
6. Designing with Objects
When you use a software product, you expect it to behave as advertised. Unfortunately, not all products live up to expectations. The problem is that when many products are produced, the majority of time and effort go into the engineering phase and not into the design phase.
Object-oriented (OO) design has been touted as a robust and flexible software development approach. The truth is that you can create both good and bad OO designs just as easily as you can create both good and bad non-OO designs. Don’t be lulled into a false sense of security just because you are using a state-of-the-art design methodology. You must pay attention to the overall design and invest the proper amount of time and effort to create the best possible product.
In Chapter 5, “Class Design Guidelines,” we concentrated on designing good classes. This chapter focuses on designing good systems. A system can be defined as classes that interact with each other. Proper design practices have evolved throughout the history of software development, and there is no reason you should not take advantage of the blood, sweat, and tears of your software predecessors, whether they used OO technologies or not.
Taking advantage of previous efforts is not limited to design practices; you can even incorporate existing legacy code in your object-oriented designs. In many cases, you can take code, which may have been working well for years, and literally wrap it in your objects. The wrapping is discussed later in the chapter.
Design Guidelines
One fallacy is that there is one true (best) design methodology. This is certainly not the case. There is no right or wrong way to create a design. Many design methodologies are available today, and they all have their proponents. However, the primary issue is not which design method to use, but whether to use a method at all. This can be expanded beyond design to encompass the entire software development process. Some organizations do not follow a standard software development process, or they have one and don’t adhere to it. The most important factor in creating a good design is to find a process that you and your organization feel comfortable with, stick to it, and keep refining it. It makes no sense to implement a design process that no one will follow.
Most books that deal with object-oriented technologies offer very similar strategies for designing systems. In fact, except for some of the object-oriented specific issues involved, much of the strategy is applicable to non-OO systems as well.
Generally, a solid OO design process includes the following steps:
Doing the proper analysis
Developing a statement of work that describes the system
Gathering the requirements from this statement of work
Developing a prototype for the user interface
Identifying the classes
Determining the responsibilities of each class
Determining how the various classes interact with each other
Creating a high-level model that describes the system to be built
For object-oriented development, the high-level system model is of special interest. The system, or object model, is made up of class diagrams and class interactions. This model should represent the system faithfully and be easy to understand and modify. We also need a notation for the model. This is where the Unified Modeling Language (UML) comes in. As you know, UML is not a design process but a modeling tool. In this book, I only use class diagrams within UML. I like to utilize class diagrams as a visual tool to assist with the design process as well as with documentation—even if I don’t use the other available UML tools.
The Ongoing Design Process
Despite the best intentions and planning, in all but the most trivial cases, the design is an ongoing process. Even after a product is in testing, design changes will pop up. It is up to the project manager to draw the line that says when to stop changing a product and adding features. I like to call this Version 1.
It is important to understand that many design methodologies are available. One early methodology, called the waterfall model, advocates strict boundaries between the various phases. In this case, the design phase is completed before the implementation phase, which is completed before the testing phase, and so on. In practice, the waterfall model has been found to be unrealistic. Currently, other design models, such as rapid prototyping, Extreme Programming, Agile, Scrum, and so on, promote a true iterative process. In these models, some implementation is attempted prior to completing the design phase as a type of proof-of-concept. Despite the recent aversion to the waterfall model, the goal behind the model is understandable. Coming up with a complete and thorough design before starting to code is a sound practice. You do not want to be in the release phase of the product and then decide to iterate through the design phase again. Iterating across phase boundaries is unavoidable; however, you should keep these iterations to a minimum (see Figure 6.1).
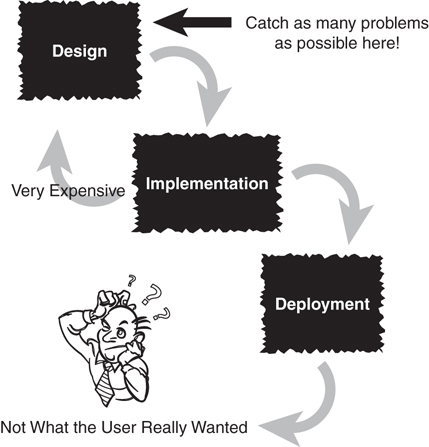
Simply put, the reasons to identify requirements early and keep design changes to a minimum are as follows:
The cost of a requirement/design change in the design phase is relatively small.
The cost of a design change in the implementation phase is significantly higher.
The cost of a design change after the deployment phase is astronomical when compared to the first item.
Similarly, you would not want to start the construction of your dream house before the architectural design was complete. If I said that the Golden Gate Bridge or the Empire State Building was constructed without any consideration of design issues, you would consider the statement absolutely crazy. Yet, you would most likely not find it crazy if I told you that the software you were using might contain some design flaws, and in fact, might not have been thoroughly tested.
In reality, it might be impossible to thoroughly test software, in the sense that absolutely no bugs exist. However, in theory, that is always the goal. We should always attempt to weed out as many bugs as possible. Bridges and software might not be directly comparable; however, software must strive for the same level of engineering excellence as the “harder” engineering disciplines such as bridge building. Poor-quality software can be lethal—it’s not just wrong numbers on payroll checks. For example, inferior software in medical equipment can kill and maim people. Yet, you may be willing to live with having to reboot your computer every now and then. But the same cannot be said for a bridge failing.
Safety Versus Economics
Would you want to cross a bridge that has not been inspected and tested? Unfortunately, with many software packages, users are left with the responsibility of doing much of the testing. This is very costly for both the users and the software providers. Unfortunately, short-term economics often seem to be the primary factor in making project decisions.
Because customers seem to be willing to pay a limited price and put up with software of poor quality, some software providers find that it is cheaper in the long run to let the customers test the product rather than do it themselves. In the short term this might be true, but in the long run it costs far more than the software provider realizes. Ultimately, the software provider’s reputation will be damaged.
Some computer software companies are willing to use the beta test phase to let the customers do testing—testing that should, theoretically, have been done before the beta version ever reached the customer. Many customers are willing to take the risk of using prerelease software because they are anxious to get the functionality the product promises. Conversely, some customers resist new releases like the plague. If it works, don’t fix it. Upgrading can be a nightmare!
After the software is released, problems that have not been caught and fixed prior to release become much more expensive. To illustrate, consider the dilemma automobile companies face when they are confronted with a recall. If a defect in the automobile is identified and fixed before it is shipped (ideally before it is manufactured), it is much cheaper than if all delivered automobiles have to be recalled and fixed one at a time. Not only is this scenario very expensive, but it damages the reputation of the company. In an increasingly competitive market, high-quality software, support services, and reputation are the competitive advantage (see Figure 6.2).

The following sections provide brief summaries of the items listed previously as being part of the design process. Later in the chapter, we work through an example that explains in greater detail each of these items.
Performing the Proper Analysis
A lot of variables are involved in building a design and producing a software product. The users must work hand in hand with the developers at all stages. In the analysis phase, the users and the developers must do the proper research and analysis to determine the statement of work, the requirements of the project, and whether to actually do the project. The last point might seem a bit surprising, but it is important. During the analysis phase, there must not be any hesitation to terminate the project if a valid reason exists to do so. Too many times, pet project status or some political inertia keeps a project going, regardless of the obvious warning signs that cry out for project cancellation. Assuming that the project is viable, the primary focus of the analysis phase is for everyone to learn the systems (both the old and the proposed new one) and determine the system requirements.
Generic Software Principles
Most of these practices are not specific to OO. They apply to software development in general.
Developing a Statement of Work
The statement of work (SOW) is a document that describes the system. Although determining the requirements is the ultimate goal of the analysis phase, at this point the requirements are not yet in a final format. The SOW should give anyone who reads it a complete, high level understanding of the system. Regardless of how it is written, the SOW must represent the complete system and be clear about how the system will look and feel.
The SOW contains everything that must be known about the system. Many customers create a request for proposal (RFP) for distribution, which is similar to the statement of work. A customer creates an RFP that completely describes the system the customer wants built and releases it to multiple vendors. The vendors then use this document, along with whatever analysis they need to do, to determine whether they should bid on the project, and if so, what price to charge.
Gathering the Requirements
The requirements document describes what the users want the system to do. Even though the level of detail of the requirements document does not need to be of a highly technical nature, the requirements must be specific enough to represent the true nature of the user’s needs for the end product. The requirements document must be of sufficient detail for the user to make educated judgments about the completeness of the system. It must also be of specific detail for a design group to use the document to proceed with the design phase.
Whereas the SOW is a document written in paragraph (even narrative) form, the requirements are usually represented as a summary statement or presented as bulleted items. Each individual bulleted item represents one specific requirement of the system. The requirements are distilled from the statement of work. This process is shown later in the chapter.
In many ways, these requirements are the most important part of the system. The SOW might contain irrelevant material; however, the requirements are the final representation of the system that must be implemented. All future documents in the software development process will be based on the requirements.
Developing a System Prototype
One of the best ways to make sure users and developers understand the system is to create a prototype. A prototype can be just about anything; however, most people consider the prototype to be a simulated user interface. By creating actual screens and screen flows, it is easier for people to get an idea of what they will be working with and what the system will feel like. In any event, a prototype will almost certainly not contain all the functionality of the final system.
Most prototypes are created with an integrated development environment (IDE). However, in some basic cases, drawing the screens on a whiteboard or even on paper might be all that is needed. Remember that you are not necessarily creating business logic (the logic/code behind the interface that actually does the work) when you build the prototype, although it is possible to do so. The look and feel of the user interface is a major concern at this point. Having a good prototype can help immensely when identifying classes.
Identifying the Classes
After the requirements are documented, the process of identifying classes can begin. From the requirements, one straightforward way of identifying classes is to highlight all the nouns. These tend to represent objects, such as people, places, and things. Don’t be too fussy about getting all the classes right the first time. You might end up eliminating classes, adding classes, and changing classes at various stages throughout the design. It is important to get something down first. Take advantage of the fact that the design is an iterative process. As in other forms of brainstorming, get something down initially, with the understanding that the final result might look nothing like the initial pass.
Determining the Responsibilities of Each Class
You need to determine the responsibilities of each class you have identified. This includes the data that the class must store and what operations the class must perform. For example, an Employee object would be responsible for calculating payroll and transferring the money to the appropriate account. It might also be responsible for storing the various payroll rates and the account numbers of various banks.
Determining How the Classes Collaborate with Each Other
Most classes do not exist in isolation. Although a class must fulfill certain responsibilities, many times it will have to interact with another class to get something it wants. This is where the messages between classes apply. One class can send a message to another class when it needs information from that class, or if it wants the other class to do something for it.
Creating a Class Model to Describe the System
When all the classes are determined and the class responsibilities and collaborations are listed, a class model that represents the complete system can be constructed. The class model shows how the various classes interact within the system.
In this book, we are using UML to model the system. Several tools on the market use UML and provide a good environment for creating and maintaining UML class models. As we develop the example in the next section, we will see how the class diagrams fit into the big picture and how modeling large systems would be virtually impossible without some sort of good modeling notation and modeling tool.
Prototyping the User Interface in Code
During the design process, we must create a prototype of our user interface. This prototype will provide invaluable information to help navigate through the iterations of the design process. As Gilbert and McCarty in Object-Oriented Design in Java aptly point out, “to a system user, the user interface is the system.” There are several ways to create a user interface prototype. You can sketch the user interface by drawing it on paper or a whiteboard. You also can use a special prototyping tool, or even a language environment like Visual Basic, which is often used for rapid prototyping. Or you can use the IDE from your favorite development tool to create the prototype. However, at this point they are basically facades; the business logic is not necessarily in place.
However you develop the user interface prototype, make sure that the users have the final say on the look and feel.
Object Wrappers
Several times in the previous chapters I have indicated that one of my primary goals in this book is to dispel the fallacy that object-oriented programming is a separate paradigm from structured programming, and is even at odds with it. In fact, as I have already mentioned, I am often asked the following question: “Are you an object-oriented programmer or a structured programmer?” The answer is always the same—I am both!
In my mind, there is no way to write a program without using structures. Thus, when you write a program that uses an object-oriented programming language and are using sound object-oriented design techniques, you are also using structured programming techniques. There is no way around this.
For example, when you create a new object that contains attributes and methods, those methods will include structured code. In fact, I might even say that these methods will contain mostly structured code. This approach fits in well with the container concept that we have encountered in earlier chapters. In fact, when I get to the point where I am coding at the method level, my coding thought process hasn’t changed much since when I was programming in structured languages, such as Cobol, C, and the like. This is not to say that it is exactly the same, because I obviously have had to adjust to some object-oriented constructs; however, the fundamental approach to coding at the method level is virtually the same as programming has always been.
Now I’ll return to the question “Are you an object-oriented programmer or a structured programmer?” I often like to say that programming is programming. By this I contend that being a good programmer means understanding the basics of programming logic and having a passion for coding. Often you will see ads for a programmer with a specific skill set—let’s say a specific language like Java.
Although I totally understand that an organization may well need an experienced Java programmer in a pinch, over the long run I would prefer to focus on hiring a programmer who has a wide range of programming experience and who can learn and adjust quickly when new technologies emerge. Some of my colleagues do not always agree with this; however, I believe that when hiring, I look more at what a potential employee can learn than what they already know. The passion part is critical because it ensures that an employee will always be exploring new technologies and development methodologies.
Structured Code
Although the basics of programming logic may be debated, as I have stressed, the fundamental object-oriented constructs are encapsulation, inheritance, polymorphism, and composition. In most textbooks that I have seen, the basic constructs of structured programming are sequence, conditions, and iterations.
The sequence part is a given, because it seems logical to start at the top and proceed in a logical manner to the bottom. For me, the meat of structured programming resides in the conditions and iterations, which I call if-statements and loops, respectively.
Take a look at the following Java code that starts at 0 and loops 10 times, printing out the value if it equals 5:
class MainApplication {
public static void main(String args[]) {
int x = 0;
while (x <= 10) {
if (x==5) System.out.println("x = " + x);
x++;
}
}
}
Now while this code is written in an object-oriented language, the code that resides inside the main method is structured code. All three basics of structured programming are present: sequence, conditions, and iterations.
The sequence part is easy to identify because the first line executed is
int x = 0;
When that line completes, the next line is executed:
while (x <= 10) {
And so on. In short, this is tried and true top-down programming: start at the first line, execute it, and then go on to the next.
There is also a condition present in this code as part of the if-statement:
if (x==5)
Finally, there is a loop to complete the structured trio.
while (x <= 10) {
}
Actually, the while loop also contains a condition:
(x <= 10)
You can pretty much code anything with just these three constructs. In fact, the concept of the wrapper is basically the same for structured programming as it is for object-oriented programming. In structured design you wrap the code in functions (such as the main method in this example), and in object-oriented design you wrap the code in objects and methods.
Wrapping Structured Code
Although defining attributes is considered coding (for example, creating an integer), the behavior of an object resides in the methods. And these methods are where the bulk of the code logic is found.
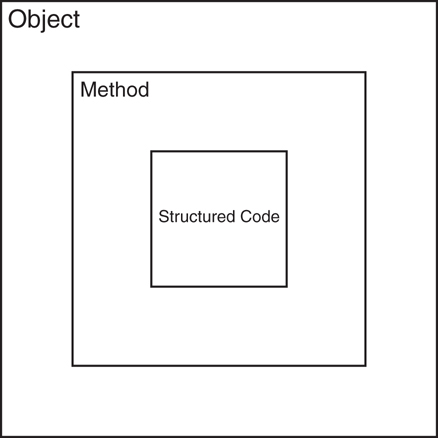
Consider Figure 6.3. As you can see, an object contains methods, and these methods contain code, which can be anything from variable declarations to conditions to loops.
Let’s consider a simple example in which we are wrapping the functionality for addition. Here we create a method named add, which accepts two integer parameters and returns their sum.
class SomeMath {
public int add(int a, int b) {
return a + b;
}
}
As you can see, the structured code used to perform the addition (a + b) is wrapped inside the add method. Although this is a trivial example, that is all there is to wrapping structured code. Thus, when the user wants to use this method, all that is needed is the signature of the method as seen next:
public class TestMath {
public static void main(String[] args) {
int x = 0;
SomeMath math = new SomeMath();
x = math.add(1,2);
System.out.println("x = " + x);
}
}
Finally, we can add some more functionality that is a bit more interesting and complicated. Suppose that we wanted to include a method to calculate the Fibonacci value of a number. We can then add a method like this:
public static int fib(int n) {
if (n < 2) {
return n;
} else {
return fib(n–1)+fib(n–2);
}
}
The whole point here is to show that we have an object-oriented method that contains (wraps) structured code, because the fib method contains conditions, recursion, and so on. And as mentioned in the introduction, it is possible to incorporate existing legacy code in wrappers as well.
Wrapping Nonportable Code
One other use of object wrappers is for the hiding of nonportable (or native) code. The concept is essentially the same; however, in this case the point is to take code that can be executed on only one platform (or a few platforms) and encapsulate it in a method providing a simple interface for the programmers using the code.
Consider the task of making the computer make a noise—in this case, a beep. On a Windows platform we can execute a beep with the following code:
System.out.println("�07");
Rather than making the programmer memorize the code (or look it up), you can provide a class called Sound that contains a method called beep as shown next:
class Sound {
public void beep() {
System.out.println("�07");
}
}
Now, rather than having to know the code for making the sound, the programmer can use the class and call the beep method:
public class TestBeep {
public static void main(String[] args) {
Sound mySound = new Sound();
mySound.beep();
}
}
Not only is this simpler for the programmer to use, but you can extend the functionality of the class to include other sounds. Perhaps more importantly, when the code is used on a non-Windows platform, the interface for the user remains the same. In short, the team that builds the code for the Sound class will have to deal with the change in platform. For the programmers who utilize the class in their applications, the change will be seamless because they will still call the beep method.
Wrapping Existing Classes
Although the need to wrap legacy structured code, or even nonportable code, into a new (object-oriented) class may seem reasonable, the need to wrap existing classes might not seem so obvious. However, there are also many reasons to create wrappers for existing (object-oriented) classes.
Software developers often utilize code written by someone else. Perhaps the code was purchased from a vendor or even written internally within the same organization. In many of these cases, the code cannot be changed. Perhaps the individual who wrote the code is no longer with the organization, or the vendor cannot perform maintenance updates, and so on. This is where the true power of wrappers emerges.
The idea is to take an existing class and alter its implementation or interface by wrapping it inside a new class—just like we did for the structured code and nonportable code. The difference in this case is that, rather than putting an object-oriented face to the code, we are altering its implementation or interface.
Why would we want to do this? Well, the answer lies with both the implementation and the interface.
Consider the database example that we used in Chapter 2, “How to Think in Terms of Objects.” Our goal was to provide the same interface for the developers regardless of which database they were using. In fact, if we need to support another database, our goal would remain the same—to make the transition to the new database transparent to the user (see Figure 2.3 as shown in Chapter 2).
Also, remember our earlier discussion about creating middleware to provide an interface between objects and relational databases. As developers, we want to use objects. Thus, we want functionality that will allow us to persist objects to a database. What we don’t want to have to do is write SQL code for every single object transaction performed to a relational database. This is where we can consider middleware to be a wrapper, and many object-relational mapping products are available.
Conceptually, for me, the ultimate example of the interface and implementation paradigm is the discussion that we had regarding the power plant example in Chapter 2 and shown in Figure 2.1. In this case we can swap out (wrap) both: We can alter the interface by changing the outlet, and we can alter the implementation by changing the power generation facility.
The use of wrappers in software development is fairly extensive, not only from a developer’s perspective but also from a vendor’s. Wrappers are an important tool when developing software systems.
In this chapter, we have focused on various design considerations, including writing new code as well as utilizing previously written code, whether in house or from vendors. In some cases, wrappers are even design paradigms unto themselves. Design patterns, for example, utilize wrappers in various cases. As we will see later, the Decorator pattern focuses on wrapping the implementation, whereas the Adaptor pattern focuses on altering the interface. The discussion of design patterns is explored in more detail in Chapter 10, “Design Patterns.”
Conclusion
This chapter covers the design process for complete systems. It is important to note that object-oriented and structured code are not mutually exclusive. In fact, you can’t create objects without using structured code. Thus, while building object-oriented systems, you are also using structured techniques in the design.
Object wrappers are used to encapsulate many types of functionality, which can range from traditional structured (legacy) and object-oriented (classes) code to nonportable (native) code. The primary purpose of object wrappers is to provide consistent interfaces for the programmers who are using the code.
In the next several chapters, we explore in more detail the relationships between classes. Chapter 7, “Mastering Inheritance and Composition,” covers the concepts of inheritance and composition and how they relate to each other.
References
Ambler, Scott. 2004. The Object Primer, Third Edition. Cambridge, United Kingdom: Cambridge University Press.
Gilbert, Stephen, and Bill McCarty. 1998. Object-Oriented Design in Java. Berkeley, CA: The Waite Group Press.
Jaworski, Jamie. 1999. Java 2 Platform Unleashed. Indianapolis, IN: Sams Publishing.
Jaworski, Jamie. 1997. Java 1.1 Developers Guide. Indianapolis, IN: Sams Publishing.
McConnell, Steve. 2004. Code Complete: A Practical Handbook of Software Construction, Second Edition. Redmond, WA: Microsoft Press.
Weisfeld, Matt, and John Ciccozzi. September, 1999. “Software by Committee,” Project Management Journal v5, number 1: 30–36.
Wirfs-Brock, R., B. Wilkerson, and L. Weiner. 1990. Designing Object-Oriented Software. Upper Saddle River, NJ: Prentice-Hall.