
13.5 Exotics
As mentioned in the beginning of this chapter, a large variety of methods exists for moving data back and forth between main memory and external storage. Since the majority of current (transaction processing) systems uses the read-write technique, all the others have been relegated to the exotics section. This does not mean they are generally inferior or less suited for transaction processing; with new storage technologies, the picture may change significantly.
The various techniques to be considered here have tried to improve on different aspects of simple read-write files, depending on what the designers thought to be important. There are two categories that have received particular attention.
The first category has to do with the issues of atomicity and error recovery. As noted before, writing a block to disk is not an atomic operation, and making each individual write atomic is unacceptably expensive. Consequently, the state of the database after a crash must be considered incorrect with respect to all integrity constraints with a scope larger than one page, and a crash may even leave blocks on disk unreadable. A whole family of techniques subsumed under the name of side file tries to avoid the unpleasant consequences of the block write interface, thereby making recovery simpler, at least at the conceptual level.17
The second category has already been mentioned in the introduction to this chapter: the single-level store. With new machine architectures using long (64-bit) addresses, this concept might become much more important than it is now. A brief discussion of the pros and cons is therefore presented here.
13.5.1 Side Files
The name side files conveys the basic, simple idea: objects are not modified “in place”; rather, the new value is written to a new location that was previously unused. As long as the transaction having performed the updates has not yet committed, the old object versions are available at their old locations. Consequently, nothing needs to be done in case the transaction aborts or the system crashes. Since all updates are written “to the side,” a failure interrupting a block write cannot cause any problems, because the old version is still available in a different location. At commit time, all references to the old object versions must be replaced by references to the new ones. The critical problem is how to make this transition from the old object versions to the new versions atomic. It needs to be atomic, of course, because otherwise some of the objects modified by a transaction could be referenced in their new states, while the others are still in their old states—a violation of the isolation property.
Put in this brief way, the idea sounds rather vague and not simple at all; several questions are raised: What is an object? What is a reference to an object? How can the new location be determined? And so on. But at the level of the block-oriented file system, things can be kept quite easy. This the list of requirements to be met when applying the side file idea to the block-oriented file system:
Update. A modified block is never written back to the slot it was read from. Rather, it is written to an empty slot in the side file. Conventional file systems, in contrast, do “update in place.”
Versioning. After the new version of a block has been written to the new slot, both the old and the new version are kept available. The duration of that depends on which particular side file technique has been chosen (see below).
Addressing. Because of versioning, there needs to be an explicit mapping of the block numbers used at the file system interface to the slot numbers on disk. Note that with the basic file system described at the beginning of this chapter, this mapping is a static 1:1 relationship. The side file concept, however, implies that a block due to updates is stored in a different slot than before. In particular, while there are two versions, two different slot numbers are associated with one block number. This is illustrated in Figure 13.22.

Propagation. At some point, the new version of the block becomes the only (current) version, which means the old version is given up. As was pointed out, this must happen in an atomic, recoverable way.
The problem of mapping block numbers to slot numbers is closely related to the problem of choosing empty slots for modified blocks. Let us gradually develop a solution by proceeding from a very simple and inefficient approach to a more elaborate one. For simplicity, assume two files, as in Figure 13.22: the original file and the side file. Of course, at the read-write interface there is only one file, but its implementation uses two sets of slots, which are referred to by these names.
13.5.1.1 A Simplistic Approach to Using Side Files
The naive method works as follows: each block read operation first looks in the side file to check if the most current version of the block is there. If not, it must be in the original file, from which it is read. For both files, there must be a mechanism that determines which slot to look in for a given block; for the moment, it is sufficient to assume that some such address translation is done. The block write operation must distinguish two cases: if the block was read from the original file (which means there was only one version of the block), a free slot in the side file is found, and the block is written to that slot. If the block was already in the side file, it is rewritten to this very same slot—the number of versions per block never exceeds two.
After a while, the contents of the side file are copied to the original file; the side file is empty after that. This process of copying the new block versions needs some additional remarks. First, it must be done in regular intervals in order to avoid too large a discrepancy between the original and the side file. Note that in case of a crash, the side file is thrown away, and restart begins with what is in the original file. On the other hand, copying should not be done too frequently, because it is expensive. Thus, the copying interval basically is determined by load balancing considerations, weighing the overhead during normal processing against the risk of higher expenses at restart. Second, copying can only be done with an action-consistent database, because each update action potentially affects more than one block, and it must be guaranteed that a consistent state is copied to the original file.18 The virtues that this has for logging and recovery are described in Chapter 10. Third, copying the side file can be made atomic simply by repeating it in case it should get interrupted by a crash (copying blocks is an idempotent operation).
There is a little twist here: most of the time, the side file has to be thrown away after a crash. Only if the crash happened while copying the sidefile to the original must the process be repeated. Hence, there must be a way to recognize at restart that copying was in progress. Exercise 20 asks the reader to design an algorithm that makes the copy process crash resistant and, thereby, truly atomic.
13.5.1.2 The Differential File Algorithm
Differential files are an implementation of the side file concept that is very close to the simplistic approach just outlined. But while the first method requires two block read operations for all blocks that are not in the side file (and, given the periodic emptying of that file, the majority of blocks at any given instant are in the original file only), the differential file algorithm uses an elaborate scheme to decide whether or not a block is in the side file at all. It is based on probabilistic filters and works as follows (see Figure 13.23).
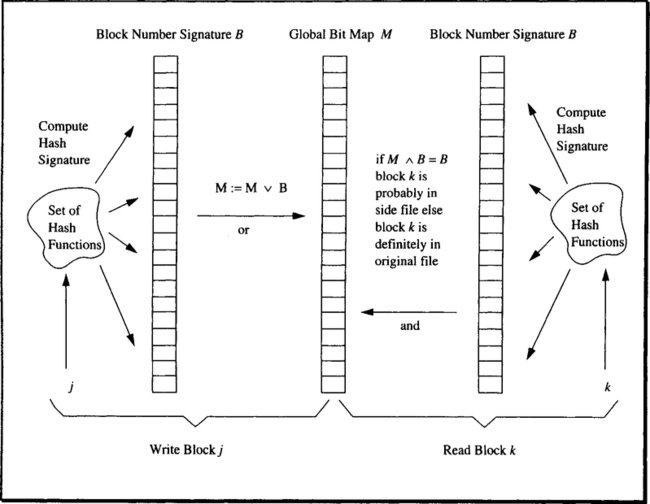
There is a bit vector M maintained by the differential file manager, which contains a “large” number of bits compared to the number of blocks that are modified on the average between two subsequent copies of the side file to the original file. Assume the vector has m = 105 bits. After the side file has been copied successfully, the bit vector is set to FALSE. In addition to that, there is a set of hashing functions that take a block number as a parameter and produce an integer between 1 and masa result. The actual number of hashing functions depends in a nontrivial way on the update frequency and the length of the copy interval. For the present discussion, it is sufficient to assume hash functions H1 through Hf.
Now consider block j, which gets modified for the first time since the side file was last copied. The write block operation puts the block into a slot of the side file. Furthermore, for each of the hash functions, the following assignment is made (j still denotes the number of the modified block): M[Hi(j)] = TRUE.
It should be easy to see what that does. As shown in Figure 13.23, the hash functions applied to the block number define another bit vector, B, of length m, in which those bits are set to TRUE, whose index is the result of one of the hash functions. B is referred to as the signature of block j. The operation makes sure that all bits set in B are also set in M, which formally is a bit-wise disjunction of M and B. M thereby accumulates the signatures of all modified blocks.
The rest is straightforward. If a block k is to be read, the addressing issue comes up: is its current version in the side file, or is there only one version in the original file? To decide that, the signature of k is computed, using the hash functions. Then the conjunction of the signature B and M is determined. If the result is equal to the signature—that is, if all its set bits are also set in M—then block k has probably been written to the side file. One cannot be sure for the following reason: the bits in M corresponding to the bits in k’s signature have been set either by block k being written to the side file, or by a number of other blocks whose signature bits happen to cover those of k’s signature being written. On the other hand, if some bits of B are not set in M, then it is clear that k’s signature has not been ORed to M, which means block k is in the original file only.
Apart from the CPU cycles required to compute the signatures and make the comparisons, then, the only access overhead here is due to read accesses to the side file for blocks that, in fact, do not have a new version there. Mathematical analysis shows that, for reasonable assumptions with respect to update frequencies, length of copy intervals, and so on, the probability of such useless accesses to the side file can be kept in the 10% range.
13.5.1.3 The Shadow Page Algorithm
Even if the number of unnecessary read operations can be kept low, the differential file technique as described in Subsection 13.5.1.2 suffers from a major performance penalty: the necessity to explicitly copy the side file back into the original file causes a large amount of additional I/O, and because of the requirement to copy action-consistent states only, there can be no update actions during the copy process. The shadow page algorithm tries to overcome that problem to a certain degree. It still uses the basic idea of writing changed blocks “to the side,” but there is no longer a static distinction between side file and original file. Rather, there is only one block-oriented file, and each slot in that file can be in any of three states:
Empty. Currently, the slot holds neither an old nor a new version of a block, so it can serve as a side file slot if required.
Current block image. The slot contains the version of a block for which no update has been performed recently. At the moment, therefore, the slot is part of what was called the original file.
New block image. The slot contains the updated version of a block for which the old version exists in some other slot.
Again, the role of slots can change dynamically. This obviously requires some additional data structures to keep track of which block is where and the contents of each slot. The following paragraphs give a brief description of the approach taken in the shadow page algorithm (see Figure 13.24).
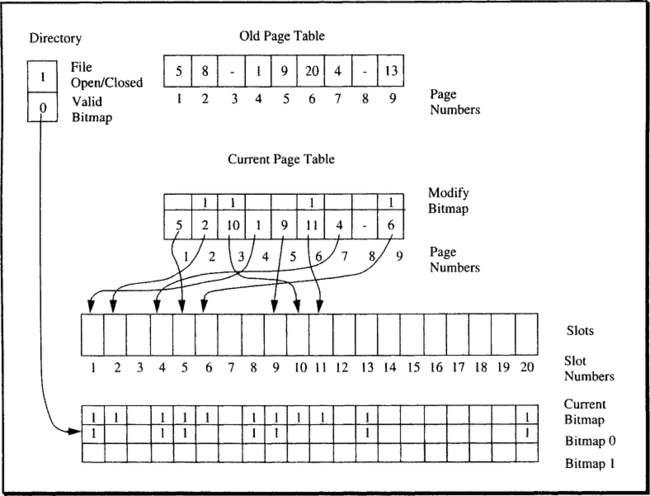
As Figure 13.24 shows, the mapping between block numbers and slot numbers is done via the page table. It is an array with one entry per block19 of the file; each entry contains the number of the slot that holds the current image of the respective block. If the block has not yet been allocated, the entry contains a NULL pointer. The slots are organized as an array, using a fixed or extent-based allocation scheme as described for the basic file system. In addition, there is a bitmap with one bit per slot, indicating whether or not the corresponding slot currently holds a block image or not. In other words, a slot is marked “free” in the bitmap if its number does not occur in an entry of the page table. Both the page table and the bitmap are stored in reserved slots on disk.
A file using the shadow page scheme is either closed for update (which means that no write operations are allowed on it), or it is open for update. Its current state is recorded in a data structure called directory in Figure 13.24; this data structure is part of the file descriptor explained in this chapter. A file that is closed for update always is in an action-consistent state; after it has been opened for update, it can be closed again only when an action-consistent state is reached. The time between opening the file for update and closing it again is called an update interval.
Let us now assume a file that is is about to be opened for update. There is one instance of the page table and one instance of the bitmap consistently describing the allocation of blocks to the slots. The file is marked as “closed” in the directory. When a file is opened, a complete copy of the current (action-consistent) state of the page table is first written to another reserved area on disk (this is called old page table in Figure 13.24). The bitmap is copied into main memory; this can be done even for very large files. The in-memory version is called current bitmap in Figure 13.24. As a last step, the file is marked as open for update; this means toggling the corresponding bit in the directory and writing the directory back to disk in an atomic fashion, using the stable write method described in Chapter 4.
While the file is open, the current page table, which is the one used to actually translate block numbers into slot numbers, is augmented by an additional data structure with one bit per entry of the page table. Initially, all bits are are set to FALSE; as soon as the corresponding block is modified, the bit is set to TRUE. This is how the data structure keeps track of which blocks have been modified (and thus relocated to a new slot) during the current update interval.20 Whether this data structure, which is called modify bitmap in Figure 13.24, is kept as a separate array or whether the bits are sub-entries of the page table entries makes no difference.
Let us now assume the following declarations:

A block read operation with a given block_no is effectively executed as a slot read operation of the following type:
The block write operation has to go through some additional logic:

Here, get_free_slot is a routine that delivers the number of a free slot and sets the corresponding bit in the current bitmap to mark it as taken. Thus, a block is written to a new slot after the first time it is modified within an update interval. All subsequent modifications of the block are written to the same new slot. Figure 13.24 shows the contents of the data structures after the blocks with block numbers 2, 3, 6, and 9 have been modified.
Now, how is action consistency in the presence of crashes achieved with the shadow page algorithm, given the fact that the blocks of the file, as well as the blocks containing the page table, are physically written according to some buffer replacement policy, and that an update action typically changes more than one block?
First, consider the case of a crash in the middle of an update interval. Upon restart, the file directory, which says the file was open for update when the crash occurred, is read. Recovery can then be performed by executing the following steps:
Restore page table. The “old page table” is copied into the location of the current page table, thereby restoring the block number mapping at the beginning of the update interval. This step is idempotent.
Restore bitmap. Nothing needs to be done, because the current bitmap was entirely kept in main memory.
Change directory. The directory switch is set to “closed for update,” and the corresponding block is written using a stable write operation.
As a result, the file is returned to the state it was in at the beginning of the update interval. Note that the contents of the modified blocks are not actually removed from the new slots they were mapped to; restoring the page table and the free space bitmap simply makes sure these new slots do not correspond to any valid block number and are marked free.
There are two reasons why, after a certain number of block changes, the update interval must be completed: First, the amount of work lost in case of a crash must be contained; and second, the system should avoid running out of free slots. Closing a shadow page file for update has to be an atomic action. This is to say that either all updates applied to it during the update interval must be correctly mapped to disk, or the file has to return to the state at the beginning of the update interval by means of the procedure just sketched; there is no other way to guarantee an action-consistent file in the presence of system crashes. The steps required to close a shadow file atomically are almost mirror images of the steps executed at restart after a crash:
Force block bufferpool. All modified blocks that have not yet been written to their new slots are forced to disk.
Force page table. All blocks of the current page table that have not been written to their place on disk are forced. Note that the old page table remains unchanged.
Force bitmap. After successful completion of the update interval, the slots containing the old images of changed blocks must be given up. In other words, the bitmap describing the overall new state of the file must mark them as free. As a result, the entries in the current bitmap corresponding to old block images must be set to 0 before writing the current bitmap to disk. This can be done efficiently using an ancillary data structure, which, for simplicity, is not introduced here. The key point is that the contents of the current bitmap do not overwrite the bitmap on the disk from which they were loaded at open time. Which disk the contents were loaded from is noted in the directory. As Figure 13.24 shows, there are two bitmaps on disk, bitmap 0 and bitmap 1, written in an alternating fashion. If the variable valid_bit_map indicates the bitmap used at open time, the current bitmap is written to the other bitmap, that is, the one with index (1 exor valid_bit_map).
Change directory. The entry valid_bit_map is set to the alternate value to point to the new valid free space bitmap; the file switch is set to closed. The directory block is written using a stable write operation.
It is easy to see that all the updates performed during the update interval will not take effect until the last step has been successfully executed. If anything goes wrong along the way, the restart procedure takes the file back to the previous state. Thus, the problem of writing a large number of modified blocks to disk atomically is reduced to writing one block (the directory) to disk atomically; this is what the stable write mechanism does. But the basic idea is the same for all the data structures involved: as long as the state transition to the new consistent state has not been completed, there must be a copy with the old (consistent) values in some other place on disk; hence, the name of the shadow page algorithm.
13.5.1.4 Summary of Side File Techniques
As explained in Chapter 10, side file techniques, and the shadow page mechanism in particular, allow logical logging at the level of, say, SQL commands. Side files provide an action-consistent database on disk even after a crash, which, in turn, means writing sets of pages in a pseudo-atomic manner. Consequently, each side file mechanism comes with a crash recovery mechanism that guarantees action consistency; based on that mechanism, a logical logging scheme can then do transaction-oriented recovery. Despite the elegance and compactness of logical logging, with current disk and memory technology, that technique cannot make up for the inherent disadvantages of side files. Let us summarize the salient points of the problems of side files in large databases, using shadow paging as an example.
First, there needs to be a page table that translates block addresses into slot addresses. For large files, these tables cannot be guaranteed to fit completely into main memory. As a result, they are read and written on a per-block basis, thus increasing the average cost of a block read operation. Second, reallocating blocks upon modification destroys data locality (clustering of data on disk), thereby increasing the number of (expensive) random block I/Os. And third, the necessity of periodically closing the file to get rid of shadows and to definitively install the new versions of blocks adds significantly to the cost of normal processing. Note that closing a file (and reopening it) as just described effectively creates a checkpoint. However, since the purpose of the file organization is to create an action-consistent version on disk, this is a direct checkpoint, requiring all modified blocks, all modified portions of the page, and the whole bitmap to be forced to disk. This creates a flurry of synchronous I/O activity, and the file is down for update operations during that period. All things considered, these drawbacks outweigh the advantages of logical logging.
13.5.2 Single-Level Storage
The notion of single-level storage was sketched briefly in the beginning of this chapter. It extends the idea of a virtual address space as it can be found in all modern operating systems in the following way: the operating systems’ virtual storage extends the amount of main memory a process can use to the maximum address that a machine instruction can have; in a 32-bit architecture, this sets a limit of 4 GB. Single-level storage both generalizes and modifies this concept of virtualization in two important ways:
Durable storage. Rather than just making main memory appear larger than the system’s actual physical main memory, the virtual address space comprises everything: files, programs, libraries, directories, databases—you name it. All these things are given their portions of the virtual address space and thus can be unambiguously referred to by a virtual address. This is why only a single (level) storage is needed.
Shared address space. Address spaces of 232 bytes are too small to hold everything on a system. Removing this boundary by using longer addresses creates another problem:
once objects are given a fixed address in a large address space, process address spaces must, in principle, be shared rather than disjoint, as they are in current operating systems. As was mentioned in Chapter 2, there is a way of selectively sharing address spaces by requesting that certain segments of address space A be mapped to the same portion of physical memory as a corresponding segment of another address space B. But clearly this is a kludge and has nothing to do with a shared virtual address space. The single-level store is inherently shared, simply because everything is in it. Since all processes (potentially) can create any address in that global address space, all things in that storage are (potentially) shared. The question of which processes are allowed to access which portion of the storage is thus decoupled from the addressing mechanism; this is an issue of access control and security, just like file access control in conventional systems.
The most obvious implication of single-level storage is that the distinction between main memory and external storage is blurred in the sense that everything appears to be data structures in the (virtual) main memory. The most obvious question is how that can be made to work efficiently.
This being the “exotics” section, we will not enter a detailed discussion of all the topics involved. Rather we present the main points of a commercially available implementation of the single-level storage, using IBM’s AS/400 system as an example.
Figure 13.25, which is borrowed from Clark and Corrigan [1989], shows the major ingredients of the single-level storage scheme in the AS/400. At the center lies the (single-level) virtual storage, which defines the scope of the system’s world. Virtual addresses at the user level are 64 bits long. The operating system and the underlying hardware are designed to provide the user with an object-oriented environment.21 Consequently, the virtual storage contains objects, which, loosely speaking, means code and data encapsulated into a named entity. Note that objects are not addressed like ordinary (passive) data; rather, they are referenced by invoking one of the methods (services) they implement. To implement a service, an object can employ other objects, and so on. Typical objects are files, which consist of data made accessible by the operations allowed for the respective file type. User programs (applications) can be viewed as objects, too. They typically support one method: execute. A database relation is an object, exporting SQL operations. An account is an object, which supports the methods create, debit, credit, inquire, delete, and a few more; it probably uses the relation object for its implementation. This should be enough to get the idea.
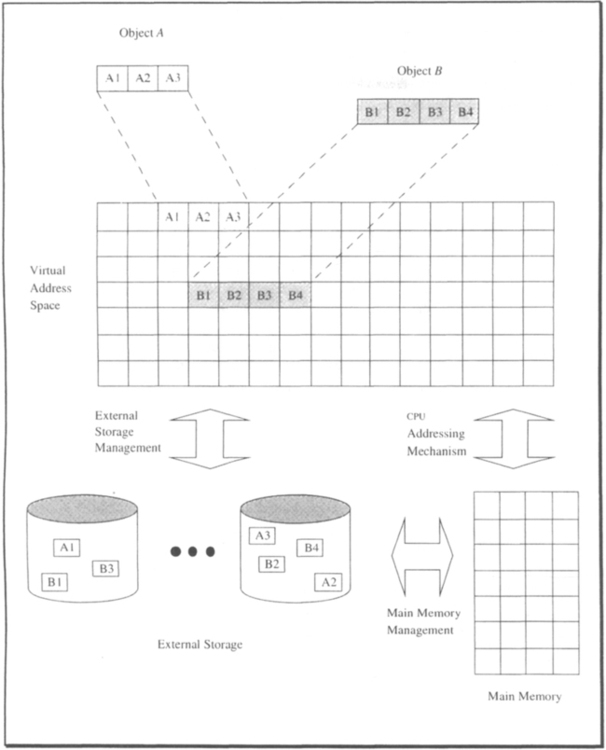
So the system at the user level provides basic services to create objects. At the moment of creation, an object is permanently mapped into virtual storage. That means it is assigned a contiguous portion of the address space, in which all its data and the code will reside. Figure 13.25 shows two examples. Another class of services allows access to an object, that is, to execute one of its methods. To do that, the system loads the portion of virtual storage given to the object into main memory and starts executing at the appropriate location. So essentially, all the virtual storage is kept on durable storage and is transparently paged in and out by the system on demand. The entire main memory serves as a buffer for the virtual storage maintained on disk.
At the user level, each object is identified by an MI (machine interface) pointer containing its virtual address. Special hardware support makes sure that such pointers can only be used for addressing; they can neither be read nor manipulated at the user level. This will be explained in more detail in a minute.
Of course, inside the object, in the code implementing the methods, the same virtual address space is visible. All addresses used here refer to the portion of address space assigned to the object at creation time. At run time, these addresses must be converted into real memory addresses. The mechanisms to do that are similar to the dynamic address translation used in operating systems to convert virtual into real addresses. This part of the implementation is referred to as CPU addressing mechanism in Figure 13.25.
External storage management is the component that maps the virtual storage space onto the external storage devices, that is, onto the set of blocks available on disk. It is the only system component to issue read and write operations at the block level. Consequently, it is also responsible for allocating disk space to new objects—note that for each virtual address in use, there must be a place on disk to which it is mapped to. Free space management is done using a binary buddy scheme like the one described in Subsection 13.3.2. The translation of virtual addresses into disk block addresses relies on directories, which are implemented as search trees similar to the B-tree scheme that is explained in detail in Chapter 15.22 Every time an object is referenced after some time of inactivity (that is to say, when it is not in main memory), its MI pointer is dereferenced using the search tree structure. From then on, of course, address translation is much faster because translation look-aside techniques are used. (As an aside: the buffer hash table used for the sample implementation of the bufferfix operation is the software version of a hardware translation look-aside buffer.)
External storage management also tries to balance the load on disk by judiciously assigning space to new objects. For small objects (≤ 32 KB), the disk is chosen by a randomized round-robin scheme. For larger objects, the disk with the largest percentage of free blocks is chosen. Apart from that, the disks can be divided into separate pools such that certain objects can only be allocated in certain pools. This allows the system administration to keep objects with a high amount of sequential traffic, such as the log, on their own disks, preventing the disk arm from being moved back and forth by other object references, which would deteriorate the log performance.
An optional feature of the external storage manager is storing parity information of disk blocks on other disks, thus allowing the reconstruction of any broken disk from the other disks—a technique that has come to be called RAIDS [Patterson, Gibson, and Katz 1988]. The basic idea is to combine the blocks of n disks by the exclusive or function and store the result on the (n + 1) disk. In this system, n ranges from 3 to 7. Similar concepts are used in disk arrays to improve availability.
Main memory management interfaces real memory to external storage. Its basic strategy is demand paging combined with an LRU replacement scheme, much like the buffer management algorithms described in this chapter. It also applies some of the optimizations mentioned, namely:
Pre-fetching. A group of (clustered) pages can be brought into main memory prior to the actual reference to the object.
Empty pages. This is the optimization embodied by the emptyfix operation.
Obsolete pages. Depending on the object type, heuristics can be applied to identify pages that are not likely to be rereferenced in the near future; these are moved to the end of the LRU chain.
Buffer types. The user can define different bufferpools, such that each application and system task will be serviced from one pool only. This is to prevent, say, batch jobs from dominating the buffer at the expense of interactive applications. See the discussion of the pros and cons of application-specific buffer pools.
In addition, there are more detailed optimizations that we will skip for the sake of brevity.
Making a single-level storage scheme viable (from a performance perspective) and secure requires carefully designed architectural support in both the hardware and the low-level system software. A simple scheme of the interface layering used in the AS/400 is shown in Figure 13.26.

To summarize, then, single-level storage is an old, recurring, attractive idea. It has a number of convincing advantages, and it is very hard to make it work properly with high performance. It may turn out to be the Wankel engine of computer architecture. Unlike side files, which have clear disadvantages, single-level storage is much harder to judge. So let us just restate the critical issues and then try a conclusion.
Basic concept. Having just one address space in which all objects can be kept (forever, if necessary) is certainly a great conceptual simplification. It provides on a system-wide scale what buffer management does for the higher-layer modules in a database system.
Language support. The impedance mismatch between relational database systems and tuple-oriented programming languages is an old observation. In the same vein, there is an impedance mismatch between classical programming languages and single-level storage. One can compile such languages to a machine interface supporting single-level storage, but the power of the concept cannot be harnessed properly.
Address translation. Translating addresses from a very large address space into disk locations for paging purposes is more expensive than in “normal” virtual memory operating systems. Therefore, associative search structures, which—depending on the type of address space—will be accessed with a high degree of concurrency, must be maintained efficiently. Chapter 15 gives an idea of which problems have to be solved in that area.
Replacement. Since in single-level storage, paging comes as part of the machine’s main-memory architecture, all the optimizations sketched previously must be applied, including pre-fetching, pre-flushing, and so on. In the AS/400 system, for example, this is achieved by (among other things) mapping an object—that is a piece of code together with a variable number of data—into adjacent addresses, which in turn are mapped onto adjacent disk blocks. Since references in that system are object-specific, the whole object (cluster) can be loaded upon the first reference. This is a version of pre-fetching. Another example is the operating system AIX, version 3, which maps files into virtual memory (this is a “weak” variant of single-level storage). Depending on the file organization, predictions of the future references can be used to optimize page replacement.
Durability. This is is probably the hardest part. Since all objects are mapped onto the single-level storage, the system accepts responsibility for durable objects. But what exactly does this responsibility cover? If machine instructions are executed on a durable object, when is this main memory update mapped to durable storage? (This is similar to the problem in some file systems, where a write operation, even if it completes successfully, cannot be trusted to really have written anything to disk, for example.) If the decision is bound to a write instruction in the application program, this basically moves (part of) the burden to the programmer—consider the mismatch described previously. If one tried a more transparent and efficient solution, based on logging as described in this book, this would require all components using durable objects to understand the logging protocols and make provisions for their own recovery. In case of programming languages, this would get us back to the topic of persistent languages. Just considering this short laundry list, one can appreciate the complexity of the problem. An interesting design of transactional virtual memory based on logging is described by Eppinger [1989]. Even though that design does not readily carry over to the design of a single-level storage manager of a general-purpose system, it contains a number of technical arguments of why a solution might be feasible.
So here comes the conclusion, which is more of a personal hypthesis than a technical analysis. Given the idea’s great simplicity, single-level storage will certainly not be discarded just because of the hard problems associated with it; the fact that there were some spectacular failures before makes it even more attractive. Judging from some recent developments (AS/400, AIX, Camelot, HP9000), developers obviously have not given up yet. If this is so, and if future systems are inherently transaction-oriented down to the very operating system (the key thesis of this book), then there is good chance for these future systems23 to be equipped with single-level storage.
13.6 Summary
The basic file system is the mediator between main memory—which is fast and volatile, and in which data must reside to be accessible to the CPU for processing—and external memory, which is slow and durable, and which has virtually unlimited capacity. The trade-off between these two types of memory is dictated by economic considerations; that is, performance requirements have to be weighed against the cost for achieving them. The guiding principle here is locality, which says that objects that have been used recently have a high likelihood of being used again; and conversely, objects that have not been referenced for a while will probably continue being unused.
This chapter presents things from a simplified perspective: main memory is assumed to have just one level, and the same assumption is made for external memory; that is, archiving is not considered. Since magnetic disks are the dominating technology for online external storage, the discussion is restricted to the problem of how to access and manage external storage on disks efficiently. The model presented here is very close to all actual implementations. The disk is formatted into slots of a fixed size (typically 2 KB to 8 KB), and these slots are addressed in terms of the disk geometry. The basic file system abstracts files, which are simple arrays of fixed-length blocks, from these slots and makes sure that blocks get efficiently mapped onto slots, which means space allocation and garbage collection are included. Blocks in files are accessed simply by relative block numbers, without having to be aware of any details of the disk geometry.
The buffer manager makes blocks that are stored on disk accessible to modules implementing higher-level database functions, such as access paths, scans, and so on. In doing so, the buffer manager must be aware of the ACID properties of the transactions requesting access to blocks. The reason is simple: all processing results reflected in the block contents are volatile unless the block is forced to disk, or unless there is sufficient redundant information in the log to reconstruct the most recent transaction-consistent state of the block, should this ever be necessary. On the other hand, for performance reasons, the buffer manager tries to avoid I/O operations whenever possible.
The behavior of the buffer manager with respect to transaction atomicity and durability is defined by a number of protocols that regulate which data have to be written in which order, and when. In relation to the log manager this is the write-ahead log (WAL) protocol. In relation to the transaction manager, these are the different propagation strategies (force/no-force), and in relation to the recovery manager the buffer manager establishes savepoints in order to limit the amount of REDO work after a crash.
Another problem is the fact that the blocks made accessible by the buffer manager are shared by many concurrent transactions. To mediate these concurrent (and potentially conflicting) access requests, the buffer manager control access to blocks by semaphores. The duration of address stability for a block in the bufferpool is regulated by the FIX-USE-UNFIX protocol.
The decision of which blocks to keep in the bufferpool for how long is based on the locality assumption and a number of heuristics for predicting the system’s future reference behavior; one of the most popular heuristics is LRU, implemented as “second chance.”
This chapter’s final section presented two methods for managing external storage that are significantly different from those discussed in the main part of the chapter. Side files have adopted a strategy for updating blocks that does not primarily involve the log, but is a mix of old master-new master techniques and logging. It is argued that these methods are fundamentally inferior for performance reasons.
Single-level storage attempts to extend the notion of virtual memory as it is used in operating systems to arbitrarily large address spaces with durable data. Some of the implementation issues involved have been discussed—especially those related to address translation and binding. The general assessment is that single-level storage is a great idea that will probably replace current architectures once the performance problems have been solved—which still requires a good amount of work.
13.7 Historical Notes
File and buffer management are straightforward technical applications of methods people have been using for millennia to organize their lives and businesses. The Sumerian scribes to whom we owe so much did not record their database on a gigantic wall without any substructure; rather, they used uniform-size clay tablets, which were grouped by some contextual criterion such as county, year, or subject. Thus, the Sumerians invented records (tablets) and files (groups of tablets with something in common). Of course, the technology of external storage media evolved; clay—which had superseded stone—was replaced by papyrus, which got replaced by paper, which finally got replaced by rust. People also came up with structured records (see Chapter 14), which are commonly known as forms. They devised means to speed up access; think of the alphabetic dividers in file hangers. All these are refinements of the same basic idea.
The main idea behind buffering is to exploit locality. Everybody employs it without even thinking about it. A desk should serve as a buffer of the things one needs to perform the current tasks.24 What I will have to touch frequently should be within reach, for the rest, I will have to perform a physical access; that is, stand up and walk to the shelf. Production lines are optimized by buffering parts and tools—note that in this case, pre-fetching rather than demand paging is used. Examples can be found everywhere.
In the context of computers, files came into the picture when operating systems were introduced—at about the time of the so-called third generation, in the mid-1950s. Before that, computers used to be programmed “on the bare metal”; real memory was real real memory, and external devices were real external devices.
Buffering the way it was described in this chapter came later. The normal way of handling external devices was to have a file buffer, which in case of a block-oriented file would be a portion of memory large enough to hold one block. Now if block 1 is to be accessed, it is read into this buffer. If it gets modified, it is written back right away. Then block 2 is accessed, overwriting block 1 in the file buffer. Then block 1 is accessed again, which means it needs to be read again—and so on. Of course this is inefficient, but it is a style of thinking about file accesses that is suggested by conventional programming languages.
To fend off the speed difference between main memory and external storage, double buffering was introduced for writing, especially for sequential files. Assume there are two buffer frames, A and B. As soon as buffer A is filled, a write operation is initiated that asynchronously transfers A to the file. The application program is “switched” to buffer B and can continue filling it. During the next round, the roles are reversed, and so on.
This is still state-of-the-art in the majority of operating system-supported file systems. Buffering on a larger scale, as described in this chapter, was employed by database systems with their “leave me alone” attitude toward the operating system, and by systems providing either memory-mapped files or single-level storage.
The aspect of durability was mostly ignored in the early file systems for a simple reason: at that time, main memory was built from magnetic cores and thus was pretty durable. So writing to main memory was just as good as writing to disk from a recovery perspective. The only relevant difference was that main memory was small (64 KB was considered plenty) compared to those huge disks with their 10 MB. Consequently, restart after a crash could pick up the most recent state of the process from main memory. It could not do that indiscriminately, because a bad control block might have been the reason for the crash, but at least the data were there. IMS actually had a scavenger routine that looked at the database buffer after restart to see if it was any good and, if so, performed a “warm” start.
Many database systems, although they used global buffering to improve performance over simple file buffers, at some point were caught cold by the rapid growth of main memories and the resulting increase in buffer sizes applications would use. The reason was that early implementations of database buffers used sequentially linked lists as look-aside data structures to check if a block was in buffer. This is acceptable for very small buffers, but as they grow, the linear increase in search time for each buffer reference costs more than is gained by higher hit rates.
The rest of the development toward current file systems and database buffer implementations followed that path, although it was not until the late 1970s that the underlying concepts were investigated and described in a systematic way. The papers about the implementation of System R and Ingres were the first to discuss the issues of a database buffer from a performance perspective and, of course with respect to the recovery issues incurred by the transaction paradigm [Astrahan et al. 1981; Blasgen et al. 1979; Gray 1978; Lindsay et al. 1979; Stonebraker et al. 1976].
At the same time, attention was brought to the fact that there was a considerable mismatch in concepts between databases and operating systems with respect to resource scheduling, file management, recovery, and some more issues. These were summarized in some frequently cited papers [Stonebraker 1981; Stonebraker 1984; Traiger 1982c]. They had considerable impact on the database community, much less on the operating systems community. But at least Stonebraker’s papers explained to a wider audience why the standard UNIX file system is utterly inadequate for databases from both a performance and a recovery perspective. The result was the introduction of raw disks into UNIX—exactly what the guys who want to be left alone need.
In parallel to that, file systems became more flexible, more versatile, and more complex. The most notable example is IBM’s VSAM under the MVS operating system. It provides a wide variety of functions and optimizations, many more than we will even mention in this book. It has associative access, and data sharing, and recovery—but it does not speak transactions, and therefore all the database systems running on MVS have to do their own thing all over again.
It is an interesting observation that there are very few transactional file systems yet; in the commercial domain, Tandem’s Guardian and DEC’S RMs are the only notable exceptions. IBM’s UNIX-style operating system for the RS/6000, AIX 3.1, purportedly uses transactions to protect its update operations on the file system directory. It therefore is one of the few UNIX implementations that will not lose files due to a crash. However, it does not give transactions to the file system’s user, and so it is not a transactional file system in the full meaning of that term.
An interesting approach was taken in a research project, Camelot, where a conventional operating system (Mach) and file system were extended by a virtual memory manager with transaction semantics. In contrast to the single-level storage idea, this does not require hardware support or larger addresses. It will be interesting to see the influence on real products. The reader is referred to Eppinger [1989] and Eppinger, Mummert, and Spector [1991] for details.
Single-level storage has a fairly long history, with a number of failures in the beginning. Two systems that have become famous for their great designs and high ambitions, the Burroughs B5000 and Multics, among other things tried to implement single-level storage. They also were capability-based (object-oriented, to use the modern words), used high-level machine languages, believed in late binding, and exhibited many more innovations like these. The other aspect they had in common was low performance, which is why they ultimately failed. In retrospect, this did not prove the inapplicability of the ideas; it just demonstrated that on machines with .3 MIPS, multiple layers of dynamic abstraction are not affordable.
After machines had become fast enough to make the trade-off between a clean design on one hand and performance on the other worth considering, some implementations of single-level storage appeared. They have been around for circa 10 years: IBM’s System /38; its successor, AS/400; and HP’s MPE operating system on the 9000-series (Precision Architecture).
Memory-mapped files have been used in all operating systems implicitly, without making the mechanism generally available. Load modules are a typical example. The main memory databases in IMS FastPath can also be viewed as an application of the mapping idea. MVS selectively maps files into the hyper space, and AIX 3.1 maps each file at open time. In the latter case, this only has consequences for the system implementation itself, because it is a UNIX implementation with all the standard file operations.
This chapter was a very brief description of the low-level issues in file management, with a focus on the database buffer manager, which is typically not covered in much detail in textbooks on file systems. On the other hand, such books contain more material about subjects such as file design, performance estimates, security, and so on, that have been mentioned just briefly or not at all in the present chapter. For further readings on file systems see Salzberg [1988] and Wiederhold [1977].
Exercises
1. [13.2, 10] Name three issues that a single-level storage scheme must support, which are not considered by today’s virtual memory managers in operating systems.
2. [13.2, 10] Find at least five examples for the principle of locality in everyday life.
3. [13.2, 20] Based on your knowledge of database systems and how they work, where is locality (in terms of locality of references in the bufferpool) most likely to occur? (Name at least three different types of local reference behavior.)
4. [13.2, discussion] There is a RAM-based storage technology that is frequently called something like “extended storage,” and that tries to bridge the gap between disks and main memory. It has the following characteristics: units of transfer are pages of 4 kb to 8 kb, the bandwidth is 1 GB/sec, and the storage is made durable by battery backup. Remember that a typical read or write access to disk proceeds in the following steps:
(1) Process calls operating system to initiate I/O operation.
(2) Process gets suspended for the duration of the I/O.
(3) When the operation completes, the process becomes “ready for execution” again.
(4) Sometime later, the process is resumed.
How would you interface an extended storage to the application program? Would you use the same interface as for disk I/O and just benefit from the faster access times (no arm movement, no rotational delay, higher bandwidth), or are there additional things to be considered? Assume a 100 mips cpu and explain how you would use a storage device with the properties explained here.
5. [13.2, 10] What are the key arguments in favor of the “main memory and tapes” prognosis of system storage architecture?
6. [13.3, discussion] A block on disk has its FILENO and its BLOCKID stored in the header as a provision for fault tolerance. Do you see any potential problem with this?
7. [13.3, 30] With the extent-based allocation, periodic garbage collection of free slots on the disk has to be performed once in a while to prevent the available extent from getting too small. Design an algorithm for this task that is fault tolerant (not necessarily acid) and that has minimum impact on the transactions executing concurrently. Hint: Try to do the space reorganization incrementally.
8. [13.3, 20] Assume a 40 GB file with single-slot allocation. Each slot is 8 KB long; a pointer has 8 bytes. Allow 20 bytes per slot for bookkeeping. If this file is accessed randomly using stochastically independent block numbers with uniform distribution, what is the average number of slots that must be read for translating a block number into a disk address? (Count the directory holding slot_ptr. [] as one slot.) How many slots are needed for the addressing tree?
9. [13.3, 25] Construct an allocation pattern for files, using the buddy system in which all extents contain only one slot and no merge is possible. What is the minimal space utilization for which such a pattern can be constructed? Whatever your answer is, prove that it is minimal.
10. [13.3, 30] Read the documentation on ms-dos and find out how its file system handles space allocation on disks. Which of the categories established in Section 13.3 does this scheme belong to? What are the performance characteristics?
11. [13.3, 20] Assume the block-oriented file system with the data structures that have been declared in Section 13.3. Explain how these structures must be written according to the principle of careful replacement after a file has been deleted. It is important that you also specify exactly how blocks are written for newly allocated files. Remember: the scheme must under all circumstances avoid multiple allocation of the same slots.
12. [13.4, 10] The task of a buffer manager is comparable to that of a virtual memory manager in an operating system. As is explained in Section 13.4, the buffer manager’s interface needs the fix/unfix brackets to function properly. There is no equivalent for that at the interface to the virtual memory manager. Why?
13. [13.4, 10] The explanation of why different page sizes make life more complicated for the buffer manager was a bit vague. Explain precisely what is different in that environment from the sample implementation presented in this chapter.
14. [13.4, 20] The text briefly mentions invalid pages. What must be done upon bufferunfix() when the invalid flag is set? Is it sufficient to just discard the page and mark the frame as free, or is there something else that needs to be done—except for starting online media recovery for the broken page?
15. [13.4, 20] The no-steal policy guarantees that no transactions need to be rolled back at restart, so no log records are required for reestablishing old states of pages. The force policy guarantees that no REDO work for completed transactions needs to be done at restart, so no log records are required for bringing pages up to the new state (ignoring the problem of media recovery for the sake of argument). Does that mean a combination of the two policies will avoid the necessity of keeping a log? If not, what is wrong with the idea? Hint: Remember that writing a single page is not an atomic operation; then consider what it means to write a set of pages; that is, all pages that have been modified by some transaction.
16. [13.4, 25] Consider a transaction abort during normal operation, with the buffer manager using a no-steal/no-force policy. Due to no-steal, all pages modified by the transaction are still in the bufferpool when abort is initiated. One could think of doing the abort by simply discarding the pages in buffer, that is, by tagging the corresponding frames as empty. What is wrong with this simple approach under the assumptions made? Design an extension that would allow the buffer manager described in this chapter to exploit the properties of no-steal for normal abort processing at least in some situations.
17. [13.4, 30] Write the code for the bufferunfix routine. Use the interface prototype declared in Section 13.4, and do the following things: make the page that gets unfixed the most-recently-used page; that is, put its control block at the head of the lru chain—unless, of course, the page comes back with the invalid flag set. Ignore the case of invalid pages. Then decrement the fix counter and release any semaphore the client may have on the page. Note that the client, while holding the page, may have given back and reacquired semaphores on the page at his leisure. When requesting semaphores on critical data structures, make sure you do not run the risk of semaphore deadlocks. Look at the order in which the bufferfix routines request and release their semaphores.
18. [13.4, 20] Consider a very simple case of pre-fetching at the interface to the basic file system: whenever a read operation is issued to a block with block number j, then j and n – 1 subsequent blocks with numbers j + 1, …, j + (n – 1) are transferred as part of the same read operation. (Here we ignore track and cylinder boundaries as well as extent sizes.) Compute the elapsed times for sequential scans reading N blocks, starting at block number 0, with n varying between 1 and 8. If the read operation of block 0, for example, has completed, then the pages mapped into blocks 1, …, n – 1 are already in buffer, so no read requests have to be issued for them. The next read operation will be directed toward block n. The sequential scan issues bufferfix requests for pages 0 to N – 1. Assume that the disk arm is moved to a random position between subsequent block read operations on behalf of the scan. Therefore, the following parameters can be used to estimate processing times: mean time for arm movement: 16 ms; mean time for rotational delay: 8 ms; time for transferring one block: 1 ms. Note that the exercise hinges upon the assumption that blocks with adjacent numbers are always mapped to adjacent slots.
19. [13.4, 10] Let us assume a buffer with n frames, on which 1 transaction is operating. After the n frames have been filled with pages, the page fault ratio drops to 0; the buffer manager uses a pure lru replacement strategy. If the same transaction were run on a buffer with n – 1 frames, the page fault ratio would be 100%. Which type of access pattern could create such a surprising result?
20. [13.5, 25] The simple version of the side file technique and the differential file require periodic copying of the side file to the primary file. This has to be atomic. The text has explained that it is idempotent, which is not sufficient to make it atomic in the presence of crashes. Design a scheme that makes the copy process atomic. Hint: Go back to Chapter 4 and look at the methods to make single block write operations atomic.
Answers
1. (1) Lifetime assignment of addresses in virtual address space to objects, (2) durability of objects in the address space (which includes recovery), (3) sharing of the single-level storage among all process address spaces (which includes synchronization and security issues).
2. (1) The stores you shop in, (2) the friends you visit, (3) the type of things you do at any given time of day, (4) the food you prefer, (5) the opinions you hold.
3. (1) Assume a relation scan: after a tuple in page p has been accessed, it is very likely that the next tuple in the same page gets accessed, too. (2) When a certain number of insert transactions are active, the page(s) holding the free space information of the respective file are accessed at least twice for each individual insert operation. See Chapter 14 for details. (3) If there are hotspots in the application, such as the tuple for the last flight out of New York to San Francisco on Friday night, there will be a high frequency of reference on these hot spots.
4. The key issue to consider here is when it makes sense to switch synchronous read/write operations in the sense that the process holds on to the processor while the I/O is going on. The rationale for suspending the process in current system is the very long latency of disk storage compared to the processor speed. Now if the latency can be reduced to a few thousand instruction equivalents (rather than more than 1 million instruction equivalents for a disk read in case of a 100 mips processor), it might be cheaper to let the process wait while holding the CPU, because now the I/O operation is in the same price range as a process switch.
5. Main memory will be large enough to hold all active data; durable storage is needed for logging and archiving only, both of which are sequentially written. Hence, tapes (of whatever technology) are most appropriate.
6. The tuple (FILENO,BLOCKID) must be unique throughout the system as long as the block exists somewhere (maybe on an old archive tape) and has a chance chance of being re-referenced.
7. In the following, we ignore all optimizations for the garbage collection process; the only concern is fault tolerance. At the beginning of the reorganization process, there are collections of slots (extents) that are currently allocated to a file, and collections of slots that had been allocated to a file in the past but have been declared free in the meantime. Reorganization can be performed incrementally by copying allocated extents into free extents one by one. So we can restrict our discussion to the problem of how to use up one free extent such that the repeated execution of this process will move the entire free space to the end of the disk. Consider the following scenarios, showing the beginning of the disk, with the disk directory in the first slots. Allocated extents are shaded gray, free extents are white.

The first free extent is E2 (we are looking at Case A first). It is followed by an allocated extent that comprises fewer slots than the free one. Here, copying requires the following steps: (1) Set an exclusive lock on the free space map in the directory. (2) Copy the slots from E3 into E2. (3) Modify the entries in the free space map accordingly. (4) Set an exclusive lock on the directory. (5) Change the base address of extent E3 (it now starts where E2 started before). (6) Write the free space map to disk. The trick here is that there are two locations on disk for the free space map, which are written alternately. (7) Write the directory to disk. We assume that the affected part of the directory fits into one block, which is written using a stable write operation (see Chapter 4).
Case B is more difficult in an environment where we cannot assume transaction support. Steps 1 and 2 are performed exactly as in Case A, up to the point where the free space in E2’ is used up. However, there are still slots in E3’ that must be moved. Assume a crash occurs at that moment. After restart, the disk comes back with the old directory, where E2’ is marked free, and where all slots of E3’ contain their proper contents. But if we continue copying slots from E3’ to E2’ and crash sometime after that, the disk will be inconsistent: The directory still says E2’ is free and E3’ is allocated, but now slots at the beginning of E3’ have been overwritten by slots from E3’ with higher addresses. For careful replacement to work, the following steps must be taken at the moment the last slot of E2’ is used up: (2.1) Set an exclusive lock on the directory. (2.2) Set a flag on the entry for extent E3’, saying how much has been copied and that it is “in transit.” (2.3) Do a stable write for the directory. Then proceed as in Case A.
8. The file has 4,882,813 blocks. A block can hold 1,021 pointers. If we assume the I-node as described in the text, we get the following addressing structure: 10 blocks can be directly addressed via the I-node, the next 1,021 block accesses go through one indirection, the next 1,043,472 block accesses go through two indirections, the remaining 3,839,341 block accesses go through three indirections. So the average number of block accesses per random access (including address translation) is:
![]()
9. The obvious answer is to have alternating slots at the lowest level: one slot free, one slot allocated. This yields 50% utilization. One could suppose that utilization gets lower when groups of two adjacent free slots are arranged such that they are neighbors but not buddies. The following illustration shows that this results in a 50% utilization, too.

11. The answer to this exercise can easily be obtained by applying the principles explained in the answer to Exercise 7.
12. The operating system (with some support from the hardware) checks before each machine instruction whether the required pages (the page holding the instruction and the page containing the data, in case the instruction references a memory location) are in real memory.
13. If page sizes are different, the replacement problem gets more complicated. Assume a bufferfix operation for a page that currently is not in the bufferpool. Making sure that there is a frame in which to put the requested page requires more than just picking a replacement victim. The buffer manager must try to replace a page that is at least as long as the one that is to be fixed. If there is no such page in the bufferpool, things get even more complicated. Either two or more pages must be replaced to make room for the new one, but now locality is not an issue anymore because these pages must be picked according to the criterion that they are stored in adjacent buffer frames. Another possibility is to replace pages strictly based on locality estimates and do garbage collection in the bufferpool after that to make sure the free space is contiguous. No matter which method is used for replacement, periodic garbage collection has to be performed anyway to reduce space fragmentation in the bufferpool. Garbage collection, of course, requires exclusive semaphores on all affected portions of the buffer and thus potentially causes wait situations for concurrent transactions.
14. Since the page is invalid, UNDO is not guaranteed to work. So recovery means that some older consistent state of the page must be rolled forward by applying REDO logs from all complete transactions before the page got invalidated. If the page on disk is consistent, this is the starting point for the REDO pass. If, however, the page got replaced while the transaction that corrupted the page was active, it might be better not to rely on its contents. So one must check the page LSN of the page version on disk and see if any log records of the failed transaction pertaining to that page exist in the log. If this is the case, the transaction updated the page before declaring the page data structure invalid, and that state was written to disk. In that case, it is safer to acquire the most recent version of the corrupted page from the archive and start REDO recovery from there. This recovery path is longer, but it starts from a version of the page that is trustworthy—in contrast to the page version on disk.
15. In order to implement the force policy, all dirty pages must be written during commit processing. While they are being written they are still dirty, so the buffer applies the steal policy. The inverse argument is also correct: If you want to implement no-steal, nothing must be written before commit completes, which implies no-force. If you want both force and no-steal, you have to implement some kind of shadow page algorithm that does the atomic write for each transaction commit. This can be done, but it is very expensive.
16. This is a strong hint rather than a complete answer: The problem is that a page P containing updates by an incomplete transaction T1 may at the same time contain updates by a committed transaction T2. So P is dirty from T2s perspective, but clean from T2’s point of view. If T1 aborts, simply discarding page P from the bufferpool would also discard T2’s updates, thus corrupting the database.
18. Ignoring CPU time, we have to model the fact that every N/n bufferfix requests a physical I/O operation is necessary, transferring n blocks. So the elapsed time as a function of n can be estimated as:
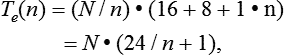
Assuming N = 10,000, one can calculate the effect of pre-fetching. If n = 1, we get Te(1) = 250 sec; for n = 8, the estimate is Te(8) = 40 sec.
19. Read Subsection 13.4.4.3.
20. A simple solution works like this: In the primary file, there are two blocks containing counters for the side file copies that have been applied to the primary file. These counters are increased monotonously. During normal operations, both blocks—let us call them B and E—contain identical values. If the side file is to be copied, block B is written with the next higher value of the counter. Then all blocks are copied back from the side file to the primary file. Once this is complete, block E is written with the new counter value. During restart after a crash, both blocks, B and E, are read. If they contain identical values, the primary file is consistent. If the values differ, the copy process was interrupted by a crash and must be repeated.
1Here and in the following, the other resource managers and application programs that use the file (resource) manager are referred to as clients. This emphasizes the execution model implicit in the abstract model of a TP system on which this book is based.
2Typical in the sense that the same abstractions and functional characteristics can be found in many existing file systems, irrespective of any implementation details.
3For simplicity, we assume that the virtual memory manager has unlimited quantities of external storage at its disposal.
4This limits the maximum size of one file to less than the maximum memory size the system can handle.
5As Figure 2.3 shows, the latency of main memory access is about four orders of magnitude shorter than a random disk access. This is often referred to as the access gap.
6Here we only consider data that already exists in the system. New data coming in through some kind of terminal shows up in main memory first and then percolates down the storage hierarchy. But, of course, for any such “new” data item the inclusion property must hold, too.
7Currently, 8 KB is a typical block length. As the bandwidth between main memory and disks increases, blocks lengths will grow. Some high-throughput disk systems for special applications already use block lengths of 64 kb and more.
8Of course, if x is in the primary extent, no accumulated length is taken from the directory.
9For reasons of practicality, there is always a maximum extent size that can be handled by the buddy system.
10There are designs for buffer managers in distributed database systems allowing for remote buffering, but such variations are not considered in this book.
11This assumption rules out mapping schemes such as shadow pages, differential files, and so on, all of which require the same page to be stored in different blocks of the underlying basic file system. But since these mapping schemes are not seriously considered in this book, the assumption can safely be made, and it helps to simplify the presentation.
12Of course, the underlying file system that provides the block interface is assumed not to have any transaction-oriented recovery facilities of its own.
13The case of multiple logs was discussed in Chapters 9 and 10.
14Rolling back a transaction during normal processing is also facilitated by the no-steal policy: all pages modified by such a transaction are simply marked “invalid” by the buffer manager.
15Keeping a log over arbitrary amounts of time also hurts performance.
16If the replacement strategy used by the buffer manager is deterministic, it can be applied in the same way during restart. If it is not, the page read records must contain additional information about which page was replaced.
17There are systems such as Rdb which use side files as a means to support versions (time domain addressing). That aspect is not considered in this chapter.
18In principle, one could copy at any time. But then the side file concept would achieve the same inconsistent database states after a crash as a conventional file system, so there would be no point in paying the higher costs of keeping a side file.
19Note that the data structure is called page table, although it is indexed by the block number. This should not cause confusion, because we use the terms page and block interchangeably. But since the literature on the shadow page algorithm calls the data structure for address mapping page table, we use the same term.
20Actually, the shadow page algorithm assumes two bits per block number for this additional data structure, the second one noting whether the new value of the block has already been propagated to the archive log file. This is ignored in our discussion.
21If you are not familiar with the ideas of object orientation, you do not have to stop reading now. The explanations of the storage handling mechanisms should still be understandable. However, a certain understanding of object-oriented systems is required to appreciate the consequences of such a machine architecture. An explanation is beyond the scope of this book.
22The AS/400 obviously uses a tree variety called binary radix tree rather than multi-way search trees. But since these binary trees are balanced at the page level, the difference is negligible for the present purposes. Readers interested in the whole story are referred to Chapter 15 and to the literature that goes with it.
23Computing history already knows about a future system with single-level store. This system was not a big success—most likely because it was not transactional.
24Andreas’s desk probably doesn’t, but that’s a different story.