redundancy Options," p. 866.
![]() For more information about advanced network adapter configurations such as dual-homing and teaming, see "Network Interface Cards (NICs)," p. 557.
For more information about advanced network adapter configurations such as dual-homing and teaming, see "Network Interface Cards (NICs)," p. 557.
RAID
RAID (redundant array of inexpensive [or independent] disks) is a set of two or more storage devices combined together to provide fault tolerance and/or improve performance.
Not every level of RAID is fault tolerant. Striping (RAID 0) improves the speed of the disk subsystem, but because data is stored across two drives, there is no fault tolerance; if either drive fails, all data is lost. Fault-tolerant levels of RAID include RAID 1 (mirroring), RAID 5, RAID 10, and RAID 50.
![]() For more information about RAID levels and RAID configuration, see "Introduction to RAID," p. 600.
For more information about RAID levels and RAID configuration, see "Introduction to RAID," p. 600.
Although RAID levels other than RAID 0 provide some level of fault tolerance in that they protect against data loss, you still experience a loss of productivity if you need to shut down the server, remove and replace the failed drive, and rebuild the array. Generally, RAID arrays that use motherboard-integrated ATA/IDE, SATA, or SCSI host adapters are more likely to require you to perform a manual array rebuild. For true fault tolerance, you should consider RAID arrays that permit automatic rebuilding.
Transparently Rebuilding Failed Drives
To permit a server to continue to operate even in the event of a drive failure in a RAID array, your RAID solution needs to incorporate the following fault-tolerant features:
- Hot drive sparing—With this feature, a drive not currently in the array is placed in standby mode, ready to take over for a failed drive.
- Automatic array rebuilding—This feature swaps the failed drive for the hot spare drive and rebuilds the array without user intervention.
- Hot drive swapping—This feature permits failed drive replacement without shutting down the system.
Host adapters that support these features are available for ATA/IDE, SATA, and SCSI hard disks from a variety of vendors, including the following:
- Adaptec (www.adaptec.com)
- HighPoint Technologies, Inc. (www.highpoint.com)
- LSI Logic (www.lsilogic.com)
- Promise Technology (www.promise.com)
![]() For more information about RAID troubleshooting and array rebuilding, see "Managing RAID," p. 611.
For more information about RAID troubleshooting and array rebuilding, see "Managing RAID," p. 611.
Improving Network Speed and Reliability
Although improving a server's fault tolerance is critical to the reliability of a network, you should not overlook the design of the network itself or the hardware you use to build the network.
If your network carries different types of traffic to two or more servers, you should divide the network into separate segments to better manage traffic flow. However, a segmented network can also be used to provide fault tolerance if you make sure that one segment can take over for another segment in case of failure.
The following sections discuss segmentation and the selection of switches and routers needed to create a faster and more fault-tolerant network.
Segmentation
Segmentation alleviates network bottlenecks by splitting network traffic loads to different network segments. You can use segmentation to lower the total network traffic that is passed on a network by splitting up the traffic as shown in Figure 13.3. If one set of systems need to communicate with each other and not the rest of the network (for example, different departments), you can segment them into different networks. You can also use network segmentation if you have multiple locations that all need to access the same server but no other resources on the other segment (for example, if multiple locations all share the same email or file server).
Figure 13.3 Using network segmentation.
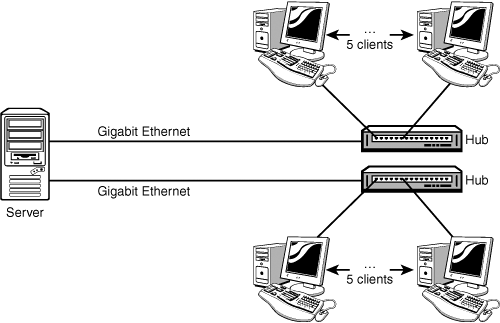
Segmentation can be used to improve a network's fault tolerance. By configuring a server's NICs to connect to different network segments (dual-homing) and using a router or Layer 3 switch to connect the segments, you enable the router to maintain a connection to all network segments, even if a direct connection to one segment fails.
Switches and Routers
You use switches and routers to create the network topology you prefer. As you have learned, the network topology can also help create a network with enhanced levels of fault tolerance. To achieve the desired level of fault tolerance at the network level, you need to understand how switches and routers can be used in a fault-tolerant installation.
Switches
If your network uses hubs to connect network nodes, there are several good reasons to upgrade to switches. Compared to hubs, switches don't generate unnecessary network traffic. Instead of broadcasting data frames to all ports, a switch transmits the packets directly to the destination port. Hubs subdivide total network bandwidth among connected devices (for example, a 10-port 100Mbps Fast Ethernet hub provides only 10Mbps bandwidth to each port), whereas switches provide full bandwidth to each connected device. Also, most recent switches, even on small networks, support full-duplex operation. Thus, a nominally 100Mbps Fast Ethernet connection becomes a 200Mbps Fast Ethernet connection if all devices in the connection (network adapters and switches) support full-duplex operation. Many switches now support Gigabit Ethernet (1000Mbps) connections for servers as well as 10/100Mbps connections for client PCs and other devices.
Intelligent network switches can also be configured to improve network reliability, using a protocol called spanning tree that provides fault tolerance for the switch. A spanning tree reroutes traffic through the secondary switch if it detects a failed network connection or a bad NIC. In this configuration, you use two switches connected to two separate NICs in your server to provide fault tolerance and redundancy for your server's NICs and your network traffic.
Routers
Routers are specialized pieces of hardware that connect at least two separate networks, sending all of the network traffic on the Internet or any other WAN connection to its correct destination, choosing among thousands of available pathways. Routers use routing tables to determine the best pathway to the destination and then send the information to the next hop in the very long data train. The next hop is usually another router that looks up the data's destination point in its routing table. The router then determines the best path to the destination and sends the packet on to the next hop. This continues to happen from router to router until the final router sends the data to the correct server or network device. The data may traverse thousands of geographical miles, but the process takes but a few seconds to complete.
Because routers are a vital component in connecting networks in different locations to each other (and to the Internet, the world's largest network), keeping routers working is essential if your network depends on those connections.
You can use routers to help provide a fault-tolerant connection in several ways. One method is to set up separate routers to connect your network to the Internet via different network segments. By using dual-homed network adapters in your server, you can maintain a connection to the other network or the Internet, even if one connection fails. The major expense in this type of redundancy is the cost of an additional leased line or ISP service.
If you have a reliable connection but are concerned about router failure, you can use routers from Cisco, Nortel, or others that support VRRP; you can also use Cisco routers that use Hot-Swap Router Protocol (HSRP) or similar methods for setting up multiple routers to appear as a single router to the network.
Tip
Although you can buy routers from SOHO vendors such as Linksys, D-Link, and others, most vendors that sell into the SOHO space do not provide routers with support for VRRP, HSRP, or similar standards.
Providing Redundancy in Server Hardware
Redundancy is a principle of fault tolerance that has many applications for servers and networks. As you have learned in this chapter, you can use redundant network adapters, routers, and hard disks in a RAID array to provide automatic failover and recovery in the event of primary device failure.
However, other parts of a server should also be protected with redundancy whenever possible. Depending on the component, it may not always be possible to arrange for automatic failover, but you should provide for as much redundancy in installed equipment as possible, and you should have spare hardware readily at hand for other types of server components.
Major component areas to consider for built-in redundancy or, at minimum, redundancy through in-stock spare parts include the following:
- Power supplies
- Fans
- Memory
- Processors
The following sections provide details.
Note
Standard servers provide integrated redundancy for only select onboard components. However, fault-tolerant servers that incorporate replicated hardware that processes instructions at the same time as the primary hardware are available from Stratus Technologies (www.stratus.com), NEC Solutions (America), Inc. (www.necsam.com), and other vendors. Essentially, fault-tolerant servers provide two complete servers that operate in parallel in a single chassis. If the primary hardware fails in a fault-tolerant server, the replicated hardware takes over automatically.
Power Supplies
A power supply is one of the most vulnerable pieces of hardware in a server or other network device. Power supplies are always carrying a load, and with the type of work they perform, they are usually one of the first major pieces of hardware in a server or other network device to fail. If you have no redundancy in place for this device, that failure will bring down everything drawing power from it.
Because of the severity of having a power supply go out, you can usually order your major network equipment and almost all servers with dual (redundant) power supplies. It's a very good idea to spend the extra money on the option for redundant power supplies in any major network device.
Note
If your server does not include an option for a redundant power supply (RPS) but you can use off-the-shelf power supplies in your server chassis, you can purchase an RPS from any one of a number of vendors as a retrofit.
![]() For more information about RPSs, see "Redundant Power Supplies (RPSs)," p. 675.
For more information about RPSs, see "Redundant Power Supplies (RPSs)," p. 675.
Power supplies are relatively inexpensive, especially compared to the loss of productivity that results when a power supply failure takes a server offline, so you should consider keeping at least one spare power supply unit for your server on hand. This is especially important if your servers are rack mounted. 3U, 2U, and 1U rack-mounted servers use power supplies customized to each form factor size.
Fans
Keeping systems cool is a crucial step in keeping a network up and running. Electronics of all types generate heat, and all of them run much better the cooler they are. You can look at almost any electronic component and see at least one fan, and most computer equipment, including network devices such as routers and switches, has at least two fans.
Servers usually have at least four or more fans, and having a redundant fan in place is a very good idea. You usually have at least one or two fans in each of your power supplies, and as you just read, you should have two power supplies. You will also have at least two system fans. You should definitely have one for each processor in the system: Your video card could have a fan on it, and some systems even have fans on the system boards. The fans for which you should consider having redundancy are the system fans. You can have online redundant system fans for some servers that will automatically switch on if another fan goes out. You should also consider keeping a spare active heatsink (processor fan) onsite because most servers will not boot if the active heatsink's fan fails.
Note that whereas tower chassis can often use standard 80mm to 120mm fans, fans in 1U, 2U, and 3U chassis are usually special models that are not sold at normal computer parts stores. Similarly, active heatsink specifications for some server processors (such as the 90nm-manufacturing process Intel Xeon) may be substantially different from those used by desktop processors. You should keep a spare or two handy to avoid unnecessary downtime.
To determine whether an onboard fan is failing, you should check the system management software installed on your server or the BIOS System Monitor.
Memory
Like most pieces of hardware for a server, you should also have redundant memory. Although this practice is the least used of the redundant items listed in this chapter, it is yet another way of preventing downtime. Some servers come with a redundant memory bank, but you must enable this feature in the system BIOS before it will work. Redundant memory is known as memory sparing. In addition to memory sparing, some systems support hot-plug RAID memory, which creates a memory array similar to a RAID 5 disk array.
![]() To learn more about hot-plug RAID memory and other methods used by servers to improve memory reliability, see "Advanced Error Correction Technologies," p. 391.
To learn more about hot-plug RAID memory and other methods used by servers to improve memory reliability, see "Advanced Error Correction Technologies," p. 391.
Physical Maintenance
There are many types of software can help you maintain your servers, but if you don't take care of the physical components of your servers, all the software in the world will be of no use to you. Because your servers need to be kept clean and in the proper operating conditions, you should take time periodically to take your servers down during off-hours in midmonth and perform a complete hardware maintenance check on them. During your hardware check, you need to do the following:
![]() For more information on maintaining servers, see, "Routine Maintenance," p. 854.
For more information on maintaining servers, see, "Routine Maintenance," p. 854.
- Use compressed air and blow out your system. When using the compressed air, make sure that you clean all parts of the server, including the fans, power supply, memory banks, hard drive cage, and cooling slots in the case. Before using compressed air, move the server outside or use a vacuum system to remove dust from the air before it can be sucked into another server or client PC nearby.
- Remove and reseat the cards in the server, including the system's memory modules.
- Pull the hard drives and reseat them. While the drives are out, blow out their connectors with compressed air.
- Make sure that all indicator lights on the system are functioning properly.
- If you have redundant parts, such as power supply or fans, make sure that they are functioning properly.
Note
Sometimes redundant hardware failures may only be reported during initial system startup. Thus, it can be useful to shut down a server occasionally, maintain it, and restart it to check for these types of failures.
- Check your server room for any water leaks in the ceiling or any other environmental conditions that would be hazardous to your server.
- Check you battery backup meter to make sure that your battery isn't overloaded or reading as bad.
- Test your battery backup. You should make sure that your battery backup system lasts the duration for which it is rated before its battery dies. Your UPS should have a serial or USB cable to your server to allow for a smart system shutdown before your UPS battery dies, and you should make sure that your UPS can properly shut down your server. For more information, see Chapter 14, "Power Protection."
Note
UPS software usually gives you the option to shut down your server X minutes before your battery dies, where X is determined by the server administrator. When you set this up, it might take three minutes for your server to shut down, so setting this option to five minutes is sufficient. Over time, adding more items to your server could cause your server to take a considerably longer time to shut down. When this happens, your UPS will run out of battery life before it gets to shut down your server, causing your server to crash.
To avoid unnecessary downtime for your network, you should schedule routine maintenance during off hours.
The Server Environment
To keep your servers running smoothly, you should make sure that the environmental conditions within the server room are optimal for your servers' performance. A common cause of server failure is improper server room environments. Sometimes server rooms are literally closets that people put their servers in. Without modifications suited to a particular server, these types of environments are asking for trouble.
![]() For more information on sever rooms, see Chapter 17, "Server Rooms."
For more information on sever rooms, see Chapter 17, "Server Rooms."
Because poor environmental conditions can cause server instability, maintaining the proper conditions for your server's operation is just another reason you need to make sure your servers are as fault tolerant as your budget will allow.
Server Software Updates
Another important defensive maintenance tool is software updates. The most important software updates are for a server's operating system. If you are running a Microsoft Windows server operating system, you are probably all too aware of the frequent updates that Microsoft releases.
Although it is true that occasionally these updates can cause some problems of their own, overall, they are far more beneficial for your server's reliability and security than they are a risk to your server's stability. These updates will keep your systems protected from recently discovered security vulnerabilities, they frequently add new features that Microsoft has developed and added to its toolbox, and they often slam the front door on new viruses that are capable of attacking holes in Microsoft's operating systems.
There are two ways to install Microsoft's latest updates onto your server: using auto-updates and using Microsoft's Windows updates website. It is generally a better idea to install updates manually than to use auto-updates; that way, you know what you are installing, just in case an update causes a problem for your system. Installing Windows updates after verifying that they will work properly with your server is a good item to add to your defensive maintenance plan.
Tip
Sometimes Microsoft patches for Windows Server 2003, Windows 2000 Server, and Windows clients cause problems. To find out whether a particular patch or update is worth installing or should be avoided, we recommend visiting the Patch Watch column in the Windows Secrets Newsletter. To subscribe, go to http://windowssecrets.com.
Hardware Drivers and BIOS Updates
Another good tool to add to your defensive maintenance plan is hardware updates. You can check your hardware manufacturer's website to see if there are any updates for your server or your server's hardware. These updates can fix minor flaws and compatibility issues with your hardware. If your server is a name-brand server such as Compaq or Dell, getting these updates is a relatively easy task. You just go to the appropriate support website and look for updates for your particular system. If you have built your server(s) from scratch, using industry-standard components, you should keep a list of the support site for each component and visit these sites regularly to look for updates.
You should upgrade hardware drivers or BIOS code under the following circumstances:
- When current versions are known to be defective
- When updates are required before other updates (such as processor updates) can be performed
In addition to these guidelines, you should follow these recommendations:
- Use only production-level drivers or BIOS code; avoid using beta (prerelease) drivers or BIOS.
- If possible, install the updates on a test server identical to production systems and test the updates under typical and exceptional circumstances before installing the updates on production hardware. Keeping your server's OS and hardware drivers up-to-date helps you avoid running into compatibility issues as well as make sure your server gives you the best possible performance for as long as it can.
![]() For more information on operating systems and drivers for your server, see "Server Hardware and Drivers," p. 776.
For more information on operating systems and drivers for your server, see "Server Hardware and Drivers," p. 776.
![]() For more information on BIOS updates, see "Upgrading a Flash BIOS," p. 314.
For more information on BIOS updates, see "Upgrading a Flash BIOS," p. 314.
Server Management Software
Many software packages on the market today allow you to monitor your servers and the rest of your network for performance and hardware issues to try to help catch a problem before it becomes a failure. In the following sections, we look at some of the features that come with Microsoft servers and then explore some of the third-party products on the market today. You can learn more from Chapter 21, "Server Testing and Maintenance," about various performance monitors and establishing baseline performance for your systems. Note that Microsoft's Windows 2000 Server and Server 2003 include useful server management features.
Server Management with Active Directory Group Policies
In Windows you can use Active Directory group policies to manage almost everything within your domain (see Figure 13.4). A huge number of policy features can be configured—too many to list them all here—but the following is a list of the most basic and commonly used configurations for a server environment:
- Manage user account policies, including the following:
- Minimum password length
- Maximum password age
- Password lockout period
- Use Local system policy.
- Redirect folders. You can redirect users' folders to the server so that to the user, everything seems local on his or her machine, but in reality, the folders are sent to and from the server. This is mainly used for users' desktop settings or the My Documents folder. How it works is a user saves files to his or her My Documents as usual, but instead of a file being stored locally on the user's workstation, there is a folder on the server for the user's documents, and the files are sent to that folder. This is used so that all the files are saved in one location and so they can be backed up without having to back up each user's workstation.
- Remotely install software. There are two types of remote software installations through group policy:
- Published applications—Published applications are sent to the user's PC and are available for installation through the Add/Remove Programs option or by clicking on a file that needs the program that is published.
- Assigned applications—Assigned applications are installed on the user's PC the next time they log in to the network. When you assign an application to a user, that person does not have a choice of having the program installed; it is done automatically.
- Block or set up Windows automatic updates.
- Control what rights a user has for Internet Explorer.
- Remove or disable features from a user's Start menu or taskbar.
- Remove or disable features from a user's desktop.
- Disable the Add/Remove Programs feature or block certain items with Add/Remove Programs.
- Lock a user's desktop background and screensaver.
- Disable a user's ability to add or remove printers.
- Disable or prevent the use of offline files.
- Disable a user's ability to lock or log off a computer.
Figure 13.4 Windows 2000 Active Directory group policy configuration.
These are just some of the options available through group policy. For a detailed look at all the available options, you can download Microsoft's whitepaper from http://download.microsoft.com/download/5/2/f/52f3dbd6-2864-4d97-8792-276544ad6426/grouppolwp.doc.
Command-Prompt Tools for Network Troubleshooting
Other network tools available through the Windows operating system include command prompt tools such as
- ping—Tells whether a specified IP address or URL can be contacted.
- telnet—Provides remote access to a server or other device for management.
- tracert—Traces the route between the current system and a remote URL or IP address.
- nslookup—Looks up the IP address of a specified URL or a URL for a specified IP address.
- netstat—Lists active connections and listening ports.
- net commands—Displays and modifies network configuration settings.
- netsh commands—Displays and modifies the network configuration for the current or specified remote server; they can work with DHCP, IP, network bridge, routing, RPC, WINS, diagnostic, and other network components and features and can create scripts.
- ipconfig commands—Displays IP address, MAC address, and other IP settings for the current system.
These are just a few of the most commonly used command-line tools, but there are many more. For more information about TCP/IP and networking command-line tools available with Windows Server 2003, go to www.microsoft.com/technet/prodtechnol/windowsserver2003/library/TechRef/. If you would like to explore the many commands available from the Windows command prompt, you can go to www.computerhope.com/msdos.htm#02.
Third-Party Software
For a truly proactive approach to managing your servers and your entire network, you can try some of the great third-party software packages available. The following sections look at two different packages that can each give you a truly proactive network. These types of packages can monitor all aspects of your servers, as well as other critical network devices, to notify you of any degradation of your devices before they become critical, causing network outages. These programs will also notify you if your devices fail so that you can get the problem resolved as quickly as possible.
Intel's Server Management
Intel's Server Management software comes in three different versions, all of which offer comprehensive local and centralized system management. You get continuous monitoring of pivotal server hardware and system resources to maintain a truly proactive approach to keeping your network up and running smoothly. The following are some features offered by Intel's Server Management software:
- Fault management and event handling—Server Management provides a proactive notification of current or potential hardware failures. Event notification allows users to be notified via email, pager, or SMS gateway if one of the user-configured policies is triggered. This allows an administrator to configure policies to notify them if predetermined events are listed in the server's event viewer. The administrator can therefore know about critical system events as soon as they occur, which eliminates the need for an administrator to constantly check a server's Event Viewer.
- Unified multisystem management—This feature allows for a true central management server. From one server, an administrator can issue a command that will initiate the command on multiple servers or nodes. This feature eliminates tedious one-at-a-time operations on each server. The integration of Intel's single-system-aware tools makes the management server multisystem aware, allowing all the systems to execute simultaneous commands on multiple nodes.
- Data collection and inventory reports—This feature enables users to prepare detailed inventory reports for all managed devices by performing detailed system scans and hardware inventory detection.
- Web browser and command-line interface—Intel's software gives an administrator the ability to use either a web browser for interactivity or a command line for automation. This ensures that Intel's Server Management fits well with the existing management processes.
This list gives you an overview of the features and functionality available with Intel's Server Management. Intel offers the Server Management software in three versions: Standard, Professional, and Advanced. Table 13.1 lists the functions available with each version of Server Management.
Table 13.1 Intel Server Management Features
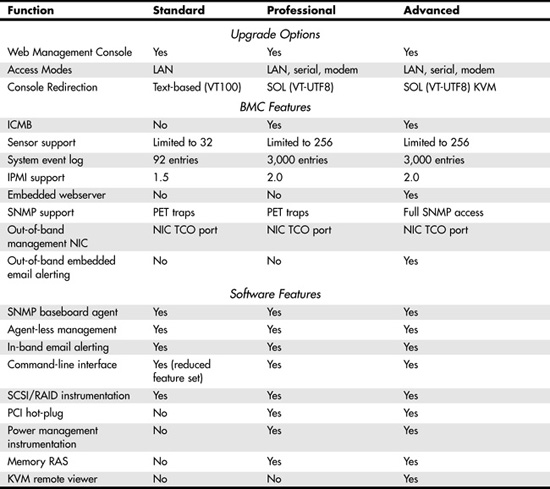
If you decide to upgrade to the Professional or Advanced version, you need to purchase Intel's add-on monitoring cards.
For more information, see the Intel Server Management page, at www.intel.com/design/servers/ism/.
Summit Digital Networks's RMS
Summit's RMS service is a monthly service that is offered to customers as a proactive monitoring service. The benefit of this RMS program is that Summit offers a wide range of service plans. Most companies that offer monitoring services require a minimum number of devices to be monitored to make it worth their setup. Summit offers its monitoring services for any number of devices. This means that small companies with just one or two devices to monitor can take advantage of the same great monitoring features as large corporations with hundreds of devices that need to be monitored.
Summit Digital Networks's RMS package works by using a central server at Summit's headquarters, combined with hardware or software probes onsite and remote monitoring agents on at least one server onsite. Using a multilocation monitoring system allows administrators to be notified even if their networks are completely down. The notifications are sent from Summit's central server at its office, so even if your servers are down, you will still receive your notification. Even if you suffer a phone or Internet failure, which is how most software notifies the administrator, you will still receive your notifications. The service is billed on a monthly fee basis for the total number of devices that you want monitored. The only upfront cost is for the hardware or software probe licenses and a server or workstation for the probes to reside on.
The RMS service is capable of monitoring almost anything on your network. You can also customize the software by setting the notification thresholds to be whatever is acceptable to you for your particular needs. You can monitor items such as your Internet service, your email service, your routers, or your server's processor usage. The following is a more detailed list of items you can monitor with this service:
- Network services
- Local services
- SNMP services
- Security services
- System services
Other major features include the following:
- Antivirus activity and update tracking for major products, including McAfee, Symantec, Sophos, and TrendMicro
- Server processor, disk space, and physical/virtual memory usage
- Connectivity, DNS service, Ethernet errors, Frame Relay, FTP, HTTP, HTTPS, NNTP, Telnet, and other network features
- Email and messaging services, including POP, Exchange Server, SMTP and IMAP
- Monitoring for Veritas Backup Pro, Microsoft IIS, Microsoft SQL Server, and Citrix Metaframe Server for thin clients
- Server processes for Windows, Linux, Solaris, and Novell servers
- Event, system change, security, and other logs
- Intrusion detection, security, and firewalls
- Patch management for Windows servers
This list should give you a good idea of the power of the Summit Digital Networks RMS service. For more information, see the Summit Digital Networks website, at www.summitnetworking.net.
Troubleshooting and Documentation
One of the most difficult, most stressful, and most common tasks for a network administrator is troubleshooting problems. No matter how well your network is designed and runs, sooner or later, you will have to troubleshoot some sort of network or server issue. If you stay calm and follow a step-by-step, logical plan to track the problem, you should be able to get the issue resolved as quickly as possible. Here is an outline, based on the CompTIA Network+ troubleshooting methodology, to follow to help resolve your issues:
- Identify and document the symptoms.
- Determine the severity of the problem and which users are affected. For example, is the entire network down, are just the users on a particular switch down, or is everyone who uses a specific database down?
- Determine what has changed on the network (hardware, software, driver or operating system patches, and so on). Jerry Pournelle's classic question, "What changed since the last time [the network] worked?" is a useful way to summarize this step.
- Determine the most likely cause of the problem. Make sure users understand how to use the network (user errors often cause problems), and check physical and logical connections on the network. To determine whether you have discovered the actual cause of the problem, re-create it and apply your suggested solution on a test network (if possible). If the re-creation and solution appear to work, proceed to step 5.
- Implement the solution developed in step 4.
- Test the solution on working systems.
- Recognize the side effects of the solution and prepare to deal with them. Examples include client software updates and IP address type changes.
- Document the solution and make sure support and management staff understand the problem and the solution. Make the information available through an online database or a FAQ list, or via some other manner that is easily accessible.
Tip
If you are managing a network, you should consider using a system for tracking tech support calls and solutions. This type of software is sometimes referred to as a trouble ticket system. Some examples include the following:
- Open Ticket Request System (OTRS; http://otrs.org)
- AnswerTrack trouble ticket system (www.answertrack.com/marketing/trouble_ticket_system.html)
- Trouble Ticket Express (www.troubleticketexpress.com)
In finding solutions to almost any problem with your server or network, documentation is a precious resource. In fact, documentation is one of the most important tools when you are trying to troubleshoot or upgrade a network. A network administrator needs to have everything documented for ease of use and to be as efficient as possible in everyday administration, but even more so when there are problems. You can know everything there is to know about your network when things are calm, but when something goes wrong and all the pressure is on your shoulders, you tend to forget some of the little details, and your thinking can sometimes be a little less reliable than usual. For this reason, it is nice to have network diagrams and documentation to help keep a clear picture of what is going on.
If you decide to upgrade items on your network or add features and servers to your network, your network documentation can help you avoid having problems. For example, you could run into little problems such as an IP conflict that could take a little bit of time to track down, but if you have your documentation handy, you could quickly look and see what IP addresses are available and make sure that you never run into that issue to begin with. You could use your documentation to make sure that you continue using the same naming context for your devices. When running a network, attention to details and all the little things really make your network run smoothly in the long run.
Tip
Network documentation software can help you easily diagram and capture network information. Some leading titles include the following:
- Neon Software's LANsurveyor (www.neon.com)
- SmartDraw Technical Edition (www.smartdraw.com)
- Microsoft Visio (www.microsoft.com); note that many vendors make add-ons for use with Visio, including Altima NetZoom (www.altimatech.com) and Neon Software LANsurveyor for Visio (www.neon.com)
If you have a network that is not large enough to require a network administrator, your documentation could be even more important. Good network documentation can help you solve problems without needing to call in network consultants. However, even if a network problem becomes so difficult that you need to bring in a network consultant, you will save time and money by providing the consultant with accurate and up-to-date network documentation. Otherwise, the consultant will need to determine how your network is configured. At typical rates of $150 to $250 per hour, the time needed to determine configuration information can add up quickly.