
The ability to interact with MediaWiki through an application programming interface is an evolving feature. In this chapter, you will learn about bots, programs used to automate certain administrative tasks on MediaWiki, as well as the MediaWiki API, which is currently in development and is intended to provide a programming interface to MediaWiki so that external applications can interact with it.
Both the section on bots and the section on the API make extensive use of examples written in the Python programming language. Even if you do not know Python, you will be able to learn a lot about how bots and the API work, which you can use to develop scripts in your language of choice. With respect to the API, all interaction is managed through URLs, so you don't even have to write any script to see samples of the API output; simply type the URL in your browser and see what is returned.
In MediaWiki parlance, a bot is a script or program that is used to perform some administrative task in support of a wiki. There is a special group called bot, so any bot that is used with MediaWiki must have a username that is in the bot group. A person with bureaucrat privileges is required to set the appropriate permissions.
The reason for requiring a special username is twofold. One, you do not want people to be able to automate tasks willy-nilly with your wiki. That's just asking for trouble from spammers and trolls. At the same time, tedious or time-consuming tasks can benefit greatly from automation. Because the work that bots do is often en masse, meaning that they perform some task that might affect hundreds of documents, MediaWiki treats changes made by bots a little differently. For example, when viewing recent changes, changes made by bots can be excluded. By having a special bot group, both issues are addressed.
Bots interact with MediaWiki programmatically, but to date most bots do not use any formal MediaWiki API, because there hasn't been one. While a new API is being crafted (which you will learn about later in the chapter), necessity requires bot developers to create other methods of interacting with MediaWiki programmatically, something that often involves writing scripts that interact with the standard MediaWiki HTML interface.
One particularly well-developed bot is pywikipedia.py, which can be downloaded at http://sourceforge.net/projects/pywikipediabot/.
Python 2.3 or later must be installed (it may work on earlier versions of Python, but this hasn't been tested). It is written in Python, and it is designed to be used with Wikipedia. This means that often some customizations need to be made to the scripts in order to make them work properly on a homegrown MediaWiki wiki.
The first step is to configure the bot with your site's information, and a username and password in the bot group.
Two files need to be created in order to use pywikipedia: user-config.py and another file named after your wiki. In the example, the file is called profwiki_family.py, which includes a subclass of the Family class. The name that is chosen is important because pywikipedia needs to know which family object to instantiate.
In the main directory of the pywikipedia distribution is a file called family.py, and a directory called families. The family.py file includes the base Family class that needs to be subclassed. The "family" in question is the family of sites that make up Wikipedia. In Wikipedia's case, the family sites are versions of Wikipedia in different languages, so much of the family.py file concerns itself with languages and being able to navigate around the collection of sites that make up Wikipedia.
Inside the families directory are sample subclasses of Family that have been developed by other MediaWiki users. These sample subclasses can be used as examples for more complex configuration.
Typically, most organizations will not have such a large family as Wikipedia, so the following example shows you how to subclass the Family class for a single site:
# -*- coding: utf-8 -*-
import family
# Prof Wikis, by Mark Choate for Wrox
class Family(family.Family):
def __init__(self):
family.Family.__init__(self)
# The name assigned needs to be the same as the
# prefix used to name the file - in this case,# that is profwiki_family.py
self.name = 'profwiki'
# There's only one language to the site, so I
# associate the domain of my site with "en".
# In this instance, I'm accessing the domain
# locally. If the site were on a different
# server, I would use the actual domain name of
# the site.
self.langs = {'en': '127.0.0.1',}
# The name of my test wiki is 'Profwikis - MySQL
# so I assign that to the following namespaces.
self.namespaces[4] = {'_default': [u'Profwikis -
MySQL', self.namespaces[4]['_default']],}
self.namespaces[5] = {'_default': [u'Profwikis -
MySQL talk', self.namespaces[5]['_default']],}
# The version of MediaWiki I am using
def version(self, code):
return "1.9.3"
# The path to the wiki
def path(self, code):
return '/mysql/index.php'Save this file in the families directory. After it is complete, the user-config.py file needs to be created.
The default configuration is in config.py. Much like the difference between DefaultSettings.php and LocalSettings.php, config.py contains the default configuration data for the bot. Place any custom configuration data specific to your wiki in a file called user-config.py:
#One line saying "mylang='language'" #One line saying "usernames['wikipedia']['language']='yy'" mylang='en' family='profwiki' # The following user name MUST be in the bot group. usernames['profwiki']['en']= u'Mchoate'
In the profwiki_family.py file is the following line:
self.langs = {'en': '127.0.0.1',}The value for "mylang" in the user-config file corresponds with the language specified in profwiki_family.py. The following line in user-config:
family='profwiki'
corresponds with self.name = 'profwiki' in profwiki_family.py.
What all of this means is that when you execute a script using pywikipedia, the default language is English, which defaults to the server located at 127.0.0.1, using the path mysql/index.php. The script will log in as user Mchoate, which, if it is in the bot group, will then be allowed to make changes to the site.
The main file is wikipedia.py, which is where much of the core functionality is coded. In most cases, a script includes the wikipedia module when executing code. The first example is editarticle.py, which is a script that enables you to edit articles directly through an external editor, rather than edit them on the wiki website. I won't go into all the specific details of the implementation, but I do want to point out that the script imports the wikipedia module and the config module, which gives it all the information needed to log in and edit a file:
import wikipedia import config mchoate$ ./editarticle.py Checked for running processes. 1 processes currently running, including the current process. Page to edit:
Type in the page title you want to edit at the prompt, and a Tkinter window will be displayed with the wikitext to be edited (as shown in Figure 10-1).
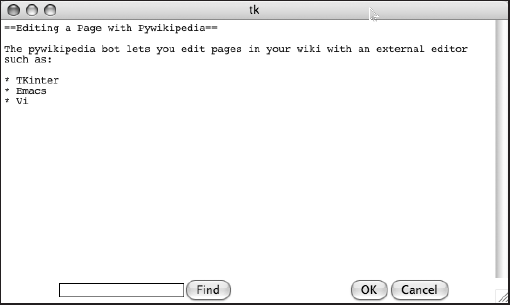
In order to edit in a different editor, the user-config.py file needs to be updated. The next example shows how to edit the pages using Emacs. The following line must be added to user-config.py:
editor = 'emacs'
Once this is done, you start the script just like before, but Emacs is launched instead of the Tkinter window, as shown in Figure 10-2.
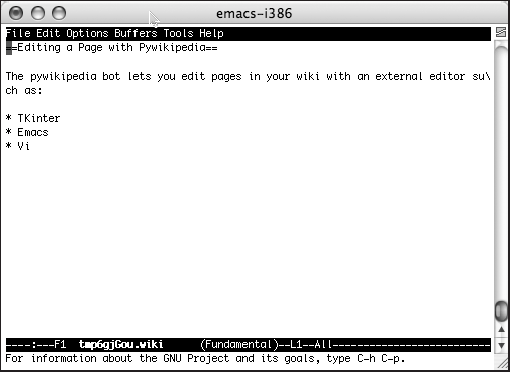
The script works by getting a copy of the page from the wiki and then saving the data to a temporary file. In the following output sample, the temporary file that was created was /tmp/tmp8YFggr.wiki.
Then, the editor that is configured opens the temporary file. Once the edits are made and the file is saved, the script checks to see whether any changes have been made. If there were, it prompts the user to provide a short summary of what was changed (just like you do when editing a page through a Web interface). Once that's entered, the file is then uploaded to the server:
mchoate$ ./editarticle.py Checked for running processes. 1 processes currently running, including the current process. Page to edit: Main Page Getting page [[Main Page]] Running editor... /tmp/tmp8YFggr.wiki + + The file has been modified. What did you change? I added a new sentence. Getting a page to check if we're logged in on profwiki:en Changing page [[en:Main Page]]
One other useful script available in pywikipedia is spellcheck.py, which (not surprisingly) performs a spell-check on wiki pages. In order to use spellcheck.py you first have to download a dictionary file from http://pywikipediabot.cvs.sourceforge.net/pywikipediabot/pywikipedia/spelling/. Included are files for several languages. The file for English is spelling-en.txt, which should be downloaded into the spelling directory in the pywikipedia distribution (it weighs in at about 2.5 megabytes of data, which is why they don't include it in the main distribution).
Once the spelling dictionaries are in place, spell-checking a page is simply a matter of executing the spellcheck.py script and passing it the name of the page to spell-check. In the next example, the article titled "Main Page" is going to be spell-checked:
mchoate$ ./spellcheck.py "Main Page"
When the script finds a questionably spelled word, the user is prompted through the console with various options. Like most spell-checkers, you are given the option to add the word to the dictionary, to ignore the word, to replace the text, to replace the text while not saving the alternative in the database, to guess, to edit by hand, or to stop checking the page altogether. In the following example, the spell-checker questions the spelling of "pywikipedia," and, amusingly, the spelling of "wiki." Once finished, the changes are saved and then uploaded back to the wiki:
Checked for running processes. 3 processes currently running, including the current process. Getting wordlist Wordlist successfully loaded. Getting page [[Main Page]] ============================================================ Found unknown word 'Pywikipedia' Context: ==Editing a Page with Pywikipedia== The pywikipedia bot lets you edit ------------------------------------------------------------ a: Add 'Pywikipedia' as correct c: Add 'pywikipedia' as correct i: Ignore once r: Replace text s: Replace text, but do not save as alternative g: Guess (give me a list of similar words) *: Edit by hand x: Do not check the rest of this page : c ============================================================ Found unknown word 'wiki' Context: kipedia bot lets you edit pages in your wiki with an external editor such as: * ------------------------------------------------------------ a: Add 'wiki' as correct i: Ignore once r: Replace text s: Replace text, but do not save as alternative g: Guess (give me a list of similar words) *: Edit by hand
x: Do not check the rest of this page : a ============================================================ Found unknown word 'TKinter' Context: with an external editor such as: * TKinter * Emacs * Vi The file has been modified ------------------------------------------------------------ a: Add 'TKinter' as correct c: Add 'tKinter' as correct i: Ignore once r: Replace text s: Replace text, but do not save as alternative g: Guess (give me a list of similar words) *: Edit by hand x: Do not check the rest of this page : a Which page to check now? (enter to stop)
These are only two examples of the scripts included in pywikipedia that can be used to assist in the maintenance of your wiki. Also included are scripts for harvesting images, uploading images, changing categories, and more. Many of them are tailored to Wikipedia, so you may find that they need to be edited to suit your needs. You will also notice that some of them require Python to run, because the script needs to access the X-Windows server.
The developers of MediaWiki know that an easier-to-use API for MediaWiki would be a great improvement. Page through the code in pywikipedia and you'll see that it's a fairly complicated bit of programming ... and very long. A new API is being developed to streamline the developer's work, and while it is not completed, it already is very capable, and affords the developer a simple, efficient way of interacting directly with the wiki's data.
Because the API is in a state of change, be sure to check www.mediawiki.org/wiki/API for the latest information about supported features. The developer is Yuri Astrakhan (User:Yurik on MediaWiki.org).
The first step to using the API is to configure MediaWiki to use it. Add the following to LocalSettings.php:
/** * Enable direct access to the data API * through api.php
*/ $wgEnableAPI = true; $wgEnableWriteAPI = true;
The API scripts are found in the /includes/api/ directory, and the entry point is api.php, which is in the top-level directory of MediaWiki, along with index.php. In order to access the API, all you need to do is replace index.php in the URL with api.php, like so (substituting your domain name, of course):
http://127.0.0.1/wiki/api.php
Because of the simplicity of the API, you can use a variety of ways to access it. Command-line tools such as wget and curl work, as do JavaScript, ruby, PHP, and Python. Any language that can generate an HTTP request can be used to access the API.
The current API implements five basic actions (and an edit action should be available by the time this book is published):
Help: The help action returns basic documentation about how to use the API.
Login: Because some activities require a user to be logged in, a login action is included.
Opensearch: This implements the OpenSearch protocol and enables the developer to search the contents of the wiki. You can learn more about the OpenSearch protocol at
http://opensearch.org/.Feedwatchlist: This returns an RSS feed of a user's watchlist.
Query: This action enables developers to query the MediaWiki database.
Using these actions is demonstrated later in the chapter.
The available formats are as follows: json, jsonfm, php, phpfm, wddx, wddxfm, xml, xmlfm, yaml, yamlfm, and rawfm (the default value is xmlfm). The formats that end with fm are HTML representations of the output so that it can be displayed on a webpage. All actions can use any output style, with one exception. The Feedwatchlist action's output can only be one of two flavors of XML: RSS or Atom.
The following examples are based on a simply query action that requests information about the wiki's Main Page article. The URL looks like this:
action=query&format=json&titles=Main+Page&meta=siteinfo&prop=info
In order to generate the different output formats, just change format=json to represent the desired output.
JSON is a format based on JavaScript. You can find specifications for it at http://json.org/. Following are the HTTP headers returned by this request. Notice that the Content-Type header value is application/json:
Date: Thu, 09 Aug 2007 02:58:44 GMT Server: Apache/1.3.33 (Darwin) PHP/5.2.0 X-Powered-By: PHP/5.2.0 Set-Cookie: wikidb_profwiki__session=onggurki4gg6v56ik26s9feef1; path=/ Expires: Thu, 01 Jan 1970 00:00:01 GMT Cache-Control: s-maxage=0, must-revalidate, max-age=0 Connection: close Transfer-Encoding: chunked Content-Type: application/json; charset=utf-8
The actual JSON output follows (it has been reformatted to make it more legible:
{"query":
{"pages":
{"1":
{"pageid":1,"ns":0,"title":"Main
Page","touched":"2007-07-21T18:34:55Z","lastrevid":166
}
},"general":
{"mainpage":"Main
Page","base":"http://127.0.0.1/mysql/index.php/Main_Page",
"sitename":"ProfWikis - MySQL","generator":"MediaWiki 1.9.3","case":"first-
letter","rights":""
}
}
}The HTTP headers for the XML format are the same as for JSON, except that the Content-Type is now text/xml:
Content-Type: text/xml; charset=utf-8
The equivalent XML output follows:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page"
touched="2007-07-21T18:34:55Z" lastrevid="166"/>
</pages>
<general mainpage="Main Page"
base="http://127.0.0.1/mysql/index.php/Main_Page"
sitename="ProfWikis - MySQL" generator="MediaWiki 1.9.3"
case="first-letter" rights=""/>
</query>
</api>WDDX (Web Distributed Data eXchange) is a standard originally developed by Macromedia for its Cold Fusion server product. The specification can be found at www.openwddx.org. While it has largely been surpassed by other data exchange specifications, it is still widely enough used that the developers felt it was important enough to include (the last news item on the OpenWDDX website was posted in 2001). The wordy WDDX output for the query follows (again formatted for clarity):
<?xml version="1.0"?>
<wddxPacket version="1.0">
<header/>
<data>
<struct>
<var name="query">
<struct>
<var name="pages">
<struct>
<var name="1">
<struct>
<var name="pageid">
<number>1</number>
</var>
<var name="ns">
<number>0</number>
</var>
<var name="title">
<string>Main Page</string>
</var>
<var name="touched">
<string>2007-07-21T18:34:55Z</string>
</var>
<var name="lastrevid">
<number>166</number>
</var>
</struct>
</var>
</struct>
</var>
<var name="general">
<struct>
<var name="mainpage">
<string>Main Page</string>
</var>
<var name="base">
<string>http://127.0.0.1/mysql/index.php/Main_Page
</string>
</var>
<var name="sitename">
<string>ProfWikis - MySQL</string>
</var>
<var name="generator">
<string>MediaWiki 1.9.3</string>
</var>
<var name="case"><string>first-letter</string>
</var>
<var name="rights">
<string/>
</var>
</struct>
</var>
</struct>
</var>
</struct>
</data>
</wddxPacket>The PHP serialized format is useful for PHP-based clients (see www.php.net/serialize). The Content-Type is application/vnd.php.serialized:
Content-Type: application/vnd.php.serialized; charset=utf-8
The icky output is as follows:
a:1:{s:5:"query";a:2:{s:5:"pages";a:1:{i:1;a:5:{s:6:"pageid";
i:1;s:2:"ns";i:0;s:5:"title";s:9:"Main
Page";s:7:"touched";s:20:"2007-07-21T18:34:55Z";s:9:"lastrevid";
i:166;}}s:7:"general";a:6:{s:8:"mainpage";
s:9:"Main Page";s:4:"base";s:42:"http://127.0.0.1/mysql/
index.php/Main_Page";s:8:"sitename";s:17:"ProfWikis - MySQL";
s:9:"generator";s:15:"MediaWiki 1.9.3";s:4:"case";s:12:"first-letter";
s:6:"rights";s:0:"";}}}Read all about YAML (and find out the definitive answer to the question regarding what YAML actually means) here: http://yaml.org/. The YAML Content-Type is as follows:
Content-Type: application/yaml; charset=utf-8
Here is the YAML output:
query:
pages:
-
pageid: 1
ns: 0
title: Main Page
touched: 2007-07-21T18:34:55Z
lastrevid: 166
general:
mainpage: Main Page
base: >
http://127.0.0.1/mysql/index.php/Main_Page
sitename: ProfWikis - MySQLgenerator: MediaWiki 1.9.3
case: first-letter
rights:The API provides a rich set of options in terms of how the data is transferred to your application. The final choice ultimately depends upon the developer's preference, or is contingent upon other environmental factors.
In the next section, the API is illustrated with a Python script. In these examples, the selected output is XML, but it could just as easily be JSON, YAML or WDDX, as Python libraries exist to parse these formats as well.
The following examples all come from a Python script written to illustrate the actions and the output of the MediaWiki API. This script is loosely based on a sample script for the old MediaWiki "Query" API, posted on MediaWiki at http://en.wikipedia.org/wiki/User:Yurik/Query_API/User_Manual#Python, but it has been expanded considerably.
I provide examples of all of the major actions, but the script is by no means exhaustive, in part because the API is still in a state of flux, with new features being added regularly. It can best be used as a starting point for developing your own scripts. It was also written with an eye toward being clear and easy to understand, rather than being particularly efficient or clever. It requires the use of Python 2.5.
Obviously, this exercise will be more informative if you are familiar with Python, but even if you are not a Python expert, you should be able to follow along as long as you have a solid understanding of computer programming. In the code and in other places where it is appropriate, you will see some additional explanation about what the Python code is doing, for readers who are unfamiliar with the language.
The first block of code in the script does some preparatory work, such as import libraries and define global variables used by the script. The urllib2 library is particularly useful in this case because it offers a rich set of tools for accessing resources through URLs, including cookie management, which is needed to track the logged-in status of the script when performing tasks that require special permissions. All the functions return XML, which is parsed by Python's ElementTree class. The global variables need to be customized to your site. The QUERY_URL is simply the base URL of the request, and the COOKIEFILE variable identifies where the cookie file will be stored, which enables the script to log in and stay logged in over a series of requests.
#!/usr/bin/env python # encoding: utf-8 " " " api.py Created by Mark on 2007-08-06. Copyright (c) 2007 The Choate Group, LLC. All rights reserved. " " " import sys import os
import urllib
import urllib2
import cookielib
import xml.etree.ElementTree
import StringIO
# global variables for the query url, http headers and the location
# of the cookie file to be used by urllib2
QUERY_URL = u"http://127.0.0.1/mysql/api.php"
HEADERS = {"User-Agent" : "API Test/1.0"}
COOKIEFILE = "/Users/mchoate/Documents/Code/MediaWiki/test.cookie"The ApiRequest class is being defined in the next block of code. The class will be used like this:
api = ApiRequest() f = api.doHelp()
In the first line, the ApiRequest is instantiated, and then the api object calls the doHelp() convenience method, which returns a file-like object that contains the XML data returned by MediaWiki:
class ApiRequest:
" " "
Encapsulates the HTTP request to MediaWiki, managing cookies and
handling the creation of the necessary URLs.
" " "
def __init__(self):
pass
def _initCookieJar(self):
" " "
The LWPCookieJar class saves cookies in a format compatible with
libwww-perl, which looks like this:
#LWP-Cookies-2.0
Set-Cookie3: wikidb_profwiki_Token=8ade58c0ee4b60180ab7214a93403554;
path="/"; domain="127.0.0.1"; path_spec; expires="2007-09-08 22:36:14Z";
version=0
Set-Cookie3: wikidb_profwiki_UserID=3; path="/"; domain="127.0.0.1";
path_spec; expires="2007-09-08 22:36:14Z"; version=0
Set-Cookie3: wikidb_profwiki_UserName=Mchoate; path="/";
domain="127.0.0.1"; path_spec; expires="2007-09-08 22:36:14Z"; version=0
" " "
cj = cookielib.LWPCookieJar()
# If the cookie file exists, then load the cookie into the cookie jar.
if os.path.exists(COOKIEFILE):
cj.load(COOKIEFILE)
# Create an opened for urllib2. This means that the cookie jar
# will be used by urllib2 when making HTTP requests.
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
return cjdef _saveCookieJar(self,cj):
" " "
Save the cookies in the cookie file.
" " "
cj.save(COOKIEFILE)
def execute(self, args):
" " "
This is a generate method called by the convenience methods.
The request takes place in three stages. First, the cookie jar
is initialized and the cookie file is loaded if it already exists. Then,
the dictionary "args" is urlencoded and urllib2 generates the HTTP request.
The result of the request is returned as a file-like object. Once it is
received, the cookie data is saved so that it will be available for the
next request, and the data is returned to the calling method.
" " "
cj = self._initCookieJar()
req = urllib2.Request(QUERY_URL, urllib.urlencode(args), HEADERS)
f = urllib2.urlopen(req)
self._saveCookieJar(cj)
return fThe remaining methods all call the execute method, using arguments appropriate for the kind of request being made. Not every option is explored in the remaining code, but the script is easily extended with new request types.
In order to get the latest information, you can make a help call to the API, which is particularly helpful considering the fact that the API is in an evolving state. The URL looks like this:
api.php?action=help
Alternatively, because it is the default action, it can also look like this:
api.php
When this is executed, a fairly detailed list of actions and their associated parameters is returned.
The ApiRequest Python class creates a Help action request with the following method. The values that will be passed to the execute() method are set in a dictionary object:
def doHelp(self, format="xml"):
args={"action": "help",
"format": format}
f = self.execute(args)
return fWhen the execute() method is called, the Python dictionary object is converted to a URL (?action=help&format=xml), and then the HTTP request is made. The results are returned in a file-like object, which, in addition to the usual Python file object methods, such as read(), also has two additional methods that can be useful, geturl() and info(), whose functionalities are described in the sample code that follows:
api = ApiRequest()
f = api.doHelp()
# Print a string representation of the URL that was called.
# Note that this doesn't include the arguments, so it would
# look something like this: http://127.0.0.1/wiki/api.php
print f.geturl()
# Print the headers from the HTTP response.
print f.info()
# Print the contents of the file-like object, which can be
# xml, wddx, yaml, json, etc., depending on the format requested.
print f.read()The login action has two required parameters and one optional parameter. Required are lgname and lgpassword; optional is lgdomain. The URL required to execute this action is as follows:
api.php?lgname=Mchoate&lgpassword=XXX&format=xml
The XML output of the action includes information about whether the login attempt was successful, the user ID of the person logged in, as well as the username, and a token that signifies a successful login, which can be used in subsequent requests to identify the logged in user.
MediaWiki also sets a cookie on the browser if the login is successful. In the mediawikiapi.py script, the urllib2 object handles accepting the cookie and sending it back on subsequent requests, which supersedes the need to use the token. The cookie encodes the same data as the value for lgtoken.
<?xml version="1.0" encoding="utf-8"?>
<api>
<login result="Success" lguserid="3" lgusername="Mchoate"
lgtoken="8ade58c0ee4b60180ab7214a93403554"/>
</api>The doLogin() method functions slightly differently than the other methods do in that it doesn't return data from the request. Instead, it returns a Boolean value indicating whether the login was successful or not. This method can be called like so:
api = ApiRequest()
if api.doLogin("Mchoate", "connor"):
print "Login was successful.
"
else:
print "Login failed.
"The doLogin() method implementation follows. Notice in the code that the XML returned is parsed by ElementTree, and the content of the XML is tested in order to determine whether the login was successful or not:
def doLogin(self, name, password, domain="", format="xml"):
" " "
The login action is used to login. If successful, a cookie
is set, and an authentication token is returned.
Example:
api.php?action=login&lgname=user&lgpassword=password
" " "
args={
"action" : "login",
"format" : format,
"lgname" : name,
"lgpassword": password,
}
# The domain is optional
if domain:
args.update({"lgdomain":domain})
# MediaWiki returns an XML document with a blank line at
# the top, which causes an error while parsing. The
# following code strips whitespace at the front and
# back of the XML document and returns a string.
s = self.execute(args).read().strip()
# ElementTree expects a file-like object,
# so one is created for it.
f = StringIO.StringIO(s)
root = xml.etree.ElementTree.parse(f).getroot()
# The root element is the <api> element.
login = root.find("login")
# The <login> element has an attribute 'result'
# that returns 'Success' is the login was successful
test = login.attrib["result"]
if test == "Success":
return True
else:
return FalseThis action enables you to search your wiki. The method is very similar to the doHelp() method and should be self-explanatory.
The Feedwatchlist action returns either an Atom or an RSS feed containing a list of pages that are being watched by the user. In this respect, it differs from the other actions in that it returns a special XML document. Unlike the others, it does not have a format parameter. Instead, it has a feedformat parameter than can be either "rss" or "atom".
def doFeedWatchList(self, feedformat="rss"):
args={
"action" : "feedwatchlist",
"feedformat": feedformat
}
f = self.execute(args)
return fIf an RSS feed is requested, then the following XML will be returned:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/css"
href="http://127.0.0.1/mysql/skins/common/feed.css?42b"?>
<rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>ProfWikis - MySQL - My watchlist [en]</title>
<link>http://127.0.0.1/mysql/index.php/Special:Watchlist</link>
<description>My watchlist</description>
<language>en</language>
<generator>MediaWiki 1.9.3</generator>
<lastBuildDate>Thu, 09 Aug 2007 22:33:30 GMT</lastBuildDate>
<item>
<title>Main Page</title>
<link>http://127.0.0.1/mysql/index.php/Main_Page</link>
<description> (WikiSysop)</description>
<pubDate>Sat, 21 Jul 2007 18:31:51 GMT</pubDate>
<dc:creator>WikiSysop</dc:creator> </item>
</channel>
</rss>If an "atom" feed is requested, then the data is reformatted to this specification:
<?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet type="text/css"
href="http://127.0.0.1/mysql/skins/common/feed.css?42b"?>
<feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en">
<id>http://127.0.0.1/mysql/api.php</id>
<title>ProfWikis - MySQL - My watchlist [en]</title>
<link rel="self" type="application/atom+xml"
href="http://127.0.0.1/mysql/api.php"/>
<link rel="alternate" type="text/html"
href="http://127.0.0.1/mysql/index.php/Special:Watchlist"/>
<updated>2007-08-09T22:33:31Z</updated>
<subtitle>My watchlist</subtitle>
<generator>MediaWiki 1.9.3</generator>
<entry>
<id>http://127.0.0.1/mysql/index.php/Main_Page</id>
<title>Main Page</title>
<link rel="alternate" type="text/html"
href="http://127.0.0.1/mysql/index.php/Main_Page"/>
<updated>2007-07-21T18:31:51Z</updated>
<summary type="html"> (WikiSysop)</summary>
<author><name>WikiSysop</name></author> </entry>
</feed>The query action is the workhorse of the MediaWiki API. It takes a complex set of parameters whose composition varies depending on the various kinds of queries that are available. The base query URL starts like this:
api.php?action=query
This doesn't get you very far because all queries need to have some kind of parameters that narrow down the selection of what is returned (otherwise, what's the point of querying?). The group of queries uses one of the following parameters: titles, pageids, or revids. These are described in the section "Searching by Title, Page ID, or Revision ID" that follows. The next query type is a list, which is described in the "Lists" section, followed by the last basic type, generators, discussed in the "Generators" section.
There are three parameters, titles, pageids, and revids, that enable you to query MediaWiki by title, page ID, or revision ID, respectively. All three work similarly, so the following examples use only titles; just bear in mind that you can do the same thing with the other parameters as well.
In all three cases, you can search for more than one value. To do so, you only need to separate the values by the pipe (|) character (a pattern used throughout the API), as is shown in the following example:
api.php?action=query&titles=Main+Page|Some+Other+Page&format=xml
Because the output of query actions are more varied than those of the others reviewed, the following sections use a slightly different format to describe them. First, you will see examples showing how the URLs can be formed to get the particular information you are looking for. Once you've reviewed the important variations, then you will learn the mediawikiapi.py script method that can be used to generate the different requests.
Simple Titles Query
A basic query that requests pages based upon their titles is illustrated in the following example:
api.php?action=query&titles=Main+Page&format=xml
The XML-formatted output of this request includes information about the page ID, plus the namespace of the page (which in this case is the default namespace):
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page"/>
</pages>
</query>
</api>This, of course, is of little value unless you simply wanted to know the page ID for this particular page. Chances are good you will want more information, and this information is requested by the prop parameter, which can be one of two values, both of which are illustrated next.
The following URL requests general information about the page titled "Main Page" by assigning the info value to the prop parameter:
api.php?action=query&format=xml&titles=Main+Page&prop=info
The output of this request now includes more information: the date the page was last "touched," and the last revision id (or current revision id, depending on whether you are a glass half-empty or glass half-full kind of person):
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page"
touched="2007-07-21T18:34:55Z" lastrevid="166"/>
</pages>
</query>
</api>The second value available to prop is the revisions value:
api.php?action=query&format=xml&titles=Main+Page&prop=revisions
When this value is used, additional information is returned about the last (or current) revision id. Actually, the only new data it adds by default is the oldid number:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page">
<revisions>
<rev revid="166" pageid="1" oldid="157"/>
</revisions>
</page>
</pages>
</query>
</api>There are times when you want more data about previous revisions, so the MediaWiki API provides a handful of parameters that can be used alongside the prop parameter when its value is set to revisions. These parameters are outlined in the following table.
Using these parameters can be somewhat tricky at first if you do not understand the impact that rvdir has on the output. It is best illustrated with a few examples. The following URL illustrates a basic request that includes a request for information about when each revision was created, who created it, and any user comments that may have been added. It also limits results to 10 revisions and returns the list of revisions in reverse order of the creation date, so that the most recent revision is listed first, followed by the rest in descending order:
api.php?format=xml&rvprop=timestamp%7Cuser%7Ccomment& prop=revisions&rvdir=older&titles=Main+Page&rvlimit= 10&action=query
The XML output is as follows:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page">
<revisions>
<rev revid="166" pageid="1" oldid="157"
user="WikiSysop" timestamp="2007-07-21T18:31:51Z"/>
<rev revid="165" pageid="1" oldid="156"
user="WikiSysop" timestamp="2007-07-17T23:47:46Z"/>
<rev revid="150" pageid="1" oldid="141"
user="WikiSysop" timestamp="2007-06-21T19:02:09Z"/>
<rev revid="149" pageid="1" oldid="140"
user="WikiSysop" timestamp="2007-06-21T19:00:21Z"/>
<rev revid="146" pageid="1" oldid="137"
user="WikiSysop" timestamp="2007-06-21T16:19:19Z"/>
<rev revid="134" pageid="1" oldid="125"
user="WikiSysop" timestamp="2007-06-21T14:58:39Z"/>
<rev revid="93" pageid="1" oldid="87"
user="WikiSysop" timestamp="2007-06-04T20:05:07Z"/>
<rev revid="91" pageid="1" oldid="85"
user="WikiSysop" timestamp="2007-06-01T19:48:49Z"/>
<rev revid="77" pageid="1" oldid="74"
user="WikiSysop" timestamp="2007-05-31T18:12:51Z"/>
<rev revid="76" pageid="1" oldid="73"
user="WikiSysop" timestamp="2007-05-31T17:43:53Z"/>
</revisions>
</page>
</pages>
</query>
<query-continue>
<revisions rvstartid="64"/>
</query-continue>
</api>At the end of the XML data is a <query-continue> XML tag. This is here because the request limited the returned values to no more than 10. Because there are more than 10 revisions for this page, the id of the next revision in sequence is returned so that it can be used on subsequent requests.
Revision Direction: older The next query is just like the previous query except that two parameters are added: rvstartid and rvendid. The query says to start with revision ID 77 and to end with revision ID 150:
api.php?format=xml&rvprop=timestamp%7Cuser%7Ccomment&prop= revisions&rvdir=older&rvstartid=77&titles=Main+Page&rvlimit =10&rvendid=150&action=query
When this query is executed, the following data is returned:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page"/>
</pages>
</query>
</api>You may have noticed that something is missing. Where are the revisions between 77 and 150? The answer is that the request is asking for a set of information that cannot exist. The order of the results is the same as the previous query, which means that the most recent revision is first, followed by the other revisions in descending order. This request tells MediaWiki to start at the 77th revision and to end at the 150th revision.
Because it is ordered in descending order, and the most recent revision is 166, MediaWiki returns nothing. One solution is to tell MediaWiki to start with the 150th revision and to end with the 77th revision. The other solution is to request the list in the reverse direction, from oldest to newest.
Revision Direction: newer The modified request now looks like the following—the only change is setting the rvdir parameter to the value newer:
format=xml&rvprop=timestamp%7Cuser%7Ccomment&prop=revisions &rvdir=newer&rvstartid=77&titles=Main+Page&rvlimit=10& rvendid=150&action=query
The results of this query are markedly different from the first. The first revision listed has a revision ID of 77, and the last revision has an ID of 150, so it has constrained the list according to the start and end properties set in the query.
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<pages>
<page pageid="1" ns="0" title="Main Page">
<revisions>
<rev revid="77" pageid="1" oldid="74"
user="WikiSysop" timestamp="2007-05-31T18:12:51Z"/>
<rev revid="91" pageid="1" oldid="85"
user="WikiSysop" timestamp="2007-06-01T19:48:49Z"/>
<rev revid="93" pageid="1" oldid="87"
user="WikiSysop" timestamp="2007-06-04T20:05:07Z"/>
<rev revid="134" pageid="1" oldid="125"user="WikiSysop" timestamp="2007-06-21T14:58:39Z"/>
<rev revid="146" pageid="1" oldid="137"
user="WikiSysop" timestamp="2007-06-21T16:19:19Z"/>
<rev revid="149" pageid="1" oldid="140"
user="WikiSysop" timestamp="2007-06-21T19:00:21Z"/>
<rev revid="150" pageid="1" oldid="141"
user="WikiSysop" timestamp="2007-06-21T19:02:09Z"/>
</revisions>
</page>
</pages>
</query>
</api>Because there are so many variations to the parameters that can be used when making these kinds of queries, the query code in the example uses a Python idiom that enables you to pass a varying number of parameters to the method. Note that the same basic method can be used for pageids and revids queries with only the slight modification of swapping pageids wherever titles appears, or revids wherever titles appears:
def doTitlesQuery(self, titles, format, **args):
args.update({
"action": "query",
"titles": titles,
"format": format}
)
f = self.execute(args)
return fThe **args argument is a dictionary of key value pairs that is generated by adding named parameters to the method call. This method requires a value for titles and format, but will accept any number of named parameters, as illustrated in the following example, which shows three different but perfectly acceptable ways of calling the method:
api = ApiRequest()
f = api.doTitlesQuery("Main Page", "xml")
f = api.doTitlesQuery("Main Page", "xml", rvprop="info")
f = api.doTitlesQuery("Main Page", "xml", rvprop="revisions", rvlimit="10)Queries that return lists work a little differently than the queries seen thus far. There are a few important things to understand:
You can request eight pre-defined lists:
allpages, logevents, watchlist, recentchanges, backlinks, embeddedin, imagelinks, andusercontribs. These are described in detail below.Lists are used instead of
titles, pageidsandrevids. All four of these query types are mutually exclusive.Lists cannot be used with any of the
propandrevisionparameters.There is an exception to rule number 3. Lists can be used as what is called a generator in the API, which means that the list can be used in place of
titles, pageids, andrevids, in which case all of thepropandrevisionparameters are available to the request. This means that instead of typing in a long list of page titles to search for, you can use alistas the source. This concept is best illustrated with examples, which can be found in the section "Generators" later in this chapter.
A basic list query is constructed like the following URL:
api.php?action=query&format=xml&list=allpages
The output of such a query follows:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query-continue>
<allpages apfrom="Image galleries"/>
</query-continue>
<query>
<allpages>
<p pageid="49" ns="0" title="ASamplePage"/>
<p pageid="28" ns="0" title="A new page"/>
<p pageid="33" ns="0" title="Basic Image Links"/>
<p pageid="34" ns="0" title="Basic Media Namespace Links"/>
<p pageid="41" ns="0" title="College Basketball"/>
<p pageid="42" ns="0" title="College Football"/>
<p pageid="39" ns="0" title="College Sports"/>
<p pageid="20" ns="0" title="Core parser functions"/>
<p pageid="19" ns="0" title="Headings"/>
<p pageid="35" ns="0" title="Image Alignment"/>
</allpages>
</query>
</api>An important item to note is that by default, all requests are limited to 10 items. This can be overridden by the correct parameter, which varies according to which list type is being requested. Each list type has its own collection of parameters that it can use, and these are documented in the following pages, along with sample output.
List: allpages
Parameter | Value |
|---|---|
| Returns a list of pages ordered alphabetically, starting with titles equal to or higher than the letter or letters used. If |
| Returns a list of pages whose title starts with the string passed as the value. If |
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| Determines which pages to list based upon one of three values: |
| Determines the maximum number of pages to return. The default is 10. |
In the previous section, an example of a simple request was already illustrated. The following request is a little more complicated, and uses the parameters available to the allpages request:
api.php?apfilterredir=all&apprefix=M&format=xml&list=allpages &apfrom=A&apnamespace=0&action=query&prop=revisions& aplimit=10
The preceding request asks for all pages that start with the letter A or higher in the alphabet and all pages that have the prefix of M. Of course, because M comes after A in the alphabet, all pages with titles that start with M are included in the results:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query>
<allpages>
<p pageid="24" ns="0" title="Magic Words"/>
<p pageid="10" ns="0" title="Magic Words that
show information about the page"/>
<p pageid="9" ns="0" title="Magic Words that use underscores"/>
<p pageid="11" ns="0" title="Magic word tests"/>
<p pageid="1" ns="0" title="Main Page"/>
<p pageid="22" ns="0" title="Math"/>
<p pageid="51" ns="0" title="MediaWiki Extensions"/>
</allpages>
</query>
</api>The remaining list types all have unique parameters, but there is a lot of overlap with the parameters used in the previous example. Therefore, the next sections document the parameters each list type uses, but do not provide specific output examples.
List: logevents
| Value |
|---|---|
| Filters log events based on the type of log event. Legal values are |
| The timestamp of the starting point of the list of log events that will be returned. |
| The timestamp of the ending point of the list of log entries that will be returned. |
| The sort order of the list of log entries that is returned. The value can be |
| Filters entries by username. |
| Returns log entries for a given page. |
| Determines the maximum number of log entries to return. The default is 10. |
List: watchlist
Parameter | Value |
|---|---|
| Includes all revisions of the pages in the watchlist that will be returned. This parameter doesn't take a value; if it is present in the query, all revisions are returned. If it is absent, only the current page is returned. |
| The timestamp of the starting point of the watchlist that will be returned. |
| The timestamp of the ending point of the watchlist that will be returned. |
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| Determines the sort direction of the returned list of pages, either from older to newer or newer to older. The value is either |
| Determines the maximum number of pages to return. The default is 10. |
| Specifies which additional items to get (nongenerator mode only). The value can be one or more of the following: |
List: recentchanges
Parameter | Value |
|---|---|
| The timestamp of the starting point of the list of recent changes that will be returned. |
| The timestamp of the ending point of the list of recent changes that will be returned. |
| Determines the sort direction of the returned list of recent changes, either from older to newer or newer to older. The value is either |
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| Includes additional properties in the return values. The value can be one or more of the following: |
| Filters returned items based on the criteria specified in the value. Possible values are |
| Determines the maximum number of pages to return. The default is 10. |
List: backlinks
Parameter | Value |
|---|---|
| When more results are available, use this to continue. |
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| Determines the maximum number of pages to return. The default is 10. |
List: emeddedin
Parameter | Value |
|---|---|
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| If the linking page is a redirect, this finds all pages that link to that redirect (not implemented). |
| Determines the maximum number of pages to return. The default is 10. |
List: imagelinks
Parameter | Value |
|---|---|
| The number of the namespace from which the list should be derived. It should be a value from 0 to 15 (unless you've added custom namespaces). |
| Determines the maximum number of pages to return. The default is 10. |
List: usercontribs
Parameter | Value |
|---|---|
| Determines the maximum number of contributions to return. The default is 10. |
| The timestamp of the starting point of the list of user contributions that will be returned. |
| The timestamp of the ending point of the list of user contributions that will be returned. |
| The username whose contributions will be returned |
| Determines the sort direction of the returned list of user contributions, either from older to newer or newer to older. The value is either |
ApiRequest.doListQuery(list=allpages, **listargs)
The Python method used to generate list queries is similar to the one used to generate titles queries. This generic query can be used for any kind of list type:
def doListQuery(self, list, format, **args):
args.update({
"action": "query",
"list": list,
"format": format}
)
f = self.execute(args)
return fNo programmer likes to type any more than they have to, so slightly more convenient methods have been included for each specific kind of list to be queried:
def doListAllpagesQuery(self, **args):
args.update({
"action":"query",
"list": "allpages",
})
f = self.execute(args)
return fdef doListLogeventsQuery(self, **args):
args.update({
"action":"query",
"list": "logevents",
})
f = self.execute(args)
return f
def doListWatchlistQuery(self, **args):
args.update({
"action":"query",
"list": "watchlist",
})
f = self.execute(args)
return f
def doListRecentchangesQuery(self, **args):
args.update({
"action":"query",
"list": "recentchanges",
})
f = self.execute(args)
return f
def doListBacklinksQuery(self, **args):
args.update({
"action":"query",
"list": "backlinks",
})
f = self.execute(args)
return f
def doListEmbeddedinQuery(self, **args):
args.update({
"action":"query",
"list": "embeddedin",
})
f = self.execute(args)
return f
def doListImagelinksQuery(self, **args):
args.update({
"action":"query",
"list": "imagelinks",
})
f = self.execute(args)
return f
def doListUsercontribsQuery(self, **args):
args.update({
"action":"query",
"list": "usercontribs",
})
f = self.execute(args)
return fEarlier in this chapter, you learned that lists could be used as generators in place of titles, pageids, and revids queries. You also saw that this concept is most easily understood by looking at sample output, which is what you will see here.
In order to use a list as a generator, all you need to do is refer to it as a generator in the query. Instead of list=allpages, use generator=allpages, as illustrated in the following example:
api.php?generator=allpages&format=xml&action=query
That's all there is to it. The advantage to using a generator is that you then have access to the prop and revision parameters and can thus query a much richer set of information than you can with lists alone.
The following two API requests will return the same data, even though one is a generator and the other is a list:
api.php?action=query&format=xml&generator=allpages api.php?action=query&format=xml&list=allpages
Both of these requests return the following data:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query-continue>
<allpages gapfrom="Image galleries"/>
</query-continue>
<query>
<pages>
<page pageid="49" ns="0" title="ASamplePage"/>
<page pageid="28" ns="0" title="A new page"/>
<page pageid="33" ns="0" title="Basic Image Links"/>
<page pageid="34" ns="0" title="Basic Media Namespace Links"/>
<page pageid="41" ns="0" title="College Basketball"/>
<page pageid="42" ns="0" title="College Football"/>
<page pageid="39" ns="0" title="College Sports"/>
<page pageid="20" ns="0" title="Core parser functions"/>
<page pageid="19" ns="0" title="Headings"/>
<page pageid="35" ns="0" title="Image Alignment"/>
</pages>
</query>
</api>The difference becomes apparent when you use both the generator and the prop parameter:
api.php?action=query&format=xml&generator=allpages&prop=revisions
This request returns the following data:
<?xml version="1.0" encoding="utf-8"?>
<api>
<query-continue>
<allpages gapfrom="Image galleries"/>
</query-continue><query>
<pages>
<page pageid="49" ns="0" title="ASamplePage">
<revisions>
<rev revid="164" pageid="49" oldid="155"/>
</revisions>
</page>
<page pageid="28" ns="0" title="A new page">
<revisions>
<rev revid="111" pageid="28" oldid="102" minor=""/>
</revisions>
</page>
<page pageid="33" ns="0" title="Basic Image Links">
<revisions>
<rev revid="121" pageid="33" oldid="112"/>
</revisions>
</page>
<page pageid="34" ns="0" title="Basic Media Namespace Links">
<revisions>
<rev revid="123" pageid="34" oldid="114"/>
</revisions>
</page>
<page pageid="41" ns="0" title="College Basketball">
<revisions>
<rev revid="138" pageid="41" oldid="129"/>
</revisions>
</page>
<page pageid="42" ns="0" title="College Football">
<revisions>
<rev revid="139" pageid="42" oldid="130"/>
</revisions>
</page>
<page pageid="39" ns="0" title="College Sports">
<revisions>
<rev revid="143" pageid="39" oldid="134"/>
</revisions>
</page>
<page pageid="20" ns="0" title="Core parser functions">
<revisions>
<rev revid="160" pageid="20" oldid="151"/>
</revisions>
</page>
<page pageid="19" ns="0" title="Headings">
<revisions>
<rev revid="59" pageid="19" oldid="56"/>
</revisions>
</page>
<page pageid="35" ns="0" title="Image Alignment">
<revisions>
<rev revid="127" pageid="35" oldid="118"/>
</revisions>
</page>
</pages>
</query>
</api>There are, of course, a large number of variations to the kind of requests that can be made this way, and all of the revision properties can be used as well to construct complex queries.
The Python method to request a generator is almost identical to the list request, except that the generator parameter is used instead of the list parameter:
def doGeneratorQuery(self, list, format, **args):
args.update({
"action": "query",
"generator": list,
"format": format}
)
f = self.execute(args)
return fThis method can be used to replicate the queries used to illustrate generator output by using them in the following way:
api = ApiQuery()
f = api.doGeneratorQuery("allpages", "xml")
print f.read()
f = api.doGeneratorQuery("allpages", "xml", prop="revisions")
print f.read()One feature missing from the API is the capability to edit pages programmatically. This feature is currently under active development and will be available in future versions of MediaWiki.
The complete code of the api.py script follows:
#!/usr/bin/env python # encoding: utf-8 " " " api.py Created by Mark on 2007-08-06. Copyright (c) 2007 The Choate Group, LLC. All rights reserved. " " " import sys import os import urllib import urllib2 import cookielib import xml.etree.ElementTree import StringIO
# Customize the following values for your wiki installation
QUERY_URL = u"http://127.0.0.1/mysql/api.php"
HEADERS = {"User-Agent" : "API Test/1.0"}
COOKIEFILE = "/Users/mchoate/Documents/Code/Metaserve/MediaWiki/test.cookie"
class ApiRequest:
" " "
Encapsulates the HTTP request to MediaWiki, managing cookies and
handling the creation of the necessary URLs.
" " "
def _initCookieJar(self):
" " "
The LWPCookieJar class saves cookies in a format compatible with
libwww-perl, which looks like this:
#LWP-Cookies-2.0
Set-Cookie3: wikidb_profwiki_Token=8ade58c0ee4b60180ab7214a93403554;
path="/"; domain="127.0.0.1"; path_spec; expires="2007-09-08 22:36:14Z";
version=0
Set-Cookie3: wikidb_profwiki_UserID=3;
path="/"; domain="127.0.0.1"; path_spec; expires="2007-09-08 22:36:14Z";
version=0
Set-Cookie3: wikidb_profwiki_UserName=Mchoate;
path="/"; domain="127.0.0.1"; path_spec; expires="2007-09-08 22:36:14Z";
version=0
" " "
cj = cookielib.LWPCookieJar()
# If the cookie file exists, then load the cookie into the cookie jar.
if os.path.exists(COOKIEFILE):
cj.load(COOKIEFILE)
# Create an opened for urllib2. This means that the cookie jar
# will be used by urllib2 when making HTTP requests.
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
return cj
def _saveCookieJar(self,cj):
cj.save(COOKIEFILE)
def doHelp(self, format="xml"):
args={"action": "help",
"format": format}
f = self.execute(args)
return f
def doLogin(self, name, password, domain="", format="xml"):
" " "
The login action is used to login. If successful, a cookie
is set, and an authentication token is returned.Example:
api.php?action=login&lgname=user&lgpassword=password
" " "
args={
"action" : "login",
"format" : format,
"lgname" : name,
"lgpassword": password,
}
# The domain is optional
if domain:
args.update({"lgdomain":domain})
# MediaWiki returns an XML document with a blank line at
# the top, which causes an error while parsing. The
# following code strips whitespace at the front and
# back of the XML document and returns a string.
s = self.execute(args).read().strip()
# ElementTree expects a file-like object,
# so one is created for it.
f = StringIO.StringIO(s)
root = xml.etree.ElementTree.parse(f).getroot()
# The root element is the <api> element.
login = root.find("login")
# The <login> element has an attribute 'result'
# that returns 'Success' is the login was successful
test = login.attrib["result"]
if test == "Success":
return True
else:
return False
def doOpenSearch(self, search="", format="xml"):
args={
"action" : "search",
"format" : format
}
f = self.execute(args)
def doFeedWatchList(self, feedformat="rss"):
args={
"action" : "feedwatchlist",
"feedformat": feedformat,
}
f = self.execute(args)
return fdef doQuery(self, **args):
return self.execute(args)
def doTitlesQuery(self, titles="Main Page", prop="info", meta="siteinfo", format="xml"):
args={
"action": "query",
"titles": titles,
"prop": prop,
"meta": meta,
"format": format
}
f = self.execute(args)
return f
def doTitlesQueryNoMeta(self, titles="Main Page", prop="info", format="xml"):
args={
"action": "query",
"titles": titles,
"prop": prop,
"format": format
}
f = self.execute(args)
return f
def doSimpleTitlesQuery(self, titles="Main Page", format="xml"):
args={
"action": "query",
"titles": titles,
"format": format
}
f = self.execute(args)
return f
def doTitlesQuery2(self, titles="Main Page",
rvprop="timestamp|user|comment", rvlimit="50", rvdir="forward", format="xml"):
args={
"action": "query",
"titles": titles,
"prop": "revisions",
"rvprop": rvprop, #timestamp|user|comment|content
"rvlimit": rvlimit,
#"rvstartid": "77",
#"rvendid": "200",
#"rvstart": rvstart, #timestamp
#"rvend": rvend, #timestamp
"rvdir": rvdir, #newer|older
"format": format
}
f = self.execute(args)
return fdef doTitlesQuery3(self, titles="Main Page",
rvprop="timestamp|user|comment", rvlimit="50", rvdir="older", format="xml"):
args={
"action": "query",
"titles": titles,
"prop": "revisions",
"rvprop": rvprop, #timestamp|user|comment|content
"rvlimit": rvlimit,
"rvstartid": "77",
"rvendid": "150",
#"rvstart": rvstart, #timestamp
#"rvend": rvend, #timestamp
"rvdir": rvdir, #newer|older
"format": format
}
f = self.execute(args)
return f
def doGeneratorQuery2(self, list_="allpages",
apfrom="aardvark", apnamespace="0", apfilterredir="all", aplimit="10",
apprefix="",rvprop="timestamp|user|comment", format="xml"):
args={
"action": "query",
"generator": list_,
"prop": "revisions",
"rvprop": rvprop, #timestamp|user|comment|content
"apfrom":apfrom,
"apnamespace":apnamespace,
"apfilterredir": apfilterredir,
"aplimit": aplimit,
"apprefix": apprefix,
"format": format
}
f = self.execute(args)
return f
def doGeneratorQuery(self, list, format, **args):
args.update({
"action": "query",
"generator": list,
"format": format}
)
f = self.execute(args)
return f
def doListQuery(self, list, format, **args):
args.update({
"action": "query",
"list": list,
"format": format}
)
f = self.execute(args)
return fdef doListAllpagesQuery(self, apfrom="aardvark", apnamespace="0",
apfilterredir="all", aplimit="10", apprefix="", format="xml"):
args={
"action":"query",
"list": "allpages",
"apfrom":apfrom,
"apnamespace":apnamespace,
"apfilterredir": apfilterredir,
"aplimit": aplimit,
"apprefix": apprefix,
"prop":"revisions",
"rvprop":"timestamp|user|comment",
"format":format
}
f = self.execute(args)
return f
def doSimpleListAllpagesQuery(self, apfrom="A", apnamespace="0",
apfilterredir="all", aplimit="10", apprefix="M", format="xml"):
args={
"action":"query",
"list": "allpages",
"apfrom":apfrom,
"apnamespace":apnamespace,
"apfilterredir": apfilterredir,
"aplimit": aplimit,
"apprefix": apprefix,
#"prop":"revisions",# doesn't do anything for the list
#"rvprop":"timestamp|user|comment",
"format":format
}
f = self.execute(args)
return f
def doListLogeventsQuery(self, **args):
args.update({
"action":"query",
"list": "logevents",
})
f = self.execute(args)
return f
def doListWatchlistQuery(self, **args):
args.update({
"action":"query",
"list": "watchlist",
})
f = self.execute(args)
return f
def doListRecentchangesQuery(self, **args):
args.update({
"action":"query",
"list": "recentchanges",})
f = self.execute(args)
return f
def doListBacklinksQuery(self, **args):
args.update({
"action":"query",
"list": "backlinks",
})
f = self.execute(args)
return f
def doListEmbeddedinQuery(self, **args):
args.update({
"action":"query",
"list": "embeddedin",
})
f = self.execute(args)
return f
def doListImagelinksQuery(self, **args):
args.update({
"action":"query",
"list": "imagelinks",
})
f = self.execute(args)
return f
def doListUsercontribsQuery(self, **args):
args.update({
"action":"query",
"list": "usercontribs",
})
f = self.execute(args)
return f
def execute(self, args):
" " "
This is a generate method called by the convenience methods.
The request takes place in three stages. First, the cookie jar
is initialized and the cookie file is loaded if it already exists. Then,
the dictionary "args" is urlencoded and urllib2 generates the HTTP request.
The result of the request is returned as a file-like object. Once it is
received, the cookie data is saved so that it will be available for the
next request, and the data is returned to the calling method.
" " "
cj = self._initCookieJar()
req = urllib2.Request(QUERY_URL, urllib.urlencode(args), HEADERS)
f = urllib2.urlopen(req)
self._saveCookieJar(cj)
return f
if __name__ == '__main__':# Test methods
api = ApiRequest()
f = api.doHelp()
if api.doLogin("Mchoate", "connor"):
print "Login was successful.
"
else:
print "Login failed.
"
print "---------------------------------------
"
f = api.doTitlesQuery(titles="Main Page", prop="info", meta="siteinfo", format="xml")
f = api.doTitlesQueryNoMeta(titles="Main Page", prop="info", format="xml")
f = api.doTitlesQueryNoMeta(titles="Main Page", prop="revisions", format="xml")
f = api.doSimpleTitlesQuery(titles="Main Page", format="xml")
f = api.doTitlesQuery2(titles="Main Page", rvprop="timestamp|user|comment",
rvlimit="10",rvdir="older", format="xml")
f = api.doTitlesQuery3(titles="Main Page", rvprop="timestamp|user|comment",
rvlimit="10",rvdir="older", format="xml")
f = api.doTitlesQuery3(titles="Main Page", rvprop="timestamp|user|comment",
rvlimit="10",rvdir="newer", format="xml")
f = api.doGeneratorQuery2(list_="allpages", rvprop="timestamp|user|comment",
format="xml")
f = api.doListAllpagesQuery()
f = api.doSimpleListAllpagesQuery()
f = api.doListQuery("allpages", "xml")
f = api.doGeneratorQuery("allpages", "xml")
f = api.doGeneratorQuery("allpages", "xml", prop="revisions")In this chapter, you learned how to configure and run sample scripts from the pywikipedia bot, as well as how to interact with the new MediaWiki API using Python. These tools can be used to automate certain administrative tasks and can save administrators a significant amount of time. Eventually, the full MediaWiki API will make it possible to create robust client applications for MediaWiki.
In the next chapter, you will learn about site maintenance and administration of your wiki, including performance management through caching.