
Advanced Transaction Manager Topics
12.2. Heterogeneous Commit Coordinators
12.2.1. Closed versus Open Transaction Managers
12.2.2. Interoperating with a Closed Transaction Manager
12.3. Highly Available (Non-Blocking) Commit Coordinators
12.5. Optimizations of Two-Phase Commit
12.1 Introduction
This chapter discusses features present in some modern transaction managers. First, it discusses how heterogeneous transaction managers can interoperate and how portable resource managers can be implemented. Then it shows how the process-pair technique can be applied to make transaction managers highly available. Next, the issue of transferring commit authority from one transaction manager to another is discussed. Transfer of commit benefits both performance and system administration.
Discussion then turns to transaction commit performance issues. First, the performance of the standard protocol is analyzed for both message and I/O costs. Earlier chapters described several commit optimizations, and a few more are described here. The chapter ends with a discussion of disaster recovery systems that can mask environmental, operations, and transient software failures.
12.2 Heterogeneous Commit Coordinators
As networks grow together, applications increasingly must access servers and data residing on heterogeneous systems, performing transactions that involve multiple nodes of a network. Frequently, these nodes have different TP monitors and different commit protocols.
This raises the issues of interoperability and portability. Applications want to interoperate in several different modes. Some want to issue transactional remote procedure calls (TRPCs); others want to establish peer-to-peer transactional sessions with other TP systems. In addition, portable applications and resource managers need a standard transaction manager interface so that they can be moved easily from one operating environment to the next.
If each transaction manager supports a standard and open commit protocol, then portability and interoperability among them are relatively easy to achieve. Today, there are two standard commit protocols and application programming interfaces:
IBM’s LU6.2 as embodied by CICS and the CICS application programming interface
OSI-TP combined with X/Open Distributed Transaction Processing.
CICS is a de facto standard. Virtually all TP monitors can interoperate with it to some degree. The X/Open standard is newer, but it has the force of a de jure standard. Both standards are likely to proliferate in the years to come.
12.2.1 Closed versus Open Transaction Managers
Some transaction managers have an open commit protocol; which means that resource managers can participate in the commit decision, and the commit message formats and protocols are public. The transaction manager described in Chapters 10 and 11 fits this description, so it is open. The standards listed in Section 12.2 are also open. CICS, DECdtm, NCR’s TOPEND, and Transarc’s transaction manager are open. Transaction managers are evolving in this direction, but the evolution is not yet complete.
Historically, many commercial TP monitors had a closed commit protocol in that resource managers could not participate in commit (there were no resource manager callbacks), and the internals of commit were proprietary. The term closed TP monitor is used to describe TP systems that have only private protocols and therefore cannot cooperate with other transaction processing systems. Unfortunately, several popular transaction processing systems are closed—among them IBM’s IMS and Tandem’s TMF. There is considerable commercial pressure to open them up; we guess they will soon become open.
If a TP monitor is open and obeys some form of the two-phase commit protocol, then it is possible to implement a gateway that translates between the TP monitor protocol and one of the standard open protocols. Subsection 12.2.3 shows how, using this technique, ACID transactions involving multiple heterogeneous TP monitors can be constructed. On the other hand, it is virtually impossible to implement general ACID transactions involving closed TP monitors and other monitors. The key problem is atomicity: the closed transaction manager can unilaterally abort any transaction, even though the others decide to commit.
The next few subsections describe the issues involved in writing gateways between one of the standard protocols and the local protocol. The need for a standard protocol is obvious. If there are 10 different transaction managers in the world, then building a special gateway between each pair of them requires building 90 different gateways (e.g., each of the 10 TMs must have 9 gateways to others). If a standard interchange protocol is used, only 10 gateways need be built. This explains the enthusiasm for interoperability standards.
12.2.2 Interoperating with a Closed Transaction Manager
It is almost impossible to write a gateway for a closed transaction manager. Some special cases can provide atomicity to distributed transactions involved with a closed transaction manager. If a set of open transaction managers shares a transaction with a single closed transaction manager, then the open transaction managers can achieve atomicity by letting the closed transaction manager be the commit coordinator. The idea is for each open transaction manager to enter the prepared state and then ask the closed transaction manager to commit. In the normal case, where there is no failure, the closed commit coordinator will quickly come to a decision to commit or abort. In these cases, the open transaction managers will promptly be informed and commit or abort as appropriate.
In the single-closed-TM case, the only problems arise when one of the transaction managers fails. If there is a communication failure or a failure of any of the transaction managers, there must be a way to atomically (all-or-nothing) resolve the in-doubt transaction. Because the closed transaction manager is the commit coordinator, it must support an interface that returns the status of any current or past trid (the Status_Transaction() call described in the previous chapter). The status will be one of {active, aborting, committing, aborted, committed}. The open transaction managers can periodically poll the closed transaction manager gateway to find out the status of any in-doubt transactions.
Typically, the closed transaction manager does not provide such a Status_Transaction() TRPC. Rather, a gateway to the closed transaction manager must implement this function. The simplest way for the gateway to maintain this information is to keep a transaction-protected file of all the successful trid’s {active, prepared, committing, and committed}. The gateway process inserts each trid into this file when the trid first arrives at the closed transaction manager. If the transaction commits, the trid will be present in the file. If the transaction aborts, the trid will be missing from the file. If the transaction is live, the trid record in the file will be locked. By reading the record via the trid key (with a bounce-mode locking), an open transaction manager (or the gateway) can determine whether the closed transaction manager committed the transaction, aborted it, or still has it live. This logic is similar to the Status_Transaction() logic mentioned in section 11.2.3.
The scheme works only for transactions involving a single, closed transaction manager. Section 12.5 will explain that this technique is an application of the last transaction manager optimization.
12.2.2.1 Closed Queued Transaction Monitors
If the transaction manager is closed and supports only a queued interface, then things are even more difficult. IMS and Tuxedo were originally queued-only transaction managers, but now both support a form of direct processing. The problem with queued systems is twofold: (1) since conversational transactions are impossible, all requests to the transaction manager must be deferred to phase 1 of commit; (2) the queued transaction system acknowledges the input message and then processes it asynchronously. Queueing complicates both the application and the gateway.
The application may be able to tolerate closed-queued TP monitors by sacrificing consistency while still attaining atomicity and durability. To do so, requests are classified as inquiry requests (ones that do not change the server’s state) and update requests (ones that do change the server’s state). Each request to a closed-queued TP monitor must be implemented as a separate transaction at the closed system—queued TP monitors do not support conversational transactions. Given this restriction, the application can send the closed TP monitor many inquiry requests and defer all update requests to phase 2 of commit.
In this design, inquiry requests give degree 1 isolation answers rather than the degree 3 isolation of ACID transactions. This lower degree of isolation results from each closed transaction releasing its locks when it commits and replies.
Update requests to the closed TP monitor must be treated as real operations. That is, the updates are deferred (by the application) until commit. The application must complete all processing on all the open transaction managers and get them to enter the commit state. Then, during phase 2 of commit, the application repeatedly sends the sum of all the update requests to the queued TP monitor gateway. This request invokes another part of the application, called the rump, that runs in the closed system. The rump does all the deferred updates, then commits and responds to the application on the open system (see Figure 12.1).
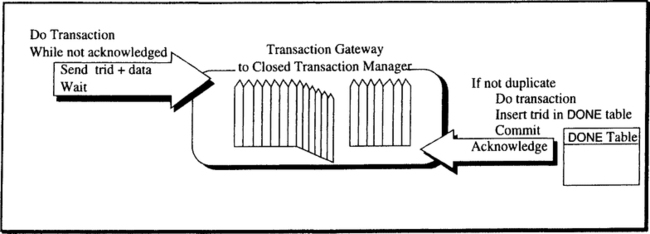
If the closed TP monitor successfully performs the rump, it will respond to the open part of the application, and atomicity plus durability will be achieved. If the rump aborts, then it must be retried. The application keeps resending the rump message until the rump is performed successfully. This might cause the rump to be processed more than once, and that would also be bad. The usual technique to achieve idempotence (exactly once processing of the rump) is to assign a unique identifier to each rump—the original trid is a good choice. The rump maintains a table of the processed trids; let us call it the DONE table. The rump has the following logic:

The use of rump transactions is not elegant, but it allows open transaction managers to interoperate with closed-queued transaction managers. Typical applications of this technique involve maintaining a duplicate database in which updates to the master file must be sent to a slave copy on an old system with a closed transaction manager. This is a short-term problem; in the long term, the LU6.2 and OSI-TP standards will force all TP monitors to become either open or obsolete.
12.2.3 Writing a Gateway to an Open Transaction Manager
The problems in writing a gateway between two open transaction managers that have slightly different communications protocols and two-phase commit protocols mostly concern name translation, full duplex-half duplex conversion, and so on. The recovery issues are relatively minor. Within the scope of the transaction manager issues, some problems lie in translating the fancy features of one or another protocol. One protocol might only support chained transactions or might not support transfer-of-commit, heuristic abort, and so on. These problems can be eliminated by a simple rule: the gateway doesn’t support or accept any features not supported by the local transaction manager. Given that extreme view, the gateway’s logic is as follows (refer to Figure 12.2).

The gateway acts as a resource manager. It joins any transactions that pass through the gateway; it participates in both phase 1 and phase 2 of commit; and it participates in transaction savepoints, rollback, and abort.
A gateway sees two kinds of transactions, incoming and outgoing. An outgoing transaction is one that originated here and is being sent elsewhere; this node will be the commit coordinator for the transaction with respect to the outgoing session. Conversely, if a transaction request arrives on an incoming session, then the transaction originated elsewhere, and this node is a participant rather than the coordinator. The logic and issues for the two can be treated separately.
12.2.3.1 Outgoing Transactions
Let us first consider an outgoing transaction. The gateway notices that this transaction is new to it and therefore joins the transaction, acting as a resource manager by issuing Join_Work() to the local transaction manager. Next, the gateway must send the outgoing request to the foreign transaction manager. The outgoing request must be tagged with a foreign trid correlated to this local trid by the gateway. As a rule, foreign and local trids have different formats; for example, LU6.2 trids are different from OSI-TP trids. Thus, the gateway must be able to invent new foreign trids, complete with a birthday, transaction manager ID, and sequence number ID. This, in turn, means that the gateway must act as a foreign transaction manager. It can use a private log file or even the local database manager to implement much of this logic. Assuming it uses the local transaction manager and database, the gateway maintains a recoverable table of the two trids:
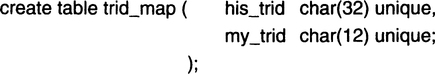
When an outgoing transaction first goes out, the gateway invents a foreign trid for the transaction and makes an entry recording the two trids in this table, all under the scope of the local trid. The entry will be made durable when the local transaction commits. At that time, the gateway gets a Prepare() callback from the local transaction manager and forwards it on the session to the foreign transaction manager. If a yes vote comes back from the foreign transaction manager, the gateway votes yes; otherwise, it votes no to the prepare request. Similarly, the gateway is invoked at phase 2 and sends the phase 2 commit message; it does not acknowledge the phase 2 callback until the remote commit coordinator responds. This is very similar to the standard logic for a resource manager at commit.
If the local transaction aborts, the gateway gets an Abort() callback from the local transaction manager, since the gateway has joined the transaction. In this case, the gateway sends an abort message on the outgoing session to the foreign transaction manager.
At restart, the remote transaction manager may ask the gateway for the transaction outcome. To determine the status of the transaction, the gateway, using the presumed-abort logic, can simply issue this query:

If the answer is “not found,” then there is no record of the transaction, and it must have aborted—this is presumed abort. If the transaction did not abort, then the record will be locked if the transaction is still in doubt (that is why browse-mode locking was used). If the record is returned, it has the added benefit of translating the foreign trid to the local trid. The transaction manager uses this trid to invoke the Status_Transaction() verb exported by the local transaction manager:

The gateway calls this routine, passing the local trid (my_trid) returned by the translate() step. If the inquiry routine returns “prepared,” then the transaction is still in doubt, and the gateway must ask again later. Otherwise, the returned status is either commit, committing, abort, or aborting. In any of these cases, the gateway returns the status to the remote transaction manager.
12.2.3.2 Incoming Transactions
The gateway logic for incoming transactions is similar, but it places more demands on the local transaction manager. In the outgoing case, the gateway acted as a simple resource manager to the local system and as a full-blown transaction manager to the remote system. For incoming transactions, the gateway acts as the local commit coordinator, and the local transaction manager must accept Prepare(), Commit() and Abort() messages from it. This can be done in two ways. The gateway can masquerade as a communication manager and simulate the messages and protocols of a peer remote commit coordinator. Alternatively, the transaction manager can export procedures to implement these functions. The masquerade approach is described here..
To handle foreign incoming transactions, the gateway must act as a local transaction manager (as opposed to a foreign TM). It gets a unique name and maintains a local durable trid counter. Thus, the gateway can generate trids in the format of the local transaction manager. When the gateway gets an incoming foreign trid, it invents a local trid and executes a local Begin_Work() to insert this record in its trid_map table. It then sends the local trid via a session to the local TP monitor as an incoming transaction request. The TP monitor views this as an incoming transaction, allocates a local server for the transaction request, and replies.
To the remote transaction manager, the gateway is acting as a transaction participant; to the local TP monitor, it is acting as coordinator. When a request arrives, the gateway does protocol translation, tags the request with the local trid, and forwards it on the local session. When the Prepare() request arrives, the gateway sends the prepare message (tagged with the local trid) via the session to the local TM. The gateway passes the reply back to the remote commit coordinator. Commit() and Abort() logic are similar. The restart logic is only slightly more complex. When the transaction manager restarts, it polls the gateway (via a session) about any in-doubt transactions coordinated by that gateway. The gateway looks up the local trid in its trid_map table and sends the inquiry about the foreign trid to the appropriate remote transaction manager. The gateway then passes the reply back to the local transaction manager.
To summarize, the gateway is acting as a transaction manager in both protocol networks. For example, it is acting as an LU6.2 transaction manager in an IBM-CICS network and as an OSI-TP transaction manager in an X/Open AT&T Tuxedo network. It translates the commit/abort messages between these two networks and translates the trids as well.
12.2.3.3 The Multiple Entry Problem
Although this design works in most cases, it has the flaw that if a foreign trid enters the local system many times via different sessions, it will get a different local trid each time. This problem can be fixed by testing the trid_map table before allocating a new trid. A more serious problem is that the trid may enter many different gateways of the same subnet. For example, it might enter the Visa net via the London and the San Mateo gateways. Detecting this situation is more difficult, but the problem is not serious. It can result in a transaction deadlocking with itself, but it will not result in incorrect execution. No good solution—that is, no efficient solution—to this problem is known.
12.2.4 Summary of Transaction Gateways
In summary, if all TP monitors are open, it is possible to write simple gateways to interconnect them and provide ACID transactions that span heterogeneous TP monitors. If a transaction involves at most one closed TP monitor that supports direct communication with the application (not just queued communication), then by making that transaction manager last in the commit chain, ACID transactions can be implemented. Updates involving multiple closed TP monitors or queued TP monitors must be treated as real operations and probably must sacrifice the consistency and isolation properties, attaining only atomicity and durability.
12.3 Highly Available (Non-Blocking) Commit Coordinators
Up to this point, our discussion has focused on reliability. How can one build a highly available transaction manager—one that continues operating after a processor or communication link fails? The obvious solution is to duplex memory and processors, as described in Chapter 3.
The first step is to make the log manager highly available. It can operate as a process pair that duplexes each log file. By doing this, the log manager can tolerate any single fault. If a processor fails, the backup process in another processor takes over almost instantly, without interrupting service. If a disk or a disk write fails, the log manager can mask the failure by reading the remaining disk. Concurrently, it can repair the failed disk by replacing it with a spare and then copying the log information from the good disk to the new disk. This is a straightforward application of the ideas set forth in Chapter 3, Section 3.7.
The transaction manager should also use process-pair techniques to tolerate hardware faults and transient software faults. The transaction manager’s persistent state is recorded in the log anchor or in log checkpoints, so that it benefits from the log manager’s fault tolerance. The transaction manager’s volatile data structures (e.g., the list of resource managers and sessions involved in a transaction shown in Figure 11.1) should be managed as a process pair. That is, these tables should be recorded in two process address spaces on separate computers, and the state transitions of these tables should be synchronized via process-pair checkpoints (see Figure 12.3). This is a standard application of the process-pair concept.
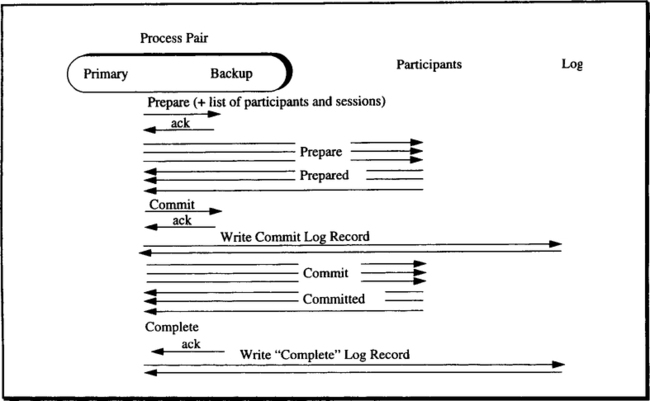
Commit coordinators implementing a process-pair scheme are called non-blocking, because they are not blocked by a failure. A blocking commit coordinator—one implemented as a single process—could be unavailable for hours or days. In that case, all in-doubt transactions coordinated by that transaction manager remain in doubt (blocked) until the coordinator returns to service.
Non-blocking commit coordinators are common in fault-tolerant systems and are much discussed for distributed systems. In fault-tolerant systems, there is a primary process and a backup. If the primary fails, the backup senses the failure and takes over. The key property of these systems is that the backup process can tell when the primary commit coordinator process has failed. Given this assumption, applying duplexed storage and process pairs to make a fault-tolerant commit coordinator is straightforward.
Distributed systems generally have a different fault model. In a distributed system, if two processes cannot communicate, the problem could be a failed process or a failed session (a broken wire). The latter case is called a network partition failure. If network partitions are possible, non-blocking protocols for distributed transactions require that the transaction be coordinated by three or more nodes; these protocols allow a majority of the nodes to declare a minority to be failed. Unfortunately, the most common case of a distributed transaction involves just two nodes. There, the non-blocking algorithms do not apply: if there is a failure, one node cannot form a majority. Consequently, non-blocking protocols are rarely used in distributed systems. Rather, fault-tolerant nodes are used with fault-tolerant (duplexed) communication sessions. Alternatively, practical recovery systems postulate that they can distinguish between network partitions and node failures; they usually ask the operator to decide (see Section 12.6).
An alternative to the process-pair design for non-blocking commit is for the coordinator to broadcast the list of participants at phase 1 of commit as part of the prepare message. Then if the coordinator fails, the participants can contact one another. If any got a commit decision from the coordinator, they can all act on it. If none got a commit decision, then they must either wait or transfer the commit coordinator authority to another participant, which is delicate. This non-blocking protocol can be made to work, but is more complex than the process-pair design and does not help in the common case of two-node transactions.
12.3.1 Heuristic Decisions Resolve Blocked Transaction Commit
There has been considerable concern about the implications of the two-phase commit protocol forcing participants to wait forever for a decision. While the participant waits, resources are locked, queued messages are in doubt, and a client is waiting for a response. Two additional mechanisms are commonly used to resolve in-doubt transactions being coordinated by a failed commit coordinator: heuristic commit and operator commit.
Heuristic commit has the participant transaction manager make a heuristic decision about the status of an in-doubt transaction when the coordinator fails or when contact with the coordinator is lost. These are some typical heuristic decision criteria:
When such decisions are made, the transaction manager records the transaction state as heuristically committed or heuristically aborted. These become new persistent states (see Figure 10.20). When the commit coordinator later contacts the participant transaction manager to announce the real commit decision, the local transaction manager compares it to the heuristic decision. If they agree, great! If they disagree, the local transaction manager tells the commit coordinator and the operator that there is a heuristic commit/abort mismatch. At that point, it is up to humans to clean up the situation.
In a related vein, the system operator is given a command to force an in-doubt transaction to commit or abort. If that transaction is holding resources that prevent the system from doing useful work, this command is essential to get the system moving again. The operator decision is treated much like the heuristic decision. If it later disagrees with the decision of the commit coordinator, an operator commit/abort mismatch diagnostic is sent to both the coordinator and the local operator.
Operator abort may appear to be more rational than heuristic abort. But, in fact, the operator rarely has much information when making the commit/abort decision. He knows the transaction identifier and perhaps can deduce the names of the local server program and the remote commit coordinator, but that is not much information. The application administrator is probably in a better position to make a decision; that person, however, may not be present at the crisis. Thus, the heuristic abort decision is often no worse than an operator abort decision.
In either case, if the operator or heuristic decision results in a later mismatch between two nodes, then system administrators must resolve the transaction at each site. This resolution mechanism must be part of the application design. Just giving the operator a list of trids that do not match will not be much help in resolving the situation. The trids must be correlated with application-level concepts, such as users and application programs.
12.4 Transfer-of-Commit
It is nice to be the commit coordinator for a transaction. The coordinator always knows the status of the transaction; it is never in doubt. A participant, on the other hand, may remain indefinitely in doubt about a prepared transaction. Consequently, everyone wants to be the commit coordinator.
By default, the beginner (transaction manager) is the commit coordinator. There are two reasons why it is sometimes desirable to transfer the commit coordinator responsibility from the beginner to another node participating in the transaction:
Asymmetry. The client may not be as reliable as the server. The transaction commit coordinator should be one of the most reliable nodes in the transaction tree.
Performance. Transferring commit can produce much better performance.
The asymmetry argument arises when a gas pump, ATM, or workstation starts a transaction (does a Begin_Work()) and then makes one or more requests to servers running on system pairs. The servers are much more reliable than the client.
Consider the case illustrated in Figure 12.4. You buy some gas from Arco using a Wells Fargo Bank (WFB) system. The gas pump is in Death Valley, California, and is attached to Wells Fargo’s Los Angeles data center. The transaction debits your account in San Francisco, but you don’t have enough money in it; the overdraft causes a debit of your Visa credit card account in London. The nodes involved in the transaction are diagrammed in Figure 12.4. The problem is that WFB does not trust the gas pump to coordinate the transaction commitment. Similar issues apply to other peripheral clients, such as workstations or sensors in distributed applications. The solution is to transfer the commit coordination responsibility from the peripheral processor to another transaction participant, which is presumably more reliable or trusted.
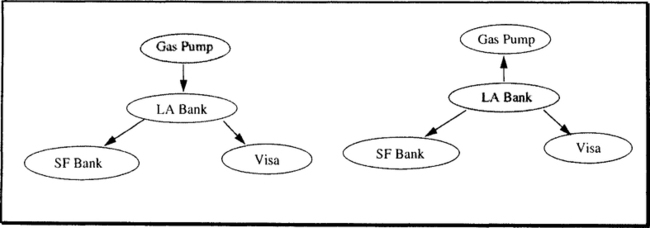
Figure 12.5 illustrates the performance benefit of transfer-of-commit. Suppose the client has performed all the work it needs to do for the transaction and is prepared to commit if the server will do some more work for the transaction. For example, moving a message from one recoverable queue to another consists of a Begin_Work() plus a dequeue at one node, and an enqueue plus a Commit_Work() at the other node. If the first node executes Prepare() before sending the request to the second node, the second node can make the commit decision. This reduces message flows by a factor of two in the simple case.

The logic involved in transferring commit responsibility is easy in the design described in Chapter 11. Recall that all transaction managers participating in a transaction form a tree (or a directed acyclic graph). The beginner of the transaction is the root of this tree. All the transaction’s sessions at that transaction manager have outgoing polarity. That transaction manager could transfer commit to any of its neighbors in the tree by simply reversing the polarity of a session between itself and one of them. Then the child would be the root of the tree. How is the polarity reversed? It is easily done by changing the local polarity to incoming and sending a message to the other end saying “you are the root.” This can be done at any time prior to making the commit decision (assuming the presumed-abort protocol is used). When the server gets the “you are the root” message on a session, it changes the polarity of that session from incoming to outgoing. This same idea is used in the last resource manager optimization of nested commit. See Section 12.5.
Is it really that simple? Almost, but there are a few nasty problems. Suppose the client calls two servers. If neither server trusts the client, the servers have a problem: both of them want to be the root. Also, the transaction’s trid carries the root transaction manager’s name. As a last resort, participants can consult the root transaction manager to see what the outcome of the transaction is. What if the root is relatively untrusted? The proposed solution to both problems is for the prepare message to be extended to include the name of the new transaction root. In this way, a server can judge the reliability of the root commit coordinator and vote no if the root seems inadequate. In addition, the new commit root should remember the outcome of any such transactions for a long time (say, a day or two). This logic is currently being considered for the OSI-TP standard.
12.5 Optimizations of Two-Phase Commit
Since Nico Garzado’s first implementation of two-phase commit in 1970, most work on commit protocols have been optimizations. The performance of the protocol can be measured in any of three dimensions:
Delay. The elapsed time to make the commit decision.
Message cost. The number of messages that must be sent.
Write cost. The number of forced disk (durable storage) writes.
Of course, delay is correlated with message cost and write cost. The standard way to reduce delay is to do things in parallel: for example, broadcasting the prepare message to all participants in parallel, rather than asking them one at a time. The coordinator broadcasts the Prepare() and Commit() callbacks to the joined local resource managers in parallel; in addition, it broadcasts these callbacks to the remote (outgoing) sessions with remote transaction managers in parallel (see Figure 12.6). If the transaction tree is deep, then parallelism can be improved if the coordinator directly sends messages to all coordinators. This, however, may not be possible if there are gateways involved (doing trid translation) or if the two transaction managers have no session in common. That is about all there is to say about delay. However, there is a lot to say about reducing message cost and write cost.

In general, if N transaction managers and L logs are involved, the transaction commit will involve 4(N–1) messages and 2L log writes. Since there is usually 1 log per site, we can assume for the rest of this discussion that N = L. The messages are prepare, prepared, commit, and committed. The log writes are commit and complete or prepare and complete. The committed message and the complete log write can be lazy, since they do not add to the delay and do not cause resources to be held longer than needed. Suppose W is the minimum delay for a synchronous log write, and M is the minimum delay for sending a message to another transaction manager. The minimal delay for a one-node transaction to reach phase 2 of commit is L • W, the delay for the log writes. These minima do not account for any processor delays or for the necessary variability that arises as more resource managers are added. But they give a sense of relative costs and delays.
To discuss distributed transaction commit costs and optimizations, the notion of the transaction tree is needed. Recall that, in general, the incoming-outgoing sessions among transaction managers form a directed graph. This graph can be pruned to a tree by discarding incoming sessions to nodes at which the transaction was already established when the incoming session was first started, as shown in the rightmost example in Figure 12.6. In that illustration, the root and the leftmost leaf both have incoming sessions that are not needed for the commit protocol. The transaction tree is a spanning tree rooted at the transaction root and connecting all participating transaction managers.
Suppose the transaction tree has height H. Then, the minimum root delay to reach phase 2 of commit for a distributed transaction is H(2M + 2W) if parallelism is used. This equation is computed as follows. For a tree of height 1, the delay is the sum of:
(1) The delay to broadcast the prepare message (M),
(2) The delay at each participant to prepare and write a prepare record in the log (W),
(3) The message delay for the participant to respond (M), and
When the tree is deep, the participant must wait for its subparticipants, which adds another 2M + 2W for each layer of the tree.
The minimal leaf participant delay to reach phase 2 of the commit has 1 additional message delay, or H(3M + 2W). If parallelism is not used, the minimum root delay for commit is 2M(N – 1) + N • W.
12.5.1 Read-Only Commit Optimization
The first and perhaps most important optimization is called the read-only optimization. It means that the participant has no work to do at commit and so does not need a Prepare(), Commit(), or Abort() callback for this transaction. The term is a misnomer: Chapter 8 explained that read-only transactions should use two-phase locking and hold locks until phase 2 of commit; thus the read-only optimization should, in fact, be called the degree 1 isolation optimization—the participant is not keeping any locks on resources it has read.
This optimization applies to individual resource managers and to whole subtrees of the transaction tree. If a remote transaction manager and all its outgoing sessions have no work to do at commit, then the transaction manager can declare this fact (declare itself “read-only”) and so avoid any transaction completion work. A slight variation occurs if the resource manager or remote node has only phase 1 or only phase 2 work to do. In these cases, half the messages can be saved. In general, the read-only optimization saves four messages per node and one synchronous log I/O per transaction manager. A true read-only transaction which provides complete isolation has only phase 2 work—it must release locks at Commit() or Abort().
12.5.2 Lazy Commit Optimization
A second important optimization is lazy commit (as opposed to eager commit). In lazy commit, all messages and disk writes are piggybacked on other message or log-write traffic. To deal with the unlikely case that there is no other such activity, the lazy commit will be converted to an eager commit after a time period (e.g., a second). Lazy commit has the same savings as the read-only optimization in that it costs no extra messages or disk I/O. Of course, it has the worst delay cost, and if multiple logs are involved, lazy commit may not be atomic because each log is written independently. That is why eager commit is the default. Lazy commit is an extreme form of group commit, already discussed in Chapter 9, Subsection 9.4.7.
12.5.3 Linear Commit Optimization
A third optimization, called linear commit, or nested commit, is just an application of the transfer-of-commit design discussed in Section 12.4. The idea is to arrange the transaction managers in a linear order, with each first preparing, then transferring commit authority to the next in the chain. The last in the chain then becomes the root, writes the commit record, and propagates the commit decision back up the chain. Each participant goes through phase 2, simultaneously passing the message back up the chain. When the commit message reaches the end of the chain, a completion record is written; then a completion message is sent back down the chain. At each node, this completion message generates a completion log record. After the completion log record is written, the message passes down the chain. If the tree is a simple chain of length H (i.e., H = N–1), the minimum root delay to reach phase 2 is 2M(H) + N • W, and the overall delay is 3M • H + 2 • W. Linear commit, then, has bad delay but good message cost: 2M(N-1) or 3M(N-1) versus 4M(N-1).
That is the theoretical analysis, but there is an important special case: N = 2. In the common two-node case, the linear commit algorithm has the same delay as the general algorithm, and it saves a message as well. Therefore, in the N = 2 case, linear commit should always be used, unless the client is afraid to transfer commit authority to the server (i.e., it doesn’t trust the server). Since this argument applies when the system knows that the next prepare message goes to the last transaction manager, it is often called the last transaction manager optimization, or sometimes the last resource manager optimization.
One can mix the general (4N messages) commit protocol with the linear (3N messages) commit protocol. But, of course, the commit coordinator must be prepared and must have prepared the rest of its commit subtree before transferring commit authority to the last one of its subtrees. An example of this mixing is shown in Figure 12.7.

Two other optimizations associated with transaction commit are discussed elsewhere in this book. Group commit appears in Chapter 9, and the presumed-abort optimization is explained in Chapter 11. Transfer-of-commit was discussed in Section 12.4. Having discussed performance, let us consider schemes that make a system super-available by replicating it at two or more sites.
12.6 Disaster Recovery at a Remote Site
As shown in Chapter 3, environmental and operations faults are a major source of system outages. The simplest technique that masks such faults is replication of hardware, data, and applications at two or more geographically distributed sites. If one site has an operations or environmental failure, the other site is not likely to have the same failure. In addition, there is evidence that these designs mask some software failures.
System-level replication is an area of active research and development. As this book is being prepared, many special systems are in operation and a few general-purpose designs are being used. Therefore, the presentation here focuses on the simple case and on basic concepts. It also shows how the transaction concept and the disaster recovery system ideas dovetail. This connection is not surprising, since transactions are intended to make distributed computations atomic and durable.
The disaster recovery idea is clear: use system pairs rather than just process pairs. Each client is in session with two systems. When one of the two systems fails, the other system continues the transaction, either completing the commit and delivering the messages or aborting the incomplete transaction and restarting the transaction. To the client, the pair looks like a single system. The key property of these systems is that the application is unaware that it is running on a system pair; little or no special programming is required. There is a close analogy between this idea and the idea of process pairs discussed in Chapter 3, Section 3.7.
System pairs can be configured in many ways. Figure 12.8 illustrates the most common designs. The simplest design is to have a single system pair: a primary system and a backup system. The backup is sometimes called a hot standby system. The data, applications, and sessions are all duplicated at the backup. The client is in session with both the primary and the backup. Ordinarily, the client sends requests to the primary, and log records generated at the primary are sent to the backup and applied to its state. The backup is continually doing the restart REDO scan, applying the log records to the session state and to the durable storage state.1 When the primary fails, the backup takes over almost instantly. The network is up, the resource managers are up, and the database is current. The backup completes the REDO scan and then rolls each application back to its most recent persistent savepoint. It then concurrently completes any committing or aborting transactions and starts accepting work from the network. Typically, the takeover requires a few seconds or minutes; by that time, the clients are becoming impatient. It is essential that the takeover complete before the network begins to time out and disconnect from the systems.

In the basic system pair design, the backup is wasted if the REDO scan does not consume most of the backup system’s resources. In these designs, the backup is often used to run other applications while it is tracking the primary. The backup can offer fuzzy read-only query service (degree 1 isolated) to the backup database for decision support applications. It can run utilities that ordinarily run on the primary, such as archive dumps and log change accumulations. The backup can also be used for other applications. When the backup becomes the primary, these lower-priority activities are suspended.
A symmetric arrangement of system pairs is possible if the application and data can be partitioned into regions such that most transactions access only one region. In this arrangement, each network node acts as primary for one region and backup for another. Regional banks, distributors, hospitals, governmental agencies, and phone companies all have been able to exploit this symmetric design. If the application is not partitionable, then the symmetric design will cause most transactions to involve requests to multiple network nodes. The cost of these remote requests in both time and processing power will likely be unacceptable. In such cases, the single primary-backup design will be more efficient.
Any pairing of systems accomplishes a symmetric design. In an n-node network, each node becomes primary for 1/n of the database and the backup for another fraction of it. Another design has a central, very large, and very reliable hub with many satellites. The hub is the backup for the satellites. The main point is that any directed graph can be used as the pairing mechanism.
Another design alternative applies the log spooling technique to achieve high durability rather than high availability. The primary sends a copy of its log and archive dumps to a remote electronic vault that can be used to reconstruct the database at a (much) later time. Support for vaulting is a consequence and an extra benefit of the basic design.
System pairs are a kind of replicated data system. However, they differ from replicated data systems in two key ways:
No partitions. System pairs assume the backup can reliably tell if the primary is unavailable (perhaps with operator assistance).
Replicate programs, network, and data. The backup system replicates applications and the network connections, as well as the data.
These two criteria are essential to allow the backup system to perform takeover and deliver service when the primary fails.
12.6.1 System Pair Takeover
On demand, the backup can become the primary. The primary system operator can use a SWITCH command to gracefully transfer control. This command causes the primary to stop accepting new work, finish all completing transactions, and then place a SWITCH record in the log. After that record goes into the log, the old primary becomes the backup of the pair. The old backup becomes the primary when it processes the SWITCH record. This takeover is used for operations on the primary, such as installing new software and doing hardware or software maintenance. It is even used when moving the primary to a new building.
The unscheduled switch is more interesting. In a local cluster where the computers are connected via many reliable LANs, it is a safe assumption that if the backup cannot communicate with the primary, then no one can, and the primary is unavailable. This is the assumption underlying the process-pair design of Chapter 3. But if the processors are geographically remote, it is much more difficult to distinguish between a WAN partition and the failure of the primary node. When log records stop arriving from the primary, it could be because the network failed or because the primary failed. There is no simple way for the backup to distinguish these two cases. In the case of a broken network, called the network partition case, the backup should not take over; the primary is still operating. But when the primary actually fails, the backup must take over, and quickly. This problem has plagued the distributed database community for decades. It all comes down to a majority vote, but with only two systems, there is no majority. The system-pairs design solves the problem by giving the operator the third and deciding vote. If someone can replace this person with a robot, so much the better.2
In such ambiguous cases, the operators of the primary and the backup consult one another and decide that the primary is dead. If the primary is still up, it is told to stop accepting new work and to abort all active transactions. The backup is told that it is the primary. The new primary (old backup) continues the REDO scan to the end of its input log. At that point, all live transactions have had their recoverable state redone in the backup system, which now becomes the primary system. The transaction manager then reestablishes the prepared and persistent transactions and undoes any work that is not persistent.
To expedite this UNDO scan, no transaction should do very much work between persistent savepoints. That is, if a transaction has done one hour of forward processing, it may well take an hour to undo the work. If that same batch transaction is broken into many mini-batch transactions or into a transaction with many persistent savepoints, the backup system can reestablish the most recent persistent savepoint at takeover. To do so, it undoes the transaction back to that savepoint, reacquires the transaction’s locks, and then begins offering service.3 This results in much higher availability, because it minimizes the repair time for a fault.
The new primary now informs the local applications that they are now primary and should start accepting work from the network. At the same time, it initiates tasks to complete any transactions that are committing or aborting.
12.6.2 Session Switching at Takeover
Now let us turn to the issue of the session pairs and the client’s management of messages arriving from the system pairs. In Figure 12.9, the client either is very intelligent or is attached to an intelligent front-end processor. In either case, things look the same to the system pair: both the primary and the backup system have a session with the client. The client application sees the system pair as a single logical session to a single logical system. This logical session is implemented by a session pair. Each of these two sessions can go to a process pair at the fault-tolerant hosts; thus, the client can actually be in session with four server processes that act as a single logical process. The front-end processor, or some fancy software in the client, converts these multiple physical sessions into one highly available logical session, masking the complexity of session pairs from the client application. Let us call this software or hardware the client’s clerk. The clerk’s logic is based on session sequence numbers stored by the clerk. These sequence numbers detect lost and duplicate messages travelling on the primary session and correlate messages retransmitted on the backup sessions.
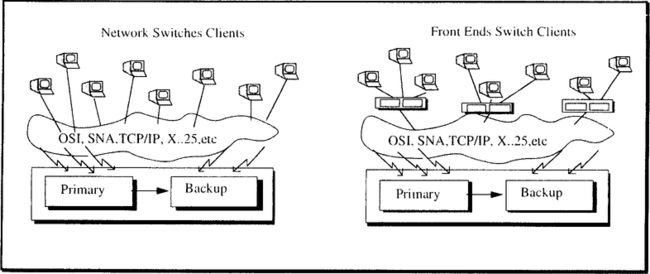
The session pair is managed as follows: the clerk sends all messages to the primary of the system pair via the primary session. During normal processing, the backup session is idle at the clerk; the backup maintains the status of the primary session’s outbound messages and sequence numbers by reading the log records (refer to Chapter 10, Subsection 10.3.3, on recoverable sessions). At takeover, the backup resends the oldest unacknowledged message on each client session. This logic is part of the backup communication manager that tracks the status of each session. The backup communication manager deduces these messages from the log. The messages travelling on the backup sessions implicitly tell the clerks that the backup has become the primary. The previous message has the previous message sequence number and, consequently, synchronizes the backup session to the sequence numbers of the new primary. If the sequence numbers do not match up, standard session recovery can be used to synchronize them (see Subsection 10.3.3).
This logic clearly places a burden on the clerk (client): it must have a durable store for its session sequence numbers. That is why the typical design uses fault-tolerant front-end processors for the system-pair clients, as diagrammed at the right of Figure 12.9. This clerk-system-pair logic is exactly the session-pair logic for process pairs in the fault-tolerant model, as described in Chapter 3, Subsection 3.7.4.
12.6.3 Configuration Options: 1-Safe, 2-Safe, and Very Safe
There are several ways to configure system pairs. They can be configured for high throughput, high availability, or high integrity. These three options are respectively called 1-safe, 2-safe, and very safe. The difference centers around transaction commitment. If a transaction’s commit response is returned to the client before the commit record arrives at the backup, the transaction might commit at the failed primary but be aborted by the backup after takeover. Such transactions are called lost transactions. The three designs trade better response time or availability for the risk of lost transactions. The three options, depicted in Figure 12.10, are as follows:
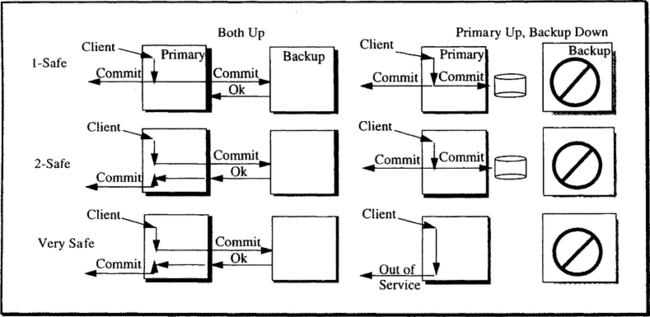
1-safe. In a 1-safe design, the primary transaction manager goes through the standard commit logic and declares completion when the commit record is written to the local log. In a 1-safe design, throughput and response time are the same as in a single-system design. The log is asynchronously spooled to the backup system. This design risks lost transactions.
2-safe. When possible, the 2-safe design involves the backup system in commit. If the backup system is up, it is sent the transaction log at the end of commit phase 1. The primary transaction manager will not commit until the backup responds (or is declared down). The backup TM has the option of responding immediately after the log arrives or responding after the log has been forced to durable storage. The 2-safe design avoids lost transactions if there is only a single failure, but it adds some delay to the transaction commit and consequent response time.
Very safe. The very safe design takes an even more conservative approach: it commits transactions only if both the primary and the backup agree to commit. If one of the two nodes is down, no transactions can commit. The availability of such systems is worse than the availability of a single system; however, very safe avoids lost transactions unless there are two site disasters. Although some systems offer very safe as an option, these authors know of no one who uses it.
The 1-safe design has the virtue of supplying high availability with a few lost transactions. When the primary returns to service, it is possible for the two systems to compare logs and report on any lost transactions. This is similar to the heuristic and operator commit decisions discussed earlier.
If the system is configured as 1-safe, transactions may not be durable and distributed transactions may not be atomic, because commitment at the primary does not assure commitment at the backup. If the primary fails, the transaction may be committed at some nodes but aborted at others. In the distributed case, the commit protocol sends messages to the other nodes as part of the commit; as a result, there is little performance justification for 1-safe distributed transactions. If distributed transactions are 2-safe, the consistency and commit issues are just the standard two-phase commit and fault-tolerant (non-blocking) commit designs.
The rationale for 1-safe designs is that 2-safe causes unacceptable delays. System pair designs generally postulate dual high-speed communication lines between the primary and the backup. It is assumed that these dual lines can tolerate any single communication line failure. The lines have round-trip latency of less than 100 ms and bandwidth of 100 KB per second, making the net latency of a transaction with 10 KB of log about 200 ms. For most applications, this added delay is imperceptible. Consequently, most system pairs are configured as 2-safe systems. They provide the ACID properties, high availability, and high reliability.4 They also have no lost transactions. Given the declining cost and increasing bandwidth of communications lines (as described in Subsection 2.2.3), it seems likely that by the year 2000, only 2-safe designs will be used.
12.6.4 Catch-up After Failure
The discussion of takeover is almost complete, but one issue remains. When a failed system is repaired, how can it return to service? The fundamental idea is that a backup system redoes the log from the time the system failed; once the repaired system has caught up with the current log, it can assume the role of an active backup.
In a very safe design, there is no real catch-up: since both systems are in the same state, there is no catching up to do. Rather, there is just a system restart once the failed system is ready to return to service.
In a 2-safe design, the current primary is saving all the log records needed by the backup until the backup is repaired and the communication link(s) between the primary and backup are repaired. Then the primary sends all recent log records to the backup, which applies them to its state as part of the REDO scan. Once REDO is complete, the backup declares itself caught up and assumes the role of a functioning backup. Should there then be a failure, the backup can switch to being the primary. A failure of the backup during catch-up just extends the catch-up work. A failure of the primary during catch-up is treated as a double failure and interrupts service.
Catch-up for 1-safe designs is more complex. If the backup failed and the primary continued service, then there is no inconsistency, and the catch-up is just like the 2-safe design. If the primary fails in a 1-safe design, the backup will take over with the risk of some lost transactions—transactions that committed at the failed primary but were not committed at the backup. When the primary is repaired and wants to return to service, it must try to bring its state into synchrony with the new primary. This means undoing any lost transactions. Lost transactions can be detected by comparing the logs of the primary and backup systems. Once detected, the backup undoes those transactions and announces the lost transactions to the system administrator. Once this is complete, the backup can proceed with catch-up.
12.6.5 Summary of System Pair Designs
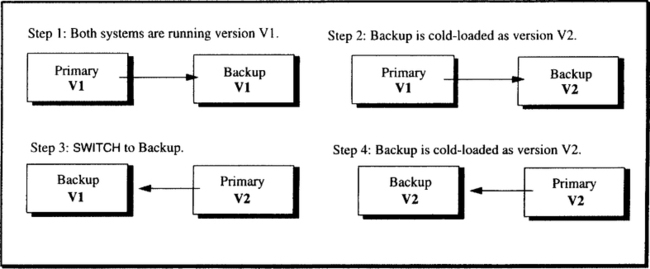
System pairs protect against environmental faults by being geographically dispersed. Weather, utility outages, and sabotage are unlikely to fault both systems at the same time. In addition, system pairs having two sets of operators protect against many forms of operator fault. They allow systems to be taken offline for software or hardware maintenance and even for physical relocation of the systems. Figure 12.11 gives an example of installing new upward-compatible software without interrupting service. Similar techniques apply to database reorganization and some other logical changes.5 To tolerate physical and logical reorganization, the log records must be made more logical than the simple physiological log scheme described in Chapter 10, (Subsection 10.3.6). The log records must represent the abstract transformations of the data if they are to be applicable to databases that have been reorganized. Devising such a scheme is an active area of database research today.
12.7 Summary
The previous three chapters developed the concepts and techniques of transaction managers, explaining how they deliver atomicity, consistency, and durability (the ACI of ACID). This chapter focused on exotic features present in some of the more modern transaction managers. First was openness, the ability of one vendor’s transaction manager to interoperate with that of other vendors; next was the ability to write portable resource managers against a standard transactional API. CICS has an open transaction manager (based on the SNA/LU6.2 protocol and CICS API). Since CICS is the best-selling TP monitor, all others are more or less forced to interoperate with it. This, in turn, forces them to support an LU6.2 gateway and, in doing so, become open. This openness will be accelerated by the adoption of the ISO/TP and X/Open DTP standards. They will force most vendors to implement such gateways and standard resource manager interfaces to their systems.
The next exotic topic was fault-tolerant, or non-blocking, commit coordinators. This turned out to be a simple application of process pairs. The commit coordinator becomes a process pair, checkpointing its state to the backup at critical points of the commit protocol.
Next, the issue of transfer-of-commit authority was discussed and shown to be a simple matter of reversing the polarity of sessions. Transfer-of-commit also had the benefit of saving messages, yielding the linear commit protocol. That led to a general discussion of commit performance. Of the several optimizations covered, the three key techniques were read-only optimization, parallelism, and the linear commit protocol.
The chapter ended with the topic of disaster recovery systems, introducing the concepts of system pairs, 1-safe, 2-safe, and very safe. This is an area of active research, but it promises to yield the next order of magnitude in system availability. It neatly handles environmental, operations, and hardware faults. In addition, it can mask some software faults.
12.8 Historical Notes
As far was we can tell at this writing, it was Nico Garzado who invented the two-phase commit protocol while implementing a distributed system for the Italian social security department. He had to solve the atomicity problem and, in doing so, invented the protocol. He told his friends about it, and gradually word of the problem and its solution spread. By 1975, the problem was well understood, and papers began to appear describing elaborations of the protocol.
Most of the more modern work on transaction processing algorithms belongs in this exotics chapter; the basics covered in the previous chapters were well understood by 1975. There have been many attempts to write gateways to closed transaction managers, and the gateway section reflects the folklore of those attempts, as well as the architecture implied by the ISO-TP and X/Open DTP designs.
Alsberg and Day [1976] introduced the idea of system pairs but seem not to have developed it much beyond that paper. Dale Skeen [1981] is credited with inventing the definition and algorithms for non-blocking commit coordinators in distributed systems. Tandem shipped such a transaction manager (working as a process pair) several years earlier. Andrea Borr is credited with that part of the design [Borr 1981].
Optimization of the two-phase commit protocol is a cottage industry. It was done quietly for several years, but as others rediscovered, named, and published the algorithms, the original inventors stepped forward to claim credit. The situation with Skeen and Borr is just one example of that phenomenon. The root problem here has been the considerable financial value of these optimizations. The original CICS commit mechanism had the linear commit optimization (the last transaction manager optimization) and a read-only optimization in which participants could vote on reply. The design of that protocol was largely the work of Pete Homan. Bruce Lindsay did a careful study and explanation of two-phase-commit protocol optimizations in his class notes [Lindsay et al. 1979]. Both Lampson [1979] and Gray [1979] published an analysis showing how to minimize commit messages by having the coordinator or the participant remember its state. This provides one-, two-, three-, and four-message commit protocols. Presumed abort was not well understood until Mohan and Lindsay clearly showed the log-force trade-offs among the various optimizations [Mohan and Lindsay 1983]. Section 12.5 of this book derives from their analysis. The group commit protocol [Gawlick and Kinkade 1985] and many other logging optimizations invented by 1975 were not described in the open literature because of their clear commercial value. In fact, the logging chapter of this book (Chapter 9) contains the first public description of some of them. The discussion of transfer-of-commit follows the design of Rothermel and Pappe [1990].
Disaster recovery systems offer a fertile ground for new algorithms and promise much higher availability. Several groups are actively pursuing these designs: the RDF group at Tandem, typified by Lyon [1990]; the IMS group at IBM, typified by Burkes and Treiber [1990]; the RTR group of Digital [Digital-RTR 1991]; and a group at Princeton, typified by Garcia-Molina and Polyzois [1990]. It is fair to say that disaster recovery and generalized transaction models (sagas, contracts, etc.) are the most active areas of transaction processing research. The presentation in Section 12.6 borrowed heavily from the ideas and terminology of Tandem’s RDF group.
Exercises
1. [12.2.1, 5] How does the discussion of the closed transaction managers relate to (a) the last transaction manager optimization, and (b) transfer-of-commit?
2. [12.2.2.1, 5] Why is it so much harder to build a transaction gateway to a queued transaction processing system?
3. [12.2.3, project 30] Assuming you have access to a local SQL database system, write a gateway to the transaction manager described in the Chapter 11. The gateway should do trid translation and should handle the Prepare(), Commit(), Abort() callbacks from the local transaction manager and from the remote one.
4. [12.2.3, 10] The discussion of the gateway for an open transaction manager mentioned that if the same trid visited a node twice from two ports, it might get two trids and deadlock with itself. Explain the scenario, and say why it will result in abort rather than inconsistency.
5. [12.3, 10] (a) How many messages are added to the commit protocol by a non-blocking commit coordinator? (b) Why are the acknowledgment messages needed?
6. [12.3, 10] Heuristic commit and abort resolve in-doubt transactions in an ad hoc way. Why bother with two-phase commit if failures are handled in this way?
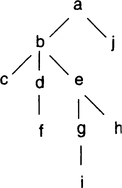
7. [12.5, 10] Consider the following commit tree, with each node representing a transaction manager with one log. What is the optimal mix of parallel and linear commits? What is the minimum message cost commit strategy and what is the minimum root delay message strategy?
8. [12.6, 10] This exercise requires an understanding of Chapter 7. (a) Give an example of a transaction execution that is read-only with respect to a resource manager, but that will not be acid if the read-only commit optimization is used for this resource manager. (b) Repeat the exercise, replacing the term RM with TM.
9. [12.6, 10] This exercise requires an understanding of the chapters on isolation. Suppose reads are allowed on data at the backup of a 1-safe or 2-safe disaster recovery site. What kind of isolation is provided to the reader?
10. [12.6, discussion] You have just sold a disaster-recovery system to a customer. Unfortunately, he read Chapter 3 after he signed the contract, and he discovered that operator errors are a major source of system failures. In addition, operators are expensive. So he has decided to eliminate operators. You have been offered a cost-is-no-object contract to replace the operator with a robot. The robot must decide when the primary system is down, and command the system to switch to the backup. You, of course, can prove that no such robot can be built, but you take the money anyway. What do you do next?
11. [12.6, 15] Some systems run two copies of the same application on one physical computer. If one copy of the system fails, the other takes over and continues offering service. For example, cics has such an option. Explain when this is a good idea.
Answers
1. The scheme of making the closed transaction manager last is the same as the last transaction manager optimization and transfer-of-commit.
2. Queued systems do not allow conversational transactions. So the gateway cannot easily track the progress of the transaction between the request and the commit steps.
4. Suppose your organization has an sna/cics network with nodes all over the world. Suppose my organization has a DECNet/DECdtm network with nodes around the world. Suppose that your computation enters my network at a DECdtm↔Lu6.2 gateway at the San Francisco node and at the Stuttgart node. Then the two entry points (gateways) will assign different trids to your one sna/cics trid. These two trids will have two independent process trees in my network and will behave like independent transactions. In particular, they will wait for one another if they try to lock the same database record. So, this may result in deadlock. They may both commit or both abort, but they will not see inconsistent information or make inconsistent transformations of the state.
5. (a) Two message pairs. (b) The acknowledgments are not needed if one only wants single-fault tolerance, but they give a degree of double-fault tolerance (primary fails and message is lost).
6. Good question! Some argue that 2-phase commit handles the 3% of the transactions that abort; it allows resource managers to vote at commit and allows distributed transactions to do unilateral abort on timeout. Since node failures are so rare, how they are handled is not much of an issue. Perhaps only 100 transactions in a million will be mishandled in this way, and the heuristic decision will guess right on half of those. The rest can be cleaned up by people if anyone cares. Well, that is the answer. Now you decide.
7. Minimum root delay time = fully parallel
Minimum Cost: Use Linear on path a→b→e→g→. Use parallel-general on the others.
8. (a) The read-only optimization implies that the resource manager has no work to do at commit. This, in turn, implies the transaction is not using two-phase locking. Imagine a transaction, T, that reads a data item, A, in one RM, and reads an item, B, in another RM. A second transaction, T2, can read and change B and then A in the interval between T1’s two reads because T1 has no long-term locks. The resulting history has a wormhole and so is not isolated (see Subsection 7.5.8.3) (b) Replace RM with tm in answer (a).
9. Degree 1 isolation; the reader gets the equivalent of browse-mode locking at the primary. If the reader acquires locks on the data, it may prevent an updater at the primary from being able to commit. In a 1-safe scheme, this will lead to inconsistency of the primary and the backup. On a 2-safe system, it will cause the primary site transactions to abort or time out. In either case, it is a bad idea to allow anything more than browse-mode access to data on the backup site.
10. (1) Take the money and run to Rio de Janeiro (and change your name). (2) Take the statistical approach used by fault-tolerant systems. Install many communications links between the two sites, so that the following assertion is likely true:
Then install an I’m Alive program at each site. If the I’m Alive messages stop arriving, the other site is dead. In that case, the robot sends a kill message on all links to it, and after a discreet time (say, 50 ms), assumes authority over the network.
11. It is a good idea when hardware (processor and memory) or communications are very expensive (it saves buying a separate computer), and when a major source of failure is software above the operating-system level. This scenario is typical of “mainframes” today and is likely to be typical for the first half of the 1990 decade. It is not true of cluster systems such as those from dec, Tandem, Teradata, and others. It is also particularly appropriate for transaction processing systems like cics, which have no fault containment (the tp monitor and all applications run in one address space with no protection among them). Again, such tp monitor designs are not likely to prosper in the next decade.
1This design, in which restart is a pure REDO scan followed by an UNDO scan, is one of the benefits of compensation logging.
2In some designs, the communications processors that front-end the primary can sense and communicate the primary failure to the backup. There are many communications processors and they are richly connected to the primary, the backup, and the network. Therefore, a partition can likely be detected by a majority of them. However, they cannot announce a network partition. If all lines between the primary and backup fail, the backup is sometimes forced to guess the situation: did the network fail, did the primary fail, or did both fail? In the vaxcluster, a disk controller may be given a vote to resolve a 2-processor situation.
3This book originally described a design that tried to reconstruct the locks of all live transactions at restart. But there were too many problems with that design. The best we could do was to reconstruct the locks of persistent savepoints including prepared transactions, ims/xrf does reconstruct locks at takeover and so quickly offers service to new transactions.
4In the near term, the common use of slow (64 Kb) communications lines and the high cost of communications software (≈ 10 instructions per byte) encourage 1-safe designs. But as processors and communication lines become faster, the 2-safe design will dominate.
5Here, upward-compatible means that the changes can understand objects in the “old” format, since the persistent data and messages will continue to have that format.