
5. Class Design Guidelines
As we have already discussed, OO programming supports the idea of creating classes that are complete packages, encapsulating the data and behavior of a single entity. So, a class should represent a logical component, such as a taxicab.
This chapter presents several suggestions for designing classes. Obviously, no list such as this can be considered complete. You will undoubtedly add many guidelines to your personal list and incorporate useful guidelines from other developers.
Modeling Real-World Systems
One of the primary goals of object-oriented (OO) programming is to model real-world systems in ways similar to the ways in which people actually think. Designing classes is the object-oriented way to create these models. Rather than using a structured, or top-down, approach, where data and behavior are logically separate entities, the OO approach encapsulates the data and behavior into objects that interact with each other. We no longer think of a problem as a sequence of events or routines operating on separate data files. The elegance of this mindset is that classes literally model real-world objects and how these objects interact with other real-world objects.
These interactions occur in a way similar to the interactions between real-world objects, such as people. Thus, when creating classes, you should design them in a way that represents the true behavior of the object. Let’s use the cabbie example from previous chapters. The Cab class and the Cabbie class model a real-world entity. As illustrated in Figure 5.1, the Cab and the Cabbie objects encapsulate their data and behavior, and they interact through each other’s public interfaces.
When OO programming was first becoming popular, it was difficult for many structured programmers to make the transition. One primary mistake structured programmers made was to create a class that had behavior but no class data, in effect creating a set of functions or subroutines in the structured model. This was not desirable because it didn’t take advantage of the power of encapsulation.
This is only partially true now. Currently, much development is done with anemic domain models, a.k.a. data transfer objects (DTOs) and view models that have just enough data to populate a view or just the right amount of data that is needed by a consumer. Much more focus has been placed on behaviors and operating on the data, and that is handled via interfaces. Encapsulating the behaviors into single-responsibility interfaces and coding to the interfaces keeps code flexible and modular and far easier to maintain.
Note
One of my favorite books pertaining to class design guidelines and suggestions remains Effective C++: 50 Specific Ways to Improve Your Programs and Designs, by Scott Meyers. It offers important information about program design in a very concise manner.
One of the reasons why Effective C++ interests me so much is that, because C++ is backward compatible with C, you can write structured code in C++ without using OO design principles. As I mentioned earlier, during interviews, some people claim that they are OO programmers simply because they program in C++. This indicates a total misunderstanding of what OO design is all about. Thus, you may have to pay more attention to the OO design issues in languages such as C++ as opposed to Java, Swift, or .NET.
Identifying the Public Interfaces
It should be clear by now that perhaps the most important issue when designing a class is to keep the public interface to a minimum. The entire purpose of building a class is to provide something useful and concise. In their book Object-Oriented Design in Java, Gilbert and McCarty state that “the interface of a well-designed object describes the services that the client wants accomplished.” If a class does not provide a useful service to a user, it should not have been built in the first place.
The Minimum Public Interface
Providing the minimum public interface makes the class as concise as possible. The goal is to provide the user with the exact interface to do the job right. If the public interface is incomplete (that is, there is missing behavior), the user will not be able to do the complete job. If the public interface is not properly restricted (that is, the user has access to behavior that is unnecessary or even dangerous), problems can result in the need for debugging, and even trouble with system integrity and security can surface.
Creating a class is a business proposition, and as with all steps in the design process, it is very important that the users are involved with the design right from the start and throughout the testing phase. In this way, the utility of the class, as well as the proper interfaces, will be assured.
Extending the Interface
Even if the public interface of a class is insufficient for a certain application, object technology easily allows the capability to extend and adapt this interface. In short, if properly designed, a new class can utilize an existing class and create a new class with an extended interface.
This is the point where, if you're adding behaviors, the developers should not be using inheritance,
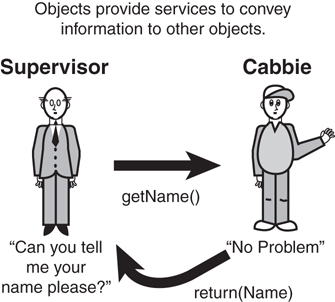
To illustrate, consider the cabbie example again. If other objects in the system need to get the name of a cabbie, the Cabbie class must provide a public interface to return its name; this is the getName() method. Thus, if a Supervisor object needs a name from a Cabbie object, it must invoke the getName() method from the Cabbie object. In effect, the supervisor is asking the cabbie for its name (see Figure 5.2).
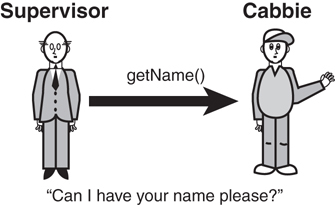
Users of your code need to know nothing about its internal workings. All they need to know is how to instantiate and use the object. In short, provide users a way to get there but hide the details.
Hiding the Implementation
The need for hiding the implementation has already been covered in great detail. Whereas identifying the public interface is a design issue that revolves around the users of the class, the implementation should not involve the users at all. The implementation must provide the services that the user needs, but how these services are actually performed should not be made apparent to the user. A class is most useful if the implementation can change without affecting the users. Basically, a change to the implementation should not necessitate a change in the user’s application code. Again, the best way to enable change of behaviors is via the use of interfaces and composition.
Customer Versus User
Sometimes I use the term customer rather than user when referring to the people who will actually be using the software. Users of the system may, in fact, be customers. In the same vein, users who are part of your organization can be called internal customers. This may seem like a trivial point, but I think it is important to think of all end users as actual customers—and you must satisfy their requirements.
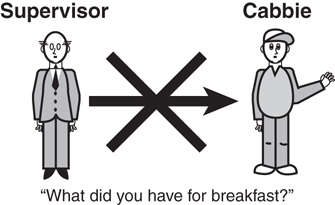
In the cabbie example, the Cabbie class might contain behavior pertaining to how, or where, he eats lunch. However, the cabbie’s supervisor does not need to know what the cabbie has for lunch. Thus, this behavior is part of the implementation of the Cabbie object and should not be available to other objects in this system (see Figure 5.3). Gilbert and McCarty state that the prime directive of encapsulation is that “all fields shall be private.” In this way, none of the fields in a class are accessible from other objects.
Designing Robust Constructors (and Perhaps Destructors)
When designing a class, one of the most important design issues involves how the class will be constructed. Constructors are discussed in Chapter 3, “More Object-Oriented Concepts.” Revisit this discussion if you need a refresher on guidelines for designing constructors.
First and foremost, a constructor should put an object into an initial, safe state. This includes issues such as attribute initialization and memory management. You also need to make sure the object is constructed properly in the default condition. It is normally a good idea to provide a constructor to handle this default situation.
In languages that include destructors, it is of vital importance that the destructors include proper clean-up functions. In most cases, this clean-up pertains to releasing system memory that the object acquired at some point. Java and .NET reclaim memory automatically via a garbage collection mechanism. In languages such as C++, the developer must include code in the destructor to properly free up the memory that the object acquired during its existence. If this function is ignored, a memory leak will result.
Constructor Injection
This is a good point at which to introduce the concept of constructor injection, where service classes are injected on object creation (via a constructor) instead of within the class (using the new keyword). For example, the cabbie can get his license object, his radio information object (frequency, call sign, etc.), and the key that starts his cab passes into the object via a constructor.
Memory Leaks
When an object fails to properly release the memory that it acquired during an object's life cycle, the memory is lost to the entire operating system as long as the application that created the object is executing. For example, suppose multiple objects of the same class are created and then destroyed, perhaps in some sort of loop. If these objects fail to release their memory when they go out of scope, this memory leak slowly depletes the available pool of system memory. At some point, it is possible that enough memory will be consumed that the system will have no available memory left to allocate. This means that any application executing in the system would be unable to acquire any memory. This could put the application in an unsafe state and even lock up the system.
Designing Error Handling into a Class
As with the design of constructors, designing how a class handles errors is of vital importance. Error handling is discussed in detail in Chapter 3.
It is virtually certain that every system will encounter unforeseen problems. Thus, it is not a good idea to ignore potential errors. The developer of a good class (or any code, for that matter) anticipates potential errors and includes code to handle these conditions when they are encountered.
The general rule is that the application should never crash. When an error is encountered, the system should either fix itself and continue, or at minimum, exit gracefully without losing any data that’s important to the user.
Documenting a Class and Using Comments
The topic of comments and documentation comes up in most programming books and articles, in every code review, and in every discussion you have about good design. Unfortunately, comments and good documentation are often not taken seriously, or even worse, they are ignored.
Most developers know that they should thoroughly document their code, but they don’t usually want to take the time to do it. However, a good design is practically impossible without good documentation practices. At the class level, the scope might be small enough that a developer can get away with shoddy documentation. However, when the class gets passed to someone else to extend and/or maintain, or it becomes part of a larger system (which is what should happen), a lack of proper documentation and comments can undermine the entire system.
Many people have said all this before. One of the most crucial aspects of a good design, whether it’s a design for a class or something else, is to carefully document the process. Implementations such as Java and .NET provide special comment syntax to facilitate the documentation process. Check out Chapter 4, “The Anatomy of a Class,” for the appropriate syntax.
Too Much Documentation
Be aware that over-commenting can be a problem as well. Too much documentation and/or commenting can become background noise and may actually defeat the purpose of the documentation. Just like in good class design, make the documentation and comments straightforward and to the point. Well-written code is, in itself, the best documentation.
Building Objects with the Intent to Cooperate
We can safely say that almost no class lives in isolation. In most cases, there is little reason to build a class if it is not going to interact with other classes, unless the class will be used only once. This is a fact in the life of a class. A class will service other classes; it will request the services of other classes, or both. In later chapters we discuss various ways that classes interact with each other.
In the cabbie example, the cabbie and the supervisor are not standalone entities; they interact with each other at various levels (see Figure 5.4).
When designing a class, make sure you are aware of how other objects will interact with it.
Designing with Reuse in Mind
Objects can be reused in different systems, and code should be written with reuse in mind. For example, when a Cabbie class is developed and tested, it can be used anywhere you need a cabbie. To make a class usable in various systems, the class must be designed with reuse in mind. This is where much of the thought is required in the design process. Attempting to predict all the possible scenarios in which a Cabbie object must operate is not a trivial task—in fact, it is virtually impossible.
Designing with Extensibility in Mind
Adding new features to a class might be as simple as extending an existing class, adding a few new methods, and modifying the behavior of others. It is not necessary to rewrite everything. This is where inheritance comes into play. If you have just written a Person class, you must consider the fact that you might later want to write an Employee class or a Customer class. Thus, having Employee inherit from Person might be the best strategy; in this case, the Person class is said to be extensible. You do not want to design Person so that it contains behavior that prevents it from being extended by classes such as Employee or Customer (assuming that in your design you really intend for other classes to extend Person). For example, you would not want to code functionality into an Employee class that is specific to supervisory functions. If you did, and then a class that does not require supervisory functionality inherited from Employee, you would have a problem.
This point touches on the abstraction guideline discussed earlier. Person should contain only the data and behaviors that are specific to a person. Other classes can then subclass it and inherit appropriate data and behaviors.
As we will cover in the SOLID discussion in Chapter 11, “Avoiding Dependencies and Highly Coupled Classes,” and Chapter 12, “The SOLID Principles of Object-Oriented Design,” classes should be open for extension but closed for modification. By using interfaces first and coding to them, you can use all sorts of patterns like Decorator to extend things without touching the code that’s been tested and deployed live, for example.
What Attributes and Methods Can Be Static?
Static methods promote strong coupling to classes. You cannot abstract a static method. You cannot mock a static method or static class. You cannot provide a static interface. The only time it is reasonable to use static classes (within application development—framework development is a bit different) is if you're working with some sort of helper class or extension method that does not produce side effects. For example, a static class to add numbers is fine. A static class that interacts with a database or a web service is not.
Making Names Descriptive
Earlier we discussed the use of proper documentation and comments. Following a naming convention for your classes, attributes, and methods is a similar subject. There are many naming conventions, and the convention you choose is not as important as choosing one and sticking to it. However, when you choose a convention, make sure that when you create classes, attributes, and method names, you not only follow the convention but also make the names descriptive. When someone reads the name, he should be able to tell from the name what the object represents. These naming conventions are often dictated by the coding standards at various organizations.
Good Naming
Make sure that a naming convention makes sense. Often, people go overboard and create con-ventions that might make sense to them but are totally incomprehensible to others. Take care when forcing others to conform to a convention. Make sure that the conventions are sensible and that everyone involved understands the intent behind them. Make variables descriptive of their use, not encoded based on their type.
Making names descriptive is a good development practice that transcends the various development paradigms.
Abstracting Out Nonportable Code
If you are designing a system that must use nonportable (native) code (that is, the code will run only on a specific hardware platform), you should abstract this code out of the class. By abstracting out, we mean isolating the nonportable code in its own class or at least its own method (a method that can be overridden). For example, if you are writing code to access a serial port of particular hardware, you should create a wrapper class to deal with it. Your class should then send a message to the wrapper class to get the information or services it needs. Do not put the system-dependent code into your primary class (see Figure 5.5).
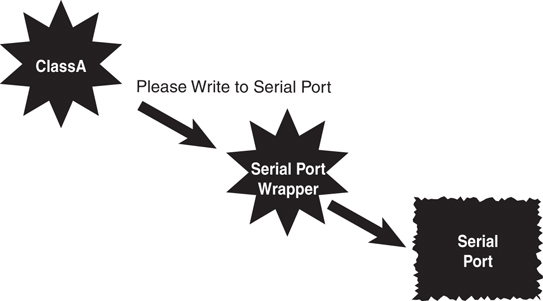
For example, consider the situation when a programmer is interfacing directly with hardware. In these cases, the object code of the various platforms will most likely be quite different, and thus code must be written for each platform. However, if the functionality is placed in a wrapper class, then a user of the class can interface directly with the wrapper and not have to worry about the various low-level code. The wrapper class will deal with the differences in these platforms and decide which code to invoke.
Providing a Way to Copy and Compare Objects
Chapter 3 discussed the issue of copying and comparing objects. It is important to understand how objects are copied and compared. You might not want, or expect, a simple bitwise copy or compare operation. You must make sure that your class behaves as expected, and this means you have to spend some time designing how objects are copied and compared.
Keeping the Scope as Small as Possible
Keeping the scope as small as possible goes hand-in-hand with abstraction and hiding the implementation. The idea is to localize attributes and behaviors as much as possible. In this way, maintaining, testing, and extending a class are much easier. Using interfaces is a great way to enforce this.
Scope and Global Data
Minimizing the scope of global variables is a good programming style and is not specific to OO programming. Global variables are allowed in structured development, yet they can get dicey. In fact, there is no global data in OO development. Static attributes and methods are shared among objects of the same class; however, they are not available to objects not of the class. You could also share data via a file or database.
For example, if you have a method that requires a temporary attribute, keep it local. Consider the following code:
public class Math {
int temp=0;
public int swap (int a, int b) {
temp = a;
a=b;
b=temp;
return temp;
}
}
What is wrong with this class? The problem is that the attribute temp is needed only within the scope of the swap() method. There is no reason for it to be at the class level. Thus, you should move temp within the scope of the swap() method:
public class Math {
public int swap (int a, int b) {
int temp=0;
temp = a;
a=b;
b=temp;
return temp;
}
}
This is what is meant by keeping the scope as small as possible].
Designing with Maintainability in Mind
Designing useful and concise classes promotes a high level of maintainability. Just as you design a class with extensibility in mind, you should also design with future maintenance in mind.
The process of designing classes forces you to organize your code into many (ideally) manageable pieces. Separate pieces of code tend to be more maintainable than larger pieces of code (at least that’s the idea). One of the best ways to promote maintainability is to reduce interdependent code—that is, changes in one class have no impact or minimal impact on other classes.
Highly Coupled Classes
Classes that are highly dependent on one another are considered highly coupled. Thus, if a change made to one class forces a change to another class, these two classes are considered highly coupled. Classes that have no such dependencies have a very low degree of coupling. For more information on this topic, refer to The Object Primer, by Scott Ambler.
If the classes are designed properly in the first place, any changes to the system should be made only to the implementation of an object. Changes to the public interface should be avoided at all costs. Any changes to the public interface will cause ripple effects throughout all the systems that use the interface.
For example, if a change were made to the getName() method of the Cabbie class, every single place in all systems that use this interface must be changed and recompiled. Finding all these method calls is a daunting task, and the likelihood of missing one is pretty high.
To promote a high level of maintainability, keep the coupling level of your classes as low as possible.
Using Iteration in the Development Process
As in most design and programming functions, using an iterative process is recommended. This dovetails well with the concept of providing minimal interfaces. Basically, this means don’t write all the code at once! Create the code in small increments and then build and test it at each step. A good testing plan quickly uncovers any areas where insufficient interfaces are provided. In this way, the process can iterate until the class has the appropriate interfaces. This testing process is not simply confined to coding. Testing the design with walkthroughs and other design review techniques is very helpful. Testers’ lives are more pleasant when iterative processes are used, because they are involved in the process early and are not simply handed a system that is thrown over the wall at the end of the development process.
Testing the Interface
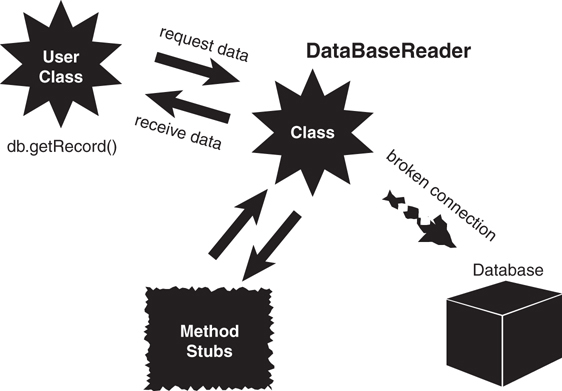
The minimal implementations of the interface are often called stubs. (Gilbert and McCarty have a good discussion on stubs in Object-Oriented Design in Java.) By using stubs, you can test the interfaces without writing any real code. In the following example, rather than connecting to an actual database, stubs are used to verify that the interfaces are working properly (from the user’s perspective—remember that interfaces are meant for the user). Thus, the implementation is not necessary at this point. In fact, it might cost valuable time and energy to complete the implementation yet because the design of the interface will affect the implementation, and the interface is not yet complete.
In Figure 5.6, note that when a user class sends a message to the DataBaseReader class, the information returned to the user class is provided by code stubs and not by the actual database. (In fact, the database most likely does not exist yet.) When the interface is complete and the implementation is under development, the database can then be connected and the stubs disconnected.
Here is a code example that uses an internal array to simulate a working database (albeit a simple one):
public class DataBaseReader {
private String db[] = { "Record1","Record2","Record3","Record4","Record5"};
private booleanDBOpen = false;
private int pos;
public void open(String Name){
DBOpen = true;
}
public void close(){
DBOpen = false;
}
public void goToFirst(){
pos = 0;
}
public void goToLast(){
pos = 4;
}
public int howManyRecords(){
int numOfRecords = 5;
return numOfRecords;
}
public String getRecord(int key){
/* DB Specific Implementation */
return db[key];
}
public String getNextRecord(){
/* DB Specific Implementation */
return db[pos++];
}
}
Notice how the methods simulate the database calls. The strings within the array represent the records that will be written to the database. When the database is successfully integrated into the system, it will be substituted for the array.
Keeping the Stubs Around
When you are done with the stubs, don't delete them. Keep them in the code for possible use later—just make sure the users can't see them and the other team members know that they are there. In fact, in a well-designed program, your test stubs should be integrated into the design and kept in the program for later use. In short, design the testing right into the class! Perhaps even better, create stubs with mock data and coded to interfaces, and then you can swap them out with the actual implementation when the time comes.
As you find problems with the interface design, make changes and repeat the process until you are satisfied with the result.
Using Object Persistence
Object persistence is another issue that must be addressed in many OO systems. Persistence is the concept of maintaining the state of an object. When you run a program, if you don’t save the object in some manner, the object dies, never to be recovered. These transient objects might work in some applications, but in most business systems, the state of the object must be saved for later use.
Object Persistence
Although the topic of object persistence and the topics in the next section might not be consid-ered true design guidelines, I believe that they must be addressed when designing classes. I introduce them here to stress that they must be addressed early on when designing classes.
In its simplest form, an object can persist by being serialized and written to a flat file. The state-of-the-art technology is now XML-based. Although it is true that an object theoretically can persist in memory as long as it is not destroyed, we will concentrate on storing persistent objects on some sort of storage device. There are three primary storage devices to consider:
Flat file system—You can store an object in a flat file by serializing the object. This is definitely outdated. More often than not, objects are serialized to XML and/or JSON and written to some sort of file system or data store or web endpoint. They can be put into a database or written to disk, which is the most common practice nowadays.
Relational database—Some sort of middleware is necessary to convert an object to a relational model.
NoSQL database—This may be a more efficient way to make objects persistent, but most companies have all their data in legacy systems and at this point in time are unlikely to convert their relational databases to OO databases. This is the most common form of a flexible structure database. MongoDB or Cosmos DB are two of the bigger names in this space.
Serializing and Marshaling Objects
We have already discussed the problem of using objects in environments that were originally designed for structured programming. The middleware example, where we wrote objects to a relational database, is one good example. We also touched on the problem of writing an object to a flat file or sending it over a network.
To send an object over a wire (for example, to a file, over a network), the system must deconstruct the object (flatten it out), send it over the wire, and then reconstruct it on the other end of the wire. This process is called serializing an object. The act of sending the object across a wire is called marshaling an object. A serialized object, in theory, can be written to a flat file and retrieved later, in the same state in which it was written.
The major issue here is that the serialization and deserialization must use the same specifications. It is sort of like an encryption algorithm. If one object encrypts a string, the object that wants to decrypt it must use the same encryption algorithm. Java provides an interface called Serializable that provides this translation.
This is another reason why data is separated from behaviors nowadays. It’s far simpler to create an interface for a data contract and push that out to a web service than it is to make sure people have the same code on both sides.
Conclusion
This chapter presents many guidelines that can help you in designing classes. This is by no means a complete list of guidelines. You will undoubtedly come across additional guidelines as you go about your travels in OO design.
This chapter deals with design issues as they pertain to individual classes. However, we have already seen that a class does not live in isolation. Classes must be designed to interact with other classes. A group of classes that interact with each other is part of a system. Ultimately, these systems provide value to end users. Chapter 6, “Designing with Objects,” covers the topic of designing complete systems.
References
Ambler, Scott. 2004. The Object Primer, Third Edition. Cambridge, United Kingdom: Cambridge University Press.
Gilbert, Stephen, and Bill McCarty. 1998. Object-Oriented Design in Java. Berkeley, CA: The Waite Group Press.
Jaworski, Jamie. 1997. Java 1.1 Developers Guide. Indianapolis, IN: Sams Publishing.
Jaworski, Jamie. 1999. Java 2 Platform Unleashed. Indianapolis, IN: Sams Publishing.
Meyers, Scott. 2005. Effective C++, Third Edition. Boston, MA: Addison-Wesley Professional.
Tyma, Paul, Gabriel Torok, and Troy Downing. 1996. Java Primer Plus. Berkeley, CA: The Waite Group.