
Transaction Processing Monitors
6.2. Transactional Remote Procedure Calls
6.2.1. The Resource Manager Interface
6.2.2. What the Resource Manager Has to Do in Support of Transactions
6.2.3. Interfaces between Resource Managers and the TP Monitor
6.2.4. Resource Manager Calls versus Resource Manager Sessions
6.3. Functional Principles of the TP Monitor
6.3.1. The Central Data Structures of the TPOS
6.3.2. Data Structures Owned by the TP Monitor
6.4. Managing Request and Response Queues
6.4.1. Short-Term Queues for Mapping Resource Manager Invocations
6.4.2. Durable Request Queues for Asynchronous Transaction Processing
6.1 Introduction
Beginning with this chapter, and continuing up to Chapter 12, we look at the topics presented in Chapter 5, but through a magnifying lens. This close-up will reveal which concepts, algorithms, and techniques are used to provide the application with a transaction-oriented execution environment. The component structure and the sample implementations are based on the functions of the basic operating system introduced in Chapter 2; that is, on processes, address spaces, messages, and sessions. The description of how it works is focused on the core mechanisms for implementing simple ACID transactions and phoenix transactions. Due to the limited space, the implementation of the large number of other transaction types (see Chapter 4) cannot be covered.
Chapter 5 has already mentioned the variety of meanings attributed to the term TP monitor. Having defined the role of a TP monitor in a transaction-oriented system by enumerating the services it provides, we will be equally careful in specifying the interfaces used for implementing a TP monitor. A good way to structure interfaces is by layers of abstraction. Let us therefore start by considering those layers in a transaction processing system.
Table 6.1 organizes the terms in the way they are used throughout this book. It contains three central layers. First, there is the basic operating system (BOS), which is assumed to know little or nothing about transactions. Next comes the transaction processing operating system (TPOS), the main task of which is to render the objects and services of the BOS in a transactional style. For example, the basic OS provides processes; in order to exercise transaction-oriented (commitment) control, each process executing code on behalf of an application must be bound to the transaction that surrounds this execution. The basic OS also provides messages: when transaction programs send protected output messages, they must not be delivered until the transaction has committed. Therefore, messages must be bound to transactions, too. The same argument applies to interprocess communication, units of durable storage, and—in some cases—physical devices.
Table 6.1
Layering of services in a transaction processing system. The description of functions and services throughout this book assumes five interface layers. The basic operating system uses the hardware directly. Its interfaces are used by the transaction processing operating system to provide a transactional programming environment. Sophisticated servers like databases, configuration management, window management, and so forth, use both the basic operating system and the transaction processing operating system to create a transaction-oriented programming environment. The application typically uses the transaction processing services and the interfaces to the transaction processing operating system, depending on the application’s sophistication.
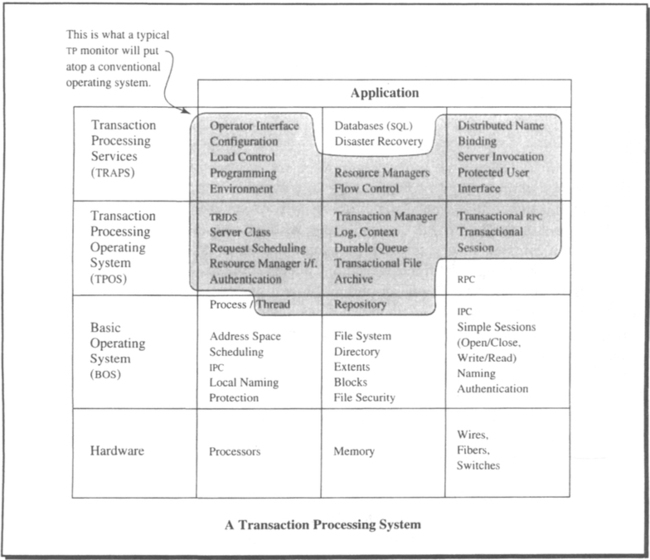 |
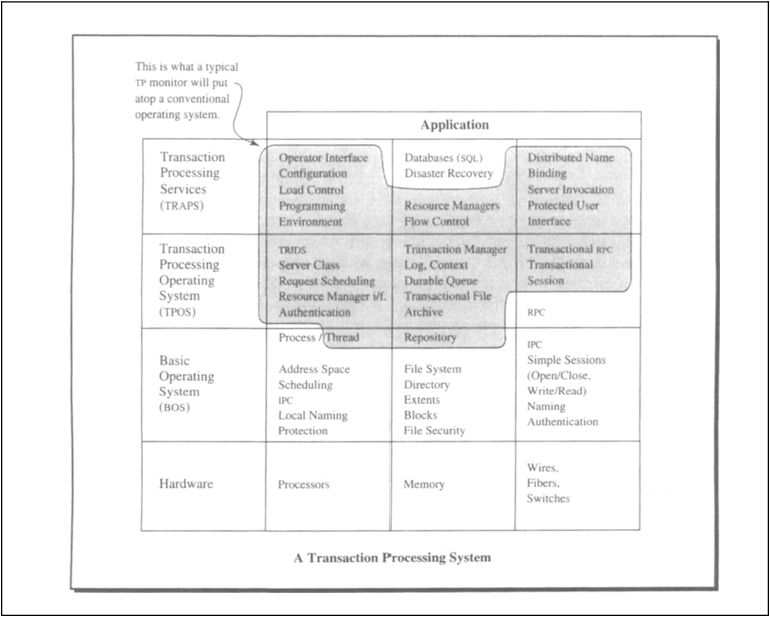
Finally, there are transaction oriented services, which make the TPOS manageable and usable for developing transaction-oriented applications. Table 6.1 also relates the services to the types of objects and functions they provide. For completeness, the table includes the hardware underneath and the application on top of the transaction processing services.
The following chapters are largely concerned with the middle layer of Table 6.1, the transaction processing operating system (TPOS), and with showing how its main functions are implemented. Discussion of functions that are attributed to other layers is restricted to the degree that the functions contribute to the main purpose of the TPOS. Chapters 13–15 then use the mechanisms of the TPOS to outline the implementation of a transaction-oriented file system. The file system has the features needed as a platform for SQL. It serves as an example for a resource manager in the sense described in Chapter 5. A precise definition of the term resource manager is given in Section 6.2.
Bear in mind that the layering in Table 6.1 does not reflect a strict implementation hierarchy. Rather, it describes a separation of concerns among different system components. It is therefore perfectly reasonable to assume that the TPOS implements some of its data structures (repositories, queues) using SQL, although SQL is shown to sit on top of the TPOS. This situation is analogous to the assumption made in Chapter 3, Section 3.7, where the operating system uses SQL to keep track of its ticket numbers.
Table 6.1 tries to relate the strongly used and weakly defined term TP monitor to the service categories used in this book, by way of the services a typical TP monitor provides (according to Chapter 5). Given the overview of terms in Table 6.1, we use TPOS and TP monitor interchangeably, whenever there is no risk of confusion.
To describe the implementation of a complete TP monitor in full detail is far beyond the scope of this book. Rather, we focus on the key services provided by a TP monitor, which encircle the transactional remote procedure call (TRPC), as was sketched in Chapter 5. TRPCs are used to invoke services from resource managers under transaction protection.
The organization of this chapter follows generally the flow of a TRPC. Section 6.2 gives a detailed description of what a transactional RPC looks like and the consequences of its use on the structure of resource managers. In particular, it discusses the interfaces of a resource manager, both in its role as a server to applications and other resource managers, and as a client invoking services via TRPC. The implementation of transactional RPCs is then described in Section 6.3. It is the longest section in this chapter and covers all related aspects, such as server classes, name binding, and transaction management.
Queue management is the topic of Section 6.4. All the miscellaneous topics that have not been given their own sections, such as load balancing, authentication and authorization, and restart processing, are briefly discussed in Section 6.5.
The discussion makes use of a number of concepts in operating systems and programming languages; we will not explain these. To avoid any confusion, here are the topics that the reader is assumed to be familiar with (for the reader unfamiliar with these topics, textbooks on operating systems are a particularly good source of information):
Linking and loading. The TP monitor is responsible for creating processes and making sure the code for the resource manager requested can be executed in them. For this, it needs to link and load the resource manager’s object modules together with the stub modules of the TPOS. There is no explanation in this chapter about how exactly this is done.
Library management. The object modules of the resource managers and application programs are stored in libraries. These can be libraries maintained by the operating system, or the TP monitor can keep it all in its own repository. There are no specific assumptions made here.
In addition to these basic techniques, we will also gloss over some TP-specific items, most notably the administrative interface. These important issues are not addressed in this book.
6.2 Transactional Remote Procedure Calls
Having introduced the notion of remote procedure call (RPC) in Chapter 5, we now proceed to explain what exactly a transactional remote procedure call (TRPC) is. It is much more than just an RPC used within a transaction. To get into the right mind set, think of a TRPC being as different from a standard RPC as a subroutine call is from an ACID transaction. For an illustration, go back to Figure 5.9. There, the request coming in at the upper left-hand corner is a TRPC from some other node, aimed at the application represented in the center of the figure. The application begins to work and calls various system resource managers, the database, and so on. Each of these invocations is a TRPC of its own, handled in the way just described. The database, in turn, calls system resource managers, some of which have also been called by the application, again using TRPCs.
The distinguishing feature is that all resource managers, by having been called through a transactional remote procedure call, become part of the surrounding transaction. Remember that in a standard RPC environment, the RPC and the operating system have only to make sure that once a call has arrived at the local node, there is a process running the server’s code. When the call returns, the server is free again, and that is all there is to it.
A TP monitor must manage a pool of server processes, and in addition, each TRPC has to be tagged with the identifier of the transaction within which the call was issued. In particular, TRPC messages going across the network have to carry the transaction identifier with them. When scheduling a process for a request, the TPOS must note that this process now works “for” that transaction. After the call returns, the process is detached from the transaction, but the response message has to be tagged with the transaction identifier.
If that were all that distinguished a TRPC from an RPC, it would not require a section to describe it; but the point is that TRPC is not just transaction control over one resource manager invocation. Rather, transaction control must be exercised over all resource manager interactions within one transaction. Keeping all resource managers together as part of the same transaction requires more than just appending a transaction identifier to each request. The TP monitor also needs to enforce certain conventions with respect to the behavior of the resource managers issuing and receiving TRPCs, and with respect to the way transactions are administered by the nodes constituting the transaction system. The following are required for the “web” of a transaction’s calls to hang together:
Control of participants. Someone must track which resource managers have been called during the execution of one transaction in order to manage commit and rollback. As part of the two-phase commit protocol, all resource managers participating in the transaction must, in the end, agree to successfully terminate that transaction; otherwise, it will be rolled back. That means somebody must go out and ask each resource manager involved whether it is okay to commit the work of the transaction. The component responsible is called the transaction manager (TM), which is explained in detail in Chapter 11. It is instructive to contemplate for a moment that a resource manager does not necessarily remember that it has been called at all. Assume a simple COBOL server that gets invoked as part of transaction T1, reads some tuple from a database, performs some computations, inserts a tuple, and returns. Each time the server is called, it starts in its initial state; that is, all the data for doing its work must be in the parameters passed. After the server is done, it forgets everything (frees its dynamic storage); thus, there is no point in asking the server later on whether transaction T1 should commit; it has no information about the transaction.
Preserving transaction-related information. As Figure 5.9 shows, the same resource manager can be invoked more than once during the same transaction—by the same or by different clients. In the process environment that we assume, each invocation can, in principle, be handled by a different process (remember the concept of server classes outlined in Chapter 5). Since each RPC finally ends up in a process, at commit each process running the same resource manager code is asked individually about its commit decision. For some types of resource managers, this may be sufficient. Assume that, upon each invocation, 10 tuples were inserted into a database; the transaction will commit if each of the 10-tuple-insert requests was successful. In other situations, however, the resource manager can only vote on commit when all the information pertaining to that transaction is available in one place. If the different invocations left their traces in different servers, this will be hard to do. The TRPC mechanism, then, must provide a means to relate multiple invocations of the same resource manager to each other.1
Support of the transaction protocol. The resource managers must stick to the rules imposed by the ACID paradigm. This must be supervised by the TRPC mechanism; in case of a violation, the transaction must abort.
The long and short of all this is that the concept of transactional remote procedure calls has two complementary aspects. One is the association of requests, messages, and processes with a transaction identifier. The other aspect is the coordination of resource managers in order to implement the transaction protection around RPCs. If this sounds recursive again, bear with us until Section 6.3, where the dynamic interaction among the TPOS components is explained in some detail.
All TRPC-related issues are handled by the TPOS, though not by the TP monitor alone. As the description progresses, it will turn out that the TP monitor acts as a kind of switchboard that receives requests and passes them on, without actually acting on most of them. However, the TP monitor makes sure that these are valid transactional RPCs and that they get routed to the proper components of the TPOS or the application. The explanation of the way TRPCs are handled is divided into two parts. First, we explain the interfaces through which transactional resource managers interact with their environment—the TPOS in particular. Second, the problem of preserving transaction-related information is discussed.
6.2.1 The Resource Manager Interface
A resource manager qualifies as such by exhibiting a special type of behavior. More specifically, a resource manager uses and provides a set of interfaces that, in turn, are used according to the protocols of transaction-oriented processing. Depending on how many of the interfaces a resource manager uses (and provides), it has more or less influence on the way a transaction gets executed in the system. This is discussed extensively in this chapter, as well as in Chapter 10. Figure 6.2 gives an overview of the types of interfaces a resource manager has to deal with.
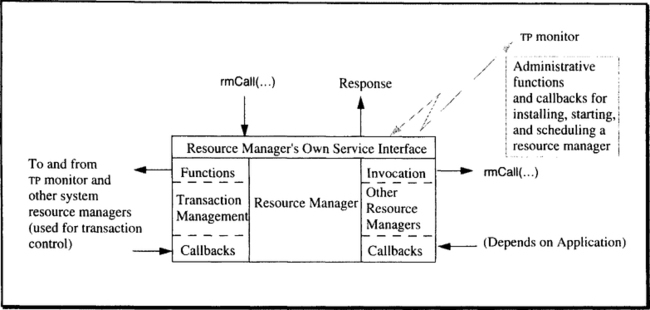
On top of Figure 6.2, there is the rmCall interface, used for invoking the resource manager’s services; the results are returned as parameters to this call.2 The function prototype declare follows. One entry in the parameter list that has not been mentioned so far, Bindld, is explained in detail in Section 6.2.4, but here is the idea: since there can be many processes executing the same resource manager code, it may be necessary in some cases to know exactly which one has serviced a request within a transaction. The parameter Bindld is a handle for such an interaction between a client and a specific server that has to be used repeatedly.

This is about all there is to say about the service interface of a transactional resource manager. Whenever such an rmCall is issued from somewhere, it gets the TRPC treatment we have outlined. In particular, the TP monitor assures that the execution of the resource manager becomes part of the transaction in which the caller is running—provided there is an ongoing transaction. If there is none, then whatever has happened so far has no ACID properties.
Some of the interactions of a resource manager or an application program with the transaction manager, which are alluded to on the left-hand side of Figure 6.2, have already been discussed with the programming examples in Chapter 5. But as the figure indicates, a resource manager generally can not only call the transaction manager, it can also be called upon by the transaction manager. This feature, which is required for the implementation of general resource managers that keep their own durable state, is discussed in the next subsection.
6.2.2 What the Resource Manager Has to Do in Support of Transactions
The transactional remote procedure calls described up to this point cover the normal business of invoking the services of resource managers from application programs or other resource managers. It has also been pointed out that the verbs for structuring programs in a transactional fashion result in calls to system resource managers, most notably to the transaction manager. But sophisticated resource managers, especially those maintaining durable data, must also be able to respond to requests from the TPOS. For example, they must vote during two-phase commit, they must be able to recover their part of a transaction (either roll it back or redo it after a crash), they must be able to take a savepoint, and so forth. There are two ways to invoke the resource managers at these special service entries:
Single entry. The server has only one service entry point (message buffer) through which it receives all its service requests. So before acting on a request, it must determine what kind of request it is and then branch to the appropriate subroutine.
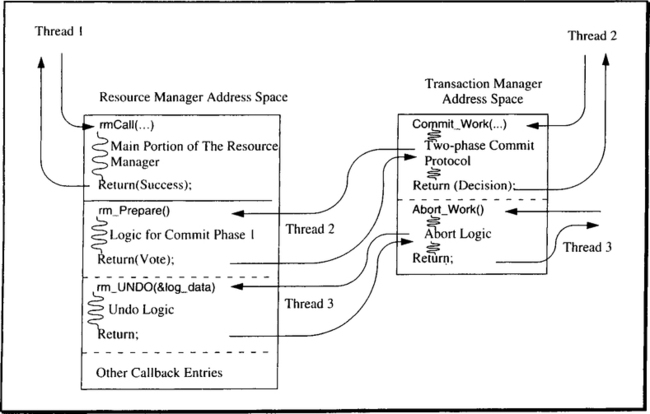
Service entry plus callback entries. Interfacing the resource managers to the transaction manager via a set of entry points is the approach taken in this book (and by X/Open DTP). As Figure 6.2 indicates, each resource manager has a service interface that defines what the resource manager does for a living. Furthermore, it declares a number of callback entries. In the resource manager’s code portion these are entry points, which can be called when certain events happen. The principle is illustrated in Figure 6.3.
The function prototype declares are shown below. Note that the invocation of a resource manager by the transaction manager at such a callback entry is just another transactional remote procedure call.


For example, the rm_Commit entry of a resource manager is called by the transaction manager when a transaction is in the prepared state and the two-phase commit protocol has made the decision to commit. The resource manager can then do whatever is required to commit its portion of the transaction, such as releasing locks or sending output messages. Details of what resource managers are expected to do at each of these entry points are explained in Chapters 10 and 11.
As mentioned, the number of callback entries provided by a resource manager depends on its level of sophistication. The types of servers discussed in the previous subsection need not provide any callback entries. They do not write log data, so they have nothing to undo or to redo. They also do not keep other context data in their own domain, which means their vote on commit is implicitly Yes when they return to the caller. This can be put in a simple rule of thumb: if the resource manager maintains any durable objects, it must be able to accept rollback and prepare/commit callbacks from the transaction manager. It must write log records and, consequently, must be able to act on undo/redo callbacks. If it has all of its state maintained by other resource managers (e.g., SQL servers), then it becomes their problem to maintain the ACID properties of the state. There is a slight deviation from this rule in case of resource managers that do not maintain durable objects but do have to remember all invocations by the client within one transaction; for example, to check deferred integrity constraints. This is discussed in Subsection 6.2.4. The rm_Checkpoint callback is listed for completeness only; its meaning is described in Chapter 11.
The resource managers, on one hand, and the transaction manager, on the other, usually run in different address spaces, all of which may be different from the address space the TP monitor uses. All addressability issues with respect to resource managers are handled by the TP monitor. Most of the callbacks, however, are needed by the transaction manager; thus, there must be a way for the transaction manager to point to the right entry points without actually knowing the addresses. This issue is discussed in the next subsection.
There is one last call from the resource manager to the transaction manager that is needed for start-up, and especially for restart after a failure. This call, Identify, informs the transaction manager that the resource manager is in the process of opening for business and wants to do any recovery that might be necessary. The transaction manager responds by providing the resource manager with all the recovery data that might be relevant; to do that, it uses the rm_restart, rm_UNDO, and rm_REDO callbacks. Details are presented in Section 6.5. The point is that after the Identify call returns, the resource manager has caught up with the most recent transaction-consistent state and from now on can accept service requests. The function prototype declaration looks as follows:

The resource manager just passes its RMID and gets a boolean back; it is TRUE if the transaction manager has gone successfully through the restart logic for that resource manager. If FALSE is returned, something serious went wrong, and the resource manager cannot be declared up.
Since Identify is needed only to start up those resource managers that have to recover durable state (sophisticated resource managers), simple resource managers and application programs do not have to call Identify at all.
The right-hand side of Figure 6.2 shows the interaction between the resource manager and servers other than the system resource managers. These could be other low-level resource managers, such as the log manager or the context manager, or any other server in the system. With each of them, the resource manager could agree on additional callback entries. The invocations of these “other” resource managers need no further explanation; they are simply TRPCs.
6.2.3 Interfaces between Resource Managers and the TP Monitor
At this point, it is necessary to remember that TRPCs never go directly from the client to the server; rather, they are forwarded by the TRPC stub, which is linked to each resource manager’s address space (see Figure 5.11). From a logical perspective, then, clients, servers, and system components are invoking their respective interfaces, but the TRPC stub intercepts the requests and thus enables the TP monitor to act upon them as necessary. This is to say, the TP monitor plays a crucial role in resource manager invocation. The TP monitor does, however, have some other roles: it is the component responsible for starting up the transaction system (bringing up the TPOS), for closing it down again, and for administering all the transaction-related resources. Startup and shutdown are described in some detail in Section 6.5; here we only introduce the TRPCs needed after startup. The administrative functions are not explained in this book; they only require updating the repository database and, as such, are part of the general operations interface, which is not described here.
The procedure calls required for system startup and shutdown are exchanged directly among the resource managers and the TP monitor. The administrative TRPCs are exchanged among the TP monitor and the repository resource manager. All this is depicted by the “lightning” in Figure 6.2. Let us start with the function calls used to install a new resource manager or to remove an existing one:

The parameter list of rmlnstall is very rudimentary. The first three parameters are spelled out. RMNAME is the user-supplied global external identifier for the new service; its actual uniqueness will be checked against the repository when the resource manager is installed.
The next parameter is an array of pointers to the callback entries in the resource manager. These callback entries are specified as relative addresses in the load module for that resource manager; as a result, invoking that callback entry means that the TRPC stub branches to the respective address. There is a convention saying that, for example, the first element of the array is the address of the rm_Startup entry, the next element is the address of the rm_Prepare entry, and so on. The TP monitor keeps this array in the TRPC stub of the respective resource manager’s address space. If the transaction manager issues a TRPC to such a callback entry, it has to specify three things: first, the name of the entry to be called; second, the RMID of the resource manager the call is directed to; and third, the parameters that go with the call. The TRPC stub then takes the entry name and associates it with the index in the rm_callbacks array. The copy of that array for the resource manager identified by RMID then contains the actual address to branch to.
As with the callbacks for the transaction manager, these entries need not be provided by simple resource managers; such resource managers can just be loaded or canceled. Sophisticated resource managers, however, may have files to open (close) or other initial (terminal) work to do. Note that in a real system there is more to say about callbacks than just an address in the event the resource manager needs to be called back for the respective event. Especially in cases where no address is provided, additional information is required by the transaction manager. For example, if a resource manager specifies no rm_Prepare entry, this indicates that under all circumstances its vote on commit is Yes. But this convention of “no entry = blind agreement” is not generally applicable. For example, specifying no rm_Rollback_Savepoint entry might indicate that the resource manager has no durable state and therefore does not object to a rollback request. It might, on the other hand, say that the resource manager is able to abort the transaction but cannot return to any local savepoint. Thus, for each missing callback address, the transaction manager must be told the default result of that function for the respective resource manager.
The remaining parameters are left vague. They merely indicate that more information is needed when installing a new resource manager. There must, for example, be an access control list that allows the TP monitor to check whether an incoming request for that resource manager is acceptable from a security point of view. Other necessary declarations include the location from which the code for the resource manager can be loaded, which other resource managers need to be available before this one can start, what its priority should be, and what the resource consumption is likely to be (processor load and I/O per invocation). Some of these issues are discussed in Section 6.5.
The second group of functions is very straightforward; they were mentioned in the description of Identify. The transaction manager invokes the callbacks for driving the transaction protocols, and the TP monitor brings a resource manager to life by calling rm_Startup. When this TRPC returns, the TP monitor knows that this resource manager is open for service (see Section 6.5). Conversely, when rmDeactivate has been called from the administrator, the TP monitor invokes rm_Shutdown and from now on rejects all further calls to that server class.

No program can participate as a resource manager in a transaction unless it has properly registered with the TP monitor. The TP monitor enters the new service to the name server, which is part of the repository, then checks its resource requirements and its dependencies on other resource managers. Note that this attitude is different from the somewhat anarchic way distributed computing is done in PC or workstation networks. There a server can come up and announce itself to the network by entering its name and address into the name server, and from then on everybody who is interested can send requests to that server directly via RPC. The scheme used by TP monitors is more controlled in the sense that there is always a TPOS, especially a TP monitor, in the invocation path. The major advantage of this approach over the anarchic one is obvious: Going through the TPOS layer allows system-wide end-to-end control, authentication, and load balancing. One can argue that the same control would be possible in the anarchic scheme by proper cooperation among the RPC mechanism and the name server. While this is true, it means that that scheme would effectively evolve into a TPOS.
6.2.4 Resource Manager Calls versus Resource Manager Sessions
Thus far, we have seen the problems of invoking different types of resource managers via transactional remote procedure calls. As mentioned at the outset, however, there is a second aspect to TRPCs that goes beyond the scope of one invocation: context. This is a loaded topic—and an important one—so we will try to give it careful treatment.
The fundamental question can be put like this: If, in the course of one transaction, a client C repeatedly invokes server class S, how should that be handled? To appreciate that there is a problem at all, note that S denotes a server class, and each invocation can go to a different process belonging to that class. Since these processes have separate address spaces, process Si has no information about what process Sk has done on behalf of C. With these constraints in mind, consider the following scenarios, which are illustrated in Figure 6.4:
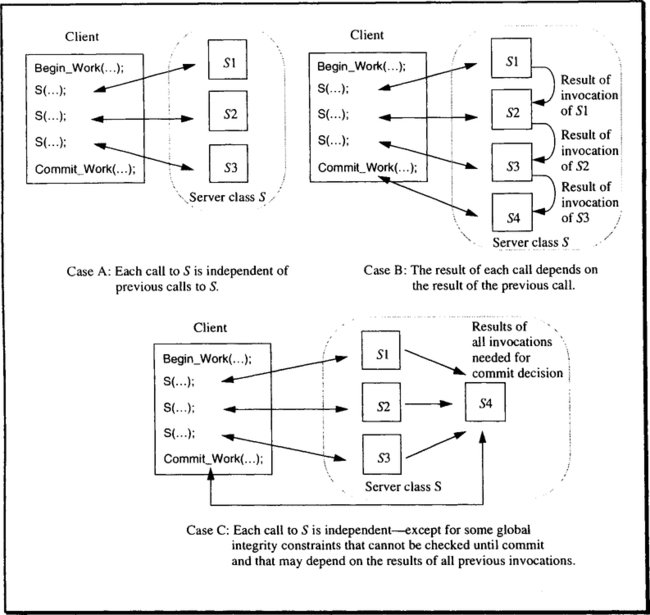
Independent invocations. A server of class S can be called arbitrarily often, and the outcome of each call is independent of whether or not the server has been called before. Moreover, each server instance can forget about the transaction by the time it returns the result. Since the server keeps no state about the call, there is nothing in the future fate of the transaction that could influence the server’s commit decision. Upon return, the server declares its consent to the transaction’s commit, should that point ever be reached. An example for this is a server that reads records from a database, performs some statistical computations on them, and returns the result.
Invocation sequence. The client wants to issue service requests that explicitly refer to earlier service requests; for example, “Give me the next 10 records.” The requirement for such service requests arises with SQL cursors. First, there is the OPEN CURSOR call, which causes the SELECT statement to be executed and all the context information in the database system to be built up. As was shown, this results in an rmCall to the SQL server. After that, the FETCH CURSOR statement can be called arbitrarily often, until the result set is exhausted. If it was an update cursor, then the server cannot vote on commit before the last operation in the sequence has been executed; that is, the server must be called at its rm_Prepare() callback entry, and the outcome of this depends on the result of the previous service call.
Complex interaction. This is the general case, of which only a simple version is shown in Figure 6.4 (Case C). The server class must remember the results of all invocations by client C until commit, because only then can it be decided whether certain deferred consistency constraints are fulfilled. Think of a mail server with which the client can interact. The server creates the mail header during the first interaction, the mail body during the next interaction, and so on. The mail server stores the various parts of a message in a database. In principle, then, all these interactions are independent; the client might as well create the body first, and the header next. However, the mail server maintains a consistency constraint that says that no mail must be accepted without at least a header, a body, and a trailer. Since this constraint cannot be determined until commit, there must be some way of relating all the updates done on behalf of the client when the server is called (back) at rm_Prepare—even if this call goes to a process that has not been called upon before. Note that all sophisticated resource managers, such as SQL database systems, entertain such complex interactions with their clients.
This whole issue of relating multiple calls of one client to the same server class is one facet of an almost religious debate that has been going on in the field of distributed computing for many years. It has to do with the question of whether computations should be session oriented or service-call oriented. This is not the place to resolve this question, but let us use the previous example to consider the fundamental issue.
This whole debate has some of the flavor of the data modeling discussions circling around the question of whether all information must be expressed by values (the relational camp), or whether positional information should be allowed, too (the hierarchical, network-and object-oriented camp). Common terms for this controversy are connection-less versus connection-oriented, context-free versus context-sensitive, stateless versus stateful, datagram versus session.
A client and a server are said to be in session if they have agreed to cooperate for some time, and if both are keeping state information about that cooperation. Thus, the server knows that it is currently servicing that client, what that client is allowed to do, which results have been produced for it so far, and so forth. If the session covers an invocation sequence, the server knows which records the client refers to and has context information pointing to the last record delivered to the client. Consider the request for “the next 10 records” issued by the client to a server it contacts for the first time—this obviously would not make any sense.
The advocates of statelessness hold that nonsensical service requests like these should not be issued in the first place. Put the other way around: each remote procedure call must contain enough information to describe completely what the service request is about, without alluding to some previous request, earlier agreement, or anything of that sort.
There are, however, many situations in which it is just very convenient to have some agreed-upon state, if only for the sake of performance. Consider the example of the cursor from which the next n tuples are read. One could think of an implementation that passes with each new request the identifier of the last record read with the previous request; that way, the server knows where to continue. But that would solve only part of the problem. Without context, each new request would have to be authenticated and authorized; that is, the server would have to decide over and again whether the client is allowed to read these records. If there is state, then the result of the security check done upon the first request is kept in the context on the server’s side.
As will become obvious in the following chapters, there is even more context that needs to be preserved in order to achieve the ACID properties. For example, guaranteeing atomicity and isolation requires the server to remember all the records a transaction has touched so far—and not just the most recent one, which would be enough to support the “fetch next” semantics. Furthermore, a transaction in itself establishes a frame of reference that can (and must) be referred to by all instances that have participated in it. Just to make the decision whether “this transaction” should be committed or aborted requires some context from which to derive which state the transaction is in (from each client’s or server’s perspective). Of course, since a transaction can involve an arbitrary number of agents, it is by nature more general than a session, which is always peer-to-peer. But the important similarity at this point is the necessity of context that can be referred to by all instances involved. The following discussion is focused on the issue of how to achieve shared context.
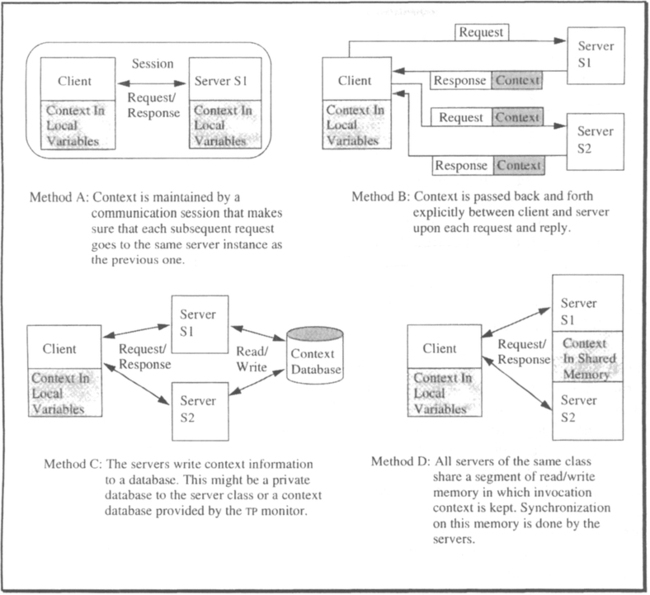
The problem of “sessions” versus independent rmCalls will come up over and again during this chapter. The position taken here is that the difference between the two at the level of the resource manager interface is not that dramatic and, therefore, the issue should not be overrated (and overheated). There are situations where maintaining context on both sides lends itself naturally toward supporting certain types of (important) resource manager request patterns. In other cases, keeping the context on one side is the more economical solution. Let us briefly sketch the different methods for keeping client-server context; it turns out that client-server association via context is a fairly general phenomenon and allows for many different implementations. Four structurally different approaches are sketched in Figure 6.5.
It is easy to see that each of these techniques can, in principle, be used to maintain the relationships among server invocations as they are illustrated in Figure 6.4. This is not to say, though, that the techniques are arbitrarily interchangeable; they are quite different with respect to the burden they put on both the client’s and the server’s implementation in terms of cost for maintaining the processing context.
Having the communication system manage the context is the simplest approach for both sides. There is some magic around them, called session, that makes sure all invocations from the same client go to the same instance of the server. Thus, the server behaves like a statically linked subroutine, which means it can keep its context in local program variables. This applies not only to the normal service invocations, but also to any callbacks the server may get from the transaction manager. Such a session has to be managed by the TPOS; all the client or the server has to do is declare that it needs one. The price for this is considerable overhead in the TPOS for maintaining and recovering sessions; see Chapter 10, Section 10.3. Note that only this method is a session according to the established terminology. The other three techniques implement a stateful relationship between a client and a server class, but most people familiar with communication protocol stacks would not call them sessions. This text takes a somewhat less rigid perspective: whenever there is relationship between a client and server for which context is kept somewhere, it is referred to it as a session, provided there is no risk of confusion.
Context passing relieves the TPOS of the problem of context management. Both the client and the server side cooperate in order not to get out of sync. The server decides what context it needs to carry on in case of a subsequent call. The client stores the context in between server calls and passes it along with the next invocation. There is a subtle problem when using Method B (shown in Figure 6.5) in a scenario of the type depicted in Case C of Figure 6.4. The server instance that gets invoked via rm_Prepare needs the context for making its decision. But, because this call comes from the transaction manager, there will be no context in the parameter list. The only solution is for the client to issue some “final” service call (with context), which tells the server that the client is about to call commit. If the server does not like the situation, it calls Abort_Work. If, on the other hand, the server returns normally, the client can call Commit_Work, and the server will not be called back by the transaction manager.
Keeping the context in the database gives the responsibility of maintaining context to the server. It has to write the state that might be required to act on future invocations into a file, database, or whatever. The state information must be supplied with the necessary key attributes to uniquely identify which thread of control it belongs to. The key attributes include the TRID, client RMID, and the sequence number of the invocation. Some of the work involved in maintaining the context can be offloaded to either an SQL database system or to the context management service of the TP monitor (see Section 6.5).
The important point is that with this method, an arbitrary instance of the server can be invoked to vote on commit. Using the MyTrid call, it can find out what the current transaction is; through the TRPC mechanism, it also knows which RMID it is working for, so that it can pick up the right context from the database.
The shared memory approach is similar to the solution using a context database, except that now the whole responsibility is with the server (class). Context has to be kept in shared memory, access to which must be carefully synchronized. This solution is used by very sophisticated resource managers, such as SQL database systems, and is only applicable when all instances of the server class are guaranteed to run at the same node. Chapters 13–15 discuss some of the problems related to that type of context management.
So far, we have ignored a very important distinction with respect to the type of context that needs to be maintained from a server’s perspective. Considering our various examples, one can easily see that there are two types:
Client-oriented context. This reflects the state of an interaction between a client and a server. The solutions presented in Figure 6.5 implicitly assume that this is the type of context to be managed. Typical examples are cursor positions, authenticated userids, and so on.
Transaction-oriented context. This type of context is bound to the sphere of control established by a transaction rather than to an isolated client-server interaction. Consider the following example: Client C invokes server S1, which in turn invokes server S3—all within T. After return from the service call, C invokes S2 (a different server class), which also invokes S3, but needs the context established by the earlier call to S3 from S1. Case C) in Figure 6.4 describes a similar situation. The point here is that the context needed by S3 is not bound to any of the previous client-server interactions, but it is bound to the transaction as such.3 This leads back to the argument about the similarities between sessions and transactions in terms of context management. Examples of transaction-oriented context are deferred consistency constraints and locks (see Chapter 7).
A general context management scheme must be able to cope with both types of state information; that is, it must distinguish whether a piece of context is identified by the client-server interaction or by the TRID. Note that communication sessions can only be used to support client-oriented context. Exercises 4 and 5 are concerned with ways to maintain both types of context based on the mechanisms introduced in Figure 6.5.
Now let us return to the example of the SQL cursor; the only way to avoid any kind of session-like notion at the TRPC level is to use Method B. In this case, all the cursor management is done by some piece of code in the client’s process. The server delivers all the result tuples to that local cursor manager and can then forget about the query. Assuming that the cursor navigates over a large relation, this is an expensive solution.
To get reasonable performance, then, the server must be involved somehow. It has to maintain the result produced by the SELECT of the cursor definition and must record the current cursor position in that result set. In other words, it must be in a position to make sense of a FETCH NEXT service request. The client and server share responsibilities for maintaining context. They must decide what context information about their interaction is to be kept from now on. Having both maintain the same context would be overkill. For example, if the client issues a SELECT, which he knows returns at most one tuple, then no client context is needed; only if he wants to process a cursor must context be maintained for the client.
Transaction-oriented context must be maintained by each server that manages persistent state, no matter what the invocation patterns with its clients look like. This aspect is elaborated over the course of the next five chapters.
The ground rule is this: Each server that manages persistent objects must be implemented such that it can keep transaction-oriented context. The TRPC mechanism must provide means for servers of any type to establish a stateful interaction with a client in case this should be needed (client-oriented context). Of course, both types of context must be relinquished after they have become obsolete, either after commit/abort or after an explicit request to terminate a particular client-server interaction. The TPOS provides two mechanisms to implement client-oriented context:
Session management. If context maintenance is handled through communication sessions, then the TP monitor is responsible for binding a server process to one client for the duration of a stateful invocation.
Process management. Even if the TP monitor has no active responsibility for context management, it may use information about the number of existing sessions per server for load balancing. The rationale is that an established session is an indicator for more work in the future.
For the purpose of our presentation, we use two TRPC calls to establish and relinquish a session among a client and a server; they assume that the request for a session is always issued by the server. Here are the function prototype declares:

It is important to understand that a Bindld uniquely identifies an association between a client instance and a server instance. Therefore, each Bindld points to one rmlnstance on the client’s side and one rmlnstance on the server’s side. Consider the use of these functions for handling SQL cursors. The sequence of SQL statements reads like this:

Using the ideas just introduced, this would be mapped onto the following sequence of TRPCs:4

The imbedded SQL calls on the client’s side are turned into rmCalls to the SQL server; the first one requests the open function, the next one the fetch operations, and so forth. Upon the first request, the server issues an rmBind request to the TP monitor, because the open establishes context to which the client subsequently is likely to refer. The server instance therefore asks to be bound to that client instance to make sure future client requests are mapped correctly. After this, the server acts on the function requests. The CLOSE CURSOR request is essentially a signal to the server to destroy the context; therefore—after its local clean-up work—it invokes rmUnbind. Of course, the SQL connection module on the client’s side must be able to associate cursor names with the Bindlds that are returned with the rmBind requesting to open the cursor. Since this has nothing to do with TP monitors in particular, it is not discussed here.
If rmCalls are to be issued without a preference for a particular instance of the server, rmlnstance is set to NULL; otherwise, the value for it must be determined by a preceding rmBind. Note that a client can entertain an arbitrary number of simultaneous bindings with the same server class, though of course, not with the same instance. The pair of rmBind/rmUnbind operations establishes a session between the client and the server.
There is one more interesting thing to note about the binding between client and server, especially in case of an SQL server. The example makes it look as though binding was meant only to protect cursors or the work within one transaction. However, sessions are generally used in a much wider scope. Imagine that an application program starts up, and the first thing it has to do is to find its proper database. For example, it could have to run with a test database or with the production database; it could have to use the order entry database of region A or of region B, and so on. In short, all its schema names need to be bound to the right schema description. This requires control blocks to be set up on both sides—again, a session between the client and the server. Once this is established during the startup of the application, it can be used for all subsequent interactions that refer to this schema. Cursors will, of course, work correctly, because the initial SELECT, as well as the corresponding FETCH NEXT, will all be sent to the same rmlnstance. Thus, the duration of an rmBind can be longer than one transaction; a client and a server “in session” can execute an arbitrary number of transactions across that session. But assuming that there is no parallelism within a transaction, each such session will, at any point in time, be used by at most one transaction. If this transaction aborts, the state on both sides will be rolled back, as atomicity demands. Since the session is essentially defined by the state kept on both ends, this implies that the session is also recovered to the beginning of the transaction. This is explained in more detail in Chapter 10.
It is interesting to consider who (i.e., at which level of programming) actually uses the rmBind/rmUnbind mechanism. A full-blown resource manager, designed to service many clients simultaneously, must be able to bind many server instances of itself—for load distribution, for throughput, or for other reasons. In that case the the resource manager’s program has to use the binding mechanism explicitly.
If, on the other hand, the resource manager is just a COBOL application, then no one can expect its programmer to use such tricks. It is therefore up to, say, the SQL pre-compiler or the TP monitor to handle properly the sessions established on behalf of the SQL server in order to let the COBOL program run correctly. You can consider some of the consequences of this as an exercise.
The foregoing explicitly assumes that sessions are established by servers only. This is a simplification for the purpose of keeping the presentation free of too many extras. Depending on the type of services provided and on the level of sophistication in the implementation of the clients and servers, it might well be the client asking to be bound to a particular server. Think, for example, of a piece of software that acts as a server to one side, but is a client to other servers. If it receives a request that requires binding, then it will have to go into session with its servers to be able to service the request. The discussion of which way to set up a session under which circumstances is beyond the scope of this book. In many of today’s systems, however, there is a clear distinction between clients (application programs) and servers (TP services) in terms of sophistication and complexity: applications do not want to be bothered with any aspects of concurrency, error handling, context maintenance, and so on, leaving the servers to take care of the context.
6.2.5 Summary
The TP monitor’s main task at run time is to implement transactional remote procedure calls (TRPCs). TRPCs look very much like standard RPCs in that a service can be invoked via its external name (RMNAME), irrespective of which node in the network actually runs the code for if. However, TRPCs come with a much more sophisticated infrastructure, which is embodied by the TPOS.
Apart from the automatic process scheduling and load balancing that is discussed in the following sections, the TP monitor makes sure that all resource manager invocations within a transaction are part of that transaction. Thus, even a simple program that uses none of the transactional verbs becomes attached to a transaction when invoked through a TRPC. That does not mean that updates it makes to an arbitrary resource become magically recoverable, but if that simple program in turn invokes recoverable resource managers, such as SQL databases, the TP monitor tags the invocation with the transaction ID of the simple program and thus keeps the whole execution within one sphere of control.
The actual management of the transactional protocols is done by the transaction manager. The TP monitor forwards TRPCs and guarantees that they carry the right TRID and go to the right process, depending on the TRID.
Sophisticated resource managers maintain durable objects, or at least state information, about the interaction with a client for the duration of a transaction, or longer. It has been demonstrated that the TP monitor needs to support these associations among clients and servers spanning multiple TRPCs by providing session-like concepts. In some implementations, the TP monitor is responsible for keeping state that belongs to such a client-server session.
This section has taken the perspective that resource managers and applications are structurally indistinguishable. In general, an application is simpler than a full-blown resource manager—say, an SQL database system—in that it does not actively participate in most of the transaction protocols, does not have any changes to durable storage that need to be undone, and so on; in principle, however, it could do all that if the application required that level of sophistication. The TP monitor treats resource managers and applications as the same type of objects.
6.3 Functional Principles of the TP Monitor
The crucial thing about resource managers and transactional applications is that all invocations of services other than calls to linked-in subroutines have to use the TRPC mechanism. In current operating systems, there is no way to effectively enforce these conditions; yet, we must appreciate that all bypasses and shortcuts will cause part of the work to be unprotected, resulting in dire consequences for the global state of the system. Ignoring the issue of side doors, we will assume a well-designed system according to Table 6.1, where the TPOS is in full control of all its resource managers.
As is apparent in the previous section, the TP monitor’s premier function is to handle TRPCs and all the resources pertaining to them. This section, therefore, focuses exclusively on this aspect. Some other services provided by the TP monitor—managing queues, authenticating users, and bringing up the system—are covered in the later sections of this chapter.
This section contains a large amount of technical detail. It begins by sketching the address space and process structure the TP monitor requires for managing its applications and resource managers. Based on that, the core data structures of the TP monitor and the transaction manager are declared. Then the logic for handling a TRPC is presented in some detail—first for a local invocation, and then for a remote invocation. This analysis shows that there are (at least) two topics that need further exploration: the binding of names of resource managers, and the dynamic interaction between the TP monitor and the transaction manager. These topics are covered in the next subsections. Finally, some subtleties omitted during the main discussion are explained. They illustrate a phenomenon that occurs with increasing frequency the closer one gets to the implementation details of a TP system: whenever things look nicely controlled and strictly synchronous, parallelism rears its head and calls for another round of complication. This is but one example of the complexities a TP system hides from the application.
6.3.1 The Central Data Structures of the TPOS
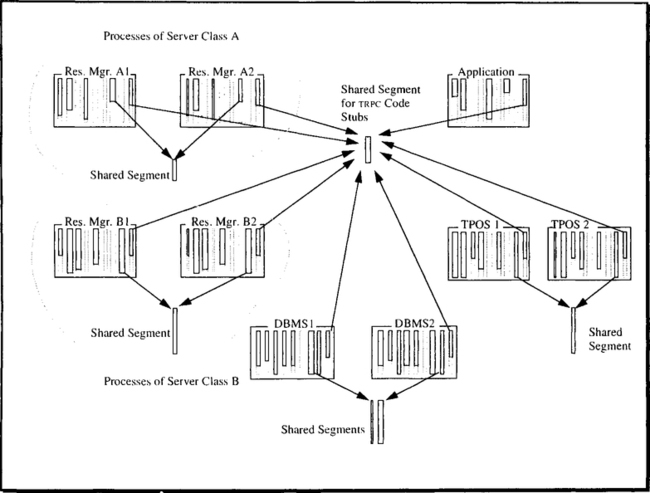
The TP monitor manages resources in terms of server classes (or resource manager types). The definition of these terms in Chapters 2 and 5 are briefly repeated here. The idea is illustrated in Figure 6.6, which is a refined version of Figure 5.11.
Remember that an RMNAME is a globally unique identifier for a service that is available in the system. At the moment the resource manager is installed at a node (function rmlnstall), it gets a locally unique RMID. At run time the TP monitor maintains a server class for each active RMID. The server class consists of a group of processes with identical address space structures; this is to say that each member of a server class runs exactly the same code. Processes in a server class are functionally indistinguishable.
For each TRPC, the TP monitor has to find the RMID for the requested RMNAME and then the server class for that RMID. If there is no unused process in that server class, the TP monitor has to create one. Otherwise, it has to select from the server class a process to receive the request. A third option is to defer execution of the TRPC for load balancing reasons; this, however, may cause deadlocks (can you see why?). All this happens within the TRPC stub.
The reason for having multiple processes running on behalf of the same resource manager is load balancing. As the load for a certain resource manager increases, the TP monitor creates more processes for it. The considerations determining how many processes should be in a given server class are outlined in Section 6.5. For the moment, let us concentrate on the address space structure required for making server class management efficient—which means low pathlength for a TRPC.
As described in Chapter 5, for all processes using TRPCs, there is one piece of shared memory, which holds the TRPC stub. This portion is displayed in the center of Figure 6.6. Each resource manager invocation via TRPC results in a branch to that stub (within the process issuing the call), and then the processing we have already sketched begins. Of course, the TRPC-stub code is re-entrant; that is, it can be executed by many processes simultaneously, as is the case for compilers, sort routines, and editors.
The remarks about what happens when a TRPC is mapped to a process do indicate that the TRPC stub needs information about the local server class configuration, as well as about remote resource managers that might be targets of TRPCs issued by local clients. For fast access, this information is kept in shared global data structures, for which the TP monitor is responsible. The segment(s) for these shared data structures is shown as the common segment for the two TPOS address spaces in Figure 6.6.
To give an idea of how the TP monitor and the other components of the TPOS cooperate, we now describe a global view of what the core data structures maintained by the TPOS are, how they hang together, and what access functions are available for them. Note that this section only presents the “grand design” plus a more detailed discussion of the TP monitor’s data structures.
6.3.1.1 Defining the System Control Blocks
To keep things manageable, it helps to have one starting point from which all data structures can be tracked down, rather than a bundle of unrelated structures that can be located only via their names in a program. Thus, above all there is an anchor data structure providing access to the other global data structures. Its declare looks like this:

Of course, a real system anchor contains more than what is shown in the example. The TPOS_Anchor is one well-defined point in the TPOS, from which all the system data structures can be reached (provided the requestor has the required access privileges). Each resource manager is assumed to have its own local anchor, where this resource manager’s data structures are rooted. Keeping the pointers to these anchors in the TPOS_Anchor ensures that addressability can be established in an orderly manner upon system startup; this is necessary, because the TPOS comes up before any of the resource managers is activated. Note that although all the data structures to be introduced are global TPOS data structures (in that they are required for all activities of the TPOS), each one is “owned” by one of the system resource managers, which tries to hide them (that is, their physical organization) from the other components of the TPOS. The degree to which this can be done depends on the flexibility of domain protection offered by the underlying operating system.
The declaration in our example assumes five system resource managers: the TP monitor, the transaction manager, the log manager, the lock manager, and the communication manager. This is a basic set; real systems might have more.
The anchor of a system resource manager has no fixed layout; it is declared by each resource manager for itself. The TP monitor’s anchor might have the following structure:

The resource manager control blocks and the others rooted at TPAnchor need more than just declarative treatment; accordingly, they are introduced immediately following the description of the global data structures. Figure 6.7 gives an overview of which data structures the TPOS keeps in its different components and how they are related. To be precise: only the global data structures entertained by the TP monitor and the transaction manager are fully shown, because these are the ones needed for handling TRPCs. For the remaining system resource managers, Figure 6.7 shows the anchor structure but none of the global data structures managed by these components.
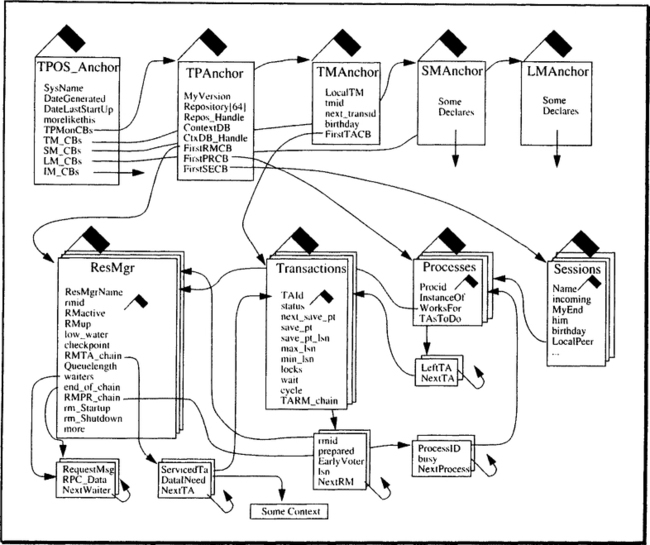
The flags attached to the control blocks in Figure 6.7 serve as metaphors for a special data type that has not yet been introduced: the semaphore. As explained in Chapter 8, semaphores are used to control the access of concurrent processes to data structures in shared memory. It is important to understand that the control blocks shown in Figure 6.7 will be heavily accessed, because the TPOS executes on behalf of virtually every process in the system. Since the control blocks are threaded together through different types of linked lists, it is important that update operations on these link structures be consistent. Consistency can be lost if different processes access the same control block simultaneously, applying contradictory updates to it. Again, exactly how this can happen is a subject of Chapter 8; for the the moment, just accept that the little flags called semaphores help to make sure that a process can operate on these central data structures without being disturbed by other processes.
The small control blocks in the lower part of Figure 6.7 are used to establish fast cross-references from one type of control block to the other; they are explained in Subsection 6.3.2. Before we come to that, let us introduce the access functions to the TPOS’s major control blocks.
6.3.1.2 Accessing the Central Data Structures of the TPOS
There is one system resource manager that is responsible for and encapsulates each type of control block in the central data structures. For example, the TP monitor is responsible for the resource manager control blocks, the process control blocks, and the session control blocks. The transaction manager is responsible for the transaction control blocks, and so on. The cross-reference control blocks are maintained by the resource manager at whose control block they are rooted.
Whenever a component of the TPOS executes one of its functions, the characteristics of transactional remote procedure calls require the TPOS to know:
In many cases, it also important to get the resource manager ID of the client that called upon the system resource manager. Based on such an identifier, the routine might request detailed information about the process, transaction, or resource manager. Of course, such data could be passed along with each TRPC, as is the case with remote invocations. But for local invocations, it is much more efficient to use the central control blocks where all this environmental information is kept.
For the purposes of this and the following chapters, we define a set of functions that allow controlled access of the TPOS’s data structures. Here is the list of function prototype definitions:

These functions can be called from any process running in the transaction system. The three types of identifiers returned are accessible to anybody involved in the processing and thus need no additional privilege for reading them. The next group of functions is not as public; their use is restricted to system resource managers that form core parts of the TPOS. The ways of enforcing these access restrictions are not discussed here; just keep in mind that an arbitrary application is not allowed to call the functions declared in the following example code.

The data structures that are returned by these functions will be explained as we go along. Processes that are entitled to call, say, MyTrans will get a copy of all descriptive data for their current transaction, but no linkage information from there to other control blocks. Access to that kind of data is reserved to those who are allowed to invoke MyTransP.
6.3.2 Data Structures Owned by the TP Monitor
If Figure 6.7 left the reader a bit puzzled, that is because it focuses on the organizational aspects of the central data structures; that is, the addressing hierarchy and the cross-referencing among the control blocks. Let us leave this to the side for a moment and consider what has to be described in the control blocks in order to handle TRPCs as laid out in the previous section. Figure 6.8 shows an entity relationship diagram with the key entities the TP monitor has to deal with, and their relationships. Don’t worry about the fact that the data structures of some of these entities are not owned by the TP monitor; for the moment, we view them as logical data objects and try to come up with a data model reflecting the TP monitor’s perspective of the world. Mapping this view to some kind of data structure is the next step. Now consider each of the entity types and their relationships.
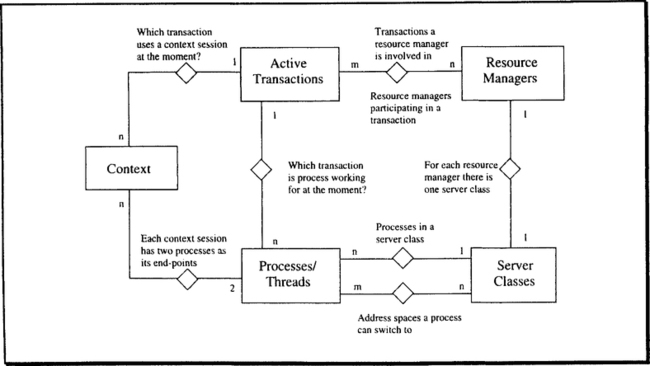
First, there are resource managers, the descriptions of which are stored in the repository. For each resource manager, there is a server class (and vice versa), which is the run-time environment for that resource manager. For mapping TRPCs, these two categories can be joined into one data structure that holds the static information from the repository as well as the dynamic data, such as request rates and queue lengths. This structure, called RMCB, is introduced later in this subsection.
Server classes are associated with processes in two ways. First, there is a 1:n relationship that describes which processes have been allocated for that server class. If a process is allocated for a server class, then its own, private address space contains the code of the resource manager corresponding to the server class. In other words, the process always starts processing in the code of the server class to which it has been assigned. Assigning processes to server classes is done by the TP monitor. Once such an assignment has been established, it can only be changed by killing the process.
Despite the fixed assignment of processes to server classes, processes can switch address spaces during execution; that is, they can execute code of other resource managers. This is an immediate consequence of the orthogonal process/address space design laid out in Chapter 2. Of course, any process cannot switch to any address space; that has to be restricted for both scheduling and protection reasons. Thus, we need a second relationship among processes and server classes describing which processes can “domain-switch” to which address spaces. It is this ability of a process to execute in different spaces that requires the system calls MyRMID and ClientRMID. Consider the scenario shown in Figure 6.9.
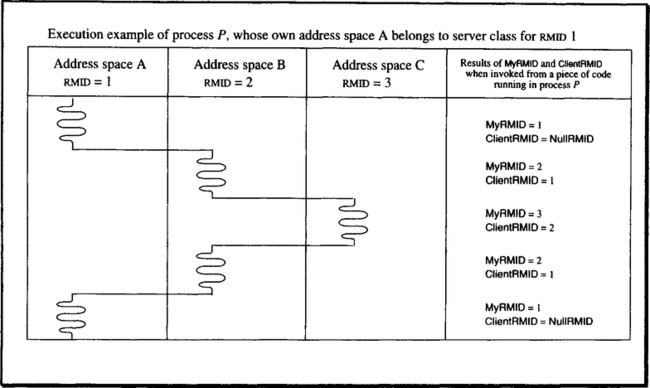
Of course, there is the static association of a process to its own resource manager, that is, to the server class running for that resource manager. Because the association is static, we have not defined a separate system call for it. Rather, it is stored at a fixed entry in the process control block.
Except for a few special situations, all execution in the system is protected by a transaction. Thus, at any point in time, a process is running code on behalf of a transaction. Over time, each process will service many transactions, but if we take a snapshot of the system each process is either idle, or it works for one transaction. Conversely, each transaction can, at one instance, have many processes working for it.
The complex m:n relationship between transactions and resource managers follows immediately from that. A transaction can invoke the services of many resource managers, and each resource manager, having many processes in its server class, can at any instant be involved in many transactions.
The last aspect is context sessions in the sense of application-level stateful interactions among clients and servers. For the implementation discussion in this chapter, we assume the session technique depicted in Figure 6.5, Method A; this means reserving a server process for a client process for the duration of the stateful interaction. Therefore, each context session is associated with exactly two processes, one for the client and one for the server. Each process, on the other hand, can entertain multiple sessions at the same time. Similar arguments hold with respect to the relationship between sessions and transactions. A transaction can have many sessions, but a session, although it may be open for a long time, is associated with only one transaction at any instant.
The perspective taken for designing the central data structures of the TPOS, therefore, is to look at the relationships that can exist at any point in time between the various entity types. Some of the relationships are static, while others can vary at a high frequency. Maintaining these is largely the job of the TP monitor.
6.3.2.1 Declaring the Control Blocks
To start with, there must be a data structure for each of the entity types shown in Figure 6.8, and there must be an efficient way of maintaining the relationships among them. The following declarations are not meant to represent an actual implementation; rather, they contain a number of simplifications that keep the descriptions of the algorithms simple.
The first simplification is to assume a linked list of control blocks for the instances of each entity type, as is shown in the declares that follow. We could have as easily declared them as relations and used SQL to get to the required entries—this would have gone well with the explanations of the principles underlying the implementation of a TP monitor.
The first group of declares contains everything the TP monitor needs to know at run time about the resource managers installed at that node. The declares for the semaphores in Figure 6.7 have been left out to avoid confusion; but, of course, in a real system they have to be there. Note there is no control block for server classes. But, as Figure 6.8 indicates, at each node there is a 1:1 relationship between resource managers and server classes, so both entity types are represented by just one type of control block.

This is but the skeleton of a resource manager control block; for a complete system, more entries would be needed. However, the ones shown here are sufficient for the explanations of the TP monitor algorithms in the next sections. Note also that in a system that makes use of the address space/protection domain facility described in Chapter 2, there would not be just one central resource manager control block. Rather, the TP monitor would have one control block with the entries it needs, the transaction manager would have another one, the log manager would keep resource manager control blocks, and so on. (This aspect is ignored during the following presentations.)
The process control block is simple in comparison to the resource manager control block:

The third group of objects for which the TP monitor is responsible is the sessions among clients and servers. There is not very much to remember about them from the TP monitor’s point of view. Note, however, that in case one end of the session is at a remote site, communication will travel along a communication session, for which the communication manager is responsible. These sessions typically are not established and released on a pertransaction basis; the cost for that would be prohibitively high. Rather, sessions are maintained between processes in different nodes over longer periods of time (in much the same spirit as the Bind/Unbind mechanism); but since they can at any point in time be used by only one transaction, it is possible to recover the state of each session in accord with the ACID paradigm. The communications manager must, of course, behave like a transactional resource manager and keep enough information about the activities of each session to able to roll back in case of a transaction failure. This is described in some detail in Chapter 12. The communications manager must also keep track of which transactions are associated with which sessions (via their processes), since it might receive messages from the network saying that a certain session is broken because of a link failure, or because the other node crashed. Those messages must then be translated into an abort message for the affected local transaction.

Now that the data structures for the entity types have been established, we need the control blocks for the cross-references among the entity types. Let us start with the control block for the m:n relationship between resource managers and transactions. Since this chapter is on the TP monitor, these control blocks are rooted in the RMCB; they might as well be rooted in the TACB, or in both.

The interesting thing about this data structure is the variable DatalNeed. It allows a resource manager (not a particular process from its server class) to maintain context for a transaction. This is a simple version of the context management techniques depicted in Figure 6.5. The way it is declared here is a mixture of keeping context data in the database and of putting it into shared memory.
Another type of control block rooted at RMCB is needed to implement volatile queues. These queues have to be kept in cases where there are more TRPCs for a resource manager than the server class has processes—and where the TP monitor for some reason decides not to create new processes. (See Section 6.4 for details.)

The entries ClientType and Clientlnst are provided to support detection of deadlocks that are caused by suspended TRPCs.
Two lists relate processes to server classes, as shown in Figure 6.8. The first one lists all the processes that may switch to a server class (i.e., to its address space), and it holds a flag saying if this is one of the processes that has been allocated for that server class. Note that the same information is also kept in the PCB entry InstanceOf.
The second list starting at PCB contains the RMIDs whose code a process is allowed to execute. That is, it can switch to the address space of the corresponding server class.

The other reference data structures mentioned in Figure 6.7 are organized in exactly the same way and therefore need not be spelled out explicitly. The transaction control block and the data structures that go with it are introduced in Chapter 11, Section 11.2.
When describing the algorithms for handling TRPCs, it will be convenient to have routines that access the control blocks declared above (such as RMCB, PCB) via their primary keys. Of course, these routines can be used only inside the components owning the respective control block. From the outside, the more restricted retrieval operations introduced at the beginning of this subsection are available.
The ancillary routines perform the following function: given the identifier of the object type, they return the pointer to the corresponding control block upon lookup, or they return the pointer to a newly allocated control block upon insert. The following prototype declaration illustrates this for the RMCB:

The operation is INSERT if a new control block is required for the given RMID, in which case there must be no existing entry with that RMID. The function returns the pointer to the control block that has been allocated for the new resource manager. If the operation is LOOKUP, the function returns the pointer to the control block belonging to the given RMID. In either case, the function returns NULL if something goes wrong. Note that access is defined via the RMID; one can easily imagine an equivalent function for accessing RMCB via RMNAME. Similar functions are assumed for the process and the session control block.
6.3.3 A Guided Tour Along the TRPC Path
This subsection takes you through a complete TRPC thread. We start at the moment the TRPC is issued by some resource manager, follow it through the TRPC stub, see how control is transferred to the callee, and then, upon return, trace the way back to the caller. To avoid unnecessary repetition, we will divide the path into a number of steps:
Local call processing. This is what happens in the caller’s TRPC stub to find out what kind of call is being made, where it is directed, and so on.
Preparing outgoing calls. In case the call is not local—that is, the server invoked runs in a different node—the communication manager has to get involved to send the message off to the other side.
Incoming call processing. When a TRPC from another node has arrived, it must be prepared so that it can be passed on to a local process.
Call delivery. After the recipient of a TRPC (be it local or remote) has been determined, it must be invoked at the proper address.
Call return. This can be described as one step, because the return path is completely set up during the call phase, no matter if it is a local or a remote call.
Let us now describe each of these steps in some detail. To do so, we rely on a mixture of explanations in plain English and portions of C code, in a style similar to that used in Chapter 3. Note, though, that what looks like C code is often just pseudo-code in C syntax. Spelling out the complete code for transactional remote procedure calls, including process scheduling and the other services of a TP monitor, would require a separate, quite sizeable book. The reader is therefore cautioned not to take the code examples as something one would want to compile and run; rather, they are a slightly stricter way of writing explanations.
6.3.3.1 Local Call Processing
A TRPC comes from an application or resource manager running in some process. Whether it is the process’s own resource manager calling or not makes no difference at all. We assume the do-it-yourself format of the call introduced in Subsection 6.2.1, and now look at the corresponding entry in the TRPC stub. As pointed out repeatedly, this is part of each address space, so it is just a subroutine call to rmCall. This routine starts out checking what kind of request has been issued. It should be easy to get this information by following the (pseudo-) code for the first part of rmCall.


As can be seen, the stub code is mostly concerned with figuring out where to send the request. If the request is local, the stub code authorizes the client; the methods for that are presented in Section 6.5. It then decides whether it can hold on to the client’s process and just do a domain switch, or if it has to find another process that is authorized to execute the callee’s code. For the first case, we assume a procedure DomainSwitch that hides all the operating system-specific aspects involved. Finding a process is the task of the TP monitor’s scheduler. The considerations going into that decision are also described in Section 6.5. The scheduler comes up with one out of three possible decisions: first, if too much is going on locally, then send the request to another node, even though the service is locally available. Thus, we have to continue at the point where outgoing requests are handled, represented by the routine RemoteRMC. The second possible decision is to put the requesting process on a waiting queue in front of the resource manager to which the TRPC is going. This problem is discussed in Section 6.4. The third possibility is to pick an idle process and send the request to it; this is done using the routine SendIPC.
In the event the TRPC flows along a preestablished session, the TP monitor has only to forward the request to the other end point of the session, which is completely identified in the rmlnstance that serves as a handle for that session.
The problem of binding the resource manager name to a server class is slightly simplified in the program just given. Strictly speaking, a TRPC name consists of a tuple 〈resource manager name, entry name〉. Thus, name binding of a resource manager at one of its entry points requires the name resolution and address binding of both components of the tuple.
Binding an RMNAME to an RMID is done through the repository, which holds the information about each RMNAME in the (distributed) system as to where the service is available, and under which RMID. The TP monitor caches these binding data as far as possible; we will not discuss that in detail. If you look closely at the declarations of the RMCB and its related data structures, you will find that they are designed to cache binding information.
Binding the entry name is straightforward. It is assumed that a resource manager, at the moment it is installed by the TP monitor, declares all its service and callback entries. Since the TP monitor loads the code for the resource managers into the address spaces it has allocated for them, and since all processes in one server class have identical structures, the addresses of all the entries are known to the TP monitor. In some implementations of TP systems, the code of resource managers may have to be relocated in their address spaces at run time, but this complication is ignored here.
Figure 6.10 summarizes the name binding to be done by the TP monitor.
6.3.3.2 Preparing Outgoing Calls
If a request has to be sent to a distant node, the major work is done by the communication manager, which is responsible for setting up and maintaining the communication sessions among processes. First, the TRPC stub in the TP monitor formats the message to be sent; this is almost identical to what a standard RPC stub does, except for the TRID that is appended to the message. If the request goes along a predefined session, the handle provided by the communication manager is put in the message header as an indication for the communication manager to use that session. The handle is kept by the TP monitor in the SECB.

The communication manager takes the message and checks if it has seen this transaction going out on that session before. It does so by checking the entry UsedBy in the SECB. If this is the first time, it stores req_trid in UsedBy and calls the transaction manager to inform it that this transaction is leaving the node on an outgoing session. As will be seen in Chapter 11, the transaction manager needs to know this for two reasons: first, it must include the remote resource managers in the commit decision, and because it cannot invoke them directly, it must go through the communication manager. Second, the session itself needs to be transaction protected, so that the communication manager becomes another local participant in this transaction. (This is also discussed in Chapter 10.)
6.3.3.3 Incoming Call Processing
This description can be kept short. As a request arrives from the network, it is delivered to the communication manager first. The communication manager goes through a logic similar to that of the rmCall in the case of local call processing:
If the incoming request travels along a preestablished session, then there is already a process allocated to it. Actually, this process has been suspended in its TRPC stub while waiting for the next request via this session. Thus, all the communication manager has to do is unpack the message (the inverse of what has been described for the preparation of outgoing calls) and then wake up the other end of the session; this means routing the call to the “right” resource manager process.
If there is no preestablished session, a process must be scheduled to handle the request. The option of just switching address spaces must be ruled out in this case, because the communication manager wants to hold on to its process in order to be able to handle other incoming and outgoing messages. Therefore, the scheduler of the TP monitor has to find a process that can execute in the address space of the requested server class. The process control block is then set up just as for local call processing.
There is one situation that has not yet been considered: assume the request comes in and there is no session on the receiving side for it, but the requestor’s side sends a handle along, thus indicating that a session should be established (see the description of the rmBind function in Section 6.2). In this case, the communication manager has to go through its logic for establishing a session (authenticate the requestor, for example). After that is done, it has to create a new SECB for that session and have the TP monitor allocate a process for it, which is from then on bound to that session. Of course, the Bindld, which is the application-level identifier of the session, is passed on to the server so that it knows it is in session with the client.
In accord with the logic of outgoing calls, the communication manager calls the transaction manager to inform it about the arrival of a new transaction on a session from the network. This also has to do with commit processing, although the role of the local transaction manager is different than in the previous case.
6.3.3.4 Call Delivery
Assume that a domain switch has been performed. The process executing the TRPC now continues in the TRPC stub of the callee’s address space at the location where incoming calls from local processes are received. There is not much left to do before the resource manager can start working on the request. The first step is optional: the resource manager might want to do some additional authorization of the client’s request, which for security reasons has to be performed in its own protection domain rather than outside.
The second step is strictly related to the logic of transactional RPC. The TP monitor has to check if the resource manager has already checked in with the transaction manager for the current transaction. Sophisticated resource managers could do that themselves, but simple resource managers cannot, and so it is good idea to have the TP monitor do it for them. This is the logic (we assume the same variable names and declarations as in the discussion of local call processing):

The effects of Join_Work are described in Chapter 10. Note that in case the incoming request has no TRID—which is quite possible if it is a message from a dumb terminal—the TP monitor cannot check in the resource manager with the transaction manager. What will happen (most likely) is that the resource manager will call Begin_Work, and as a consequence of that, the transaction manager will automatically register the resource manager as a participant of that new transaction. Once all this is done, the resource manager can start unpacking the message and act on it.
6.3.3.5 Call Return
The logic of call return handling is essentially the same, no matter which way the TRPC went. There are slight variations, though, with respect to the clean-up work in the global data structures. A TRPC returning within the same process (coming back from a domain switch) is like a return from a subroutine call. The only thing the TP monitor has to do is restore the entries Runsln and ClientID in the process control block. A return from an outgoing call looks just like a return from a local call with a process switch involved, because the response message is first received by the communication manager, who sends it (via IPC) to the caller’s process. In either case, the caller’s process is suspended in the TRPC stub, waiting to be woken up again with a response message.
We can restrict the description to the case of a local return from a TRPC handled by another process. The administrative work on the TP monitor’s part consists of two things: first, the process control block of the returning process must be reset; second, requests must be checked to see if there are any waiting in front of the resource manager that just completed, so that the process can immediately be scheduled for one of them. This is the logic:

If no unserviced requests are waiting, the process enters the wait state by invoking an operating system service called “wait,” which is described in Chapter 8. For convenience, our code here is written as though it were executed in the process of the original caller, which it is not. Given all the previous arguments, the reader should be able to figure out which process actually activates the process waiting in the resource manager’s request queue.
6.3.4 Aborts Racing TRPCs
The discussion in Section 6.2 was simplified in a number of respects; two aspects omitted from the earlier discussion are at least mentioned here. First, the code examples were written like simple sequential programs, which they absolutely are not. Remember that TRPC processing takes place in the TRPC stub, which is in everybody’s address space and thus gets executed in parallel by many processes—potentially on a number of processors. To allow for that, all the central control blocks must be protected by special functions called semaphores, depicted by flags in Figure 6.7. The details are described later in this book; for the moment, it should be sufficient to assume that there is a mechanism providing the required level of coordination among the processes.
The next problem is more subtle. When describing the flow of control, we have assumed that at any point in time only one process could be working on any given transaction. Because we have ruled out intratransaction parallelism, this seems to be a reasonable assumption. However, it is not quite that simple. In a distributed transaction, no matter which node is currently handling a request for that transaction, an unsolicited abort message from another node can arrive at any instant. Without control, this could cause two processes at the same node to start working concurrently on behalf of the same transaction, resulting in major inconsistencies.
Without referring to technical detail that has not yet been established, let us sketch the problem in very simple terms. Assume a process A is working for transaction T, updating some objects, generating log records, and so on. An abort message arrives because a remote site, which was also involved in T, has crashed and restarted again, and it tells all affected nodes to abort T. If a process B were allowed to run in parallel to process A (on the same node), trying to do the rollback work for T, then the following situation could occur.
Process B works its way back through the log to undo what was done on behalf of T, while process A keeps adding records to the log, which process B will never see. At some point B declares victory—rollback complete—while in fact the object is now in a thoroughly inconsistent state. Therefore, the TP monitor enforces a simple protocol:
(1) Whenever a process runs under a TRID, that process protects the control blocks it uses, preventing all other processes from using and, in particular, from updating them. Of course, the transaction manager protects its control blocks, too.
(2) Whenever the TP monitor tries to handle a resource manager invocation for a transaction and finds the transaction busy, it immediately rejects the call, unless it is an abort call.
(3) An abort call checks if the abort is already under way; if so, the call can be rejected without consequences.
(4) If no abort is under way, it might still be the case that a process is doing normal (forward) work for the transaction. The TP monitor checks this with its central control blocks. If a process is working for that transaction, the TP monitor waits for the call to return. Then the TP monitor blocks all the control blocks pertaining to that transaction and thus makes sure that the rollback of T will be executed without interruptions at this node.
This protocol is transparent to both clients and servers.5 It is the TP monitor that reserves the control blocks before invoking the requested resource manager entry. The TP monitor frees them when the transaction is completed and the resource manager is no longer involved. In the case of abort handling, this requires some cooperation between the TP monitor and the transaction manager.
If the description of the abort racing problem sounded a bit difficult, it is. A detailed analysis of all the options there are would take up too much space. Thus, this complication is only mentioned; it is typical of a transactional remote procedure call, as opposed to standard RPC.
6.3.5 Summary
This section started out with a digest description of standard RPC mechanisms. It then proceeded to transactional remote procedure calls, focusing on what makes them different from the standard ones. The key difference is that TRPCs are not just one-time interactions between clients and servers, but that each invocation is automatically bound into the control sphere of an ongoing transaction. Some examples have pointed out that even simple programs that do not know anything about transactions are given the ACID treatment when invoked in a TRPC environment. Programs actively using the features provided by transactional remote procedure calls are called resource managers. They have to interact with their environment in a well-defined manner, which is specified as the resource manager interface. The major components of this interface have been introduced via examples.
We then proceeded to describe how the TP monitor implements TRPCs. First, the required global process and address space structure were laid out, and then the central data structures needed by the TP monitor were explained in detail. Finally, we took a tour along a TRPC through the TP monitor stub and the communications manager, to investigate what exactly needs to be done for mapping TRPCs onto processes. To recap the major steps: bind the name of the requested service to a server class, local or remote. If it is remote, prepare a message to be sent and hand it to the communication manager. The communication manager will check with the transaction manager to register the fact that a transaction leaves the node to continue execution elsewhere. If the call is local, a process must be allocated for handling the request. Upon return, the basic work consists in freeing resources that had been allocated to the TRPC. Some of the tasks along the way, like scheduling and authorization, have only been mentioned for the moment; they are discussed in the upcoming sections.
6.4 Managing Request and Response Queues
A look back at Figure 5.3 shows that there are two ways transactional requests can get into (and out of) the TP system. One is the “fast lane”: requests are immediately authorized, dispatched, and executed, and responses are returned to the client without delay. This mode of operation is called direct transactions and is typically used for interactive processing. The other mode is asynchronous and involves the system queueing requests over potentially longer periods of time. So far, we have considered only direct transactions.
As mentioned in Chapter 5, queueing is used in transaction processing systems for a variety of reasons. Let us briefly recapitulate them to see which properties an implementation of transactional queueing services must have in order to meet these requirements. These are the main applications of queues:
Load control. If there is a temporary peak in the request rate for a resource manager, it might not be a good idea to react by creating additional processes. If the load can be expected to return to normal quickly, it might be more economical to put the requests into a temporary queue in front of the server class rather than flood the system with new processes, which will rarely be used later on. Note that this type of queue is used during direct transaction processing (it was actually mentioned in the pseudo-code example) and is kept entirely in volatile storage.
End-user control. Responses from transaction programs usually involve messages to be displayed to the user, either as text or pictures on the screen, as a ticket that gets printed, as money from a teller machine, or for whatever purpose you can name. Since this always is a real action of some sort, it is critical for the end points of the system to be in accord with the central resource managers with respect to which steps were completed and which were not. At first glance, there does not seem to be a problem, because the two-phase commit protocol is designed to take care of that, and one of our key prognoses was that in real transaction processing systems all terminals will be intelligent enough to run that protocol. With asynchronous processing, however, the system transaction updating the database may have completed successfully, whereas the subsequent output transaction presenting the result to the user was rolled back because of a system crash or simply because the user had switched off his workstation. Thus, there is a need for maintaining the output of asynchronous transactions for redelivery as long as the user has not explicitly acknowledged its receipt.
Recoverable data entry. There are applications that are essentially driven by data entry. Data are fed into the system at a high rate, and each record is the input to a transaction that does consistency checking and takes further actions. However, there is no feedback to the data source. Such systems can be configured for high throughput rather than short response times. This is to say, the input data are put on a queue from which the server running the application takes them as fast as it can. The key point here is not to lose any input data, even if the system crashes before they get processed.
Multi-transaction requests. The discussion in Chapter 4 made the point that under the flat transaction ACID paradigm, typical TP systems offer no control beyond transaction boundaries. Because this is insufficient for many applications, the TP monitor generally provides some additional support. Consider the example mentioned in the previous paragraph. The idea is to collect the input data at some point and make them recoverable. Then they are processed by some server S1, which passes results on to another server 52 for further processing. This can go on for an arbitrary number of steps. As long as none of the steps interacts with a user, they can all be executed asynchronously; that is, scheduled for high throughput. Some final step is then likely to present something to the outside world. Explicitly programming all this chaining of processing steps in the application would be unacceptably complicated. Lacking more general transaction models, there is a way of achieving the desired effect, at least with respect to the control flow: by employing queues. The idea is illustrated in Figure 6.11.
It is obvious from this list of requirements that two types of queues are needed: first, volatile queues must be provided to support the management of server classes for direct transactions. Second, durable (recoverable) queues must be supported for handling asynchronous transaction processing. Let us first briefly consider the implementation of volatile queues as part of the server class scheduler; there is really not much to say about this. After that, the techniques for providing durable queues are described in some detail.
6.4.1 Short-Term Queues for Mapping Resource Manager Invocations
The need for a short-term queueing mechanism was illustrated by the pseudo-code example in Section 6.3, which describes the handling of generic resource manager calls. There is one situation in which these queues are needed: a server class has been installed with P processes, and at some point the number of concurrent requests for that server class exceeds P. If the TP monitor decides not to initiate more processes (and if the service is not available at remote nodes), then there are two possibilities:
(1) Let the client decide what to do. That means the TP monitor rejects the call with a return code indicating overload. The client process might decide to wait for some time and then reissue the call. This method offloads the problem of how to handle wait situations to the client, who is probably not prepared to cope with it and simply calls Rollback_Work. Even if the client were able to wait in its own process, this would not be a good solution because with the reject the request disappears from the TP monitor’s domain; that is, the TP monitor has no control of how much unfinished work is in the system. As a consequence, the TP monitor cannot use that information for making its scheduling decisions.
(2) The TP monitor keeps a dynamic request queue anchored at the control block for the server class. In that queue, the excessive requests are stored for dispatch at the next occasion. The next occasion arises whenever one of the processes in that server class completes its current request; that is why, upon return from a request, the temporary queue must be checked for any entries. Note that with this scheme, a resource manager invocation, which is a synchronous call from the client’s perspective, turns into queued processing that is typical of asynchronous request handling. But then, the same is true for the basic operating system, where processes are queued in front of processors and other physical resources. The underlying assumption is that waits are short enough to be tolerable, even in an interactive environment.
The basic implementation problem associated with this type of queue is illustrated in Figure 6.12.
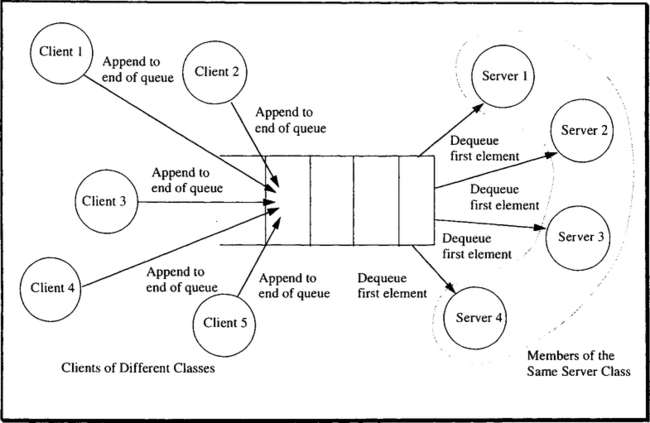
As can be seen from the declarations in Section 6.3, there is one anchor for a volatile request queue in each resource manager control block, that is, for each server class at each node. The queue itself is assumed to be maintained as a linked list of request control blocks. This is sufficient for strict FIFO processing (which we assume here); for other policies, including priorities, more sophisticated data structures would be required. The queueing aspects themselves are not particularly exciting: it is a single queue with multiple servers (processes of the server class), and each queue entry can be serviced by any of the processes. What makes things interesting, though, is the process configuration shown in Figure 6.6. Because there may be many processes in the server class, more than one of them might try to remove the same first element from the queue at the same time. An equivalent observation holds for the tail of the queue: more than one process may want to append a request to the queue at the same time. And, of course, in a queue with just one element, the first entry is also the last one, causing these processes to compete for access to the same control block. However, the following must be guaranteed:
(1) Each request must be taken from the queue and executed by a server exactly once.
(2) The structure of the queue must always be maintained correctly.
Chapter 8 presents methods to achieve the protection required for the moment, we will leave it at that.
It is important to understand the following point: although these server class-specific request queues contain transactional requests, there is no need to bind request queues strictly to the ACID paradigm. In other words, it is not necessary to keep the first element of such a queue reserved until it is clear whether the transaction having issued the request has committed or aborted. These queues can be accessed and modified by many transactions at the same time, the requirements just discussed notwithstanding. Given a system that supports multilevel transactions, each operation on a request queue would be a subtransaction.
6.4.2 Durable Request Queues for Asynchronous Transaction Processing
Durable queues are needed for a style of processing that, at first glance, seems to be quite different from online transaction processing. To make this point very clear, let us repeat the basic idea of queue-oriented processing: there is a transaction handling the client request; presentation services, some authentication, consistency checking, and so on, are part of that transaction. It eventually produces a request to a server, but this request is not passed to the server along a TRPC; rather, it is put onto a request queue in front of that server, and then the client transaction commits. The client process can then begin a new transaction that creates another request to the server, and so forth. Finally (in this example), the client will enter a wait state until the response from the server to the first of the client’s requests has arrived. Before considering that in more detail, let us switch to the server’s side.
In essence, the server sits there watching its work-to-do queue. Whenever there is an entry, it starts a transaction, picks an entry from the queue—according to FIFO, based on priorities, or whatever—processes the request, puts the response on a queue the client is watching, and then commits the server transaction. If there is more work in its input queue, the server does the same thing over again.
The client, as noted, enters a wait state if it is interested in the responses, and actually waits for an entry to appear in its response queue. As soon as that happens, it starts a transaction, takes the response from the queue, does whatever the response requires, and commits the transaction.
Note that for each request there are three transactions:
(1) The first transaction creates the request and enters it into the server’s input queue.
(2) The second transaction processes the request in the server and enters the result into the client’s response queue.
(3) The third transaction takes the response out of the client’s response queue and presents it to the user (or does whatever is required).
This style of processing called queued transaction processing (QTP), which is essentially the way IMS/DC structures its work, is illustrated in Figure 6.13. Given the fact that each resource manager can act as a server to the resource managers that invoke it, and as a client to those whose services it needs, the QTP model implies durable relationships between a resource manager and a number of queues. A resource manager can designate some queues as input queues—queues through which it is willing to accept requests. The minimum is one such queue, but the resource manager may decide to have different queues for different types of clients or for different types of services it provides. Accordingly, each resource manager has to relate to different output queues that receive its results. Again, there can be a standard output queue per server class, or the server can place its results into a queue that has been designated by the client. Note that the output queue from the perspective of one resource manager is the input queue from the viewpoint of the other.
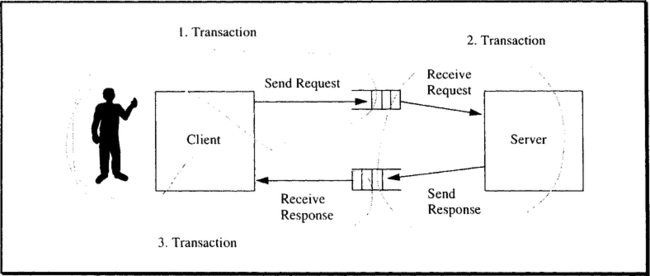
Queues, then, are distinguishable, stable objects that are manipulated through ACID transactions. They are, in fact, much like database relations. We will see later on that durable queues can be implemented as SQL relations, but we will also observe that there are good reasons for not making them part of the global database.
To understand what it means for a resource manager to have durable relationships to a queue, imagine the way direct transactions (those we have implicitly assumed so far) get executed. An activity starts at a terminal when a user hits a function key, selects a menu item, or enters his credit card. From then on, all requests flow through the system on TRPCs or sessions until the transaction commits and the final message is delivered to the user—provided the transaction commits. If it does not commit there is no final message, of course, thanks to the ACID properties. Now assume the transaction fails because of a system crash. If recovery takes a while, the user probably decides to come back later, when the system has recovered. He then wants to know what the last successful interaction with the system (the last committed transaction) was, because he has to pick up his work at that point. Using only transactions, this is a problem. The last successful transaction had gone through the two-phase commit protocol: the resource manager at the user’s workstation had voted Yes, because the user had seen the result, and then all participating resource managers had forgotten about the transaction. Subsequent aborted transactions have left no traces anyway. Asking for the last successful transaction, then, is asking for something that no longer exists; one would have to read the log to find the requested information. Yet fundamentally—in the transaction paradigm—the outcome of a transaction is a durable event, though no standard interface to the system exists to allow inquiries about that type of durable event.
6.4.2.1 The Client’s View of Queued Processing
Queues in the sense described here allow such questions to be asked. They maintain durable information about the association between different resource managers. Remember that in our “favorite” model of transaction systems, each end point (workstation) will be represented in the system by at least one resource manager that manages the local context and presentation services. Since each request, as well as each response, is recorded durably in a queue, there is a history of resource manager interactions that makes it possible to determine specifically what happened last between a certain client and its server. Put another way, if the client has crashed and later restarts, the client can go back to its response queue and check which response was last delivered to it before the crash. The behavior of such queue-oriented client-server interactions can be characterized by three properties.
Request-reply matching. The system guarantees that for each request there is a reply—even if all it says is that the request could not be processed.
ACID request handling. Each request is executed exactly once. Storing the response is part of the ACID transaction.
At-least-once response handling. The client is guaranteed to receive each response at least once. As explained previously, there are situations where it might be necessary to present a response repeatedly to the client. We will discuss shortly how the client must prepare itself for properly dealing with duplicate responses. The important thing about the at-least-once guarantee, though, is the fact that no responses will be lost.
Figure 6.14 shows the corresponding state diagram for the behavior of the client with respect to one request. The client has to be connected to the queueing system in order to issue requests. It then can switch back and forth between sending requests to servers and receiving responses from them. Finally, it can disconnect from the queueing system, but only after having received all responses it has asked for.
To achieve the guarantees just listed, a mechanism for relating requests to responses must be in place. The obvious way to determine which request corresponds to which response is to have a unique identifier for each request (RQID), supplied by the client, which is returned with the response. There is no need for these identifiers to be contiguous. The requests they are attached to are manipulated inside ACID transactions; consequently, there can be no holes due to lost messages or anything like that. For convenience, let us assume the TRID of the transaction issuing the request is used as the RQID.
6.4.2.2 The Client Interface to the Queueing System
With these preparations, we can now define the client’s interface to the queueing system of the TPOS. Each queue is identified in much the same way resource managers are identified; in fact, the queueing system can best be thought of as a special resource manager that handles request and response queues. Thus, each queue has a globally unique name and a locally unique queue identifier, which is reflected in the following declares:

Before describing the functions for connecting to the queueing system, let us consider the operations that can be invoked once connection has been established. For our simple processing model, three operations are sufficient:

Registering a client with a queue establishes a recoverable session between the client and the queue resource manager. This is another example of a stateful interaction between a client and a server. The queue resource manager remembers the RQIDs it has processed, and the client knows whether it can send a request to the server queue, or whether it has to wait for a response from its input queue. The session is recoverable in that after a crash of either side, it can be resumed with all state information reestablished as of the last successful transaction that updated the queue. The function prototypes for opening and closing a session with a queue are as follows:

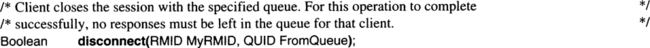
The key point is that a session between a client and a queue can only be closed if there are no responses that have not yet been received by the client. By calling disconnect, the client explicitly states that it has properly processed all replies and waives all rights of future inquiries into the state of that session. In case of a failure, however, the session is kept up by the system (or is recovered if the entire node fails), and the client has to call connect after restart. The client then gets back the state of the session as declared above. This state is characterized by the RQID of the last request entered in the queue and by the RQID of the last response received by the client (more precisely, the RQID of the request that triggered this response). Excluding special error conditions, there are two cases to consider:
LastSent = LastRcvd. The client has received the response to the last request it made. It now has to decide whether the response was processed completely—remember that part of the response handling might be a real action. If the response to the outside world is idempotent (such as a message displayed on a screen), then it can simply be repeated. If it is not idempotent, then the question is if the device the client talks to is testable, that is, if it can be queried about its current state. A ticket printer, for example, advances a counter that can be read from the client process each time a ticket is printed. If the client is about to respond to such a device, it reads the counter value, receives the response from the queue (passing the counter value in the parameter KeepThat), commits, and then prints the ticket. Upon restart, it gets the last value passed in KeepThat; if it is equal to the counter in the device, the response had not been processed before the crash, so printing must be done. Otherwise, the ticket has already been printed. If the response processing is not testable either, it is up to the application to put all the information required for a correct restart decision into KeepThat.
LastSent != LastRcvd. Response processing had been completed before the crash, and a subsequent request had been entered. The response to that request has not yet arrived, so all the client has to do is to enter the request sent state.
6.4.2.3 Implementation of the Queue Resource Manager
Queues have to maintain durable, transaction-protected state. As later chapters will show, it is hard to implement something like this with only a simple (non-transactional) file system underneath. A much simpler approach—and the one taken here—is to offload all the problems related to durable state to somebody else and just focus on the queue-specific aspects. In addition to greatly simplifying the discussion, that approach has the advantage of demonstrating the power of the resource manager architecture that is the leitmotif of this book. In order to turn a simple queue manager into a regular resource manager, we only have to support the resource manager interfaces described earlier and provide the callback entries for the various transaction-specific events. The SQL resource manager takes care of the durable storage, and the TPOS, with all its transaction-oriented services, makes sure that the interaction among all components involved comes out as an ACID transaction.
To keep things simple, assume that all queues are maintained in a single relation that has been created by the following statement:

It is assumed that the binding of quid to the corresponding quname is done in the repository. All the attributes have been discussed before, with three exceptions:
q_type. Describes the usage of this queue. ‘CS’ denotes a queue in which a client places requests to a server; ‘SC’ denotes a queue with responses from a server to a client; ‘SS’ denotes queues for work-in-progress in multi-transaction executions (see Figure 6.11).
no_dequeues. Counter for keeping track of how often a server has tried to process that request (explained later on).
delete_flag. Tags deleted queue elements. If it is NULL, this is an active entry; if it is ‘D,’ the element has already been used but is kept in the relation for restart purposes.
The sessions between “other” resource managers and the queue resource manager are stored in a separate relation that has the following schema:

The attribute role denotes whether the rmid participates in the session as a client or as a server.
The functions provided by the queue resource manager either establish sessions between a queue and a resource manager, or they act on entries of a single queue object; that is, on entries pertaining to one quid. This is important to note, because the client interface to the queue resource manager we have described permits referencing more than one queue object per call; see the description of the send function earlier in this section.
The first function is the send which appends an entry to a specified queue. Here is the implementation:

At first glance, one might wonder why the insert pays no attention to any queueing discipline; in particular, there are no provisions for making sure that the new entry is appended at the end of the queue. That is because of the decision to use relations as the implementation vehicle for the queues. Tuples in relations have no system-maintained order whatsoever. If the user wants them ordered, he has to specify a sort order based on the attributes in the relation when retrieving them. In other words, the effective queueing discipline depends on how the tuples are selected when deciding which one to remove from the queue. This is part of the second operation provided by the queue resource manager, the receive function.


These are the two service interfaces of the queue resource manager. It calls the database manager using embedded SQL but so far makes no references to other (system) resource managers. What about its callback entries for transaction handling? Some careful thought to this matter shows that there is actually nothing to do. For example, at startup the queue manager has neither control blocks to initialize nor anything else like that. Its callback entry therefore looks like this:
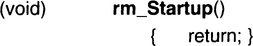
The queue resource manager’s logic during commit processing is not sophisticated, either; whenever it is asked about the outcome of a transaction, it votes Yes:

The other callback entries look exactly the same. Neither has the queue manager any updates to undo (SQL does that), nor is there any savepoint state to write to the log, and so on. Joining the queue manager to a transaction is done automatically by the TP monitor, as described previously.
The result of these considerations, then, is that the code for the transactional queue resource manager is strikingly simple. There is really nothing else to do. And although it looks like a straightforward sequential program, the queue resource manager runs in a multiuser environment and maintains its objects under the protection of ACID transactions. This little example shows that writing resource managers in a transaction processing system is simple—provided they do not keep their own state. Keep this in mind as a general rule for dealing with such systems: whenever possible, have a transactional database system that is able to act as a resource manager to take care of your data; don’t mess around with files.
Of course, this is not a comprehensive implementation of a queue resource manager. The coding is not defensive at all, and except for the functions to establish a session between a resource manager and a queue, further administrative functions are required for a complete queueing system. For example, there must be a way for the client to retract requests it no longer wants to be executed, or requests that have turned out to be invalid for other reasons (see Subsection 6.4.2.4). However, adding all this would not change the basic simplicity of the queue resource manager; it would only be more of the same.
6.4.2.4 Some Details of Implementing Transactional Queues
Two interesting details about transactional queues can be observed in the code for the dequeue function. The cryptic remark in our program about “some isolation clauses” refers to the same problem that has already been discussed for the volatile queues: since many server processes can operate on the same queue concurrently, they must protect themselves against each other. For the in-memory queues maintained by the TP monitor, critical sections are the appropriate solution. Durable queues implemented as SQL relations require a slightly different approach.
As we will see in the next two chapters, SQL database systems have a whole set of mechanisms for coordinating the operations of concurrent transactions on shared data. Without using concepts that have not yet been introduced, let us briefly consider the queue-specific problems. Dequeueing an element from a queue is part of a transaction; that is, if the transaction fails, the element must remain in the queue. Now if some transaction Ta has dequeued the first element E1 no other transaction can take it (exactly-once semantics). On the other hand, E1 is still the “first element”—the one with the lowest RQID. Thus, each concurrent access asking for the first element will be directed to E1. And, of course, one cannot say it is no longer there; if Ta aborts, E1 will remain in the queue as the first element. The only solution preserving FIFO processing in a strict sense would require all other transactions to wait until the fate of Ta is known. If Ta commits, then there is a new “first element”; if it aborts, another transaction will pick up E1. This, however, is not acceptable from a performance perspective. The following, then, is what the SQL clause not spelled out in the code example says: scan the tuples in the selected queue in their RQID order, but if you find one that is currently being worked on by another transaction, skip it and try the next tuple.
The second remark has to do with a fairly subtle detail of queued transaction processing. If something goes wrong in a direct transaction, the transaction is rolled back, and the user can decide how to react to that. With queued transactions, the first step consists of putting the request into a server queue. Now assume the request is invalid in some way, causing the server transaction to abort. What will happen?
A server process receives the faulty request as part of its processing transaction and sooner or later has to invoke Rollback_Work. As a result, the request reappears in the queue, only to be picked up by the next server process, which also aborts its transaction, and so forth. Given a thoroughly corrupted request, this could go on forever. It is therefore a good idea to have a counter that contains the number of rollbacks caused by the request associated with each queue entry—this is what the attribute no_dequeues is there for. It is set to zero when the tuple is stored, and the plan is to increase it by one each time a transaction having received this entry aborts. The question, though, is how to do that. It basically requires that an aborting transaction produce a durable update—which, by definition, it can’t. There are three obvious approaches to solving this problem:
No aborts. One could rule out the use of transaction abort for the server, forcing it to masquerade all failed transactions as successful ones. In this scenario, if something goes wrong, the server calls rollback to savepoint 1, which is the state of the transaction right after executing Begin_Work. It then updates the tuple in the sys_queues relation, setting the delete_flag back to NULL and increasing no_dequeues. After that, it calls Commit_Work.
Unprotected updates. If the update of the queue entry increasing the attribute no_dequeues is made an unprotected action, then it is not affected by the server transaction’s rollback. If the queue resource manager were implemented on top of the basic file system, this would be an option. However, because we have chosen SQL as the implementation vehicle for queues, there is no such thing as an unprotected SQL operation.
Nested top-level transaction. One can try to employ the idea that was used for the Bartlett server in Chapter 5; that is, the updates that have to be detached from the scope of a rollback operation are wrapped into a separate top-level transaction. In contrast to the quotation server, this must happen only in case the server transaction aborts; thus, the logic goes into the routine associated with the rm_Abort callback entry. This is illustrated in the following piece of code:

Readers familiar with the problems of executing concurrent transactions on shared data may point out that the above solution does not work for the following reason: the new transaction tries to modify a tuple that has also been modified by the old transaction. When that happens, the old transaction is not completely over—the transactions manager is just going through the abort sequence—meaning that the old transaction still protects this tuple from other transactions. The queue manager, on the other hand, starts a new transaction to update the tuple. If the old transaction still holds on to it, the new transaction will wait for that transaction to finish. Given the logic, though, the old transaction will not finish before the new one has updated the tuple; in other words, nothing moves.
Those who came to that assessment are fundamentally right, but not entirely. Note that the piece of code for the nested top-level transaction is not part of the “mainline” implementation of the queue manager’s services; rather, it is part of a callback that gets invoked by the transaction manager at a well-defined point in time, namely at the end of the abort phase, after all undo work has been done. Chapters 10 and 11 explain that the order in which the resource managers participating in a transaction are invoked during commit (or during abort, for that matter) can be specified according to their particular needs. If in our example the queue resource manager is invoked at its rm_Abort entry after the database system, then the logic described works correctly.
6.4.3 Summary
Queues are needed for scheduling transactional processing requests in an asynchronous fashion. The reasons for that are twofold: in direct online transaction processing, temporary system overload can cause requests for certain resource managers to wait in front of the corresponding server class. These queues are volatile. The TP monitor maintains them as temporary control blocks in its pool of shared data structures. The second type of queues is used for queued transaction processing, which by its very nature is asynchronous. Requests, rather than being expedited directly from the requestor to the server via TRPC, are forwarded through durable request queues. Adding entries to such a queue is part of one transaction; taking an entry out is part of another one. Request and response queueing helps in a number of situations, such as coupling a non-transactional end-user environment to the transaction system and implementing multi-transactional activities.
In this section, only one type of queue was implicitly assumed, the so-called ASAP queues. As the name suggests, the entries in such a queue are supposed to be processed as soon as possible. TP monitors support other types of queued processing policies as well. Batch applications are known to run for a long time, consuming many resources; thus, they should be scheduled at times with low system utilization, such as during the night. Requests for such applications are put into timed queues, which will not be activated before a prespecified time. A third type of queue is called threshold queue; such queues are not activated unless a prespecified number of requests is in them. This is useful for applications that require resources that are not normally kept available and are expensive to set up, such as parts of tertiary storage or a communication session to a remote node. If a number of requests all requiring these resources are batched together via a threshold queue, the expensive set-up can be amortized over all of them.
6.5 Other Tasks of the TP Monitor
The previous sections explained three major aspects of the transaction processing operating system, down to the level of coding examples: the resource manager interface, including the rules for constructing transactional resource managers; the notion of server classes, including the means for implementing transactional remote procedure calls; and the implementation of queues for queued transaction processing. Some other tasks of the TP monitor in particular have only been mentioned in passing, and there is not enough space to give them an equally detailed treatment. The purpose of this section is to give an overview of the techniques typically used by TP monitors to do load balancing, authentication and authorization, and restart processing.
6.5.1 Load Balancing
The load balancing problem is easy to describe and hard to solve. Given a set of requests (in case of direct transactions) or a request queue (in case of queued processing), how many processes should be given to that server class? When a request arrives at a server class, and all processes are busy handling requests, should a new process be created for the server class, or should the request wait for a process to become available? In the same situation, if the server class is distributed among several nodes, should the request be sent there rather than kept waiting locally? All this boils down to the question of how many virtual machines of which type should be maintained, and where.
Allocating processes to a server class has many problems in common with operating systems, with one big difference: from the perspective of the basic OS, processes are created by application programs or by scripts specified by the system administrator, and these processes are meant to exist for a long time. The operating system, then, only has to select among processes that are ready to execute. The TP monitor, in contrast, has to do scheduling on a per-request basis, and requests are very short compared to the lifetime of an OS process. Depending on the load, the TPOS has to either create processes, which will then request CPU time from the operating system, or kill other processes that are no longer needed.
6.5.1.1 Local Process Scheduling
The operating system bases its scheduling decisions on a small set of parameters, both static and dynamic, that describe the resource requirements of a process. These are the most important ones:
Priority of the process. The execution priority is set at process creation time and can later be modified through special system calls.
Working set size. This says how much real memory should be available at any given point in time for the process to run properly. That means a process never needs at one time all the code and all the data structures that have been loaded into it in memory. But the system should be able to keep the process’s working set 6 in real memory when the process is using the (real) processors. The size of the working set depends on what type of processes run in the system and what their response time characteristic should be—assuming that the processes run interactive programs. The working sets must be chosen such that the portion of memory used is not likely to change completely from one request to the next. Different portions of the same program can create different working set sizes for the process.
Completion time constraints. This says that the request must be processed by a certain time.
The TP monitor, operating at a higher level of abstraction, has more information than the BOS about the requestors and the resource requirements that come with a request. Whereas the operating system often treats processes as black boxes—that is, rather than looking at the program running in a process, it observes its behavior from the outside—the TP monitor knows which server classes it creates a process for. It also keeps statistics about that server class utilization. However, this wealth of additional information may as well lead to “paralysis by analysis.” Exploiting the performance characteristics for each single resource request is particularly infeasible, because it violates the requirement that each load balancing measure should save more resources than it consumes. As a consequence, there must be a mix of static decisions implemented at startup time and dynamic decisions that must be very fast, based on just a few parameters, mostly heuristic ones. Static decisions can be modified when system monitoring suggests that the overall behavior of the system is outside the specification. In most systems, dynamic scheduling relies on table lookups (and therefore is essentially predetermined by the static decision), along with a few rules of thumb. To get an impression of what those rules look like, consider the following list:
(1) If the service is available in the same address space where the request originates, just keep the process and the address space. This is the case of different resource managers being linked together; a resource manager invocation is little other than a branch in the address space, with some moderation by the TRPC facility along the way. The TP monitor might, for example, change the process priority before actually branching to the destination resource manager (see the discussion of priority inversion in Chapter 2, Section 2.4).
(2) If the service is available in a different address space, the current process can bind to, or keep, the process. Otherwise, the aspects are the same as in the first case.
(3) If the service is not locally available, pick a node where it is (access to the name server) and send out the request via the communication manager. Now the request is that node’s problem.
(4) If the service is locally available (not cases 1 and 2), and there is an idle process providing that service, send the request to that process.
(5) If none of the cases holds, and the service is only locally available, decide on the basis of CPU and server class utilization whether or not to create a new process. If the service is also available at other nodes, see if there is a lightly loaded one, which can (presumably) provide fast response; else queue it.
6.5.1.2 Interdependencies of Local Server Loads
Entry 5 in the rules-of-thumb list is the nontrivial one; the others rely on the static load distribution being correct. If that should not be the case, a reconfiguration of the TP system’s process structure may be required. Let us forget about the remote nodes for a moment and just focus on the decision whether or not to expand the local part of a busy server class by one process.
This decision in essence determines where on the curve shown in Figure 2.13 the system will be for the next time interval. If there are more requests than processes, this indicates that higher throughput is required. Higher throughput, though, means higher response times—a situation that is tolerable only up to a certain level. Note that all performance requirements at the core read like this: provide maximum throughput, while keeping response times below t seconds in 90% of all transactions. This is, for example, the basis of the TPC benchmark definition.
Creating a new process moves the system to the right on the response-time curve; more processes mean more load on the CPU. No new process means the system stays on its curve, but the request waits in front of the server class. An intuitive reaction might suggest that it makes no difference whether the request waits in front of the CPU (having a new process) or in front of the server class. This, however, is a misleading intuition.
Consider a server class “database system” to which a sequence of requests of the same type are submitted. Each request is an instantiation of the same program, just with different parameters, and they all operate on shared data. By massive simplification, we reduce the whole system to one server with one queue. Let the arrival rate of requests7 be R and the service time T1. Then, assuming a simple M/M/l queue with an infinite number of requests coming in, the average service time per request is S1 = T1/(1 − T×R). Implicit in this formula is that only one database request is processed at a time. If we admit more than one process per server class (say, n), we would expect the system to behave like a single queue with n identical servers. However, two assumptions are required for this to hold true: (1) there is enough CPU for everybody, and (2) there is no interference on the data. Let us grant the unlimited CPU capacity for the moment; we still have to take into account the fact that transactions will get into conflict on the shared data. A model of this is sketched in Chapter 7, Section 7.11; for the present discussion, the following argument is sufficient. If there are n processes (n transactions accessing the database concurrently), the chances for an arbitrary transaction to be delayed by another transaction are proportional to n. The degree to which data sharing among transactions may cause conflicts, and thereby transaction wait situations, is measured by c. If the duration of the delay is assumed to be fixed,8 the original service time is increased by an amount that is proportional to n. Of course, each server now only gets 1/n of the total load.
This very simple model then yields the following estimate of the service time:
![]()
To give an idea of what that amounts to, Figure 6.15 shows a plot of Sn over n; T is set to 0.8 second, R is set to 0.9 requests per second, and c is 0.02. Note that this is not another version of Figure 2.13; here the abscissa is the number of server processes at a fixed arrival rate, whereas Figure 2.13 plots the response time over the arrival rate. The important aspect of this simple model is that CPU utilization has not been taken into account, and still there is a fairly narrow margin (given a response time threshold) within which the server class behaves properly.
Of course, a complete analysis cannot ignore CPU load as we have done here. When all processes allocated to a server class are busy and more are needed, then this not only shifts the system to the right on Figure 6.15, but it is also an indicator for a higher arrival rate, which increases R as well. A higher R affects the abstract server class as well as the physical resources (the CPU), so these effects are cumulative.
The point of this example is that request-based load balancing performed by the TP monitor must look at both the utilization of each server class and the utilization of the underlying physical resources. Just monitoring the physical resources, and basing all scheduling decisions on that, would not be sufficient. Consider the same scenario with the database server class, and assume that CPU utilization was the only criterion for the decision whether or not new processes should be admitted. Let the CPU utilization with 40 transactions running in parallel be 60%—not a very high value. As long as the utilization is below 85%, the system will allow new server processes to be created. With parallelism increasing, the service time per transaction goes up. More and more transactions actually wait for other transactions to finish, which reduces the load on the CPU. This allows more processes to be created, which further increases the service time—this is a version of thrashing, a phenomenon better known from virtual memory management.9 The transition from normal system behavior to thrashing, which is always caused by making scheduling decisions with insufficient information, is shown in Figure 6.16.
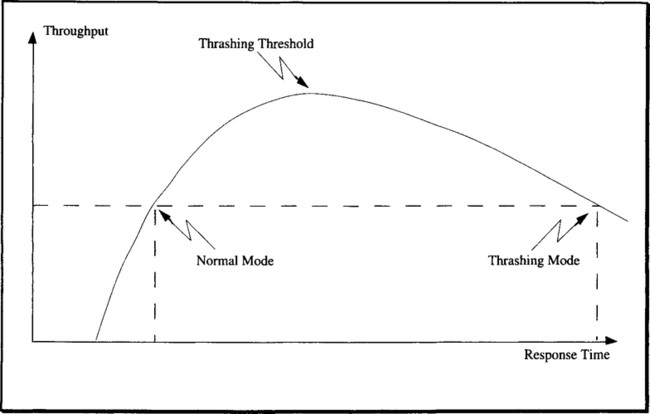
The consequence of all this can be put as follows: the TP monitor has to monitor the utilization of all server classes, as well as the utilization of the CPU(s) and perhaps other physical resources, such as communication busses and disks. For its dynamic scheduling, it then needs heuristics, which specify the minimum and maximum number of processes per class, depending on the utilization. That requires careful a priori analysis of the system load. For example, the degree of interference of transactions on data must be determined (parameter c in our model); this task is performed by the system administrator. Fully adaptive systems that, without prior knowledge, automatically achieve optimal balance with respect to a specified set of performance criteria, do not currently exist, and they probably will not for a long time.
6.5.1.3 Scheduling Across Node Boundaries
In distributed systems, where nodes do not share memory but are connected via a high-bandwidth, low-latency communication channel (a fast bus or a switch), scheduling a request at a remote node is not significantly slower than scheduling it locally—especially, if the local CPU is highly loaded. Let Tc be the communication overhead for sending the request to a remote node and for sending the response back. The scheduling decision then has to be based on the following considerations:
(1) What is the expected local response time Sl, based on CPU utilization and server class utilization?
(2) What is the expected response time Sr at the remote server, given the utilization of its resources?
(3) What is the expected Tc, based on the utilization of the communication medium?
If any remote node can be found such that Sr + Tc < Sl, then the request should be executed at that node, rather than locally. To make these estimates, the TP monitor has to keep track of the performance figures of remote servers as well as local ones. These figures do not have to be kept current to the millisecond; the principle of locality is applicable to load balancing, too, and thus states that load patterns change gradually. TP monitors supervising parts of the same server classes need to be in session with each other anyway, and one type of message that is exchanged via such sessions is a periodic sample of the utilizations, response time, and so on, of the local resources at the participating nodes. Note that the scheduling decision need not actually be made according to the response time estimates we have given. As long as the utilization samples show that all nodes are running within the prespecified load limits, each node can schedule requests to all nodes that provide that service using a round-robin scheme. Given stability of load conditions, this is cheap to implement and is a good heuristic for keeping the load evenly distributed.
Simple as that seems, this approach to global scheduling has two problems that may go unnoticed and result in high overhead as well as (potentially) poor overall performance. One is frequently referred to as control block death, and the other has to do with data affinity.
Control block death becomes a problem as the number of nodes and the number of processes per node increase. This is likely to happen in large systems. Assume two server classes, A and B. If there are N nodes in the system and each node has Ia processes for A and Ib processes for B, then—according to our current scheduling model—each instance of A could send its request to any instance of B. If these requests are not context-free, the instances must bind to each other: a session has to be established. Now each session requires a control block describing its end points, the context that is associated with it, and other administrative details. If the assumed configuration operates in that mode for a while, each instance of A eventually will be in session with each instance of B, yielding c = (NIa)(NIb) = N 2IaIb control blocks. As N gets large, there will be a point where the number of control blocks growing quadratically will get too large—this is control block death.
The problem of data affinity can best be described by referring to Figure 6.17. There is a database, which is partitioned across two nodes, 1 and 2. Node 1 is currently heavily loaded; node 2 has little to do. A request from a terminal attached to node 1 is routed to node 2, using the global balancing strategy already described.
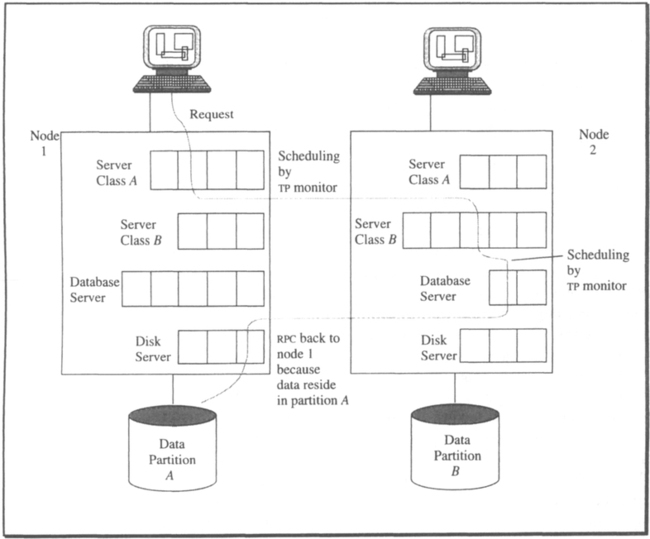
The service effectively invoked at node 2 needs access to the database, and the TP monitor makes sure that this resource manager invocation is kept local. It turns out, though, that the data to be accessed are in partition A, so the actual data manipulation has to be requested from node 1 via RPC, adding further to its high load. The problem is that the TP monitor at node 1 could not foresee the service requests done by server class 2. And even if it had that information, the need to access data partition A may depend on parameter values in the request. But let us go even further and assume the TP monitor understood these data fields. The best thing it could do would be to keep the request for server class 2 local to node 1; this would improve things just marginally, because node 1 had too high a load to start with.
If the high load results from frequent requests to data partition A (which is frequently observed), the dynamic load balancing cannot help. A static balancing measure has to redistribute the data across the nodes such that each one gets about the same number of accesses. In current systems, such a load-sensitive data partitioning is often combined with application-specific routing; after all, the TP monitor does not understand the parameter fields. The application router knows the partitions and their value ranges and makes sure requests are routed to the node where the data are. Given the way the TP monitor works, this requires hiding the fact that the server classes are the same at each node; they only pretend to be different. Specifically, server class 2 at node 1 is announced as “server class 2 needing data from partition A,” while server class 2 at node 2 is “server class 2 needing data from partition B.”
6.5.2 Authentication and Authorization
The issue of authentication and authorization was touched upon in Chapter 2, in the discussion of the role of operating systems. The OS supports system security in the following areas:
User authentication. When a user is admitted to the system (given a userid), he is granted certain privileges on files, libraries, and system functions. These are specified by the system administrator, who is a trusted user with higher authority than other users. Upon admission, the user is given a secret (usually a password) by which he proves his identity to the system. From then on, the user can modify this secret in direct contact with the system, without administrative assistance. Whenever the user wants to establish a session with the system (logon), the operating system authenticates him by checking if he knows the secret. A userid that has been successfully authenticated is called an authorization ID (authid, for short). The two terms are used interchangeably here.
Session authentication. This is similar to user authentication, except that the “user” is mainly a process running on a different node. The process pretends to run under a certain authid; that is, it claims to have been authenticated by its local system, but the other end typically does not believe it. One could use the simple password mechanism, but having passwords flow across the network is not a good idea. The next possibility is challenge response, as described in Chapter 2, Section 2.4. It requires two rounds of messages (which may be piggybacked).
File access control. File security is normally protected by a two-dimensional access matrix that specifies which subject is allowed to do what on which object. A subject in the access matrix is either a userid, a group name (denoting a group of users), or a program in a library. An object is either a file, a group of files (a sub-tree in a hierarchical directory), or a program. The operations are the usual operations on files and programs: create, delete, read, write, link, load, and execute. In a typical situation, a user A is not allowed any access to file X but is allowed to run program P, which in turn reads and writes file X. This ensures that the user can get to the file only through controlled channels—in that case, via the program that manipulates it.
Memory access control. In systems supporting protection rings, the operating system, with support from the hardware, ensures that boundaries between protection domains are crossed properly. That is, one can get from a lower authority domain to a higher authority domain only through special instructions or operating system calls. Higher authority domains may address or branch directly into lower authority domains. The same holds for switching address spaces while holding on to the same process.
The first of the two entries on our list describe authentication services (checking the identity of a subject); the last two entries are concerned with authorization (checking if an authenticated subject is allowed to do what it wants to do). A TP monitor has to perform all this checking for the TP system environment, and the question is whether it can just use the operating system services and leave it at that.
Judging from the current situation in that area, the answer has to be no. The reason is simple: the units for which the operating system has access control are large and long-lived: processes, sessions, and files. The TP monitor, on the other hand, handles small transactional requests, which hold on to a process only for a short time and access tuples or attribute values rather than files; they may, on the other hand, invoke services on many nodes. In other words, the TP monitor has to do authorization on a per-request basis, not on a session basis. Its authorization scheme can also be described by an access matrix, but one with more dimensions than the file protection matrix used by the operating system. In its general form, the problem can be stated thus: the TP monitor, upon each request for service S issued by a user with authid A, has to check whether

6.5.2.1 The Role of Authids in Transaction-Oriented Authorization
In a classical time-sharing environment, for which the operating system’s security mechanisms have been designed, the question of which userid an application runs under is trivial to answer. As the user logs on, he gets a process (or a number of them), which runs under his authid. Programs that are loaded into this process’s address space execute under the same authid, making it easy to decide on whose behalf a request (say, for accessing a file) is issued: it is the authid of the process the program runs in. This is also what makes such systems penetrable by Trojan horses. In a transaction processing system (or, more precisely, in each client-server system), the situation is a little more involved. To appreciate this, consider Figure 6.18.
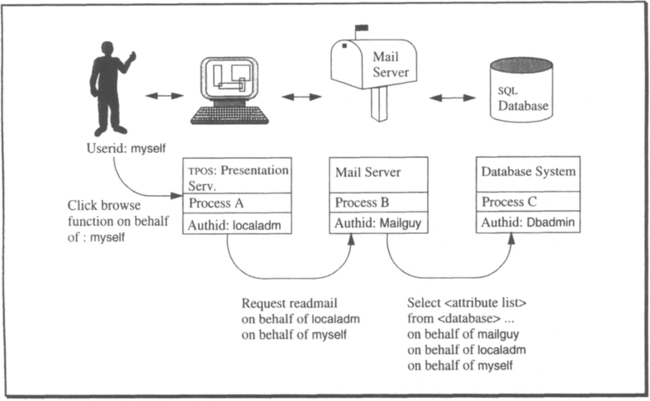
Figure 6.18 is an elaboration of the mail system application depicted in Figure 1.2. A mail system user at his workstation is logged in under userid myself. At some point, he decides to run the mail application, which executes within transaction system at his node. The application runs under the authid localadm. The local TPOS does exactly what is described in this chapter, namely, handling transactional RPCs, commit processing, and all the other services of the TPOS. On behalf of the user, it issues a call to the mail server node, where the mail system runs in a process under userid mailguy. The call arrives; from the mail server’s perspective, it is user localadm that is requesting service. As this continues, the mail server uses an SQL database system to implement its services. As far as the database is concerned, the arriving SQL select has been issued by user mailguy (the database is running under DBadmin). But as the figure points out, mailguy is, in fact, working on behalf of localadm, which in turn is working on behalf of myself. What should be the criteria for access control under these circumstances?
The simple solution of having each process along the way take on the user’s authid does not work. There are two reasons: first, in a distributed system, the userids cannot be expected to be known at all nodes. Second, the end user (myself, in this example) usually has fewer rights on shared resources like databases than the administrator of these services. Referring to Figure 6.18, authid DBadmin is well authorized to access the SQL database catalog, for example, whereas userid myself is not authorized to do so at all. In other words, running process C under myself (even if it were registered at the database node) would merely result in denial of access.
The other extreme is to collect all the authids along the way and specify access rights for these concatenations. This does not make sense either, because it is neither manageable nor even required. Request-based access control exercised by the TP monitor is usually based on a two-level scheme: it authorizes clients’ requests for the servers it invokes directly (for example, is the mail server running under mailguy allowed to issue requests to the SQL database server?), and it passes the transaction’s authid along with each request. This is the authid of the user who started the transaction and who eventually will receive the result. Thus, the basic idea is to authorize each invocation step individually and tell the server what the transaction’s authid is; that way, the server can decide, even if it accepts in principle the request from the client, whether it can provide the service to the client, given that it works on behalf of that user. This attitude is reflected in the message format declared in Subsection 6.3.3.
Note that this scheme with two authids has two effects; one is restrictive, the other one permissive. The restrictive effect is easy to see: from the perspective of the SQL database, the mail server can access all the tuples in the mail database, because that is how it implements its services. But it must be prevented, of course, from giving a user (like myself) tuples that do not belong to his mailbox. If the database knows the transaction’s userid, it can properly restrict mailguys access rights where necessary. As an example of the permissive effect, take the following: assume I want to use the mail system to send a file out of my private database to Jim. As usual, the mail system calls upon the database, and, yes, it can access its files, but mailguy has no access rights on my file. Knowing, though, that its actually myself calling, these rights can be granted temporarily.
Note that the TP monitor checks only the client’s authority to call the server; the second part, which uses the transaction authid, is left to the resource managers. All the TPOS does to help in that is to pass on the original authid. This reflects a simple separation of concerns: the TP monitor does not “own” the database, or the log, or the user files; the only resources it manages is the set of resource managers that run the database, maintain the log, and so on. Consequently, the TP monitor only controls access to the resource managers. Each server is left to protect its own resources, in turn.
As mentioned, authorization in TP systems is a multidimensional problem. In addition to controlling who is going to access what, restrictions can be applied on when a request can be made (certain services are made available only between, say, 9 and 5, or only on Fridays, or whatever), and on where requests are allowed to originate. For example, a user may have the right to execute a fund transfer application involving large amounts of money, but only from a special terminal in a particularly protected area. There are many more restrictions and regulations one could think of, but these are the criteria applied by normal TP monitors. Some of them allow an invocation-specific password to be checked. The access matrix is stored in a relation that is part of the local repository and, thus, is owned by the TPOS. Accesses to it require the invocation of TPOS functions—and, of course, these accesses have to be authorized in the access matrix. There is a simple recursion problem here, which is left to the reader to figure out. A sample declaration of the TP monitor access matrix looks like this:

6.5.2.2 When to Do Authentication and Authorization
The previous subsection dealt with authorization, and only from the perspective of which criteria go into the decision. Let us now put everything together and describe how the TP monitor controls access to its services from the moment the user logs on to the system until the last resource manager in the line is invoked. Refer back to Figure 6.17 as an illustration of the different steps.
We assume that the user at the workstation is interested only in transaction processing, so switching back and forth between a transactional and a non-transactional environment need not be considered. First, the user logs on to the TPOS; that is, a session is established between the TPOS and the user. The user can be either a human or a machine, such as an automated teller machine (ATM). Establishing the session requires authentication. Once this has happened, the TPOS considers the user working on that terminal as authenticated; that is, upon future function requests from the terminal, the TPOS performs no authentication. Thus, the possibility of the user physically changing in midsession is ruled out. As part of the logon handling, the TPOS loads the user’s security profile from the repository. The profile describes general capabilities of the user, which are independent of a specific resource manager invocation. The user’s password (or his public encryption key) is kept here, along with the expiration date of the password, which days of the week he is not allowed to use the system, and more things of this kind.
With this, the user has been accepted as a legal citizen; as before, his authid is myself. The TP monitor typically provides a selection menu that contains the names of applications (resource managers) the user is allowed to use. These can be all the services he is granted in the TP_access_matrix, or a restricted set of those services. The name of the entry menu is specified as part of the user profile. In case the user can run only one application (think of the ATM), the input menu of that application is displayed. Returning to Figure 6.17, the user invokes the application running in server class A. This requires the TP monitor to do a lookup in the privileges relation:

If there is no tuple, the user has no right to call the service. If there is one, the TP monitor must further check if there are date and time restrictions and if the user works on the right terminal.
It is too expensive to query an authorization database every time some client issues a resource manager call. This leads to the distinction of run-time authorization versus bind-time authorization. Assume a transactional application that needs to invoke a number of servers—for example, the mail server mentioned before. At some point, the TP monitor has to load the code for that application into a process’s address space. In doing so, it has to resolve all the external references, like any linker or loader does. Some of these external references go to the stubs provided by the TPOS to handle the TRPCs. If the application supplies constants for the names of the services, the TP monitor can check right away if the application program makes any nonauthorized calls. If no such calls are detected, then at run time there is no need to reauthorize all the resource manager calls coming out of that process.10 Strictly speaking, this is true only if the access condition does not contain time constraints or restrictions with respect to the terminal, because those can only be checked at run time. This leads us directly to the methods for run-time authorization.
There is nothing really new here. The process circles around, caching, as in the case of name binding. The TP monitor keeps an in-memory copy of authorized requests in a data structure that provides fast access via authid; see Section 6.3 for a discussion of how to access the TP monitor’s system control blocks. If the number of users per node is not too large, the whole TP_access_matrix might fit into main memory. To further speed things up, each process control block could have a tag saying whether any authentication is necessary for resource manager calls issued by that process—except for the value-dependent parts.
So far, this all takes place in one node. In the example of Figure 6.17, the next TRPC goes to an instance of server class B at node 2. What does that mean in terms of authentication and authorization?
From the perspective of the process running server class B, neither the process at node 1 issuing the call nor the user has been heard about. That would suggest authenticating them both before accepting the request. And, indeed, a truly paranoid system might do just that. However, in normal systems, one tries to exploit the knowledge about the way requests are sent and about the components involved.
According to the architecture outlined in this chapter, remote requests are sent via the session managers of the participating nodes. Because these session managers keep at least one session between the TPOSs on either side, they have authenticated each other and have no reason to question the identity of their peers. Each TPOS administers its local resource managers by creating processes and loading the code; this is something like a session, too. If a TPOS sends out a request saying it comes from resource manager A, its peer in the other node can accept this as enough support for A’s claimed identity. If the client TPOS has also authenticated the user, it can indicate this in the request message, suggesting that the server need not do so again. Both types of confirmation can be ignored by the server in favor of doing its own authentication.
Figures 6.17 and 6.18 illustrate that as soon as there is a chain of requestors/servers working on behalf of one user, the TP monitor provides step-by-step authentication rather than end-to-end authentication. The problem of achieving higher security without losing too much flexibility and performance is an area of active research.
6.5.3 Restart Processing
Restart processing by the TP monitor has been mentioned so often that there is not much left to say. After a crash, the basic operating system first bootstraps itself back into existence. For simplicity, we assume that the log comes up very early with the operating system. This is not as bold an assumption as may appear. First, the log cannot rely on any transactional services for its recovery (see Chapter 9), because it is instrumental in giving ACID properties to other components; this is where the recursion halts. Moreover, the operating system might want to protect its file system and catalogs by something like system transactions,11 which also require the log to come up early. By the log we mean the one special log that is dear to the heart of the transaction manager; it stores the commit/abort outcome of the active transactions. There may be many other logs entertained by various resource managers, but they can wait to be brought up later.
As usual, the operating system performs its restart according to a startup script that specifies which processes must be created, which programs loaded, which lines opened. As part of this script, the TPOS is brought up. That means a process is fired up with the code of the complete TPOS in it. This process is given control at the rm_Startup entry point. It then performs the following steps:
(1) Format all the system control blocks needed for managing the resource managers (See Section 6.3).
(2) Load the descriptions of all resource managers registered at that node into RMTable. Mark the log as up, and enter its processes into PRTable. From now on, all steps taken by the TP monitor to restart the TP system are guided by a TPOS startup script that is similar in function to the one used by the basic operating system for its restart.
(3) For each active resource manager, start the prespecified number of processes for that server class and load the code. If the resource manager provides an explicit rm_Startup entry, mark it as down in RMTable; the others are marked as up right away. Update the PRTable according to the processes created.
(4) Call the the transaction manager at its rm_Startup entry. It opens the log, tries to find its own most recent log entries, and reestablishes its TM_Anchor. It reads the log to determine the transactions that were active at the time of the crash, as well as the resource managers involved, and formats the TATable accordingly. After this, it is ready for business again. If the transaction manager does not respond to the TP monitor, it will crash the TPOS and try restart all over again. If that fails repeatedly, panic.
(5) Call the communications manager at its rm_Startup entry. The communications manager opens its connections to the other nodes. It then calls Identify (see Section 6.2) to tell the transaction manager it is back. In response to that, the transaction manager starts feeding all relevant log records to the communications manager in order for it to recover its sessions. Once all transactional sessions have been reestablished,12 the communications manager is also ready for business again.
With this last step, all major components of the TPOS are back. The rest of restart handling consists of bringing up all the resource managers at that node and orchestrating their recovery. Let us illustrate this procedure by looking at one arbitrary resource manager, R; the next steps are illustrated in Figure 6.19.
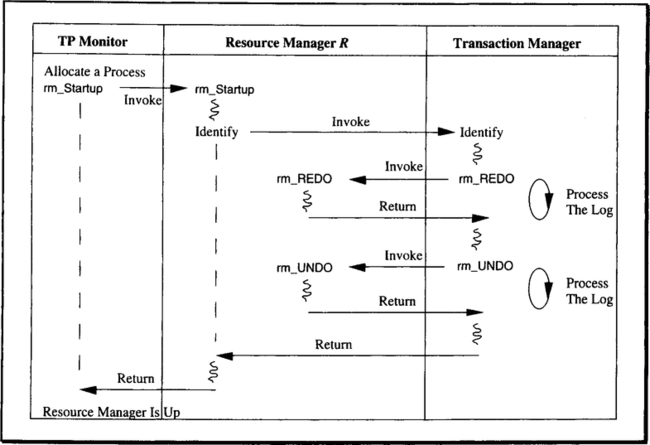
(6) Resource managers are brought up according to the sequence prescribed in the startup script. This is necessary to make sure that services required for the restart of other resource managers are in place before they are brought up. Thus, if R needs the database for its own restart, the database must be operational before R can be restarted. Remember that these dependencies can be declared as part of the registration with the TP monitor.
(7) Assume R can be brought up. The TP monitor picks a process for that server class and activates it at the rm_Startup entry point. The resource manager then does whatever is needed for its own initialization and eventually calls the Identify function of the transaction manager. The transaction manager takes this as the signal to start recovery for R. It starts by feeding the log records for REDO purposes (checkpoint and REDO records) to the resource manager through its rm_REDO callback entry. Note that this phase is executed single-threaded; that is, the TP monitor needs to allocate only one process for it.
(8) After the REDO phase is completed, the UNDO phase starts. When the TP monitor gets to see the first TRPC to the rm_UNDO entry of R, it checks its entry in the RMTable to see if the resource manager can be declared up; that is, if the remaining recovery can proceed in parallel to normal system operation. The TP monitor also has to make provisions for doing the UNDO recovery in parallel. It has been established by now which transactions R was involved in; the corresponding control blocks have been established. All the TP monitor needs to do is assign one process for each transaction R needs to UNDO; from then on, UNDO can run in parallel. It works the same way REDO recovery does: the transaction manager feeds the UNDO records to the resource manager through the rm_UNDO callback interface. After that is done, it returns from the Identify call, which in turn makes the resource manager return from the rm_Startup call to the TP monitor. Then, at last, R can be declared up again. There is an interesting aside: If UNDO is done in parallel, then the TP monitor has called rm_Startup for R out of one process, and R returns from it in many processes. The reader should be satisfied that this does not create any difficulties.
(9) When the last resource manager has gone through UNDO for a transaction, the transaction can be removed from the TATable. This also holds in the case where a resource manager that has participated in some of the transactions fails to come up. It will be informed later on that the transactions have long been rolled back.
There is some additional work for the transaction manager in case of resource managers failing to restart; this is discussed in Chapter 11, Section 11.4.
6.6 Summary
This chapter has described the TP monitor from an implementation-oriented perspective. It becomes clear that the TP monitor is a resource manager that manages other resource managers and processor resources such as processes, threads, access rights, programs, and context. In that respect, the TP monitor is very much like an operating system, but there are important differences. For one thing, a conventional operating system allocates resources to requests on a long-term basis (a logon creates a session that can be expected to go on for minutes or hours), while a TP monitor has to allocate resources on a per-request basis. This leads to the second difference: all the administrative tasks an operating system carries each time a session is created (or opened) must be performed by the TP monitor upon each request. This applies to authentication, authorization, process allocation, and storage allocation. Not only is the rate of these tasks much higher in a transaction system, but doing these things on a per-request basis also introduces more dimensions to the decision space. This is illustrated in the complex authorization criteria a TP monitor has to apply. A third difference between operating systems and TP monitors has to do with consistency: a TP monitor must support all applications and resource managers upon restart after a crash; an operating system, on the other hand, typically takes care of its own system files (catalog, and so on) and lets everybody else do what they please.
The explanation of the implementation principles was organized into four major sections. First, the notion of transactional remote procedure call was specified. The key issue here is that all interactions in a transaction system are kept under transaction control, which applies both to the normal commit case and to an abnormal transaction termination (abort). To exercise this type of control, a well-defined resource manager interface is required, one that allows the transaction manager to communicate all transaction-related events to the applications and resource managers. Another special aspect of TRPCs is the notion of context. It allows stateful (context-sensitive) interactions among applications and resource managers (or clients and servers in general), with the guarantee of the context information being transaction protected as well.
The second part of the description dealt with the TP monitor’s control blocks and their relationships to the other system resource managers’ control blocks. Their use was illustrated in a detailed tour along a complete TRPC path, which included a discussion of remote invocation and the way sessions are included into the transaction web.
The third section dealt with queues, both volatile and durable. Volatile queues are a means to control the workload and to fend off peaks in the request rates for certain services. Without such queues, the TP monitor would have to reject requests, or a large number of processes would have to be created (in case of momentary request peaks). Durable queues support queued transaction processing and chained transactions. They are also a means for delivering response messages in a transaction-controlled manner; that is, these message can be given the “exactly-once” semantics, provided the application adheres to a certain protocol on these durable queues. The section also illustrated that implementing durable queues on an SQL database system is almost straightforward.
The fourth section briefly sketched the approaches to implementing further services of the TP monitor. One is load balancing. In a distributed system, the fundamental problem of dynamic load balancing is what to do with an incoming request for which there is no idle local process at the moment. One possibility is to put the request on a volatile queue. Another option is to create a new (local) process. The third possibility it to send the request to another node. It was shown that the TP monitor needs a rudimentary model of the resource manager’s behavior in order to make proper decisions. It is also necessary to monitor the load of all relevant system components.
Authentication and authorization were mostly described with respect to their requirements; implementation issues were not considered. It was demonstrated by means of a simple example that authorization in a distributed system with chains of resource manager calls can lead to fairly complicated problems in determining whether a certain resource manager A, acting on behalf of resource manager B, which is acting on behalf of resource manager C, and so on, is authorized to execute function f on resource X.
Finally, restart processing was explained in detail. We have seen which components of the system are brought up in which order, when the TP monitor takes over, in which way the resource managers are informed about the necessity of restart, and which protocol they have to adhere to in the event of restart.
6.7 Historical Notes
The “history” related to this chapter is almost exclusively product history. Because the term TP monitor is itself anything but well-defined, there is no established topic in computer science that would cover “TP monitor concepts and their implementation.” It is necessary to go and look at existing TP monitors, find out what they do and how they do it, and then try to conceptualize backwards from the specific to the general. Only in this way can we determine what makes a TP monitor different from an operating system, or a communications manager, or a forms manager.
Given this situation, it is difficult to say that concept X was first implemented in system S, because it is often the case that at the time system S was developed, the concepts had not been sorted out completely. And even if it is possible to trace in retrospect the origin of X back to S, it is usually mixed up with many other features and optimizations that reflect the particular constraints the implementors had to face. Remember that, until just recently, no TP system has been designed and implemented as such. Rather, such systems resulted from tying together other components that were already there. With these caveats in mind, let us look at the origins of the concepts that we have used for structuring this chapter, namely server class management (including process scheduling), queue management, and resource manager interfaces.
Process management is what all TP monitors started out doing. Batch-oriented operating systems on .5 mips machines would just crumble under the load of 100 terminals; thus the tele-processing monitors of the early days provided cheap processes (threads) inside an (expensive) OS process, handled screen forms, loaded the programs run in the threads, and so forth. CICS was designed to do that, as were Com-Plete, INTERCOMM, Shadow, and many others.
IMS/DC took a different approach by employing multiple OS processes and dispatching the requests among them. This results in a large number of (expensive) process switches—more than an acceptable number for transaction-oriented processing. As a consequence, the underlying operating system (MVS) was extended in order to allow for fast switches from one address space to another, while holding on to the same process. To do this efficiently, the S/370 architecture was augmented by several instructions for exchanging the process’s register sets, for branching into another address space, for moving data across address space boundaries, and the like—in a controlled fashion, one should add.
IMS also pioneered the use of transaction-protected queues for handling requests in a reliable fashion. IMS/DC still supports the scheme illustrated in Figure 6.13 as its only model of execution. There is another IMS, called IMS FastPath, which pioneered many ideas for high-performance transaction processing; many of them will be mentioned in chapters to come. One of them, called expedited message handling was a way of reliably processing requests without first having to explicitly queue them.
The description of queue management borrows heavily from Bernstein, Hsu, and Mann [1990], whose paper does a nice job of extracting the concepts from the many implementations of volatile and persistent queues in existing TP monitors. The earliest implementation of recoverable queues was in IMS/DC, which had queued transactions as the only type of processing it supported. Each request was put in a queue; a server would get a request from a queue and put its response into another queue, from whence it was finally delivered to its destination (terminal, printer, or whatever). Yet the extent to which queues should be exposed to the application in modern TP systems is still an open issue. Some people claim that queues are fine for scheduling and for recovering output messages, but that using them for implementing multi-transaction activities is awkward; it is said that such things should be handled by the transaction manager. Let us just say that this is still an area of active research.
The history of program management done by TP monitors is even fuzzier. Given their general “bypass the operating system” attitude (with the exception of ACMS, IMS/DC, Pathway and a few others), they did not use any of the standard linker/loader facilities. Rather, they maintained their own libraries for executables and did their own management of the portion of their address space that was to contain transaction program code. Without going into any detail, let us briefly summarize the reasons for implementing TP-specific program management (these issues are discussed at great length in Meyer-Wegener [1988]):
Memory. At the time these systems were developed, main memories tended to be small (less than 1 MB), yet the number of different transaction programs to be kept available was increasing. As a result, the size of all transaction programs linked together (including their temporary storage requirements) was much larger than the memory available. In principle, one could leave the mapping problem to virtual memory management. But remember that transaction processing is driven by high rates of short requests, with response time being the performance measure. On the other hand, virtual memory works with acceptable performance only if paging is rare—that is, if locality is high. This, however, cannot be guaranteed if all applications of a TP environment are simply linked together and then loaded into the virtual address space of the TP monitor process(es). Therefore, many TP monitors provide means to group transaction programs, depending on which are executed together and which are not. Based on this, whole groups of programs can be replaced in memory in one (sequential) I/O operation, rather than be replaced one block after the other by demand paging.
Addresses. Of course, the argument extends to situations where the total length of the application exceeds the maximum address space provided by the operating system. Remember that many of the systems discussed here were built at a time when addresses had, at most, 24 bits.
Process structure. TP monitors started out doing process management for performance reasons. This often meant implementing threads on top of normal OS processes. To control these threads, of course, the TP monitors had to be able to allocate the pieces of code pertaining to the different transaction programs according to their storage management policies. Some systems apply different techniques depending on whether the transaction program code is re-entrant, partially reusable, or of unknown properties.
Code protection. There is one last reason for doing program management inside the TP monitor: these systems typically come with a database system as the “preferred”resource manager, and with a number of tools such as 4GL systems on top. To prevent users from running programs developed on such a platform outside the proprietary environment, the executable code is stored in the database rather than in an OS library.
Remote procedure calls and, along with them, the notion of client-server computing have been implemented and used long before the name was coined and the papers were published—nothing new in the domain of transaction systems. The first commercially available versions of RPCs are probably those in Tandem’s Guardian operating system and in the ICS (inter-systems communication) feature of CICS. Both came out in the mid 1970s. At about the same time, much of the research into RPC mechanisms to support computing in large workstation networks, including network file systems, was done at Xerox PARC and at MIT. It was this work, rather than the commercial systems, that influenced the subsequent development of RPCs as a general distributed operating system facility. There are two publications to mention in that respect. The first one [Birrell et al. 1982], describes a research prototype of a distributed mail server named Grapevine. It is a fairly complex exercise in distributed computing, based on the client-server paradigm. A general RPC mechanism is used to invoke remote services, a database system acts as a name server, there are provisions for load balancing and fault tolerance, and so on. That system is also worth mentioning in another respect: it used local transactions on the database, but it did not use distributed transactions for the RPC mechanism. This caused substantial problems in controlling the complexity of error situations that could occur and eventually it limited the size to which the system could be extended.
The other paper [Birrell and Nelson 1984] explains the implementation issues related to RPC, parameter marshalling, name binding, program management, piggybacking of acknowledgments, and so on. In that area, it is a classic.
This work influenced most of the RPC facilities found in today’s UNIX systems, such as the de facto standard Sun RPC, or the RPC mechanism that is used in Apollo’s Domain operating system; the latter one is also the basis of the RPC used for the distributed computing environment (DCE) defined by the OSF [OSF-DCE 1990]. DCE incorporates many features described for TP monitors, such as threads, distributed authentication, synchronization, remote procedure calls, but so far, it does not have transactions. It is quite likely, though, that sooner or later DCE will evolve into something that subsumes most of the functions of a conventional TP monitor.
Exercises
1. [6.2, 10] Name three properties a trpc has that a standard RPC has not.
2. [6.2, 25] Consider an application program with the following structure:

The SQL database is one other resource manager. Draw the complete thread of TRPC invocations, starting with the Begin_Work statement.
3. [6.2, 30] Read about the RPC mechanism available in your local workstation environment. Find out whether the invocations are context-sensitive or context-free. If they can be context-sensitive, find out how context is kept and how fault tolerant it is.
4. [6.2, 30] Go back to the trip planning example discussed in Chapter 4. The application consists of a sequence of processing steps, each of which makes a reservation or cancels one. Assume that flat transactions are all the TP system gives you. Assume further that it has no sessions at the TP monitor level; that is, there is no way to reserve a process for an ongoing activity. For performance reasons, you have the requirement of making each reservation (or cancelation) a separate transaction. How do you keep the processing context?
5. [6.2, 30] Consider the mail server example discussed in Section 6.5 Assume the same system as in the previous exercise (flat transactions, no context-sensitive servers). Sending a mail message is a conversational transaction that may require multiple interactions with the user. How would you maintain the context so that at commit time (which corresponds to the request to now send the message) the global integrity constraints can be checked?
6. [6.3, 10] Explain why the trpc stub must be shared among all the address spaces in the system.
7. [6.3, 20] As was explained in Chapter 5, there are TP monitors using only one operating system process. They do their own multi-threading inside that process. The threads are what is called process throughout this book. How does the addressing structure shown in Figure 6.6 look for such a single os-process, multi-threaded TP monitor?
8. [6.3, 20] Go back to the second exercise (the simple program invoking SQL). For each piece of code involved, make the following analysis: when that piece of code is executing within that sample transaction, which process is it running in, which resource managers is it associated with, what is the current value of MyTrid?
9. [6.3, 20] Consider the methods for name binding described in Section. 6.3. Which steps have to be taken as a consequence of removing a resource manager from the system? Where do they have to be taken, and when? Hint: There are a number of possible solutions. You might compare the pros and cons of at least two of them.
10. [6.3, 20] Why are special provisions needed against aborts racing normal processing? Sketch a simple scenario that shows what could go wrong if the system would not detect it.
11. [6.4, 20] Rewrite the Computelnterest program based on the mini-batch approach, but this time use recoverable queues to keep the processing context.
12. [6.4, 40] Assume you have to write a version of the debit/credit transaction that dispenses money through an atm. The interesting question at restart after a crash is: if a transaction was going on at an atm when the crash occurred, was the transaction committed, and if so, was the money really dispensed? Obviously, you want to have the “exactly once” semantics for the action “dispense money”; the “at least once” semantics is not popular with the bank. Assuming the atm is an intelligent terminal (that is, you can program it to behave as a resource manager; it has persistent memory), how would you implement the debit-service? Specify exactly which failure cases your design handles correctly, and which ones it does not.
13. [6.5, 30] Assume a bank wants to implement an extremely sensitive transaction (much money is involved one way or the other). In order to keep the risk of misuse as low as possible, it decides to use end-to-end authentication and authorization for each individual invocation of that transaction. Design a viable scheme for doing that, and specify precisely which part of the work is done by the TP monitor, and what is left to the application. Hint: An approach to be found in some applications is to use one-time passwords. Each password is good for one transaction only; and, of course, a whole list of passwords has to be set up at the beginning of, say, each week. Take this as a staring point for your design, and see how that can be made to work.
Answers
1. (1) Resource Manager called automatically becomes part of the ongoing transaction. (2) TP monitor does server class management, that is, it determines to which server the call is directed and creates a new server if necessary. (3) If any of the resource managers calls Rollback_Work, all the resource managers invoked during the transaction are called back by the transaction manager, independent of their position in the call stack.
2. Application to transaction manager (TM): Begin_Work.
Application to SQL server: UPDATE ….; en route: TP monitor to tm: Join_Work for the SQL server. SQL server to log manager: log_insert. Depending on the implementation of the SQL server, there may be more trpcs to the file manager, to the lock manager, and so on.
Application to tm: Commit_Work. As a consequence of this, the TMissues trpcs to the SQL server (Prepare), to the log manager (log_insert), to the SQL server (Commit), and to the log manager again (log_flush).
The explanation for the sequence of trpcs triggered by the Commit_Work call is given in Chapter 10.
4. The key observation is that the context has to be kept in the database, just like the restart information was stored in the database in the mini-batch example of Section 4.11. For each new trip (which may consist of many steps), a new order is prepared, and the system hands out a unique order number that from now on serves as an identifier for the context of that order, that is, for all reservations made on behalf of the customer. At the end of each reservation, the transaction commits, thereby externalizing all the updates pertaining to the reservation. As part of the same transaction a context record is written to the database, saying that the order with the given order number is currently being processed from terminal X by travel agent Y on behalf of customer Z. Thereby, the context is durably linked to all relevant entities, which means in case of a restart or when the customer comes back some days later after having reconsidered her plans, order processing can be picked up at the most recently committed state. Of course, all this context saving and restart processing has to be part of the travel agency application.
5. The solution is very similar to the answer to the previous exercise. Each new mail is identified by a system-generated Mailld. All the records generated during the process of preparing a mail are tagged by the current value of Mailld. As each partial transaction commits, these records are committed to the mail database. When a mail with a given Mailld is to be sent, the transaction that implements the Send function reads the database to see if there is at least one tuple qualified by <Mailid,”header”>, because the integrity rule says there has to be a valid mail header. The Send transaction then goes on to check if there is at least one tuple qualified by <Mailid, “body”>, because there must be a mail body, and finally it is checked if there is a tuple qualified by <Mailid, “trailer”>. If all checks succeed, the mail is sent, otherwise the Send function fails, and the user is asked to complete or correct the missing parts of the mail.
6. All servers of all server classes are—potentially—shared among all transactions in the system, and the dynamic mapping of function requests issued on behalf of transactions to servers is done by the TRPC stub. This requires the use of a number of shared control blocks, access to which must be strictly synchronized among all activations of the stub code.
7. The resulting address space configuration is shown in the following figure.
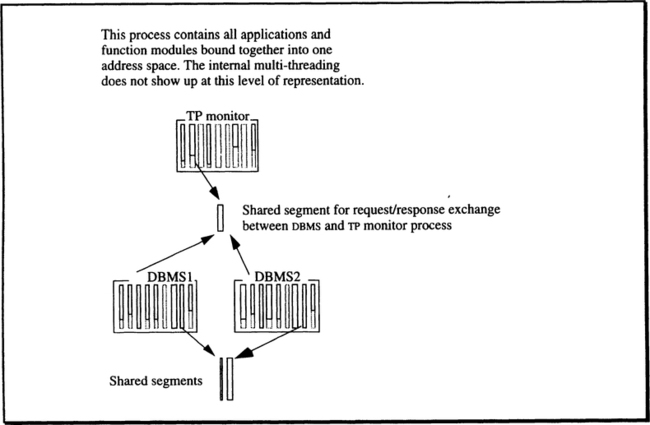
Note that the component denoted as tpos in Figure 6.6 completely hides in the TP monitor process in the scenario assumed here.
9. First, the server class corresponding to the resource manager must be shut down. This requires all transactions using that use the resource manager to terminate. Then the control blocks pertaining to the resource manager can be deallocated. After that, the TP monitor can remove the code for the server class from its library and delete the addressing information about the resource manager from the local repository.
The first variant stops here. Of course, there may be binding information for the removed resource manager cached in other nodes, but they will learn about the deactivation of the RM upon the next TRPC. That way, news about the deactivation travels slowly, and remote clients learn it “the hard way” by getting their calls rejected. On the other hand, this method requires local activities only when removing a resource manager.
A second variant might try to inform all nodes in the system about the deactivation of the resource manager. Such a broadcast operation, however, is not trivial in a large distributed system if the messages are to be delivered reliably. One reason is that one cannot expect all nodes to be up at any point in time. So the typical method will be to first deactivate the rm locally and then spread the news by either invalidating pre-bound calls (based on cached naming information), or by piggy backing the deactivation-message on other message exchanges among the local TP monitors.
Of course, the rmname of the deactivated rm must not be issued again—at least not until it is guaranteed that no references to the old resource manager can come from anywhere in the network.
10. Assume a transaction T1 started at node A, and then invoked a distributed sub-transaction at node B. The TRPC returns from B, and processing continues at node A (T1 is still active). Meanwhile, node B has crashed and restarted, and as a part of the restart activities the tpos of node B informs node A’s tpos that it has aborted Tl. As a consequence, the transaction manager at node A invokes the local resource managers at their rollback entries. Consider one of these resource managers. The program might be executing along the normal path of the code in its own process, issuing calls to other rms and so on. At the same time, the same resource manager is activiated at the rollback entry under the tp monitor’s process and starts accessing and updating the same shared control blocks. Since this may lead to arbitrary consistency anomalies, abort racing must be protected against.
11. This is simple. Replace the update operation on the batchcontext relation at the end of each step by a (durable) enqueue operation. Correspondingly, retrieval of the restart information from batchcontext is replaced by a dequeue operation. Creating and dropping the batchcontext relation corresponds to the creation and deletion of a named queue used for the mini-batch application.
12. All the necessary information for a solution is given in the answer to Exercise 8 in Chapter 4. If you are still uncertain how to proceed, you might want to read the detailed explanation of the two-phase-commit protocol in Chapter 10. The key point here is to reconsider the issue that makes ATMs different from normal resource managers: at a certain point they have to perform a critical physical action that takes some seconds and cannot be undone by the system, namely dispensing the cash. The solution to the problem is based on two ideas:
— Move the dispense action to the very end of the debit transaction and make sure there can be no reason whatsoever to undo it.
— Before that, write information to durable storage that allows to check after a crash that interrupts the dispense action whether or not that action was executed successfully. Of course, such a test may require human intervention.
13. Assume there is a special resource manager $$$T handling these sensitive, high-value transactions. The TP monitor controls access to its environment by authenticating the users based on a simple password scheme. The authorization to invoke $$$T is restricted to certain users and certain terminals, that is, even a user who can use $$$T may do so from a special terminal only. A user who has passed authentication and authorization so far is then authenticated again by $$$T, this time using a challenge-response scheme. After that is completed, $$$T is willing to accept requests from that user (at that terminal). Let us assume $$$T provides a single service, namely electronic fund transfer from account A to account B. So the only parameters the user has to provide are the account numbers (source and destination) and the amount to be transferred. Each transfer is executed as one transaction. Given that the amounts are typically in the multi-million dollar range, each individual transaction is to be further protected. One way to achieve this is that for each legal user the resource manager allows n transactions to be executed without invoking a higher authority. It does that by generating n passwords pi (1≤i≤n) and storing them in the database as tuples of the form <Userld,i,pi>. For security, this relation should be stored in some encrypted form that only $$$T understands. In the beginning, the list of pi is given to the user via some other protected channel (e.g. printing them on those special carbon copy envelopes that must be tom open to read the information). In addition, $$$T keeps context information for each legal user. The context basically contains the number of transactions executed so far. For an arbitrary user, let this value be h. Then for the next transaction this user wants to run (after having been authenticated by $$$T), the resource manager retrieves ph+ 1 from the password relation, and expects the user to provide exactly this password. Independent of whether or not the transaction is successful, the tuple with ph+ l is deleted from the relation. So even if the transaction fails, the transaction program goes back to savepoint 1, then does the delete and calls Commit_Work to make sure the password cannot be used again. After n such transactions, another list of passwords must be given to the user, which typically involves a higher authority.
1This still may sound like a subroutine using static variables to keep data across subsequent activations. Remember, though, that the trpc’S “subroutines” can have multiple instantiations in different processes at different nodes.
2Of course, there are other ways of returning results, such as writing to the database tuples that the client can read. But again, this has nothing to do with the resource manager interface.
3One could argue that this type of context can be thought as being bound to the client, but that essentially creates a confusion among concepts. Note that it is the server that needs the context; the client is unlikely even to know that the context exists. Hence, it is not a good idea to bind context to a class of resource managers that have no interest in (and probably no authority on) the data involved.
4The SQL standard has the verbs CONNECT and DISCONNECT for that purpose, but since the presentation in this chapter talks about arbitrary resource managers, fictional function names are used.
5It is transparent as far as it goes. What the programmer of a resource manager must be prepared to see is a bad return code from a server call, indicating that in the meantime the abort of the transaction has been initiated. The resource manager can then just call Rollback_Work itself, and quit. The transaction manager makes sure the resource manager gets invoked at its proper callback entries in order to undo its work.
6We assume the normal definition of a working set: the portion of the process’s address space it references within a predefined time window.
7Throughout this section, only mean values are used.
8This is not quite right, because the duration of the actual delay also depends on the number of concurrent transactions, but for the present argument the simple (more optimistic) model will do.
9There is an equivalent to memory thrashing in operating systems in the buffer pool of database systems. For this discussion, however, the position is taken that memory will be unlimited in the near future, and thus should no longer create any such problems.
10There is a small problem when the access matrix is modified at run time, to the effect that access rights are revoked from a user. Then there must be means for finding out if there are any processes with bind-time authorization running under his authid.
11This is not state-of-the-art in commercial operating systems. Judging from some recent developments, however, it is reasonable to assume that the log will become an integral part of the basic os. This assumption implies that the system is in deep trouble should the log fail to come up. See Chapters 10–12 for a detailed discussion of component recovery.
12At least on this end; a peer might have crashed meanwhile, leaving its end of the session down.