
This chapter covers the following topics:
This chapter examines various conferencing system architectures, their design, and the interactions of the modules that comprise the system. Details are provided about the user interface, conference control, and control and media planes from which conferencing systems are constructed.
The later sections of this chapter discuss architectural models. In addition, specific conferencing system features and operational modes are reviewed in detail. Topics include the role of a conference moderator, floor control, lecture and panel mode.
A conferencing system is composed of several components, including a user interface, a conference policy manager, media control, a player/recorder, and other subsystems. This section explores these individual elements, providing details about the functionality found in each service and how together they make up a conferencing system.
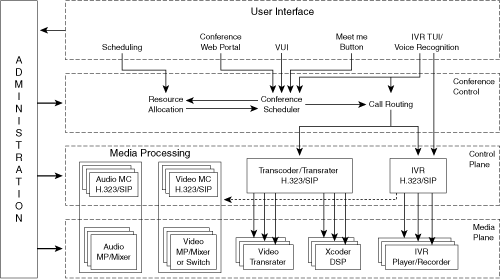
Figure 2-1 shows the major layers of a conferencing system:
User interface—. The user interface typically consists of several separate interfaces:
A scheduler to arrange conferences in advance.
A web portal for system access and control via a browser.
A voice user interface (VUI) to allow users to manage the conference after participants join.
A Meet Me button to create a conference. In the most basic user interface, conference creation can be accomplished by having the user press the Meet Me button on a phone and enter a conference number.
An Interactive Voice Response (IVR) system to deliver voice prompts to users who dial into the conference. The user may interact with this system via the telephony user interface (TUI) or via voice recognition.
Conference control—. Conference control performs resource allocation, conference management, and call routing. The user interface and scheduler interact with conference control to create meetings, insert and remove users from meetings, and connect them to the IVR based on user input.
Control plane—. The control plane contains the signaling stacks, such as H.323 or Session Initiation Protocol (SIP). It controls incoming and outgoing connections and negotiates session parameters based on the server’s media capabilities.
Media plane—. The media plane consists of the video and audio mixers, which have inputs and outputs for media streams. In addition, the player/recorder subsystem resides in the media plane. Under the control of the VUI, the player can read audio files and play them to the user. The VUI may also direct the recorder to record a stream. Recorded streams may be from an endpoint, such as when recording a user’s name for playing into the conference, or it may record the entire conference call for later retrieval.
Transcoding services are used for converting streams from one compression algorithm to another. Transcoders use digital signal processors (DSP) and reside in the media plane.
Administrative interface—. The administrative interface provides access for the system administrator to control and configure the system. It can interact with the conference control, control plane, and media plane layers. Configuration options can include the following:
Setting resource allocation defaults, such as the minimum number of ports each scheduled meeting will reserve
Configuring the number of overbook and floater ports
Specifying the maximum meeting length
Enabling and configuring the signaling protocols and defining which one should be used when the system initiates an outbound call
Configuring a system name
Configuring audio codecs and preferences
Setting video capabilities and bandwidth limitations
Adding and configuring system users and capabilities
Adding or updating recorded prompts
Setting the system to an enabled or disabled state
The following sections describe each layer in more detail.
The user interface enables the user to interact with and control the conferencing system. The user can schedule new meetings, attend meetings, and have access to a set of in-conference controls. The two main interfaces are a web browser interface and the telephone.
The web portal provides a web browser interface to the conferencing system. It allows a user to log in, schedule meetings, attend meetings, view the active speaker list, and perform moderator functions. Such functions include muting and unmuting participants and controlling the audio volume of certain callers. When joining a meeting, users may request that the system initiate an outbound call directly to the user’s phone, eliminating the need for users to call in and re-authenticate themselves. They can also eliminate the need to enter the meeting identification number, because the system already knows which meeting the user wants to attend from the browser session.
The IVR is the user interface externally visible to the caller. The interface generally consists of a series of menus, allowing the caller to interact with the system based on a set of context-sensitive scripts running on the IVR. Callers can input requests by using the telephone keypad, or sometimes by means of voice recognition.
The initial script may play a welcome prompt and present some high-level menu choices. Then, depending on the user’s selection, new scripts are executed that control that specific context. At some point, the user enters the meeting ID and is connected. Meetings can also be access protected, requiring the user to enter a password or authentication code too before being allowed to join.
The IVR interacts with the user by means of a set of prerecorded audio prompts, which may be either bundled with the devices or recorded by the system administrator. These prompts may be recorded in the various languages supported by the conferencing system.
While a meeting is in progress, participants and moderators can invoke in-conference controls. These features include operations such as allowing a caller to mute the outgoing stream to the conference, initiating a roll-call announcement, or moving the caller to a breakout conference.
These in-conference features constitute a Voice User Interface (VUI). Participants can often access these features via a website hosted by the conference server.
Conference moderators may use the VUI to control other aspects of the conference. One especially useful feature of a VUI is the ability to identify callers who are contributing excessive background noise to the conference by showing them in the active speaker list. The moderator can then mute or eject these disruptive participants. Users can mute and unmute their own input streams by pressing a key sequence on the phone. This feature enables them to participate in meetings when they are in environments with excessive background noise without disrupting the meeting.
Another often used VUI feature enables the moderator to play announcements to meeting participants in breakout sessions, requesting they rejoin the main meeting.
For simple conference systems, the telephone of the end user may have conference control buttons, such as the Meet Me or Conference button, used for creating ad hoc conferences. You can read about their use in Chapter 1, “Overview of Conferencing Services.”
The conference control layer has three main functions:
Resource allocation
Conference management and scheduling
Call routing
The conference scheduler works with the resource allocation module to reserve ports during the time window when meetings are scheduled to be active. The resource allocation module is aware of how the administrator has configured the system with respect to conferencing, floater, and overbook ports and uses this information when responding to resource allocation requests.
At meeting time, after the user has entered a meeting ID, the scheduler checks the resource availability for the conference and then directs the call routing module to add the caller to the meeting.
The conference scheduler is responsible for managing resources used for current and future conferences. Conference servers typically have a capacity measured in ports, and each connected conference participant consumes a port. The conference scheduler and resource allocation module keep track of the total number of ports available and the number of ports used. When a user schedules a conference, the scheduler may optionally reserve ports in advance. The conference scheduler must keep track of meeting start and end times along with port reservations for those periods. The scheduler also provides utilization statistics, and may have log files for billing purposes.
The scheduler may separate the entire pool of ports into partitions and use different partitions in different ways: one partition might be used for reserved conferences, another might be used for overbooked ports, and another might be used for ad hoc conferences.
The scheduler uses the overbook pool whenever the number of ports to be reserved exceeds the actual number of available ports on the system. In this case, if the overbook pool contains available ports, the scheduler can assign these ports to a scheduled conference, allowing the scheduling request to complete successfully. Overbooking allows more-complete utilization of the system, because some number of reserved ports may go unused. Floater ports are a pool of ports that are accessed when the number of actual participants in a meeting exceeds the reservation. Floater ports may not be reserved and are used to handle overflow conditions.
Before a participant is allowed to enter a meeting, the conference scheduler performs a number of checks. First, it verifies that the requested meeting is valid and scheduled for the current time. If the meeting is valid and the participant is the first to join, the scheduler creates the meeting instance. If a suitable port is available, the scheduler allocates a port for the conference, debits the port pool, and adds the incoming party to the meeting. As each participant departs, the scheduler returns the port used by that participant to the available port pool.
One significant challenge for the resource management aspects of the scheduler is how to deal with the various types of media streams and their characteristics at run time. The resource allocation originally made for an audio port might be inadequate if the caller calls in with a high-complexity codec. These calls take more compute power from the DSP, and the DSP cannot process as many of these stream types. Unfortunately, it is not often possible to know in advance how many of these types of callers may want to participate in a conference.
Video stream characteristics have a similar impact, because video streams have a variable bit rate. In these cases, a particular conference might need to be configured with a bit rate maximum. Even though some callers might call in at a lower rate, the only way to have a deterministic outcome is for the scheduler to assume that all callers will use the maximum rate allowed. Another factor is the number of transrating and transcoding resources to be reserved. Depending on the network topology, the types of video endpoints in use, and where the calling endpoints reside in the network, varying numbers of transcoding and transrating resources might be needed at meeting time.
The control plane of the conference server is responsible for establishing a signaling channel with each endpoint, negotiating the type of media, and connecting the endpoints with the mixers on the media plane. The control plane opens H.323 or SIP ports, listens on those ports, and waits for incoming connections. When an endpoint connects to the control plane, the control plane provides the endpoint with the audio and video session capabilities of the conference server as part of media negotiations. As discussed in Chapter 5, “Signaling Protocols: Conferencing Using SIP,” and Chapter 6, “Signaling Protocols: Conferencing Using H.323,” the capability negotiation may occur in the form of the H.323 terminal capabilities exchange or a SIP offer/answer.
After the control plane and the endpoint complete the media negotiations, the two sides open logical channels for media streaming. If the connection fails at any time during the call, the control plane must notify the underlying layers. This allows the lower layers to free allocated resources associated with the session.
Different standards refer to two different terminologies when discussing the conferencing server, depending on the signaling protocols in use. In H.323 mode, the International Telecommunications Union (ITU) term multipoint control unit (MCU) may be used when referring to the conference server. In SIP mode, the Internet Engineering Task Force (IETF) term focus is frequently referenced.
After the user has entered the meeting ID, the IVR notifies the conference scheduler. The conference scheduler then performs the final step of connecting the user to the meeting, and media streaming begins.
The IVR also controls the player/recorder, providing functions such as recording a user’s name and playing it as an announcement to the main conference upon joining and departing.
The media plane contains the infrastructure that processes media streams and includes the audio and video mixers. The media plane manages Real-time Transport Protocol (RTP) and Real-time Transport Control Protocol (RTCP) port allocation and may control a DSP for setting audio and video stream characteristics. Stream characteristics include elements such as the codec, the RTP payload type, the picture size, the frame rate, and so on.
The media plane is also responsible for RTCP message exchanges and for detecting stream failures. Media stream failures may take the form of incoming RTP stream loss or Internet Control Message Protocol (ICMP) port unreachable events. ICMP events are errors returned by the remote device when network error conditions arise. As an example, an ICMP port unreachable error occurs when the receiving device detects packets are arriving for a closed port.
Depending on the implementation, the conference server may report session loss to an external component, or notify the signaling and control planes so that they can tear down the connection and free resources.
The player/recorder operates under the control of the IVR and VUI. Its purpose is to play audio prompts to the user and record audio, such as the name of a participant or location. It can also record the audio from a meeting and play announcements to the entire conference.
After the control plane has successfully negotiated the video stream characteristics and conference management has determined the type of video presentation required, the video mixer/compositor is responsible for creating the overall video experience. It receives and decodes the incoming streams in various formats and creates the appropriate output streams for the endpoints based on conference policy.
Stream characteristics from the various connected endpoints can be different, depending on the sending and receiving capabilities of the attached devices. In addition, it is possible for devices to send asymmetric streams. For example, a device with a low-resolution camera can transmit a smaller Quarter Common Interchange Format (QCIF), or 176×144, stream, but expect to receive a larger Common Interchange Format (CIF), or 352×288, picture size as the receive stream.
The video mixer must be capable of receiving streams in a wide range of bit rates, picture formats, and compression schemes, and it must be capable of sending streams in formats expected by the other devices. After decoding, the mixer may opt to create an output stream by tiling together smaller versions of the input streams, a mode known as continuous presence (CP). Alternatively, it may instead select a specific stream for transmission based on the loudest talker, a mode known as voice-activated switched (VAS) mode.
There are two common presentation modes: one in which all participants see the active speaker (including the person speaking), and another in which the active speaker instead sees the previous speaker. The mode in which the active speakers see themselves is useful if there is no other indicator that their image has been selected for distribution. The downside to this mode is that some delay usually occurs between the audio and video, and the lag in lip synchronization can be a distraction to the speaker.
A simplified form of a video mixer is a video switch. The video switch operates in image passthrough mode, in which it simply takes incoming video packets from one participant (such as the current speaker) and forwards the packets to the other participants. The video switch does not operate on the video payload, but updates the packet header so that it can be forwarded.
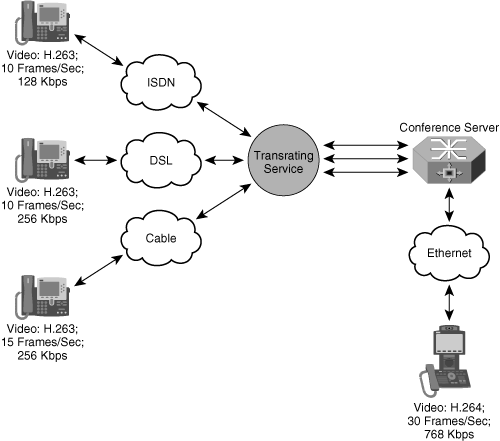
A video transrater is a device inserted in the path between two endpoints that lowers the video bit rate in one direction. Figure 2-2 shows a topology with several endpoints and a transrater. Video transrating is a key component needed to create an integrated conferencing service that links endpoints from LAN, broadband, and mobile networks.
When endpoints negotiate video characteristics for the media streams, they decide on three main attributes:
The send/receive bit rate
The frame rate
The send/receive compression scheme (video codec)
Depending on the network topology, some devices may connect to the conference with high-speed connections, and others may be restricted to lower speeds. Connecting at lower speeds could be a result of link bandwidth limitations or network policy restrictions. The device may also connect at a lower speed if it has processor limitations that limit the rate at which it can receive video data.
For bandwidth-constrained devices to receive a high-bandwidth video stream, the conference server must add a transrater to the video path. The transrater performs rate matching by converting the high-bandwidth stream to a lower-bandwidth stream suitable for the destination endpoint.
Because high-speed video devices on a high-bandwidth network can always accept lower-speed incoming streams, video conferencing network topologies apply transrating in only one direction, from the high-bandwidth endpoint to the low-bandwidth endpoint.
In the opposite direction, the video mixer simply forwards the lower-speed stream without processing. Figure 2-3 shows the block diagram for a transrater. In Figure 2-3, video RTP packets are received from the network. Because packets may arrive out of order, they are first placed into a jitter buffer and reordered based on their RTP sequence number. Packets are then decoded and the media content placed into a raw picture buffer. The raw picture information is then re-encoded at a lower bit rate as required by the device to which the packets will be sent.

Video transcoding converts one stream type into another and changes one or more of the video characteristics. The block diagram of a transcoder is shown in Figure 2-4. A video transcoder may change the encoding format (codec), bit rate, resolution, and frame rate by decoding the incoming stream into a raw video buffer and then re-encoding it. Because the transcoder can easily select the output bit rate, transrating functionality is built in, and therefore, conference topologies do not need a separate transrater.

Within a conference, the audio mixer is responsible for selecting the input streams and summing these streams into a mixed output stream. This section provides a detailed view into the various modules that comprise it.
The audio mixer is the core component in the media plane. It is responsible for selecting incoming audio streams, summing them, and distributing the summed output back to the participants.
When mixing audio streams in a large conference, the audio mixer selects only a subset of the input streams; typically, the mixer selects three or four of the loudest streams for summation. The reason is because the human ear is capable of differentiating between only three or four distinct talkers. The mixer discards the remaining audio streams.
The mixer may also include an event reporting mechanism, allowing it to communicate internal events to other system components. For example, a conferencing system component might need to display on a web interface which participants are currently speaking. Another event of interest is media streaming failure detection. Media failure events can notify the signaling stack to initiate a call disconnection.
In addition to creating an output stream containing the three or four loudest participants, the audio mixer must also satisfy another requirement: participants who are included in the mix should not hear their own audio in the mix. Some delay occurs in the summation and return of the composite audio, and therefore, participants in the mix could potentially hear a delayed echo of their own streams played back to them, after mixing.
To avoid self-echo, each endpoint that contributes a stream for the audio mix receives a unique output stream, which does not contain audio from the same participant.
This approach is referred to as N–1 summation, where N is the number of mixed streams, and the stream returned to a conferee is the summation of the mixed streams, minus the stream contributed by that individual.
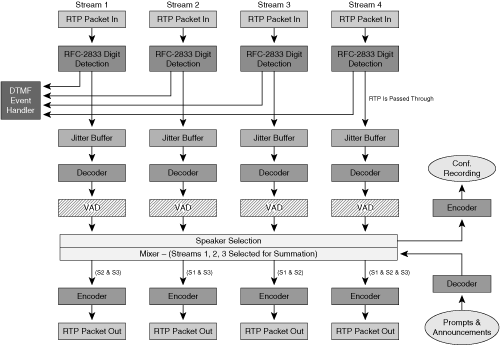
Figure 2-5, which illustrates the basic components of an audio conferencing system, shows an example in which the mixer has four input streams: stream 1, stream 2, stream 3, and stream 4. Streams 1, 2, and 3 have been selected for summation, but stream 4 has not. Figure 2-5 illustrates how endpoints that have streams selected for summation (mixing) receive a special mix in which the audio from their own stream is omitted. For the device assigned to steam 1, the mixed stream is the summation of stream 2 and steam 3. For stream 2, the mixed stream is the summation of stream 1 and stream 3, and so on. For stream 4, which is not contributing to the mix, the return stream is made up of all three contributing streams (that is, steam 1, stream 2, and stream 3).
The following sections describe the components of the audio mixer block.
The User Datagram Protocol (UDP) stack is responsible for sending and receiving RTP packets to and from the remote devices. Each incoming stream requires one socket. An endpoint signals the desired address and port for an incoming stream to the remote endpoint during the initial call setup. For H.323, the endpoint includes this information in the H.245 signaling. For SIP, the endpoint lists this information in the SDP part (offer/answer) of the SIP signaling.
RFC 2833 is a standard that specifies a method of signaling Dual Tone Multiple Frequency (DTMF) digits using an RTP payload. The RFC 2833 DTMF detection and generation module is used by the audio mixer to detect incoming digits and to generate outgoing digits if directed to do so by media processing. The detector examines the incoming packet header payload type. If the payload type matches the negotiated RFC 2833 value, the packet is further interpreted to determine the DTMF digit it contains. The mixer drops RFC 2833 digit packets before they enter the jitter buffer.
If an RFC 2833 packet arrives, the detector sends the decoded digit event to a DTMF event handler. The event handler usually forwards these events to a voice user interface to invoke some function, such as playing a roll call of participants, entering a breakout session, or possibly muting the ingress stream.
In some situations, it might be necessary for the mixer to receive and then regenerate RFC 2833 packets. This situation arises when a participant wants to bring a voice-mail system and then play a message from the mailbox to other participants in the meeting. After adding the voice-mail system to the meeting, the participant presses digits on the phone, and the mixer forwards those packets to the conference system, allowing the voice-mail system to respond accordingly.
Another situation that requires a mixer to generate DTMF occurs when DTMF is required to manually connect two separate conferences, using an out-dial process.
Receivers must handle three potential anomalies in the input audio stream:
RTP packets arriving at a receiver may exhibit variability in arrival times (jitter), encountered during transmission over the network.
Packets may arrive at the mixer in the incorrect order.
RTP packets can be duplicated in the network, resulting in two or more of the same packet.
However, for the mixer to operate properly, it must receive a stream of packets with uniform interpacket spacing, in the order they were transmitted.
A jitter buffer at the input of the receiver corrects error conditions introduced by the packet network and provides the mixer with a continuous stream of data. For each input stream, the receiver allocates a jitter buffer. As packets arrive, the receiver places the packets in the jitter buffer and then reorders the packets using the RTP sequence number. Duplicate packets are discarded.
A jitter buffer maintains an input buffer level, equal to the amount of data in the buffer, measured in units of time. This input buffer level may have a fixed or dynamic size. If the jitter buffer is a fixed size, it is not changed based on packet arrival characteristics.
In more-advanced implementations, the buffer can have a dynamic size and is referred to as an adaptive jitter buffer. In the dynamic or adaptive mode, as packets begin to arrive, the jitter buffer algorithm can recalculate the buffer size needed based on the packet arrival pattern. If the incoming stream exhibits highly variable rates of packet arrival, the algorithm maintains a larger steady-state input buffer level to absorb momentary periods of input buffer starvation. When this occurs, the buffer is unable to provide packets at the real-time audio rate.
A large jitter buffer level provides more protection against jitter buffer starvation. However, if a jitter buffer maintains an input level that is too large, the jitter buffer adds significant delay to the stream, resulting in perceptible audio delay.
If the jitter buffer level is small, the latency is reduced, but the buffer provides less protection against starvation. If the packet experiences a high delay through the network and arrives late, the mixer is forced to play concealed audio in place of the packet. In this case, the jitter buffer discards the packet if it arrives too late to play. The mixer cannot always produce acceptable concealed audio to replace the discarded packet, a situation that can result in audio quality issues, in the form of audible clicks and pops in the output stream.
Generally, an audio jitter buffer should be sized as small as possible to avoid excess latency while avoiding RTP packet starvation.
Voice Activity Detection (VAD) is a network optimization that omits packets with a low energy level. If the energy level drops below a certain threshold, RTP packets are no longer transmitted. The use of VAD can significantly reduce the amount of bandwidth consumed by a VoIP call. When VAD is active, the sending side stops transmitting audio RTP packets and instead transmits a special silence packet to the remote device. The silence packet carries a silence detection (SID) payload, indicating that packets are not being sent because VAD is active. The receiving side can then generate a local replacement stream to the listener, referred to as comfort noise. This process is known as comfort noise generation (CNG). Receipt of a silence packet also notifies the receiver that it can temporarily suspend packet loss calculations.
The receive-side VAD module serves two purposes. It examines the incoming RTP packets for voice content and flushes the jitter buffer if a silence packet is received. The silence packet indicates that the sender is no longer actively sending RTP packets with audio data.
The second purpose is to check the incoming packets to identify whether the packet contains speech from a participant or ambient background noise. If the packet is deemed to be background noise, the receiver does not include the stream in the audio mix.
The speaker selection module is a critical component of the conferencing system. Its purpose is to examine incoming streams and select the correct streams for inclusion in the set of mixed participants. The speaker selection algorithm should change the current mix of participants in a way that is smooth and imperceptible to the participants. It should also avoid clipping the leading and trailing part of talk spurts.
An example of a stream selection algorithm follows.
For each incoming stream, three criteria are assessed:
The short-term window value, containing a running average of the voice energy level for a period of less than 50 milliseconds
The long-term window value, containing a running average voice energy level for a period up to 200 milliseconds
The currently observed inactivity or silent period, which is the amount of time the speaker has remained silent
After the speaker selection algorithm calculates these values, it then determines which, if any, of these streams are eligible for potentially becoming one of the active speakers.
If the selection algorithm finds a potential candidate, the algorithm compares the preceding parameters with the same parameters associated with participants in the current mixed stream.
The algorithm first determines the number of currently active streams. If the number is less than the maximum allowed (usually three to four), the algorithm includes the next available stream in the mixed stream. Any time the number of current speakers is less than the maximum, the mixer does not invoke the speaker selection algorithm, as long as the stream meets the earlier eligibility criteria.
If the number of active streams exceeds the maximum, the algorithm must determine whether a new stream should replace one of the existing streams. An example of the steps in a speaker selection algorithm follows:
Selection Criteria One: Silent Participant Replacement
The algorithm checks each active participant for voice activity. If some streams have been silent for a period of time, the selection algorithm replaces the one with the longest silent period with the loudest new active stream.
Selection Criteria Two: Short Window Comparison
If selection criteria one is not met, the algorithm checks the value for the short window period (< 50 ms) for each active participant.
If the short window power level of a new stream exceeds the power level of an existing stream in the mix (by a threshold T1), the new stream replaces the existing stream.
Selection Criteria Three: Long Window Comparison
If neither of the preceding criteria is met, the algorithm uses the long window power level. If a new stream has a long window power level that exceeds the power level of an existing stream by a threshold T2, the new winner replaces the weakest previous stream.
After the algorithm selects the active streams, it combines them into a set of N composite streams and then forwards the composed streams to the encoder for transmission.
The encoding module compresses the mixed stream using the compression algorithm (for example, G.711uLaw, G.729, G.722, and so on) negotiated for this endpoint. After compression, the encoder performs the RTP packetization. The steps in RTP packetization include the following:
Setting the RTP payload type—. The encoder sets the payload type field based on the codec used for compressing the payload. The payload type indicates to the receiver how to decode the arriving packet.
Setting the RTP time stamp field—. Each RTP packet contains a time stamp, which reflects the sampling instant of the first octet in the packet. Initial time stamps are picked randomly. The sampling instant is derived from a sampling clock. For audio streams, RTP time stamps are essentially sample counts. The RTP time stamp between one packet and the next increases by a sample count that corresponds to the packetization period. For example, if the mixer is generating G.711 audio packets, transmitted at 8-kHz mono, with a 20-millisecond sampling period, each packet contains 160 samples of 1 byte each. In this example, the RTP time stamps between successive packets would be seen to increase by 160 samples.
When used with time stamps contained in Real Time Control Protocol (RTCP) sender reports, it is possible for the receiver to synchronize an audio stream with another stream, such as video. Chapter 4, “Media Control and Transport,” and Chapter 7, “Lip Synchronization in Video Conferencing,” provide much more detail on this topic.
Assigning an RTP sequence number—. Each RTP packet is assigned a 16-bit monotonically increasing sequence number; this field of the RTP packet wraps around after reaching a value of 65535. The receiver uses the RTP sequence number to put arriving packets in order and to detect lost packets.
Setting the Synchronization Source field—. The Synchronization Source ID (SSRC) is used to uniquely identify RTP streams from a specific sender. The SSRC is a 32-bit number and is used to label specific streams.
Adding the contributing source IDs—. The Contributing Source IDs (CSRC) field contains a list of SSRCs identifying the streams that contributed (were mixed) to create this packet. The CSRC field is optional, and the sender can choose not to include it.
After the RTP packets’ headers are populated, the encoder then forwards the completed RTP packet to the UDP stack for transmission.
Conferencing architectures can be classified into two basic models: centralized and distributed. A centralized architecture provides multiple services to video conferencing endpoints, but one single, standalone device provides each service. This approach is the most common architecture for audio and video conferencing systems. Centralized architecture provides single points for administration and management. Adding new functionality involves simply upgrading one device in the network.
In a distributed architecture, each service provides a logical functionality distributed among multiple physical devices. The constituent devices for each service communicate with each other using various protocols to provide this logical service. An argument in favor of distributed conferencing is the fact that the network load is more distributed, which might provide more flexibility when adding features to endpoints.
The following sections provide a high-level discussion about different aspects of centralized and distributed architectures.
In a centralized model, all the components of a conferencing system are implemented in a single server. Figure 2-6 shows an example of a centralized conferencing system with the necessary software modules. These software modules interact with each other through the interprocess communication methods provided by the operating system running in that server.
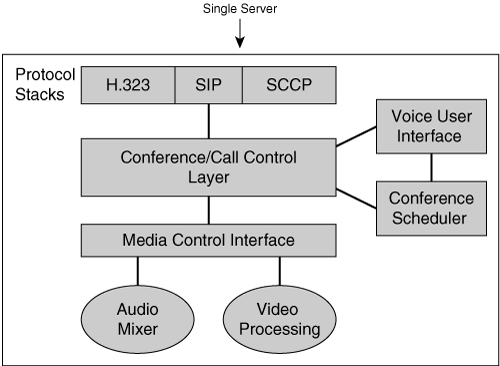
The conference control (also known as call control) module processes the signaling messages, decides whether to admit the incoming request to join a conference, and creates and processes requests to and from other internal components. The VUI and conference scheduler functions were discussed earlier in this chapter. The media control interface provides an application programming interface (API) for the conference control module to access the media services such as audio mixing. The media components send and receive audio and video packets and provide media services such as audio or video mixing. The media components can be software modules or perhaps DSP cards co-located in that server.
To scale a conferencing system to a large number of participants, the conferencing system must be decomposed into many different components, each on a separate hardware platform, which are geographically dispersed across the network. These components must establish signaling relationships to work together as a single system.
The distributed system appears to the end user as a single device, but in fact, it is a network of devices, each providing a specific service. The Session Initiation Protocol (SIP) is especially well suited to supporting such a distributed framework, so the next section describes one example of a distributed conferencing system built on top of SIP. This model consists of several components:
A conference control entity called the focus
A conference policy server that defines and controls the conference
Media policies that run on a media server to process the audio and video streams
The central entity in the distributed architecture is called the focus. The focus maintains a signaling relationship with all the endpoints (or participants) in the conference. Conference and participant operations such as creating/maintaining/destroying conferences and adding/deleting participants occur in the focus. Each conference must have a unique address of record (AoR) that corresponds to a focus. A conference server could contain multiple focus instances, and each focus may control a single conference.
A caller joins a conference by connecting to a SIP Uniform Resource Identifier (URI). This SIP URI in the context of a conference is also called a conference URI. An example of a SIP URI is SIP:[email protected]. When a user connects to this conference, the user’s endpoint connects to the focus.
Each conference operates under the constraints described by the conference policy. The conference policy describes the operational characteristics of the conference instance.
This governance controls all meeting services, including security aspects such as membership policy and media policy. Membership policy controls such attributes as which endpoints can join the conference, what capabilities they have, how long a meeting should last, and when a conference should remove a participant.
Media policy prescribes the range of stream characteristics for the various streams in the conference. These characteristics include allowable audio and video codecs, the minimum and maximum bandwidth, the maximum number of participants, and so on.
The conference policy server is the repository for the various policies stored in the system. There is only one instance of the conference policy server within the system. No standard protocol exists for communication between the focus and the policy server.
Users join a conference by sending a SIP INVITE to the unique URI of the focus. If the conference policy allows it, the focus connects the participant to the conference. When a participant SIP endpoint wants to leave the conference, the endpoint sends a SIP BYE message to the focus, indicating that it is leaving the conference.
When a conference is to be terminated, the focus sends a BYE message to each endpoint. After all endpoints have been disconnected, the instance of the focus and the conference policy associated with the conference are destroyed. All the resources (audio and video ports) associated with that conference are freed. The focus rejects attempts by endpoints to reconnect to the unique conference URI.
The media server establishes a signaling relationship with the focus on the control plane. It provides all the services of an audio mixer and video media processor (MP). The media server terminates all media streams from the endpoints and returns the mixed audio and video streams to each device based on conference policy.
Another option for decentralized conferencing is a full-mesh conference, shown in Figure 2-7. This architecture has no centralized audio mixer or MP. Instead, each endpoint contains an MP that performs media mixing, and all endpoints exchange media with all other endpoints in the conference, creating an N-by-N mesh. Endpoints with less-capable MPs provide less mixing functionality. Because each device sends its media to every other device, each one establishes a one-to-one media connection with every other conferenced endpoint.
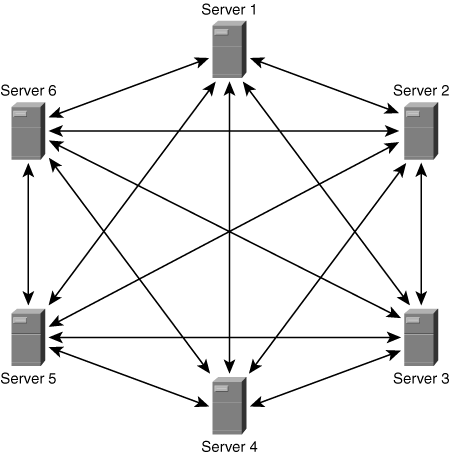
Within this N-by-N mesh, two connected endpoints must be able to negotiate a common codec. However, endpoints may use different codecs for other pairwise connections.
Endpoints that send media with the same characteristics (codec, frame rate) to multiple endpoints may use IP multicasting; in general, however, such support is not widely deployed in corporate networks.
If no centralized signaling server is present, each endpoint must similarly establish a one-to-many signaling connection with all other endpoints in the conference. Endpoints may not use IP multicast for these signaling connections.
In the full-mesh conference topology, each device provides its own media processing, and therefore endpoints do not need to transrate or transcode video streams. Because endpoints negotiate media characteristics between device pairs, it is not necessary to reduce the quality of the entire conference to the “lowest common denominator.” In contrast, a nondistributed conference server may implement video mixing by simply passing through video from the loudest endpoint to all other endpoints with no video processing, a mode called image passthrough. In this case, the media processor in the conference server must reduce the quality of the single output video stream to the lowest common denominator of quality among the destination endpoints.
Modern conferencing system designs provide more features by integrating the conference control with other collaboration services. For example, a user can join a conference call with a single mouse click instead of dialing a number and going through an authenticating process. This section provides some examples of those advanced features. These scenarios assume that the endpoints have some basic capability such as support for call transfer.
In this scenario, a point-to-point call between two participants becomes a conference call with more than two parties. Participant A is in a point-to-point call with participant B and wants to invite a third participant, participant C. Participant A finds a conference server, sets up the conference, gets the URI or meeting ID, and transfers the point-to-point call to the conference server. Participant A then invites participant C into the conference call. Participant A can add participant C using different methods, one of which is a dial-out process. In a dial out, the conference server sends the invite to the endpoint to join a conference.
A lecture mode conference has a lecturer who presents a topic, and the rest of the participants can ask questions. There are two different styles of lecture mode meetings:
Open—. Open meetings allow participants to ask questions any time without requesting permission to speak.
Controlled—. In a controlled meeting, the meeting administrator or lecturer must give a participant permission to ask questions or speak. If the administrator denies the request from an audience member to ask a question, the audio from that audience member is not mixed, even if that participant is the loudest speaker. In this case, the focus instructs the mixer to exclude video from that participant in the mix.
In lecture mode video conferences, participants see the lecturer, and the lecturer sees the last participant who spoke. If none of the participants has spoken yet, the lecturer might see all the participants in a round-robin mode. In round-robin mode, the lecturer sees each participant for a few seconds.
Lecture-style meetings usually have data streams (web conferencing) associated with them. The participants can see the documents that the lecturer shares in a browser window.
A panel mode conference is a variation of the lecture mode conference. A panel mode conference has few panelists and more participants. This scenario is similar to having more than one lecturer in a lecture mode conference. Depending on the conference policy, end users can see one or more panelists in a continuous presence mode, in addition to seeing the participant who is speaking or asking a question.
Floor control coordinates simultaneous access to the media resources in a conference. For instance, the meeting organizer or moderator can ensure that all participants hear only one participant. Or, the moderator can allow only certain participants to enter information into a shared document. End users can make floor control requests through a web interface or IVR. In addition, endpoints can provide access to floor control via floor control protocols. Floor control protocols allow the endpoints and conference servers to initiate and exchange floor control commands.
When a user joins a video conference, the conference server offers the user one of a set of predefined video presentations. The conference server describes each video presentation using a textual description and an image specifying how the presentation will appear on the screen. In this scenario, by choosing a video presentation, the user chooses how many video streams (participants) to view simultaneously and the layout of these video streams on the screen.
Either conference policy or authorized participants may control the contents of each subwindow. Other aspects, such as the number of different mixes in the conference and the format of a custom mix for each user, are similar to audio mixing and use similar server capabilities and authorization methods.
The following is a list of typical video presentations; these are some of the common layouts available today in commercial products:
Single view—. This presentation typically shows the video of the loudest speaker. The loudest speaker sees the last speaker. If the last speaker has dropped out of the conference, the video mixer shows the previous last speaker.
Dual view—. This presentation shows two streams.
Quadrate view—. This presentation shows four streams.
In multiview presentations. , one of the streams shows the loudest speaker.
This chapter provided an overview and comparison of several conferencing architectures and described the internal components that comprise these systems. It also provided a detailed look at the theory of operation for an audio mixer and described the purpose and operations involved in video composition, transrating, and transcoding.
The chapter closed with a review of the various types of meetings and video mixing scenarios.
Even, R. and N. Ismail. IETF RFC 4597, Conferencing Scenarios. June 2004.
Rosenberg, J. IETF RFC 4353, A Framework for Conferencing with the Session Initiation Protocol. February 2006.
Schulzrinne, H. and S. Petrack. IETF RFC 2833, RTP Payload for DTMF Digits, Telephone Tones, and Telephony Signals. May 2000.
Schulzrinne, H., S. Casner, R. Frederick, and V. Jacobson. IETF RFC 3550, RTP: A Transport Protocol for Real-Time Applications. July 2003.