
Chapter 17. Buffering Plans for Uncertainty
“To be uncertain is to be uncomfortable, but to be certain is to be ridiculous.”
—Chinese proverb
One of the complaints I often hear about agile planning is that it doesn’t work well in some environments. Typically, the environments cited are ones in which:
• The project is planned far in advance.
• The project must meet a firm deadline and include a reasonably firm set of functionality.
• The project is contracted from one organization to another.
• Requirements are understood only at a very superficial level.
• The organization is uncomfortable allowing too much flexibility in schedules, even on projects that don’t need firm deadlines and deliverables.
Being able to create reliable plans in these environments is extremely important. It is often not enough to use just the approach covered in the previous chapters. What projects in these environments have in common is that each comes with either an additional amount of uncertainty or with greater consequences to being wrong. For example, I was previously a vice president of software development at a Fortune 40 company, and our projects were typically scheduled onto the calendar twelve to eighteen months in advance, when we’d start setting the following year’s budget. We certainly didn’t lock down requirements, but we would establish the nature of the products we would be building. Even though requirements were only vaguely understood, we had to make first-level commitments that would allow us to staff the organization appropriately. There was further uncertainty because I rarely knew who from my team would work on projects that far in advance. Often, they had not even been hired yet.
Compare this situation with a project on which you are required to state a firm deadline and commit to a core set of functionality. Missing the deadline, or delivering much less functionality, will damage your company’s reputation in the industry and your reputation within the company. Even if you have a reasonable understanding of the requirements and know who will compose the team (unlike in my case above), the risk of being wrong is significant.
In these cases, there is either greater uncertainty or greater implication to being wrong about a release schedule. Because of this, it is useful to include a buffer in the determination of the schedule. A buffer is a margin for error around an estimate. In cases where there is significant uncertainty or the cost of being wrong is significant, including a buffer is wise. The buffer helps protect the project against the impact of the uncertainty. In this way, buffering a project schedule becomes an appropriate risk management strategy. In this chapter, we’ll look at two types of buffers: feature buffers and schedule buffers.
Feature Buffers
I went to the grocery store last night with a list of thirty-seven items to get. I had only thirty minutes to shop and drive home because I wanted to watch a basketball game that was scheduled to start at that time. As always, I started at one end of the store and worked my way to the other. But as I went down each aisle, I was mostly focused on the twenty or so items that I knew we needed most. If I came home without milk, bread, or sliced turkey, I knew I’d be in trouble, and at half-time I’d be back at the store. But if I forgot items of lesser importance, my wife would be content, my daughters could eat, and I could watch the basketball game.
Buffering a project with features is exactly the same. We tell our customers, “We’ll get you all of the functionality in this pile and ideally some of the functionality in that pile.” Creating a feature buffer is simple to do on an agile project. First, the customer selects all of the absolutely mandatory work. The estimates for that work are summed. This represents the minimum that can be released. The customer then selects another 25% to 40% more work, selecting toward the higher end of the range for projects with more uncertainty or less tolerance for schedule risk. The estimates for this work are added to the original estimate, resulting in a total estimate for the project. The project is then planned as normal for delivery of the entire set of functionality; however, some amount of the work is optional and will be included only if time permits. The optional work is developed last, only after the mandatory work is complete.
To see how this works, assume that the product owner identifies 100 story points as mandatory. Each story selected is required to release a product that will be favorably accepted by the market. The product owner then selects an additional 30% more work, identifying user stories worth an additional 30 story points. These are added as optional work to the project. The total project is now expected to be 130 story points. Using the techniques described in Chapter 16, “Estimating Velocity,” the team estimates velocity will be ten points per one-week iteration. The project is then planned to take thirteen iterations (130/10). If all goes well, the mandatory work will be done after the first ten iterations, and the remaining three will be spent on the optional features.
This feature buffering process is consistent with that used in the agile process, DSDM (Dynamic Systems Development Method). On DSDM projects, requirements are sorted into four categories: Must Have, Should Have, Could Have, and Won’t Have. DSDM refers to this sorting as the MoSCoW rules. No more than 70% of the planned effort for a project can be targeted at Must Have requirements. In this way, DSDM projects create a feature buffer equivalent to 30% of the duration of the project.
Schedule Buffers
Suppose I need to go to the airport and catch a flight to Italy. (As long as I’m supposing, I might as well suppose I need to go somewhere nice.) An airplane flight has a very firm deadline. The flight will take off with or without me. In creating a plan for getting from my house to the proper gate at the airport, I need to leave early enough that I’m reasonably confident I’ll make my flight, but not so early that I’m at the airport three days ahead.
I think about all of the steps involved: driving to the airport, parking my car, checking in and dropping off my luggage, and going through the security checkpoint. I think about how long that should take me if everything goes well and decide it should take seventy minutes. That’s how long it should take. It may take even a few minutes less, but it could take a whole lot longer. If there’s an accident on the highway, and if the parking lot is full, and if there’s a long line to check in, and if there’s a long line to go through security, it could take quite a while longer. I don’t need to plan on all of these things going wrong on the same trip; but because this is an important trip, and I don’t want to miss my flight, I should add some extra time to the seventy minutes it should take if everything goes well.
Let’s say I decide to leave for the airport 100 minutes before my flight. If things go well, that will leave me thirty minutes to pass in the airport, which isn’t bad. If things go really well (all the traffic lights are green, I park in the front row, no one is ahead of me to check in or at security) then maybe I have forty minutes in the airport. But if I get stuck in traffic or in a big line to check in, this extra time will most likely be enough to get me on the plane before it leaves. The extra thirty minutes are my schedule buffer; they protect the on-time completion of the overall project (getting to the airport).
For a trip to the airport, it is not appropriate to take a guess at my rate of progress (my velocity) and then provide the airline (the customer) with periodic updates about my expected arrival time. My expected arrival time and my rate of progress don’t matter to the airline; the departure time is fixed, just like deadlines are on many software development projects. In this cases, a schedule buffer protects against uncertainty that can affect the on-time completion of the project.
Note that I am not concerned with whether any one activity (driving, parking, checking in, or going through security) takes too long. I am concerned only with whether the overall chain of activities takes too long. To make my flight, I add a thirty-minute buffer to my overall schedule for getting to the airport. What we’d like to do is add a similar schedule buffer to projects with greater uncertainty or with greater consequences for missing a deadline.
Reflecting Uncertainty in Estimates
To protect a project schedule against uncertainty, we need a way to quantify the uncertainty. When we estimate and assign a single value to a user story, we pretend that a single number reflects our expectations about the amount of time developing the feature will take. More realistically, though, we know the work may be completed within a range of durations. A team may estimate a particular user story as three ideal days, knowing that three ideal days typically represents four or five elapsed days of work. If the story takes six days to complete, however, no one will be shocked; things sometimes take longer than planned. If we graph the possible completion times for a task, it will look approximately like Figure 17.1.
Figure 17.1. The distribution of completion times.
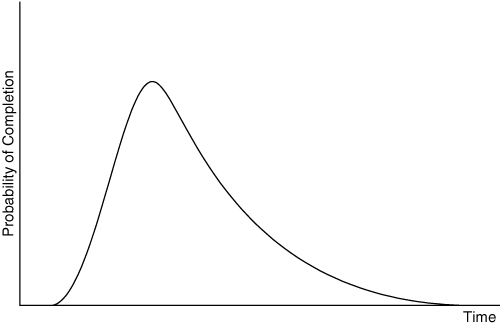
The curve takes on this general shape because there normally is not much that can be done to accelerate the completion of a task, but there are an indefinite number of things that can go wrong and delay the completion of a task. For example, just as I’m about to finish coding a particular new feature, my computer crashes, and I lose unsaved changes. Then lightning hits the building and fries our source repository. We request a backup tape to be delivered tomorrow morning, but the delivery service loses the tape. But I don’t care, as I’m run over by the proverbial bus on the way to work.
The single most likely completion time in Figure 17.1 is where the line peaks. Overall, however, finishing by that time is less than 50% likely. We know this because less than 50% of the area under the curve is to the left of the peak. If a developer were to provide an estimate corresponding to the peak of Figure 17.1, she would most likely take longer than that estimate to finish the work. A more useful way of visualizing this is in Figure 17.2, which shows the cumulative probability of finishing on or before the times on the horizontal axis.
Figure 17.2. The cumulative distribution of completion times.

Whereas Figure 17.1 shows the probability of finishing at a specific time, Figure 17.2 shows the probability of finishing at or before that time. When estimating and planning, this is more important to us than the probability of finishing on any one day (as shown in Figure 17.1).
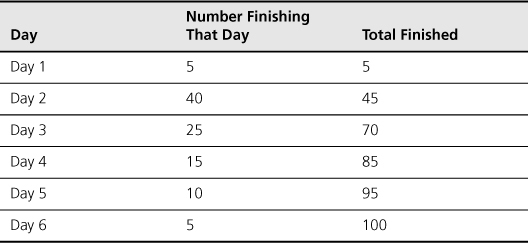
Another way to think about Figure 17.2 and cumulative probability of completion times is to assume that 100 different but equally skilled and experienced programmers independently develop a new feature. By what date would each finish? The results might be similar to those shown in Table 17.1. This table shows the number finishing on each day and, more important, the total number finished by a given date.
Table 17.1. Number of Developers Finishing a Feature on a Given Day
Suppose we want to be 90% confident in the schedule we commit to. One initial approach to doing this might be to estimate the 90% likely duration for each user story in the project and then use those estimates. However, if we do this, the project schedule will almost certainly be too long. To see how a schedule buffer works, let’s again consider my trip to the airport, a possible schedule for which is shown in Figure 17.3.
Figure 17.3. The 50% and 90% estimates for making a flight at the airport.
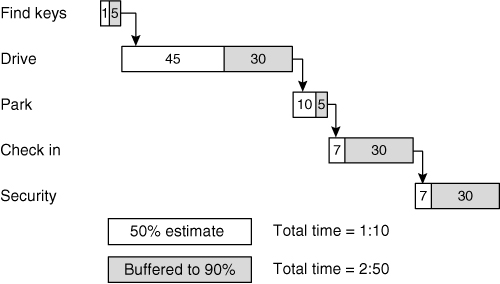
The first number for each task (in the clear box) is the 50% estimate of how long the task should take. I expect tasks to take longer half the time and shorter half the time. The second number (in the shaded box) is the additional amount of time to reach my 90% estimate. The additional time between the 50% and the 90% estimate is called local safety. We often add local safety to an estimate we want to be more confident of meeting. In this case, I think I can find my keys in one to six minutes. I can drive to the airport in forty-five to seventy-five minutes, and so on.
Adding up the 50% numbers gives me an expected duration of an hour and ten minutes. However, if I leave my house that close to departure time, the slightest delay will cause me to miss my flight. On the other end, adding up the 90% estimates gives a total of 2:50. I don’t want to leave nearly three hours ahead of my flight, because there’s very little chance that everything will go wrong. What I really want is a project plan that looks like Figure 17.4.
Figure 17.4. A buffered trip to the airport.
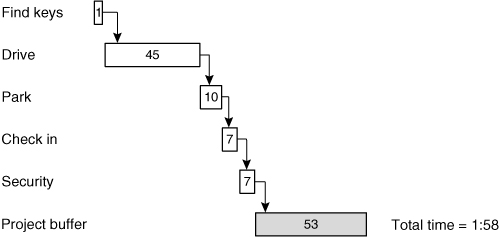
The plan in Figure 17.4 is built using the 50% estimates and then adding a project buffer. This type of plan makes much more sense than one built entirely from summing the 50% or the 90% estimates. The plan in Figure 17.4 protects the only deadline that matters: the overall project deadline. Because it isn’t important if any one task on my way to the airport finishes late, I do not need to buffer the on-time completion of the tasks. This allows me to construct a schedule that removes local safety from the individual tasks and puts a fraction of that time into a buffer that protects the overall schedule. Notice that the buffered schedule of Figure 17.4 is only 1:58—nearly an hour shorter than the schedule created by summing the 90% estimates.
Even better, by moving local safety into an overall project buffer, we are able to avoid the impact of Parkinson’s Law and student syndrome. As you’ll recall from Chapter 2, “Why Planning Fails,” Parkinson’s Law says that work expands to fill the time available. Student syndrome (Goldratt 1997) refers to starting something at the last possible moment that doesn’t preclude successful completion—for example, starting a college term paper three days before it’s due. Because it averts the problems caused by Parkinson’s Law and student syndrome, a shorter schedule that includes a schedule buffer is more likely to be met than is a longer schedule.
To create a schedule buffer for a software project, the first thing we need to do is revise our estimating process so that it generates two estimates for each user story or feature. Just like with the trip to the airport, we need to know the 50% and the 90% estimate for each. This is easy enough: When the team meets to estimate, start by estimating the 50% case for the first story. Then estimate the 90% case for that story before moving on to the next story or feature.
Sizing the Project Buffer
The project buffer in Figure 17.4 was sized to be fifty-three minutes. How did I come up with that duration? It was based on the 50% and 90% estimates for that project, as shown in Figure 17.4. The beauty of associating two estimates with each user story is that the numbers very clearly point out the degree of schedule risk associated with each item. For example, if one story is estimated as being three to five and another story is estimated as being three to ten, we know that the second story brings more schedule risk to the project. The project buffer will be sized to accommodate the amount of schedule risk brought by the work planned in the project. Think about an extreme example: If you are planning a project schedule, you will need a smaller project buffer for tasks estimated to be 3 to 7 than you will for tasks estimated to be 3 to 100. Clearly, if the project has some 3-point tasks that could turn into 100-point tasks, the project buffer needs to be larger than if the worst case for those tasks were 10 points. So the spread between the 50% and 90% estimates influences the size of the project buffer.[1]
Because our estimates are at the 50% and 90% points for each item, this means that the difference between these two estimates is about two standard deviations. The standard deviation for each item is then (wi - ai)/2, where wi represents the worst case (90% estimate) for story i and ai represents the average case (50% estimate) for the same story. We’d like the project buffer to protect the overall project to the same 90% level that each task was protected by its own 90% estimate. This means our project buffer should be two standard deviations and can be determined from this formula:
where σ is the standard deviation. This can be simplified to the following:
Let’s see how we use this formula to determine the size of the schedule buffer. Suppose our project includes the six user stories shown in Table 17.2 and that each story has the 50% and 90% estimates shown. These estimates can be in story points or ideal days. The final column of Table 17.2 is calculated by taking the worst-case (90%) estimate of a story, subtracting the average case (50%) of that story, and squaring the result. The first story, for example, is (3 – 1)2 = 4. The schedule buffer is the square root of the sum of these squares.[2] In this case, the schedule buffer equals the square root of 90, which is 9.4, so we’ll round it to 9. The overall project duration is the sum of the 50% estimates plus the project buffer, or 17 + 9 = 26 in this case.
Table 17.2. Calculating the Project Buffer for a Project with Six Stories
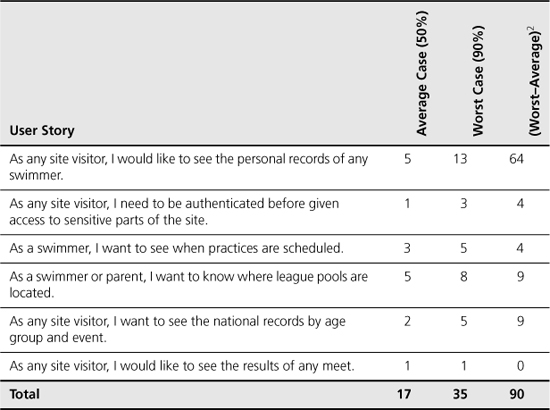
Intuitively, the buffer calculated in Table 17.2 makes sense. The user story that contributes the most to the size of the schedule buffer (the first story) is the one with the most uncertainty (an eight-point difference between its 50% and 90% estimates). Similarly, a story with no uncertainty (the last story) doesn’t contribute to the buffer at all.
Adding in a schedule buffer may or may not add one or more iterations to the length of a project. Most often it will. Suppose the team in this example had forecast their velocity to be nine points per iteration. If they had estimated the project to be seventeen points (the sum of the 50% estimates), they would have expected to finish in two iterations. However, with the project buffer included, the full project is twenty-six points and will take three iterations to complete if their velocity is nine.
A Simpler Buffer Calculation
The preceding approach to sizing the project buffer is the best way to size the project buffer. But if for some reason you cannot come up with both 50% and 90% estimates, there is a simpler way to size the project buffer. Estimate each story at the 50% level and then set the buffer at half the size of the sum of the 50% estimates. Be sure that the entire team is aware that their estimates are to be ones they are 50% confident in. We want estimates that are just as likely to be high as they are to be low.
Although this calculation is far simpler, it has the serious flaw of not being influenced by the actual uncertainty around the specific user stories in the project. Suppose there are two stories, each estimated at five story points. Each of these stories will contribute the same amount to the project buffer (half of their size, or 2.5 points each). This will be true even if one of the stories would have had a 90% estimate of 100 and the other a 90% estimate of 10.
For these reasons, and because it’s extremely easy just to ask for two estimates at the time you’re estimating, I prefer the approach based on the square root of the sum of the squares.
Buffer Guidelines
Regardless of whether you prefer to take the square root of the sum of the squares approach or the 50% approach, you should consider these additional guidelines based on advice from Leach (2000).
• The square root of the sum of the squares approach is most reliable if there are at least ten user stories or features being estimated. But if your project has fewer than ten items, you probably shouldn’t be planning with a buffer anyway.
• The project buffer should represent at least 20% of the total project duration. A smaller buffer may not provide adequate protection for the overall project.
Combining Buffers
At first, it may seem like overkill to have multiple buffers. However, it is often appropriate to use multiple buffers, because we are protecting the project against multiple types of uncertainty. My car has shoulder belts and air bags because each buffers me against a different type of collision. We should always buffer a given type of project uncertainty with the right units, which means we buffer feature uncertainty with features and schedule uncertainty with time. Additionally, when multiple buffers are used, the size of each can be smaller.
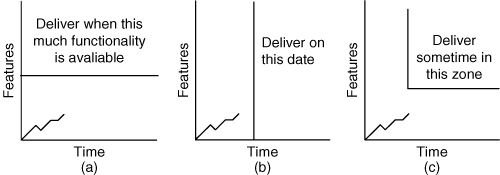
It is when we combine feature and schedule buffers on a project that projects become truly protected against uncertainty. Consider the three projects shown in Figure 17.5. In this figure, (a) shows a project that must deliver a defined set of functionality but allows the schedule to vary. Figure 17.5(b) shows the opposite: a project whose date is fixed but has complete flexibility around the functionality to be built. Now look at Figure 17.5(c), and see that by including both a feature buffer and a schedule buffer the team is able to commit to both a delivery date and a minimum set of features. When creating a release plan, our goal is to use buffers so that the team can make these types of commitments.
Figure 17.5. Three projects with different approaches to buffering.
Also, keep in mind that a project may use other buffers besides feature and schedule. A project may include a budget buffer where, for example, thirty developers are assigned to the project, whereas the budget allows up to thirty-three. This is a common practice on medium and large projects but is seen less frequently on small projects for two reasons.
1. The additional person or two who would make up the personnel buffer on a small project would almost certainly be able to make direct contributions to the project. There may be little or no productivity gains in fully staffing from thirty to thirty-three developers. There will, however, almost certainly be productivity gains from fully staffing from four to five.
2. It is difficult to buffer anything in small numbers. When a thirty-person project has a three-person buffer to a full staff size of thirty-three, it has a 10% personnel buffer. A similar buffer on a three-person project implies a buffer of three-tenths of a developer. Clearly, it’s easier to add whole rather than partial people to a project.
A Schedule Buffer Is Not Padding
The term padding has the pejorative meaning of excess time arbitrarily added to an estimate. I pad an estimate when I think it will take three days but decide to tell you five, just in case. Individuals add padding to an estimate if they expect to be beaten up if they are wrong. A schedule buffer is different: A schedule buffer is a necessary margin of safety added to the sum of estimates from which local safety has been removed.
When you put five car lengths between your car and the one ahead, you do that because you fully expect to use up most of that buffer if forced to brake suddenly. Yes, it’s possible you could drive for hours with one car length separating you and the car ahead, but it’s not likely. The buffer around your car is critical to your safety. Appropriate buffers around your project are critical to the safety of your project.
When we allow small amounts of flexibility in both delivery date and functionality, we can buffer two dimensions of the project. More important, we buffer each project constraint with the appropriate resource: We buffer the deadline with time; we buffer functionality with functionality. When we cannot buffer a constraint appropriately, we are forced to increase the size of other buffers. If I am forced to guarantee the functionality, I will support that guarantee with a larger schedule buffer.
Some Caveats
Although knowing how to add one or more buffers to a project is an important skill to have at your disposal, it is also good to be aware of some caveats on their use.
• When adding a schedule buffer, use the two-estimate approach described in this chapter or be sure that the single-value estimates represent estimates at the 50% point. Adding a schedule buffer on top of already pessimistic 90% estimates will result in an overly long schedule.
• On many projects, a precise deadline with a precise set of delivered functionality is not needed. Instead, the team simply needs to deliver high-quality software as fast as possible over a sustained period. If you’re in this situation, don’t take on the extra work of adding buffers to your project.
• Be careful with how you communicate buffers. You should not hide their existence or how they are used. However, a buffer (especially a schedule buffer) can appear to be padding. This means you’ll need to communicate how you derived the estimates and the buffer, and how the buffer is intended to provide a schedule everyone can be highly confident of.
Summary
Most projects contain a tremendous amount of uncertainty. This uncertainty is often not fully reflected in the schedules and deadlines that project teams create. There are times when this uncertainty is so large or significant that extra steps should be taken when estimating the duration of the project. This may be the case when the project is planned far in advance, the project must absolutely meet a deadline with a reasonably firm set of functionality, the project is outsourced, requirements are still at a superficial level, or there is a significant impact (financial or otherwise) to being wrong about a date.
The two most common types of buffers are feature buffers and schedule buffers. A feature buffer is created when a product’s requirements are prioritized and it is acknowledged that not every feature may be delivered. The agile process DSDM, for example, recommends that 30% of the effort of the project be considered optional, which creates a feature buffer for the project. If time runs short, the schedule can still be met by dropping items in the feature buffer.
A schedule buffer, on the other hand, is created by including in the schedule an amount of time that reflects the uncertainty inherent in a team’s size. A feature buffer can be constructed by estimating both a 50% likely size and a 90% likely size for each user story. By applying the square root of the sum of the squares formula to each of the 50% and 90% estimates, an appropriately sized schedule buffer can be estimated.
A project should protect against feature uncertainty with a feature buffer and against schedule uncertainty with a schedule buffer. A feature buffer may be combined with a schedule buffer. In fact, this is usually a good idea, as it allows the size of each to be smaller.
Discussion Questions
1. Are there conditions in your organizations that could benefit from the extra effort of calculating a schedule buffer?
2. Is your current project buffered against any types of uncertainty? If so, how? If not, which types of buffer would be most beneficial?
3. Do you see evidence of Parkinson’s Law or the student syndrome in your organization? Beyond the suggestions in this chapter, what might you be able to do to reduce the impact of these?