
Transaction Manager Structure
11.2.1. Transaction Identifiers
11.2.2. Transaction Manager Data Structures
11.2.3. MyTrid(), Status_Transaction(), Leave_Transaction(), Resume_Transaction()
11.2.7. Remote Commit_Work(): Prepare() and Commit()
11.4.1. Transaction States at Restart
11.4.2. Transaction Manager Restart Logic
11.4.3. Resource Manager Restart Logic, Identify()
11.4.4. Summary of the Restart Design
11.4.5. Independent Resource Managers
11.4.6. The Two-Checkpoint Approach: A Different Strategy
11.4.8. Distributed Transaction Resolution: Two-Phase Commit at Restart
11.5. Resource Manager Failure and Restart
11.1 Introduction
This chapter sketches the implementation of a simple transaction manager. It uses the ideas and terminology developed in the previous chapter. The first section deals with normal processing: Begin_Work(), Save_Work(), Commit_Work(), and the no-failure case of application-generated Rollback_Work(). The remaining sections explain how the transaction manager handles various failure scenarios. The TM prepares for failures by writing checkpoints to persistent memory. At resource manager restart or system restart, the transaction manager reads these checkpoints and orchestrates recovery. Recovery of objects from archive copies is also discussed. The techniques used to replicate data and applications at remote sites are covered in Chapter 12.
The presentation here is simplified by the lack of parallelism within a transaction. Still, this is an open, distributed transaction manager that allows independent resource managers to vote at every step of the transaction and supports persistent savepoints.
11.2 Normal Processing
During normal processing, there are no resource manager failures or system failures. The transaction manager is invoked by applications calling Begin_Work(), Save_Work(), Prepare_Work(), Commit_Work(), Rollback_Work(), and Read_Context(). In some systems, the Leave_Transaction(), Resume_Transaction(), and Status_Transaction() calls are frequently used. In addition, resource managers invoke the transaction manager with Identify() and Join_Work() calls.
The begin, save, and prepare work calls each establish a savepoint and have the application context as an optional parameter. This context can be retrieved when the application returns to that savepoint. The context typedef says that the context is a variable-length string. The transaction manager does not understand the meaning of the context beyond that.

Each resource manager may also be maintaining some context associated with the transaction. Each context record is understood only by the subsystem that wrote it. For example, the contexts saved by a persistent programming language, a database system, and a transactional windows system all look quite different.
11.2.1 Transaction Identifiers
Most of transaction management and recovery centers around transaction identifiers, trids. Thus, it is best to begin by defining them in detail. Within the network, trids must be unique for all time; each identifies some ACID unit of work. In addition, it is convenient for a trid to define which transaction manager created it. That transaction manager is sure to know whether the transaction committed, aborted, or is still in progress. Consequently, each transaction manager is given a unique identifier, or name, and a unique number, or transaction manager identifier (here called TMID). This TMID will appear in each trid created by this transaction manager. Each transaction manager, in turn, has a private counter that increments each time it creates a new transaction.
It is possible for a transaction manager to restart with amnesia—having lost its logs, it goes through a complete restart. In that case, its trid sequence counter resets to zero. This is never supposed to happen, but it does. To allow other transaction managers to detect amnesia, each transaction manager remembers its birthday: the oldest timestamp it can remember. The form of trid that is actually unique is the triple, 〈birthday, TMID, counter〉, where TMID is the unique identifier of the transaction manager, and counter is its sequence number. This is the form of trids exchanged among transaction managers (i.e., in the network). Hence, the definition of trid:

11.2.2 Transaction Manager Data Structures
The transaction manager, along with the TP monitor, keeps a data structure describing each resource manager that has called ldentify(). It also keeps a data structure for each live transaction: its status, its log records, the resource managers joined to it, and the sessions allocated to it. This data structure is diagrammed in Figure 11.1. It is a subset of the data structures shown in Figure 6.7.
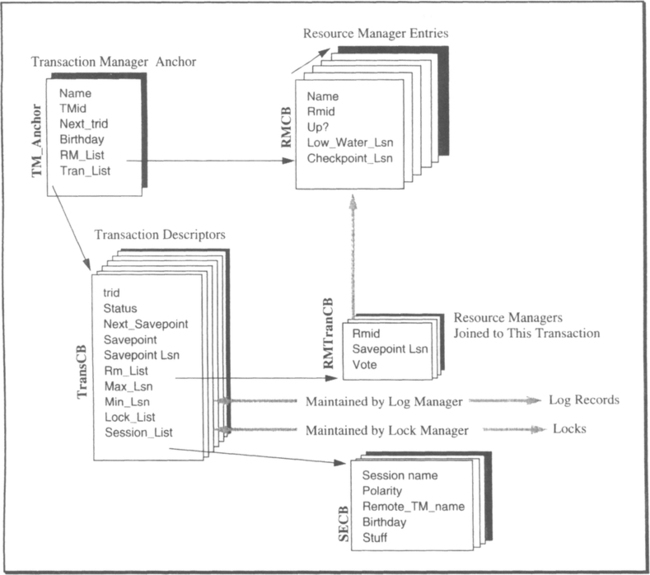
When a transaction begins, a descriptor of the transaction (a TransCB) is added to the list of live transactions. Initially, the transaction has no locks and only a begin transaction log record. As resource managers do work for the transaction, the transactional remote procedure call (TRPC) mechanism automatically invokes Join_Work(rmid,trid) for that resource manager. This causes the transaction manager to create a link between the resource manager and the transaction, diagrammed as the RMTransCB in Figure 11.1. As the transaction’s log grows, the log manager and the transaction manager maintain the addresses of the first and last log records of the transaction (min and max LSN). At savepoints, commit, and rollback, each resource manager in the transaction’s RM_Iist is invoked to perform the next step of the transaction. The rest of this subsection elaborates on the transaction manager data structures and the routines that manipulate them.
The transaction manager’s root data structure, called the anchor, stores a few key values (e.g., the TM name, the next trid, and the birthday), but its primary job is to point to the list of identified resource managers and the list of transactions that resource manager has joined. The anchor’s declaration in C is as follows:

The RM_list is a linked list of all resource managers known to this transaction manager, their names and IDs, their status (up or down), and their pointers to two relevant places in the log. These places are (1) the low-water mark, where this resource manager’s REDO should start for resource manager recovery (log records earlier than that are not needed to recover this resource manager’s online state), and (2) the log address of the resource manager’s most recent log checkpoint record. These two items are clarified later, in Subsection 11.4.3. Here are the relevant fields of each resource manager control block:

This structure tells the transaction manager all it needs to know about resource managers. When a resource manager first comes on the scene, it informs the transaction manager of the resource manager callbacks and requests recovery via an ldentify() call. Thereafter, the transaction manager invokes the resource manager’s callbacks at critical system events (checkpoint, etc.). In addition, once a resource manager has identified itself, it can invoke Join_Work() for a transaction. This causes the transaction manager to inform the resource manager about all subsequent events related to that transaction. These events include savepoints and rollbacks as well as participation in the prepare, commit, and abort steps of the transaction. Chapter 6 explained that the ldentify() call also calls the TP monitor, to allocate structures needed for transactional remote procedure calls (TRPCs) to the resource manager.
The transaction manager keeps a description of each active transaction—transactions that have not completely committed or aborted. Each description, called a TransCB, carries the trid and transaction status. It also records the current and next savepoint numbers. It might seem that these would be simply X and X + 1, but that would ignore rollback. Savepoint numbers do increase monotonically. Begin_Work() creates savepoint 1, and each successive Save_Work() increments next_save_pt. If a transaction was at savepoint 98 but has just rolled back to savepoint 7, then it has two relevant savepoint numbers: the current savepoint (7) and the next savepoint (99). Both these savepoint numbers, then, are recorded in the transaction description. In addition, it is convenient to have a quick way to find the transaction’s current savepoint record, so that the application can restore its context. This hint is stored in the save_pt_lsn.
As discussed in Chapter 9, the transaction descriptor also stores the min_lsn and max_lsn of log records created by the transaction. Min_lsn bounds how far back in the log an UNDO scan of this transaction may go; it is the transaction low-water mark. The max_lsn says where to start the UNDO scan for Rollback_Work(). As the transaction’s log grows, the log manager and the transaction manager maintain the min_lsn and max_lsn field of the transaction via the log_transaction() routine explained in Section 9.4.
The lock manager uses the transaction descriptor to keep a list of all locks held by a transaction. Each time a transaction gets a lock, the new lock request block is chained to the lock header and to the transaction lock list (see Figure 8.8). Of course, the transaction descriptor has a list of all resource managers joined to the transaction and all sessions allocated to the transaction. Given those hints, it should be easy to read the declaration of the transaction control block:

The global list of all the resource managers (RMCBs) was given previously. Not all resource managers, however, participate in each transaction. The TransCB.RM_list enumerates all resource managers that have joined the transaction. Each element of the list, an RMTransCB, describes the resource manager, its vote on prepare, and its most recent savepoint context. The following is, therefore, the basic structure of entries in the resource manager list:

At each savepoint, each interested resource manager is invoked via its Savepoint() callback to optionally write a savepoint record in the log. The returned LSN is recorded in RMTransCB.save_pt_lsn. The transaction may later be returned to that savepoint by an application rollback or by a system restart that reestablishes that persistent savepoint. When such events occur, the resource manager is expected to restore its state as of that time; its savepoint record can help it do so. The UNDO_Savepoint(LSN) and REDO_Savepoint(LSN) callbacks to the resource manager pass the LSN returned by the original Savepoint() callback.
The communication manager maintains the list of sessions allocated to this transaction. New TRPCs allocate sessions to the transaction. When the transaction commits, the sessions continue to exist, but they are no longer associated with the transaction. These sessions carry messages among the processes performing the transaction, track distributed transactions, and are used to perform the two-phase commit protocol. Each entry in the session list has this format:

The development here also postulates a set of addressing routines that lets the caller find its control blocks. These are the addressing routines for transactions:

Given these global structures, the logic of the Begin_Work(), Commit_Work(), Save_Work(), and Rollback_Work() can be discussed. Before doing that, however, let us describe the very simple housekeeping routines, such as MyTrid(). This should help provide some groundwork for the basic data structures and how they are used.
11.2.3 MyTridO, Status_Transaction(), Leave_Transaction(), Resume_Transaction()
Recall that at any instant, each process may be executing in the scope of some transaction. That is called the process-transaction identifier. A process can use the following code to ask what its current trid is:

The status of any transaction can be queried. If the transaction is currently live (active, prepared, aborting, or committing), then a record of it will be found in the TM_anchor.tran_list. In those cases, the following code will work for Status_Transaction():

On the other hand, if the transaction aborted or committed, then it will not be present in the list, and the log or another data structure must be consulted. The simplest design is to run the following SQL query on the log table:
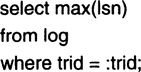
If the max(LSN) comes back zero, then there is no record of the transaction (max of the empty set is zero). In that case, it must have aborted—this is the presumed abort protocol. If the record comes back nonzero, then it is the transaction completion record, because it is the last record the transaction wrote. The completion record can be read to see if the transaction committed or aborted. That describes the logic for Status_Transaction(). Exercise 3 discusses some optimizations of it (systems do not typically scan the log in this way).
The implementation of Leave_Transaction() and Resume_Transaction() is straightforward. Recall that if a process running under one transaction identifier wants to begin a new transaction or work on another one, it must first leave its current transaction. It can then begin the new transaction, work on it, leave it, commit it, or issue a rollback. At any point, it can resume the previous transaction. This allows programmers to write multi-threaded server processes that work on multiple trids, perhaps having a separate internal thread for each one.
Leave_Transaction() is trivial to implement; it simply sets the process trid to NULLTrid. Resume_Transaction() is more difficult. A process can only resume trids that it has left. Thus, the transaction manager maintains such a list and updates it each time a transaction is left by the process, is committed, or is aborted. Resume_Transaction() searches this list and, if the trid is present, makes it the current TransCB of the process. The necessary process structure is not shown here, but the field PCB.TAsToDo in the process control block is shown in Chapter 6, Section 6.2.2.
11.2.4 Savepoint Log Records
From the transaction manager’s perspective, every transaction event is a kind of savepoint. This can sometimes be a difficult concept to grasp. Begin is a savepoint (numbered 1), and transaction completion is a savepoint. Some savepoints, notably prepare and abort, are persistent, but they are otherwise all alike. They all have similar log records as well.
Treating all savepoints in the same manner simplifies the code and easily provides for persistent savepoints. The reason is as follows: the two-phase commit protocol requires that the prepared-to-commit state be persistent. That means that each resource manager must be able to reinstantiate its prepared transaction context if the system fails and restarts. After phase 1 of commit, every resource manager has established a persistent savepoint. If the system fails before the transaction finally commits, the resource manager is able to reinstantiate the prepared transaction state: the prepared-to-commit state is a persistent savepoint. If that mechanism exists for commit, why not make it available for long-running and for chained transactions? In that sense, then, persistent savepoints come for free.
Savepoint records all have a record type, a savepoint number, a flag showing if the state transition is persistent, and then a list of resource managers and sessions involved in the transaction at this point. All that is followed by the application context passed by the state-change call. Begin, save, prepare, rollback, commit, abort, and complete all write such records. The structure of a savepoint log record is as follows:

11.2.5 Begin Work()
The logic for Begin_Work() is to allocate a new transaction identifier, add an entry in the transaction table, and format the entry to reflect savepoint 1. The transaction manager then writes a begin transaction log record that causes the log manager to set the min and max LSN pointers in the transaction entry to that log record. The log manager maintains the LSN fields, and the lock manager maintains the trans->lock_list. If the transaction wants to establish a persistent savepoint (one that will survive restarts), then the Begin_Work() request forces the log record to persistent memory. The last step is to set the process transaction identifier to this trid. From this point until the process commits, aborts, or leaves the transaction, all work done by this process and all RPCs it issues will be tagged with this trid.

The transaction manager is the resource manager owning commit, prepare, savepoint, and abort savepoint records. This savepoint log record and all other log records written by the transaction manager use the resource manager identifier of the transaction manager, TMID, in the log record header. This means that the transaction manager invokes (recursively) its own UNDO and REDO entry points when this log record is undone or redone. In that way, the transaction manager acts like any other resource manager during UNDO and REDO as described in Subsections 11.2.9 and 11.4.2.
11.2.6 Local Commit_Work()
Committing a transaction is a simple matter. The resource managers vote by being invoked at their Prepare() callbacks. The outgoing sessions vote by being sent Prepare() TRPCs and then replying with a yes or no vote. If all vote yes, the transaction is prepared to commit. The commit call writes a commit record (savepoint record) and forces it to persistent memory. The commit operation then broadcasts the commit decision to the local resource managers and to the remote sessions via the Commit() TRPC. When they all respond, the transaction manager writes a completion record in the log and deallocates the transaction control block. The overall logic for Commit_Work() is roughly this:

Figure 11.2 gives a schematic presentation of one round-trip data flow. The two-phase commit protocol has two such flows.

To illustrate this essential logic, fairly detailed pseudo-code for Commit_Work() is shown next. The code uses the syntax rmid.Prepare() to mean that the designated resource manager (rmid) is being invoked via a TRPC at its Prepare() callback. The same syntax is used to invoke other transaction managers participating in the transaction. The syntax TM.Prepare() invokes that transaction manager at the other end of an outgoing session at its Prepare() callback. The next section explains the remote callbacks in more detail. Guideposts in the flow are printed in boldface.


The Prepare() invocations ask the resource managers to vote on the transaction consistency. The resource manager must perform any deferred integrity checks; if the transaction does not pass checks, the resource manager votes no. Because a resource manager can invoke other resource managers during the prepare step, it is possible for new resource managers and new sessions to join the transaction at this time. In addition, a resource manager or session that voted yes to the prepare may subsequently be invoked by another resource manager to do more work. In this case, the invokee calls the transaction manager and asks for a second vote—that is, it rejoins the transaction. The transaction manager makes sure that all “new” resource managers and sessions have voted before it computes the outcome of the prepare step. This logic is implicit in the pseudo-code just given.
The program for Commit_Work() leaves one issue vague: how are errors handled during phase 2 of commit? If a session or resource manager does not respond during the prepare phase, the transaction manager simply calls Abort_Work(). If a failure occurs during phase 2, the transaction manager must eventually deliver the message and get a response from the resource manager or the remote transaction manager. The code given just signals this situation by calling rm_commit(RMTransCB) or session_failure(session CB). In these cases, the Commit_Work() code returns to the caller without having completed the transaction; that is, no completion record is written, and the transaction control block is not deallocated. These routines—rm_commit() and session_failure()—are TRPCs that run asynchronously. The caller continues to execute, and the callee is responsible for completing the transaction. The code for session_failure() is executed by an independent process and reads approximately as follows:

Subsection 11.2.7 discusses the programs executing at the other end of this failed session. Besides these programs, the remote participant can also try to resolve the in-doubt transaction by sending Status_Transaction() messages. Eventually, these two TMs will connect, and the process will terminate. The code for rm_commit() is discussed with resource manager recovery (Subsection 11.4.3.); for now, let us consider the programs executed by a remote transaction manager as part of the commit protocol.
11.2.7 Remote Commit_Work(): Prepare() and Commit()
The Commit_Work() code of Subsection 11.2.6 is for the transaction root—the application process and the transaction manager that began the transaction. If the transaction involves several transaction managers, only one of them is the root. The others receive a pair of TRPCs via each incoming session. The participant transaction managers are invoked by their communication managers, first to perform the Prepare() and later to perform Commit(). These look like ordinary local callbacks. Figure 11.3 illustrates this idea.

Participant transaction managers export two routines that perform the two phases of commit. Since these routines are very similar to the two parts of the Commit_Work() routine shown in the previous subsection, the code is not repeated here. Only the differences are explained.
Prepare() performs the first half of Commit_Work(), as described in Subsection 11.2.6, with the following differences. Prepare() does not have a context parameter; it writes a savepoint log record of type prepare; and, just prior to the statement in Commit_Work() that sets the transaction status to committing, the routine returns TRUE to the caller.
Commit() continues where the Prepare() ended in Commit_Work(), as described in Subsection 11.2.6. It sets the state to committed and completes the transaction. Ignoring failures, that is all there is to the Prepare() and Commit() routines. The use of TRPC considerably simplifies both the local and the distributed protocol.
Only one problem remains: what happens if one of the two session end points fails? Looking at Figure 11.3 again, what happens if the root fails, or if the right-most participant fails? Let us consider the two cases in turn.
If the participant fails, the root session_failure() routine mentioned in the previous subsection continues to invoke the participant’s TM.Commit() until the participant replies. As explained in the discussion of transaction manager restart (Section 11.4), if the root fails—or if any TM with an active session_failure() routine fails—the transaction manager will reinstantiate that process at restart. Thus, session_failure() is executed by a persistent process (see Chapter 3), which means that eventually the participant will execute and reply to the session_failure(), and the entire transaction will complete. This covers the case of failure of the participant transaction manager.
Participant transaction managers handle resource manager failures and outgoing session failures in the same way the root does, with one exception. In a pure presumed-abort design, the participant cannot acknowledge the commit—that is, return from the TRPC—until the transaction has completed. Consequently, the session_failure() and rm_commit() calls cannot be asynchronous; they must complete before the transaction manager responds to its parent. This may be a problem if some resource manager or outgoing session fails: the commit completion could be delayed for a very long time.
Two design alternatives allow the Commit() call to return early: (1) write a persistent “committing” savepoint record in the local log and reinstantiate the Commit() call if the local system restarts, or (2) assume that the Status_Transaction() can determine the outcome of committed transactions at restart by polling the root. The Status_Transaction() design is chosen here; that is, it is assumed that the transaction manager will be able to answer the Status_Transaction() question many years into the future, perhaps by asking the root or perhaps by examining the log. With that design, the session_failure() and rm_commit() calls can execute asynchronously with respect to the caller.
The cases just discussed cover all the participant transaction manager failures. But what if the root fails? In that event, the participant is prepared to commit but is in doubt. As explained in Section 11.4, if the failure happens after the commit record is present in the durable log (after the log force), root restart will initiate a session_failure() process to assure that the participant executes phase 2 of commit. This handles most in-doubt transactions.
If the failure happens before the commit record is durable, the root transaction manager may have no record of the transaction, since all the transaction’s records may have been in volatile memory. The transaction will have aborted at the root transaction manager, but the participant transaction managers may not get an Abort() callback from the root because the root has no record of the transaction. In this case, the prepared participant will wait in doubt forever unless something is done.
To handle such in-doubt transactions, prepared participants periodically issue TM.Status_Transaction(trid) callbacks to the parent transaction manager. These calls can also be directed to the transaction root or to any other participant. If the call gets no response, the transaction manager is still in doubt about the transaction outcome. If the call gets a response, the transaction manager can act on it, executing either the phase 2 Commit() callback or the Abort() callback. This again behaves as an asynchronous process trying to resolve in-doubt transactions. Here is the rough pseudo-code for this program:

We have now covered all the failure cases of transaction commit. To summarize, each committing node invokes the Prepare() callbacks of all local transaction managers on outgoing sessions. If all respond yes, the commit record is written, and a second round of Commit() callbacks is issued. If any respond no to the first round of callbacks, the transaction is aborted. If any failures happen during the second round, persistent processes are created to resolve the in-doubt participants. Having covered the basic begin-commit case, let us now consider savepoints and rollback.
11.2.8 Save_Work() and Read_Context()
The previous discussion was intentionally vague concerning exactly what goes into savepoint records. This is because in normal forward processing, begin-prepare-commit does not read savepoint records, it just creates them. Now that we are about to discuss Read_Context() and Rollback_Work(), the contents of savepoint records become more important.
Many resource managers and many sessions participate in a savepoint. Each may write its own savepoint information in the log. Thus, a savepoint is actually a sequence of savepoint log records consisting of the transaction manager’s record, the communication manager’s records, and the records of other resource managers joined to the transaction—such as the context manager, the queue manager, the database system, or the persistent programming language. Figure 11.4 shows the general structure of savepoint records in the transaction log.
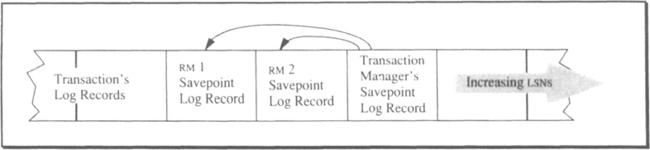
At a savepoint, the transaction manager first invokes each resource manager participating in the transaction at the resource manager’s Savepoint() callback by asking it to freeze-dry its state into a savepoint log record and, as a result, return the LSN of that record. Each resource manager does whatever is needed to allow it to return to this savepoint in case of UNDO or REDO.
If the resource manager’s state changes generate incremental log records, then the REDO/UNDO scans will reconstruct the resource manager’s state, and no extra log records will need to be written at a savepoint. This was the case with the one-bit resource manager introduced in the previous chapter. Hence, its savepoint and prepare codes were empty.
Many resource managers do not log each state transition incrementally; rather, they summarize their state transitions at the save and prepare steps. For example, database read operations typically do not generate log records; consequently, the states of read cursors must be recorded at each savepoint. Similarly, lock and unlock calls do not generate log records; the status of the locks acquired by a resource manager must therefore be recorded at phase 1 of commit and at persistent savepoint records. The transaction manager itself does not log changes to its TransCB structure. Rather, when a transaction reaches a savepoint or a commit point, the transaction manager writes a log record containing the list and status of resource managers and sessions associated with the transaction. In general, frequently changing data use the checkpoint-restart scheme embodied in writing periodic log records (savepoint log records), rather than the incremental logging scheme that generates one or more log records per action. When the transaction returns to the savepoint, the savepoint data are used to reset the object state. Exercise 26 in Chapter 10 gives an example of the prepare record holding the locks of the one-bit resource manager.
Once all resource managers return from their Savepoint() callbacks, the transaction manager increments the savepoint number, and writes a savepoint log record describing all the resource managers and sessions joined to this transaction (as well as the application context passed as a parameter). If the savepoint is persistent, the transaction manager forces the log. The new savepoint number is returned to the application.
Hiding in this logic is the mechanism to establish savepoints within distributed transactions. The Savepoint() callback of the communication manager causes it to send a Savepoint() TRPC on all its outgoing and incoming sessions, thereby establishing the savepoint for the entire transaction tree (see Exercise 5).
There is great similarity among the programs for Save_Work(), phase 1 of Commit_Work(), and the final phases of Rollback_Work(). Of course, each of these procedures calls its associated resource manager callbacks—for example, Savepoint(), Prepare(), and Abort()—and each sets the savepoint record type to a different value; otherwise, the logic is the same. To reinforce this point, the code for Save_Work() is repeated here:


An application can read its current savepoint context by calling Read_Context(). This routine reads the savepoint log record (via a log_read(MyTransP()->save_pt_lsn,…) extracts the context from the end of that record, and returns it to the caller. Beyond that, there is not much to say about either Save_Work() or Read_Context(). Let us therefore consider Rollback_Work().
11.2.9 Rollback_Work()
Having discussed the logic for forward transaction processing, we now look at the logic for transaction rollback. This is an UNDO scan back through the log. The rollback can return to any previous savepoint. When the UNDO scan reaches the requested savepoint, the transaction manager polls each resource manager, asking it to reinstantiate that savepoint. If a resource manager cannot reinstate that savepoint, the UNDO scan proceeds to the previous savepoint. Ultimately, the UNDO scan reaches a savepoint that each resource manager can agree to, or it reaches savepoint 0, that is, a complete UNDO of the transaction. Resource managers are not allowed to veto savepoint 0. Hiding in this UNDO code is the UNDO of distributed transactions. At each savepoint, the session manager is invoked to UNDO that savepoint. This generates an UNDO_Savepoint() callback on all incoming and outgoing sessions. (For a mechanism to prevent cycles in this process, see Exercise 5.) For example, in Figure 11.3, if any resource manager at any of the five nodes in that network calls Rollback_Work(), then all the other nodes of that transaction graph and all participating resource managers at all nodes will vote on the destination savepoint. The code is as follows:


How to implement this mechanism is clear; how to use it is less clear. As an example of a curious situation, the root of the transaction tree in Figure 11.3 established savepoint 1. If a leaf of the tree rolls back to savepoint 1 then the computation should return to the root process. After all, at savepoint 1, no other process was even part of the transaction. But the way the routines are defined, control returns to the process that called Rollback_Work(). In practice, savepoints are used in a controlled way, and these problems do not arise (see Chapter 4, Subsection 4.7.3 and Section 4.9, and Chapter 16, Subsection 16.7.3).
If a resource manager or session fails during an UNDO scan, the rollback operation causes the transaction to abort: the transaction will not be able to establish a unanimous vote on any savepoint (this is the purpose of the abort flag in the code). Transactions involved in a resource manager that is down cannot commit; therefore, unless the transaction is at a persistent savepoint, it is aborted. Clearly, this approach could be improved. The abort operation completes without the participation of the down resource manager. When the down resource manager is recovered, the UN DO-REDO protocol allows the resource manager to reconstruct its most recent consistent state. All transactions in which it was actively involved either will have been returned to their most recent persistent savepoint or will have aborted.
The code for rollback has one interesting feature, the UNDO of savepoints. Such UNDOs are actually executed by the transaction manager’s UNDO routine. That routine reads as follows:

The code is rather dull, but two details are of interest. First, the code reads the savepoint record and reestablishes the state of each resource manager by getting the RMtransCB.save_pt_lsn current at the time of the savepoint. This is the LSN of the savepoint record the resource manager wrote at the time of that savepoint. That LSN is passed to the resource manager as part of the UNDO_Savepoint() callback.
Second, if a transaction returns to savepoint S, a new savepoint record is written by the transaction manager just prior to the end of the UNDO scan. This record is a copy of the original savepoint record. In particular, it has the same tran_prev_lsn (the third-to-last line of the program does this). Subsequent UNDOs of the transaction will skip all intervening records, since they have already been undone and since the tran_prev_lsn of the new savepoint record points past them. Figure 11.5 illustrates this skipping. The shaded records are matching DO-UNDO pairs. Thus, if the transaction is to be undone during normal processing, the shaded records can be skipped. In addition, since all the shaded records are redone at restart, the UNDO of the shaded records can also be skipped at restart. This is easily accomplished, as the program shows.

11.3 Checkpoint
Checkpoint is used to speed restart in the unlikely event of a resource manager or node failure. At restart, all volatile memory is reset—this is the definition of volatile memory. The most recent committed state must be reconstructed from records kept in persistent memory. In theory, restart could go back to the beginning of the log and redo all work since then. After a few years, restarting such a system would take a few years. But restart should be fast; ideally, restart would have no work to redo.
Checkpoints are used to quickly reestablish the current state. A checkpoint is a relatively recent persistent copy of the state that can be used as a basis for restart. Checkpoint frequency is a performance trade-off: frequent checkpoints imply quick restart, but they also imply much wasted work because each checkpoint is unlikely to be used. Each checkpoint is superceded by the next checkpoint. The checkpoint is only needed and used at restart. At that, only the most recent checkpoints are used.
The process pairs described in Chapter 3 (Subsection 3.7.3) checkpoint many times a second, because they want quick takeover times. Large database systems routinely checkpoint every few minutes. If REDO proceeds much faster than normal processing, restart from such checkpoints should complete in a minute. One strategy is to control checkpoint frequency by log activity; for example, checkpointing every time the log grows by a megabyte, or by 10,000 records.
Since volatile memory is lost at restart, any committed updates to volatile memory that appear in the durable log but not in persistent memory must be redone. To reestablish the state of persistent and prepared transactions, their log records must also be redone: their locks must be reacquired and their other state changes reestablished. Any uncommitted transactions must be undone. In general, each resource manager has some state that it must recover before it can accept new work. Each resource manager, then, places requirements on how far back in the log the restart REDO logic must go. These are generically called low-water marks.
Chapter 9 (Section 9.6) introduced the notion of low-water marks. Now would be a good time to review that section. Briefly, the transaction low-water mark is the minimum LSN of any live transaction present in the log. If the transaction called rollback right now, or if the system restarted, the UNDO scan would require the log back to this LSN. The resource manager low-water mark is the minimum LSN needed by any resource manager to redo its work; that is, it is the LSN of the oldest update not present in a persistent copy of the object.
Also explained in Chapter 9 (Section 9.5) are the log manager routines to save a pointer to the transaction manager’s two most recent checkpoint records. The routines have the interface

The transaction manager anchor (checkpoint record), in turn, points to the checkpoint records of the resource managers. Figures 9.6 and 9.7 illustrate these ideas.
Resource managers keep their low-water marks close to the current LSN by periodically copying volatile memory objects to persistent memory. This operation is called resource manager checkpointing. Typically, such flushing is done as a low-priority background activity, so that updates are reflected in persistent memory within a few minutes. If the low-water mark becomes too old (say, more than 5 minutes), then the priority of the flush task is increased, and it may become a foreground activity.
11.3.1 Sharp Checkpoints
Some systems periodically checkpoint the entire state of volatile memory to persistent memory as a synchronous operation. That brings the resource manager low-water LSN up to the current LSN. Such events are called sharp checkpoints. As memories become large, sharp checkpoints become infeasible because they imply moving gigabytes and, consequently, denying service for a period of seconds.
To demonstrate checkpoints, let us generalize the one-bit resource manager described in the previous chapter. Assume that it manages an array of 1,000 pages of bits, rather than just 1 page. Here the get_bit(i) and free_bit(i) programs have to compute the page number (i/BITS) and then operate on bit (i mod BITS) within that page. Each page continues to have a semaphore and a page.lsn. Beyond the more complex bit addressing, the logging and semaphore logic is unchanged. Recall that the one-bit resource manager had the following checkpoint code:

A sharp checkpoint of 1,000 such pages would proceed as follows:
(1) Get the exclusive semaphores on each of the 1,000 pages.
(2) Observing the write-ahead-log protocol, copy all 1,000 pages to persistent memory (disk).
(3) Set the resource manager low-water LSN to current durable LSN.
This is an easy program to write, but it denies service for at least 1 second, while all the semaphores are held and all the I/Os are performed. A more fundamental problem with sharp checkpoint is that it may fail. If it fails when only half the pages have been copied out, then half the pages may be inconsistent with the others. The sharp checkpoint therefore needs two copies in persistent memory; each checkpoint overwrites the oldest copy. (This is an example of shadows.) The simple idea of a sharp checkpoint has turned into a substantial space and complexity problem.
11.3.2 Fuzzy Checkpoints
Fuzzy checkpoints write changes to persistent memory in parallel with normal activity. They do not disrupt service. Fuzzy checkpoints get their name from the fact that the collection of checkpointed pages may not be mutually consistent—the checkpoint may be fuzzy in time, since it was taken while the objects were changing. Each page will be consistent, though. The state is page consistent but not action consistent or transaction consistent.
A fuzzy checkpoint is made into a sharp checkpoint by applying to it all the log records generated during the checkpoint. This operation is an implicit part of restart.
Using the one-bit resource manager example of the previous subsection, a fuzzy checkpoint of the 1,000 pages would execute the one-page checkpoint logic for each of the 1,000 pages. This does not deny service to any page for very long, and it accepts mutual inconsistency among persistent pages from the start (the write-ahead-log protocol will resolve this inconsistency at restart).
What is the log low-water mark for such a fuzzy checkpoint? It is the minimum LSN containing a log record that may need to be redone after this checkpoint completes. The low_water_lsn is the LSN current at the time the fuzzy checkpoint began. Nothing prior to that needs to be redone, but someone may update the first page immediately after its semaphore is freed by the checkpoint and that new update will have to be redone. This is the REDO low-water mark. The UNDO at restart must go back to the min LSN of all transactions active when the checkpoint began. The minimum LSN is the UNDO low-water mark.
Such checkpoints are called fuzzy because the pages are each checkpointed as of some time between the LSN at the end of the checkpoint and the low_water_lsn. By starting at the low-water mark and redoing all subsequent updates, all the pages are converted to a sharp (current) picture of memory. Idempotence is the key property needed to allow fuzzy checkpoints. Because the update may already be in persistent memory, the approach of starting with a pessimistic “low” LSN and working forward on a fuzzy checkpoint works only if redoing an operation many times is the same as doing it once. As explained in Chapter 10, Subsection 10.3.9, the use of LSNs plus physiological logging makes REDO idempotent.
There are many optimizations of this idea. Here are just few of them: (1) The optimization shown in Exercise 21 of Chapter 10, which avoids holding the semaphore during an I/O by copying each page to a buffer, then releasing the semaphore and performing the I/O. (2) Each page can carry a bit indicating it has been updated since it was last read from or written to persistent memory. Initially, the bit is false, and each checkpoint sets the bit false; each update sets the bit true. Checkpoint need only write updated pages. (3) Chapter 2 pointed out that sequential writes have much higher bandwidth than random writes. Thus, checkpoint may want to write out many contiguous pages at a time, rather than just one at a time. (4) Rather than writing all the checkpointed pages out in a burst, the fuzzy checkpoint can spread the writes across the checkpoint interval by adding a delay between each write. The delay time is approximately the checkpoint interval divided by the number of writes needed to perform the checkpoint. These and other optimizations are discussed in Subsection 11.4.6 and in Chapter 13.
That completes the preliminaries. We can now proceed to a fairly simple description of the transaction manager checkpoint logic.
11.3.3 Transaction Manager Checkpoint
Checkpointing is orchestrated by the transaction manager. The decision to take a checkpoint can be driven by time or by log activity. The goal is to minimize REDO time. Not much can be done about UNDO time, since that is determined by how many transactions are aborted at restart and how much work each of those transactions has done. The number of bytes added to the log since the last checkpoint is a measure of how long REDO will take. Thus, every few minutes—or every few megabytes of log activity—the transaction manager initiates checkpoint.
Each time the transaction manager decides a checkpoint is needed, it invokes each active resource manager to record the resource manager’s current volatile state in a checkpoint log record. The resource manager returns the LSN of this checkpoint record, as well as its low-water LSN. The function prototype for such callbacks is
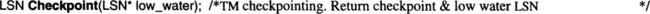
The one-bit resource manager provided an example of such a callback. It has no checkpoint state and, accordingly, returns NULLIsn as its checkpoint LSN, but it does return a low-water LSN. The buffer manager discussed in Chapter 13 gives a more complete example of a checkpoint callback.
The transaction manager’s checkpoint logic is as follows:
Checkpoint callbacks. In parallel, invoke each resource manager to take a checkpoint.
Write checkpoint record. When all up resource managers reply with their LSNs, write a TM_checkpoint record in the log and force it to durable memory.
Save the checkpoint LSN. Ask the log manager to copy the LSN of the checkpoint record to durable memory.
In the interest of simplicity, this chapter ignores the semaphores needed to prevent the transaction manager data structures from changing while they are being traversed. It is enough to say that these semaphores are held for short periods and do not disrupt normal system services.
The TM_checkpoint record has all the information needed to reconstruct the data structure shown in Figure 11.1. It contains the transaction manager anchor (TM_anchor), a description of all installed resource managers (the RMCB list), and a description of each live transaction.1 Restating this in more programmatic terms, the TM_savepoint record nicely describes transactions, and the RMCB nicely describes installed resource managers. The checkpoint record can be declared as follows:

If a resource manager has failed, or if it fails to successfully write the checkpoint record within some time limit (say, 30 seconds), then the checkpoint operation declares that resource manager to be down, and the checkpoint will complete without it. Such failed resource managers will go through resource manager restart (discussed in the following section). In addition, if the resource manager’s low-water mark is too old (less than the previous checkpoint), the resource manager is marked as down.
The whole checkpoint process ordinarily takes less than a second and generates a few tens of kilobytes of log data. While a checkpoint is being taken, the system is continuing to process transactions and do other work. Should a system failure occur during the checkpoint, restart would begin from the previous checkpoint. Once the TM_checkpoint record is written and recorded by the log manager as the checkpoint anchor, restart will begin from this point.
In summary, then, the transaction manager periodically invokes each resource manager to take a checkpoint. The resource manager records its current state and its low-water mark. The transaction manager then writes a checkpoint record summarizing the state of all transactions and resource managers. It saves a pointer to this checkpoint record with the log manager. At restart, the transaction manager will read its checkpoint record, and REDO will begin from the checkpoint low-water mark.
11.4 System Restart
Many systems make distinctions between different types of restarts: hotstart starts from an active state (something like a takeover), warmstart starts from persistent memory, and coldstart starts from the archive. Hotstart is included in the discussion of disaster recovery and fault-tolerant commit protocols (Chapter 12, Section 12.6). Warmstart is called restart here and is described in this section. Coldstart from an archive copy to the current state or to some previous timestamp state is discussed along with archive recovery (Section 11.6).
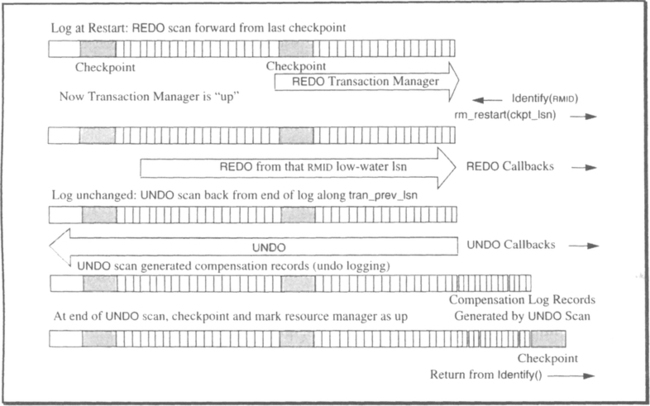
The logic for system restart is diagrammed in Figure 11.6 and is explained in the figure legend. The overall recovery plan is for the transaction manager to first recover itself, rebuilding the data structures shown in Figure 11.1. Once that is complete, resource managers invoke the transaction manager via ldentify() to request recovery. The transaction manager reads them the log, performing first a REDO scan and then an UNDO scan for any actions that are uncommitted or not persistent. Then the transaction manager marks the resource manager as up and returns from the ldentify() call. The following subsections explain first the transaction manager restart, then resource manager restart.
11.4.1 Transaction States at Restart
The discussion of restart needs a generic classification of transaction states at restart (see Figure 11.7):
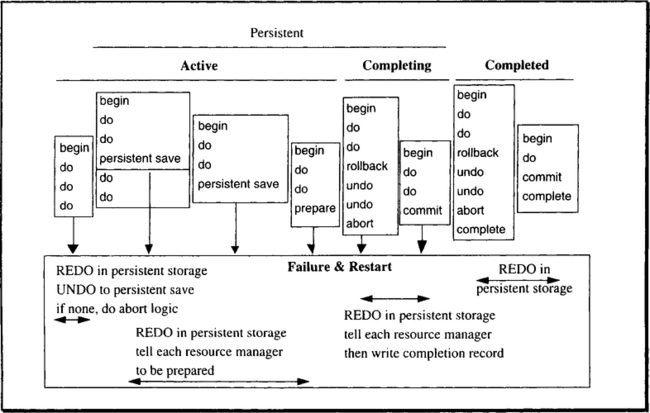
Completed. The transaction committed or aborted and wrote a completion record in the durable log. All resource managers have been informed about the transaction. Incomplete transactions are generically called live transactions.
Completing. The commit or abort decision has been made and the commit record has been written to the log, but some of the transaction’s resource managers may not yet have received the phase-2 invocation.
Persistent. The outcome of the transaction is in doubt, either because it is a “prepared” distributed transaction with a remote commit coordinator or because the transaction is at a persistent savepoint. In either case, the transaction cannot yet be committed or aborted. Completion of this transaction is dependent on the remote commit coordinator or the application that established the persistent savepoint.
Active. The transaction has done some work but has not established a persistent savepoint. In this case, the transaction is aborted at restart.
11.4.2 Transaction Manager Restart Logic
At system restart, the TP monitor starts the log manager, the transaction manager, and other installed resource managers. The TP monitor invokes the rm_Startup() callbacks of each such resource manager. When started, the transaction manager first asks the log manager for the LSN of the most recent checkpoint log record. That checkpoint record describes the transaction manager’s data (the control blocks in Figure 11.1) as of the checkpoint. Using this, the transaction manager reestablishes its tables of installed resource managers and live transactions. It then brings these tables up to date by scanning the log forward, reading transaction log records. When it sees a begin transaction log record, it allocates a TransCB; when it sees a commit_complete or abort_complete log record, it deallocates the associated TransCB. When it sees any other type of savepoint record (save, prepare, commit, or abort record) it updates the TransCB and the lists of joined resource managers and sessions allocated to that transaction. This is the code to perform the REDO of a single transaction manager log record:

Transaction manager restart invokes the above REDO routine for every durable transaction record written after the checkpoint. At the end of this REDO scan, the transaction manager has a list of all transactions that have not completed. Then, for each transaction that is in doubt at restart, the transaction manager launches a process that executes the coordinator_failure() routine (see Subsection 11.2.7) to resolve in-doubt transactions during normal processing. That process persistently asks the remote coordinator (transaction manager) for the status of the transaction and acts on the result. Similarly, for each outgoing session of a committing or aborting transaction, the transaction manager creates a process that executes session_failure() to persistently send the Commit() or Abort() decision to the participant at the other end of the session.
After a transaction manager failure, the transaction manager at restart may not know about the last few trids it created. The trid counter is only made persistent at checkpoints (see Section 11.3). Recent transaction identifiers may have been sent to other nodes. To avoid duplicate trids, the transaction manager at restart advances the sequence counter well beyond any such unrecorded trids. There is little more to say about the following code for transaction manager restart.


After executing this code, the transaction manager is up. It has a current TransCB structure for every transaction that has not completed. It knows what sessions those transactions have and what resource managers are joined to them. It has launched persistent processes to resolve distributed transactions that are committing or are in doubt. It is now ready to help recover the local resource managers.
Because checkpoints are relatively frequent, transaction manager restart usually scans less than a megabyte of log before it is available for operation. This sequential scan completes in less than a second.
11.4.3 Resource Manager Restart Logic, ldentify()
At system restart, the TP monitor starts all resource managers at their rm_Startup() callbacks. As described in the previous subsection, the transaction manager comes back to life by reading its checkpoint record and performing a REDO scan of the log since that checkpoint. While this is happening, each resource manager is doing some of its own startup work: opening files, setting up its process structure, and perhaps even running its own recovery using a private log. Once this initialization is done, the resource manager calls transaction manager ldentify() to declare itself ready for recovery.
The identify call waits on a semaphore within the transaction manager until transaction manager restart is complete. Then, if the resource manager is simple—that is, if it has no callbacks—the ldentify() call marks the resource manager as up and returns. The resource manager is then ready to offer services. Some resource managers keep their own logs and perform their own recovery. Such resource managers only need to resolve in-doubt transactions at restart—they have no records in the common log. The more interesting case of a sophisticated resource manager that generates log records in the common log and participates in transaction commit is shown in Figure 11.8.
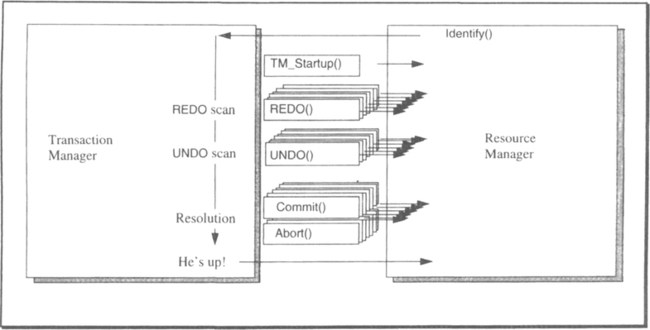
The transaction manager coordinates the recovery of a sophisticated resource manager via a sequence of callbacks. First, it invokes the resource manager’s rm_restart(checkpoint_lsn), passing the most recent checkpoint LSN of that resource manager (RMCB.checkpoint_lsn). Then the transaction manager performs a REDO scan of the log from the resource manager’s low-water mark, invoking rmid.REDO() for each log record written by that resource manager. At the end of the REDO scan, the transaction manager searches the list of live transactions for ones joined to that resource manager. The transaction manager calls rmid.Commit() for each committing transaction. If any are aborting, it initiates an UNDO scan. When this work is complete, the ldentify() call marks the resource manager as up and returns to the resource manager.
Let us now step through the key parts of this recovery scenario a little more slowly. The transaction manager REDO scan from the resource manager’s low-water mark forward to the end of the log passes any log records of the down resource manager to that resource manager’s REDOQ callback:

This completes the REDO scan. At the end of this scan, the resource manager will have redone the work of all completed and live transactions. It will have reestablished the savepoints of all transactions that have not yet completed. The transaction manager then searches for any transactions joined to this resource manager (any RMTransCBs of this RMID). If there are no such transactions, or if all of them are in doubt or at a persistent savepoint, then recovery is complete. In that case, the transaction manager marks the resource manager as up and returns from the ldentify() call.
If, on the other hand, there are committing or aborting transactions, then recovery is not yet complete. In that event, the committing transactions are handled first. For each committing transaction this resource manager has joined, the recovery manager invokes the following routine:

That resolves any committing transactions. If there are no aborting transactions, then recovery is complete. Otherwise, an undo scan of the log is needed to reverse the changes of aborting transactions. The scan goes to the min_lsn of all transactions joined to this resource manager. The UNDO scan is straightforward:

When the UNDO scan is complete, the transaction manager removes the resource manager from the RM_list of all these aborting transactions. If that causes any transactions to complete, the logic of rm_commit() is used to write a transaction completion record in the log and deallocate the transaction. Once all that is done, the ldentify() call marks the resource manager as up, and returns.
There are many fine points associated with resource manager restart, but a major one concerns who needs whom. If one resource manager needs another in order to restart, there must be some way for the first to wait for the second to recover. The ldentify() call gives an example of this situation. It allows other resource managers to wait for the transaction manager to restart. Similarly, the log_read_anchor() call allows the transaction manager to wait for the log manager to start. This staged recovery must be part of the client resource manager design.
If there is a failure during resource manager restart, the whole restart procedure starts over from the beginning. The idempotence of REDO scans allows such restarts.
11.4.4 Summary of the Restart Design
The preceding two subsections explained how the transaction manager reconstructs its state at restart from the most recent checkpoint and from the durable log records since that checkpoint. Once it has restarted, the transaction manager helps other resource managers restart as they invoke ldentify(). This simple design has a REDO scan from the low-water mark, followed by an UNDO scan. The transaction manager orchestrates these scans, helping the resource manager to remember its checkpoint to resolve in-doubt transactions. The next two subsections describe alternate designs for resource managers and for transaction manager restart. The final subsection rationalizes why the REDO-UNDO approach works when combined with physiological logging.
11.4.5 Independent Resource Managers
The design described in Subsection 11.4.3 assumes the resource manager is using the common log and wants help in reading that log. There may be resource managers that keep their own logs or that have their own ideas about performing recovery. Such resource managers want only one thing from the transaction manager: they want it to coordinate the transaction commitment. They would rather do their own recovery. They want only Prepare(), Commit(), and Abort() callbacks, as well as support for Status_Transaction(). With those primitives, they can write their own logs and recover their own states.
Portable systems often maintain their own logs and, therefore, take this view. Such a system first recovers its own state at restart with a private REDO scan, which calls Status_Transaction() to resolve incomplete transactions. It typically uses a private log to do this. Then it invokes ldentify() to get the Commit() and Abort() callbacks for transactions that are committing or aborting. It uses the Commit() callbacks to trigger phase-2 commit work and completion of the transaction. Abort() callbacks trigger a private UNDO scan. Once these tasks have been performed, the resource managers are marked up, and the ldentify() calls return.
11.4.6 The Two-Checkpoint Approach: A Different Strategy
In the decentralized recovery design presented in Subsections 11.4.2 and 11.4.3, each resource manager is recovered independently and asynchronously. This simple design was chosen because it unifies system restart (Section 11.4) and resource manager restart (Section 11.5). The same logic is used if the resource manager failed for internal reasons while the system was operating, or if it failed because the whole system failed.
All this is great, but there is one problem with the design. If n resource managers need recovery at restart, the transaction manager scans the log 2n + 1 times: once for itself and twice for everybody else (a REDO scan and an UNDO scan). Why not piggyback all these scans and have just two scans to recover everybody? To be sure, that is a good idea—it is what many systems do, and it was the original design used in this book—but the centralized design was not presented here because it is a little longer and a little more complex. Here is the basic idea (see Figure 11.9).
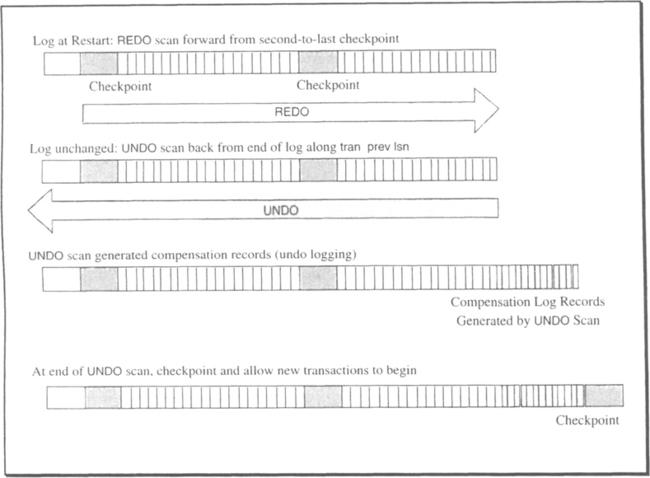
At checkpoint, the transaction manager insists that each resource manager’s low-water mark be more recent than the last transaction manager checkpoint. This is called the two-checkpoint rule: no low-water mark is more than two checkpoints old. Thus, a REDO scan from the second-to-last checkpoint will redo everybody. Note how well this interacts with the fuzzy-checkpoint strategy mentioned in Subsection 11.3.2. It allows the fuzzy checkpoint to spread its writes over an entire checkpoint interval, thereby avoiding any bursts of write activity.
At restart, the transaction manager goes back two checkpoints and restores its state. It waits for everybody to call Identify() and for them to respond to the rm_restart() callback.
Then it performs a global REDO scan, invoking the rmid.REDO(lsn) of every log record after the restart checkpoint. Actually, it can suppress such calls if the rmid.low_water_lsn is greater than the log record LSN.
After this REDO scan, all up resource managers have recovered their states, and all the completed transactions have their effects reflected in the volatile state. The transaction manager then begins the UNDO of all live transactions back to their most recent persistent savepoint. The UNDO scan generates compensation log records and eventually completes, but it could take a very long time if some transaction has done a huge amount of work without establishing a persistent savepoint. If the UNDO scan lasts more than a few minutes, new checkpoints may be taken by the transaction manager. Eventually, all live transactions are returned to their most recent persistent savepoints. Aborted transactions have been undone, and transactions that are prepared or are at a persistent savepoint are reinstantiated: in particular, their locks have been reacquired. At this point, a new checkpoint is taken, and the transaction manager allows new transactions to begin.
Once normal service is started, the transaction manager resolves distributed transactions as described in Subsection 11.4.2.
11.4.7 Why Restart Works
The restart and REDO logic seems quite simple, but it would not work correctly without all the mechanisms described in Chapter 10. The FIX protocol assures that the persistent store is page consistent. The write-ahead-log protocol ensures log consistency; that is, it ensures that the log records needed to UNDO any uncommitted changes in persistent memory are also present in the durable memory log. The force-log-at-commit rule ensures that the log records of any committed transactions are present in persistent memory. Page log sequence numbers (LSNs) make REDOs of physical and physiological log records idempotent, so that restart can fail and restart arbitrarily many times and still produce the correct result.
Table 11.10 is a case analysis of why persistent memory recovery indeed reproduces the most recent atomic and consistent memory state. Consider any transaction and any page update by that transaction. The transaction may or may not have committed; the update may or may not be persistent (the persistent page may be old or new), that update corresponds to a log record; and the log record may or may not be durable. This gives rise to the eight possibilities cataloged in Table 11.10 and discussed individually in the following paragraphs.
Table 11.10
A case analysis of the restart state of a transaction’s outcome, the state of its log record, and the state of the page in persistent memory.
| Case | Transaction | Log record | Persistent Page | Why Recovery Works |
| 1 | committed | volatile | old | impossible: force-log-at-commit |
| 2 | new | impossible: WAL + force-log-at-commit | ||
| 3 | durable | old | REDO makes it new | |
| 4 | new | REDO idempotence | ||
| 5 | aborted | volatile | old | no record at restart (implicit UNDO). |
| 6 | new | impossible: WAL | ||
| 7 | durable | old | REDO then UNDO | |
| 8 | new | REDO idempotence + UNDO |

Let us step through the cases one by one. If the transaction is committed, then the log record must be durable (force-at-commit), and the transaction will be redone. Cases 1 and 2, then, are precluded by force-at-commit. If the page update is volatile (not persistent) and the log record is durable, then restart will redo the update as part of the REDO scan. Therefore, case 3 is handled correctly. If the persistent page is already updated, the REDO idempotence will leave the page in the correct state. Case 4, too, is handled correctly. This, incidentally, is quite important, since restart itself may crash and need to start again. Restart will eventually succeed, and when it does, the page update may have been redone many times. Idempotence means that all these REDOs will leave the page in the correct state.
The logic for committed transactions applies equally well to in-doubt transactions and to transactions with persistent savepoints. Each of these transactions will have its persistent state restored—all their persistent updates will be done and all their locks will be reacquired.
Now let us consider the aborted transaction case. The transaction’s persistent memory updates must be undone unless the transaction already was undone and wrote an abort completion record. The recovery scheme presented here redoes all persistent transaction records found in the log: committed ones and aborted ones. After this REDO scan, the incomplete transactions are undone. If the transaction’s rollback record (the undo_begin record in Figure 10.17) was recorded in the log, then the restart logic realizes that the transaction was aborted and all its changes were reversed by the REDO scan. If the abort completion record was found in the log, then nothing more need be done to abort the transaction; all of its changes to persistent state and the network have been undone as part of the REDO scan. If the aborted transaction has no completion record, the transaction manager carries out the abort completion, informing all the transaction’s local resource managers and outgoing sessions, and then writes the abort completion record. This is done as an asynchronous task by the transaction manager.
If, on the other hand, the transaction was not yet aborting, then transaction UNDO is initiated as though this were an active transaction. If the log record is volatile, then it will not be present at restart. WAL assures that the corresponding page update will also not be present in persistent memory. Thus, in case 5 UNDO is not needed, since the update itself was lost. The whole purpose of WAL is to prevent case 6. Case 7 is the standard UNDO case: the persistent update is undone. Case 8 is quite interesting; it explains why UNDO need not be idempotent in this design. The REDO scan will redo the update before UNDO is called to reverse the update. As a result, at restart (and during normal processing) UNDO will never be presented with an “old” state. Since the system state has been reconstructed using the log REDO, the “online” transaction UNDO logic can be used. The only special feature about UNDO at restart is that no locks are held or acquired except at a persistent savepoint that survives restarts.
11.4.8 Distributed Transaction Resolution: Two-Phase Commit at Restart
The previous subsection explained why REDO and UNDO eventually produce the most-recent committed local memory state, once the outcome of the transaction is known. Now, consider the logic for resolving in-doubt transactions. If the transaction manager is the root coordinator for a transaction that has not completed—one that was committing or aborting—it tries to complete the transaction by notifying the local resource managers and by sending the commit decision to all of the transaction’s outgoing sessions. The root transaction manager is never in doubt about the outcome of the transaction, because it makes the decision.
For transactions that are aborting, the commit coordinator can write the abort completion record in the log and deallocate the transaction structure once the local resource managers have responded. As a consequence of the presumed-abort protocol, the commit coordinator does not have to remember that it aborted the transaction. The absence of any record of an in-doubt transaction implies that the transaction aborted. On the other hand, if the transaction committed, the coordinator must wait for an acknowledgment from all participants before it can claim the transaction is complete.
The participant’s logic is similar. It repeatedly sends inquiries to the coordinator (say, once a minute), asking the status of in-doubt transactions. If no reply is received, it tries again. Eventually, the coordinator responds with the commit or abort message. When this happens, the participant resumes its commit or abort logic and completes the transaction.
There is one case that should never happen, but it does: the commit coordinator is reset, and the transaction manager fails and cannot recover its state. This is considered a disaster and is called amnesia. How can the system sense amnesia and deal with it? As explained in Subsection 11.2.1, each transaction manager remembers its birthday, the day its logs began and the day its memory began. When a transaction manager is reset, it gets a new birthday. Transaction managers cooperating in a distributed transaction exchange birthdays as part of the commit protocol. If at restart the transaction manager’s birthday does not match the birthday it had when the commit started, then something is terribly wrong. The birthday mechanism detects transaction manager failures; it is up to system administrators to resolve any transactions involved in such a failure. Transactions that are in doubt and get a birthday mismatch should remain in doubt and send diagnostic messages to the system administrators. This is quite similar to the logic used by heuristic commit and operator commit (see Chapter 12, Section 12.5).
11.4.9 Accelerating Restart
Restart speed is critical. If restart takes twice as long, unavailability doubles. Chapter 3 pointed out the need for short repair times to provide high availability. The main techniques for speeding up restart are to minimize the work needed at restart (e.g., checkpointing); to perform the restart work incrementally (e.g., recover the most critical resources first); and to perform the restart work in parallel, using all the processors, memory, disks, and communications lines at once.
Incremental restart has many variants. Each resource manager can be recovered independently. If some resources are more critical than others, they can be recovered in priority order. If it is difficult to recognize this priority, the redo log can be sorted by resource and redo can be performed on demand—when the objects are accessed. The data that new transactions want to access will typically be the same as the data accessed a few moments ago—indeed, the transactions may even be identical if the clients are resubmitting work that was interrupted by the restart. So restart will probably have to recover the data in use at the time of the restart.
The redo scan must be performed prior to accepting new work on a resource. At the end of the REDO scan, locks are held on all resources held by incomplete transactions. New transactions can be processed against the database while the UNDO scan is proceeding.
Parallelism offers the greatest opportunities for speedup. Each resource manager can be recovered in parallel, and, in fact, each resource can be recovered in parallel. Exercises 13 and 14 explore these ideas.
11.4.10 Other Restart Issues
The discussion of restart mentioned the two-checkpoint rule: no resource manager should have a low-water mark more than two checkpoints old. This rule limits the REDO work. Similar problems arise with UNDO: undoing a transaction that has been generating log for an hour could easily take an hour. If the transaction establishes persistent savepoints, then restart only needs to undo back to the most recent one. If these savepoints are frequent, the UNDO work will be limited to a few seconds or minutes. At the time this book is being written, no system supports persistent savepoints. To avoid the problem of long restart times, the application programmer must issue frequent commits; this involves converting a batch program to a sequence of mini-batch transactions. In general, systems that want to limit restart times must abort any transaction that would take more than a few seconds to undo. Obviously, this adds considerable complexity to application programming and system operation. It is probable that the rationale for adding persistent savepoints to transaction processing systems will ultimately come from the benefits persistent savepoints provide for quick restart.
To support online UNDO, the log manager must keep the log records of all live transactions online. If a live transaction is a year old, the log manager must keep a year of log online. There are three schemes to deal with this situation:
Abort. Abort any transaction that spans more than N megabytes of log.
Copy-forward. Copy the transaction’s log records forward in the log.
Copy-aside. Copy the transaction’s log records to a side file.
The abort scheme is commonly used today, but it does not support persistent long-lived transactions—ones that last for weeks. Chapter 10 discusses the implementation of copy-forward and copy-aside (also called a dynamic log, after a comparable mechanism in IBM’s IMS program isolation facility). Exactly the same issues come up with resource managers: if a resource manager is down, its low-water mark will be very old. In this case, the transactions cannot be aborted completely, because the resource manager is needed to carry out the rollback. Consequently, resource manager recovery forces a copy-forward or copy-aside scheme for all log records belonging to a resource manager that is down. Because the volume of log data could be quite large in these situations, a copy-aside scheme is preferable.
11.5 Resource Manager Failure and Restart
Supporting the independent failure of various resource managers within a system is one of the key fault-containment techniques of transaction systems. If one resource manager fails, it should only affect the transactions using that resource manager and the objects managed by that resource manager.
A resource manager can fail unilaterally, declaring itself to be down and requesting restart. Alternatively, the transaction manager can decide that the resource manager is broken because it is not responding to transaction commit requests, UNDO requests, or checkpoint requests. In such cases, the transaction manager marks the resource manager as down and denies it permission to join transactions until it has completed a recovery step.
When a resource manager first fails, all live transactions using that resource manager are aborted. Transactions that are prepared, are committing, or are at a persistent savepoint are not aborted, but rollback is initiated on the others. Of course, the down resource manager is not called for the UNDOs of these transactions, because it is not servicing requests. Consequently, the abort completion records for these transactions cannot be written (they require that the down resource manager be consulted). All other resource managers go through their UNDO logic, and after the rollback is complete, the effects of the transactions have been undone for all the up resource managers.
When the down resource manager is ready, it asks to be recovered by invoking the transaction manager via an Identify(rmid) call. The transaction manager then recovers the resource manager, as explained in Section 11.4 (see Figure 11.8). It does a REDO scan from the low-water mark, then an UNDO scan for aborted transactions. Once the REDO scan is complete, the resource manager is considered to be up. If there is a failure during resource manager restart, the whole restart procedure starts over from the beginning. The idempotence of REDO scans allows such restarts.
Resource manager restart is, therefore, quite similar to ordinary restart. The previous subsection discussed copying log records of down resource managers to a side file (the copy-aside logic) so that the online logs need to extend back only a day or a week. The copy-aside logs allow a resource manager to be down for longer periods without causing the online logs to overflow.
11.6 Archive Recovery
If the online version of an object in persistent memory is damaged in some way, it can often be recovered from an archive copy of the object and from the log of all updates to the object since the copy was made. For example, if the online copy of a page somehow gets a double failure (both disks fail), or if the software somehow damages it, then the page might be recovered by starting with an archive copy of the page and redoing all changes to it. Since the logic for this is identical to the REDO scan at restart, such archive recovery is virtually free.
Moving a copy of an object to the archive is called taking a dump of the object. If the dump is made while the object is being updated, then it is a fuzzy dump. This terminology is an exact analogy to the terminology used for checkpoints. Fuzzy dumps are used in the same way as fuzzy checkpoints. Each archive object has a REDO LSN: the LSN at which the REDO scan should begin. This is the LSN that was current when the fuzzy dump began. Updates after the REDO LSN may not be reflected in the fuzzy dump.
The REDO LSN is recorded as an attribute of the object’s fuzzy dump descriptor. Archive recovery of an object, then, consists of the following:
Get exclusive access to the object.
Replace it with the value of its fuzzy dump (archive copy).
REDO all changes to the object from its REDO LSN to the current LSN.
This logic is virtually identical to resource manager recovery, except that it is restricted to a single object (the resource manager itself is functioning regularly). If there is a failure during archive recovery, the whole process begins again.
To complete archive recovery, the entire log (all the way back to the REDO LSN) must be brought online. Since the scan is sequential, the archived sections of the log can be retrieved a gigabyte at a time (or in some smaller unit), and once they have been applied to the object, the online copies can be discarded. The archive copy of the log continues to exist. An archived object also has an UNDO LSN that is the min LSN of any transaction that might have to be undone against the object (see Figure 9.7). In the absence of long-lived transactions, the UNDO LSN is a few hours old, while the REDO LSN is days or weeks old. This, again, is a consequence of logging undos: any UNDO logging needed for complete transactions (aborted or committed) will be encountered by the REDO scan. If long-lived transactions are supported, the UNDO scan places no extra requirements on the online log—those transactions need to have their log records online anyway, in case they need to be aborted. Presumably, their “old” log records have been moved to a copy-aside log.
There are various schemes to accelerate archive recovery: the log can be sorted by resource manager and by object, so that only the log records for the relevant object need be scanned. In addition, the object’s log can be sorted so that duplicates are eliminated. All these optimizations are generically called change accumulation. They are elaborated in Chapter 9, Subsection 9.6.5.
Occasionally, the online copy of an object is so damaged that the system administrators want to go back to the way it was yesterday. When that happens, the whole system state is set back to a previous version. In the typical scenario, a new program with a serious bug is installed. The program manages to contaminate most of the database before the operations staff discovers the situation. Management decides to recover the state as of the time the buggy program was installed. Most recovery systems provide a mechanism to recover the system state (or an object’s state) to a certain timestamp. Recover-to-a-timestamp aborts all transactions that committed after that timestamp. It can be implemented as forward recovery (REDO from the archive) or backward recovery (UNDO from the current state). Recover-to-a-timestamp violates the durability of committed transactions. In particular, the local parts of any distributed transactions that were committed are now aborted. To allow other transaction managers to detect this situation, the recover-to-a-timestamp operation gives the transaction manager a new birthday (see Subsection 11.2.2). In addition, the transaction manager can detect the trids and transaction managers of distributed transactions that were reversed and generate an exception report.
Archive recovery is the last hope of recovering the data. If it fails due to a bug, the data is lost until the bug is fixed. Thus, it is dangerous to use exactly the same programs for system restart, resource manager restart, and archive recovery. If the code has a bug in it, all three attempts at recovery will fail in exactly the same way. To deal with this problem, some systems employ design diversity (see Chapter 3, Section 3.6): they implement archive recovery as a logical REDO. The basic design is to notice that the physiological log records contain all the information needed for a logical REDO or logical UNDO. Hence, a separate archive recovery program can be written. This program first uses physiological logging to make an action-consistent state from a fuzzy checkpoint—that is, recovery to a timestamp just after the end of the checkpoint. Once this state has been reconstructed, a logical REDO of the log from that timestamp forward can be performed. This is an example of fault tolerance through design diversity. Logical archive recovery has failure modes different from those of physiological recovery.
11.7 Configuring the Transaction Manager
The transaction manager has relatively few configuration parameters. At coldstart it is given a name and number, which it uses to identify itself to other transaction managers in the network, and a resource manager identifier, which it uses to identify itself in subsystem calls. It is also given the name of its master log and the name of its TP monitor. Thereafter, logs can be added and resource managers can be registered with it.
The transaction manager can be adjusted to take checkpoints more or less frequently (a configuration parameter discussed in Section 11.3) and to have one or another attitude about heuristic abort (see Chapter 12, Subsection 12.3.1).
The transaction manger’s reporting interface displays the current status of each transaction and each resource manager. Historical reports about committed transactions can be generated from the log tables using the SQL query processor.
11.7.1 Transaction Manager Size and Complexity
Despite the length of this chapter, the structure of the transaction manager is quite simple. Most of the actual recovery work (UNDO and REDO) is inside the resource managers themselves. In fact, the code to write log records and to undo and redo operations typically makes a resource manager about 50% larger.
A basic transaction manager that provides savepoints, archive recovery, and distributed transactions can be written in about 10,000 lines of code. Industrial-strength transaction managers are often 10 times that size. The bulk of this additional code is in areas such as managing archive dumps, generating exception reports, and automating operations tasks. Still, that makes the transaction manager much smaller than an industrial-strength database system or operating system, which would occupy about a million lines of code.
11.8 Summary
The transaction manager implements the transaction verbs and coordinates both transaction commit and transaction rollback. In addition, it helps the resource managers checkpoint their state and reconstruct their state at restart or from the archive.
The transaction manager design presented here is open (extensible). It anticipates the proliferation of transactional resource managers such as database systems, persistent programming languages, TRPC mechanisms of various stripes (SNA LU6.2, OSI/TP, X/OpenDTP, etc.), persistent queue managers, and specialized applications that have their own ideas about recovery.
Chapter 10 covered the basic ideas needed to supply the A, C, and D aspects of ACID transactions. This chapter described how those ideas are embodied in a simple transaction manager. It showed first how commit works and then how rollback and rollback to a savepoint work in the no-fault situation. In essence, this was simply the DO-UNDO protocol.
The discussion then turned to checkpoint-restart. Checkpoints are written to accelerate restart. At restart, the system reads the log and uses the DO-UNDO-REDO protocol to redo all the work of committed transactions. Then uncommitted transactions are resolved, either by aborting them or by returning them to their most recent persistent savepoints.
Finally, the issues of resource manager restart and archive recovery were covered. As it turns out, the techniques used for these two problems are the same as those for online restart. This is no accident, since minimizing the size and complexity of the recovery mechanism is a conscious goal; simple things work. Chapter 12, Section 12.5 will show how this same mechanism provides disaster protection by replicating the objects at two or more sites.
Exercises
1. [11.2.1, 5] How does the birthday detect amnesia?
2. [11.2.2, 5] Suppose the transaction manager stores all its anchor structures in non-volatile RAM so that its data structures are persistent and atomically updated (a neat trick). What would change about its restart logic?
3. [11.2.3, 10] (a) Design a set of optimizations that will make most Status_Transaction() calls quick. (b) What about distributed transactions?
4. [11.2.7, 5] In the discussion of Figure 11.3 and the Commit() callback, it was stated that in a pure presumed-abort protocol, the participant cannot acknowledge until all its outgoing sessions and joined resource managers have responded yes to the Commit() callback. Why? Give an example of what might go wrong if the participant responds early.
5. [11.2.8,10] The presentation of Save_Work() broadcasts the Savepoint() callback on all incoming and outgoing sessions, (a) What is wrong with this idea? (b) How can it be fixed to work?
6. [11.2.9, project] Rollback lets a process roll back over savepoints it never saw. A process that joined the transaction at savepoint 100 can roll the transaction back to savepoint 50. A process needs to abort the transaction, so it must roll back to savepoint 0. Come up with a set of rules that allow abort (rollback to savepoint 0) but also prevent an application from rolling back to a point that it never saw. Hint: Think in terms of a persistent programming language.
7. [11.2.9, 5] Using the ideas and tools discussed in Subsection 11.2.9, implement Abort_Work().
8. [11.2,10] Consider a transaction manager that uses multiple logs. What needs to change about the design of Save_Work(), Commit_Work() and Rollback_Work()?
9. [11.2,15] Consider a resource manager that maintains its own log (it does not use the system services log). What does it do at each of the prepare, commit, UNDO_Savepoint, and abort callbacks? How does it handle restart?
10. [11.2, 5] What exactly is the logic for lazy commit? What needs to be synchronous with the caller and what can be deferred?
11. [11.2, 5] The discussion of commit processing was vague on the logic for chained commit.
Assuming that resource managers want to preserve context across the commit point, how does the nonchained commit logic described in this chapter change?
12. [11.3.2,10] Suppose your resource manager is doing fuzzy checkpoints in a system that enforces the two-checkpoint rule. Suppose it manages a 1 gb volatile storage pool caching data in a 1 tb persistent store. Also suppose that a 10 kb page is updated at random every millisecond. (a) After 5 minutes, what fraction of the pages have been updated? Using the statistics for disks from Chapter 2, how many disks are needed to service these writes if the disks are written (b) at random, (c) sequentially?
13. [11.4,15] This chapter assumed that there is no parallelism within a transaction. Suppose that were false; suppose that a database system supported parallel processes reading and updating different parts of the database. To what extent could UNDO be run as parallel processes?
14. [11.4,15] Repeat Exercise 12 for restart.
15. [11.6,15] The discussion of recovery-to-a-timestamp was vague on exactly which log records are ignored (not redone). What is the answer?
Answers
1. If the TM can only remember back to 10 A.M., then any transactions or sessions with earlier birthdays will have been forgotten. By comparing the transaction or session birthday with the current birthday, a remote tm can detect that this tm has forgotten those objects.
2. It could avoid the redo scan to rebuild the data structures. It would just mark all RMs as down. It would still have to create processes to resolve committing, aborting, and in-doubt transactions. It would still have to service Identify() calls.
3. (a) (1) Keep a hash table or B-tree of all transactions that aborted since restart (many fewer abort than commit). (2) Checkpoint this table and, at restart, update it to include the “big” gap introduced by restart, and all transactions that aborted lately. If the table is too large, hash it into a bitmap for quick negative answers, (b) For distributed transactions, cache the answers locally (both commit and abort), but go to the root commit coordinator to find the answer.
4. If the participant responds early, the coordinator may deallocate the transaction state and so presume that the transaction aborted (in a pure presumed-abort protocol). If the participant fails and restarts, it would then abort the transaction. But we assume here that the coordinator will respond correctly to a Status_Transaction() call, so early replies cause no inconsistency.
5. (a) The broadcast will, in turn, cause a broadcast on all incoming and outgoing sessions. The algorithm will never terminate. (b) This is a standard problem called flooding. The usual way to flood a system is to never send exactly the same callback on the same session (in either direction). So each callback will travel on each session exactly once.
6. The use of multilevel transactions prevents a subtransaction from returning to savepoints it cannot name. See Chapter 4, Subsection 4.7.3 and Section 4.9, and Chapter 16, Subsection 16.7.3.
8. The transaction manager must track all the logs containing records generated by a particular transaction. At the savepoint of a transaction, the TM must write a savepoint record in each participating log. At the prepare of a transaction, the TM must force all participating logs before forcing the master log. At UNDO, it must UNDO all the participating logs. At restart, it must perform a REDO-UNDO scan on all logs.
9. At each event, it must replicate the recovery manager logic. It must force logs at commit and write savepoint records at savepoint, prepare, commit, and abort. At restart, it must execute its own UNDO=REDO scan as a slave to the master log. That is, when the restart scan invokes Abort() for a transaction, the resource manager must do the abort using its private log. Similarly, it must commit if it gets an Commit() invocation, and so on.
10. The phase-1 work that tests for consistency needs to be synchronous. The actual force of the log record and the phase-2 work can be done asynchronously. The premise is that failures are very rare, so the transaction will probably commit if it gets to the end of phase 1. The only case that would prevent commit would be a transaction manager restart.
11. The prepare call must have a flag indicating that the commit is chained. The phase-1 savepoint record of each resource manager must include data needed to reinstantiate either the phase-1 state or the state at phase-2. The phase-2 logic of each resource manager resets the transaction context to the context as of the begin of the next transaction. The begin transaction log record points to these dual-function log records. At restart, if the transaction is committed and the chaining is persistent, the restart logic calls each resource manager to reinstantiate the process/transaction context from the most recent savepoint record.
12. (a) 5 minutes = 300,000 ms, which is 300,000 updates to 100,000 pages. So almost all pages are updated. (b) Must write 100,000 pages in 300 seconds, so 333 pages per second. Using the data from 2.2.1., and random access disks, this is ≈10 disks. (c) Using sequential access disks, this is 3.3 mb/s, which is the bandwidth of 1 disk.
13. First, each node can undo a distributed transaction in parallel. Within a node, if physical or physiological logging is used, one can run the recovery of each page as a parallel stream. That is, UNDOs of two log records can proceed in parallel if they apply to disjoint resource managers, objects, or pages. In general, if the UNDO work can be partitioned so that no partition depends on data from other partitions, then UNDO can be split and run in parallel for each partition. The UNDO work must be synchronized at target savepoints. For example, UNDO of each log may proceed in parallel if there are multiple logs covering different data partitions.
14. The answer is the same. The restart logic can split one or more logs into N streams. Each stream can run the restart logic in parallel, synchronizing only at persistent savepoints.
15. Ignore all log records belonging to transactions with commit records greater than that timestamp. Redo all other transactions. Write a “special” checkpoint log record at the end of the log and undo all transactions that committed after the timestamp or did not complete.
1The transaction manager does not record the transaction lock list. The transaction’s locks are controlled by the resource managers that acquire the locks.